A Privacy Measurement Framework for Multiple Online Social Networks against Social Identity Linkage


Abstract
:1. Introduction
2. Related Work
- (1)
- We consider the use of spurious contents to protect privacy. Therefore, we propose the quantification of an attribute’s content.
- (2)
- We improve the method of visibility quantification. Meanwhile, we heuristically propose a quantitative method to measure a user’s privacy awareness.
- (3)
- We use and simplify the half-suppressed fuzzy C-means clustering algorithm [39] to quantify visibility, which can still obtain an excellent result.
- (4)
- We found that user behaviour and consciousness are out of sync; thus, we use questionnaires to measure attribute sensitivity and real OSNs settings to calculate visibility.
- (5)
- We experimented with the data in a previous study [38], and original data obtained from real OSN users for comparison with the existing study.
3. Problem Descriptions and Notation
4. The Measurement Method
4.1. Extraction Difficulty
4.2. Accessibility
| Algorithm 1. Calculation of accessibility |
| Input: , s Output: 1 for i in do 2 if i is 0 or repetitive in do 3 delete i 4 s = s − 1 5 = sum ()/s 6 end |
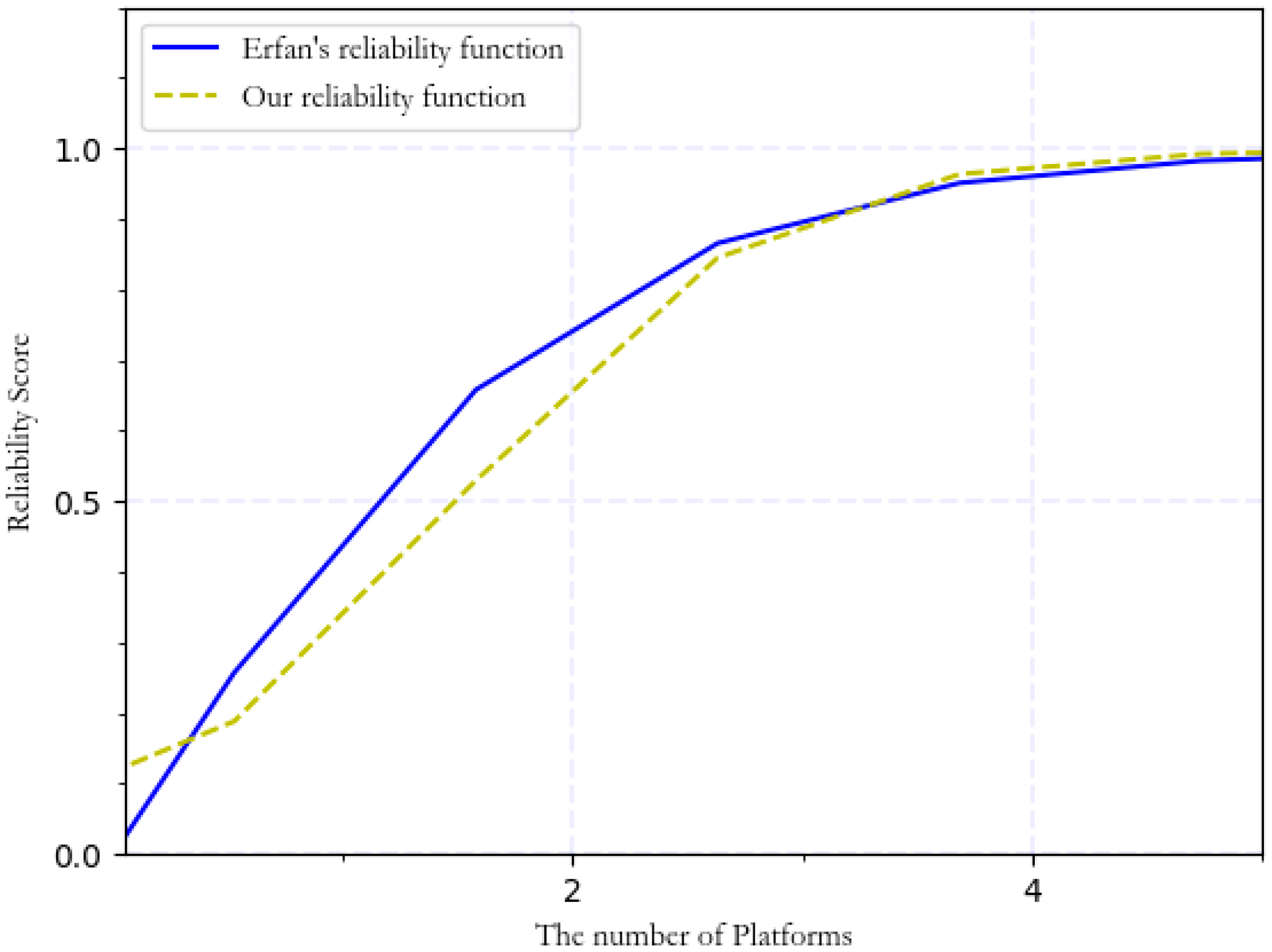
4.3. Reliability
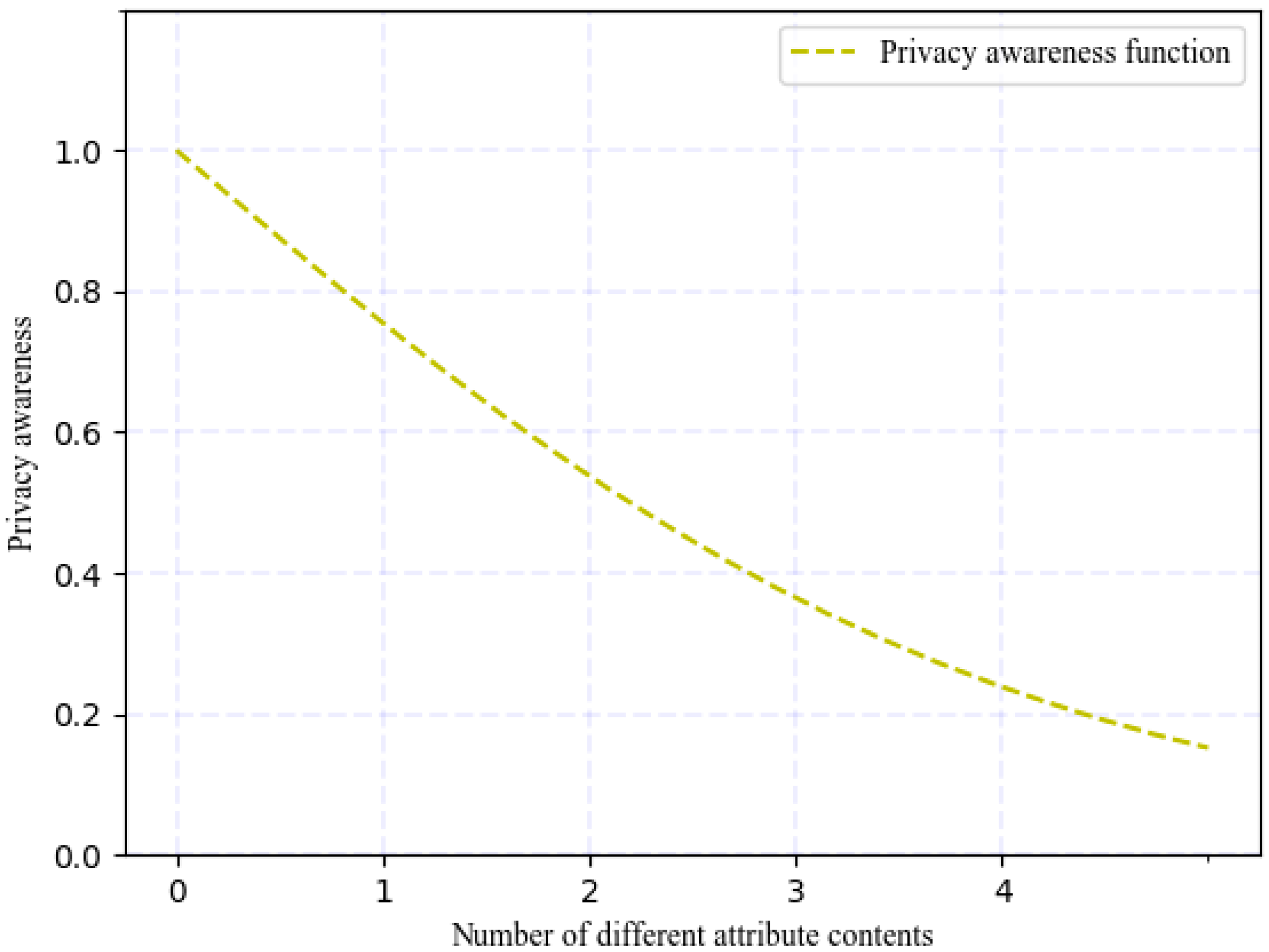
4.4. Privacy Awareness
4.5. Visibility
- (1)
- Initialize cluster centers , the inhibiting factor is , inhibition threshold is , prime index factor is , error threshold is and the maximum number of iterations is K, set the number of iterations = 0.
- (2)
- Use to calculate .
- (3)
- According to the above correction equation to get by fuzzy classification matrix .
- (4)
- Calculate new cluster center from and .
- (5)
- If or < K, the iteration is over; Otherwise = + 1, , return to the step 2.
4.6. Sensitivity
4.7. Privacy Score
5. Experimental Evaluation
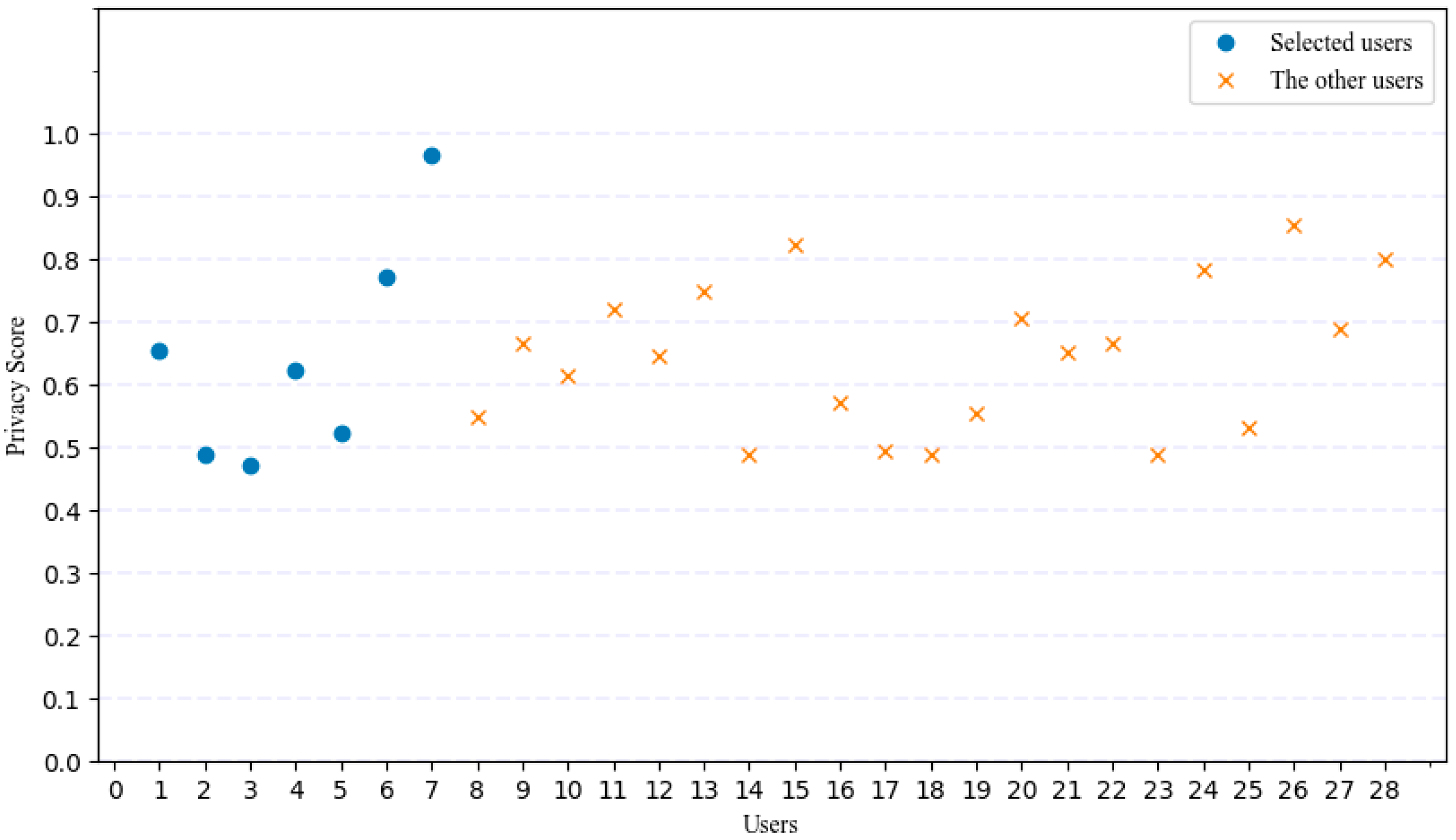
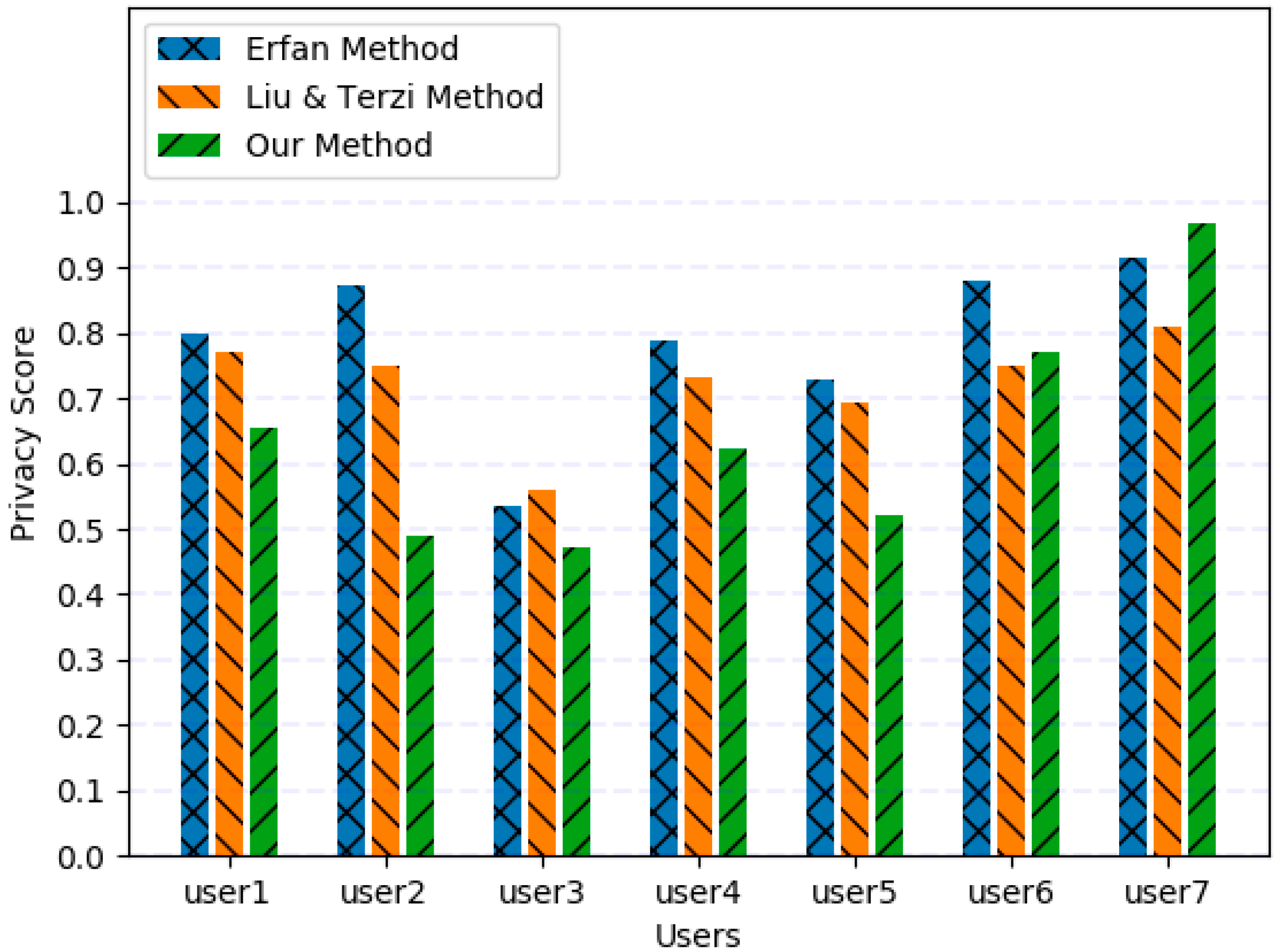
5.1. Experiment 1
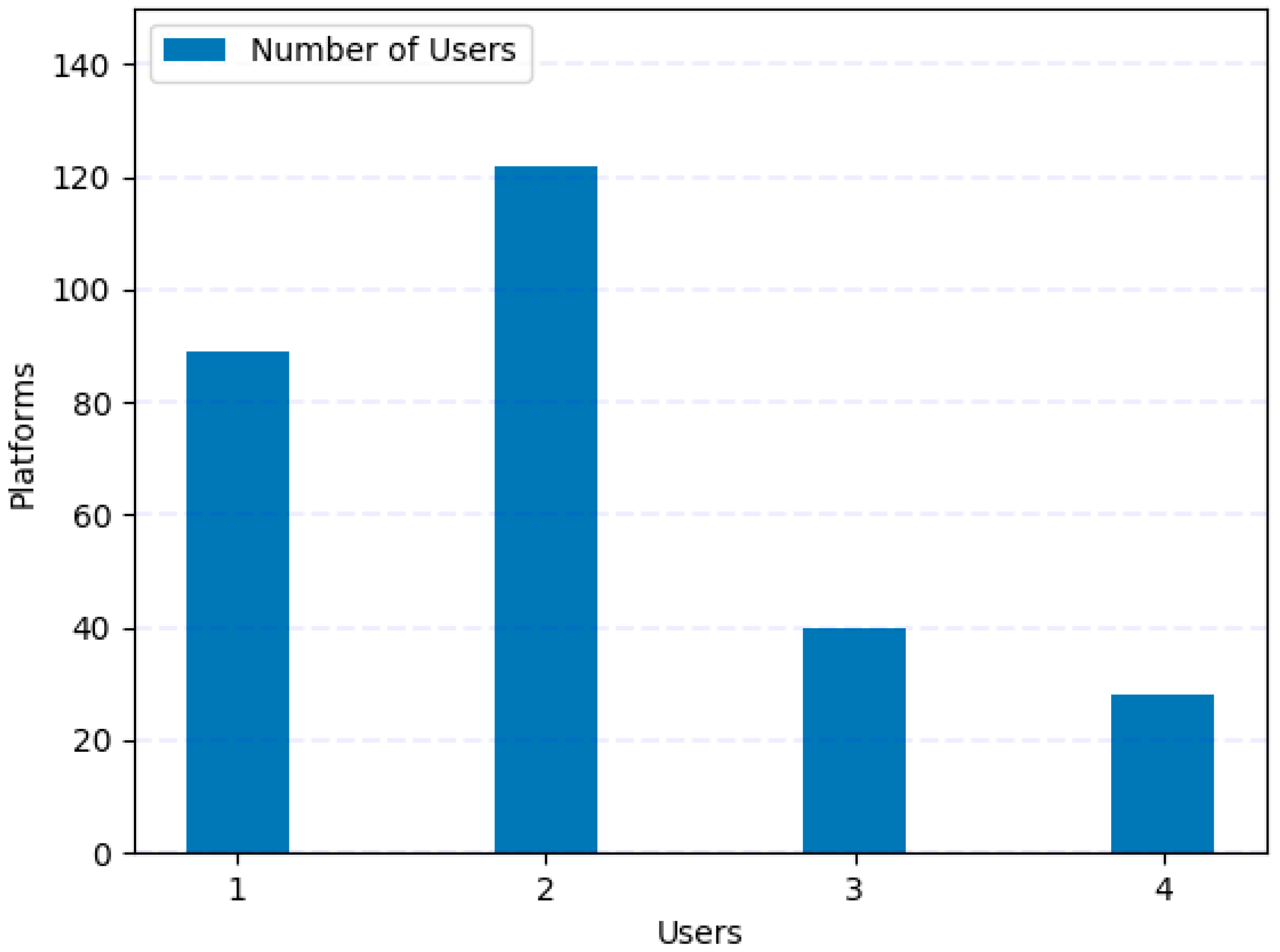
5.2. Data Collection
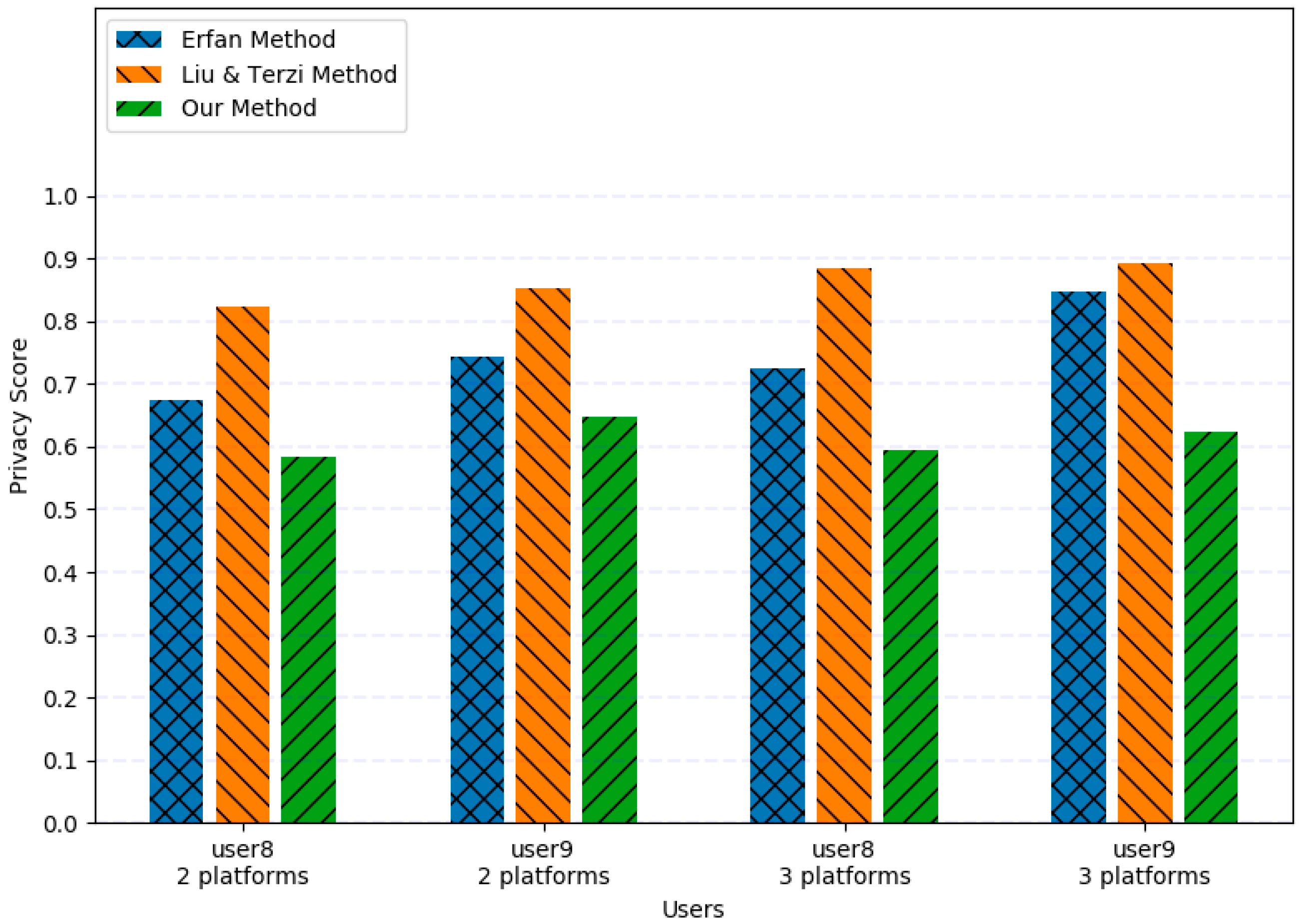
5.3. Experiment 2
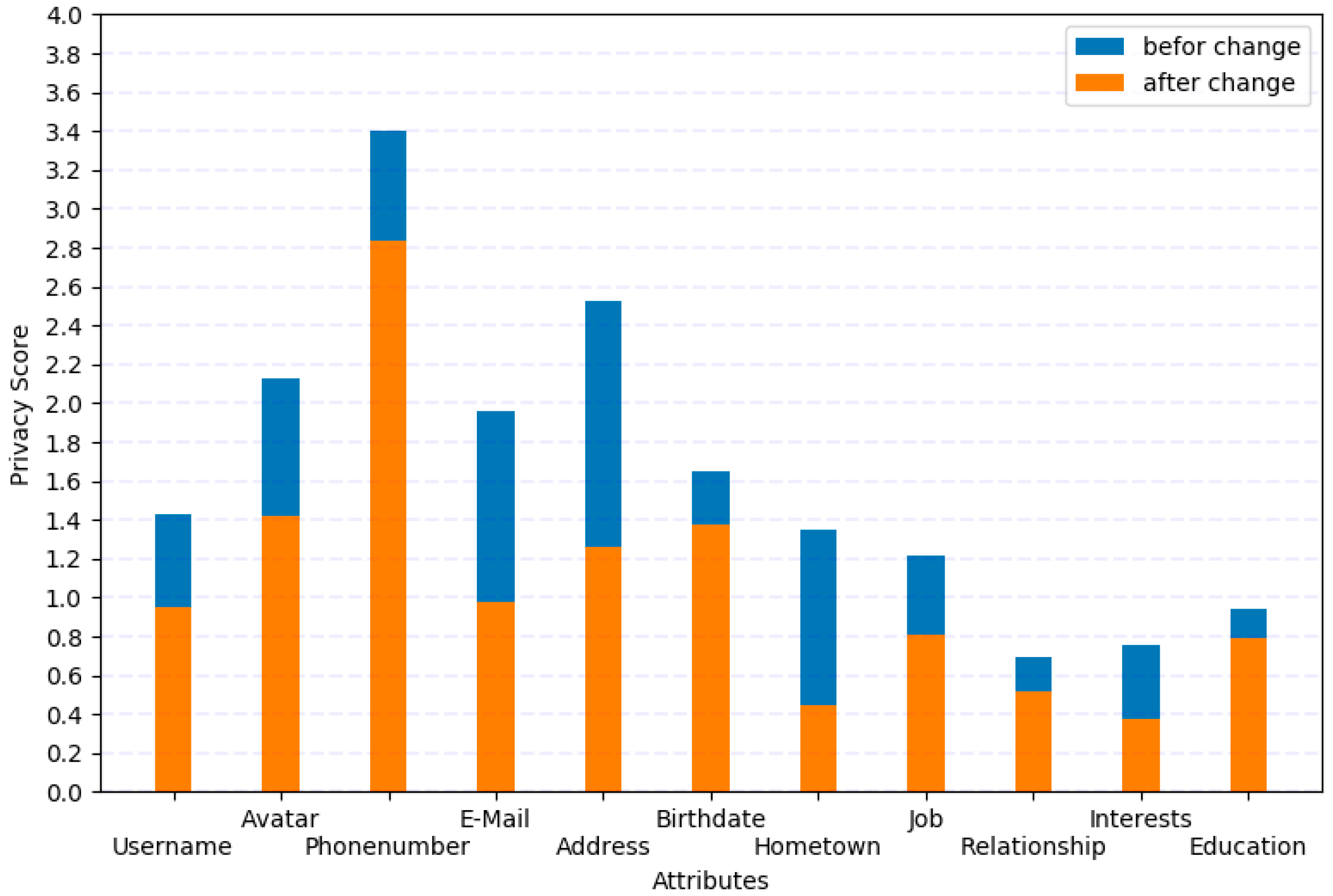
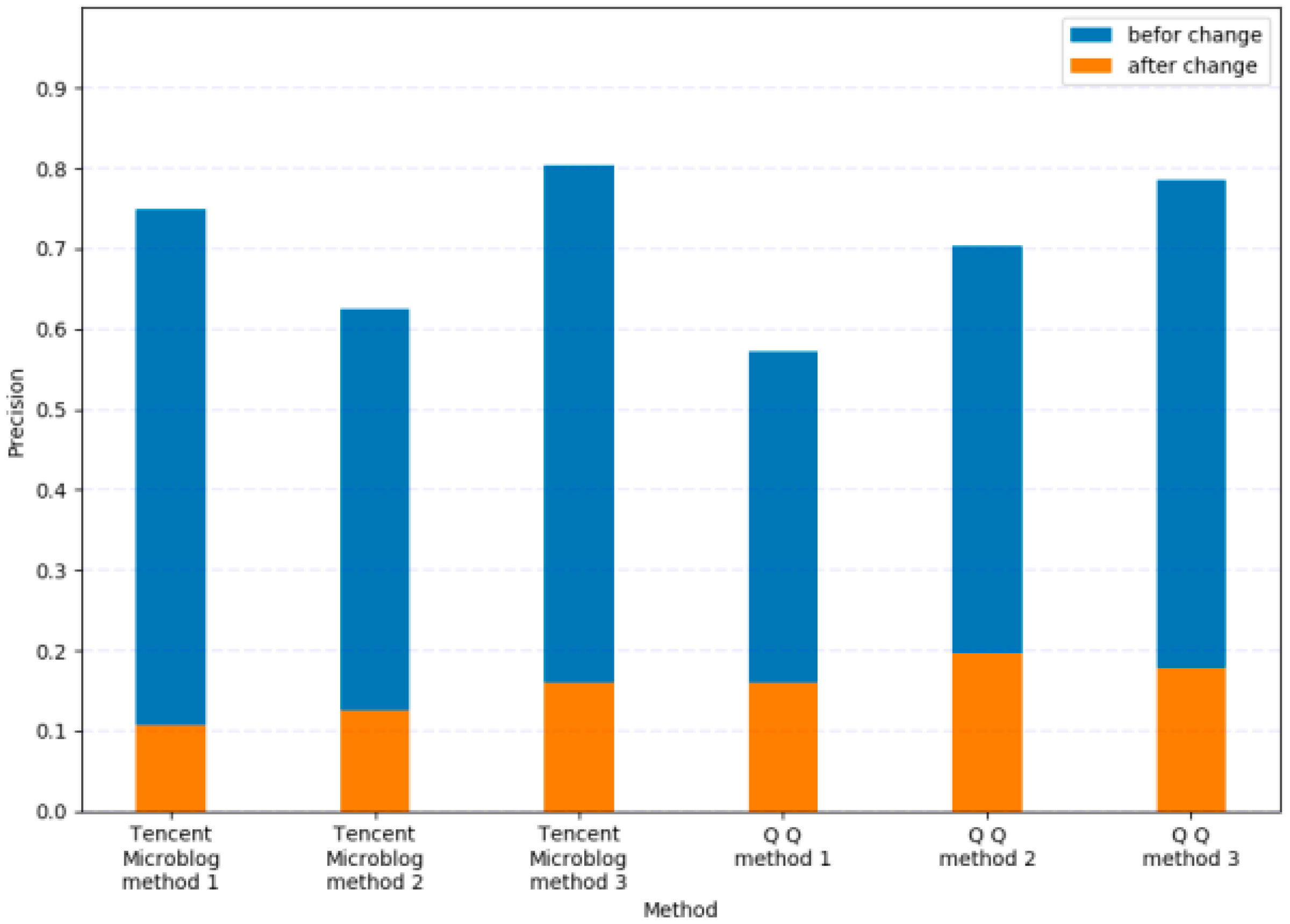
5.4. Experiment 3
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- He, Z.; Cai, Z.; Yu, J. Latent-data privacy preserving with customized data utility for social network data. IEEE Trans. Veh. Technol. 2018, 67, 665–673. [Google Scholar] [CrossRef]
- He, Z.; Cai, Z.; Wang, X. Modeling propagation dynamics and developing optimized countermeasures for rumor spreading in online social networks. In Proceedings of the 35th IEEE International Conference on Distributed Computing Systems, (ICDCS), Columbus, OH, USA, 29 June–2 July 2015; pp. 205–214. [Google Scholar]
- Ge, J.; Peng, J.; Chen, Z. Your privacy information are leaking when you surfing on the social networks: A survey of the degree of online self-disclosure (DOSD). In Proceedings of the 2014 IEEE 13th International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC), London, UK, 18–20 August 2014; pp. 329–336. [Google Scholar]
- Jiang, J. Personal Information Leakage on The Rise in China: Report. 2017. Available online: http://en.people.cn/n3/2017/0331/c90000-9197748.html (accessed on 31 March 2017).
- Gross, R.; Acquisti, A. Information revelation and privacy in online social networks. In Proceedings of the 2005 ACM Workshop on Privacy in the Electronic Society, WPES’05, Alexandria, VA, USA, 7 November 2005; ACM: New York, NY, USA, 2005; pp. 71–80. [Google Scholar]
- Tufekci, Z. Can you see me now? Audience and disclosure regulation in online social networksites. Bull. Sci. Technol. Soc. 2008, 28, 20–36. [Google Scholar] [CrossRef]
- Fang, L.; LeFevre, K. Privacy wizards for social networking sites. In Proceedings of the 19th international Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 351–360. [Google Scholar]
- Cai, Z.; He, Z.; Guan, X.; Li, Y. Collective data-sanitization for preventing sensitive information inference attacks in social networks. IEEE Trans. Depend. Sec. Comput. 2018, 15, 577–590. [Google Scholar] [CrossRef]
- Han, M.; Li, J.; Cai, Z.; Han, Q. Privacy reserved influence maximization in GPS-enabled cyber-physical and online social networks. In Proceedings of the 9th IEEE International Conference on Social Computer Networking, Sustainable Computing and Communications, Atlanta, GA, USA, 8–10 October 2016; pp. 284–292. [Google Scholar]
- He, Z.; Cai, Z.; Yu, J.; Wang, X.; Sun, Y.; Li, Y. Cost-efficient strategies for restraining rumor spreading in mobile social networks. IEEE Trans. Veh. Technol. 2017, 66, 2789–2800. [Google Scholar] [CrossRef]
- Zheng, X.; Cai, Z.; Yu, J.; Wang, C.; Li, Y. Follow but no track: Privacy preserved profile publishing in cyber-physical social systems. IEEE Internet Things J. 2017, 4, 1868–1878. [Google Scholar] [CrossRef]
- Zhang, Y.; Tang, J.; Yang, Z.; Pei, J.; Yu, P.S. Cosnet: Connecting heterogeneous social networks with local and global consistency. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10 August 2015; pp. 1485–1494. [Google Scholar]
- Liu, S.; Wang, S.; Zhu, F.; Zhang, J.; Krishnan, R. Hydra: Large-scale social identity linkage via heterogeneous behavior modeling. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 51–62. [Google Scholar]
- Wang, Y.; Feng, C.; Chen, L.; Yin, H.; Guo, C.; Chu, Y. User identity linkage across social networks via linked heterogeneous network embedding. In World Wide Web; Springer: Berlin, Germany, 2018; pp. 1–22. [Google Scholar]
- Mu, X.; Zhu, F.; Lim, E.P.; Xiao, J.; Wang, J.; Zhou, Z.H. User identity linkage by latent user space modelling. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13 August 2016; pp. 1775–1784. [Google Scholar]
- Iofciu, T.; Fankhauser, P.; Abel, F.; Bischoff, K. Identifying Users across Social Tagging Systems. In Proceedings of the 5th International AAAI Conference on Weblogs and Social Media, ICWSM, Barcelona, 17–21 July 2011. [Google Scholar]
- Vosecky, J.; Hong, D.; Shen, V.Y. User identification across multiple social networks. In Proceedings of the First International Conference on Networked Digital Technologies, Ostrava, Czech Republic, 28–31 July 2009; pp. 360–365. [Google Scholar]
- Nie, Y.; Jia, Y.; Li, S.; Zhu, X.; Li, A.; Zhou, B. Identifying users across social networks based on dynamic core interests. Neurocomputing 2016, 210, 107–115. [Google Scholar] [CrossRef]
- Shu, K.; Wang, S.; Tang, J.; Zafarani, R.; Liu, H. User identity linkage across online social networks: A review. ACM SIGKDD Explor. Newslett. 2017, 18, 5–17. [Google Scholar] [CrossRef]
- Zafarani, R.; Liu, H. Connecting corresponding identities across communities. In Proceedings of the ICWSM 2009, San Jose, CA, USA, 17–20 May 2009; pp. 354–357. [Google Scholar]
- Krishnamurthy, B.; Wills, C. Privacy diffusion on the web: A longitudinal perspective. In Proceedings of the 18th international conference on World Wide Web, Geneva, Switzerland, 1 April 2009; pp. 541–550. [Google Scholar]
- He, Z.; Cai, Z.; Han, Q.; Tong, W.; Sun, L.; Li, Y. An energy efficient privacy-preserving content sharing scheme in mobile social networks. Pers. Ubiquitous Comput. 2016, 20, 833–846. [Google Scholar] [CrossRef]
- Pensa, R.G.; Di Blasi, G. A privacy self-assessment framework for online social networks. Expert Syst. Appl. 2017, 86, 18–31. [Google Scholar] [CrossRef]
- Lam, I.F.; Chen, K.T.; Chen, L.J. Involuntary information leakage in social network services. In International Workshop on Security; Springer: Berlin, Germany, 2008; pp. 167–183. [Google Scholar]
- Patsakis, C.; Zigomitros, A.; Papageorgiou, A.; Galván-López, E. Distributing privacy policies over multimedia content across multiple online social networks. Comput. Netw. 2014, 75, 531–543. [Google Scholar] [CrossRef]
- Gope, P.; Lee, J.; Quek, T.Q. Lightweight and Practical Anonymous Authentication Protocol for RFID Systems Using Physically Unclonable Functions. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2831–2843. [Google Scholar] [CrossRef]
- Gope, P.; Sikdar, B. An Efficient Data Aggregation Scheme for Privacy-Friendly Dynamic Pricing-based Billing and Demand-Response Management in Smart Grids. IEEE Internet Things J. 2018, 5, 3126–3135. [Google Scholar] [CrossRef]
- Wang, K.; Chen, R.; Fung, B.; Yu, P. Privacy-preserving data publishing: A survey on recent developments. ACM Comput. Surv. 2010, 42. [Google Scholar] [CrossRef]
- Yin, D.; Shen, Y.; Liu, C. Attribute Couplet Attacks and Privacy Preservation in Social Networks. IEEE Access 2017, 5, 25295–25305. [Google Scholar] [CrossRef]
- Dey, R.; Tang, C.; Ross, K.; Saxena, N. Estimating age privacy leakage in online social networks. In Proceedings of the INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 2836–2840. [Google Scholar]
- Liang, K.; Liu, J.K.; Lu, R.; Wong, D.S. Privacy concerns for photo sharing in online social networks. IEEE Internet Comput. 2015, 19, 58–63. [Google Scholar] [CrossRef]
- Srivastava, A.; Geethakumari, G. Measuring privacy leaks in online social networks. In Proceedings of the 2013 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Mysore, India, 22–25 August 2013; pp. 2095–2100. [Google Scholar]
- Maximilien, E.M.; Grandison, T.; Sun, T.; Richardson, D.; Guo, S.; Liu, K. Privacy-as-a-service: Models, algorithms, and results on the Facebook platform. In Proceedings of the Web 2.0 Security and Privacy Workshop, Oakland, CA, USA, 21 May 2009; Volume 2. [Google Scholar]
- Liu, K.; Terzi, E. A framework for computing the privacy scores of users in online social networks. ACM Trans. Knowl. Discov. Data 2010, 5, 6. [Google Scholar] [CrossRef]
- Zeng, Y.; Sun, Y.; Xing, L.; Vokkarane, V. Trust-aware privacy evaluation in online social networks. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, Australia, 10–14 June 2014; pp. 932–938. [Google Scholar]
- Li, M.; Liu, Z.; Dong, K. Privacy Preservation in Social Network against Public Neighborhood Attacks. In Proceedings of the Trustcom/BigDataSE/I SPA, Tianjin, China, 23–26 August 2016; pp. 1575–1580. [Google Scholar]
- Irani, D.; Webb, S.; Li, K.; Pu, C. Modeling unintended personal-information leakage from multiple online social networks. IEEE Internet Comput. 2011, 2011, 13–19. [Google Scholar] [CrossRef]
- Erfan, A.; Garg, S.; Gao, L.; Yu, S.; Montgomery, J. Scoring Users’ Privacy Disclosure Across Multiple Online Social Networks. IEEE Access 2017, 5, 13118–13130. [Google Scholar]
- Zhao, Q.H.; Ha, M.H.; Peng, G.B.; Zhang, X.K. Support vector machine based on half-suppressed fuzzy c-means clustering. In Proceedings of the 2009 International Conference on Machine Learning and Cybernetics, Baoding, China, 12–15 July 2009; Volume 2, pp. 1236–1240. [Google Scholar]
- Clearinghouse, Privacy Rights. Social Networking Privacy: How to Be Safe, Secure and Social. Available online: https://www.privacyrights.org/consumer-guides/social-networking-privacy-how-be-safe-secure-and-social (accessed on 1 June 2018).
- Zwick, R.; Thayer, D.T.; Wingersky, M. Effect of Rasch Calibration on Ability and DIF Estimation in Computer-Adaptive Tests. J. Educ. Meas. 1995, 32, 341–363. [Google Scholar] [CrossRef]
- Bock, R.D.; Aitkin, M. Marginal maximum likelihood estimation of item parameters: Application of an EM algorithm. Psychometrika 1981, 46, 443–459. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| p | privacy score |
| user of OSNs | |
| s | number of OSNs |
| n | number of users |
| m | number of attributes |
| extraction difficulty of attribute | |
| accessibility to a certain attribute | |
| individual privacy awareness | |
| reliability of attribute | |
| visibility of attribute | |
| Sensitivity of attribute | |
| attribute content |
| Attribute | Platform 1 | Platform 2 | Platform 3 | …… | Platform s |
|---|---|---|---|---|---|
| Attribute 1 | 1A | 3A | 4B | …… | 1C |
| Attribute 2 | 2A | 1A | 2B | …… | 3E |
| Attribute 3 | 1A | 4B | 3B | …… | 2A |
| Attribute 4 | 1A | 3B | 0 | …… | 2C |
| …… | …… | …… | …… | …… | …… |
| Attribute m | …… |
| Platforms | Attribute Reliability |
|---|---|
| 1 | 0.32 |
| 2 | 0.67 |
| 3 | 0.91 |
| 4 | 0.98 |
| 5 | 0.99 |
| Attribute | Sensitivity |
|---|---|
| Username | 0.2381 |
| Avatar | 0.3553 |
| Phone number | 0.5669 |
| 0.3260 | |
| Address | 0.4212 |
| Birthdate | 0.2748 |
| Hometown | 0.2253 |
| Job Details | 0.2024 |
| Relationship Status | 0.1731 |
| Interests | 0.1255 |
| Education | 0.1575 |
| Attribute | User1 Accessibility | A | B | User2 Accessibility | A | B |
|---|---|---|---|---|---|---|
| Contact number | 2A,2B,4A,3A | 2.75 | 2.75 | 1A,1A,1A,2B | 2.75 | 1.5 |
| 2A,2A,3B,4B | 2.75 | 3 | 1A,1A,1A,2B | 1.25 | 1.5 | |
| Address | 2A,2A,2A,3B | 2.5 | 2.5 | 2A,1B,2A,1B | 1.5 | 1.5 |
| Birthdate | 3A,2A,3A,4A | 3 | 3 | 1A,1A,1A,1A | 1 | 1 |
| Hometown | 3A,2B,3A,4C | 3 | 3 | 2B,1A,1A,1A | 1.25 | 1.5 |
| Current town | 3A,3A,2A,4A | 3 | 3 | 3A,1B,2A,1B | 1.75 | 2 |
| Job Details | 2A,4A,4A,4A | 3 | 3 | 2A,1A,4B,1A | 3 | 2.33 |
| Relationship Status | 3A,2A,2A,4B | 2.75 | 3 | 2A,1A,1A,1A | 1.25 | 1.5 |
| Interests | 3A,3A,2A,3B | 2.75 | 2.67 | 2A,1A,3B,1A | 1.75 | 2 |
| Religious Views | 3A,2A,2A,4A | 2.75 | 3 | 1A,1A,1A,1A | 1 | 1 |
| Political | 2A,2A,1A,1A | 1.5 | 1.5 | 1A,1A,1A,1A | 1 | 1 |
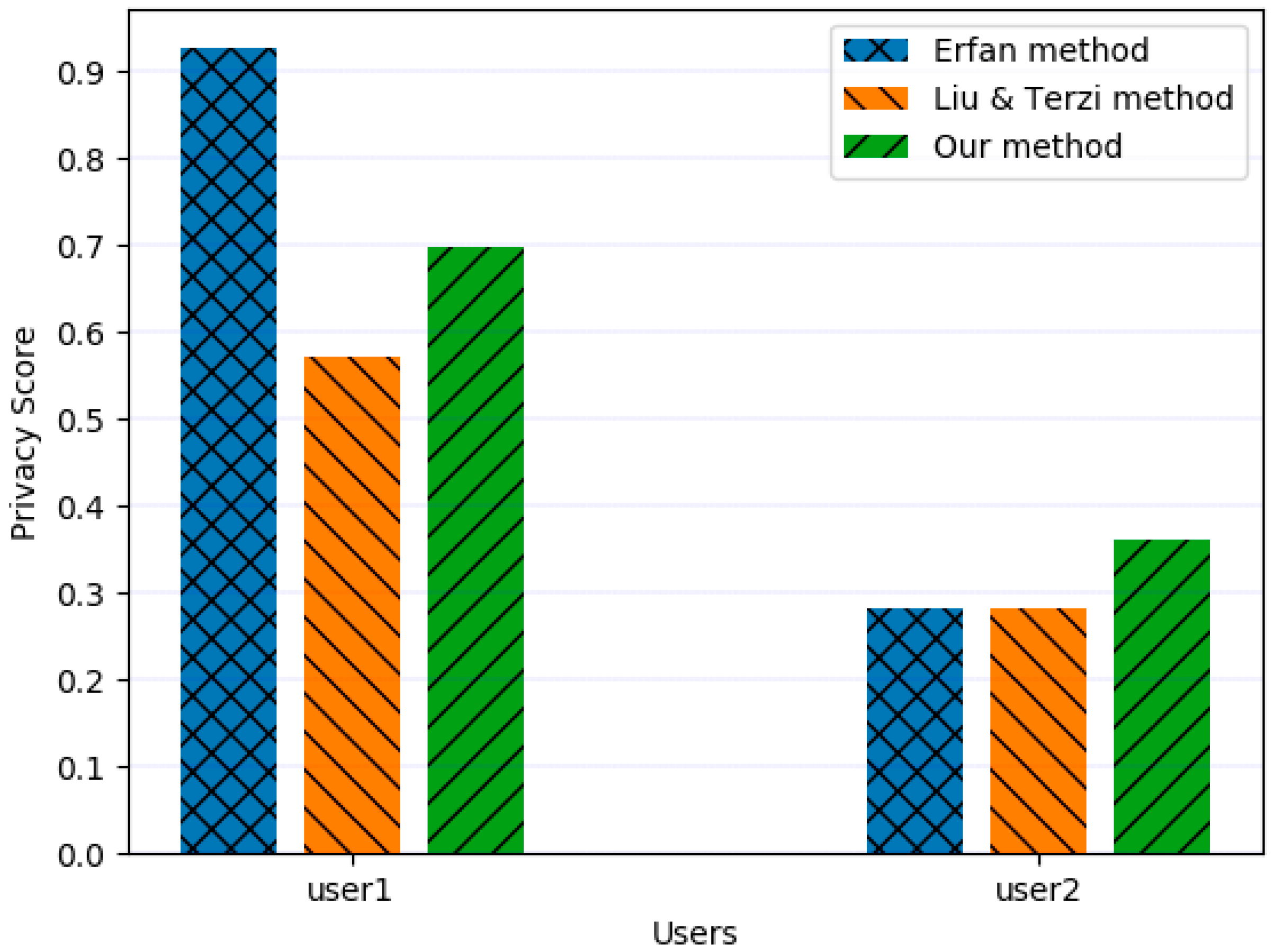
| Attribute | User1 Visibility (A) | User1 Visibility (B) | User2 Visibility (A) | User2 Visibility (B) | User1 Score | User2 Score |
|---|---|---|---|---|---|---|
| Contact number | 7.32 | 4 | 1.5 | 3 | (A) 2.582 (B) 1.592 | (A) 0.790 (B) 0.825 |
| 7.32 | 4 | 1.52 | 3 | |||
| Address | 7.3 | 4 | 4.11 | 2 | ||
| Birthdate | 7.32 | 6 | 0 | 2 | ||
| Hometown | 7.32 | 4 | 1.5 | 3 | ||
| Current town | 7.32 | 6 | 4.11 | 3 | ||
| Job Details | 7.32 | 6 | 7.32 | 3 | ||
| Relationship Status | 7.32 | 5 | 1.5 | 3 | ||
| Interests | 7.32 | 5 | 4.11 | 3 | ||
| Religious Views | 7.32 | 5 | 0 | 1 | ||
| Political | 4.11 | 2 | 0 | 1 |
| User1 | User2 | User3 | User4 | User5 | User6 | User7 | |
|---|---|---|---|---|---|---|---|
| Username | 4A,4A,4A,4B | 4A,4B,4A,4A | 4A,4A,4A,4A | 4A,4A,4B,4C | 4A,4B,4B,4B | 4A,4A,4A,4A | 4A,4A,4A,4A |
| Avatar | 4A,4A,4A,4B | 4A,4B,4C,4A | 4A,4A,4B,4B | 4A,4A,4B,4B | 4A,4A,4B,4A | 4A,4B,4B,4B | 4A,4A,4A,4A |
| Phone number | 2A,0, 4B,1C | 2A,0,4B,1A | 0,0,0,0 | 2A,0,4B,2A | 0,0,0,1A | 4A,0,4A,2A | 4A,4A,4A,4A |
| 4A,2B, 1B,1B | 0,1A, 1A,2B | 4A,2B,0,1A | 4A,1A,1A,2A | 4A,4A,4B,2B | 4A,2A,4A,4A | 4A,4A,4A,4B | |
| Address | 2A,2A,1A,1A | 2A,2A,0,1B | 1A,1A,1B,0 | 2A,2A, 4B,1B | 2A,2B, 0,2A | 2A,4A, 4B,2B | 2A,2A,4A,4B |
| Birthdate | 4A,4A,4B,4A | 4A,4B,4C,2D | 2A,2A, 4B,2B | 4A,1B, 4A,2B | 4A,4B,0,2C | 4A,4A,4A,4A | 4A,4A,4A,4A |
| Hometown | 4A,4B,4B,2B | 4A,2B,4A,2B | 4A,2B,0,2A | 4A,0,0,2A | 4B,2A,4A,2A | 4A,2A,4B,4A | 4A,4A,4A,2A |
| Job Details | 4A,2B,4A,2B | 2A,4A,2B,2A | 1A,1A,0,2B | 2A,2A,1A,2B | 4A,2A,4A,2B | 4A,4A,4B,4A | 4A,4A4A,4A |
| Relationship Status | 0,4A,0,2A | 2A,4A,0,2A | 0,1A, 0,1A | 0,2A, 0,2A | 0,2A,2A,2A | 0,0,0,2A | 0,2A,0,4A |
| Interests | 4A,4B,4A,2B | 4A,4B,4C,2B | 0,0,0,2A | 0,4A,4B,2C | 0,4A,2B,4C | 0,4A,4A,2B | 4A,4A,4A,4A |
| Education | 0,4A,1A,2A | 2A,0,1A,2B | 2A,0, 1A,0 | 4A,4A, 1A,2A | 4A,0,1A,2A | 4A,4A,4A,4A | 4A,4A,4A,4A |
| User7 (Before Change) | User7 (After Change) | |
|---|---|---|
| Username | 4A,4A,4A,4A | 4A,4B,4C,4A |
| Avatar | 4A,4A,4A,4A | 4A,4B,4A,4C |
| Phone number | 4A,4A,4A,4A | 2A,2A,4B,2A |
| 4A,4A,4A,4B | 4A,2B,2C,4B | |
| Address | 2A,2A,4A,4B | 2A,2A,2B,4C |
| Birthdate | 4A,4A,4A,4A | 2A,4A,4B,4A |
| Hometown | 4A,4A,4A,2A | 2A,1B,0,2A |
| Job Details | 4A,4A,4A,4A | 2A,2A,2A,4B |
| Relationship Status | 0,2A,0,4A | 0,2A,0,4A |
| Interests | 4A,4A,4A,4A | 2A,2A,4B,2C |
| Education | 4A,4A,4A,4A | 4A,2A,2A,2A |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Yang, Y.; Chen, Y.; Niu, X. A Privacy Measurement Framework for Multiple Online Social Networks against Social Identity Linkage. Appl. Sci. 2018, 8, 1790. https://doi.org/10.3390/app8101790
Li X, Yang Y, Chen Y, Niu X. A Privacy Measurement Framework for Multiple Online Social Networks against Social Identity Linkage. Applied Sciences. 2018; 8(10):1790. https://doi.org/10.3390/app8101790
Chicago/Turabian StyleLi, Xuefeng, Yixian Yang, Yuling Chen, and Xinxin Niu. 2018. "A Privacy Measurement Framework for Multiple Online Social Networks against Social Identity Linkage" Applied Sciences 8, no. 10: 1790. https://doi.org/10.3390/app8101790
APA StyleLi, X., Yang, Y., Chen, Y., & Niu, X. (2018). A Privacy Measurement Framework for Multiple Online Social Networks against Social Identity Linkage. Applied Sciences, 8(10), 1790. https://doi.org/10.3390/app8101790