Enhanced Automatic Speech Recognition System Based on Enhancing Power-Normalized Cepstral Coefficients



Abstract
:1. Introduction
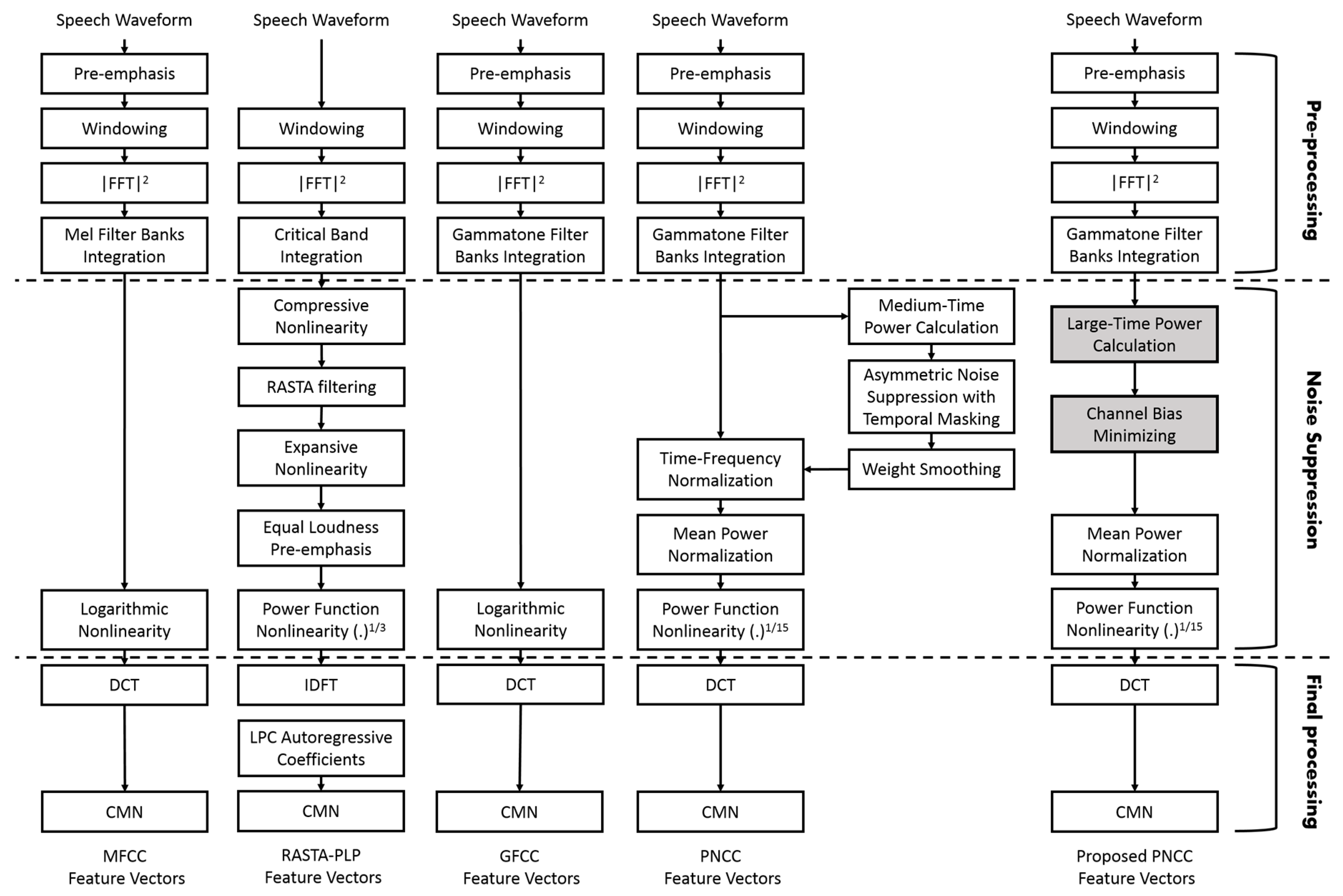
2. Proposed Enhanced PNCC Algorithm
2.1. Proposed Enhanced PNCC Algorithm
2.2. Noise Suppression
2.2.1. Large-Time Power Calculation
2.2.2. Channel Bias Minimizing
2.2.3. Mean Power Normalization
2.2.4. Power Function Nonlinearity
2.3. Final Processing
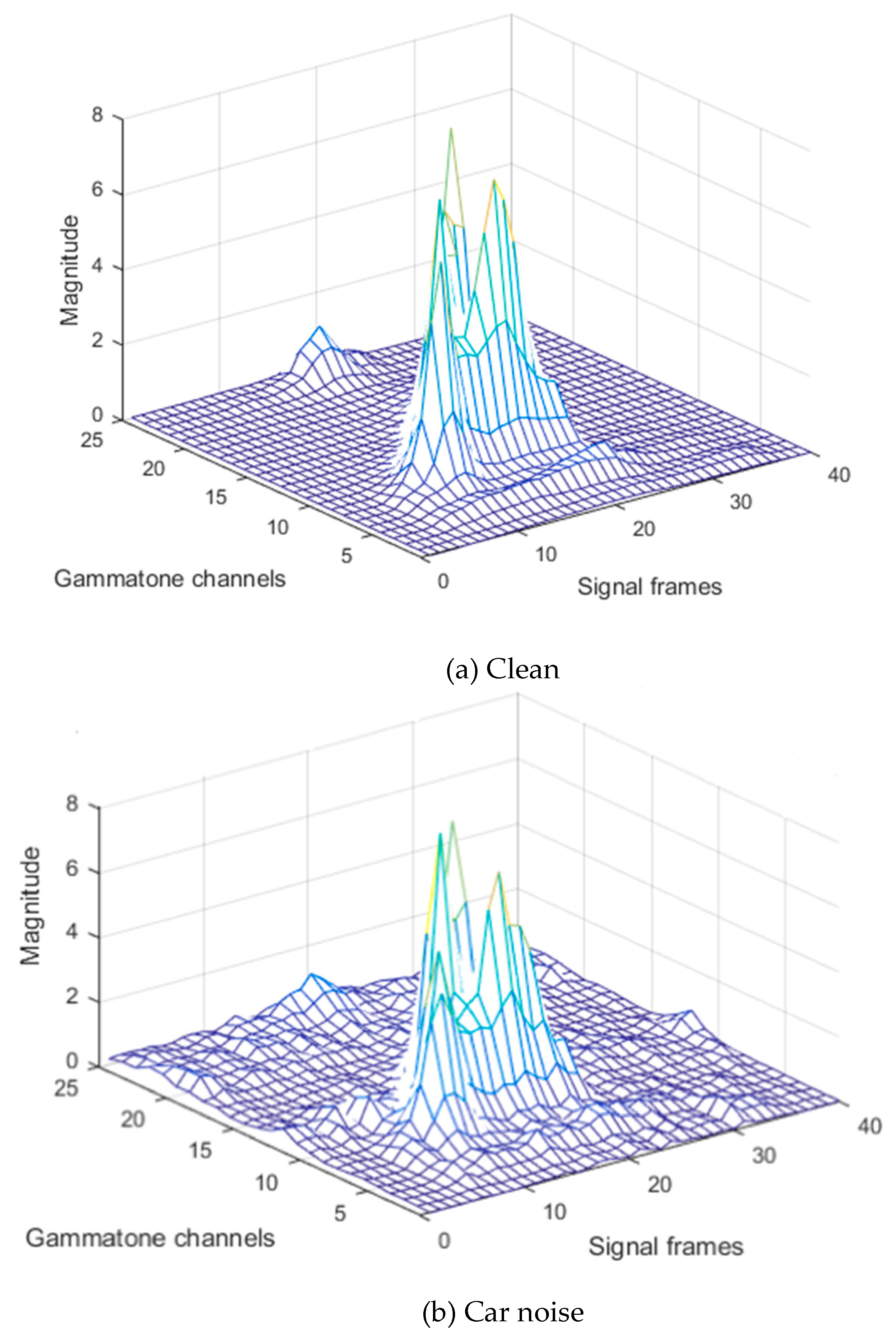
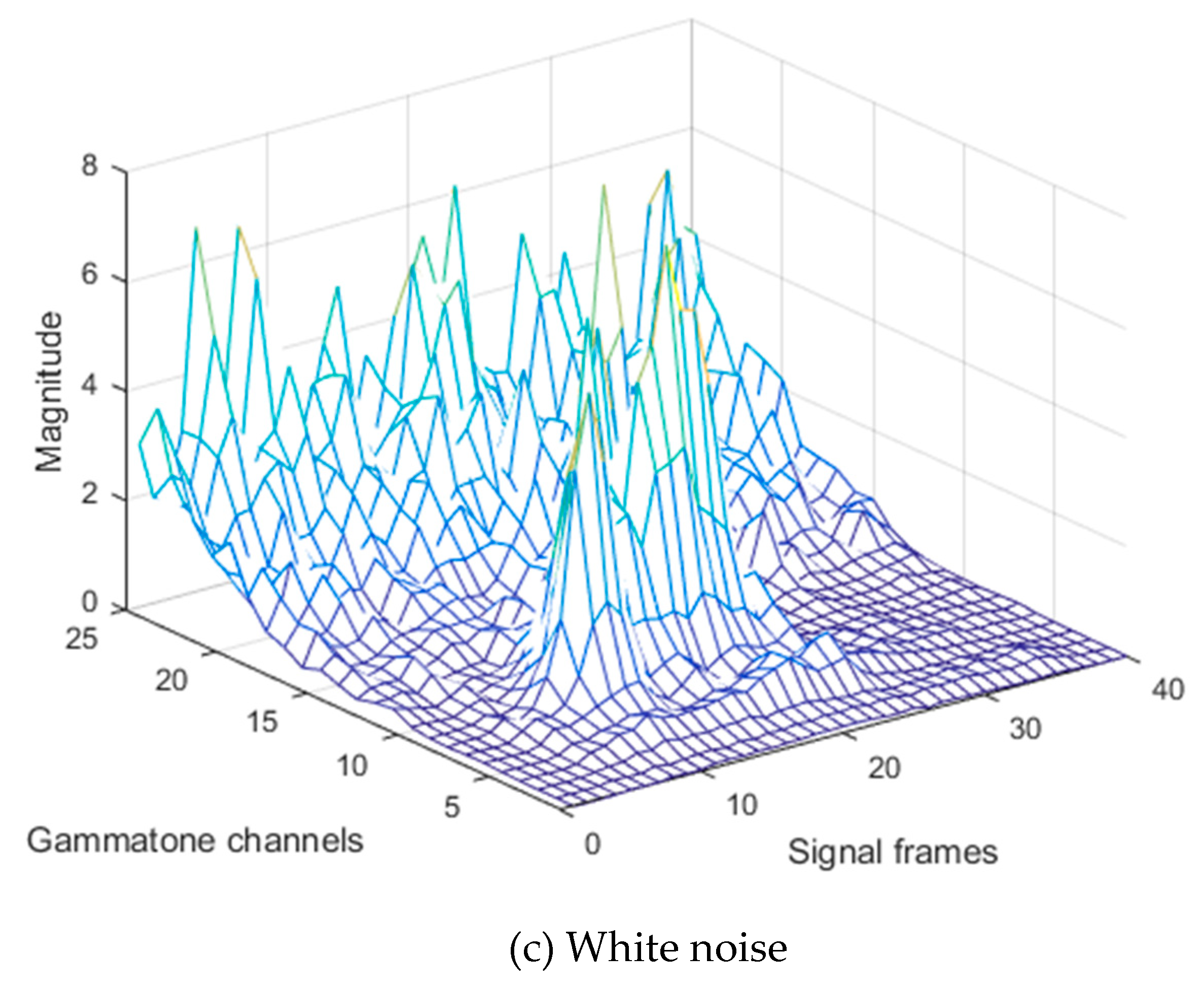
3. Experimental Work and Results
3.1. Experimental Work
3.2. Results and Discussion
3.3. Computational Complexity
4. Conclusions and Future Work
- Under clean conditions, the recognition accuracy for all systems was almost equivalent.
- The highest robust proposed PNCC features in comparison to MFCC and RASTA–PLP were achieved in the subway noise condition at SNR 5 dB, whereas, for GFCC and PNCC methods, they were obtained in the case of car noise at SNR 0 dB and −5 dB, respectively. The achieved recognition accuracies for the proposed PNCC system were 86.89% in the subway noise condition at SNR 5 dB, 79.32% in the car noise condition at SNR 0 dB, and 53.58% in the car noise condition at SNR −5 dB.
Author Contributions
Funding
Conflicts of Interest
References
- Li, J.Y.; Deng, L.; Gong, Y.F.; Haeb-Umbach, R. An Overview of Noise-Robust Automatic Speech Recognition. IEEE-ACM Trans. Audio Speech Lang. Process. 2014, 22, 745–777. [Google Scholar] [CrossRef]
- Rabiner, L.; Juang, B.-H. Fundamentals of Speech Recognition; Prentice Hall: Englewood Cliffs, NJ, USA, 1993; Volume 14. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, 2nd ed.; Prentice Hall, Pearson Education International: Upper Saddle River, NJ, USA, 2008. [Google Scholar]
- Davis, S.B.; Mermelstein, P. Comparison of Parametric Representations for Monosyllabic Word Recognition in Continuously Spoken Sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef]
- Hermansky, H. Perceptual linear predictive (PLP) analysis of speech. J. Acoust. Soc. Am. 1990, 87, 1738–1752. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hermansky, H.; Morgan, N. RASTA processing of speech. IEEE Trans. Speech Audio Process. 1994, 2, 578–589. [Google Scholar] [CrossRef]
- Hermansky, H.; Morgan, N.; Bayya, A.; Kohn, P. RASTA–PLP Speech Analysis Technique. In Proceedings of the ICASSP-92: 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing, Vols 1–5, San Francisco, CA, USA, 23–26 March 1992; pp. A121–A124. [Google Scholar] [CrossRef]
- Viikki, O.; Bye, D.; Laurila, K. A recursive feature vector normalization approach for robust speech recognition in noise. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, Seattle, WA, USA, 15 May 1998; Volume 2, pp. 733–736. [Google Scholar] [CrossRef]
- Shao, Y.; Srinivasan, S.; Jin, Z.Z.; Wang, D.L. A computational auditory scene analysis system for speech segregation and robust speech recognition. Comput. Speech Lang. 2010, 24, 77–93. [Google Scholar] [CrossRef]
- Kim, D.S.; Lee, S.Y.; Kil, R.M. Auditory processing of speech signals for robust speech recognition in real-world noisy environments. IEEE Trans. Speech Audio Process. 1999, 7, 55–69. [Google Scholar] [CrossRef]
- Ali, A.M.A.; Van der Spiegel, J.; Mueller, P. Robust auditory-based speech processing using the average localized synchrony detection. IEEE Trans. Speech Audio Process. 2002, 10, 279–292. [Google Scholar] [CrossRef]
- Yapanel, U.H.; Hansen, J.H.L. A new perceptually motivated MVDR-based acoustic front-end (PMVDR) for robust automatic speech recognition. Speech Commun. 2008, 50, 142–152. [Google Scholar] [CrossRef]
- Fazel, A.; Chakrabartty, S. Sparse Auditory Reproducing Kernel (SPARK) Features for Noise-Robust Speech Recognition. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 1362–1371. [Google Scholar] [CrossRef]
- Schadler, M.; Meyer, B.T.; Kollmeier, B. Spectro-temporal modulation subspace-spanning filter bank features for robust automatic speech recognition. J. Acoust. Soc. Am. 2012, 131, 4134–4151. [Google Scholar] [CrossRef] [PubMed]
- Kim, C.; Stern, R.M. Power-Normalized Cepstral Coefficients (PNCC) for Robust Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1315–1329. [Google Scholar] [CrossRef] [Green Version]
- Kim, C.; Stern, R.M. Feature Extraction for Robust Speech Recognition Based on Maximizing the Sharpness of the Power Distribution and on Power Flooring. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech, and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4574–4577. [Google Scholar] [CrossRef]
- Gouda, A.M.; Tamazin, M.; Khedr, M. Robust Automatic Speech Recognition System Based on Using Adaptive Time-Frequency Masking. In Proceedings of the 2016 11th International Conference on Computer Engineering & Systems (ICCES), Cairo, Egypt, 20–21 December 2016; pp. 181–186. [Google Scholar]
- Irino, T.; Patterson, R.D. A compressive gammachirp auditory filter for both physiological and psychophysical data. J. Acoust. Soc. Am. 2001, 109, 2008–2022. [Google Scholar] [CrossRef] [PubMed]
- Irino, T.; Patterson, R.D. A time-domain, level-dependent auditory filter: The gammachirp. J. Acoust. Soc. Am. 1997, 101, 412–419. [Google Scholar] [CrossRef]
- Kingsbury, B.E.D.; Morgan, N.; Greenberg, S. Robust speech recognition using the modulation spectrogram. Speech Commun. 1998, 25, 117–132. [Google Scholar] [CrossRef]
- Dau, T.; Püschel, D.; Kohlrausch, A. A quantitative model of the “effective” signal processing in the auditory system. I. Model structure. J. Acoust. Soc. Am. 1996, 99, 3615–3622. [Google Scholar] [CrossRef] [PubMed]
- Kim, C.; Stern, R.M. Nonlinear enhancement of onset for robust speech recognition. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010; pp. 2058–2061. [Google Scholar]
- Heinz, M.G.; Zhang, X.; Bruce, I.C.; Carney, L.H. Auditory nerve model for predicting performance limits of normal and impaired listeners. Acoust. Res. Lett. Online 2001, 2, 91–96. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Heinz, M.G.; Bruce, I.C.; Carney, L.H. A phenomenological model for the responses of auditory-nerve fibers: I. Nonlinear tuning with compression and suppression. J. Acoust. Soc. Am. 2001, 109, 648–670. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stern, R.M.; Acero, A.; Liu, F.-H.; Ohshima, Y. Signal processing for robust speech recognition. In Automatic Speech and Speaker Recognition; Springer: Berlin/Heidelberg, Germany, 1996; pp. 357–384. [Google Scholar]
- Viikki, O.; Laurila, K. Cepstral domain segmental feature vector normalization for noise robust speech recognition. Speech Commun. 1998, 25, 133–147. [Google Scholar] [CrossRef]
- Leonard, R. A database for speaker-independent digit recognition. In Proceedings of the ICASSP’84, IEEE International Conference on Acoustics, Speech, and Signal Processing, San Diego, CA, USA, 19–21 March 1984; pp. 328–331. [Google Scholar]
- Ellis, D.P.W. PLP and RASTA (and MFCC, and Inversion) in Matlab. Available online: http://www.ee.columbia.edu/%7Edpwe/resources/matlab/rastamat/ (accessed on 16 April 2019).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | RASTA–PLP | PNCC | Proposed Method |
|---|---|---|---|
| Pre-emphasis | 205 | 205 | |
| Windowing | 205 | 205 | 205 |
| FFT | 2560 | 2560 | 2560 |
| Magnitude squared | 128 | 128 | 128 |
| Time power calculation | 25 | 125 | |
| Spectral integration | 2477 | 2492 | 2739 |
| ANS filtering | 100 | ||
| Channel bias minimizing | 125 | ||
| Equal loudness pre-emphasis | 128 | ||
| Temporal masking | 120 | ||
| Weight averaging | 120 | 120 | |
| IDFT | 120 | ||
| LPC and cepstral recursion | 115 | ||
| DCT | 240 | 240 | |
| Sum | 5733 | 6195 | 6447 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tamazin, M.; Gouda, A.; Khedr, M. Enhanced Automatic Speech Recognition System Based on Enhancing Power-Normalized Cepstral Coefficients. Appl. Sci. 2019, 9, 2166. https://doi.org/10.3390/app9102166
Tamazin M, Gouda A, Khedr M. Enhanced Automatic Speech Recognition System Based on Enhancing Power-Normalized Cepstral Coefficients. Applied Sciences. 2019; 9(10):2166. https://doi.org/10.3390/app9102166
Chicago/Turabian StyleTamazin, Mohamed, Ahmed Gouda, and Mohamed Khedr. 2019. "Enhanced Automatic Speech Recognition System Based on Enhancing Power-Normalized Cepstral Coefficients" Applied Sciences 9, no. 10: 2166. https://doi.org/10.3390/app9102166
APA StyleTamazin, M., Gouda, A., & Khedr, M. (2019). Enhanced Automatic Speech Recognition System Based on Enhancing Power-Normalized Cepstral Coefficients. Applied Sciences, 9(10), 2166. https://doi.org/10.3390/app9102166