Confidence Measures for Deep Learning in Domain Adaptation

Abstract
:1. Introduction
- Epistemic uncertainty is related to the lack of knowledge and, in the case of a neural network model, means that the parameters are poorly determined due to the data scarcity, so that the posterior probability over them is broadly captured.
- Aleatoric uncertainty is due to genuine stochasticity in the data; if the data are inherently noisy, then also the best prediction may have a high entropy.
2. Related Work
2.1. Unsupervised Domain Adaptation
2.2. Generative Adversarial Networks
2.3. Uncertainty Estimation
3. Confidence Measures
3.1. Entropy and Max Scaled Softmax Output
- Entropy
- Max Scaled Softmax Output
3.2. Distance from the Classification Boundary
- Euclidean distance between and
- Magnitude of the gradient computed at the first step of the adversarial example generation procedure
3.3. Auto-Encoder Feature Distance
- Difference between the first and the second minimum distance inwhere
- Concordance between the prediction () of the classifier and the class of the auto-encoder that better reconstruct the original featureswhere y is the classifier output and .
3.4. Combined Confidence Measures
4. Experimental Setup
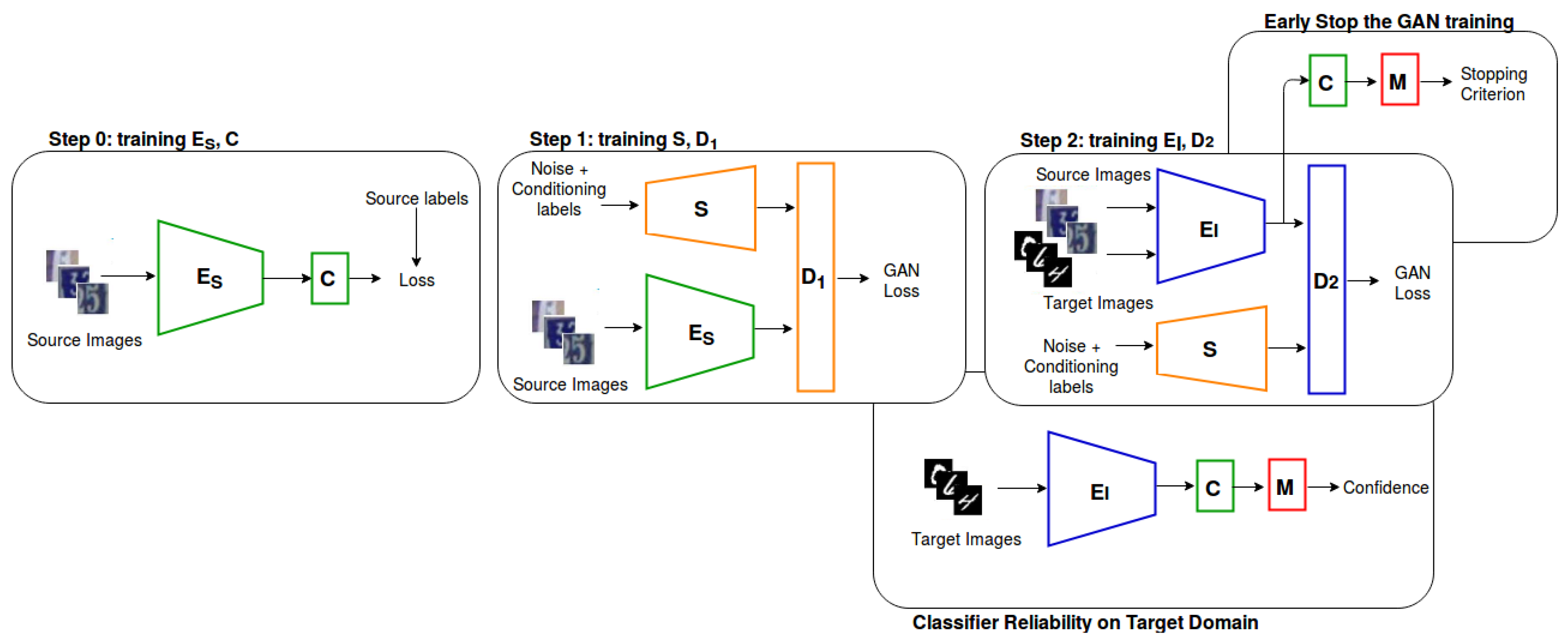
4.1. Domain Adaptation Network
- Step 0. The validation set of the source domain is used to early stop the training.
- Step 1. The CGAN generator, S, produces features for a given class; then, every 1000 training steps, C is engaged in classifying the features generated by S, using the conditioning labels to evaluate the error and early stop the training.
- Step 2. Every 1000 iteration, the classifier C is used to classify the features extracted from . The proposed confidence measures are used to evaluate the performance of the classifier to early stop the training.
4.2. Datasets
4.2.1. SVHN → MNIST
4.2.2. CIFAR → STL
4.3. Network Training
5. Results
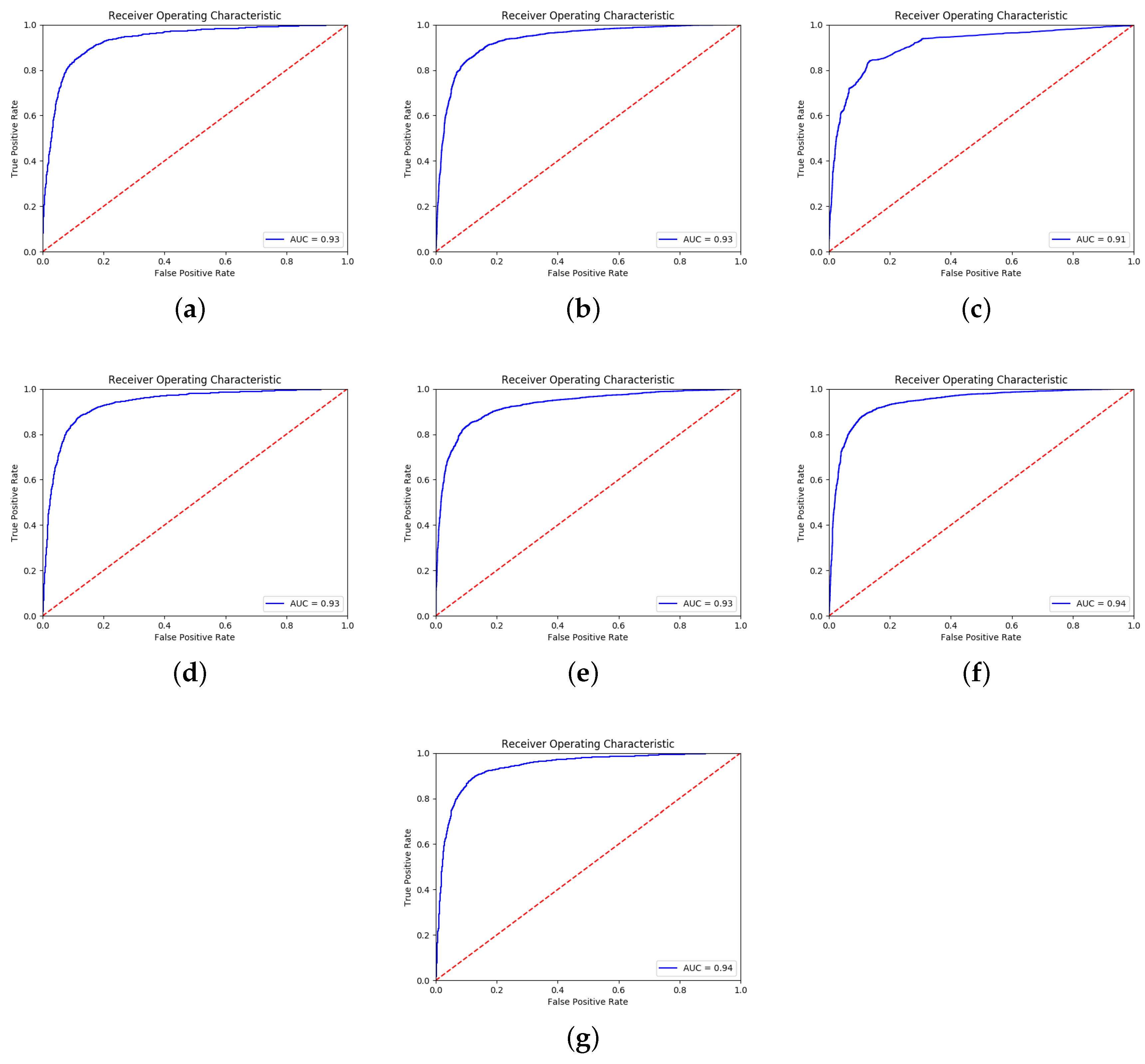
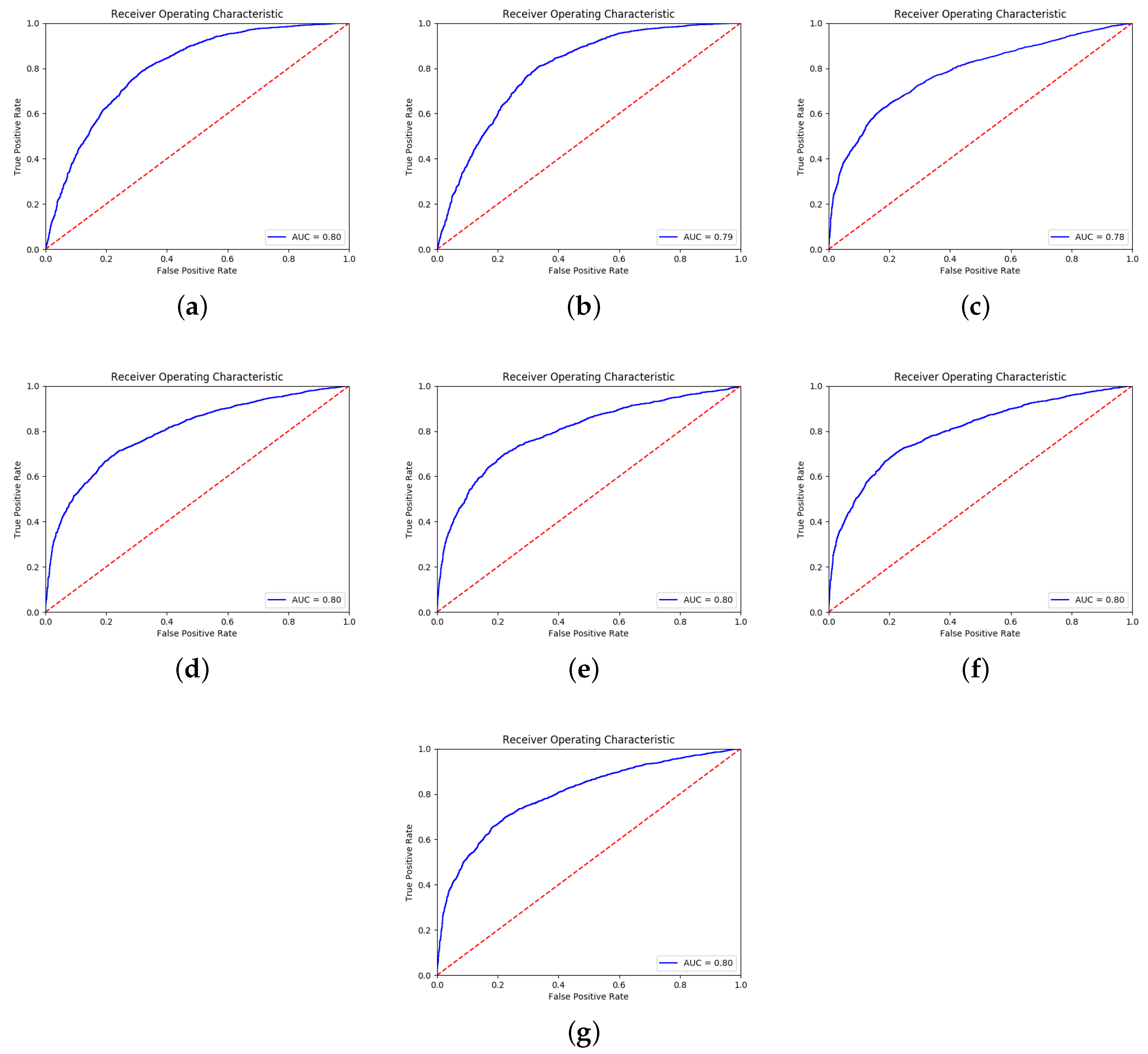
5.1. Early Stop of the GAN Training
- The training was stopped according to the confidence measures (e, s, , g, , and ) computed by the reliability estimator M.
- The GAN was trained for a fixed number (200,000) of iterations (Fix Iter.).
- The early stop was based on the accuracy calculated on the validation set (Max Acc.)
5.1.1. SVHN → MNIST
5.1.2. CIFAR → STL
5.2. Classifier Reliability
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End–to–end speech recognition in English and Mandarin. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 173–182. [Google Scholar]
- Caruana, R.; Lou, Y.; Gehrke, J.; Koch, P.; Sturm, M.; Elhadad, N. Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 1721–1730. [Google Scholar]
- Andreini, P.; Bonechi, S.; Bianchini, M.; Mecocci, A.; Scarselli, F. A Deep Learning Approach to Bacterial Colony Segmentation. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 522–533. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large–scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Gretton, A.; Smola, A.J.; Huang, J.; Schmittfull, M.; Borgwardt, K.M.; Schölkopf, B. Covariate Shift by Kernel Mean Matching; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. Decaf: A deep convolutional activation feature for generic visual recognition. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 647–655. [Google Scholar]
- Torralba, A.; Efros, A.A. Unbiased look at dataset bias. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1521–1528. [Google Scholar]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Pereira, F. Analysis of representations for domain adaptation. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2007; pp. 137–144. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Volpi, R.; Morerio, P.; Savarese, S.; Murino, V. Adversarial feature augmentation for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Smith, L.; Gal, Y. Understanding Measures of Uncertainty for Adversarial Example Detection. arXiv 2018, arXiv:1803.08533. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading digits in natural images with unsupervised feature learning. In NIPS Workshop on Deep Learning and Unsupervised Feature Learning; NIPS: San Diego, CA, USA, 2011; Volume 2011, p. 5. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An analysis of single–layer networks in unsupervised feature learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 215–223. [Google Scholar]
- Saenko, K.; Kulis, B.; Fritz, M.; Darrell, T. Adapting visual category models to new domains. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 213–226. [Google Scholar]
- Jhuo, I.H.; Liu, D.; Lee, D.; Chang, S.F. Robust visual domain adaptation with low–rank reconstruction. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2168–2175. [Google Scholar]
- Hoffman, J.; Rodner, E.; Donahue, J.; Darrell, T.; Saenko, K. Efficient learning of domain–invariant image representations. arXiv 2013, arXiv:1301.3224. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 443–450. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning transferable features with deep adaptation networks. arXiv 2015, arXiv:1502.02791. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Unsupervised domain adaptation with residual transfer networks. In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 2016; pp. 136–144. [Google Scholar]
- Haeusser, P.; Frerix, T.; Mordvintsev, A.; Cremers, D. Associative domain adaptation. In Proceedings of the International Conference on Computer Vision (ICCV), Italy, France, 22–27 October 2017; Volume 2, p. 6. [Google Scholar]
- Luo, Z.; Zou, Y.; Hoffman, J.; Fei-Fei, L.F. Label efficient learning of transferable representations acrosss domains and tasks. In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 2017; pp. 165–177. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Darrell, T.; Saenko, K. Simultaneous deep transfer across domains and tasks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4068–4076. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 4. [Google Scholar]
- Damodaran, B.B.; Kellenberger, B.; Flamary, R.; Tuia, D.; Courty, N. DeepJDOT: Deep Joint distribution optimal transport for unsupervised domain adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11208. [Google Scholar]
- Shu, R.; Bui, H.; Narui, H.; Ermon, S. A DIRT–T Approach to Unsupervised Domain Adaptation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Taigman, Y.; Polyak, A.; Wolf, L. Unsupervised cross-domain image generation. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Liu, M.Y.; Tuzel, O. Coupled generative adversarial networks. In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 2016; pp. 469–477. [Google Scholar]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised pixel–level domain adaptation with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 7. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image–to–image translation networks. In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 2017; pp. 700–708. [Google Scholar]
- Sankaranarayanan, S.; Balaji, Y.; Castillo, C.D.; Chellappa, R. Generate to adapt: Aligning domains using generative adversarial networks. arXiv 2017, arXiv:1704.01705. [Google Scholar]
- Murez, Z.; Kolouri, S.; Kriegman, D.J.; Ramamoorthi, R.; Kim, K. Image to Image Translation for Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Smolley, S.P. Least squares generative adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2813–2821. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 11–15 August 2017; pp. 214–223. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training GANs. In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 2016; pp. 2234–2242. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 2016; pp. 2172–2180. [Google Scholar]
- Reed, S.E.; Akata, Z.; Mohan, S.; Tenka, S.; Schiele, B.; Lee, H. Learning what and where to draw. In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 2016; pp. 217–225. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Neal, R.M. Bayesian Learning for Neural Networks; Springer Science & Business Media: Berlin, Germany, 2012; Volume 118. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016; pp. 1050–1059. [Google Scholar]
- Louizos, C.; Welling, M. Multiplicative Normalizing Flows for Variational Bayesian Neural Networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 11–15 August 2017. [Google Scholar]
- Atanov, A.; Ashukha, A.; Molchanov, D.; Neklyudov, K.; Vetrov, D. Uncertainty Estimation via Stochastic Batch Normalization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and scalable predictive uncertainty estimation using deep ensembles. In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 2017; pp. 6402–6413. [Google Scholar]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 2017; pp. 5574–5584. [Google Scholar]
- DeVries, T.; Taylor, G.W. Learning Confidence for Out–of–Distribution Detection in Neural Networks. arXiv 2018, arXiv:1802.04865. [Google Scholar]
- DeVries, T.; Taylor, G.W. Leveraging Uncertainty Estimates for Predicting Segmentation Quality. arXiv 2018, arXiv:1807.00502. [Google Scholar]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On calibration of modern neural networks. arXiv 2017, arXiv:1706.04599. [Google Scholar]
- Mallidi, S.H.; Ogawa, T.; Hermansky, H. Uncertainty estimation of DNN classifiers. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 283–288. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- French, G.; Mackiewicz, M.; Fisher, M. Self–ensembling for visual domain adaptation. arXiv 2017, arXiv:1706.05208. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Max Acc. | Fix Iter. | e | s | g | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc. | 92.34% | 91.67% | 91.81% | 91.79% | 91.56% | 91.80% | 91.65% | 91.66% | 91.87% | 91.79% |
| Max Acc. | Fix Iter. | e | s | g | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | - | 0.67% | 0.53% | 0.56% | 0.78% | 0.54% | 0.69% | 0.68% | 0.47% | 0.55% |
| Std | - | 0.27 | 0.29 | 0.26 | 0.47 | 0.30 | 0.34 | 0.31 | 0.21 | 0.25 |
| Max Acc. | Fix Iter. | e | s | g | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc. | 56.81% | 55.90% | 56.08% | 56.04% | 55.92% | 55.94% | 55.95% | 56.04% | 56.06% | 56.18% |
| Max Acc. | Fix Iter. | e | s | g | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | - | 0.91% | 0.73% | 0.77% | 0.89% | 0.87% | 0.86% | 0.77% | 0.75% | 0.63% |
| Std | - | 0.33 | 0.33 | 0.36 | 0.35 | 0.42 | 0.36 | 0.24 | 0.33 | 0.33 |
| e | s | g | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | 89.44% | 89.15% | 86.99% | 88.37% | 82.27% | 91.36% | 87.94% | 83.28% |
| AUROC | 71.21% | 72.90% | 73.21% | 66.58% | 63.22% | 52.75% | 69.39% | 67.79% |
| e | s | g | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | 67.22% | 67.45% | 65.80% | 66.56% | 67.01% | 58% | 67.70% | 66.77% |
| AUROC | 68.32% | 72.82% | 72.20% | 73.08% | 73.10% | 51.99% | 73.39% | 72.60% |
| e | s | g | ||||||
|---|---|---|---|---|---|---|---|---|
| CC | IC | CC | IC | CC | IC | CC | IC | |
| Certain | 8646 | 517 | 8609 | 509 | 8324 | 440 | 8515 | 493 |
| Uncertain | 539 | 298 | 576 | 306 | 861 | 375 | 670 | 322 |
| CC | IC | CC | IC | CC | IC | CC | IC | |
| Certain | 7918 | 506 | 9082 | 771 | 8470 | 491 | 8101 | 588 |
| Uncertain | 1267 | 309 | 103 | 54 | 715 | 324 | 1084 | 227 |
| e | s | g | ||||||
|---|---|---|---|---|---|---|---|---|
| CC | IC | CC | IC | CC | IC | CC | IC | |
| Certain | 2913 | 1209 | 2833 | 1112 | 2305 | 703 | 2981 | 1324 |
| Uncertain | 1151 | 1927 | 1231 | 2024 | 1759 | 2433 | 1083 | 1812 |
| CC | IC | CC | IC | CC | IC | CC | IC | |
| Certain | 2972 | 1283 | 4006 | 2966 | 2885 | 1146 | 2939 | 1267 |
| Uncertain | 1092 | 1853 | 58 | 170 | 1179 | 1990 | 1125 | 1869 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bonechi, S.; Andreini, P.; Bianchini, M.; Pai, A.; Scarselli, F. Confidence Measures for Deep Learning in Domain Adaptation. Appl. Sci. 2019, 9, 2192. https://doi.org/10.3390/app9112192
Bonechi S, Andreini P, Bianchini M, Pai A, Scarselli F. Confidence Measures for Deep Learning in Domain Adaptation. Applied Sciences. 2019; 9(11):2192. https://doi.org/10.3390/app9112192
Chicago/Turabian StyleBonechi, Simone, Paolo Andreini, Monica Bianchini, Akshay Pai, and Franco Scarselli. 2019. "Confidence Measures for Deep Learning in Domain Adaptation" Applied Sciences 9, no. 11: 2192. https://doi.org/10.3390/app9112192
APA StyleBonechi, S., Andreini, P., Bianchini, M., Pai, A., & Scarselli, F. (2019). Confidence Measures for Deep Learning in Domain Adaptation. Applied Sciences, 9(11), 2192. https://doi.org/10.3390/app9112192