1. Introduction
Delivering a high-quality product should be the main goal of every software project. The quality of software depends on activities within the software development process [
1], part of which is the quality assessment phase, including source code analysis. Quality in software engineering is usually understood as an absence of errors within the software [
2]. In addition to this, it is also important to consider deficient source code. Fowler et al. [
3] list several smells within a source code. Code smell is a structural characteristic of software that can indicate code or design problems and can have an impact on software maintenance and growth [
3,
4]. Additionally, it indicates the presence of anti-patterns and the use of inappropriate development practices [
5]. Though code smells do not cause an interruption in execution, they can present a challenge at a certain step of further evolution. Additionally, when ignored, it can result in the occurrence of defects [
6].
Since deficient code impacts different parts of the development process, it is important that we treat it properly. This starts with the reliable identification of a deficient code, which, as a result, offers a manageable number of potentially deficient program entities. Different strategies for detecting code smells exist, among others it can be detected with software metrics [
7]. However, only a single dimension of quality is evaluated when using an individual software metric or criterion within the identification. This usually results in a large number of potentially deficient program entities and many of them turn out to be false positives [
7,
8,
9], meaning, software metrics indicate a deficient quality in the evaluated program entity but developers do not perceive the entity as problematic.
Code smell detection rules are an attempt at combining different software metrics. In related work [
8,
10], these rules present a prevailing way of identifying deficient code, aimed at finding different types of code smells. Although many studies are available, it is hard to detect a generally accepted composition and validation of detection rules. This presents a challenge for the reliable identification of deficient entities. Also, different interpretations of detection rules exist [
11] and a comparison between potentially deficient entities identified with different code smell detection tools reveals very small intersections in resulting sets of potentially deficient program entities [
12].
A very large number of allegedly deficient program entities are identified [
12] using existing code smell detection tools. This represents a challenge, especially within the context of the manual review that follows. To be precise, the automatic validation of identified entities is not possible as confirmed by Fontana et al. [
8]. Therefore, the inclusion of experts to perform a manual review is necessary. It is crucial to develop an approach that would provide a manageable number of detected potentially deficient program entities and would reduce false positive cases to a minimum.
To address the above-mentioned challenges, we propose a novel approach for the identification of deficient source code, that is based on applying a majority function upon the combination of software metrics. Although attempts at combining multiple software metrics within software evaluation can be found within the context of code smell detection rules, the use of majority functions for the quality evaluation of program entities has not been used yet. The proposed identification is based on the assumption that the overall quality of a program entity that exceeds the threshold value of an individual software metric is not necessarily deficient. However, when the assessed program entities exceed threshold values for more software metrics, evaluating different quality aspects, the probability that an evaluated program entity really contains a deficient code, increases. The presented research study was guided by the following research question: Does the identification approach based on the majority function applied on the combination of software metrics identify a deficient source code in a reliable way? The aim is to identify program entities with deficient overall quality and not on identifying particular types of code smells or even faulty classes. The proposed approach was implemented and evaluated on the three major object-oriented programming languages Java, C++ and C#. The process of identifying deficient source code and the quality rating of detected software classes was performed with the proposed approach. Expert judgment was used in order to validate the proposed approach. For this purpose, software developers and software architects with multiple years of experience assessed selected program entities within a performed study. Their evaluation was compared to the results, obtained by the proposed novel approach for the identification of deficient source code based on a combination of software metrics using a majority function. The comparison confirmed the correctness of the proposed approach.
The rest of the paper is organized as follows. The research background and related work are presented first. Next, the proposed novel approach is described in detail, followed by its implementation on object-oriented programming languages. The division of software metrics within different quality aspects for evaluating object-oriented software classes are proposed next. Afterwards, the identification of deficient classes is illustrated and the results of the validation of the performed identification based on expert judgment is presented. Furthermore, a reliability analysis of the proposed approach is provided. Finally, limitations and threats to validity are presented.
2. Research Background and Related Works
Software metrics are functions that use software data as an input, provide independent numeric values as an output and can be interpreted as the level at which software suits the chosen quality attribute [
13]. The measurement of software metrics is carried out within a quality assurance process [
14] and constitutes a key component in successful software engineering [
15]. In the latter case, it is recommended to follow the prescribed guidelines and by using software metrics it is possible to control the achieved level of software product quality [
16].
Different types of metrics quantify different aspects of software development [
16]. Misra et al. [
17] list several object-oriented software metrics collections, like Chidamber and Kemerer (CK) metrics, Lorenz and Kidd metrics and MOOD software metrics. A variety of software metrics is used in practice and it is essential to know the connection between each metric and different software quality aspects. Furthermore, the meaningful use of software metrics is possible only with reliable threshold values [
16,
18]. The more reliable the thresholds are, the more accurately the quality can be evaluated.
Evaluating quality with software metrics thresholds is a known and accepted strategy [
19]. The main motivation of deriving threshold values is to identify those program entities that can represent a potential risk [
20,
21,
22]. In the literature, many different approaches are proposed for deriving metrics thresholds. The majority of studies identify threshold values with the goal of finding errors, such as in [
23,
24,
25,
26,
27]. Only some of them, like the study by Fontana et al. [
8], focus on finding code smells. Among methods that are used for calculating metrics thresholds there are also approaches that derive thresholds based on software metrics values acquired from benchmark data. Those approaches are used in [
8,
10,
16,
20,
28,
29,
30] and as a result offer concrete threshold values that can be used in the process of software quality evaluation. Furthermore, with derived threshold values, it is possible to find and evaluate code smells adequately [
8].
The detection of deficient program entities is a commonly discussed topic, but usually in the context of finding errors, like in [
23,
24,
25,
31]. Studies that identify code smells based on exceeding threshold values of software metrics can be found; however, they mostly detect code smell types presented by Lanza and Marinescu [
16] with the use of code smell detection rules. Code smells are detected in a study by Fontana et al. [
8], where also the calculation of threshold values for selected software metrics is presented. Identification is done with detection rules which are presented in [
16] and no validation of acquired results is presented. Vale and Figueiredo [
10] present the detection of code smells for software product lines. Ferreira et al. [
18] identify poor classes within the context of experimental validation of the proposed threshold values. They also combine derived metrics within identification and point to a decreasing number of detected classes. However, no rules or more detailed proposal are available. Other papers presenting code smell detection strategies are listed by Sharma and Spinellis [
7]. Among the classified detection methods there are also strategies based on software metrics, like [
32,
33,
34,
35]. However, again, studies focus on the identification of code smells using manually defined code smell detection rules.
Among the most known code smells are Brain Class, God Class, Brain Method and Feature Envy presented by Lanza and Marinescu [
16]. They also present identification rules and some of them are implemented in Jdeodorand [
36] and JSpIRIT [
34]. The results of the conducted identification presented in [
12], shows that the intersection between identified entities, using different detection methods and/or tools, is very small. The intersection within Jdeodorand, JSpIRIT and SonarQube was 2.70% when identifying God Class/Brain Class code smell and 6.08% when detecting Long Method/Brain Method. This can be the case due to the varying and nontransparent implementation of detection rules, which occurs despite the provided definitions. A study about code smell detection tools was also done by Paiva et al. [
37]. It concluded that the comparison between tools is difficult, since each is based on a different but similar informal definition of code smells made by researchers or developers. This is the main reason an identification based on rules at this point does not present a reliable method for identifying code smells .
To the previously outlined problems we can also add challenges related to expert perceptions of defined code smells, which was a research domain in [
11,
38]. Therefore, our research moves away from frequently used types of code smells presented by Fowler et al. [
3] and Lanza and Marinescu [
16], and focuses on detecting deficient entities as program entities with a deficient overall quality. By examining an overall quality evaluated with a set of software metrics that assess different quality aspects and using a majority function, true positive program entities that indeed contain deficient code should be detected in a more reliable way, and, consequentially, the identification of false positive examples should be significantly reduced.
3. Proposed Theoretical Framework for the Identification of Deficient Source Code
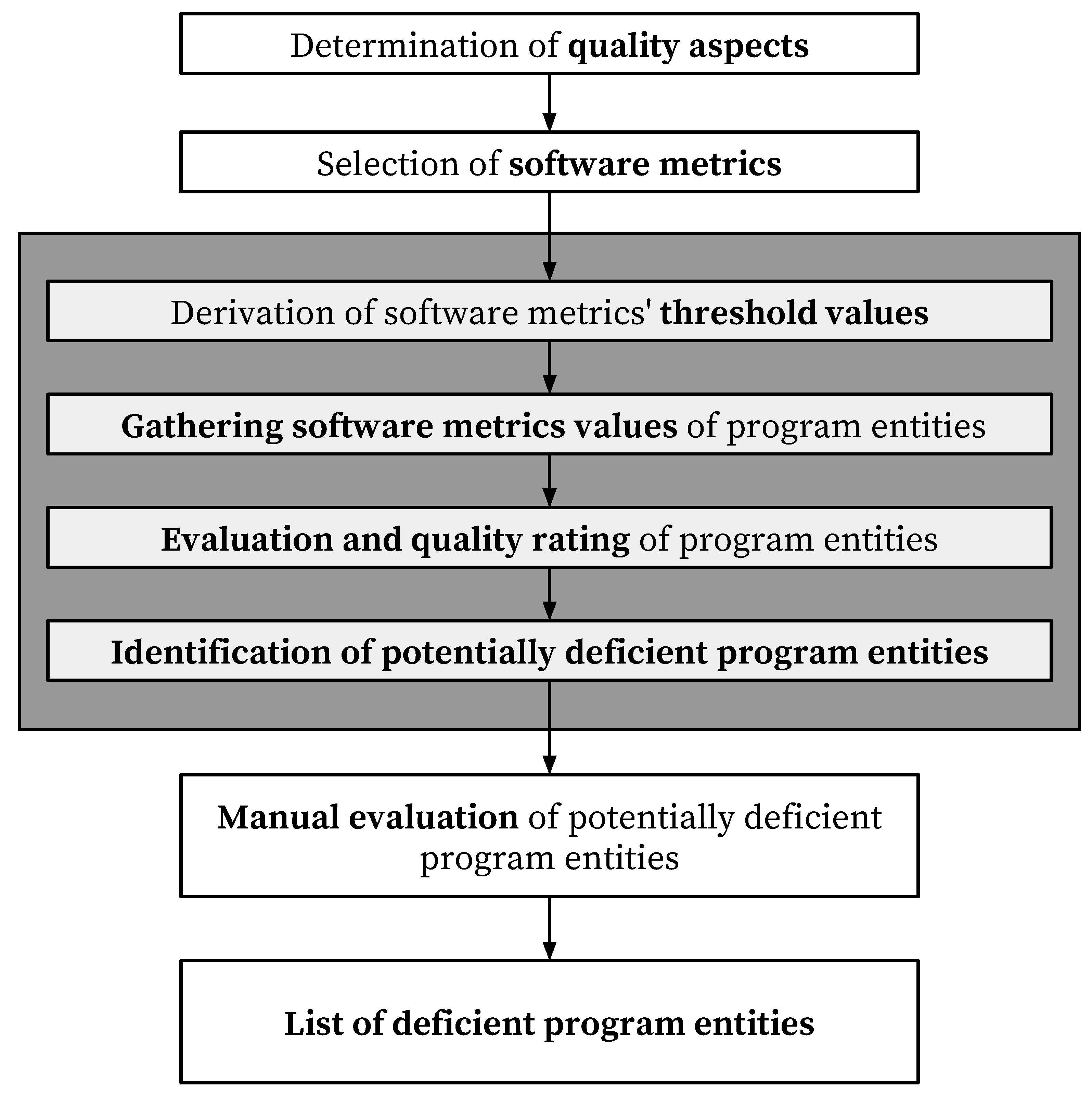
Based on the presented challenges we propose a novel approach for identifying deficient source code with a combination of software metrics and by applying the majority function. The main steps of the proposed approach are presented in
Figure 1 in the colored shape, joined with other commonly used activities performed within the identification of deficient source code.
After setting the criteria, i.e., determining the quality aspects and selecting the individual software metrics, the proposed approach starts by deriving the threshold values for the selected software metrics. Then the actual values of selected software metrics are gathered for all the program entities. The evaluation and quality rating of program entities is done next, based on the gathered software metrics values and the derived thresholds. The last step of our proposed approach is the identification of entities that potentially include deficient source code, after which the identification of deficient entities may continue by manually reviewing the identified potentially deficient entities, providing a final list of assuredly deficient program entities. Although the first two and the last two steps are not a part of the proposed approach itself, they contribute to overall understanding of the identification approach.
The proposed approach arises from challenges connected to the identification of deficient program entities based on an individual software metric. The challenge was also recognized by Bouwers et al. [
39] and Lanza and Marinescu [
16]. If software metrics are used in isolation, it is difficult to characterize the software as a whole since each metric evaluates only a certain aspect of software [
16]. As they noted, a balanced overview of the current state of software can be achieved by combining multiple metrics [
39]. Consequently, it makes sense to combine related single metrics into categories, expressing different quality aspects. Finally, all these categories, each representing a special quality aspect of a software, can be combined into a single quality score.
This division constitutes a starting point for the proposed approach. After the determination of quality aspects that need to be covered during the evaluation, the appropriate software metrics are selected and assigned to each aspect. In general, the selection of software metrics and their division into quality aspects are not fixed and can be tailored to one’s needs. Specific software metrics could be added and/or existing metrics could be changed for the purpose of evaluating different aspects of software. After a set of specific software metrics is determined, their threshold values are derived which serve as a measure of whether a program entity can be considered as potentially deficient regarding a specific metric.
With the selected set of software metrics, divided into certain quality aspects, the identification of deficient source code can begin. After gathering software metrics values for program entities we want to evaluate, they are compared to the derived thresholds. If an actual value of a single software metric for a program entity exceeds the derived threshold, the entity is considered to be potentially deficient with regard to this single metric. The combined quality rate of each quality aspect, which is composed of several single metrics, is determined by the use of the majority function, based on the majority voting principle.
The majority function is defined by Equation (
1):
where
stands for a single component value, contributing to a combined measure
.
When the majority function is used for calculating the majority within a certain quality aspect, stands for that quality aspect, and stands for a single software metric within the respected aspect. If the software metric value exceeds the threshold value, the is 1, otherwise is 0.
Based on the calculated majority measure, the quality rate of a single quality aspect is determined by Equation (
2), and can be evaluated as either 1 or 0:
where
stands for the quality aspect. In this manner, the quality rate 1 represents a poor and 0 represents a good quality aspect. If the calculated value of the majority function is more than 0.5 the final quality rate is evaluated as 1 (poor) and if the value is less than or equal to 0.5, the quality rate is evaluated as 0 (good).
Similarly, for determining an overall quality of a program entity, which includes all different quality aspects, the same majority function (Equation (
1)) and quality rate (Equation (
2)) equations are used. In this manner, when the majority function (Equation (
1)) is used for calculating the overall quality of program entities,
stands for the specific program entity and
stands for the quality rate of an evaluated quality aspect, as determined based on Equation (
2). In the end, the overall quality of the program entity is determined as poor if the quality rate of the program entity is 1 and as good if the quality rate of the program entity is 0.
The detailed steps of the proposed approach are summarized by Algorithm 1. As proposed with the approach, the identification of potentially deficient program entities is done based on the calculated majority function and determined quality rate. First, for each program entity the majority function is applied within every quality aspect, considering single software metric values, and afterwards , the majority function is calculated for the program entity considering quality ratings of all quality aspects. Each evaluated program entity, the overall quality rate of which is determined as poor, is identified as potentially deficient. The list of such potentially deficient program entities constitutes a final output of the proposed identification approach.
| Algorithm 1 Detailed structure of the proposed approach for the identification of deficient program entities |
- 1:
derive thresholds for selected software metrics - 2:
for each program entity do - 3:
gather software metrics - 4:
execute evaluation - 5:
for each quality aspect do - 6:
calculate majority function based on software metrics - 7:
define quality rate - 8:
end for - 9:
calculate majority function based on quality aspect - 10:
define quality rate - 11:
if quality rate equals poor then - 12:
add program entity to list of potentially deficient program entities - 13:
end if - 14:
end for
|
5. The Validation of the Proposed Approach With Expert Judgment
In
Section 3 the approach for identifying deficient classes is presented and in
Section 4 the implementation within object-oriented programming languages was illustrated. To evaluate the proposed approach, we validated it by comparing the obtained results with the expert judgment upon the same set of software classes. Within the approach, potentially deficient classes were first identified using the proposed combination of eight software metrics, organized within four quality aspects, and corresponding threshold values and quality ratings were provided in accordance with the majority function. In real-world software development, each of the potentially problematic classes is usually assessed manually. Therefore, it is important that the results do not include too many false positive results. In this manner, the main goal of our approach was not necessarily to detect all deficient classes, but to significantly reduce the number of false positive cases within the identified classes, whose quality is determined as poor based on the majority function. To objectively evaluate the proposed approach, an expert judgment was conducted.
The main goal of the expert judgment in the scope of our study was to validate the reliability of identification using the proposed approach, based on a combination of software metrics and by applying the majority function, and correctness of the identified potentially deficient program entities. The reliability and correctness are reflected in occurrences of true positive and false positive examples. The experts evaluated if the identified software classes really contain deficient source code that reflects in deficient code quality. The conception of deficient code was left to the participating experts, since they have multiple years of experience as software developers and software architects. The classes used within the study were selected based on the research question: Do classes that exceed the threshold values for the majority of used quality aspects really contain deficient code or does the proposed approach for identification result in false positive examples?
The validation was carried out for projects developed in three programming languages: Java, C++ and C#. Using the developed tool, experts assessed the selected software classes. Our tool enables source code evaluation based on collaboration between participating experts. First, each entity is assessed independently by each assessor and next, the assessment has to be coordinated between the pair of assessors. If the pairs are not formed, the coordination step is not performed. Because of the cooperation between assessors the results are more reliable and the bias is reduced. Each assessor evaluates four quality aspects for each entity. The main aspect is the assessment of overall quality, whereas the other three quality aspects represent three out of four selected quality aspects. The assessment was done on a four level scale: very poor - poor - good - very good. The scale was set based on the quality rating steps defined within the proposed approach, where each class quality is determined as good or poor.
In the performed study, 18 experts participated, each with multiple years of experience. Participating experts assessed 93 software classes, evaluating overall quality and quality aspects of size, complexity, cohesion and coupling. The quality of assigned classes differed, and assessors were not aware of whether the selected program entity was evaluated as good or poor. A profile of participants is presented in
Table 9.
As presented, participants evaluated their experiences in software development with an average of 8.4 on a scale from 1 to 10. The same scale was also used for evaluating their knowledge of the programming language they assessed. Knowledge of the programming language Java was rated with an average of 8.6, knowledge of C++ with 9 and knowledge of C# with 8.2. All the experts that evaluated C++ and C# have more than 10 years of experience with the mentioned programming languages. The same amount of experience was also recorded by 81% of the experts evaluating Java software classes.
To answer the research question, we selected different classes from the evaluated software products presented in
Section 4.2. Classes were assessed by the participating experts and the assessment was compared to evaluations done using the proposed approach presented in
Section 3. It was analyzed if expert assessment coincides with the quality rating determined using the majority function. With this, the correctness and reliability of the proposed novel approach can be researched.
The expert judgment in the programming language Java was done for 33 software classes from 3 different software projects. Classes were selected from the identified potentially deficient classes that are listed in
Section 4.2. With the proposed identification using combination of software metrics and by applying the majority function, 28 out of 33 classes were determined as poor and 5 as good. Within classes with poor quality, all 9 classes from the Alfresco Repository exceed the threshold values of all eight software metrics. Also, 10 out of 15 classes corresponding to the same condition within the JasperReports Library were used within the evaluation. Five classes were skipped due to detected similarities. The numbers of identified classes can be seen in
Table 6. The results of the expert judgment are presented in
Table 10. The entity column presents an identifier of the evaluated class and the next two columns present the number of evaluations made and the number of pairs that were formed within those evaluations. As can be seen, each class was assessed multiple times, usually with two pairs of experts. The expert judgment confirmed the evaluation of overall quality determined by the proposed approach for all of the evaluated classes. The evaluation also confirmed the proposed quality rating for quality aspects measuring size, complexity and coupling. Only in 2 cases was the evaluation of cohesion not confirmed by experts. The results also confirmed the complete absence of false positive program entities within the identified software classes.
For the expert judgment of C++ software classes, 6 software projects were included that are presented in
Section 4.2. 32 classes were evaluated as poor and 10 as good using the proposed quality rate based on the majority function. From Notepad++ and 7-Zip, all classes that were identified as exceeding the thresholds of all eight software metrics, participated. The numbers can be seen in
Table 7. The results of the expert assessment are presented in
Table 11. In all of the assessed classes, the evaluated overall quality was confirmed. Also, the quality aspects evaluating source code size and complexity were confirmed. For one class, the quality aspect of coupling was not confirmed and in the case of cohesion, for three classes the experts did not confirm the proposed evaluation. Again, the results also confirmed the non-existence of false positive results.
Within the programming language C#, 3 software products were analyzed and in total 18 classes were assessed, 13 of them were assessed as poor and 5 as good using the proposed identification approach. With the software KeePass and iTextSharp all classes corresponding to the criterion of exceeding the thresholds of all eight software metrics were included. The numbers are presented in
Table 8. Classes were assessed by experts who were teamed into pairs, which is presented in the third column in
Table 12. All of the entities were assessed by two pairs of experts and some of the classes were additionally assessed by an individual assessor to confirm the results. As shown in
Table 12, the proposed overall quality was confirmed for all of the evaluated classes. Also, the evaluation was confirmed for quality aspects of size, complexity and coupling. The evaluation of cohesion was not confirmed for one software class. The results also confirmed the absence of false positive results.
The goal of the expert judgment was to answer the research questions presented at the beginning of the section. As the results show, the overall quality was confirmed for all classes in all three programming languages by all of the experts. With this, the correctness of the identification is confirmed. The important part of the validation is also how reliable the proposed identification is. This is especially vital in comparison with the evaluation based on an individual software metric. As the results of the experts’ judgment show, no example of false positive identification was found. The correctness and reliability of the proposed identification approach based on the combination of software metrics and the use of the majority function was evaluated by using the confusion matrix, presented in
Table 13.
The confusion matrix is a two dimensional matrix that summarizes the performance of a classification [
55]. It consists of a predicted and true condition and divides cases into four quality aspects: true positive (TP), false positive (FP), false negative (FN) and true negative (TN). Based on the provided data, it is also possible to calculate accuracy, precision, recall and F-Measure, presented with Equations (
5)–(
8). Accuracy measures how a prediction matches the reality [
56], whereas precision and recall present values for how well relevant entities are retrieved [
57]. Finally, the F-Measure presents information retrieval performance [
58].
To calculate accuracy, precision, recall and F-Measure for the proposed identification based on a combination of software metrics and by applying the majority function, we used the results of the validation of the proposed identification, presented in
Section 5. We considered only the part of the study where the evaluation of Java classes was performed.
Table 14 shows the confusion matrix and the calculated measures of predictive performance. 28 classes were identified as true positive and five classes as true negatives. No classes were detected as a false positive or false negative. Consequently, the accuracy, precision and recall for the presented identification is 100%. The same is also true for the value of the F-Measure.
The proposed approach addresses multiple quality aspects of the evaluated program entities. On the other hand, if the quality of a program entity is evaluated using an individual software metric, only one aspect of the program entity is assessed. If the entity exceeds the threshold according to an individual software metric and is in good shape according to other metrics, it is hard to generalize that the evaluated entity really contains deficient code. This can result in many false positive and false negative results.
If we assume that a class that exceeds the threshold value of at least one of the evaluated software metrics is rated as poor, the number of potentially deficient classes would be very large. This can be seen from
Table 3,
Table 4 and
Table 5. For the purposes of studying the reliability and occurrence of false positive and false negative results, we selected 40 software classes in the programming language Java for another expert judgment with 6 other Java experts with multiple years of experiences. Detailed profiles of the participants are presented in
Table 15 and are similar to the profiles of participants in the previously presented assessment. The process of assessment was the same as previously described in
Section 5, but the quality evaluation of the chosen software classes that experts assessed was based on an individual software metric. They were asked to determine if a class contained a deficient source code. If yes, it should be evaluated as poor, otherwise as good.
The results of expert judgment that confirms or rejects the proposed evaluation of overall quality which is based on an individual software metric, are presented in
Table 16. Among 40 classes the evaluation of overall quality was confirmed for 21 classes, where 14 classes were evaluated as poor and 7 as good. The results were transferred to the confusion matrix presented in
Table 17. Sixteen classes were identified as false positive and 3 classes as false negatives.
Table 17 also presents the calculated values of accuracy, which is 52.5%; precision, with 46.7%; and recall which is 82.4%. The F-Measure is calculated as 59.6%.
If we compare the results in
Table 17, that represent measures based on an evaluation with an individual software metric, with the results in
Table 14 that presents measures based on an evaluation with the proposed approach, we can see that software metrics combined into quality aspects and rated according to the majority function provide a more reliable identification of deficient source code than an evaluation based on individual software metrics. This can also be seen from the numbers in the confusion matrix, as well as by comparing the F-Measure that increased from 59.6% to 100%. In addition, most importantly, the number of identified false positive cases dropped significantly using the proposed approach, as the precision of identification deficient classes increased from 46.7% to 100%.
6. Limitations
Despite careful planning of the presented study and its previous research, the results can be affected by different factors. Hereinafter, the limitations and potential threats to validity are presented.
The study was limited to object-oriented programming languages and evaluating quality at the class level. We did not identify specific types of code smells defined by Fowler et al. [
3] and classified by Mantyla et al. [
59], but deficient source code in general. We are aware of the definitions of different code smells and their detection, but since they are not unified they were not used in the presented study. We identified classes as poor or good, where poor classes are classes that are exposed to a high risk for containing deficient source code.
The results can be affected by the derived threshold values of the software metrics. We calculated thresholds by ourselves, using a carefully selected method, systematically collected benchmark data and a single tool used for collecting metric values. The results can also depend on the chosen software metrics that evaluate each quality aspect.
Calculated F-Measure , accuracy, precision and recall may be affected by the selection of software classes. Two different expert judgments were performed in order to evaluate the proposed novel identification approach. Number of identified potentially deficient classes differ if a majority rule is applied on a combination of software metrics or identification is based on an individual software metric. For example, within Alfresco Repository, 441 out of 3314 classes were identified as potentially deficient, when considering the combination of all software metrics, which were evaluated as poor when applying the majority function. On the other hand, 2293 out of 3314 classes were identified as potentially problematic when evaluation was done using an individual software metric. Since each expert judgment assessed only a subset of identified classes using a certain approach, the used program entities vary.
The execution and results of the expert judgment can also be influenced by the expertise of the participating experts. Since we chose experts with many years of experience, we do not doubt their knowledge. However, the bias was also limited by forming a different pair within the participating assessors.





{kind=link}