Estimating Maize-Leaf Coverage in Field Conditions by Applying a Machine Learning Algorithm to UAV Remote Sensing Images



Abstract
:1. Introduction
2. Data Acquisition and Preprocessing
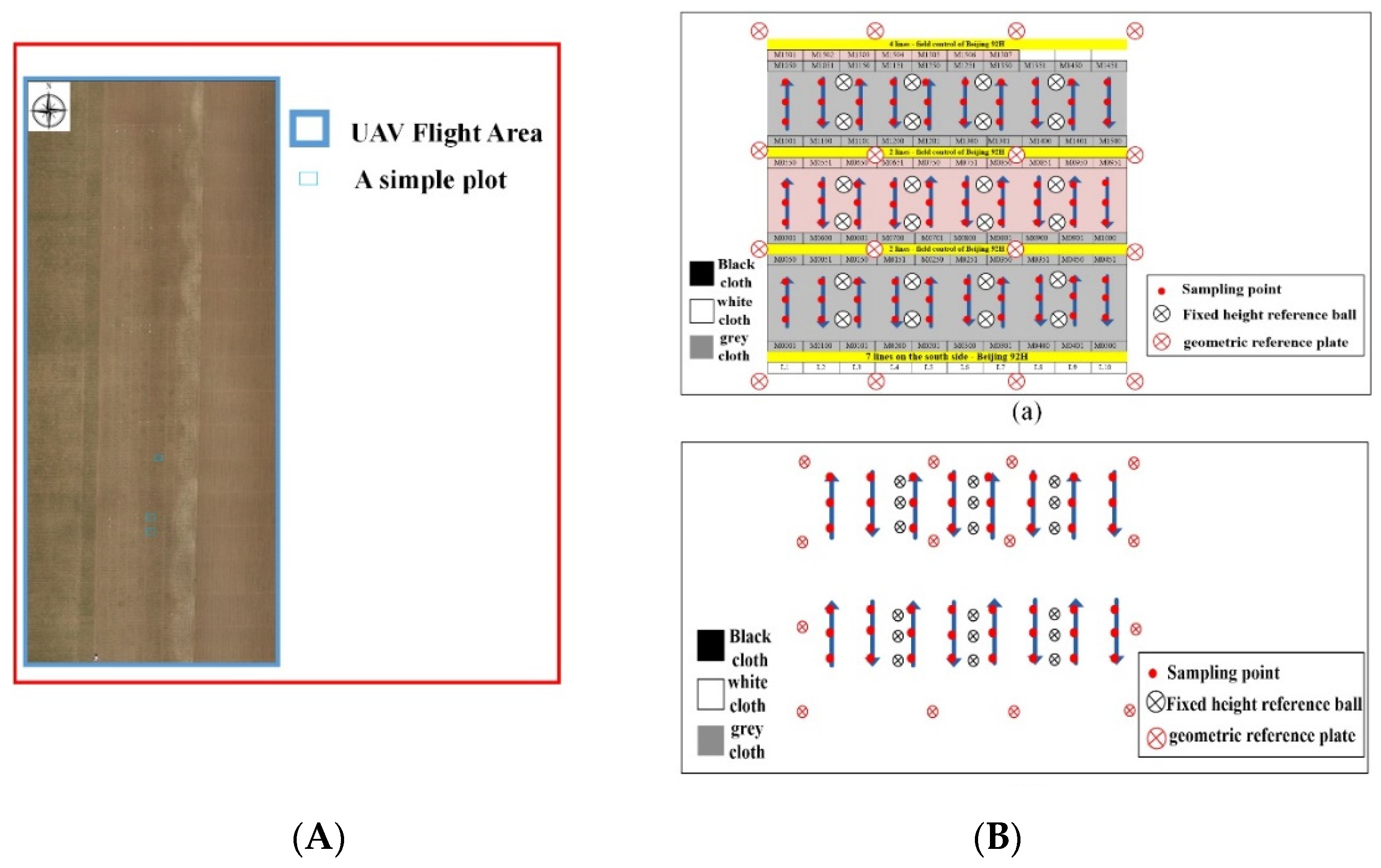
2.1. Data Acquisition
2.2. Data Preprocessing
2.2.1. Image Mosaicking and Generating Subgraphs
2.2.2. Manual Ground Truth
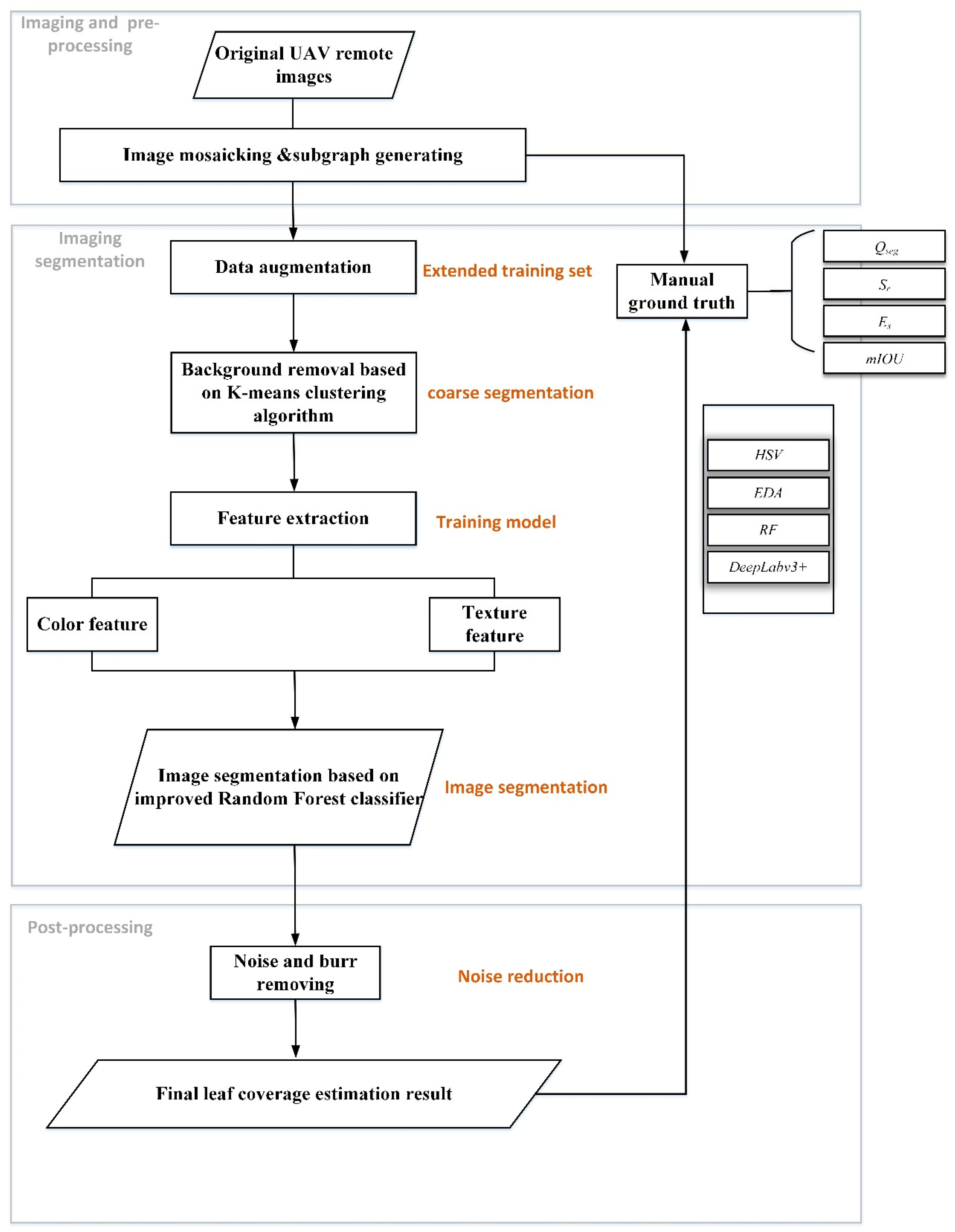
3. Methods
3.1. Dataset Augmentation
3.2. Background Removal based on Improved K-means Clustering Algorithm
- (a)
- As initial clusters, choose k data points at random from the dataset.
- (b)
- Calculate the Euclidean distance from each data point xi (i = 1,2,…,k) to each cluster center mi and assign each data point to its nearest cluster center.
- (c)
- Calculate new cluster centers mi so that the squared error distance of each cluster is a minimum.
- (d)
- Repeat steps (b) and (c) until the lustering centers mi remain constant.
- (e)
- Terminate the process.
- (a)
- Take the threshold of the Otsu segmentation T1-Tk as the initial clustering center of the K-means algorithm.
- (b)
- Calculate the Euclidean distance from each data point xi (i=1, 2, …, n) to each cluster center Ti and assign each data point to the nearest cluster center.
- (c)
- Calculate the new cluster center ti to minimize the squared error distance of each cluster.
- (d)
- Repeat steps (b) and (c) until the clustering centers ti remain constant.
- (e)
- Calculate the arithmetic mean for ti and Ti and then obtain the final segmentation threshold Mi.
- (f)
- Use Mi to complete the image segmentation.
3.3. Leaf Exaction based on Multi-feature and Improved Random Forest Classifier
3.3.1. Feature Extraction
3.3.2. Proposed Image-Segmentation Model
| Algorithm 1 |
| Input: initial training dataset as D, the number Fn of input features of each training sample. |
| Step 1: In a node of the decision tree to be split, attributes are randomly selected from the set of sample attributes as the attributes to be combined. represents the rounding operation. |
| Step 2: Let be weight vectors , where Xi is the vector of F times obtained from a real number sample in the interval (0, 1). |
| Step 3:L new features selected by the decision tree in the split node are obtained by linear weighted summation; that is, . |
| Step 4: The best new feature is selected by the Gini index as the splitting property of the node. The Gini index can be used to measure the purity of the node, and we use the minimum distance based on the Gini index to select the splitting attribute. |
| Step 5: Each node is constructed recursively until the node sample has only a single category, which guarantees the complete growth of the decision tree. |
| Step 6: Repeat steps (1)–(5) N times to generate a random forest of scale N. |
3.4. Noise and Burr Removal
3.5. Evaluation Methods
4. Results
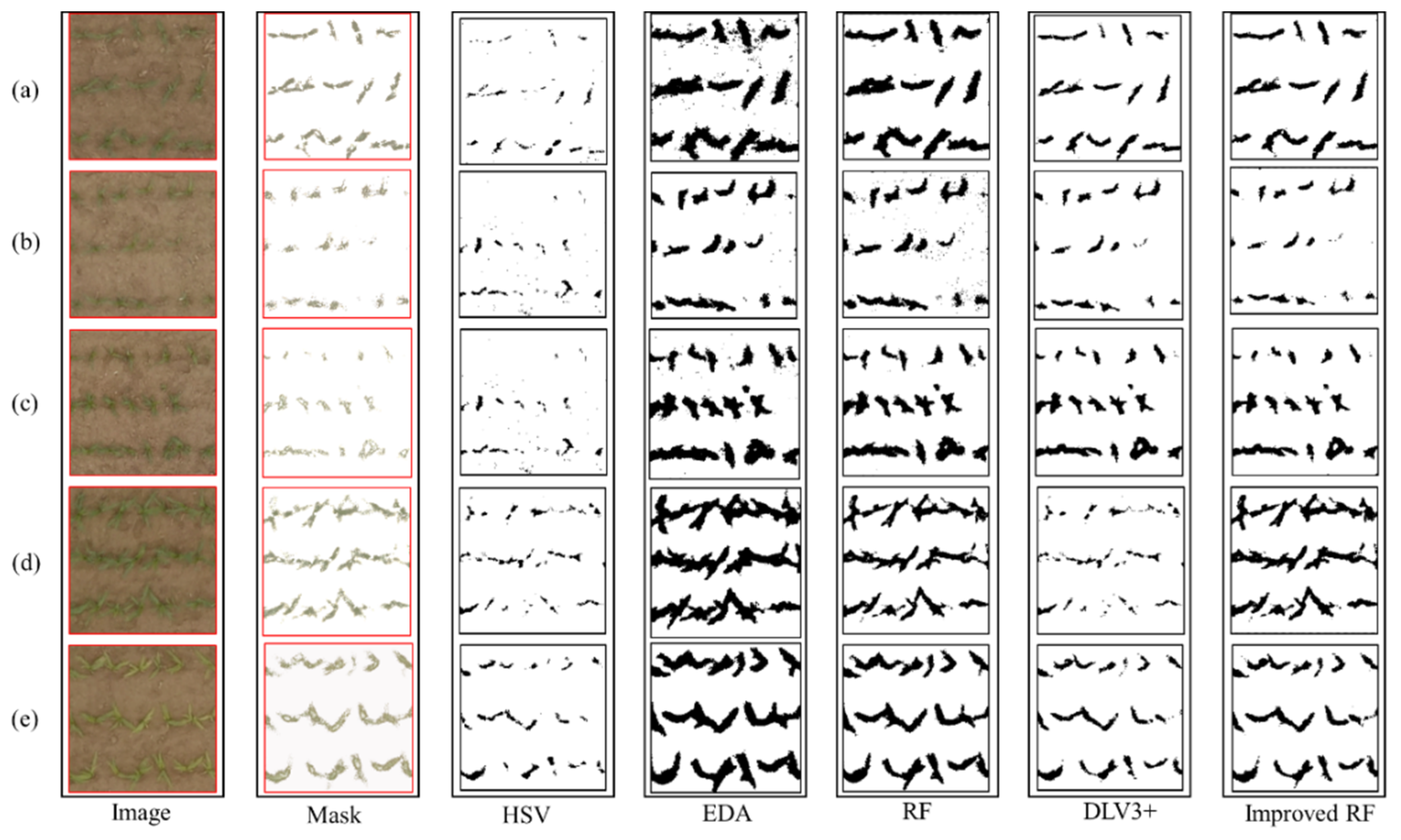
4.1. Estimating Maize Leaf Coverage with Different Image-segmentation Methods
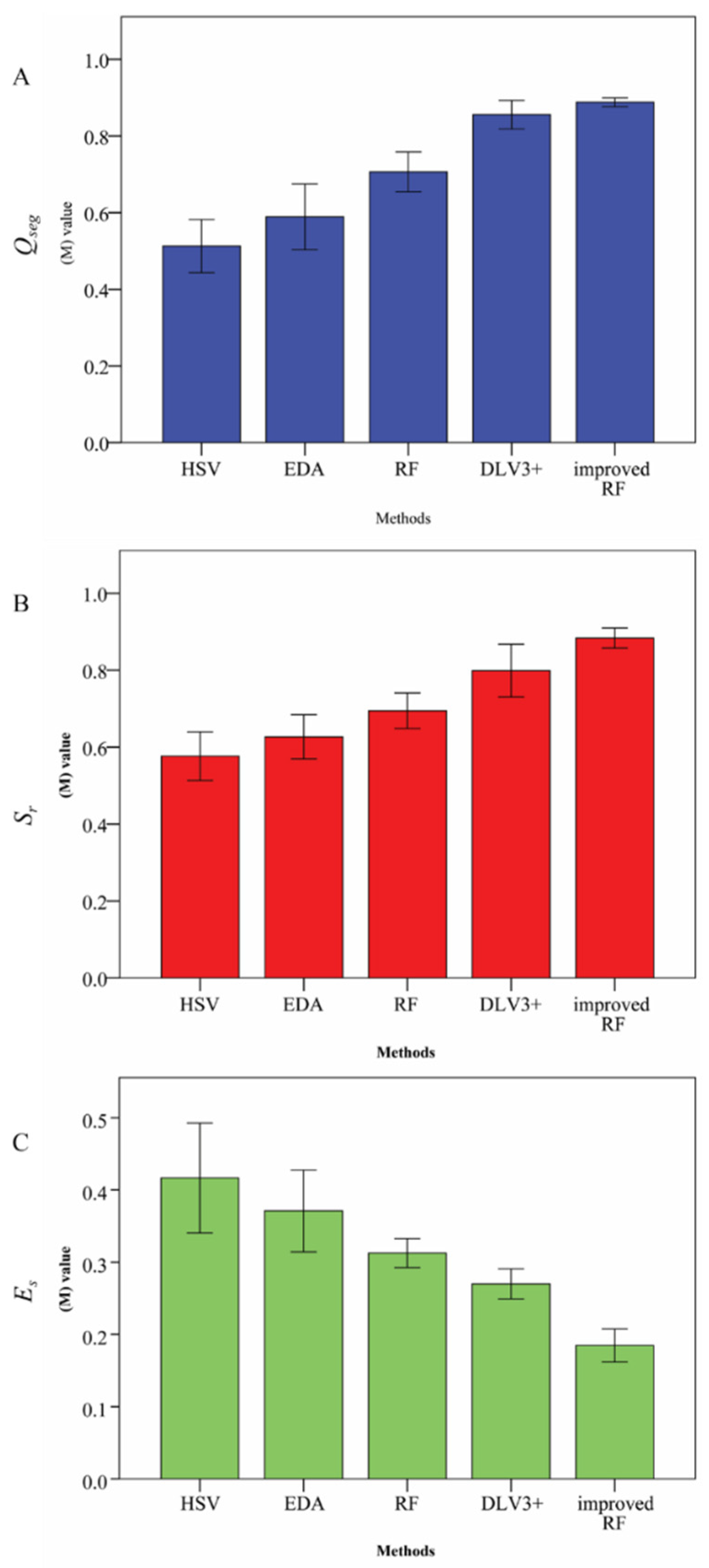
4.2. Segmentation Accuracy
5. Discussion
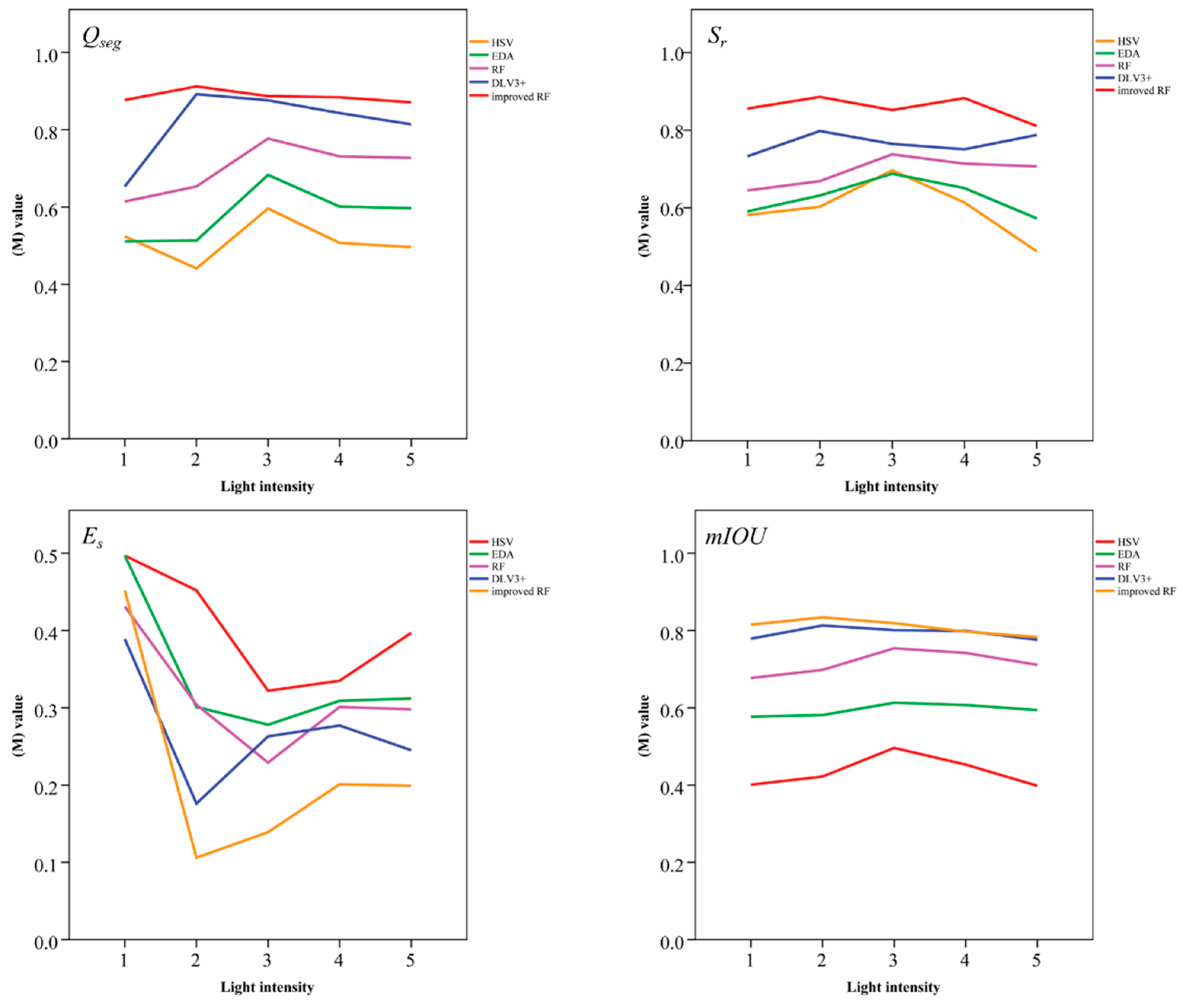
5.1. Dependence of Image-segmentation Models on Illumination
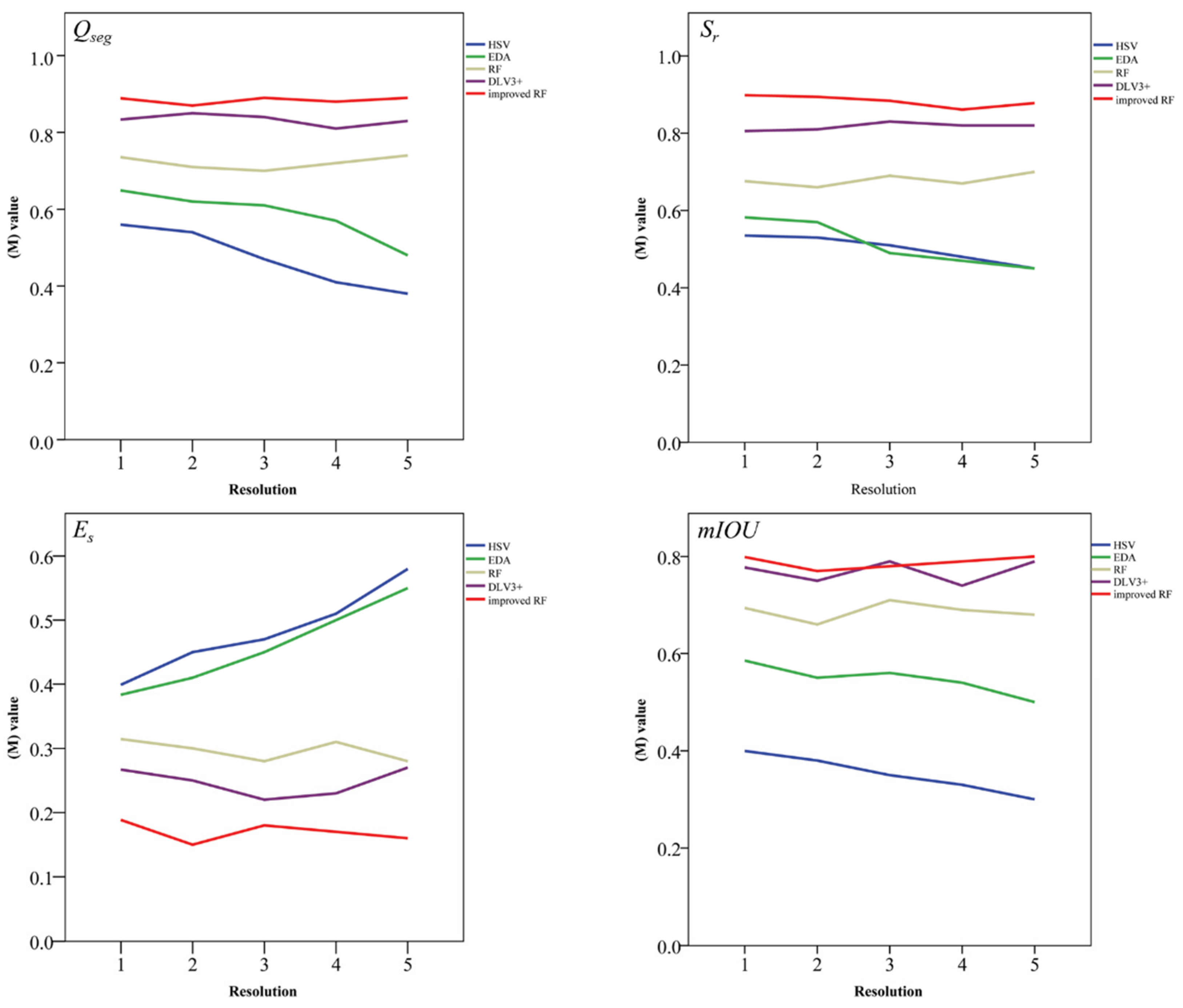
5.2. Dependence of Image-segmentation Models on Image Resolution
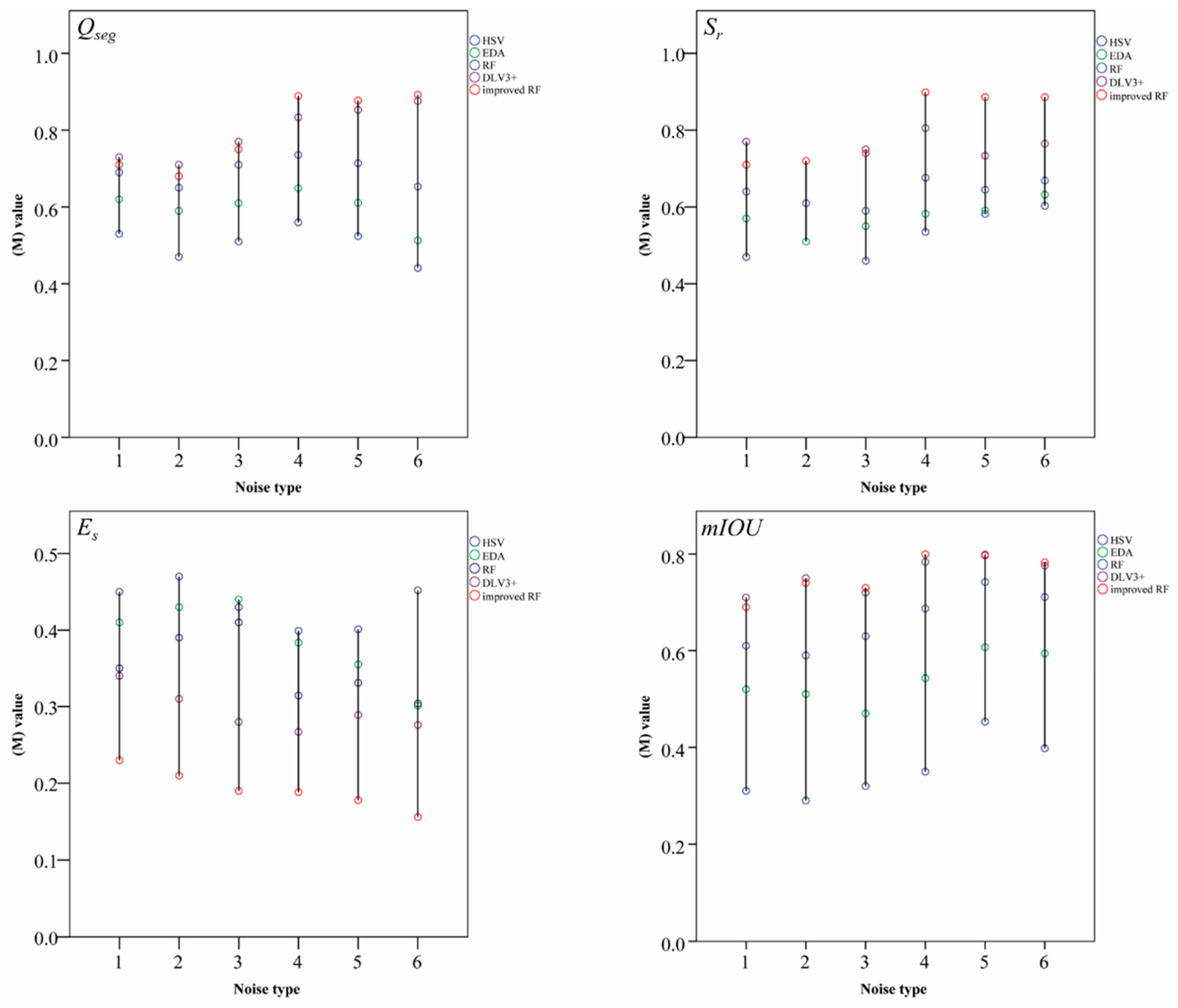
5.3. Dependence of Image-segmentation Models on Image Noise
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Fiorani, F.; Schurr, U. Future Scenarios for Plant Phenotyping. Annu. Rev. Plant Biol. 2013, 64, 267–291. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lupski, J.R.; Stankiewicz, P. Genomic disorders: Molecular mechanisms for rearrangements and conveyed phenotypes. PLoS Genet. 2005, 1, e49. [Google Scholar] [CrossRef] [PubMed]
- Singh, D.; Singh, K.P.; Sharan, S.K. Microwave response to broad leaf vegetation (Spinach) and vegetation covered moist soil for remote sensing. J. Indian Soc. Remote Sens. 2000, 28, 153–158. [Google Scholar] [CrossRef]
- Dahan, M.J.; Chen, N.; Shamir, A.; Cohen-Or, D. Combining color and depth for enhanced image segmentation and retargeting. Vis. Comput. 2012, 28, 1181–1193. [Google Scholar] [CrossRef]
- Panjwani, D.K.; Healey, G. Unsupervised segmentation of textured color images using Markov random field models. In Proceedings of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition (CVPR), New York, NY, USA, 15-17 June 1993. [Google Scholar]
- Shafarenko, L.; Petrou, M.; Kittler, J. Automatic watershed segmentation of randomly textured color images. IEEE Trans. Image Process. 1997, 6, 1530–1544. [Google Scholar] [CrossRef] [PubMed]
- Hoang, M.A.; Geusebroek, J.M.; Smeulders, A.W.M. Color texture measurement and segmentation. Signal Process. 2005, 85, 265–275. [Google Scholar] [CrossRef]
- Xiong, L.L.; Wang, X.Z. Research of Double-Threshold Segmentation of Brazing-Area Defect of Saw Based on Otsu and HSV Color Space. In Proceedings of the International Congress on Image & Signal Processing, Tianjin, China, 17–19 October 2009. [Google Scholar]
- Wang, W.; Zhang, Y.; Yi, L.; Zhang, X. The Global Fuzzy C-Means Clustering Algorithm. In Proceedings of the World Congress on Intelligent Control & Automation, Dalian, China, 21–23 June 2006. [Google Scholar]
- Bai, X.; Wang, W. Principal pixel analysis and SVM for automatic image segmentation. Neural Comput. Appl. 2016, 27, 45–58. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. IEEE Trans. Pattern Analysis & Machine Intelligence. 2014, 4, 357–361. [Google Scholar]
- Ravì, D.; Bober, M.; Farinella, G.M.; Guarnera, M.; Battiato, S. Semantic segmentation of images exploiting DCT based features and random forest. Pattern Recognit. 2016, 52(C), 260–273. [Google Scholar] [CrossRef]
- Valindria, V.V.; Lavdas, I.; Bai, W.; Kamnitsas, K.; Aboagye, E.O.; Rockall, A.G.; Glocker, B. Reverse Classification Accuracy: Predicting Segmentation Performance in the Absence of Ground Truth. IEEE Trans. Med. Imaging 2017, 36, 1597–1606. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, S.; You, Z.; Wu, X. Plant disease leaf image segmentation based on superpixel clustering and EM algorithm. Neural Comput. Appl. 2019, 31, 1225–1233. [Google Scholar] [CrossRef]
- Bakhshipour, A.; Jafari, A.; Nassiri, S.M.; Zare, D. Weed segmentation using texture features extracted from wavelet sub-images. Biosyst. Eng. 2017, 157, 1–12. [Google Scholar] [CrossRef]
- Han, D.; Liu, Q.; Fan, W. A new image classification method using CNN transfer learning and web data augmentation. Expert Syst. Appl. 2018, 95, 43–56. [Google Scholar] [CrossRef]
- Leng, B.; Kai, Y.; Yu, L.; Qin, J. Data Augmentation for Unbalanced Face Recognition Training Sets. Neurocomputing 2017, 235, 10–14. [Google Scholar] [CrossRef]
- Zhao, F.; Chen, Y.; Hou, Y.; He, X. Segmentation of blood vessels using rule-based and machine-learning-based methods: A review. Multimed. Syst. 2017, 4, 1–10. [Google Scholar] [CrossRef]
- Yang, B.; Ma, A.J.; Yuen, P.C. Learning Domain-Shared Group-Sparse Representation for Unsupervised Domain Adaptation. Pattern Recognit. 2018, 81, 615–632, S0031320318301614. [Google Scholar] [CrossRef]
- Cai, Q.; Liu, H.; Zhou, S.; Sun, J.; Li, J. An adaptive-scale active contour model for inhomogeneous image segmentation and bias field estimation. Pattern Recognit. 2018, 82, 79–93, S0031320318301729. [Google Scholar] [CrossRef]
- Hamuda, E.; Glavin, M.; Jones, E. A survey of image processing techniques for plant extraction and segmentation in the field. Comput. Electron. Agric. 2016, 125, 184–199. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Manufacturer | Resolution | Pixel Size (μm2) | Ground Resolution (mm/pix) | Focal Length (mm) | FOV |
|---|---|---|---|---|---|---|
| QX-100 | Sony | 5472 × 3648 | 2.44 × 2.44 | 0.56 | 35 | 60° |
| Feature Kind | Computational Formula | Implication |
|---|---|---|
| ASM | Image gray distribution uniformity and textural detail | |
| ENT | Image gray distribution heterogeneity or complexity | |
| CON | Image clarity and texture depth | |
| COR | Local gray correlation in image |
| output_stride | 16 |
| crop_size | 513 × 513 |
| initial_learning rate | 0.007 |
| atrous rates | [6,12,18] |
| Method | mIOU |
|---|---|
| HSV | 0.4728 |
| EDA | 0.5941 |
| RF | 0.7316 |
| DeepLabv3+ | 0.7984 |
| Improved RF | 0.8237 |
| Method | mIOU | Change (%) |
|---|---|---|
| HSV | 0.4021 | 17.5 |
| EDA | 0.5364 | 10.8 |
| RF | 0.6897 | 6.1 |
| DeepLabv3+ | 0.7916 | 0.9 |
| Improved RF | 0.8055 | 2.3 |
| Method | Qseg | Sr | Es | mIOU |
|---|---|---|---|---|
| ExG | 0.59 | 0.57 | 0.45 | 0.38 |
| ExGR | 0.61 | 0.60 | 0.38 | 0.47 |
| CIVE | 0.55 | 0.53 | 0.46 | 0.50 |
| Improved RF | 0.87 | 0.86 | 0.18 | 0.81 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, C.; Ye, H.; Xu, Z.; Hu, J.; Shi, X.; Hua, S.; Yue, J.; Yang, G. Estimating Maize-Leaf Coverage in Field Conditions by Applying a Machine Learning Algorithm to UAV Remote Sensing Images. Appl. Sci. 2019, 9, 2389. https://doi.org/10.3390/app9112389
Zhou C, Ye H, Xu Z, Hu J, Shi X, Hua S, Yue J, Yang G. Estimating Maize-Leaf Coverage in Field Conditions by Applying a Machine Learning Algorithm to UAV Remote Sensing Images. Applied Sciences. 2019; 9(11):2389. https://doi.org/10.3390/app9112389
Chicago/Turabian StyleZhou, Chengquan, Hongbao Ye, Zhifu Xu, Jun Hu, Xiaoyan Shi, Shan Hua, Jibo Yue, and Guijun Yang. 2019. "Estimating Maize-Leaf Coverage in Field Conditions by Applying a Machine Learning Algorithm to UAV Remote Sensing Images" Applied Sciences 9, no. 11: 2389. https://doi.org/10.3390/app9112389
APA StyleZhou, C., Ye, H., Xu, Z., Hu, J., Shi, X., Hua, S., Yue, J., & Yang, G. (2019). Estimating Maize-Leaf Coverage in Field Conditions by Applying a Machine Learning Algorithm to UAV Remote Sensing Images. Applied Sciences, 9(11), 2389. https://doi.org/10.3390/app9112389