The initial model selected to be applied to the system is YOLOv5s (hereafter, defined as ‘basic’). Hyperparameters set up for model learning are shown in
Table 2. Epoch, Batch size, Image size, and Learning rate are set to 300, 16, 640 × 640, and 0.01. The hyperparameter value is not changed to identify the tendency of the technique used in this study, and model training is conducted by applying the basic value. Afterwards, performance analysis according to changes in hyperparameters is conducted for further model optimization. The model learning environment is presented in
Table 3.
The initial model of the system refers to a model without any technique applied. Its mAP and inference time are approximately 95.3 and 1.6 ms, respectively. We set the initial model as a performance comparison criterion for future performance-enhanced models. We aimed to improve the performance using three performance enhancement techniques (structure modification, model scaling, and lightweight design) to find the optimized model for the system. In
Section 3, learning conditions and comparative analysis of results obtained by applying three techniques are presented. Conditions for each technique are set up directly, and the reason why there are various conditions is to analyze the tendency of the technique. The hyperparameters and hardware are equally used in the learning in each case.
4.1. Case Study
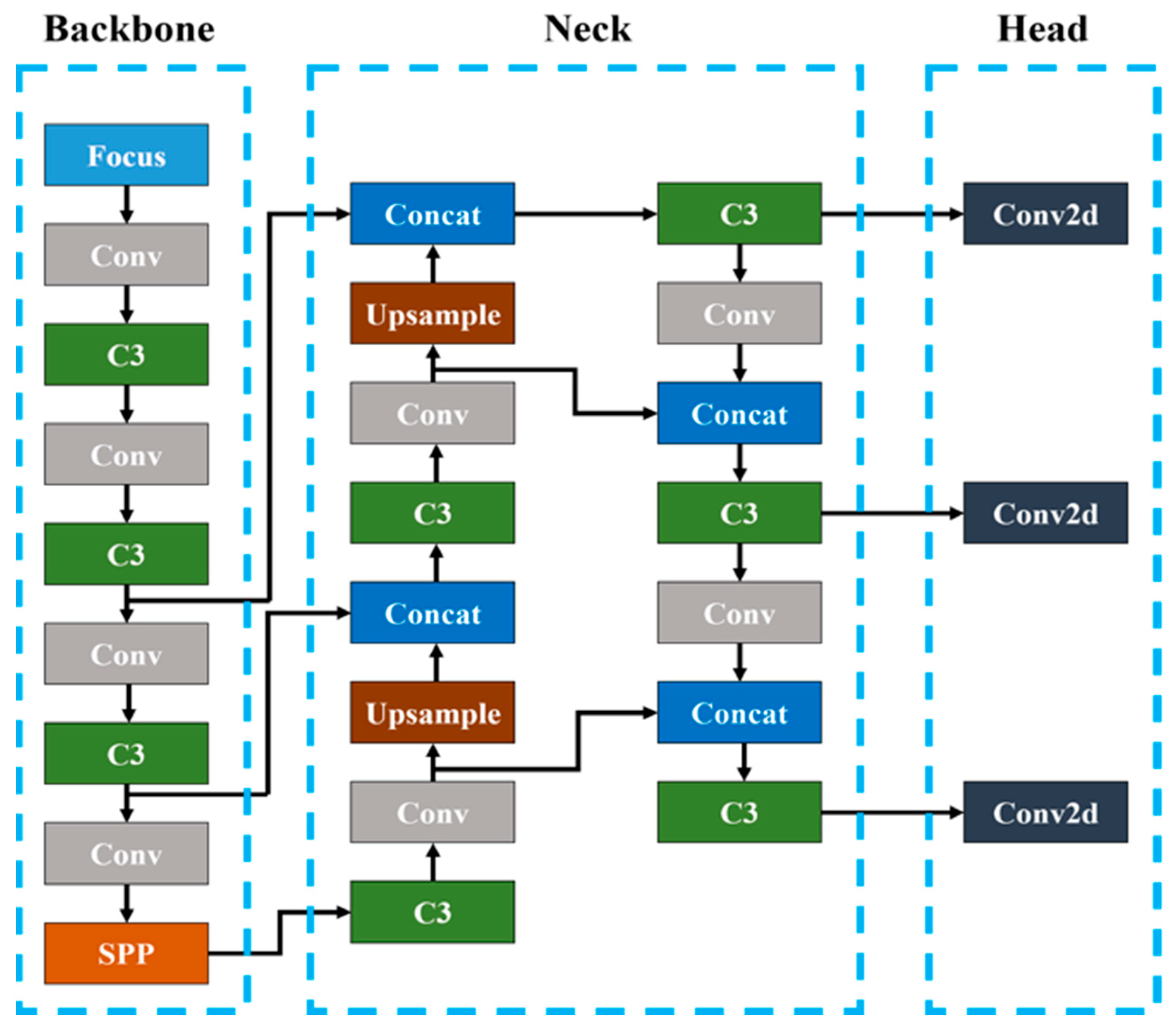
To improve the performance of the YOLOv5 model, we analyzed techniques on performance improvements as model and dataset modifications. A Conv block was added to the backbone in the YOLOv5s model. The model learning was conducted for four cases as shown in
Figure S1 and performance results were comparatively analyzed.
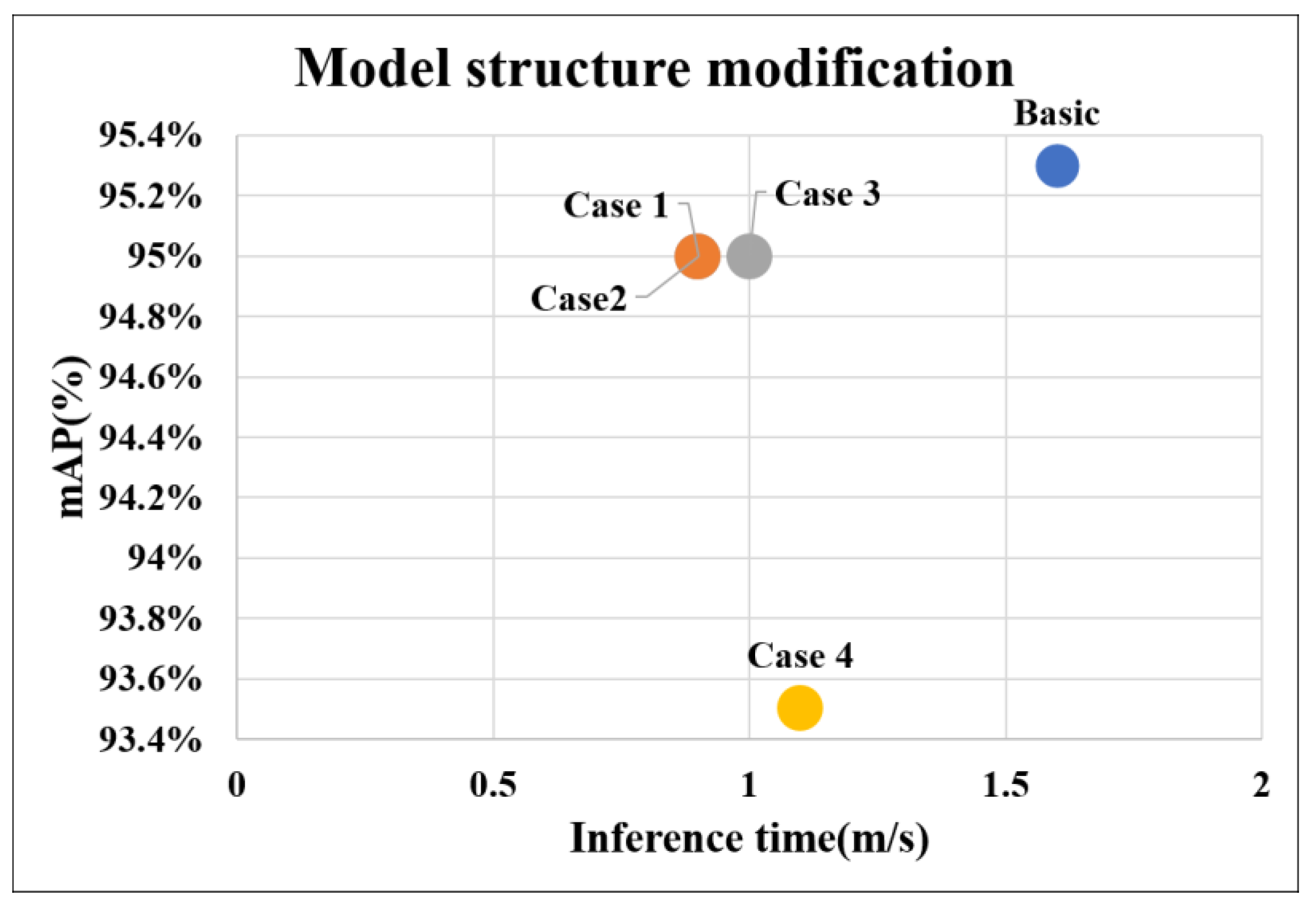
As shown in
Figure 14, the mAP and inference time of Cases 1 and 2 are approximately 95% and 0.9 ms, those of Case 3 were approximately 95% and 1.0 ms, and those of Case 4 were approximately 93.5% and 1.1 ms, respectively. In conclusion, Cases 1 and 2 had higher mAP and faster inference times than those of Cases 3 and 4 despite having fewer number of layers. This result verifies that the performance did not increase as the model’s depth increased, which is easily known in a deep learning model.
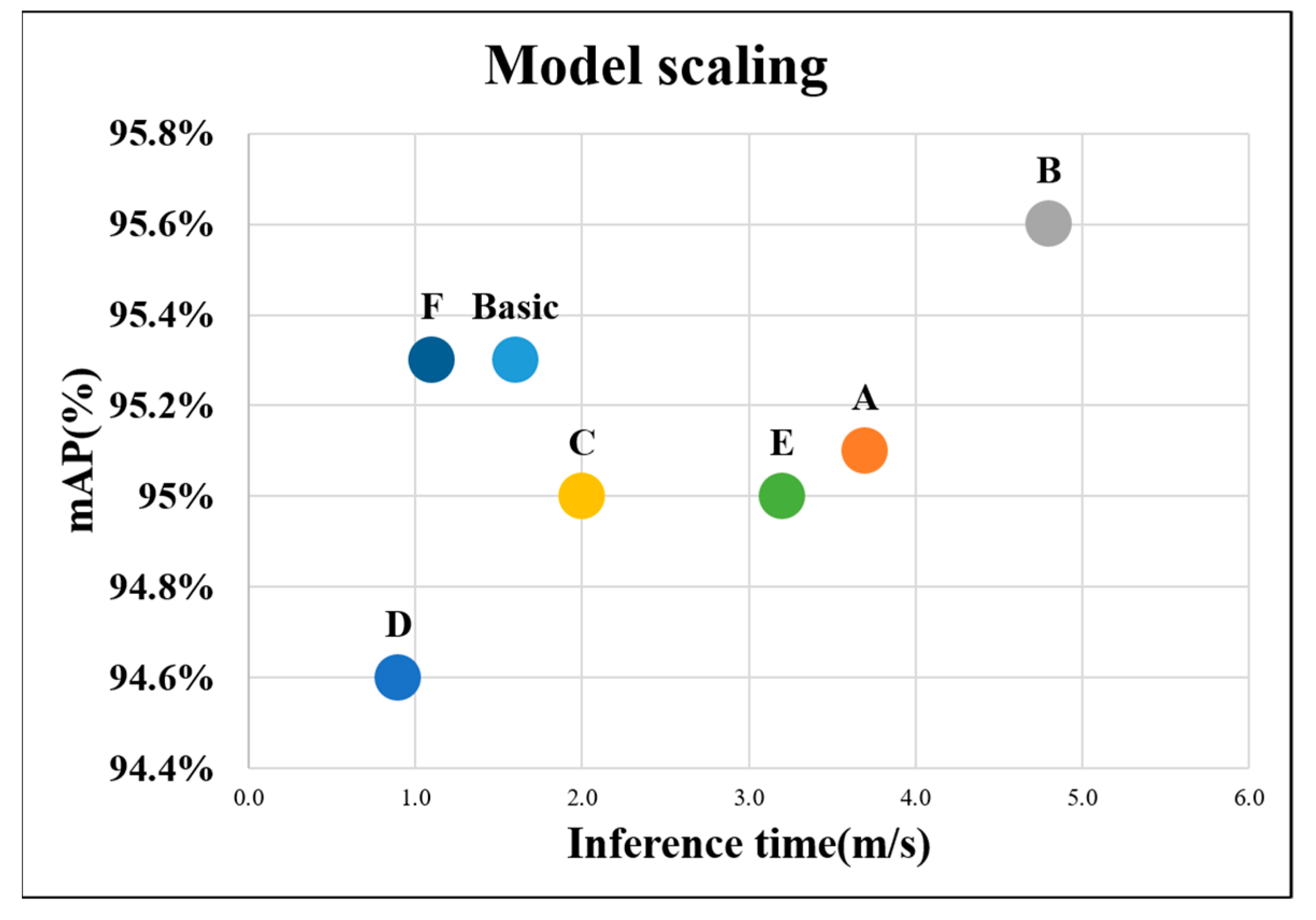
In model scaling, various values are applied to the models to find the optimized model for the proposed system. The model learning is conducted by applying seven cases of different model depths and widths, including the initial model of the system to compare the results.
Table 4 summarizes the model scaling values of model depth and width, which are applied during model learning.
Figure 15 shows the graph summarizing mAP and inference time.
When a ratio of 0.67 and 1.00 for the model depth and width, respectively, was applied, the highest mAP value of approximately 95.6% was obtained; further, when a ratio of 0.67 and 0.25 was applied, mAP was the lowest at approximately 94.6%. In 6 cases, except for the initial model, when a ratio of 1.00 and 0.25 for the model depth and width, respectively, was applied, mAP and inference time were approximately 95.3% and 1.1 ms, respectively, which is the most suitable model for the system.
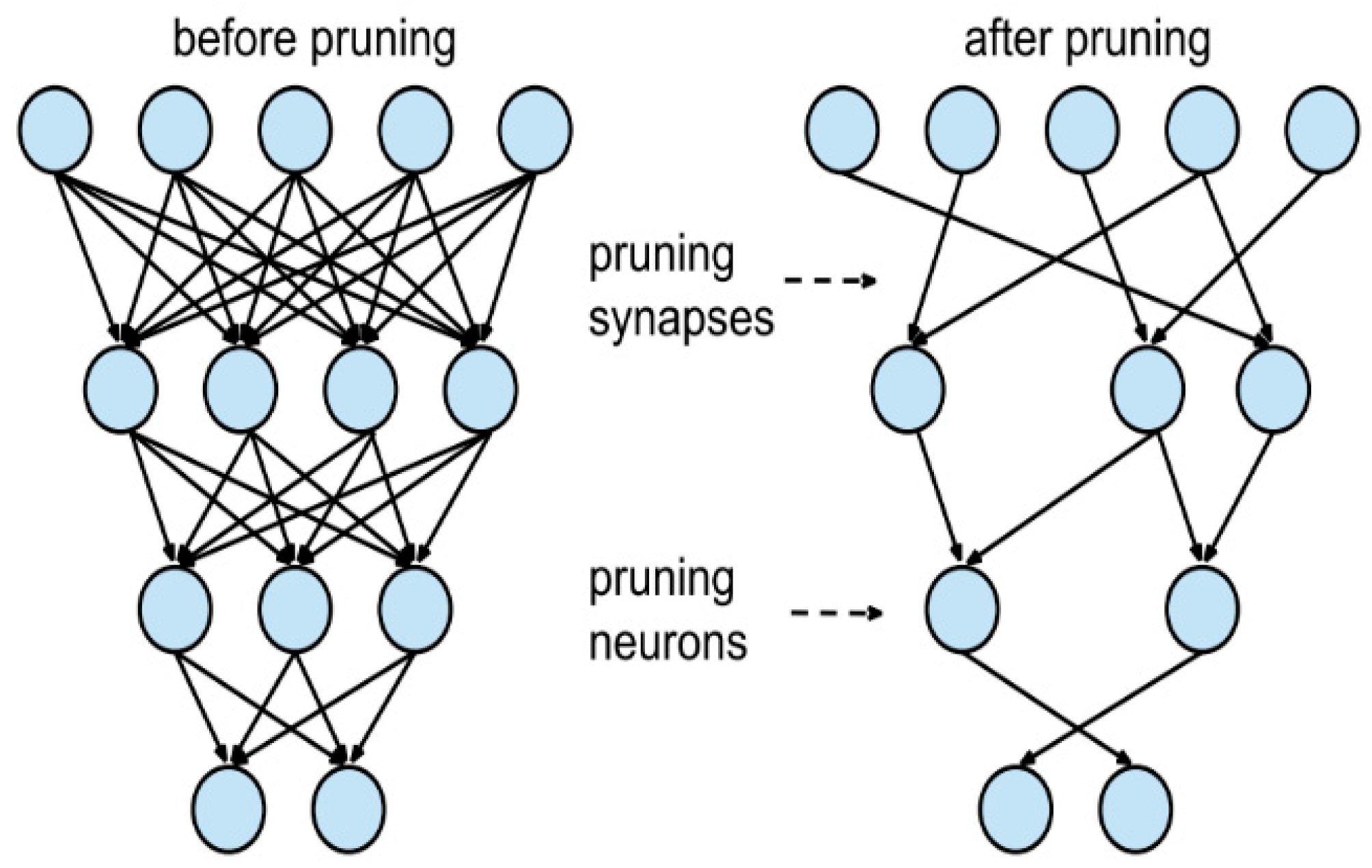
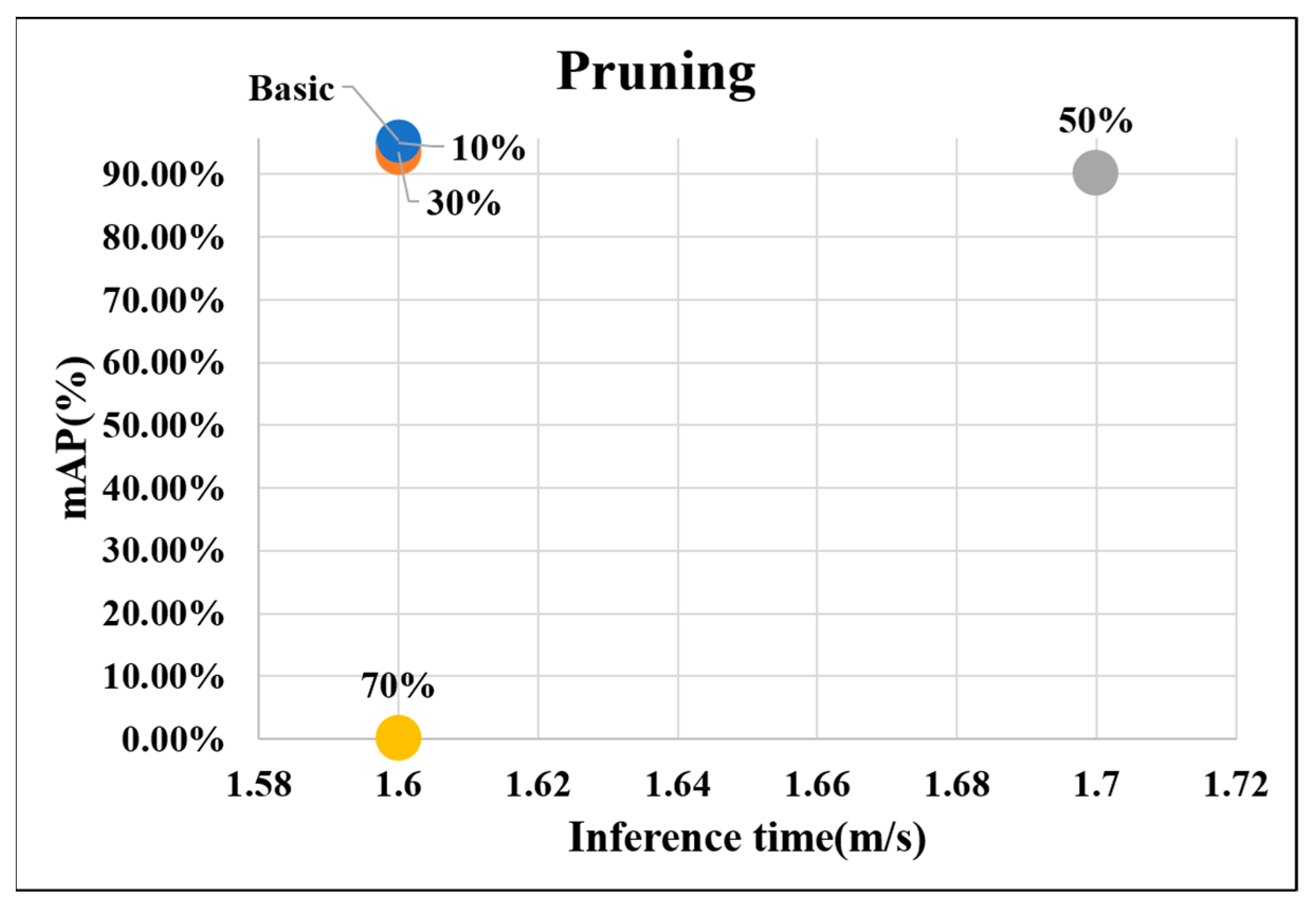
To analyze the trend of model performance that is revealed through the change in pruning value and find the suitable model, 4 cases of pruning values—10%, 30%, 50%, and 70%—were analyzed.
Figure 16 shows the graph summarizing the results of the four cases. When the pruning values were 10%, 30%, 50%, and 70%, mAP values were approximately 95%, 93.5%, 90.2%, and 0.0601%, and the inference times were 1.6, 1.6, 1.7, and 1.6 ms, respectively.
In conclusion, the performance tended to decrease as the lightweight value increased. Thus, the best performance was exhibited when the lightweight technique was set to 10%, which is the most suitable model for the system.
4.2. Analysis of Case Application Results
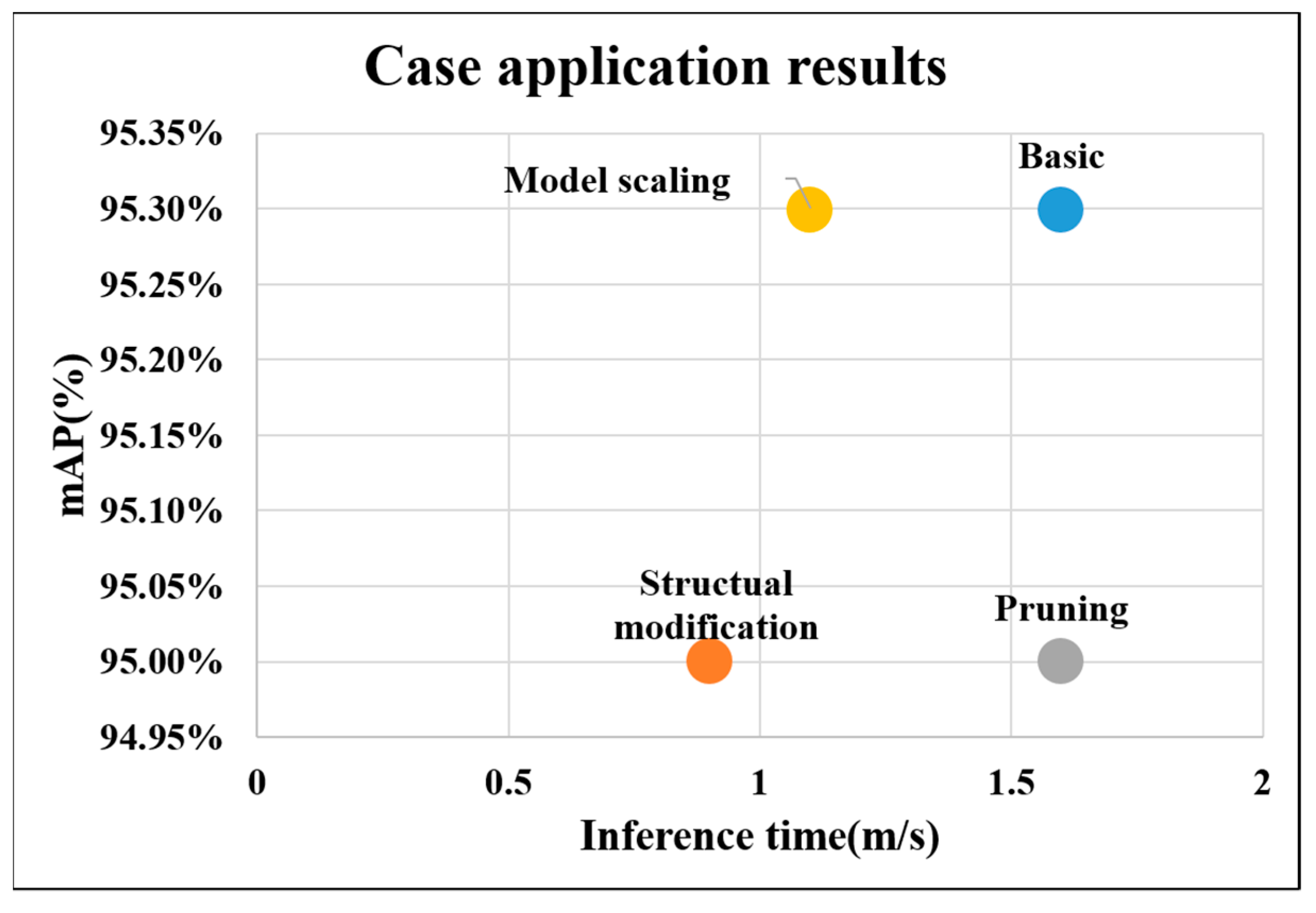
To find a suitable model for the defect detection system, three model improvement techniques were applied and their results were comparatively analyzed except for the initial model of the system.
In the case of structure modification, when one or two Conv blocks were added to the backbone, mAP was approximately 95% and the inference time was 0.9 ms, which was found to be the most suitable model for the system. In the case of model scaling, when a ratio of model depth and width (1.00 and 0.25) was applied, mAP was approximately 95.3% and the inference time was 1.1 ms, which was found to be the most suitable model. Finally, in the case of the lightweight technique, when 10% of the pruning value was applied, mAP was approximately 95% and the inference time was 1.6 ms, which was found to be the most suitable model for the system.
Figure 17 shows a graph comparing the most suitable models obtained using the three techniques applied to improve the performance of the initial system model. As verified in
Figure 16, when the initial model and the case of applying the lightweight technique were compared, the same inference time was revealed; however, the mAP value was relatively lower in the case of pruning. In the case of model scaling, the same mAP was exhibited, but the inference time was faster. Finally, in the case of structure modification, mAP was lower than that of the initial model, but the inference time was the fastest. In this study, the model that applied model scaling was selected as the most suitable model for the proposed system because it has the same mAP value as that of the initial model but a faster inference time based on the criteria that false defect detection should be low in practical inspection although faster inference time is preferred for the system application.
AP values for each class were analyzed through
Table 5. The AP values of ‘T-OK’ and ‘T-NG’ were high at about 98.3% and 99.5%, respectively. On the other hand, the AP values of ‘OK’ and ‘NG’ were measured relatively low at about 90.4% and 92.9%. Therefore, classes that measure relatively low AP values rather than the entire class should perform better.
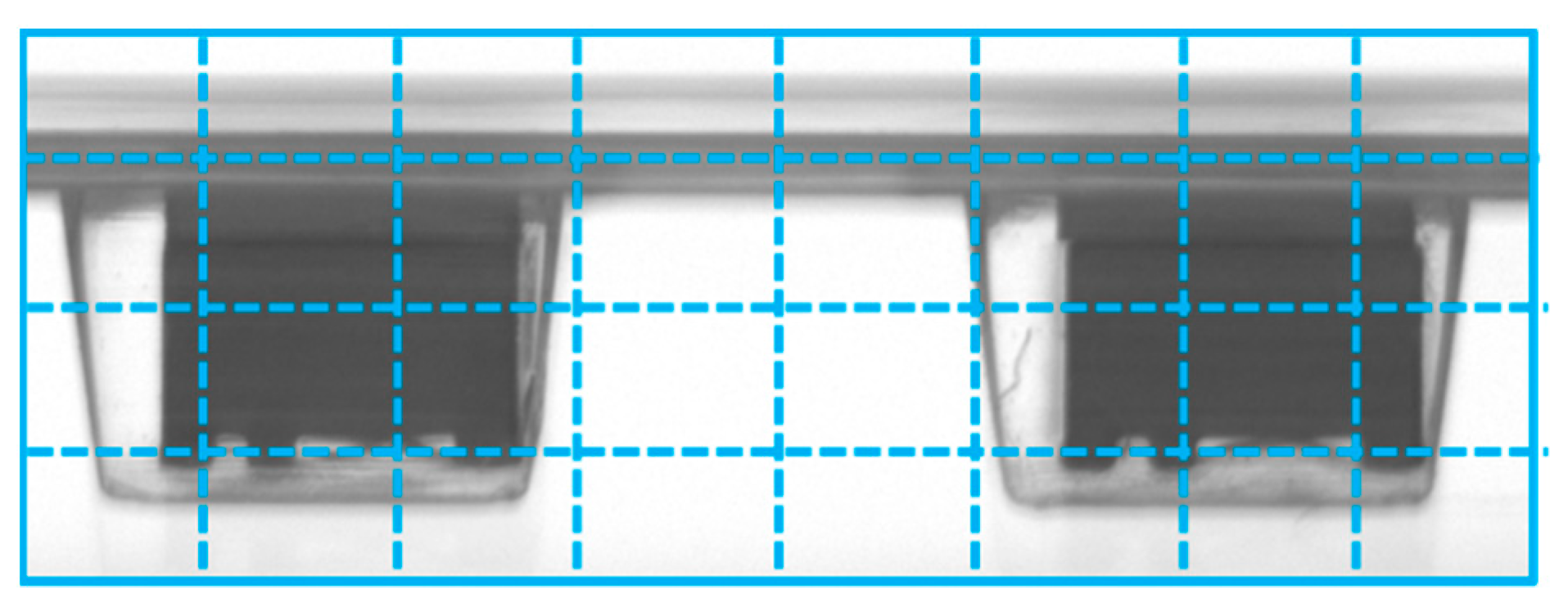
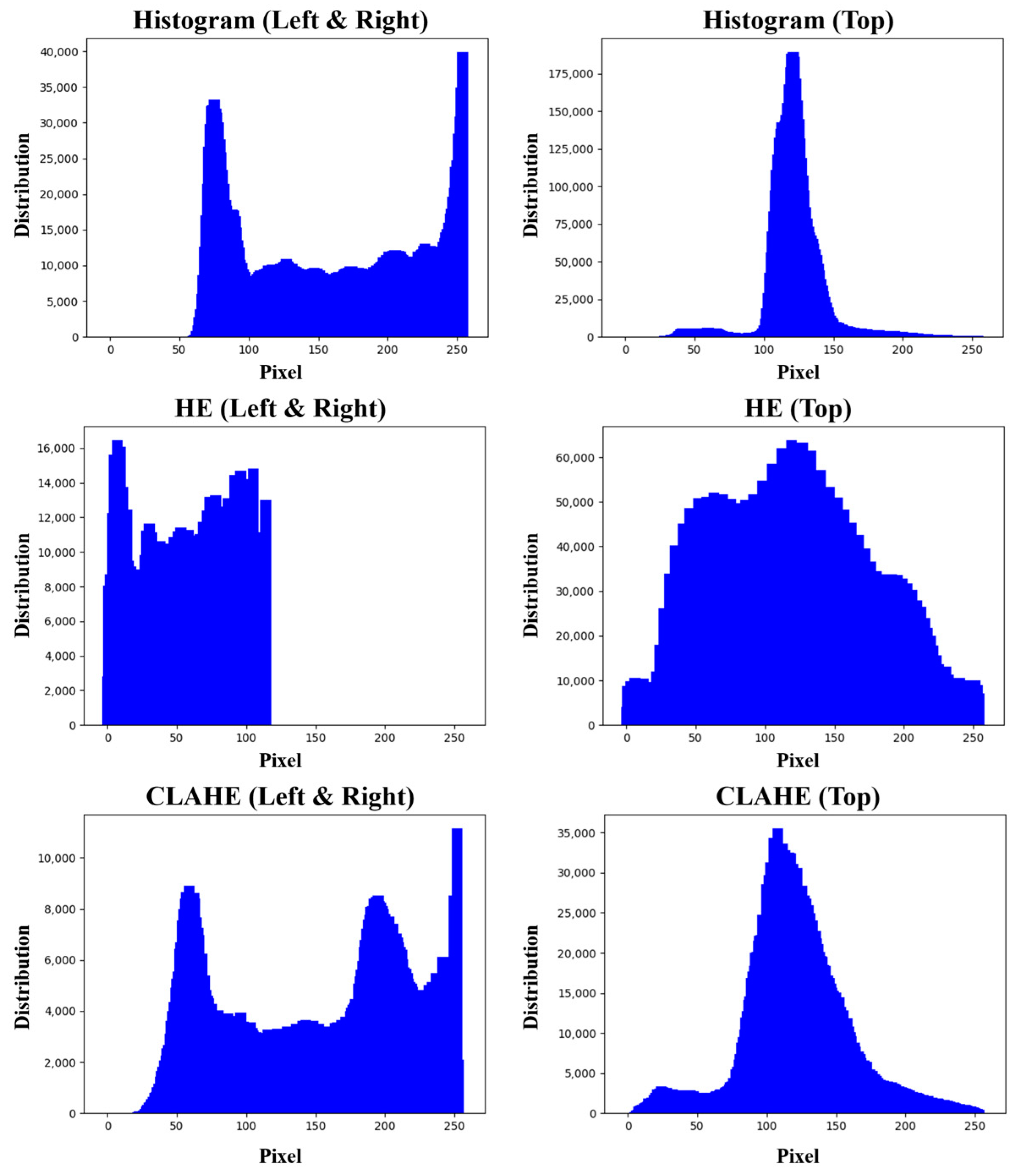
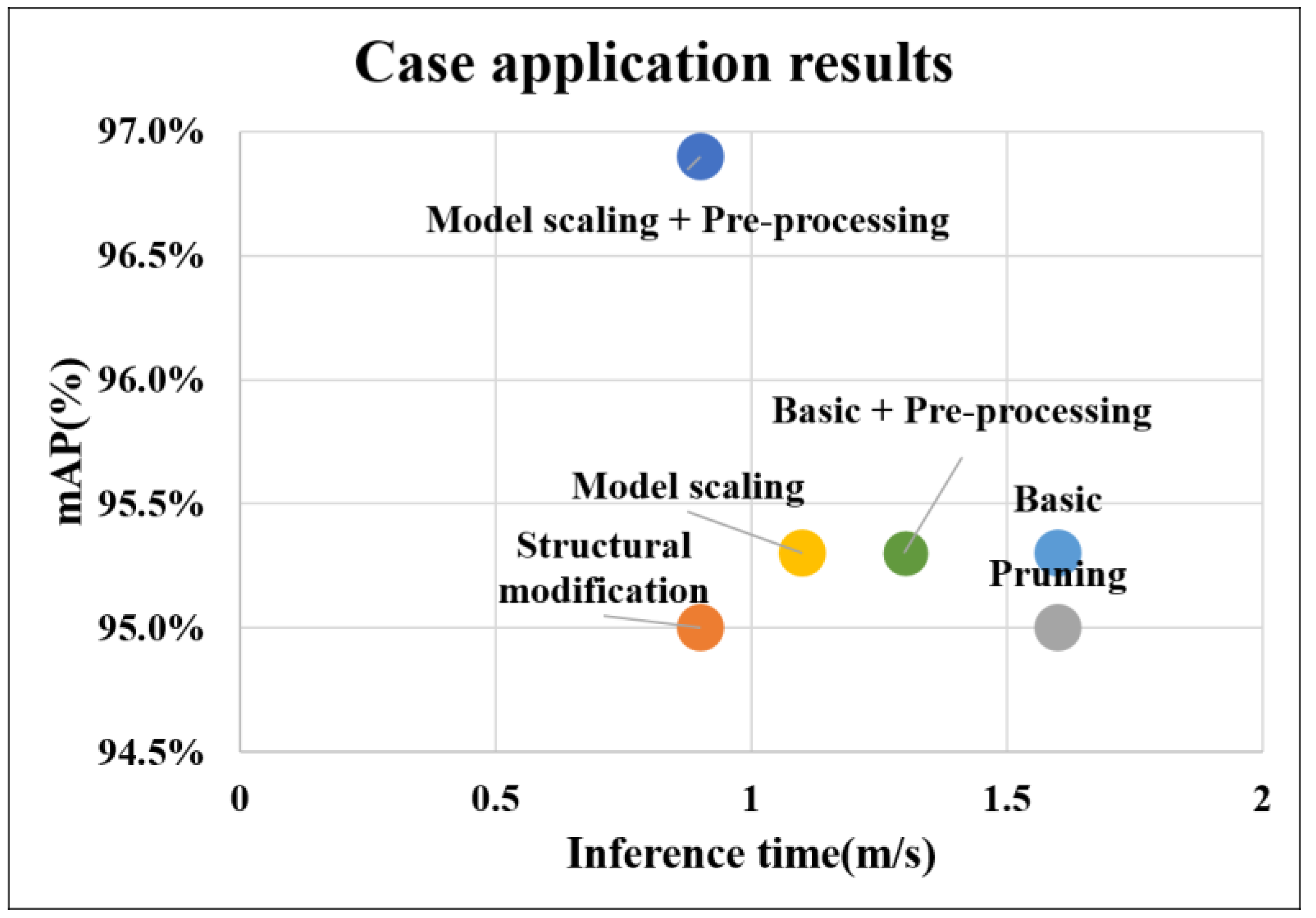
CLAHE was applied to the original dataset to further improve model performance, and model training was conducted in the same way as the model learning conditions of the model scaling, which was analyzed as the best model in
Figure 18. We aimed to find suitable parameters of CLAHE using the SSIM image similarity measurement technique. SSIM was used to calculate the similarity of 1000 images of original data extracted randomly from “Top,” “Left,” and “Right” classes and CLAHE-applied data.
Table 6 presents the calculation results obtained using 3 different grid sizes (8, 16, and 32), where the similarity is the highest when the grid size is 8 in all classes.
Based on the results in
Table 6, CLAHE-applied data with a grid size of 8 were added to the original dataset to perform learning. The added dataset contained 7600 images. Thus, a total of 20,541 images were used in model learning.
Figure 18 shows the results of training by adding data applying CLAHE to the basic model and the model applying model scaling, respectively. The final result shows that mAP were approximately 95.3% and 96.9% and the inference times were 1.3 ms and 0.9 ms. When analyzing the mAP value through
Table 7, it was observed that the mAP values of the ‘T-OK’ and ‘T-NG’ classes were maintained, and the mAP values of the ‘OK’ classes were improved. However, the value of ‘NG’ was relatively lowered by about 1.4%.
For further model optimization, performance analysis was conducted according to changes in hyperparameters.
Table 8 below summarizes the results of applying hyperparameter changes. The performance change according to the epoch shows the best performance when the epoch is 300. The learning rate shows the best performance in the cases of 0.01 and 0.001. Therefore, the optimal hyperparameter in this study is when the Epoch is 300 and the learning rate is 0.01 or 0.001. Based on this, it can be determined that the existing hyperparameters are appropriate for this study.


 ,
, 




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}