
A Modified Feature Selection and Artificial Neural Network-Based Day-Ahead Load Forecasting Model for a Smart Grid

 ,
,  , , and
, , and
Abstract
:1. Introduction

2. Related Work
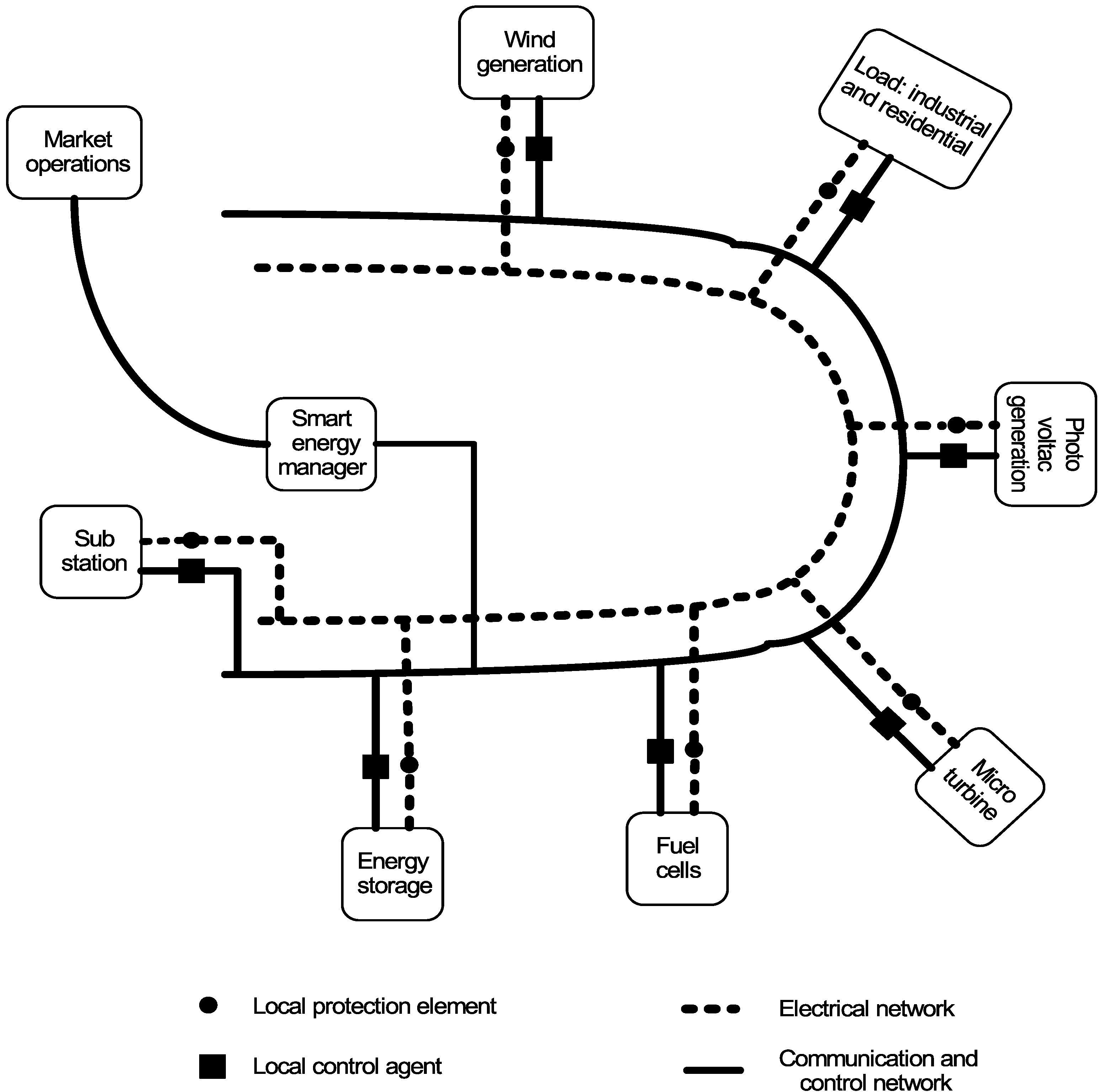
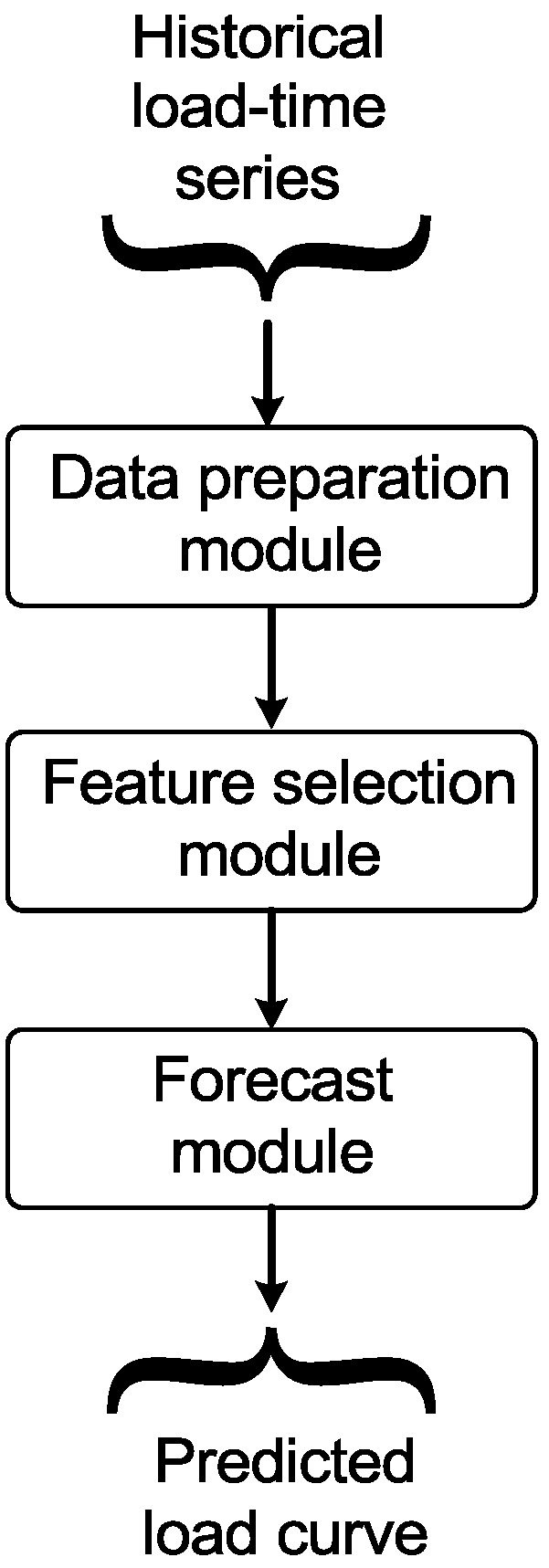
3. Our Proposed Work

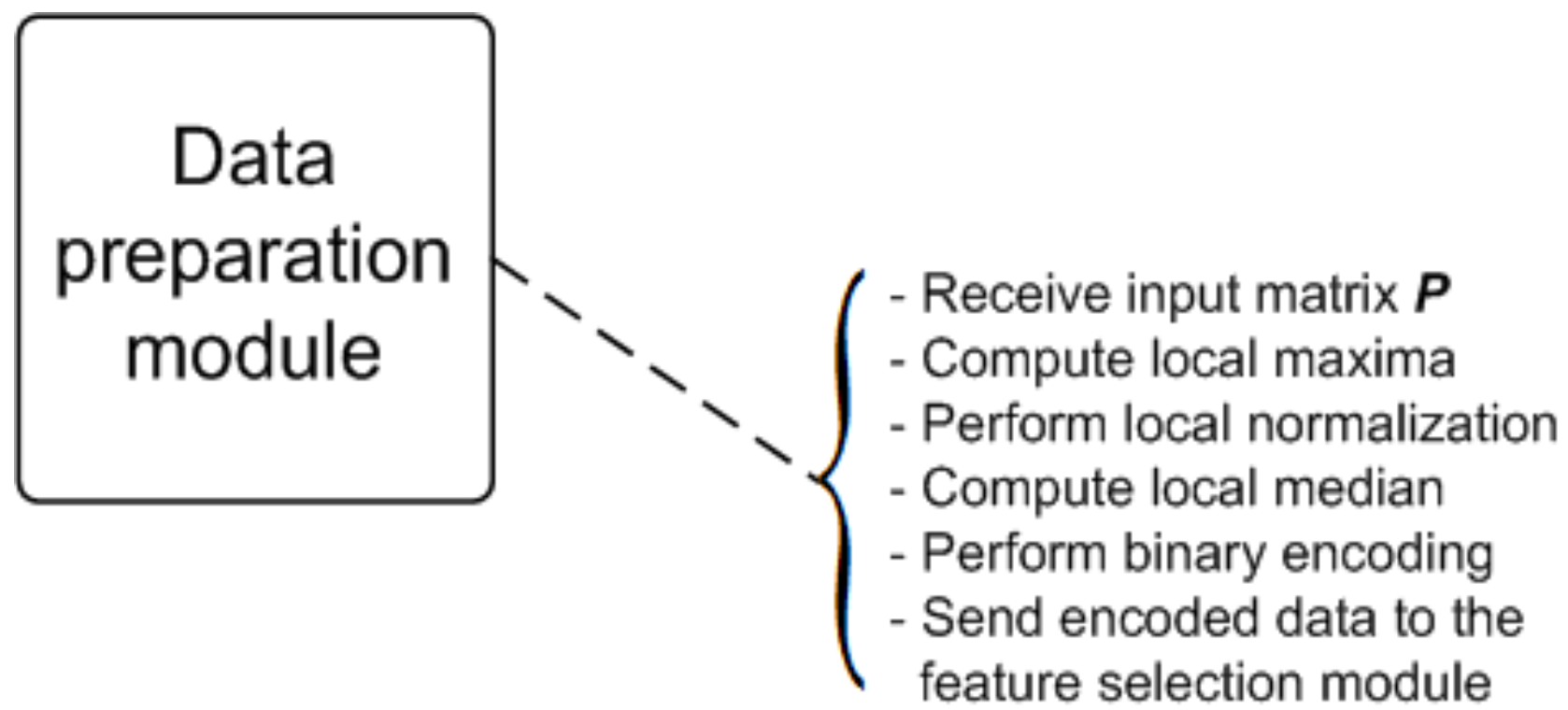
3.1. Pre-Processing Module
- Local maximum: Initially, a local maximum value is calculated for each column of the P matrix; , .
- Local normalization: In this step, each column of the matrix P is normalized by its respective local maxima, such that the resultant matrix is represented by . Now, each entry of ranges between zero and one.
- Local median: For each column of the matrix, a local median value is calculated ().
- Binary encoding: Each entry of the matrix is compared to its respective value. If the entry is less than its respective local median value, then it is encoded with a binary zero; else, it is encoded with a binary one. In this way, a resultant matrix containing only binary values (zeroes and ones), , is obtained.

3.2. Feature Selection Module
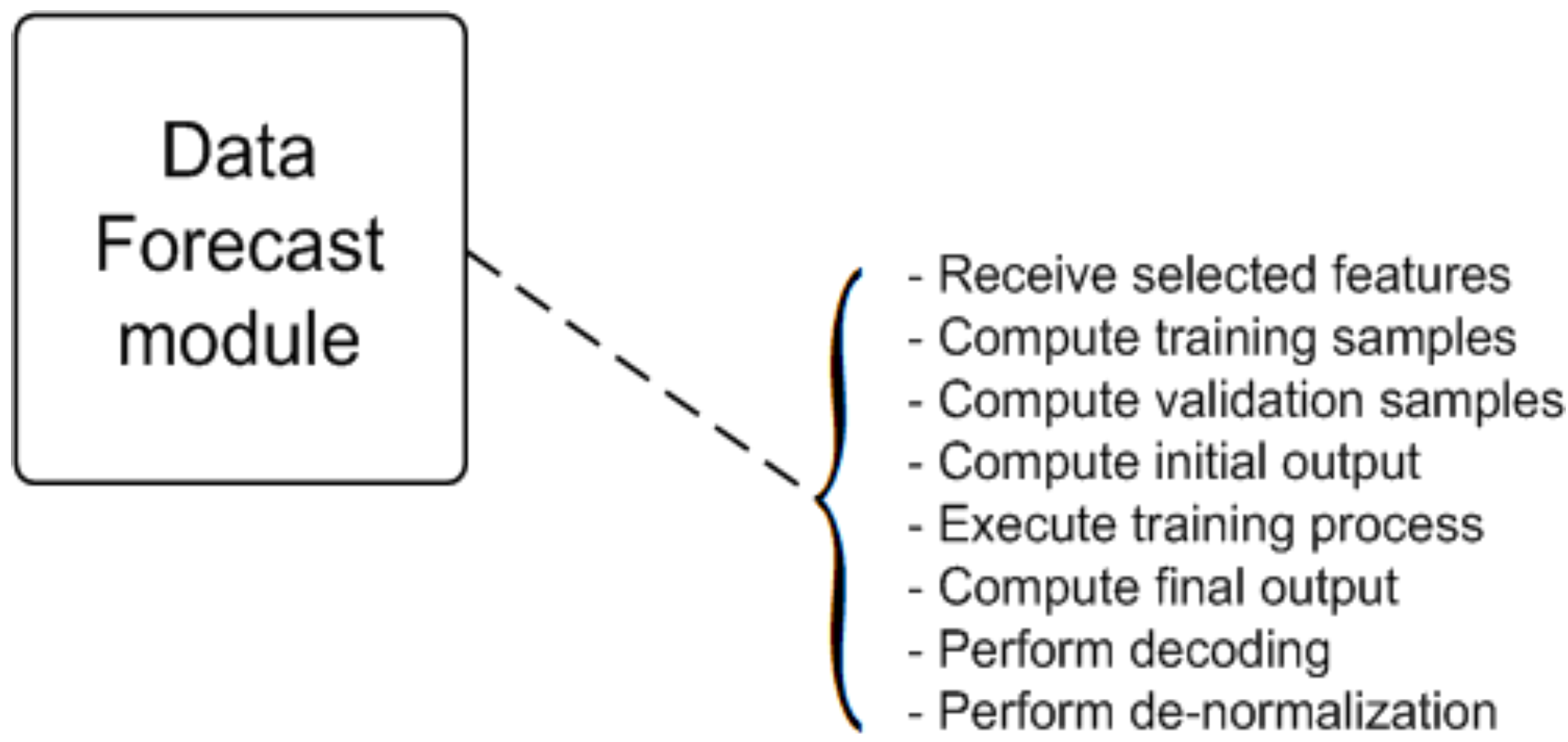
3.3. Forecast Module


| Algorithm 1 Day-ahead load forecast. |
|
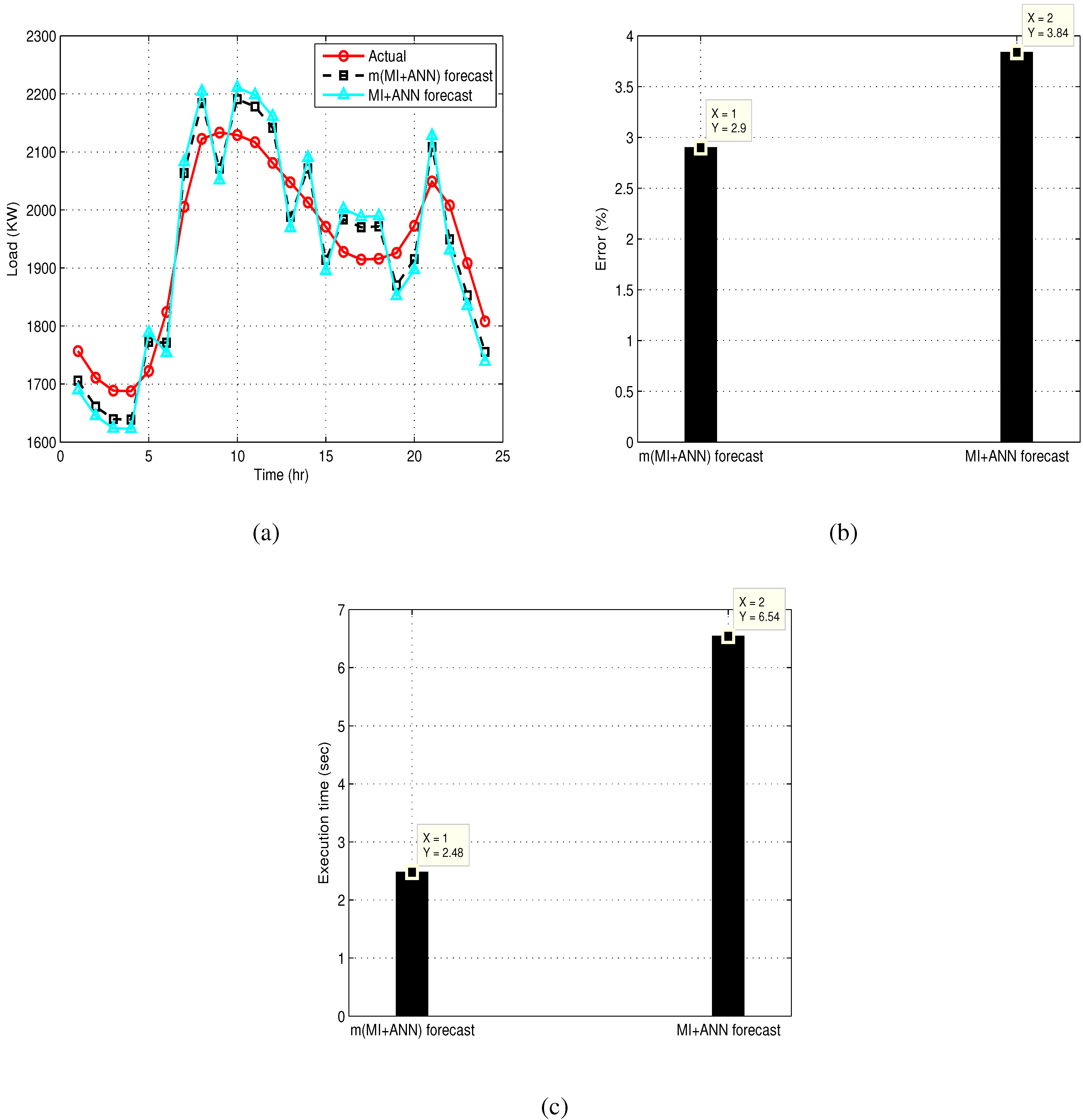
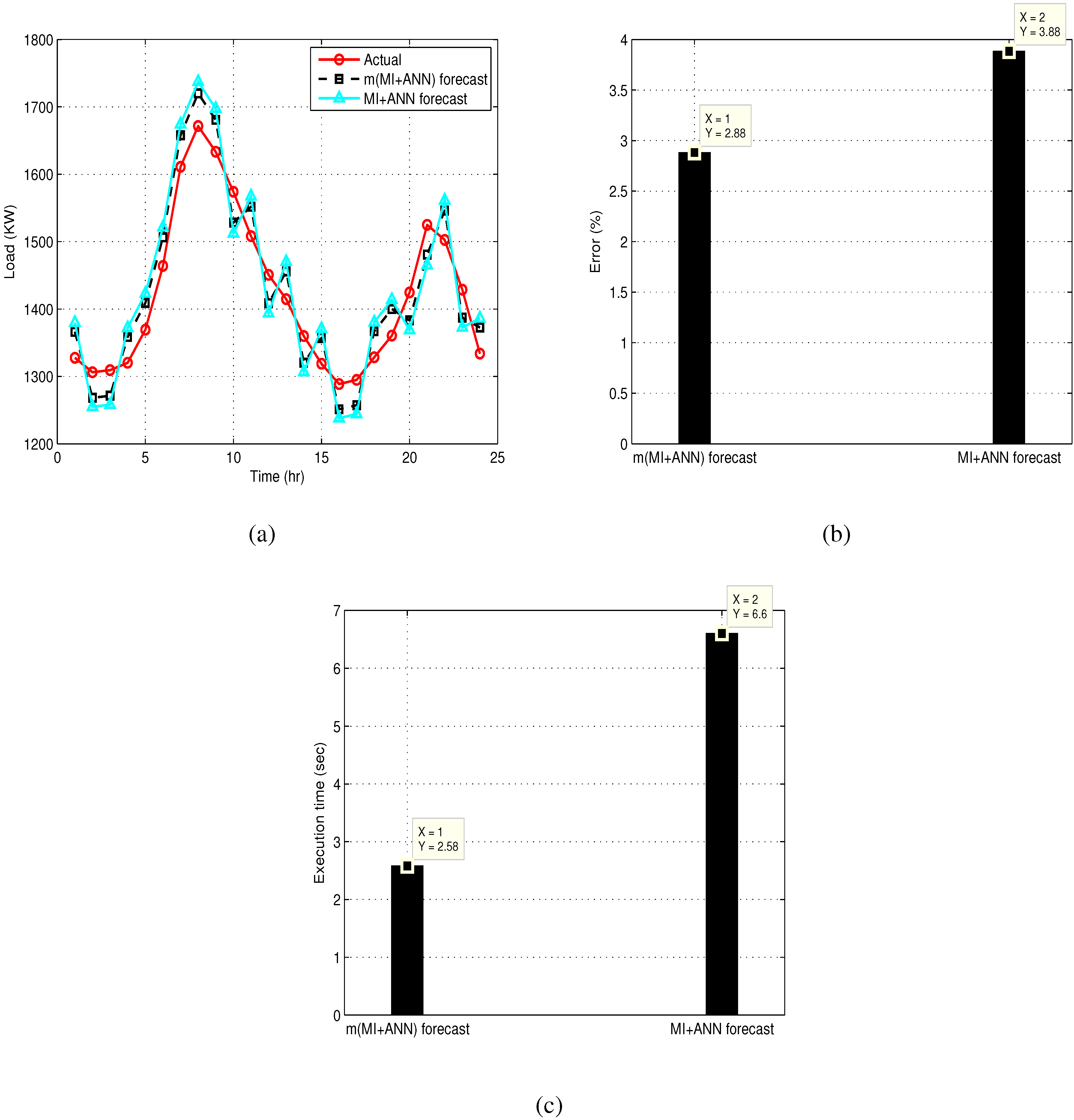
4. Simulation Results
- Error performance: This is the difference between the actual and the forecast signal/curve and is measured in %.
- Convergence rate or execution time: This is the simulation time taken by the system to execute a specific forecast model. Forecast models for which the execution time is small are said to converge quickly as compared to the opposite case. In this paper, execution time is measured in seconds.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of forecasters | 24 |
| Number of hidden layers | 1 |
| Number of neurons in the hidden unit | 5 |
| Number of iterations | 100 |
| Momentum | 0 |
| Initial weights | |
| Historical load data | 26 days |
| Bias value | 0 |


5. Conclusion and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Unveiling the Hidden Connections between E-mobility and Smart Microgrid. Available online: http://www.zeitgeistlab.ca/doc/Unveiling_the_Hidden_Connections_between_E-mobility_and_Smart_Microgrid.html (accessed on 20 February 2015).
- Yan, Y.; Qian, Y.; Sharif, H.; Tipper, D. A Survey on Smart Grid Communication Infrastructures: Motivations, Requirements and Challenges. IEEE Commun. Surv. Tutor. 2013, 15, 5–20. [Google Scholar] [CrossRef] [Green Version]
- Siano, P. Demand response and smart grids: A survey. Renew. Sustain. Energy Rev. 2014, 30, 461–478. [Google Scholar] [CrossRef]
- Mohassel, R.R.; Fung, A.; Mohammadi, F.; Raahemifar, K. A survey on advanced metering infrastructure. Int. J. Electr. Power Energy Syst. 2014, 63, 473–484. [Google Scholar] [CrossRef]
- Atzeni, I.; Ordonez, L.G.; Scutari, G.; Palomar, D.P.; Fonollosa, J.R. Demand-Side Management via Distributed Energy Generation and Storage Optimization. IEEE Trans. Smart Grid 2013, 4, 866–876. [Google Scholar] [CrossRef]
- Adika, C.O.; Wang, L. Autonomous Appliance Scheduling for Household Energy Management. IEEE Trans. Smart Grid 2014, 5, 673–682. [Google Scholar] [CrossRef]
- Koutsopoulos, I.; Tassiulas, L. Optimal Control Policies for Power Demand Scheduling in the Smart Grid. IEEE J. Sel. Areas Commun. 2012, 30, 1049–1060. [Google Scholar] [CrossRef]
- Hermanns, H.; Wiechmann, H. Demand-Response Management for Dependable Power Grids. Embed. Syst. Smart Appl. Energy Manag. 2013, 3, 1–22. [Google Scholar]
- Amjady, N.; Keynia, F.; Zareipour, H. Short-Term Load Forecast of Microgrids by a New Bilevel Prediction Strategy. IEEE Trans. Smart Grid 2010, 1, 286–294. [Google Scholar] [CrossRef]
- Gruber, J.K.; Prodanovic, M. Residential energy load profile generation using a probabilistic approach. In Proceedings of the 2012 UKSim-AMSS 6th European Modelling Symposium, Valetta, Malta, 14–16 November 2012; pp. 317–322.
- Kou, P.; Gao, F. A sparse heteroscedastic model for the probabilistic load forecasting in energy-intensive enterprises. Electr. Power Energy Syst. 2014, 55, 144–154. [Google Scholar] [CrossRef]
- Amjaday, N.; Keynia, F. Day-Ahead Price Forecasting of Electricity Markets by Mutual Information Technique and Cascaded Neuro-Evolutionary Algorithm. IEEE Trans. Power Syst. 2009, 24, 306–318. [Google Scholar] [CrossRef]
- Yang, H.T.; Liao, J.T.; Lin, C.I. A load forecasting method for HEMS applications. In Proceedings of 2013 IEEE Grenoble PowerTech (POWERTECH), Grenoble, France, 16–20 June 2013; pp. 1–6.
- Meidani, H.; Ghanem, R. Multiscale Markov models with random transitions for energy demand management. Energy Build. 2013, 61, 267–274. [Google Scholar] [CrossRef]
- Amjady, N.; Keynia, F. Electricity market price spike analysis by a hybrid data model and feature selection technique. Electr. Power Syst. Res. 2009, 80, 318–327. [Google Scholar] [CrossRef]
- Liu, N.; Tang, Q.; Zhang, J.; Fan, W.; Liu, J. A Hybrid Forecasting Model with Parameter Optimization for Short-term Load Forecasting of Micro-grids. Appl. Energy 2014, 129, 336–345. [Google Scholar] [CrossRef]
- Anderson, C.W.; Stolz, E.A.; Shamsunder, S. Multivariate autoregressive models for classification of spontaneous electroencephalographic signals during mental tasks. IEEE Trans. Biomed. Eng. 1998, 45, 277–286. [Google Scholar] [CrossRef] [PubMed]
- Engelbrecht, A.P. Computational Intelligence: An Introduction, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- PJM Home Page. Available online: www.pjm.com (accessed on 8 December 2015).
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, A.; Javaid, N.; Alrajeh, N.; Khan, Z.A.; Qasim, U.; Khan, A. A Modified Feature Selection and Artificial Neural Network-Based Day-Ahead Load Forecasting Model for a Smart Grid. Appl. Sci. 2015, 5, 1756-1772. https://doi.org/10.3390/app5041756
Ahmad A, Javaid N, Alrajeh N, Khan ZA, Qasim U, Khan A. A Modified Feature Selection and Artificial Neural Network-Based Day-Ahead Load Forecasting Model for a Smart Grid. Applied Sciences. 2015; 5(4):1756-1772. https://doi.org/10.3390/app5041756
Chicago/Turabian StyleAhmad, Ashfaq, Nadeem Javaid, Nabil Alrajeh, Zahoor Ali Khan, Umar Qasim, and Abid Khan. 2015. "A Modified Feature Selection and Artificial Neural Network-Based Day-Ahead Load Forecasting Model for a Smart Grid" Applied Sciences 5, no. 4: 1756-1772. https://doi.org/10.3390/app5041756
APA StyleAhmad, A., Javaid, N., Alrajeh, N., Khan, Z. A., Qasim, U., & Khan, A. (2015). A Modified Feature Selection and Artificial Neural Network-Based Day-Ahead Load Forecasting Model for a Smart Grid. Applied Sciences, 5(4), 1756-1772. https://doi.org/10.3390/app5041756