1. Introduction
Texture pattern classification was considered an important problem in computer vision for many years because of the great variety of possible applications, including non-destructive inspection of abnormalities on wood, steel, ceramics, fruit, and aircraft surfaces [
1,
2,
3,
4,
5,
6]. Texture discrimination remains a challenge since the texture of objects varies significantly according to the viewing angle, illumination conditions, scale change, and rotation [
1,
4,
7,
8]. There is also the special problem of color image retrieval related to appearance-based object recognition, which is a major field of development for several industrial vision applications [
1,
4,
7,
8].
Feature extraction of color, texture, and shape from images was used successfully to classify patterns by reducing the dimensionality and the computational complexity of the problem [
3,
9,
10,
11,
12,
13,
14,
15,
16]. Determining the appropriate features for each problem is a recurring challenge which is yet to be fully met by the computer vision community [
1,
3,
16]. Feature extraction and selection enable representation of the information present in the image, and limit the number of features, thus allowing further analysis within a reasonable time. Feature extraction was used in a wide range of applications, such as biometrics [
12,
14,
15], classification of cloth, surfaces, landscapes, wood, and rock minerals [
16,
17], saliency detection [
18], and background subtraction [
19], among others. During the past 40 years, while a substantial number of methods for grayscale texture classification were developed [
3,
5], there was also a growing interest in colored textures [
1,
2,
9,
10,
13,
20,
21]. The adaptive integration of color and texture attributes into the development of complex image descriptors is an area of intensive research in computer vision [
21]. Most of these investigations focused on the integration process in applications for digital image segmentation [
20,
22] or the aggregation of multiple preexisting image descriptors [
23]. Deep learning was applied successfully to object or scene recognition [
24] and scene classification [
25], and the use of deep neural networks for the classification of image datasets where texture features are important for generating class-conditional discriminative representations was investigated [
26].
Current approaches to color texture analysis can be classified into three groups: the parallel approach, the sequential approach, and the integrative approach [
11,
27]. The parallel approach considers texture and color as separate phenomena. Color analysis is based on the color distribution in an image, without regard to the spatial relationship between the intensities of the pixels. Texture analysis is based on the relative variation of the intensity of the neighbors, regardless of the color of the pixels. In Reference [
2], the authors first converted the original RGB images into other color spaces: HSI (Hue, Saturation, Lightness), CIE XYZ (Comission Internationale de l´Éclairage Tristimulus values), YIQ (Luminance In phase Quadrature), and CIELAB (Comission Internationale de l´Éclairage Lightness-Green-Blue), and then extracted the texture features and color separately. In a similar manner, as reported in Reference [
13], the images were transformed to the color spaces HSV and YCbCr, obtaining wavelet intensity channel features of first-order statistics on each channel. The choice of the best performing color space was an open question in recent years, since using one space instead of another can bring considerable improvements in certain applications [
28]. The quaternion representation of color was shown to be effective in segmentation in Reference [
29] and the feature extraction method, binary quaternion moment preserving (BQMP), is a method of image binarization using quaternions, with the potential for being a powerful tool in color image analysis [
6].
In the sequential approach to color texture analysis, the first step is to apply a method of indexing color images. As a result, indexed images are processed obtaining grayscale textures. The co-occurrence matrix was used extensively since it represents the probability of occurrence of the same color pixel pair at a given distance [
9]. Another example of this approach is based on texture descriptors using three different color indexing methods and three different texture features [
11]. This results in nine independent classifiers that are combined through various schemes.
Integration models are based on the interdependence of texture and color. These models can be divided into single bands, if the data of each channel is considered separately, or a multiband, if two or more channels are considered together. The advantage of the single-band approach is the easy adaptation of classical models based on a grayscale domain, such as Gabor filters [
15,
30,
31,
32], local binary patterns (LBP) or variants [
5,
7,
8,
33,
34,
35,
36,
37,
38], Galois fields [
39], or Haralick statistics [
3]. In Reference [
2], the main objective was to determine the contribution of color information for the overall performance of classification using Gabor filters and co-occurrence measures, yielding results almost 10% better than those obtained with only grayscale images. In Reference [
4], the results reported using co-occurrence matrices reached 94.41% and 99.07% on the Outex and Vistex databases, respectively. Different classifiers, such as k-nearest neighbors, neural networks, and support vector machines (SVM) [
40], are used to combine features. The latter was proven to be more efficient when feature selection is performed [
41,
42] or clustering is used [
22].
There are other methods that reached the best results in color texture analysis on databases that are publicly available. In Reference [
1], a multi-scale architecture (Multi-Scale Supervised self-Organizing Orientational-invariant Neural or multi-scale SOON) was presented that reached 91.03% accuracy on the Brodatz database, which contains 111 different colored textures. These results were compared with those of two previous studies on the same database, reported in References [
43,
44], which reached classification rates of 89.71% and 88.15%, respectively. Another approach used all the information from sensors that created the image [
4]. This method improved the results to 98.61% and 99.07%, on the same database, but required a non-trivial change in the architecture of the data collection. A texture descriptor based on a local pattern encoding scheme using local maximum sum and difference histograms was proposed in Reference [
8]. The experimental results were tested on the Outex and KTH-TIPS2b databases reaching 95.8% and 91.3%, respectively. In References [
32,
33,
36,
39], the methods were not tested in the complete databases. In References [
26,
45,
46], the methods used a different metric to calculate the classification.
A new method for the classification of complex colored textures is proposed in this paper. The images are divided into global and local samples where features are extracted to provide a new representation into global and local features. The feature extraction from different samples of the image using quadrants is described. The extraction of the features in each of the image quadrants, obtaining color and texture features in different spatial scales, is presented: the global scales using the whole image, and the local scales using quadrants. This representation seems to capture most of the information present in the image to improve colored texture classification. Then, a support vector machine classification that was performed is reported and, finally, the post-processing stage using the bagging that was implemented is presented. The proposed method was tested on four different databases: Colored Brodatz Texture [
20], VisTex [
4], Outex [
47], and KTH-TIPS2b [
48] databases. The subdivision of the training partition of the database into sub-images while extracting information from each sub-image of different sizes is also new. The results were compared to state-of-the art methods whose results were already published on the same databases.
2. Materials and Methods
The objective was to create a method for colored texture classification that would improve the classification of different complex color patterns. The BQMP method was used previously in color data compression, color edge detection, and multiclass clustering of color data, but not in classification [
6,
47]. The BQMP reduces an image to representative colors and creates a histogram that indicates the parts of the image that are represented by these colors. Therefore, the color features of the image are represented in this histogram. Haralick’s features [
3] are often extracted to characterize textures that measure the grayscale distribution, as well as considering the spatial interactions between pixels [
3,
9,
23,
38]. Creating a training set is part of the strategy for obtaining local and global features that contain all the information, local and global, for achieving correct classification. Different classifiers, such as k-nearest neighbors, neural networks, and support vector machines (SVM) [
41], are used to combine features. In Reference [
44], an SVM showed good performance compared to 16 different classification methods.
2.1. Feature Extraction Quadrants
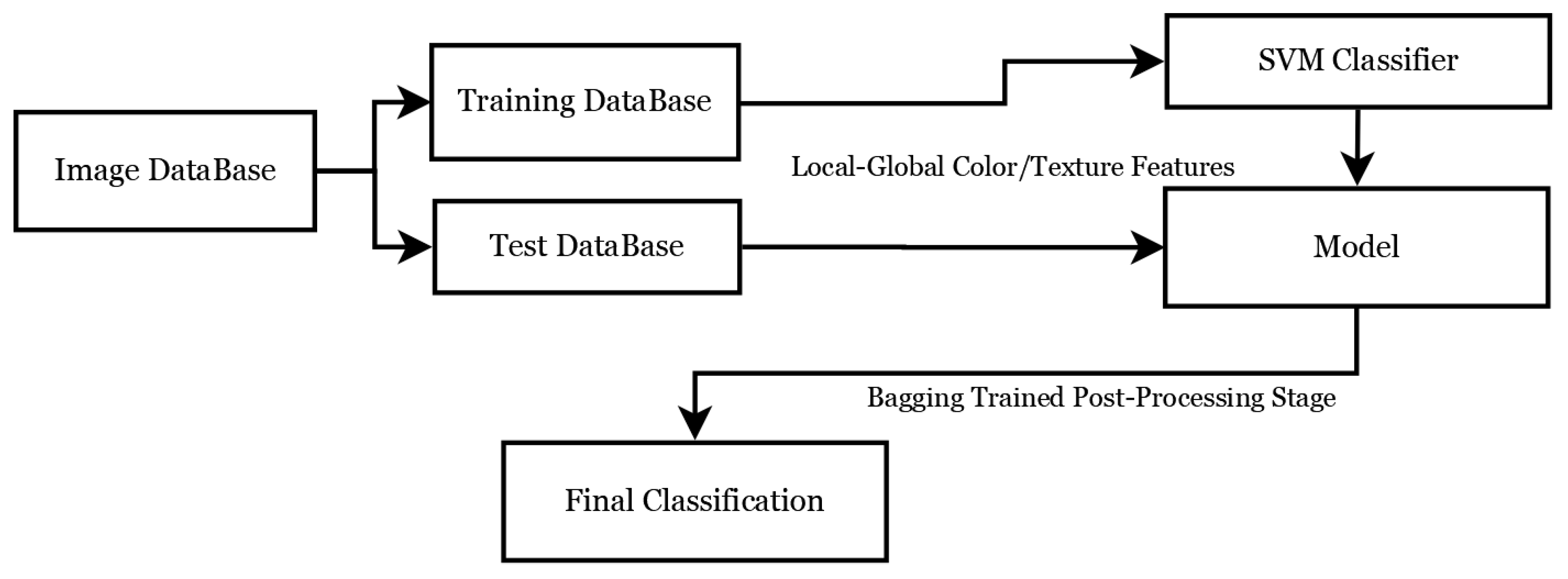
The proposed method divides the images to obtain local and global features from them. The method consists of four stages: firstly, the images in the database are divided into images to be used in training and those to be used in testing. In the second stage, color and texture features are extracted from the training images on both global and local scales. In the third stage, color and texture features are fused to become the inputs to the SVM classifier, and the last stage is a post-processing stage that uses bagging with the test images for classification. These stages are summarized in the block diagram of
Figure 1.
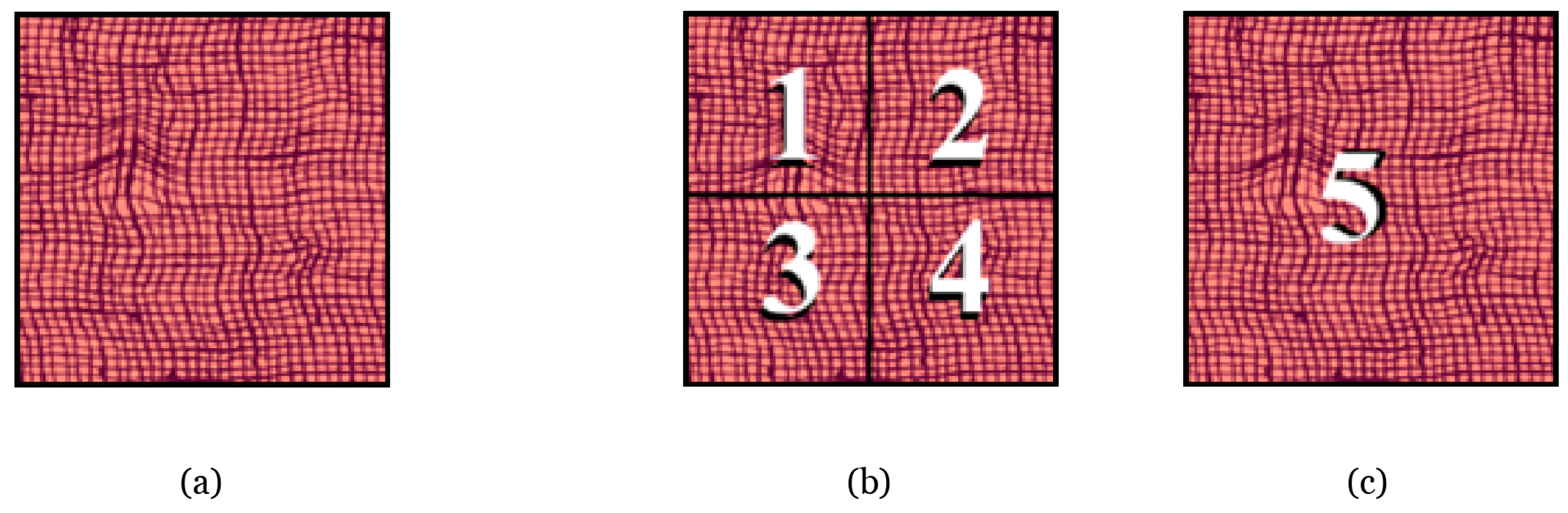
To be able to compare the performance of our method with previously published results, we used the same partition, into training and testing sets, in each database. In the case of the Brodatz database, as in Reference [
1], each colored texture image was partitioned into nine sub-images, using eight for training, and one for testing. An example of this partition is shown in
Figure 2a–c. The Brodatz Colored Texture (CBT) database has 111 images of 640 × 640 pixels. Each image in the database has a different texture.
For the Vistex database, the number of training and testing images was eight as in Reference [
4]. In the case of the Outex database, the number of training and testing sub-images was 10 as in References [
4,
9,
47]. The KTH-TIPS2b database was already partitioned into four samples, and we performed a cross-validation as in References [
7,
48].
In each case, we subdivided the training database and the test database using two parameters: n is the number of images divided by side, and r is the times we take n
2 local images from each sample. We can take r × n
2 local images to extract features from all the samples in each database.
Figure 3 shows the image subdivision scheme for the training images. It can be observed that the partitioning scheme allows obtaining features from different parts of the image, at a global and local level. The method was designed to follow this approach so that no relevant information would be lost from the image.
BQMP and Haralick (without using co-occurrence matrices) are invariant to translation and rotation; the same features are obtained if an exchange of the position of two pixels is made in the image [
3,
6,
47]. This suggests that there is spatial information present in the image that is not extracted by these features. In our proposed method, we use the two-scale scheme, local and global, to add spatial information to the extracted features. This is shown in
Figure 4, and explained in detail in
Section 2.4. The BQMP and Haralick features are extracted in each quadrant. The test images can be subdivided into local images from which the features are extracted. This allows the creation of a post-processing stage in which a bagging process can be performed. Our method is invariant to translation because of the randomness of the local image positions, but it is partially invariant to rotation because the features are concatenated in an established order. However, color features, as well as Haralick texture features, are invariant to rotation. There are problems where orientation dependency is desirable [
49].
2.2. BQMP Color Feature Extraction
After image subdivision, the BQMP was applied to each one of the local and global sub-images. This method is used as a tool for extracting color features using quaternions. Each pixel in the RGB space is represented as a quaternion. In Reference [
6], the authors showed that it is possible to obtain two quaternions that represent a different part of the image, obtaining a binarization of the image in the case of two colors. For more colors, this method can be performed recursively n times, yielding 2
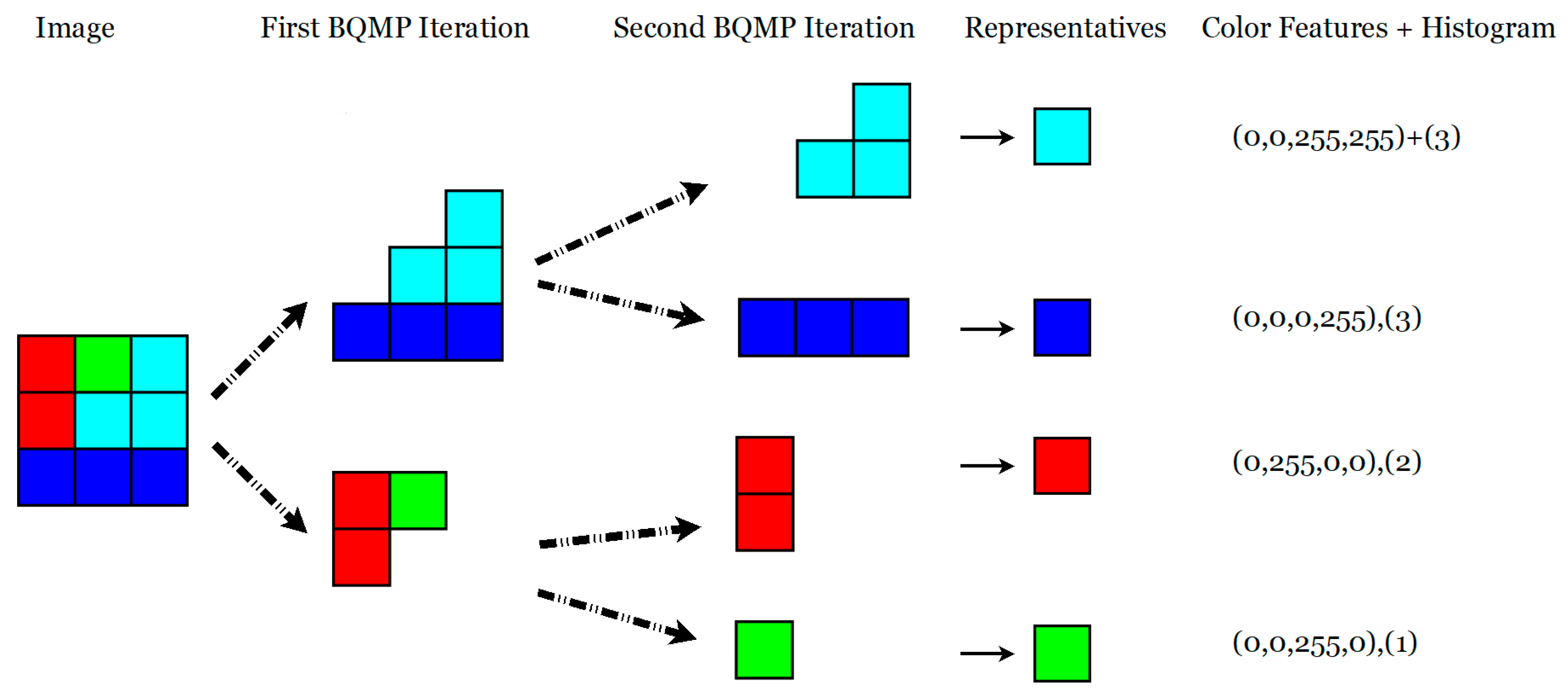
n representatives of an image, and the part of the image that each representative represents in a histogram. The process is repeated, obtaining a result with a binary tree structure.
Figure 5 shows the BQMP method for the case of four different colors. The numbers show the color code and the number of pixels represented by each.
Figure 6 shows the second iteration for the same case.
The feature vector is formed by concatenating the color code and histograms, through normalization. This vector is concatenated with the ones in other scales and the ones made using Haralick statistics, which are also normalized.
2.3. Haralick Texture Features
The Haralick texture features are angular second moment, contrast, correlation, sum of squares, inverse difference moment, sum average, sum variance, sum entropy, entropy, difference variance, difference entropy, and information measures of correlation [
3]. Other measures characterize the complexity and nature of tone transitions in each channel of the image. The usual practice is to use the first 13 Haralick features with a co-occurrence matrix [
4], but in this work, we extracted the 13Haralick features directly from the images because they provide spatial information from different regions within each image.
The Haralick features used to extract the texture features were Equations (1)–(13), and Equations (14)–(21) explain the notation employed.
Contrast:
where
.
Correlation:
where
,
,
and
are the means and standard deviations of
and
Inverse difference moment:
Information measures of correlation:
where
HX and
HY are the entropies of
px and
py, and
In Equations (1)–(13), to calculate the features, the following notation was used:
which is the (
i,
j)th pixel in a gray sub-image matrix.
which is the
ith entry in the sub-image matrix, obtained by summing the rows of
p.
which is the
jth entry in the sub-image matrix, obtained by summing the columns of
p.
where
i +
j = k and k = 2, 3, …, 2N.
where |
i −
j| = k and k = 0,1, …, N − 1.
2.4. Feature Extraction
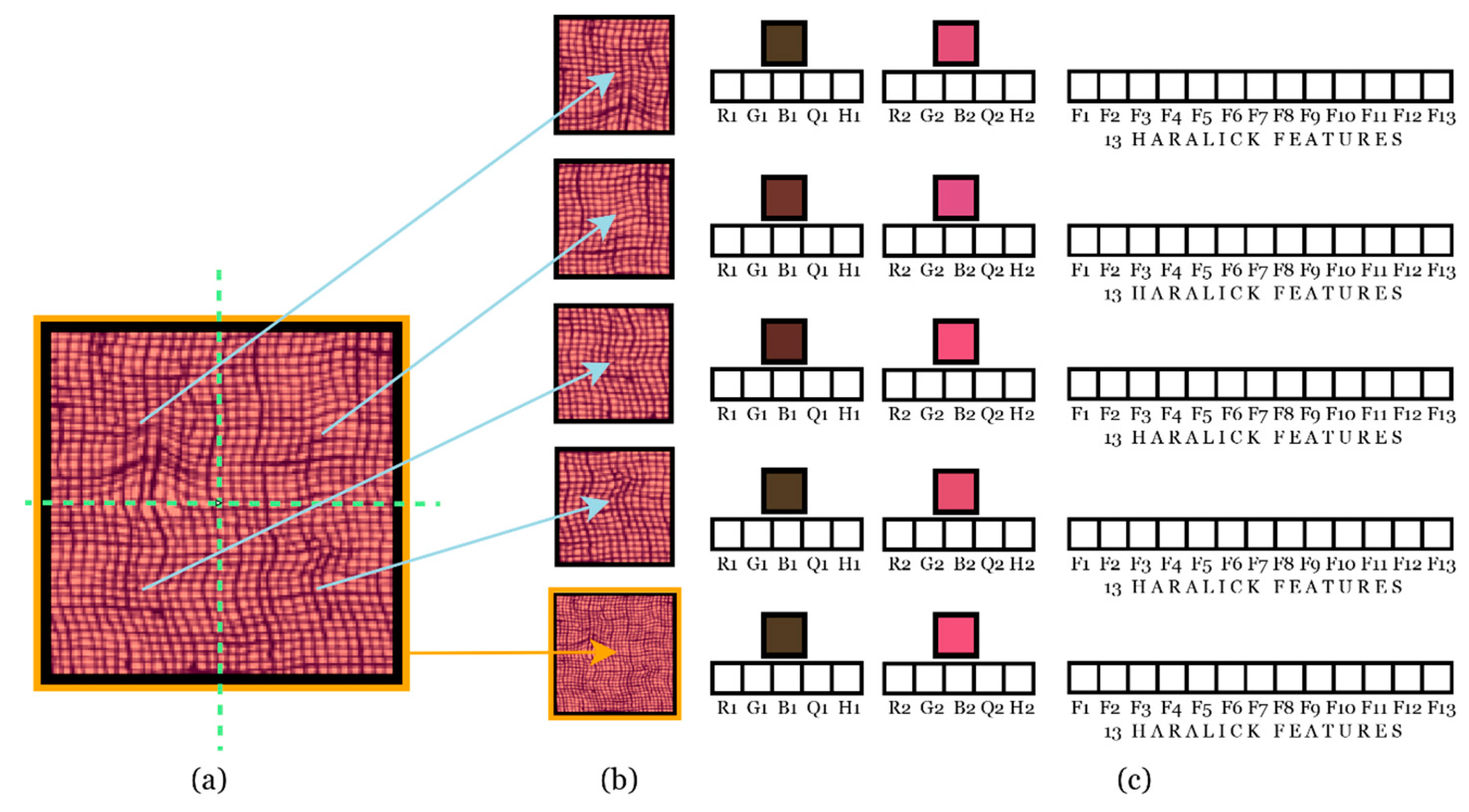
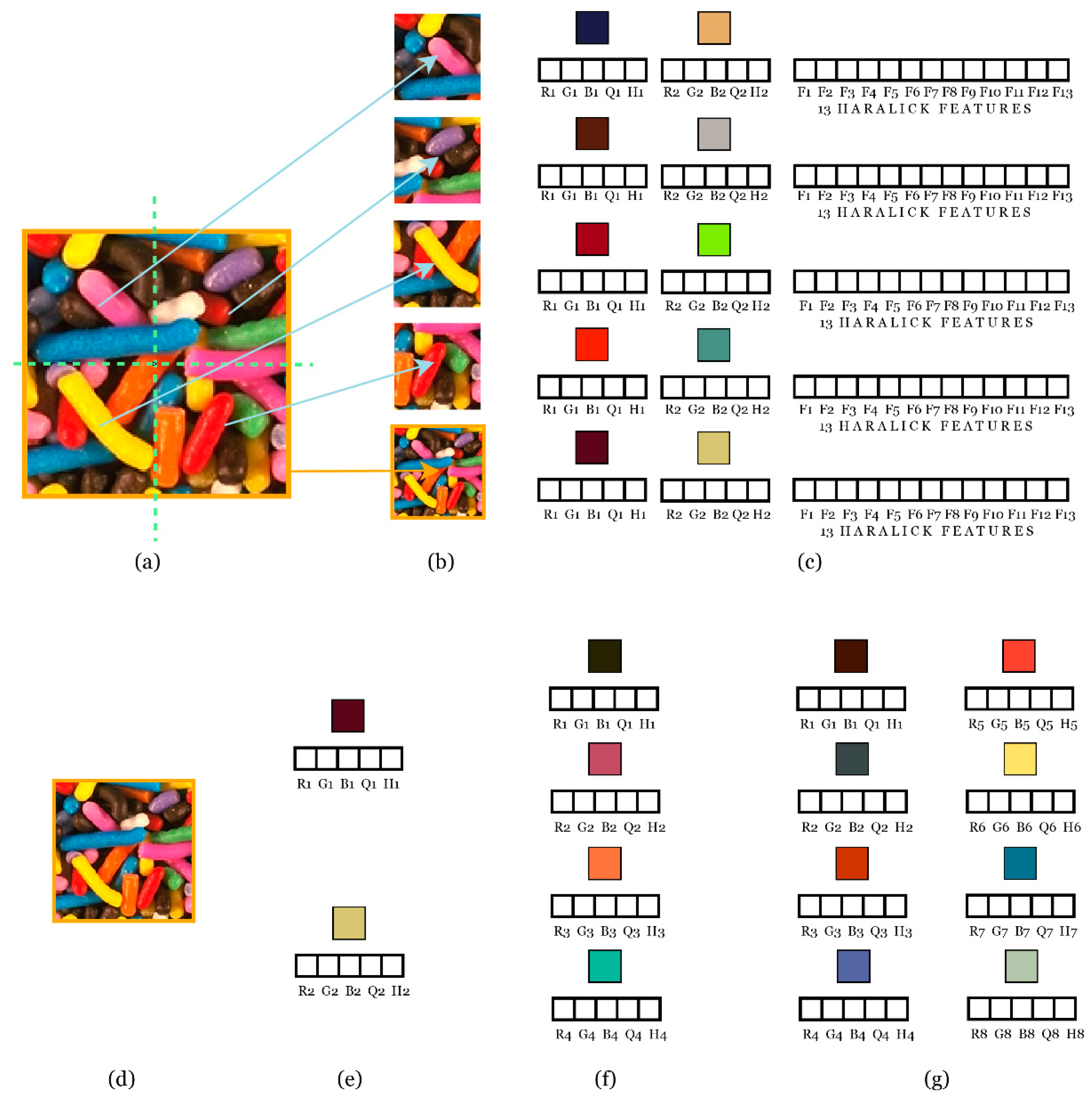
The feature extraction is performed using local and global scales. The feature vector is created by extracting features from each different image partition (local and global). An example is shown in
Figure 7. The original image (a) is divided into five partitions, (b) four local and one global (the same original image), as shown in
Figure 4. The feature vector is obtained from each partition as shown in (c). Since BQMP is applied once, we obtain different values for two representative colors for each sub-image. As in the example shown in
Figure 7c, the first representative color is brown with R1 = 78, G1 = 62, and B1 = 39. The other color is pink with R2 = 215, G2 = 80, B2 = 119. Through binarization, we know that brown represents 41% of the image and pink 59%; therefore, H1 = 0.41 and H2 = 0.59.
To achieve the binarization, the three-dimensional RGB information was transformed in a four-dimensional quaternion. Those quaternions were used to obtain the moments of order 1, 2, and 3, and the moments were used to obtain the equations of momentum conservation, to obtain the representative colors (R1,G1,B1 and R2,G2,B2) and the representative histograms (H1 and H2), as Reference [
6] described. The moments were computed using quaternion multiplication that is a four-dimensional operation. For example, in the case of two quaternions
and
, the product will be equal to
. Therefore, even if
and
are equal to zero, the real part of the multiplication will not necessarily be zero. In the case of the example, this extra information is Q1 = −0.61 in the first color and Q2 = 0.43 in the second color.
Then, we extracted the 13 Haralick features (explained in
Section 2.3) in each sub-image and each color channel, obtaining 13 × 5 × 3 = 195 more features to concatenate into the final vector.
In the texture of
Figure 7, we performed only one BQMP iteration in an image from Brodatz database, obtaining only two color representatives. In general, the BQMP method generates 2
n representatives from each image, when n iterations are used. In
Figure 5 and
Figure 6, an example for a simple color pattern shows the representatives for two iterations, n = 2. In our preliminary experiments, the results did not improve significantly for n ≥ 3, and computational time increased significantly. The feature extraction was performed in local and global scales, so that the representative colors would capture the diversity of the whole image in a local and global manner.
In the case of more complex textures, it is possible to use more iterations of the BQMP method obtaining more representative colors, histograms, and quaternions.
Figure 8 shows the feature extraction from one sample image from the Vistex database (Food0007) using one, two, or three iterations of the method.
As in the example shown in
Figure 8c, the first representative color is dark blue with R1 = 30, G1 = 32, and B1 = 69. The other color is cream with R2 = 217, G2 = 172, and B2 = 106. Through binarization, we know that dark blue represents 74% of the image and cream 26%; therefore, H1 = 0.74 and H2 = 0.26. Q1 and Q2 are 1.49 and −2.43, respectively. The Haralick features computed from Equations (1)–(13) for the first sub-image are the following: F1 = 1.09 × 10
−4, F2 = 2.66 × 10
3, F3 = 9.90 × 10
8, F4 = 4.75 × 10
3, F5 = 2.60 × 10
−2, F6 = 1.24 × 10
2, F7 = 1.65 × 10
4, F8 = 5.28, F9 = 9.32, F10 = 2.43 × 10
−5, F11= 4.63, F12 = −6.37 × 10
−2, and F13 = 6.78 × 10
−1.
2.5. SVM Classifier and Post-Processing
After features were extracted from each image, an SVM classifier was used to determine each texture class. The SVM became very popular within the machine learning community due to its great classification potential [
41,
42]. The SVM maps input vectors in a non-linear transformation to a high-dimensional space where a linear decision hyperplane is constructed for class separation. A Gaussian SVM kernel was used, and a coarse exhaustive search over the remaining SVM parameters was performed to find the optimal configuration on the training set.
A grid search with cross-validation was used to find the best parameters for the multiclass SVM cascade. We used half of the training set to determine the SVM parameters, and the other half in validation. For testing, we used a different set as explained in
Section 3.1. In the case of bagging, we took repeated samples from the original training set for balancing the class distributions to generate new balanced datasets. Two parameters were tuned: the number of decision trees voting in the ensemble, and the complexity parameter related to the size of the decision tree. The method was trained for texture classification using the training sets as they are specified for each database.
In order to have a fair comparison between our obtained classification rates and those previously published, we employed the same partitions used for training and testing as in Diaz-Pernas et al., 2011 [
1], Khan et al., 2015 [
7], Arvis et al., 2004 [
9], Mäenpää et al., 2004 [
27], Qazi et al., 2011 [
28], Losson et al., 2013 [
4], and Couto et al., 2017 [
50]. The training and test sets came from separate sub-images, and the methods never used the same sub-image for both training and testing.
In general, combining multiple classification models increases predictive performance [
51]. In the post-processing stage, a bagging predictive model composed of a weighted combination of weak classifiers was performed with the results of the SVM model [
52]. Bagging is a technique which uses bootstrap sampling to reduce the variance and improve the accuracy of a predictor [
51]. It may be used in classification and regression. We created a bagging ensemble for classification using deep trees as weak learners. The bagging predictor was trained with new images taken from the training set of each database. This result was assigned as the final classification for each image.
We compared our results with those published previously on the same databases.
2.6. Databases
It is important to validate the method on standard colored texture databases with previously published results [
53]. Therefore, we chose four colored texture databases that were used recently for this purpose: the Colored Brodatz Texture (CBT) [
20], Vistex [
4], Outex [
47], and KTH-TIPS2b [
48] databases.
The Brodatz Colored Texture (CBT) database has 111 images of 640 × 640 pixels. Each image in the database has a different texture. The Vistex Database was developed at Massachusetts Institute of Technology (MIT). It has 54 images of 512 × 512 pixels. Each image in the database has a natural color texture. The Outex Database was developed at the University of Oulu, Finland. We used 68 color texture images of 746 × 538, to obtain 1360 images of 128 × 128 with 68 different textures. Each image in the database has a natural color texture. Finally, the KTH-TIPS2b database contains images of 200 × 200 pixels. It has four samples of 108 images of 11 materials at different scales. Each image in the database has a natural color texture.
4. Discussion
The idea of combining color and texture was proposed previously, but the proposed feature extraction process allows the method to preserve the information available in the original image, yielding significantly better results than those previously published. A possible drawback of previous texture classification methods is that important information is lost from the original image with the feature extraction method, hampering its ability to improve texture classification results. The feature extraction process that includes global and local features is something new from the point of view of combining color with texture. Sub-dividing the training partition of the database into sub-images, and trying to obtain all the information present in the image using various image sizes or a different number of images is something that was not reported in previous publications.
Color and texture features are extracted in order to classify complex colored textures. However, the feature extraction process loses part of the information present in the image because the two-dimensional (2D) information is transformed into a reduced space. By using global and local features extracted from many different partitions of the image, the information needed for colored texture classification is preserved better. Sub-dividing the training data into sub-images (local–global) and trying to obtain all the information present using different image sizes is a new approach.
Although the BQMP method was proposed several years ago [
6], it was used in color data compression, color edge detection, and multiclass clustering of color data. The reduction of an image into representative colors and a histogram that indicates which part of the image is represented by these colors achieves excellent results. In addition, local and global features are extracted from each image. The results of our method were compared with those of several other feature extraction implementations on the Brodatz database with those published in References [
1,
27,
28,
31,
43,
44,
50], on the Vistex database with those published in References [
4,
9,
13,
23,
27,
28,
30,
38,
45,
46,
50], on the Outex database with those published in References [
4,
8,
9,
11,
27,
28,
30,
38,
45,
46,
50], and on the KTH-TIPS2b with those published in References [
7,
8,
31,
34,
35] (please see
Table 2,
Table 4,
Table 6 and
Table 8). The proposed method generated better results than those that were published previously.
The databases Brodatz, Vistex, Outex, and KTH2b-Tips are available for comparing the results of different texture classification methods. Tests should be performed under the same conditions. We compared our results with those of References [
1,
7] under the same conditions using the same training/test distribution, and an SVM as a classifier. We also compared our results with those of Reference [
4] in which they used a nearest-neighbor classifier (KNN) and, therefore, we tested our method with KNN instead of SVM. The results with KNN are shown in
Table 2,
Table 4,
Table 6 and
Table 8, corroborating that SVM achieves better results. The proposed method achieved better results than those previously published.
5. Conclusions
In this paper, we presented a new method for classifying complex patterns of colored textures. Our proposed method includes four main steps. Firstly, the image is divided into local and global images. This image sub-division allows feature extraction in different spatial scales, as well as adding spatial information to the extracted features. Therefore, we capture global and local features from the texture. Secondly, texture and color features are extracted from each divided image using the BQMP and Haralick algorithms. Thirdly, a support vector machine is used to classify each image with the extracted features as inputs. Fourthly, a post-processing stage using bagging is employed.
The method was tested on four databases, the Brodatz, VisTex, Outex, and KTH-TIPS2B databases, yielding correct classification rates of 97.63%, 97.13%, 90.78%, and 92.90% respectively. The post-processing stage improved the results to 99.88%, 100%, 98.97%, and 95.75%, respectively, for the same databases. We compared our results on the same databases to the best previously published results finding significant improvements of 8.85%, 0.93% (to 100%), 4.12%, and 4.45%.
The partition of the image into local and global images provides information about features at different scales and spatial locations within each image, which is useful in color/texture classification. The above, combined with the use of a post-processing stage using a bagging predictive model, allows achieving such results.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}