1. Introduction
Path planning (PP) has been fundamental in many areas in recent decades, for instance mobile robots [
1,
2,
3], unmanned surface vehicles (USVs) [
4,
5], wireless sensor networks (WSNs) [
6,
7,
8] and video games [
9]. For mobile robots, path planning is devised to find one or more feasible routes from the initial location to the target in a given workspace. The related algorithms in the field of path planning are reviewed in [
10,
11]. In [
12], several path planning and navigation algorithms commonly employed in the domain of unmanned aerial vehicles (UAVs) were studied. The commonly-used methods are the probabilistic roadmap method (PRM) [
13], the artificial potential field method (ARF) [
14], the rapidly-exploring random tree method (RRT) [
15], A* and its variants [
16,
17], and so on. In [
18], the fast marching method (FMM) was applied to the path planning problem. Moreover, the research revealed that the algorithm can successfully attain the collision-free shortest route in many static environments. Most conventional approaches attain available paths and seldom optimize several objectives concurrently.
However, optimization problems in most disciplines should study multiple objectives simultaneously, not just a single one. For example, in the product design process, the cost and quality of the product are often contradictory, that is and decrease in the price of the product and the quality has to decrease, and vice versa. How to decrease the cost of the product and enhance the quality comprise a dual-objective optimization problem. Path planning problems are no exception. In this study, three objectives are presented. Path length is related to the operation time of the mobile robot. Path safety represents the length from the path to the nearest obstacle. Path smoothness indicates the degree of bending of the path. In general, at least two objectives are conflicting.
At present, based on the complexity of the path planning problem, this issue is identified as NP-hard [
19]. Multiple competing goals need to be considered concurrently. Subsequently, common multi-objective weighting methods are employed to solve problems [
20,
21]. The principle of the weighting method is to set the weighting factors of the objectives and combine the targets into a new one. However, because there is no apparent measurable relationship between these objectives, it is difficult to set their weighting factors. In other words, the transformation process itself is also a multi-objective optimization problem. Therefore, the weighting method is not proper. On the other hand, some researchers extended the deterministic heuristic A* algorithm to multi-objective cases [
22,
23,
24]. In these algorithms, the heuristic function of any node in the graph search space is a vector.
In later years, evolutionary algorithms (EA) were universally employed for path planning. A practical framework of multi-objective evolutionary algorithm (MOEA) was designed in [
25]. Besides, several practical evolution operators were presented. To further advance the computational efficiency, in the initial step, some individuals were generated by the Dijkstra algorithm. In [
26], the traditional method was first employed to generate the roadmap in the workspace, and then, the Hopfield neural network was applied to improve path length and safety. In [
27], the modified rapidly-exploring random tree was presented to obtain the path. Then, the path length and smoothness were improved based on the neural network curve post-processing strategy. In [
28], the Q-learning method was developed to optimize the path. A fast two-stage ant colony optimization algorithm was shown in [
29]. This algorithm contained two phases: map preprocessing and ant colony optimization. In the map preprocessing, they calculated the minimum number of steps from all free nodes to the target node. Next, the path length was optimized by the modified ant colony optimization. In [
30], the modified tabu search algorithm was designed for the optimal path length in grid environments. In [
31], path length and smoothness were enhanced by two multi-objective memetic algorithms. In [
32], an intelligent water drop algorithm was proposed to increase the length and safety. An available path was found by the artificial bee colony algorithm in [
33], then the length and smoothness of the obtained path were optimized by evolutionary programming. In [
34], a model of path length and danger degree was solved by the improved particle swarm algorithm. The degree of risk and path length were minimized by particle swarm optimization (PSO) in unknown circumstances [
35]. In [
36], the chaotic particle swarm optimization algorithm was used to enhance the control points of the Bezier curve to reach a short and smooth route. The hierarchical global path planning method was introduced in [
37]. The method designed a three-stage structure to obtain an optimal route. First, a free geometric configuration space was determined with the triangular decomposition method, and then based on the configuration space, the Dijkstra algorithm was utilized to obtain a viable route. Finally, constrained particle swarm optimization was designed to optimize length and smoothness. Similar hierarchical strategies could be found in [
38]. Individuals within the initial population were generated by the surrounding point set algorithm. Then, the length and smoothness were enhanced by the particle swarm optimization algorithm.
In this study, the multi-objective path planning is solved with the improved NSGA-II. The work is shown below:
The framework of the improved NSGA-II is introduced. Several practical evolutionary operators are presented to enhance the feasibility of the route and optimize three objectives (length, smoothness and safety). They can enhance the local search capabilities of the improved NSGA-II.
The parameters in the algorithm are systematically studied. The results show that larger population sizes, larger numbers of generations and high operator probabilities are indispensable in complex environments.
The improved NSGA-II is tested with an existing evolutionary algorithm and different quality metrics. The comparisons show that the non-dominated solutions received via the improved NSGA-II have good characteristics.
The path corresponding to the knee point of non-dominated solutions is shown. The route is shorter, smoother and safer.
The rest of the work is designed below. The associated work is introduced in
Section 2.
Section 3 defines environmental modeling, representation of the path and the objectives that need to be optimized.
Section 4 details NSGA-II and evolutionary operators. The parametric study is presented in
Section 5.
Section 6 exhibits the comparison results. Lastly, the conclusions are displayed in
Section 7.
2. Related Work
Since the advent of the genetic algorithm, it has been favored by many scholars due to its simple operation process and powerful search ability [
39,
40]. Genetic algorithms demonstrate robust optimization performance in various areas [
41,
42,
43]. In path planning, genetic algorithms have also received extensive attention. In [
44], the genetic algorithm was designed to shorten the path length in the grid space. In [
45], the efficiency of probabilistic roadmap (PRM) and genetic algorithm (GA) for attaining a viable route was studied. NSGA-II was employed to optimize path length and clearance in the grid environments [
46]. In [
47], multiple techniques of representing a path in the grid environments were presented. Moreover, NSGA-II was used to improve length, smoothness and safety. A new selection operator was designed to avoid falling into a local trap and premature convergence [
48]. Then, the adaptive method based on GA was designed to optimize path length. In [
49], control points of the Bezier curve were enhanced by NSGA-II to reach the Pareto-optimal solutions. In [
50], an efficient initialization technique based on directed acyclic graphs was proposed. This technique can provide multiple feasible minimum paths for the genetic algorithm, which enhances the computational efficiency of the entire genetic algorithm. In [
51], a viable route was given with the genetic algorithm and then smoothed by the piecewise cubic Hermite interpolation polynomial. In [
52], the environment was converted with a matrix-binary code-based genetic algorithm (MGA). Then, the navigation time and the path length were optimized. Control points of the Bezier curve were optimized with an improved genetic algorithm in [
53]. Then, the optimum smooth path could be selected by choosing these control points. In [
54], an improved crossover operator was designed in static environments. In [
55], NSGA-II was used to improve the clearance and smoothness of the path by optimizing the three parameters obtained by the potential field method. Moreover, the position of the virtual obstacle was redefined for the case where the end point of the path was farther away from the obstacle. This can help the robot safely drive away from obstacles. Finally, a method for identifying obstacles that affect the robot in cluttered environments was presented. As far as we know, genetic algorithms show great vitality in path planning problems. However, due to the existence of obstacles, after using the traditional operators (crossover, mutation), the newly-generated individuals are generally no longer feasible paths. More practical evolutionary operators are needed to further enhance evolution efficiency.
In this study, the path planning problem is resolved with the improved NSGA-II in static environments. Multiple objectives are considered. More practical evolutionary operators are presented. In the remainder of this article, the improved algorithm is proposed in detail.
3. Path Planning Problem
Path planning is to find one or more available paths in the workspace. In this article, statically known environments are considered. That is, all obstacles within the workspace are static, and their location information is entirely known to the robot. The starting location and target of the robot are signified as
S and
T, respectively. Then, path planning is devised to find one or more paths from
S to
T that do not collide with obstacles. Next, the environment modeling, path representation and the three optimization objectives are defined. In this work, two-dimensional space is adopted. Any obstacle is supposed to be an arbitrary polygonal shape. Moreover, a polygon robot can be converted into a single point by using the Minkowski sums in the field of computational geometry [
56]. A path is signified with
.
is the
i-th rotation points (RPs).
and
are connected by straight segments. The representation of a path is shown in
Figure 1. The coordinate of
is denoted as (
).
3.1. Objectives
In this paper, three objectives are introduced: smoothness, safety and length. The energy loss is associated with path smoothness and length. In addition to considering energy loss, the safety of the driving path cannot be ignored. When the distance of the robot from the obstacles during driving is less than the safe range of the sensors, this can be a critical situation, even damaging the robot and the items that are seen as obstacles. Therefore, the farther away from the nearest obstacle, the safer the route. Considering the above factors, the three objectives are designed to enhance the driving route of the robot. This is the multi-objective optimization problem. For convenience, it can be converted into a minimization problem. Next, the mathematical definition of these objectives is presented.
3.1.1. Path Length
The line segment formed by any two points in the space can be calculated based on the Euclidean distance. Thus, for two consecutive rotation points (
,
), the line segment of the points can be computed. Then, the path length can be given by summing all the ordered line segments. The mathematical expression is presented in Equation (
1):
3.1.2. Path Smoothness
Path smoothness denotes the degree of sleekness of the path. The smoother the route, the less energy the robot consumes as it travels along the way. In this paper, it is defined by the average turning angle of the path. The corner formed by two consecutive line segments can be determined. Then, the average turning angle of the route can be calculated by Equation (
2).
3.1.3. Path Safety
Firstly, the secure interval is defined. It is the minimum distance of the path from the nearest obstacle. The barrier set (
) contains all the obstacles in the space; the number is
m.
is the minimum length between the line segment (
) and the obstacle (
). Thus,
is the safe interval. For convenience, the maximum safety interval problem is converted to a minimum problem. The general operation is to add a negative sign before the safe distance to convert the function to a negative number. The safety objective of the path can be expressed by Equation (
3):
At this time, a model of path planning is presented below:
In the above model, the only constraint is that the path does not collide with the obstacle, but it is allowed to reach the edge of the obstacle. If the path intersects the obstacle, then it is not feasible. The edge of the workspace is also regarded as an obstacle.
In general, at least two goals are contradictory. That is to say, one or more other objectives have to be sacrificed while increasing one objective. This problem is a typical multi-objective optimization problem. There is no longer one best solution, but a set of solutions. Moreover, these solutions are non-dominated. In other words, when one or more objectives of one solution are better than the other, there must be at least one or more poor objectives. In recent years, some surpassing evolutionary algorithms have emerged for solving path planning problems. However, due to the complexity and practicality of this issue, many scholars remain interested.
4. NSGA-II for the Multi-Objective Path Planning Problem
NSGA-II is one of the most popular multi-objective genetic algorithms [
40]. It has the advantage of fast running speed and good convergence of solutions. Moreover, it has become the benchmark for evaluating numerous optimization algorithms. NSGA-II is the second generation non-dominated sorting genetic algorithm, and its improvements mainly include three aspects:
A fast non-dominated sorting algorithm is designed, which stratifies the population according to the non-domination level of the individuals. Individuals within the same layer are non-dominated.
The crowding distance of individuals in the same layer is calculated. Then, the individuals with higher values are preferentially selected, so that the same layer individuals can be more evenly distributed in the objective space to preserve the population diversity.
The elite strategy combines the parental population with the offspring population. First, infeasible solutions within the collection are eliminated. Secondly, the remaining individuals are ranked according to the non-dominated sorting algorithm. From the low to high levels, the individuals in each layer are placed sequentially in the new population until the number of individuals exceeds the capacity of the population. Finally, according to the crowding distance metric, the individuals in the specific layer are placed into the new population in descending order until the population is full. The elite strategy preserves all the good individuals in the parental and offspring populations, thereby improving the accuracy and robustness of the optimization results.
Due to the above characteristics, NSGA-II has strong optimization capabilities. Therefore, the path planning is solved with NSGA-II. However, individuals formed by the traditional operators are generally not feasible paths. It is not enough to rely solely on traditional operators. This requires a larger population capacity and more evolutionary algebra. In the work, several practical evolutionary operators are introduced to solve this problem. These evolutionary operators are more purposeful to reduce the length and improve the smoothness and safety. Next, NSGA-II and all the operators are described in detail.
4.1. Flowchart
The process of NSGA-II is as follows:
- 1
The population (POP) is initialized.
- 2
In the population (POP), the objectives of each individual are evaluated.
- 3
An empty set (NDPOP) is generated to save the found feasible non-dominated individuals.
- 4
While the termination condition has not been reached, DO:
- (1)
Two empty populations (NEWPOP, POPc) are generated.
- (2)
The individuals are chosen from the population (POP) by the selection operator and put into the population (POPc).
- (3)
Individuals within the population (POPc) are paired. Then, the crossover operator is performed on the two individuals. Next, new individuals are generated and stored in the population (NEWPOP).
- (4)
For any individual in the population (POPc), the practical operators are sequentially executed. Then, the generated individuals are put into the population (NEWPOP).
- (5)
Each individual within the population (NEWPOP) is evaluated, and the feasible solutions are put into the set (NDPOP). Then, the non-dominated individuals of the set (NDPOP) are retained.
- (6)
Parental and children populations (POP) and (NEWPOP) are merged. Individuals in the combined population are classified according to the individual feasibility: feasible solutions’ set and infeasible solutions’ set. Then, the non-dominated sorting and crowding distance metric are performed on the two sets respectively. Next, individuals are picked from the two sets, and a new population (POP) is formed. The size of the population (POP) remains the same.
- (7)
The loop counter is incremented by one.
In the entire algorithm, a viable individual is a collision-free path. Steps 1–3 are the initialization process. The initial population (POP) is generated and evaluated. An empty set (NDPOP) is then made to store the found non-dominated solutions. This set is only used for storage and does not participate in the evolution of the population. Step 4 is the core of the algorithm, and the total iterative process is completed in this step until the termination condition is reached.
In each iteration, two empty populations (POPc and NEWPOP) are created. The population (POPc) is used to store the selected individuals of the parental population (POP). The population (NEWPOP) stores the children individuals. First, the selection operator is applied to choose individuals from the population (POP), and the selected individuals are stored in the population (POPc). Individuals of the population (POPc) are then paired. New individuals are generated by using the crossover operator and then placed in the child population (NEWPOP). Next, a series of operators is executed for each within the population (POPc). When each operator is applied, a new individual is generated and stored in the child population (NEWPOP). After the individuals in the population (POPc) are treated with the evolutionary operators, the individuals in the children population (NEWPOP) are evaluated, and the feasible individuals are put into the set (NDPOP). Then, individuals of the population (NDPOP) are updated; in other words, the non-dominated solutions of the population (NDPOP) are retained; other individuals are excluded.
Then, the elite strategy is executed. The parental population (POP) and the offspring population (NEWPOP) are merged, and the individuals in the merged set are classified according to individual feasibility: feasible solutions’ set and infeasible solutions’ set. Then, the non-dominated sorting and crowding distance metric are performed on the two sets, respectively. Then, individuals are picked from the two sets to form a new population (POP). In this step, the infeasible individuals are not entirely discarded, but some better individuals are preserved. Besides, the size of the population (POP) is unchanged. Then, the loop counter is incremented by one.
Step 4 is iterated until the end condition is satisfied. At this point, the entire algorithm ends, and the set (NDPOP) is output. Furthermore, the operators are introduced. Each operator acts on an individual, and a new individual is generated and then stored in the child population (NEWPOP). Besides the traditional operators, these evolutionary operators can improve the length, smoothness and safety of the path more effectively. Next, these operators and the initialization process are presented in detail.
4.2. Selection Operator
The selection operator is to elect individuals from the parental population (POP). The constrained tournament selection operator is applied. It selects two solutions at a time, then the tournament between them is run, and the winner participates in the succeeding evolution. For two chosen individuals, if one is not attainable and the other is available, the victor is the viable one. If none are feasible or viable, the non-dominated regulation is applied to pick the victor. If both are non-dominated, the individual with a larger crowding distance is picked as the winner. Finally, the winners are stored in the population (POPc).
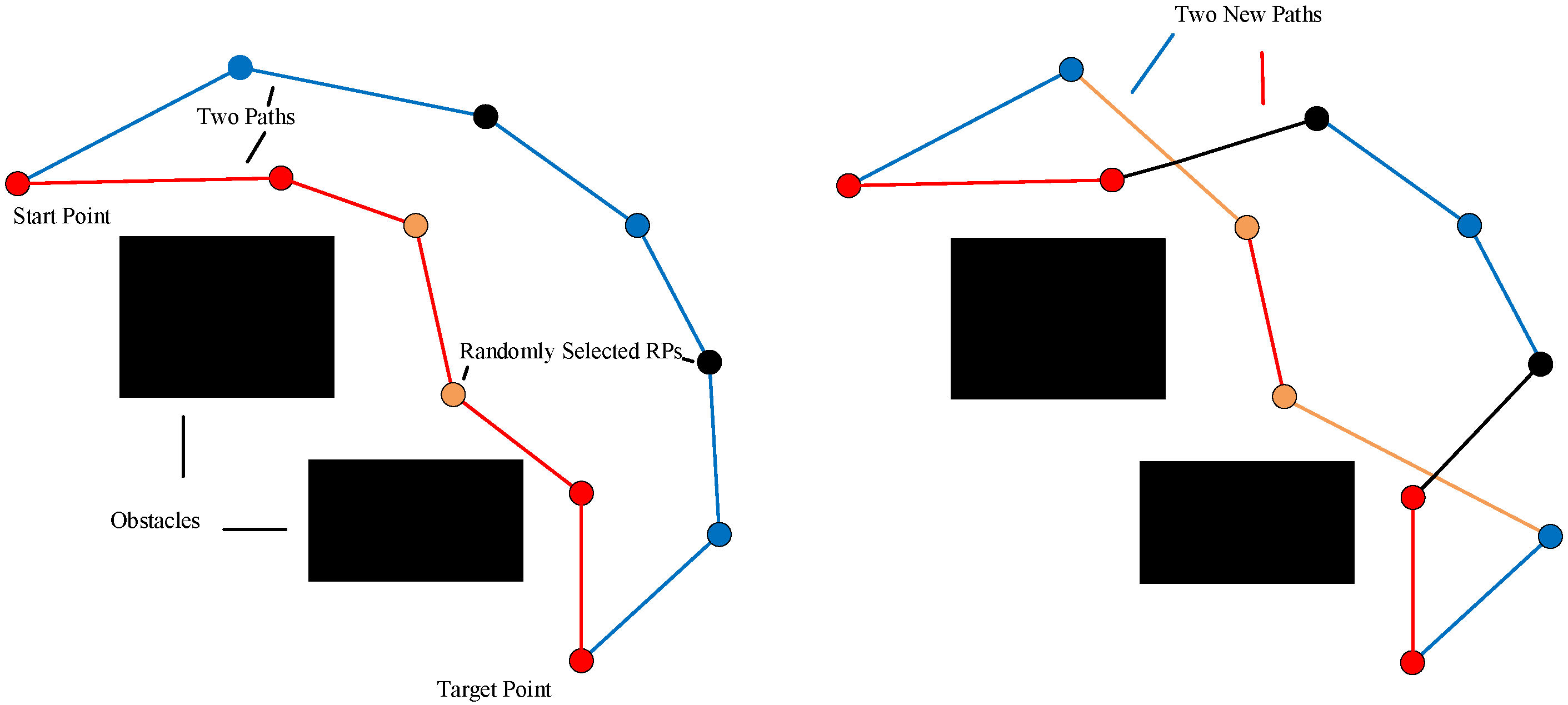
4.3. Crossover Operator
For two randomly-selected individuals in the population (
POPc), the crossover operator is used to form new individuals by swapping parts of the individuals. The newly-generated individuals are stored in the child population (
NEWPOP). Suppose that
and
are two randomly-chosen paths,
and
are two randomly-selected rotation points (RPs) on path (
p). Similarly,
and
are two randomly-selected rotation points on path (
q). The line segments connecting
with
and the line segments linking
with
are exchanged. Finally, two new paths (
,
) are generated.
Figure 2 shows the result of exchanging line segments with the crossover operator.
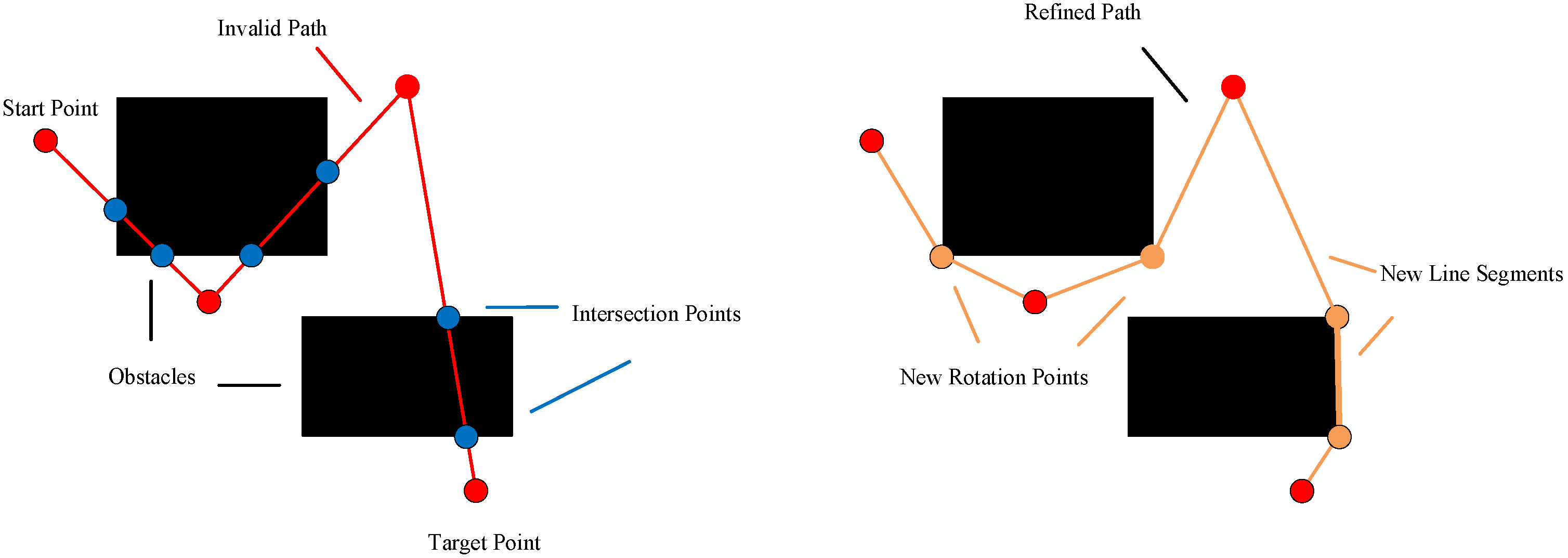
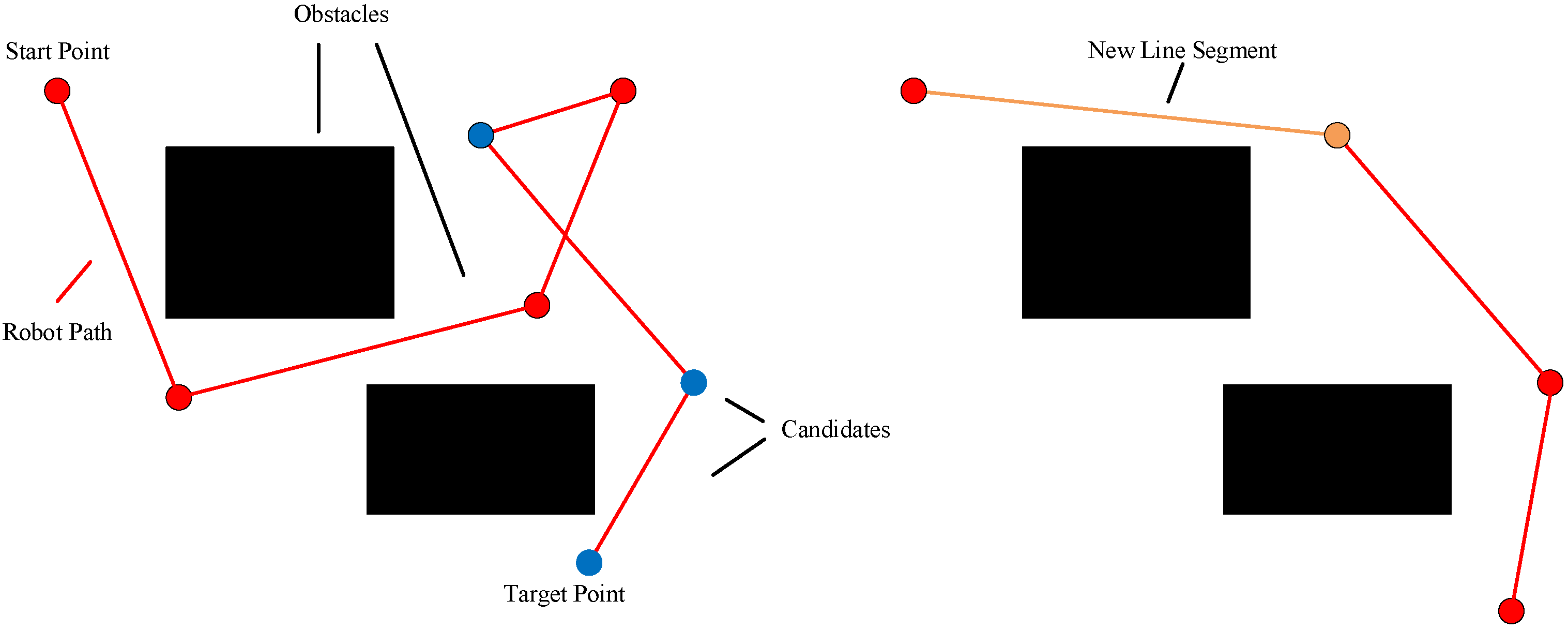
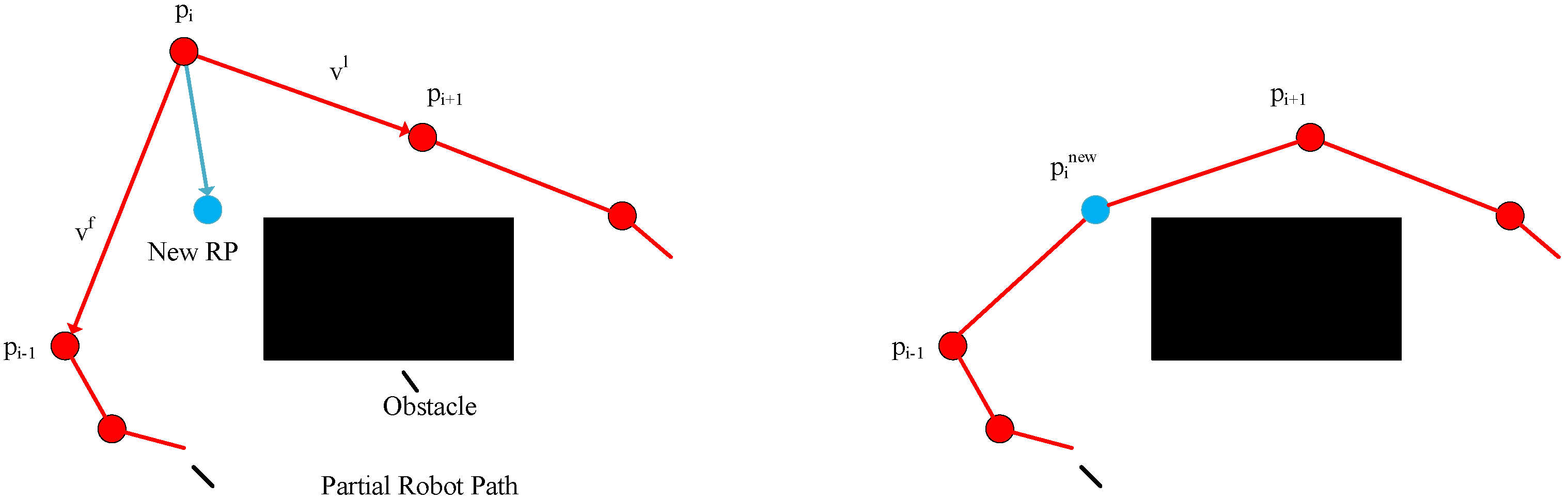
4.4. Invalid Solution Operator
The invalid solution operator is used to convert the path () that collides with the obstacles () into a feasible path. The design process of this operator is expressed as follows:
Along the path, it is determined in turn whether the line segment () of the path collides with the obstacles. If so, the intersection points and the obstacles () that collide with the line segment are found.
Then, the vertices of the obstacles (
), the two rotation points (
,
) and the intersection points form the vertices of the graph. Any two vertices within the set of vertices are linked to form the set of edges. Meanwhile, the edges that collide with all obstacles (
O) are deleted. Then, based on the vertices and edges of the graph, the Dijkstra algorithm can be applied to attain a feasible shortest path (
) from
to
. Next, the line segment (
) of path (
p) can be replaced with the path (
q), and the path (
) is generated. Finally, the viable path (
) is made by repeating the above operation from
to
n. The invalid solution operator is presented in
Figure 3.
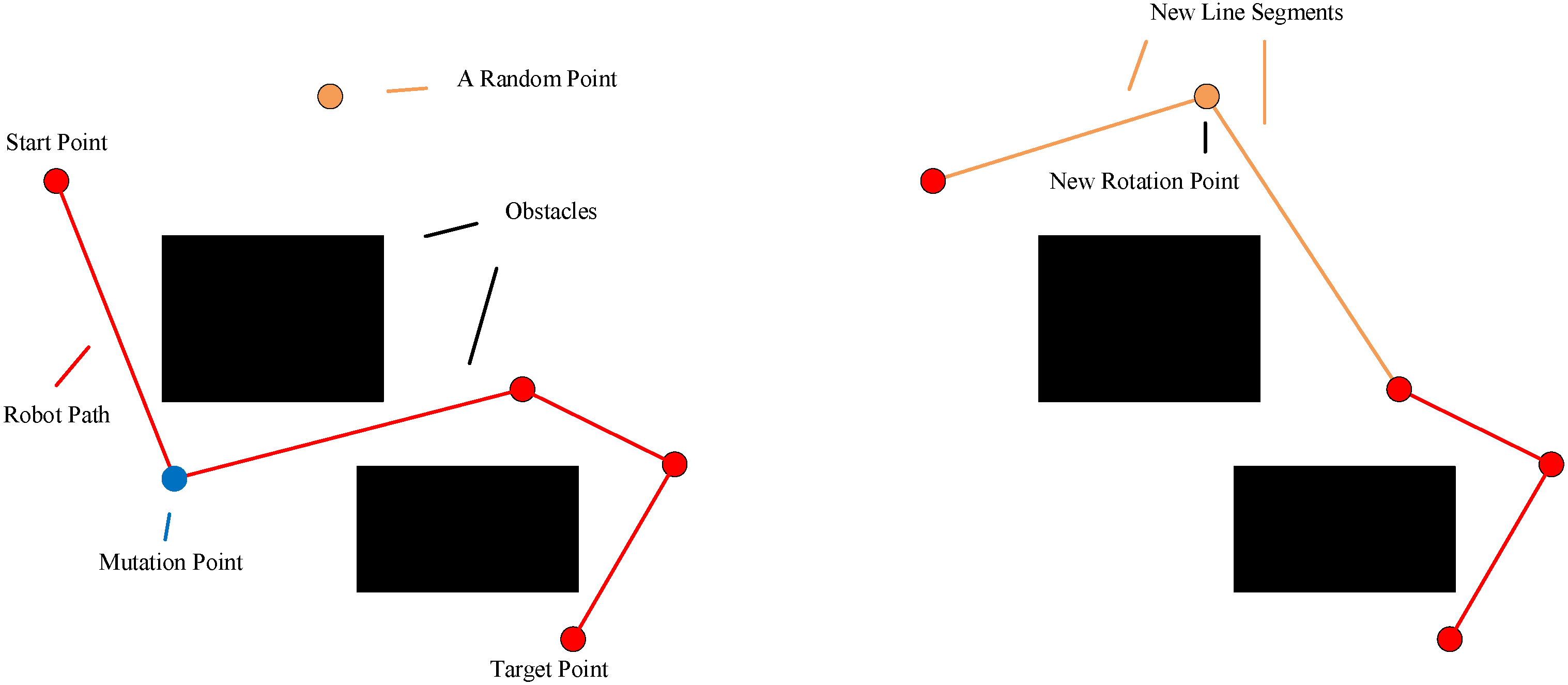
4.5. Mutation Operator
The single point variation is used in this operator. A rotation point on the path is arbitrarily chosen and displaced by an arbitrary free point. It should be noted that the path after the mutation may be worse or better than before the variation. The mutation operator is displayed in
Figure 4.
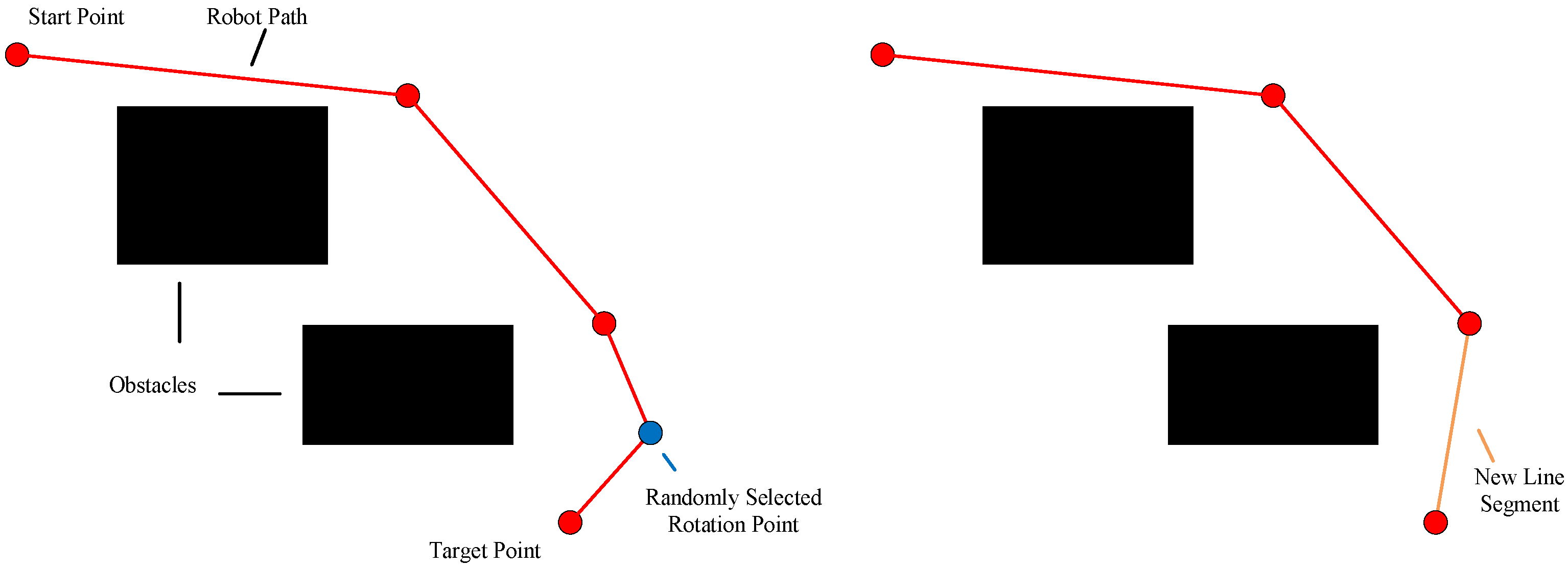
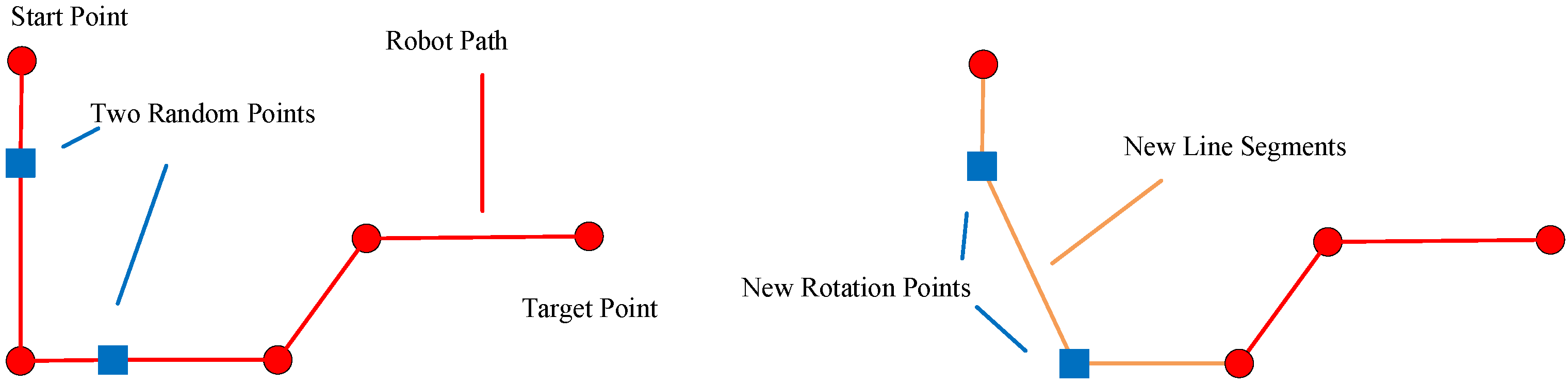
4.6. Shortness Operator
The path is changed in arbitrary deleting manner in this operator. It randomly removes a rotation point.
Figure 5 displays the shortness operator.
4.7. Insertion Operator
A single point insertion is adopted to design the insertion operator. A line segment on the path is randomly selected, and then, a random free point is inserted on the segment. The practice of the insertion operators is similar to the mutation operator. The random points in free space are used in both operators. The difference is that the mutation operator changes a rotation point and two line segments. The insertion operator increases a rotation point and converts one line segment into two new line segments.
Figure 6 is an illustration of the insertion operator.
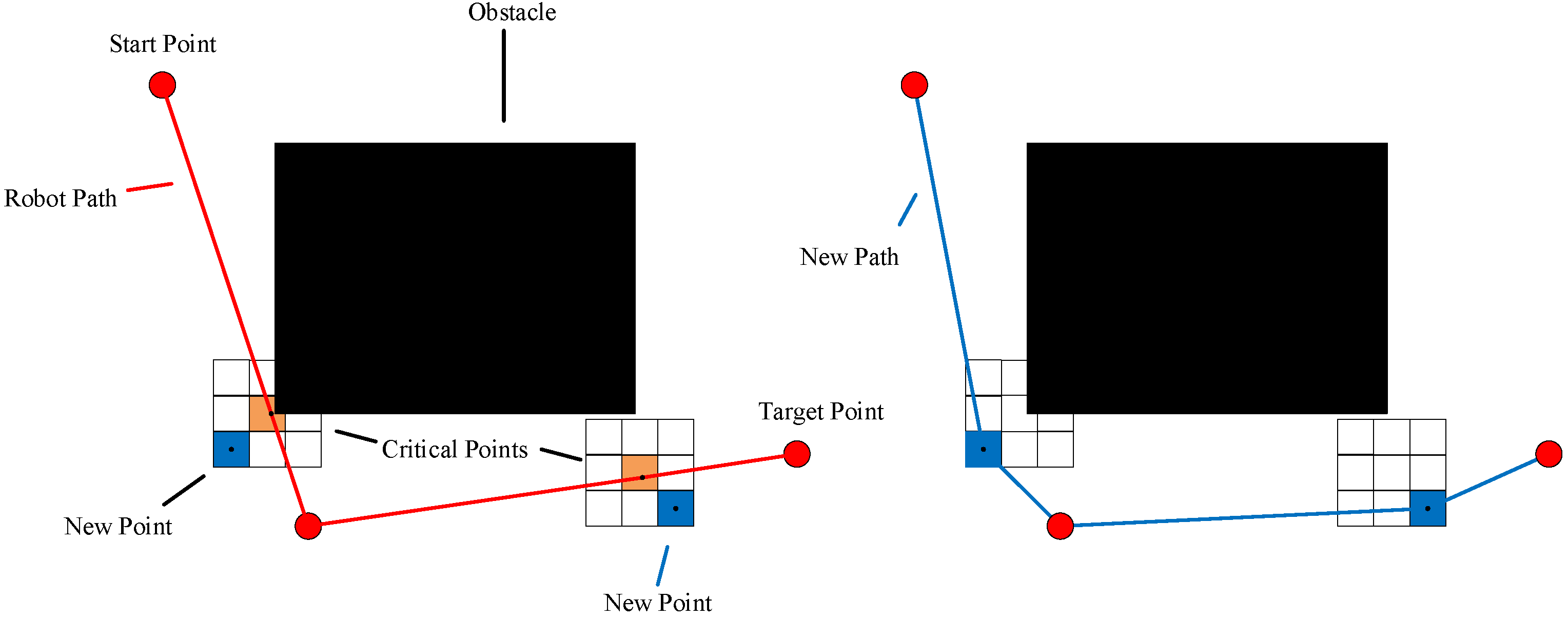
4.8. Safety Operator
The path safety is improved with the safety operator. On each line segment, the nearest point to the obstacles can be found. The point is named the critical point. Next, the region near the critical point can be meshed. Eight nearby lattices of the critical point are found. By comparing the safety distances of the lattices, the lattice with the largest safety distance is the winner. The center point of the lattice is chosen as a rotation point and then inserted into the line segment. The above method is iterated until all line segments on the route have been considered. At this point, the safety operator is over.
Figure 7 shows the safety operator.
4.9. Smoothness Operator
A smoother route can be found by the smoothness operator. In this operator, it is improved by decreasing the maximum turning angle formed by two consecutive segments on the path. Two free points are randomly generated on the two line segments and replace the intersection of the two line segments. Therefore, the maximum corner of the route is reduced.
Figure 8 exhibits the smoothness operator.
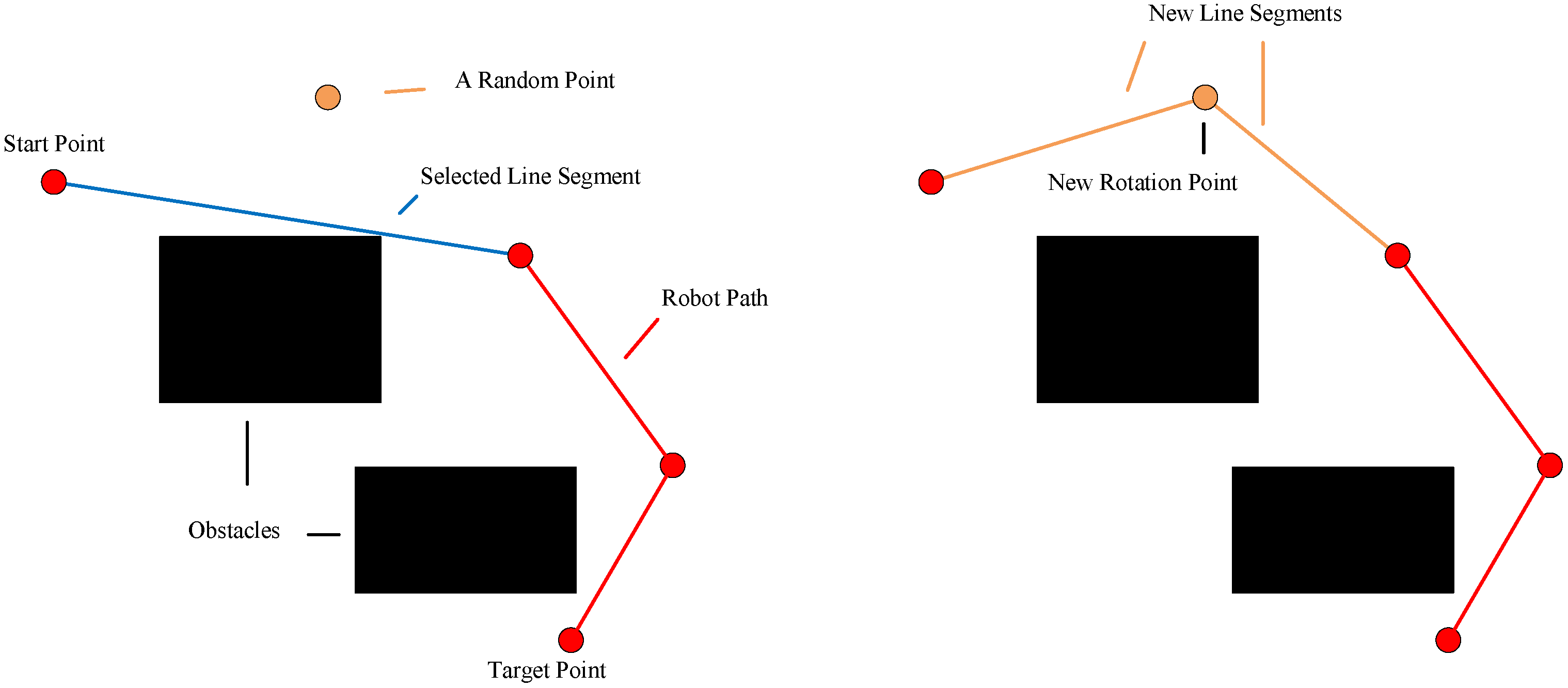
4.10. Shortest Operator
The length of the path (
) can be minimized by the shortest operator. For the rotation point (
), another rotation point (
) is sequentially selected as a candidate from the target point (
) to the rotation point (
). If the new line segment (
) is feasible, other rotation points between the rotation points (
,
) are deleted. The above operation is repeated from
to
. The shortest operator can remove extra rotation points to obtain the shortest path.
Figure 9 presents this operator.
4.11. Position Update Operator
The idea of this operator comes from particle swarm optimization (PSO). Based on the positions of three continuing rotation points (
,
and
), the position of the middle point (
) is updated by Equation (
5). This operator is shown in
Figure 10.
In Equation (
5), the vector (
v) should meet a restraint. The restraint is set to be
of the workspace coordinates. In addition, the position (
) and the line segments (
and
) should be feasible. The position (
) is adjusted continually by using Equation (
6) until the above conditions are satisfied. Furthermore,
,
and
are set to random numbers from zero to one.
4.12. Initialization
In general, the initialization process is essential. In the initial phase, the initial population is generated. Each within the population is a randomly generated path. That is, the rotation points on the path are random points in free space. The number of rotation points is set to a random number from one to three. Of course, these initial individuals are generally not feasible in a complicated space. Three objectives are designed to evaluate the path. They are the path length, smoothness and safety, respectively. Additionally, all parameters involved are displayed. The maximum number of generations and population size are 100 and 80 individually. The probabilities of selection, crossover and shortest operators are 1, and . The probabilities of the remaining operators are set to . Next, through the parameter study, the parameters of the genetic algorithm are reasonably set.
5. Parametric Study
In this section, the parameters studied are population size, the number of generations, crossover rate, mutation rate, insertion rate, invalid solution operation rate, safety operator rate, smoothness rate, position update operator rate, short operator rate and shortest operator rate. The likelihood of optimality (
) is used to evaluate the non-dominated solutions obtained by different parameter selections [
57]. Based on the same parameter setting, the algorithm is run
n times independently. If the optimal solution is found
m times, the likelihood of optimality (
) of this set of parameters is the estimated probability
. This measurement technique was originally used to evaluate the parameter setting of the single-objective optimization algorithm. For multi-objective problems, the optimal solution can be understood as the optimal values of each objective. In the d-dimensional solution space, the
of any parameters setting
k is the estimated probability
. In this work, Let
n be 100.
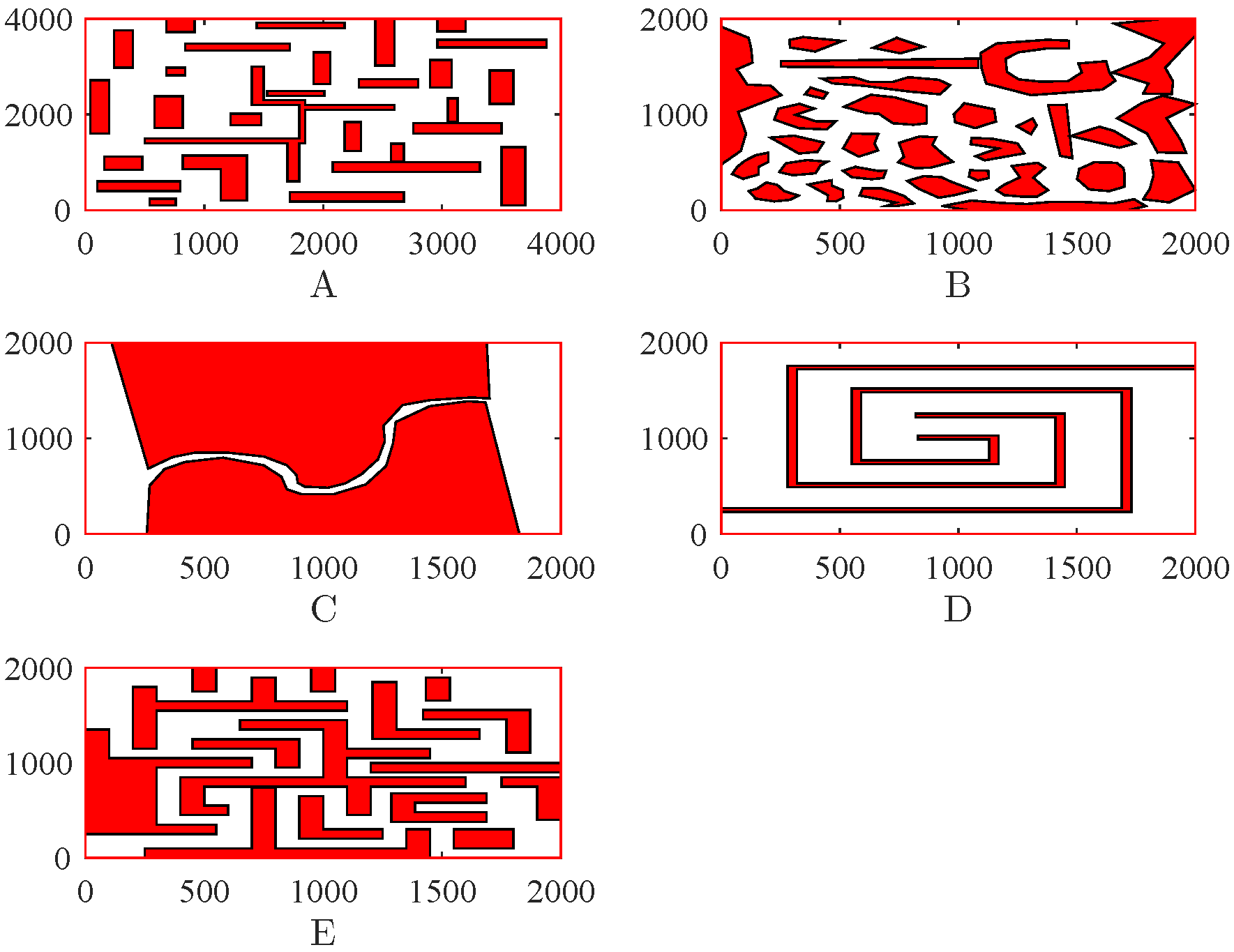
Figure 11A is considered. The starting and target points of this map is displayed in
Table 1. These maps will be used to test the algorithm in detail in
Section 6.
Figure 12,
Figure 13,
Figure 14,
Figure 15,
Figure 16,
Figure 17,
Figure 18,
Figure 19,
Figure 20,
Figure 21 and
Figure 22 present the effects of these parameters.
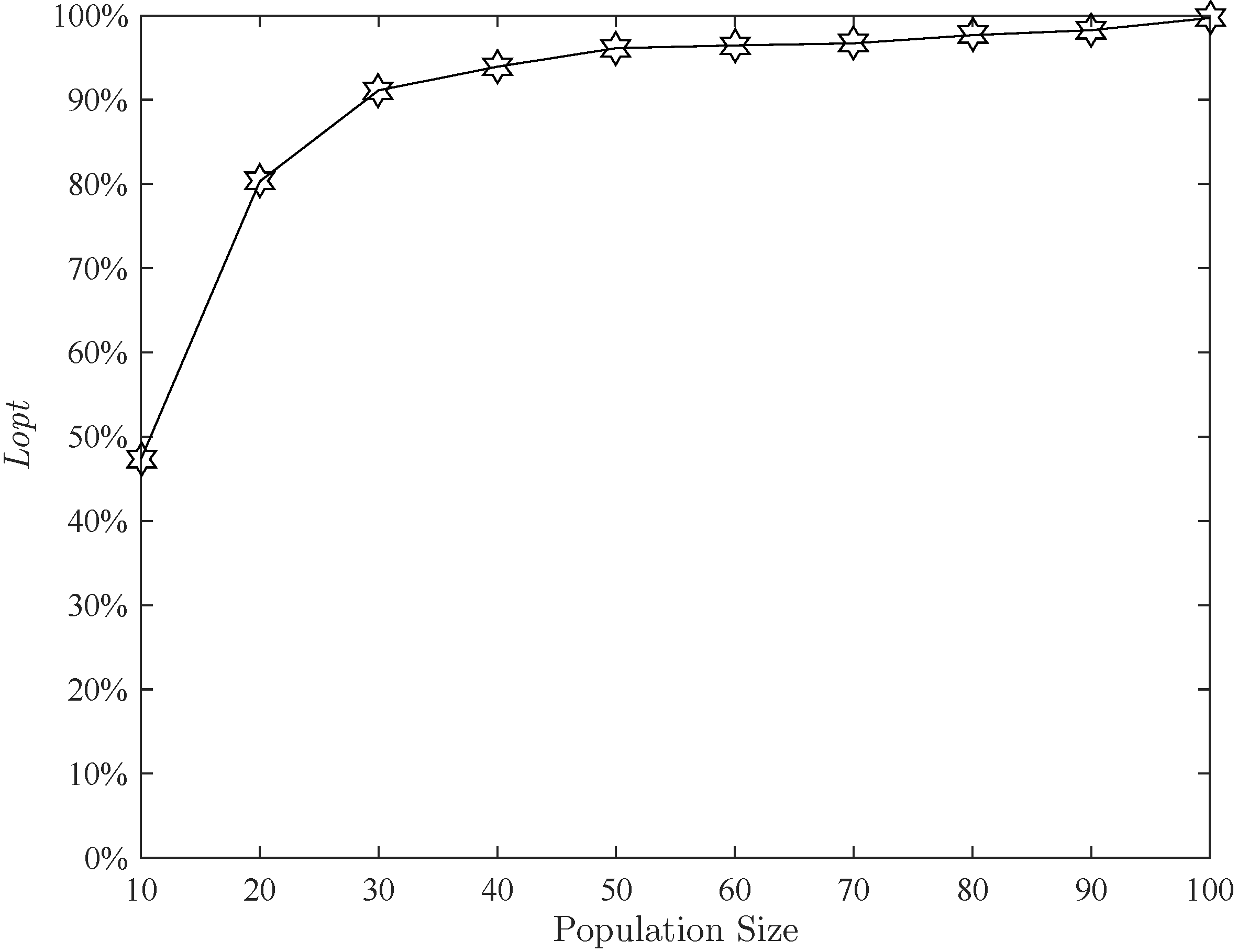
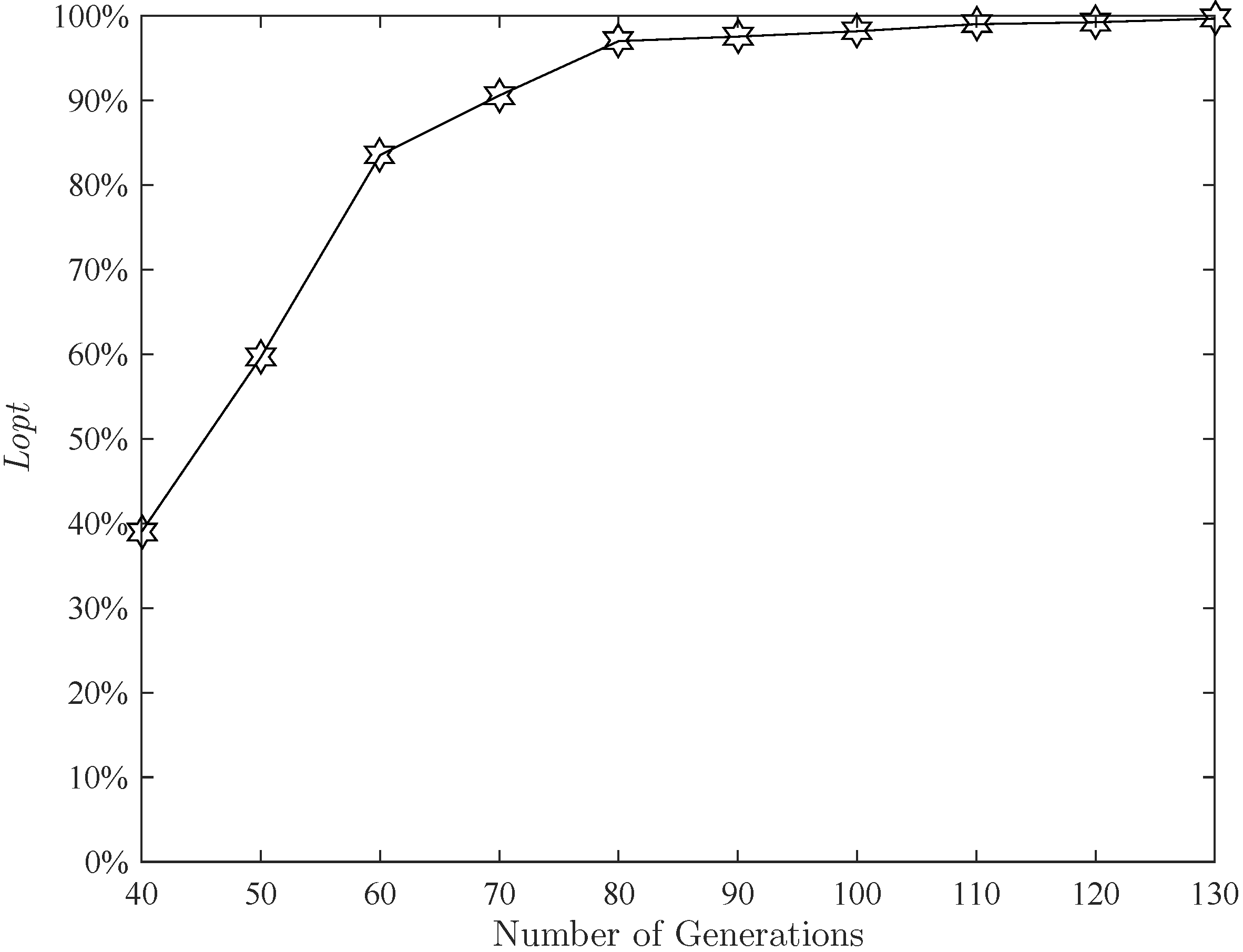
Figure 12 presents the effect of population size. Other parameters remain the same as mentioned before. This figure shows that when the population size exceeds 60, the algorithm can run stably. For more safety, the population size is set to 80. The effect of the number of generations is shown in
Figure 13. When the number of generations exceeds 80,
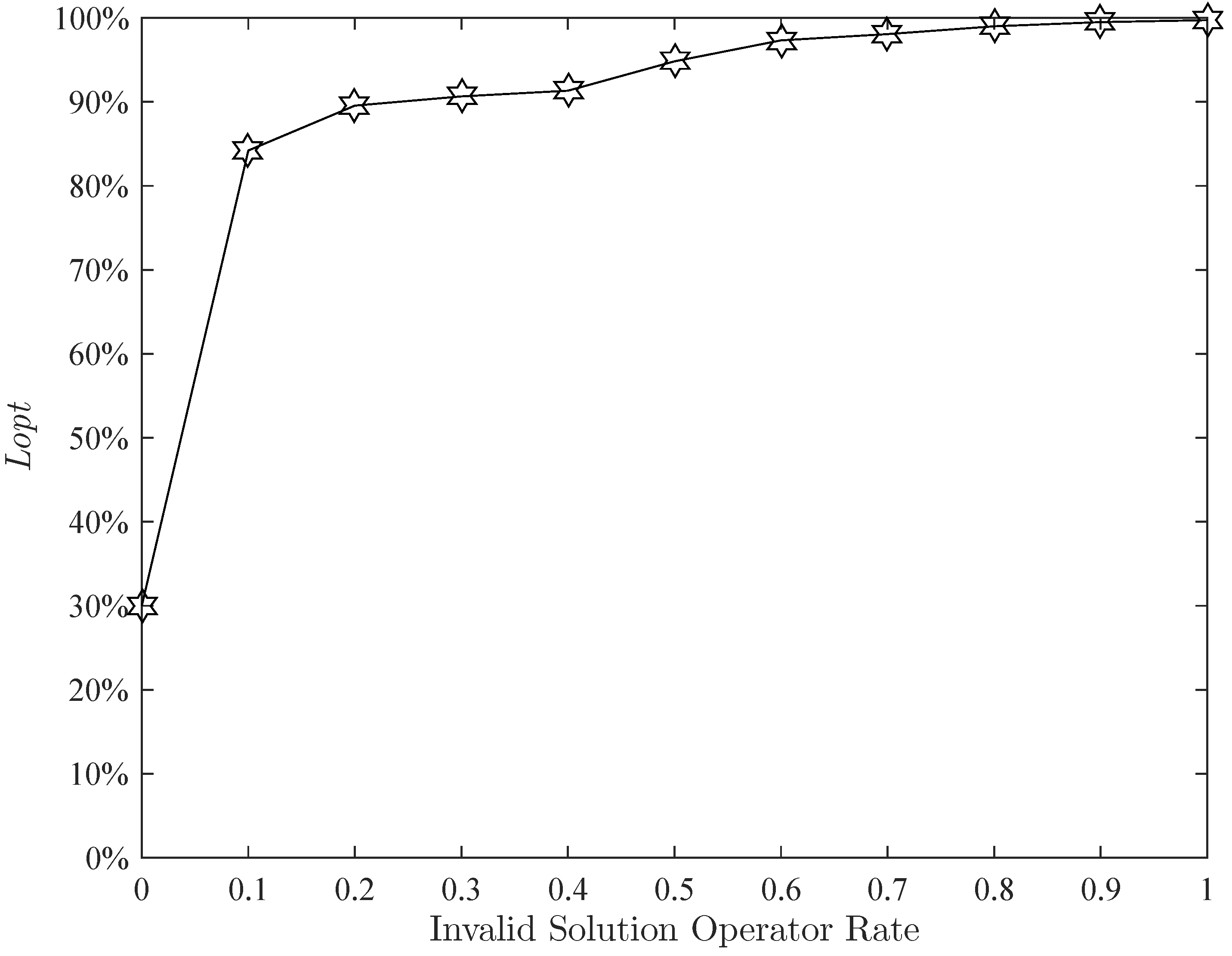
is already good. In view of this, the maximum generation of the population is set to 80. The effect of the invalid solution operator rate on
is given in
Figure 14. The figure shows that the higher the invalid solution operator rate, the more stable the algorithm. In the next parametric study, the invalid solution operator rate is set to
. Next,
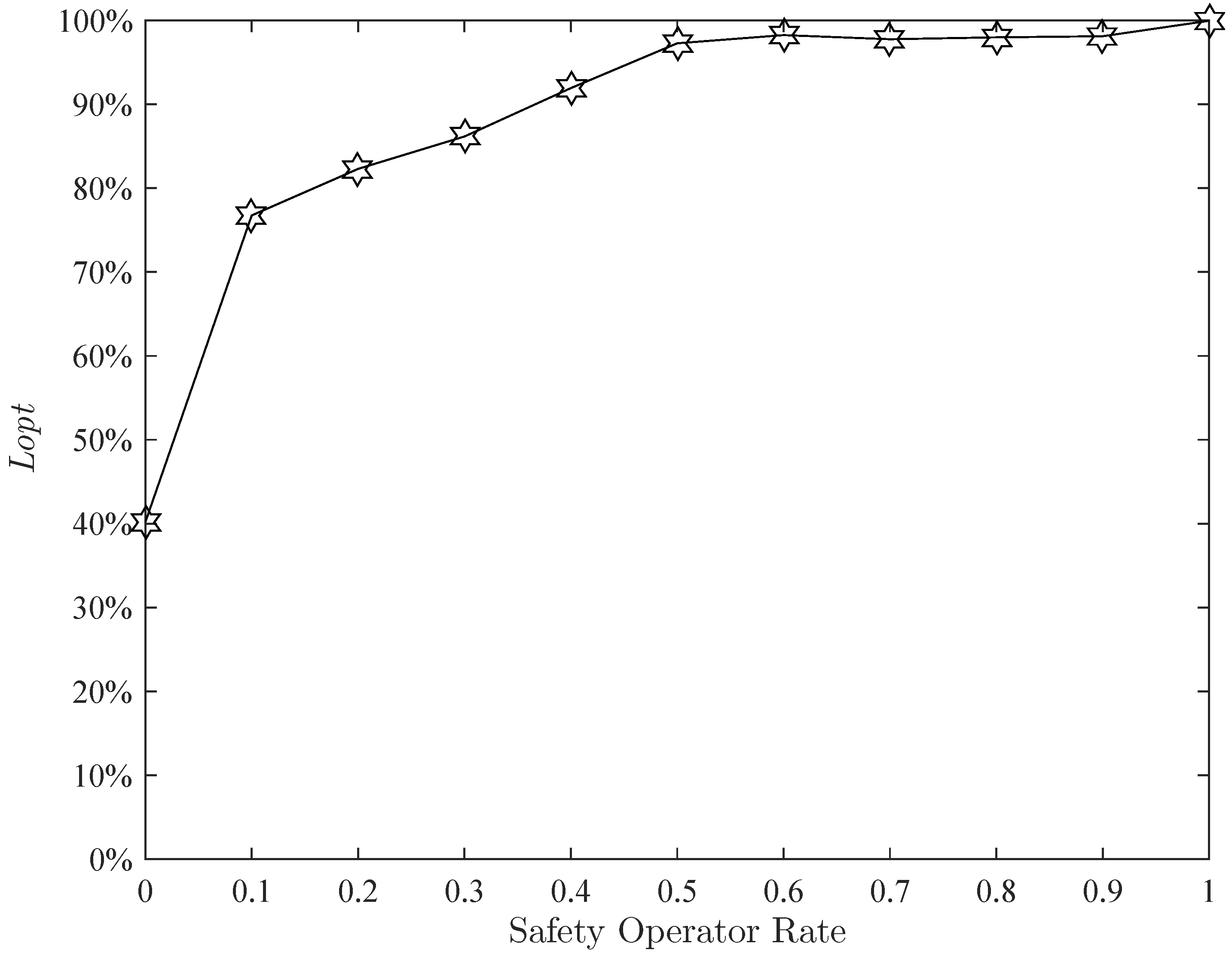
Figure 15 presents the effect of the safety rate. The higher the safety operator rate, the better the
. The value is also set to
.
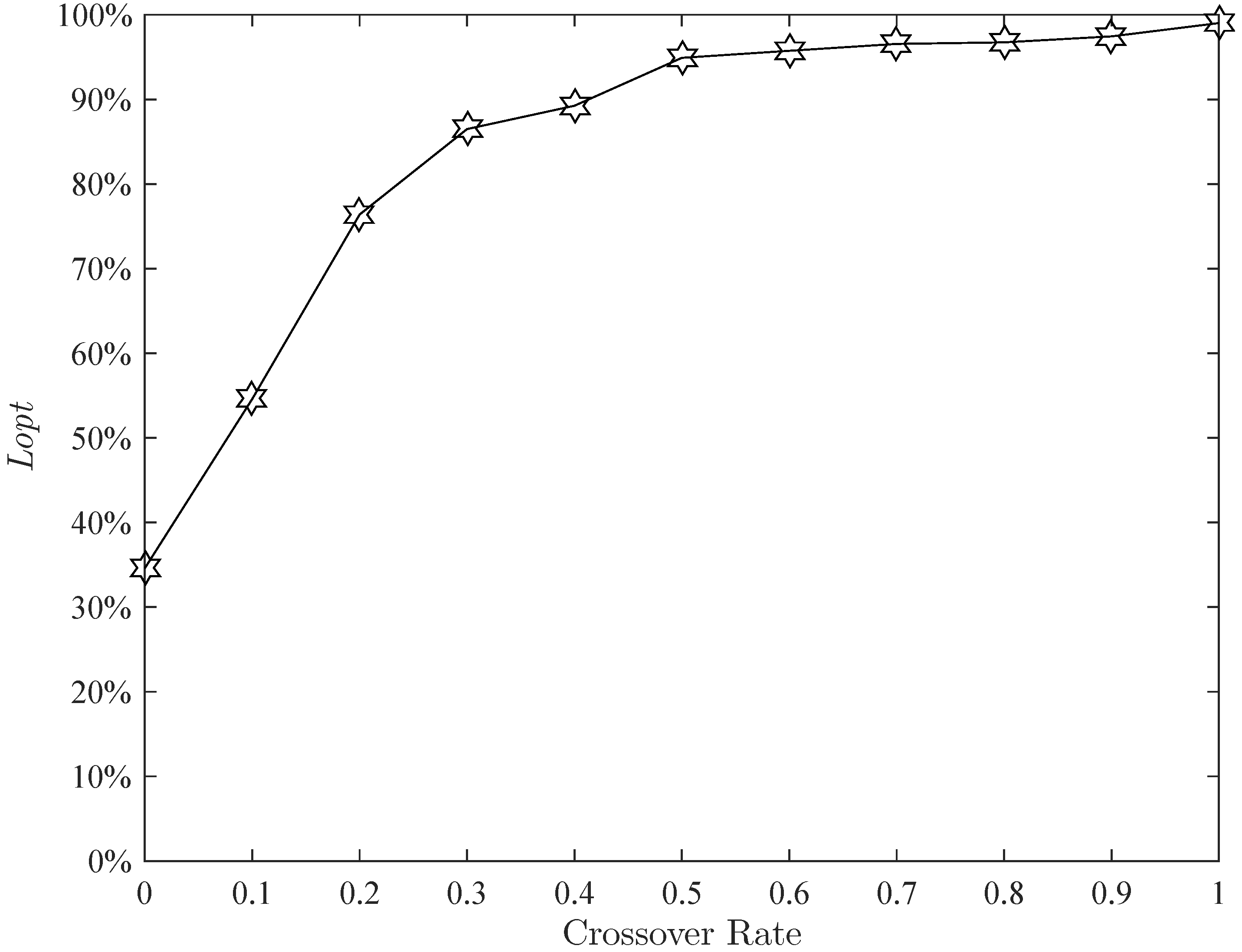
Figure 16 shows that an excessively low crossover rate can affect the stability of the algorithm. Therefore, the crossover rate is set to
.
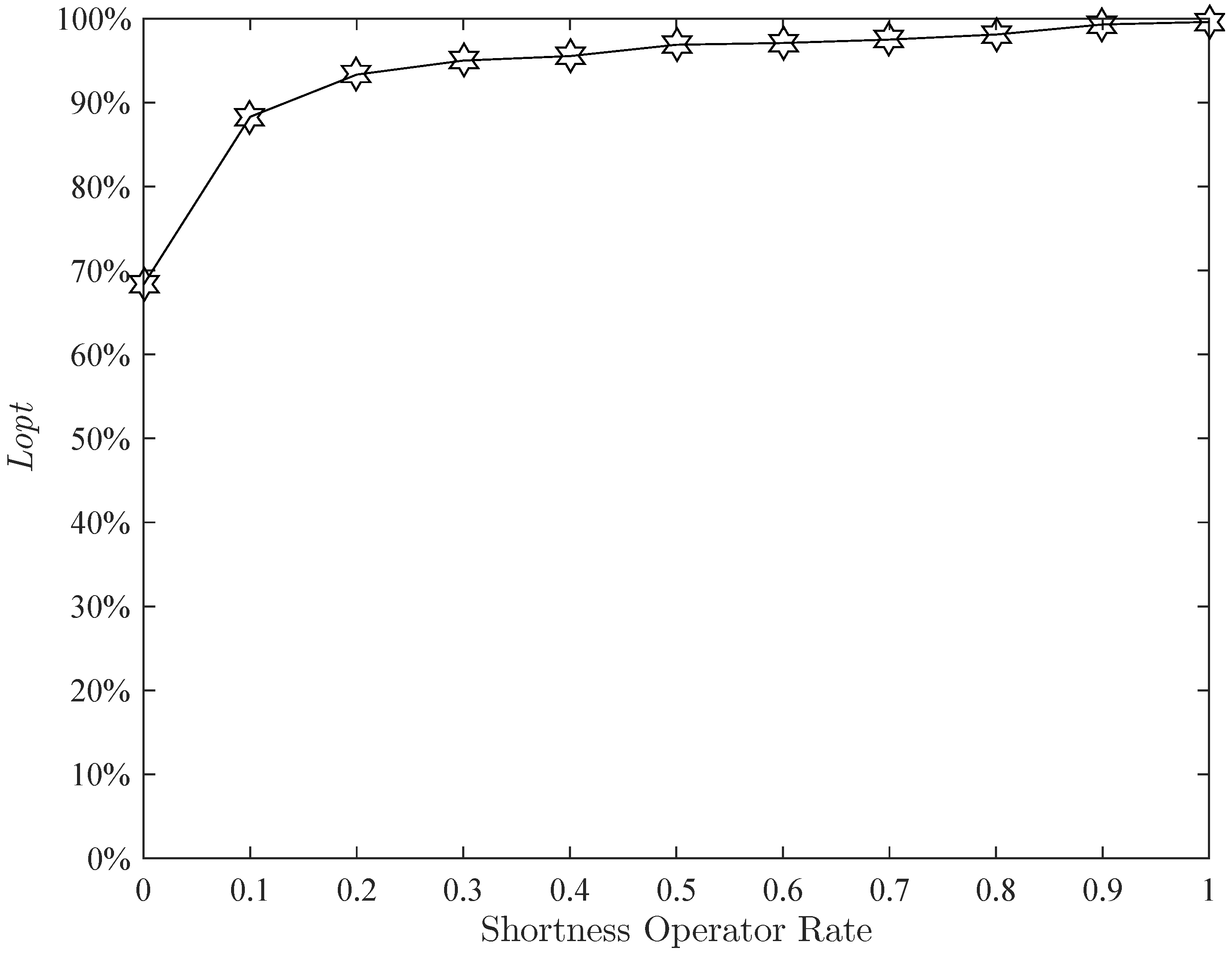
Figure 17 implies that when the shortness operator rate changes from
to one,
is basically unchanged. The shortness operator rate is set to
. The effect of smoothness operator rate is shown in
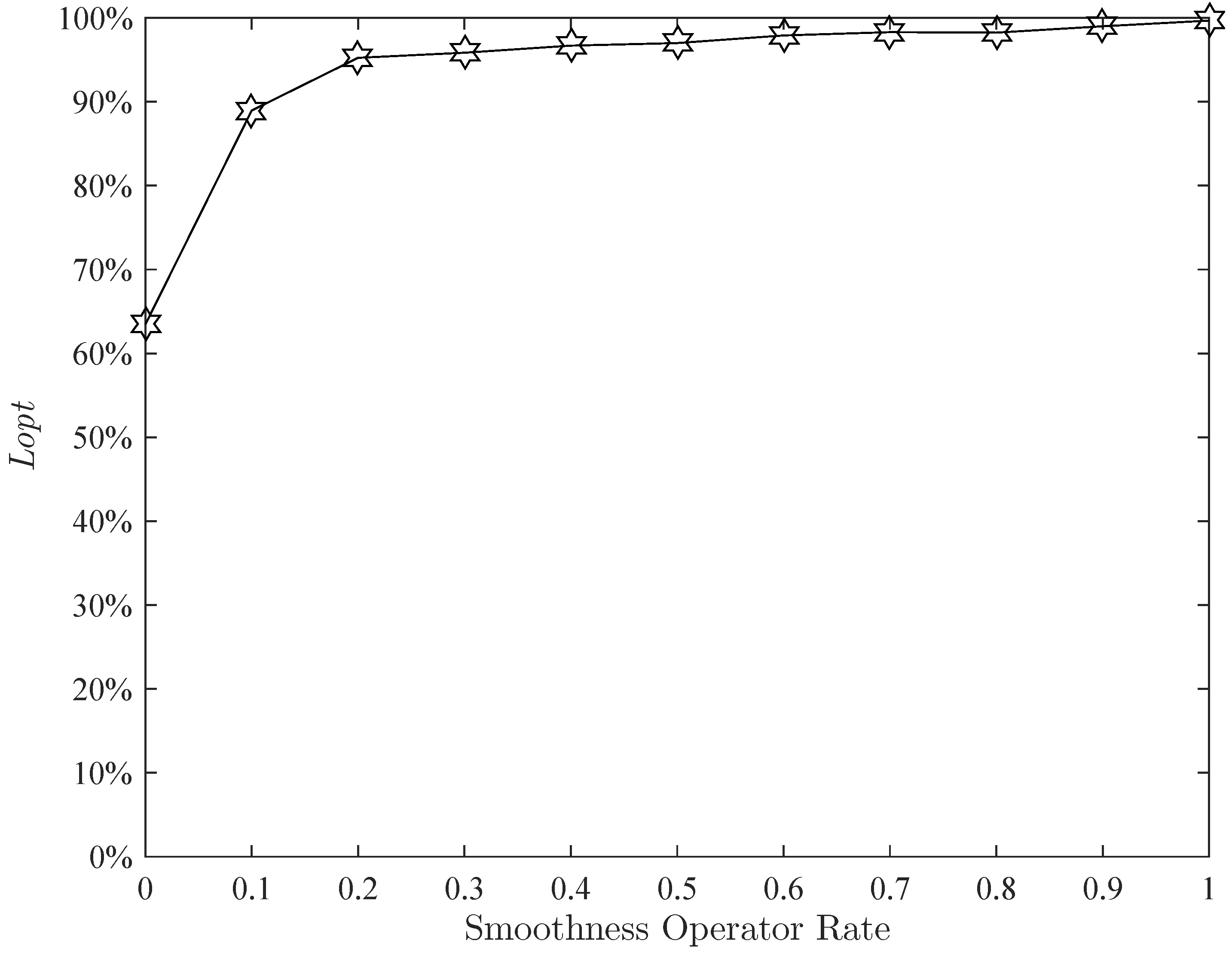
Figure 18. We set the smoothness operator rate to
.
Figure 19,
Figure 20 and
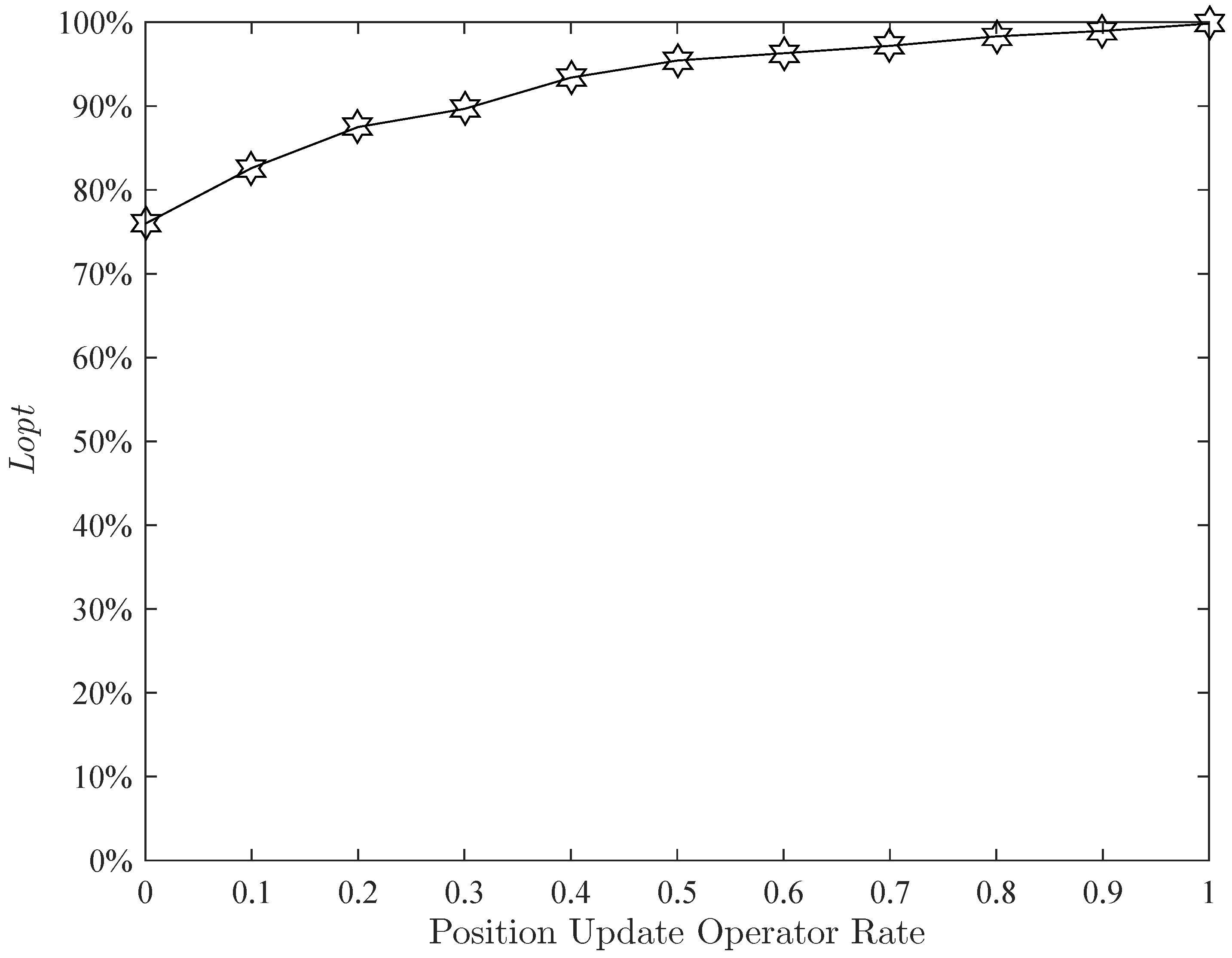
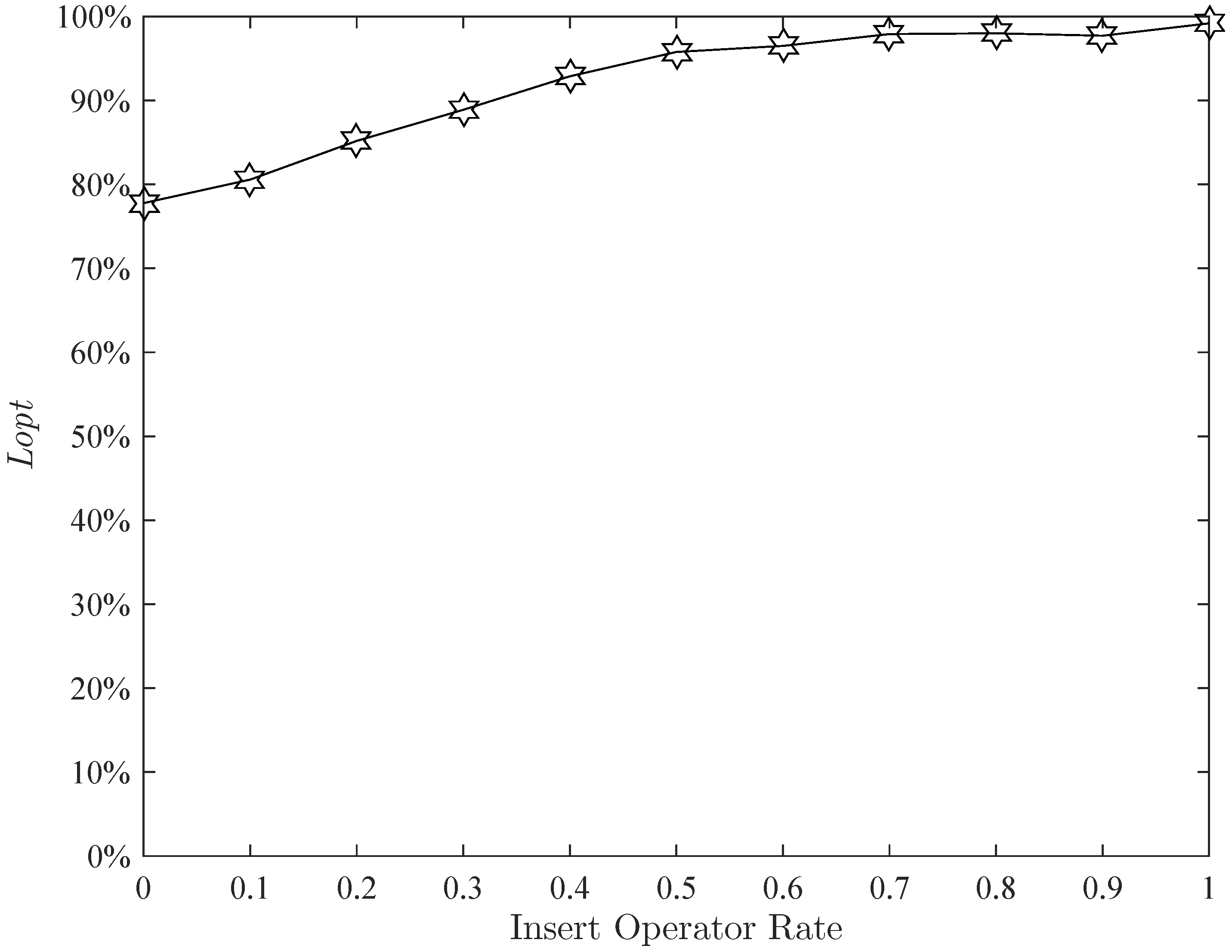
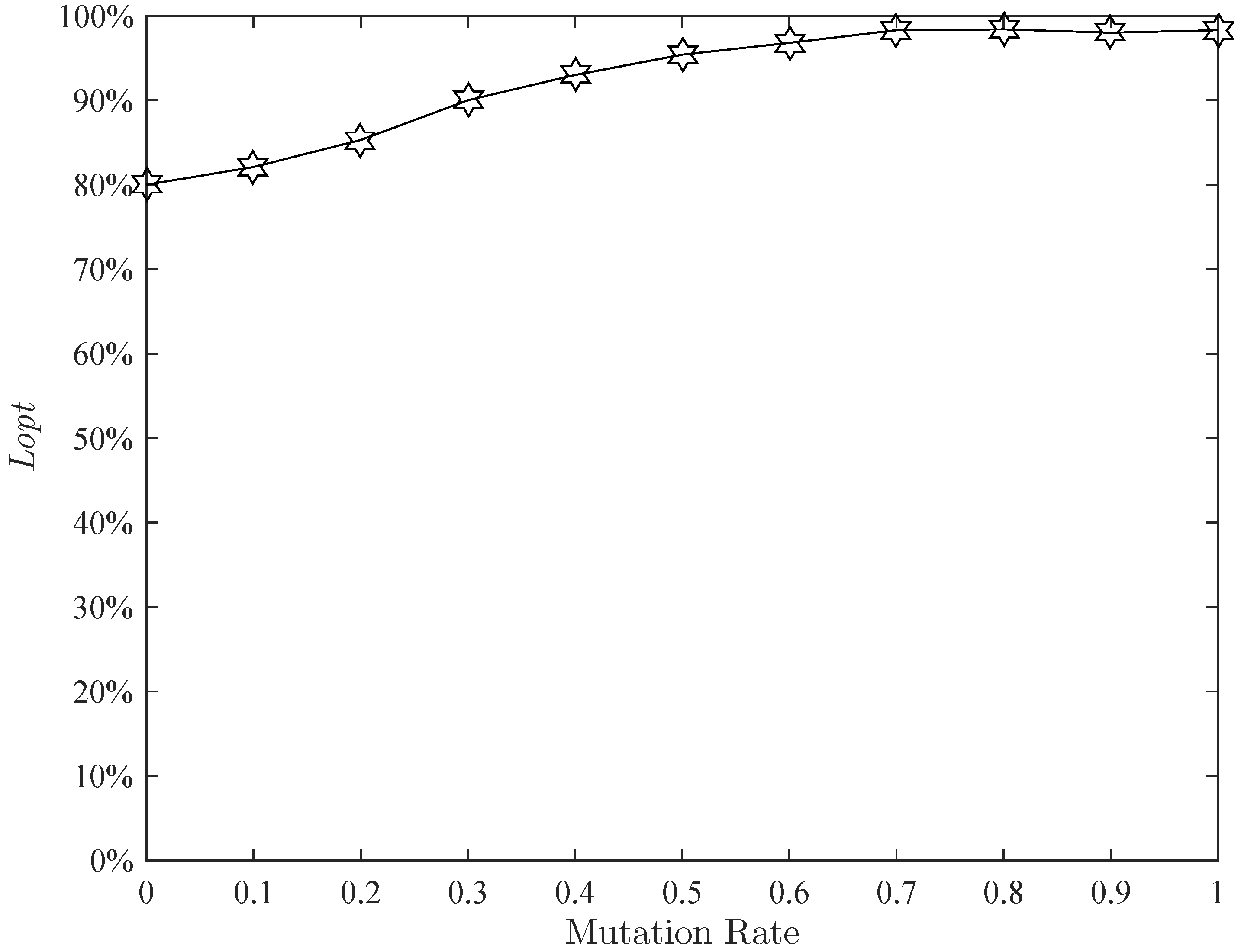
Figure 21 display the effects of the position update operator rate, insert rate and mutation rate, respectively. The effect of the shortest operator rate is presented in
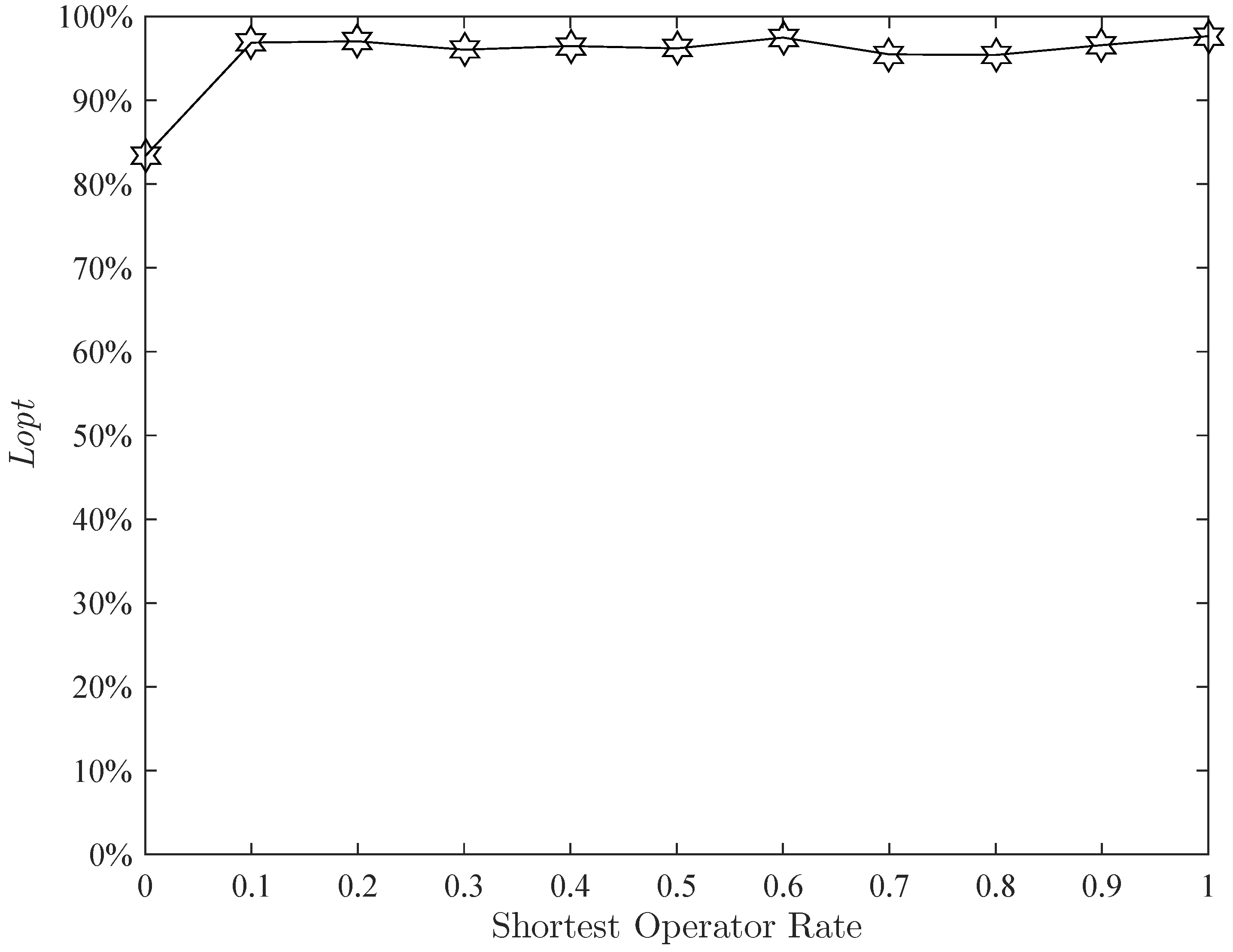
Figure 22. When the shortest operator rate changes from
to one, the algorithm is robust. This is different from other parameters.
The above parameter study also confirms the setting of the parameters in the initialization process. For more complex scenarios, it may be necessary to choose a higher population size, a larger number of generations, a higher invalid solution operator rate, a higher safety operator rate, a higher crossover rate and a higher smoothness operator rate.
6. Results
In this work, the results of the improved non-dominated sorting genetic algorithm (NSGA-II) in various spaces are presented. To better examine the results, different quality metrics [
58,
59] and the multi-objective evolutionary algorithm (MOEA) algorithm [
25] were employed.
The hypervolume indicator (HV) [
58] can be used to evaluate the volume of non-dominated solutions in the solution space. In the d-dimensional solution space, the related concepts are defined.
is the non-dominated solutions, and
denotes the reference point, respectively. The Lebesgue measure [
60] can be used to compute the hypervolume area of the non-dominated solutions bound by the reference point. The calculation of the HV is shown in Equation (
8).
Furthermore, the set coverage metric (SCM) [
59] can be applied for computing the dominance ratio of the two sets of non-dominated solutions.
and
denote the two sets. Consequently,
can be computed with Equation (
9). As the relationship (⪯) represents a weak dominance relationship and is asymmetrical, it is also essential to determine
.
In this work, several maps are considered in
Figure 11. There are different shapes of obstacles on each map. The starting and target points for these maps are displayed in
Table 1. On each map, both algorithms run 30 times. In each run, the two sets of non-dominated solutions obtained by the two algorithms are compared with the quality metrics. The results of the hypervolume are given in
Table 2. In contrast, these two sets are dense. Besides, in
Table 3, the results of the set coverage metric (SCM) are exhibited. The average of scm (NSGA-II,MOEA) and SCM (MOEA,NSGA-II) is
and
, respectively. It is evident that the most solutions within any set are non-dominated relative to another set. This also implies that the solutions obtained by these two algorithms are close to the Pareto front.
Additionally, in each map, the reference points need to be calculated. The ideal reference point is optimal in every dimension, and the nadir reference point is worst.
Table 4 shows the reference points. An ideal shortest route is the line segment from the start to the destination. The smoothness of the ideal smoothest path should be zero. For the minimum safety of path, this value can be estimated with enhancing the safety of the safest route by
in the non-dominated solutions. At this point, the three values of the ideal reference point have been set. Next, the three values of the nadir reference point are set. For the length and smoothness of the nadir reference point, the two values can be calculated by referring to the above means of estimating the minimum safety. The maximum safety of path is zero.
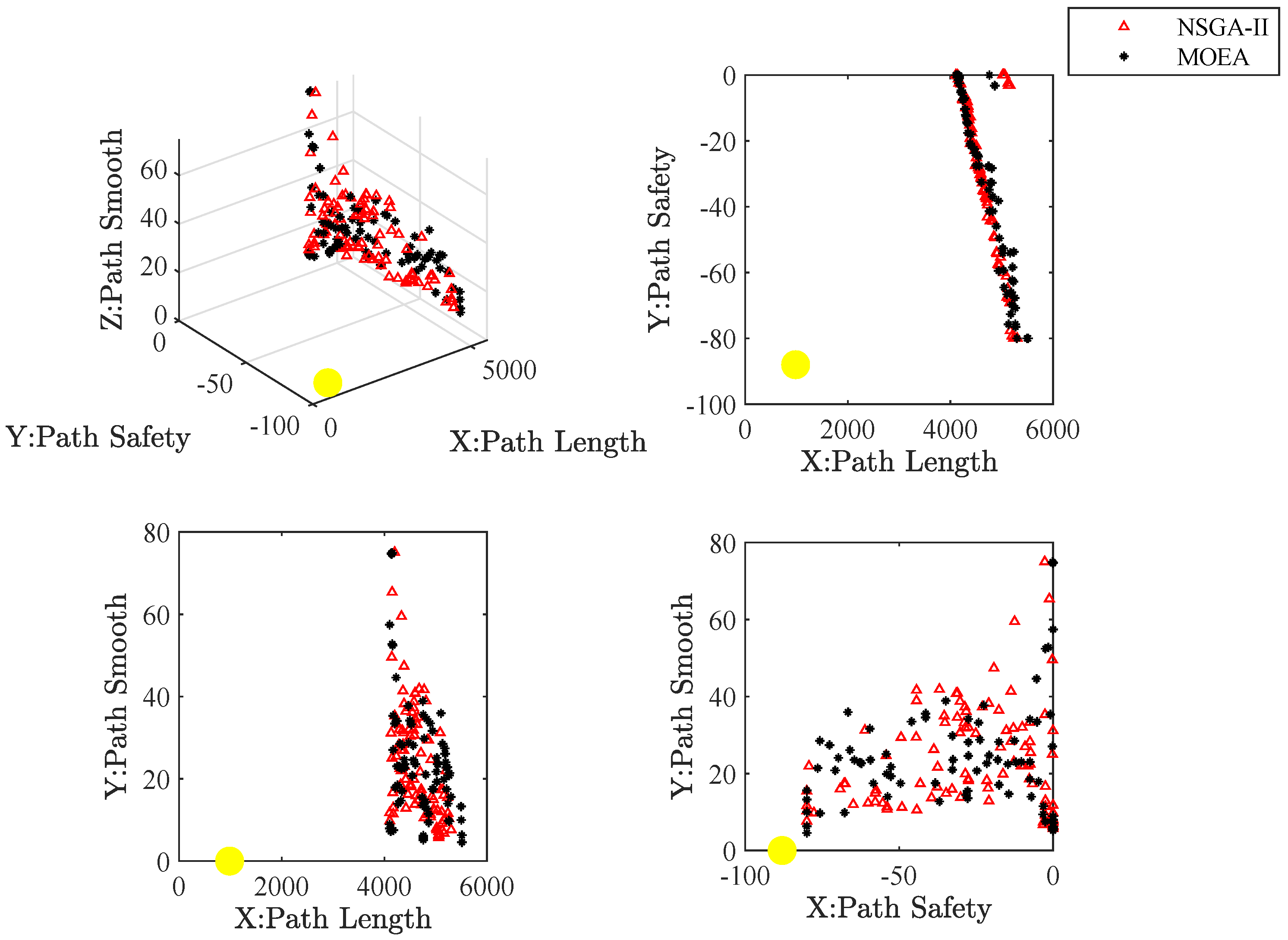
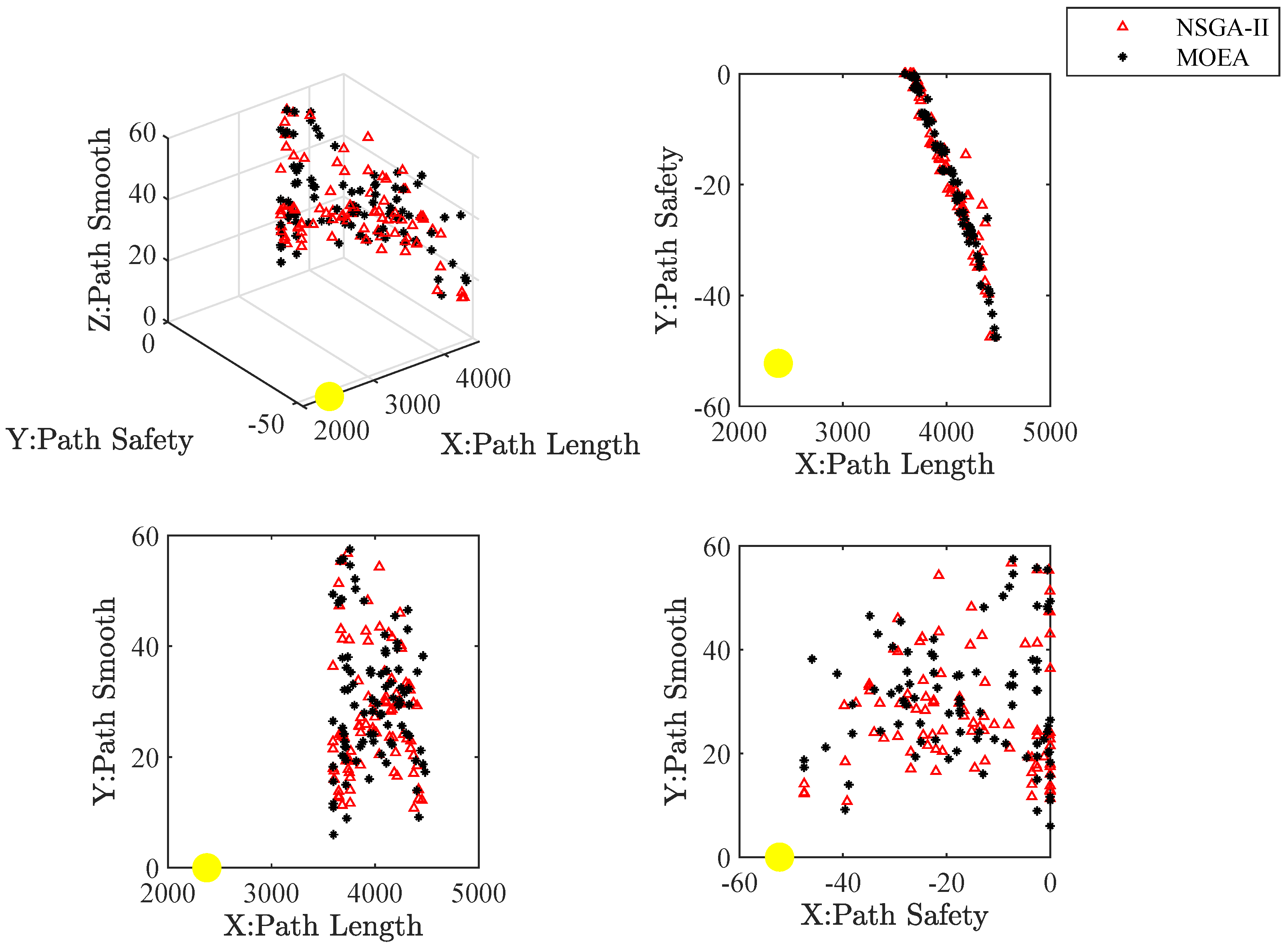
Figure 23,
Figure 24,
Figure 25,
Figure 26 and
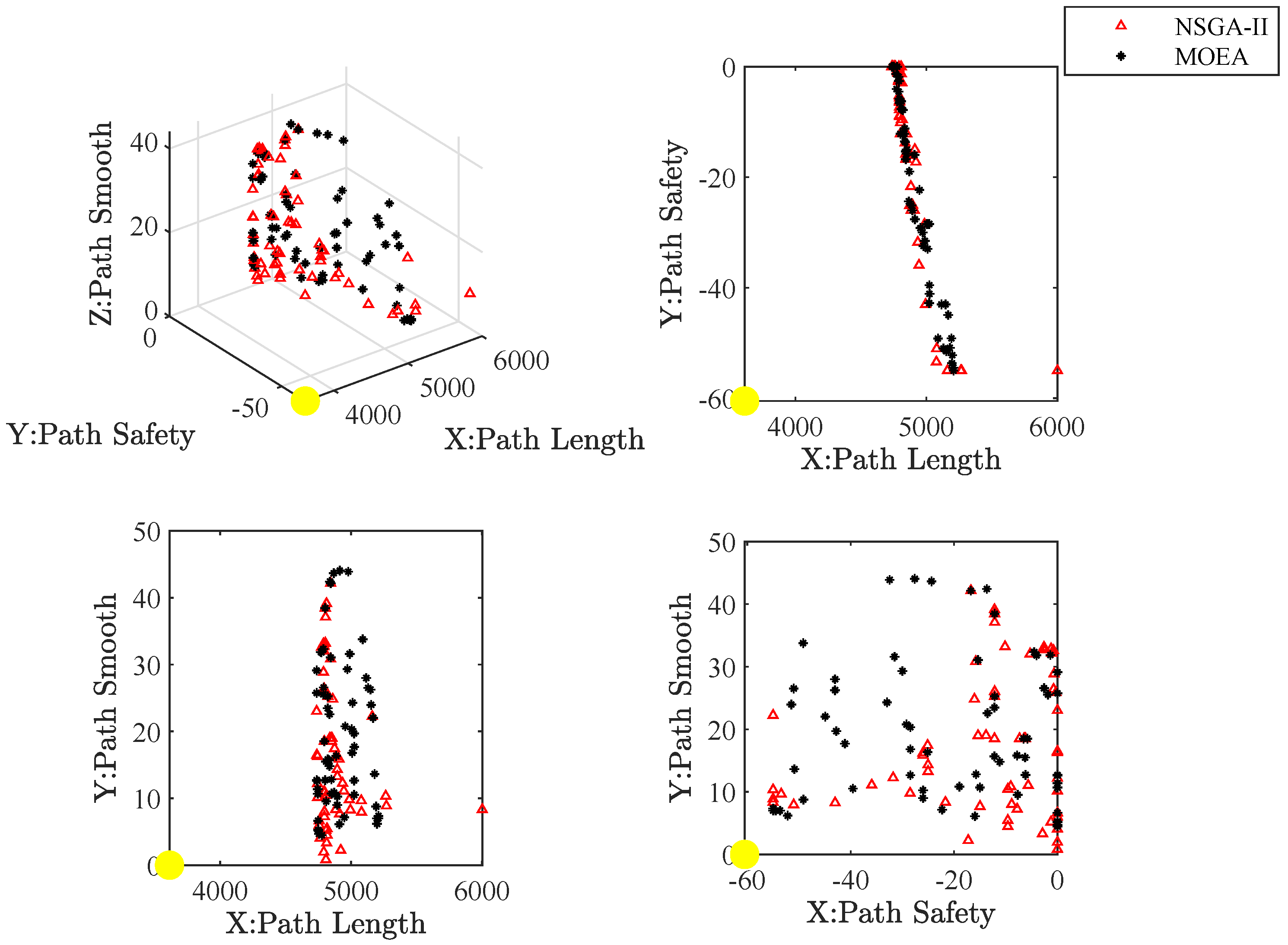
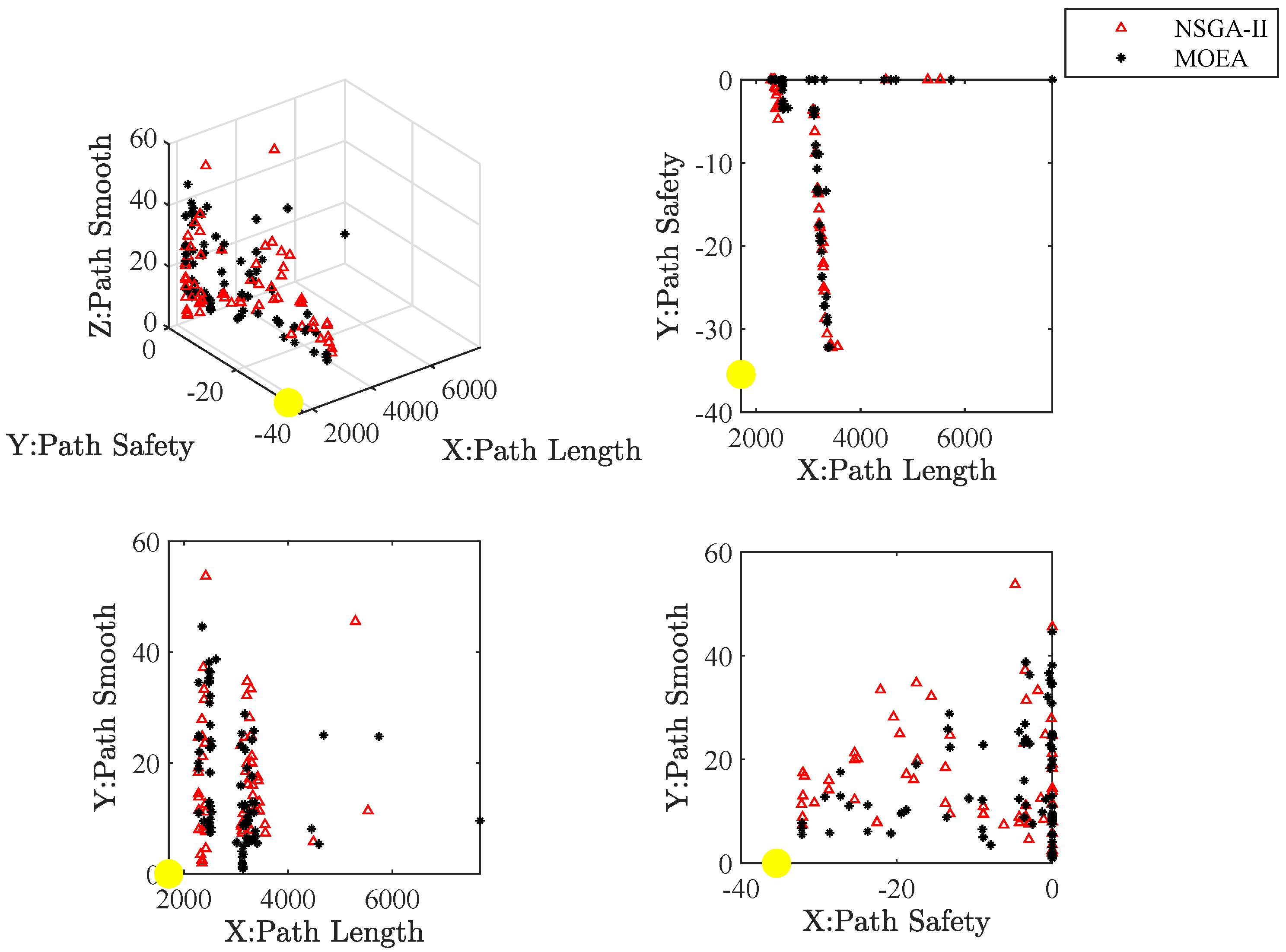
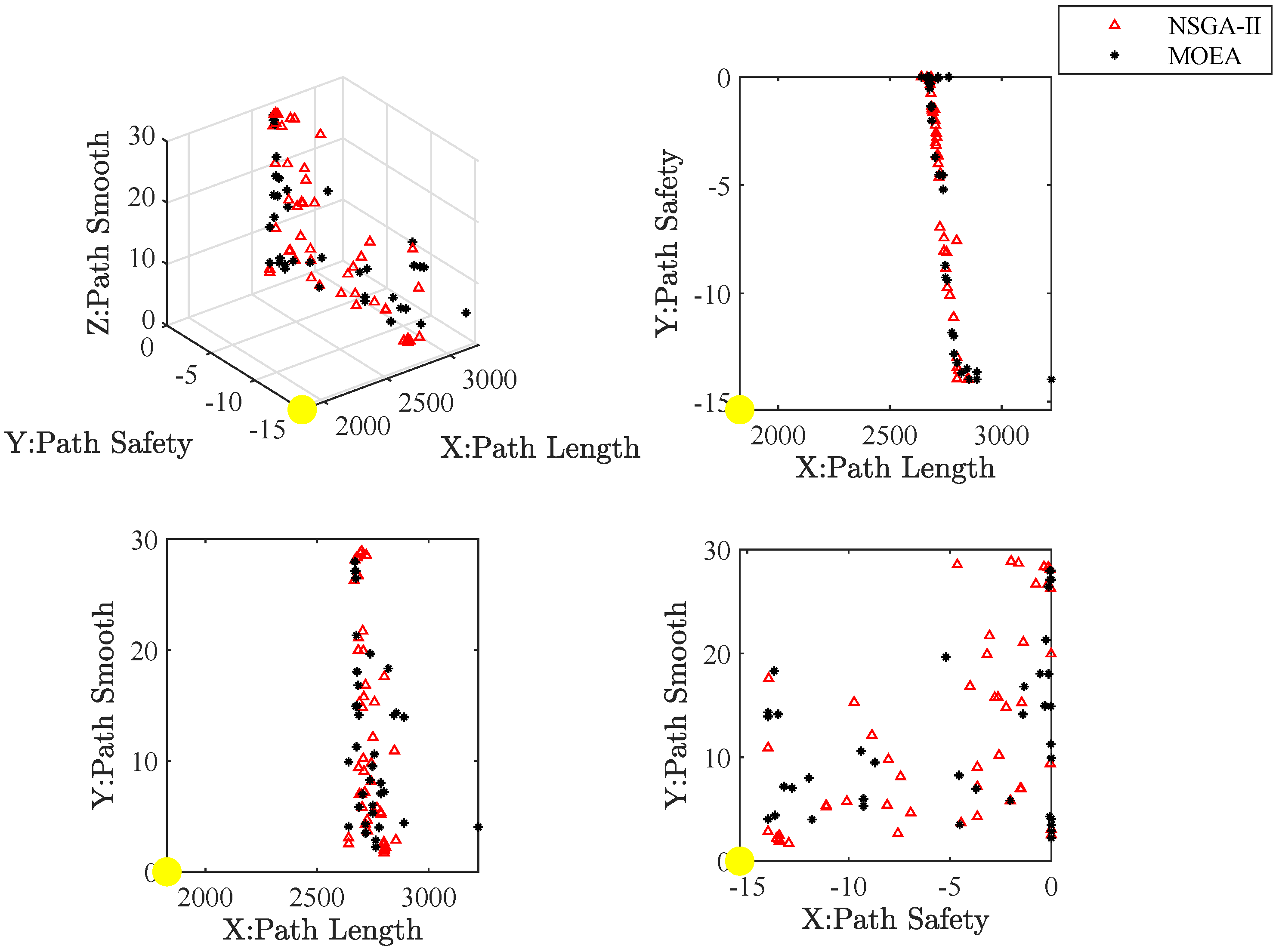
Figure 27 present the approximate Pareto front of maps. The yellow circle is the ideal reference point. Red triangles and black asterisks are the non-dominated solutions with the improved NSGA-II and MOEA, respectively. In non-dominated solutions, the knee spot is a solution closest to the ideal reference point.
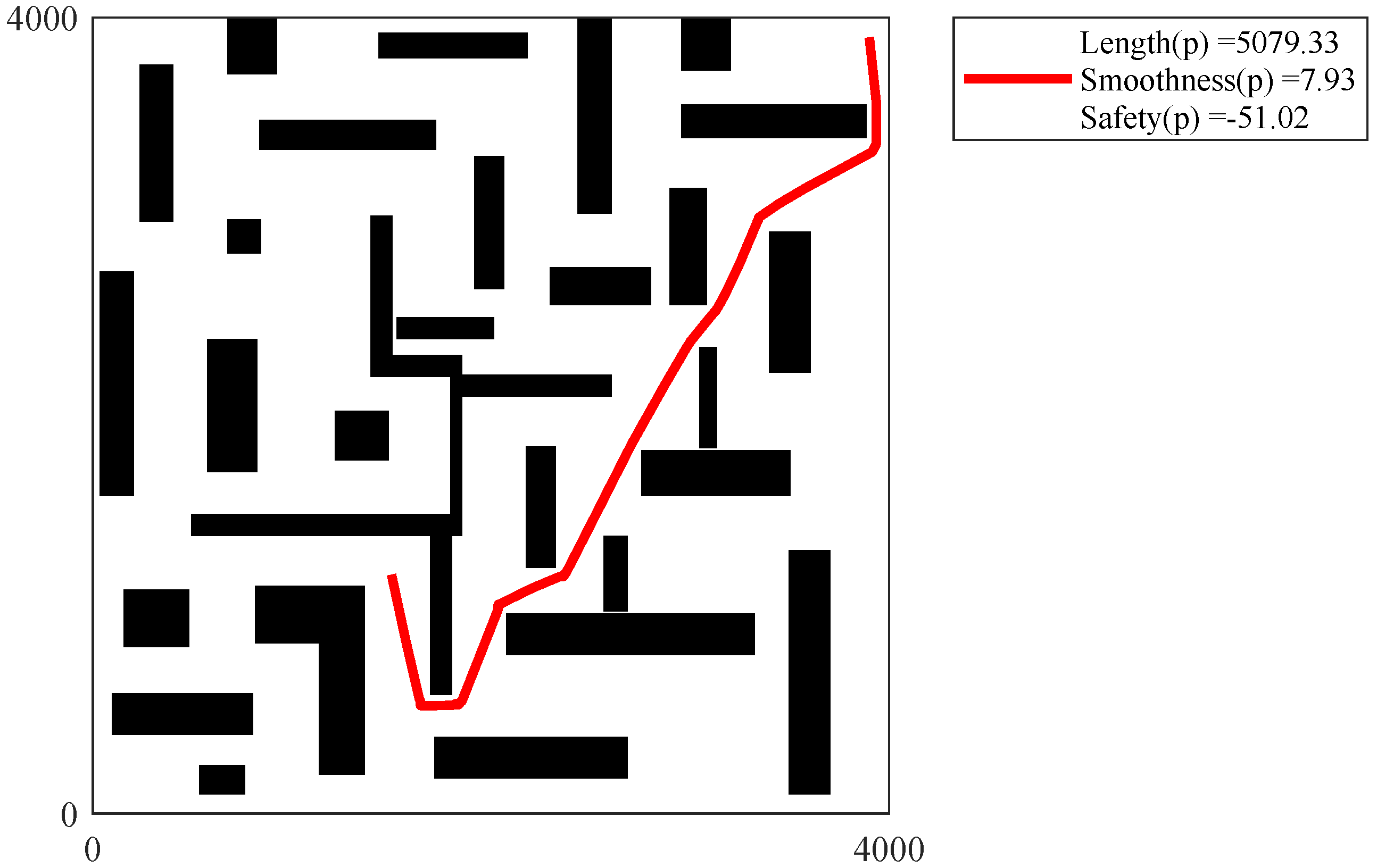
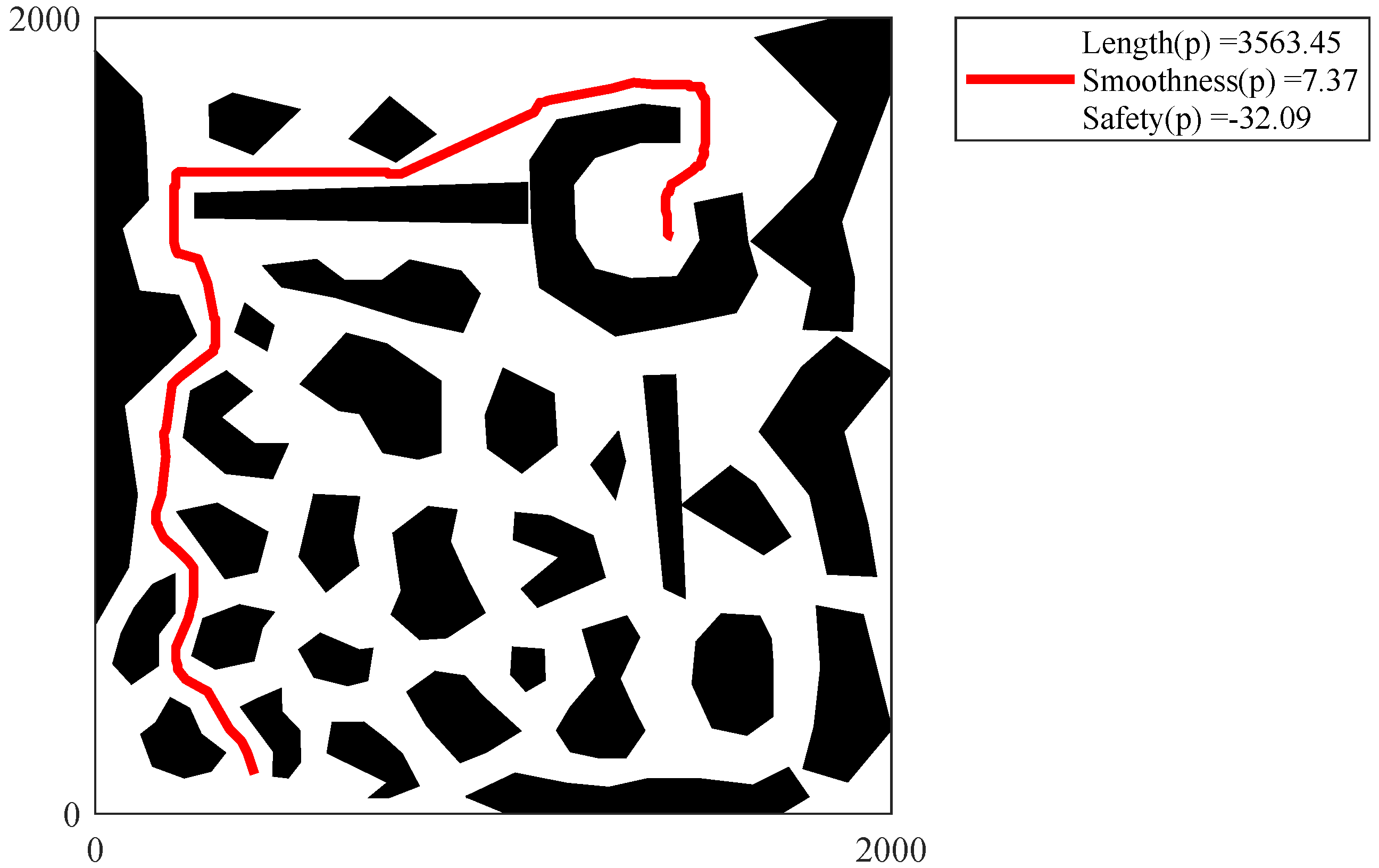
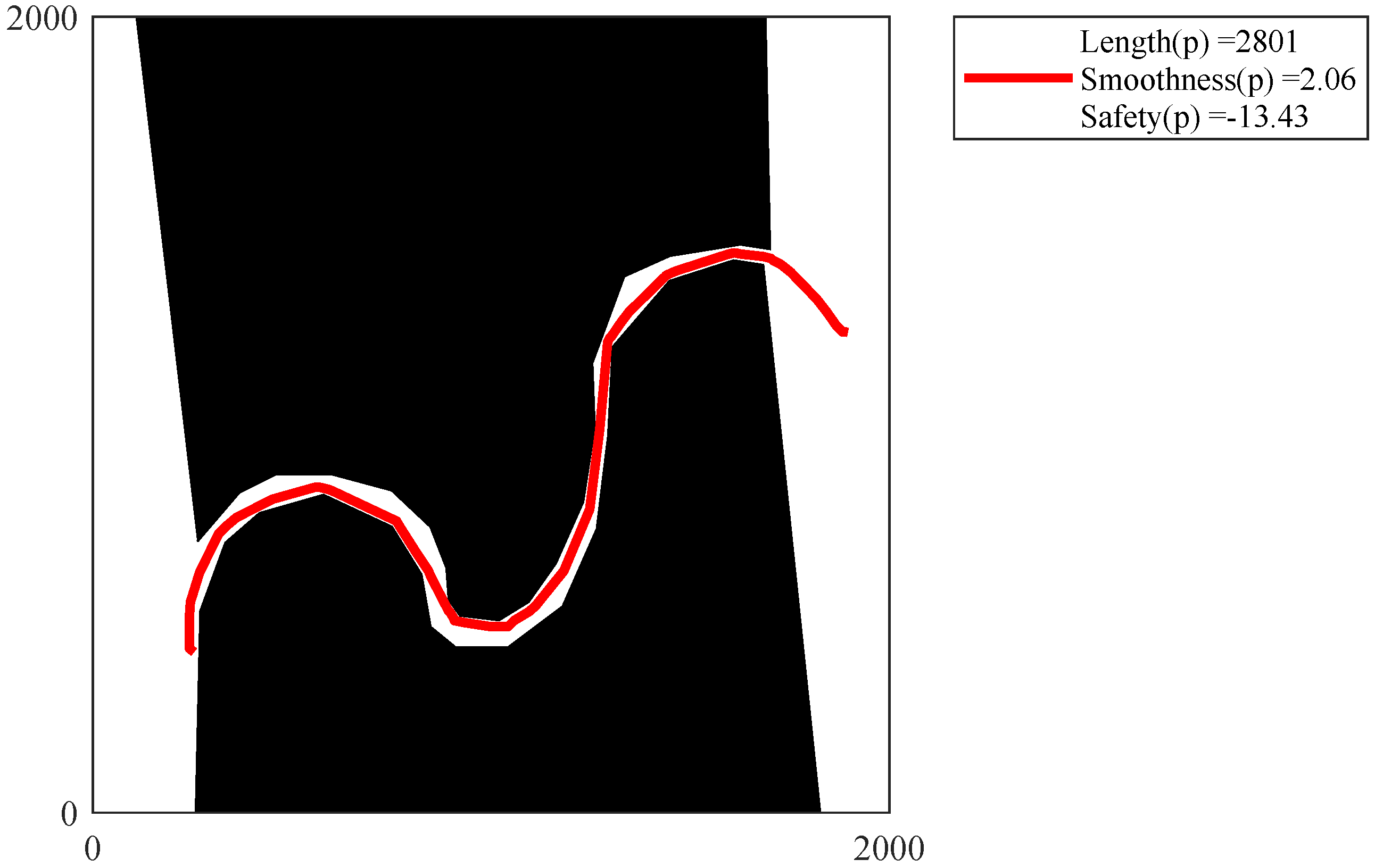
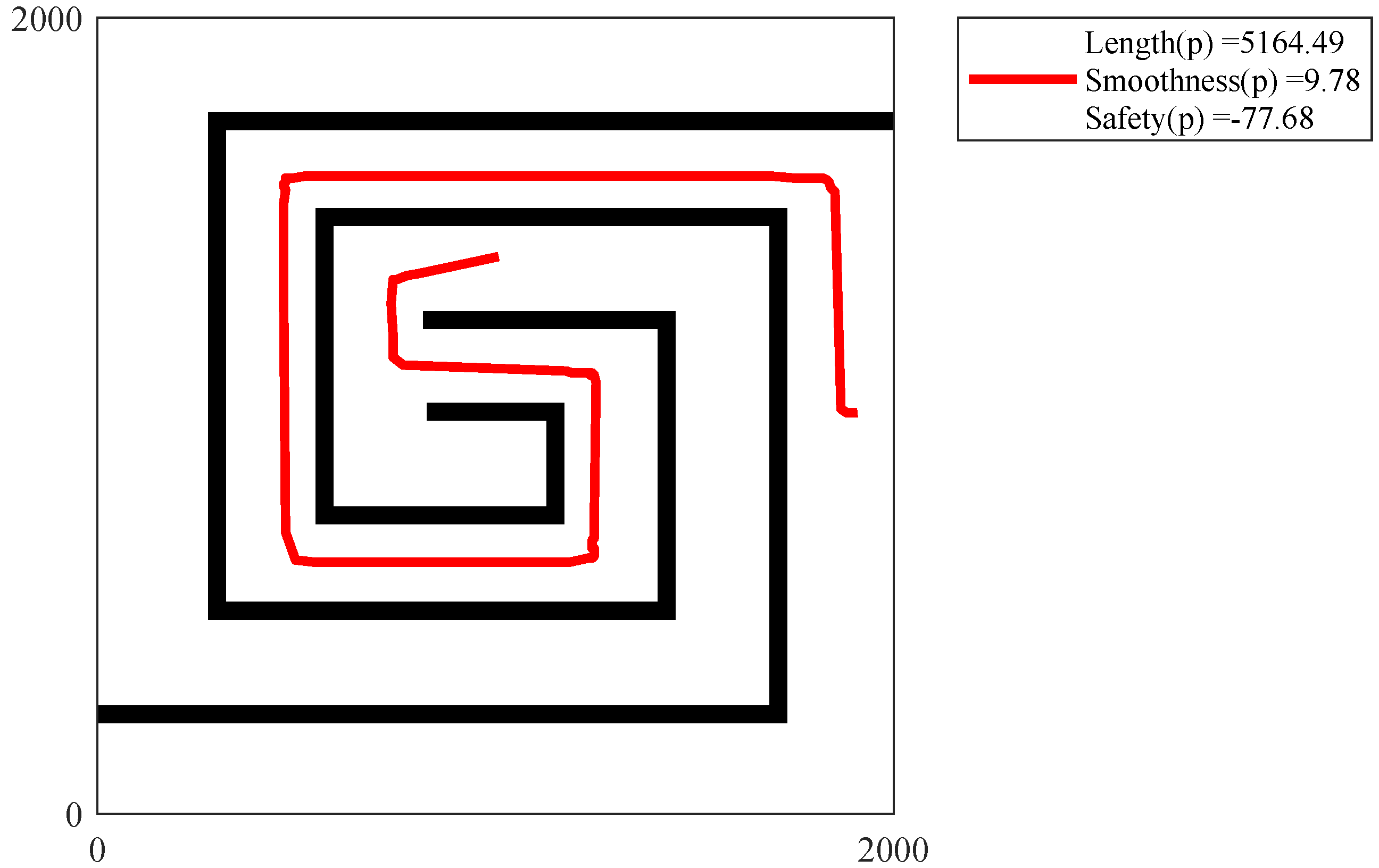
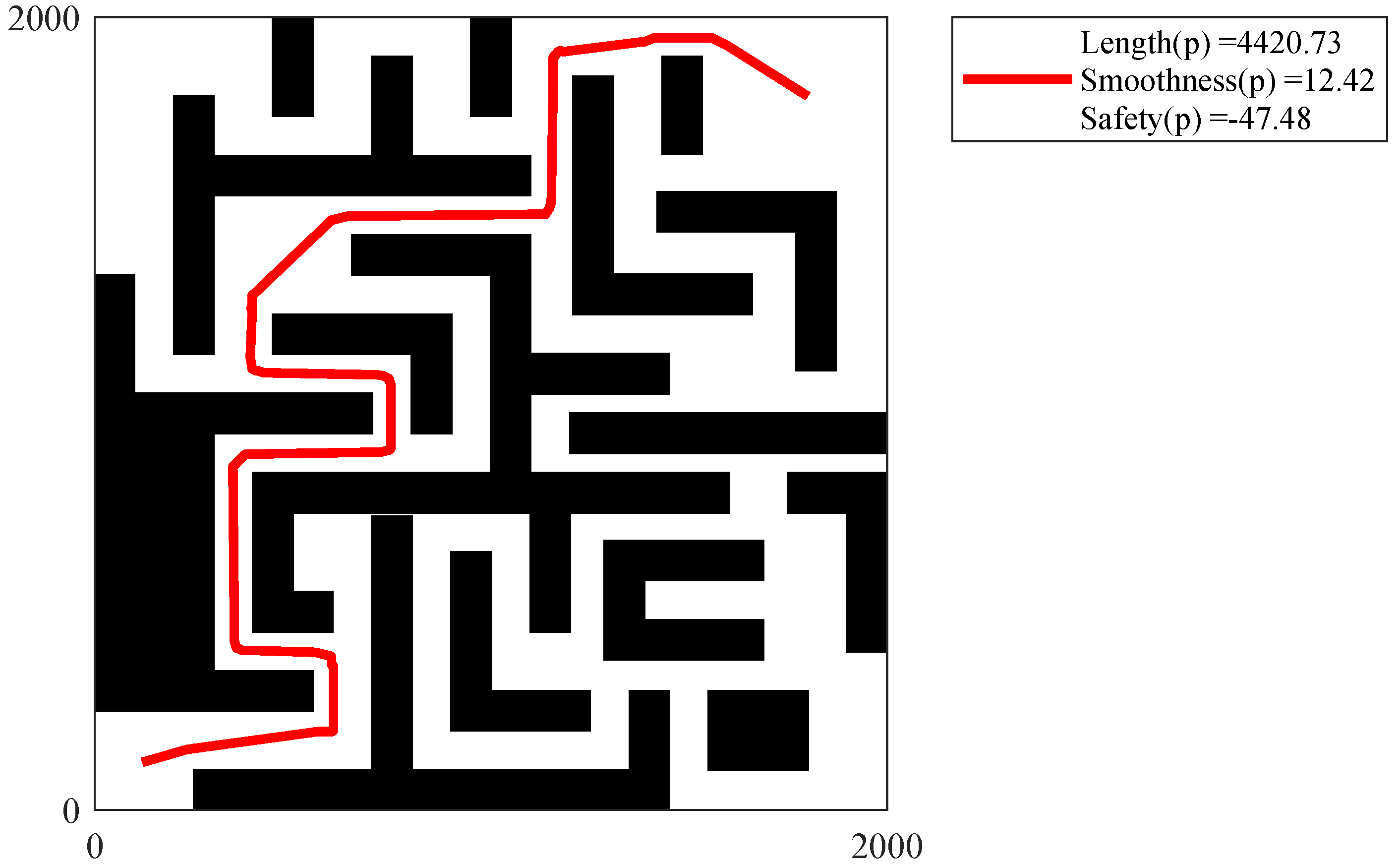
Figure 28,
Figure 29,
Figure 30,
Figure 31 and
Figure 32 show the path of the knee point obtained via NSGA-II. Comparison results are analyzed as follows. From the two different quality metrics of hypervolume and set coverage, the improved NSGA-II demonstrates a characteristic that is no worse than MOEA. Moreover, the non-dominated solutions generated via NSGA-II are denser. Besides, the path corresponding to the knee point also takes into account several designed objectives. The path is shorter, smoother and safer.
7. Concluding Remarks
In this work, an improved non-dominated sorting genetic algorithm (NSGA-II) is presented to solve the multi-objective path planning problem in statically known environments. The model and the three objectives to be optimized are introduced. Based on the framework of NSGA-II, more practical operators are proposed to accelerate the evolutionary speed of individuals. These operators help individuals become shorter, safer and smoother. Then, the parameters in the algorithm are systematically studied. To discern the capabilities of the algorithm, an effective multi-objective evolutionary algorithm is employed for comparison. The set coverage metric and hypervolume are adopted. Comparison results demonstrate that the non-dominated solutions generated by the improved NSGA-II have excellent characteristics in the solution space. Finally, the path corresponding to the knee point is displayed. The path is shorter, smoother and safer. It can be adopted as the tracking path of the mobile robot in the later decision.
Due to the speed of the operators in the algorithm, it is currently only applicable to offline path planning. Moreover, the kinematics of the robot is not considered. Besides, the improved algorithm only consider the statically known environments, so the situation with dynamic obstacles in the unknown environments deserves further research.


































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}