
SupCon-MPL-DP: Supervised Contrastive Learning with Meta Pseudo Labels for Deepfake Image Detection

Abstract
:1. Introduction
- (1)
- The proposed method enables additional training through unlabeled data. Especially, while two models are trained simultaneously, the student model infers information about unlabeled data from the other model and provides feedback, allowing for additional training to be conducted with less bias towards a specific model. Ultimately, the proposed method enhances the performance of deepfake detection by enabling additional training with a large amount of unlabeled data.
- (2)
- Our model enables generalized deepfake detection model training through contrastive learning. We improved the generalized deepfake detection performance on unknown data, which was previously low in the Meta Pseudo Labels-based deepfake detection model [24], through contrastive learning.
- (3)
- Our model exhibited higher deepfake detection performance compared with all other models in the comparison with various generalized deepfake detection models [24,31,34,35]. The experimental results demonstrate that our model outperforms existing deepfake detection models, showing robust detection capability across diverse labeled datasets and even unknown generational deepfakes.
2. Related Works
2.1. Generalized Deepfake Detection
2.2. Contrastive Representation Learning in Deepfake Detection
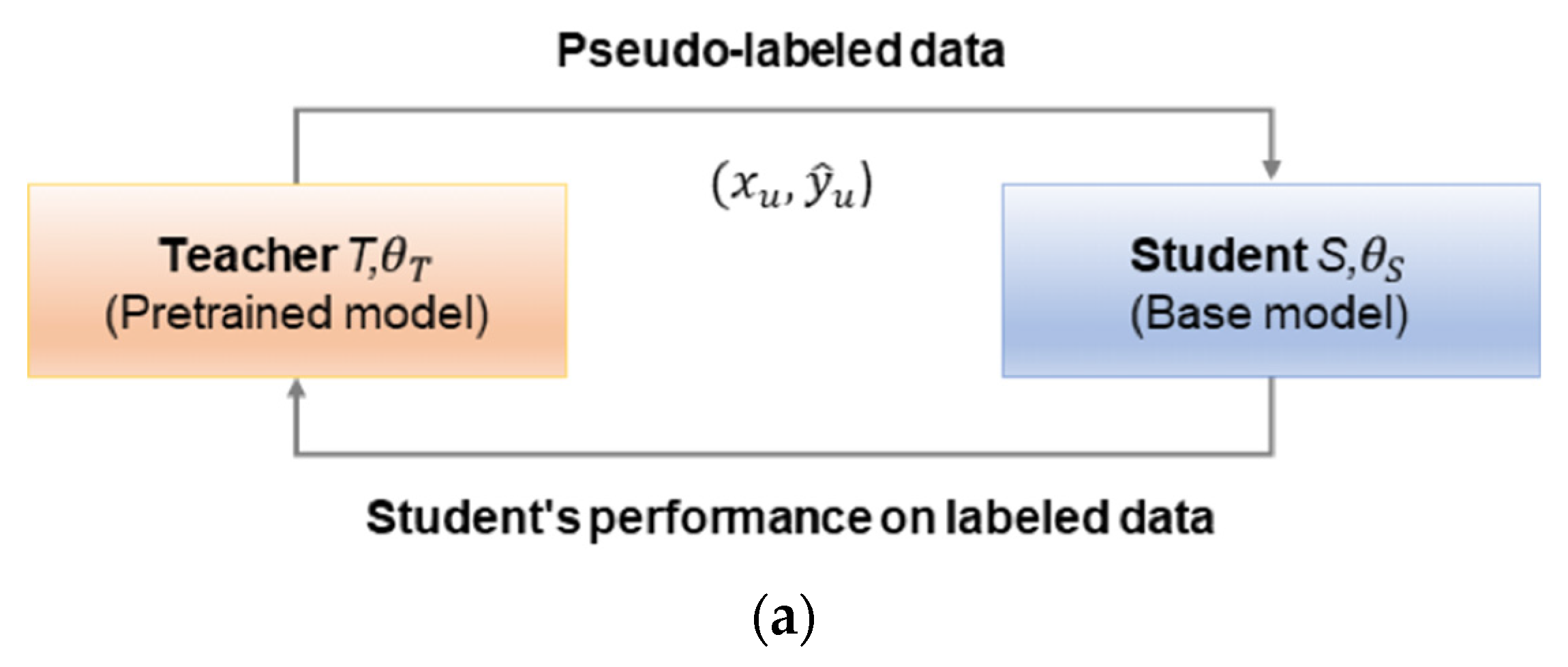
2.3. Meta Pseudo Labels
3. Proposed SupCon-MPL-Based Deepfake Detection
3.1. Proposed Training Strategy
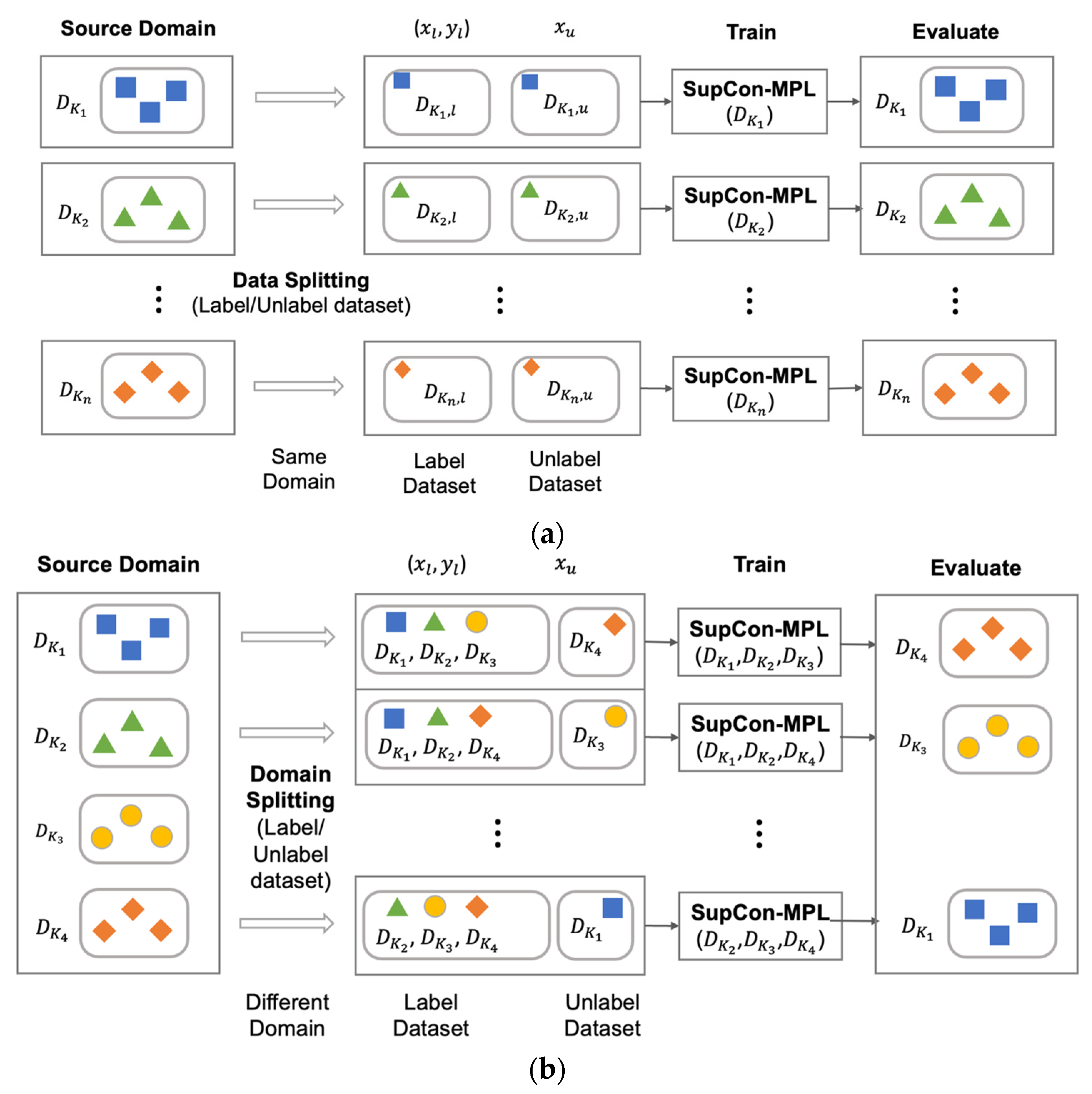
3.1.1. Known Domain and Unknown Domain in Deepfake
3.1.2. Training Strategy for Deepfake Unknown Domain Detection
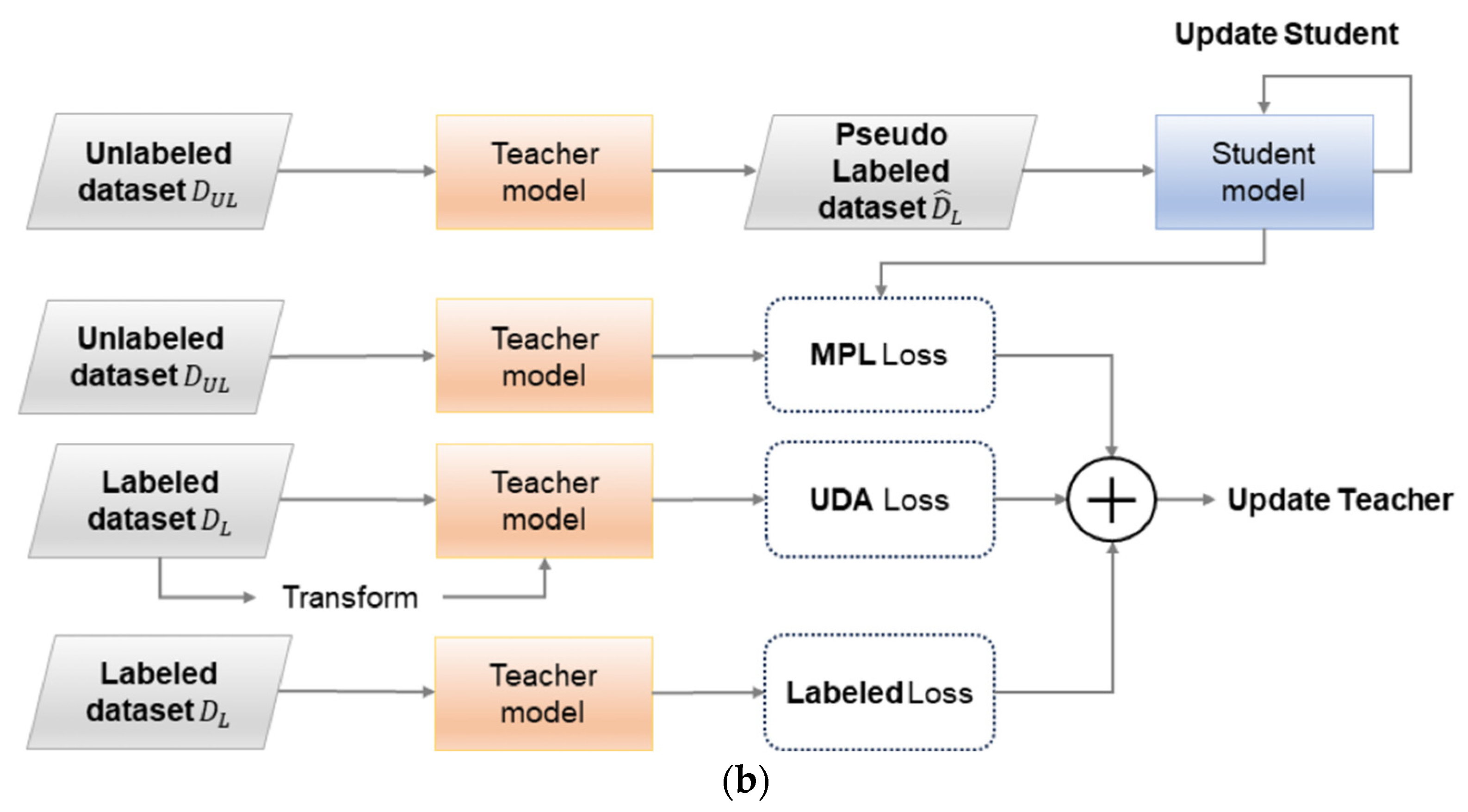
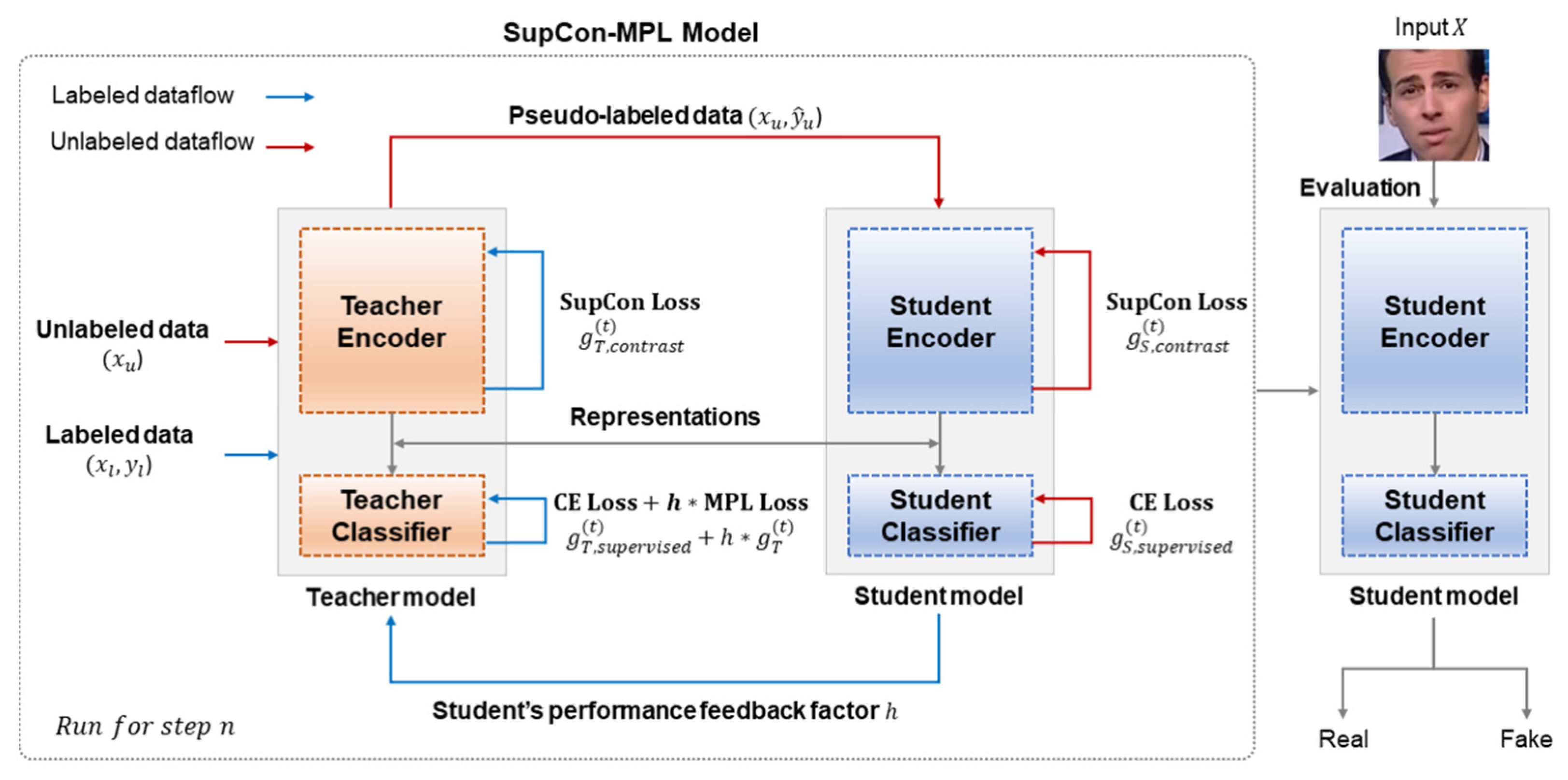
3.2. SupCon-MPL: Supervised Contrastive Learning with Meta Pseudo Labels
3.3. SupCon-MPL Loss Function
| Algorithm 1 The Deepfake detection method based on SupCon-MPL (Pseudo code) | ||
| Set Labeled data, Unlabeled data with domain splitting [37]. Input: Labeled data , and unlabeled data . Initialize and . Pretrain Teacher model with , . For to do | ||
| Sample an unlabeled example and a labeled example , . | ||
| Sample a pseudo label . | ||
| Compute contrastive loss of student encoder using the pseudo label : | ||
| Update the student encoder using the pseudo label : | ||
| Update the student classifier using the pseudo label : | ||
| Compute contrastive loss of teacher encoder using the labeled data : | ||
| Update the teacher encoder using the labeled data : | ||
| Compute gradient on labeled data : | ||
| Compute feedback factor from student: | ||
| Compute MPL loss from unlabeled data : | ||
| Update the teacher classifier : | ||
| end for return Only the student encoder and classifier are returned for evaluations. | ||
4. Experiment
4.1. Experiment Setup
4.2. Single-Domain Experiment
4.3. Multi-Domain Experiment
4.4. SupCon-MPL Experiment
4.5. Deepfake Scenario Experiment
4.6. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| CRL | Contrastive Representation Learning. |
| MPL | Meta Pseudo Labels. |
| GAN | Generative Adversarial Networks. |
| VAE | Variational Auto Encoder. |
| Known domain which involves a set of known deepfake generative models. | |
| Unknown domain which involves a set of unknown deepfake generative models. | |
| Deepfake datasets of the known domain which are labeled. | |
| Deepfake datasets of the unknown domain which are unlabeled. | |
| -th known deepfake generative model in known domain. | |
| -th unknown deepfake generative model in unknown domain. | |
| Images of real and deepfake. | |
| Labels of real and deepfake. | |
| Labeled dataset used while training. | |
| Unlabeled dataset used while training. | |
| Teacher model of SupCon-MPL. | |
| Student model of SupCon-MPL. | |
| Parameters of the teacher model’s classifier. | |
| Parameters of the student model’s classifier. | |
| Minimized parameters of model in SupCon-MPL. | |
| Parameters of teacher encoder. | |
| Parameters of student encoder. | |
| Learning rate used while training. | |
| Classifier in the teacher model. | |
| Encoder in the teacher model. | |
| Classifier in the student model. | |
| Encoder in the student model. | |
| Labeled images used while training. | |
| Unlabeled images used while training. | |
| Labels used while training. | |
| Pseudo label generated by the teacher model. | |
| Embedding value derived by passing the labeled data through the teacher encoder. | |
| Embedding value derived by passing the unlabeled data through the student encoder. | |
| Student model’s feedback factor. | |
| Index of the randomly augmented data. | |
| Set of indices for all positives in the batch. | |
| Embedding values of each randomly augmented image. |
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Sohn, K.; Lee, H.; Yan, X. Learning structured output representation using deep conditional generative models. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar] [CrossRef]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the ICML 2021 Workshop on Unsupervised Reinforcement Learning, Virtual, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- DeepFaceLab. Available online: https://github.com/iperov/DeepFaceLab (accessed on 5 March 2024).
- Deepswap. Available online: https://deepfaceswap.ai/ (accessed on 5 March 2024).
- Synthesia. Available online: https://www.synthesia.io (accessed on 5 March 2024).
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar] [CrossRef]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Norouzi, M. Photorealistic text-to-image diffusion models with deep language understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36479–36494. [Google Scholar]
- Song, Y.; Dhariwal, P.; Chen, M.; Sutskever, I. Consistency models. arXiv 2023, arXiv:2303.01469. [Google Scholar]
- Li, Y.; Lyu, S. Exposing deepfake videos by detecting face warping artifacts. arXiv 2018, arXiv:1811.00656. [Google Scholar]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops, Waikoloa, HI, USA, 7–11 June 2019; pp. 83–92. [Google Scholar] [CrossRef]
- Li, Y.; Chang, M.C.; Lyu, S. In ictu oculi: Exposing ai generated fake face videos by detecting eye blinking. arXiv 2018, arXiv:1806.02877. [Google Scholar]
- Ciftci, U.A.; Demir, I.; Yin, L. Fakecatcher: Detection of synthetic portrait videos using biological signals. IEEE Trans. Pattern Anal. Mach. Intell. 2020, early access. [CrossRef]
- Coccomini, D.A.; Messina, N.; Gennaro, C.; Falchi, F. Combining efficientnet and vision transformers for video deepfake detection. In Proceedings of the International Conference on Image Analysis and Processing, Lecce, Italy, 23–27 May 2022; pp. 219–229. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Los Angeles, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar] [CrossRef]
- Moon, K.-H.; Ok, S.-Y.; Seo, J.; Lee, S.-H. Meta Pseudo Labels Based Deepfake Video Detection. J. Korea Multimed. Soc. 2024, 27, 9–21. [Google Scholar] [CrossRef]
- Jain, A.; Korshunov, P.; Marcel, S. Improving generalization of deepfake detection by training for attribution. In Proceedings of the 2021 IEEE 23rd International Workshop on Multimedia Signal Processing, Tampere, Finland, 6–8 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Nadimpalli, A.V.; Rattani, A. On improving cross-dataset generalization of deepfake detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 91–99. [Google Scholar] [CrossRef]
- Hsu, C.C.; Lee, C.Y.; Zhuang, Y.X. Learning to detect fake face images in the wild. In Proceedings of the 2018 International Symposium on Computer, Consumer and Control, Taichung, Taiwan, 6–8 December 2018; pp. 388–391. [Google Scholar] [CrossRef]
- Dong, F.; Zou, X.; Wang, J.; Liu, X. Contrastive learning-based general Deepfake detection with multi-scale RGB frequency clues. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 90–99. [Google Scholar] [CrossRef]
- Shiohara, K.; Yamasaki, T. Detecting deepfakes with self-blended images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18720–18729. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, Y.; Song, Y.; Wang, J.; Liu, L. Ost: Improving generalization of deepfake detection via one-shot test-time training. Adv. Neural Inf. Process. Syst. 2022, 35, 24597–24610. [Google Scholar]
- Aneja, S.; Nießner, M. Generalized zero and few-shot transfer for facial forgery detection. arXiv 2020, arXiv:2006.11863. [Google Scholar]
- Kim, M.; Tariq, S.; Woo, S.S. Fretal: Generalizing deepfake detection using knowledge distillation and representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1001–1012. [Google Scholar] [CrossRef]
- Qi, H.; Guo, Q.; Juefei-Xu, F.; Xie, X.; Ma, L.; Feng, W.; Zhao, J. Deeprhythm: Exposing deepfakes with attentional visual heartbeat rhythms. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 4318–4327. [Google Scholar] [CrossRef]
- Lee, S.; Tariq, S.; Kim, J.; Woo, S.S. Tar: Generalized forensic framework to detect deepfakes using weakly supervised learning. In Proceedings of the IFIP International Conference on ICT Systems Security and Privacy Protection, Oslo, Norway, 22–24 June 2021; pp. 351–366. [Google Scholar] [CrossRef]
- Xu, Y.; Raja, K.; Pedersen, M. Supervised contrastive learning for generalizable and explainable deepfakes detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 379–389. [Google Scholar]
- Fung, S.; Lu, X.; Zhang, C.; Li, C.T. DeepfakeUCL: Deepfake Detection via Unsupervised Contrastive Learning. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Pham, H.; Dai, Z.; Xie, Q.; Le, Q.V. Meta pseudo labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11557–11568. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Niessner, M. Faceforensics++: Learning to Detect Manipulated Facial Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar] [CrossRef]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C.C. The deepfake detection challenge (dfdc) dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Li, Y.Z.; Yang, X.; Sun, P.; Qi, H.G.; Lyu, S. Celeb-DF: A Large-scale Challenging Dataset for DeepFake Forensics. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3207–3216. [Google Scholar] [CrossRef]
- Korshunov, P.; Marcel, S. Deepfakes: A new threat to face recognition? assessment and detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 1735–1742. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10687–10698. [Google Scholar] [CrossRef]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised data augmentation for consistency training. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 6256–6268. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]




| Baseline Model | Train Dataset | Test Dataset | Pretrained Model | MPL Model | ||||
|---|---|---|---|---|---|---|---|---|
| ACC | AUC | F1 Score | ACC | AUC | F1 Score | |||
| EfficientNetb5 [21] | DF | DF | 89.35 | 89.35 | 89.19 | 90.08 | 90.08 | 90.36 |
| F2F | F2F | 77.21 | 77.21 | 77.61 | 80.35 | 80.35 | 79.45 | |
| FS | FS | 84.52 | 84.31 | 83.20 | 87.90 | 87.43 | 85.98 | |
| NT | NT | 64.13 | 63.33 | 58.18 | 74.79 | 74.47 | 71.36 | |
| Baseline Model | Train Dataset | Test Dataset | Pretrained Model | MPL Model | ||||
|---|---|---|---|---|---|---|---|---|
| ACC | AUC | F1 Score | ACC | AUC | F1 Score | |||
| EfficientNetb5 [21] | DF | F2F | 51.59 | 51.60 | 22.09 | 51.70 | 51.70 | 23.01 |
| FS | 55.97 | 52.06 | 23.23 | 56.45 | 52.65 | 25.01 | ||
| NT | 55.37 | 51.26 | 20.06 | 55.41 | 51.37 | 21.28 | ||
| F2F | DF | 57.56 | 57.55 | 47.78 | 53.87 | 53.84 | 32.11 | |
| FS | 56.47 | 54.05 | 39.66 | 55.48 | 51.92 | 26.57 | ||
| NT | 54.63 | 51.91 | 33.96 | 54.76 | 50.99 | 23.26 | ||
| FS | DF | 57.25 | 57.22 | 39.84 | 57.61 | 57.88 | 36.54 | |
| F2F | 51.76 | 51.77 | 25.78 | 51.98 | 51.99 | 20.16 | ||
| NT | 53.79 | 49.89 | 20.80 | 54.32 | 49.80 | 12.35 | ||
| NT | DF | 58.72 | 58.71 | 52.73 | 61.03 | 61.00 | 52.78 | |
| F2F | 54.52 | 54.53 | 45.23 | 55.88 | 55.89 | 43.68 | ||
| FS | 51.65 | 49.42 | 34.03 | 53.29 | 49.34 | 27.25 | ||
| Baseline Model | Train Dataset | Test Dataset | Pretrained Model | MPL Model | ||||
|---|---|---|---|---|---|---|---|---|
| ACC | AUC | F1 Score | ACC | AUC | F1 Score | |||
| ResNet50 [50] | DF | DF | 91.16 | 91.16 | 90.91 | 91.29 | 91.30 | 90.97 |
| F2F | F2F | 82.47 | 82.48 | 81.84 | 83.98 | 83.97 | 82.75 | |
| FS | FS | 87.55 | 87.21 | 86.01 | 88.31 | 88.09 | 87.06 | |
| NT | NT | 74.96 | 74.28 | 71.20 | 76.22 | 75.84 | 73.15 | |
| Baseline Model | Train Dataset | Test Dataset | Pretrained Model | MPL Model | ||||
|---|---|---|---|---|---|---|---|---|
| ACC | AUC | F1 Score | ACC | AUC | F1 Score | |||
| ResNet50 [50] | DF | F2F | 52.91 | 52.89 | 22.41 | 51.92 | 51.86 | 20.36 |
| FS | 56.80 | 52.68 | 21.41 | 57.02 | 53.00 | 22.63 | ||
| NT | 55.91 | 51.77 | 18.54 | 55.45 | 51.33 | 18.53 | ||
| F2F | DF | 53.94 | 53.90 | 31.72 | 53.79 | 53.75 | 28.28 | |
| FS | 54.62 | 50.97 | 24.47 | 55.32 | 51.35 | 21.84 | ||
| NT | 54.76 | 51.20 | 24.07 | 54.96 | 51.04 | 21.00 | ||
| FS | DF | 56.34 | 56.30 | 33.89 | 59.57 | 59.53 | 41.50 | |
| F2F | 51.16 | 51.10 | 20.08 | 51.57 | 51.52 | 21.01 | ||
| NT | 53.67 | 49.44 | 14.32 | 53.81 | 49.61 | 15.49 | ||
| NT | DF | 60.45 | 60.43 | 49.93 | 60.17 | 60.15 | 50.85 | |
| F2F | 54.74 | 54.70 | 38.88 | 53.56 | 53.51 | 36.77 | ||
| FS | 51.59 | 48.15 | 22.30 | 51.84 | 48.51 | 25.20 | ||
| Baseline Model | Train Dataset | Test Dataset | Pretrained Model | MPL Model | ||||
|---|---|---|---|---|---|---|---|---|
| ACC | AUC | F1 Score | ACC | AUC | F1 Score | |||
| ResNet101 [50] | DF | DF | 91.16 | 91.16 | 90.84 | 91.13 | 91.13 | 90.85 |
| F2F | F2F | 81.41 | 81.41 | 80.27 | 83.50 | 83.49 | 82.73 | |
| FS | FS | 87.59 | 87.37 | 86.13 | 87.75 | 87.66 | 86.39 | |
| NT | NT | 74.17 | 74.56 | 73.16 | 76.03 | 75.53 | 73.22 | |
| Baseline Model | Train Dataset | Test Dataset | Pretrained Model | MPL Model | ||||
|---|---|---|---|---|---|---|---|---|
| ACC | AUC | F1 Score | ACC | AUC | F1 Score | |||
| ResNet101 [50] | DF | F2F | 52.69 | 52.63 | 21.22 | 51.26 | 51.20 | 18.01 |
| FS | 56.90 | 52.73 | 20.42 | 56.02 | 51.84 | 18.71 | ||
| NT | 55.93 | 51.74 | 18.33 | 54.93 | 50.73 | 16.53 | ||
| F2F | DF | 53.63 | 53.59 | 30.44 | 53.50 | 53.46 | 27.42 | |
| FS | 54.33 | 50.08 | 22.82 | 54.86 | 50.85 | 19.67 | ||
| NT | 54.62 | 51.01 | 23.30 | 55.17 | 51.28 | 20.98 | ||
| FS | DF | 57.04 | 57.70 | 37.00 | 59.55 | 59.51 | 42.55 | |
| F2F | 51.43 | 51.37 | 20.63 | 51.84 | 51.79 | 24.60 | ||
| NT | 53.66 | 49.55 | 15.04 | 53.61 | 49.59 | 17.59 | ||
| NT | DF | 62.66 | 62.65 | 59.08 | 60.16 | 60.14 | 49.99 | |
| F2F | 52.69 | 52.63 | 47.55 | 51.26 | 51.20 | 37.97 | ||
| FS | 56.90 | 52.73 | 29.98 | 56.02 | 51.84 | 21.29 | ||
| Baseline Model | Train Dataset | Test Dataset | Pretrained Model | MPL Model | ||||
|---|---|---|---|---|---|---|---|---|
| ACC | AUC | F1 Score | ACC | AUC | F1 Sore | |||
| ResNext50 [51] | DF | DF | 90.29 | 90.29 | 90.01 | 91.14 | 91.14 | 91.02 |
| F2F | F2F | 81.19 | 81.17 | 80.07 | 82.87 | 82.85 | 82.11 | |
| FS | FS | 87.04 | 86.77 | 85.44 | 87.36 | 87.36 | 86.36 | |
| NT | NT | 74.26 | 74.43 | 73.21 | 76.32 | 75.78 | 73.30 | |
| Baseline Model | Train Dataset | Test Dataset | Pretrained Model | MPL Model | ||||
|---|---|---|---|---|---|---|---|---|
| ACC | AUC | F1 Score | ACC | AUC | F1 Score | |||
| ResNext50 [51] | DF | F2F | 51.83 | 51.73 | 20.17 | 51.66 | 51.56 | 18.92 |
| FS | 56.57 | 52.53 | 21.48 | 57.24 | 53.21 | 23.08 | ||
| NT | 55.25 | 51.57 | 18.50 | 54.72 | 50.50 | 15.47 | ||
| F2F | DF | 54.57 | 54.58 | 31.56 | 54.46 | 54.47 | 31.25 | |
| FS | 54.31 | 50.38 | 18.21 | 55.28 | 51.45 | 22.28 | ||
| NT | 54.67 | 50.89 | 21.12 | 54.80 | 51.02 | 21.58 | ||
| FS | DF | 59.23 | 59.23 | 41.25 | 60.33 | 60.33 | 46.22 | |
| F2F | 52.02 | 51.93 | 23.43 | 52.98 | 52.89 | 27.91 | ||
| NT | 53.31 | 49.22 | 15.05 | 53.41 | 49.55 | 17.30 | ||
| NT | DF | 60.58 | 60.58 | 43.46 | 58.50 | 58.51 | 44.82 | |
| F2F | 54.16 | 54.11 | 30.69 | 52.46 | 52.38 | 31.00 | ||
| FS | 49.17 | 46.78 | 19.36 | 51.26 | 47.80 | 21.71 | ||
| Baseline Model | Train Dataset | Unlabeled Dataset | Pretrained Model | MPL Model | ||||
|---|---|---|---|---|---|---|---|---|
| ACC | AUC | F1 Score | ACC | AUC | F1 Score | |||
| ResNext50 [51] | F2F, FS, NT | DF | 63.33 | 63.32 | 70.02 | 66.23 | 66.22 | 70.35 |
| DF, FS, NT | F2F | 57.35 | 57.39 | 60.69 | 58.04 | 58.08 | 61.64 | |
| DF, F2F, NT | FS | 50.69 | 50.53 | 46.69 | 51.81 | 51.54 | 47.22 | |
| DF, F2F, FS | NT | 53.63 | 53.05 | 47.65 | 53.89 | 53.06 | 46.28 | |
| Baseline Model | Train Dataset | Unlabeled Dataset | Pretrained Model | MPL Model | ||||
|---|---|---|---|---|---|---|---|---|
| ACC | AUC | F1 Score | ACC | AUC | F1 Score | |||
| WideResNet50 [52] | F2F, FS, NT | DF | 63.17 | 63.14 | 69.19 | 66.03 | 66.00 | 70.15 |
| DF, FS, NT | F2F | 56.86 | 56.87 | 60.76 | 57.60 | 57.60 | 58.91 | |
| DF, F2F, NT | FS | 48.37 | 47.74 | 39.32 | 52.86 | 51.13 | 41.60 | |
| DF, F2F, FS | NT | 54.22 | 53.43 | 47.37 | 53.92 | 51.96 | 39.87 | |
| Baseline Model | Train Dataset | Unlabeled Dataset | Pretrained Model | SupCon Model [35] | SupCon-MPL(Ours) Model | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | AUC | F1 Score | ACC | AUC | F1 Score | ACC | AUC | F1 Score | |||
| ResNet50 [50] | FF (without DF) | DF (unknown) | 64.24 | 64.27 | 65.49 | 62.88 | 62.84 | 58.55 | 64.60 | 64.55 | 61.60 |
| F2F + FS + NT (known) | 70.56 | 71.36 | 83.36 | 75.44 | 75.52 | 83.01 | 75.84 | 76.00 | 83.50 | ||
| FF (without F2F) | F2F (unknown) | 55.76 | 55.64 | 40.63 | 56.61 | 56.64 | 49.47 | 58.74 | 58.77 | 51.52 | |
| DF + FS + NT (known) | 77.26 | 76.89 | 81.66 | 75.54 | 75.54 | 84.13 | 78.11 | 78.28 | 85.84 | ||
| FF (without FS) | FS (unknown) | 54.47 | 52.07 | 79.18 | 55.75 | 53.68 | 77.20 | 55.72 | 53.41 | 79.29 | |
| DF + F2F + NT (known) | 75.99 | 75.87 | 81.66 | 76.02 | 75.88 | 84.84 | 77.22 | 77.12 | 85.84 | ||
| FF (without NT) | NT (unknown) | 56.71 | 54.95 | 62.66 | 56.58 | 54.31 | 66.27 | 56.76 | 54.02 | 69.43 | |
| DF + F2F + FS (known) | 77.39 | 77.41 | 81.66 | 79.09 | 79.26 | 84.13 | 81.22 | 81.32 | 85.84 | ||
| Model | Scenario Deepfakes (Known) | Current-Generation Deepfakes (Unknown) | Post-Generation Deepfakes (Unknown) |
|---|---|---|---|
| Tar [34] | 52.40 | 44.62 | 49.96 |
| DDT [31] | 80.41 | 44.62 | 49.49 |
| MPL [24] | 79.82 | 56.53 | 43.16 |
| SupCon [35] | 79.01 | 56.66 | 47.77 |
| SupCon-MPL (ours) | 81.40 | 57.85 | 51.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moon, K.-H.; Ok, S.-Y.; Lee, S.-H. SupCon-MPL-DP: Supervised Contrastive Learning with Meta Pseudo Labels for Deepfake Image Detection. Appl. Sci. 2024, 14, 3249. https://doi.org/10.3390/app14083249
Moon K-H, Ok S-Y, Lee S-H. SupCon-MPL-DP: Supervised Contrastive Learning with Meta Pseudo Labels for Deepfake Image Detection. Applied Sciences. 2024; 14(8):3249. https://doi.org/10.3390/app14083249
Chicago/Turabian StyleMoon, Kyeong-Hwan, Soo-Yol Ok, and Suk-Hwan Lee. 2024. "SupCon-MPL-DP: Supervised Contrastive Learning with Meta Pseudo Labels for Deepfake Image Detection" Applied Sciences 14, no. 8: 3249. https://doi.org/10.3390/app14083249
APA StyleMoon, K. -H., Ok, S. -Y., & Lee, S. -H. (2024). SupCon-MPL-DP: Supervised Contrastive Learning with Meta Pseudo Labels for Deepfake Image Detection. Applied Sciences, 14(8), 3249. https://doi.org/10.3390/app14083249