Efficient Implementations of Four-Dimensional GLV-GLS Scalar Multiplication on 8-Bit, 16-Bit, and 32-Bit Microcontrollers



Abstract
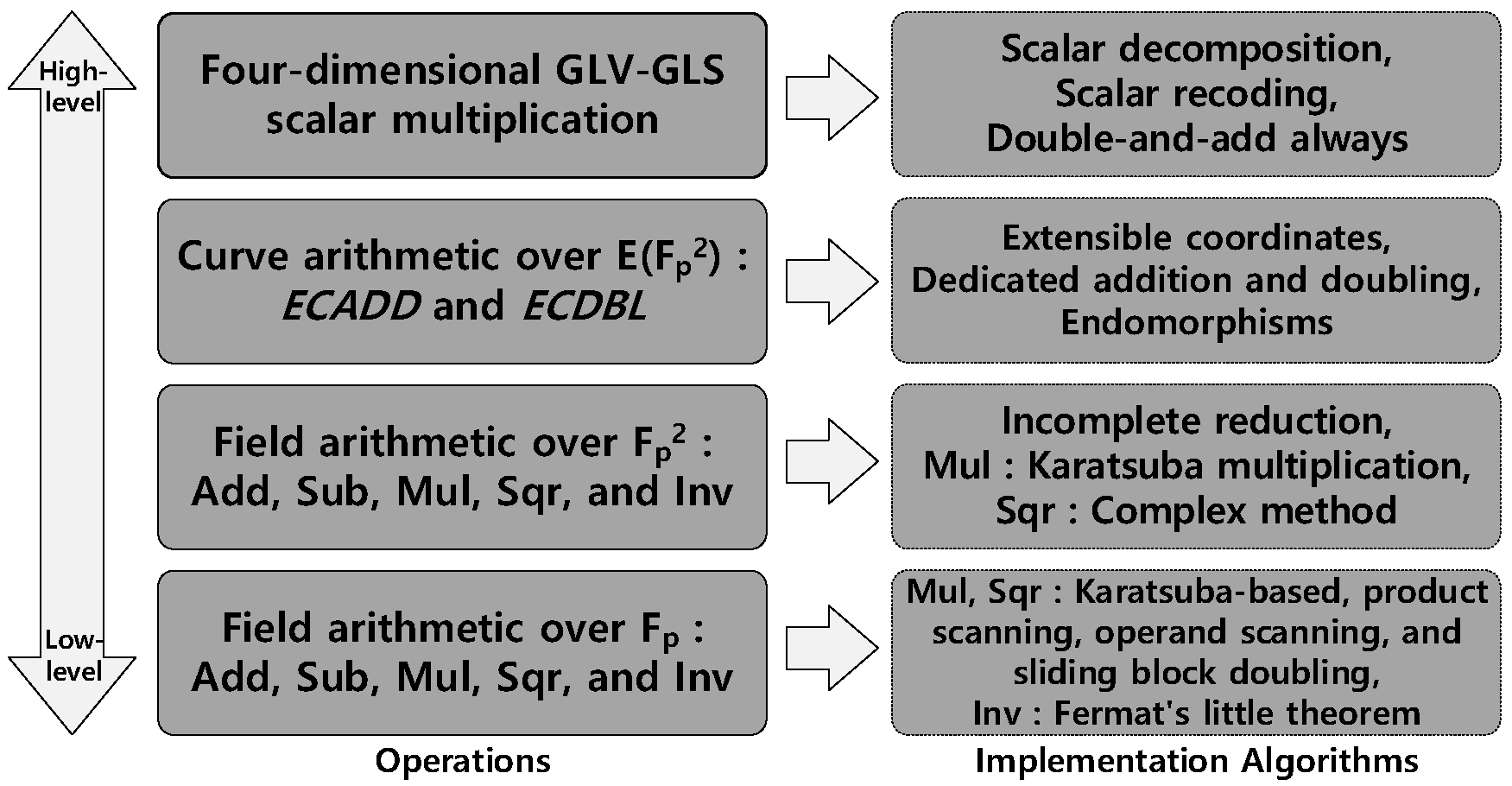
:1. Introduction
- We present efficient implementations at each level of the implementation hierarchy of four-dimensional GLV-GLS scalar multiplication considering the features of 8-bit AVR, 16-bit MSP430, and 32-bit ARM Cortex-M4 processors. To improve the performance of scalar multiplication, we carefully selected the internal algorithms at each level of the implementation hierarchy. These implementations also run in constant time to resist timing and cache-timing attacks [26,27].
- We demonstrate that the efficiently computable endomorphisms can accelerate the performance of four-dimensional GLV-GLS scalar multiplication. For this purpose, we analyze the operation counts of two elliptic curves “Ted127-glv4” and “Four”, which support the four-dimensional GLV-GLS scalar multiplication. The GLV-GLS curve - requires fewer number of field arithmetic operations than Four-based implementation to compute a single variable-base scalar multiplication. However, because Four uses a Mersenne prime and the curve - uses a Mersenne-like prime , Four has a computational advantage of faster field arithmetic operations. By using the computational advantage of endomorphisms, we overcome the computational disadvantage of curve - at field arithmetic level.
- We present the first constant-time implementations of four-dimensional GLV-GLS scalar multiplication using curve - on three target platforms, which have not been considered in previous works. The proposed implementations on AVR, MSP430, and ARM processors require 6,856,026, 4,158,453, and 447,836 cycles to compute a single variable-base scalar multiplication, respectively. Compared to Four-based implementations [24], which have provided the fastest results to date, our results are 4.49% slower on AVR, but 2.85% and 4.61% faster on MSP430 and ARM, respectively. Our MSP430 and ARM implementations set new speed records for variable-base scalar multiplication.
2. Preliminaries
2.1. Field Representation and Notations
2.2. Elliptic Curve Cryptography
2.3. Twisted Edwards Curves
2.4. The GLV-GLS Method
3. Review of Four-Dimensional GLV-GLS Scalar Multiplication
| Algorithm 1: Scalar multiplication using curve - [21]. |
|
4. Implementation Details of Field Arithmetic
4.1. Field Addition and Subtraction over
4.2. Modular Reduction
4.3. Inversion over
4.4. Field Arithmetic over
| Algorithm 2: Field multiplication over [25]. |
|
| Algorithm 3: Field squaring over [25]. |
|
4.5. Optimization Strategy on 8-Bit AVR
| Algorithm 4: Subtractive Karatsuba multiplication [34]. |
|
4.6. Optimization Strategy on 16-Bit MSP430X
| Algorithm 5: Product scanning multiplication. |
|
4.7. Optimization Strategy on 32-Bit ARM
5. Implementation Details of Curve Arithmetic
5.1. Scalar Decomposition
5.2. Point Arithmetic
| Algorithm 6: Twisted Edwards point addition over . |
|
| Algorithm 7: Twisted Edwards point doubling over . |
|
5.3. Endomorphisms
6. Performance Analysis and Implementation Results
6.1. Operation Counts
6.2. Implementation Results of Field Arithmetic
6.3. Implementation Results of Scalar Multiplication
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Shojafar, M.; Canali, C.; Lancellotti, R.; Baccarelli, E. Minimizing computing-plus-communication energy consumptions in virtualized networked data centers. In Proceedings of the 2016 IEEE Symposium on Computers and Communication (ISCC), Messina, Italy, 27–30 June 2016; pp. 1137–1144. [Google Scholar]
- Baccarelli, E.; Naranjo, P.G.V.; Shojafar, M.; Scarpiniti, M. Q*: Energy and delay-efficient dynamic queue management in TCP/IP virtualized data centers. Comput. Commun. 2017, 102, 89–106. [Google Scholar] [CrossRef]
- Miller, V.S. Use of Elliptic Curves in Cryptography. In Proceedings of Conference on the Theory and Application of Cryptographic Techniques, Santa Barbara, CA, USA, 18–22 August 1985; Springer: Heidelberg/Berlin, Germany, 1985; pp. 417–426. [Google Scholar]
- Koblitz, N. Elliptic curve cryptosystems. Math. Comput. 1987, 48, 203–209. [Google Scholar] [CrossRef]
- Rivest, R.L.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- SafeCurves: Choosing Safe Curves for Elliptic-Curve Cryptography. Available online: http://safecurves.cr.yp.to (accessed on 10 March 2018).
- Barker, E.; Kelsey, J. NIST Special Publication 800-90A Revision 1: Recommendation for Random Number Generation Using Deterministic Random Bit Generators; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2015. [Google Scholar]
- Bernstein, D.J. Curve25519: New Diffie–Hellman Speed Records. In Proceedings of 9th International Workshop on Public Key Cryptography, New York, NY, USA, 24–26 April 2006; Springer: Heidelberg/Berlin, Germany, 2006; pp. 207–228. [Google Scholar]
- Hamburg, M. Ed448-Goldilocks, a new elliptic curve. IACR Cryptol. ePrint Arch. 2015, 2015, 625. [Google Scholar]
- Bernstein, D.J.; Birkner, P.; Joye, M.; Lange, T.; Peters, C. Twisted Edwards Curves. In Proceedings of 1st International Conference on Cryptology in Africa, Casablanca, Morocco, 11–14 June 2008; Springer: Heidelberg/Berlin, Germany, 2008; pp. 389–405. [Google Scholar]
- Gallant, R.P.; Lambert, R.J.; Vanstone, S.A. Faster Point Multiplication on Elliptic Curves with Efficient Endomorphisms. In Proceedings of 21st Annual International Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2001; Springer: Heidelberg/Berlin, Germany, 2001; pp. 190–200. [Google Scholar]
- Galbraith, S.D.; Lin, X.; Scott, M. Endomorphisms for Faster Elliptic Curve Cryptography on a Large Class of Curves. In Proceedings of 28th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Cologne, Germany, 26–30 April 2009; Springer: Heidelberg/Berlin, Germany, 2009; pp. 518–535. [Google Scholar]
- Longa, P.; Gebotys, C. Efficient Techniques for High-Speed Elliptic Curve Cryptography. In Proceedings of 12th International Workshop on Cryptographic Hardware and Embedded Systems, Santa Barbara, CA, USA, 17–20 August 2010; Springer: Heidelberg/Berlin, Germany, 2010; pp. 80–94. [Google Scholar]
- Longa, P.; Sica, F. Four-Dimensional Gallant–Lambert–Vanstone Scalar Multiplication. In Proceedings of 18th International Conference on the Theory and Application of Cryptology and Information Security, Beijing, China, 2–6 December 2012; Springer: Heidelberg/Berlin, Germany, 2012; pp. 718–739. [Google Scholar]
- Hu, Z.; Longa, P.; Xu, M. Implementing the 4-dimensional GLV method on GLS elliptic curves with j-invariant 0. Des. Codes Cryptogr. 2012, 63, 331–343. [Google Scholar] [CrossRef]
- Bos, J.W.; Costello, C.; Hisil, H.; Lauter, K. Fast cryptography in genus 2. In Proceedings of 32nd Annual International Conference on the Theory and Applications of Cryptographic Techniques, Athens, Greece, 26–30 May 2013; Springer: Heidelberg/Berlin, Germany; pp. 194–210.
- Bos, J.W.; Costello, C.; Hisil, H.; Lauter, K. High-Performance Scalar Multiplication Using 8-Dimensional GLV/GLS Decomposition. In Proceedings of 15th International Workshop on Cryptographic Hardware and Embedded Systems, Santa Barbara, CA, USA, 20–23 August 2013; Springer: Heidelberg/Berlin, Germany, 2013; pp. 331–348. [Google Scholar]
- Oliveira, T.; López, J.; Aranha, D.F.; Rodríguez-Henríquez, F. Lambda Coordinates for Binary Elliptic Curves. In Proceedings of 15th International Workshop on Cryptographic Hardware and Embedded Systems, Santa Barbara, CA, USA, 20–23 August 2013; Springer: Heidelberg/Berlin, Germany, 2013; pp. 311–330. [Google Scholar]
- Guillevic, A.; Ionica, S. Four-Dimensional GLV via the Weil Restriction. In Proceedings of 19th International Conference on the Theory and Application of Cryptology and Information Security, Bengaluru, India, 1–5 December 2013; Springer: Heidelberg/Berlin, Germany, 2013; pp. 79–96. [Google Scholar]
- Smith, B. Families of Fast Elliptic Curves from -Curves. In Proceedings of 19th International Conference on the Theory and Application of Cryptology and Information Security, Bengaluru, India, 1–5 December 2013; Springer: Heidelberg/Berlin, Germany, 2013; pp. 61–78. [Google Scholar]
- Costello, C.; Longa, P. Four: Four-Dimensional Decompositions on a -Curve over the Mersenne Prime. In Proceedings of 21st International Conference on the Theory and Application of Cryptology and Information Security, Auckland, New Zealand, 29 November–3 December 2015; Springer: Heidelberg/Berlin, Germany, 2015; pp. 214–235. [Google Scholar]
- Longa, P. FourNEON: Faster Elliptic Curve Scalar Multiplications on ARM Processors. IACR Cryptol. ePrint Arch. 2016, 2016, 645. [Google Scholar]
- Järvinen, K.; Miele, A.; Azarderakhsh, R.; Longa, P. Four on FPGA: New Hardware Speed Records for Elliptic Curve Cryptography over Large Prime Characteristic Fields. In Proceedings of 18th International Workshop on Cryptographic Hardware and Embedded Systems, Santa Barbara, CA, USA, 17–19 August 2016; Springer: Heidelberg/Berlin, Germany, 2016; pp. 517–537. [Google Scholar]
- Liu, Z.; Longa, P.; Pereira, G.C.; Reparaz, O.; Seo, H. Four on Embedded Devices with Strong Countermeasures Against Side-Channel Attacks. In Proceedings of 19th International Workshop on Cryptographic Hardware and Embedded Systems, Taipei, Taiwan, 25–28 September 2017; Springer: Heidelberg/Berlin, Germany, 2017; pp. 665–686. [Google Scholar]
- Faz-Hernández, A.; Longa, P.; Sánchez, A.H. Efficient and secure algorithms for GLV-based scalar multiplication and their implementation on GLV–GLS curves (extended version). J. Cryptogr. Eng. 2015, 5, 31–52. [Google Scholar] [CrossRef]
- Kocher, P.C. Timing attacks on implementations of Diffie–Hellman, RSA, DSS, and other systems. In Proceedings of 16th Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 1996; Springer: Heidelberg/Berlin, Germany; pp. 104–113.
- Page, D. Theoretical use of cache memory as a cryptanalytic side-channel. IACR Cryptol. ePrint Arch. 2002, 2002, 169. [Google Scholar]
- Edwards, H. A normal form for elliptic curves. Bull. Am. Math. Soc. 2007, 44, 393–422. [Google Scholar] [CrossRef]
- Bernstein, D.J.; Lange, T. Faster addition and doubling on elliptic curves. In Proceedings of 13th International Conference on the Theory and Application of Cryptology and Information Security, Kuching, Malaysia, 2–6 December 2007; Springer: Heidelberg/Berlin, Germany; pp. 29–50.
- Hisil, H.; Wong, K.K.H.; Carter, G.; Dawson, E. Twisted Edwards curves revisited. In Proceedings of 14th International Conference on the Theory and Application of Cryptology and Information Security, Melbourne, Australia, 7–11 December 2008; Springer: Heidelberg/Berlin, Germany; pp. 326–343.
- Hankerson, D.; Menezes, A.J.; Vanstone, S. Guide to Elliptic Curve Cryptography; Springer Science & Business Media: Heidelberg/Berlin, Germany, 2006. [Google Scholar]
- Yanık, T.; Savaş, E.; Koç, Ç.K. Incomplete reduction in modular arithmetic. IEE Proc. Comput. Digit. Tech. 2002, 149, 46–52. [Google Scholar] [CrossRef]
- Microchip. 8/16-Bit AVR XMEGA A3 Microcontroller. Available online: http://ww1.microchip.com/downloads/en/DeviceDoc/Atmel-8068-8-and16-bit-AVR-XMEGA-A3-Microcontrollers_Datasheet.pdf (accessed on 26 February 2018).
- Hutter, M.; Schwabe, P. Multiprecision multiplication on AVR revisited. J. Cryptogr. Eng. 2015, 5, 201–214. [Google Scholar] [CrossRef]
- Seo, H.; Liu, Z.; Choi, J.; Kim, H. Multi-Precision Squaring for Public-Key Cryptography on Embedded Microprocessors. In Proceedings of Cryptology—INDOCRYPT 2013, Mumbai, India, 7–10 December 2013; Springer: Heidelberg/Berlin, Germany, 2013; pp. 227–243. [Google Scholar]
- Texas Instruments. MSP430FR59xx Mixed-Signal Microcontrollers. Available online: http://www.ti.com/lit/ds/symlink/msp430fr5969.pdf (accessed on 26 February 2018).
- STMicroelectronics. UM1472: Discovery kit with STM32F407VG MCU. Available online: http://www.st.com/content/ccc/resource/technical/document/user_manual/70/fe/4a/3f/e7/e1/4f/7d/DM00039084.pdf/files/DM00039084.pdf/jcr:content/translations/en.DM00039084.pdf (accessed on 26 February 2018).
- FourQlib library. Available online: https://github.com/Microsoft/FourQlib (accessed on 10 March 2018 ).
- Babai, L. On Lovász’lattice reduction and the nearest lattice point problem. Combinatorica 1986, 6, 1–13. [Google Scholar] [CrossRef]
- Park, Y.H.; Jeong, S.; Lim, J. Speeding Up Point Multiplication on Hyperelliptic Curves With Efficiently-Computable Endomorphisms. In Proceedings of International Conference on the Theory and Applications of Cryptographic Techniques, Amsterdam, The Netherlands, 28 April–2 May 2002; Springer: Heidelberg/Berlin, Germany, 2002; pp. 197–208. [Google Scholar]
- Hamburg, M. Fast and compact elliptic-curve cryptography. IACR Cryptol. ePrint Arch. 2012, 2012, 309. [Google Scholar]
- Wenger, E.; Werner, M. Evaluating 16-bit processors for elliptic curve cryptography. In Proceedings of the International Conference on Smart Card Research and Advanced Applications, Leuven, Belgium, 14–16 September 2011; Springer: Heidelberg/Berlin, Germany; pp. 166–181.
- Wenger, E.; Unterluggauer, T.; Werner, M. 8/16/32 shades of elliptic curve cryptography on embedded processors. In Proceedings of Cryptology—INDOCRYPT 2013, Mumbai, India, 7–10 December 2013; Springer: Heidelberg/Berlin, Germany; pp. 244–261.
- Hinterwälder, G.; Moradi, A.; Hutter, M.; Schwabe, P.; Paar, C. Full-size high-security ECC implementation on MSP430 microcontrollers. Proceedings of Cryptology—LATINCRYPT 2014, Florianópolis, Brazil, 17–19 September 2014; pp. 31–47. [Google Scholar]
- Düll, M.; Haase, B.; Hinterwälder, G.; Hutter, M.; Paar, C.; Sánchez, A.H.; Schwabe, P. High-speed Curve25519 on 8-bit, 16-bit, and 32-bit microcontrollers. Des. Codes Cryptogr. 2015, 77, 493–514. [Google Scholar] [CrossRef] [Green Version]
- De Santis, F.; Sigl, G. Towards Side-Channel Protected X25519 on ARM Cortex-M4 Processors. Proceedings of Software performance enhancement for encryption and decryption, and benchmarking, Utrecht, The Netherlands, 19–21 October 2016. [Google Scholar]
- Renes, J.; Schwabe, P.; Smith, B.; Batina, L. μKummer: Efficient Hyperelliptic Signatures and Key Exchange on Microcontrollers. In Proceedings of 18th International Workshop on Cryptographic Hardware and Embedded Systems, Santa Barbara, CA, USA, 17–19 August 2016; Springer: Heidelberg/Berlin, Germany, 2016; pp. 301–320. [Google Scholar]
- Hutter, M.; Schwabe, P. NaCl on 8-Bit AVR Microcontrollers. In Proceedings of Cryptology—AFRICACRYPT 2013, Cairo, Egypt, 22–24 June 2013; Springer: Heidelberg/Berlin, Germany, 2013; pp. 156–172. [Google Scholar]


{kind=link}
| Operation | - | |||||||
|---|---|---|---|---|---|---|---|---|
| Compute endomorphisms | - | 13 | 2 | 11.5 | 43 | - | 66 | 30 |
| Precompute lookup table | - | 63 | - | 70 | 189 | - | 329 | 140 |
| Scalar decomposition | - | - | - | - | - | - | - | - |
| Scalar recoding | - | - | - | - | - | - | - | - |
| Main computation | - | 715 | 260 | 848 | 2665 | - | 4101 | 1950 |
| Normalization | 1 | 2 | - | - | 21 | 128 | 8 | 4 |
| Total Cost | 1 | 793 | 262 | 929.5 | 2918 | 128 | 4504 | 2124 |
| Operation | Four [21] | |||||||
|---|---|---|---|---|---|---|---|---|
| Compute endomorphisms | - | 73 | 27 | 59.5 | 273 | - | 365 | 200 |
| Precompute lookup table | - | 63 | - | 56 | 189 | - | 301 | 126 |
| Scalar decomposition | - | - | - | - | - | - | - | - |
| Scalar recoding | - | - | - | - | - | - | - | - |
| Main computation | - | 704 | 256 | 835 | 2,624 | - | 4038 | 1,920 |
| Normalization | 1 | 2 | - | - | 18 | 128 | 8 | 4 |
| Total Cost | 1 | 842 | 283 | 950.5 | 3,104 | 128 | 4712 | 2,250 |
| Operation | 8-Bit AVR | 16-Bit MSP430 | 32-Bit ARM | ||||
|---|---|---|---|---|---|---|---|
| - (This Work) | Four [24] | - (This Work) | Four [24] | - (This Work) | Four [24] | ||
| Add | 198 | 155 | 120 | 102 | 55 | n/a | |
| Sub | 196 | 159 | 126 | 101 | 55 | n/a | |
| Sqr | 1221 | 1026 | 837 | 927 | 88 | n/a | |
| Mul | 1796 | 1598 | 1087 | 1027 | 99 | n/a | |
| Inv | 176,901 | 150,535 | 119,629 | 131,819 | 12,135 | n/a | |
| Add | 452 | 384 | 266 | 233 | 82 | 84 | |
| Sub | 448 | 385 | 278 | 231 | 82 | 86 | |
| Sqr | 4093 | 3622 | 2476 | 2391 | 195 | 215 | |
| Mul | 6277 | 5758 | 3806 | 3624 | 341 | 358 | |
| Inv | 183,345 | 156,171 | 123,740 | 135,315 | 12,612 | 21,056 | |
| Platform | Implementations | Bit-Length of Curve Order | Cost (Cycles) | Code Size (Bytes) | Stack Usage (Bytes) |
|---|---|---|---|---|---|
| AVR | NIST P-256 [43] | 256 | 34,930,000 | 16,112 | 590 |
| Curve25519 [48] | 252 | 22,791,579 | n/a | 677 | |
| Curve25519 [45] | 252 | 13,900,397 | 17,710 | 494 | |
| Kummer [47] | 250 | 9,513,536 | 9490 | 99 | |
| Four [24] | 246 | 6,561,500 | n/a | n/a | |
| - (This work) | 251 | 6,856,026 | 13,891 | 2539 | |
| MSP430 | NIST P-256 [42] | 256 | 23,973,000 | n/a | n/a |
| NIST P-256 [43] | 256 | 22,170,000 | 8378 | 418 | |
| Curve25519 [44] | 252 | 9,139,739 | 11,778 | 513 | |
| Curve25519 [45] | 252 | 7,933,296 | 13,112 | 384 | |
| Four [24] | 246 | 4,280,400 | n/a | n/a | |
| - (This work) | 251 | 4,158,453 | 9098 | 2568 | |
| ARM Cortex-M4 | Curve25519 [46] | 252 | 1,423,667 | 3750 | 740 |
| Four [24] | 246 | 469,500 | n/a | n/a | |
| - (This work) | 251 | 447,836 | 7532 | 2792 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwon, J.; Seo, S.C.; Hong, S. Efficient Implementations of Four-Dimensional GLV-GLS Scalar Multiplication on 8-Bit, 16-Bit, and 32-Bit Microcontrollers. Appl. Sci. 2018, 8, 900. https://doi.org/10.3390/app8060900
Kwon J, Seo SC, Hong S. Efficient Implementations of Four-Dimensional GLV-GLS Scalar Multiplication on 8-Bit, 16-Bit, and 32-Bit Microcontrollers. Applied Sciences. 2018; 8(6):900. https://doi.org/10.3390/app8060900
Chicago/Turabian StyleKwon, Jihoon, Seog Chung Seo, and Seokhie Hong. 2018. "Efficient Implementations of Four-Dimensional GLV-GLS Scalar Multiplication on 8-Bit, 16-Bit, and 32-Bit Microcontrollers" Applied Sciences 8, no. 6: 900. https://doi.org/10.3390/app8060900
APA StyleKwon, J., Seo, S. C., & Hong, S. (2018). Efficient Implementations of Four-Dimensional GLV-GLS Scalar Multiplication on 8-Bit, 16-Bit, and 32-Bit Microcontrollers. Applied Sciences, 8(6), 900. https://doi.org/10.3390/app8060900