A New Hybrid Approach for Wind Speed Forecasting Applying Support Vector Machine with Ensemble Empirical Mode Decomposition and Cuckoo Search Algorithm


Abstract
:Featured Application
Abstract
1. Introduction
1.1. Background and Motivation
1.2. Existing Models
1.3. Introduction of the Proposed Model
- The newly proposed approach in this paper takes advantage of the data preprocessing method and the algorithm of parameter optimization to enhance the performance of the SVM model. In this paper, the raw time series is first decomposed into several sub-signals, among which signals with high frequency ones are removed and the rest are restructured to obtain a stationary time series, with which the intrinsic characteristics of the wind speed data can be better captured and analyzed so that the forecasting accuracy can be greatly improved.
- This paper employs the Cuckoo Search algorithm to optimize the parameters of the SVM before training. The CS algorithm, which has the advantage of a powerful capability in terms of global optimization, requires few parameters and has strong multi-objective problem solving ability, and therefore can significantly improve the accuracy of the forecasting. The Support Vector Machine can overcome the difficulties of traditional models, such as the curse of dimensionality, falling into local optima easily, and over-learning.
- To verify the forecasting ability of the proposed approach, conventional models like BPNN, RBFNN, and ARIMA are used for comparison. A more comprehensive evaluation is conducted, including multi-step forecasting experiments and performance evaluation metrics such as six indexes and a DM(Diebold-Mariano) test, to assess and analyze the performance of the newly developed method.
1.4. Structure of the Paper
2. Materials and Methods
2.1. Empirical Mode Decomposition (EMD)
- (a)
- Set all local maxima and minima of time series.
- (b)
- Connect all local extreme to produce the upper bound and the lower bound by applying a cubic spline.
- (c)
- Compute the mean value from the upper and lower bounds .
- (d)
- Compute the difference value between the raw data and the mean value .
- (e)
- Inspect if fits characteristics of IMF. If yes, is defined as the ith IMF and the residual will replace . If no, will be replaced by .
- (f)
- Repeat the above-mentioned procedures. Stop when the value of the two successive siftings’ standard deviation is lower than the threshold set earlier.
2.2. Ensemble Empirical Mode Decomposition (EEMD)
- Step (a). Add a white noise to the raw time series.
- Step (b). Based on the method of EMD, decompose the time series with the added white noise to nIMFs.
- Step (c). Repeat the mentioned two steps, but add the white noise at different scales each time.
- Step (d). Calculate the means of each IMF of decomposition to constitute the final IMFs.
2.3. Cuckoo Search Optimization (CSO) Algorithm
- The egg which is generated by each cuckoo bird represents a solution in a time period, and it is dumped randomly in the nest.
- The nests which contain better eggs (better solution) are described as the best nests and they will be passed to the next generation.
- The available host nests’ number is restricted to n, and each host bird is able to recognize the cuckoo bird’s egg with a probability . As a result, the host bird has two possible choices, which are either throwing away the egg or giving up the whole nest and finding a new location to build a new nest.
2.4. Support Vector Machine (SVM)
2.5. Introduction of the EEMD-CSO-SVM Model
2.6. DM Test and Forecasting Effectiveness
3. Performance Evaluation Criterion
4. Numerical Experimentation
4.1. Introduction of Datasets
4.2. Forecasting Model Parameter Setting
- (1)
- For BPNN, the newff function of the neural network toolbox is employed to build the network. The dimensions of the input, hidden, and output layers are 4, 5, and 1, respectively. The learning rate is set to 0.1, the maximum number of iterations is set to 100, and the training precision is set to 0.00004.
- (2)
- For ARIMA, the forecasting results are influenced by the moving average and the order of auto-regressive. The observed value’s fitting effect is measured by the AIC criterion, and the AIC also calculates the most suitable number for the parameters. When the AIC reaches the lowest value, the ARIMA method can achieve the best order.
- (3)
- For RBFNN, similar with BPNN, the newrb function of the neural network toolbox is employed to build the forecasting network. The same parameters as the BPNN are used in the RBFNN.
4.3. Experimental Results for Datasets
5. Analysis of the Forecasting Results
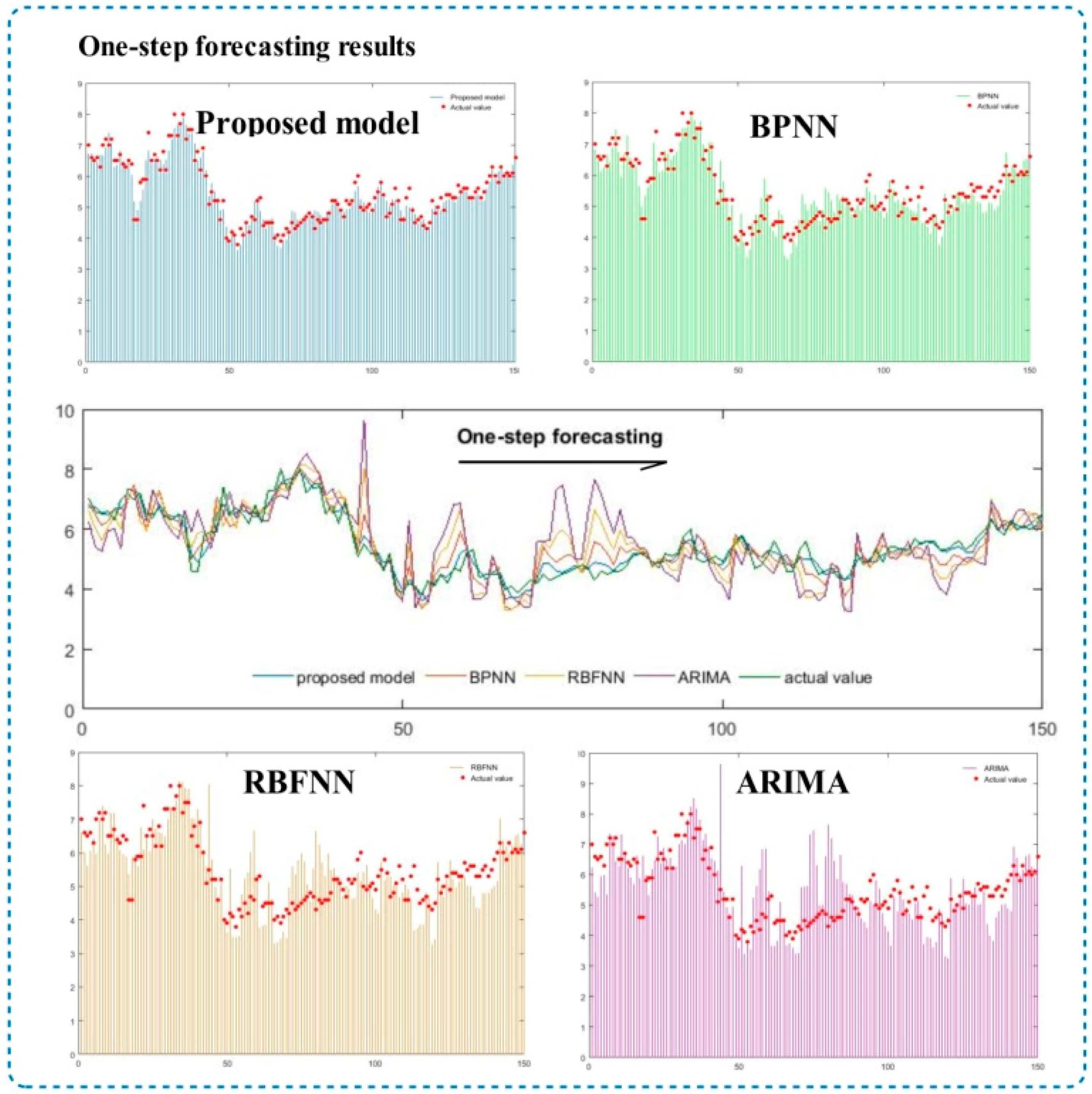
5.1. Single-Step Forecasting
5.1.1. Analysis of the Proposed Method and Conventional Models
5.1.2. Analysis of the Four Different Wind Turbines
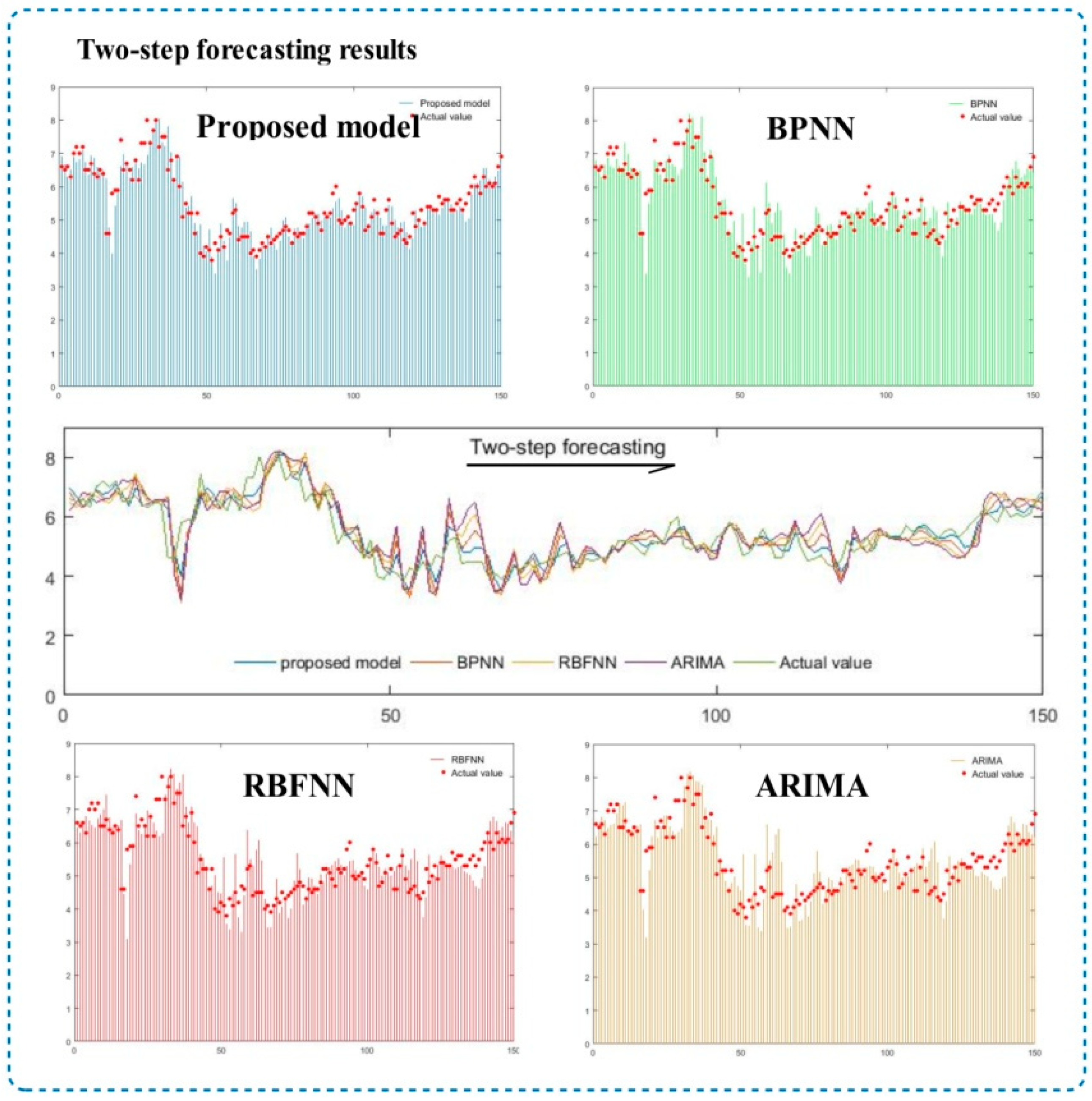
5.2. Multi-Step Forecasting
6. Discussion
6.1. Sample Selection
6.2. Forecasting Error Analysis
6.3. Validity of the Data Preprocessing Technique
6.4. Significance of the Error Evaluation Indexes
6.5. Results of DM Test and Forecasting Effectiveness
7. Conclusions
Author Contributions
Conflicts of Interest
Abbreviation
| Variables | Meaning |
| s(t) | Raw data |
| ci(t) | Residuals in raw data |
| rn(t) | IMFs of the raw data |
| Amplitude of the added noise | |
| Standard deviation of the error | |
| Value of ensemble member | |
| New solution of cuckoo search | |
| Current solution of cuckoo search | |
| α | Size of each step in cuckoo search |
| ⊕ | Entry wise multiplications |
| Lévy distribution | |
| Nonlinear mapping | |
| w | Weight vector of SVM |
| b | Scalar of SVM |
| Penalty factor of the error | |
| Loss function | |
| Empirical error | |
| Regularization term | |
| l | Quantity of elements in the sample data series |
| Multipliers of Lagrange function | |
| Kernel function of SVM | |
| γ | Parameter of the kernel function |
| N | Total output samples |
| Actual series | |
| Predicting results |
References
- Salcedo-Sanz, S.; Pérez-Bellido, Á.M.; Ortiz-García, E.G.; Portilla-Figueraa, A.; LuisPrieto, L.; Correosoc, F. Accurate short-term wind speed forecasting by exploiting diversity in input data using banks of artificial neural networks. Neurocomputing 2009, 72, 1336–1341. [Google Scholar] [CrossRef]
- Soman, S.S.; Zareipour, H.; Malik, O.; Mandal, P. A review of wind power and wind speed forecasting methods with different time horizons. In Proceedings of the North American Power Symposium 2010, Arlington, TX, USA, 26–28 September 2010. [Google Scholar]
- Wang, J.; Heng, J.; Xiao, L.; Wang, C. Research and application of a combined model based on multi-objective optimization for multi-step ahead wind speed forecasting. Energy 2017, 125, 591–613. [Google Scholar] [CrossRef]
- Mohandes, M.A.; Halawani, T.O.; Rehman, S.; Hussaina, A.A. Support vector machines for wind speed prediction. Renew. Energy 2004, 29, 939–947. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.-Q.; Chen, C.; Li, Y. A hybrid statistical method to predict wind speed and wind power. Renew. Energy 2010, 35, 1857–1861. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.Q.; Pan, D.F.; Li, Y.F. Forecasting models for wind speed using wavelet, wavelet packet, time series and artificial neural networks. Appl. Energy 2013, 107, 191–208. [Google Scholar] [CrossRef]
- Li, G.; Shi, J. On comparing three artificial neural networks for wind speed forecasting. Appl. Energy 2010, 87, 2313–2320. [Google Scholar] [CrossRef]
- Barbounis, T.G.; Theocharis, J.B.; Alexiadis, M.C.; Dokopoulos, P.S. Long-term wind speed and power forecasting using local recurrent neural network models. IEEE Trans. Energy Convers. 2006, 21, 273–284. [Google Scholar] [CrossRef]
- Cheng, C.H.; Wei, L.Y. A novel time-series model based on empirical mode decomposition for forecasting TAIEX. Econ. Model. 2014, 36, 136–141. [Google Scholar] [CrossRef]
- Zhou, J.Y.; Shi, J.; Li, G. Fine tuning support vector machines for short-term wind speed forecasting. Energy Convers. Manag. 2011, 52, 1990–1998. [Google Scholar] [CrossRef]
- Liu, D.; Niu, D.X.; Wang, H.; Fan, L. Short-term wind speed forecasting using wavelet transform and support vector machines optimized by genetic algorithm. Renew. Energy 2014, 62, 592–597. [Google Scholar] [CrossRef]
- Hu, Q.H.; Zhang, S.G.; Xie, Z.X.; Mi, J.S.; Wan, J. Noise model based v-support vector regression with its application to short-term wind speed forecasting. Neural Netw. 2014, 57, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.H.; Wu, J.; Lu, H.Y.; Wang, J.Z. A case study on a hybrid wind speed forecasting method using BP neural network. Knowl.-Based Syst. 2011, 24, 1048–1056. [Google Scholar] [CrossRef]
- Guo, Z.H.; Zhao, J.; Zhang, W.Y.; Wang, J.Z. A corrected hybrid approach for wind speed prediction in Hexi Corridor of China. Energy 2011, 36, 1668–1679. [Google Scholar] [CrossRef]
- Pourmousavi Kani, S.A.; Aredhali, M.M. Very short-term wind speed prediction: A new artificial neural network-Markov chain model. Energy Convers. Manag. 2011, 52, 738–745. [Google Scholar] [CrossRef]
- Pourmousavi Kani, S.A.; Riahy, G.D.; Mazhari, D. An innovative hybrid algorithm for very short-term wind speed prediction using linear prediction and markov chain approach. Int. J. Green Energy 2011, 8, 147–162. [Google Scholar] [CrossRef]
- Liu, H.; Chen, C.; Tian, H.Q.; Li, Y.F. A hybrid model for wind speed prediction using empirical mode decomposition and artificial neural networks. Renew. Energy 2012, 48, 545–556. [Google Scholar] [CrossRef]
- Mohammadi, A.; Dehghani, M.J.; Ghazizadeh, E. Game Theoretic Spectrum Allocation in Femtocell Networks for Smart Electric Distribution Grids. Energies 2018, 11, 1635. [Google Scholar] [CrossRef]
- Kianoosh, G.; Boroojeni, M.; Hadi, A.; Bahrami, S.S.; Iyengar, A.I.; Sarwat, O.K. A novel multi-time-scale modeling for electric power demand forecasting: From short-term to medium-term horizon. Electr. Power Syst. Res. 2017, 142, 58–73. [Google Scholar]
- Haque, A.U.; Mandal, P.; Kaye, M.E.; Meng, J.L.; Chang, L.C.; Senjyu, T. A new strategy for predicting short-term wind speed using soft computing models. Renew. Sustain. Energy Rev. 2012, 16, 4563–4573. [Google Scholar] [CrossRef]
- Li, G.; Shi, J. On comparing three artificial neural networks for wind speed forecasting. Appl. Energy 2010, 87, 2313–2320. [Google Scholar]
- Ortiz-García, E.G.; Salcedo-Sanz, S.; Perez-Bellido, A.M.; Gascon-Moreno, J.; Portilla-Figueras, J.A.; Prieto, L. Short-term wind speed prediction in wind farms based on banks of support vector machines. Wind Energy 2011, 14, 193–207. [Google Scholar]
- Xiao, L.; Wang, J.; Hou, R.; Wu, J. A combined model based on data pre-analysis and weight coefficients. optimization for electrical load forecasting. Energy 2015, 82, 524–549. [Google Scholar] [CrossRef]
- Vapnik, V. Statistical Learning Theory, 2nd ed.; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1999. [Google Scholar]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Yang, X.S.; Deb, S. Engineering optimization by cuckoo search. Int. J. Math. Model. Numer. Optim. 2010, 1, 330–343. [Google Scholar]
- Yang, W.; Wang, J.; Wang, R. Research and application of a novel hybrid model based on data selection and artificial intelligence algorithm for short term load forecasting. Entropy 2017, 19, 52. [Google Scholar] [CrossRef]
- Yang, X.S.; Deb, S. Cuckoo search via Lévy flights. Presented at 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009. [Google Scholar]
- Pai, P.; Lin, C. A hybrid ARIMA and support vector machines model in stock price forecast. Omega 2005, 33, 497–505. [Google Scholar] [CrossRef]
- Huang, C.; Davis, L.; Townshend, J. An assessment of support vector machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Sung, A.H.; Mukkamala, S. Identifying important features for intrusion detection using support vector machines and neural networks. In Proceedings of the 2003 Symposium on Applications and the Internet, Orlando, FL, USA, 27–31 January 2003. [Google Scholar]
- Xiao, L.; Shao, W.; Wang, C.; Zhang, K.; Lu, H. Research and application of a hybrid model based on multi-objective optimization for electrical load forecasting. Appl. Energy 2016, 180, 213–233. [Google Scholar] [CrossRef]
- Iversen, E.B.; Morales, J.M.; Møller, J.K.; Madsen, H. Short-term probabilistic forecasting of wind speed using stochastic differential equations. Int. J. Forecast. 2015, 32, 981–990. [Google Scholar] [CrossRef]
- Chao, R.; Ning, A.; Wang, J.Z.; Li, L.; Hu, B.; Shang, D. Optimal parameters selection for BP neural network based on particle swarm optimization: A case study of wind speed forecasting. Knowl.-Based Syst. 2014, 56, 226–239. [Google Scholar]
- Wang, J.; Zhu, S.; Zhao, W.; Zhu, W. Optimal parameters estimation and input subset for grey model based on chaotic particle swarm optimization algorithm. Expert Syst. Appl. 2011, 38, 8151–8158. [Google Scholar] [CrossRef]
- Zhou, J.Z.; Sun, N.; Jia, B.J.; Peng, T. A Novel Decomposition-Optimization Model for Short-Term Wind Speed Forecasting. Energies 2018, 11, 1752. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Definition | Equation |
|---|---|---|
| MAE | The mean absolute error of N forecasting results | |
| MAPE | The average of N absolute percentage error | |
| RMSE | The square root of the average of the error square | |
| WI | Willmott’s Index | |
| ENS | Nash-Sutcliffe coefficient | |
| ELM | Legates and McCabe Index |
| Model | RMSE | MAE | MAPE (%) | RMSE | MAE | MAPE (%) |
|---|---|---|---|---|---|---|
| Wind turbine 1 | Wind turbine 3 | |||||
| EEMDCSOSVM | 0.3513 | 0.1815 | 4.79 | 0.2463 | 0.2120 | 2.69 |
| EEMDPSOSVM | 0.4652 | 0.2159 | 5.63 | 0.3027 | 0.2436 | 2.82 |
| CSOSVM | 0.8294 | 0.2975 | 10.67 | 0.5121 | 0.4251 | 5.08 |
| PSOSVM | 1.0135 | 0.7100 | 12.18 | 0.7928 | 0.6362 | 9.70 |
| Wind turbine 2 | Wind turbine 4 | |||||
| EEMDCSOSVM | 0.2342 | 0.1841 | 3.07 | 0.2679 | 0.3028 | 3.91 |
| EEMDPSOSVM | 0.2744 | 0.2191 | 3.24 | 0.3147 | 0.1869 | 4.44 |
| CSOSVM | 1.1381 | 0.1927 | 7.63 | 0.9204 | 0.6137 | 9.27 |
| PSOSVM | 0.6680 | 0.5165 | 8.58 | 1.1478 | 0.8190 | 10.15 |
| Model | WI | ENS | ELM | WI | ENS | ELM |
|---|---|---|---|---|---|---|
| Wind turbine 1 | Wind turbine 3 | |||||
| EEMDCSOSVM | 0.9838 | 0.9332 | 0.7600 | 0.9918 | 0.9670 | 0.8268 |
| EEMDPSOSVM | 0.9723 | 0.9251 | 0.7148 | 0.9744 | 0.9310 | 0.7201 |
| CSOSVM | 0.9152 | 0.6858 | 0.4460 | 0.9667 | 0.8720 | 0.6525 |
| PSOSVM | 0.8622 | 0.5367 | 0.3599 | 0.8239 | 0.4950 | 0.1197 |
| Wind turbine 2 | Wind turbine 4 | |||||
| EEMDCSOSVM | 0.9929 | 0.9713 | 0.8388 | 0.9839 | 0.9350 | 0.7565 |
| EEMDPSOSVM | 0.9876 | 0.9424 | 0.7950 | 0.9786 | 0.9234 | 0.7159 |
| CSOSVM | 0.9206 | 0.7011 | 0.5134 | 0.8274 | 0.4885 | 0.2514 |
| PSOSVM | 0.9174 | 0.6852 | 0.4812 | 0.7490 | 0.3355 | 0.1253 |
| Model | RMSE | MAE | MAPE (%) | RMSE | MAE | MAPE (%) |
|---|---|---|---|---|---|---|
| Wind turbine 1 | Wind turbine 3 | |||||
| BPNN | 0.5939 | 0.4984 | 8.68 | 0.4794 | 0.3286 | 5.28 |
| RBFNN | 0.8867 | 0.5924 | 10.32 | 0.6587 | 0.4468 | 6.52 |
| ARIMA | 0.5784 | 0.4672 | 8.41 | 0.4472 | 0.2907 | 5.13 |
| EEMDCSOSVM | 0.3513 | 0.1815 | 4.79 | 0.2463 | 0.2120 | 2.69 |
| Wind turbine 2 | Wind turbine 4 | |||||
| BPNN | 0.3998 | 0.3232 | 5.42 | 0.4585 | 0.3385 | 6.34 |
| RBFNN | 0.4847 | 0.3806 | 6.41 | 1.2374 | 0.5543 | 10.32 |
| ARIMA | 0.3627 | 0.2925 | 5.61 | 0.4122 | 0.3679 | 5.88 |
| EEMDCSOSVM | 0.2342 | 0.1841 | 3.07 | 0.2679 | 0.3028 | 3.91 |
| Model | WI | ENS | ELM | WI | ENS | ELM |
|---|---|---|---|---|---|---|
| Wind turbine 1 | Wind turbine 3 | |||||
| BPNN | 0.9410 | 0.7822 | 0.5403 | 0.9708 | 0.8850 | 0.6806 |
| RBFNN | 0.8926 | 0.6017 | 0.4630 | 0.9429 | 0.7751 | 0.6128 |
| ARIMA | 0.9476 | 0.8137 | 0.6512 | 0.9755 | 0.9024 | 0.7148 |
| EEMDCSOSVM | 0.9838 | 0.9332 | 0.7600 | 0.9918 | 0.9670 | 0.8268 |
| Wind turbine 2 | Wind turbine 4 | |||||
| BPNN | 0.9731 | 0.8889 | 0.6962 | 0.9412 | 0.7628 | 0.5877 |
| RBFNN | 0.9595 | 0.8320 | 0.6422 | 0.7035 | 0.3339 | 0.3248 |
| ARIMA | 0.9752 | 0.8933 | 0.7017 | 0.9503 | 0.7937 | 0.6128 |
| EEMDCSOSVM | 0.9929 | 0.9713 | 0.8388 | 0.9839 | 0.9350 | 0.7565 |
| Dataset | MAE | MAPE (%) | RMSE | WI | ENS | ELM | |
|---|---|---|---|---|---|---|---|
| Dataset 1 | 1-Step | 0.1815 | 4.79 | 0.3513 | 0.9838 | 0.9332 | 0.7600 |
| 2-Step | 0.3622 | 6.19 | 0.4546 | 0.9720 | 0.8874 | 0.6699 | |
| 3-Step | 0.5895 | 10.14 | 0.7354 | 0.9249 | 0.7115 | 0.4609 | |
| Dataset 2 | 1-Step | 0.1841 | 3.07 | 0.2342 | 0.9929 | 0.9713 | 0.8388 |
| 2-Step | 0.3962 | 6.53 | 0.5034 | 0.9583 | 0.8355 | 0.6310 | |
| 3-Step | 0.6579 | 10.70 | 0.8291 | 0.8887 | 0.6073 | 0.3925 | |
| Dataset 3 | 1-Step | 0.2120 | 2.69 | 0.2463 | 0.9918 | 0.9670 | 0.8268 |
| 2-Step | 0.4814 | 5.97 | 05308 | 0.9529 | 0.8306 | 0.5820 | |
| 3-Step | 0.8694 | 9.52 | 0.8329 | 0.8599 | 0.5705 | 0.3240 | |
| Dataset 4 | 1-Step | 0.3028 | 3.91 | 0.2679 | 0.9839 | 0.9350 | 0.7565 |
| 2-Step | 0.4275 | 5.12 | 0.3652 | 0.9645 | 0.8604 | 0.6667 | |
| 3-Step | 0.5310 | 8.03 | 0.5437 | 0.9189 | 0.6883 | 0.4797 |
| Datase | Forecasting Steps | Raito Between the Training Sample and Testing Sample (MAPE (%)) | ||||
|---|---|---|---|---|---|---|
| 7:3 | 8:2 | 9:1 | 14:1 | 29:1 | ||
| Dataset 1 | 1-step | 5.40 | 4.92 | 4.79 | 4.95 | 5.11 |
| 2-step | 9.57 | 8.15 | 6.19 | 8.82 | 8.97 | |
| 3-step | 13.94 | 13.46 | 10.14 | 14.84 | 15.73 | |
| Dataset 2 | 1-step | 4.16 | 3.91 | 3.07 | 3.54 | 3.76 |
| 2-step | 9.32 | 7.52 | 6.53 | 7.32 | 8.44 | |
| 3-step | 12.69 | 11.24 | 10.70 | 11.15 | 11.80 | |
| Dataset 3 | 1-step | 3.48 | 3.28 | 2.69 | 3.41 | 3.97 |
| 2-step | 6.62 | 6.12 | 5.97 | 6.15 | 6.72 | |
| 3-step | 10.73 | 9.82 | 9.52 | 9.84 | 10.15 | |
| Dataset 4 | 1-step | 4.88 | 4.09 | 3.91 | 4.16 | 4.51 |
| 2-step | 7.26 | 6.65 | 5.12 | 5.52 | 5.84 | |
| 3-step | 11.01 | 10.39 | 8.03 | 8.85 | 8.99 | |
| Datasets | BPNN | RBFNN | ARIMA | |
|---|---|---|---|---|
| Dataset 1 | 1-step | 7.2859 | 7.4392 | 8.0205 |
| 2-step | 6.8073 | 7.1682 | 7.5217 | |
| 3-step | 6.5270 | 6.9463 | 7.2258 | |
| Dataset 2 | 1-step | 6.9469 | 7.4245 | 6.2829 |
| 2-step | 6.7716 | 7.2839 | 6.5691 | |
| 3-step | 6.8358 | 7.1475 | 6.2039 | |
| Dataset 3 | 1-step | 7.1325 | 6.2161 | 6.2934 |
| 2-step | 7.0413 | 6.4755 | 6.7390 | |
| 3-step | 6.9427 | 6.3586 | 6.4803 | |
| Dataset 4 | 1-step | 6.8941 | 7.2790 | 7.1783 |
| 2-step | 7.2564 | 7.2387 | 7.0492 | |
| 3-step | 6.4396 | 6.9257 | 6.5864 |
| Dataset | BPNN | RBFNN | ARIMA | EEMDCSOSVM | |
|---|---|---|---|---|---|
| Dataset 1 | First order | 0.8951 | 0.8889 | 0.8874 | 0.9146 |
| Second order | 0.8322 | 0.8257 | 0.8283 | 0.8638 | |
| Dataset 2 | First order | 0.9130 | 0.9029 | 0.9072 | 0.9367 |
| Second order | 0.8384 | 0.8362 | 0.8436 | 0.8842 | |
| Dataset 3 | First order | 0.9283 | 0.9177 | 0.9220 | 0.9409 |
| Second order | 0.8517 | 0.8582 | 0.8625 | 0.8975 | |
| Dataset 4 | First order | 0.8956 | 0.8934 | 0.9031 | 0.9269 |
| Second order | 0.8344 | 0.8360 | 0.8492 | 0.8816 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, T.; Liu, S.; Heng, J.; Gao, Y. A New Hybrid Approach for Wind Speed Forecasting Applying Support Vector Machine with Ensemble Empirical Mode Decomposition and Cuckoo Search Algorithm. Appl. Sci. 2018, 8, 1754. https://doi.org/10.3390/app8101754
Liu T, Liu S, Heng J, Gao Y. A New Hybrid Approach for Wind Speed Forecasting Applying Support Vector Machine with Ensemble Empirical Mode Decomposition and Cuckoo Search Algorithm. Applied Sciences. 2018; 8(10):1754. https://doi.org/10.3390/app8101754
Chicago/Turabian StyleLiu, Tongxiang, Shenzhong Liu, Jiani Heng, and Yuyang Gao. 2018. "A New Hybrid Approach for Wind Speed Forecasting Applying Support Vector Machine with Ensemble Empirical Mode Decomposition and Cuckoo Search Algorithm" Applied Sciences 8, no. 10: 1754. https://doi.org/10.3390/app8101754
APA StyleLiu, T., Liu, S., Heng, J., & Gao, Y. (2018). A New Hybrid Approach for Wind Speed Forecasting Applying Support Vector Machine with Ensemble Empirical Mode Decomposition and Cuckoo Search Algorithm. Applied Sciences, 8(10), 1754. https://doi.org/10.3390/app8101754