A Survey on Robust Video Watermarking Algorithms for Copyright Protection




Abstract
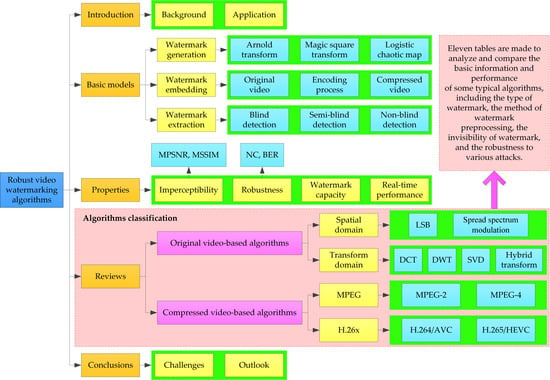
:
1. Introduction
2. Basic Models of Video Watermarking
2.1. Watermark Generation
2.1.1. Arnold Transform
2.1.2. Magic Square Transform
2.1.3. Logistic Chaotic Map
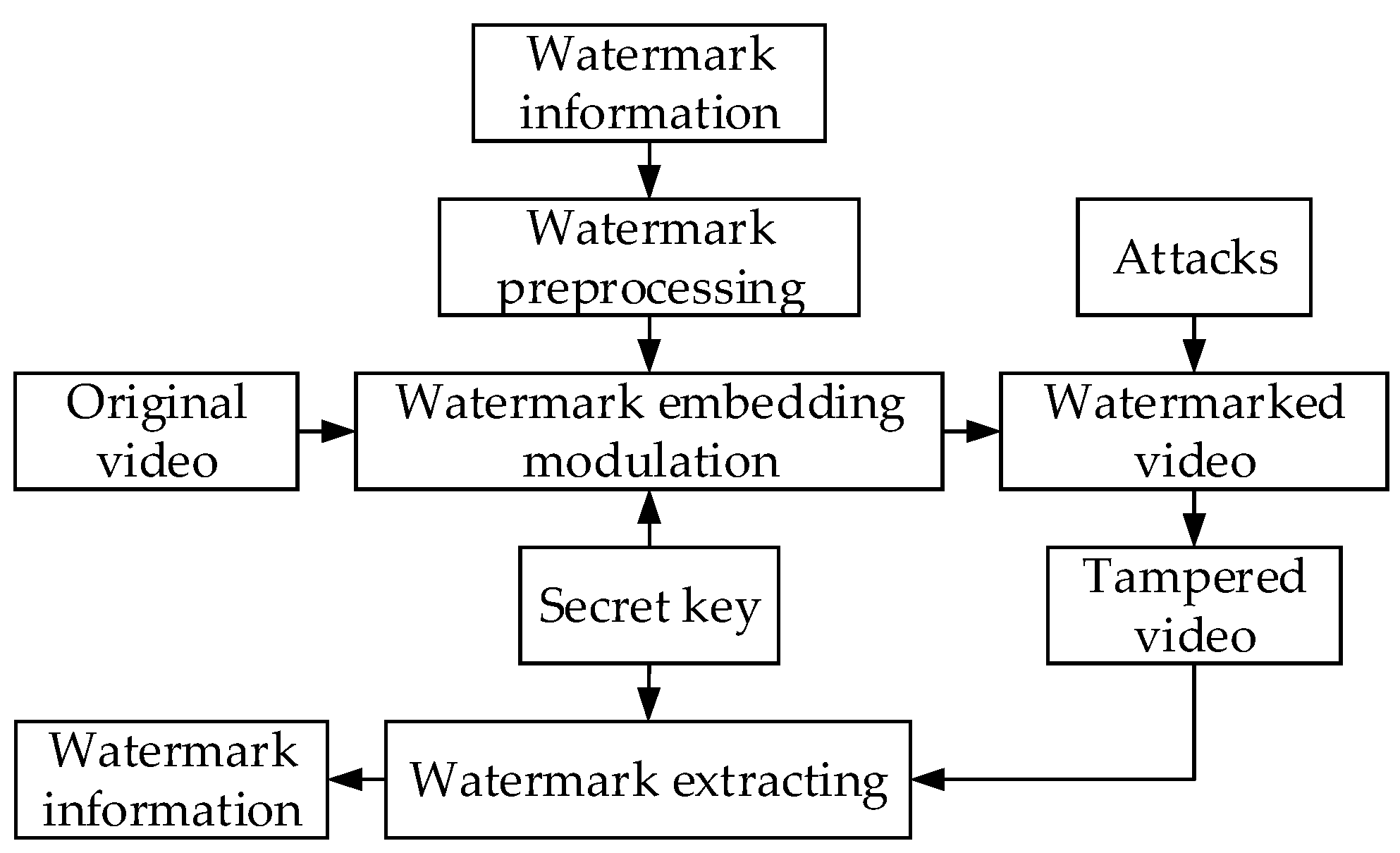
2.2. Watermark Embedding
2.2.1. Original Video-Based Watermarking Algorithms
2.2.2. Video Watermarking Algorithms in Encoding Process
2.2.3. Video Watermarking Algorithms after Compression
2.3. Watermark Extraction
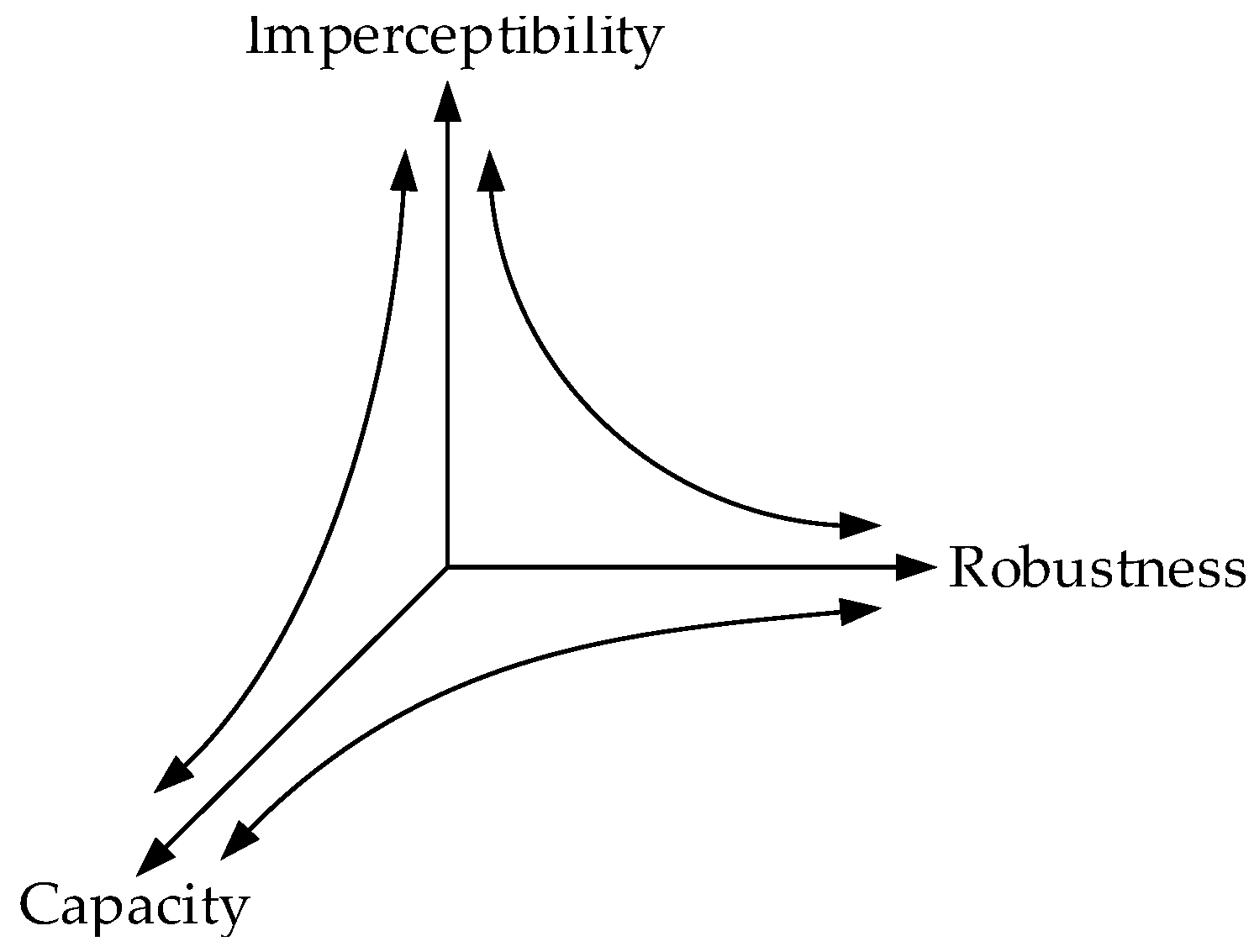
3. Properties of Video Watermarking
3.1. Imperceptibility
3.2. Robustness
3.3. Watermark Capacity, BIR, and Real-Time Performance
4. Robust Watermarking Algorithms Based on Original Videos
4.1. Video Watermarking in Spatial Domain
4.2. Video Watermarking in Transform Domain
4.2.1. DCT-Based Watermarking Algorithms
4.2.2. DWT-Based Watermarking Algorithms
4.2.3. SVD-Based Watermarking Algorithms
4.2.4. Hybrid Transform-Based Watermarking Algorithms
5. Robust Watermarking Algorithms Based on Compressed Videos
5.1. MPEG-Based Watermarking Algorithms
5.2. H.264-Based Watermarking Algorithms
5.3. H.265-Based Watermarking Algorithms
6. Conclusions and Outlook
6.1. Conclusions
6.2. Challenges and Outlook
Author Contributions
Funding
Conflicts of Interest
References
- Eldering, C.A.; Sylla, M.L.; Eisenach, J.A. Is there a Moore’s law for bandwidth? IEEE Commun. Mag. 1999, 37, 117–121. [Google Scholar] [CrossRef]
- Wolfgang, R.B.; Podilchuk, C.I.; Delp, E.J. Perceptual watermarks for digital images and video. Proc. IEEE 1999, 87, 1108–1126. [Google Scholar] [CrossRef] [Green Version]
- Lempel, A. Cryptology in transition. Comput. Surv. 1979, 11, 285–303. [Google Scholar] [CrossRef]
- Jung, K.H. A survey of reversible data hiding methods in dual images. IETE Tech. Rev. 2016, 33, 441–452. [Google Scholar] [CrossRef]
- Carpentieri, B.; Castiglione, A.; De Santis, A.; Palmieri, F.; Pizzolante, R. One-pass lossless data hiding and compression of remote sensing data. Future Gener. Comput. Syst. 2019, 90, 222–239. [Google Scholar] [CrossRef]
- Parah, S.A.; Sheikh, J.A.; Akhoon, J.A.; Loan, N.A.; Bhat, G.M. Information hiding in edges: A high capacity information hiding technique using hybrid edge detection. Multimedia Tools Appl. 2018, 77, 185–207. [Google Scholar] [CrossRef]
- Atawneh, S.; Almomani, A.; Sumari, P. Steganography in digital images: Common approaches and tools. IETE Tech. Rev. 2013, 30, 344–358. [Google Scholar] [CrossRef]
- Van Schyndel, R.G.; Tirkel, A.Z.; Osborne, C.F. A digital watermark. In Proceedings of the 1st IEEE International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994. [Google Scholar]
- Zhang, H.X.; Zhang, Z.Y.; Qiu, P.L. A novel algorithm of covert communication. Acta Electron. Sin. 2003, 31, 514–517. [Google Scholar]
- Doërr, G.; Dugelay, J.L. A guide tour of video watermarking. Signal Process. Image Commun. 2003, 18, 263–282. [Google Scholar] [CrossRef]
- Lu, C.S.; Liao, H.Y.M. Multipurpose watermarking for image authentication and protection. IEEE Trans. Image Process. 2001, 10, 1579–1592. [Google Scholar] [PubMed] [Green Version]
- Verma, V.S.; Jha, R.K. An overview of robust digital image watermarking. IETE Tech. Rev. 2015, 32, 479–496. [Google Scholar] [CrossRef]
- Devi, B.P.; Singh, K.M.; Roy, S. New copyright protection scheme for digital images based on visual cryptography. IETE J. Res. 2017, 63, 870–880. [Google Scholar] [CrossRef]
- Channapragada, R.S.R.; Prasad, M.V.N.K. Digital watermarking based on magic square and Ridgelet transform techniques. Adv. Intell. Syst. Comput. 2014, 243, 143–161. [Google Scholar]
- Liu, R. An improved Logistic chaotic map and self-adaptive model for image encryption. J. Comput. Methods Sci. Eng. 2016, 16, 287–301. [Google Scholar] [CrossRef]
- Biswas, S.N.; Nahar, S.; Das, S.R.; Petriu, E.M.; Assaf, M.H.; Groza, V. MPEG-2 digital video watermarking technique. In Proceedings of the International Instrumentation and Measurement Technology Conference, Graz, Austria, 13–16 May 2012. [Google Scholar]
- Wang, C.Y.; Zhang, Y.P.; Zhou, X. Review on digital image watermarking based on singular value decomposition. J. Inf. Process. Syst. 2017, 13, 1585–1601. [Google Scholar]
- Zheng, X.S.; Zhao, Y.L.; Li, N. Classification model and enhancement of robustness in video digital watermark. In Proceedings of the Chinese Control and Decision Conference, Yantai, China, 2–4 July 2008. [Google Scholar]
- Li, Z.H.; Zhang, Z.Z.; Guo, S.; Wang, J.W. Video inter-frame forgery identification based on the consistency of quotient of MSSIM. Secur. Commun. Netw. 2016, 9, 4548–4556. [Google Scholar] [CrossRef]
- Wang, C.Y.; Zhang, Y.P.; Zhou, X. Robust image watermarking algorithm based on ASIFT against geometric attacks. Appl. Sci. 2018, 8, 410. [Google Scholar] [CrossRef]
- Hu, H.T.; Hsu, L.Y. Exploring DWT-SVD-DCT feature parameters for robust multiple watermarking against JPEG and JPEG2000 compression. Comput. Electr. Eng. 2015, 41, 52–63. [Google Scholar] [CrossRef]
- Lei, B.Y.; Tan, E.L.; Chen, S.P.; Ni, D.; Wang, T.F.; Lei, H.J. Reversible watermarking scheme for medical image based on differential evolution. Expert Syst. Appl. 2014, 41, 3178–3188. [Google Scholar] [CrossRef]
- Jindal, S.; Goel, S.; Puri, T.; Bhardwaj, A.; Mahant, I.; Singh, S.; Sood, D. Performance analysis of LSB based watermarking for optimization of PSNR and MSE. Int. J. Secur. Its Appl. 2016, 10, 345–350. [Google Scholar] [CrossRef]
- Cox, I.J.; Kilian, J.; Leighton, F.T.; Shamoon, T. Secure spread spectrum watermarking for multimedia. IEEE Trans. Image Process. 1997, 6, 1673–1687. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kaur, H.; Kaur, E.V. Invisible video multiple watermarking using optimized techniques. In Proceedings of the Online International Conference on Green Engineering and Technologies, Coimbatore, India, 19 November 2016. [Google Scholar]
- Bayoudh, I.; Jabra, S.B.; Zagrouba, E. Online multi-sprites based video watermarking robust to collusion and transcoding attacks for emerging applications. Multimedia Tools Appl. 2017, 77, 14361–14379. [Google Scholar] [CrossRef]
- Masoumi, M.; Rezaei, M.; Hamza, A.B. A blind spatio-temporal data hiding for video ownership verification in frequency domain. AEU-Int. J. Electron. Commun. 2015, 69, 1868–1879. [Google Scholar] [CrossRef]
- Tokar, T.; Kanocz, T.; Levicky, D. Digital watermarking of uncompressed video in spatial domain. In Proceedings of the 19th International Conference Radioelektronika, Bratislava, Slovakia, 22–23 April 2009. [Google Scholar]
- Preda, R.O.; Vizireanu, N. New robust watermarking scheme for video copyright protection in the spatial domain. UPB Sci. Bull. 2011, 73, 93–104. [Google Scholar]
- Venugopala, P.S.; Sarojadevi, H.; Chiplunkar, N.N.; Bhat, V. Video watermarking by adjusting the pixel values and using scene change detection. In Proceedings of the 5th International Conference on Signal and Image Processing, Bangalore, India, 8–10 January 2014. [Google Scholar]
- Bahrami, Z.; Tab, F.A. A new robust video watermarking algorithm based on SURF features and block classification. Multimedia Tools Appl. 2018, 77, 327–345. [Google Scholar] [CrossRef]
- Li, X.; Wang, X.J.; Yang, W.M.; Wang, X. A robust video watermarking scheme to scalable recompression and transcoding. In Proceedings of the International Conference on Electronics Information and Emergency Communication, Beijing, China, 17–19 June 2016. [Google Scholar]
- Li, J.F.; Sui, A.N. A digital video watermarking algorithm based on DCT domain. In Proceedings of the 5th International Joint Conference on Computational Sciences and Optimization, Harbin, China, 23–26 June 2012. [Google Scholar]
- Liu, G.Q.; Zheng, X.S.; Zhao, Y.L.; Li, N. A robust digital video watermark algorithm based on DCT domain. In Proceedings of the International Conference on Computer Application and System Modeling, Taiyuan, China, 22–24 October 2010. [Google Scholar]
- Cheng, M.Z.; Xi, M.C.; Yuan, K.G.; Wu, C.H.; Lei, M. Recoverable video watermark in DCT domain. J. Comput. 2013, 8, 533–538. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Duan, D.N. A robust blind video watermarking in DCT domain using even-odd quantization technique. In Proceedings of the International Conference on Advanced Technologies for Communications, Ho Chi Minh City, Vietnam, 14–16 October 2015. [Google Scholar]
- Bayoudh, I.; Jabra, S.B.; Zagrouba, E. A robust video watermarking for real-time application. In Proceedings of the 18th International Conference on Advanced Concepts for Intelligent Vision Systems, Antwerp, Belgium, 18–21 September 2017. [Google Scholar]
- Thanh, T.M.; Hiep, P.T.; Tam, T.M.; Tanaka, K. Robust semi-blind video watermarking based on frame-patch matching. AEU-Int. J. Electron. Commun. 2014, 68, 1007–1015. [Google Scholar] [CrossRef]
- Chen, B.; Wornell, G.W. Quantization index modulation: A class of provably good methods for digital watermarking and information embedding. IEEE Trans. Inf. Theory 2001, 47, 1423–1443. [Google Scholar] [CrossRef]
- Yang, C.H.; Huang, H.Y.; Hsu, W.H. An adaptive video watermarking technique based on DCT domain. In Proceedings of the 8th International Conference on Computer and Information Technology, Sydney, Australia, 8–11 July 2008. [Google Scholar]
- Huang, H.Y.; Yang, C.H.; Hsu, W.H. A video watermarking technique based on pseudo-3D DCT and quantization index modulation. IEEE Trans. Inf. Forensics Secur. 2010, 5, 625–637. [Google Scholar] [CrossRef]
- Campisi, P.; Neri, A. 3D-DCT video watermarking using quantization-based methods. In Proceedings of the 15th European Signal Processing Conference, Poznan, Poland, 3–7 September 2007. [Google Scholar]
- Cedillo-Hernandez, A.; Cedillo-Hernandez, M.; Miyatake, M.N.; Meana, H.P. A spatiotemporal saliency-modulated JND profile applied to video watermarking. J. Vis. Commun. Image Represent. 2018, 52, 106–117. [Google Scholar] [CrossRef]
- Abdulfetah, A.A.; Sun, X.; Yang, H. Robust adaptive video watermarking scheme using visual models in DWT domain. Inf. Technol. J. 2010, 9, 1409–1414. [Google Scholar] [CrossRef]
- El’Arbi, M.; Koubaa, M.; Charfeddine, M.; Amar, C.B. A dynamic video watermarking algorithm in fast motion areas in the wavelet domain. Multimedia Tools Appl. 2011, 55, 579–600. [Google Scholar] [CrossRef]
- Singh, K.M. A robust rotation resilient video watermarking scheme based on the SIFT. Multimedia Tools Appl. 2018, 77, 16419–16444. [Google Scholar] [CrossRef]
- Gao, Q.; Li, Z.; Chen, S.Q. A video dual watermarking algorithm against geometric attack based on integer wavelet and SIFT. In Proceedings of the International Conference on Cryptography, Security and Privacy, Wuhan, China, 17–19 March 2017. [Google Scholar]
- Preda, R.O.; Vizireanu, D.N. A robust digital watermarking scheme for video copyright protection in the wavelet domain. Measurement 2010, 43, 1720–1726. [Google Scholar] [CrossRef]
- Preda, R.O.; Vizireanu, D.N. Robust wavelet-based video watermarking scheme for copyright protection using the human visual system. J. Electron. Imaging 2011, 20, 146–152. [Google Scholar] [CrossRef]
- Gupta, G.; Gupta, V.K.; Chandra, M. An efficient video watermarking based security model. Microsyst. Technol. 2018, 24, 2539–2548. [Google Scholar] [CrossRef]
- Masoumi, M.; Amiri, S. A blind scene-based watermarking for video copyright protection. AEU-Int. J. Electron. Commun. 2013, 67, 528–535. [Google Scholar] [CrossRef]
- Bhardwaj, A.; Verma, V.S.; Jha, R.K. Robust video watermarking using significant frame selection based on coefficient difference of lifting wavelet transform. Multimedia Tools Appl. 2018, 77, 19659–19678. [Google Scholar] [CrossRef]
- Kerbiche, A.; Jabra, S.B.; Zagrouba, E.; Charvillat, V. Robust video watermarking approach based on crowdsourcing and hybrid insertion. In Proceedings of the International Conference on Digital Image Computing: Techniques and Applications, Sydney, Australia, 29 November–1 December 2017. [Google Scholar]
- Himeur, Y.; Boukabou, A. A robust and secure key-frames based video watermarking system using chaotic encryption. Multimedia Tools Appl. 2018, 77, 8603–8627. [Google Scholar] [CrossRef]
- Adul, V.; Mwangi, E. A robust video watermarking approach based on a hybrid SVD/DWT technique. In Proceedings of the IEEE AFRICON: Science, Technology and Innovation for Africa, Cape Town, South Africa, 18–20 September 2017. [Google Scholar]
- Panda, J.; Garg, P. An efficient video watermarking approach using scene change detection. In Proceedings of the India International Conference on Information Processing, Delhi, India, 12–14 August 2016. [Google Scholar]
- Sathya, S.P.A.; Ramakrishnan, S. Fibonacci based key frame selection and scrambling for video watermarking in DWT-SVD domain. Wirel. Pers. Commun. 2018, 102, 2011–2031. [Google Scholar] [CrossRef]
- Agilandeeswari, L.; Ganesan, K. A robust color video watermarking scheme based on hybrid embedding techniques. Multimedia Tools Appl. 2016, 75, 8745–8780. [Google Scholar] [CrossRef]
- Ponnisathya, S.; Ramakrishnan, S.; Dhinakaran, S.; Sabari, A.P.; Dhamodharan, P. Chaotic map based video watermarking using DWT and SVD. In Proceedings of the International Conference on Inventive Communication and Computational Technologies, Coimbatore, India, 10–11 March 2017. [Google Scholar]
- Shanmugam, M.; Chokkalingam, A. Performance analysis of 2 level DWT-SVD based non blind and blind video watermarking using range conversion method. Microsyst. Technol. 2018, 1–9. [Google Scholar] [CrossRef]
- Zhang, X.P.; Li, K. Comments on “An SVD-based watermarking scheme for protecting rightful Ownership”. IEEE Trans. Multimedia 2005, 9, 421–423. [Google Scholar]
- Kerbiche, A.; Jabra, S.B.; Zagrouba, E.; Charvillat, V. A robust video watermarking based on feature regions and crowdsourcing. Multimedia Tools Appl. 2018, 77, 26769–26791. [Google Scholar] [CrossRef]
- Gaj, S.; Rathore, A.K.; Sur, A.; Bora, P.K. A robust watermarking scheme against frame blending and projection attacks. Multimedia Tools Appl. 2017, 76, 20755–20779. [Google Scholar] [CrossRef]
- Joshi, A.M.; Gupta, S.; Girdhar, M.; Agarwal, P.; Sarker, R. Combined DWT-DCT-based video watermarking algorithm using Arnold transform technique. In Proceedings of the International Conference on Data Engineering and Communication Technology, Lavasa City, India, 10–11 March 2016. [Google Scholar]
- Kunhu, A.; Nisi, K.; Sabnam, S.; Majida, A.; Al-Mansoori, S. Index mapping based hybrid DWT-DCT watermarking technique for copyright protection of videos files. In Proceedings of the Online International Conference on Green Engineering and Technologies, Coimbatore, India, 19 November 2016. [Google Scholar]
- Jiang, D.Y.; Li, D.; Kim, J.W. A spread spectrum zero video watermarking scheme based on dual transform domains and log-polar transformation. Int. J. Multimedia Ubiquitous Eng. 2015, 10, 367–378. [Google Scholar] [CrossRef]
- Gall, D.L. MPEG: A video compression standard for multimedia applications. Commun. ACM 1991, 34, 46–58. [Google Scholar] [CrossRef]
- Luthra, A.; Sullivan, G.J.; Wiegand, T. Introduction to the special issue on the H.264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 557–559. [Google Scholar] [CrossRef] [Green Version]
- Pan, Z.Q.; Lei, J.J.; Zhang, Y.; Sun, X.M.; Kwong, S. Fast motion estimation based on content property for low-complexity H.265/HEVC encoder. IEEE Trans. Broadcast. 2016, 62, 675–684. [Google Scholar] [CrossRef]
- Frossard, P.; Verscheure, O. AMISP: A complete content-based MPEG-2 error-resilient scheme. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 989–998. [Google Scholar] [CrossRef]
- Wang, Y.; Pearmain, A. Blind MPEG-2 video watermarking in DCT domain robust against scaling. IEE Proc. Vis. Image Signal Process. 2006, 153, 581–588. [Google Scholar] [CrossRef]
- Li, J.F.; Wang, Y.B.; Dong, S.S. Video watermarking algorithm based DC coefficient. In Proceedings of the 2nd International Conference on Image, Vision and Computing, Chengdu, China, 2–4 June 2017. [Google Scholar]
- Biswas, S.; Das, S.R.; Petriu, E.M. An adaptive compressed MPEG-2 video watermarking scheme. IEEE Trans. Instrum. Meas. 2005, 54, 1853–1861. [Google Scholar] [CrossRef]
- Tsai, T.H.; Wu, C.Y.; Fang, C.L. Design and implementation of a joint data compression and digital watermarking system in an MPEG-2 video encoder. J. Signal Process. Syst. 2014, 74, 203–220. [Google Scholar] [CrossRef]
- Khalilian, H.; Bajic, I.V. Video watermarking with empirical PCA-based decoding. IEEE Trans. Image Process. 2013, 22, 4825–4840. [Google Scholar] [CrossRef] [PubMed]
- Barni, M.; Bartolini, F.; Checcacci, N. Watermarking of MPEG-4 video objects. IEEE Trans. Multimedia 2005, 7, 23–32. [Google Scholar] [CrossRef]
- Bian, X.B.; Zhu, Q.X. Video protection for MPEG-4 FGS with watermarking. Multimedia Tools Appl. 2008, 40, 61–87. [Google Scholar] [CrossRef]
- Alattar, A.M.; Lin, E.T.; Celik, M.U. Digital watermarking of low bit-rate advanced simple profile MPEG-4 compressed video. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 787–800. [Google Scholar] [CrossRef]
- Su, P.C.; Kuo, T.Y.; Li, M.H. A practical design of digital watermarking for video streaming services. J. Vis. Commun. Image Represent. 2017, 42, 161–172. [Google Scholar] [CrossRef]
- Gujjunoori, S.; Amberker, B.B. DCT based reversible data embedding for MPEG-4 video using HVS characteristics. J. Inf. Secur. Appl. 2013, 18, 157–166. [Google Scholar] [CrossRef]
- Joshi, A.M.; Mishra, V.; Patrikar, R.M. Design of real-time video watermarking based on Integer DCT for H.264 encoder. Int. J. Electron. 2015, 102, 141–155. [Google Scholar] [CrossRef]
- He, Y.L.; Yang, G.B.; Zhu, N.B. A real-time dual watermarking algorithm of H.264/AVC video stream for video-on-demand service. AEU-Int. J. Electron. Commun. 2012, 66, 305–312. [Google Scholar] [CrossRef]
- Zhang, W.W.; Li, X.; Zhang, Y.Z.; Zhang, R.; Zheng, L.X. Robust video watermarking algorithm for H.264/AVC based on JND model. KSII Trans. Internet Inf. Syst. 2017, 11, 2741–2761. [Google Scholar]
- Buhari, A.M.; Ling, H.C.; Baskaran, V.M.; Wong, K. Fast watermarking scheme for real-time spatial scalable video coding. Signal Process. Image Commun. 2016, 47, 86–95. [Google Scholar] [CrossRef]
- Gaj, S.; Patel, A.S.; Sur, A. Object based watermarking for H.264/AVC video resistant to RST attacks. Multimedia Tools Appl. 2016, 75, 3053–3080. [Google Scholar] [CrossRef]
- Fallahpour, M.; Shirmohammadi, S.; Ghanbari, M. A high capacity data hiding algorithm for H.264/AVC video. Secur. Commun. Netw. 2015, 8, 2947–2955. [Google Scholar] [CrossRef]
- Nair, R.; Varadharajan, V.; Joglekar, S.; Nallusamy, R.; Paul, S. Robust transcoding resistant watermarking for H.264 standard. Multimedia Tools Appl. 2014, 73, 763–778. [Google Scholar] [CrossRef]
- Li, J.; Liu, H.M.; Huang, J.W.; Shi, Y.Q. Reference index-based H.264 video watermarking scheme. ACM Trans. Multimedia Comput. Commun. Appl. 2012, 8, 33. [Google Scholar] [CrossRef]
- Mohammed, A.A.; Ali, N.A. Robust video watermarking scheme using high efficiency video coding attack. Multimedia Tools Appl. 2018, 77, 2791–2806. [Google Scholar] [CrossRef]
- Gaj, S.; Sur, A.; Bora, P.K. A robust watermarking scheme against re-compression attack for H.265/HEVC. In Proceedings of the 5th National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics, Patna, India, 16–19 December 2015. [Google Scholar]
- Gaj, S.; Kanetkar, A.; Sur, A.; Bora, P.K. Drift-compensated robust watermarking algorithm for H.265/HEVC video stream. ACM Trans. Multimedia Comput. Commun. Appl. 2017, 13, 11. [Google Scholar] [CrossRef]
- Liu, Y.X.; Liu, S.Y.; Zhao, H.G.; Liu, S.; Feng, C. A data hiding method for H. In 265 without intra-frame distortion drift. In Proceedings of the 13th International Conference on Intelligent Computing, Liverpool, UK, 7–10 August 2017. [Google Scholar]
- Liu, Y.X.; Liu, S.Y.; Zhao, H.G.; Liu, S. A new data hiding method for H.265/HEVC video streams without intra-frame distortion drift. Multimedia Tools Appl. 2018. [Google Scholar] [CrossRef]
- Cai, C.T.; Feng, G.; Wang, C.; Han, X. A reversible watermarking algorithm for high efficiency video coding. In Proceedings of the 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics, Shanghai, China, 14–16 October 2017. [Google Scholar]
- Chang, P.C.; Chung, K.L.; Chen, J.J.; Lin, C.H.; Lin, T.J. A DCT/DST-based error propagation-free data hiding algorithm for HEVC intra-coded frames. J. Vis. Commun. Image Represent. 2014, 25, 239–253. [Google Scholar] [CrossRef]
- Elrowayati, A.A.; Abdullah, M.F.L.; Manaf, A.A.; Alfagi, A.S. Robust HEVC video watermarking scheme based on repetition-BCH syndrome code. Int. J. Softw. Eng. Its Appl. 2016, 10, 263–270. [Google Scholar] [CrossRef]
- Dutta, T.; Gupta, H.P. A robust watermarking framework for high efficiency video coding (HEVC)—Encoded video with blind extraction process. J. Vis. Commun. Image Represent. 2016, 38, 29–44. [Google Scholar] [CrossRef]
- Dutta, T.; Gupta, H.P. An efficient framework for compressed domain watermarking in P frames of high-efficiency video coding (HEVC)—Encoded video. ACM Trans. Multimedia Comput. Commun. Appl. 2017, 13, 12. [Google Scholar] [CrossRef]
- Long, M.; Peng, F.; Li, H.Y. Separable reversible data hiding and encryption for HEVC video. J. Real-Time Image Process. 2018, 14, 171–182. [Google Scholar] [CrossRef]
- Swati, S.; Hayat, K.; Shahid, Z. A watermarking scheme for high efficiency video coding (HEVC). PLoS ONE 2014, 9, e105613. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.Y.; Shan, R.Y.; Zhou, X. Anti-HEVC recompression video watermarking algorithm based on the all phase biorthogonal transform and SVD. IETE Tech. Rev. 2018, 35, 1–17. [Google Scholar] [CrossRef]
- Yang, J.; Li, S.B. An efficient information hiding method based on motion vector space encoding for HEVC. Multimedia Tools Appl. 2018, 77, 11979–12001. [Google Scholar] [CrossRef]
- Shanableh, T. Altering split decisions of coding units for message embedding in HEVC. Multimedia Tools Appl. 2018, 77, 8939–8953. [Google Scholar] [CrossRef]
- Sujatha, P.; Devi, R. A glance of digital watermarking techniques with an evaluation of Haar and Daubechies wavelet. Int. J. Appl. Eng. Res. 2017, 9, 9652–9657. [Google Scholar]
- Tew, Y.; Wong, K. An overview of information hiding in H.264/AVC compressed video. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 305–319. [Google Scholar] [CrossRef]
- Asikuzzaman, M.; Pickering, M.R. An overview of digital video watermarking. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2131–2153. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Signal Processing Operations | Geometric Attacks | Temporal Synchronization |
|---|---|---|
| Gaussian filter (GF), Median filter (MF) | Scaling (Scl) | Frame dropping (FD) |
| Average filter (AF), Wiener filter (WF) | Cropping (Crp) | Frame swapping (FS) |
| Circular filter (CF), High-pass filter (HPF) | Rotation (Rtt) | Frame insertion (FI) |
| Gaussian noise (GN), Impulsive noise (IN) | Frame averaging (FA) | |
| Salt & pepper noise (SPN), Speckle noise (SN) | Frame cropping (FC) | |
| JPEG, MPEG-2, MPEG-4, H.264, H.265 | ||
| Gamma correction (GC), Sharpening (Shp) | ||
| Histogram equalization (HE), Blurring (Blu) | ||
| Luminance modification (LM), Recompression (Rec) | ||
| Contrast enhancement (CE), Transcoding (Trs) |
| Ref. | Type | Watermark Preprocessing | Embedding Position |
|---|---|---|---|
| [26] | Blind | Encoding | MIDSB of Y component; LSB of U and V components |
| [28] | Blind | Pseudonoise sequence | Each frame |
| [29] | Blind | Pseudorandom noise generator | Luminance component of each frame |
| [30] | Blind | - | Luminance component of each frame |
| [31] | Semi-blind | - | Blocks with robustness to most attacks |
| [32] | Blind | Arnold transform | Frames selected by scene change |
| Ref. | Type | Watermark Preprocessing | Embedding Position |
|---|---|---|---|
| [34] | Blind | Arnold transform | High-frequency coefficients of R, G, and B components |
| [35] | Blind | CDMA | DCT coefficients of Y component |
| [36] | Blind | - | Robust DCT coefficients selected in Y component |
| [37] | Non-blind | - | Selected coefficients in KDCT matrix of Y component |
| [38] | Semi-blind | Arnold transform | Low-frequency DCT coefficients of Y component |
| [40] | Blind | Permuted processing | AC values of selected DCT blocks in Y component |
| [41] | Blind | Pseudorandom generator | Y component of each I frame |
| [43] | Blind | - | AC coefficients of each 2D DCT block in Y component |
| Ref. | Type | Watermark Preprocessing | Embedding Position |
|---|---|---|---|
| [44] | Blind | Arnold transform | Middle-frequency DWT coefficients of Y component |
| [45] | Blind | Pseudorandom generator | Middle-frequency DWT coefficients of Y component |
| [46] | Blind | Arnold transform | High-frequency DWT coefficients of Y component |
| [47] | Non-blind | Chaotic encryption | Selected blocks of Y component based on human visual masking threshold |
| [48] | Blind | Spread-spectrum technique | LH2, HL2, and HH2 sub-bands of Y component |
| [49] | Blind | Pseudorandom generator | LH2, HL2, and HH2 sub-bands of Y component |
| [50] | Blind | Resize | LL and HL sub-bands |
| [51] | Blind | Spread-spectrum technique | 3D coefficients of HL, LH, and HH sub-bands |
| [52] | Blind | Random shuffling | LH3 sub-band of luminance component |
| Ref. | Type | Watermark Preprocessing | Embedding Position |
|---|---|---|---|
| [54] | Blind | Chaotic encryption | Singular value matrix of LL1 sub-bands in Y component |
| [55] | Blind | Pseudorandom generator | Singular value matrix of diagonal detail coefficients of G component |
| [56] | Non-blind | SVD | Singular value matrix of LL2 sub-bands in Y component |
| [57] | Blind | Fibonacci–Lucas transform | Singular value matrix of LH sub-bands of R component |
| [58] | Non-blind | Arnold transform | Singular value matrix of 2-level DWT LH and HL sub-bands in Y component |
| [59] | Blind | Chaotic map | Singular value matrix of LL sub-bands in Y component |
| [60] | Blind | 2-level DWT | Singular value matrix of HL2 sub-bands of LH sub-bands in Y component |
| Ref. | Type | Watermark Preprocessing | Embedding Position |
|---|---|---|---|
| [62] | Blind | Scrambling | Feature regions obtained by crowdsourcing and moving objects |
| [63] | Blind | - | Low-frequency DCT coefficients of regions around SIFT points in LLL sub-bands |
| [64] | Blind | Arnold transform | Middle-frequency components |
| [65] | Blind | Index mapping table | Three selected DCT coefficients of LL2 sub-bands in suitable channel |
| [66] | Blind | Spread spectrum and Logistic map | Feature values generated by dual transform and log-polar in luminance component |
| Ref. | [26] | [29] | [38] | [41] | [43] | [45] | [46] | [48] | [52] | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR (dB) | [58, 73] | [33, 44] | 36.85 | [31, 69] | [44, 56] | 56.18 | ≥38 | [45, 49] | 41.50 | |||||
| SSIM | - | - | ≥0.93 | - | [0.97, 1] | - | [0.99, 1] | - | - | |||||
| Robustness | NC | BER | BER | NC | NC | BER | NC | NC | BER | BER | NC | BER | ||
| A T T A C K S | MF (3 × 3) | - | ≤0.007 | - | 0.993 | - | - | - | - | 0.149 | 0.990 | 0.005 | ||
| GN | (0.004) | 0.259 | 0.440 | (0.0005) 0.000 | - | 0.997 | 0.050 | - | (0.05) | (0.005) | (0.01) | |||
| (0.006) | - | 0.090 | - | 0.985 | 0.015 | 0.001 | 0.841 | 0.080 | ||||||
| SPN (0.0005) | 1.000 | 0.000 | 0.000 | - | 0.993 | - | - | - | - | 0.000 | (0.01) | |||
| 0.937 | 0.032 | |||||||||||||
| JPEG (Q = 80) | - | ≤0.447 | - | - | - | - | 0.713 | 0.287 | 0.020 | 0.999 | 0.000 | |||
| MPEG-2 | (4 Mbps) | - | ≤0.406 | - | 1.000 | 0.008 | 0.940 | - | - | 0.074 | - | 0.065 | ||
| (2 Mbps) | ≤0.476 | - | 1.000 | 0.009 | - | - | 0.252 | - | 0.201 | |||||
| MPEG-4 | (2 Mbps) | 0.921 | 0.027 | - | 1.000 | - | 0.008 | 0.790 | - | - | - | - | - | |
| (1 Mbps) | 0.921 | 0.027 | 1.000 | 0.009 | ||||||||||
| Scl | (1.2) | 1.000 | 0.000 | - | 1.000 | - | 0.064 | 0.673 | - | - | - | (0.5) | ||
| (0.8) | 0.868 | 0.046 | 1.000 | 0.023 | 0.979 | 0.012 | ||||||||
| Crp | (40%) | 0.495 | 0.129 | - | - | - | - | 0.660 | 0.718 | 0.282 | - | (25%) | ||
| (20%) | 1.000 | 0.000 | - | 0.863 | 0.136 | 0.926 | 0.043 | |||||||
| FD (10%) | Robust | - | 0.677 | - | - | Robust | 0.996 | 0.004 | 0.015 | 0.894 | 0.051 | |||
| FA (10%) | - | ≤0.006 | 1.000 | - | - | Robust | 0.996 | 0.004 | 0.013 | - | - | |||
| Other attacks the algorithm can resist | PN, IN, AF, GF, HPF, Trs, Rtt, H.264, and FS | Blu | GF, Rtt, FI, FS, and Blu | WF, LM, and H.264 | IN, Trs, and H.264 | CE, LM, and Rtt | IN, Blu, Shp, GC, Rtt, FS, and FC | Blu and LM | SN, GF, AF, HE, Shp, LM, GC, and H.264 | |||||
| Ref. | [54] | [57] | [58] | [63] | [64] | [66] | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR (dB) | [44, 50] | [41, 53] | [55, 68] | [32, 46] | 48.726 | - | ||||||
| SSIM | - | - | ≥0.700 | ≥0.976 | - | - | ||||||
| Robustness | NC | BER | NC | BER | NC | BER | NC | NC | NC | BER | ||
| A T T A C K S | MF (3 × 3) | 1.000 | 0.000 | 0.963 | - | 0.883 | 0.048 | 0.784 | 0.994 | 0.998 | 0.003 | |
| GN (0.01) | 1.000 | 0.000 | 0.970 | 0.127 | 0.954 | 0.022 | - | 0.985 | 0.982 | 0.025 | ||
| SPN | (0.01) | 1.000 | 0.000 | 0.970 | 0.269 | - | - | 0.864 | (0.05) 0.995 | 0.999 | 0.002 | |
| (0.02) | - | - | 0.988 | 0.035 | 0.788 | 0.994 | 0.009 | |||||
| FA | 0.990 | 0.013 | 0.950 | 0.300 | - | 0.921 | 0.976 | 0.034 | ||||
| FD | - | 0.983 | 0.163 | 0.985 | 0.019 | - | 0.933 | 0.985 | 0.020 | |||
| FS | - | 0.990 | 0.120 | 0.941 | 0.036 | - | 0.936 | 0.980 | 0.027 | |||
| Other attacks the algorithm can resist | CF, Blu, Shp, HE, Crp, Scl, and H.264 | Blu and LM | Rtt and CE | GF, CE, LM, Scl, and H.265 | Shp, HE, and GC | GF, NF, Crp, and Rtt | ||||||
| Ref. | Type | Standard | Embedding Position |
|---|---|---|---|
| [71] | Blind | MPEG-2 | AC coefficients of luminance component of shadow frames |
| [72] | Blind | MPEG-2 | Last DC coefficient of the last macroblock of each slice in Y component |
| [73] | Blind | MPEG-2 | DCT coefficients of luminance blocks decomposed from bit streams |
| [74] | Blind | MPEG-2 | Spatial or frequency domain of Y-component |
| [75] | Blind | MPEG-2 | LL sub-bands of I frames |
| [76] | Blind | MPEG-4 | Luminance blocks of selected MBs |
| [78] | Blind | MPEG-4 | DCT coefficients of luminance blocks of VOPs |
| [79] | Blind | MPEG-4 | Local areas of I frames based on the extraction of feature points |
| [80] | Blind | MPEG-4 | Middle-frequency DCT coefficients of Y-component of I frames |
| Ref. | Type | Watermark Preprocessing | Embedding Position |
|---|---|---|---|
| [82] | Blind | CDMA technique | Low-frequency DCT coefficients of Y component of I frames |
| [83] | Blind | Spread spectrum | Medium–high frequency DCT coefficients of I frames |
| [84] | Non-blind | Pseudorandom sequence | Highest energy coefficient in 4 × 4 luma intra-predicted blocks |
| [85] | Non-blind | DCT | DCT coefficients of motion coherent blocks in all frames |
| [86] | Blind | Encryption operation | High-frequency DCT coefficients of all frames |
| [87] | Blind | Random sequence | I_4 × 4 type of MBs of I frames |
| [88] | Blind | Pseudorandom sequence | Index of the reference frame |
| Ref. | Type | Watermark Preprocessing | Embedding Position |
|---|---|---|---|
| [90] | Blind | - | NNZ difference of 4 × 4 luma TBs of intra-predicted frames |
| [91] | Blind | Pseudorandom sequence | 4 × 4 luma TBs with high NNZ values in homogeneous regions of I frames |
| [92] | Blind | Encoding | Multi-coefficients of the 4 × 4 luminance DCT blocks of selected frames |
| [93] | Blind | Encoding | Multi-coefficients of the 4 × 4 luma DST blocks of selected frames |
| [94] | Blind | - | QDST coefficients in 4 × 4 luminance PU of I frames |
| [95] | Blind | - | QDCT and QDST coefficients of intra prediction residuals |
| [96] | Blind | BCH code | Residual QDCT or QDST coefficients within the different size of TUs of I frames |
| [97] | Blind | - | Low-frequency nonzero quantized AC coefficients in 4 × 4 blocks of I frames |
| [98] | Blind | - | Low-frequency nonzero quantized AC coefficients in 4 × 4 blocks of P frames |
| [99] | Blind | Exclusive OR operation | Nonzero AC residual coefficients |
| [100] | Blind | - | LSBs of selected nonzero of QTCs of I frames |
| [101] | Blind | Arnold transform and APBT | Nonzero coefficient blocks in luminance components with the size of 4 × 4, 8 × 8, and 16 × 16 of I frames |
| [102] | Blind | Binarization | Motion vectors of the smallest PUs in CTU |
| Ref. | [75] | [83] | [85] | [88] | [91] | [97] | [98] | ||
|---|---|---|---|---|---|---|---|---|---|
| PSNR (dB) | 50.89 | 36.33 | [25, 44] | [32, 42] | [32, 50] | [30, 35] | [40, 44] | ||
| Capacity (bit) | 2080 | 1317 | - | 1680 | 100 bits/I frame | - | - | ||
| BIR (%) | - | ≤1.26 | ≤2.90 | ≤6.48 | ≤2.08 | ≤0.27 | ≤0.14 | ||
| Standard | MPEG-2 | MPEG-4 | H.264 | H.264 | H.265 | H.265 | H.265 | ||
| Robustness | BER | BER | NC | BER | NC | BER | BER | ||
| A T T A C K S | GF (5 × 5) | - | 0.008 | 0.603 | 0.070 | 0.848 | 0.157 | - | |
| GN (0.001) | ≤0.197 | (0.005) 0.038 | - | 0.060 | 0.763 | 0.017 | 0.131 | ||
| SPN | (0.01) | - | 0.038 | 0.61 | - | 0.877 | (0.001) 0.015 | (0.001) 0.106 | |
| (0.02) | - | 0.49 | 0.774 | ||||||
| Rec | - | 0.006 | - | 0.044 | 0.812 | 0.074 | 0.070 | ||
| Other attacks the algorithm can resist | MF, FS, FA, FI, MPEG-2, and H.264 | - | MF, Rtt, and Scl | LM, Blu, Shp, and H.264 | Scl, CE, FA, FD, and H.264 | AF, H.264, and H.265 | AF, H.264, and H.265 | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, X.; Wang, C.; Zhou, X. A Survey on Robust Video Watermarking Algorithms for Copyright Protection. Appl. Sci. 2018, 8, 1891. https://doi.org/10.3390/app8101891
Yu X, Wang C, Zhou X. A Survey on Robust Video Watermarking Algorithms for Copyright Protection. Applied Sciences. 2018; 8(10):1891. https://doi.org/10.3390/app8101891
Chicago/Turabian StyleYu, Xiaoyan, Chengyou Wang, and Xiao Zhou. 2018. "A Survey on Robust Video Watermarking Algorithms for Copyright Protection" Applied Sciences 8, no. 10: 1891. https://doi.org/10.3390/app8101891
APA StyleYu, X., Wang, C., & Zhou, X. (2018). A Survey on Robust Video Watermarking Algorithms for Copyright Protection. Applied Sciences, 8(10), 1891. https://doi.org/10.3390/app8101891