Business Process Configuration According to Data Dependency Specification

 , and
, and
Abstract
:1. Introduction
2. Detailing an Example
- To find the input of the activities that optimize the trip by means of minimizing the price: The process has to provide customers with various possibilities of trips with flights, hotel and car rental (if necessary), while taking into account the existing combinations between a set of possible dates and airports. In addition, there is an objective function to optimize which selects only one of all the possible combinations obtained by the process. An evaluation and a proposal of this part of the problem is analyzed in [15].
- To obtain an imperative model that minimizes the execution time of the BP taking into account the data dependencies: Although the activities to enjoy during the trip are: “take a car to go to the airport”, “catch the flight” and “arrive to the hotel”, the process of booking each part of the trip does not have to follow the same sequence. If the input data of each activity were known, all the activities related to the provider could be executed in parallel. The problem arises when certain activity inputs are related to other activity outputs, or when the activities are executed or not depending on the information obtained from activities executed previously. The objective of this paper is the use of Artificial Intelligence techniques based on Constraint Programming in order to create an imperative model where the data dependencies are taken into account to minimize the execution time of each instance. For example, it is possible for a flight to arrive at its destination on a different day to when it takes off (overseas route), and therefore the check-in date in the hotel cannot be determined until this information is known. The question is: how to configure a business process formed by these activities to minimize the execution time of the instances? This implies the analysis of every combination of activities and to select the control flow gates that relate them.
3. Related Work
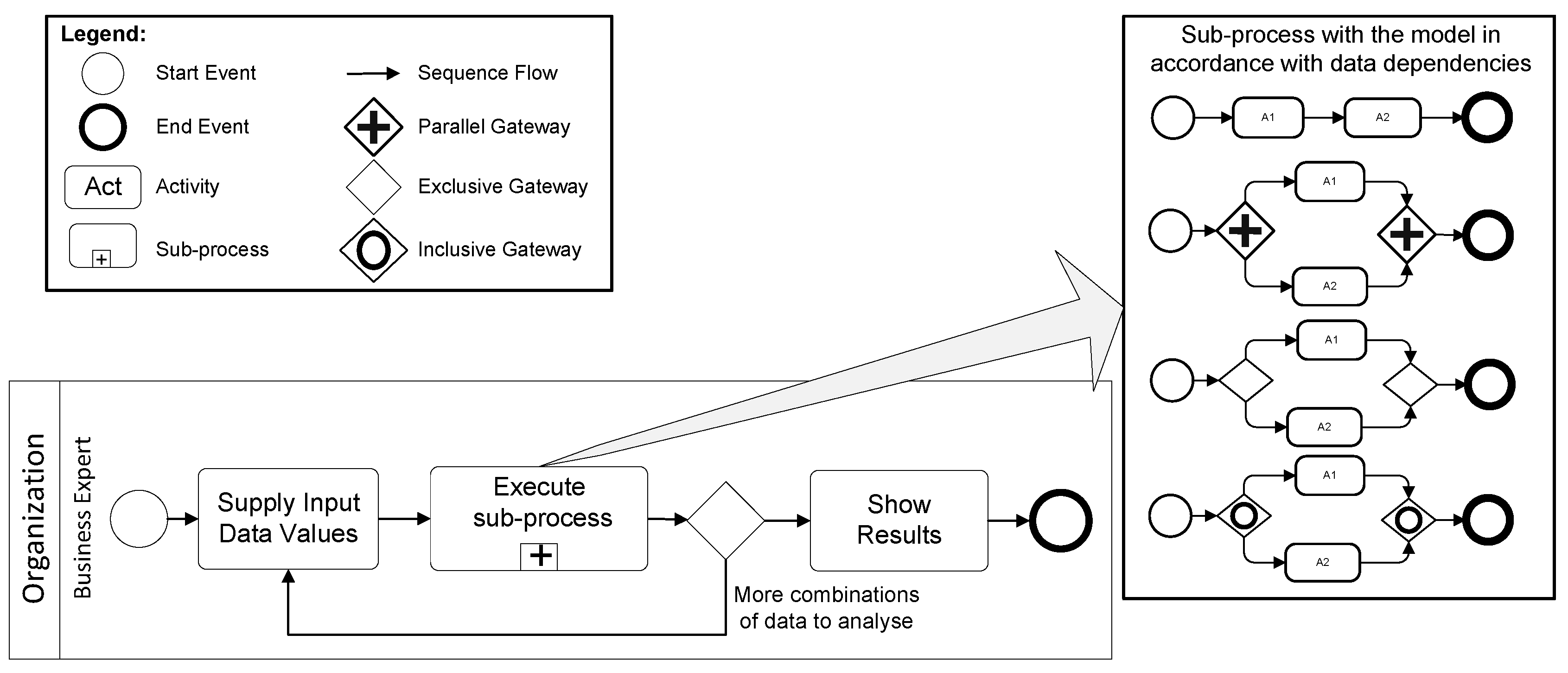
4. Conf-BP Framework: A Configurable System to Create Imperative BP
4.1. Conf-BP Declarative Specification (ConfD-BP). A Formalization of the Language
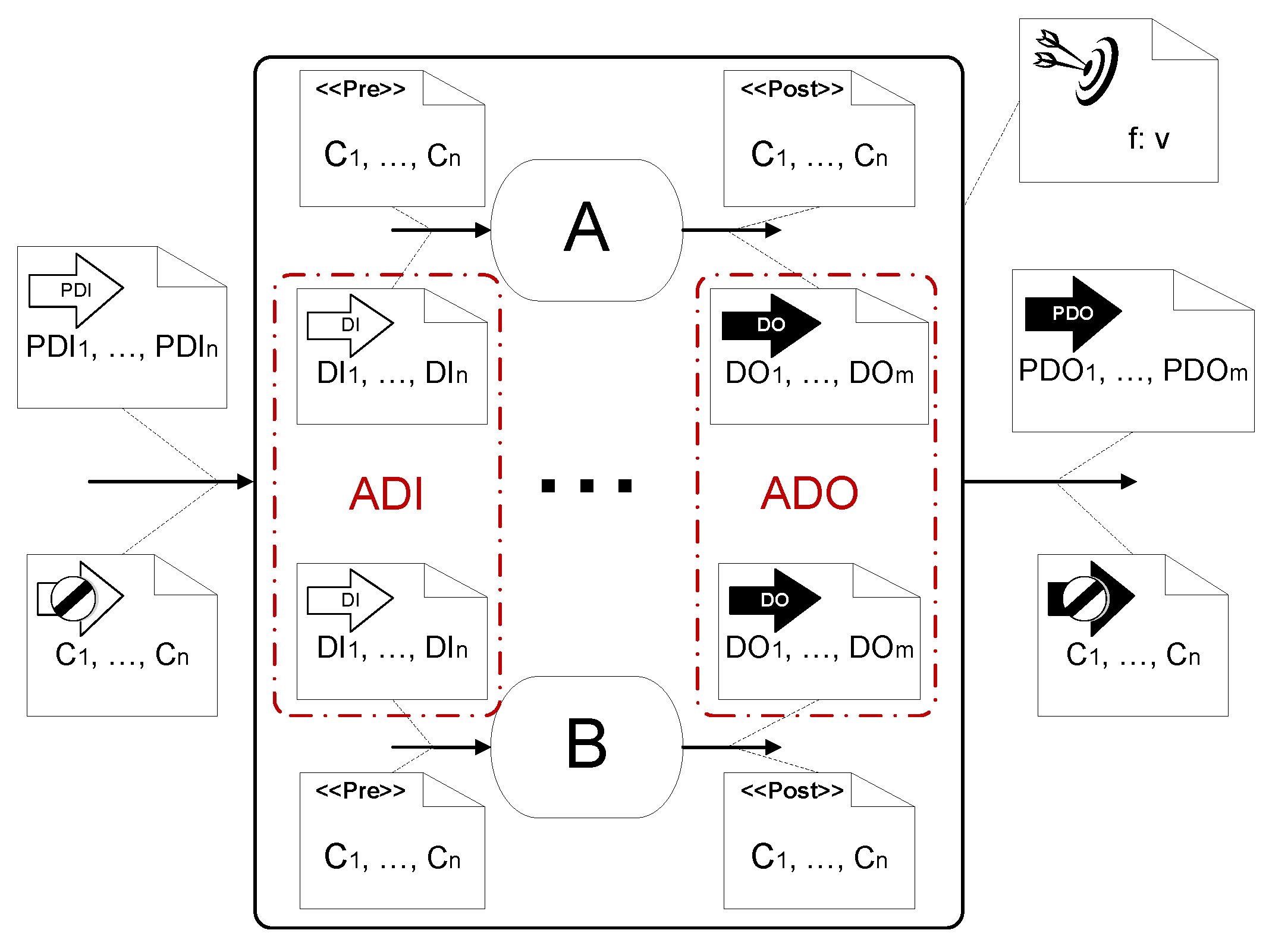
4.1.1. Sub-Process Description
4.1.2. Sub-Process Relationships
4.1.3. Grammar
Constraint := ’IF’ General_Constraint’THEN’ General_Constraint| General_ConstraintGeneral_Constraint :_ Atomic_Constraint BOOL_OP General_Constraint| Atomic_Constraint| ‘¬’ Constraint| Variable SET_FUNCTION SetBOOL_OP:= ‘∨’ | ‘∧’SET_FUNCTION:= ‘∈’ | ‘∉’Atomic_Constraint:= function PREDICATE functionfunction:= Variable FUNCTION_SYMBOL function| Variable| ConstantPREDICATE:= ‘=’ | ‘≠’ | ‘<’ | ‘≤’ | ‘>’ | ‘≥’{For the String domain only ‘=’ and ‘≠’ are allowed }FUNCTION_SYMBOL:= ‘+’ | ‘−’ | ‘*’ | ‘/’{These operators are only applicable to Numerical variables}
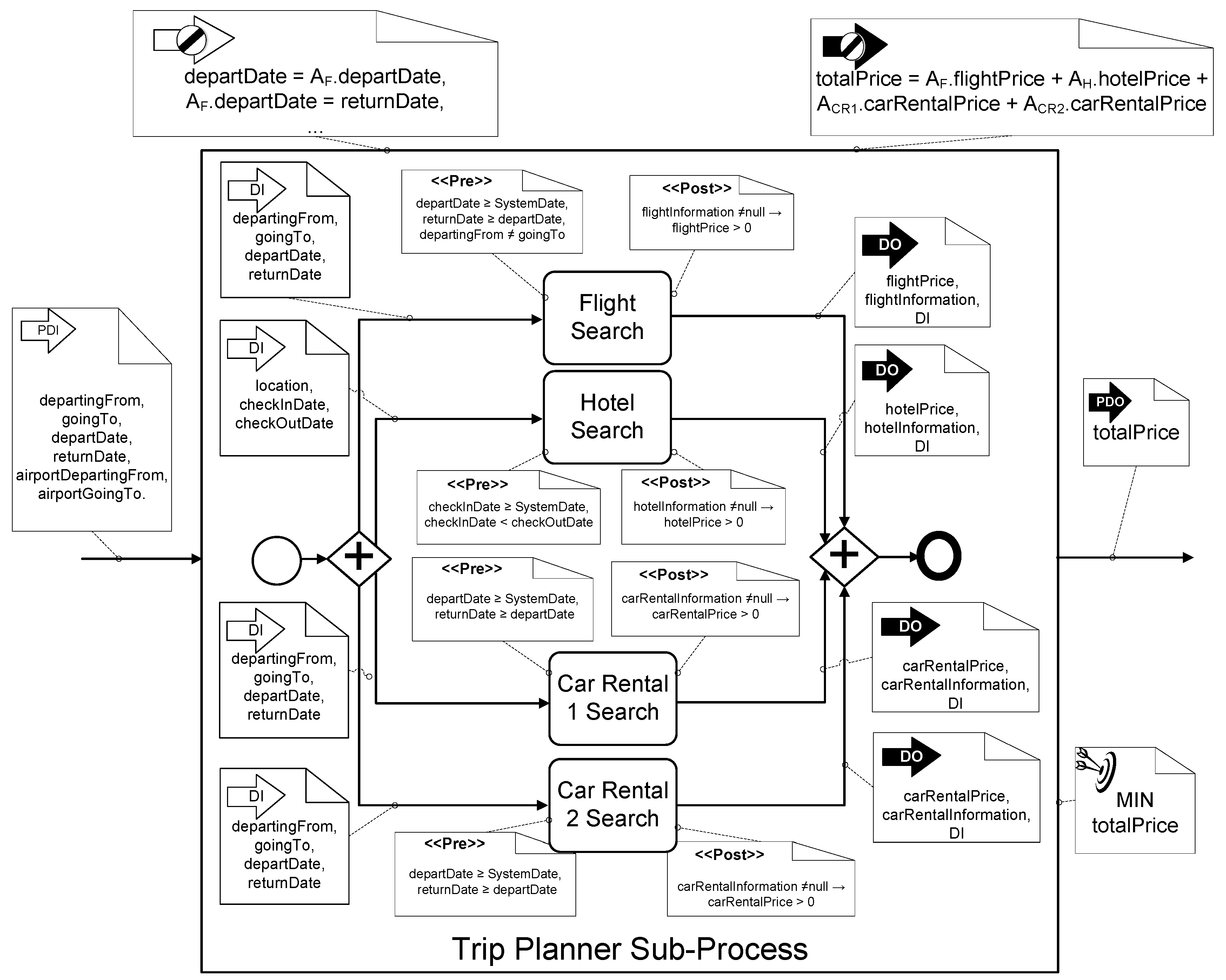
4.1.4. Specification Applied to the Trip Planner Example
- departingFrom: city from where the customer departs.
- goingTo: destination city.
- departDate: the day that the customer prefers to depart.
- returnDate: the day that the customer prefers to return.
- airportDepartingFrom: the departure airport to catch the flight.
- airportGoingTo: the arrival airport for the flight.
- Flight Search Activity () returns the price of flights for a tuple of values for the data input.= {departingFrom, goingTo, departDate, returnDate}= {flightPrice, flightInformation, } where flightInformation = {outwardArrivalDate, returnArrivalDate, seat, number, …}The pre- and post-conditions of the activity A are:==
- Hotel Search Activity () is employed to ascertain the cost of booking a hotel room.= {location, checkInDate, checkOutDate}= {hotelPrice, hotelInformation, }The pre- and post-conditions of the activity A are:==
- Car Rental Search Activities ( and ) are employed to determine the price of renting a car. Two cars can be rented during the trip, one at the source () and another at the destination (). Nevertheless, the price of renting both cars is represented by , where , depends on these entries:= {departingFrom, goingTo, departDate, returnDate}= {carRentalPrice, carRentalInformation, }The pre- and post-conditions of the activity A are:==
- :
- -
- The constraints that establish the values of departure date () and return date () of the flights have to coincide with the input data proposed by the customer.
- -
- The constraints that describe the values of the departure airport () and arrival airport () of the flight have to coincide with the input data proposed by the customer.
- -
- The date of check-in into the hotel should coincide with the arrival date of the outward flight ().
- -
- If the flight does not depart from the departure location (), then the rental of a car () is necessary.
- -
- If the flight arrives at the destination city , then it is not necessary to rent a car at the destination city.
- -
- If the flight does not depart from the departure location (), then the rental of a car () is necessary.
- :
- -
- The total price is the sum of all the prices returned by the activities, as presented in constraint ().
4.2. Conf-BP Imperative Modelling (ConfM-BP)
4.3. Automatic Transformation from Declarative to Imperative Model
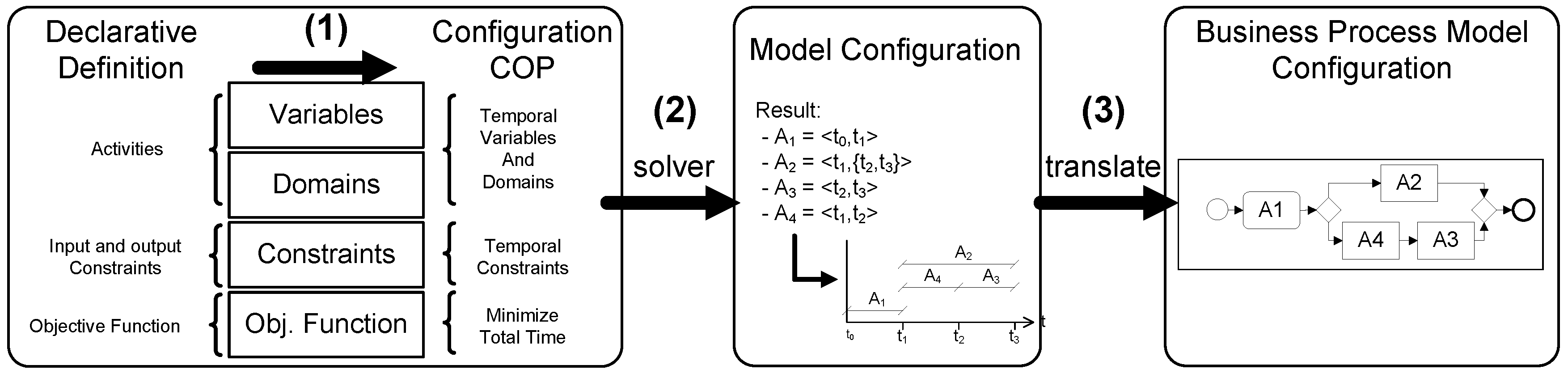
- Create a Constraint Optimization Problem using the declarative Model: As explained in detail in Section 4.3.1, we used Constraint Satisfaction Problems (CSPs) [48] to solve the configuration problem.CSPs represent a reasoning methodology consisting of the representation of a problem by means of a set of variables, domains and constraints. CSPs have also a declarative description, then very similar to the Declarative Specification of ConfD-BP. CSPs are a widely used model-based knowledge representation formalism. In a formal way, it is defined as a tuple 〈X, D, C〉, where {, , …, } is a finite set of variables, {, , …, } is a set of domains of the values of the variables, and {, , …, } is a set of constraints. A constraint specifies the possible values of the variables in that simultaneously satisfy . Let {, , …, } be a subset of X, and an l-tuple (, , …, ) from , , …, can therefore be called an instantiation of the variables in . An instantiation is a solution if and only if it satisfies the constraints C. If an objective function is included in the CSP, it is called a Constraint Optimization Problem (COP). It is necessary to highlight that CSP and COP specifications are very similar to the process models proposed here, since both are declarative models which define the problem but do not solve it. A solver of CSPs or COPs tries to find a possible tuple of values for the variables that satisfy the constraints defined in the domain.
- Solve the COP: To solve the COP created in the second step, it is necessary to analyze the possible values of the variables to find the satisfied tuples. To avoid the analysis of every possibilities of values of variables, the solvers use a combination of search and consistency techniques [49] reducing drastically the complexity and time consuming. The consistency techniques remove inconsistent values from the domains of the variables during or before the search. Several local consistency and optimization techniques have been proposed as ways of improving the efficiency of search algorithms. There are several commercial constraint problem solvers. The main difference between them is the programming language that they use, and the types of constraints that can be included. For the proof of concept to validate the configuration problem, we have used JsolverTM [50], although any of the existing CSP solvers could be used, since the constraints that we need to include (explained in Section 4.3.1) are very common and supported by every commercial solvers. The resolution of the COP will obtain a set of time intervals, each of them associated with an activity, representing the moment when each activity can start and end.
- Translate the COP solution into a BPMN Model: As explained in detail in Section 4.3.2, by using the results obtained from the COP, the imperative model can be created. This result has to be interpreted as gateways that relate the activities. For example, if the COP allows that two activities A and B could start at the same instant of time, perhaps there is a constraint which states that only one activity can be executed in each instance. In that case, there can be an exclusive or inclusive gateway relating the two activities. The decision between the possible gateways between the various activities is based on: (a) the study of the domains of the data related in the declarative problem description, and; (b) the data obtained from the resolution of the COP as it is explained in Section 4.3.2.
4.3.1. Configuration of a BP Model: Creating a COP from the Declarative Model
- Variables: The possible instants when each activity can be executed, are defined as the tuple of variables , where is the instant of time in which the activity begins, and is the instant of time in which the activity finishes. For each activity , the COP will include a couple of variables . To represent the execution time of the whole process, the variable T is included, that represents the of the last activity executed. If every activities is executed in parallel, T will be the maximum value of , but if every activities are executed sequentially, the value of T will be the summation of every .
- Domain: The domain of the and variables is related to the execution time of each activity. If we suppose that each activity spends units of time, then the domain of each variable is:
- -
- : 0..
- -
- : ..
- -
- T: max()..
- Constraints: The necessary constraint to model the COP are:
- -
- It is mandatory that for every activity , ≤
- -
- T has to be the greatest value of t, then T ≥ for every A.
- -
- For each element of the list of tuples building by using the data relations, a numerical constraint is included in the COP. Each relation between data input and output in the way 〈c, , 〉 is translated into the constraint ≥ . For example, in the trip planner, the constraint is translated into . Therefore, all the activities could start at the same instant unless there exists a relationship requiring one activity to start after another.
- Objective: The optimization function of the COP is the minimization of the total time, it implies to minimize the value of T (minimization(T)).
| Algorithm 1 Creation of a COP from a Declarative Specification. |
|
4.3.2. Transformation of the COP results into a BP Imperative Model
- (R1) , ,
- (R2) , ,
- (R3) , ,
- (R4) , ,
- (R5) ,
- (R6) , ,
- (R7) ,
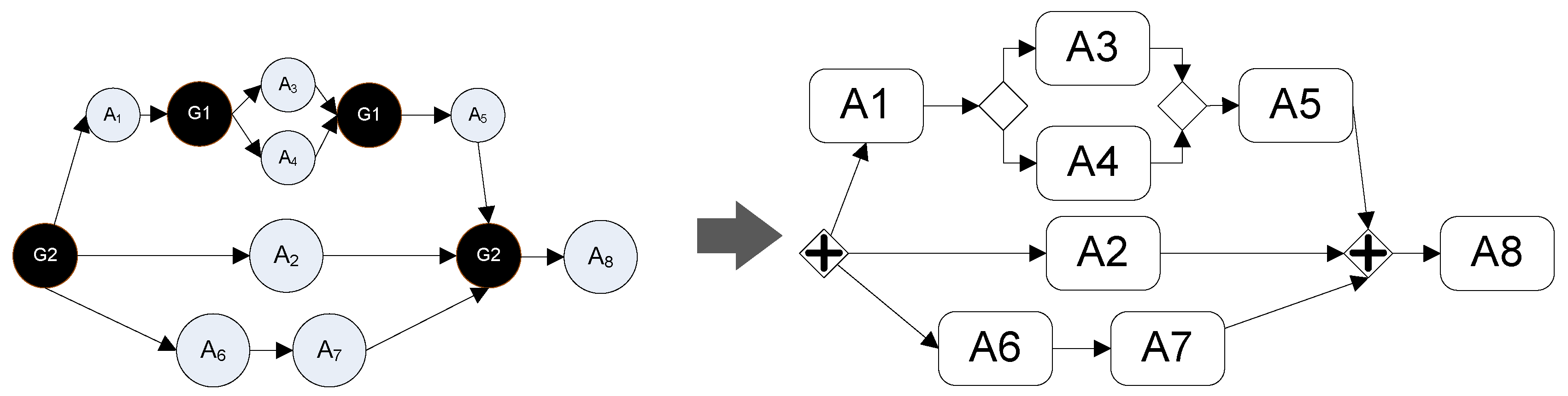
- Look for sequential points: Firstly, the set of activities should be separated by the sequential points (arrow 1 in Figure 8). The separation is carried out by detecting those instants of time where there is a sequential point. The intervals that are derived from these sequential points delimit the subset of activities. In the example, the set of activities is separated into two subsets of activities, since there is only one sequential point in . The first subset goes from to and includes all activities except activity . On the other hand, the second subset goes from to and only includes activity .
- Solving sequential sub-problems: Each subset of activities is solved as a sub-problem (arrows 2 and 3) and combined sequentially both BPMN-sub-graphs are solved.
- Look for parallel subsets: The is separated in three parallel subsets: , and . To obtain these subsets, the idea described in Definition 10 is applied:
- (a)
- Create a subset of each activity: {: {}, : {}, : {}, : {}, : {}, : {}, : {}}.
- (b)
- Since is related with in , and with in , both subsets are merged. Also, and are related in . The obtained parallel subsets are: {: {, , }, : {}, : {}, : {, }}.
- (c)
- Since is related with in , and with in , both subsets are merged. Therefore, the parallel subsets: {: {, , , }, : {}, : {, }} are also obtained.
- (d)
- Tuple relations and are not used in the creation of subsets since is not involved in the parallel analysis.
- Solving parallel sub-problems: The next step implies to solve each sub-problem (arrows 4, 5 and 6), followed by the search of sequential points.
- Combining parallel sub-problems: To solve it is necessary to combine the sub-graphs obtained by solving , and (return of arrow 4, 5 and 6). These BPMN-sub-graphs are combined as various branches joined by a split and join node ( in the example).
- Combining sequential sub-problems: The obtained results after a sequential analysis of sub-graphs (returns of arrow 2 and 3) implies joining the results of and . To this end, the result (BPMN-Graph) of and are joined by an edge between the final vertex of and the initial vertex of , which are and respectively.
| Algorithm 2 Create a BP model from COP result. |
|
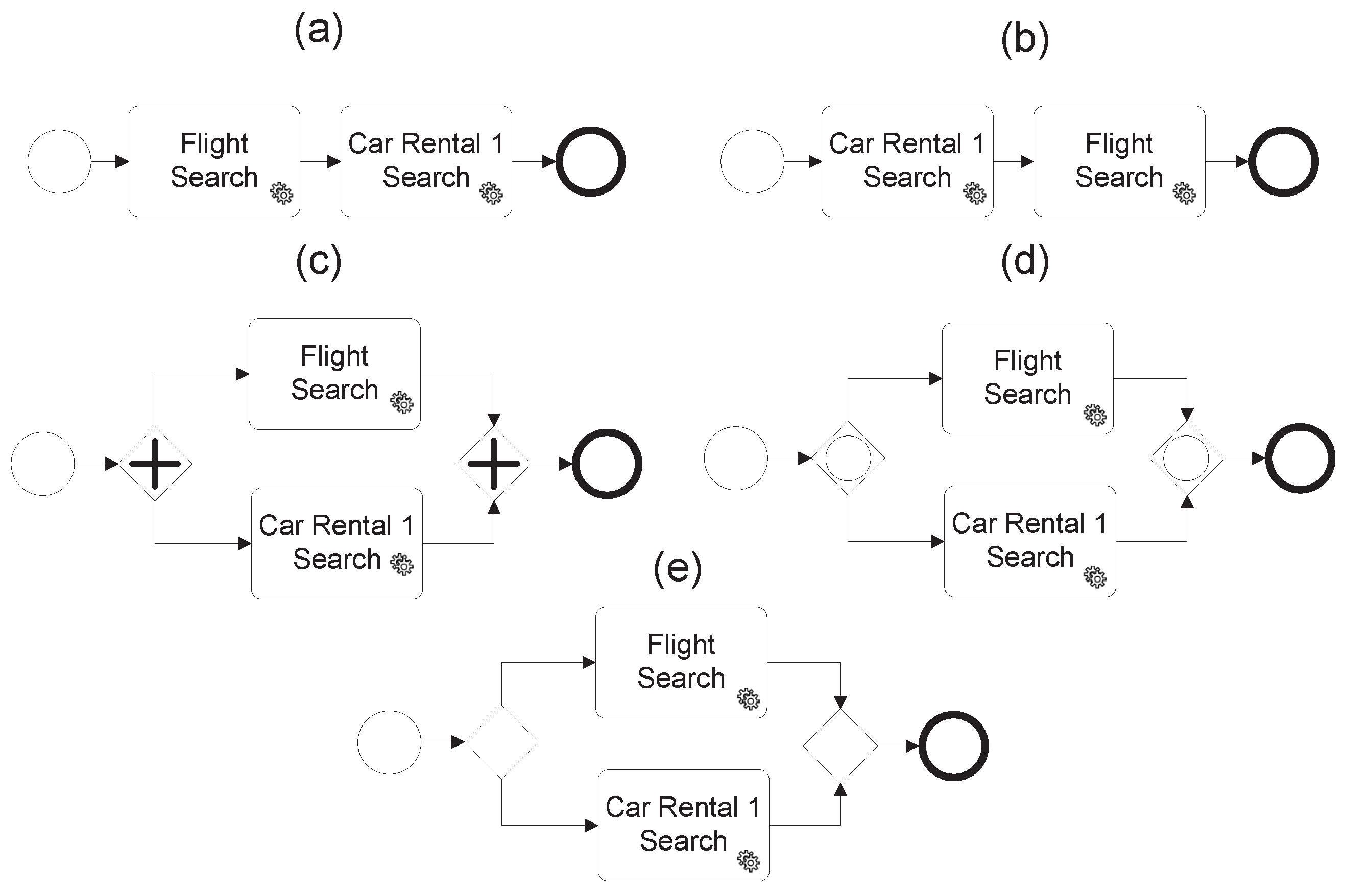
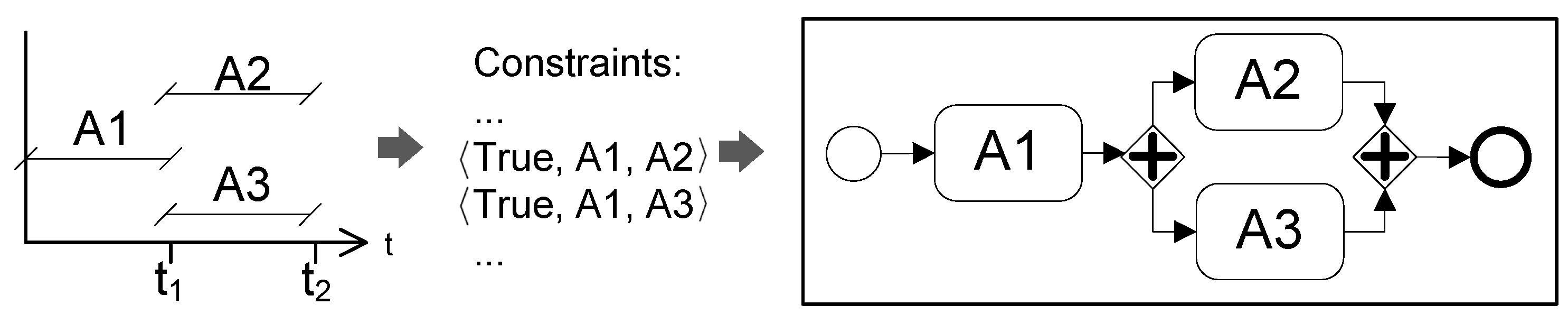
- Parallel: two activities are executed in a parallel way if there are no conditions that relate the of both activities (see Figure 9).
- Exclusive: two activities are executed in an exclusive way if the constraints that relate the of the two activities and the domain of these constraints are complete and do not overlap. For example, as shown in Figure 10, if the execution of and depends on a value of the output data , but there are no overlaps ( is executed when is less than 50 and is executed when is greater than or equal to 50), then there is an exclusive relationship between them. There is another possibility when only one condition is described, for example only exists the condition ( is executed when is less than 50), in that case it means that there are two branches for the XOR gateway, but one of them with no activities.
- Inclusive: two activities are executed in an inclusive way if there are conditions that relate the of both activities, and the domain of these conditions are complete and overlapped. For example, as shown in Figure 11, if the execution of and depends on a value of the output data , but there are overlaps between the domains that satisfy the constraints ( is executed when is less than 75 and is executed when is greater or equal to 25, and hence both coincide when is greater than 25 and less than 75), then there is an inclusive relationship.
5. Results: Transformation Applied to the Trip Planner Example
- Variables:, , , , , , , , T.
- Domain: Supposing that the theoretical execution time of each activity is a unit of time, the domains are:
- -
- , , , : 0..3 //Since there are 4 different activities.
- -
- , , , : 1..4
- -
- T: 1..4
- Constraints:
- -
- ≤
- -
- ≤
- -
- ≤
- -
- ≤
- -
- T ≥ ∧ T ≥ ∧ T ≥ ∧ T ≥
- -
- For the list of tuples of Condition-Relation mentioned above, the constraints included in the COP are:
- ∗
- ≥
- ∗
- ≥
- Goal:, , ,
- Objective: minimization(T).
- : 2
- : 0 and : 1
- : 1 and : 2
- : 0 and : [1..2], selecting the greatest value (2).
- : 1 and : 2
Empirical Evaluation
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ADI | Activities Data Input |
| ADO | Activities Data Output |
| BP | Business Process |
| BPEL | Business Process Executation Language |
| BPM | Business Process Management |
| BPMN | Business Process Model and Notation |
| BPMS | Business Process Management System |
| Conf-BP | Configuration of Activities in Business Processes |
| ConfD-BP | Conf-BP Declarative Specification |
| ConfM-BP | Conf-BP Imperative Modelling Specification |
| COP | Constraint Optimization Problem |
| CSP | Constraint Satisfaction Problem |
| OBJ_FUNC | Objective Function |
| PDI | Process Data Input |
| PDO | Process Data Output |
References
- Weske, M. Business Process Management: Concepts, Languages, Architectures; Springer: Berlin, Germany, 2007. [Google Scholar]
- Aguilar-Saven, R.S. Business process modelling: Review and framework. Int. J. Prod. Econ. 2004, 90, 129–149. [Google Scholar] [CrossRef] [Green Version]
- Tsai, A.; Wang, J.; Tepfenhart, W.; Rosea, D. EPC Workflow Model to WIFA Model Conversion. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, SMC ’06, Taipei, Taiwan, 8–11 October 2006; Volume 4766/2007, pp. 2758–2763. [Google Scholar]
- Sinogas, P.; Vasconcelos, A.; Caetano, A.; Neves, J.; Mendes, R.; Tribolet, J.M. Business Processes Extensions to UML Profile for Business Modeling. ICEIS 2001, 2, 673–678. [Google Scholar]
- List, B.; Korherr, B. A UML 2 Profile for Business Process Modelling. In Proceedings of the ER (Workshops), Klagenfurt, Austria, 24–28 October 2005; pp. 85–96. [Google Scholar]
- Bosilj-Vuksic, V.; Hlupic, V. Petri Nets and IDEF diagrams: Applicability and efficacy for business process modelling. Int. J. Comput. Inform. 2001, 25, 123–133. [Google Scholar]
- Pichler, P.; Weber, B.; Zugal, S.; Pinggera, J.; Mendling, J.; Reijers, H.A. Imperative versus Declarative Process Modeling Languages: An Empirical Investigation. In Business Process Management Workshops; Lecture Notes in Business Information Processing; Springer: Berlin, Germany, 2011; Volume 99, pp. 383–394. [Google Scholar]
- Zugal, S.; Soffer, P.; Haisjackl, C.; Pinggera, J.; Reichert, M.; Weber, B. Investigating expressiveness and understandability of hierarchy in declarative business process models. Softw. Syst. Model. 2015, 14, 1081–1103. [Google Scholar] [CrossRef]
- Fahland, D.; Lubke, D.; Mendling, J.; Reijers, H.; Weber, B.; Weidlich, M.; Zugal, S. Declarative versus Imperative Process Modeling Languages: The Issue of Understandability. In Enterprise, Business-Process and Information Systems Modeling; Lecture Notes in Business Information Processing; Springer: Berlin/Heidelberg, Germany, 2009; Volume 29, pp. 353–366. [Google Scholar]
- Fahland, D.; Mendling, J.; Reijers, H.; Weber, B.; Weidlich, M.; Zugal, S. Declarative versus Imperative Process Modeling Languages: The Issue of Maintainability. In Business Process Management Workshops; Lecture Notes in Business Information Processing; Springer: Berlin/Heidelberg, Germany, 2010; Volume 43, pp. 477–488. [Google Scholar]
- Sadiq, S.W.; Orlowska, M.E.; Sadiq, W. Specification and validation of process constraints for flexible workflows. Inf. Syst. 2005, 30, 349–378. [Google Scholar] [CrossRef]
- Rychkova, I.; Regev, G.; Wegmann, A. High-level design and analysis of business processes: The advantages of declarative specifications. In Proceedings of the Second International Conference on Research Challenges in Information Science, RCIS 2008, Marrakech, Morocco, 3–6 June 2008; Pastor, O., Flory, A., Cavarero, J.L., Eds.; pp. 99–110. [Google Scholar]
- Pesic, M.; van der Aalst, W.M.P. A Declarative Approach for Flexible Business Processes Management. In Business Process Management Workshops; Lecture Notes in Computer Science; Eder, J., Dustdar, S., Eds.; Springer: Berlin, Germany, 2006; Volume 4103, pp. 169–180. [Google Scholar]
- Rychkova, I.; Regev, G.; Wegmann, A. Using Declarative Specifications in Business Process Design. IJCSA 2008, 5, 45–68. [Google Scholar]
- Parody, L.; Gómez-López, M.T.; Gasca, R.M. Hybrid business process modeling for the optimization of outcome data. Inf. Softw. Technol. 2016, 70, 140–154. [Google Scholar] [CrossRef]
- Van der Aalst, W.M.P. Process Mining: Data Science in Action, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Fernández-Cerero, D.; Fernández-Montes, A.; Jakóbik, A.; Kołodziej, J.; Toro, M. SCORE: Simulator for cloud optimization of resources and energy consumption. Simul. Model. Pract. Theory 2018, 82, 160–173. [Google Scholar] [CrossRef]
- Teppan, E.C.; Friedrich, G. The Partner Units Configuration Problem. arXiv, 2013; arXiv:1308.6206. [Google Scholar]
- GröNer, G.; BošKović, M.; Silva Parreiras, F.; GašEvić, D. Modeling and Validation of Business Process Families. Inf. Syst. 2013, 38, 709–726. [Google Scholar] [CrossRef]
- Petrie, C.J. Automated Configuration Problem Solving; Springer Publishing Company: New York, NY, USA, 2012. [Google Scholar]
- Gillmann, M.; Mindermann, R.; Weikum, G. Benchmarking and Configuration of Workflow Management Systems. In Cooperative Information Systems; Springer: Berlin/Heidelberg, Germany, 2000; Volume 1901, pp. 186–197. [Google Scholar]
- Van der Aalst, W.M.P.; van Hee, K. Workflow Management: Models, Methods, and Systems; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Czarnecki, K.; Helsen, S.; Eisenecker, U. Formalizing cardinality-based feature models and their specialization. Softw. Process Improv. Pract. 2005, 10, 7–29. [Google Scholar] [CrossRef]
- Gottschalk, F.; van der Aalst, W.M.P.; Jansen-Vullers, M.H.; Rosa, M.L. Configurable Workflow Models. Int. J. Coop. Inf. Syst. 2008, 17, 177–221. [Google Scholar] [CrossRef]
- La Rosa, M.; van der Aalst, W.M.P.; Dumas, M.; ter Hofstede, A.H.M. Questionnaire-based variability modeling for system configuration. Softw. Syst. Model. 2009, 8, 251–274. [Google Scholar] [CrossRef] [Green Version]
- Moon, M.; Hong, M.; Yeom, K. Two-Level Variability Analysis for Business Process with Reusability and Extensibility. In Proceedings of the 2008 32nd Annual IEEE International Computer Software and Applications Conference, Turku, Finland, 28 July–1 August 2008; pp. 263–270. [Google Scholar]
- Reijers, H.; Mans, R.; van der Toorn, R. Improved model management with aggregated business process models. Data Knowl. Eng. 2009, 68, 221–243. [Google Scholar] [CrossRef]
- Kumar, A.; Yao, W. Design and management of flexible process variants using templates and rules. Managing Large Collections of Business Process Models. Comput. Ind. 2012, 63, 112–130. [Google Scholar] [CrossRef]
- Baran, M.; Kluza, K.; Nalepa, G.J.; Ligęza, A. A hierarchical approach for configuring business processes. In Proceedings of the 2013 Federated Conference on Computer Science and Information Systems, Krakow, Poland, 8–11 September 2013; pp. 915–921. [Google Scholar]
- Albert, P.; Henocque, L.; Kleiner, M. An End-to-End Configuration-Based Framework for Automatic SWS Composition. In Proceedings of the 20th IEEE International Conference on Tools with Artificial Intelligence, Dayton, OH, USA, 3–5 November 2008; Volume 1, pp. 351–358. [Google Scholar]
- Bertoli, P.; Pistore, M.; Traverso, P. Automated composition of Web services via planning in asynchronous domains. Artif. Intell. 2010, 174, 316–361. [Google Scholar] [CrossRef]
- Mesmoudi, A.; Mrissa, M.; Hacid, M.S. Combining configuration and query rewriting for Web service composition. In Proceedings of the IEEE International Conference on Web Services (ICWS), Washington, DC, USA, 4–9 July 2011; pp. 113–120. [Google Scholar]
- Drescher, C. The Partner Units Problem a Constraint Programming Case Study. In Proceedings of the IEEE 24th International Conference on Tools with Artificial Intelligence, ICTAI 2012, Athens, Greece, 7–9 November 2012; pp. 170–177. [Google Scholar]
- Mittal, S.; Frayman, F. Towards a Generic Model of Configuraton Tasks. In Proceedings of the 11th International Joint Conference on Artificial Intelligence, San Francisco, CA, USA, 20–26 August 1989; Volume 2, pp. 1395–1401. [Google Scholar]
- Rosa, M.L.; Dumas, M.; ter Hofstede, A.H.M.; Mendling, J. Configurable multi-perspective business process models. Inf. Syst. 2011, 36, 313–340. [Google Scholar] [CrossRef] [Green Version]
- Van der Aalst, W.M.P.; Dumas, M.; Gottschalk, F.; ter Hofstede, A.H.M.; Rosa, M.L.; Mendling, J. Correctness-Preserving Configuration of Business Process Models. In Proceedings of the 11th International Conference on Fundamental Approaches to Software Engineering, FASE 2008, Budapest, Hungary, 29 March–6 April 2008; Held as Part of the Joint European Conferences on Theory and Practice of Software, ETAPS 2008; Lecture Notes in Computer Science. Fiadeiro, J.L., Inverardi, P., Eds.; Springer: Berlin, Germany, 2008; Volume 4961, pp. 46–61. [Google Scholar]
- Rosemann, M.; van der Aalst, W.M.P. A configurable reference modelling language. Inf. Syst. 2007, 32, 1–23. [Google Scholar] [CrossRef]
- Vanderfeesten, I.; Reijers, H.A.; van der Aalst, W.M. Product-based workflow support. Inf. Syst. 2011, 36, 517–535. [Google Scholar] [CrossRef]
- Vanderfeesten, I.T.P.; Reijers, H.A.; van der Aalst, W.M.P. Product Based Workflow Support: Dynamic Workflow Execution. Lecture Notes in Computer Science. In Proceedings of the 20th International Conference on Advanced Information Systems Engineering, CAiSE 2008, Montpellier, France, 16–20 June 2008; Bellahsene, Z., Léonard, M., Eds.; Springer: Berlin, Germany, 2008; Volume 5074, pp. 571–574. [Google Scholar]
- Kluza, K.; Honkisz, K. From SBVR to BPMN and DMN Models. Proposal of Translation from Rules to Process and Decision Models. In Artificial Intelligence and Soft Computing; Rutkowski, L., Korytkowski, M., Scherer, R., Tadeusiewicz, R., Zadeh, L.A., Zurada, J.M., Eds.; Springer International Publishing: New York, NY, USA, 2016; pp. 453–462. [Google Scholar]
- Object Management Group (OMG). Semantics of Business Vocabulary and Business Rules (SBVR); Version 1.4: Formal Specification; OMG: Needham, MA, USA, 2017. [Google Scholar]
- Natschläger, C.; Kossak, F.; Schewe, K.D. Deontic BPMN: A powerful extension of BPMN with a trusted model transformation. Softw. Syst. Model. 2015, 14, 765–793. [Google Scholar] [CrossRef]
- Wiśniewski, P.; Kluza, K.; Ligęza, A. An Approach to Participatory Business Process Modeling: BPMN Model Generation Using Constraint Programming and Graph Composition. Appl. Sci. 2018, 8, 1428. [Google Scholar] [CrossRef]
- Borrego, D.; Eshuis, R.; López, M.T.G.; Gasca, R.M. Diagnosing correctness of semantic workflow models. Data Knowl. Eng. 2013, 87, 167–184. [Google Scholar] [CrossRef]
- Vanhatalo, J.; Völzer, H.; Leymann, F.; Moser, S. Automatic Workflow Graph Refactoring and Completion. In Proceedings of the Service-Oriented Computing–ICSOC 2008, Sydney, Australia, 1–5 December 2008; Bouguettaya, A., Krueger, I., Margaria, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 100–115. [Google Scholar]
- Hasanov, E. Enhancing BPMN Conformance Checking with OR Gateways and Data Objects. Ph.D. Thesis, University of Tartu, Tartu, Estonia, 2017. [Google Scholar]
- Object Management Group (OMG). Business Process Model and Notation (BPMN) Version 2.0; Object Management Group Standard; OMG: Needham, MA, USA, 2011. [Google Scholar]
- Rossi, F.; van Beek, P.; Walsh, T. Handbook of Constraint Programming (Foundations of Artificial Intelligence); Elsevier Science Inc.: New York, NY, USA, 2006. [Google Scholar]
- Dechter, R. Constraint Processing; Elsevier Morgan Kaufmann: Burlington, MA, USA, 2003; Available online: https://www.ibm.com/es-es/marketplace/ibm-ilog-cplex (accessed on 20 October 2018).
- Manual, R. JSolver 2.1. Available online: https://www.ibm.com/es-es/marketplace/ibm-ilog-cplex (accessed on 24 February 2014).
- Gómez López, M.T.; Gasca, R.M.; Pérez-Álvarez, J.M. Decision-Making Support for the Correctness of Input Data at Runtime in Business Processes. Int. J. Coop. Inf. Syst. 2014, 23, 1450003. [Google Scholar] [CrossRef]
- Cheeseman, P.; Kanefsky, B.; Taylor, W.M. Where the Really Hard Problems Are; IJCAI; Mylopoulos, J., Reiter, R., Eds.; Morgan Kaufmann: Burlington, MA, USA, 1991; pp. 331–340. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Declarative | COP |
|---|---|
| Activity | |
| PDI, ADI, PDO, ADO | Variables |
| Numerical Constraints (Input and Output Constraints) | Temporal Constraints |
| Pre and Post Conditions | Activity Definition |
| Objective Function | Minimize Total Time |
| Gateway | Constraints Conditions |
|---|---|
| Parallel | No dependencies in domains |
| Exclusive | Domains without overlaps |
| Inclusive | Domains with overlaps |
| Test | Num. of Activities | Num. of | Num. of Constraints |
|---|---|---|---|
| Test 1–10 | 10 | [5–15] | [10–30] |
| Test 11–20 | 100 | [5–15] | [10–30] |
| Test 21–30 | 1000 | [10–25] | [20–50] |
| Test 31–40 | 5000 | [10–25] | [20–50] |
| Test 41–50 | 10,000 | [10–25] | [20–50] |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Parody, L.; Gómez-López, M.T.; Varela-Vaca, A.J.; Gasca, R.M. Business Process Configuration According to Data Dependency Specification. Appl. Sci. 2018, 8, 2008. https://doi.org/10.3390/app8102008
Parody L, Gómez-López MT, Varela-Vaca AJ, Gasca RM. Business Process Configuration According to Data Dependency Specification. Applied Sciences. 2018; 8(10):2008. https://doi.org/10.3390/app8102008
Chicago/Turabian StyleParody, Luisa, María Teresa Gómez-López, Angel Jesús Varela-Vaca, and Rafael M. Gasca. 2018. "Business Process Configuration According to Data Dependency Specification" Applied Sciences 8, no. 10: 2008. https://doi.org/10.3390/app8102008
APA StyleParody, L., Gómez-López, M. T., Varela-Vaca, A. J., & Gasca, R. M. (2018). Business Process Configuration According to Data Dependency Specification. Applied Sciences, 8(10), 2008. https://doi.org/10.3390/app8102008