1. Introduction
Detection of objects in the unfavorable environment is an important issue that receives great interest in various fields, including the military and civilian areas. Detecting an object on a seafloor composed of sand and mud in the shallow water is a significant technology in the military detection field [
1,
2,
3]. In this problem, the reflections coming from the clutter surrounding a target and the ambient noise are the main hurdles. Furthermore, when the target is lying on the seabed in the shallow water, the detection is more difficult because the noise radiated by the target is maintained to be minimal and its target strength is relatively reduced by a narrow incident angle of the signal from the active sonar source. Thus, effective detection methods under such an environment are required to be developed.
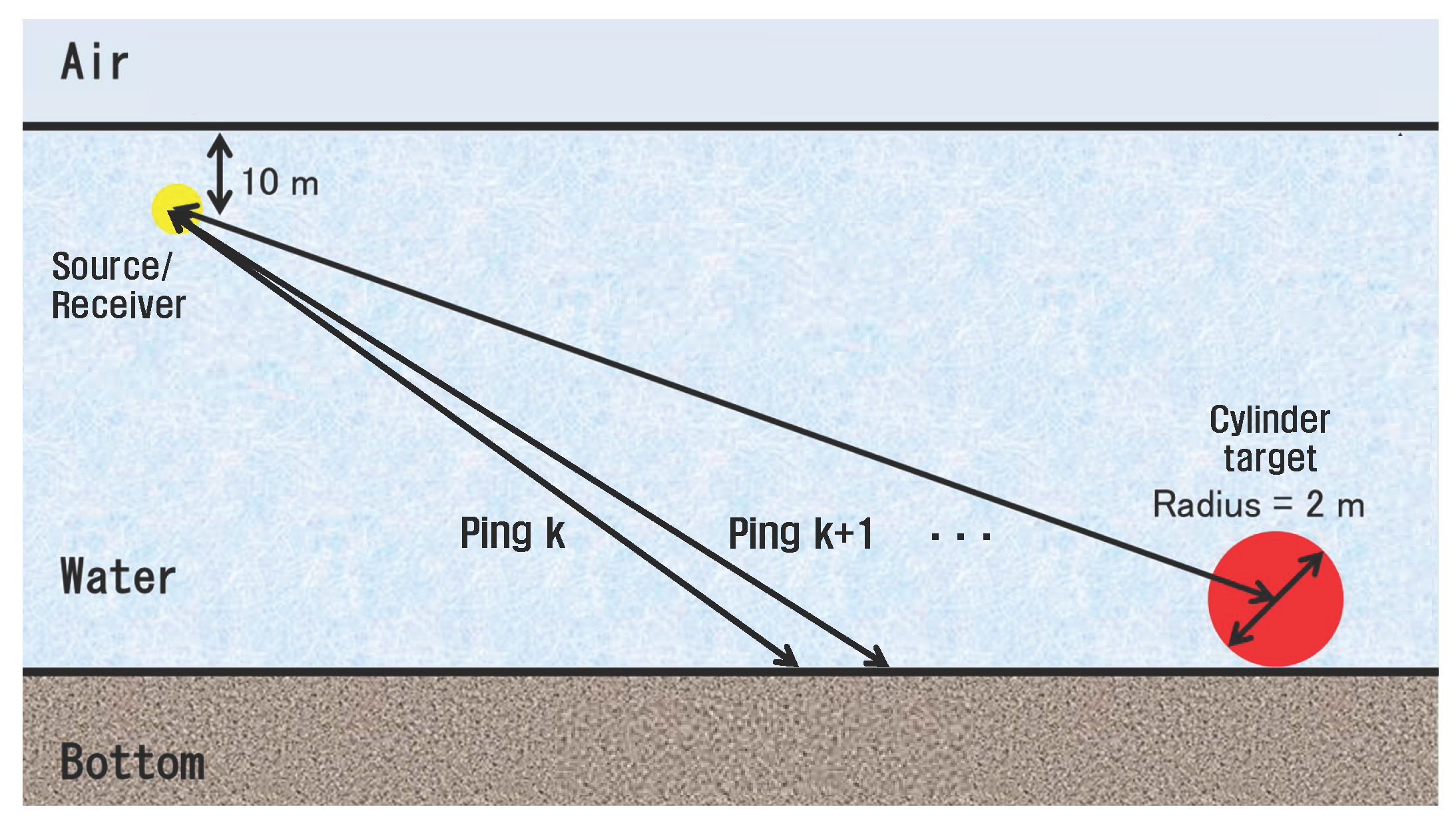
The actual underwater environment considered in this study is the Yellow Sea in Korea. The depth of the Yellow Sea is less than 100 m, so it may be anticipated that small submarines can find places on the sea floor to exploit. Thus, the target considered here is like a cylinder with a length of 20 m and a radius of 2 m. For detecting this type of target at a distance from 500 to 800 m, an active sonar is designed with the linearly frequency modulated (LFM) signal of a band from 6 kHz to 20 kHz and a planar array of 9 m by 11 m [
3,
4,
5], which has a bearing-range resolution of 0.67
.
Figure 1 schematically illustrates the underwater environment considered in this study. Since the detection area is from 500 m to 800 m, the grazing angle decreases from 10.2
to 6.4
, which can hardly be distinguished by the sonar system due to a relatively wide vertical beam width. Since this sonar system uses a mid-frequency LFM signal, imaging is impossible and the detection method is based on the approach proposed in [
3,
6].
There are several approaches to the similar problem. One of them is the application of a side scan sonar to acquire images of the detection fields [
7,
8,
9]. Unfortunately, obtaining clean images by a side scan sonar requires slow scan speed and additional efforts are required to recognize a target submerged into the sediments. Various studies have been carried out from the viewpoint of classification. In [
10], Fawcett et al. investigated four information fusion methods for classification of underwater objects through two sidescan sonar images. Huang et al. used various machine learning models to create prediction maps and prediction uncertainty maps [
11]. The study presented in [
12] proposed an automated target detection approach that combines image based feature extraction, independent component analysis, and unsupervised classification. It is demonstrated its suitability for detecting small targets in side scan sonar imagery. In [
13], Williams and Fakiris introduced a new context-dependent classification algorithm and demonstrated its performance using measured data. In this situation, the approach employed by the Applied Physics Lab. (APL) at the University of Washington, Seattle, WA, USA draws attention for detecting sea mines at the bottom of the seabed in the shallow sea [
1,
2]. This approach is based on the mathematical target and seabed models to obtain the features of the bottoming target, which are simultaneously verified with the measurements. Through this study, the target signature database is constructed to enable the detection probability of the active sonar system to increase. However, this approach has a disadvantage of investigating whether each received signal matches any component in the database. This is very time-consuming. Thus, in order to save this time and effort, the signal energy-based threshold scheme can be applied. That is, for a specific received signal that has greater energy than the prespecified threshold only, comparison with the database is carried out, but this still needs comparison time.
The logistic regression is one of the supervised learning models for classification, which trains a set of parameters that maximizes the likelihood of the categories for training data [
14]. Williams et al. [
15] employed the infinitely imbalanced logistic regression [
16] to the problem of mine classification on ground-penetrating radar images and sidescan sonar images exploiting the imbalanced characteristic of information. In [
17], the detection of mines or other objects on the seabed from multiple side-scan sonar views is considered and the logistic regression models are used for comparison. In [
18], the semi-supervised and active learning schemes are developed and applied to detection of buried unexploded ordnances (UXO’s) using several machine learning models including the logistic regression. Note that the previous works are based on target images while the approach in this study relies on the matched filtered signal samples.
In this paper, the logistic regression model is employed for this detection problem since the target detection is a kind of classification problem. As mentioned above, the energy of the received signal is one of the various features. The reflected signals from the hard sediment such as rocks can trigger a false alarm by the active sonar system, which degrades the system performance. In order to improve detection performance and speed, the logistic regression model is trained by the feature vectors of the target in the clutter and those of the clutter without any target. For generating the target signals in the clutter, the target response with respect to the linearly frequency modulated signal is developed by the cylindrical object model proposed by Ye [
19] and the clutter signals are generated based on the K-distribution model introduced by Abraham and Lyons [
3,
20]. The interaction between the target and the contacted sediment and the resulting multipath components are developed using the similar approach presented in [
2].
The objective of this study is to investigate whether the logistic regression model trained through simulated data generated by the mathematical model for a cylinder’s backscattering can operate for the experimental data. The motivation of this study is that, in general, it is not easy to obtain abundant experimental data in the underwater field. Thus, it is difficult to train the model with sufficient amount of the data. For this reason, the simulated data are generated by using the mathematical model of a cylinder, and then applied to the logistic regression model to perform cross-validation of the model. In the following step, the logistic regression models trained using the simulated data based on the mathematical model are evaluated using the experimental data. In the first stage, the feature vector consists of the magnitude spectrum of the signal, that is, the absolute value of the discrete Fourier transform (DFT) of the signal because the target response has different spectrum shape from that of the clutter signal, which is random with the K-distribution. In addition, the magnitude spectrum is dependent on the rotation angle of the target. These facts have been reflected in the generation of the feature vectors. The training method employed in this work is a kind of the truncated Newton approach for maximum likelihood estimation [
21]. For the cross validation, the shuffle and split is employed. The performance of the model is evaluated in terms of the receiver operation characteristic (ROC) curve and its area under ROC curve (AUC), and the classification table. Since the information on the environment including the sound speed, the sediment type, and so on is not available with the data, the simulated data are generated under various conditions when applying the model to the experimental data, and the valid data are selected using the samples of the experimental data and the selected simulated data are used to train the logistic regression model and the samples randomly selected experimental data are applied to evaluate the model.
The paper is organized as follows.
Section 2 briefly introduces the logistic regression model and its features. In
Section 3, the underwater environment considered in this study is described and the target scattering and clutter signal models are introduced. The generation of the feature vector is explained in
Section 4. In
Section 5, the performance of the logistic regression model with the simulated data is presented and discussed.
Section 6 demonstrates the performance of the proposed approach with the experimental data. Finally, the paper is concluded in
Section 7.
2. Introduction to Logistic Regression
Logistic regression is a statistical model that expresses its input–output relationship stochastically through the logistic function, where the output of the logistic regression model is categorical. It is characterized by high analytical power and adaptability in determining the relationship between two or more variables. This method has already been applied in many research fields because of its high performance in a binary classification problem [
14].
In this study, the
vector
consisting of
d feature values represents the
i-th feature vector while the scalar
represents its corresponding category label (e.g., clutter or target). The binary logistic regression model considered in this study has the learning parameters
vector
and scalar
. For a set of
N labeled data points
, the cost function for the parameters
and
b is the log-likelihood of the defined by
where
represents the probability that the output
belongs to the category of 1 given
and
N is the number of the feature vectors. For the binary logistic model considered here, the probability
is given by
where the superscript
T represents transpose.
In order to find the optimal learning parameters
and
b that maximize the likelihood function for a given training set, the trust region Newton scheme [
21] is employed in this study. This scheme relies on approximate Newton stages in the initial stage but obtains fast convergence. The performance of the model is evaluated by measuring the AUC of the ROC curves [
22], the classification tables for the test data set and the detection rate according to the target-to-clutter ratio (TCR), which is defined by
where
and
are the power spectral densities of the target signal and the seabed clutter at frequency bin
, respectively, and Q is the total number of frequency bins in the section of the signal bandwidth.
4. Feature Vector Generation
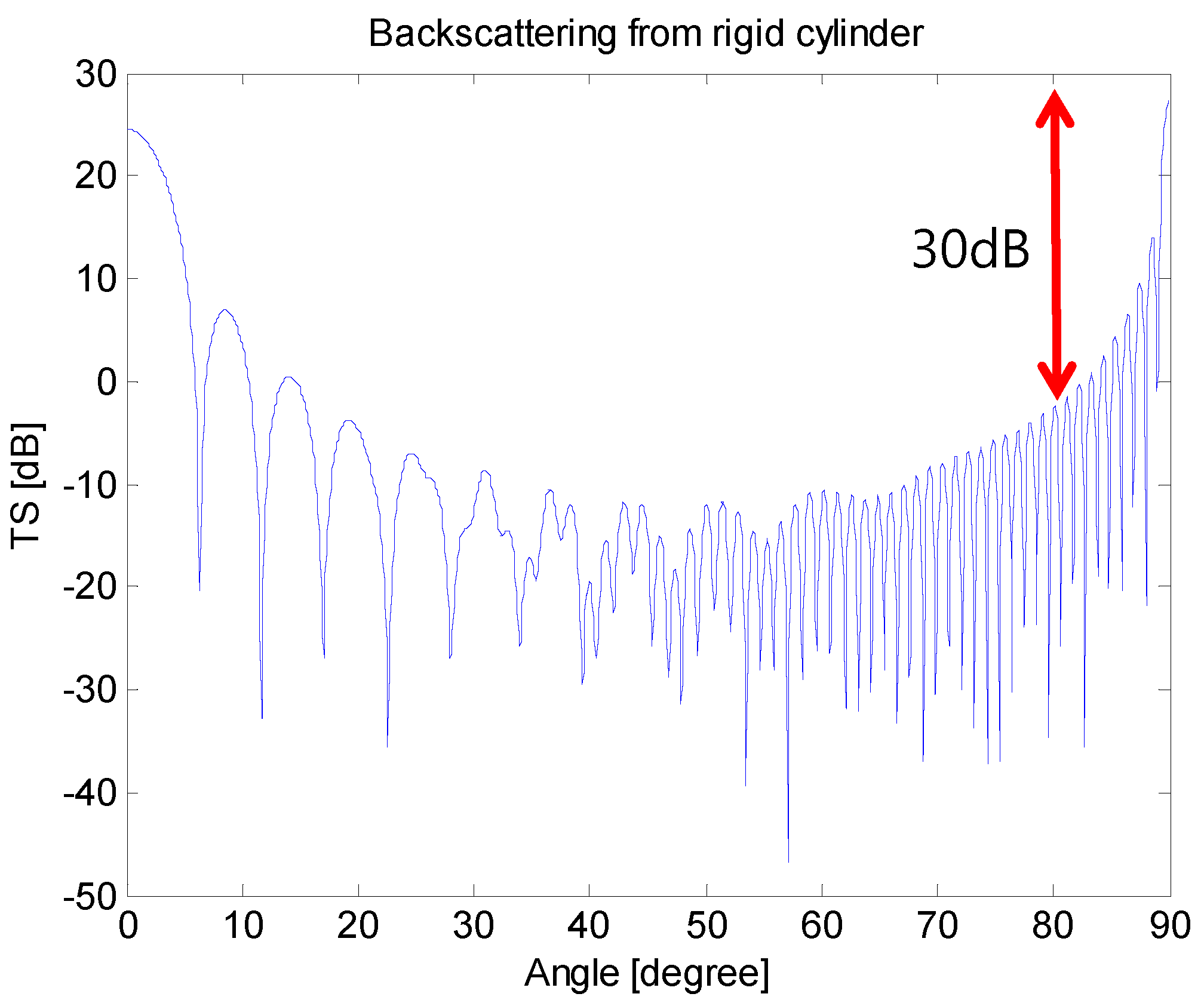
For generating a feature vector for the logistic regression model, the DFT is applied to the matched filtering output of the sonar, the magnitude of this DFT result is used as a feature. The target strength is shown in
Figure 3 according to the rotation angle of the target with respect to the incident signal. A significant change in target strength can be observed depending on the angle.
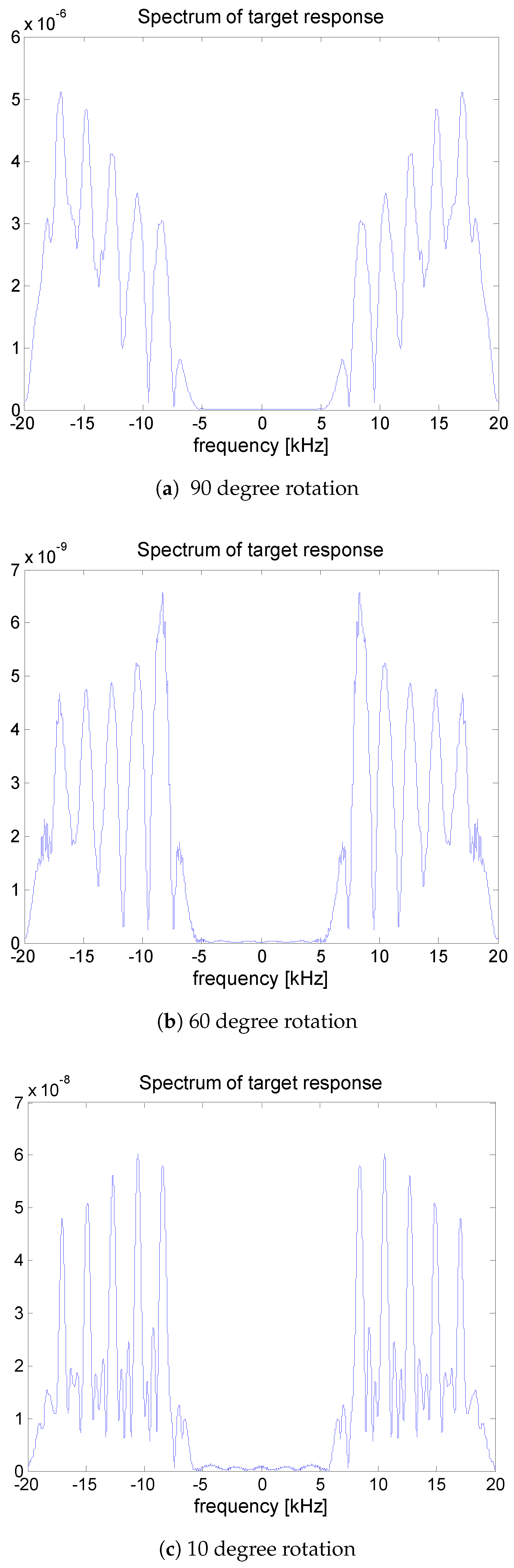
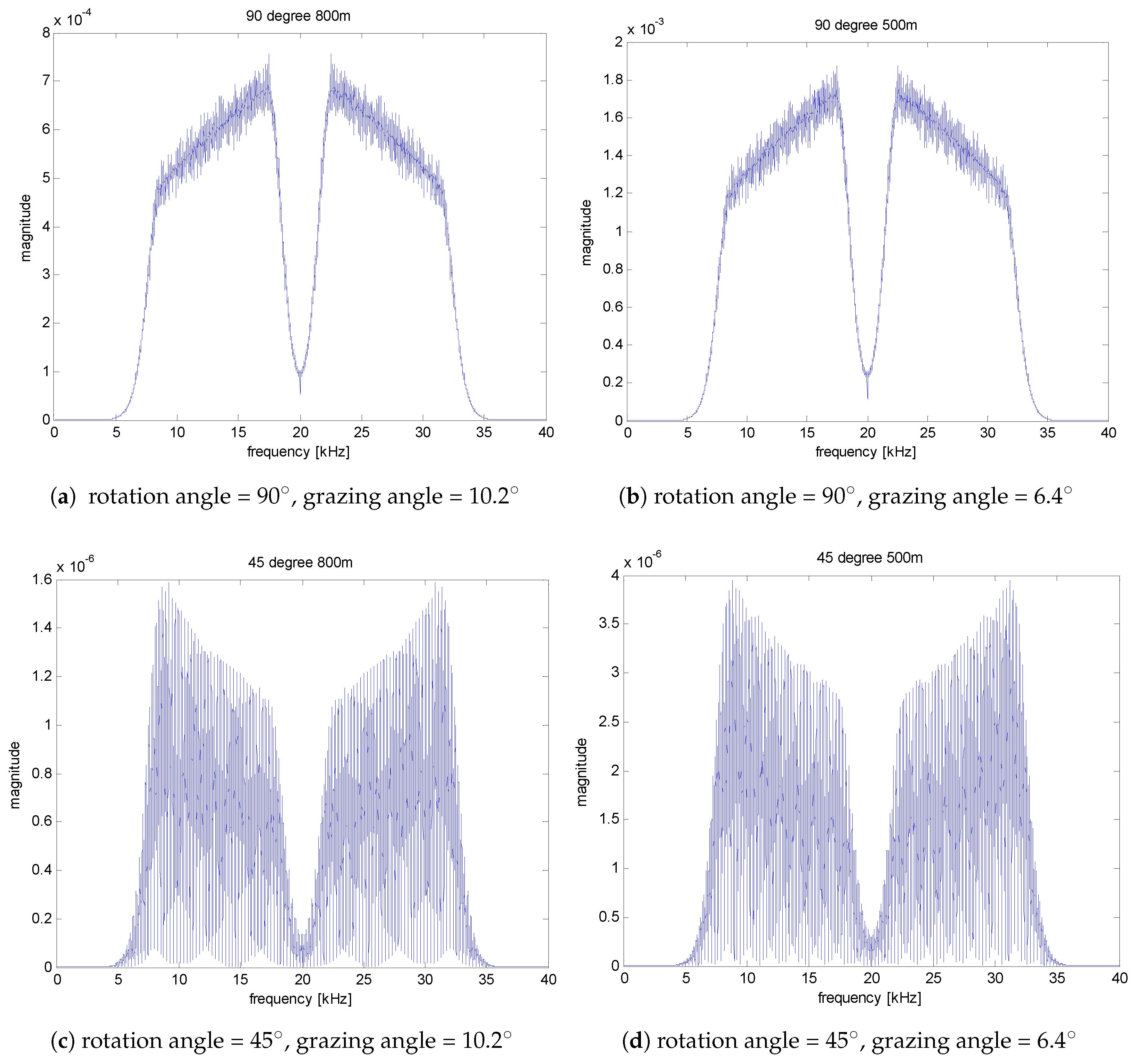
Figure 4 shows examples of the magnitude spectrum for the received signal for rotation angles of 10 degrees, 60 degrees, and 90 degrees, respectively. It is observed that the spectrum varies depending on the angle. The feature vector reflecting these spectral characteristics are utilized in the logistic regression model. Note that the target response is depending on the grazing angle from the sonar. However, since the water depth is 100 m and the target is located in the range from 500 m to 800 m in this study, the grazing angle varies from 10.2
to 6.4
, which does not make a notable difference in the spectrum, as observed in
Figure 5.
The data set employed to develop the model can be denoted by , which consists of the feature vector composed of the magnitude of the DFT of the received signal and the corresponding class label , which indicates the existence of the target. That is, the label represents the state that there is a target signal in the feature vector while the label indicates no target.
In this study, 22,000 feature vectors are generated; 11,000 feature vectors are obtained from the signals representing that a target is in the detection range while the remaining 11,000 vectors are from the clutter signals without a target in the region.
For the case that a target is present, the rotation angle of the target is changed by 10 degrees from 0 degrees to 90 degrees. For each rotation angle, TCR is increased by 1 dB from −5 dB to 5 dB. 100 signals, , are generated for each TCR and each rotation angle, where is the target response and is the clutter signal.
Whenever one feature vector
with
is generated, the same condition is applied to the generation of the corresponding clutter signal
and another clutter signal
with the same power of the target signal for a given TCR is generated and added to the clutter signal
. Note that each signal consists of 1501 samples and DFT is performed to obtain a magnitude of each frequency band to construct a feature vector.
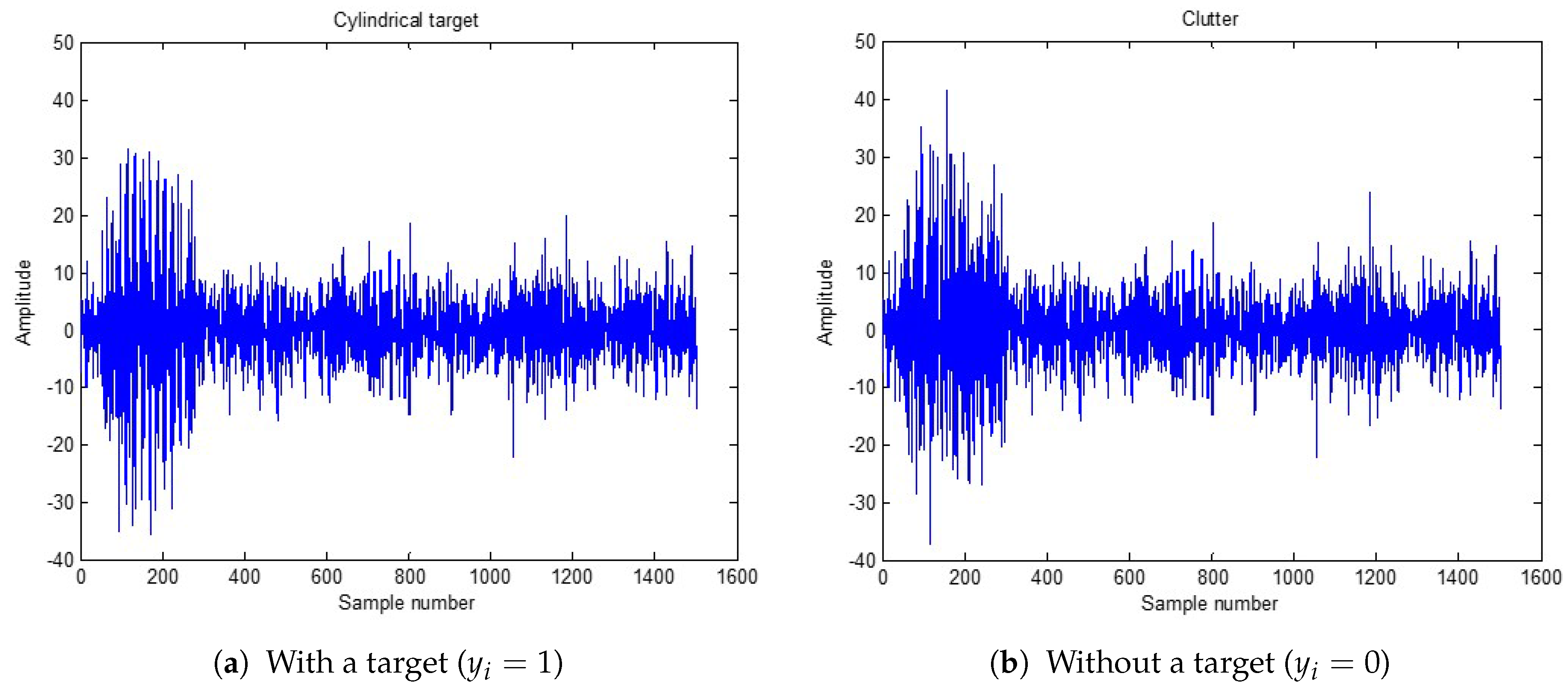
Figure 6 shows an example of the time domain waveform pair with
(
Figure 6a) and
(
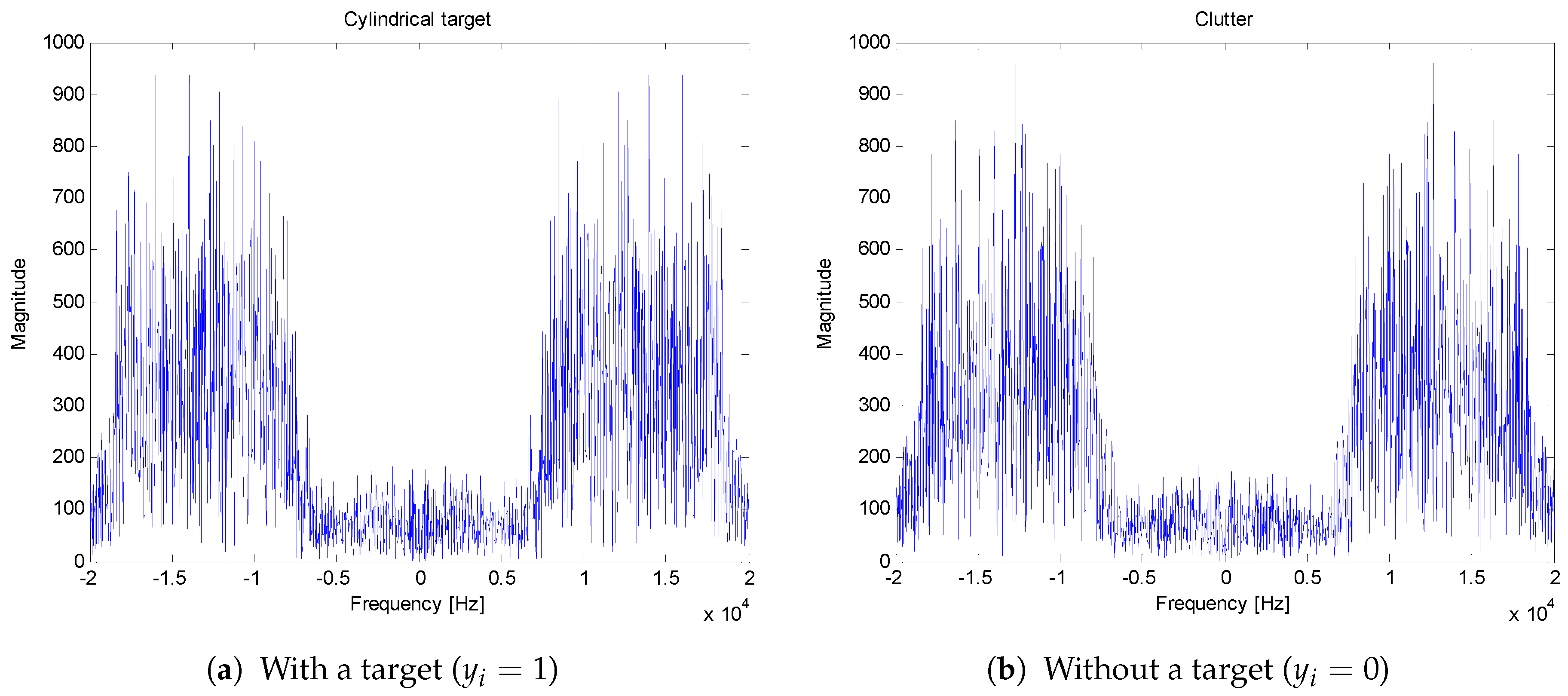
Figure 6b). The two waveforms are very similar and the magnitude spectra of the two waveforms shown in
Figure 6 are shown in
Figure 7. It is difficult to discriminate one from another. However, the magnitude spectrum in
Figure 7a has a specific spectrum structure as shown in
Figure 4.
Note that the magnitude spectrum is an even function for a real signal. Since the feature vector is generated from the magnitude spectrum of the DFT of the signal, the size of the feature vector is half of the length of the DFT, which can reduce the number of learning parameters. Since the advantage of using the magnitude spectrum is that delay or time synchronization is not critical, the energy of the signal of interest should be just in the DFT window interval.
5. Learning and Prediction
In order to find the learning parameter
and
b in the logistic regression model (
2), the trust region Newton method [
21] is employed in the learning stage using the
liblinear library [
29]. The validation of the learned model is carried out in two ways. The first approach for the cross validation is the shuffle and split cross validation. Eighty percent of the total data set is randomly selected for learning and the remaining is used for prediction. This cross-validation is carried out 10 times for evaluating the average performance. The second one is to divide the total data set into two groups. In this case, 50% of the data is randomly selected for each TCR and each rotation angle to evaluate the detection performance of the model for each TCR.
The goodness-of-fit of the learned model is assessed using the classification table [
30,
31] and the AUC [
22,
31]. The ROC curve shows the performance of the model in two dimensions. Therefore, intuitive judgment is difficult in comparing or evaluating performance. Considering this aspect, it is necessary to show performance as a single scalar value. The AUC value is between 0 and 1 because it represents the area of the unit square in which the ROC curve is drawn and computation of AUC is easy. It is known that AUC = 0.5 represents no discrimination, 0.8 ≤ AUC < 0.9 is evaluated as excellent discrimination, and AUC
is considered outstanding discrimination [
14]. As another performance index, the classification table is a useful table for visualizing the performance of algorithms in statistical classification problems.
5.1. 8:2 Shuffle-Split Cross-Validation
In this experiment, the training and test data are randomly selected at 8:2 for the 22,000 data and training and testing are performed ten times.
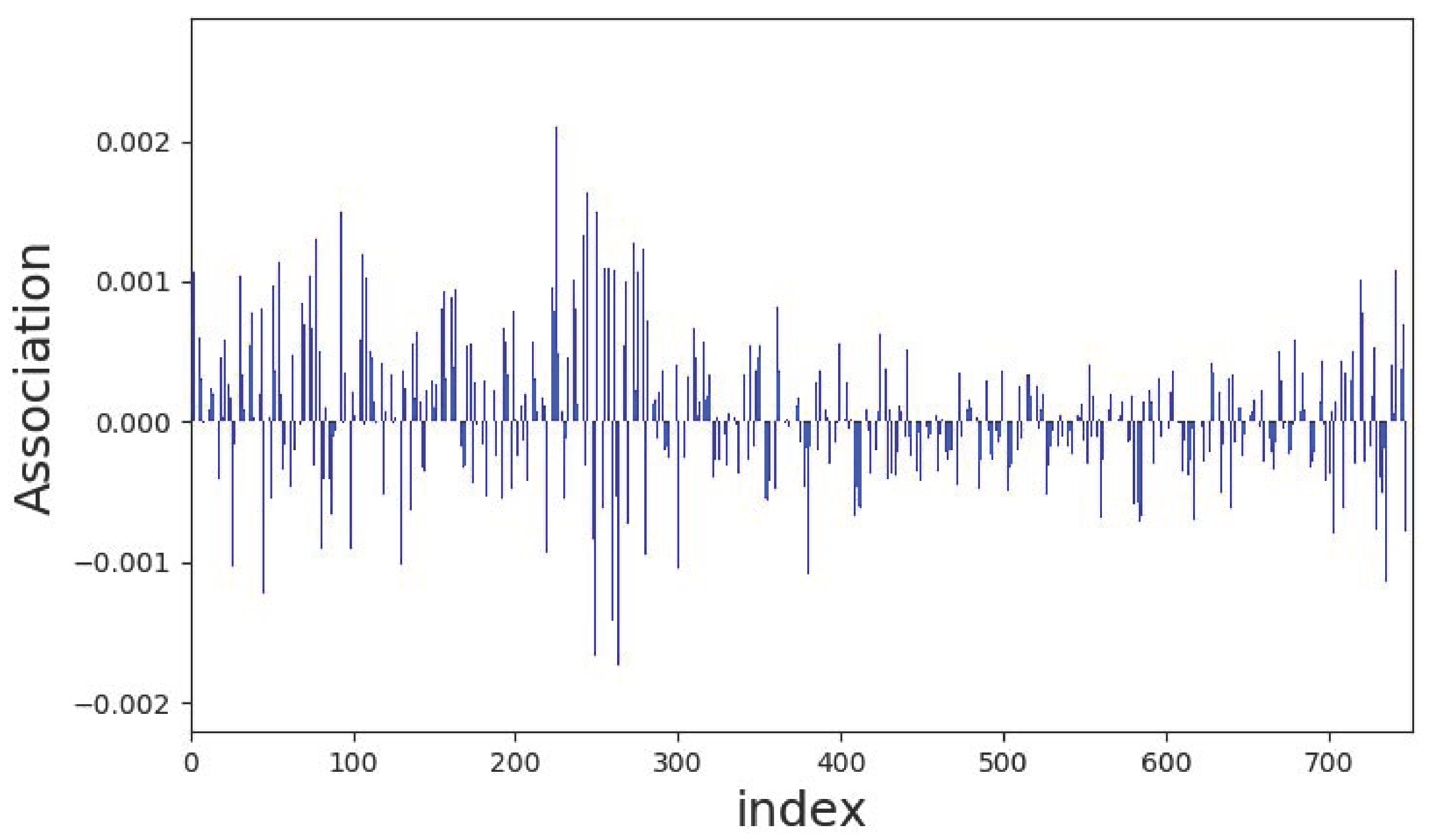
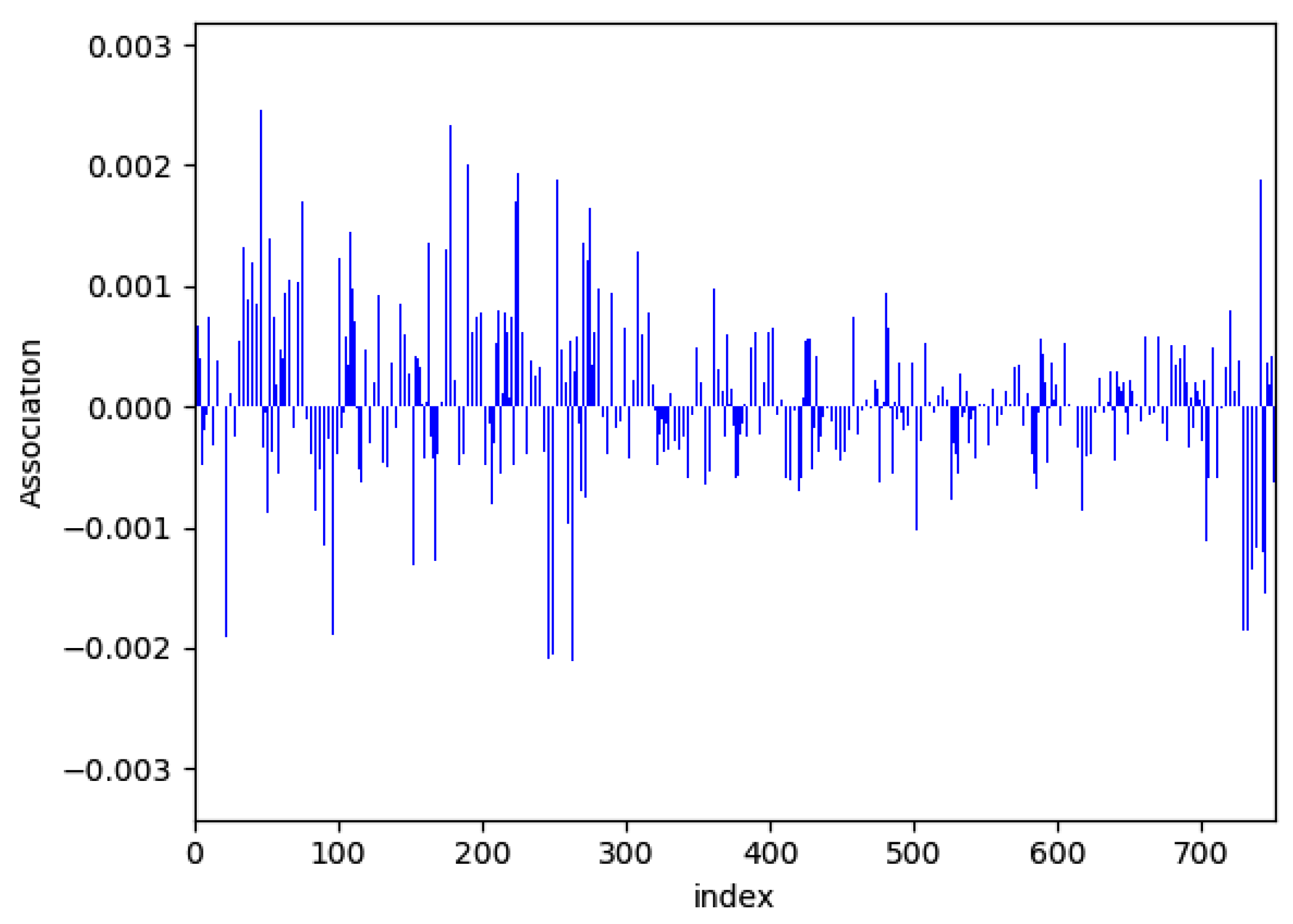
Figure 8 shows one example of the learning parameters
obtained through ten training sessions. It is observed in the figure that the parameters marked indices 50 to 300 have relatively larger magnitudes. These parameters are closely related to the significant spectral components of the target signals.
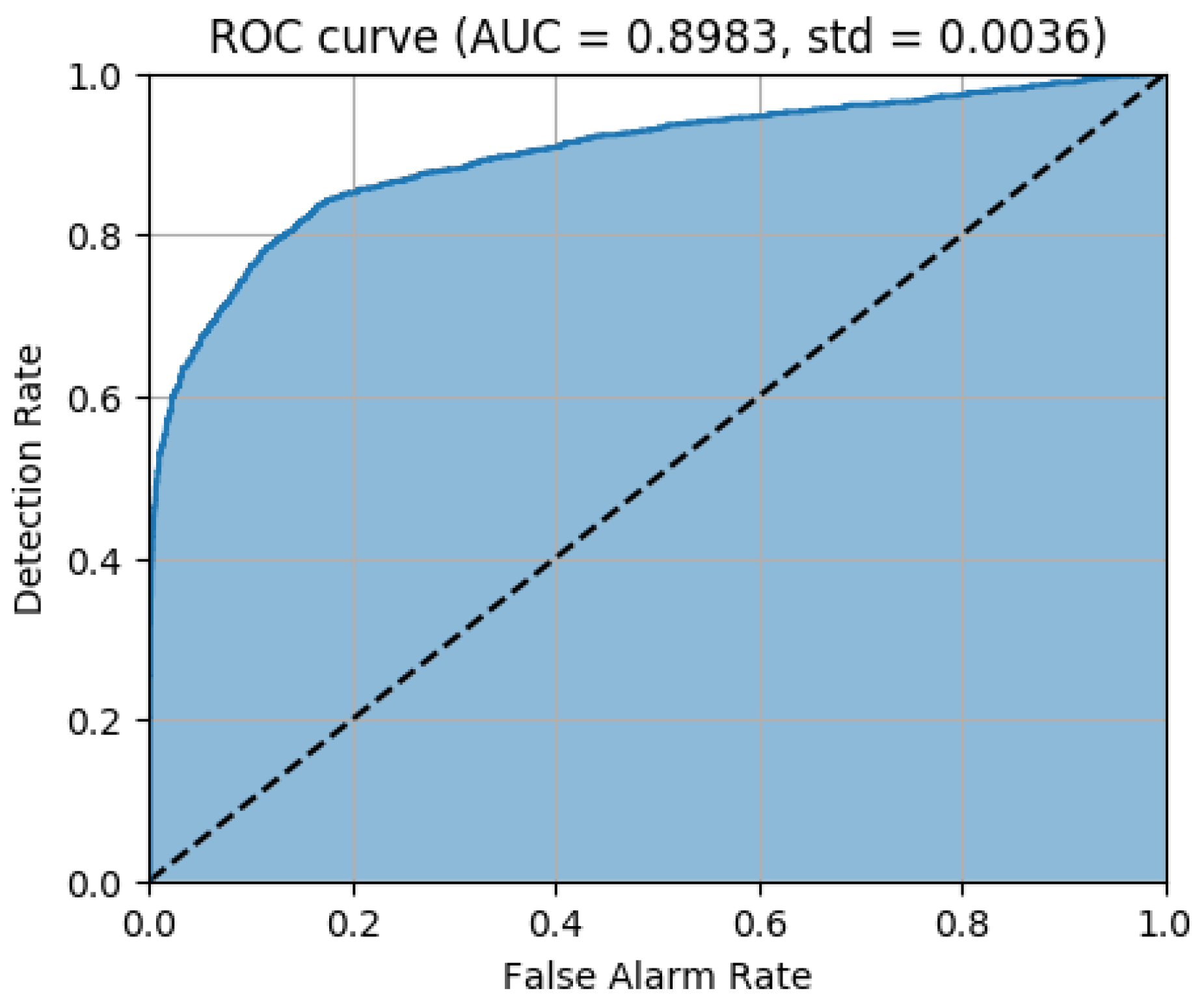
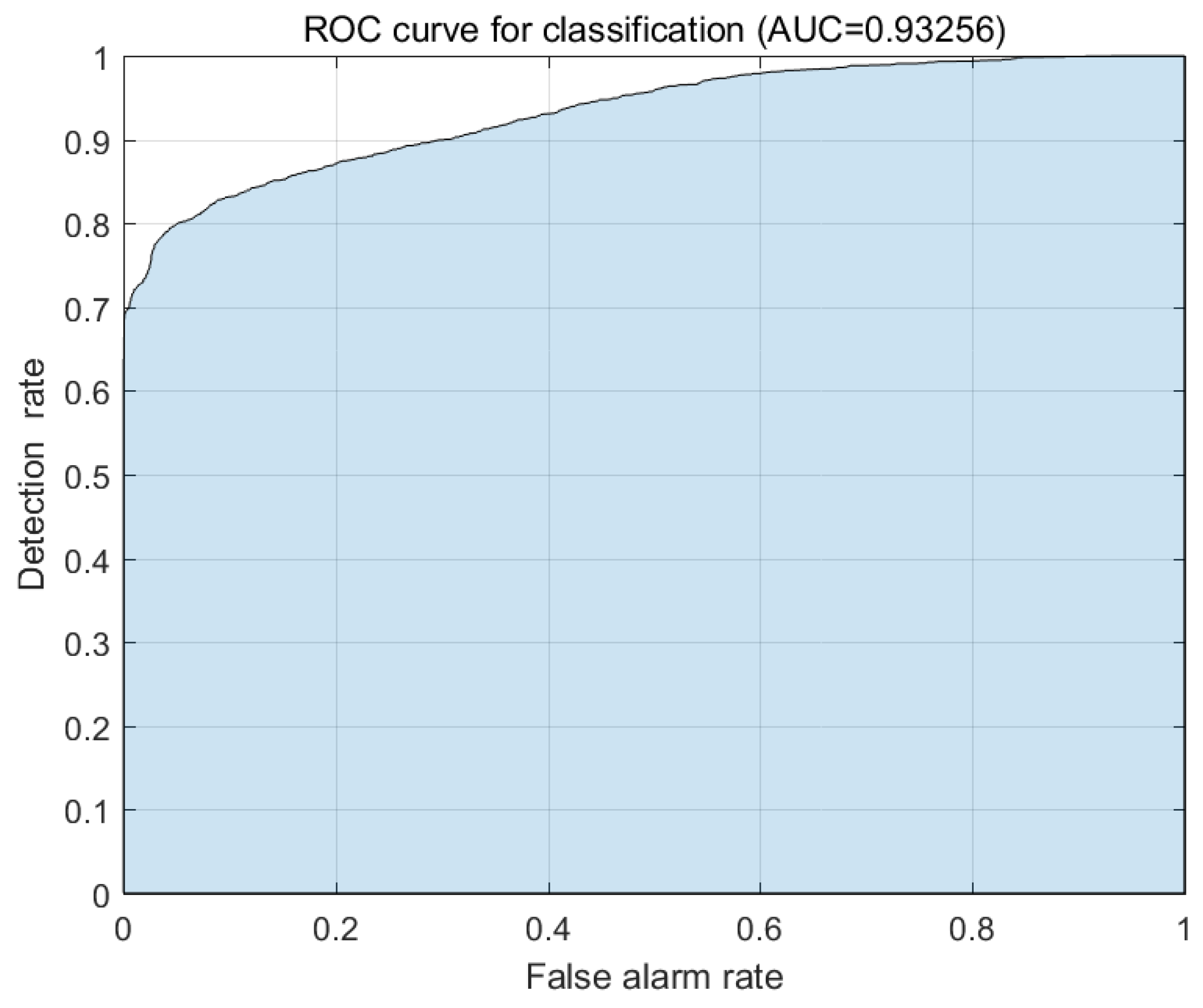
Figure 9 shows one example of the ROC curves for the ten trials. The mean of ten AUC values is 0.8983 and the standard deviation is 0.0036. As mentioned previously, the model can be assessed as an excellent model. In
Table 1, the accumulated classification table is demonstrated for the test data. According to this table, the hit rate of the model is 0.8267.
5.2. Detection Performance
In order to evaluate the detection performance according to TCR, 11,000 training data are selected as mentioned above and the test is performed for each TCR. The AUC and probability of detection are observed for each TCR while the ROC curve is measured for the total test data.
Figure 10 shows the learning parameter
of the model for the 11,000 training data. The parameters of
Figure 10 show a similar shape as in
Figure 8.
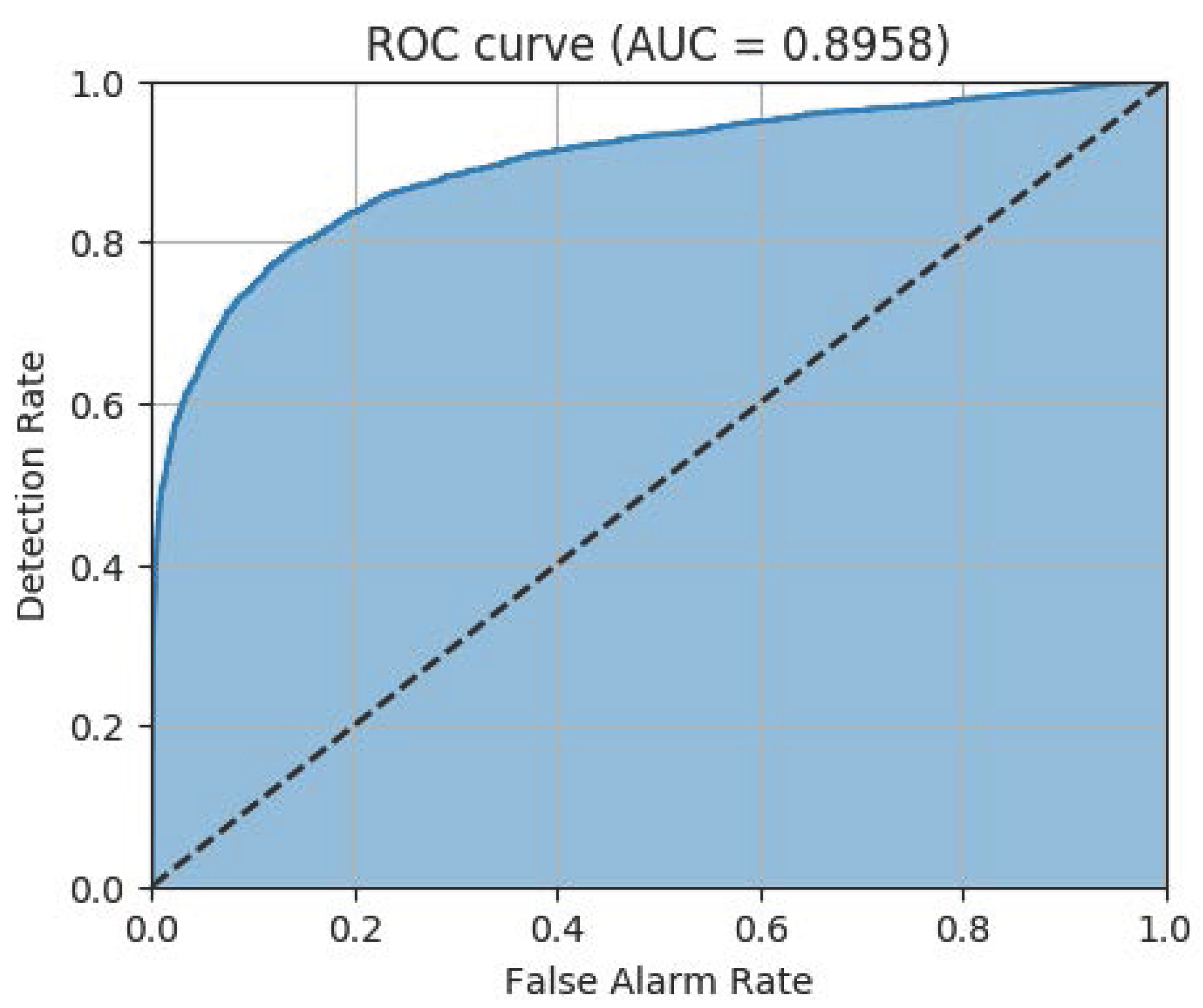
For the 11,000 test data, the ROC curve of the model with the parameters in
Figure 10 is displayed in
Figure 11. AUC of 0.8958 implies that the model operates as an excellent classifier noting that the worst AUC is 0.5 in binary classification [
14]. These results are observed in the classification table of
Table 2. According to this table, the hit rate is 0.8115.
In addition, AUC values according to TCR are displayed in
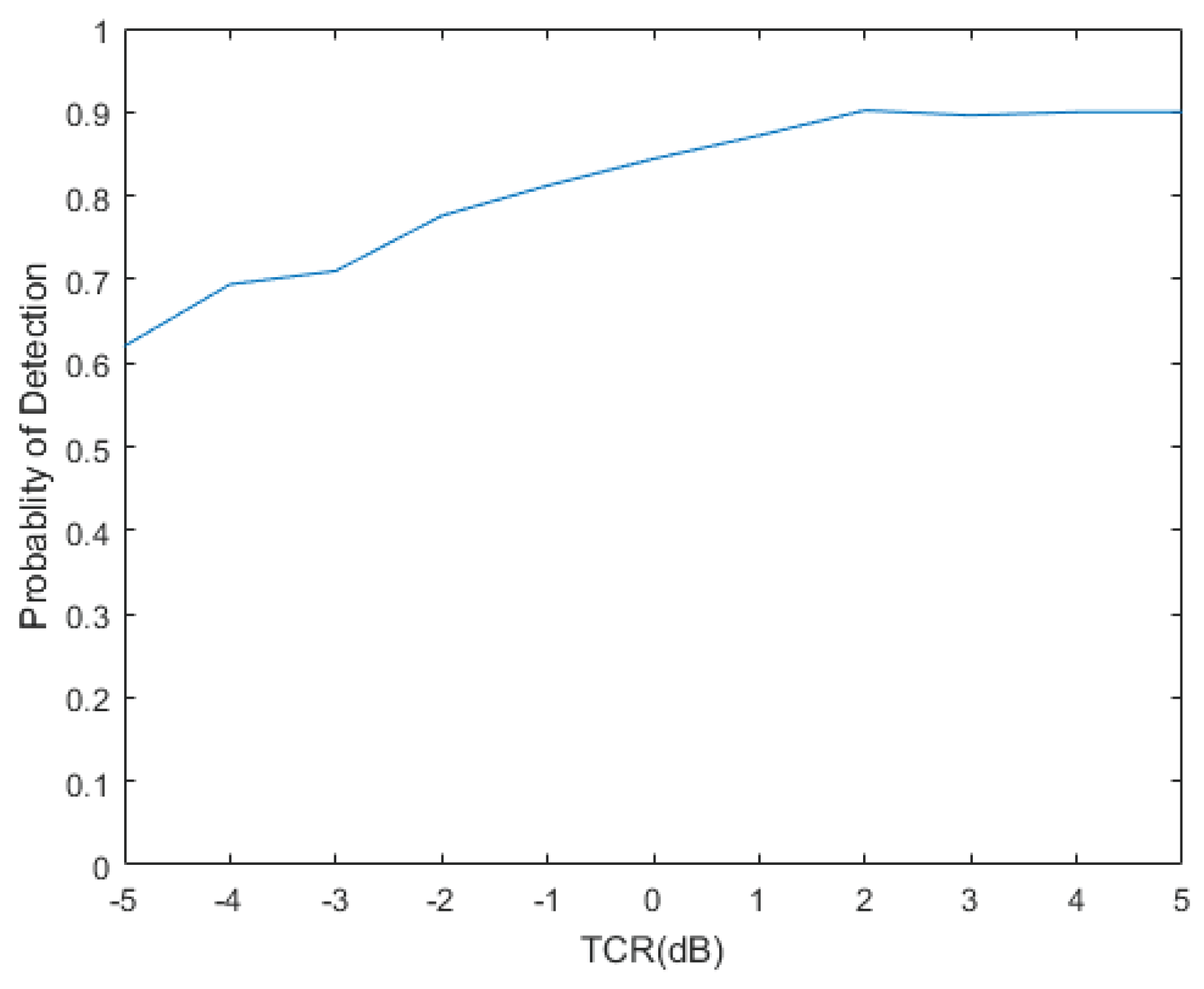
Figure 12. The minimum is 0.74 at TCR = −5 dB while the maximum is 0.94 at TCR = 3 dB. As the target signal power is getting better over the clutter power, AUC improves, which shows excellent discrimination. The probability of detection is plotted with respect to TCR in
Figure 13, where the detection probability of 0.62 at TCR of −5 dB is observed, while, for TCR greater than or equal to 2 dB, the detection probability of about 0.9 is maintained.
7. Conclusions
In this paper, it was investigated whether clutters having similar power to the target power can be distinguished by using the logistic regression model. Therefore, the clutter signals considered in this study have such significant power as to lead to a false alarm with the threshold detection scheme. The target signals corresponding to the clutter signals are generated for various rotation angles and for assorted values of TCR. These signals are used to construct the feature vectors and the shuffle–split cross validation technique is applied to the trained model. The models are evaluated in terms of receiver operation characteristic, area under ROC curve, classification table and detection rate. According to the evaluation results, the use of the logistic regression model is very useful for underwater target discrimination. Furthermore, the experimental data are employed to verify the proposed approach. Note that the experimental data are collected for the purpose that is not related to this study. According to the application result, the model trained by the simulated data can discriminate the cylinder from the rock even though it is not perfect. In addition, note that the mathematical model can describe the scattering of the real cylinder well.
In the simulation study, training and testing have been performed using every component of the magnitude spectrum of the received signal. Considering the spectral characteristics of the target and clutter, only the frequency bins carrying the main energy portion can be selected as feature components, which accelerates the processing time by reducing the size of the model. In the simulation study, various TCR conditions were considered since the spectrum is sensitive to magnitude. For further study, the cepstrum may be a good candidate for the feature vector component due to its scale invariance property. The application of the real experiment data reveals the need for the research on the reflection of the multipath components and modeling environments where a target is placed.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}