We conduct experiments in two Chinese copus: Fudan university corpus and the reduced version of Sougou classification corpus, and two English corpus: Reuters-21578 R8 and Reuters-21578 R52. In order to evaluate the performance of the proposed multi-stream model based on background knowledge, multiple comparison experiments are conducted to:
4.1. Dataset and Preprocessing
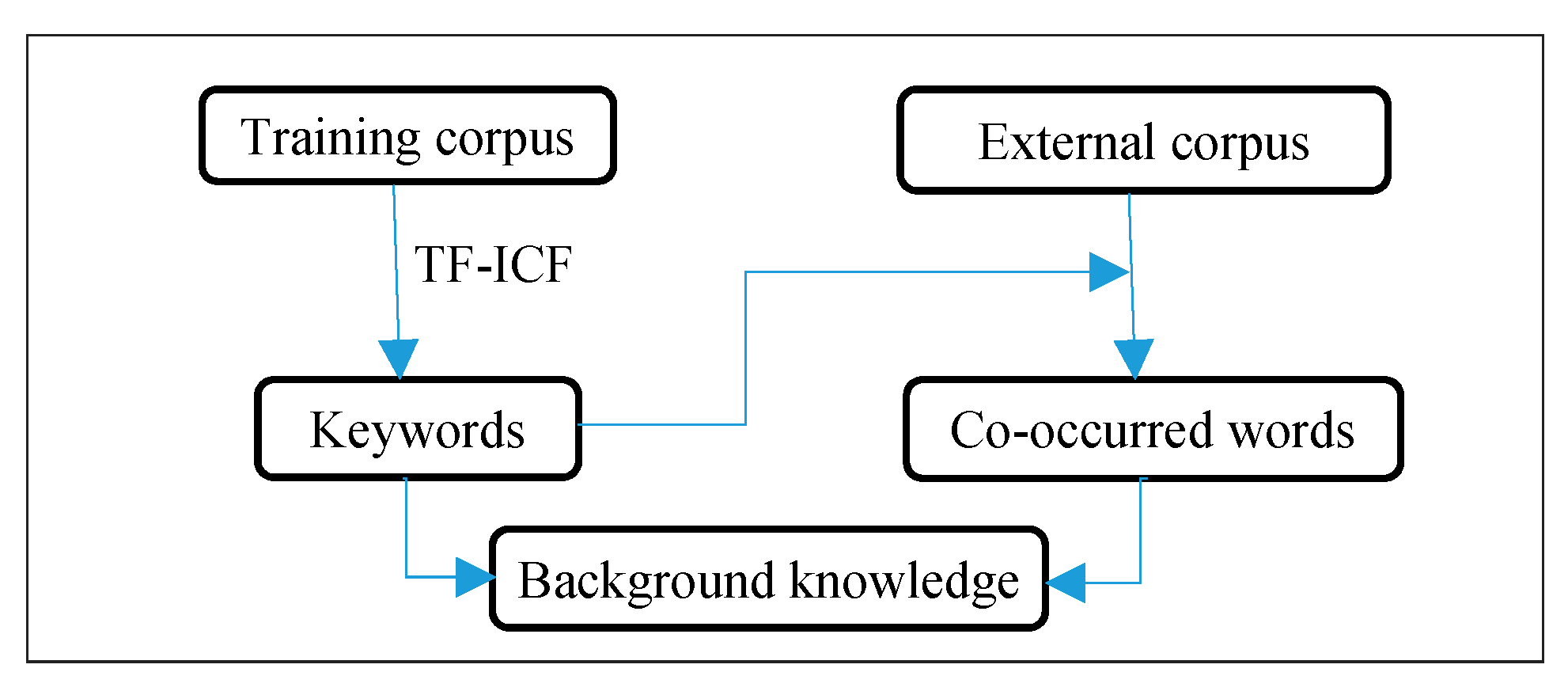
Three unlabeled external corpus are used to extract background knowledge, and four training corpus are used to train classification model and do predict. All corpus have been preprocessed. Referred Chinese corpus are preprocessed by word segmentation by Stanford-Segmenter (
http://nlp.stanford.edu/software/segmenter.html), part-of-speech tagging by Stanford-Postagger (
http://nlp.stanford.edu/software/tagger.html), non-Chinese words removal, non-nouns removal, and stop words removal. The English corpus are preprocessed by stem and stop words removal.
While reading an article, human often can accurately judge the related area after reading some paragraphs instead of the whole. Especially in text classification task, it is able to do classification after obtaining the category information. For above common sense and to reduce the computing cost during the experiments, a fixed text length is set according to the length distribution of corpus. If the length of original text is higher than the fixed value, only the previous words are retained, otherwise, 0-padding is employed.
4.1.1. Training Corpus
There are two Chinese corpus, Fudan University text classification corpus and the reduced version of Sougou classification corpus, and two English corpus, Reuters-21578 R52 and Reuters-21578 R8 which are partial data of Reuters-21578, are used as training corpus to test the performance of the proposed method.
Fudan University text classification corpus (hereinafter referred as Fudan corpus, (
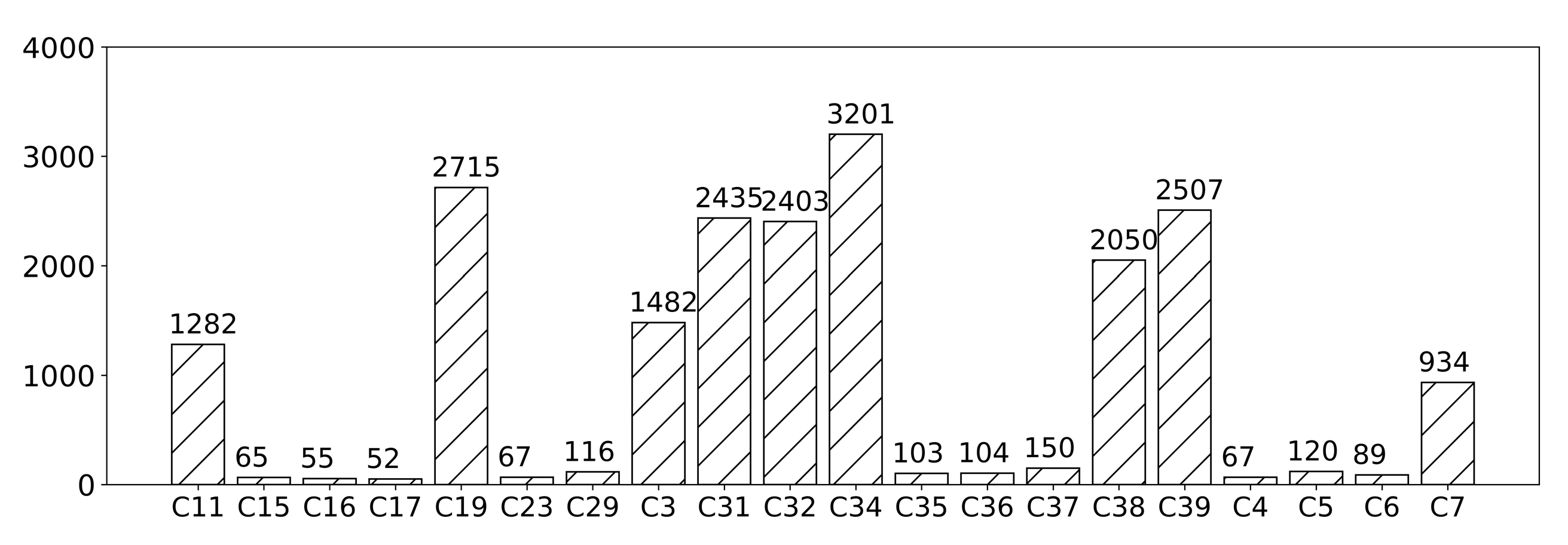
http://www.nlpir.org/?action-viewnews-itemid-103), are provided by the natural language processing group of international database in computer information and technology department of Fudan University. It has two parts, training corpus including 9833 texts and testing corpus including 9804 texts. This corpus has 20 categories and the number of texts in each category is different, which is an imbalanced corpus.
Figure 3 shows the distribution of all texts in Fudan corpus.
Reuters-21578, a collection of documents that appeared on Reuters newswire in 1987 (
http://www.cs.umb.edu/~smimarog/textmining/datasets/). This English corpus contains 90 classes of news documents. Reuters-21578 R8 (hereinafter referred as Reuter R8), in which there are 8 classes selected from Reuters-21578. The reduced corpus contain 7674 documents, and the average number of texts in each class is 959, in which the max number of texts in a certain class is 3923 while the minimum is 51.
Figure 4 shows the distribution of all texts in Reuter R8. Reuters-21578 R52 (hereinafter referred as Reuter R52), in which there are 52 classes selected from Reuters-21578 for the multiclass text classification experiments. The reduced corpus contains 9100 documents, and the average number of texts in each class is 175, in which the max number of texts in a certain class is 3923 while the minimum number is 3.
4.1.2. Background Corpus
There are two corpus are severed as external corpus to extract background knowledge:
4.3. Results and Discussion
Results of Reuter-21578 R8 are shown as
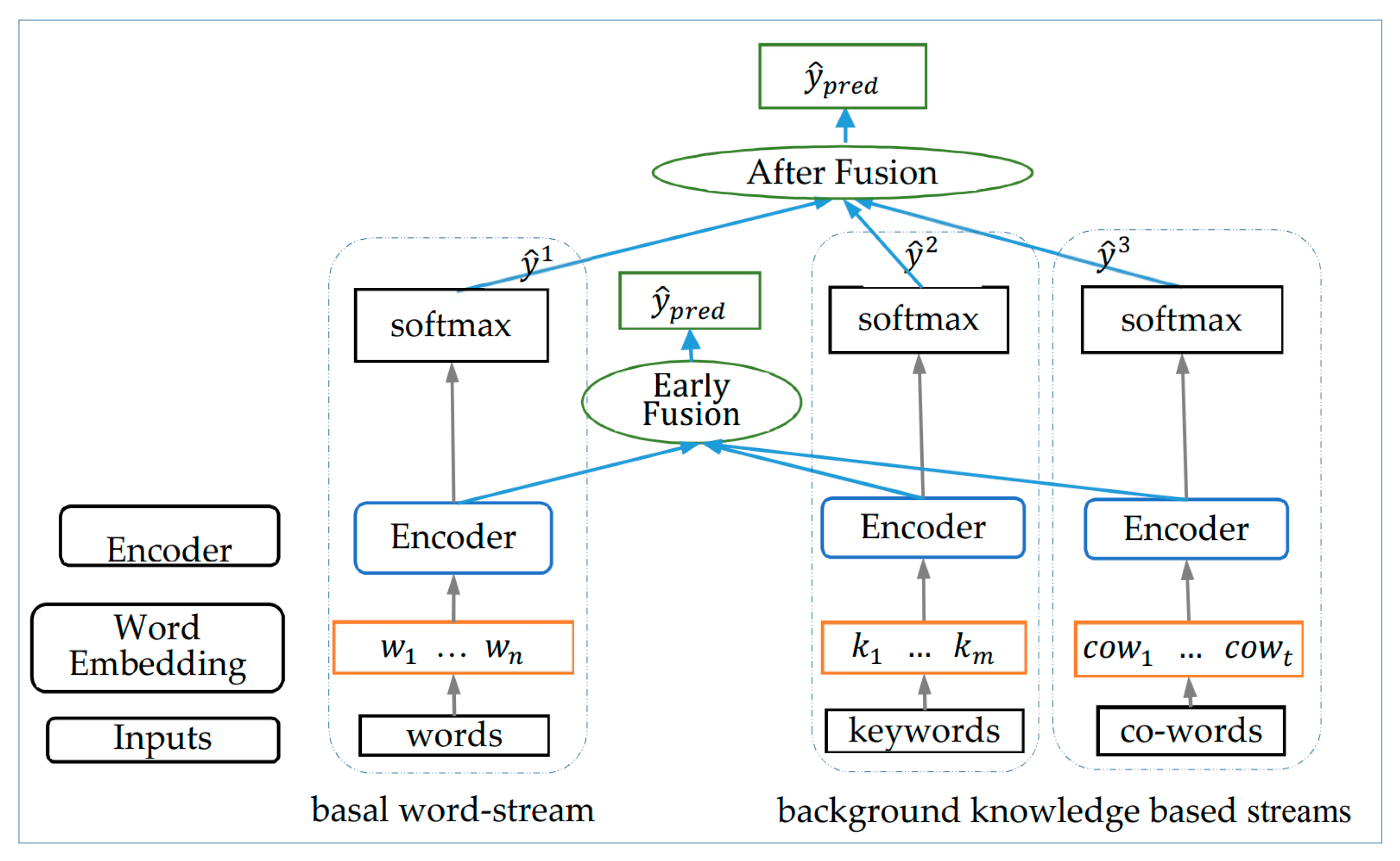
Table 3. From the results of single-stream in the table, it can be seen that in the single-streams based on background knowledge: key-stream, cow-stream and keycow-stream, the macro precision, recall and F1 score have been significantly improved while the accuracy is not much different compared with the basal word-stream. In the multi-stream network, the overall macro value increased significantly while the accuracy also improved whether in early-fusion or after-fusion strategy. The highest three results under different evaluation indicators are bolded in the table. Under comprehensive consideration, the best one is obtained in three-stream network with average pooling (
P =
95.28,
R =
94.75,
F1 =
95.02), which is superior than baseline (word-stream,
P =
84.71,
R =
85.37,
F1 =
85.04). The improved classification results mean that the incorporation of background knowledge has enriched the text representation to a great extent. Therefore, we can infer that the background knowledge can not only make up for the insufficient information of training data, but also make up for the deep feature extraction of those data sparse categories.
The effectiveness of background knowledge incorporation in multi-stream neural network also verified in Reuters-20578 R52 and two Chinese corpus. The results of Reuters-20578 R52 are shown in
Table 4, the best one acquired in three-stream network with after fusion of soft voting:
P =
81.96,
R =
71.06,
F1 =
76.12 (while
P =
64.09,
R =
63.95,
F1 =
64.02 in baseline). The results of SougouC corpus are shown in
Table 5, the best one is acquired in three-stream network with early fusion:
P =
87.23,
R =
87.30,
F1 =
87.27 (while
P =
83.72,
R =
83.30,
F1 =
83.36 in baseline). The results of Fudan corpus are shown in
Table 6, and the best one is acquired in three-stream network with early fusion:
P =
88.69,
R =
81.65,
F1 =
85.03 (while
P =
76.70,
R =
76.41,
F1 =
76.55 in baseline). In this way, we can infer that the background knowledge with multi-stream network contributes a lot for text classification task.
The comparison results between above optimal model and basal model show that the macro indicators have significantly improved while the overall accuracy growth is slight. The reason can be that in these three imbalance corpus, there are some categories with less data, and their classification results effect slightly on overall accuracy results because of the data distribution. However, during the model training, accuracy is often used as evaluation indicator and the categories with less data often be ignored. Therefore, macro evaluation can reflect the overall classification results more objective for imbalance corpus.
The background knowledge based single-streams: key-stream, cow-stream and keycow-stream, perform well in Reuter-21578 R8, as shown in
Table 3. However, the results are not stable in other three corpus: the macro values have a slight rise or fall compared with word-stream, as shown in
Table 4,
Table 5 and
Table 6. This is mainly caused by two aspects. On one hand, the contribution of background knowledge based feature extraction in single-stream has a great relationship of the quality of background knowledge and the training data distribution. On the other hand, the information extracted from background knowledge based stream are not as comprehensive as the word-stream. In background knowledge based stream, the inputs are keywords, co-occurred words or the both extracted from original text, while all words are taken as input in word-stream. The features extracted will be too sparse compared with basal model if the coverage of background knowledge is not so comprehensive, which means the case that not all keywords or those words carry abundant category information in original texts are concluded in background knowledge. Therefore, it is not certain that the classification results of background knowledge based stream can be better than basal word-stream model.
In the multi-stream network, the overall classification results are improved a lot after feature fusion. It means that, as the knowledge supplement, the background knowledge based features can make up for the problem caused by data imbalance in basal word-stream network. The imbalance referred two aspects, the first is the feature imbalance in a certain category. For example, because of the limitation of data coverage, testing data and training data may come from different sub-categories of a certain category and contain different feature words. The incorporation of background knowledge which contain almost all sub-categories information are served as bridge, create a connection between training data and testing data. The second is amount imbalance between categories. There are some categories with less data and result in less feature extracted for them. The incorporation of background knowledge can largely alleviate the limitation caused by imbalanced data distribution.
To investigate the performance of our model on certain corpus, some comparisons are conducted with other typical models. Such as GRUs [
47], Multinomial NB, SVM, Bayes Network, and KNN, which are all analyzed on Reuters R8 and Reuters R52 in [
48]. As shown in
Table 7, the comparisons of optimum results of our proposed method against above methods are listed with the same datasets. The best results on each dataset are in bold, and they are obtained by our proposed method.
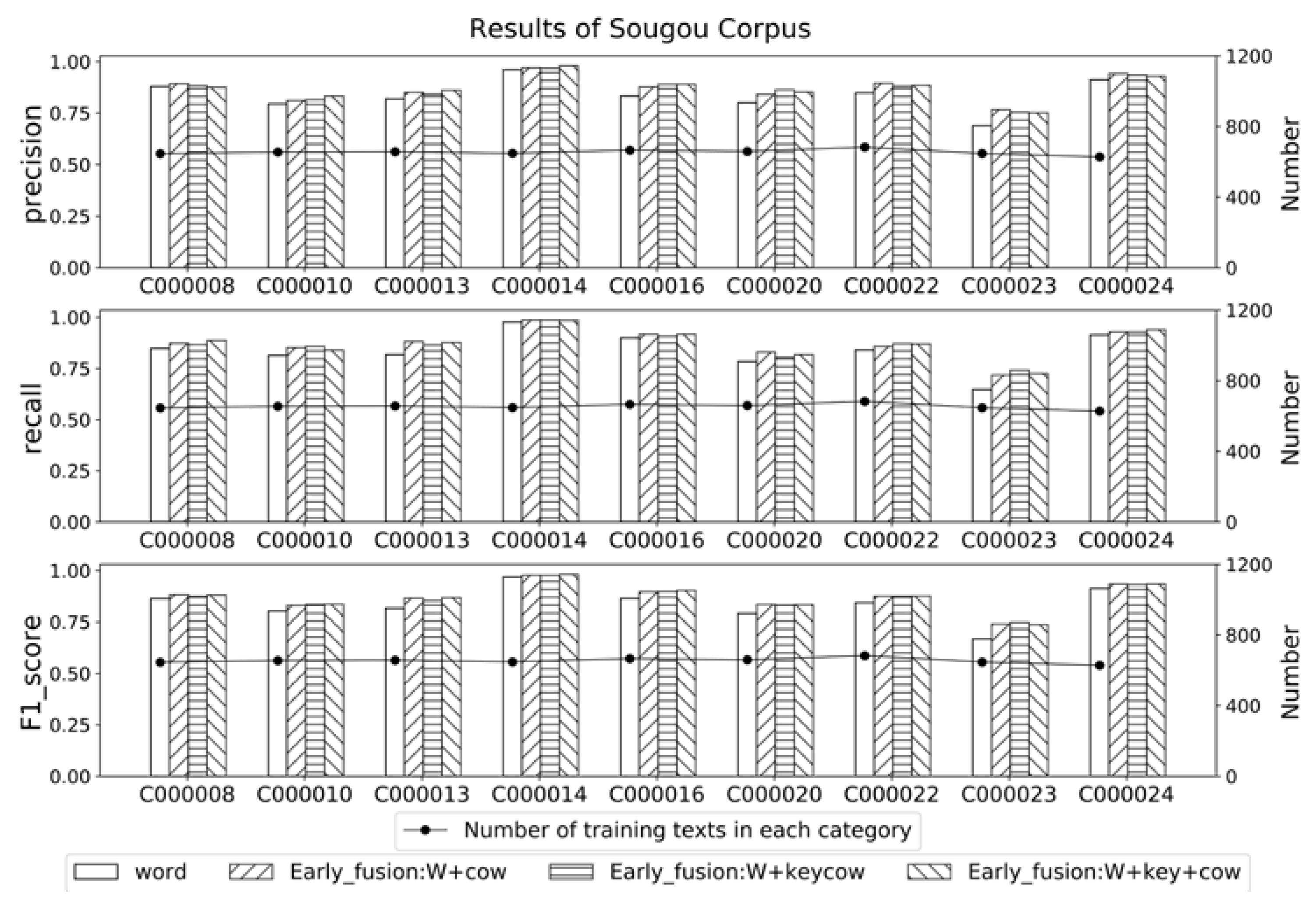
To investigate the contribution of background knowledge on different categories in a certain corpus, the optimal three group of experimental results obtained to compare with the basal word-stream model. The results of each category are shown as
Figure 5,
Figure 6 and
Figure 7 respectively. Horizontal axis refers to the categories, the bar charts refers to the classification results, and the line graph refers to the number of training texts in corresponding category.
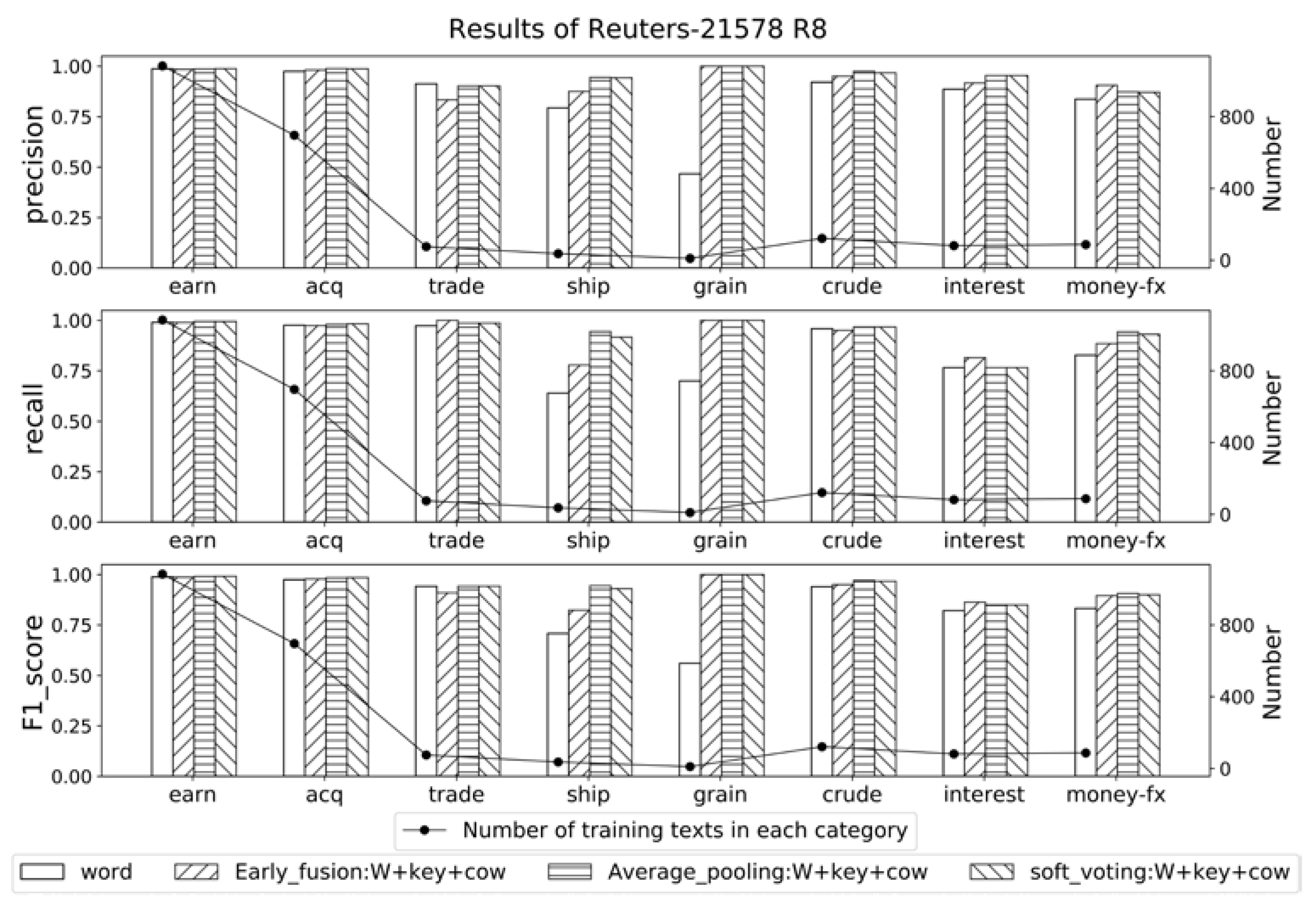
According to the results of Reuters-21578 R8, as shown in
Figure 5, the categories with relatively few training data, like ‘ship’ with 36 training texts and ‘grain’ with 10 training texts, improved a large amount in macro precision, recall, and F1 score, while the categories with relatively abundant training data, like ‘earn’ and ‘acq’, improved not very obviously. These results also verify the previous viewpoint about imbalance corpus: the incorporation of background knowledge can conspicuously make up for the insufficient information of some categories with less data, thus contribute to the overall results of classification model.
The results of another imbalance Chinese corpus, Fudan Corpus, also verified the above assumption, as shown in
Figure 6. The categories with relatively abundant training data above 600, like ‘C11’ and ’C19’, the variation is slight. However, for other categories in which training texts are less than 100, the improvement is relatively distinct.
The results of the balance Sougou corpus, in which each category is composed of same number of texts, are shown as
Figure 7. Compared with base model, the incorporation of background knowledge in multi-stream neural network seems contributions to each category uniformly. Although not particularly improved, the recognition accuracy of each category are all improved to some extent, which proved that the multi-stream model is not only applicable to imbalanced corpus, but also applicable to balanced corpus.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}