Could We Realize the Fully Flexible System by Real-Time Computing with Thin-Film Transistors? †


Abstract
:1. Introduction
2. Materials and Methods
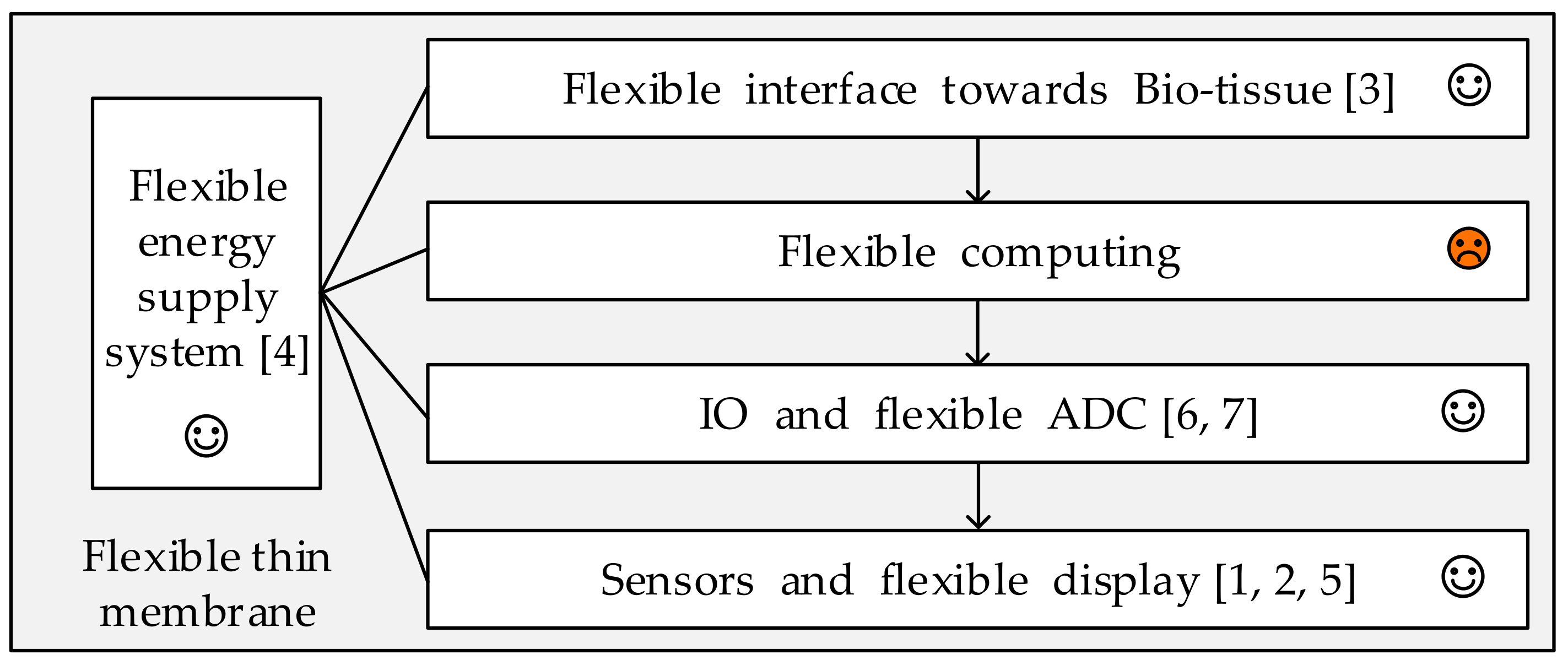
2.1. Flexible Electronic Device
2.2. Fault-Tolerant Image Processing Algorithm
2.2.1. Pre-Processing Algorithms
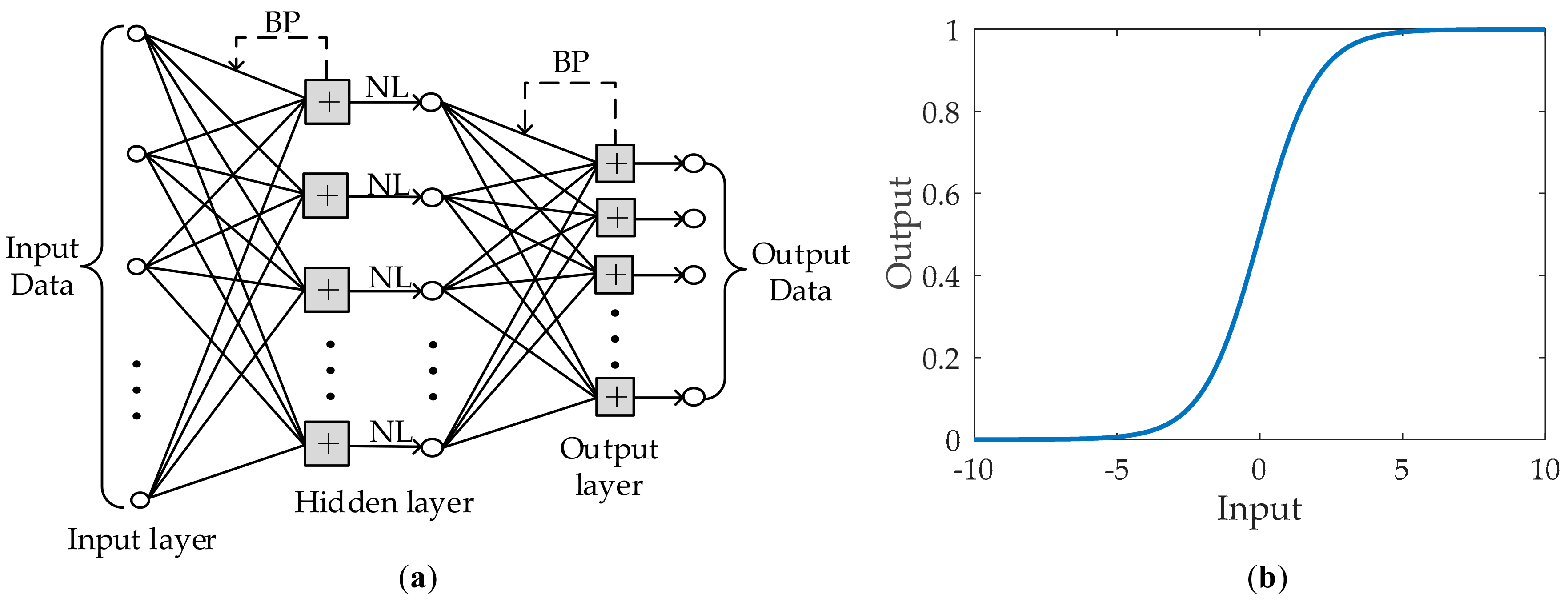
2.2.2. Classification Algorithms: Feature Processing
2.3. Analog-To-Information Processing Method
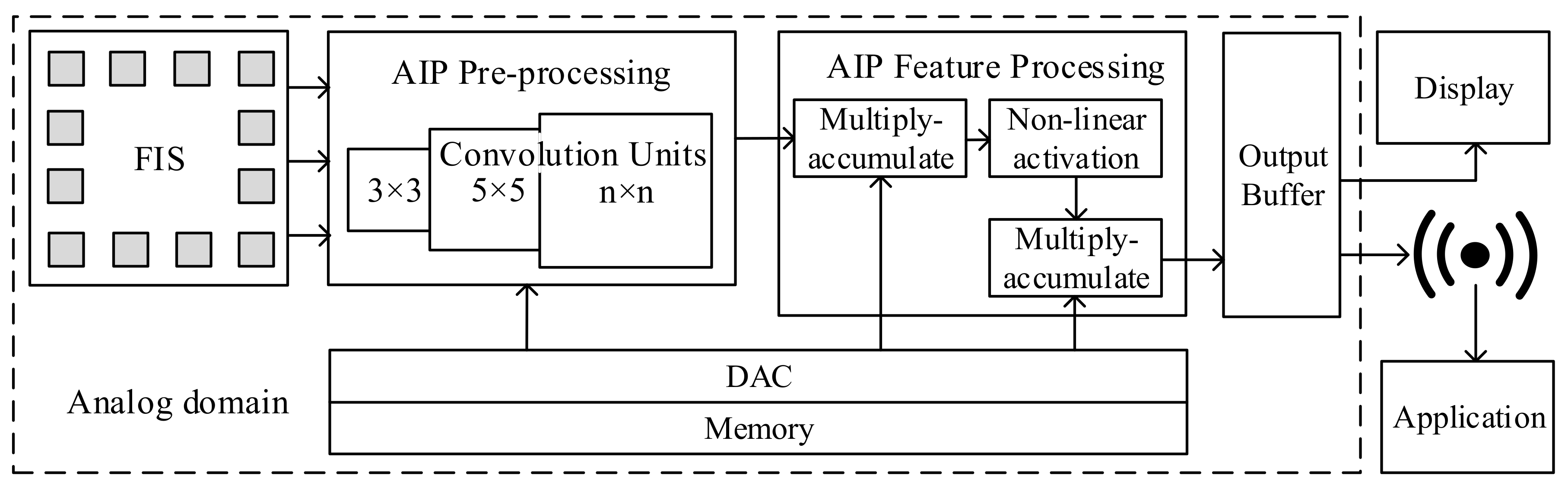
3. Architecture and System Overview
4. Circuit Design
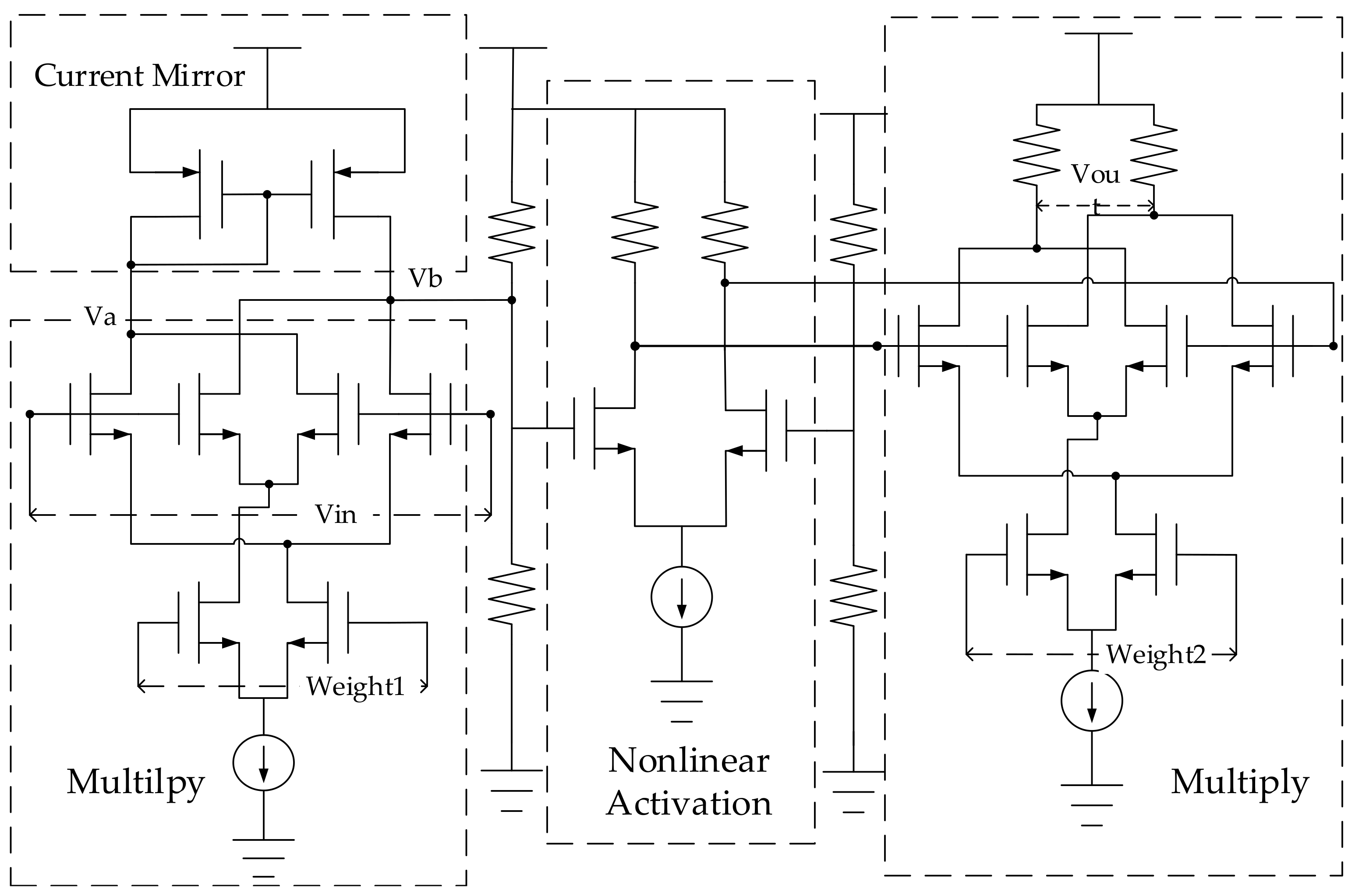
4.1. The Basic Circuit Unit Design of Gaussian Convolution
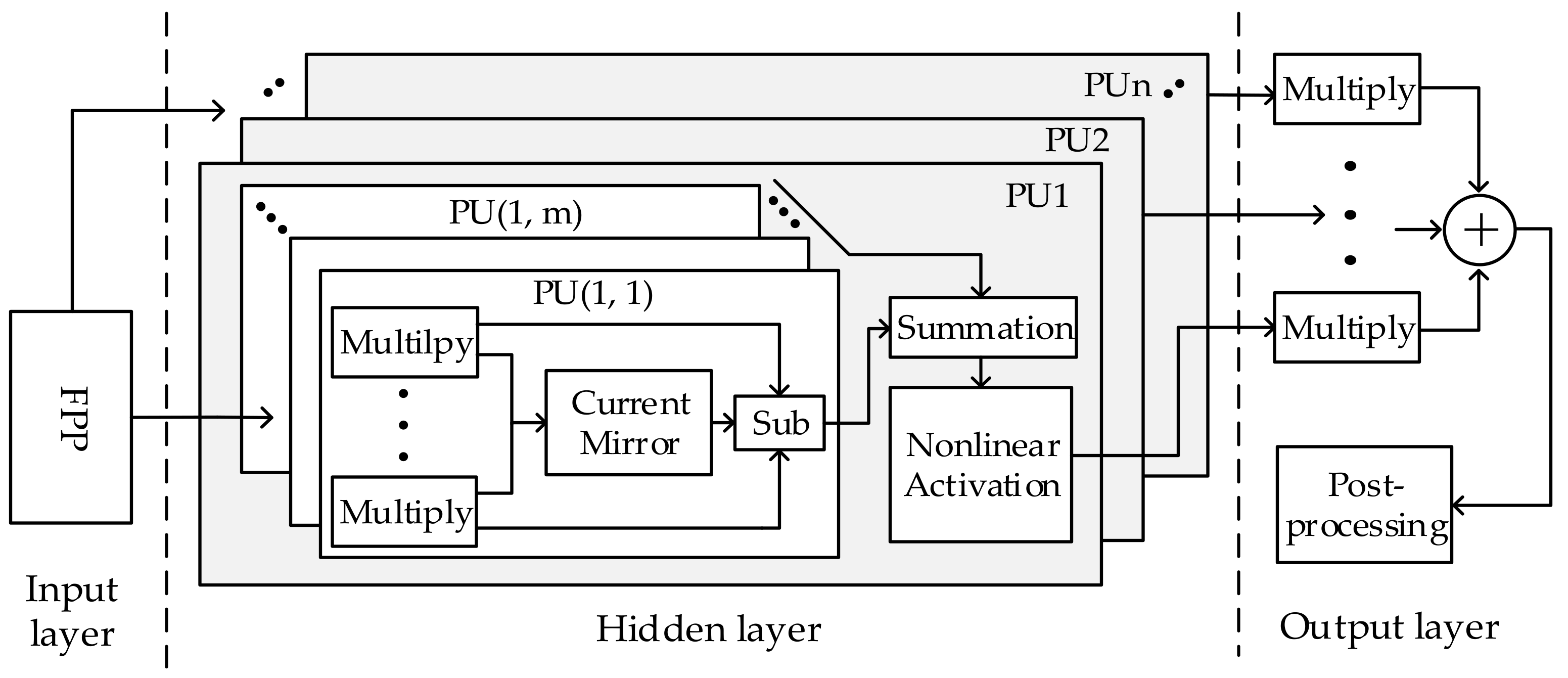
4.2. The Basic Circuit Unit Design of MLP
5. Simulations and Analysis
5.1. Verification of Functional Correctness
5.2. Performance Analysis
5.2.1. Settling Time
5.2.2. Energy Efficiency
5.3. Fault Tolerance Analysis
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Wang, X.; Liu, Z.; Zhang, T. Flexible sensing electronics for wearable/attachable health monitoring. Small 2017, 13, 1602790. [Google Scholar] [CrossRef] [PubMed]
- Park, J.-S.; Kim, T.-W.; Stryakhilev, D.; Lee, J.-S.; An, S.-G.; Pyo, Y.-S.; Lee, D.-B.; Mo, Y.G.; Jin, D.-U.; Chung, H.K. Flexible full color organic light-emitting diode display on polyimide plastic substrate driven by amorphous indium gallium zinc oxide thin-film transistors. Appl. Phys. Lett. 2009, 95, 013503. [Google Scholar] [CrossRef]
- Schwartz, G.; Tee, B.C.K.; Mei, J.; Appleton, A.L.; Kim, D.H.; Wang, H.; Bao, Z. Flexible polymer transistors with high pressure sensitivity for application in electronic skin and health monitoring. Nat. Commun. 2013, 4, 1859. [Google Scholar] [CrossRef] [PubMed]
- Green, M.A.; Emery, K.; Hishikawa, Y.; Warta, W.; Dunlop, E.D. Solar cell efficiency tables (version 47). Prog. Photovolt. Res. Appl. 2016, 24, 3–11. [Google Scholar] [CrossRef]
- Zhang, Y.; Fu, H.; Xu, S.; Fan, J.A.; Hwang, K.-C.; Jiang, J.; Rogers, J.A.; Huang, Y. A hierarchical computational model for stretchable interconnects with fractal-inspired designs. J. Mech. Phys. Solids 2014, 72, 115–130. [Google Scholar] [CrossRef]
- Sun, W.; Zhao, Q.; Qiao, F.; Liu, Y.; Yang, H.; Guo, X.; Zhou, L.; Wang, L. An 8b 0.8 kS/s configurable VCO-based ADC using oxide TFTs with Inkjet printing interconnection. In Proceedings of the IEEE International Symposium on Circuits and Systems, Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Song, I.; Kim, S.; Yin, H.; Kim, C.J.; Park, J.; Kim, S.; Choi, H.S.; Lee, E.; Park, Y. Short channel characteristics of gallium–indium–zinc–oxide thin film transistors for three-dimensional stacking memory. IEEE Electron Device Lett. 2008, 29, 549–552. [Google Scholar] [CrossRef]
- Yoon, J.; Lee, S.M.; Kang, D.; Meitl, M.A.; Bower, C.A.; Rogers, J. Heterogeneously integrated optoelectronic devices enabled by micro-transfer printing. Adv. Opt. Mater. 2015, 3, 1313–1335. [Google Scholar] [CrossRef]
- Myny, K.; Smout, S.; Rockele, M.; Bhoolokam, A.; Ke, T.H.; Steudel, S.; Obata, K.; Marinkovic, M.; Pham, D.-V.; Gulati, A.; et al. 30.1 8b Thin-film microprocessor using a hybrid oxide-organic complementary technology with inkjet-printed P 2 ROM memory. In Proceedings of the 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), San Francisco, CA, USA, 9–13 February 2014; pp. 486–487. [Google Scholar]
- LiKamWa, R.; Hou, Y.; Gao, J.; Polansky, M.; Zhong, L. RedEye: Analog ConvNet image sensor architecture for continuous mobile vision. In Proceedings of the 43rd International Symposium on Computer Architecture, Seoul, Korea, 18–22 June 2016; pp. 255–266. [Google Scholar]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, p. 1150. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Verhelst, M.; Bahai, A. Where Analog Meets Digital: Analog-to-Information Conversion and Beyond. IEEE Solid-State Circuits Mag. 2015, 7. [Google Scholar] [CrossRef]
- Wu, N.; Liu, Z.; Qiao, F.; Wei, Q.; Guo, X.; Xie, Y.; Yang, H. A Real-Time and Energy-Efficient Implementation of Difference-of-Gaussian with Flexible Thin-Film Transistors. In Proceedings of the 2016 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Pittsburgh, PA, USA, 11–13 July 2016; pp. 455–460. [Google Scholar]
- Liu, Z.; Wu, N.; Qiao, F.; Wei, Q.; Guo, X.; Liu, Y.; Yang, H. Computable flexible electronics: circuits exploring for image filtering accelerator with OTFT. In Proceedings of the 2016 7th International Conference on Computer Aided Design for Thin-Film Transistor Technologies (CAD-TFT 2016), Beijing, China, 26–28 October 2016; p. 1. [Google Scholar]
- Li, Q.; Liu, Z.; Qiao, F.; Wu, X.; Wang, C.; Wei, Q.; Yang, H. From “MISSION: IMPOSSIBLE” to mission possible: Fully flexible intelligent contact lens for image classification with analog-to-information processing. In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Nomura, K.; Ohta, H.; Takagi, A.; Kamiya, T.; Hirano, M.; Hosono, H. Room-temperature fabrication of transparent flexible thin-film transistors using amorphous oxide semiconductors. Nature 2004, 432, 488–492. [Google Scholar] [CrossRef] [PubMed]
- Xie, H.; Liu, G.; Zhang, L.; Zhou, Y.; Dong, C. Amorphous Oxide Thin Film Transistors with Nitrogen-Doped Hetero-Structure Channel Layers. Appl. Sci. 2017, 7, 1099. [Google Scholar] [CrossRef]
- Bae, J.U.; Baeck, J.H.; Yun, P.; Kim, D.H.; Jang, Y.H.; Park, K.S.; Yoon, S.Y.; Kang, I.B. High mobility oxide TFT for OLED pixel circuits. In Proceedings of the 2017 24th International Workshop on Active-Matrix Flatpanel Displays and Devices (AM-FPD), Kyoto, Japan, 4–7 July 2017; pp. 309–311. [Google Scholar]
- Rumelhart, D.E.; Mcclelland, J.L. Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Foundations (Parallel Distributed Processing); MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Lindeberg, T. Scale-space for discrete signals. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 234–254. [Google Scholar] [CrossRef]
- Kang, K.; Shibata, T. An on-chip-trainable Gaussian-kernel analog support vector machine. IEEE Trans. Circuits Syst. I Regul. Pap. 2010, 57, 1513–1524. [Google Scholar] [CrossRef]
- Chandramoorthy, N.; Swaminathan, K.; Cotter, M.; Li, X.; Narayanan, V.; Palit, I.; Irick, K. Understanding the landscape of accelerators for vision. In Proceedings of the 2014 IEEE Workshop on Signal Processing Systems (SiPS), Belfast, UK, 20–22 October 2017; pp. 1–6. [Google Scholar]
- Li, Y.; Qiao, F.; Wei, Q.; Yang, H. Physical computing circuit with no clock to establish Gaussian pyramid of SIFT algorithm. In Proceedings of the 2015 IEEE International Symposium on Circuits and Systems (ISCAS) 2015, Lisbon, Portugal, 24–27 May 2015; pp. 2057–2060. [Google Scholar]
- Gilbert, B. A precise four-quadrant multiplier with subnanosecond response. IEEE J. Solid-State Circuits 1968, 3, 365–373. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | CMOS | A-Si:H TFTs | A-Oxide TFTs |
|---|---|---|---|
| Carrier Mobility (cm2/Vs) | 480–1350 | <1 | 10–50 |
| Transparent | × | √ | √ |
| Soft | × | √ | √ |
| Biocompatible | × | √ | √ |
| Process Variation | Small | Medium | Large |
| Cost | High | Medium | Low |
| Manufacture Temperature | High | ≅110 °C | Room temperature |
| Unit | Cell Number | Energy Consumption (μJ) |
|---|---|---|
| Multipliers | 39,760 | 9.23 |
| Non-linear activation | 50 | 1.65 × 10−3 |
| Current mirror | 3950 | 5.93 |
| Total | - | 15.16 |
| Key Point | Circuit | Software | Matching | Matching Rate |
|---|---|---|---|---|
| Maximum | 70 | 60 | 50 | 83.3% |
| Minimum | 82 | 62 | 43 | 69.4% |
| Avg. Rate | - | - | - | 76.2% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Liu, Z.; Qiao, F.; Wei, Q.; Yang, H. Could We Realize the Fully Flexible System by Real-Time Computing with Thin-Film Transistors? Appl. Sci. 2017, 7, 1224. https://doi.org/10.3390/app7121224
Li Q, Liu Z, Qiao F, Wei Q, Yang H. Could We Realize the Fully Flexible System by Real-Time Computing with Thin-Film Transistors? Applied Sciences. 2017; 7(12):1224. https://doi.org/10.3390/app7121224
Chicago/Turabian StyleLi, Qin, Zheyu Liu, Fei Qiao, Qi Wei, and Huazhong Yang. 2017. "Could We Realize the Fully Flexible System by Real-Time Computing with Thin-Film Transistors?" Applied Sciences 7, no. 12: 1224. https://doi.org/10.3390/app7121224
APA StyleLi, Q., Liu, Z., Qiao, F., Wei, Q., & Yang, H. (2017). Could We Realize the Fully Flexible System by Real-Time Computing with Thin-Film Transistors? Applied Sciences, 7(12), 1224. https://doi.org/10.3390/app7121224