1. Introduction
The coming of the Internet of Things (IoT) brings about more and more various smart services. Occurring with a massive stream of data, these services are typically viewed as event-driven. Generally speaking, these massive amounts of data from IoT have the following characteristics: (1) predictability, which means these data show cyclical fluctuations as massive sensors send sensing data periodically; (2) asynchronous and multicasting-suitable, which means the similar nature of events, which may have multi-senders and multi-receivers; even receivers are concerned with the what in a communication instead of the specific who sending events; similarly, multi-senders do not care about who will receive data; (3) time-sensitive, which means most of the data need to be delivered within a prescribed time, etc.
Therefore, how to deliver such complex multi-source sensor data in real time efficiently is a vital problem [
1,
2]. Fortunately, the publish/subscribe paradigm can exactly facilitate this data dissemination mode instead of using traditional request-reply messaging. A publish/subscribe system is a universal many-to-many communication paradigm [
3], especially for those applications with loosely-coupled entities. In a topic-based publish/subscribe system, events are published with specific identifiers called topics. The publish/subscribe paradigm then guarantees disseminating every new event to those subscribers who have expressed their interest in the topic similar to the event [
4,
5].
However, under the traditional network architecture, due to the lack of global traffic information, publish/subscribe systems suffer from insufficient utilization of the physical network infrastructure, such as traffic imbalance on different links. In such a largely distributed IoT environment, the emerging mass data mega-trends also worsen the traffic imbalance phenomenon. To address this concern, some methods, including static load balancing (preplanned allocation bandwidth) and dynamic load balancing (dynamic allocation bandwidth during run-time), were proposed [
6,
7,
8]. However, this problem is not solved, essentially owing to the global knowledge insufficiency under the distributed management of the traditional Internet. On the one hand, the filtering operation, which mainly saves bandwidth in a publish/subscribe system, is performed by specific components called brokers. This imposes a significant delay by lengthening the end-to-end path with a detour to the brokers and a processing delay for matching events against filters’ rules. On the other hand, the best-effort service provided by the traditional Internet cannot meet delay-sensitive requirements.
Recently, software-defined networking (SDN) [
9,
10] emerged as a new-style network architecture that decouples the control plane from the forwarding plane. Maintaining a network-wide view of up-to-date datapath elements and link state information, SDN makes it possible to enable on-demand resource allocation, self-service provisioning and network virtualization. OpenFlow as the actual standard for SDN enables many filtering operations to match received packets efficiently through specifying the interface to install and modify flows directly on SDN-configurable switches. Therefore, it is possible to flexibly control the forwarding plane, which is conducive to outperforming the traditional Internet in the overall performance of the network, as well as assuring the desired performance for diverse applications, by adopting a traffic management mechanism [
11].
In this paper, we propose and construct a topic-based publish/subscribe system in an SDN environment named SDNPS. The implemented prototype deploys traffic engineering by making full use of the centralized control nature under SDN. Firstly, we obtain the global overview of the topology by abstracting and aggregating the network link state. Then, we predict the traffic distribution for some time to come in terms of the predictability of the mass data from IoT. Finally, we calculate minimum overlay networks per topic and extract multicast routing paths in light of the well-known shortest path algorithm. Our design makes a better tradeoff between global load balancing of links and the minimum cost forwarding for per-topic events.
The contributions of this paper are summed up in the following.
In SDNPS, we organize all of the topics into a topic tree in terms of their natural language semantics. On account of the subscription coverage relationship among topics at different levels of the topic tree, we present a topic-connected overlay constructing algorithm, which solves the specified multicasting problem among publishers and subscribers. This algorithm achieves minimum forwarding costs for every topic, as well as load balancing for the whole network. By means of incrementally generating and storing overlays, the time complexity and the space complexity of this algorithm are both significantly reduced.
SDNPS can filter and forward events directly on SDN-configurable switches with the aid of dexterously mapping topics to binary identifiers and embedding these identifiers into packet headers as matching fields. This helps to reduce end-to-end latency. We devise traffic engineering in SDNPS, which performs routing computation based on traffic prediction. It also dynamically adjusts routing in the presence of physical topology changing induced by traffic bursting and link/switch failures, as well as subscription topology changing brought by new (un)subscription events.
The remainder of this paper is structured as follows. In
Section 2, the related work is reviewed and discussed.
Section 3 presents the system architecture; other corresponding aspects, including topic management, topology management and strategy management, are also described.
Section 4 presents the problem statement and model for the minimal cost topic-connected overlay problem (in short MCTCO), then a heuristic algorithm for this problem is described in detail.
Section 5 exhibits the performance evaluation, and conclusion remarks are given in
Section 6.
3. Architecture
This section delves into the overall architecture of SDNPS. Learning from the traditional Internet, we adopt hierarchical thinking to organize brokers and manage routing. All of the participants are partitioned into multiple clusters according to their regional characteristics (belonging to the same data center or LAN). Each cluster is a logically-autonomous area containing a representative broker and some agent brokers, as well as a certain number of SDN-configurable switches, communicating with other clusters through border switches. All of the clusters are treated equivalently. Above this, we adopt a global server to manage topology and to compute routing holistically. It is important to note that we devise an alternative distributed schema (it is still under testing) in order to avoid single point failure and heavy burden on the server. As depicted in
Figure 1, the system is logically structured in three layers: the switch hardware layer, the cluster controller layer and the global management layer. The switch hardware layer does not run complex control protocols. Its primary task is filtering and forwarding events. The controller layer runs both the OpenFlow protocol and network control applications. A controller is meanwhile a representative broker of the cluster where it is located. The global management layer consists of a major server and a standby server, which have global information about the physical topology and subscription topology. The servers enable central traffic engineering by constructing topic-connected overlay networks based on global traffic prediction and link information collection.
As depicted in
Figure 2, we devise a strategy-driven topic tree aggregation routing schema. From the subscription list and topic tree, we extract the subscription topology in incremental storage mode. From link state database(LSDB) and cluster information, we extract the cluster-level physical topology. Then, we compute multicast routing paths per topic based on the subscription topology and cluster-level physical topology, as well as the strategy base in our schema.
3.1. Topology Management
SDNPS maintains two kinds of topologies: subscription topology and physical topology.
For the former, every cluster (to be more exact, the representative broker) has global subscription information for all topics, which constitutes to the subscription topology. Each new (un)subscription event should be broadcast to all of the clusters, so that every cluster can receive it and then update its subscription topology. The representative broker of the cluster, which originally generates (un)subscription events, also answers for forwarding this (un)subscription information to the server. This is the subscription topology.
For the latter, on the one hand, a controller detects the physical link states of its own cluster, which forms an intra-cluster topology; on the other hand, it maintains the reachability information to the neighbor clusters they selected by periodically sending out heartbeat information, then applying network virtualization [
32] technology to abstract the physical network to the virtual network with tuples (source cluster, destination cluster, and bandwidth), which forms the cluster-level topology. When centralized routing computation is adopted, every controller delivers its cluster-level topology formatted with JSON (JavaScript Object Notation) to the server. Then, the server forms an inter-cluster topology by aggregating and abstracting these data and computing inter-cluster routing paths. When distributed routing computation is adopted, every controller maintains this inter-cluster topology through a distributed protocol and computes inter-cluster routing paths, respectively. In this paper, we adopt the centralized routing computation for brevity. In subsequent work, we will adopt distributed computation for better flexibility and reliability. This is the physical topology.
Each update of the cluster topology or subscription topology would trigger a routing recalculation, so as to add or delete paths among relevant switches.
3.2. Topic Management
In topic-based publish/subscribe paradigm, topics contact publishers and subscribers. However, topics are not arbitrary strings in actual systems. To prevent from topic bursting, topics must be registered to the server before they are put into use. In SDNPS, topics are structured as a topic tree in which a topic covers all of the topics in its descendant nodes. That is to say, if a subscriber subscribes to a topic, then it also automatically subscribes to those topics on its subtrees. Due to the subscription cover relationship between father topic and child topics in the topic tree, we devise an incremental minimal cost topic-connected overlay algorithm, which significantly reduces the time and space complexity.
Now that SDN switches can perform filtering operations at low latency [
27], we can manipulate flow matching to support this work. The topic tree is an arbitrary multi-bifurcated tree. Transforming the topic tree into a binary tree and then coding this binary tree by the left branch with zero and the right branch with one, we get a binary string named the topic-expression (
tp) for each topic.
Figure 3 exhibits the methods of encoding a topic tree in this paper.
In particular, all of the events matching the topic tree constitute the event space called Ω, which is a one-dimensional space. Ω can be divided into subspaces according to topics. Any subspace can be identified by a topic-expression. In order to define the subscription cover relation of topics, two functions are defined: is used for deleting all of the rear “1" of tp; deletes the rear “0” of tp. If equals , we say topic is the father of topic . It is obvious that topic-expression has a partial relation. It fulfills the following characteristics: (1) a subspace covers the subspace , iff is a prefix of , written ; (2) if , the subscriber set of is a subset of the subscriber set of , written .
For a topic
, there are three kinds of events: publish events, subscribe events and unsubscribe events. Subscribe and unsubscribe events should be broadcast to all of the nodes. Therefore, flooding is an appropriate method. Publish events should be routed to those subscribers who have subscribed to them beforehand. SDN-configurable switches must identify these three types of events so that they can perform different processing. For this purpose, we encode event type simultaneously. Two-bit binary coding meets this requirement. This two-bit type code for events is stitched with
, forming the identifier (called
typetp) of a topic
. When an event is generated, the
typetp is enclosed in its packet header. It is noteworthy that the subspace relationship mentioned above allows the events whose topics have the cover relation to share a common subpath. Recall that the routing of a publish/subscribe system is an obvious multicast problem, so we adopt the IPV6 multicast address to embed
typetp.
Figure 3 describes this process.
The length of the IPV6 address is 128 bits. According to
Figure 3, except for the frontal 25 bits, which are occupied by a fixed section, there are 103 bits for topic codes. Theoretically, the code space is
. This means that there are at most
topics, and it is adequate for our system. In fact, the excessive number of topics, which is associated with the items of flow entries in flow tables, may increase the workload for flow table lookup and degrade the forwarding performance at SDN-configurable switches. Therefore, the flow table entries’ aggregation is indispensable to address this problem. This can be easily implemented in light of the hierarchy of the topic tree.
3.3. Strategy Management
Sometimes, some clusters may prohibit events with specific topics from passing through for security or privacy reasons. We adopt a strategy to define these constraints. The introduction of a strategy makes it possible to distinguish different powers among clusters, which contributes to preventing the system from some unfavorable conditions, such as information leakage, network traffic anomalies, etc. The organization of the strategy is also in accord with the topics in the topic tree. The strategy information is formatted as an XML file, and any cluster can download and store this file. The administrator is responsible for the configuration of the strategy, including addition, deletion and modification of the strategy. When a new strategy message comes, the strategy module will merge it with the existing strategy data. If there is an update to the strategy data, this will be reflected in the subscribe list, and the corresponding routing computation will be triggered.
The strategy is usually implemented in the forwarding plane by setting the filter conditions. However, even if efficient filtration technology, such as a Bloom filter, is used, this still causes a delay. Nevertheless, we innovatively adopt another method in SDNPS. We impose a strategy on the routing schema in the period of routing computation. When computing the routing path for topic t, relative strategy constraints will be considered. If the strategy is cluster level, the routing path should not include clusters constrained by it. However, if the strategy is broker level, routing computation will not be affected; those brokers constrained by the strategy autonomously decide whether to receive this type of event or not.
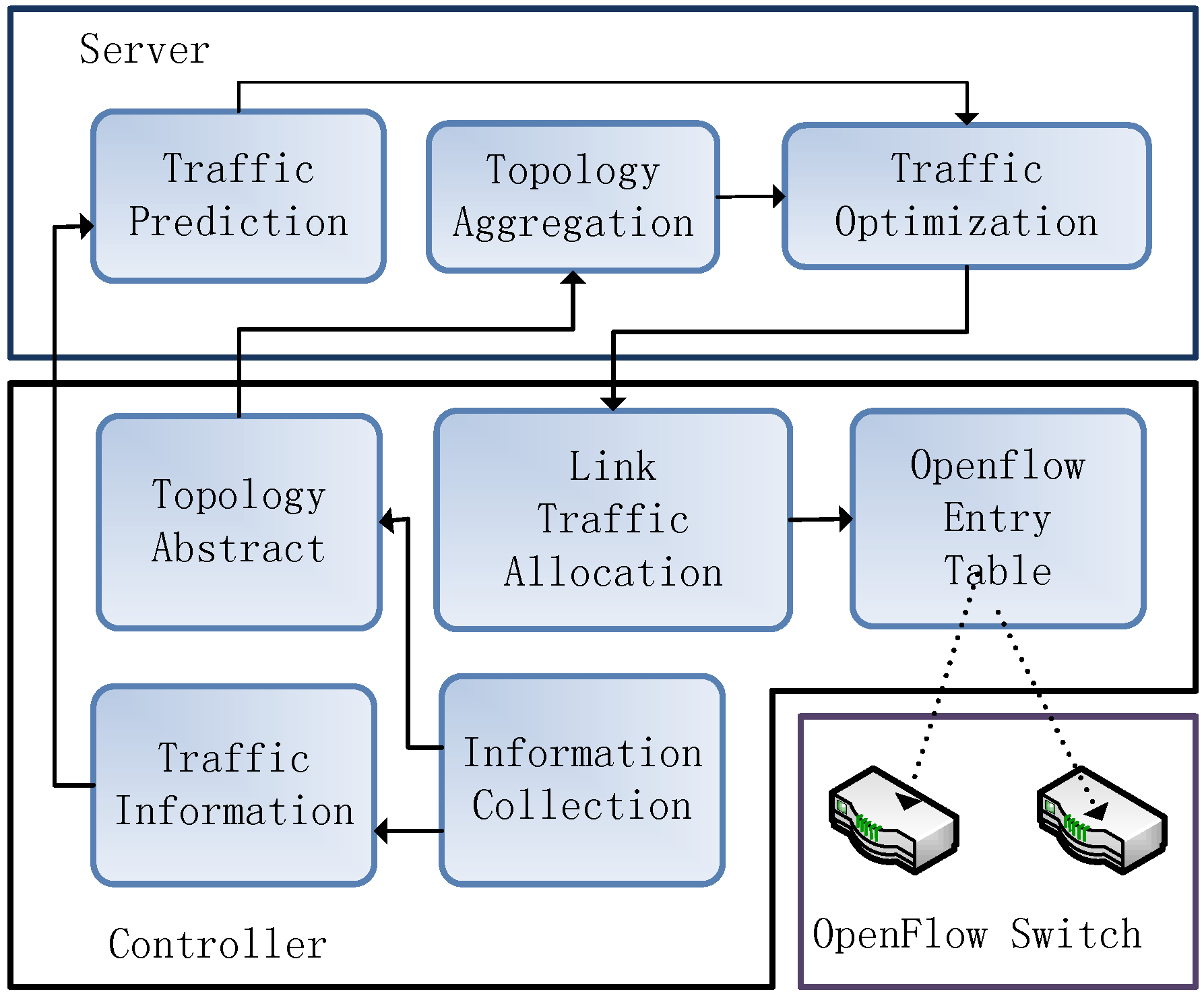
3.4. Traffic Engineering Architecture
We design traffic engineering for our system to achieve approximate optimal performance. All of the functions are deployed on the server and controllers. The server accounts for seeking optimized routing paths among clusters while controllers split flows among multiple paths to balance traffic.
Figure 4 shows an overview of the traffic engineering architecture.
The controllers operate over the following aspects:
- (1)
The information collection module provides information for traffic prediction. It is responsible for gathering statistics information, including packet size and the number of every flow, the queue size for every port of the switch, etc.
- (2)
The link traffic allocation module allocates traffic evenly among multiple links between any two connected clusters. Besides this, it also answers for installing and updating flow tables.
- (3)
The topology abstract module detects switch connection information when the system starts and abstracts away topology information. When there is a link state change at run-time, it reports this information to the topology aggregation module and traffic prediction module. We call it link-level abstraction, which lays the basis for the link traffic allocation module in the controllers and the traffic aggregation module in the server.
The server achieves the following functions:
- (1)
The topology aggregation module chalks up the network topology graph in which vertices represent clusters and edges represent the links between clusters by consolidating topology information from multiple controllers and then aggregating trunks between clusters. We call it cluster-level abstraction, which is the basis of inter-cluster routing computation. This abstraction significantly reduces the size of the graph, thus simplifying the routing optimization algorithm.
- (2)
The traffic prediction module is responsible for predicting future traffic for a period of time in terms of traffic statistics information of the past time. Treating prediction values as inputs to the optimization algorithm can gain more reasonable routing congestion avoidance. The reason why traffic can be predicted is mainly due to the characteristics of data in the Internet of things (IoT) environment.
- (3)
The traffic optimization algorithm computes optimal or suboptimal routing paths according to the global network topology and traffic value,s which are obtained from the traffic prediction module and the topology aggregation module mentioned above. This module will be described in detail in the remainder of this paper.
3.5. Event Routing
The routing of SDNPS is divided into two levels: routing among clusters, also known as inter-cluster routing, and routing in a cluster, also known as intra-cluster routing. Because the server has holistic information about publish information, subscribe information and a global topology, it takes charge of computing inter-cluster routing. Similarly, the controllers are responsible for intra-cluster routing.
3.5.1. Inter-Cluster Routing
The topology abstract module, which is run on the controller, has the topology information of the cluster in which it is located. Naturally, it can also perceive its adjacent clusters through the link information of border switches. We map the cluster-level routing table into the link-level routing table by allocating the traffic evenly among relevant links and then write it into flow tables of switches.
When a border switch receives an event, it just searches for its flow tables. If there is a matched item, it processes the event in terms of the corresponding instructions. If a table-miss event occurs, it forwards the packet or its header to the controller in order to get further instructions. Substantially, the routing is accomplished through flow tables. The installation of the flow tables is essential for efficient routing. The controllers are responsible for installing flow tables of the switches attached to them in terms of global routing computation (we call it inter-cluster routing), which is completed by the server. The inter-cluster routing schema is substantially a multicast routing on the experience of “link matching” [
33] and multi-stream multi-source multicasting routing [
34].
3.5.2. Intra-Cluster Routing
By abstracting clusters into nodes, we get a cluster-level topology, which lays the foundation for the inter-cluster routing mentioned above. However, every cluster may have multiple border switches to connect with other adjacent clusters, so the routing table obtained from inter-cluster routing must be mapped into flow entries on switches.
When a broker receives an event published by a sensor or other terminal device, which is connected to it, it firstly identifies the type and the topic (t) of the event, then searches the topic tree for its binary code. Following this, it multicasts this event using UDP by encapsulating the type and topic code into the packet header as the IPV6 address. This IP address is the IPV6 multicast address for topic t. Finally, it delivers this event to the representative broker by reliable transmission, called TCP, aiming at ensuring that every event can be transferred to the representative broker. When a broker receives an event from another broker or switch, it checks its subscription list to decide whether to receive it or not.
4. Traffic Optimization Algorithm
4.1. Problem Definition
The publish/subscribe system is represented by an undirected graph with n nodes and m edges, where V is a set of nodes (clusters) and E is a set of links, respectively. Assume that , . For each link , a non-negative parameter named the bandwidth capacity is associated with it.
Postulate that there are in total topics in SDNPS; events for topic t, which may be originated from a set of publishers (source nodes), need to be disseminated to all subscribers denoted by (destination nodes), who have registered their interests in topic t beforehand, where ⊆ V and ⊆ V. Note that , and . For events tagged with topic t, there are publishers; each of them has a different publish probability. Let () denote the probability of node i publishing events tagged with topic t, . We denote as a multicast session for topict.
4.2. Problem Model
First, we model the nodes’s publish and subscribe interests formally: given a set of nodes V and a set of topics T, a publish interest function PubInt, which is defined to be a probability-valued function over domain , and a subscription interest function SubInt, which is similarly defined to be a Boolean-valued function over the same domain. That is to say, we say a node is interested in publishing an event with topic t iff PubInt(v,t) ∈ (0,1), and a node is interested in receiving a topic t iff SubInt(v,t) = true.
Then, The problem is formally defined as follows: Given , link bandwidth capacity c: C(E), a publish interest function PubInt and a subscribe interest function SubInt over , a topic t ∈ T, we define the topic-connected subgraph = (, ) of G for topic t to be a minimal support graph induced by , such that the cost is minimum. It is worth noting that the ‘minimum’ can be measured in different ways, such as minimal cost or minimal numbers of nodes and edges. We call it ‘the minimal cost topic-connected overlay’ problem (MCTCO).
Definition 1 (The bottleneck bandwidth of the path)
. Given G = (V, E), r(e) is the available bandwidth of edge e (e ∈ E), a path path(s, d) between s and d is described by a sequence of links e(s, i), e(i, j), e(j, k), ⋯, e(u, d), each of which belongs to E. The bottleneck bandwidth of path(u, v) is given in the following: Definition 2 (MCTCO)
. Given G = (V, E), a cost matrix c(E), a topic t, two interest function and over , construct a topic-connected overlay network = (, ), such that is minimum, limited , .
The following lemma goes immediately after Definition 2.
Lemma 1. MCTCO is NP-hard.
Proof. Consider the distinguished Steiner tree problem in graphs. Given an undirected graph G(V, E), an accident with a cost function
c:
, and a terminal set
D where
D ⊆ V(G), find a tree
in
G, such that D
and
is minimum. Karp
et al. has proven that the Steiner tree problem is one of the classical
NP-hard problems [
29].
Now, consider the MCTCO problem. According to the definition, the constructed overlay network must be acyclic; that means a tree spanning all of the publish nodes (set S) and subscribe nodes (set D). There are probably some indispensable relay nodes. Note that the MCTCO is identical to the Steiner tree problem if we select one node s from S as the root node and treat as terminal nodes. Therefore, MCTCO can be reducible to the Steiner tree problem.
Hence, the MCTCO problem is NP-hard.
Note that the above problem considers only one topic. For a set of topics, we can construct a set of minimal topic-connected overlay subgraphs. To avoid the imbalance of link traffic, when constructing minimal topic-connected overlay subgraphs, link residual bandwidth is considered as an important factor. Following, we define the residual bandwidth of graph G.
Definition 3 (The residual bandwidth of graph
G)
. Given G = (V, E). is the residual bandwidth of link e, the residual bandwidth of graph G is defined as the minimum available bandwidth for all links in E. That is, With the above definitions, the load-balanced MCTCO problem can be mathematically stated as follows:
Maximize .
The objective function measures the maximum residual bandwidth of graph G using constraint set Equation (8). Among the links of graph G, maximizing the bottleneck bandwidth of the link, which is the minimal residual bandwidth of all links, contributes to balancing traffic. When is less than zero, the instance is infeasible. Constraint set Equations (3) and (4) ensure that every topic-connected subgraph is acyclic. Constraint Equation (5) is a decision function, which indicates whether a link e of graph G is an edge of subgraph or not. Constraint Equation (6) defines the consumed bandwidth of link e in graph G; here, b is a bandwidth unit. Constraint Equation (7) restricts that the consumed bandwidth cannot go beyond the capacity of link e.
4.3. The Load-Balanced Topic-Connected Overlay Algorithm
Aiming at the objective function mentioned above, we put forward a heuristic algorithm. This algorithm is evolved from the algorithms solving the multi-stream multi-source multicasting routing problem (MMMRP) [
34]. There are other incidental algorithms proposed for inter-cluster routing.
| Algorithm 1 Inter-cluster routing algorithm. |
- Require:
G = (V, E), C(E) // C(E) is the bandwidth capacity matrix - Ensure:
//, for //R(E) is residual bandwidth matrix, equals C(E) initially.
- 1:
for each topic t do - 2:
; //call for MCTCO algorithm - 3:
cb = ; - 4:
for each do - 5:
c(e) = c(e)-cb; //update the residual bandwidth; - 6:
end for - 7:
endfor
|
The main idea of inter-cluster routing algorithm (Algorithm 1) is as follows. For every topic t, we construct a topic-connected overlay subgraph that spans its publish nodes and subscribe nodes (Line 2). Following, we compute the consumed bandwidth of links in (Line 3) with the node’s publishing probability considered. Then, we update the residual bandwidth by subtracting from if is in (Line 5). These are repeated until all topics are processed (Lines 1–7).
| Algorithm 2 Minimal cost topic-connected overlay algorithm (MCTCO). |
- Require:
G = (V, E), , , P - Ensure:
is a tree, , ), for
- 1:
if T.father is NULL then - 2:
= ∅; modify c(E) by strategy set for topic t; - 3:
for each source do - 4:
Tree = WidestPTathTree (G, ); - 5:
end for - 6:
for each SubInt do - 7:
EnQueue (Q, ); - 8:
end for - 9:
while not empty (Q) do - 10:
currnode = DeQueue (Q); - 11:
while TRUE do - 12:
nextnode = the nextnode in path(currnode, ); - 13:
nextwidth = rp(path(currnode, )); - 14:
for each do - 15:
tempwidth=rp(path(currnode, )) in ; - 16:
if tempwidth > nextwidth then - 17:
nextnode = the nextnode in path(currnode, ); - 18:
nextwidth = tempwidth; - 19:
end if - 20:
end for - 21:
Add (currnode, nextnode) to ; - 22:
if nextnode PubInt then - 23:
break; - 24:
end if - 25:
currnode = nextnode; - 26:
end while - 27:
end while - 28:
traverse graph to get all the connected subgraph; - 29:
Add the widest edges which can connect two subgraphs to until is connected; - 30:
else - 31:
TF = T.father; ; - 32:
TFnodes = TF.subscribelist ⋃ TF.publishlist; - 33:
Tnodes = T.subscribelist ⋃ T.publishlist; - 34:
Bnodes = Tnodes-TFnodes; - 35:
for each node N in Bnodes do - 36:
Add the widest path from N to to ; - 37:
end for - 38:
end if
|
Algorithm 2 is constructing a topic-connected overlay network. Remember that we organize topics as a topic tree. Owing to the overlay relationship between child topic and its father topic, when a topic is in the first layer in the topic tree, we build the overlay network completely ab initio for this topic; otherwise, we generate the overlay network for a topic from its father topic overlay network by adding some vertices and edges. For the first case, we firstly generate (also denoted with ) spanning trees, which are widest (Lines 2–4). There are several algorithms proposed for this, e.g., a modified Dijkstra’s algorithm or a modified Bellman–Ford algorithm, etc. In this paper, we adopt a modified Kruskal’s algorithm, which has the same time complexity asymptotically and a faster run-time compared to the modified Dijkstra algorithm. Then, we find the widest path from each destination vertex (SubInt) to any source vertex (PubInt) (Lines 6–27); this procedure will generate several disjoint and acyclic subgraphs. Finally, we merge these subgraphs into a minimum spanning tree (also known as a minimum overlay network) (Lines 28–29). For the latter case, we first figure out the vertices that are not in the father topic’s overlay network (denoted as ), but meanwhile in its own publishlist or subscribelist (Lines 31–34). Then, we add these vertices to to form a connected spanning tree adopting the Kruskal algorithm (Lines 35–37).
Algorithm 3 depicts the routing fine-tuning operations for physical topology change. In fact, any changes on the subscription topology or physical topology would trigger a routing update. For the first case, when a node v adds to the subscribelist for topic t, the routing update algorithm first checks the overlay ; if , it finds the shortest and widest path from v to and adds this path to . On the contrary, if a node v unsubscribes from topic t, it first checks whether v is a leaf node in or not. If v is a leaf node, it will remove node v, as well as the edge attached to v. Otherwise, v is a relay node, and there is nothing to do. There is no difficulty in performing this update, so this algorithm is omitted in this paper. For the latter, as any link can suffer from a failure, the traffic flowing through the invalid link originally should take detours via other links. When a new link comes into operation, it should share the traffic of other links to balance the load as much as possible. To avoid traffic vibrating, this process moves mildly. It just depend on subsequent adjustment. Algorithm 3 carries out routing fine-tuning when the link state changes. Note that the routing update induced by node failure is included in Algorithm 3, because this situation equals multiple links’ failure.
| Algorithm 3 Routing fine-tuning algorithm for physical topology change. |
- Require:
// is the residual bandwidth capacity matrix // is overlay network for topic t - Ensure:
//, for //R(E) is residual bandwidth matrix, equals C(E) initially.
- 1:
if the links set is invalid - 2:
find the affected overlay network set GA; - 3:
foreach in GA - 4:
merge the connected subgraphs split by failed links - 5:
endfor - 6:
else //there is newly added link - 7:
update the residual bandwidth matrix - 8:
endif
|
4.4. Complexity Analysis for Algorithm 2
Lemma 2. The time complexity of Algorithm 2 is O(max(, n)).
Proof. The time complexity of WidestPathTree(G, ) is O(). Here, n is the number of vertices and m is the number of edges. This procedure is executed times. Therefore, the time complexity of Lines 2–4 is O().
The time complexity from Lines 5–27 in Algorithm 2 is O(). Here, , .
Lines 28–29 adopt Prim’s algorithm to merge several connected components into a connected graph; the time complexity of the worst case is O(). If the Fibonacci heap and adjacency list are used for storing edges and weights, the time complexity can be reduced to O().
Therefore, the time complexity of constructing a topic-connected overlay network ab initio is the sum of these three items discussed above, that is O(max(, )).
The function of Lines 31–36 equals Line 29; the same algorithm can be adopted. Therefore, the time complexity of constructing a topic-connected overlay network based on its father topic overlay network is O().
Therefore, the total time complexity of Algorithm 2 is O(max(, )).
6. Conclusions
In this paper, we attempt to construct a topic-based publish/subscribe system in an SDN environment.
The improvements provided by SDNPS constitute the basis for a highly reliable event diffusion infrastructure able to efficiently balance the load of links and avoid imprudent forwarding for events. By encoding topics and embedding them into packet headers as IPV6 multicast addresses, we can directly perform filtering and forwarding operations on SDN switches without detours to brokers. As a result, this significantly reduces the end-to-end latency.
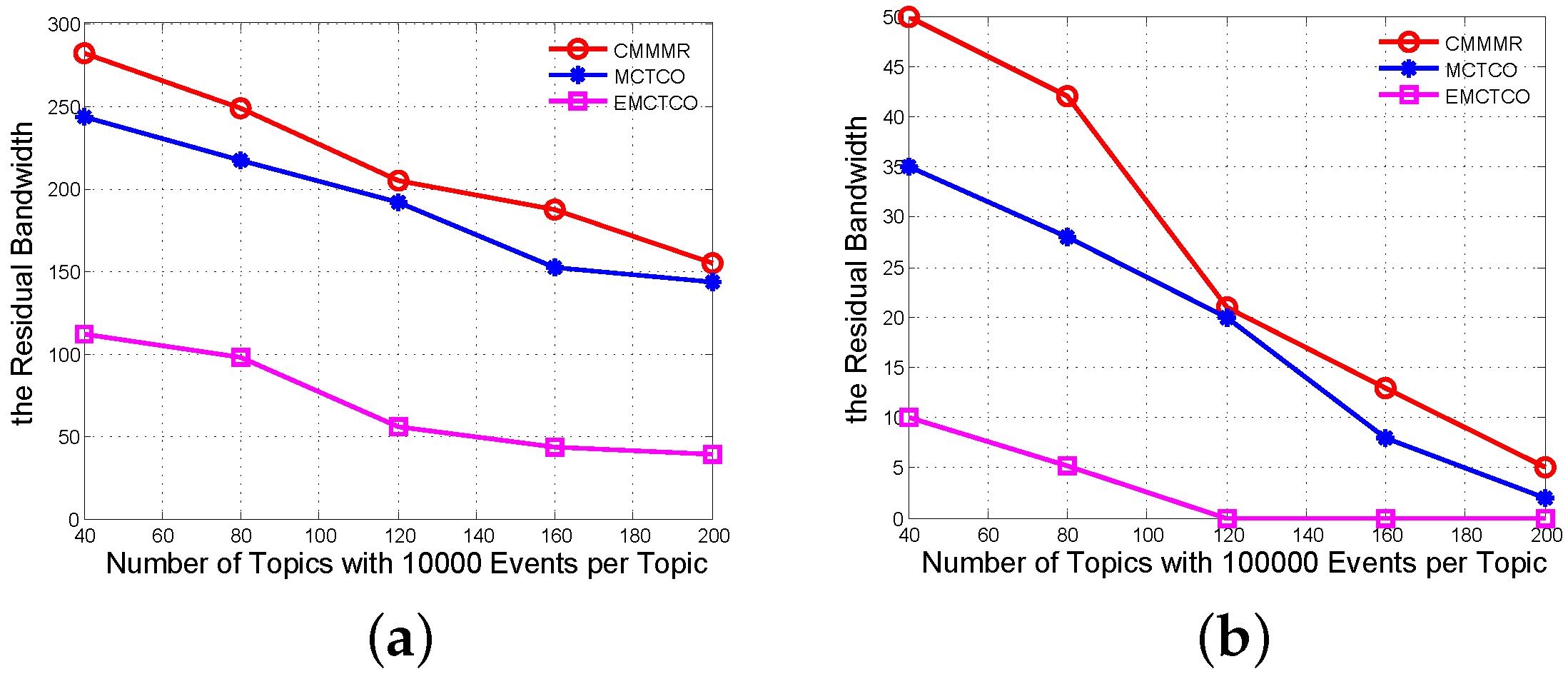
The paper pays most of its attention to the inter-cluster routing mechanism incidentally with several different aspects of the event dissemination mechanism and proposes algorithms to construct topic-connected overlay networks, which in fact are a set of minimal cost Steiner trees induced by relevant publishers and subscribers. Particularly, our algorithms are interrelated with the topic tree. In this way, we can restrict the event dissemination scope to those pertinent nodes only, which greatly saves the bandwidth. Simultaneously, we also take the residual bandwidth into account. By maximizing the residual bandwidth as the optimization objective, we realized a load-balanced routing schema.
For all that, there are still some rough edges. These can be ameliorated later. In the future, we are going to work on two aspects of the system. The first fundamental aspect that must be pursued is the real-time requirement for some events, e.g., real-time alarm event for the Internet of Things (IoT). End-to-end latency can be cut down further by manipulating and fully capitalizing on the programmable characteristic of SDNs. Second, we will extend our experiments and test the system with reference to [
35].












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}