
A Real-Time Sound Field Rendering Processor


Abstract
:
1. Introduction
- (1)
- The hybrid architecture to speed up computation and improve the sampling rate of the output sound. The system architecture and function modules are introduced.
- (2)
- Simple interface for system scalability. The data transceiver, receiver, and decoder are introduced, and the related operation flows are described.
- (3)
- Design and implementation of the FPGA-based prototype machine and application specific integrated circuit (ASIC), which achieve significant performance gain over multi-core based software simulation.
- (4)
- Evaluation and analysis of system performance based on the prototype machine and ASIC, including rendering time, sample rate of the output sound, and throughput.
2. HO-FDTD Algorithm
2.1. General Grids
2.2. Boundary Condition
3. System Architecture
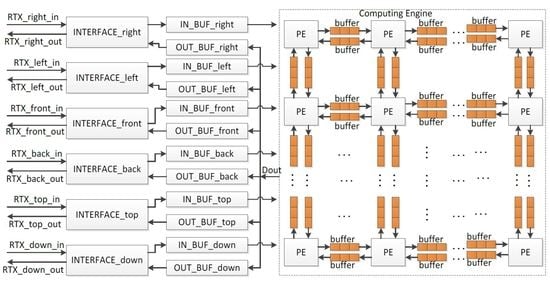
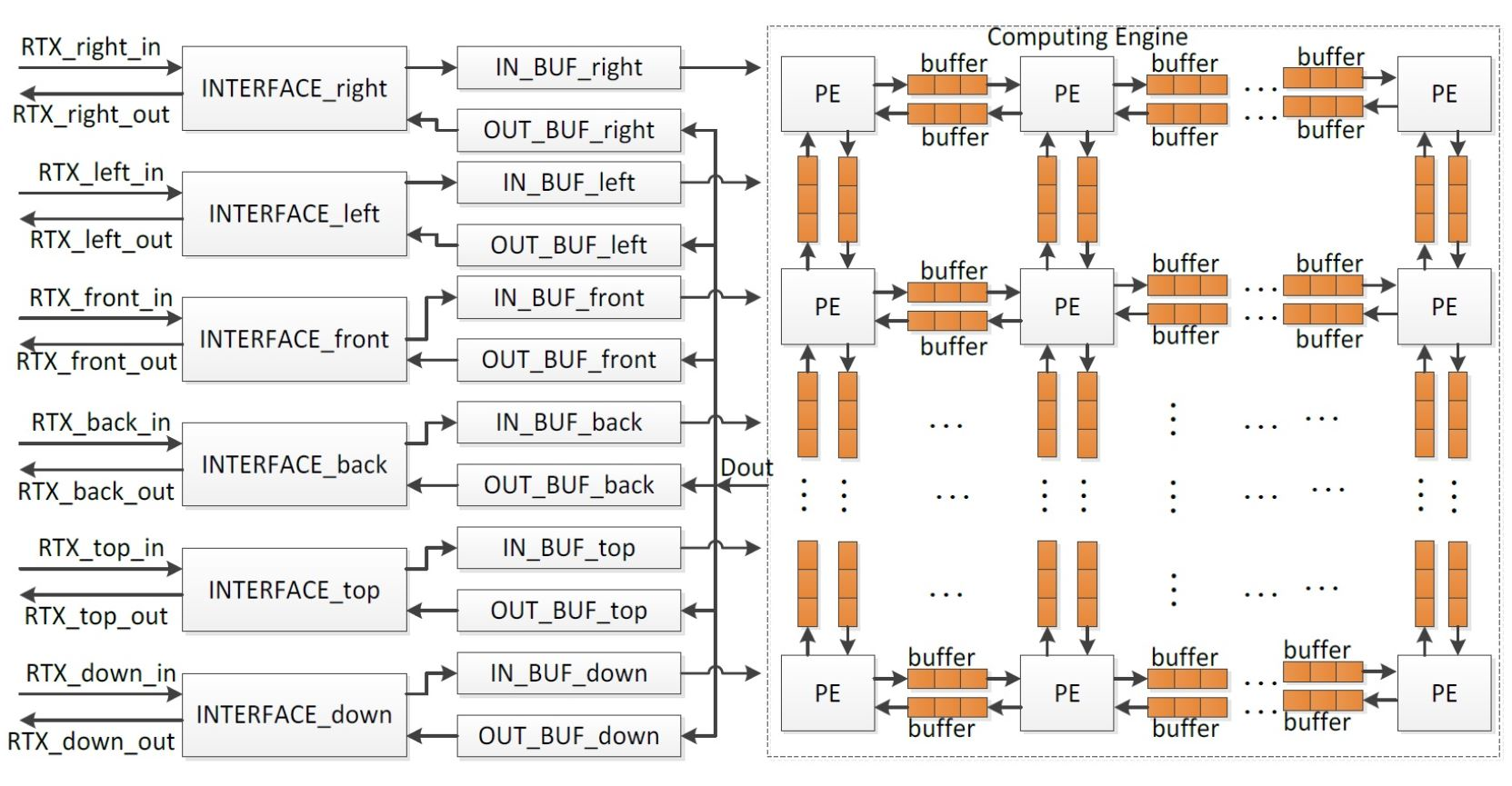
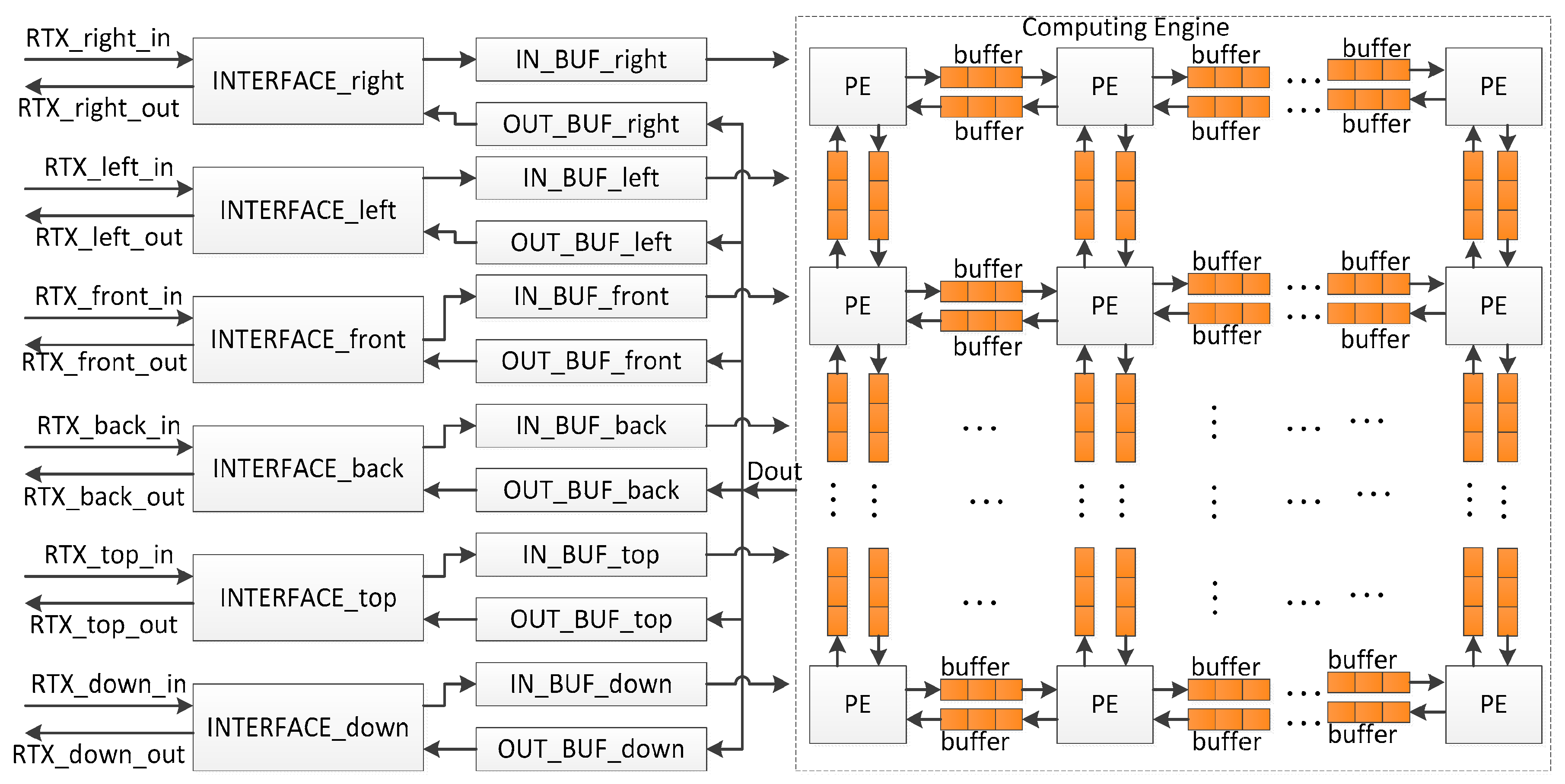
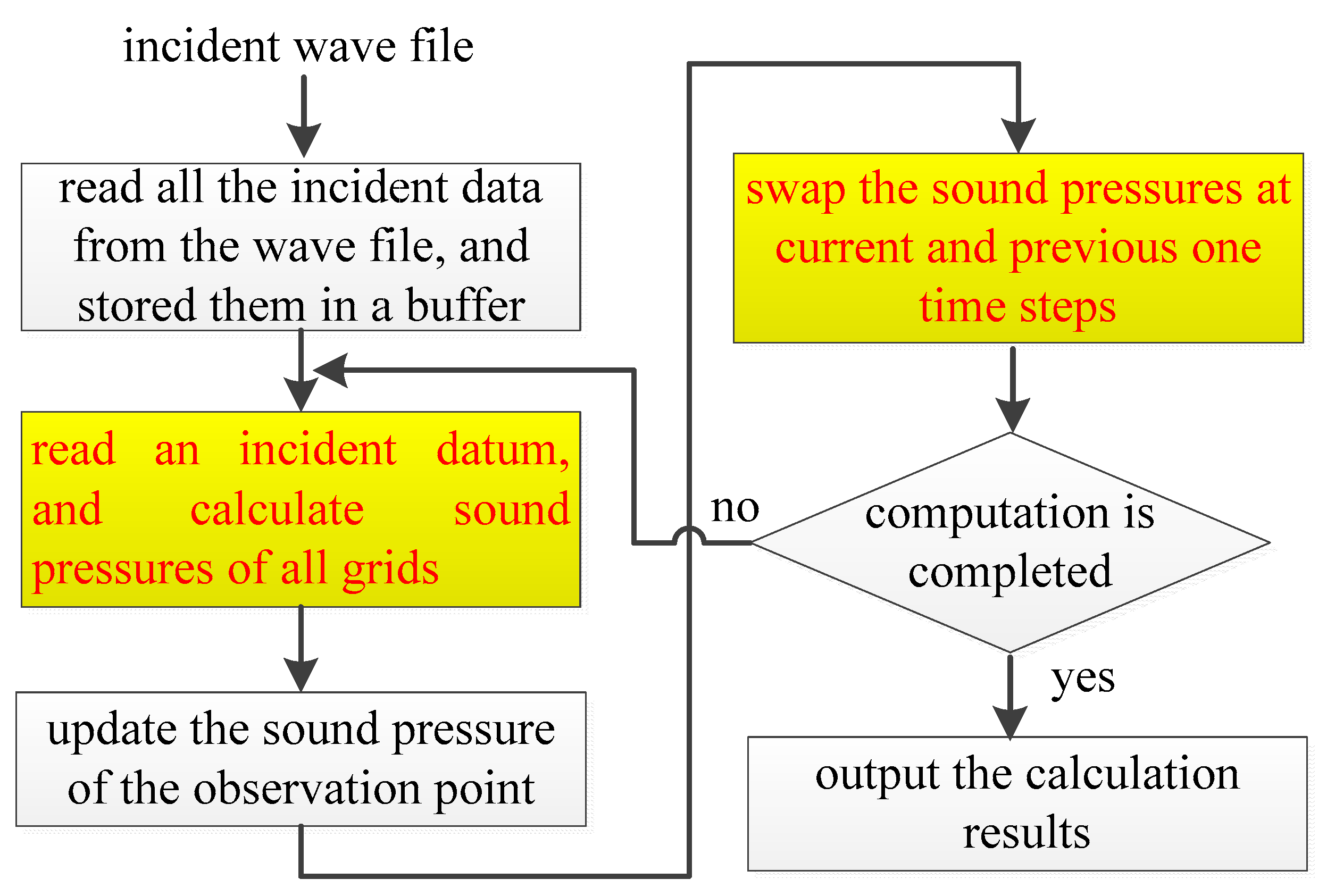
- Computing Engine. The Computing Engine calculates the sound pressures of grids, and it is the core of the system. In the current solution, a sound space is divided into small sub-spaces, for example, a sound space with 8 × 8 × 8 grids can be divided into 8 small sub-spaces with each having 4 × 4 × 4 grids. A PE is used to analyze sound behavior in each small sub-space, and all PEs are cascaded to work in parallel to perform rendering in the whole sound space. The sound pressures of the grids on the boundaries between neighboring small sound spaces are written into the relevant buffers for further use by the neighbor PEs. Therefore, two buffers are required between two neighboring PEs. They are applied to keep the input data from and output data for the neighbor PE.
- INTERFACEs. The INTERFACEs provide the possibility for system scalability to extend the simulated sound area. From Equation (6), when multiple processors are cascaded, one chip exchanges data with neighbor chips in six directions, namely top, down, right, left, front, and back. Thus, a processor provides six interfaces for data communication.
- IN_BUFs and OUT_BUFs. The IN_BUFs and OUT_BUFs are utilized to store the sound pressures of grids on the boundaries between the neighboring small sound spaces when multiple processors are cascaded to perform rendering in a much larger sound space. The data from the neighbor processors are stored in the IN_BUFS and the data for the neighbor chips are kept by the OUT_BUFs.
3.1. Processing Elements
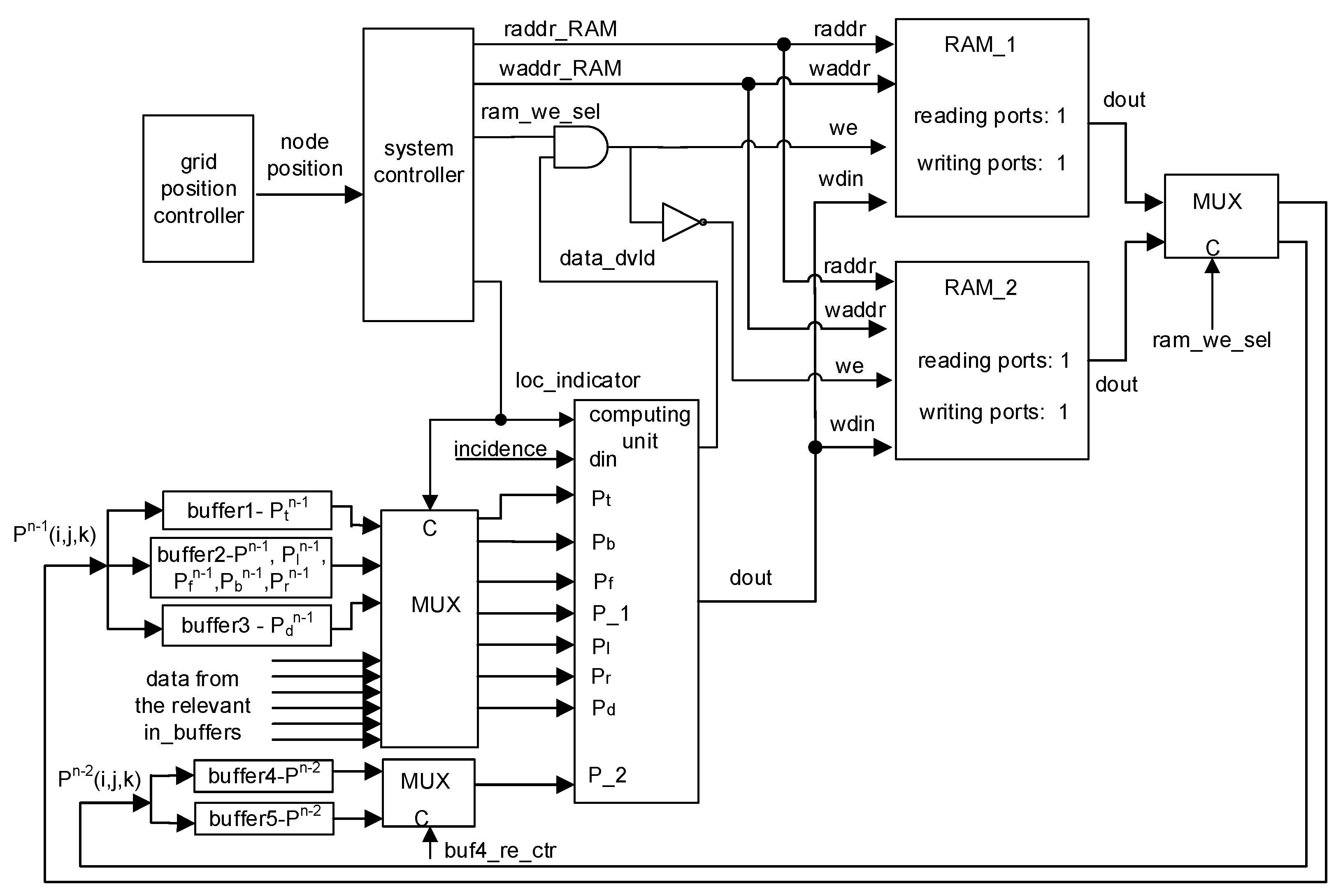
- Computing Unit. The computing unit calculates the sound pressure of a grid according to the input sound pressures at previous time steps, location indicators, and incident data. Based on Equation (13), a uniform computing unit was designed, which consists of a 7-input adder, a subtractor, two 32-bit fixed-point multipliers, and four multiplexers [19]. In Figure 3, the multipliers are for boundary grids while they are replaced by the right and left shifters for grids outside boundaries. The multiplicands are selected by the multiplexers according to the location indicator of a grid.
- Grid Position Controller. The grid position controller generates the grid position by using a counter, which is updated at every clock cycle.
- System Controller. The system controller maintains the computation flow and generates control signals, such as grid location flag (loc_indicator), read/write enable signal (we) of the RAMs, reading/writing addresses of the RAMs (raddr_RAM and waddr_RAM), and RAM selection signal (ram_we_sel).
- RAM_1 and RAM_2. The sound pressures of grids at previous one and two time steps, namely and , are stored in the RAM_1 and RAM_2. During computation, sound pressures at different time steps are stored in and read out from the RAM_1 and RAM_2 alternatively, and the calculation results at current time step are kept by the same RAM as that in which the sound pressures of grids at the previous two time steps are stored. For example, at a time step, and are stored in RAM_1 and RAM_2, respectively. Then, the calculation results at the current time step are written into the RAM_2. At the next time step, the reading and writing operations for the RAMs are switched; is read out from the RAM_1 while others are taken from the RAM_2. In addition, the calculation results are stored in the RAM_2. Such switching for RAM operations is repeated until all calculated time steps are over. The writing-enable signals of the RAMs are controlled by the signals ram_we_sel and data_dvld output by the system controller and the computing unit, respectively. When computations at a time step are finished, the signal ram_we_sel is reversed to invert the writing-enable signals of the RAMs. The size of RAMs is determined by the number of grids and data width. If data are 32-bit, and a sound space has N × M × L grids, each RAM is 4 NML bytes.
- Buffer 1–5. Data are read out from the RAMs and written in the five buffers in advance to reduce data access latency during calculation. The buffers are updated along with the computation. If data width is 32-bit, and a sound space has N × M × L grids, each buffer is 4 NM bytes in size.
- Multiplexers. Three multiplexers are used to select data for the computing unit. In the system, the input data of the computing unit may be from the local buffers within the same PE or the external input buffer, in which the data from the neighbor PE are stored.
3.2. INTERFACEs
- Receiver. The receiver receives serial data from the neighbor processors, checks the data type (data or control instructions), and stores data to the first in first out (FIFO) buffer or buffer according to the data type. The receiver is composed of a data type detector (RX_FHD) and a state machine (RX_STATE) to control the receiving flow. As shown in Figure 5, the system firstly detects the 8-bit type flag, which is AB and 54 in hexadecimal for pure data and the control instructions, respectively. After the type flag is received, system then receives the data length, which is 8-bit and denotes the data length in byte. Finally, data are received and stored in the RX_FIFO for the control instructions or IN_BUF for the pure data.
- Decoder. The DECODER decodes and executes the control instructions. Eleven control instructions are defined for system configuration and data communication. Furthermore, an automatic instruction forwarding mechanism is provided to forward the control instructions to other processors when multiple processors are cascaded.
- Transmitter. The transmitter (TX_STATE) transmits the control instructions or pure data to the neighbor processors. Data are transmitted in the manner of data frame, which consists of type flag, data length, chip ID, and the relevant pure data or instructions. Before data transmission, the bus is checked. If it is free, transmission is started; otherwise, the system waits for some clock cycles and checks again until the bus is free. Three types of data are transmitted, which are pure data, forwarded instructions, and the acknowledgement instruction. To transmit the pure data or the forwarded instructions, the data valid instruction is firstly sent out. Then, the system waits for the acknowledgment signal from the receiver. After the signal is received, the related data frame is transmitted serially. When the system receives the data valid instruction from the neighbor processors, it responds the data communication request by sending back the acknowledgement instruction. The whole procedure is shown in Figure 6 and is controlled by a state machine.
4. Performance Estimation
4.1. Performance of the Prototype Machine
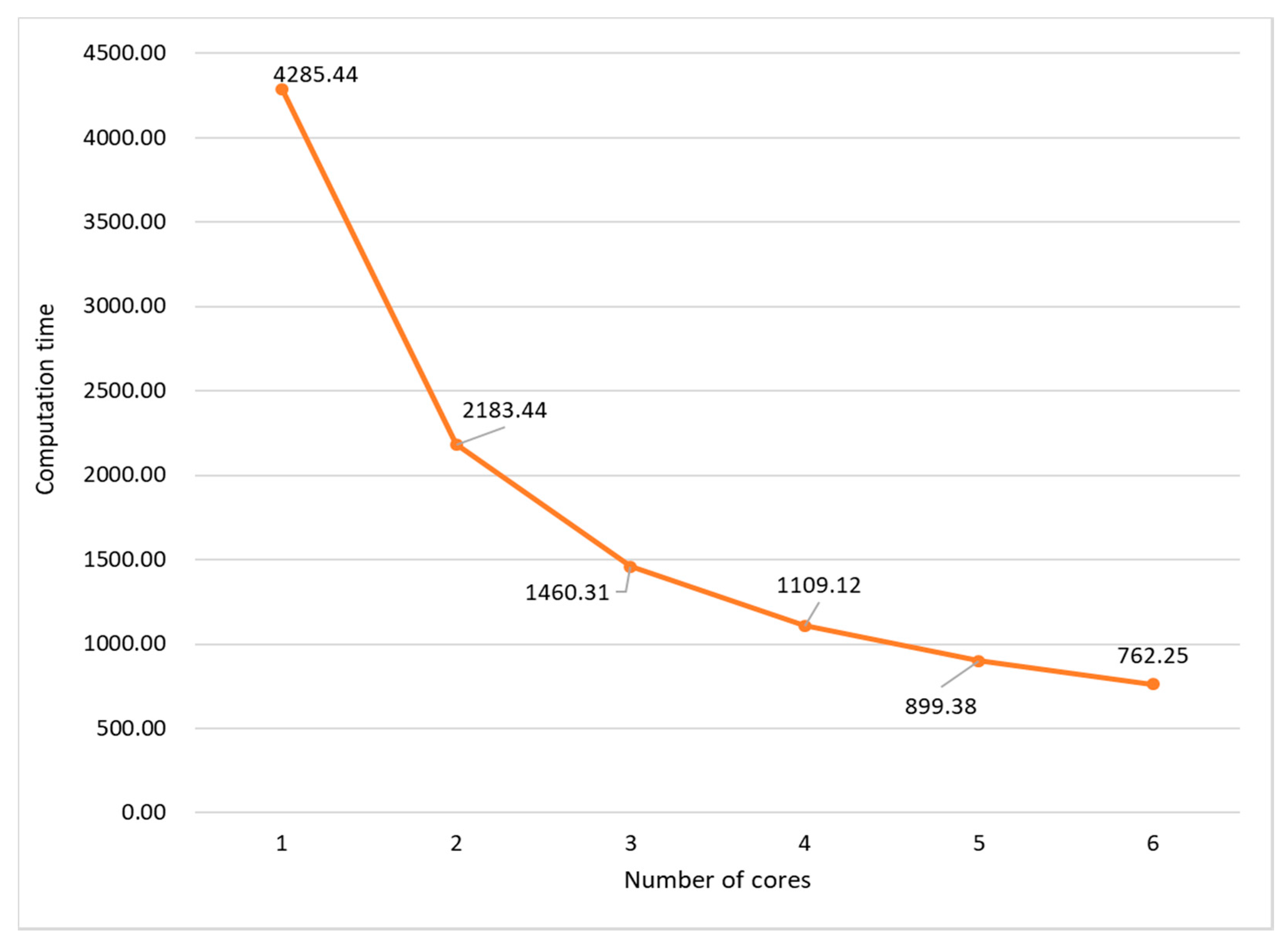
4.1.1. Rendering Time
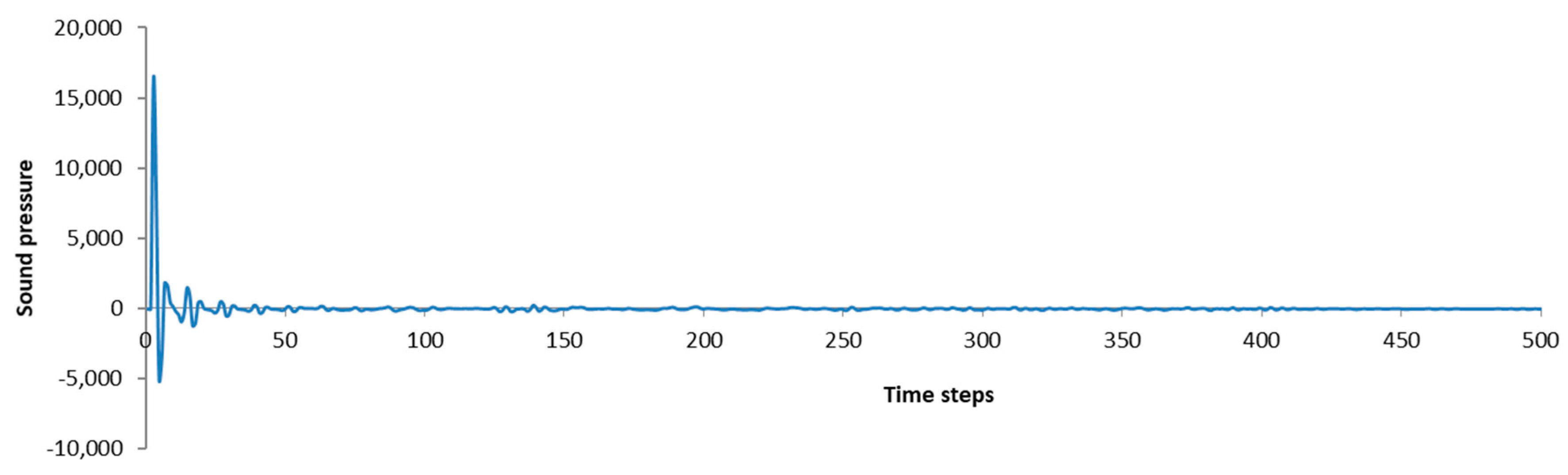
4.1.2. Sample Rate of the Output Sound
4.1.3. Throughput
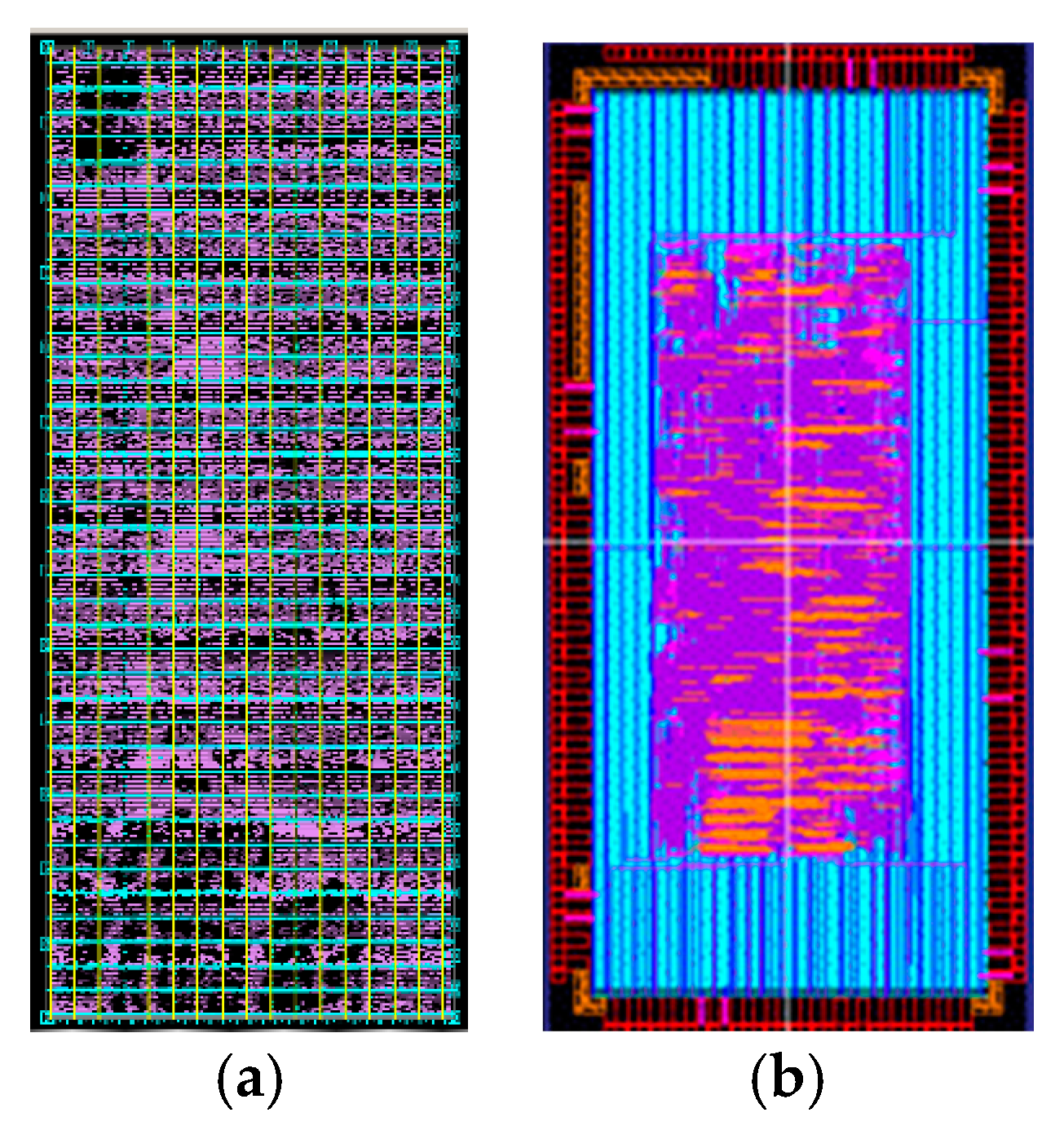
4.2. System Implementation by ASIC
5. Conclusions
Acknowledgment
Author Contributions
Conflicts of Interest
References
- Botteldooren, D. Acoustical finite-difference time-domain simulation in a quasi-Cartesian grid. J. Acoust. Soc. Am. 1994, 95, 2313–2319. [Google Scholar] [CrossRef]
- Botteldooren, D. Finite-difference time-domain simulation of low-frequency room acoustic problems. J. Acoust. Soc. Am. 1995, 98, 3302–3308. [Google Scholar] [CrossRef]
- Chiba, O.; Kashiwa, T.; Shimoda, H.; Kagami, S.; Fukai, I. Analysis of sound fields in three dimensional space by the time-dependent finite-difference method based on the leap frog algorithm. J. Acoust. Soc. Jpn. 1993, 49, 551–562. [Google Scholar]
- Savioja, L.; Valimaki, V. Interpolated rectangular 3-D digital waveguide mesh algorithms with frequency warping. IEEE Trans. Speech Audio Process. 2003, 11, 783–790. [Google Scholar] [CrossRef]
- Campos, G.R.; Howard, D.M. On the computational efficiency of different waveguide mesh topologies for room acoustic simulation. IEEE Trans. Speech Audio Process. 2005, 13, 1063–1072. [Google Scholar] [CrossRef]
- Murphy, D.T.; Kelloniemi, A.; Mullen, J.; Shelley, S. Acoustic modeling using the digital waveguide mesh. IEEE Signal Process. Mag. 2007, 24, 55–66. [Google Scholar] [CrossRef] [Green Version]
- Kowalczyk, K.; van Walstijn, M. Room acoustics simulation using 3-D compact explicit FDTD schemes. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 34–46. [Google Scholar] [CrossRef] [Green Version]
- Van Mourik, J.; Murphy, D. Explicit higher-order FDTD schemes for 3D room acoustic simulation. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 2003–2011. [Google Scholar] [CrossRef]
- Hamilton, B.; Bilbao, S. Fourth-order and optimised finite difference schemes for the 2-D wave equation. In Proceedings of the 16th Conference on Digital Audio Effects (DAFx-13), Maynooth, Ireland, 2–6 September 2013. [Google Scholar]
- Hamilton, B.; Bilbao, S.; Webb, C.J. Revisiting implicit finite difference schemes for 3D room acoustics simulations on GPU. In Proceedings of the International Conference on Digital Audio Effects (DAFx-14), Erlangen, Germany, 1–5 September 2014; pp. 41–48. [Google Scholar]
- Brian, H.; Stefan, B. FDTD methods for 3-D room acoustics simulation with high-order accuracy in space and time. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2112–2124. [Google Scholar]
- Valimäki, V.; Parker, J.D.; Savioja, L.; Smith, J.O.; Abel, J.S. Fifty years of artificial reverberation. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 1421–1448. [Google Scholar] [CrossRef]
- Ishii, T.; Tsuchiya, T.; Okubo, K. Three-dimensional sound field analysis using compact explicit-finite difference time domain method with Graphics Processing Unit Cluster System. Jpn. J. Appl. Phys. 2013, 52, 07HC11. [Google Scholar] [CrossRef]
- Tsuchiya, T. Three-dimensional sound field rendering with digital boundary condition using graphics processing unit. Jpn. J. Appl. Phys. 2010, 49, 07HC10. [Google Scholar] [CrossRef]
- Savioja, L. Real-time 3D finite difference time domain simulation of low and mid-frequency room acoustics. In Proceedings of the International Conference on DAFx, Graz, Austria, 6–10 September 2010; pp. 77–84. [Google Scholar]
- Tanaka, M.; Tsuchiya, T.; Okubo, K. Two-dimensional numerical analysis of nonlinear sound wave propagation using constrained interpolation profile method including nonlinear effect in advection equation. Jpn. J. Appl. Phys. 2011, 50, 07HE17. [Google Scholar] [CrossRef]
- Tan, Y.Y.; Inoguchi, Y.; Sugawara, E.; Otani, M.; Iwaya, Y.; Sato, Y.; Matsuoka, H.; Tsuchiya, T. A real-time sound field renderer based on digital Huygens’ model. J. Sound Vib. 2011, 330, 4302–4312. [Google Scholar]
- Tan, Y.Y.; Inoguchi, Y.; Sato, Y.; Otani, M.; Iwaya, Y.; Matsuoka, H.; Tsuchiya, T. A hardware-oriented finite-difference time-domain algorithm for sound field rendering. Jpn. J. Appl. Phys. 2013, 52, 07HC03. [Google Scholar]
- Tan, Y.Y.; Inoguchi, Y.; Sato, Y.; Otani, M.; Iwaya, Y.; Matsuoka, H.; Tsuchiya, T. A real-time sound rendering system based on the finite-difference time-domain algorithm. Jpn. J. Appl. Phys. 2014, 53, 07KC14. [Google Scholar]
- Tan, Y.Y.; Inoguchi, Y.; Sato, Y.; Otani, M.; Iwaya, Y.; Matsuoka, H.; Tsuchiya, T. Analysis of sound field distribution for room acoustics: from the point of view of hardware implementation. In Proceedings of the International Conference on DAFx, York, UK, 17–21 September 2012; pp. 93–96. [Google Scholar]
- Tan, Y.Y.; Inoguchi, Y.; Sugawara, E.; Sato, Y.; Otani, M.; Iwaya, Y.; Matsuoka, H.; Tsuchiya, T. A FPGA implementation of the two-dimensional digital huygens model. In Proceedings of the International Conference on Field Programmable Technology (FPT), Beijing, China, 8–10 December 2010; pp. 304–307. [Google Scholar]
- Inoguchi, Y.; Tan, Y.Y.; Sato, Y.; Otani, M.; Iwaya, Y.; Matsuoka, H.; Tsuchiya, T. DHM and FDTD based hardware sound field simulation acceleration. In Proceedings of the International Conference on DAFx, Paris, France, 19–23 September 2011; pp. 69–72. [Google Scholar]
- Kuttruff, H. Room Acoustics; Taylor & Francis: New York, NY, USA, 2009. [Google Scholar]
- Maxwell, J.C. A Treatise on Electricity and Magnetism, 3rd ed.; Clarendon: Oxford, UK, 1892; Volume 2, pp. 68–73. [Google Scholar]
- Kowalczyk, K.; Walstijn, M.V. Formulation of locally reacting surfaces in FDTD/K-DWM modelling of acoustic spaces. Acta Acust. United Acust. 2008, 94, 891–906. [Google Scholar] [CrossRef]
- Yiyu, T.; Inoguchi, Y.; Otani, M.; Iwaya, Y.; Tsuchiya, T. Design of a Real-time Sound Field Rendering Processor. In Proceedings of the RISP International Workshop on Nonlinear Circuits, Communications and Signal Processing, Honolulu, HI, USA, 6–9 March 2016; pp. 173–176. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grid Position | D1 | D2 |
|---|---|---|
| General | ||
| Interior | ||
| Edge | ||
| Corner |
| Grid | Prototype | PC |
|---|---|---|
| 32 × 32 × 16 | run-time | 762.25 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yiyu, T.; Inoguchi, Y.; Otani, M.; Iwaya, Y.; Tsuchiya, T. A Real-Time Sound Field Rendering Processor. Appl. Sci. 2018, 8, 35. https://doi.org/10.3390/app8010035
Yiyu T, Inoguchi Y, Otani M, Iwaya Y, Tsuchiya T. A Real-Time Sound Field Rendering Processor. Applied Sciences. 2018; 8(1):35. https://doi.org/10.3390/app8010035
Chicago/Turabian StyleYiyu, Tan, Yasushi Inoguchi, Makoto Otani, Yukio Iwaya, and Takao Tsuchiya. 2018. "A Real-Time Sound Field Rendering Processor" Applied Sciences 8, no. 1: 35. https://doi.org/10.3390/app8010035
APA StyleYiyu, T., Inoguchi, Y., Otani, M., Iwaya, Y., & Tsuchiya, T. (2018). A Real-Time Sound Field Rendering Processor. Applied Sciences, 8(1), 35. https://doi.org/10.3390/app8010035