1. Introduction
Source separation is a major research area in both signal processing and social internet of things. The information obtained by sound source separation can be widely used for speech enhancement, sound scene reconstruction, and spatial audio production [
1,
2,
3,
4,
5]. In addition, source separation appears as the central problem of speech recognition and speaker identification problems as well [
6,
7,
8,
9]. There are several categories of source separation techniques.
Stochastic methods, such as independent component analysis (ICA), rely on a statistical assumption, i.e., mutual statistical independence of sources. They have been widely used in blind source separation (BSS) techniques to recover the sources from mixtures in a determined case [
10]. In an overdetermined case, ICA is combined with principal component analysis (PCA) to reduce the dimension of the mixtures, or with least-squares (LS) to minimize the overall mean-square error (MSE) [
10,
11]. For the most common underdetermined case, where there are fewer mixtures than sources, sparse representations of the sources are usually employed to increase the likelihood of sources being disjointed [
3]. The underlying principle of all existing ICA methods is to achieve mutual independence among separator outputs. The relative success of this approach is mainly due to the convenience of the corresponding mathematical setting, provided by the independence assumption, for algorithm development. Another important factor is the applicability of the independence assumption to a relatively large subset of BSS application domains. However, the ICA-based separation schemes require large amounts of data recorded in a stationary acoustic condition to provide a reasonable estimate of model parameters. In addition, they impose a permutation problem due to misalignment of the individual source components [
12,
13,
14].
The second group of separation methods is based on adaptive algorithms that optimize a multichannel filter structure according to the signal properties. In other words, an alternative geometric demixing strategy is derived based on the capability of a microphone array for directional acquisition or beamforming. This procedure achieves source separation by steering the beam pattern of the microphone array towards the desired source, thus filtering out the interferences regardless of their signal nature [
15,
16]. The underlying hypothesis is that the sources are uncorrelated; this assumption is vulnerable to reverberation so the beamformer can mitigate or cancel the desired signal in acoustic reverberation. An additional limiting factor is the spatial resolution for resolving closely located sources. Furthermore, unlike the ICA approach, beamforming requires precise information about the microphone array configuration and the desired source location. Recent work considers a non-linear mixture of beamformers which incorporates the sparsity of the spectrotemporal coefficients to address underdetermined demixing [
17]. The application of this method is limited to anechoic mixtures and the performance is degraded due to reverberation.
The other major categories of the separation techniques are based on the sparseness of speech signals in the time-frequency (TF) domain. They assume that the sources approximately meet the W-disjoint orthogonality (W-DO) [
18] in the TF domain, i.e., there is at most one sound source active at a certain TF instant. As a result, they achieve separation by partitioning the TF representations of the mixtures belonging to the same speech source. Such groupings can be based on time and phase delays [
18] obtained from processing spaced microphone array recordings or intensity-based direction of arrival (DOA) estimates obtained from co-located (spatial) microphone recordings and using microphone directivity. The principle virtue of the W-DO based methods is that they are more computationally efficient compared to stochastic-based methods [
19].
When the W-DO of simultaneously occurring speech signals is met, DOA estimates performed in the TF domain will correspond to the location of a true speech source. In practice, simultaneously occurring speech signals are not strictly W-DO for all TF instants, and the separated speech signals using these sparse-based approaches applied to the mixture suffer from musical and crosstalk distortion. This is a result of the non-sparse components (i.e., the TF components derived from more than one source) combining in the mixture, leading to unpredictable DOA estimates that do not correspond to true DOA estimates. The non-sparse TF component is discarded, causing musical distortion of the separated source. Further, if three frontal sources of equal energy are considered (one directly in line with the array and two at equal angles but opposite sides of the array), the non-sparse components contributed by the left and right sources may lead to the same DOA estimate as the middle source. This causes crosstalk distortion, where the separated sources contain spectral content from more than one source at the corresponding TF.
Considering this situation, a collaborative blind source separation method is proposed by using pair location-informed coincident microphone arrays in [
20]. This method can jointly separate simultaneous speech sources based on TF source localization estimates from each microphone recording. The musical and crosstalk distortion is effectively reduced by the combination of the microphone pair and vector decomposition. However, if there are three or more speech sources, the vector decomposition will get more difficult and the computation will increase exponentially.
In previous work [
21], we achieved an effective multiple sound source localization method by applying “single source zone detection”. The method proposed in [
21] provides the possibility and necessary parameters for further separation of the corresponding sound sources, including the source number and the corresponding DOA estimations. In this paper, in contrast to existing methods, only a B-format microphone with four channels is used to separate the TF components of the signals. We firstly measure the proportion of overlapped components among multiple sources and find that there exist many overlapped TF components with increasing source number. Thus, a multiple speech source separation method by using inter-channel correlation and half-K assumption is proposed. Specifically, considering the relaxed sparsity of speech sources, we propose a dynamic threshold-based separation approach of sparse components where the threshold is determined by the inter-channel correlation among the recording signals. Thereafter, after conducting a statistical analysis of the number of the active sources at each TF instant, it is concluded that no more than half of the sources are active in a certain TF bin among simultaneously occurring speech sources. By applying the assumption, the non-sparse components are recovered by using the extracted sparse components combined with vector decomposition and matrix factorization. Eventually, the final TF coefficients of each source will be recovered by the synthesis of sparse and non-sparse components.
The remainder of the paper is organized as follows:
Section 1 presents the signal model and the limitations of the W-DO assumption.
Section 2 introduces the proposed separation method. Experimental results are presented in
Section 3, while conclusions are drawn in
Section 4.
3. Proposed Method
Based on the investigation in
Section 2, we can conclude that the W-DO has less accuracy as the number of simultaneously occurring sources increases. In order to eliminate the problem of poor separation quality caused by this phenomenon, we propose a multiple source separation method based on self-reduction of dimensionality by using a B-format microphone. After proposing an effective detection method of the active sources in a non-sparse bin, we conduct a statistical analysis on the active source number that is involved in the non-sparse components and the corresponding possibility. It is found that when there exist
K sound sources simultaneously and the non-sparse components are mostly caused by less than
sound sources, it is very rare that the TF components of all sound sources are overlapped. Therefore, based on this phenomenon, we assume that when
K sound sources simultaneously occur in a sound scene, the active source number corresponding to the non-sparse component does not exceed
, which we call the half-K assumption. In addition, due to the recording characteristics of B-format microphone, we can get three linear equations with K source signals as independent variables. If the number of sound sources is greater than three, the linear equations will have multiple solutions, so the B-format microphone can only be used to separate the source signals of the scene with three sound sources. Based on the half-K assumption proposed in this paper, the B-format microphone can be used to solve the separation problem in the sound scene with six sound sources.
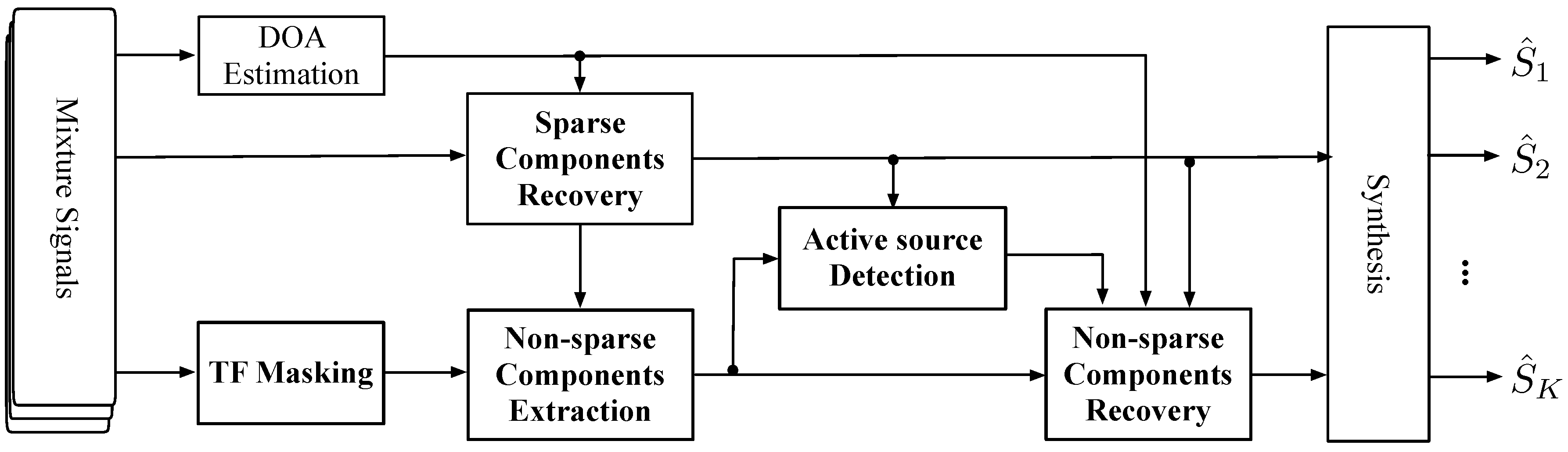
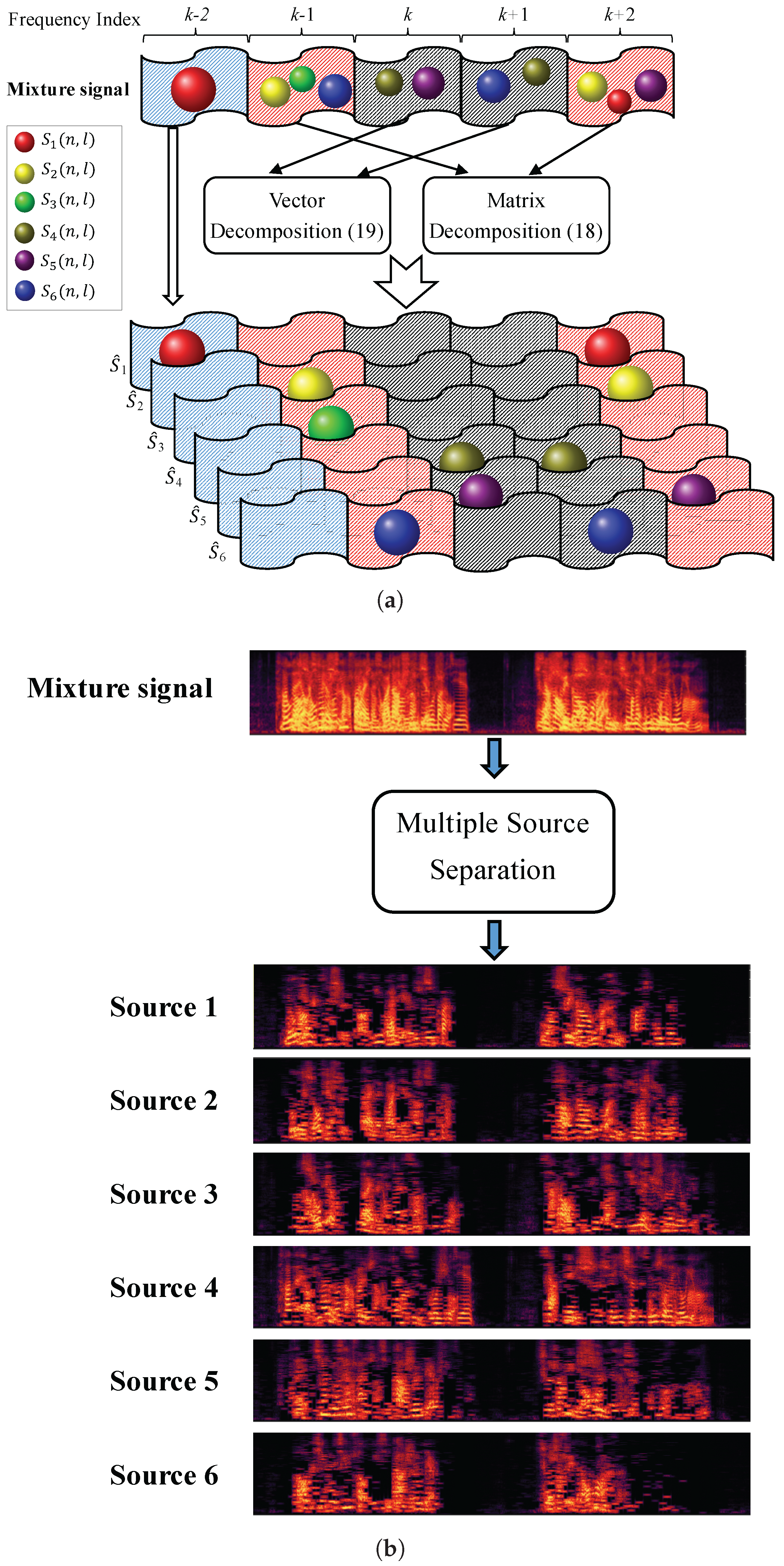
The illustration of the proposed BSS scheme is shown in
Figure 3. For the input mixture signals (four recording signals of the B-format microphone [
21]), the DOA estimation can be obtained by a traditional localization procedure [
21]. Thereafter, the sparse components recovery can be achieved by a clustering process of TF bins. The unprocessed non-sparse components are then obtained by masking the recovered sparse components from mixture signals. The half-K assumption provides a reduction of the dimensionality of the linear equations. By solving the linear equations, the non-sparse components will be effectively separated. Eventually, the final TF coefficients of each source will be recovered by the synthesis of sparse and non-sparse components.
3.1. Separation of Sparse Components
Under the sparse assumption discussed in [
20], one source will have the same mixing parameter pairs
A and
. For a given TF instant of
source, this pair is approximated by:
The separated sources can be derived by grouping the TF instants using these parameter pairs. If the estimated DOA of source is , the task is to determine a range around (i.e., ) such that the TF instants having the DOA estimates within this range are considered as the source i. It should be noted that if the threshold is set small enough, less interference from other sources may be contained in the separation. However, this may fail to derive many TF components whose DOA estimates are slightly different to the true source DOA due to the low fault tolerance of the estimation approach. If the threshold is larger, this may lead to the inclusion in the separated source of TF components from other sources. Hence, an efficient clustering method is needed to dynamically achieve the separation of sparse components.
Based on the directional characteristic of B-format microphone, it can be seen that a strong correlation between the recording signals of adjacent channels in a certain TF zone implies that there is only one source active, while a weaker correlation means it is a region where multiple sources exist [
21]. Hence, in this paper, we proposed a dynamic threshold clustering method of sparse components based on the inter-correlation of the raw recording (A-format) signals [
21], and the threshold
is dynamically set by:
where
,
, and
are initial thresholds for the user to define;
is the threshold to control the dynamic range of the
,
is a threshold for controlling the
change curve, and
is a symmetric point corresponding to the change curve.
is the average of normalized cross-correlation coefficients [
21] among four recording signals of the B-format microphone. More specifically, for any pair of soundfield microphone-recorded signals (
and
), the function is defined as:
where
,
. The normalized cross-correlation coefficient can be obtained by:
It can be seen from Equation (
8) that the value of
is proportional to the correlation coefficient. Specifically, if the correlation coefficient is close to one, the threshold will be large to obtain more extractions of the corresponding source, while in other TF zones, it will get smaller with the average correlation coefficient being smaller in order to get rid of the interference of other sources. Considering this issue and the value range of the cross-correlation coefficient, Equation (
8) should be a function whose independent and dependent variables are both with a value range in [0, 1]. By adjusting the value of
and
, we find
and
can perfectly meet the requirement mentioned above. Future work will investigate alternative methods for optimizing the choice of these values and find whether there might be a more efficient function that can describe the relation between
and
.
To make full use of the directional characteristic of B-format microphone, we can obtain the most appropriate vector as the mixed signal for source separation which can be obtained by
and
. It was found experimentally that the performance degrades when processing of
is employed for source separation, and a similar phenomenon was also found in other work [
28]. In detail, the most appropriate vector
of
K sources can be obtained by:
The separation of sparse components in a certain frame proceeds as per Algorithm 1.
| Algorithm 1 Sparse Component Separation |
| Input: . |
| Initialize: Divide the frame into sub-band regions with a equal width in the TF domain. |
| for do |
| Calculate the average of normalized cross-correlation , and obtain the by Equation (8). |
| Obtain the sparse components of source i by clustering the TF components by parameter pair {, }. |
| end for |
| Output: Eventually, we will get the sparse components of each source. |
3.2. Exploring Inter-Sparsity among Multiple Sources
Further, in order to investigate the inter-sparsity among multiple sources, and how many active sources are involved in the overlapped TF bins, we proposed a statistic algorithm of the number of the active source at each TF instant when there occur multiple sources. In detail, the source whose energy at a certain TF instant is dominant among all the sources is regarded as the active source at this instant, i.e., its energy occupies a significant proportion of the total energy of all sources. To find the proportion of active source number when different numbers of sources occur, we define a statistical measure which is reflected in Algorithm 2.
| Algorithm 2 Statistic of Active Source Number |
| Input: , where . |
| Initialize: , c is used for counting the active source number within current TF bin, , loop frequency index: l = 1, loop source index: i = 0. |
| for do |
| for do |
| if |
| increment c. |
| end if |
| end for |
| increment (i.e., increment value of the element in counter whose index is c). |
| Reset: . |
| end for |
| Output:. |
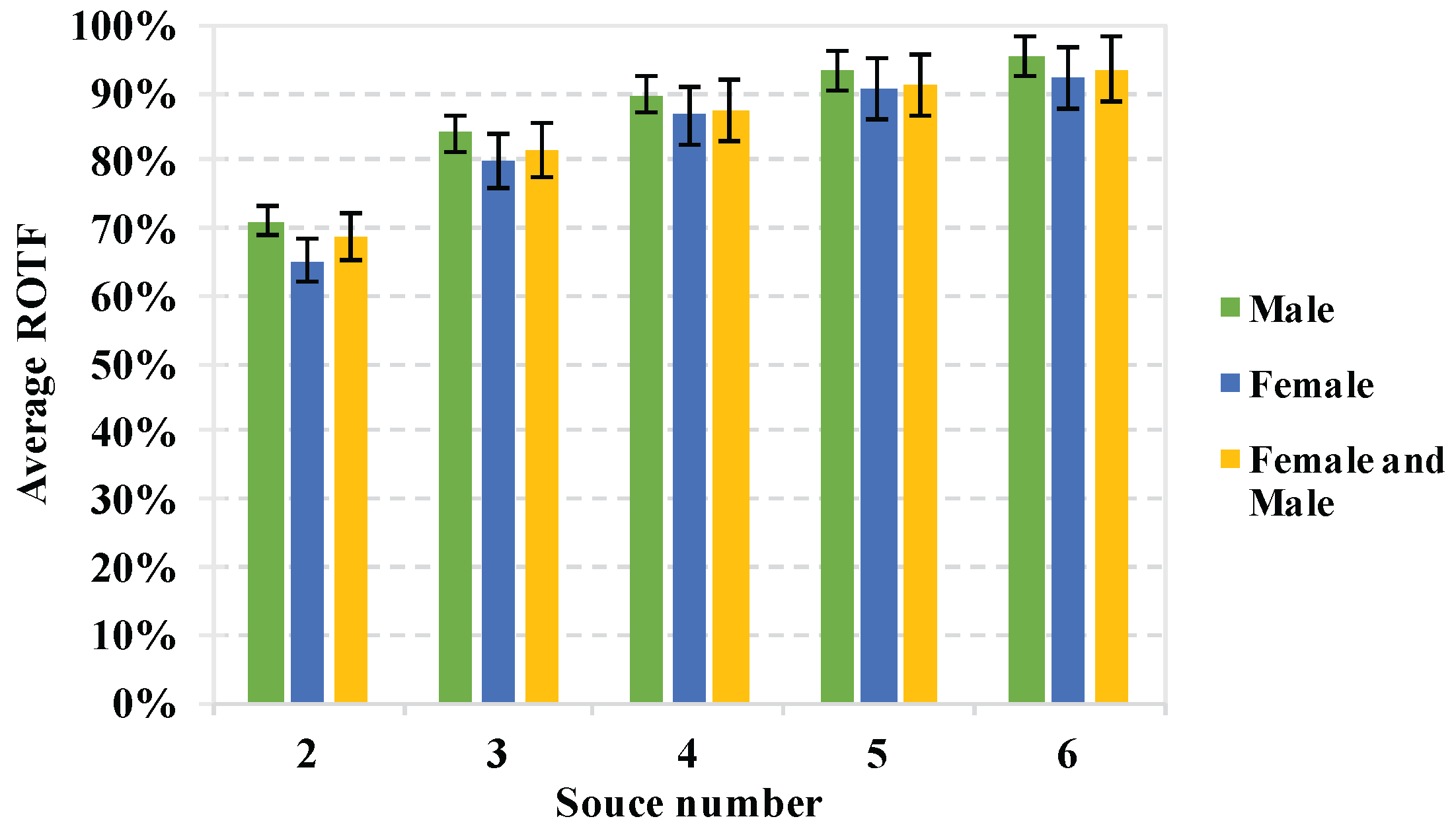
Then, we can calculate the probability of active source number (
) among
K simultaneously occurring sources as:
where
denotes the number of TF instants when
c sources are active simultaneously,
L is the number of STFT points in a frame, and
represents the probability of TF bins which contain
c active sources. In other words, it implies the probability of
c sources active simultaneously over all TF bins. In order to analyze the
among
K simultaneously occurring sources, we calculate the
of all groups mentioned above when
. The results are shown in
Figure 4 with 95% confidence intervals.
It can be seen that when there are six simultaneously occurring speech sources, most of the time only two or three sound sources are active at the same time over the non-sparse TF bins (occupying nearly 70%), i.e., most of the non-sparse components are involved with two or three sources. This implies that the proposed half-K assumption that no more than sources are active in a certain TF bin when there are K simultaneously occurring speech sources is reasonable.
3.3. Separation of Non-Sparse Components
Based on the statistical results in
Section 3.2, we have validated the half-K assumption that the active source number in a certain TF bin does not exceed half the total number of simultaneously occurring sources. It means that for
K sources, there are no more than
K/2 sources active at a certain TF bin. We set
to ensure the localization accuracy in this work. Based on the proposed assumption, we can conclude that the number of active sources at a certain TF bin (
) is no more than three. It should be noted that
means that there is only one source active at a certain TF bin, i.e., the sparse bin. The set of these sparse bins are the above-mentioned sparse components.
Aiming to separate the corresponding non-sparse components of each source, we have to know all the active sources of the non-sparse components. Here, the problem is solved by first dividing the TF band into several zones with same width, and then calculating the similarity between the separated sparse components and the mixture signal in this TF zone. In detail, if the similarity exceeds a certain threshold, the frequency components of the regions are mostly derived from this source signal and the signal set that satisfies the threshold is named the active source in the current TF zone of non-sparse components. The normalized cross-correlation function is utilized for similarity calculation, and the cross-correlation coefficient between the mixture signal
and a sparse component signal
in a TF zone
is calculated as follows:
where
represents the separated sparse component signal and
. To obtain all the active sources of non-sparse components in a TF-analyzed one
, we define a active detecting vector
; the
ith element
can be obtained by:
where
is an experimental threshold, in order to ensure that the number detected active sound source is not larger than the real one. We set
in this paper (informal testing found this value generally led to satisfactory results but future work can explore the optimization of this value). The index value of the detected active source is recorded in a vector
, which can be obtained by a
function as:
where
is a non-zero index searching function; the output parameter is a vector that contains all the indexes of non-zero elements of the input vector.
, i.e.,
, where
counts the number of non-zero components in its argument. This means there are three active sources at the current zone. Hence, the corresponding TF coefficient of these active sources is rewritten to find a solution to the linear equations:
where
,
,
denote the estimated DOA of the active source by applying the method in [
21]. Equation (
16) can be rewritten as a vector form as:
where
and
. The separation problem is converted to solve the linear equations by regarding the TF coefficient of each active source as an independent variable. It should be mentioned that the process is based on the hypothesis that the mixing matrix of Equation (
16) is a column full rank matrix. To jointly consider the case
, the aim is converted to find a vector
to minimize
, i.e.,
where
represents the Frobenius norm.
represents the separated TF coefficients of the active sources at
.
For the case
, i.e.,
, we can omit the first equation in Equation (
16) i.e.,
We can still get the solution by solving Equation (
18) for this case. Then, we can get the actual TF coefficients of
and
by:
Finally, the final recovered signal can be obtained by a synthesis as:
Figure 5a illustrates an example of the TF component extraction of the proposed method.
Figure 5b is an example of the recovered signals from the mixture signal.
4. Evaluation
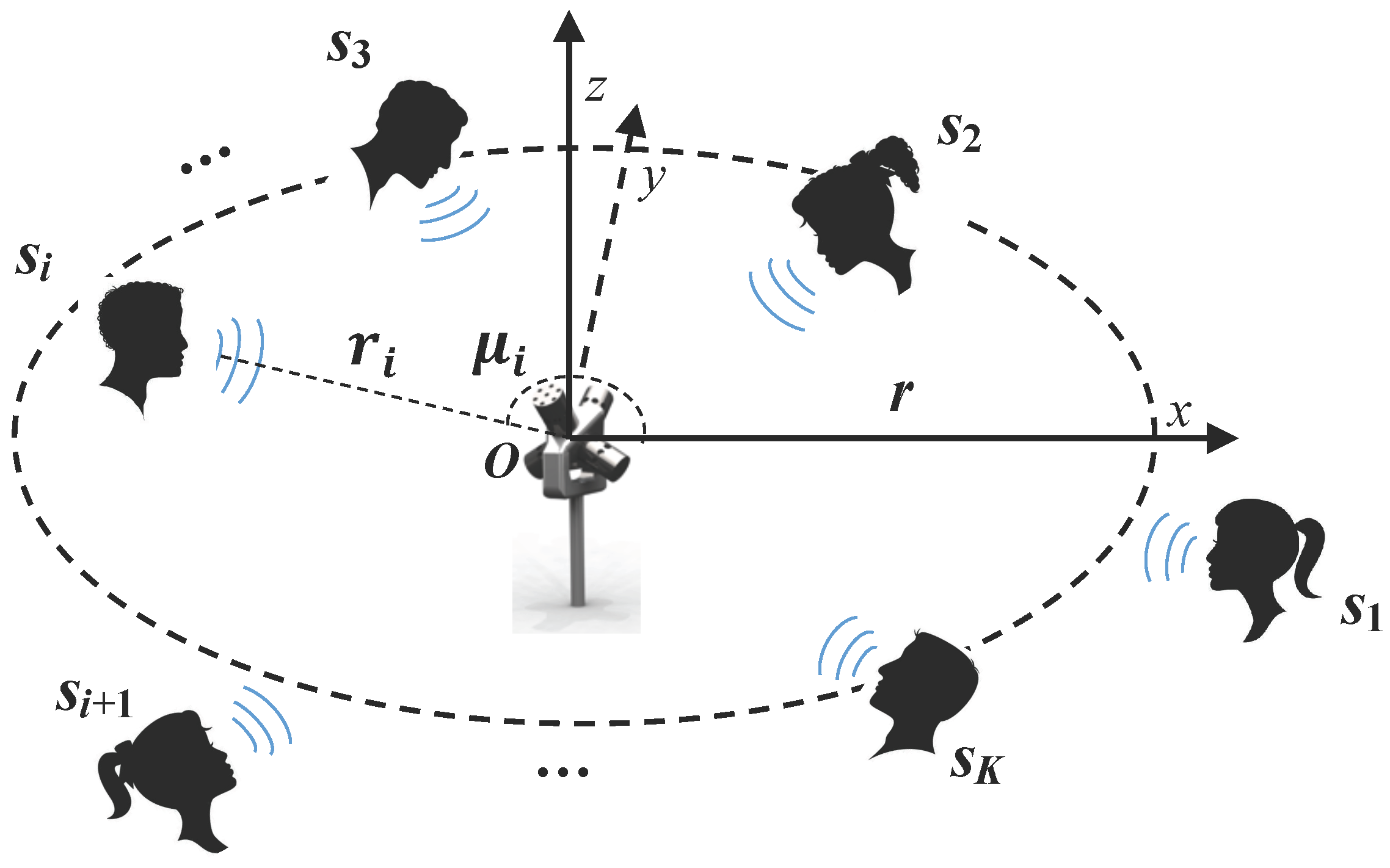
In this section, to verify the effectiveness of the proposed method, a series of objective and subjective evaluation tests are presented. Several aspects are considered in the tests to assess the separation quality including source number, the angle between sources, and the environment.
NTT [
27], as a speech database including various speakers from different countries, has been chosen as the testing database. In addition, all the data are monorecordings and the energy of all speech in NTT database is the same. Thus, this database is suitable for evaluating the quality of multiple speech object separation methods. For the evaluation in simulated scenarios, all of the test segments are derived from the database. Each test segment representing a speech source is created with a length of 8 s. In order to evaluate the separation quality when different types of multiple speech sources are active simultaneously, a complicated situation where different proportions of male and female speakers are simultaneously talking is considered in this work.
To evaluate the proposed method in different environments, we used Roomsim [
29] to simulate a room measuring
m
3 with different reverberation conditions. The main parameters of the simulated rooms are illustrated in
Table 1. The B-format microphone was placed in the center of the room parallel with the
z-axis, and the power of sound sources from different directions was equal in each simulation. It should be noted that the B-format microphone was simulated via Roomsim, and was completed by simulating the recording condition of each channel. In addition, the radius of the cube (radius of the circumscribed circle) is 12 mm. The azimuth and elevation pairs of the four channels (i.e., FLU, FRD, BLD, and BRU) are
. For the objective evaluation in real environments, all the test data was recorded in a room measuring
m
3,
= 20 dB,
= 0.5 s.
In addition, the width of TF-analyzed region mentioned in
Section 2 is determined by applications. In this work, in order to obtain a most efficient width of the TF-analyzed zone, we took a number of tests and found that the score keeps stable for five different widths:
. We chose 64 as the width in [
21] for “single-source” zone detecting, so the width of analyzed TF zone was also set by a constant of 64 considering both efficiency and low computational complexity. Other allocation strategies might improve the quality of individual speech sources or balance the quality amongst all sources, which will be investigated as the future work.
4.1. Objective Evaluation
For objective evaluation, three measurements, i.e., perceptual evaluation of speech quality (PESQ) [
30], signal-to-distortion ratio (SDR) and signal-to-interference ratio (SIR) were adopted to evaluate the perceptual quality of extracted speech signals. Specifically, the PESQ generated by the evaluation software [
30] was used to evaluate the perceptual similarity between the separated signal and the original signal. The score interval of PESQ is
, where smaller values imply a degradation of the quality of separated speech signal. The SDR and SIR were obtained by using the BSS EVAL Toolbox [
31]; the SDR measures the overall performance (quality) of the algorithm, and the SIR focuses on the interference rejection. The tests were conducted in both simulated scenarios and real environments.
For comparison, one of the most efficient sparse component separation (SCS) methods was selected as the reference method [
28] to indicate the effect of the non-sparse component recovery by using the proposed method. Then, five outstanding existing methods were chosen for further evaluation. Specifically, for the determined case (
in this paper), we compared the PESQ score of our proposed method with BSS methods, which belongs to other categories under simulated condition.
4.1.1. Simulated Environment
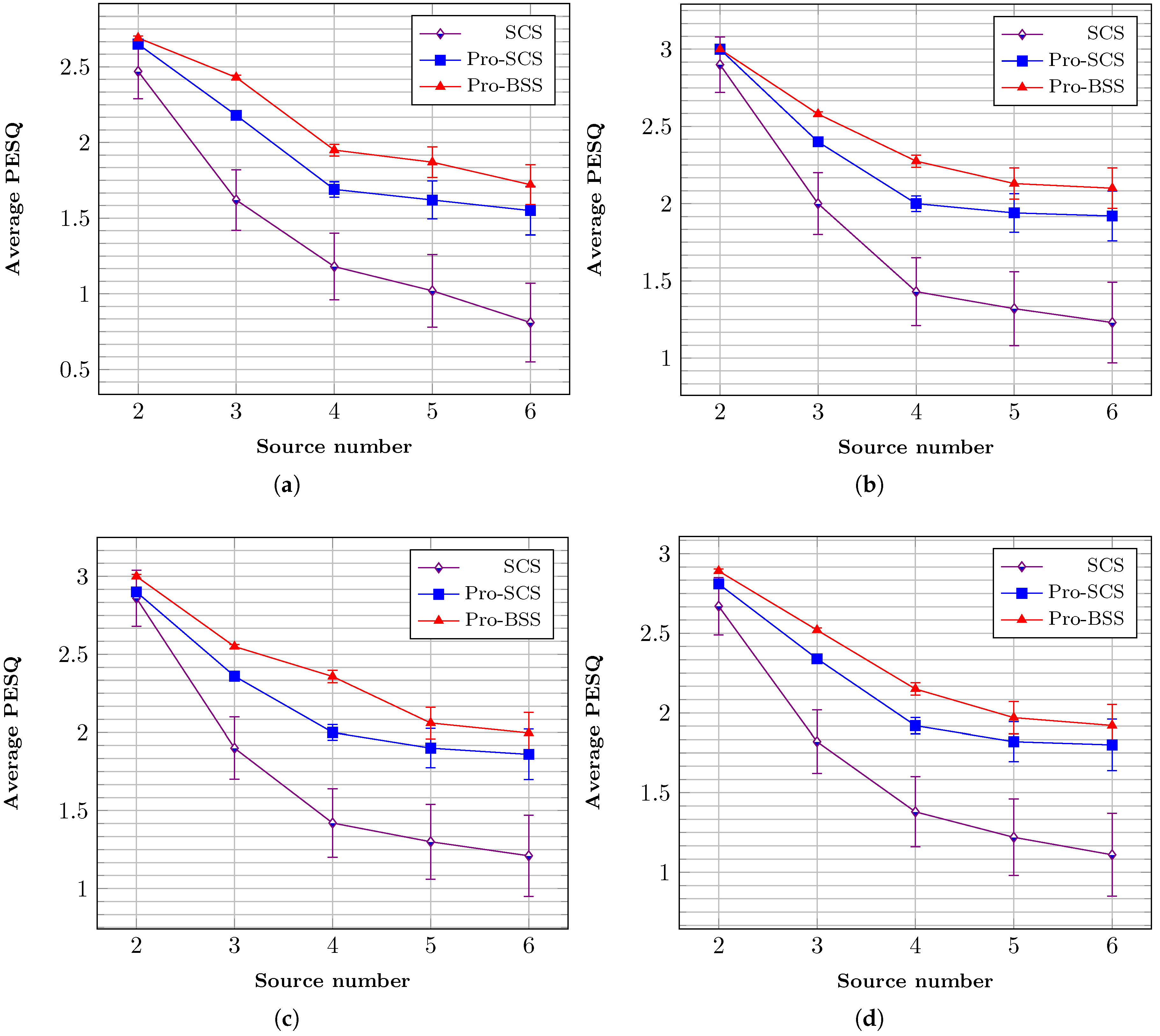
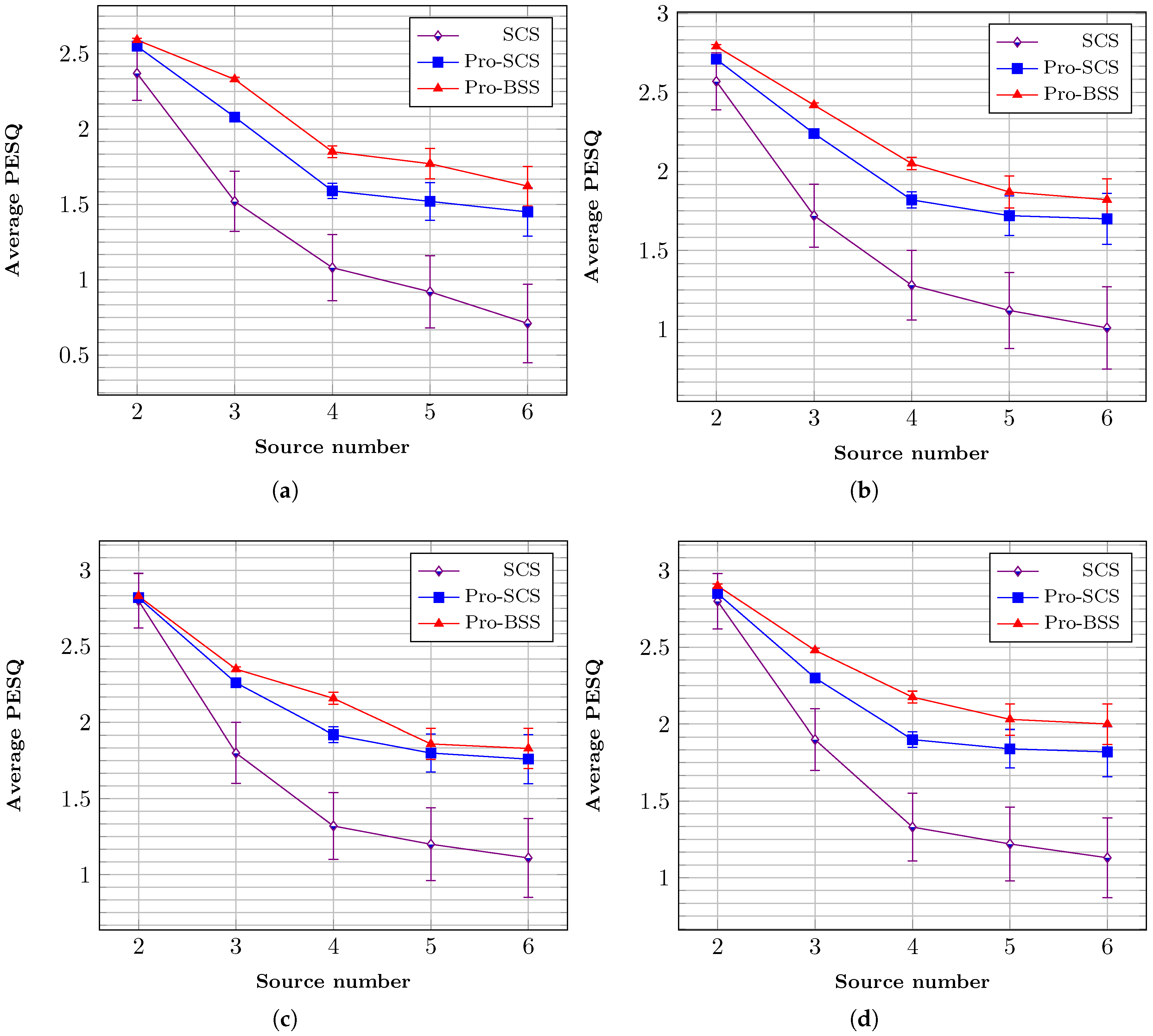
First, by evaluating the same test data in s environment, the average PESQ scores of fixed threshold method and our proposed approach virus different source numbers and separations are shown in
Figure 6. Condition SCS is the result extracted by the fixed threshold (i.e.,
) sparse component separation method, while Pro-SCS is the proposed approach of sparse components with a dynamic threshold, and condition Pro-BSS is the proposed sparse and non-sparse component separation method.
Figure 6a–d represents the result for separations {
,
}. It can be seen that the two proposed separation methods reach a higher score, especially for
. In addition, Pro-BSS reaches the highest score, and the average scores are all above 2 for all source numbers, which indicates a better perceptual quality of the proposed method compared to the fixed threshold separation approach.
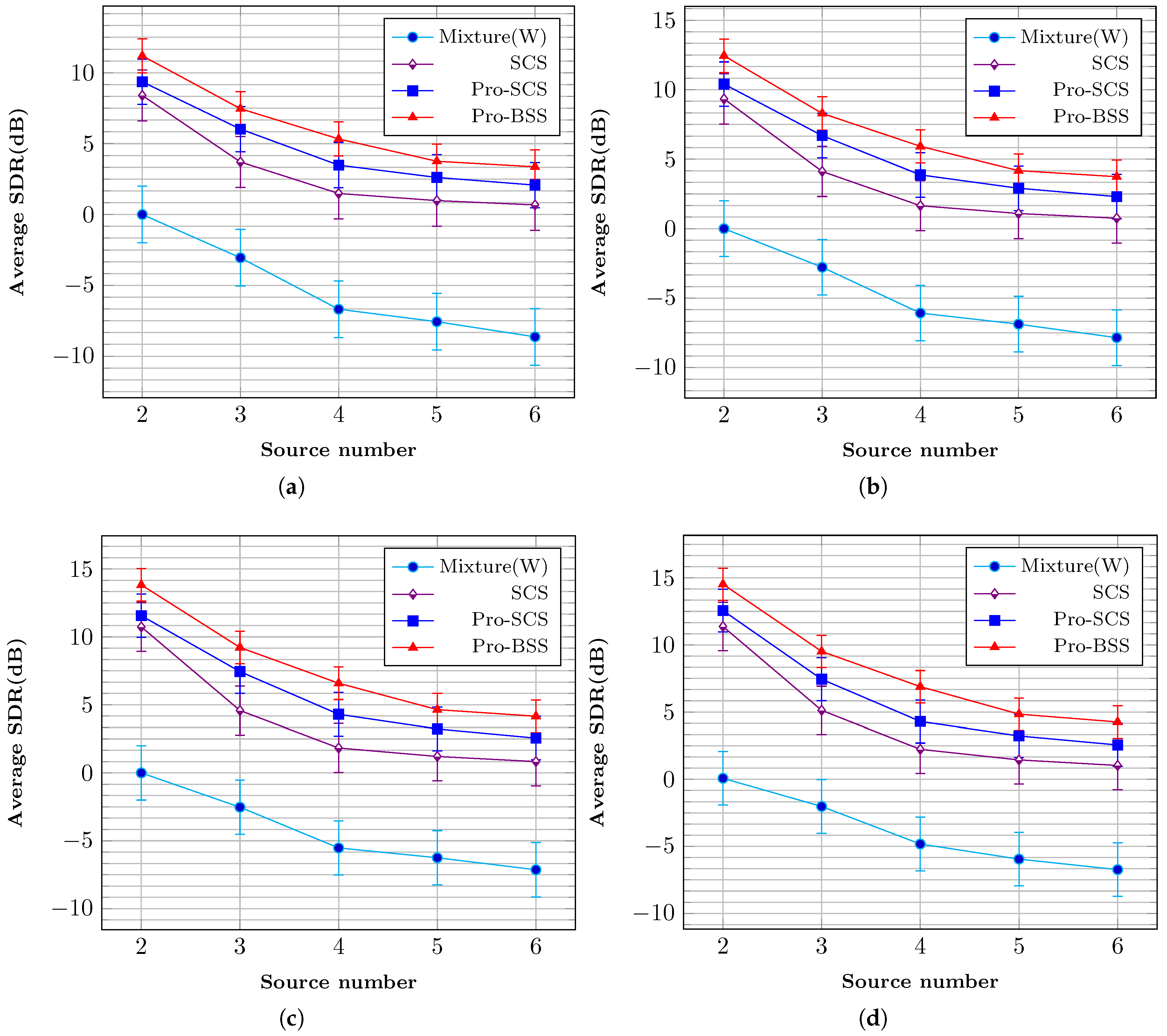
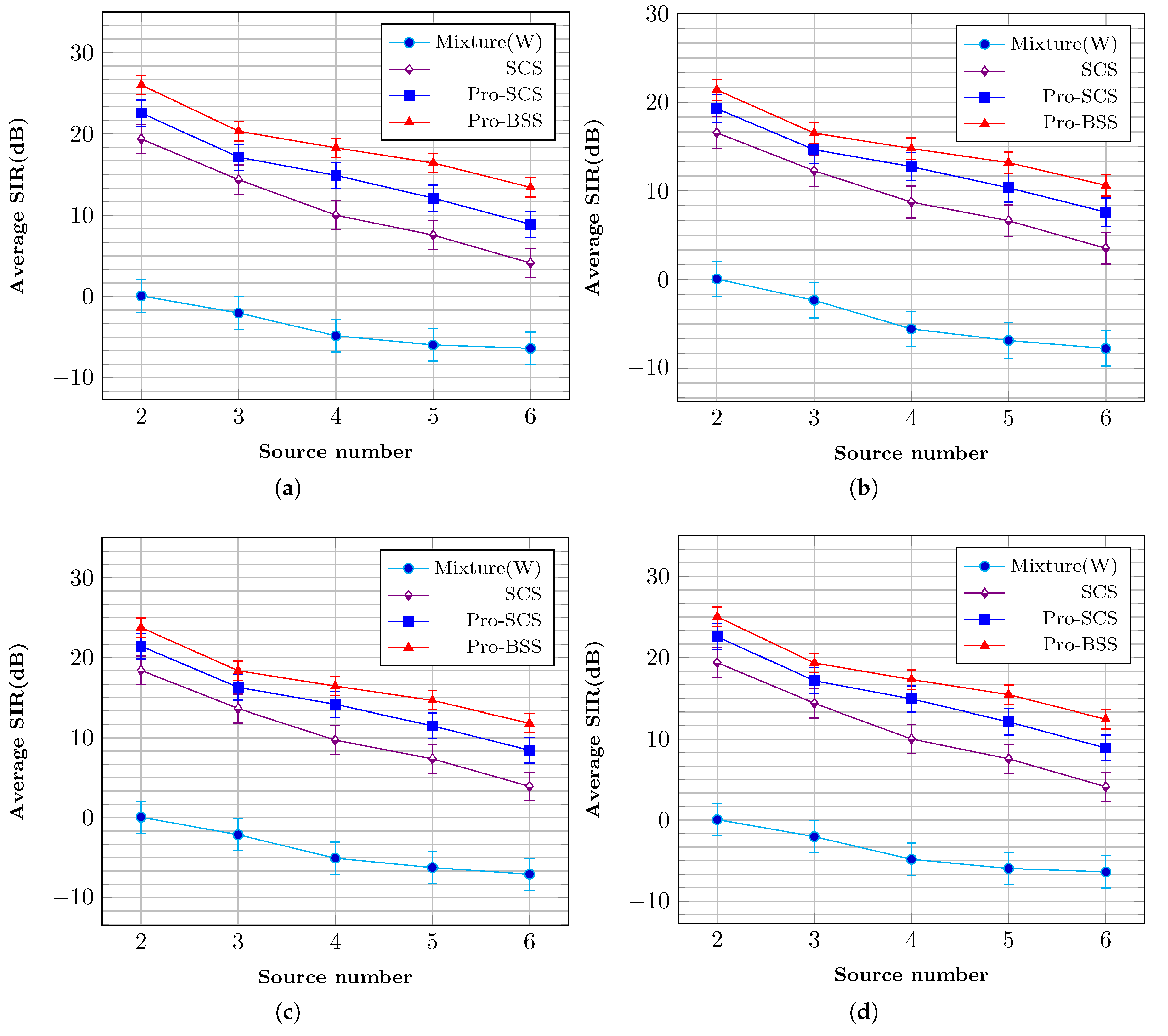
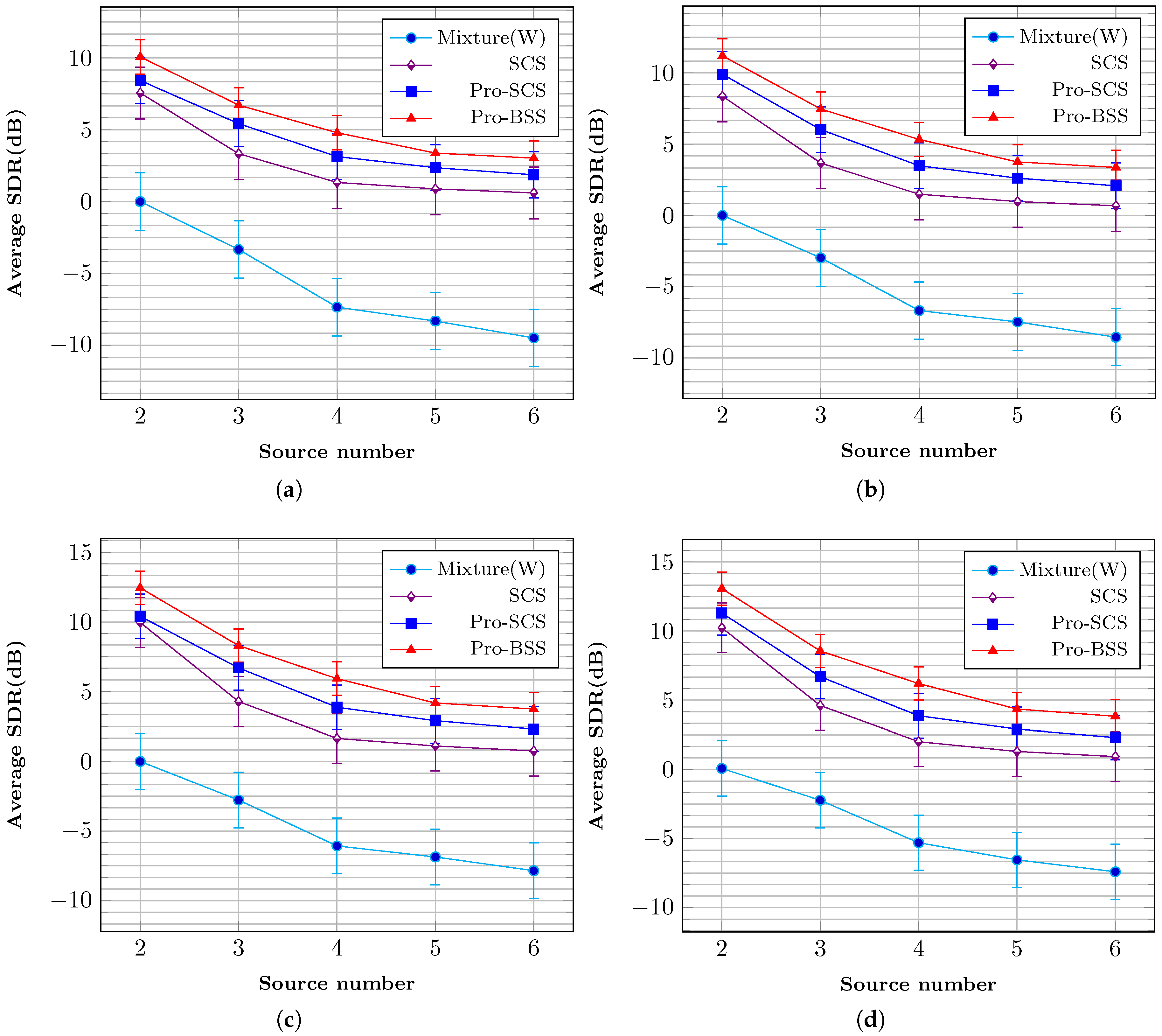
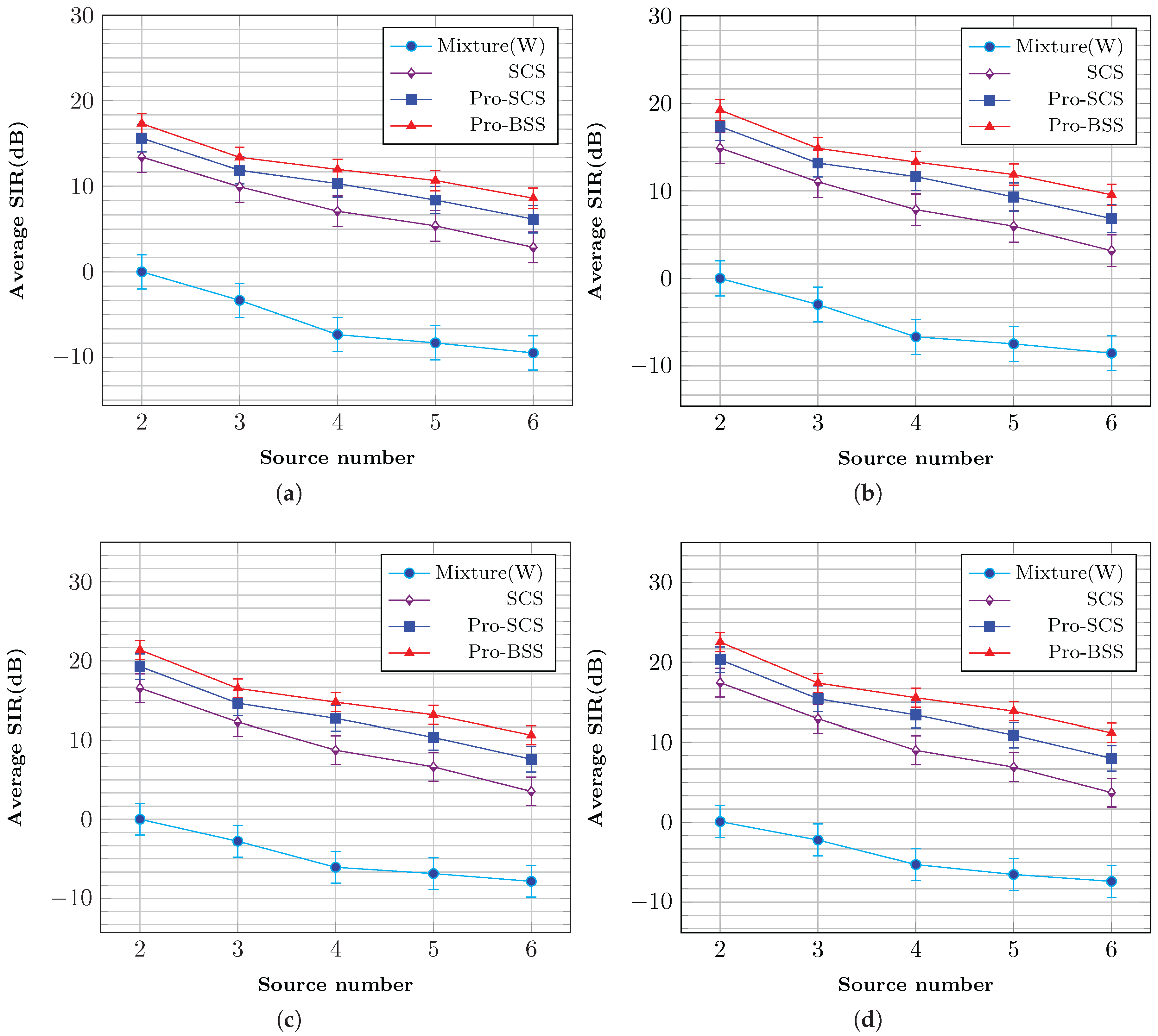
The corresponding results are shown in
Figure 7 and
Figure 8, respectively. Condition mixture (W) represents the B-format input signal
. The SDR and SIR results follow a similar trend to the PESQ results. Overall, it can be concluded that the proposed method obtains a great improvement in extracted sources.
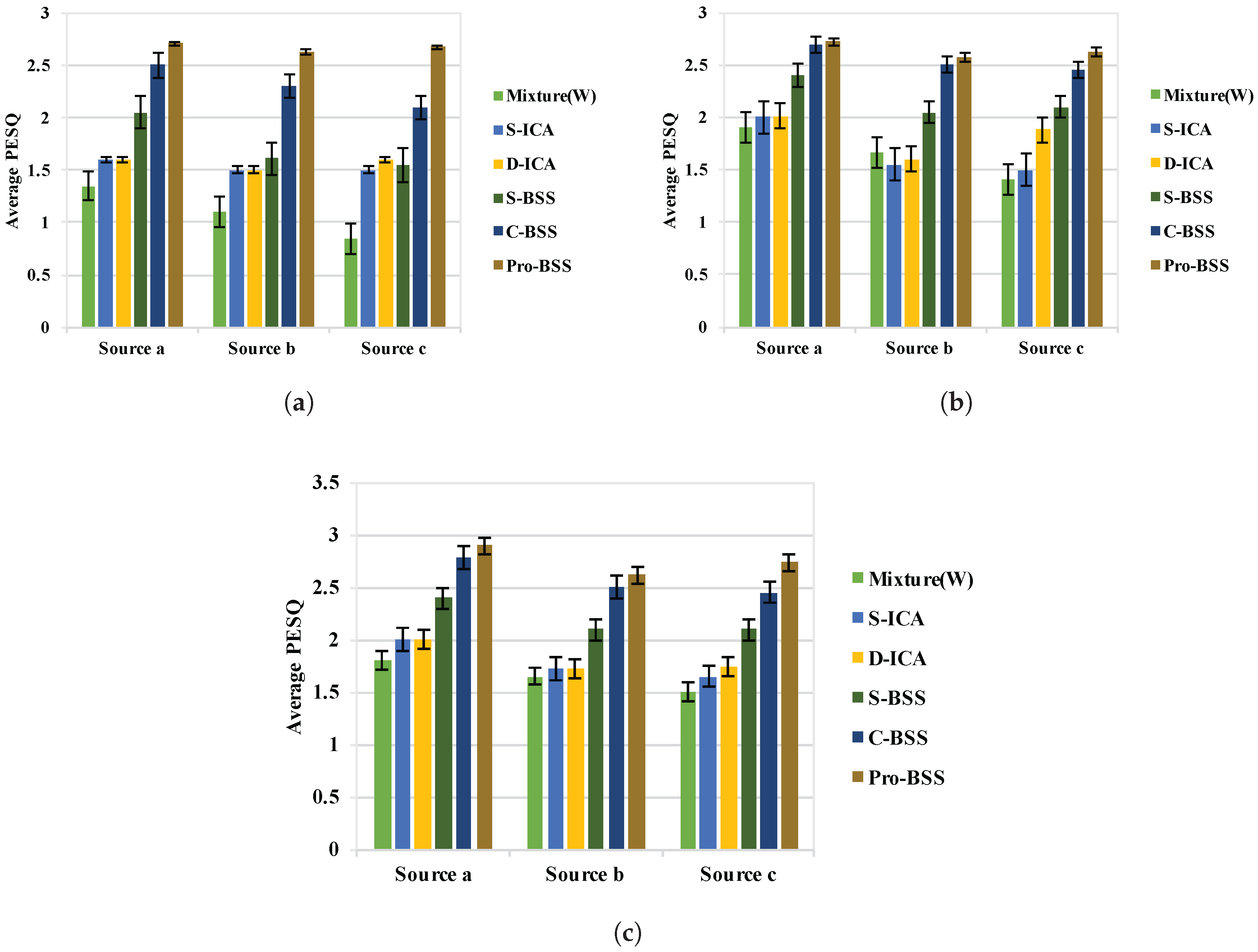
Eventually, for the determined case (i.e.,
K = 3), we conducted a comparison with four other existing approaches: (a) spatio-temporal ICA [
32] applied using a single (recording from
using channel
,
,
) B-format speech mixture (S-ICA); (b) spatio-temporal ICA applied using a dual (recording from
using channel
,
,
and corresponding channels of
) B-format speech mixture (D-ICA); (c) source DOA-based BSS using single coincident microphone recording (S-BSS) [
28]; and DOA-based collaborative BSS (CBSS) [
20] using a pair of coincident spatial microphones. Note that the reference mixture (W) is an unprocessed speech mixture (W channel of the B-format recording) used for indicating the worst quality. It should be noted that there are still many good algorithms, like the independent vector analysis (IVA)-based method [
33,
34], the independent low-rank matrix analysis (ILRMA)-based method, and so on [
35]. Their methods focus on audio source separation, while we prefer the case with all speech sources, so only a few algorithms are chosen for comparison.
From
Figure 9, the proposed BSS approach outperforms the other BSS techniques based on the PESQ measure. It should be noted that
Figure 9a–c are calculated by different references in order to compare the separated speech using different methods under the same acoustic condition. In detail, for the reverberant conditions, the reference is selected as the clean speech with the same level of reverberation rather than anechoic clean speech. The major improvement (approximately 1 against the third best) is achieved by the proposed dynamic threshold-based sparse components and stability-based non-sparse components separation. Specifically, compared with C-BSS, we achieve a better perceptual quality by using only a B-format microphone, while C-BSS adopts a pair.
4.1.2. Real Environment
In total, 36 sentences (sampling frequency 16 kHz) recorded in a room measuring
m
3 (
= 20 dB,
= 0.5 s) were utilized for the evaluation in a real environment. The average length of each recording is also about 8 s same as NTT [
27] database. Based on the aforementioned conditions, a statistical analysis of
is taken. Statistical results are shown in
Figure 10 with
confidence intervals.
From
Figure 10, we can concluded that the proposed method greatly improved the perceptual quality of extracted sources. The corresponding SDR and SIR results are shown in
Figure 11 and
Figure 12, respectively. Condition mixture (W) represents the B-format input signal
. Similar to the results in the simulated environment, the SDR and SIR results follow a similar trend to the PESQ results. Overall, it can be concluded that the proposed method obtain a great improvement of extracted sources.
4.2. Subjective Evaluation
Subjective evaluation consists of two major listening tests. For all cases (the overdetermined case, determined case, and underdetermined case), the perceptual quality of speech sources generated in section IV-A-1 corresponds to the case where
. The separation is
, and the source radius is 1 m. Note that each separated speech source is evaluated separately by using headphones for playback. A MUSHRA [
36] listening test which contains 16 listeners is employed to measure the subjective perceptual quality with four conditions, namely, Ref, Pro-BSS, Pro-SCS, SCS, and Anchor. Condition Ref refers to the original speech sources in each test, which are also served as the hidden references of this MUSHRA test. Condition SCS, Pro-SCS, and Pro-BSS are the same as in the objective evaluation. Condition Anchor is the unprocessed (W channel of the B-format recording) mixed signal. In total, 16 listeners participated in the test.
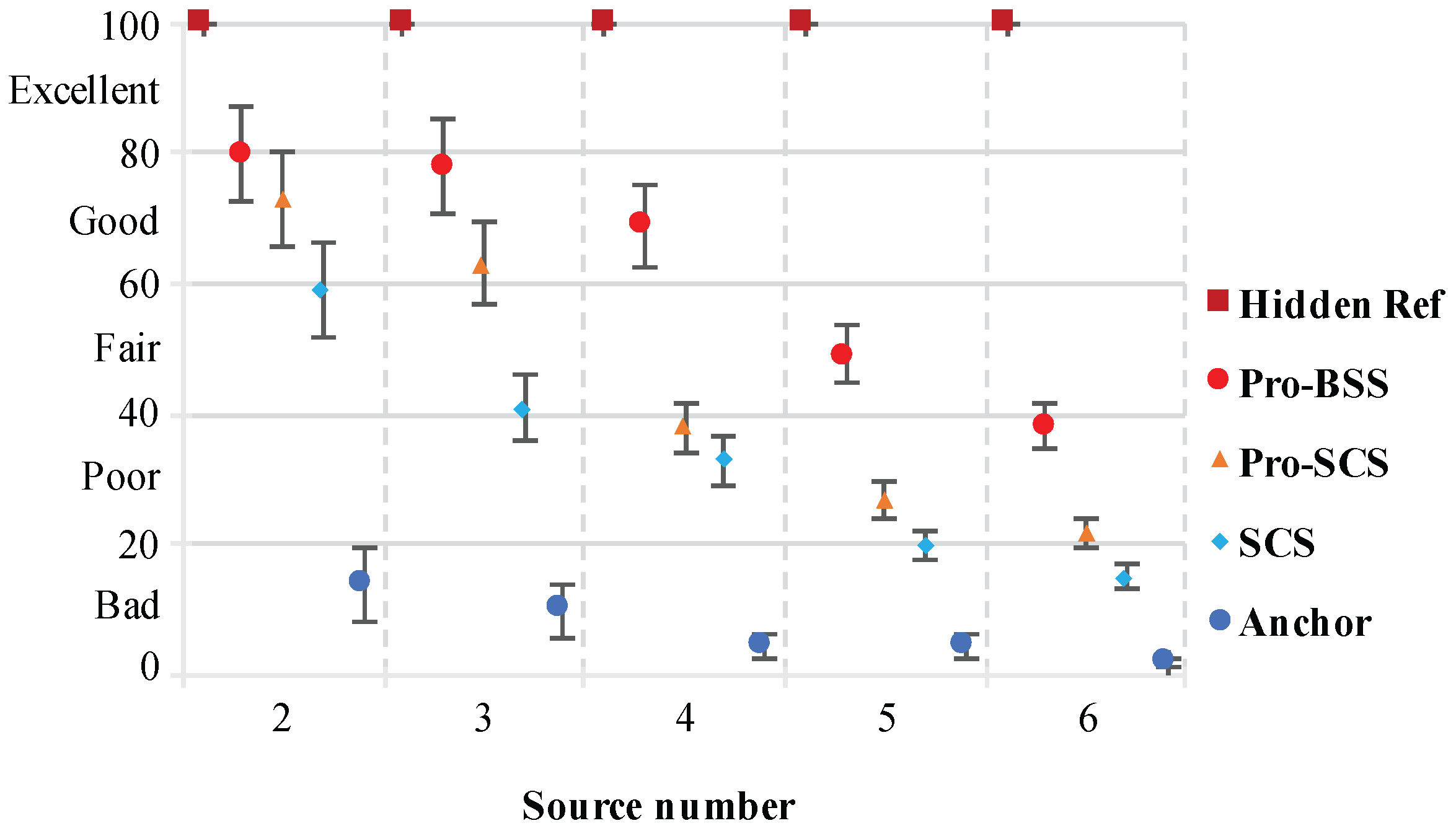
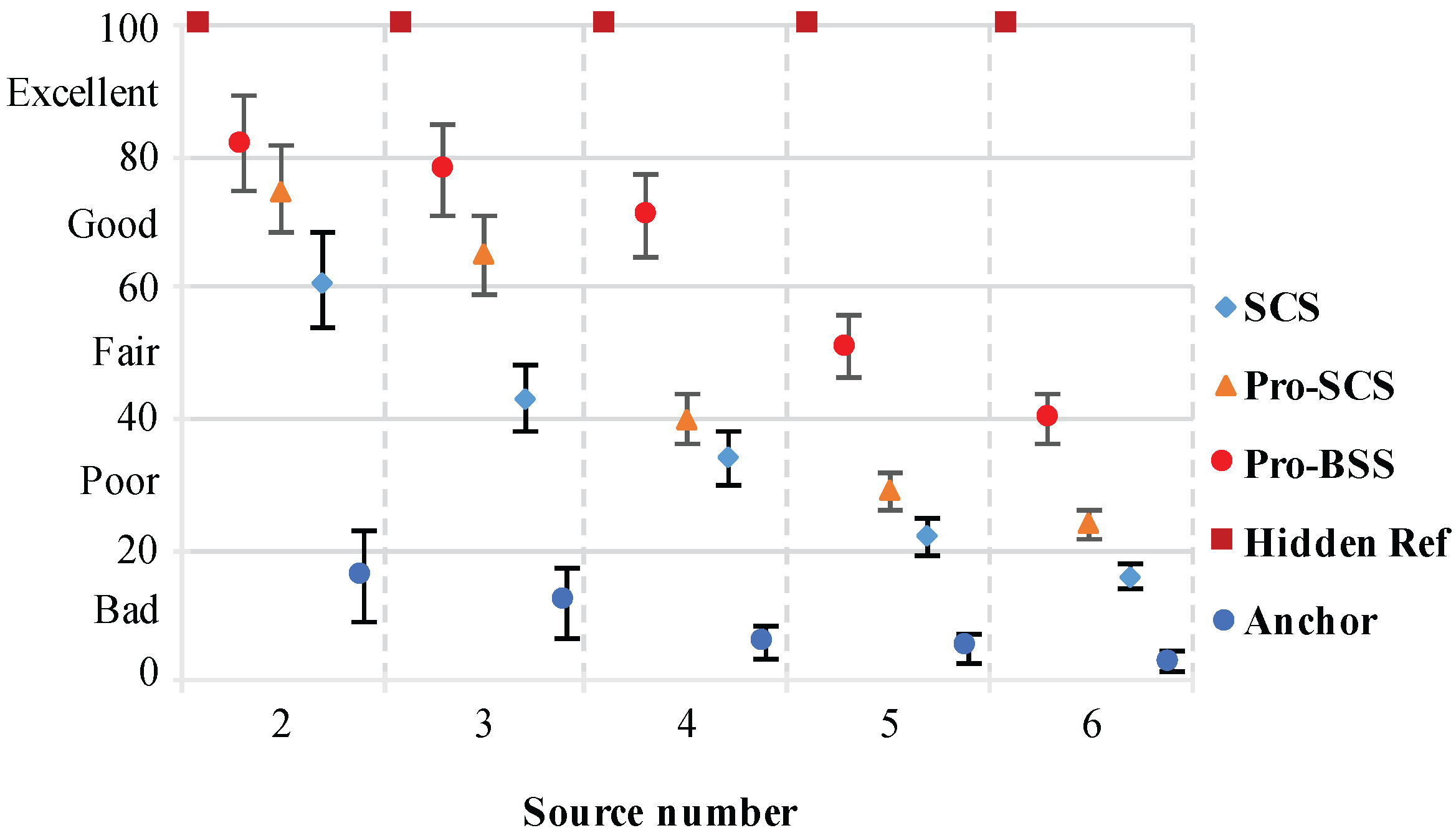
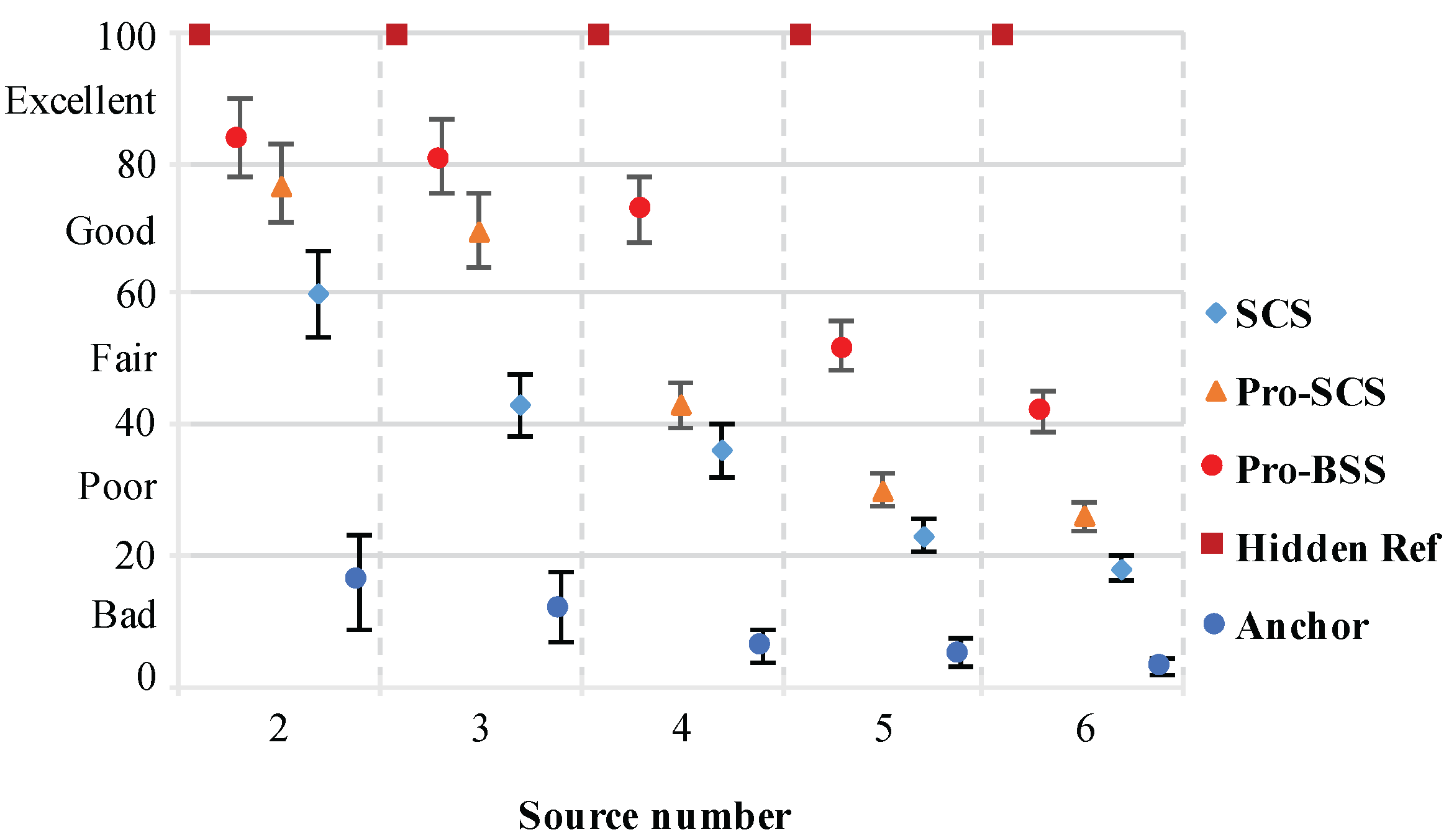
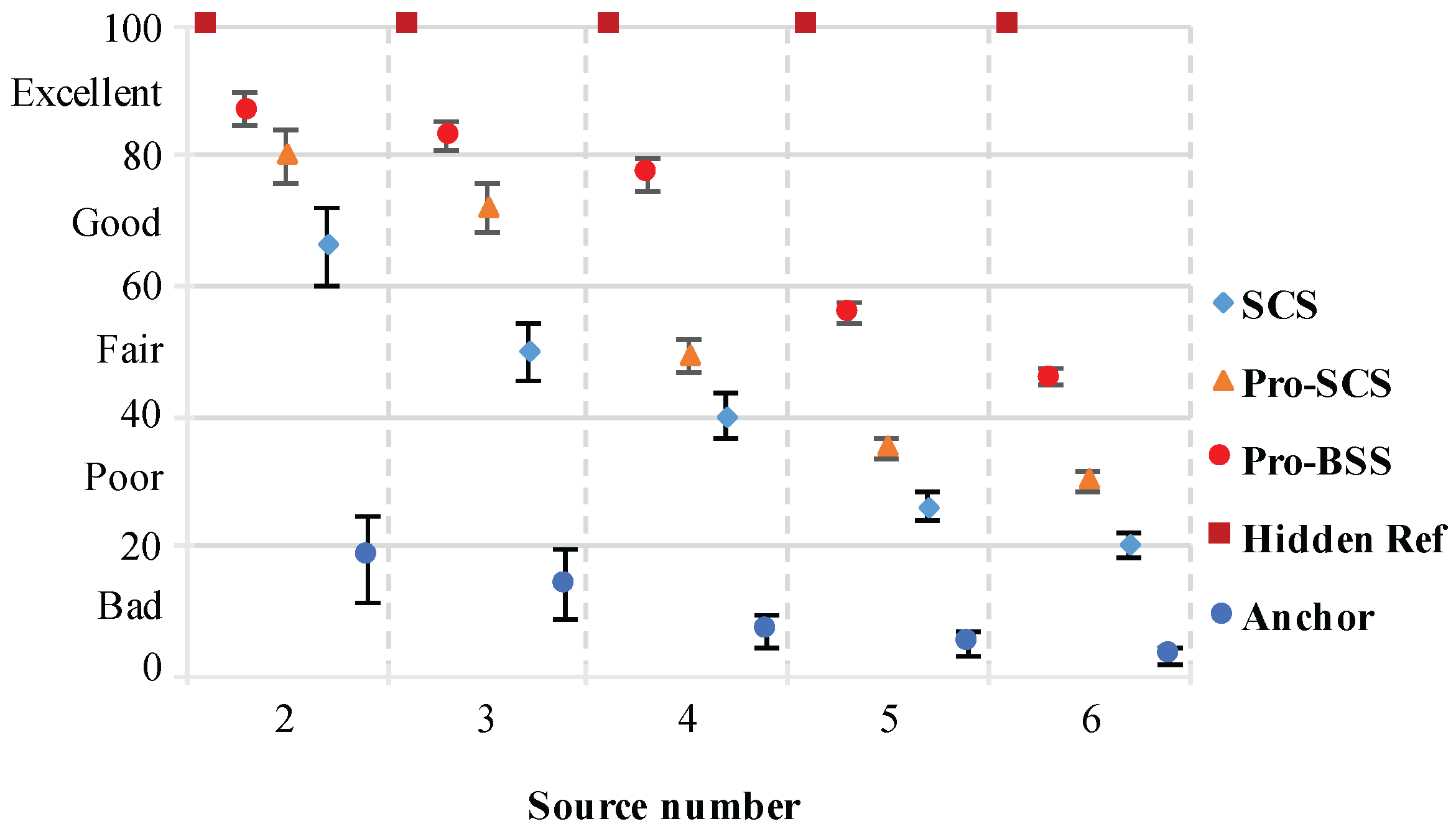
For each source number and separation, we calculated the average of all tested speeches and results are shown in
Figure 13,
Figure 14,
Figure 15 and
Figure 16. It can be observed that our proposed method achieves significantly higher scores compared to the fixed threshold BSS approach, which uses the same number of microphones as our proposed method. In addition, the PSM scores decreases as the source number increases from 2 to 6, and rises as the separation between the two adjacent sources gets larger. For the cases
K = 2, 3, the scores are always about 0.8, which reaches a nearly excellent quality. For the undermined case, the MUSHRA scores are about 0.7 when the source number is four, while for the cases
K = 5, 6, the quality of the extracted speech is below 0.6 but still over 0.4. This means that the extracted speech is not quite euphonious but can still represent clear and understandable speech.
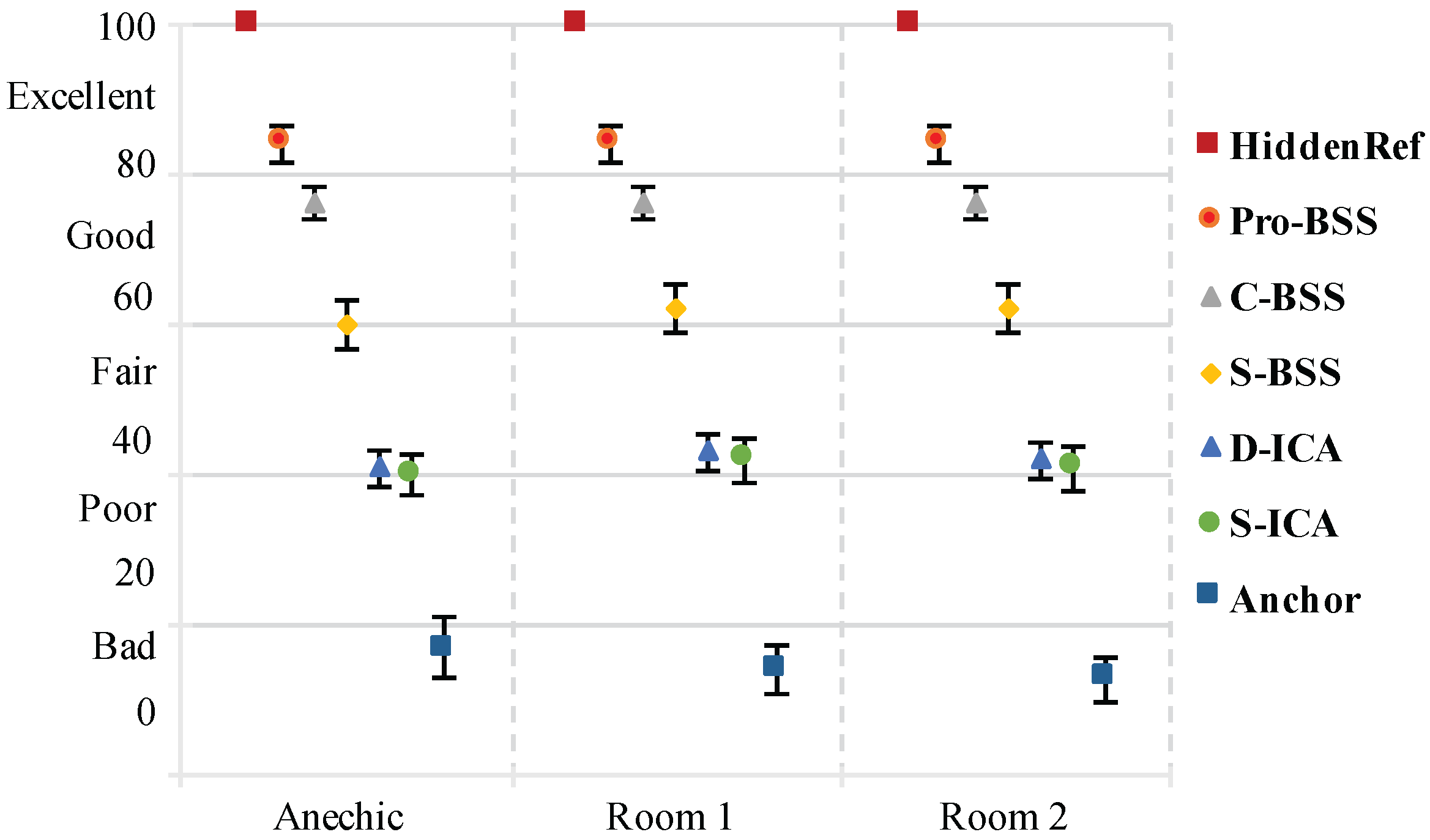
To compare the extracted speech quality with the reference method in objective evaluation further, a MUSHRA test was also employed to measure the subjective quality of the separated speech. Six middle sources from each test group were selected for the listening test. Similarly, the unprocessed (W channel of the B-format recording) mixed signal was used as the anchor and the original speech was used as the hidden reference. Note that each separated speech source is evaluated separately by using loudspeakers for playback in the Anechoic Room, Room 1, and Room 2. Average MUSHRA scores are presented in
Figure 17.
It can be seen that a significant improvement in the separation quality is achieved by applying the proposed scheme. The MUSHRA score for the proposed method is of nearly ‘excellent’ quality, the second best score is about ‘good’. It should be noted that we just use one B-format microphone, while C-BSS adopts a pair. The majority of listeners indicated that their choice for the closest match to the reference was based on files which contained the minimal amount of crosstalk and musical distortion. For other conditions, listeners reported that while the target speech is significantly separated from the mixture, there is audible crosstalk from other talkers with higher musical distortion.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}