1. Introduction
An automatic modulation classification task aims at detecting the modulation type of a received signal and recovering the signal by demodulation. Currently, it has been widely used in military electronic warfare, surveillance and threat analysis [
1,
2]. The likelihood-based (LB) method [
3] and feature-based (FB) method [
4] are two conventional methods for automatic modulation classification. LB method mainly includes the average likelihood ratio test (ALRT) method [
5] and the generalized likelihood ratio test (GLRT) [
6]. Although the LB method obtains high accuracy, it requires more calculating time to fulfill parameter estimation, which greatly limits its application [
7]. FB methods usually work in two steps: Feature extraction and classification. In previous papers based on FB methods, many signal features, such as spectrum [
8], high-order cumulant [
9] and wavelet coefficients [
10], are used to classify the modulation types. With the emergence and development of machine learning (ML), many researches employ ML to implement classification in FB method. For examples, Aslam et al. [
11] reported a modulation classifier based on genetic programming and K-nearest neighbor (GP-KNN), but this classifier only worked well for PSK. Han et al. [
12] employed the support vector machine (SVM) to classify the phase shift keying (PSK) and quadrature amplitude modulation (QAM) and obtained a good classification accuracy under the known channel. Although the FB method shows great advantages in automatic digital modulation classification, there are still two challenges: Artificial feature extraction and noise covering. The performance of FB methods severely depends on the quality and quantity of extracted features, but the artificial feature extraction is complex and difficult for various modulated wireless signals. Moreover, when the signal-noise ratio (SNR) of the modulated signal is very low, the performance of classifier is unsatisfied due to the limited quantity of features extracted.
The neural network [
13] is a fascinating classification method with a series of state-of-the-art achievements automatic modulation classification [
14,
15]. For instance, O’Shea et al. [
16] trained a deep neural network (DNN) using a baseband IQ waveform to identify modulation. They reported that it was feasible to use DNN for automatic modulation classification and had a better accuracy with low SNR. Ramjee et al. [
17] verified the classification performance of long short-term memory (LSTM), convolutional long short-term memory deep neural network (CLDNN) and deep residual network (ResNet) structures. Experimental results showed that the three methods could achieve good classification results on the dataset RadioML2016.10b [
16]. The paper also verified the impact of training data with different SNRs, and minimized the training data to reduce training time. However, a neural network is very easy to overfit and memorize data noise when using it in modulation classification [
18]. Noises will be introduced into the signal when it goes through channels, inducing a sharp decrease in SNR. If this low SNR data is used to train the neural network, local optimum could appear and cause significant decline in the performance of classifier.
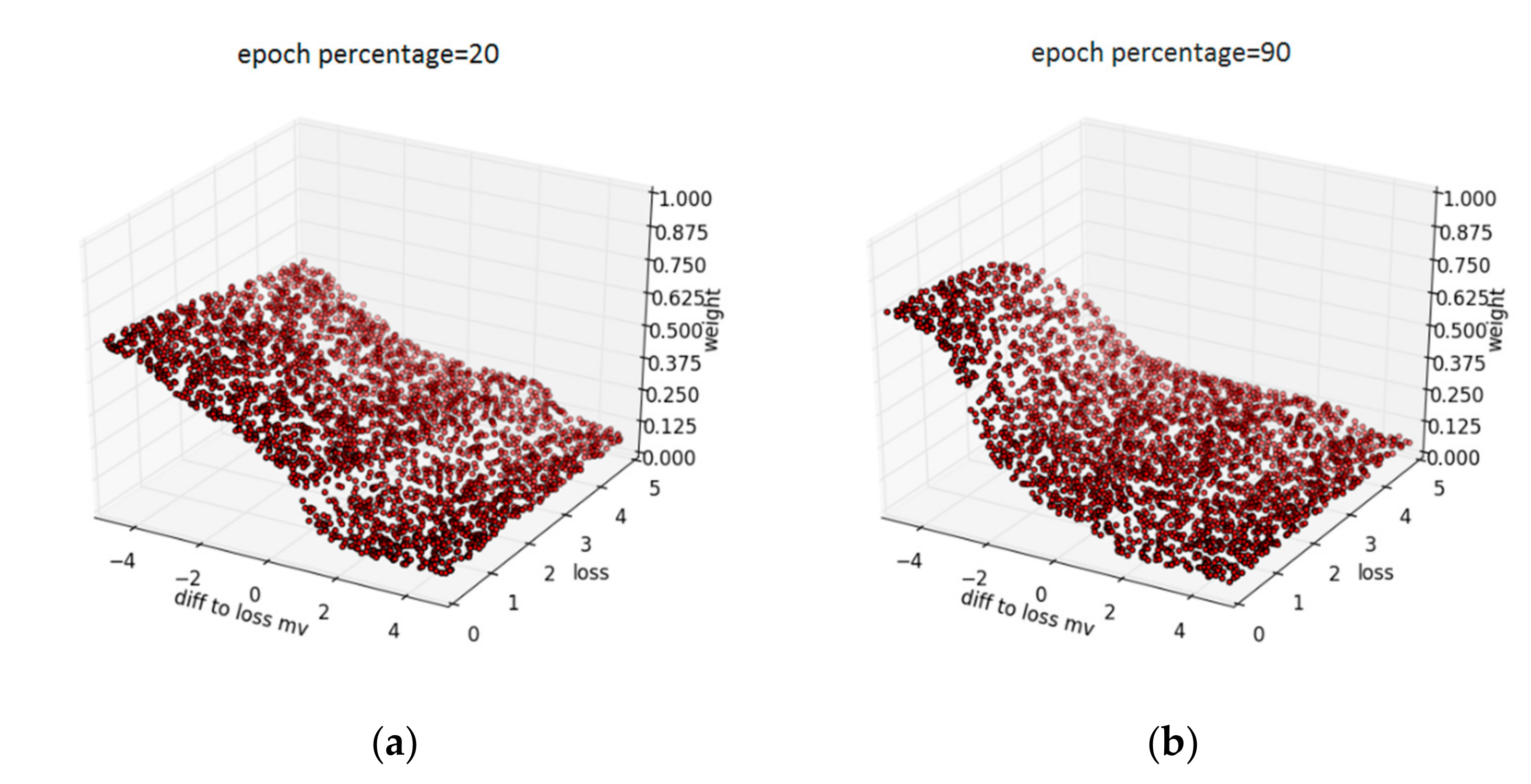
To solve the overfitting of neural network, we propose a novel automatic digital modulation classifier with two neural networks, namely the StudentNet and MentorNet. The StudentNet is used to classify the signal, and the MentorNet is employed to supervise the training of StudentNet according to curriculum learning. Experimental results show that our classifier can accurately identify 11 common digital modulated signals, including 2-ary amplitude shift keying (2ASK), 2-ary Frequency Shift Keying (2FSK), 2PSK, 4ASK, 4FSK, 4PSK, 8ASK, 8FSK, 8PSK, 16QAM and 64QAM. The overall classification accuracy can be up to 99.3%, which is much higher than other classifiers.
The structure of this paper is organized as follows.
Section 2 shows the signal model and relative theories.
Section 3 presents the performance improvement in modulation classification by curriculum learning.
Section 4 reports the experimental results and discussion, and concludes this paper in
Section 5.
4. Results and Discussion
In this section, a series of measurements are implemented to verify the classification accuracy of the automatic digital modulation classifier. In our experiment, various modulated signals were tested, including 2ASK, 4ASK, 8ASK, 2FSK, 4FSK, 8FSK, 2PSK, 4PSK, 8PSK, 16QAM and 64QAM. The relative parameters are shown in
Table 1. We generated a training set and test set by using Matlab2018a. Every training set included 110,000 samples, while each validation set and test set included 11,000 samples. All these samples possessed the same length of 1024 and various SNRs obeying uniform distribution. The training, validation and test sets were used to implement the training, evaluation and exam of classifier, respectively. In addition, the classifier with only StudentNet was named as the Baseline classifier, and the one containing both StudentNet and MentorNet was called the MentorNet classifier.
4.1. The Accuracy of MentorNet Classifier
4.1.1. Overall Accuracy of MentorNet Classifier Under Different SNRs
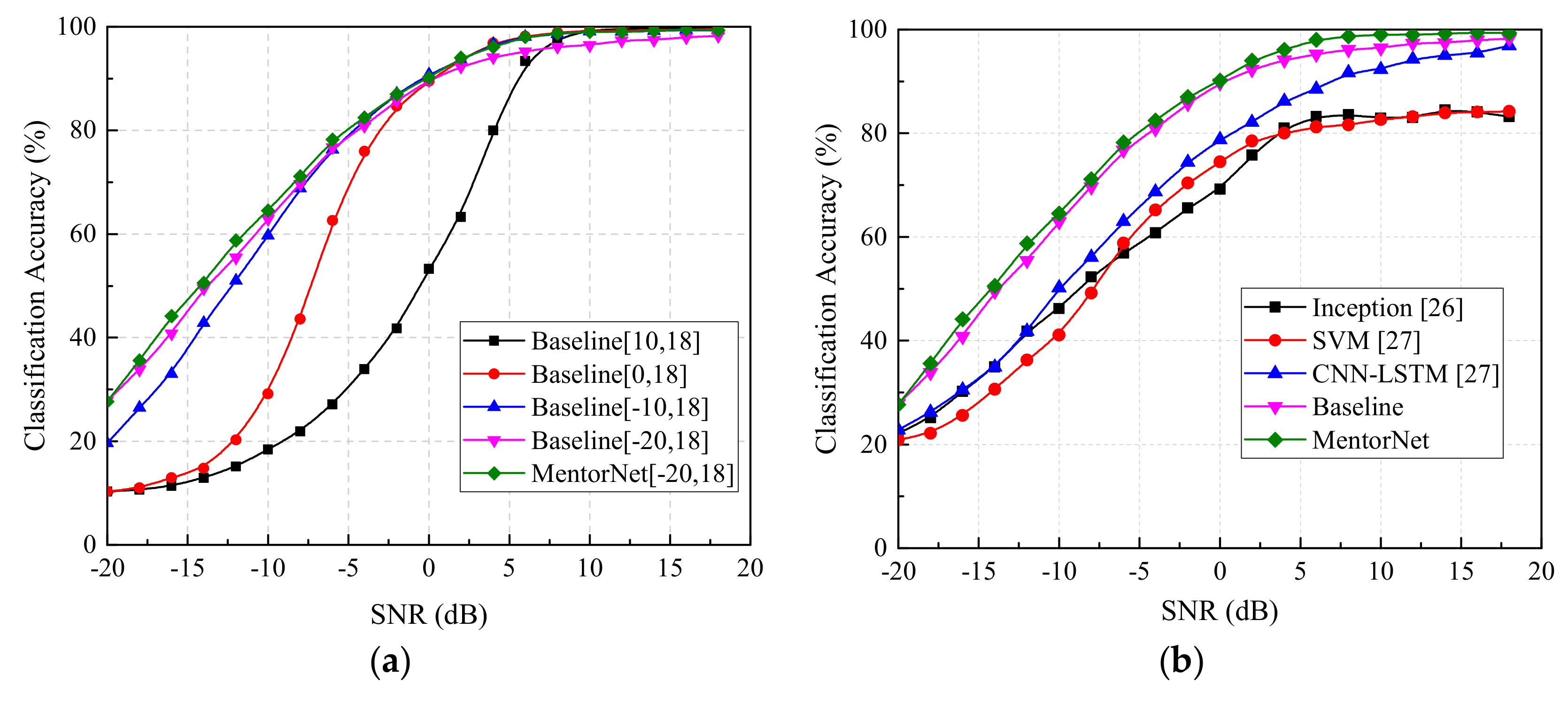
Before investigating the performance of MentorNet classifier, the Baseline classifier was established and trained by four training set with different SNR ranges. Herein, samples in the training set and test set were the signals passing through additive white Gaussian channel without phase drift and frequency drift Therefore, SNR was the ratio between the amplitudes of Gaussian noise and signal. Then the performance of trained Baseline classifiers was measured on one test set with SNRs ranging from
to 18 dB and the results are shown in
Figure 7a. It is obvious that when the SNR of the training set was relatively high (such as 10–18 dB, Black line in
Figure 7a), the Baseline classifier possessed higher classification accuracy, whereas an unsatisfactory performance occurred on the samples with low SNR in the test set. Unfortunately, once the SNR range of the training set broadened to −20–18 dB (Purple line in
Figure 7a), the performance of the Baseline classifier showed an improvement on samples with low SNR in the test set but deterioration on samples with high SNR in the test set. We suppose this phenomenon should be induced by the overfitting of StudentNet in the Baseline classifier. To overcome this problem, the MentorNet classifier was proposed and tested. The MentorNet classifier was trained by only one training set with −20–18 dB SNR and its performance was verified on the same test set with the Baseline classifier. The green and magenta curves in
Figure 7a revealed that for the training set with −20–18 dB SNR, the MentorNet classifier could overcome the overfitting, and results in a 1.7% improvement in classification accuracy.
Besides, we also compared the accuracy of the MentorNet classifier with several existing modulation classifiers, including the classifiers based on the Inception [
26], the fusion model of convolutional neural network and long short-term memory (CNN-LSTM) [
27], and SVM [
27]. The five classifiers were trained and tested with the same training set and test set, and then the classification accuracy are shown in
Figure 7b. Comparison results indicated that both the accuracy of the MentorNet classifier and Baseline classifier was higher than others, which verifies that ResNet could improve the classification accuracy significantly. Due to the existence of overfitting in the Baseline classifier, its performance was worse than the MentorNet classifier. Therefore, we can conclude that the MentorNet classifier proposed by us could achieve the higher classification accuracy.
4.1.2. Intra-Class and Inter-Class Accuracy of the MentorNet Classifier Under Different SNRs
In addition to the overall accuracy, the intra-class and inter-class accuracy of the classifier is also worthy to mention. The common modulation signals can be divided into four classes including ASK, FSK, PSK and QAM according to the modulation method. According to the modulation order, these four classes also can be divided into eleven types, including 2ASK, 4ASK, 8ASK, 2FSK, 4FSK, 8FSK, 2PSK, 4PSK, 8PSK, 16QAM and 64QAM. The intra-class accuracy of MentorNet classifier for each modulation class at different SNR is reported in
Figure 8, which denotes that all classification accuracy increased with SNR until approaches closed to 100%. In details, when SNR was larger than –10 dB, the classification accuracy of 2ASK was largest in ASK and saturated at 10 dB. Meantime, the classification accuracy of 2PSK was also the largest in PSK and saturated at −10 dB. Besides, the modulation order had few impacts on the classification accuracy of FSK as SNR was lower than 0 dB. However, the intra-class accuracy of QAM was almost unaffected by the modulation order. These results suggest that the modulation order has a different influence on the intra-class accuracy of different classes.
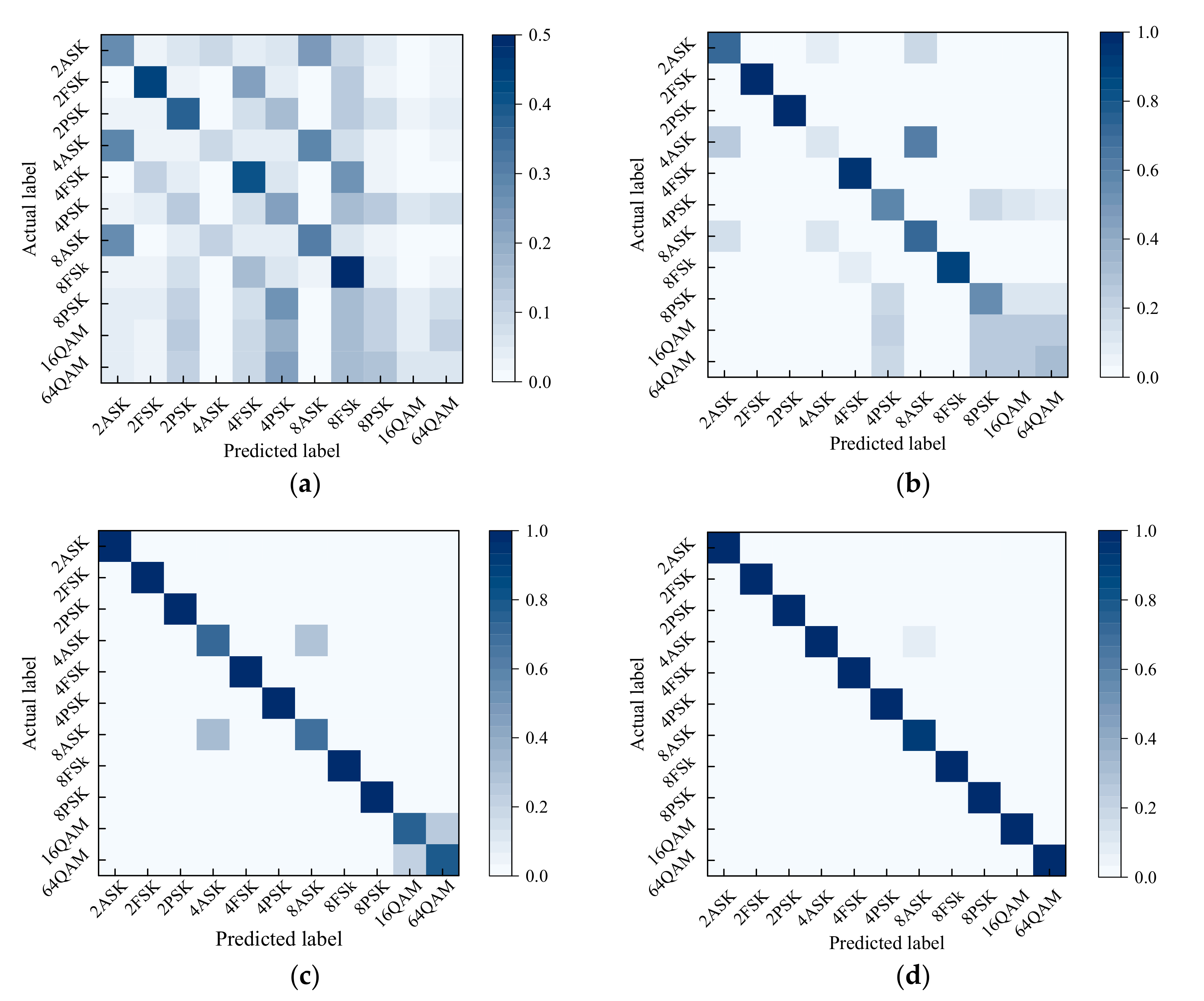
The inter-class accuracy of MentorNet classifier was obtained by its confusion matrix as shown in
Figure 9. The confusion matrix illustrates the prediction error of the classifier, where the horizontal and vertical axes represent the actual and predicted modulation types. The inter-class accuracy was calculated by ignoring the modulation order and adding the probability of achieving the correct modulation class. From
Figure 9, we can conclude that it was difficult to identify both the modulation order and the modulation class accurately at low SNR (such as −20 dB) due to the large noise interference, which is consistent with
Figure 7 and
Figure 8. It is well-known that the wrong modulation order cannot pose a fatal threat to the demodulated signal so that the demodulated signal showed a large deviation with the original signal. The correct modulation class was the most urgent need for us. Hence, we presented the inter-class accuracy of MentorNet classifier in
Figure 10. As shown in
Figure 10, the MentorNet classifier could effectively distinguish modulation classes such as ASK, FSK and PSK even if SNR was very low (such as −20 dB). However, the inter-class accuracy of QAM was relatively low as SNR was lower than –10 dB, because QAM was easy to be recognized as PSK according to
Figure 9. However, the original signal of QAM can be recovered by conventional demodulation in the case of misjudgment. Therefore, the performance of the MentorNet classifier could satisfy the accuracy requirements for modulation recognition in most applications.
4.2. The Robustness of the MentorNet Classifier
4.2.1. The Impact of Rayleigh Fading
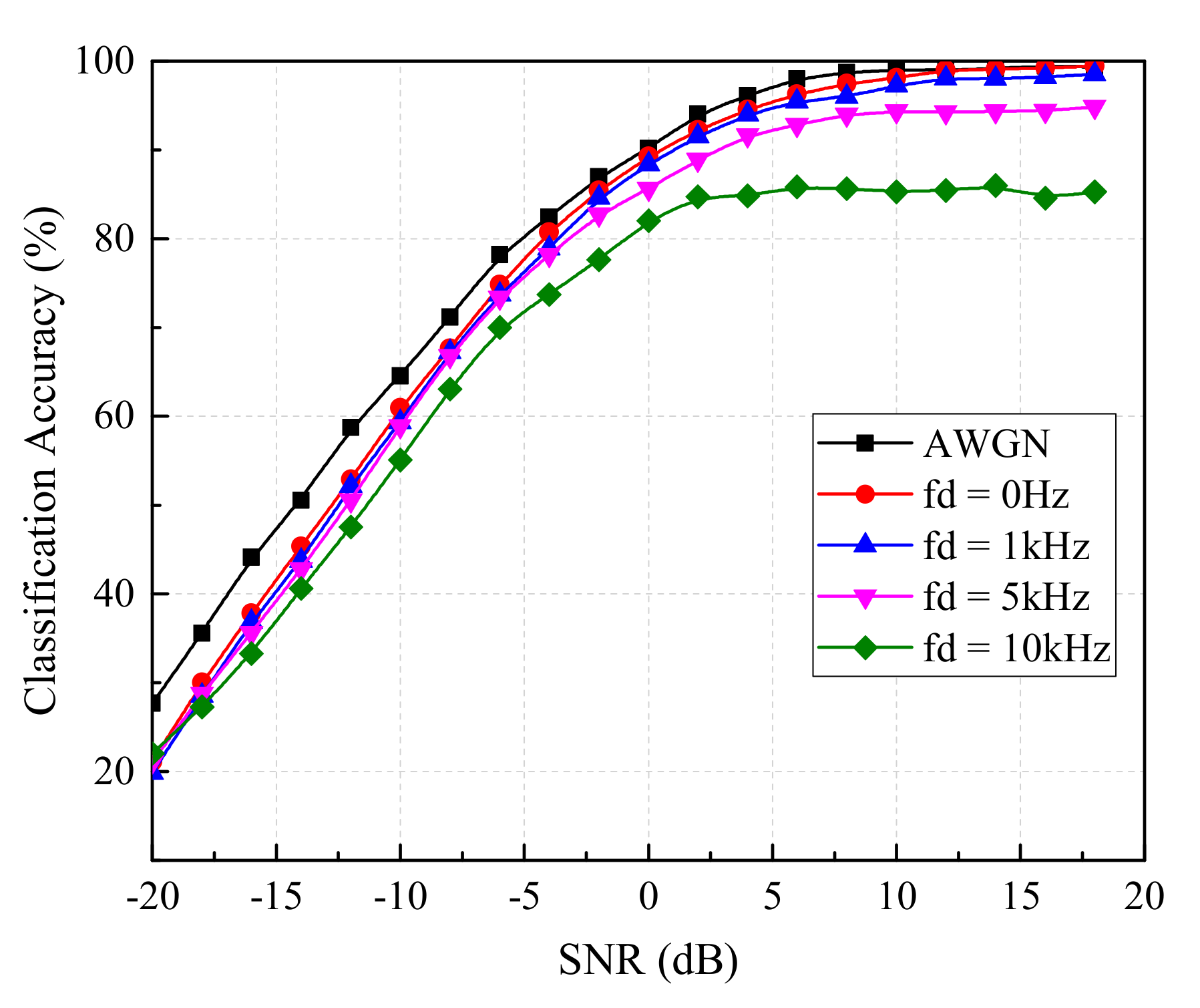
As known, AWGN and Rayleigh fading are two common noise sources. The samples with AWGN have been tested above. Hence, this subsection will investigate the impact of Rayleigh fading on the accuracy of the MentorNet classifier. In the experiment, the modulation parameters and the number of samples in the test set were the same as above. Besides, we assumed that the received signal was a combination of two signals coming from two reflection paths. The gains of these two paths were 0 dB and −10 dB, respectively, while the delay between them was s. In the meantime, the maximum Doppler frequency shift (fd), induced by the relative motion between the receiver and the transmitter in the propagation of two signals, was supposed as 0 Hz, 1 kHz, 5 kHz and 10 kHz.
The experimental results are shown in
Figure 11. It is worth mentioning that the black and red curves both represent the classification accuracy of test samples with a 0 Hz Doppler shift, but a multipath fading existed in the test samples of the red curves, leading to the relatively low classification accuracy. However, the red curve could also reach 20% at −20 dB SNR and 99% at 10 dB SNR, which was close to the black curve. When the different Doppler shifts existed, the classification accuracy at very low SNR (such as −20 dB) was very similar until the SNR was up to −5 dB. With the further increase of SNR, the difference of classification accuracy increased and a larger Doppler shift corresponded to a lower classification accuracy classifier. When the SNR was 10 dB the classification accuracy of test samples containing Rayleigh fading ranged from 85% to 98%, which is enough for the application in military electronic warfare equipment. These results indicate the MentorNet classifier possesses a great robustness to endure the Rayleigh fading.
4.2.2. The Impact of Carrier Frequency Offset and Phase Offset
As shown in Equation (1), the carrier frequency offset and phase offset induced by the drift of the clock could also increase the difficulty of modulation classification. In this subsection, we would explore the impact of carrier frequency offset and phase offset on the classification accuracy of the MentorNet classifier. Firstly, the ratio of carrier frequency deviation to sampling frequency
was set within
to investigate the anti-interference ability of the MentorNet classifier to carrier frequency offset. For a fair comparison, the Inception classifier, Baseline classifier and MentorNet classifier were trained by a training set with −20–18 dB SNR, and then they were tested in a test set with an SNR of 10 dB. The experimental results are reported in
Figure 12a. We could find the accuracy of all classifier decreased monotonously with
, but the reduction of Inception classifier was the smallest (around 5%), due to its simple network structure [
28] Meanwhile the reductions of the Baseline classifier and MentorNet classifier were around 13% and 12% separately. Although the accuracy of the Baseline classifier and MentorNet classifier was significantly disturbed by the carrier frequency offset, their accuracy was still 14% and 18% higher than the Inception classifier, respectively. Hence, it was obtained that in the presence of frequency offset, the performance of the MentorNet classifier was still the best, so that has actual importance in the field of communication.
Then, the impact of the phase offset
on the accuracy of the classifier was studied and discussed. The experimental parameters are the same as above, except the carrier frequency offset and phase offset. The phase offset was set within 0–10
, while the carrier frequency offset was set to 0 Hz. The results are shown in
Figure 12b. It is obvious that the phase offset had little effect on the accuracy of classifier, which suggests the strong robustness to phase offset. Moreover, the accuracy of the MentorNet classifier could maintain at 99% regardless of the phase offset, while the Inception classifier and Baseline classifier could only achieve a classification accuracy of 96% and 83%, respectively. This phenomenon reveals that among these three classifiers, the designed MentorNet classifier obtained a better performance.
4.3. Classification Accuracy on a Generic Dataset
An additional experiment was conducted to evaluate the classification performance on analog modulation signals, and a GUN radio generated dataset (RML2016b) was used [
16]. In the test, the dataset was divided into a training set, validation set and test set. We used the training set to train StudentNet, and used the validation set to evaluate the performance of the current classifier and select the best classifier for testing. For the MentorNet classifier, the trained MentorNet was used to supervise the training of StudentNet. For the Baseline classifier, the StudentNet was trained without MentorNet. As shown in
Figure 13, the comparison of classification accuracy was made among MentorNet classifier and some classical methods such as the Baseline, ResNet and CLDNN [
29] classifiers. When the SNR was greater than 0 dB, our proposed MentorNet classifier could achieve the overall classification accuracy up to 85.5%, which was better than the Baseline (82.2%), CLDNN (83.1%) and ResNet (80.5%). The comparison results indicate that the proposed MentorNet classifier could also deal with the analog modulation signals with better versatility and classification accuracy.
5. Conclusions
In this paper, we reported a novel automatic digital modulation classifier called the MentorNet classifier, which consists of two neural networks: StudentNet and MentorNet. The MentorNet supervises the training of StudentNet to overcome the overfitting in the classification process. In order to verify the performance of this classifier, several comparative tests with other classifiers were conducted in the presence of AWGN, Rayleigh fading, carrier frequency offset and phase offset. Experimental results showed the accuracy of the MentorNet classifier and Baseline classifier was much higher than the Inception classifier and classifier based on SVM, which suggests the deep residual network is suitable for digital modulation classification. Meantime, the accuracy of the MentorNet classifier at high SNR was higher than that of the Baseline classifier, indicating the curriculum learning can solve the overfitting of the neural network. In the interference of Rayleigh fading, the MentorNet classifier still owned the highest accuracy, which ranged from 80%–90% at 10 dB SNR as the Doppler frequency shift was within 0–10 kHz, which suggests the outstanding robustness of MentorNet classifier. When the carrier frequency offset and phase offset were taken into account, the accuracy of the MentorNet classifier presented quite different tendencies. When only the carrier frequency offset was considered, the accuracy of the MentorNet classifier showed a smooth reduction from 98% to 85% with ranging within , while it maintained at 99% in the presence of a 0–10 phase offset. Moreover, the proposed classifier could also achieve favorable classification performance for analog baseband signals, indicating the transplantation feasibility of the proposed classifier. Although the proposed MentorNet classifier had outstanding performance, when SNR was −20 dB the classification accuracy remains to be improved.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}