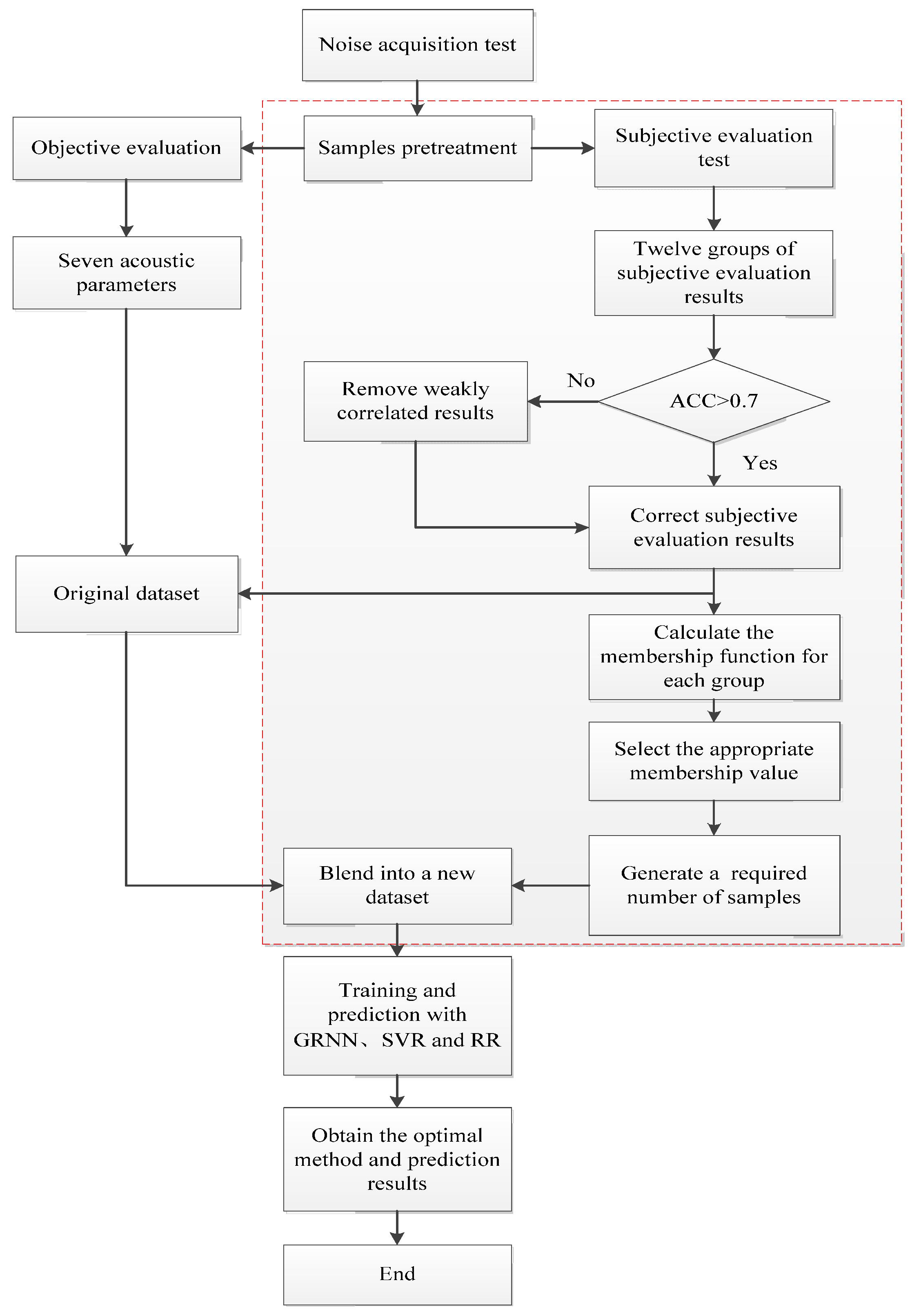
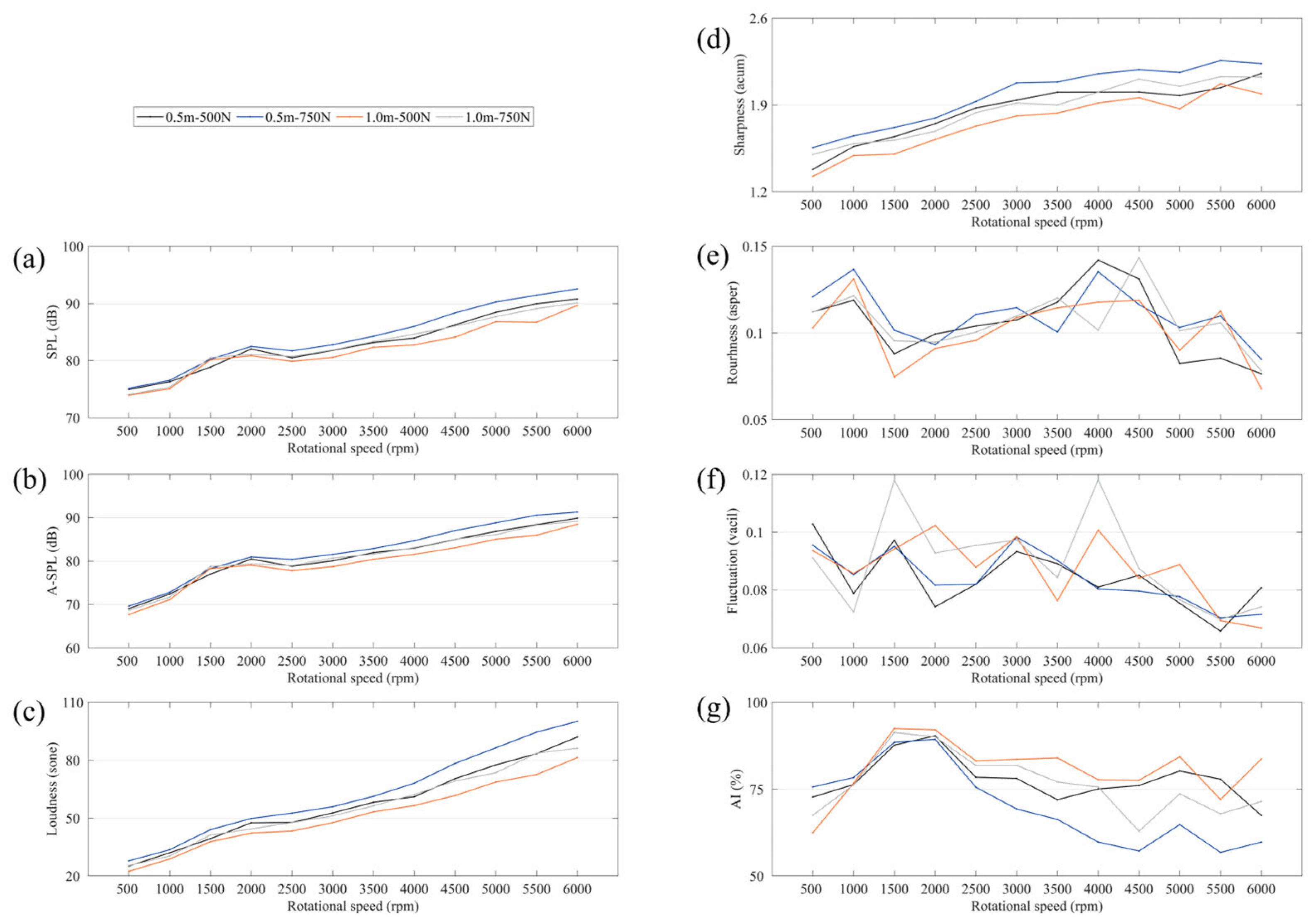
4.1. Modeling
To test the effect of fuzzy generation, different models need to be trained on the old and new datasets to compare the advantages and disadvantages of prediction results, and the ratio of training set to test set is 4:1. At the same time, the influence of five membership values on prediction results can be compared. Furthermore, when training with the original dataset, it can be regarded as the case where the membership value is equal to 1. In this paper, we set up different prediction models based on three methods: general regression neural network (GRNN), support vector regression (SVR) model, and ridge regression (RR). The reason why these three methods are chosen is that they all have their specific advantages: GRNN has a strong nonlinear mapping ability and can handle the nonlinear relationship between acoustic parameters and evaluation scores. SVR is more concerned with determining the best-fit line and limiting the error to a certain threshold. There is often a certain correlation between objective acoustic parameters, and RR can handle the strong correlation between variables to improve the stability of the model.
- (1)
GRNN model
General regression neural network (GRNN) is a type of neural network based on radial basis function (RBF), which is mainly used for regression analysis and function approximation. Generally speaking, GRNN mainly has two biggest advantages, on the one hand, the structure is simple, including the input layer, mode layer, summation layer, and output layer. On the other hand, there is only one key parameter called the smoothing factor, a small smoothing factor will cause the network to overfit, while a large smoothing factor may cause the network to underfit [
17,
18,
19].
To find the optimal smoothing factor, we choose to use the particle swarm optimization (PSO) algorithm. In this paper, the number of particles is set to 30 and the maximum number of iterations is set to 20. The optimization results of the smoothing factor are shown in the following
Table 6.
- (2)
SVR model
Support vector regression (SVR) is a regression version of support vector machines (SVM), but unlike SVM classification, where the goal is to find a hyperplane that maximizes the interval, SVR aims to find a hyperplane so that most of the data points fall within the tolerance range of this hyperplane. To perform nonlinear regression in high-dimensional space, SVR can use different kernel functions, such as linear kernel, polynomial kernel, RBF kernel, and sigmoid kernel. There are two key parameters
c and
g in SVR,
c is called the regularization parameter and
g is called the kernel parameter. The size of the
c value determines the tolerance of the model to error, and the size of the
g value determines the influence range of each training sample [
20,
21,
22].
We establish an SVR model with the RBF kernel in this research and use PSO to obtain the best
c value and best
g value. The initial conditions of PSO are set: the number of particles is 30 and the maximum number of iterations is 20. The final optimization results are shown in
Table 7.
- (3)
RR model
Ridge regression (RR), also known as Tikhonov regularization, is a regularized version of linear regression. It solves the multicollinearity problem in linear regression by adding a regular term to the loss function, thereby improving the stability and predictive power of the model. RR has a parameter
λ that controls the strength of the regularization, and when
λ = 0, RR is an ordinary linear regression. As
λ increases, the intensity of regularization increases and the complexity of the model decreases. Through cross-validation, we can find the best
λ value that minimizes the cross-validation error [
23,
24,
25,
26]. In this paper, we use five-fold cross-validation to get the best
λ value under different datasets, as shown in
Table 8.
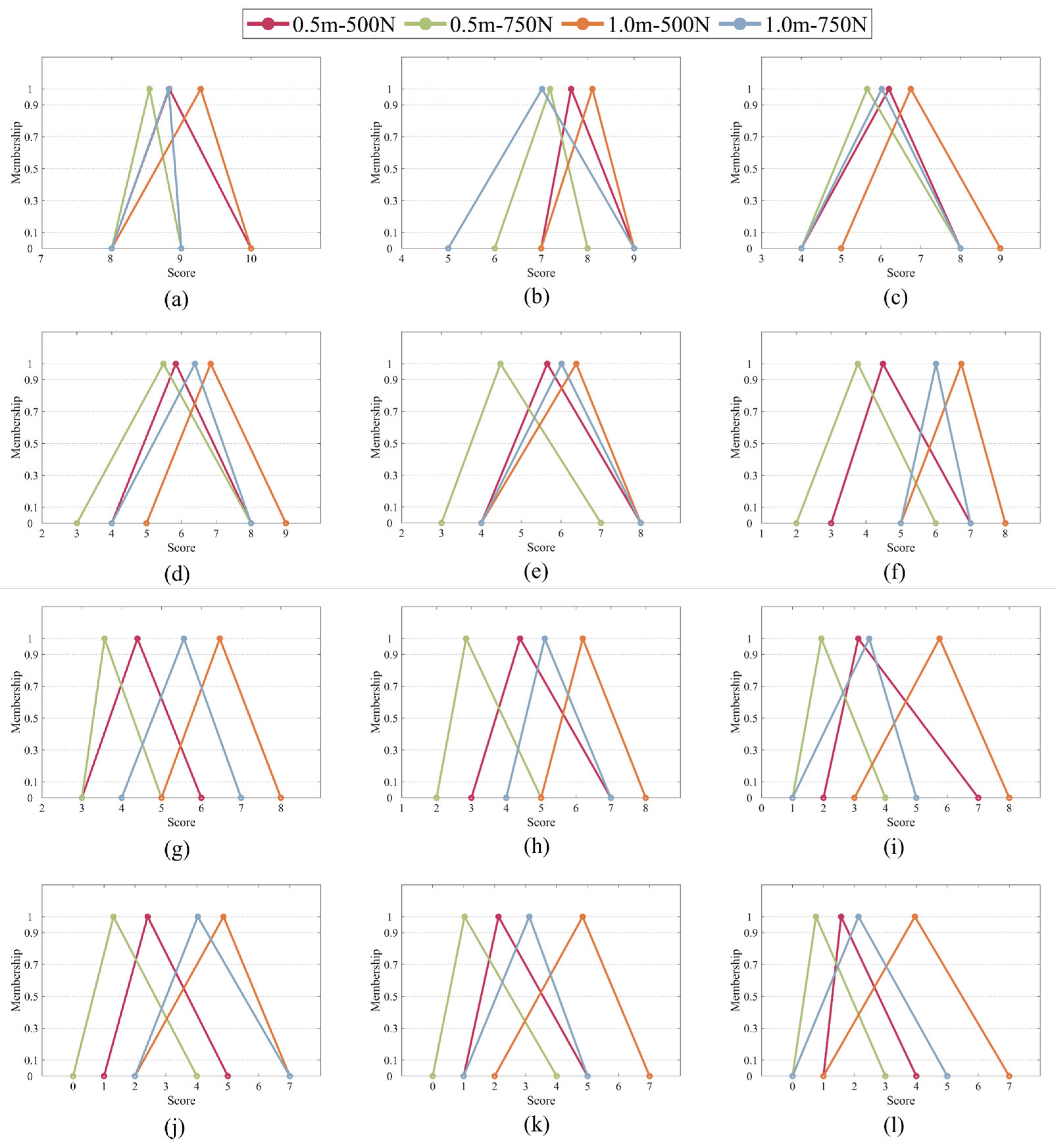
4.2. Comparison of Prediction Results
To evaluate the effect of the prediction model more directly, mean absolute percentage error (MAPE), coefficient of determination (R2), and residual predictive deviation (RPD) are used as evaluation indexes. Among the three evaluation indexes, MAPE is used to compare the prediction accuracy of the three models, R2 is used to represent the fitting degree of the three models, and RPD is used to measure the generalization ability and stability of the three models.
MAPE is a percentage that represents the average relative difference between the predicted error and the true value. A lower MAPE value indicates that the model’s predictions are more accurate. Based on MAPE, we can compute the prediction accuracy as follows:
where
n is the number of samples,
is the predicted value of the sample, and
yi is the true value of the sample.
On the six datasets, we trained the three models with seven acoustic parameters as inputs and subjective evaluation scores as outputs, and the optimal parameters of each model are substituted by
Table 6,
Table 7 and
Table 8 above. The comparison of prediction accuracy on the three models is shown in
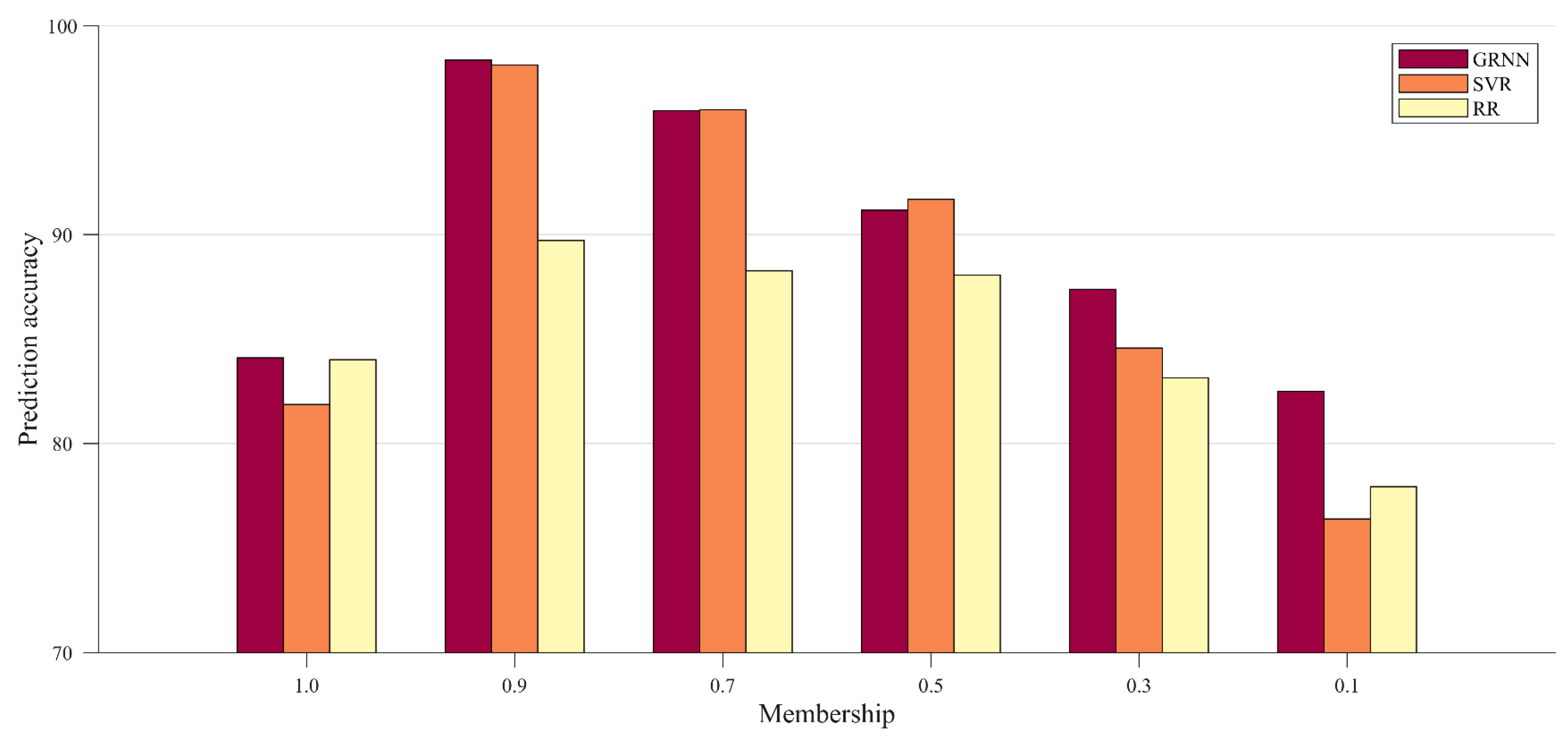
Figure 8.
As can be seen from
Figure 8, on the new data set generated by fuzzy generation, the prediction accuracy of the three models all showed a downward trend with the decrease of membership value. Among the three models, the GRNN model has more advantages than the other two models. Although the accuracy of the GRNN model decreases with the decrease in membership value, the decline trend is more uniform. When the membership value is less than 0.5, the advantages of the GRNN model are more prominent. For the SVR model, when the membership value is not less than 0.5, its prediction accuracy is close to the GRNN model, and sometimes even a little better. However, when the membership value is less than 0.5, the accuracy of the SVR model drops sharply. When the membership value is not less than 0.3, the prediction accuracy of the SVR model is obviously greater than that of the RR model, but when the membership value is a minimum of 0.1, the prediction accuracy of the SVR model is the lowest. For the RR model, the changing trend of its prediction accuracy is basically the same as the SVR model. Though the decline trend is slower, the RR model is always weaker than the SVR model when the membership value is not less than 0.3.
In
Figure 8, compared with training on the original dataset (i.e., when the membership value is equal to 1), when the membership value is not less than 0.5, the use of the fuzzy generation method greatly improves the prediction accuracy of the models. When the membership value is 0.3, the accuracy of the GRNN model and the SVR model is still greater, but the RR model is no longer better. When the membership value is 0.1, the accuracy of the three models is worse than that trained under the original dataset, and the accuracy of the SVR model is the lowest. In general, the results show that rational use of fuzzy generation can improve the prediction accuracy of models. By comparing the prediction accuracy of the three models, it can be found that the GRNN model has the best performance, and it not only has high prediction accuracy when the membership value is large, but it also has strong resistance to large data noise when the membership value is small.
The values of R
2 range from 0 to 1, the closer the value is to 1, the better the model fits. If the R
2 value is close to 0, it means that the model is not explaining most of the variation in the data.
where
n is the number of samples,
is the predicted value of the sample,
yi is the true value of the sample, and
is the average of the predicted values.
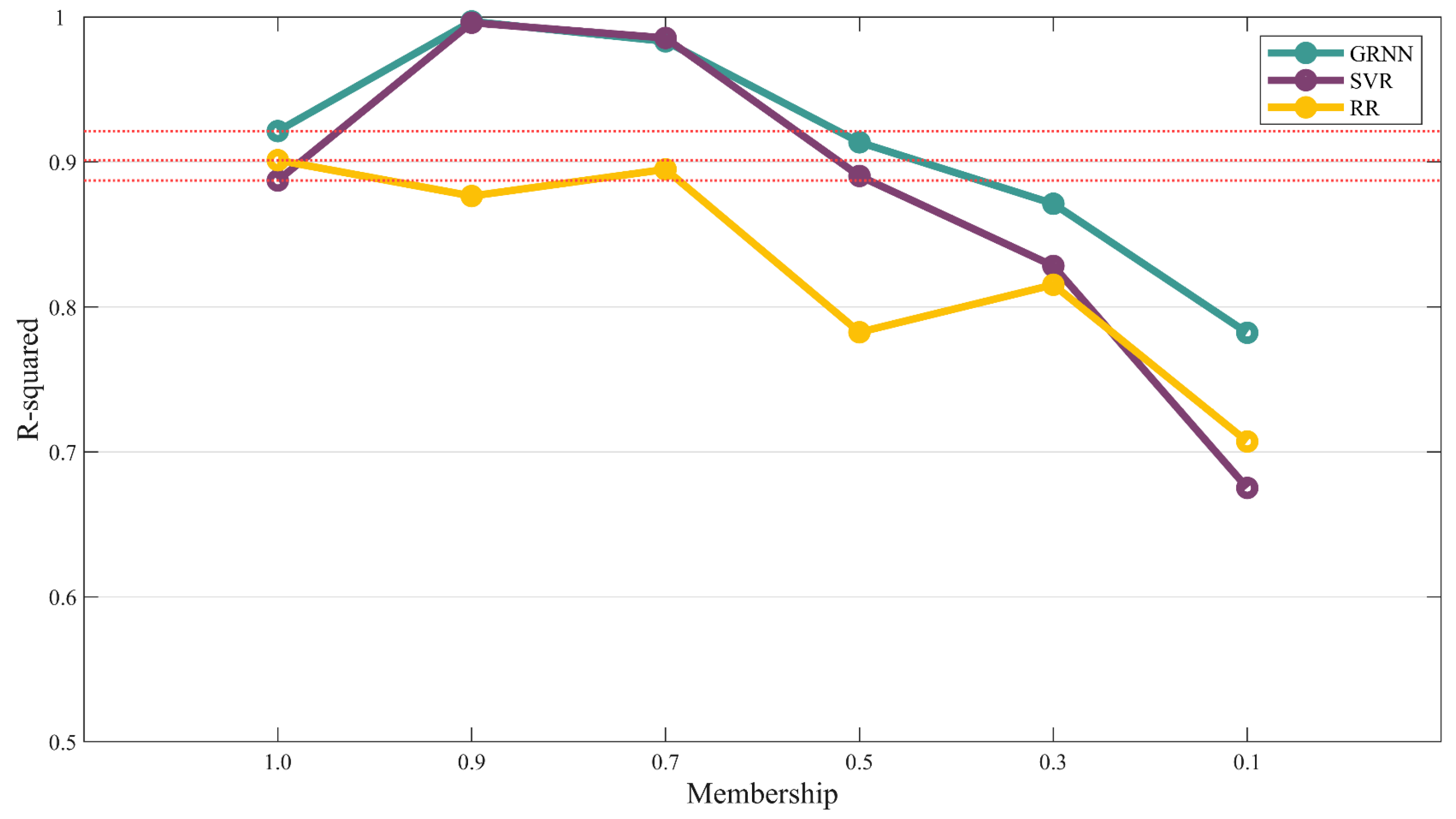
The comparison of R
2 on the three models is shown in
Figure 9. Based on
Figure 9, we can see that on the new dataset, the fitting degree of both the GRNN model and the SVR model is positively correlated with the membership value, and the GRNN model is better than the SVR model overall. For the RR model, the fitting degree fluctuates up and down as the membership value decreases. This phenomenon of R
2 value fluctuation indicates that with the decrease in membership value, the degree of disturbance gradually increases, and the noise of data also increases. However, the specific form and distribution of the noise may be different every time, and the RR model cannot handle the influence of these noises well, resulting in the fluctuation of the R
2 value. Compared with the membership value of 1, the fitting degrees of both the GRNN model and SVR model are obviously better when the membership value is 0.7 and 0.9. But when the membership value is less than 0.5, the fitting degree is worse. For the RR model, the fitting degree is lower for all membership values, indicating that the data noise introduced by fuzzy generation damages the performance of the model. By comparing the fitting degree of the three models, it can be found that when the membership degree is large, the fitting degree of the GRNN and SVR models is similar and far better than that of the RR model. When the membership value decreases gradually, it can be seen that the GRNN model has the strongest fitting ability.
A high RPD value means that the prediction error of the model is relatively small, indicating that the model has good consistency and stability under different datasets or conditions.
where
n is the number of samples,
is the predicted value of the sample,
yi is the true value of the sample, and
is the average of the predicted values.
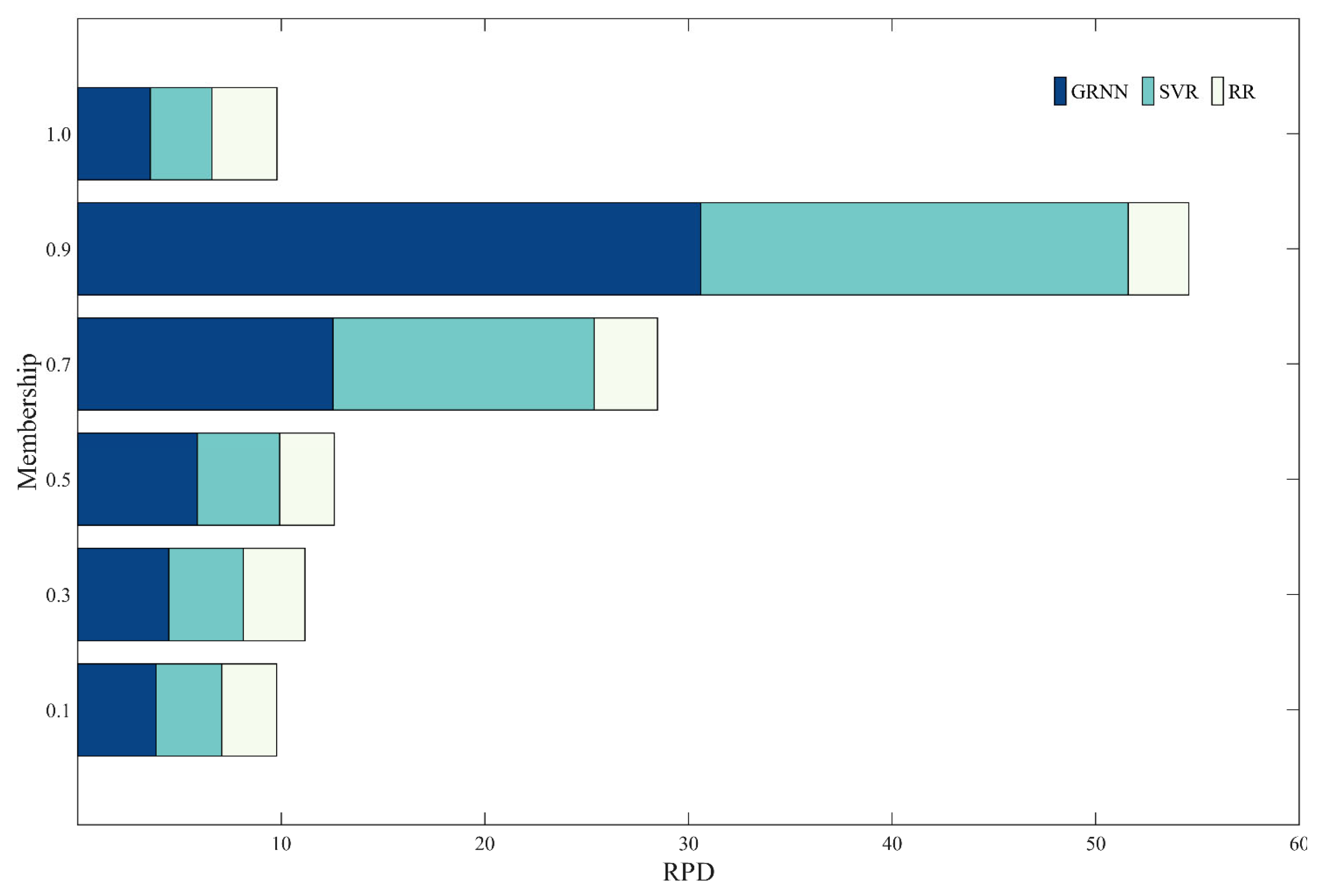
The comparison of RPD on the three models is shown in
Figure 10. As can be seen from
Figure 10, after the fuzzy generation method is used, the model stability of the GRNN model is the best, the SVR model is second, and the RR model is the worst. With the decrease in membership value, the RPD values of both the GRNN model and the SVR model show a decreasing trend, which indicates that the stability of the model becomes worse. For the RR model, the RPD value is not related to the size of the membership value, and the stability of the model remains basically unchanged at a low level. Compared with the membership value of 1, the stability of both the GRNN model and the SVR model is greatly improved by using the fuzzy generation method. Even when the membership value is at the minimum of 0.1, they still have a good performance. However, for the RR model, the use of the fuzzy generation method slightly reduces the stability of the model. By comparing the stability of the three models, the use of fuzzy generation can make GRNN and SVR models more stable, in which the GRNN model is stronger than the SVR, but both of them are significantly better than the RR model.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}