Model-Based 3D Pose Estimation of a Single RGB Image Using a Deep Viewpoint Classification Neural Network


Abstract
:Featured Application
Abstract
1. Introduction
1.1. Motivation
1.2. Related Works
1.3. Our Contributions
2. Materials and Methods
2.1. Notation and Preliminaries
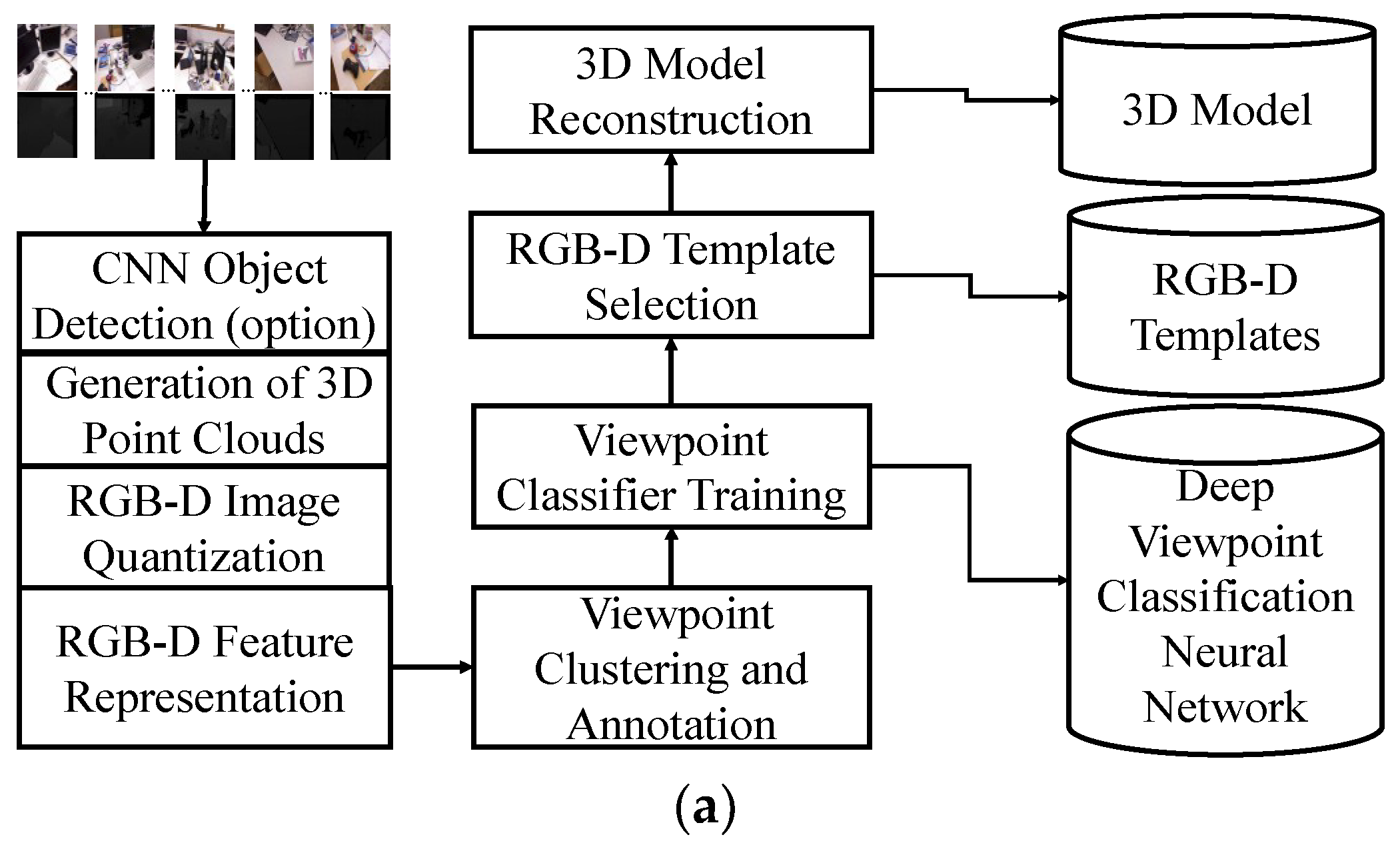
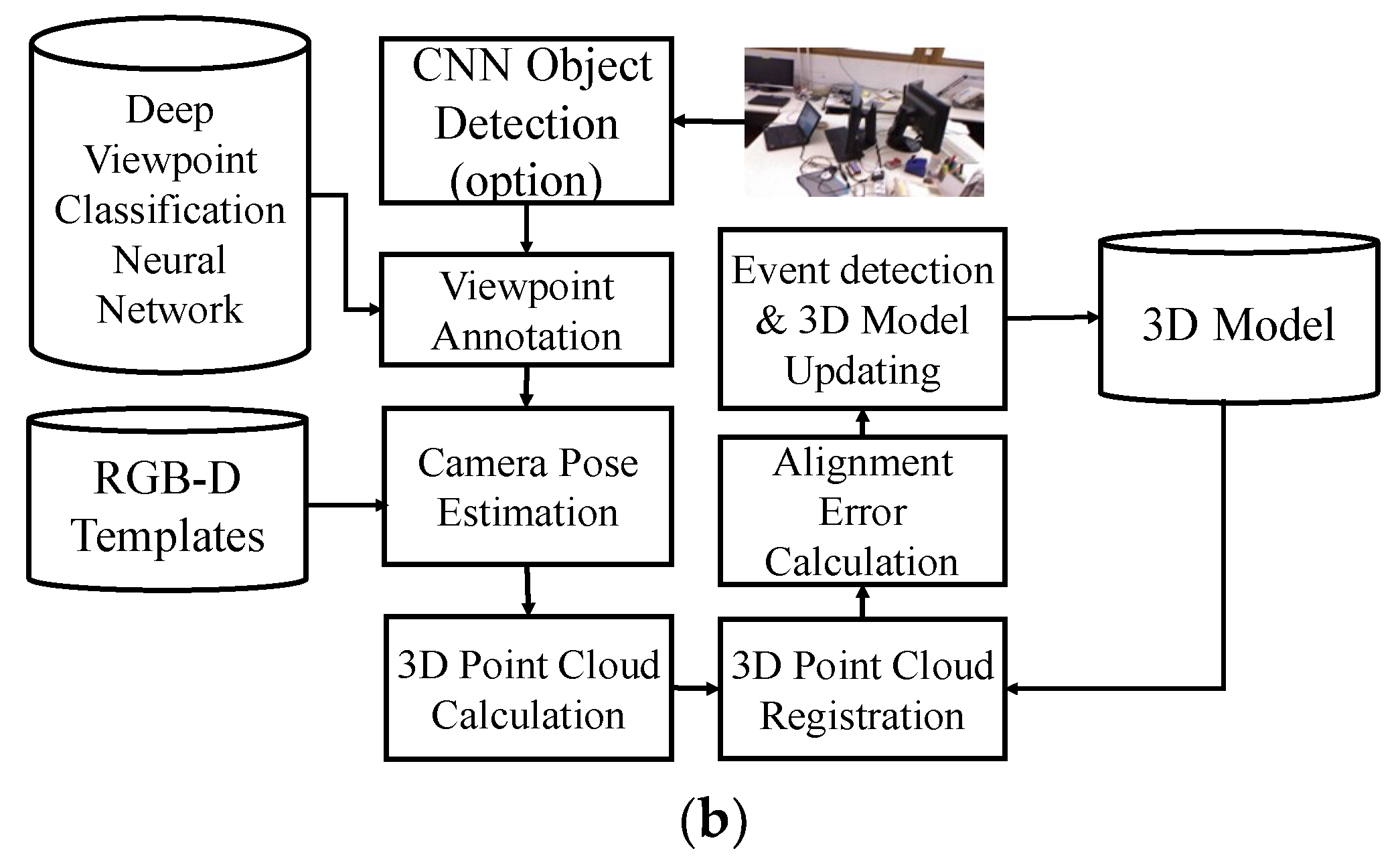
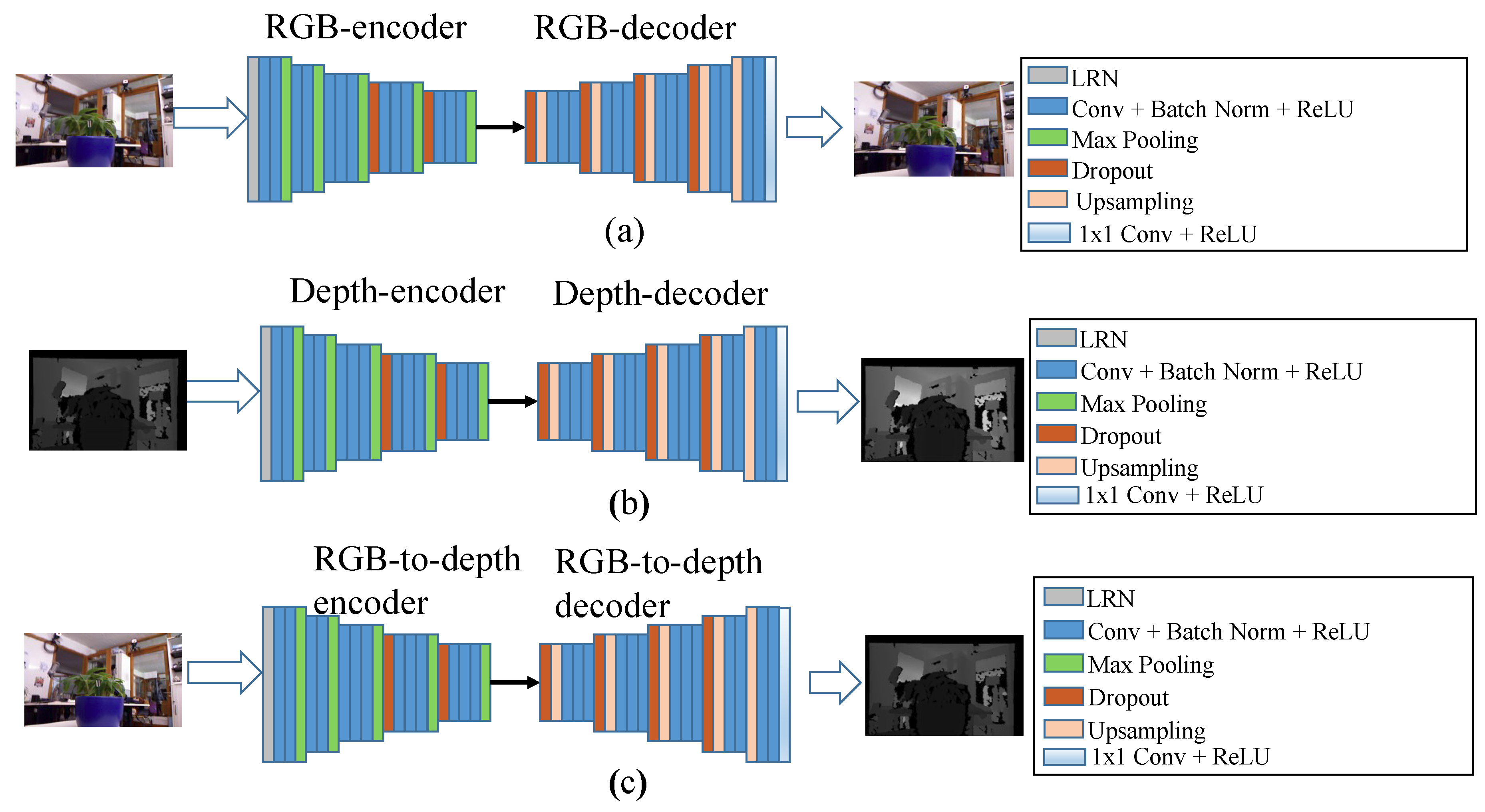
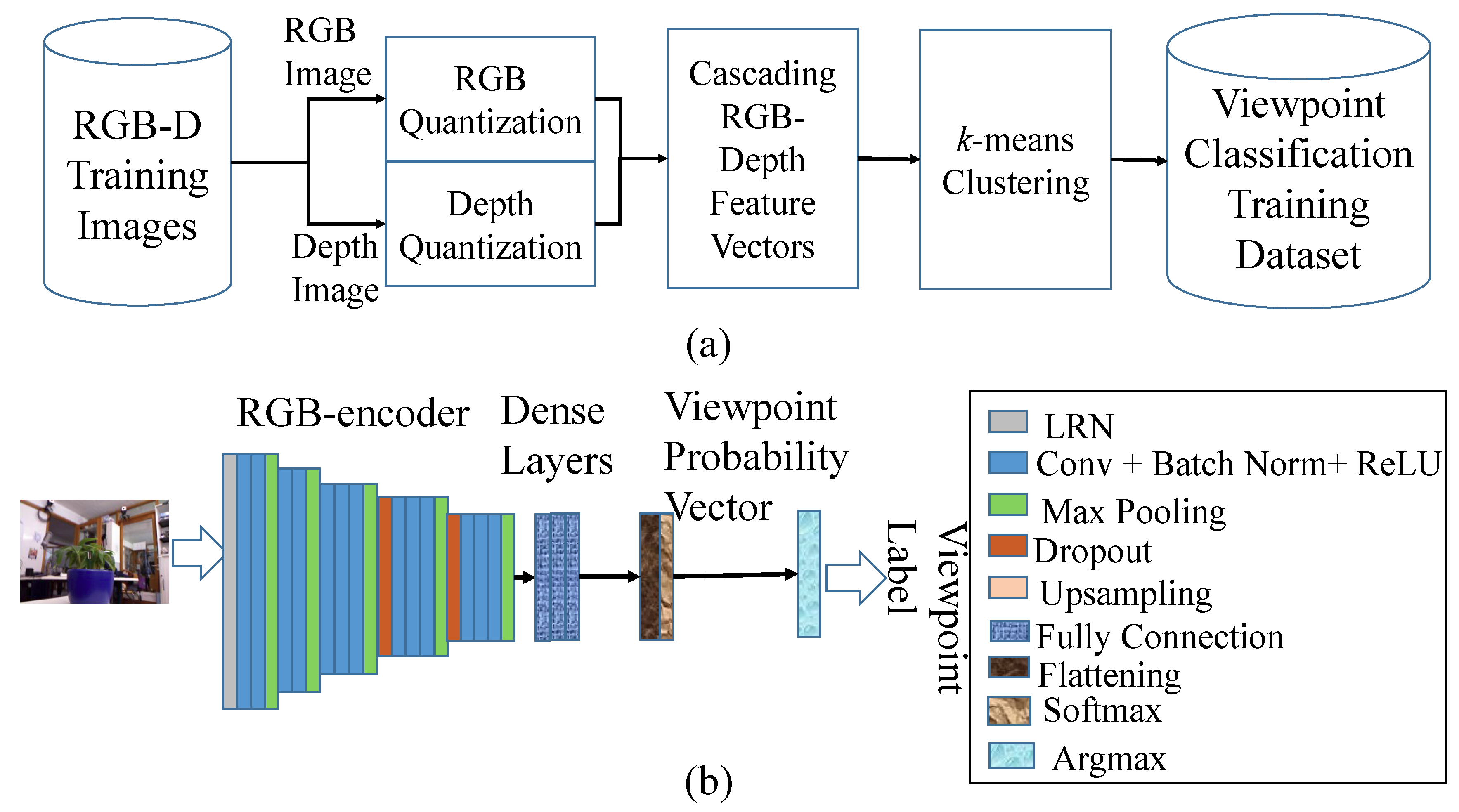
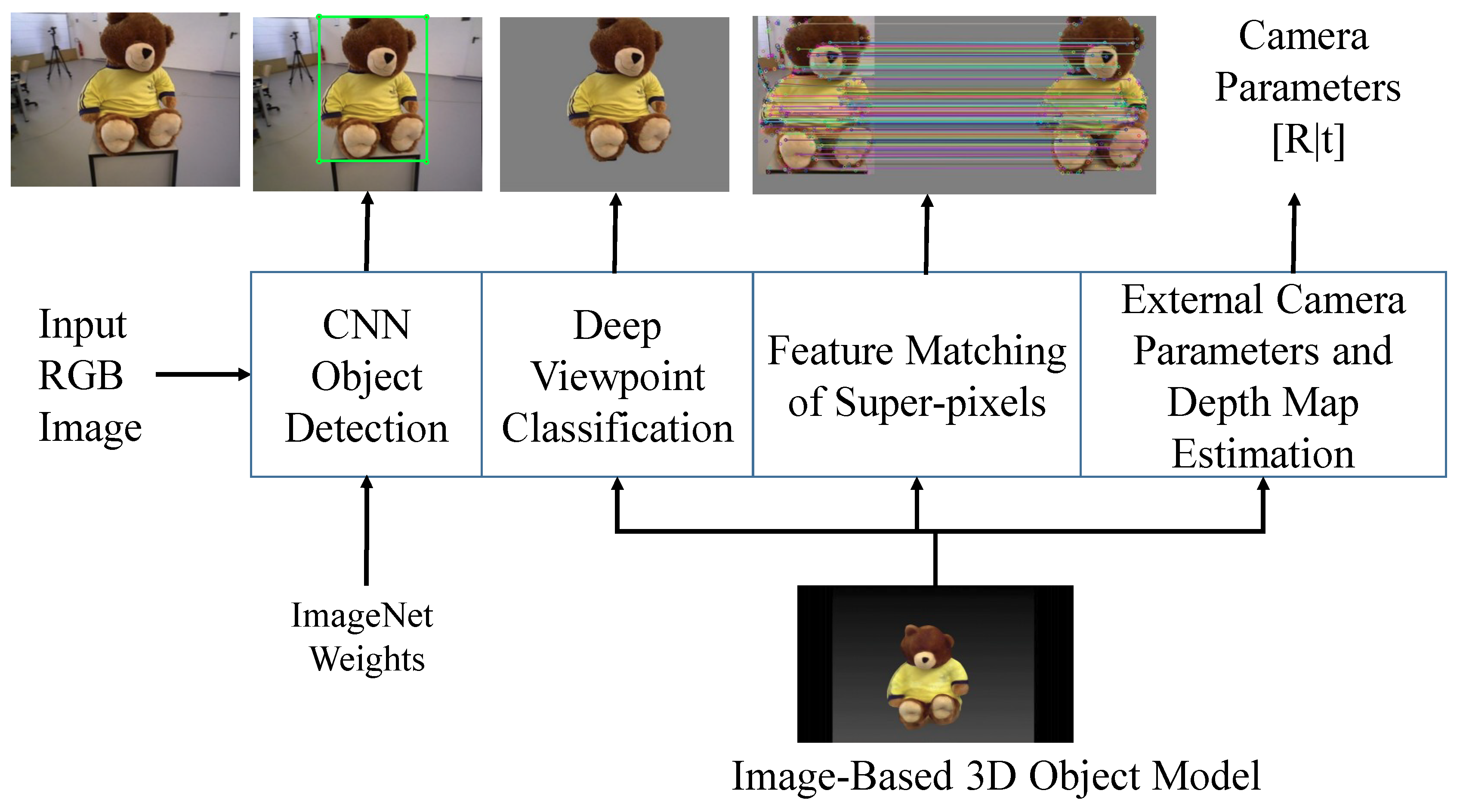
2.2. Our Approach
2.2.1. Template-Based 3D Scene Modeling
| Algorithm 1. Generation of 3D Scene Point Clouds. |
| Input: A multiview RGB-D video V characterized by n image frames, calibrated intrinsic camera parameter K and frame-by-frame external camera parameters . Output: A set of local point clouds PL and a global point cloud PG. PL is a collection of point cloud Pi which is generated from a single RGB-D image frame in the RGB-D video.PG is constructed by joining all the point cloud Pi by using the 3D point cloud registration algorithm [34]. Method: 1. for each RGB image Ii and depth image Di in V do: 1.1 Compute the i-th local point cloud Pi using Equations (2) and (4). 1.2 Perform Algorithm 2 (discussed later) to construct the binary tree of Pi and order the leave nodes as a list of super-points using the depth-first tree traversal. 1.3 for each super-point SPj in Γi do: 1.3.1 Compute the center coordinates , mean color vector , mean depth value , and normal vector of SPj. 1.3.2 Add the tuple (, , , ) to the local point cloud Pi. 1.4 Add Pi to PL. 1.5 Join Pi into the global point cloud PG using the 3D point cloud registration algorithm [34]. Next, the major steps of the algorithm will be discussed in detail and analyzed. |
| Algorithm 2. Binary tree Representation of Point Cloud with the MPPA. |
| Input: A point cloud . Output: A binary tree of Pi and the list of super-points . Method:
|
2.2.2. The Pose Estimation Algorithm
| Algorithm 3. Model-based Pose Estimation |
| Input: A single RGB image I Output: The pose parameters of I and the registration error E Method:
|
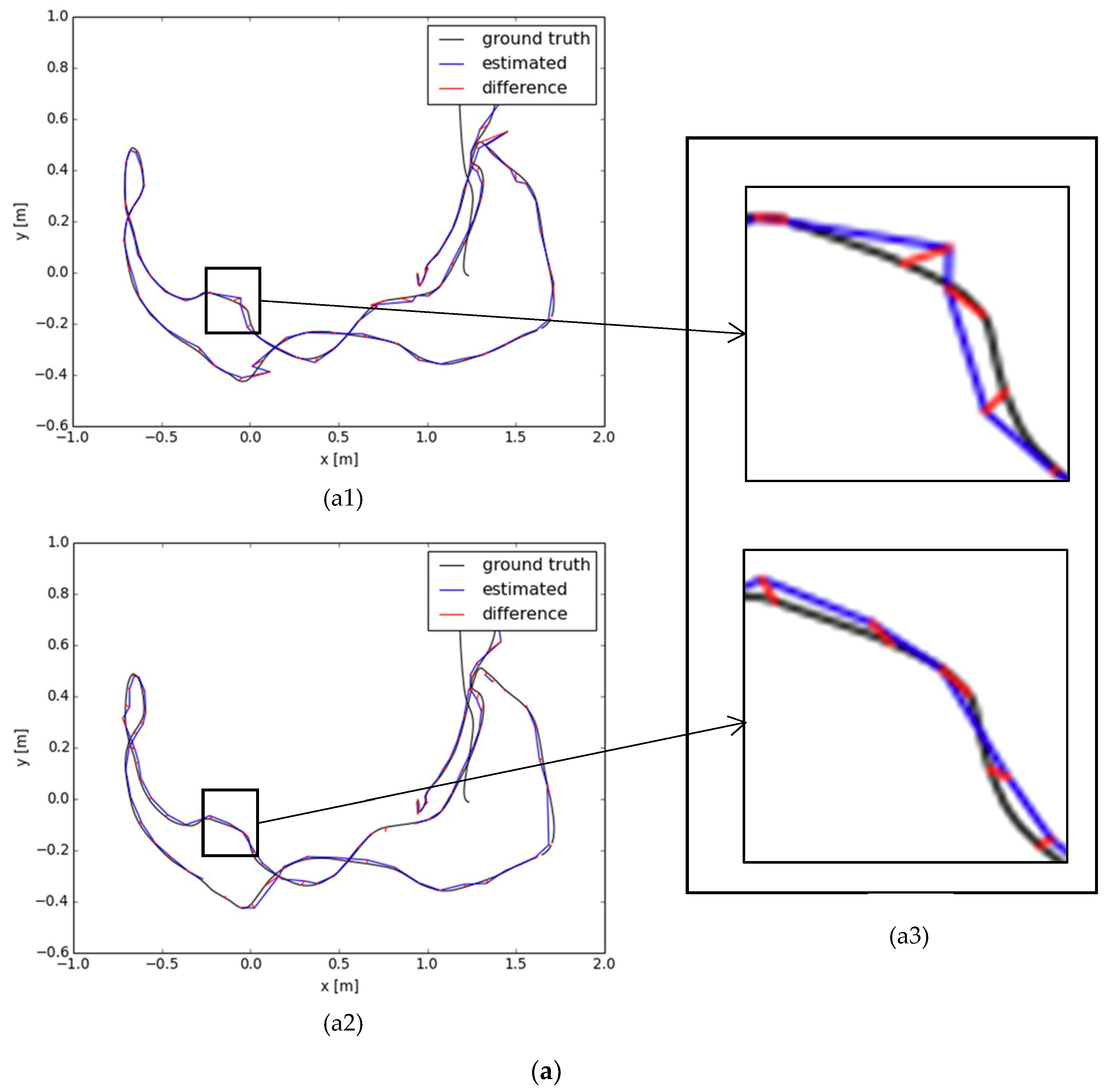
3. Results
4. Discussion
- To the best of our best knowledge, there are very few researchers working on the problem of pose estimation using a single RGB image. Conventional pose estimation algorithms use a sequence of RGB images to compute the depth map and the external camera parameters. However, this highly increases the complexity of the resulting pose estimation. On the contrary, in this work, the input to the model-based pose estimation algorithm is only a single image. This facilitates the real-time reconstruction of 3D models.
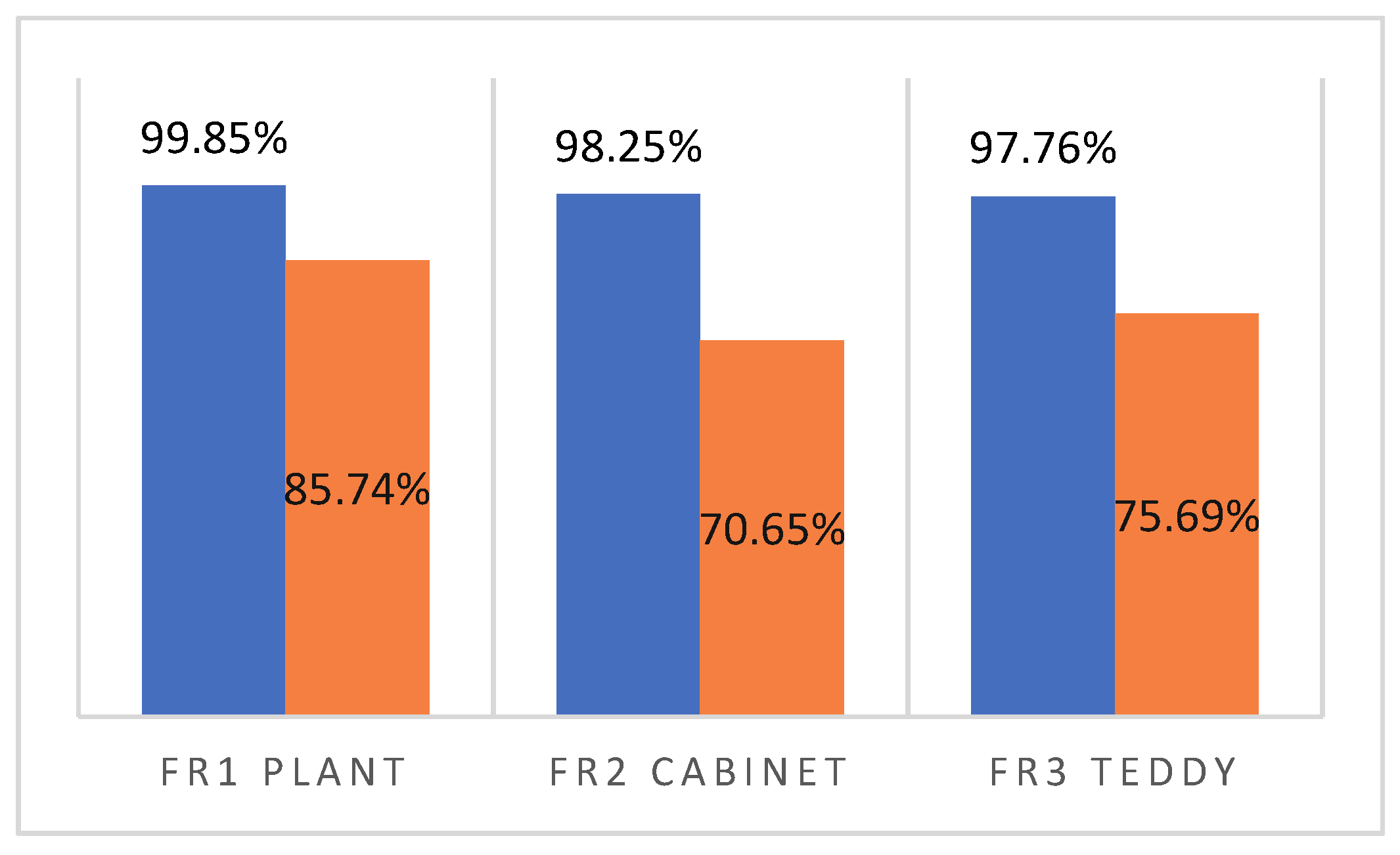
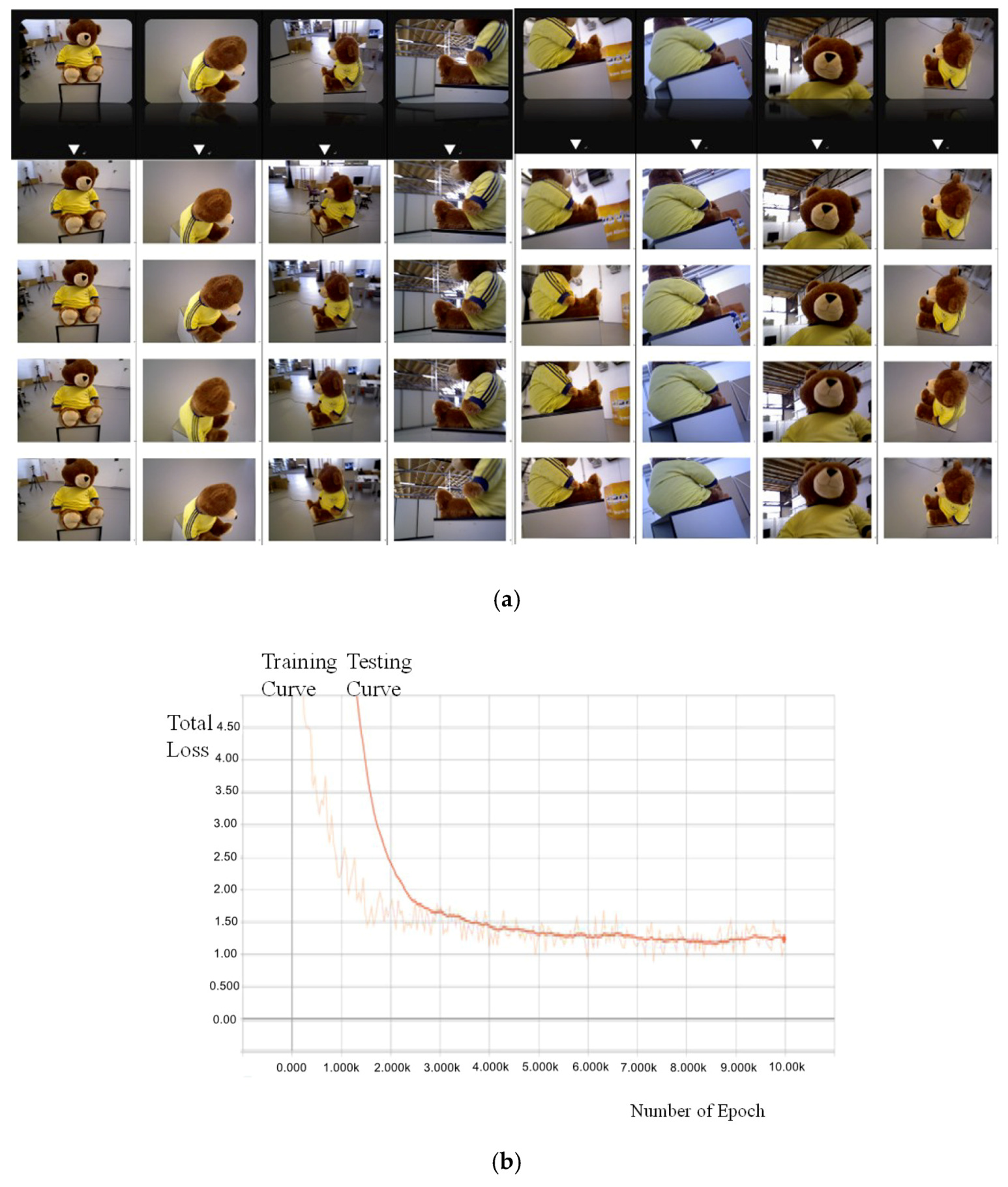
- The tedious human annotation effort required to prepare a large amount of training data for improving the recognition accuracy of the DVCNN is avoided by representing scene point clouds as a collection of super-points using the MPPA algorithm. Although the number of training RGB-D image frames for 3D scene modeling is often small, the average recognition rate for viewpoint classification using the DVCNN achieves 98.34% according to our experimental results. Moreover, the learning curves of testing and learning for the DVCNN closely coincide with each other. This implies the overfitting problem of conventional deep neural networks is solved even when the training data is automatically labeled.
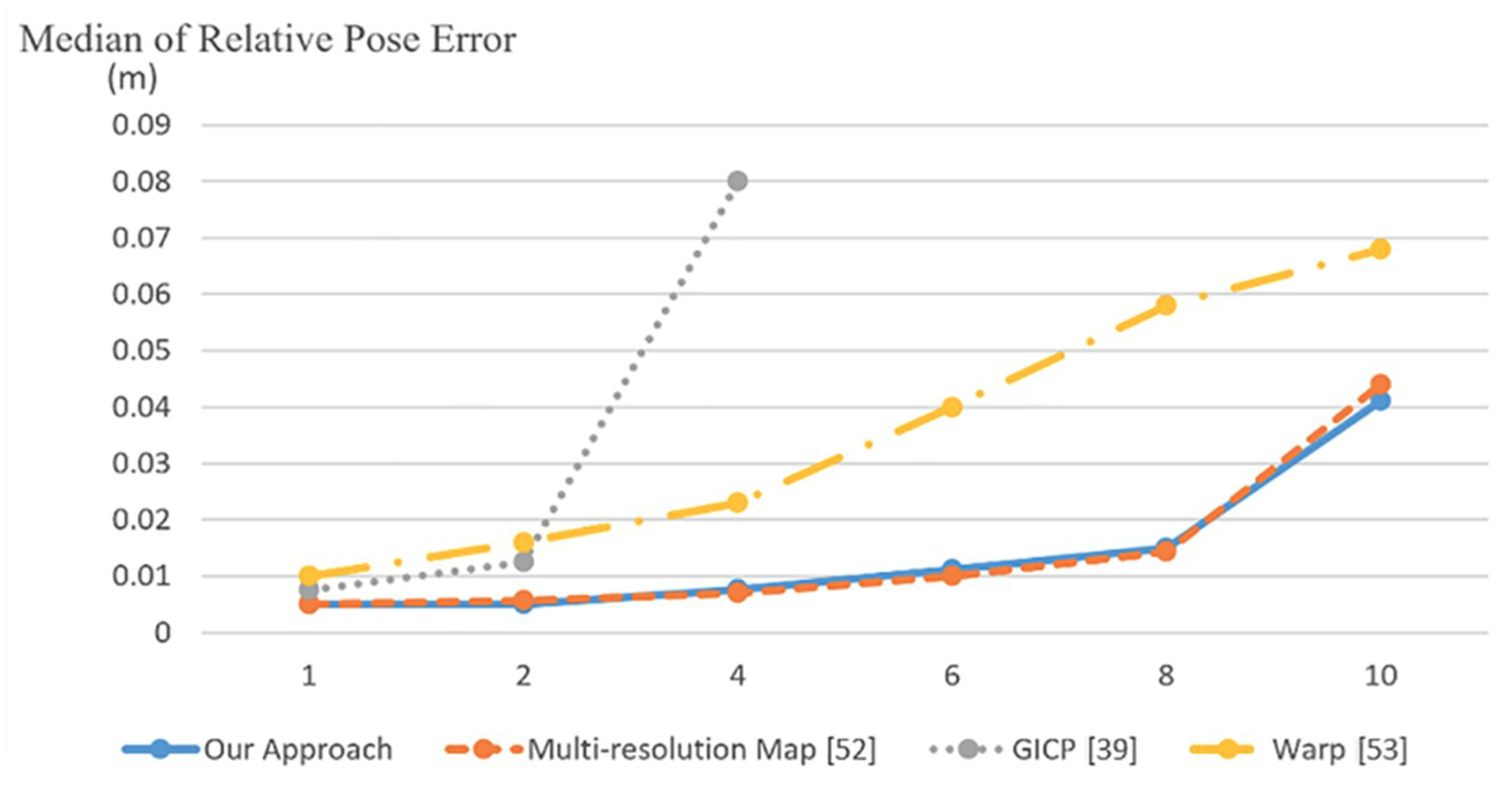
- The performance of the proposed pose estimation is obviously dependent on the number of templates used to model a 3D scene. As shown in Table 2, the usage of fewer templates for 3D scene modeling leads to more significant errors in registration between the current point cloud, generated by the input RGB image, and the model point cloud. In the application of abnormal event detection, the registration error introduced by the model-based pose estimation algorithm should be minimized to a very small degree in order to reduce the number of false positives in the construction of an event alarm system. Thus, we suggest using more templates in 3D model reconstruction even though it increases the computational complexity.
- The usage of deep features obtained by the deep neural networks shown in Figure 4 is not suggested when the training datasets are not large enough. The usage of features of super-points and super-pixels offers good discrimination power in the learning of the DVCNN according to our experimental results. The proposed MPAA is actually much like the conventional PCA dimensionality reduction technique. This implies that the claim that deep learning outperforms traditional learning schemes in all aspects of applications is a pitfall.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wolf, P.R.; Dewitt, B.A. Elements of Photogrammetry: With Applications in GIS; McGraw-Hill: New York, NY, USA, 2000. [Google Scholar]
- Ackermann, F. Airborne laser scanning–present status and further expectations. ISPRS J. Photogramm. Remote Sens. 1999, 54, 64–67. [Google Scholar] [CrossRef]
- Davison, A.; Reid, I.; Molton, N.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed]
- Seitz, S.M.; Curless, B.; Diebel, J.; Scharstein, D.; Szeliski, R. A comparison and evaluation of multi-view stereo reconstruction algorithms. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 1, pp. 519–528. [Google Scholar]
- Furukawa, Y.; Curless, B.; Seitz, S.M.; Szeliski, R. Towards internet-scale multi-view stereo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1434–1441. [Google Scholar]
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multi-view stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1362–1376. [Google Scholar] [CrossRef] [PubMed]
- Snavely, N.; Seitz, S.M.; Szeliski, R. Modeling the world from internet photo collections. Int. J. Comput. Vis. 2008, 80, 189–210. [Google Scholar] [CrossRef]
- Guan, W.; You, S.; Neumann, U. Recognition-driven 3D navigation in large-scale virtual environments. In Proceedings of the IEEE Virtual Reality, Singapore, 19–23 March 2011. [Google Scholar]
- Alexiadis, D.S.; Zarpalas, D.; Daras, P. Real-time, full 3-D reconstruction of moving foreground objects from multiple consumer depth cameras. IEEE Trans. Multimed. 2013, 15, 339–358. [Google Scholar] [CrossRef]
- Chen, K.; Lai, Y.-K.; Hu, S.-M. 3D indoor scene modeling from RGB-D data: A survey. Comput. Vis. Media 2015, 1, 267–278. [Google Scholar] [CrossRef]
- Schönberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohli, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011. [Google Scholar]
- Cheng, S.-C.; Su, J.-Y.; Chen, J.-M.; Hsieh, J.-W. Model-based 3D scene reconstruction using a moving RGB-D camera. In Proceedings of the International Multimedia Modeling, Reykjavik, Iceland, 4–6 January 2017; pp. 214–225. [Google Scholar]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Holzer, S.; Bradski, G.; Konolige, K.; Navab, N. Model-based training, detection and pose estimation of texture-less objects in heavily cluttered scenes. In Lecture Notes in Computer Science, Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7724, pp. 548–562. [Google Scholar]
- Kerl, C.; Sturm, J.; Cremers, D. Robust odometry estimation for RGB-D cameras. In Proceedings of the International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany, 6–10 May 2013; pp. 3748–3754. [Google Scholar]
- Li, J.N.; Wang, L.H.; Li, Y.; Zhang, J.F.; Li, D.X.; Zhang, M. Local Optimized and scalable frame-to-model SLAM. Multimed. Tools Appl. 2016, 75, 8675–8694. [Google Scholar] [CrossRef]
- Tong, J.; Zhou, J.; Liu, L.; Pan, Z.; Yan, H. Scanning 3D full human bodies using kinects. IEEE Trans. Vis. Comput. Graph. 2012, 18, 643–650. [Google Scholar] [CrossRef]
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. KinectFusion: Real-time 3D reconstruction and interaction using a moving depth camera. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; pp. 559–568. [Google Scholar]
- Xiao, J.; Furukawa, Y. Reconstructing the world’s museums. Int. J. Comput. Vis. 2014, 110, 243–258. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, G.; Bao, H. Robust 3D reconstruction with an RGB-D camera. IEEE Trans. Image Process. 2014, 23, 4893–4906. [Google Scholar] [CrossRef]
- Bokaris, P.; Muselet, D.; Trémeau, A. 3D reconstruction of indoor scenes using a single RGB-D image. In Proceedings of the 12th International Conference on Computer Vision Theory and Applications (VISAPP 2017), Porto, Portugal, 27 February–1 March 2017. [Google Scholar]
- Li, C.; Lu, B.; Zhang, Y.; Liu, H.; Qu, Y. 3D reconstruction of indoor scenes via image registration. Neural Process. Lett. 2018, 48, 1281–1304. [Google Scholar] [CrossRef]
- Iddan, G.J.; Yahav, G. Three-dimensional imaging in the studio and elsewhere. In Proceedings of the International Society for Optics and Photonics, San Jose, CA, USA, 20–26 January 2001; Volume 4289, pp. 48–55. [Google Scholar]
- Zhang, J.; Kan, C.; Schwing, A.G.; Urtasun, R. Estimating the 3D layout of indoor scenes and its clutter from depth sensors. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1273–1280. [Google Scholar]
- Beardsley, P.; Zisserman, A.; Murray, D. Sequential updating of projective and affine structure from motion. Int. J. Comput. Vis. 1997, 23, 235–259. [Google Scholar] [CrossRef]
- Sato, T.; Kanbara, M.; Takemura, H.; Yokoya, N. 3-D reconstruction from a monocular image sequence by tracking markers and natural features. In Proceedings of the 14th International Conference on Vision Interface, Ottawa, Ontario, Canada, 7–9 June 2001; pp. 157–164. [Google Scholar]
- Tomasi, C.; Kanade, T. Shape and motion from image streams under orthography: A factorization method. Int. J. Comput. Vis. 1992, 9, 137–154. [Google Scholar] [CrossRef]
- Sato, T.; Kanbara, M.; Yokoya, N.; Takemura, H. 3-D modeling of an outdoor scene by multi-baseline stereo using a long sequence of images. In Proceedings of the 16th IAPR International Conference on Pattern Recognition (ICPR2002), Quebec City, QC, Canada, 11–15 August 2002; Volume III, pp. 581–584. [Google Scholar]
- Pixel4D: Professional Photogrammetry and Drone-Mapping. Available online: https://www.pix4d.com/ (accessed on 17 June 2019).
- Tam, G.K.L.; Cheng, Z.-Q.; Lai, Y.-K.; Langbein, F.C.; Liu, Y.; Marshall, D.; Martin, R.R.; Sun, X.-F.; Rosin, P.L. Registration of 3d point clouds and meshes: A survey from rigid to nonrigid. IEEE Trans. Vis. Comput. Gr. 2013, 19, 1199–1217. [Google Scholar] [CrossRef] [PubMed]
- Bazin, J.C.; Seo, Y.; Demonceaux, C.; Vasseur, P.; Ikeuchi, K.; Kweon, I.; Pollefeys, M. Globally optimal line clustering and vanishing point estimation in manhattan world. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 638–645. [Google Scholar]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer-Verlag London Limited: London, UK, 2011. [Google Scholar]
- Rashwan, H.A.; Chambon, S.; Gurdjos, P.; Morin, G.; Charvillat, V. Using curvilinear features in focus for registering a single image to a 3D Object. arXiv 2018, arXiv:1802.09384. [Google Scholar]
- Elbaz, G.; Avraham, T.; Fischer, A. 3D point cloud registration for localization using a deep neural network auto-encoder. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Levinson, J.; Askeland, J.; Becker, J.; Dolson, J.; Held, D.; Kammel, S.; Kolter, J.Z.; Langer, D.; Pink, O.; Pratt, V.; et al. Towards fully autonomous driving: Systems and algorithms. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 163–168. [Google Scholar]
- Wu, H.; Fan, H. Registration of airborne Lidar point clouds by matching the linear plane features of building roof facets. Remote Sens. 2016, 8, 447. [Google Scholar] [CrossRef]
- Open3D: A Modern Library for 3D Data Processing. 2019. Available online: http://www.open3d.org/docs/index.html (accessed on 17 June 2019).
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Segal, A.; Haehnel, D.; Thrun, S. Generalized-ICP. In Proceedings of the Robotics: Science and Systems (RSS) Conference, Seattle, WA, USA, 28 June–1 July 2009. [Google Scholar]
- Endres, F.; Hess, J.; Engelhard, N.; Sturm, J.; Cremers, D.; Burgard, W. An evaluation of the RGB-D SLAM system. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2012. [Google Scholar]
- Choi, S.; Zhou, Q.-Y.; Koltun, V. Robust reconstruction of indoor scenes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Johnson, A.E.; Kang, S.B. Registration and integration of textured 3D data. Image Vis. Comput. 1999, 17, 135–147. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations 2015 (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the International Conference on Intelligent Robot Systems (IROS), Vilamoura, Algarve, Portugal, 7–12 October 2012. [Google Scholar]
- Žbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and multi-View CNNs for object classification on 3D data. arXiv 2016, arXiv:1604.03265. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. PAMI 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Besl, P.J.; McKay, N.D. Method for registration of 3-d shapes. Robot.-DL Tentat. 1992, 1611, 586–607. [Google Scholar] [CrossRef]
- Makadia, A.A.P.; Daniilidis, K. Fully automatic registration of 3D point clouds. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 1297–1304. [Google Scholar]
- Lowe, D. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Computer Vision Group—Dataset Download. Available online: https://vision.in.tum.de/data/datasets/rgbd-dataset/download (accessed on 9 June 2019).
- JörgStückler, J.; Behnke, S. Multi-resolution surfel maps for efficient dense 3D modeling and tracking. J. Vis. Commun. Image Represent. 2014, 25, 137–147. [Google Scholar] [CrossRef]
- Steinbruecker, F.; Sturm, J.; Cremers, D. Real-time visual odometry from dense RGB-D images. In Proceedings of the Workshop on Live Dense Reconstruction with Moving Cameras at ICCV, Barcelona, Spain, 6–13 November 2011; pp. 719–722. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Results | Freiburg1_Plant | Freiburg1_Teddy | Freiburg2_Coke | Freiburg2_Flower | Freiburg3_Cabinet | Freiburg3_Teddy | |
|---|---|---|---|---|---|---|---|
| Input Classes | |||||||
| freiburg1_plant | 97 | 3 | 0 | 0 | 0 | 0 | |
| freiburg1_teddy | 1 | 97 | 0 | 2 | 0 | 0 | |
| freiburg2_coke | 0 | 0 | 98 | 2 | 0 | 0 | |
| freiburg2_flower | 0 | 0 | 3 | 97 | 0 | 0 | |
| Freiburg3_cabinet | 4 | 0 | 0 | 0 | 94 | 2 | |
| freiburg3_teddy | 1 | 0 | 0 | 0 | 2 | 95 | |
| Sequence | RMSE of the Relative Camera Pose Error | |||||
|---|---|---|---|---|---|---|
| Our Approach | Multiresolution Map [52] | RGB-D SLAM [40] | ||||
| k = 1 | k = 5 | k = 10 | k = 20 | |||
| freiburg1 desk2 | 1.50 × 10−16 | 0.024 | 0.052 | 0.108 | 0.060 | 0.102 |
| freiburg1 desk | 1.39 × 10−16 | 0.019 | 0.041 | 0.086 | 0.044 | 0.049 |
| freiburg1 plant | 1.22 × 10−16 | 0.015 | 0.033 | 0.066 | 0.036 | 0.142 |
| freiburg1 teddy | 1.62 × 10−16 | 0.020 | 0.044 | 0.087 | 0.061 | 0.138 |
| freiburg2 desk | 2.84 × 10−16 | 0.005 | 0.010 | 0.018 | 0.091 | 0.143 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, J.-Y.; Cheng, S.-C.; Chang, C.-C.; Chen, J.-M. Model-Based 3D Pose Estimation of a Single RGB Image Using a Deep Viewpoint Classification Neural Network. Appl. Sci. 2019, 9, 2478. https://doi.org/10.3390/app9122478
Su J-Y, Cheng S-C, Chang C-C, Chen J-M. Model-Based 3D Pose Estimation of a Single RGB Image Using a Deep Viewpoint Classification Neural Network. Applied Sciences. 2019; 9(12):2478. https://doi.org/10.3390/app9122478
Chicago/Turabian StyleSu, Jui-Yuan, Shyi-Chyi Cheng, Chin-Chun Chang, and Jing-Ming Chen. 2019. "Model-Based 3D Pose Estimation of a Single RGB Image Using a Deep Viewpoint Classification Neural Network" Applied Sciences 9, no. 12: 2478. https://doi.org/10.3390/app9122478
APA StyleSu, J. -Y., Cheng, S. -C., Chang, C. -C., & Chen, J. -M. (2019). Model-Based 3D Pose Estimation of a Single RGB Image Using a Deep Viewpoint Classification Neural Network. Applied Sciences, 9(12), 2478. https://doi.org/10.3390/app9122478