An Improved Image Semantic Segmentation Method Based on Superpixels and Conditional Random Fields


Abstract
:1. Introduction
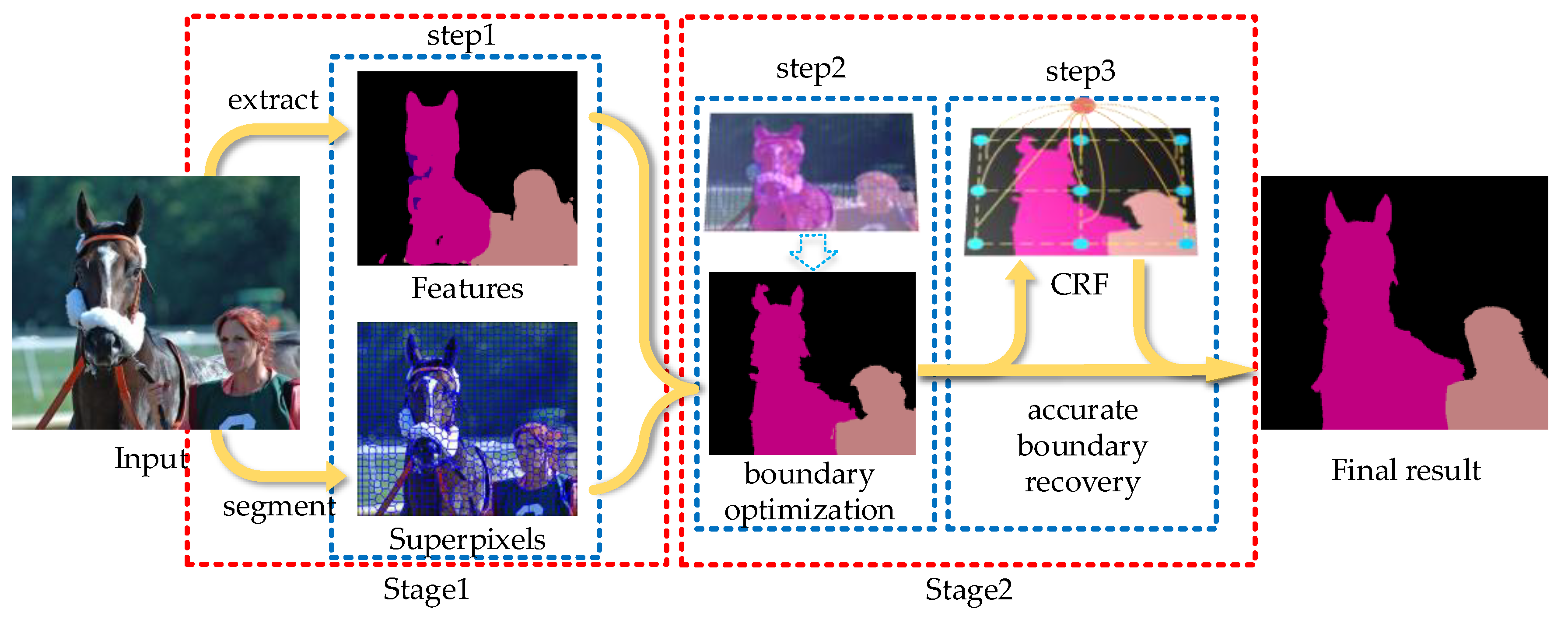
2. Overview
3. Key Techniques
3.1. Feature Extraction
3.2. Boundary Optimization
| Algorithm 1. The algorithm of boundary optimization. |
|
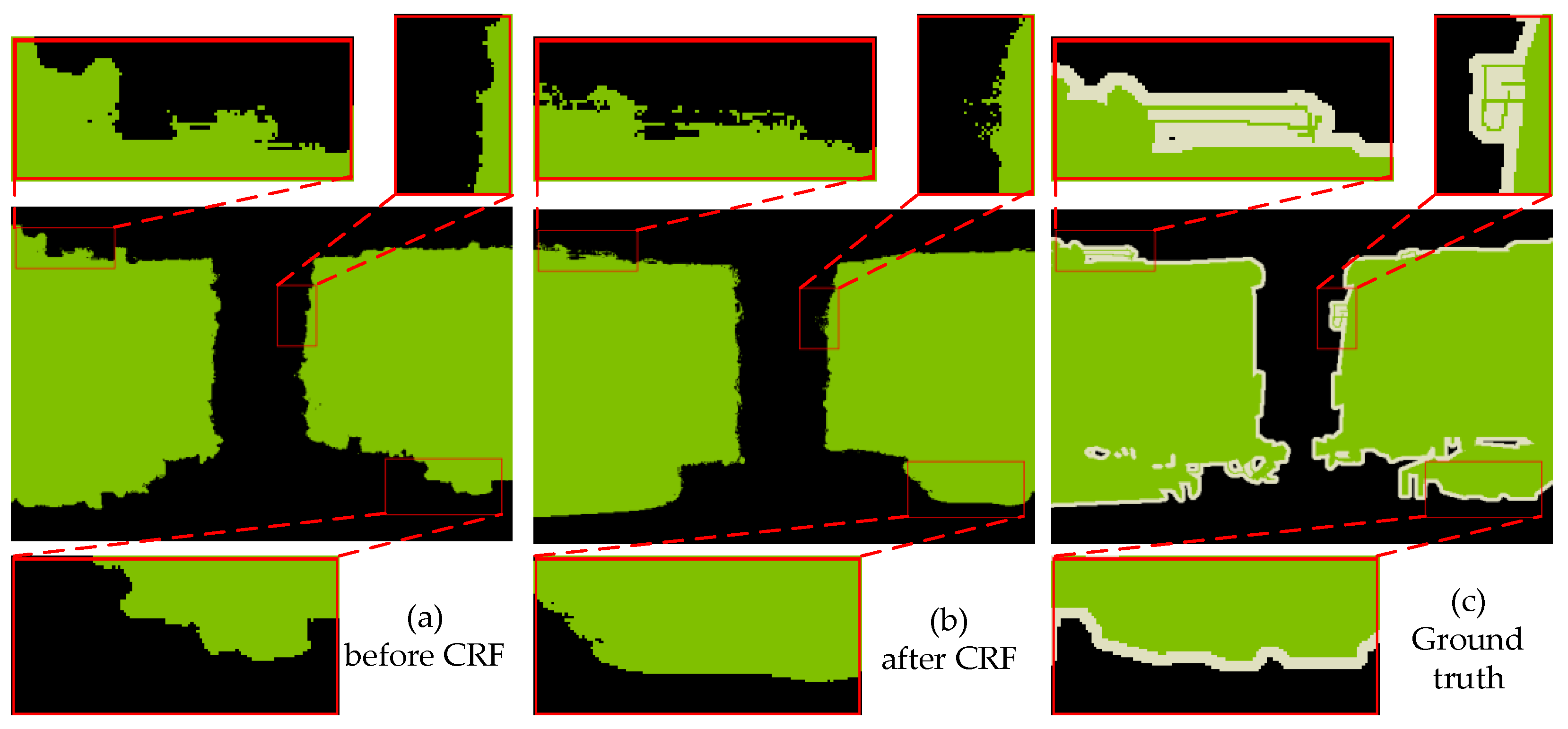
3.3. Accurate Boundary Recovery
4. Experimental Evaluation
4.1. Experimental Setup
4.2. Ablation Study
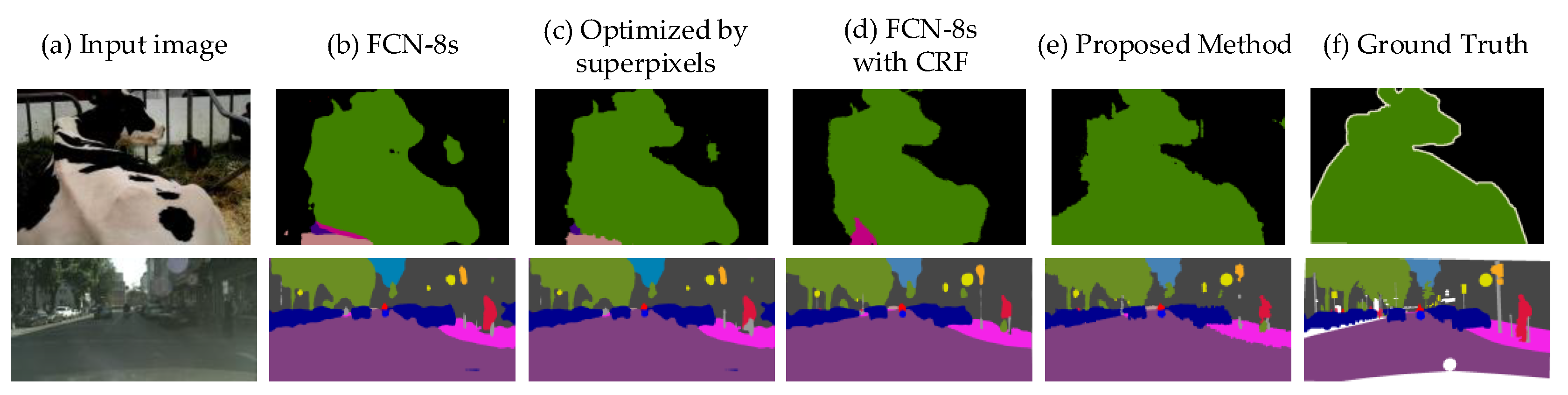
4.3. Experimental Results
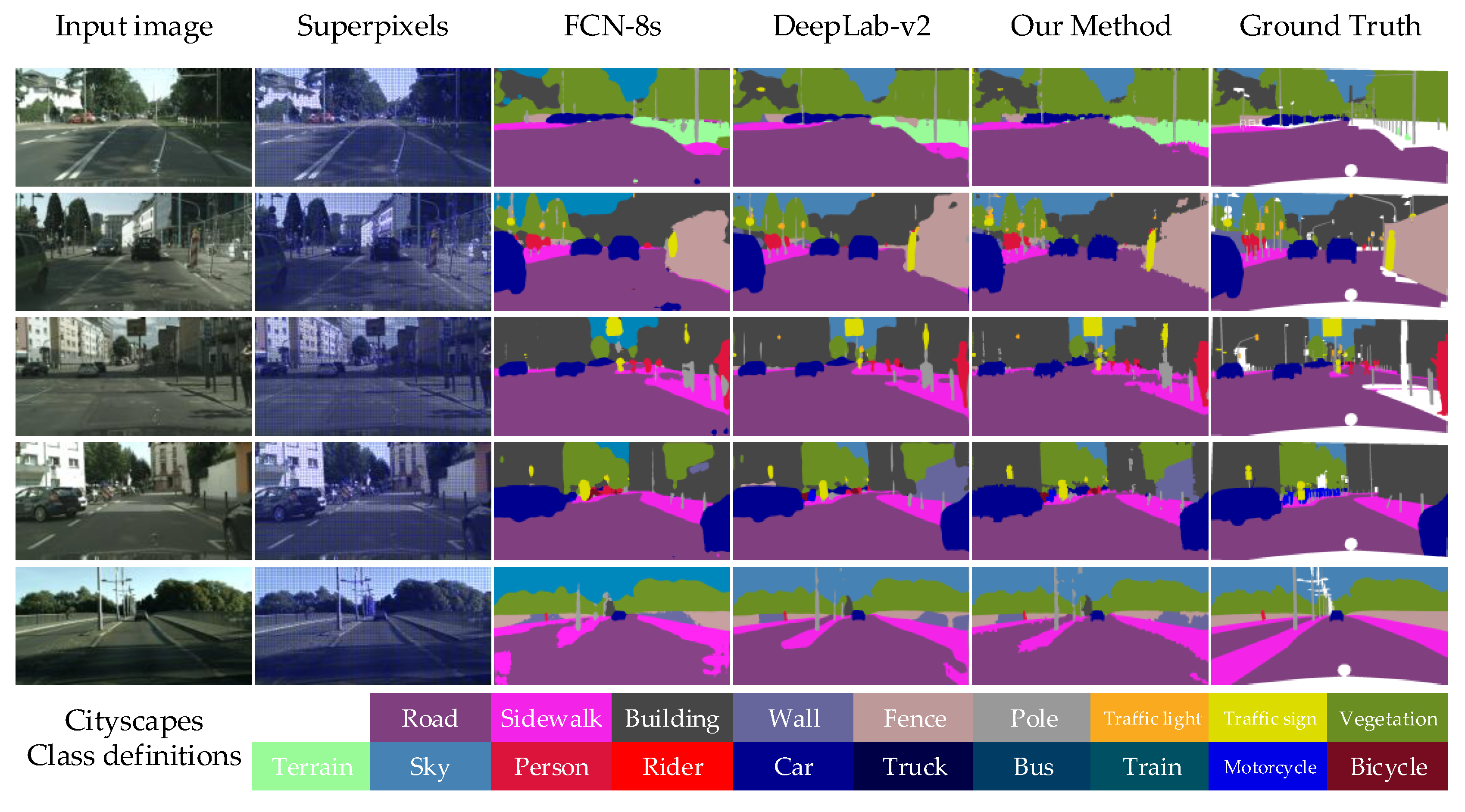
4.3.1. Qualitative Analysis
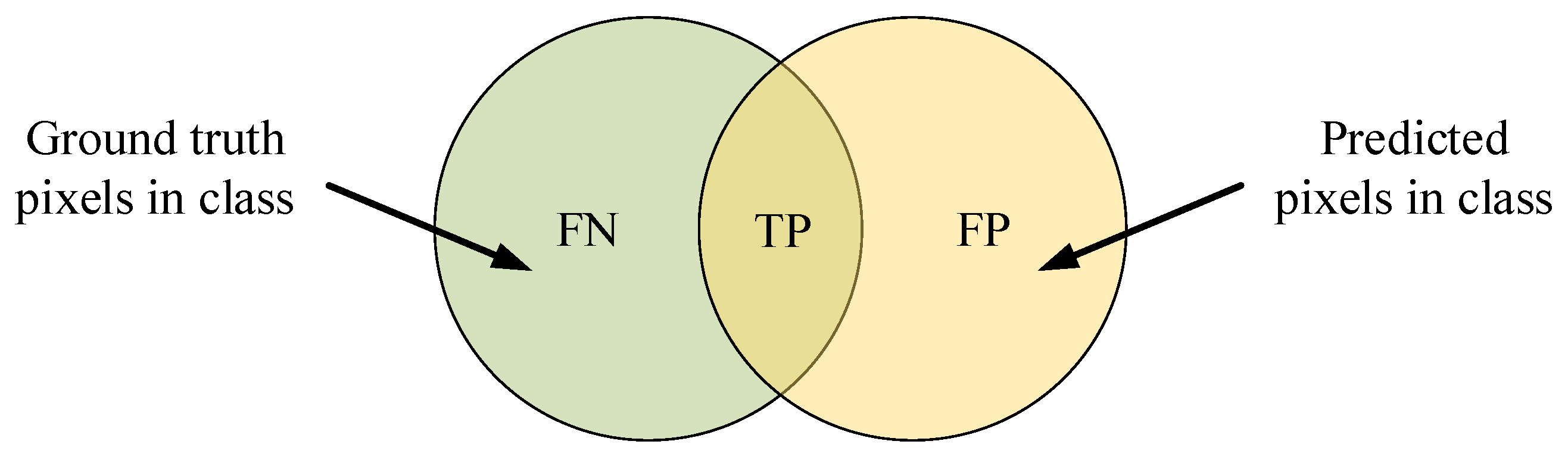
4.3.2. Quantitative Analysis
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Hands deep in deep learning for hand pose estimation. arXiv, 2015; arXiv:1502.06807. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: New York, NY, USA, 2012; pp. 3354–3361. [Google Scholar]
- Wan, J.; Wang, D.; Hoi, S.C.H.; Wu, P.; Zhu, J.; Zhang, Y.; Li, J. Deep learning for content-based image retrieval: A comprehensive study. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; ACM: Orlando, FL, USA, 2014; pp. 157–166. [Google Scholar]
- Kang, W.X.; Yang, Q.Q.; Liang, R.P. The comparative research on image segmentation algorithms. In Proceedings of the 2009 First International Workshop on Education Technology and Computer Science, Wuhan, China, 7–8 March 2009; pp. 703–707. [Google Scholar]
- Ciresan, D.; Giusti, A.; Gambardella, L.M.; Schmidhuber, J. Deep neural networks segment neuronal membranes in electron microscopy images. In Proceedings of the Advances in Neural Information Processing Systems 25, Lake Tahoe, NV, USA, 3–6 December 2012; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 2843–2851. [Google Scholar]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from rgb-d images for object detection and segmentation. In European Conference on Computer Vision; Springer: New York, NY, USA, 2014; pp. 345–360. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In European Conference on Computer Vision; Springer: New York, NY, USA, 2014; pp. 297–312. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Luo, P.; Wang, G.; Lin, L.; Wang, X. Deep dual learning for semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2718–2726. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Ravì, D.; Bober, M.; Farinella, G.M.; Guarnera, M.; Battiato, S. Semantic segmentation of images exploiting dct based features and random forest. Pattern Recogn. 2016, 52, 260–273. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Wang, Y.; Lu, H. Stacked deconvolutional network for semantic segmentation. arXiv, 2017; arXiv:1708.04943. [Google Scholar]
- Wu, Z.; Shen, C.; Hengel, A.V.D. Wider or deeper: Revisiting the resnet model for visual recognition. arXiv, 2016; arXiv:1611.10080. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; IEEE: New York, NY, USA, 2015; pp. 3431–3440. [Google Scholar]
- Ghiasi, G.; Fowlkes, C.C. Laplacian pyramid reconstruction and refinement for semantic segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: New York, NY, USA, 2016; pp. 519–534. [Google Scholar]
- Lin, G.; Shen, C.; Hengel, A.V.D.; Reid, I. Exploring context with deep structured models for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1352–1366. [Google Scholar] [CrossRef] [PubMed]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 8–10 June 2015; pp. 1520–1528. [Google Scholar]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June–1 July 2016; IEEE: New York, NY, USA, 2016; pp. 3640–3649. [Google Scholar]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.Z.; Du, D.L.; Huang, C.; Torr, P.H.S. Conditional random fields as recurrent neural networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE: New York, NY, USA, 2015; pp. 1529–1537. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv, 2014; arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv, 2017; arXiv:1706.05587. [Google Scholar]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Van den Bergh, M.; Boix, X.; Roig, G.; de Capitani, B.; Van Gool, L. Seeds: Superpixels extracted via energy-driven sampling. In Proceedings of the 12th European Conference on Computer Vision-Volume Part VII, Florence, Italy, 7–13 October 2012; Springer: New York, NY, USA, 2012; pp. 13–26. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Susstrunk, S. Slic superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2281. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Rother, C.; Kolmogorov, V.; Blake, A. Grabcut: Interactive foreground extraction using iterated graph cuts. In Proceedings of the ACM Transactions on Graphics (TOG), Los Angeles, CA, USA, 8–12 August 2004; ACM: New York, NY, USA, 2004; Volume 23, pp. 309–314. [Google Scholar]
- Maini, R.; Aggarwal, H. Study and comparison of various image edge detection techniques. Int. J. Image Process. 2009, 3, 1–11. [Google Scholar]
- Gadde, R.; Jampani, V.; Kiefel, M.; Kappler, D.; Gehler, P.V. Superpixel convolutional networks using bilateral inceptions. In Computer Vision, ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 597–613. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. In Proceedings of the 24th International Conference on Neural Information Processing Systems, Granada, Spain, 12–15 December 2011; Curran Associates Inc.: Red Hook, NY, USA, 2011; pp. 109–117. [Google Scholar]
- Wu, F. The potts model. Rev. Mod. Phys. 1982, 54, 235. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Hariharan, B.; Arbelaez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic contours from inverse detectors. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE Computer Society: Washington, DC, USA, 2011; pp. 991–998. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Scharwächter, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset. In Proceedings of the CVPR Workshop on the Future of Datasets in Vision, Boston, MA, USA, 11 June 2015; p. 3. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv, 2017; arXiv:1704.06857. [Google Scholar]
- Mostajabi, M.; Yadollahpour, P.; Shakhnarovich, G. Feedforward semantic segmentation with zoom-out features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3376–3385. [Google Scholar]
- Vemulapalli, R.; Tuzel, O.; Liu, M.-Y.; Chellapa, R. Gaussian conditional random field network for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June–1 July 2016; pp. 3224–3233. [Google Scholar]
- Liu, Z.; Li, X.; Luo, P.; Loy, C.-C.; Tang, X. Semantic image segmentation via deep parsing network. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: New York, NY, USA, 2015; pp. 1377–1385. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DatasetMethod | Plain FCN-8s | With BO 1 | With CRF | Our Method |
|---|---|---|---|---|
| VOC 2012 | 62.7 | 65.9 | 69.5 | 74.5 |
| Cityscapes | 56.1 | 58.9 | 61.3 | 65.4 |
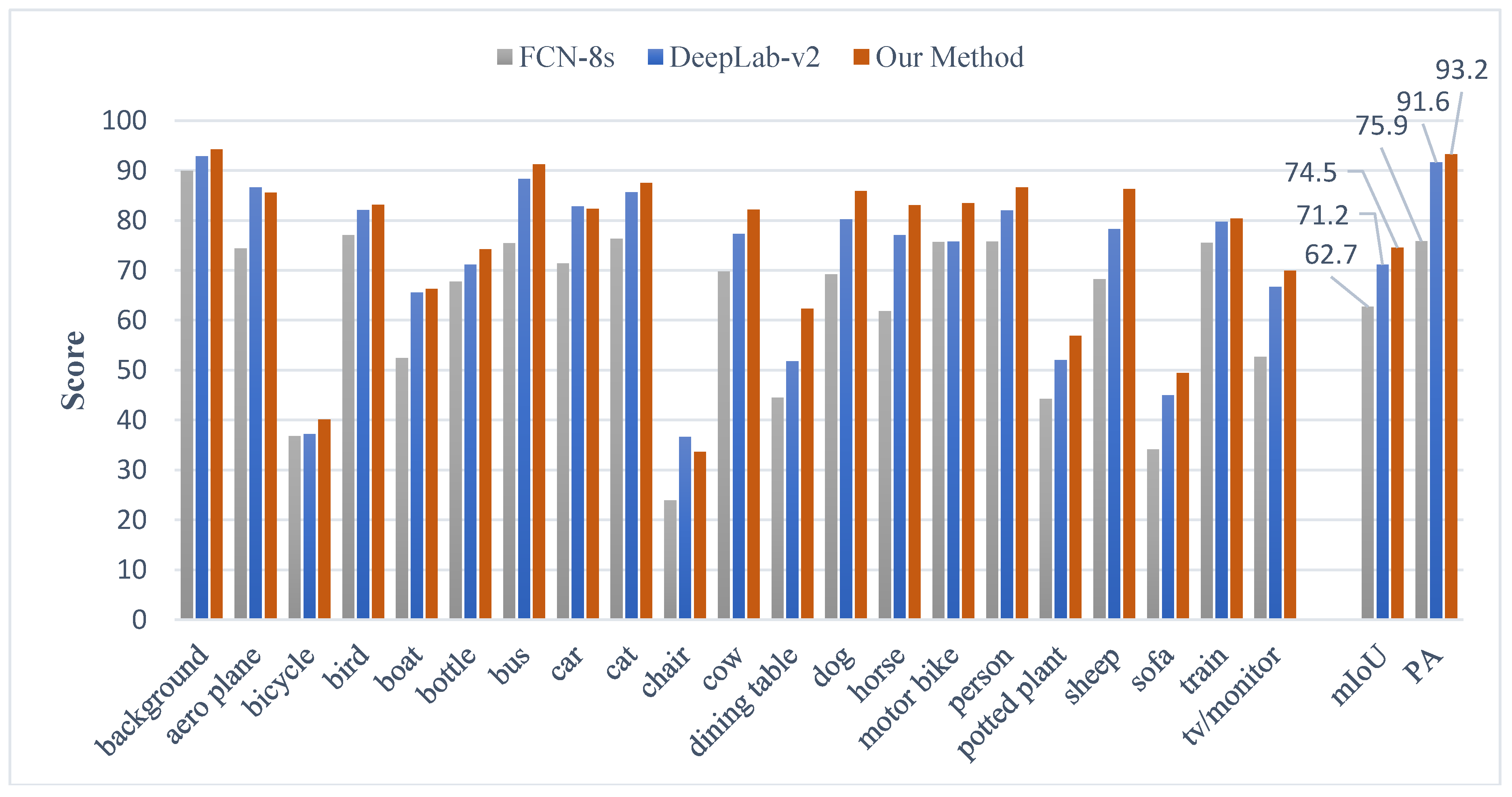
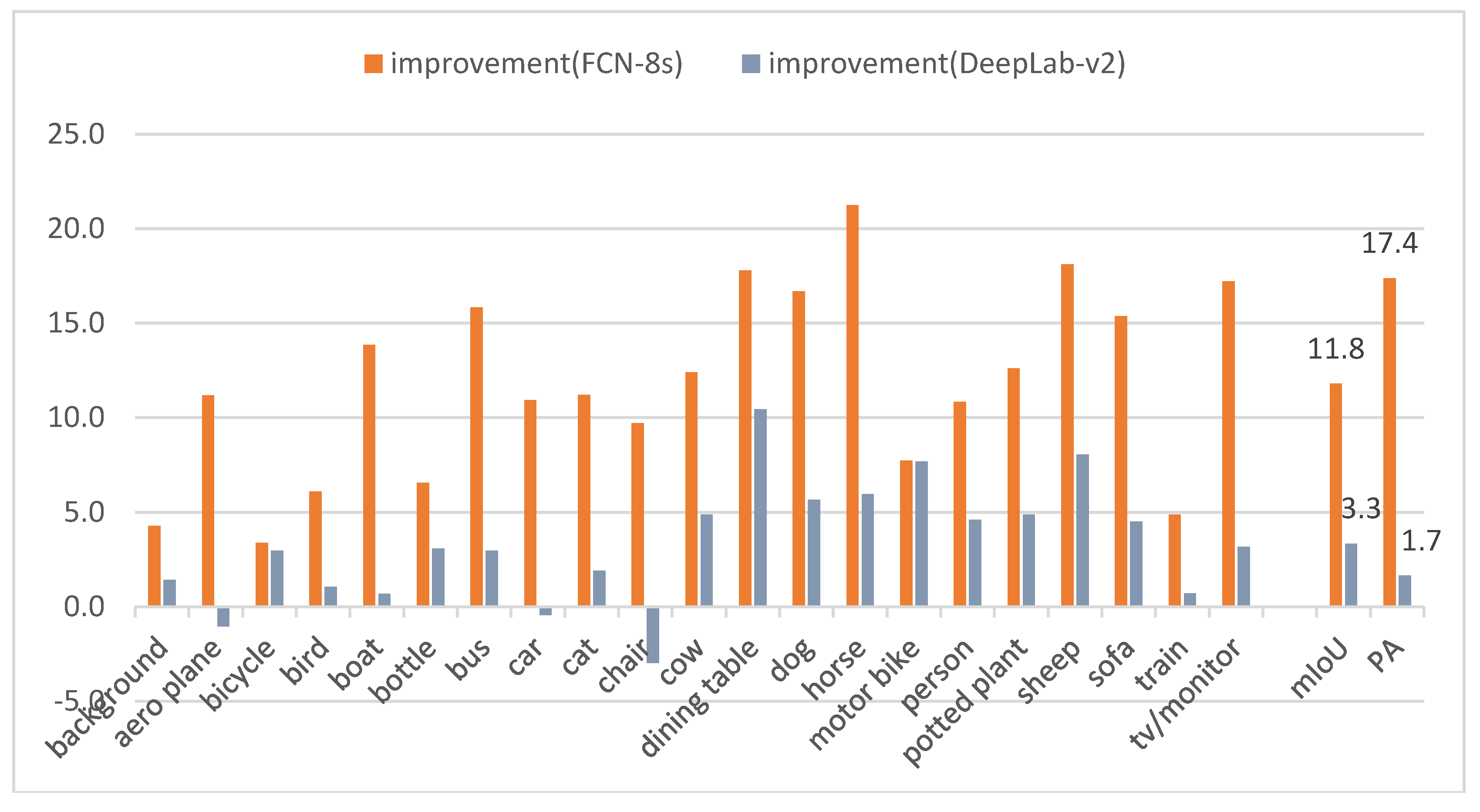
| FCN-8s | Zoom-Out [38] | DeepLab-v2 | CRF-RNN [20] | GCRF [39] | DPN [40] | Our Method | |
|---|---|---|---|---|---|---|---|
| areo | 74.3 | 85.6 | 86.6 | 87.5 | 85.2 | 87.7 | 85.5 |
| bike | 36.8 | 37.3 | 37.2 | 39.0 | 43.9 | 59.4 | 40.1 |
| bird | 77.0 | 83.2 | 82.1 | 79.7 | 83.3 | 78.4 | 83.1 |
| boat | 52.4 | 62.5 | 65.6 | 64.2 | 65.2 | 64.9 | 66.3 |
| bottle | 67.7 | 66.0 | 71.2 | 68.3 | 68.3 | 70.3 | 74.2 |
| bus | 75.4 | 85.1 | 88.3 | 87.6 | 89.0 | 89.3 | 91.3 |
| car | 71.4 | 80.7 | 82.8 | 80.8 | 82.7 | 83.5 | 82.3 |
| cat | 76.3 | 84.9 | 85.6 | 84.4 | 85.3 | 86.1 | 87.5 |
| chair | 23.9 | 27.2 | 36.6 | 30.4 | 31.1 | 31.7 | 33.6 |
| cow | 69.7 | 73.2 | 77.3 | 78.2 | 79.5 | 79.9 | 82.2 |
| table | 44.5 | 57.5 | 51.8 | 60.4 | 63.3 | 62.6 | 62.3 |
| dog | 69.2 | 78.1 | 80.2 | 80.5 | 80.5 | 81.9 | 85.9 |
| horse | 61.8 | 79.2 | 77.1 | 77.8 | 79.3 | 80.0 | 83.0 |
| mbike | 75.7 | 81.1 | 75.7 | 83.1 | 85.5 | 83.5 | 83.4 |
| person | 75.7 | 77.1 | 82.0 | 80.6 | 81.0 | 82.3 | 86.6 |
| plant | 44.3 | 53.6 | 52.0 | 59.5 | 60.5 | 60.5 | 56.9 |
| sheep | 68.2 | 74.0 | 78.2 | 82.8 | 85.5 | 83.2 | 86.3 |
| sofa | 34.1 | 49.2 | 44.9 | 47.8 | 52.0 | 53.4 | 49.4 |
| train | 75.5 | 71.7 | 79.7 | 78.3 | 77.3 | 77.9 | 80.4 |
| tv | 52.7 | 63.3 | 66.7 | 67.1 | 65.1 | 65.0 | 69.9 |
| mIoU | 62.7 | 69.6 | 71.2 | 72.0 | 73.2 | 74.1 | 74.5 |
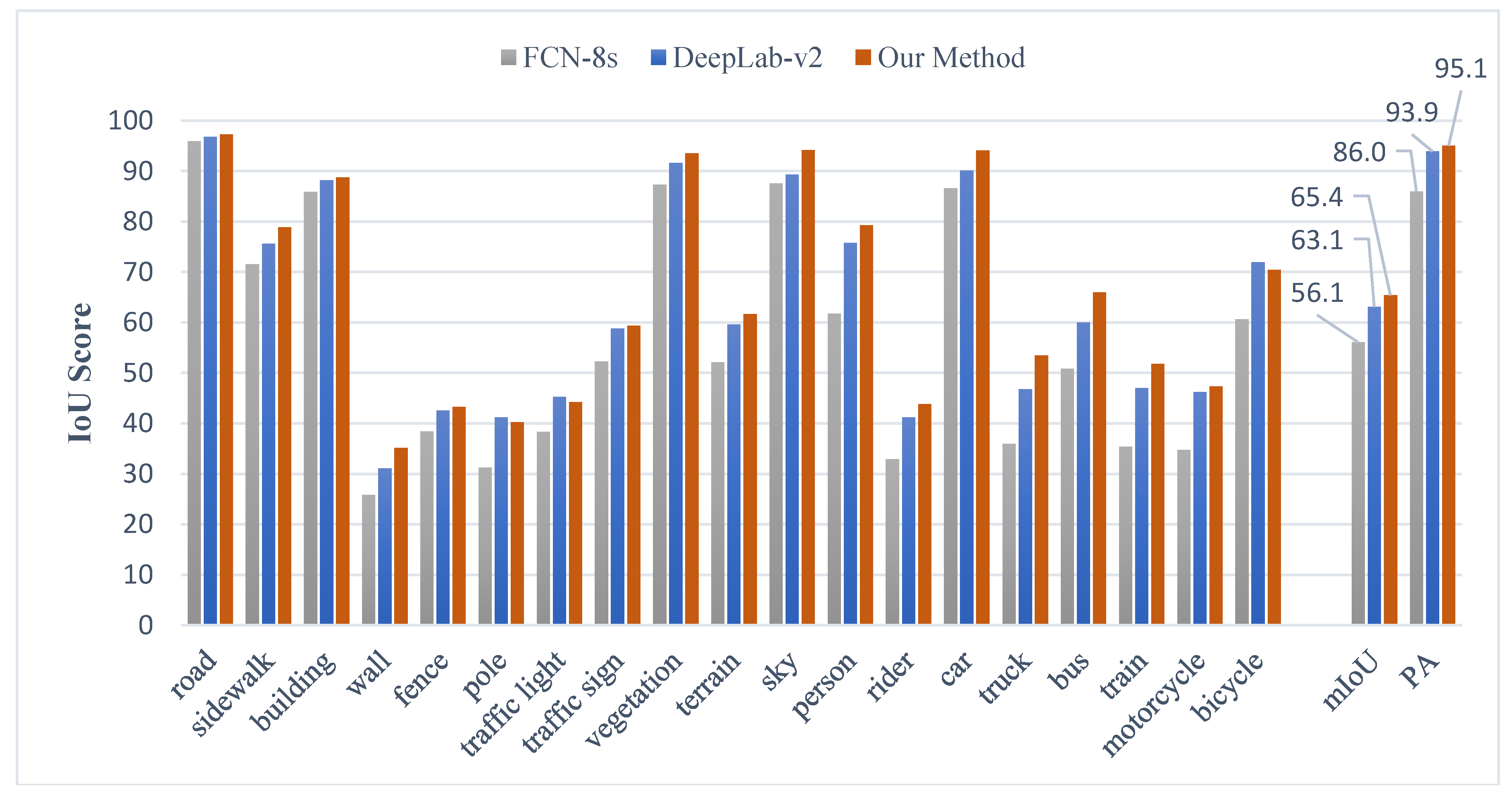
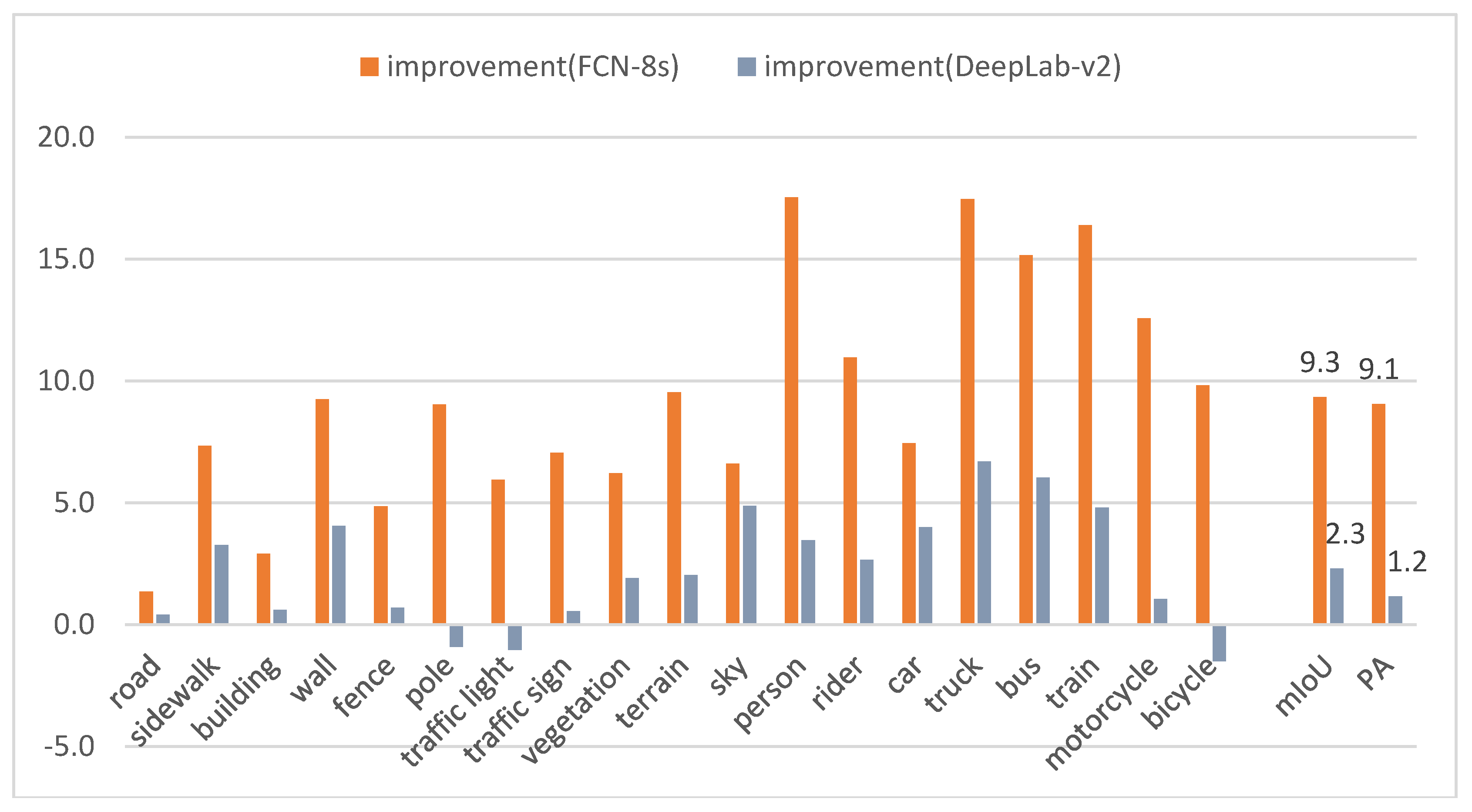
| FCN-8s | DPN [40] | CRF-RNN [20] | DeepLab-v2 | Our Method | |
|---|---|---|---|---|---|
| road | 95.9 | 96.3 | 96.3 | 96.8 | 97.2 |
| sidewalk | 71.5 | 71.7 | 73.9 | 75.6 | 78.9 |
| building | 85.9 | 86.7 | 88.2 | 88.2 | 88.8 |
| wall | 25.9 | 43.7 | 47.6 | 31.1 | 35.1 |
| fence | 38.4 | 31.7 | 41.3 | 42.6 | 43.3 |
| pole | 31.2 | 29.2 | 35.2 | 41.2 | 40.2 |
| traffic light | 38.3 | 35.8 | 49.5 | 45.3 | 44.3 |
| traffic sign | 52.3 | 47.4 | 59.7 | 58.8 | 59.3 |
| vegetation | 87.3 | 88.4 | 90.6 | 91.6 | 93.5 |
| terrain | 52.1 | 63.1 | 66.1 | 59.6 | 61.6 |
| sky | 87.6 | 93.9 | 93.5 | 89.3 | 94.2 |
| person | 61.7 | 64.7 | 70.4 | 75.8 | 79.3 |
| rider | 32.9 | 38.7 | 34.7 | 41.2 | 43.9 |
| car | 86.6 | 88.8 | 90.1 | 90.1 | 94.1 |
| truck | 36.0 | 48.0 | 39.2 | 46.7 | 53.4 |
| bus | 50.8 | 56.4 | 57.5 | 60.0 | 66.0 |
| train | 35.4 | 49.4 | 55.4 | 47.0 | 51.8 |
| motorcycle | 34.7 | 38.3 | 43.9 | 46.2 | 47.3 |
| bicycle | 60.6 | 50.0 | 54.6 | 71.9 | 70.4 |
| mIoU | 56.1 | 59.1 | 62.5 | 63.1 | 65.4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, W.; Fu, Y.; Wei, X.; Wang, H. An Improved Image Semantic Segmentation Method Based on Superpixels and Conditional Random Fields. Appl. Sci. 2018, 8, 837. https://doi.org/10.3390/app8050837
Zhao W, Fu Y, Wei X, Wang H. An Improved Image Semantic Segmentation Method Based on Superpixels and Conditional Random Fields. Applied Sciences. 2018; 8(5):837. https://doi.org/10.3390/app8050837
Chicago/Turabian StyleZhao, Wei, Yi Fu, Xiaosong Wei, and Hai Wang. 2018. "An Improved Image Semantic Segmentation Method Based on Superpixels and Conditional Random Fields" Applied Sciences 8, no. 5: 837. https://doi.org/10.3390/app8050837
APA StyleZhao, W., Fu, Y., Wei, X., & Wang, H. (2018). An Improved Image Semantic Segmentation Method Based on Superpixels and Conditional Random Fields. Applied Sciences, 8(5), 837. https://doi.org/10.3390/app8050837