The Multiple-Update-Infill Sampling Method Using Minimum Energy Design for Sequential Surrogate Modeling


Abstract
:1. Introduction
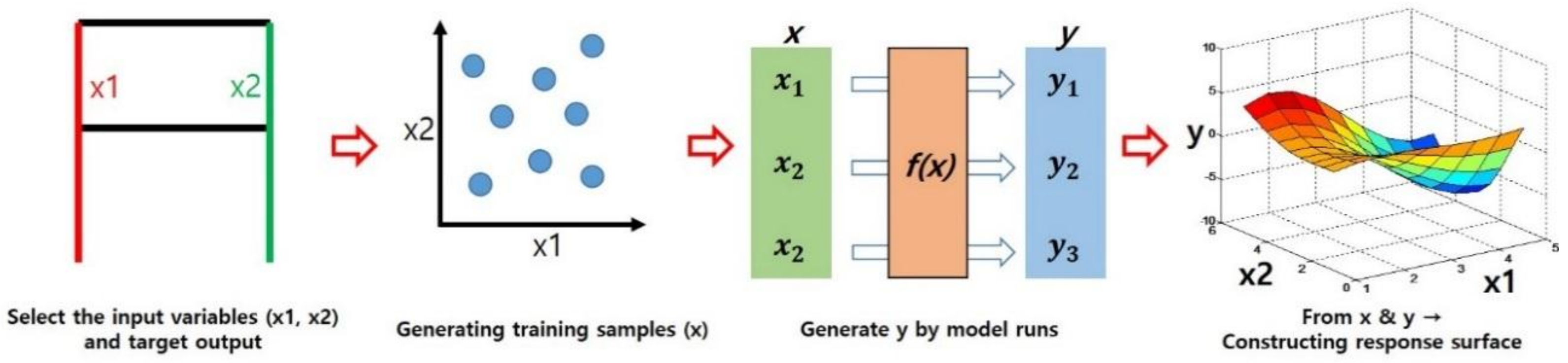
2. The Surrogate Model for Computer Experiments
2.1. The Kriging Model
2.2. Space-Filling Design
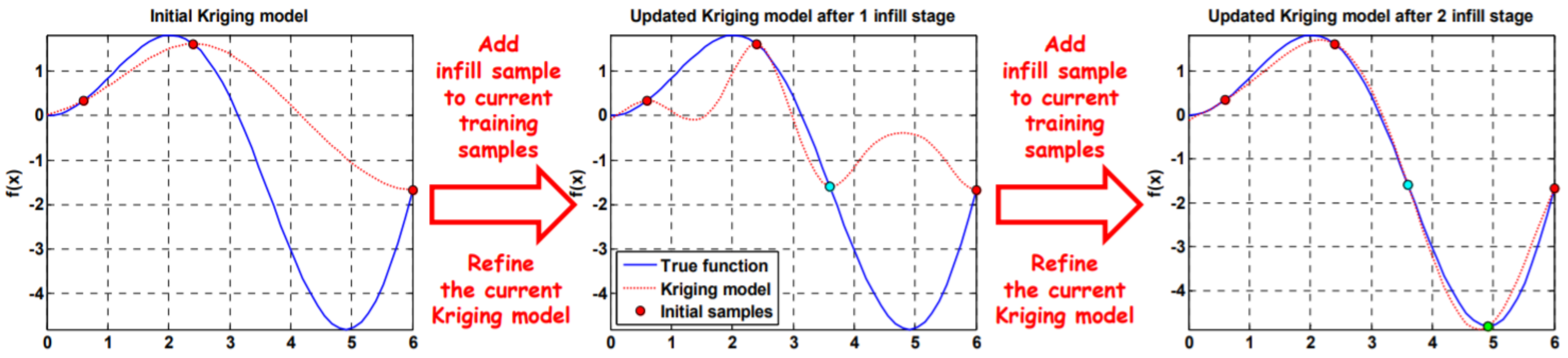
3. The Sequential Sampling Method
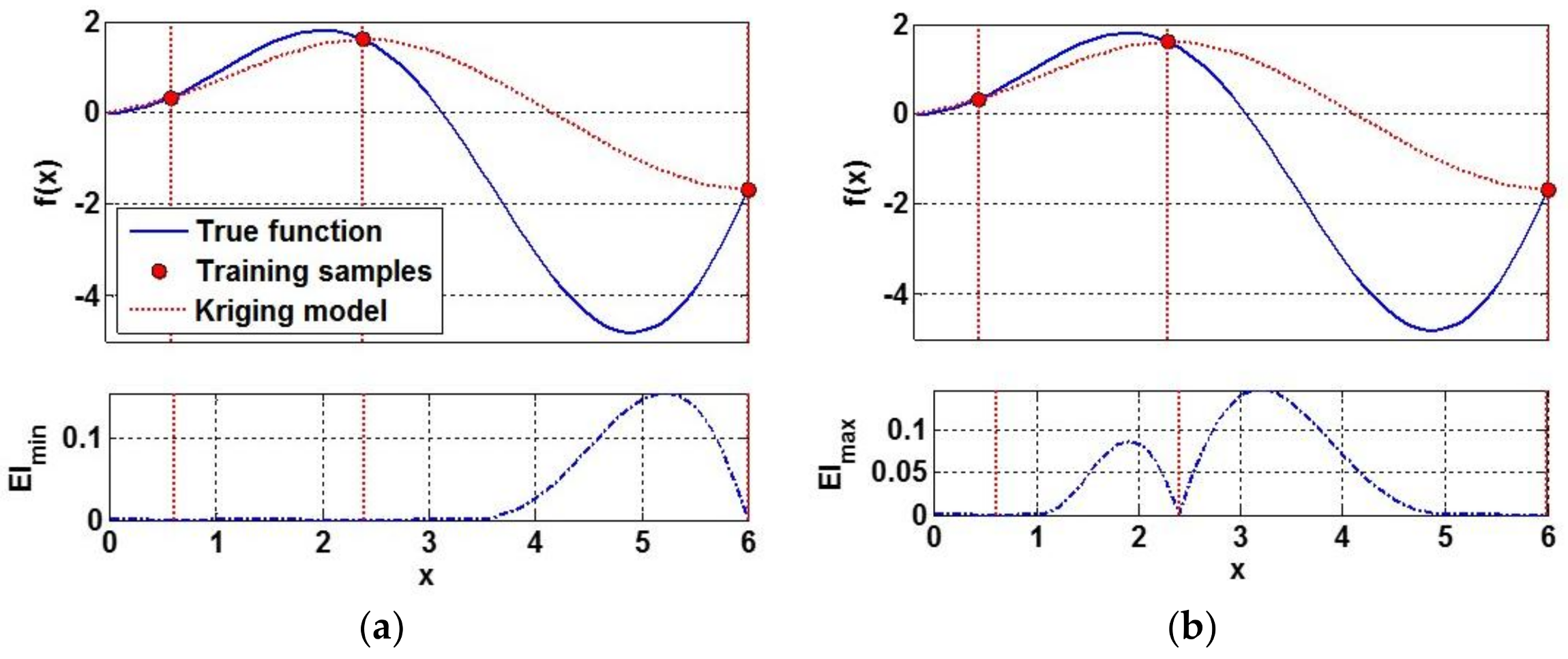
3.1. Infill Criterion I: Mean Squared Error
3.2. Infill Criterion II: Expected Improvement
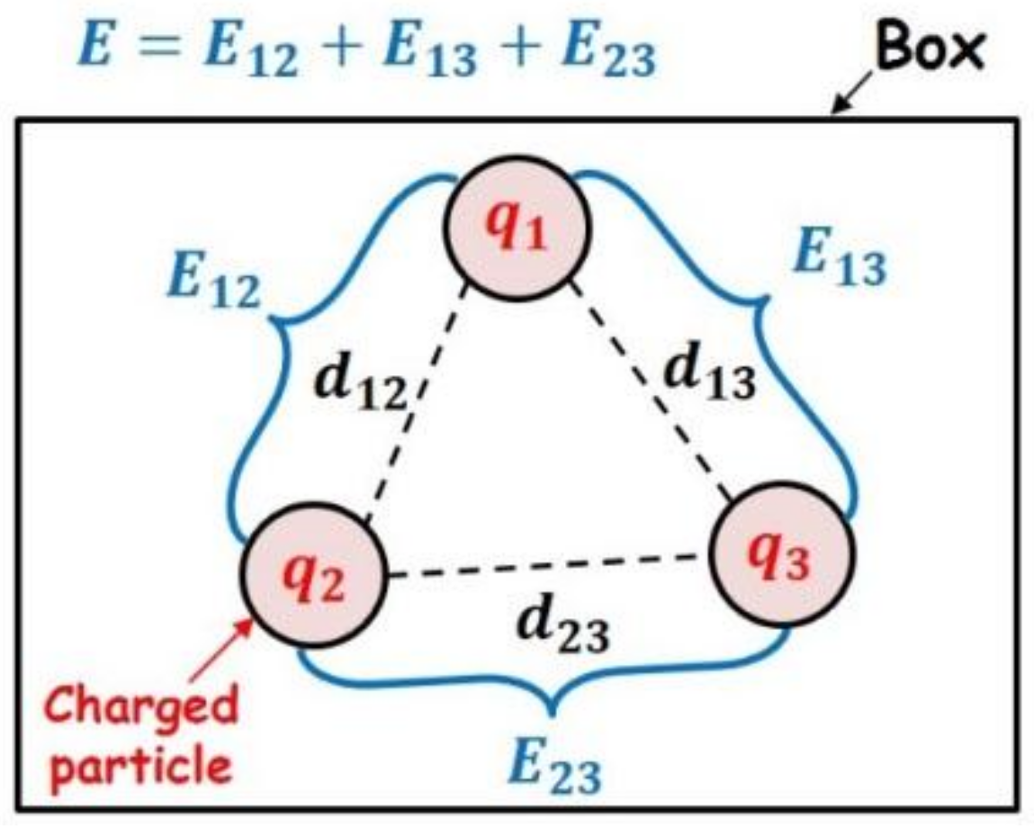
3.3. Infill Criterion III: Minimum Energy Design
3.4. The Multiple-Update-Infill Sampling Method
4. Case Study on the Multiple-Update-Infill Sampling Methods
4.1. Preliminary Description of the Case Studies
4.2. Case Study I: The Friedman Function
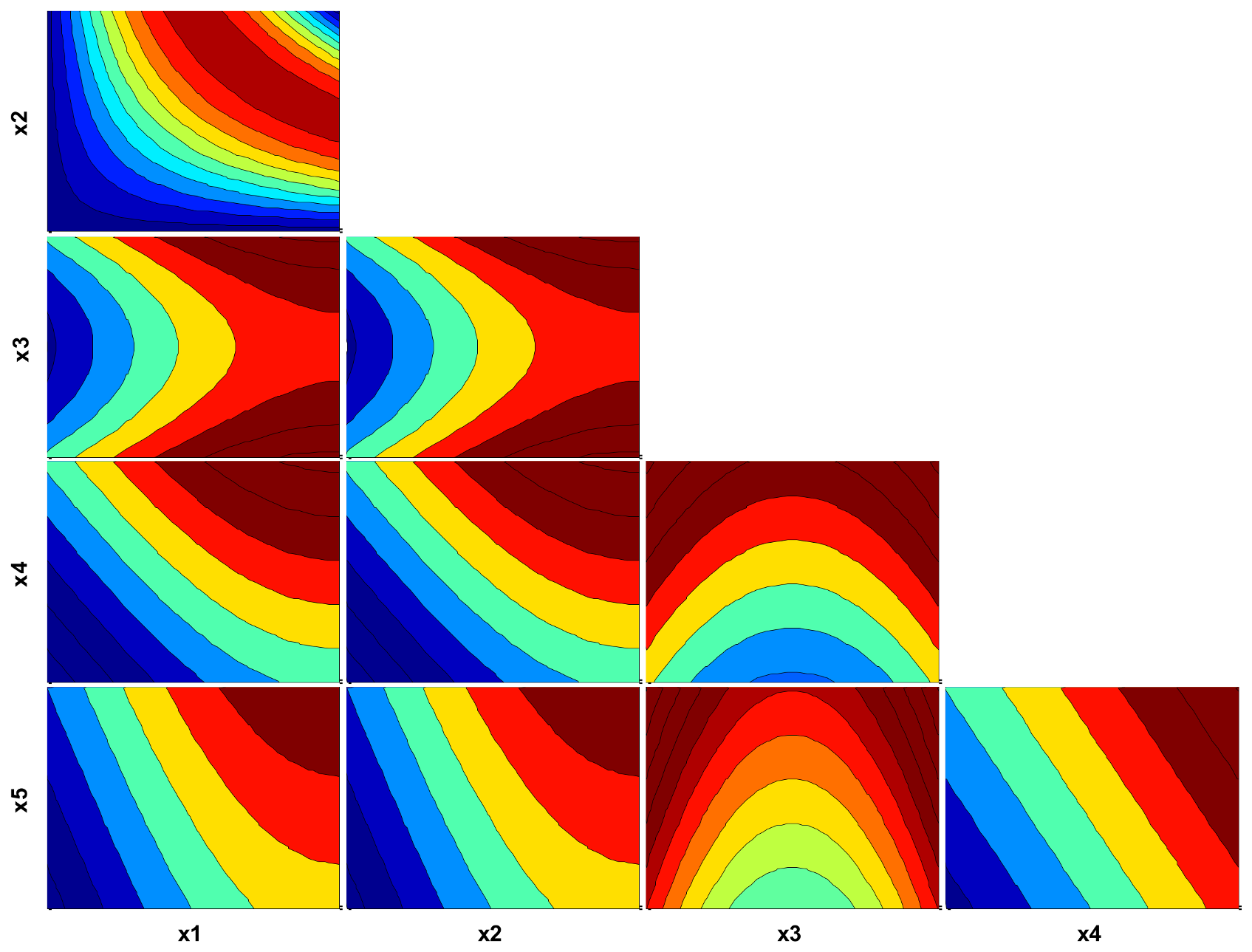
4.3. Case Study II: The Borehole Model
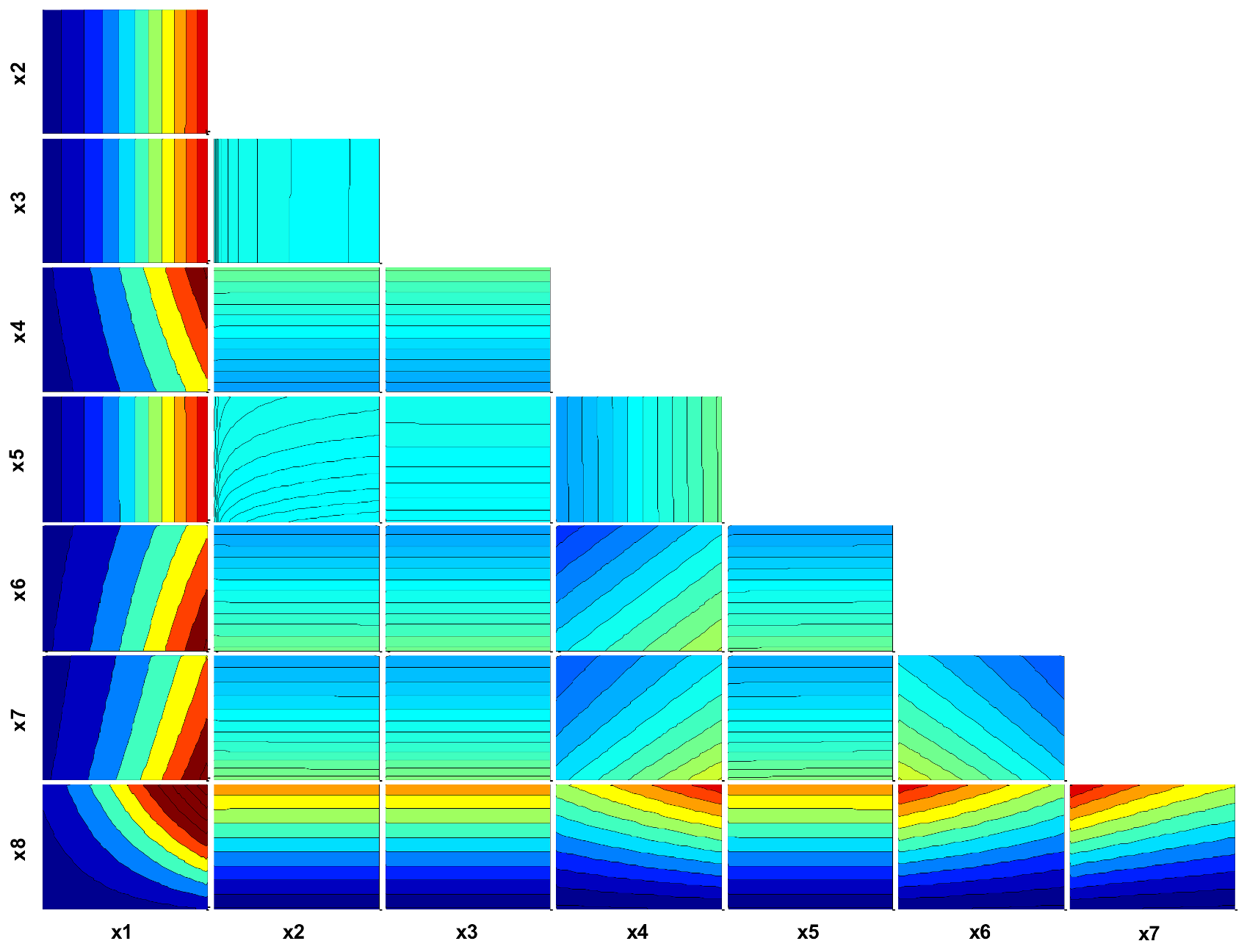
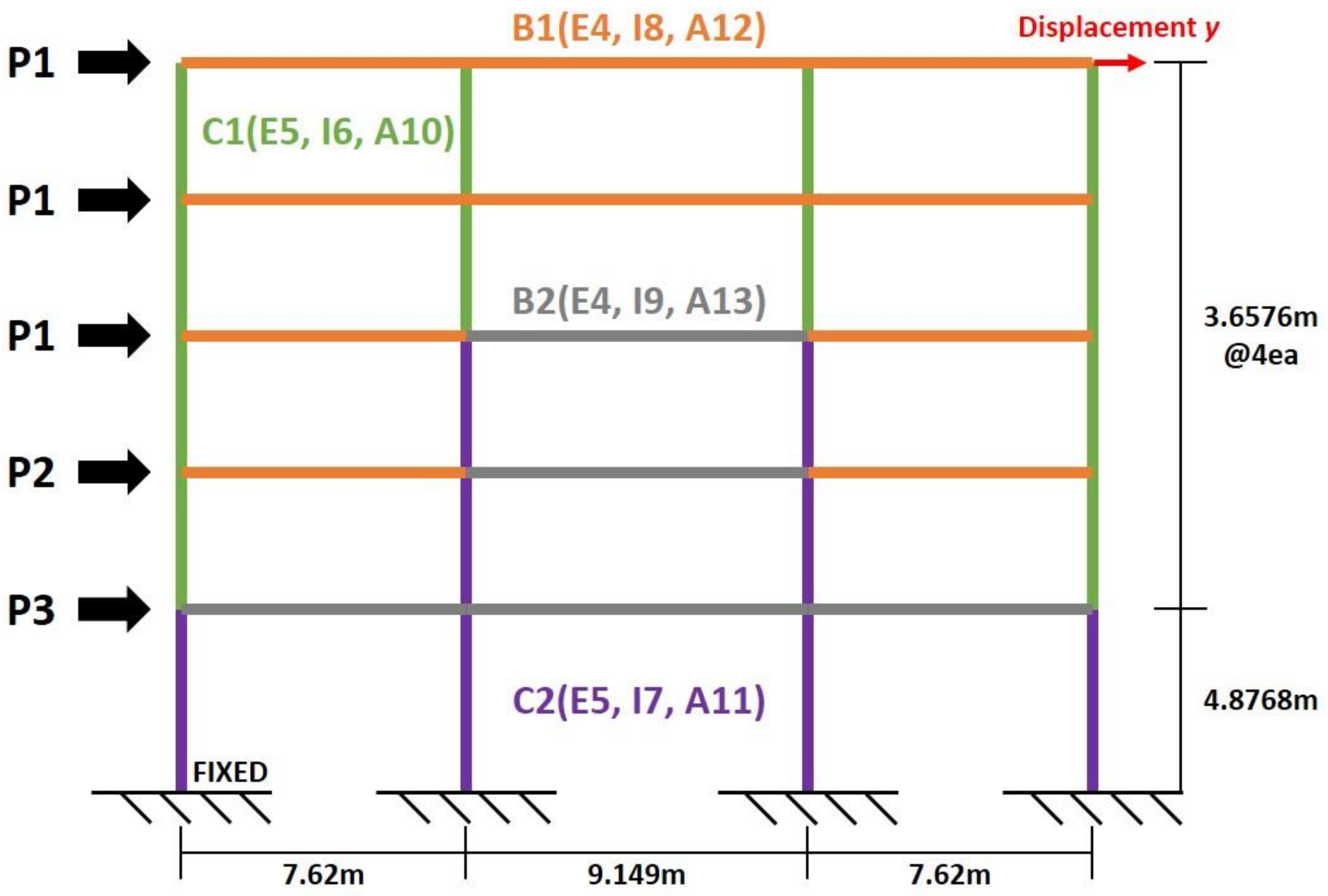
4.4. Case Study III: The FE Model Based on a 3-Bay-5-Story Frame Structure
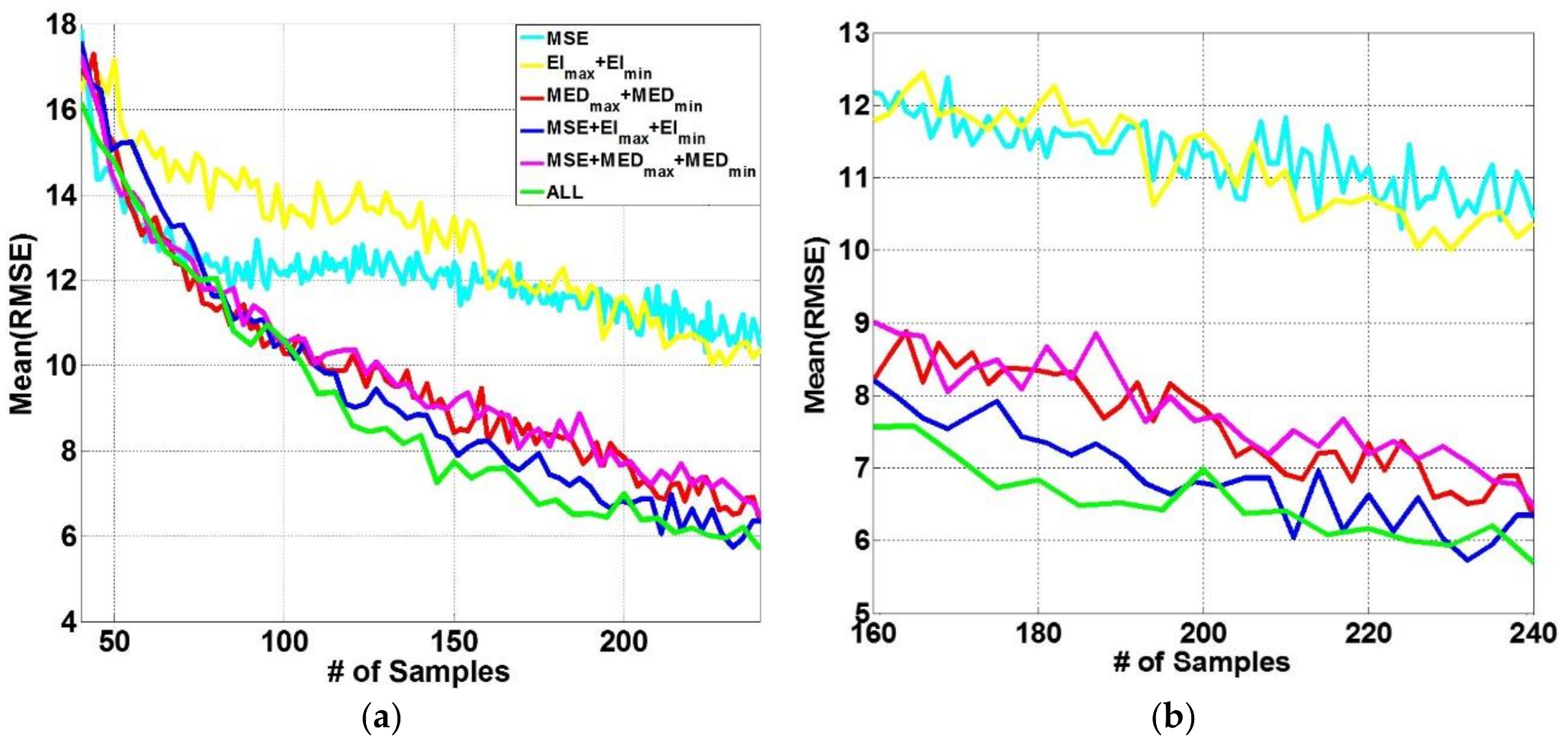
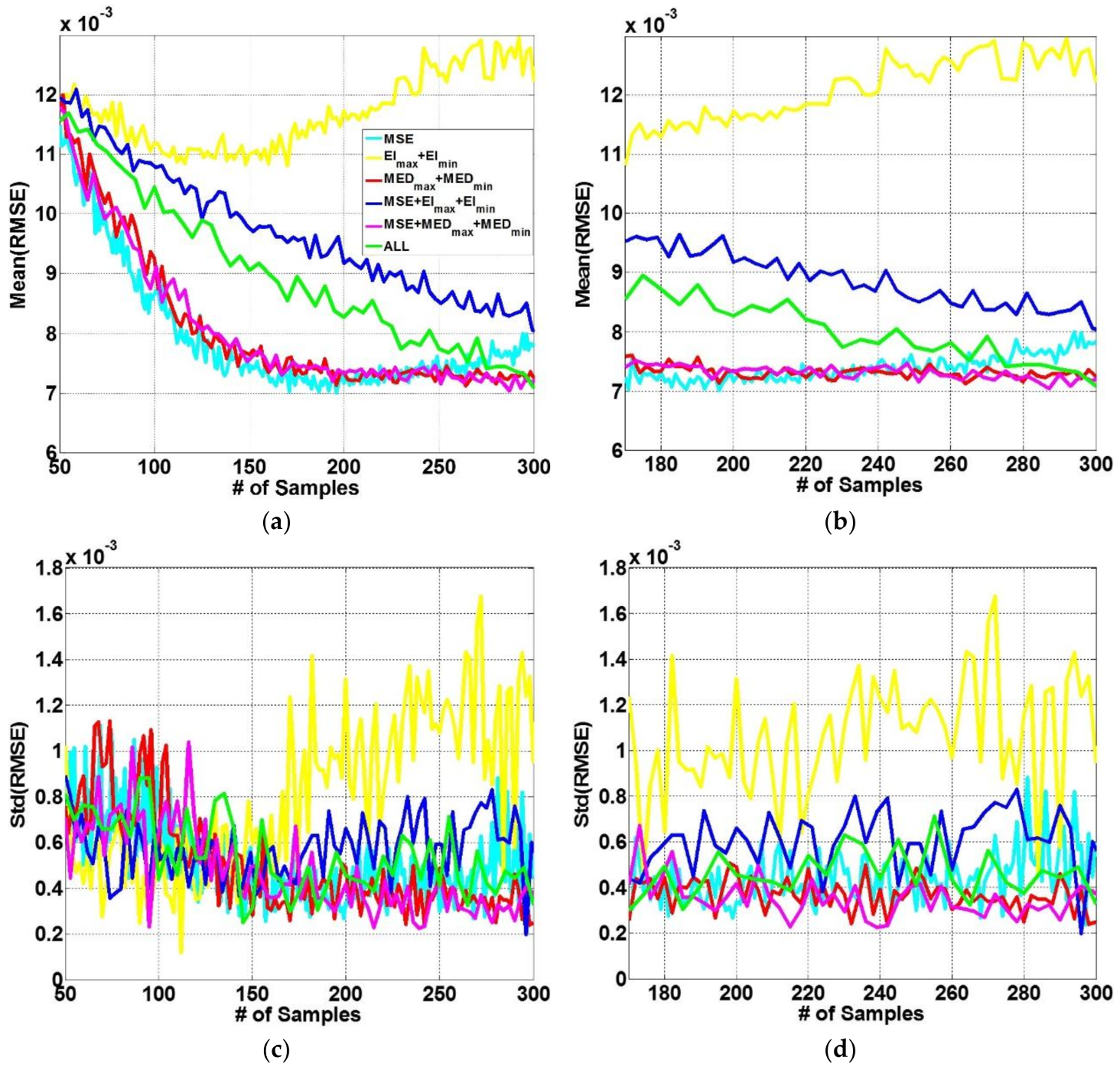
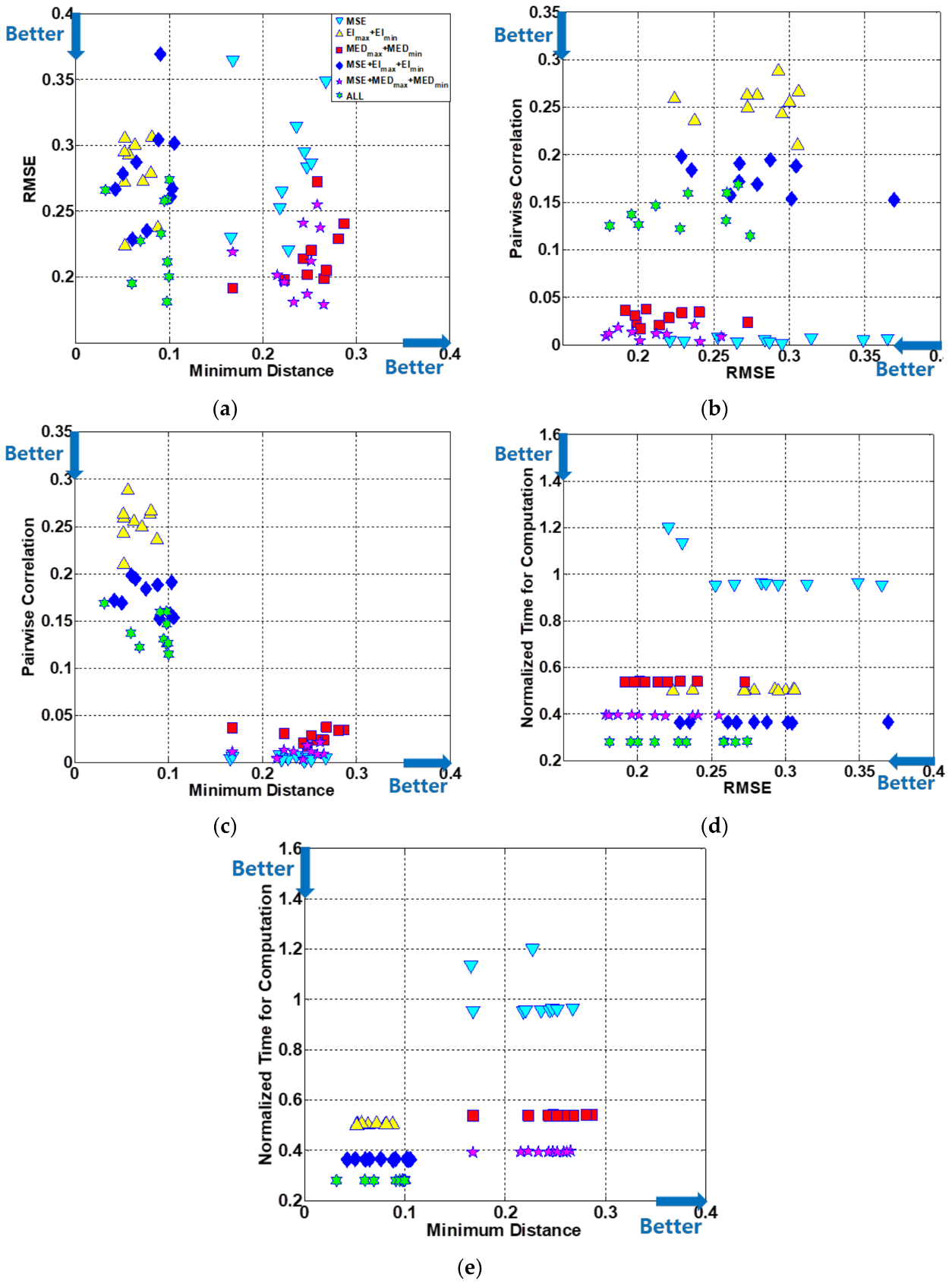
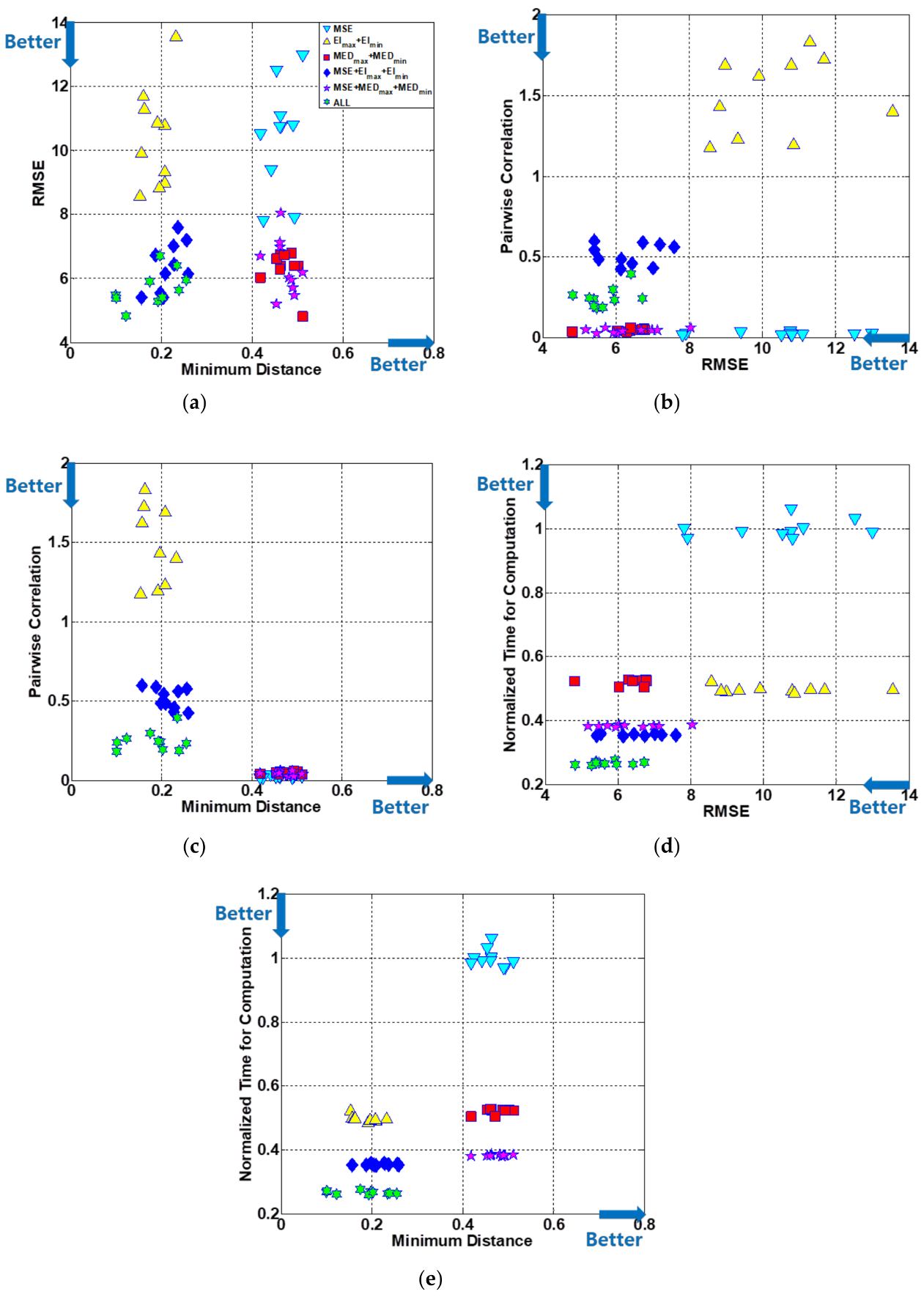
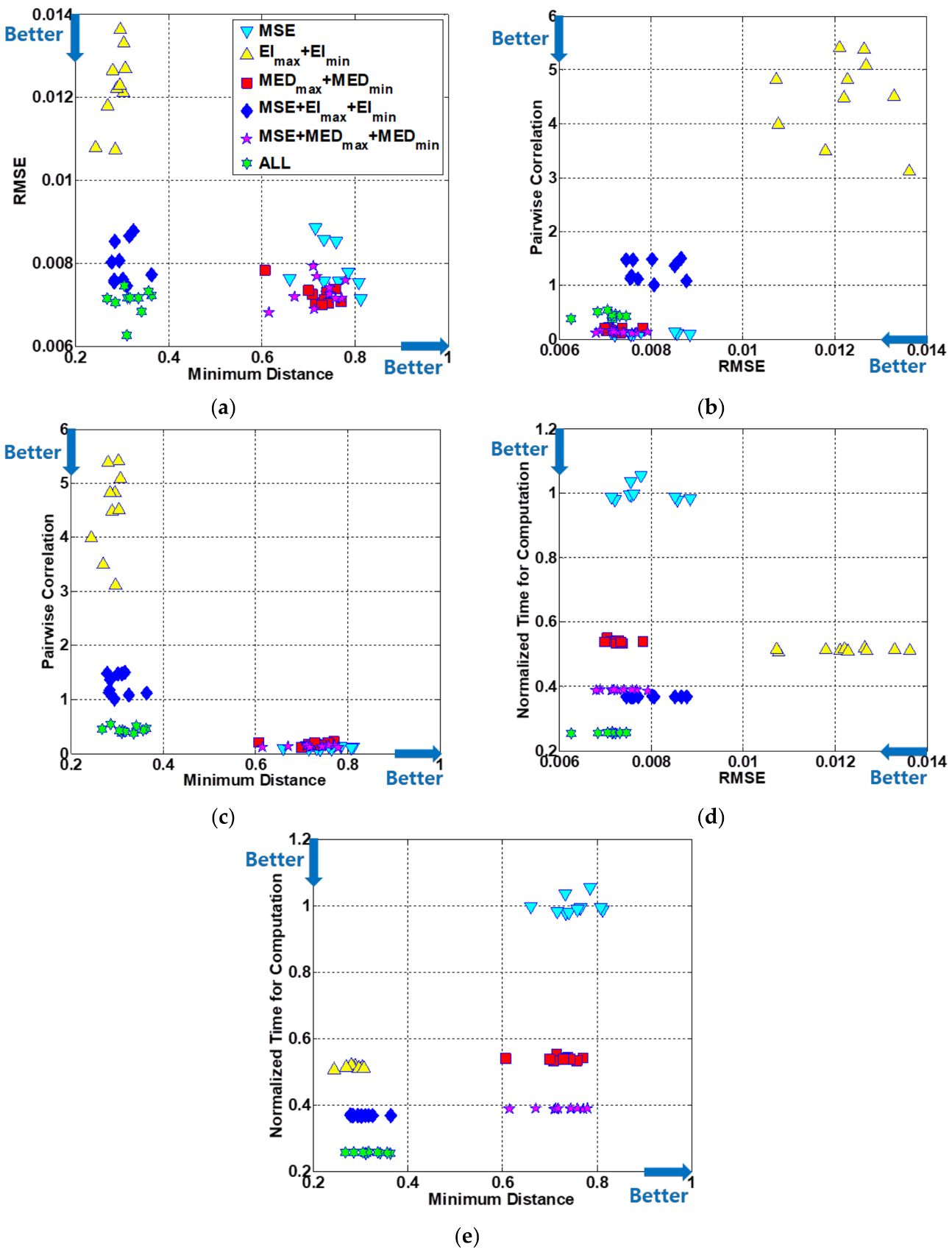
4.5. Results and Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Jung, B.C.; Park, J.; Oh, H.; Kim, J.; Youn, B.D. A framework of model validation and virtual product qualification with limited experimental data based on statistical inference. Struct. Multidiscip. Optim. 2015, 51, 573–583. [Google Scholar] [CrossRef]
- Forrester, A.; Keane, A. Engineering Design via Surrogate Modelling: A Practical Guide; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Queipo, N.V.; Haftka, R.T.; Shyy, W.; Goel, T.; Vaidyanathan, R.; Tucker, P.K. Surrogate-based analysis and optimization. Prog. Aerosp. Sci. 2005, 41, 1–28. [Google Scholar] [CrossRef]
- Ren, W.-X.; Chen, H.-B. Finite element model updating in structural dynamics by using the response surface method. Eng. Struct. 2010, 32, 2455–2465. [Google Scholar] [CrossRef]
- Yang, X.; Guo, X.; Ouyang, H.; Li, D. A kriging model based finite element model updating method for damage detection. Appl. Sci. 2017, 7, 1039. [Google Scholar] [CrossRef]
- McKay, M.D.; Beckman, R.J.; Conover, W.J. Comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics 1979, 21, 239–245. [Google Scholar]
- Ye, K.Q. Orthogonal column latin hypercubes and their application in computer experiments. J. Am. Stat. Assoc. 1998, 93, 1430–1439. [Google Scholar] [CrossRef]
- Fang, K.T.; Lin, D.K.J.; Winker, P.; Zhang, Y. Uniform design: Theory and application. Technometrics 2000, 42, 237–248. [Google Scholar] [CrossRef]
- Dette, H.; Pepelyshev, A. Generalized latin hypercube design for computer experiments. Technometrics 2010, 52, 421–429. [Google Scholar] [CrossRef]
- Jin, S.S.; Jung, H.J. Self-adaptive sampling for sequential surrogate modeling of time-consuming finite element analysis. Smart Struct. Syst. 2016, 17, 611–629. [Google Scholar] [CrossRef]
- Jones, D.R. A taxonomy of global optimization methods based on response surfaces. J. Glob. Optim. 2001, 21, 345–383. [Google Scholar] [CrossRef]
- Joseph, V.R.; Dasgupta, T.; Tuo, R.; Wu, C.F.J. Sequential exploration of complex surfaces using minimum energy designs. Technometrics 2015, 57, 64–74. [Google Scholar] [CrossRef]
- Jin, S.S.; Jung, H.J. Sequential surrogate modeling for efficient finite element model updating. Comput. Struct. 2016, 168, 30–45. [Google Scholar] [CrossRef]
- Sacks, J.; Welch, W.J.; Mitchell, T.J.; Wynn, H.P. Design and analysis of computer experiments. Stat. Sci. 1989, 4, 409–423. [Google Scholar] [CrossRef]
- Parr, J.; Keane, A.; Forrester, A.I.; Holden, C. Infill sampling criteria for surrogate-based optimization with constraint handling. Eng. Optim. 2012, 44, 1147–1166. [Google Scholar] [CrossRef]
- Schonlau, M.; Welch, W.J.; Jones, D.R. Global versus local search in constrained optimization of computer models. Lect. Notes Monogr. Ser. 1998, 34, 11–25. [Google Scholar] [CrossRef]
- Krige, D.G. A statistical approach to some basic mine valuation problems on the witwatersrand. J. South. Afr. Inst. Min. Metall. 1951, 52, 119–139. [Google Scholar]
- Morris, M.D.; Mitchell, T.J. Exploratory designs for computational experiments. J. Stat. Plan. Inference 1995, 43, 381–402. [Google Scholar] [CrossRef]
- Joseph, V.R. Space-filling designs for computer experiments: A review. Qual. Eng. 2016, 28, 28–35. [Google Scholar] [CrossRef]
- Liu, H.; Cai, J.; Ong, Y.-S. An adaptive sampling approach for kriging metamodeling by maximizing expected prediction error. Comput. Chem. Eng. 2017, 106, 171–182. [Google Scholar] [CrossRef]
- Liu, J.; Han, Z.; Song, W. Comparison of infill sampling criteria in kriging-based aerodynamic optimization. In Proceedings of the 28th Congress of the International Council of the Aeronautical Sciences, Brisbane, Australia, 23–28 September 2012; pp. 23–28. [Google Scholar]
- Wang, C.; Duan, Q.; Gong, W.; Ye, A.; Di, Z.; Miao, C. An evaluation of adaptive surrogate modeling based optimization with two benchmark problems. Environ. Model. Softw. 2014, 60, 167–179. [Google Scholar] [CrossRef]
- Stuckman, B.E. A global search method for optimizing nonlinear systems. IEEE Trans. Syst. Man Cybern. 1988, 18, 965–977. [Google Scholar] [CrossRef]
- Cox, D.D.; John, S. A statistical method for global optimization. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Chicago, IL, USA, 18–21 October 1992; pp. 1241–1246. [Google Scholar]
- Deschrijver, D.; Crombecq, K.; Nguyen, H.M.; Dhaene, T. Adaptive sampling algorithm for macromodeling of parameterized s-parameter responses. IEEE Trans. Microw. Theory Tech. 2011, 59, 39–45. [Google Scholar] [CrossRef]
- Liu, H.T.; Xu, S.L.; Ma, Y.; Chen, X.D.; Wang, X.F. An adaptive bayesian sequential sampling approach for global metamodeling. J. Mech. Des. 2016, 138, 011404. [Google Scholar] [CrossRef]
- Yang, X.-S. Firefly algorithm, stochastic test functions and design optimisation. Int. J. Bio-Inspir. Comput. 2010, 2, 78–84. [Google Scholar] [CrossRef]
- Tang, B. Selecting latin hypercubes using correlation criteria. Stat. Sin. 1998, 8, 965–977. [Google Scholar]
- Moon, H.; Dean, A.M.; Santner, T.J. Two-stage sensitivity-based group screening in computer experiments. Technometrics 2012, 54, 376–387. [Google Scholar] [CrossRef]
- Morris, M.D.; Mitchell, T.J.; Ylvisaker, D. Bayesian design and analysis of computer experiments: Use of derivatives in surface prediction. Technometrics 1993, 35, 243–255. [Google Scholar] [CrossRef]
- Zhou, Q.; Qian, P.Z.; Zhou, S. A simple approach to emulation for computer models with qualitative and quantitative factors. Technometrics 2011, 53, 266–273. [Google Scholar] [CrossRef]
- Khennane, A. Introduction to Finite Element Analysis Using Matlab® and Abaqus; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Vu-Bac, N.; Lahmer, T.; Zhuang, X.; Nguyen-Thoi, T.; Rabczuk, T. A software framework for probabilistic sensitivity analysis for computationally expensive models. Adv. Eng. Softw. 2016, 100, 19–31. [Google Scholar] [CrossRef]
- Gutmann, H.M. A radial basis function method for global optimization. J. Glob. Optim. 2001, 19, 201–227. [Google Scholar] [CrossRef]
- Gramacy, R.B.; Lee, H.K.H. Adaptive design and analysis of supercomputer experiments. Technometrics 2012, 51, 130–145. [Google Scholar] [CrossRef]
- Xiong, Y.; Chen, W.; Apley, D.; Ding, X. A non-stationary covariance-based kriging method for metamodelling in engineering design. Int. J. Numer. Methods Eng. 2007, 71, 733–756. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input: | Number of initial training samples ; Validation samples ; Number of final training samples |
| 1. Generate validation samples over input space | |
| (1) Generate using Mm LHD (Equation (10)) | |
| (2) Compute outputs using the computational model of | |
| 2. Perform sequential sampling method | |
| For | |
| (1) Set current infill stage to | |
| (2) Generate using Mm LHD (Equation (10)) with | |
| (3) Compute outputs using the computational model of | |
| (4) Construct kriging model () using and | |
| (5) Set # of training sample to | |
| Until () | |
| (6) Predict outputs of () using | |
| (7) Evaluate and save performance measures using and | |
| (8) Search the infill sample(s) () based on | |
| (9) Compute outputs using computational model of | |
| (10) Add and to and | |
| (11) Update kriging model () using and | |
| (12) Set and | |
| End | |
| (13) Save final results: , , and history of the performance measure | |
| End | |
| Input Variable | Baseline | Lower Bound | Upper Bound |
|---|---|---|---|
| 0.5 | 0 | 1 | |
| 0.5 | 0 | 1 | |
| 0.5 | 0 | 1 | |
| 0.5 | 0 | 1 | |
| 0.5 | 0 | 1 |
| Input Values | Baseline | Lower Bound | Upper Bound | |
|---|---|---|---|---|
| Radius of borehole | 0.1 | 0.05 | 0.15 | |
| Radius of influence | 25,050 | 100 | 50,000 | |
| Transmissivity of upper aquifer | 89,335 | 63,070 | 115,600 | |
| Potentiometric head of upper aquifer | 1050 | 990 | 1110 | |
| Transmissivity of lower aquifer | 89.55 | 63.1 | 116 | |
| Potentiometric head of lower aquifer | 760 | 700 | 820 | |
| Length of borehole | 1400 | 1120 | 1680 | |
| Hydraulic conductivity of borehole | 8250 | 9855 | 12,045 | |
| Input Variable | Baseline | Lower Bound | Upper Bound | |
|---|---|---|---|---|
| P1 | Load (KN) | 133.45 | 53.38 | 333.63 |
| P2 | 88.97 | 35.59 | 222.43 | |
| P3 | 71.18 | 28.47 | 177.95 | |
| E4 | Young’s Modulus (MPa) | 21,738 | 10,869 | 32,606 |
| E5 | 23,796 | 11,898 | 35,659 | |
| I6 | Moment of Inertia () | 0.0081 | 0.0041 | 0.0122 |
| I7 | 0.0115 | 0.0058 | 0.0173 | |
| I8 | 0.0232 | 0.0116 | 0.0348 | |
| I9 | 0.0259 | 0.0130 | 0.0389 | |
| A10 | Sectional Area () | 0.0312 | 0.0156 | 0.0468 |
| A11 | 0.3716 | 0.1858 | 0.5574 | |
| A12 | 0.3725 | 0.1863 | 0.5588 | |
| A13 | 0.4181 | 0.2091 | 0.6272 | |
| Case Study | # Initial Samples | # Final Samples | # Validation Samples | |
|---|---|---|---|---|
| 1 | Friedman Function | 30 | 210 | 20,000 |
| 2 | Borehole Model | 240 | ||
| 3 | FE Model Based on 3-bay-5- story Frame Structure | 300 | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, Y.; Cha, S.-L.; Kim, S.; Jin, S.-S.; Jung, H.-J. The Multiple-Update-Infill Sampling Method Using Minimum Energy Design for Sequential Surrogate Modeling. Appl. Sci. 2018, 8, 481. https://doi.org/10.3390/app8040481
Hwang Y, Cha S-L, Kim S, Jin S-S, Jung H-J. The Multiple-Update-Infill Sampling Method Using Minimum Energy Design for Sequential Surrogate Modeling. Applied Sciences. 2018; 8(4):481. https://doi.org/10.3390/app8040481
Chicago/Turabian StyleHwang, Yongmoon, Sang-Lyul Cha, Sehoon Kim, Seung-Seop Jin, and Hyung-Jo Jung. 2018. "The Multiple-Update-Infill Sampling Method Using Minimum Energy Design for Sequential Surrogate Modeling" Applied Sciences 8, no. 4: 481. https://doi.org/10.3390/app8040481
APA StyleHwang, Y., Cha, S. -L., Kim, S., Jin, S. -S., & Jung, H. -J. (2018). The Multiple-Update-Infill Sampling Method Using Minimum Energy Design for Sequential Surrogate Modeling. Applied Sciences, 8(4), 481. https://doi.org/10.3390/app8040481