Parallel Technique for the Metaheuristic Algorithms Using Devoted Local Search and Manipulating the Solutions Space




Abstract
:1. Introduction
2. Optimization Problem and the Method of Finding the Optimal Solution
2.1. Genetic Algorithm
| Algorithm 1: Genetic Algorithm | |
| 1: | Start, |
| 2: | Define fitness function , |
| 3: | Create an initial population, |
| 4: | Evaluate all individuals in the population, |
| 5: | Define , , and the number of iteration T, |
| 6: | , |
| 7: | while do |
| 8: | Sort individuals according to , |
| 9: | Select best individuals according to Equation (2), |
| 10: | Make a mutation by Equation (5), |
| 11: | Make a crossover using Equation (7), |
| 12: | Evaluate all new individuals in the population, |
| 13: | Replace the worst with new ones, |
| 14: | , |
| 15: | end while |
| 16: | Return the best chromosome, |
| 17: | Stop. |
2.2. Artificial Ant Colony Algorithm
| Algorithm 2: Ant Colony Optimization Algorithm | |
| 1: | Start, |
| 2: | Define fitness function , |
| 3: | Create an initial population of ants, |
| 4: | Evaluate all individuals in the population, |
| 5: | Define , n, m and the number of iteration T, |
| 6: | , |
| 7: | while do |
| 8: | for each ant do |
| 9: | Calculate the probability using Equation (8), |
| 10: | Find the best nest by Equation (9), |
| 11: | Determine Gaussian sampling according to Equation (10), |
| 12: | Create m new solutions and destroy m the worst ones, |
| 13: | end for |
| 14: | , |
| 15: | end while |
| 16: | Sort individuals according to , |
| 17: | Return the best ant, |
| 18: | Stop. |
2.3. Particle Swarm Optimization Algorithm
- In each iteration, the number of individuals is constant,
- Only the best ones are transferred to the next iteration and the rest are randomly selected.
| Algorithm 3: Particle Swarm Optimization Algorithm | |
| 1: | Start, |
| 2: | Define , , , number of iteration T and n, |
| 3: | Define fitness function , |
| 4: | Create an initial population, |
| 5: | , |
| 6: | while do |
| 7: | Calculate velocity using Equation (13), |
| 8: | Move each individual according to Equation (12), |
| 9: | Sort population according to , |
| 10: | Take of population to next iteration, |
| 11: | Complete the remainder of the population randomly, |
| 12: | , |
| 13: | end while |
| 14: | Return the best particle, |
| 15: | Stop. |
2.4. Firefly Algorithm
- – light absorption coefficient,
- – coefficient of motion randomness,
- – attractiveness ratio,
- – light intensity.
- Each firefly is unisex,
- The attractiveness is proportional to the brightness, which means that the less attractive firefly will move to more attractive,
- The distance is greater, the attractiveness is lower,
- If there is no attractive partner in the neighborhood, then firefly moves randomly.
| Algorithm 4: Firefly Algorithm | |
| Start, | |
| Define all coefficients and the number of iteration T and size of population, | |
| Define fitness function , | |
| Create at initial population, | |
| , | |
| while do | |
| Calculate all distances between individuals in whole population according to Equation (14), | |
| Calculate all light intensity between individuals in whole population according to Equation (15), | |
| Calculate attractiveness between individuals in whole population according to Equation (16), | |
| Evaluate and sort population, | |
| Move each firefly using Equation (17), | |
| , | |
| end while | |
| Return the best firefly, | |
| Stop. | |
2.5. Cuckoo Search Algorithm
- Cuckoo is identified with the egg,
- Each cuckoo has one egg,
- The nest owner decides to keep or throw the egg out with the probability . If the egg is thrown out, the new cuckoo is replace these one and the position is chosen at random.
| Algorithm 5: Cuckoo Search Algorithm | |
| Start, | |
| Define all parameters , , , , , number of and iterations T, | |
| Define fitness function , | |
| Create an initial population, | |
| t:=0, | |
| while do | |
| Move individuals to another position using Equations (18) and (19), | |
| According to Equation (20), the nest host decides whether the cuckoo eggs remain, | |
| Evaluate the whole population, | |
| Sort the population according to fitness condition, | |
| , | |
| end while | |
| Return the best cuckoo, | |
| Stop. | |
2.6. Wolf Search Algorithm
- initiative stage – wolf moves in the area of his vision and looks for food. This behavior is modeled by changing the position of the wolf in the following waywhere v is the velocity of a wolf.
- passive stage – wolf waits for the opportunity to attack on a given position and tries to attack by Equation (21).
- escape – in case of lack of food or the appearance of another predator, the wolf escapes bywhere k is the step size.
| Algorithm 6: Wolf Search Algorithm | |
| Start, | |
| Define basic parameters of the algorithm – the number of iterations T, the number of wolves n, radius of view r, step size k, velocity coefficient and rate of appearance of the enemy , | |
| Generate a population of wolves at random, | |
| , | |
| while do | |
| for each wolf in population do | |
| Check the viewing area by Equation (22), | |
| Calculate the new position using Equation (21), | |
| if then | |
| Move the wolf from to , | |
| end if | |
| Select the value of the parameter at random, | |
| if then | |
| The wolf performs escape by Equation (23), | |
| end if | |
| end for | |
| , | |
| end while | |
| Return the fittest wolf in the population, | |
| Stop. | |
3. Manipulation of Swarms Positions and Space Solution Using Multi-Threaded Techniques
3.1. Proposition I
| Algorithm 7: Metaheuristic with devoted local search |
|
3.2. Proposition II
| Algorithm 8: Analysis of the solution space for the initial population |
|
3.3. Proposition III
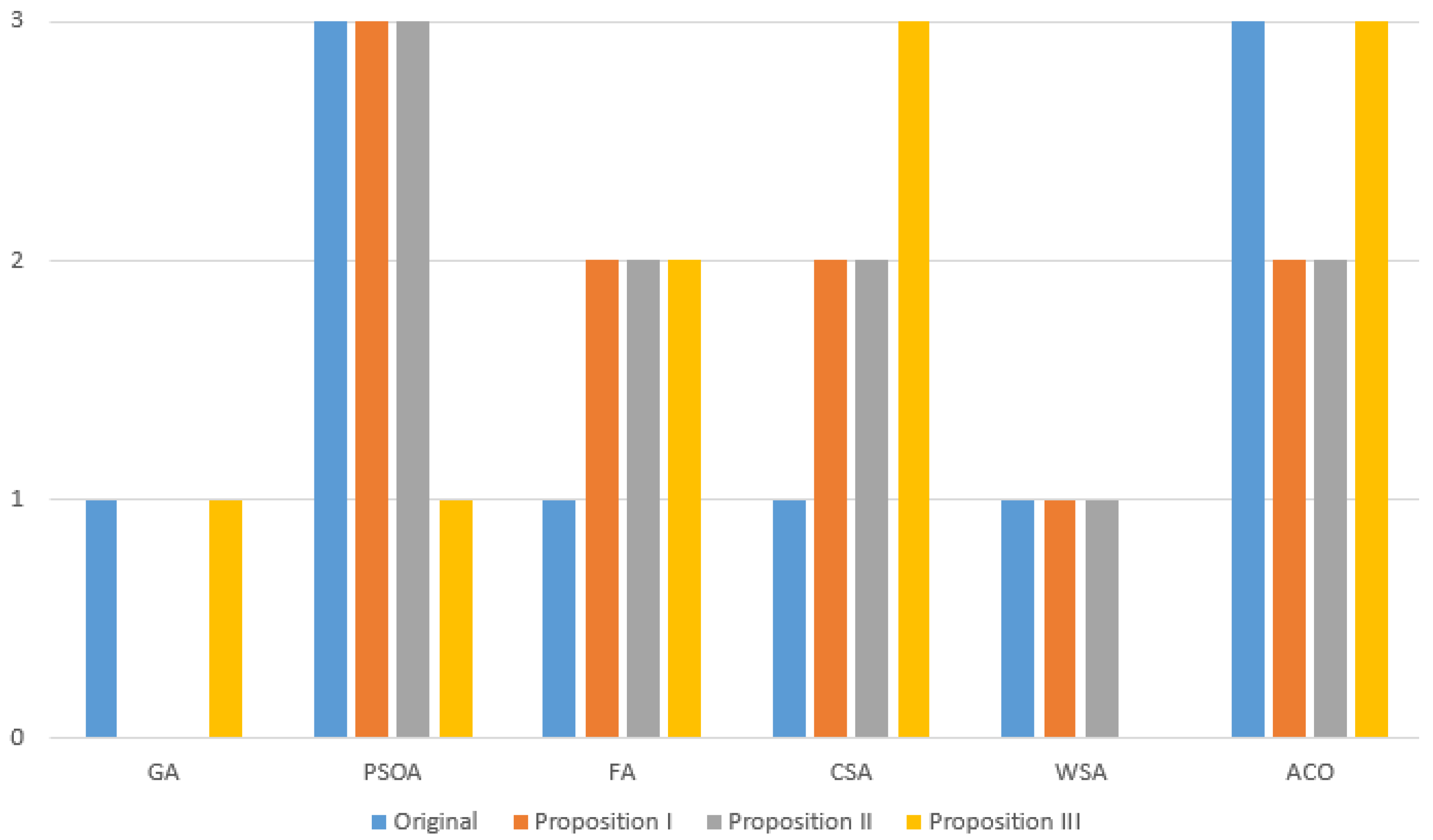
4. Test Results
4.1. The Benchmark Functions
4.2. Experimental Settings
- Genetic algorithm – ,
- Ant Colony Optimization Algorithm – , , ,
- Particle Swarm Optimization Algorithm – , , ,
- Firefly Algorithm – , ,
- Cuckoo Search Algorithm – , , , , ,
- Wolf Search Algorithm – , , .
4.3. Performance Metrics
4.4. Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Shaoping, L.; Taijiang, M.; Zhang, S. A survey on multiview video synthesis and editing. Tsinghua Sci. Technol. 2016, 21, 678–695. [Google Scholar]
- Hong, Z.; Jingyu, W.; Jie, C.; Shun, Z. Efficient conditional privacy-preserving and authentication scheme for secure service provision in vanet. Tsinghua Sci. Technol. 2016, 21, 620–629. [Google Scholar]
- Rostami, M.; Shahba, A.; Saryazdi, S.; Nezamabadi-pour, H. A novel parallel image encryption with chaotic windows based on logistic map. Comput. Electr. Eng. 2017, 62, 384–400. [Google Scholar] [CrossRef]
- MY, S.T.; Babu, S. An intelligent system for segmenting lung image using parallel programming. In Proceedings of the International Conference on Data Mining and Advanced Computing (SAPIENCE), Ernakulam, India, 16–18 March 2016; Volume 21, pp. 194–197. [Google Scholar]
- Lan, G.; Shen, Y.; Chen, T.; Zhu, H. Parallel implementations of structural similarity based no-reference image quality assessment. Adv. Eng. Softw. 2017, 114, 372–379. [Google Scholar] [CrossRef]
- Khatami, A.; Babaie, M.; Khosravi, A.; Tizhoosh, H.R.; Nahavandi, S. Parallel Deep Solutions for Image Retrieval from Imbalanced Medical Imaging Archives. Appl. Soft Comput. 2017, 63, 197–205. [Google Scholar] [CrossRef]
- Alzubaidi, M.; Otoom, M.; Al-Tamimi, A.K. Parallel scheme for real-time detection of photosensitive seizures. Comput. Biol. Med. 2016, 70, 139–147. [Google Scholar] [CrossRef] [PubMed]
- Munguía, L.; Ahmed, S.; Bader, D.A.; Nemhauser, G.L.; Goel, V.; Shao, Y. A parallel local search framework for the fixed-charge multicommodity network flow problem. Comput. OR 2017, 77, 44–57. [Google Scholar] [CrossRef]
- Gomis, H.M.; Migallón, V.; Penadés, J. Parallel alternating iterative algorithms with and without overlapping on multicore architectures. Adv. Eng. Softw. 2016, 10, 27–36. [Google Scholar]
- Woźniak, M.; Połap, D. Hybrid neuro-heuristic methodology for simulation and control of dynamic systems over time interval. Neural Netw. 2017, 93, 45–56. [Google Scholar] [CrossRef] [PubMed]
- Tapkan, P.; Özbakir, L.; Baykasoglu, A. Bee algorithms for parallel two-sided assembly line balancing problem with walking times. Appl. Soft Comput. 2016, 39, 275–291. [Google Scholar] [CrossRef]
- Tian, T.; Gong, D. Test data generation for path coverage of message-passing parallel programs based on co-evolutionary genetic algorithms. Autom. Softw. Eng. 2016, 23, 469–500. [Google Scholar] [CrossRef]
- Maleki, S.; Musuvathi, M.; Mytkowicz, T. Efficient parallelization using rank convergence in dynamic programming algorithms. Commun. ACM 2016, 59, 85–92. [Google Scholar] [CrossRef]
- De Oliveira Sandes, E.F.; Maleki, S.; Musuvathi, M.; Mytkowicz, T. Parallel optimal pairwise biological sequence comparison: Algorithms, platforms, and classification. ACM Comput. Surv. 2016, 48, 63. [Google Scholar]
- Truchet, C.; Arbelaez, A.; Richoux, F.; Codognet, P. Estimating parallel runtimes for randomized algorithms in constraint solving. J. Heuristics 2016, 22, 613–648. [Google Scholar] [CrossRef]
- D’Andreagiovanni, F.; Krolikowski, J.; Pulaj, J. A fast hybrid primal heuristic for multiband robust capacitated network design with multiple time periods. Appl. Soft Comput. 2015, 26, 497–507. [Google Scholar] [CrossRef]
- Gambardella, L.; Luca, M.; Montemanni, R.; Weyland, D. Coupling ant colony systems with strong local searches. Eur. J. Oper. Res. 2012, 220, 831–843. [Google Scholar] [CrossRef]
- Whitlay, D.; Gordon, V.; Mathias, K. Lamarckian evolution, the Baldwin effect and function optimization. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Jerusalem, Israel, 9–14 October 1994; pp. 5–15. [Google Scholar]
- Woźniak, M.; Połap, D. On some aspects of genetic and evolutionary methods for optimization purposes. Int. J. Electr. Telecommun. 2015, 61, 7–16. [Google Scholar] [CrossRef]
- Blum, C.; Roli, A.; Sampels, M. Hybrid Metaheuristics: An Emerging Approach to Optimization; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Luenberger, D.G.; Ye, Y. Linear and Nonlinear Programming; Springer: Berlin/Heidelberg, Germany, 1984. [Google Scholar]
- Lawrence, D. Handbook of Genetic Algorithms; Van Nostrand Reinhold: New York, NY, USA, 1991. [Google Scholar]
- Dorigo, M.; Gambardella, L.M. Ant colony system: A cooperative learning approach to the traveling salesman problem. IEEE Trans. Evolut. Comput. 1997, 1, 53–66. [Google Scholar] [CrossRef]
- Ojha, V.K.; Ajith, A.; Snášel, V. ACO for continuous function optimization: A performance analysis. In Proceedings of the 14th International Conference on Intelligent Systems Design and Applications (ISDA), Okinawa, Japan, 28–30 November 2014; pp. 145–150. [Google Scholar]
- Clerc, M. Particle Swarm Optimization; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Yang, X.-S. Firefly algorithm, stochastic test functions and design optimization. Int. J. Bio-Inspir. Comput. 2010, 2, 78–84. [Google Scholar] [CrossRef]
- Yang, X.-S.; Deb, S. Cuckoo search via Lévy flights. In Proceedings of the NaBIC 2009 World Congress on Nature & Biologically Inspired Computing, Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Rui, T.; Fong, S.; Yang, X.; Deb, S. Wolf search algorithm with ephemeral memory. In Proceedings of the Seventh IEEE International Conference on Digital Information Management (ICDIM), Macau, Macao, 22–24 August 2012; pp. 165–172. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function Name | Function f | Range | Solution | |
|---|---|---|---|---|
| Dixon-Price | 0 | |||
| Griewank | 0 | (0,…,0) | ||
| Rotated Hyper–Ellipsoid | 0 | (0,…,0) | ||
| Schwefel | 0 | (420.97,…,420.97) | ||
| Shubert | (0,…,0) | |||
| Sphere | 0 | (0,…,0) | ||
| Sum squares | 0 | (0,…,0) | ||
| Styblinski-Tang | (,…,) | |||
| Rastrigin | 0 | (0,…,0) | ||
| Zakharov | 0 | (0,…,0) |
| Function | GA | PSOA | FA | CSA | WSA | ACO |
|---|---|---|---|---|---|---|
| 0.07593 | 0.08617 | 0.26872 | 0.16432 | 0.00257 | 0.00319 | |
| 0.12283 | 0.16489 | 0.18691 | 0.1729 | 0.1275 | 0.13129 | |
| 0.00172 | 0.27991 | 0.05206 | 0.00948 | 0.00029 | 0.00192 | |
| 0.00506 | 0.00963 | 0.00174 | 0.01354 | 0.00981 | 0.00166 | |
| −185.843 | ||||||
| 0.00001 | 0 | 0.00001 | 0.0002 | 0.00001 | 0.00001 | |
| 0.00105 | 0.00062 | 0.66179 | 0.00035 | 0.00025 | 0.00037 | |
| 0.19899 | 0.07731 | 0.13266 | 0.07822 | 0.1328 | 0.09898 | |
| 0.00103 | 0.00172 | 0.04368 | 0.33444 | 0.00103 | 0.00098 |
| Function | GA | PSOA | FA | CSA | WSA | ACO |
|---|---|---|---|---|---|---|
| 0.05754 | 0.02098 | 0.06574 | 0.03123 | 0.16919 | 0.00317 | |
| 0.09337 | 0.10636 | 0.08035 | 0.09318 | 0.10691 | 0.08546 | |
| 0.00046 | 0.00019 | 0.01644 | 0.15137 | 0.04208 | 0.00043 | |
| 0.00083 | 0.00165 | 0.00203 | 0.00913 | 0.0002 | 0.00035 | |
| 0 | 0 | 0 | 0.00004 | 0 | 0.00053 | |
| 0.00272 | 0.00101 | 0.00023 | 0.00001 | 0.00634 | 0.00053 | |
| 9411-391 | ||||||
| 0.1072 | 0.23339 | 0.1063 | 0.98148 | 0.19899 | 0.00977 | |
| 0.00172 | 0.00006 | 0.00094 | 0.01052 | 0.00109 | 0.0015 |
| Function | GA | PSOA | FA | CSA | WSA | ACO |
|---|---|---|---|---|---|---|
| 0.03072 | 0.00027 | 0.08178 | 0.00217 | 0.0039 | 0.00032 | |
| 0.09337 | 0.07208 | 0.05691 | 0.07437 | 0.10287 | 0.06821 | |
| 0.00001 | 0 | 0 | 0.00006 | 0.00005 | 0.00002 | |
| 0.00079 | 0.00083 | 0.00166 | 0.00015 | 0.00011 | 0.00029 | |
| 0.00001 | 0 | 0.00001 | 0.00003 | 0 | 0 | |
| 0.00124 | 0.00023 | 0.00005 | 0.00002 | 0.00013 | 0.00012 | |
| 0.01592 | 0.03343 | 0.0199 | 0.00995 | 0.01 | 0.00899 | |
| 0.00314 | 0 | 0.00971 | 0.00117 | 0.00073 | 0 |
| Function | GA | PSOA | FA | CSA | WSA | ACO |
|---|---|---|---|---|---|---|
| 0.00892 | 0.00913 | 0.00088 | 0.01001 | 0.00785 | 0.00339 | |
| 0.06694 | 0.02898 | 0.00948 | 0.01298 | 0.0238 | 0.00539 | |
| 0 | 0 | 0.0001 | 0.00044 | 0.00005 | 0.00001 | |
| 0.00218 | 0.001 | 0.00012 | 0.00179 | 0.00019 | 0.00049 | |
| 0 | 0 | 0 | 0.00002 | 0 | 0 | |
| 0.00001 | 0.00007 | 0 | 0 | 0.00003 | 0.00008 | |
| 0.00996 | 0.02995 | 0.12367 | 0 | 0.03033 | 0.00139 | |
| 0.00658 | 0.00023 | 0.00014 | 0.01467 | 0.00022 | 0 |
| Function | GA | PSOA | FA | CSA | WSA | ACO |
|---|---|---|---|---|---|---|
| −0.08617 | −0.16432 | −0.00257 | −0.00319 | |||
| −0.12283 | −0.16489 | −0.18691 | −0.17290 | −0.12750 | −0.13129 | |
| −0.00172 | −0.27991 | −0.05206 | −0.00948 | −0.00029 | −0.00192 | |
| −0.00506 | −0.00963 | −0.00174 | −0.01354 | −0.00981 | −0.00166 | |
| −0.68573 | −0.86850 | −0.85691 | −0.87632 | −0.89550 | −0.88475 | |
| 0 | 0 | −0.00001 | −0.00020 | 0 | 0 | |
| −0.00106 | −0.00062 | −0.66179 | −0.00035 | −0.00025 | −0.00037 | |
| −0.67100 | −0.41761 | −0.65646 | −0.25370 | −0.40180 | −0.40560 | |
| −0.33445 | −0.00103 | −0.00172 | −0.00006 | −0.00094 | −0.01052 | |
| −0.00103 | −0.00172 | −0.04368 | −0.33445 | −0.00103 | −0.00098 |
| Function | GA | PSOA | FA | CSA | WSA | ACO |
|---|---|---|---|---|---|---|
| −0.05754 | −0.02098 | −0.06574 | −0.03123 | −0.16919 | −0.00317 | |
| −0.09337 | −0.10636 | −0.08035 | −0.09318 | −0.10690 | −0.08546 | |
| −0.00046 | −0.00019 | −0.01644 | −0.15137 | −0.04208 | −0.00043 | |
| −0.00083 | −0.00165 | −0.00203 | −0.00913 | −0.00020 | −0.00035 | |
| 0.21804 | 0.37145 | 0.21421 | 0.26740 | 0.35291 | 0.28987 | |
| 0 | 0 | 0 | −0.00004 | 0 | 0 | |
| −0.00272 | −0.00101 | −0.00023 | −0.00001 | −0.00634 | −0.00053 | |
| −0.21651 | −0.17610 | −0.17057 | −0.08075 | −0.06011 | −0.05886 | |
| −0.01052 | −0.00109 | −0.00314 | 0 | −0.00971 | −0.00117 | |
| −0.00172 | −0.00006 | −0.00094 | −0.01052 | −0.00109 | −0.00150 |
| Function | GA | PSOA | FA | CSA | WSA | ACO |
|---|---|---|---|---|---|---|
| −0.03072 | −0.00027 | −0.08178 | −0.00217 | −0.00390 | −0.00032 | |
| −0.09337 | −0.07208 | −0.05691 | −0.07437 | −0.10287 | −0.06782 | |
| −0.00001 | 0 | 0 | −0.00006 | −0.00005 | −0.00002 | |
| −0.00079 | −0.00083 | −0.00166 | −0.00015 | −0.00011 | −0.00029 | |
| −0.26173 | −0.41035 | −0.10293 | −0.13672 | −0.06741 | −0.00622 | |
| 0 | 0 | 0 | −0.00003 | 0 | 0 | |
| −0.00124 | −0.00023 | −0.00005 | −0.00002 | −0.00013 | −0.00012 | |
| −0.03217 | −0.10752 | −0.01222 | −0.01671 | −0.07361 | −0.02173 | |
| −0.00117 | −0.00073 | −0.00658 | −0.00023 | −0.00014 | −0.01467 | |
| −0.00314 | 0 | −0.00971 | −0.00117 | −0.00073 | 0 |
| Function | GA | PSOA | FA | CSA | WSA | ACO |
|---|---|---|---|---|---|---|
| −0.00892 | −0.00913 | −0.00088 | −0.01001 | −0.00785 | −0.00339 | |
| −0.06694 | −0.02898 | −0.00948 | −0.01298 | −0.02380 | −0.00539 | |
| 0 | 0 | −0.00010 | −0.00044 | −0.00005 | −0.00001 | |
| −0.00218 | −0.00100 | −0.00012 | −0.00179 | −0.00019 | −0.00049 | |
| −0.00843 | −0.00147 | −0.00634 | −0.00199 | −0.00136 | 0.400033 | |
| 0 | 0 | 0 | −0.00002 | 0 | 0 | |
| −0.00001 | −0.00007 | 0 | 0 | −0.00003 | −0.00008 | |
| −0.10710 | −0.08110 | −0.00981 | −0.00009 | −0.00710 | −0.00009 | |
| −0.01467 | −0.00022 | 0 | −0.10287 | −0.06782 | −0.06694 | |
| −0.00658 | −0.00023 | −0.00014 | −0.01467 | −0.00022 | 0 |
| Function | GA | PSOA | FA | CSA | WSA | ACO |
|---|---|---|---|---|---|---|
| 2006 | 1821 | 1648.8 | 1841 | 1626.3 | 1798 | |
| 2617 | 2775 | 2757 | 2647 | 2687 | 2674 | |
| 1151 | 905 | 896 | 898 | 903 | 891 | |
| 1432 | 1422 | 1421 | 1392 | 1401 | 1387 | |
| 5421 | 5500 | 5458 | 5240 | 5521 | 5341 | |
| 651 | 645 | 879 | 664 | 673 | 632 | |
| 730 | 720 | 783 | 715 | 706 | 711 | |
| 2818 | 2756 | 2929 | 2749 | 2755 | 2765 | |
| 801 | 804 | 935 | 798 | 803 | 803 | |
| 2252 | 2114 | 2769 | 2648 | 2273 | 2178 |
| Function | GA | PSOA | FA | CSA | WSA | ACO |
|---|---|---|---|---|---|---|
| 1609.2 | 1784 | 1820 | 1802 | 1589 | 1673 | |
| 2377.7 | 2409.44 | 2432.7 | 2400.3 | 2382.3 | 2401 | |
| 812.7 | 822.6 | 808.2 | 815.4 | 806.4 | 812 | |
| 1417 | 1282.5 | 1275.3 | 1286.1 | 1276.2 | 1267 | |
| 4868.1 | 4860 | 4932 | 4914 | 4908.6 | 4912 | |
| 591.3 | 653 | 601.2 | 589.5 | 583.2 | 592.5 | |
| 635.4 | 633.6 | 682.6 | 636.3 | 586.08 | 581.4 | |
| 2301 | 2318 | 2529 | 2249 | 2492 | 2498 | |
| 720 | 702.24 | 763.6 | 714.6 | 732.6 | 712 | |
| 2048 | 2047 | 2234 | 2021 | 2089 | 2091 |
| Function | GA | PSOA | FA | CSA | WSA | ACO |
|---|---|---|---|---|---|---|
| 1643.4 | 1584 | 1622.72 | 1583.12 | 1573.44 | 1602 | |
| 2399.4 | 2280 | 2583 | 2349 | 2482 | 2403 | |
| 789.36 | 801.68 | 786.72 | 762 | 782.32 | 773 | |
| 1247.84 | 1291.5 | 1260.16 | 1245.2 | 1249.84 | 1267 | |
| 4785.44 | 4772.24 | 4843.52 | 4762.56 | 4670.16 | 4694.95 | |
| 571.12 | 589.6 | 581.4 | 583.44 | 586.08 | 582.2 | |
| 648 | 583.44 | 603 | 586.08 | 602.8 | 589.2 | |
| 2491 | 2429 | 2539 | 2349 | 2483 | 2424 | |
| 601.5 | 728.64 | 704.88 | 620.25 | 724.24 | 636 | |
| 2124 | 2148 | 2348 | 2189 | 2290 | 2201 |
| Function | GA | PSOA | FA | CSA | WSA | ACO |
|---|---|---|---|---|---|---|
| 1623.6 | 1349.25 | 1345.5 | 1367.25 | 1335.75 | 1401 | |
| 2418.24 | 2286.75 | 2449.8 | 2399.76 | 2690.25 | 2650 | |
| 788.48 | 756 | 673.5 | 678 | 672 | 673 | |
| 1258.4 | 1060.5 | 1062.75 | 1061.25 | 1060.5 | 1064 | |
| 4094.25 | 4091.25 | 4122.75 | 4001 | 4104 | 4005 | |
| 483 | 567.6 | 488.25 | 491.25 | 486 | 473 | |
| 584.32 | 495.75 | 545.75 | 497.25 | 496.5 | 491 | |
| 2202 | 2121 | 2292 | 2160.75 | 2176.5 | 2189 | |
| 718.96 | 601.5 | 703 | 597 | 635 | 606 | |
| 2103 | 2014 | 2261 | 2127 | 2221 | 2134 |
| Metric | Proposition I | Proposition II | Proposition III |
|---|---|---|---|
| 1.11911 | 1.13374 | 1.24793 | |
| 0.18652 | 0.18896 | 0.20799 | |
| G | 1.78599 | 1.79463 | 1.86089 |
| Proposition | GA | PSOA | FA | CSA | WSA | ACO |
|---|---|---|---|---|---|---|
| Proposition I | 28 | 27 | 29 | 30 | 31 | 28 |
| Proposition II | 37 | 35 | 35 | 41 | 33 | 32 |
| Proposition III | 40 | 39 | 43 | 44 | 41 | 39 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Połap, D.; Kęsik, K.; Woźniak, M.; Damaševičius, R. Parallel Technique for the Metaheuristic Algorithms Using Devoted Local Search and Manipulating the Solutions Space. Appl. Sci. 2018, 8, 293. https://doi.org/10.3390/app8020293
Połap D, Kęsik K, Woźniak M, Damaševičius R. Parallel Technique for the Metaheuristic Algorithms Using Devoted Local Search and Manipulating the Solutions Space. Applied Sciences. 2018; 8(2):293. https://doi.org/10.3390/app8020293
Chicago/Turabian StylePołap, Dawid, Karolina Kęsik, Marcin Woźniak, and Robertas Damaševičius. 2018. "Parallel Technique for the Metaheuristic Algorithms Using Devoted Local Search and Manipulating the Solutions Space" Applied Sciences 8, no. 2: 293. https://doi.org/10.3390/app8020293
APA StylePołap, D., Kęsik, K., Woźniak, M., & Damaševičius, R. (2018). Parallel Technique for the Metaheuristic Algorithms Using Devoted Local Search and Manipulating the Solutions Space. Applied Sciences, 8(2), 293. https://doi.org/10.3390/app8020293