Comparison of Heuristic Algorithms in Discrete Search and Surveillance Tasks Using Aerial Swarms



Abstract
:1. Introduction
1.1. Multi-Agent and Swarm Robotics
1.2. Search with Swarms
- Exploration: This differs from search in that there does not exist a previous map of the area.
- Surveillance: This is basically persistently searching a given area. Each zone must be re-visited frequently enough to ensure up-to-date information.
- Patrolling: Similar to surveillance, the area of interest is restricted to singular points or lines (for instance, corridors inside a building).
- Probabilistic maps and obstacles: Another extension of the search task in its simplest form is the inclusion of probabilistic maps, which consider prior knowledge about where it is more likely that a target is located in the area. Moreover, obstacles may be included, it being impossible for the agents to go through them.
1.3. Search Patterns
- Contour following: This leads the agent along boundaries, i.e., cells that have at least one non-visited cell surrounding them. This is the behavior with the highest priority.
- Avoidance: When two agents are within a given range, this behavior is triggered. The velocity command is perpendicular to their mutual collision course, and it is added to the contour following the behavior output.
- Gradient descend: Having defined a distance field, computed at each cell as the distance to the closest non-visited cell, when this behavior is active, it leads the agent along the gradient. It is activated when an agent is completely surrounded by visited cells.
- Random movement: The agent decides randomly which cell to visit next. It is activated when none of the other behaviors are active.
- Random search: Each agent follows its current heading until one boundary is reached. At that moment, it changes its direction to re-enter the search area.
- Search lanes: The area is organized into lanes, and each agent is assigned to a unique one. Once a lane has been traveled, a new one is assigned.
- Grid-based search: The agents go to the closest non-visited cell.
- Lawn mower: Each agent moves in a straight line, and when it encounters an obstacle, it turns to head in a clear direction.
- Raster scan: The agents move in parallel lanes north/south or east/west.
- Gradient climb: This is a greedy algorithm based on the surrounding cell scores.
- Randomized Voronoi: The area is partitioned with the Voronoi diagram using the agent’s position as the generators.
- Full algorithm: This is the same algorithm, developed in previous works, but without the Voronoi partitioning.
1.4. Optimal Methods in Discrete Search Tasks
1.5. Organization of This Paper
2. Problem Formulation
2.1. Scenario
2.2. Plain, Obstacles and Probability Scenarios
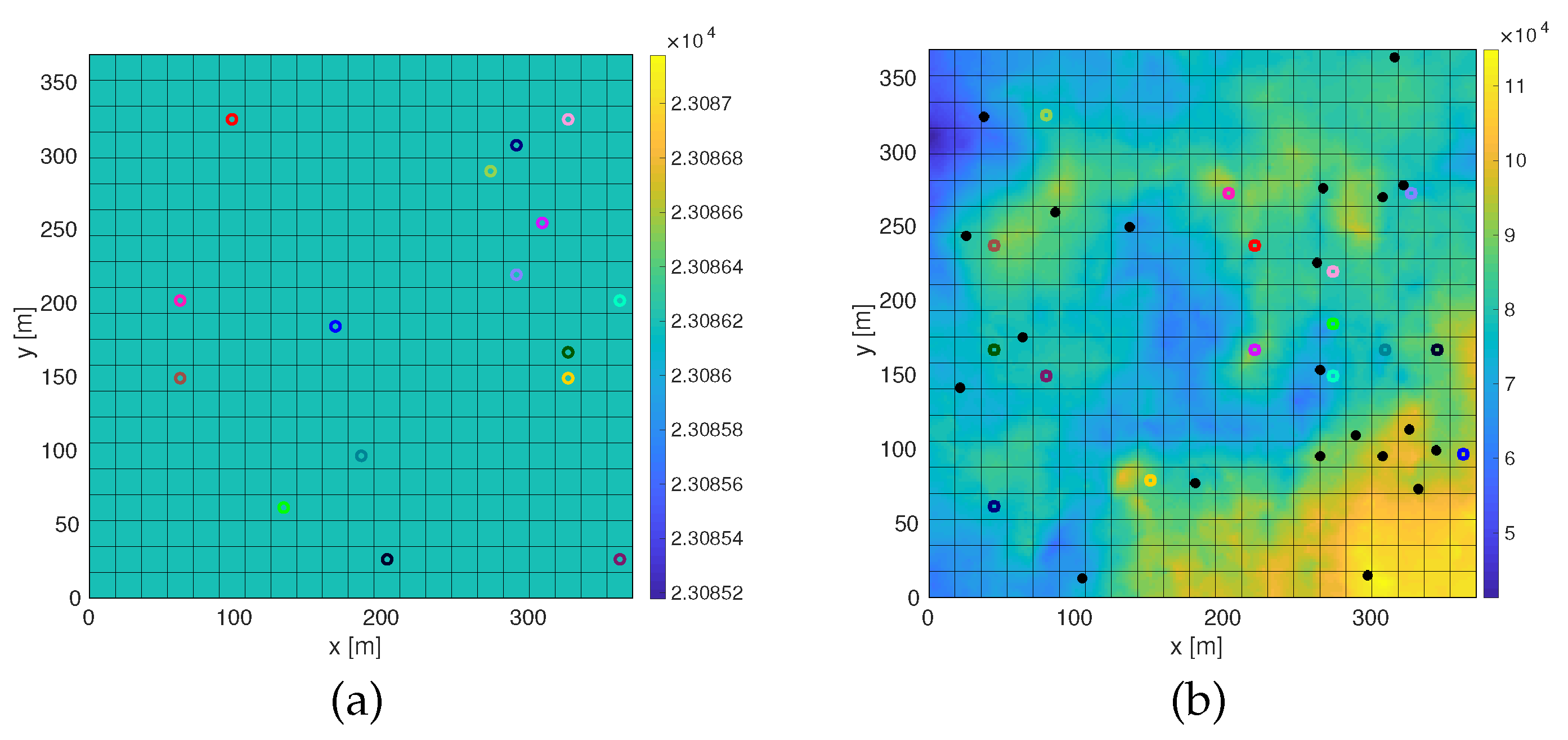
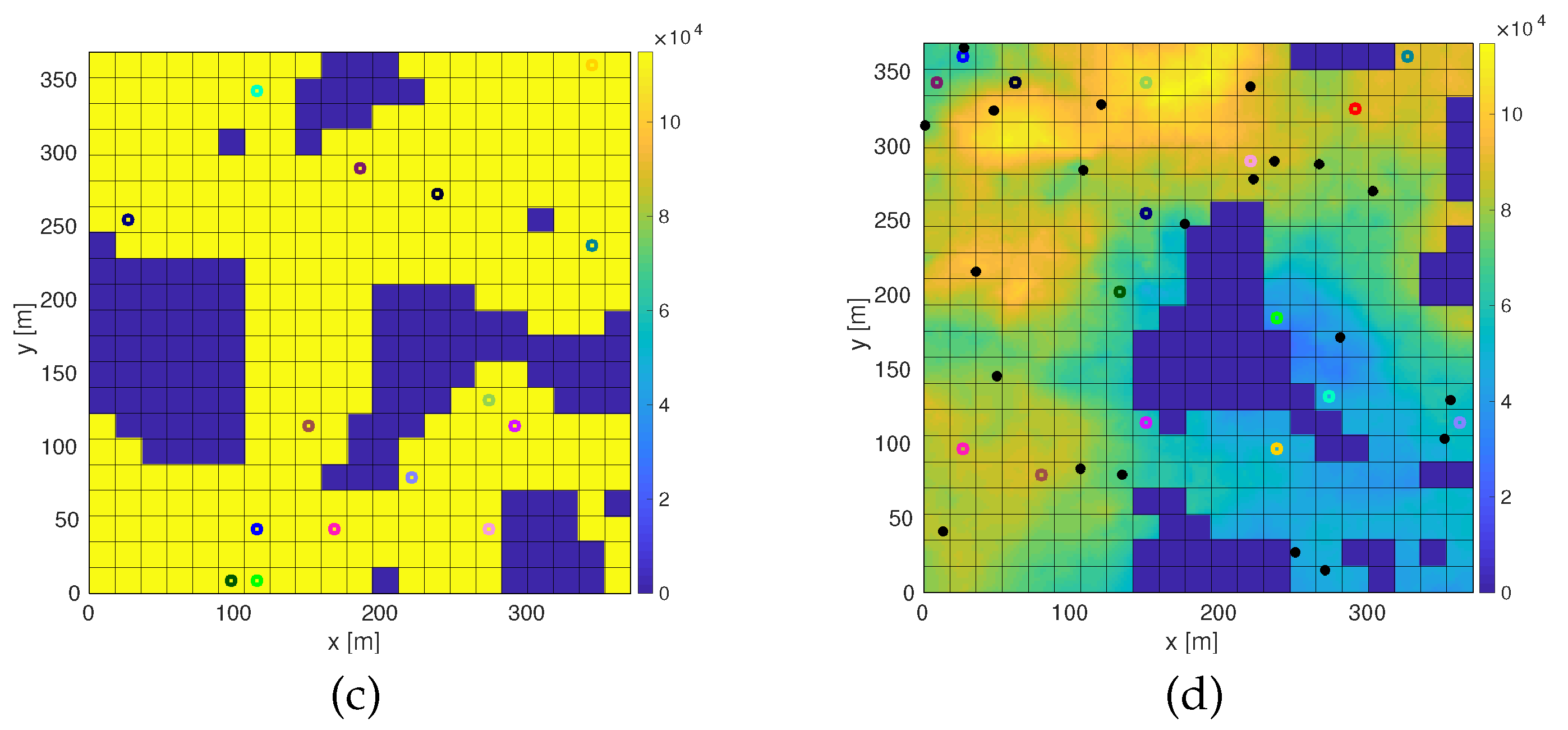
- Plain scenario: In the simplest scenario type, every cell is flyable, and all the discretization cells must be observed at least once to finish the mission (see Figure 2a).
- Probability distribution scenario: We assume prior knowledge about the possible location of targets to be found. According to this distribution, targets are generated. The search is finished when all the targets have been observed. The probability distribution is generated using the midpoint displacement method, normally used as a terrain generator method. The initial distribution is generated randomly with a roughness and its derivative . Seven iterations are applied. In Figure 2b, an example of this scenario type is shown.
- Obstacles scenario: Some of the search cells are occupied, and the agents cannot fly through them. The search is completed when all the discrete cells that are not inside the obstacles have been observed at least once. The map is generated using the Schelling segregation model, fixing the tolerance limit to 0.3 and the percentage of the population that look for new houses to 0.7. The percentage of non-flyable search cells is drawn from a normal distribution , while the percentage of empty cells (cells that may be occupied by obstacles) is drawn from . Once the equilibrium has been reached, the empty cells are transformed into flyable cells. It is checked that every flyable cell can be reached (i.e., there are no cells completely surrounded by obstacles). An example of the result of this procedure has been shown in Figure 2c.
- Probability distribution and obstacles scenario: Both the probability distribution of target locations and obstacles are considered; see Figure 2d.
2.3. Model of the Agent
2.3.1. Dynamics
2.3.2. Energy Consumption
2.4. Measuring the Performance
2.4.1. Model 1
2.4.2. Model 2
2.4.3. Model 3
2.4.4. Fitness Function
3. Proposed Search Algorithm, a Set of Behaviors: A1
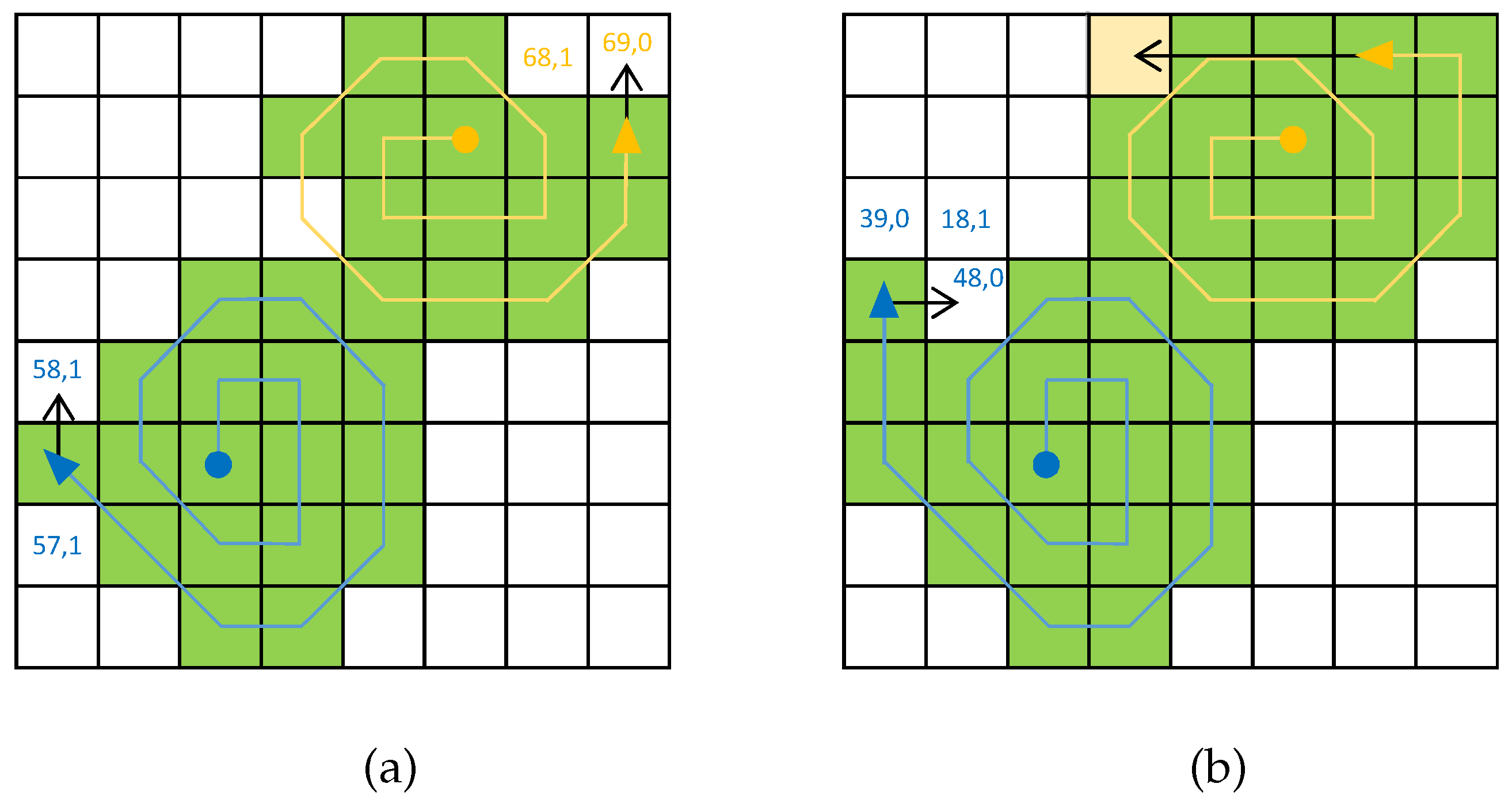
3.1. Search Behavior
3.1.1. Pheromone Dynamics
3.1.2. Cell Types and Properties
- Non-observed cells: cells that have not been observed yet:
- Observed cells: cells already observed by any agent:
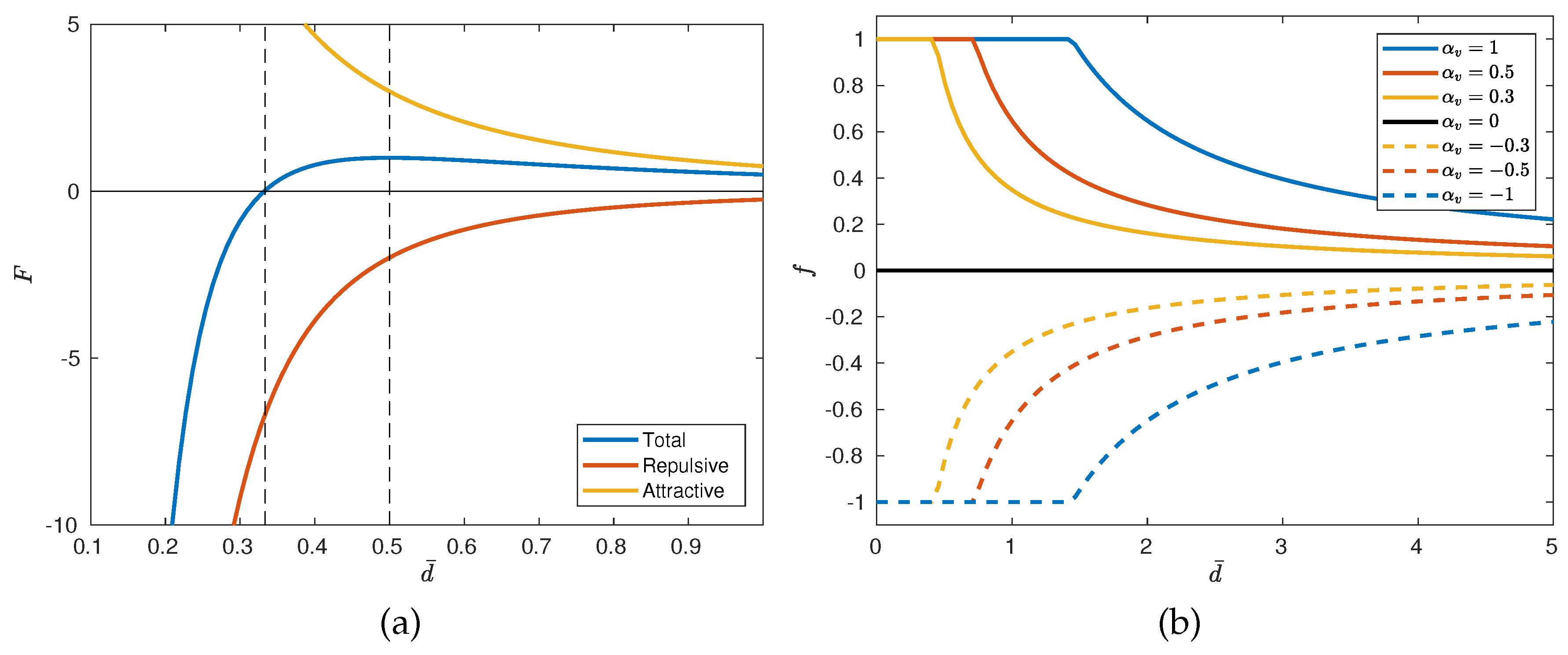
- Recently-observed cells: if a cell has just been observed, there is n instantaneous drop of its pheromone concentration of:where indicates variation due to the fact that the cell has recently been observed and . This drop is accounted only once, so that at the next time step, a recently-visited cell becomes a regularly-visited cell.
- Isolated cells: Each non-observed cell has associated a so-called isolation index, , which is the number of observed cells surrounding it. If the cell has already been observed, its isolating index is forced to be equal to zero. Every time step the isolation index changes, there is an increment in the pheromone concentration of:where is the variation of the isolation index from time k to :The parameter makes the concentration increase when its isolation index changes. Moreover, there is an extra pheromone creation proportional to the isolation index in these cells:
3.1.3. Layers of Pheromones
- Standard layer (L1): There is no impact of the isolation index on this layer, and it has different diffusion coefficients for observed and unobserved cells.
- Long-range layer (L2): Intended to transmit information from unobserved cells along the entire search area. The diffusion coefficients of observed and unobserved cells are equal, and the observed cells do not produce pheromones.
- Isolation layer (L3): This mainly considers pheromone creation due to the isolation index. Once the cells are observed, they lose their pheromone concentration at this layer.
3.1.4. Evaluating Modes
- Mean values: The mean values of the pheromone concentration of the cells inside each search cell are considered. The income for each surrounding cell is then calculated:
- Maximum values: The maximum value of the concentration inside each search cell is considered.
3.2. Energy Saving Behavior
3.3. Diagonal Movement Behavior
3.4. Collision Avoidance Behavior
3.5. Keep Distance Behavior
3.6. Keep Velocity Behavior
3.7. Final Decision
3.8. Configuration of the Algorithm
- Chain of genes: a vector made up by the 23 parameters of the algorithm. Each of the genes is normalized with a range of possible values.
- Population: 100 members.
- Initial population: Half of the initial population is taken from the two closest scenarios already optimized, 25 from each one. To select those members, a trade-off between fitness and genetic diversity is considered. The other half is taken as a prediction of the model. Since the model is probabilistic, these 50 member are drawn from the normal distribution of the Gaussian process.
- Fitness function: To evaluate each member, Equation (14) is used. In order to measure the noise due to the variability of the initial conditions, each member is tested 100 times.
- Crossover: The members will be combined using the roulette-wheel technique, with a probability proportional to the fitness value. Two pairs made up by the same two members is forbidden. Two members being selected for the crossover, a new member will be created by applying a weighted sum of each gene individually. The weighting coefficient is a random number between zero and one. The offspring is made up of 50 new individuals.
- Next generation selection: After evaluating the new individuals, elitism is used to select the 100 best members for the next generation from the 150 available members.
- Stopping criteria: The optimization is stopped when one of these criteria is met:
- –
- Maximum number of generations (30) has been reached.
- –
- Maximum time for each optimization (24 h) has been reached.
- –
- Maximum number of generations (10) without an improvement higher than 10% of the best member has been reached.
- –
- Maximum number of generations (3) without an improvement higher than 10% of the mean fitness of the population has been reached.
4. Search Patterns
4.1. Random Walk: A2
4.2. Go to the Closest Non-Visited Cell: A3
4.3. Boundary Following: A4
4.4. Energy Saving: A5
4.5. Billiard Random Movement: A6
4.6. Lanes Following: A7
5. Comparison of the Algorithms
5.1. Quantitative Comparison
5.1.1. Plain Scenarios
5.1.2. Scenarios with the Probability Distribution
5.1.3. Scenarios with Obstacles
5.1.4. Scenarios with Probability Distribution and Obstacles
5.2. Communication Needs and Adaptation to Surveillance
- A1, behaviors set: This algorithm requires a demanding communication system because the behaviors implemented need up-to-date information in order to update the individual map of pheromones, calculate the resulting forces, etc. Surveillance and patrolling are easy to implement: L3 may be eliminated, and visited and non-visited cells may be equally treated; this way, once a zone is visited and its level of pheromones is reduced, it will gradually create pheromones. After some time, it will become a tractor for the agents, which will then return periodically to it.
- A2, random: The random movement only needs communication between agents when they are close and a collision may take place, not needing to share information with other agents. Surveillance and patrolling missions are already covered, since a random walk will statistically revisit the areas with some frequency.
- A3, closest: The requires updated information to know which cells have not been visited yet, besides short-range communication in case a collision may occur. Although the transmitted information is less than for A1, it is also considered as heavy. For surveillance and patrolling, the ”age” of the cell (measured as time passed since it was last observed) may be used similarly as the probability map.
- A4, boundary: This algorithm needs the same information as A3, which is considered as high. The surveillance task can only be carried out if the essence of the behavior is lost; if for instance, the decision is made as a weighted sum of the isolation index and the age of the cell, the compaction of the search, which is the main value of the algorithm, will be probably lost. Note that the algorithm makes heavy use of the distinction between visited and non-visited cells, which cannot be easily overridden in persistent missions.
- A5, energy: this algorithm is basically similar to the random movement regarding the communication complexity and its use in surveillance and patrolling.
- A6, billiard: similarly to A2 and A5, the billiard movement only needs the agents to share information if a collision may take place. The surveillance task is already included in the algorithm, since it recursively visits the cells.
- A7, lanes: This requires only medium communications because the agents must only share the lanes they are visiting, which happens with low frequency. The surveillance mission is fulfilled if the visited lanes are marked with incremental numbers (instead of visited and non-visited). The proximity of the lanes and their visit index (i.e., the number of times the lane has been observed) may be then considered together. To do this, a weighted decision may be made.
6. Conclusions and Future Works
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Dudek, G.; Jenkin, M.R.M.; Milios, E.; Wilkes, D. A taxonomy for multi-agent robotics. Auton. Robot. 1996, 3, 375–397. [Google Scholar] [CrossRef]
- Jackson, D.E.; Ratnieks, F.L.W. Communication in ants. Curr. Biol. 2006, 16, R570–R574. [Google Scholar] [CrossRef] [PubMed]
- Deneubourg, J. Self-organizing Collection and Transport of Objects in Unpredictable Environments. Japan–USA Symposium on Flexible Automation; American Society of Mechanical Engineers: New York, NY, USA, 1990; pp. 1093–1098. [Google Scholar]
- Kube, C.R.; Zhang, H. Collective robotics: From social insects to robots. Adapt. Behav. 1993, 2, 189–218. [Google Scholar] [CrossRef]
- Mataric, M.J. Designing emergent behaviors: From local interactions to collective intelligence. In Proceedings of the Second International Conference on Simulation of Adaptive Behavior, Honolulu, HI, USA, 13 April 1993; pp. 432–441. [Google Scholar]
- Şahin, E. Swarm Robotics: From Sources of Inspiration to Domains of Application. In Swarm Robotics; Şahin, E., Spears, W.M., Eds.; Number 3342 in Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, 2004; pp. 10–20. [Google Scholar]
- Bayındır, L. A review of swarm robotics tasks. Neurocomputing 2016, 172, 292–321. [Google Scholar] [CrossRef]
- Sauter, J.A.; Matthews, R.; Van Dyke Parunak, H.; Brueckner, S.A. Performance of digital pheromones for swarming vehicle control. In Proceedings of the Fourth International Joint Conference on Autonomous Agents and Multiagent Systems, Utrecht, Netherlands, 25–29 July 2005; ACM: New York, NY, USA, 2005; pp. 903–910. [Google Scholar]
- McCune, R.R.; Madey, G.R. Control of artificial swarms with DDDAS. Proc. Comput. Sci. 2014, 29, 1171–1181. [Google Scholar] [CrossRef]
- Sutantyo, D.K.; Kernbach, S.; Levi, P.; Nepomnyashchikh, V.A. Multi-robot searching algorithm using lévy flight and artificial potential field. In Proceedings of the 2010 IEEE International Workshop on Safety Security and Rescue Robotics (SSRR), Bremen, Germany, 26–30 July 2010; pp. 1–6. [Google Scholar]
- Liu, W.; Taima, Y.E.; Short, M.B.; Bertozzi, A.L. Multi-scale Collaborative Searching through Swarming. In Proceedings of the International Conference on Informatics in Control, Automation and Robotics (ICINCO), Funchal, Portugal, 15–18 June 2010; pp. 222–231. [Google Scholar]
- Waharte, S.; Symington, A.C.; Trigoni, N. Probabilistic search with agile UAVs. In Proceedings of the International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 3–7 May 2010; pp. 2840–2845. [Google Scholar]
- Pastor, I.; Valente, J. Adaptive sampling in robotics: A survey. Revista Iberoamericana de Automática e Informática Industrial (RIAI) 2017, 14, 123–132. [Google Scholar] [CrossRef]
- Altshuler, Y.; Yanovsky, V.; Wagner, I.A.; Bruckstein, A.M. Efficient cooperative search of smart targets using uav swarms. Robotica 2008, 26, 551–557. [Google Scholar] [CrossRef]
- Stirling, T.; Wischmann, S.; Floreano, D. Energy-efficient indoor search by swarms of simulated flying robots without global information. Swarm Intell. 2010, 4, 117–143. [Google Scholar] [CrossRef]
- Jevtić, A.; Gutiérrez, A. Distributed bees algorithm parameters optimization for a cost efficient target allocation in swarms of robots. Sensors 2011, 11, 10880–10893. [Google Scholar] [CrossRef] [PubMed]
- Siciliano, B.; Khatib, O. Springer Handbook of Robotics; Springer Science & Business Media: Berlin, Germany, 2008. [Google Scholar]
- Karapetyan, N.; Benson, K.; McKinney, C.; Taslakian, P.; Rekleitis, I. Efficient multi-robot coverage of a known environment. In Proceedings of the IEEE Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1846–1852. [Google Scholar]
- Senthilkumar, K.; Bharadwaj, K. Multi-robot exploration and terrain coverage in an unknown environment. Robot. Auton. Syst. 2012, 60, 123–132. [Google Scholar] [CrossRef]
- Erignac, C. An exhaustive swarming search strategy based on distributed pheromone maps. In Proceedings of the AIAA Infotech@Aerospace 2007 Conference and Exhibit, Rohnert Park, CA, USA, 7–10 May 2007; p. 2822. [Google Scholar]
- George, J.; Sujit, P.; Sousa, J.B. Search strategies for multiple UAV search and destroy missions. J. Intell. Robot. Syst. 2011, 61, 355–367. [Google Scholar] [CrossRef]
- Maza, I.; Ollero, A. Multiple UAV Cooperative Searching Operation Using Polygon Area Decomposition and Efficient Coverage Algorithms. In Distributed Autonomous Robotic Systems 6; Springer: Berlin, Germany, 2007; pp. 221–230. [Google Scholar]
- Lum, C.; Vagners, J.; Jang, J.S.; Vian, J. Partitioned searching and deconfliction: Analysis and flight tests. In Proceedings of the IEEE American Control Conference (ACC), Baltimore, MD, USA, 30 June–2 July 2010; pp. 6409–6416. [Google Scholar]
- Berger, J.; Lo, N. An innovative multi-agent search-and-rescue path planning approach. Comp. Op. Res. 2015, 53, 24–31. [Google Scholar] [CrossRef]
- Peng, H.; Su, F.; Bu, Y.; Zhang, G.; Shen, L. Cooperative area search for multiple UAVs based on RRT and decentralized receding horizon optimization. In Proceedings of the IEEE Asian Control Conference (ASCC), Hong Kong, China, 27–29 August 2009; pp. 298–303. [Google Scholar]
- Saska, M.; Vakula, J.; Přeućil, L. Swarms of micro aerial vehicles stabilized under a visual relative localization. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–5 June 2014; pp. 3570–3575. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K. Gaussian Processes for Machine Learning; MIT Press Cambridge: Cambridge, MA, USA, 2006; Volume 1. [Google Scholar]
- Nigam, N.; Bieniawski, S.; Kroo, I.; Vian, J. Control of multiple UAVs for persistent surveillance: Algorithm and flight test results. IEEE Trans. Control Syst. Technol. 2012, 20, 1236–1251. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Range of Values |
|---|---|---|
| Search area per agent | [2, 15] m | |
| Number of agents | [2, 30] | |
| Nominal velocity of the agents | [2, 20] m/s | |
| Radius of the sensor footprint | [5, 20] m | |
| Aspect ratio of the search area | [0.25, 1] |
| Parameter | Description | Equation | Value |
|---|---|---|---|
| Velocity reduction time due to | (6) | 5 s | |
| Energy-distance coefficient | (7) | 0.1 m | |
| Energy-change-of-heading coefficient | (8) | 2 | |
| Max available energy | (9) | 180 |
| L1 | 0 | 0 | ||||||
| L2 | 0 | 0 | 0 | |||||
| L3 | 0 | 0 | 0 | −1 |
| Model 1 | Model 2 | Model 3 | ||||
|---|---|---|---|---|---|---|
| Eff | Fit | Eff | Fit | Eff | Fit | |
| A1: Behaviors set | 0.70 | 0.58 | 0.57 | 0.49 | 0.39 | 0.29 |
| A2: Random | 0.61 | 0.21 | 0.57 | 0.20 | 0.09 | 0.03 |
| A3: Closest | 0.75 | 0.68 | 0.62 | 0.57 | 0.36 | 0.27 |
| A4: Boundary | 0.78 | 0.67 | 0.59 | 0.53 | 0.31 | 0.22 |
| A5: Energy | 0.66 | 0.21 | 0.59 | 0.19 | 0.16 | 0.04 |
| A6: Billiard | 0.61 | 0.23 | 0.55 | 0.22 | 0.16 | 0.05 |
| A7: Lanes | 0.73 | 0.68 | 0.61 | 0.57 | 0.35 | 0.28 |
| Plain | Probability | Obstacles | Prob. + Obs. | |||||
|---|---|---|---|---|---|---|---|---|
| Eff | Fit | Eff | Fit | Eff | Fit | Eff | Fit | |
| A1: Behaviors set | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| A2: Random | 0.23 | 0.09 | 0.22 | 0.14 | 0.24 | 0.13 | 0.21 | 0.18 |
| A3: Closest | 0.91 | 0.93 | 0.81 | 0.86 | 0.87 | 0.84 | 0.76 | 0.77 |
| A4: Boundary | 0.78 | 0.78 | 0.63 | 0.72 | 0.86 | 0.84 | 0.66 | 0.71 |
| A5: Energy | 0.41 | 0.15 | 0.42 | 0.28 | 0.44 | 0.20 | 0.43 | 0.34 |
| A6: Billiard | 0.42 | 0.17 | 0.43 | 0.31 | 0.45 | 0.22 | 0.44 | 0.37 |
| A7: Lanes | 0.90 | 0.99 | 0.76 | 0.90 | 0.59 | 0.60 | 0.52 | 0.53 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garcia-Aunon, P.; Barrientos Cruz, A. Comparison of Heuristic Algorithms in Discrete Search and Surveillance Tasks Using Aerial Swarms. Appl. Sci. 2018, 8, 711. https://doi.org/10.3390/app8050711
Garcia-Aunon P, Barrientos Cruz A. Comparison of Heuristic Algorithms in Discrete Search and Surveillance Tasks Using Aerial Swarms. Applied Sciences. 2018; 8(5):711. https://doi.org/10.3390/app8050711
Chicago/Turabian StyleGarcia-Aunon, Pablo, and Antonio Barrientos Cruz. 2018. "Comparison of Heuristic Algorithms in Discrete Search and Surveillance Tasks Using Aerial Swarms" Applied Sciences 8, no. 5: 711. https://doi.org/10.3390/app8050711
APA StyleGarcia-Aunon, P., & Barrientos Cruz, A. (2018). Comparison of Heuristic Algorithms in Discrete Search and Surveillance Tasks Using Aerial Swarms. Applied Sciences, 8(5), 711. https://doi.org/10.3390/app8050711