Anomaly Detection of CAN Bus Messages Using a Deep Neural Network for Autonomous Vehicles

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. Anomaly Detection Based on Traditional Methods
2.2. Anomaly Detection Based on Deep Learning Architecture
2.3. Triplet Loss Network
3. Proposed Method
3.1. The Overall Framework
3.2. The Shared-Weight DNN Module
3.3. The Triplet Loss Network
4. Experimental Results
4.1. Datasets
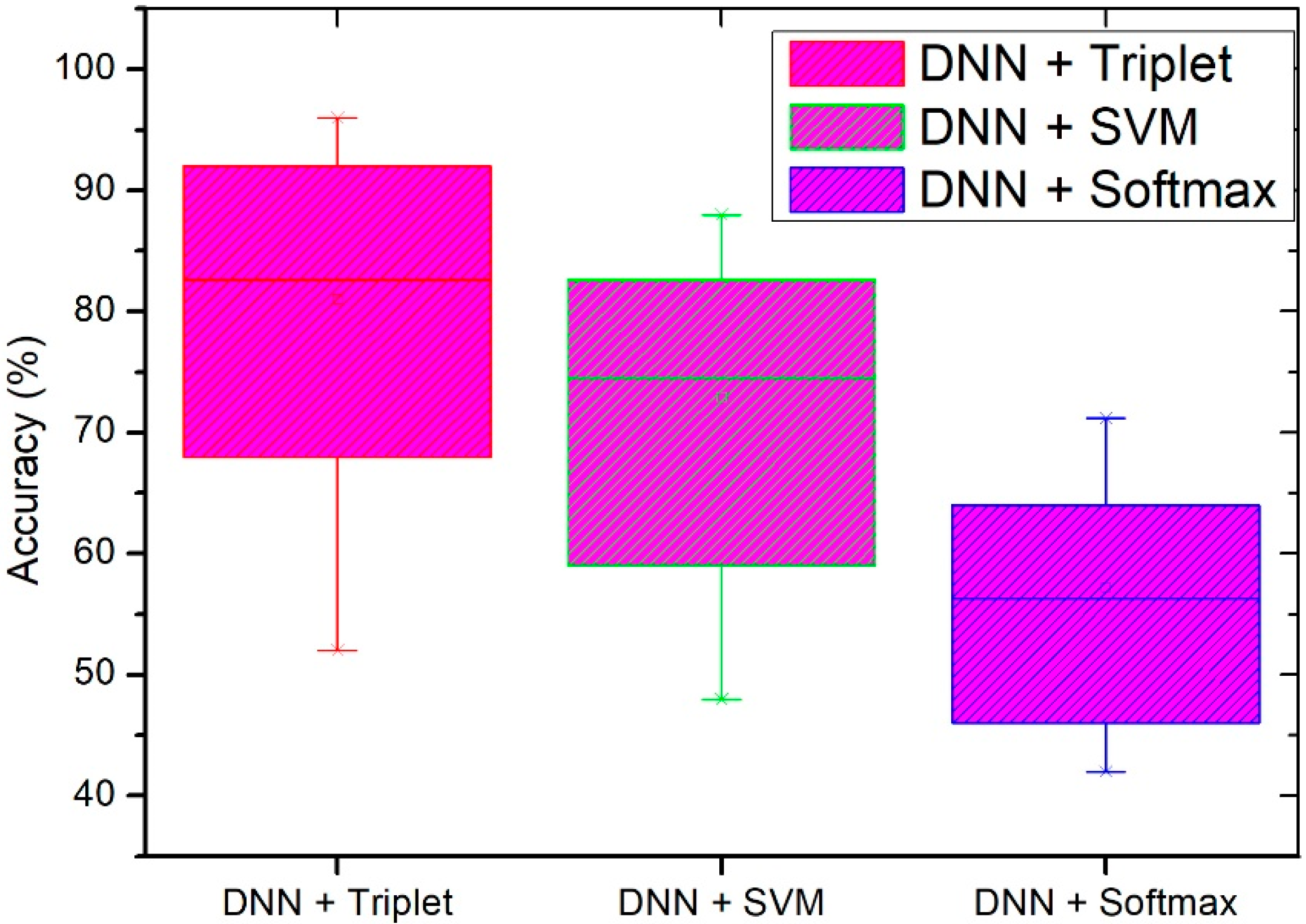
4.2. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Müter, M.; Asaj, N. Entropy-based anomaly detection for in-vehicle networks. In Proceedings of the IEEE Intelligent Vehicles Symposium, Baden-Baden, Germany, 5–9 June 2011. [Google Scholar]
- Nilsson, D.; Larson, U.E. Simulated attacks on CAN buses: vehicle virus. In Proceedings of the 5th IASTED International Conference on Communication Systems and Networks, Palma de Mallorca, Spain, 1–3 September 2008. [Google Scholar]
- Miller, C.; Valasek, C. Adventures in automotive networks and control units. Def Con. 2013, 21, 260–264. [Google Scholar]
- Miller, C.; Valasek, C. A survey of remote automotive attack surfaces. In Proceedings of the Black Hat, Las Vegas, NV, USA, 2–7 August 2014; p. 94. [Google Scholar]
- Othmane, L.B.; Weffers, H.; Mohamad, M.M.; Wolf, M. A survey of security and privacy in connected vehicles. In Wireless Sensor and Mobile Ad-Hoc Networks; Springer: New York, NY, USA, 2015; pp. 217–247. [Google Scholar]
- Markovitz, M.; Wool, A. Field classification, modeling and anomaly detection in unknown can bus networks. Veh. Commun. 2017, 9, 43–52. [Google Scholar] [CrossRef]
- Wang, J.; Ma, H. Humanoid force information detection system based on can bus. J. Huazhong Univ. Sci. Technol. 2004, 32, 164–166. [Google Scholar]
- Müter, M.; Groll, A.; Freiling, F.C. A structured approach to anomaly detection for in-vehicle networks. In Proceedings of the Sixth IEEE International Conference on Information Assurance and Security, Atlanta, GA, USA, 23–25 August 2010; pp. 92–98. [Google Scholar]
- Woo, S.; Jo, H.J.; Lee, D.H. A Practical Wireless Attack on the Connected Car and Security Protocol for In-Vehicle CAN. IEEE Trans. Intell. Transp. Syst. 2014, 16, 1–14. [Google Scholar] [CrossRef]
- Groza, B.; Murvay, S. Efficient Protocols for Secure Broadcast in Controller Area Networks. IEEE Trans. Ind. Inform. 2013, 9, 2034–2042. [Google Scholar] [CrossRef] [Green Version]
- Groza, B.; Murvay, P.S. Broadcast Authentication in a Low Speed Controller Area Network. In Proceedings of the International Conference on E-Business and Telecommunications, Rome, Italy, 24–17 July 2012; Springer: Berlin/Heidelberg, Germany. [Google Scholar]
- Groza, B.; Murvay, S.; Herrewege, A.V.; Verbauwhede, I. LiBrA-CAN: Lightweight Broadcast Authentication for Controller Area Networks. ACM Trans. Embed. Comput. Sys. 2017, 16, 1–28. [Google Scholar] [CrossRef]
- Marchetti, M.; Stabili, D. Anomaly detection of CAN bus messages through analysis of ID sequences. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017. [Google Scholar]
- Kang, M.J.; Kang, J.W. Intrusion detection system using deep neural network for in-vehicle network security. PLoS ONE 2016, 11, e0155781. [Google Scholar] [CrossRef] [PubMed]
- Moore, M.R.; Bridges, R.A.; Combs, F.L.; Starr, M.S.; Prowell, S.J. Modeling inter-signal arrival times for accurate detection of can bus signal injection attacks: a data-driven approach to in-vehicle intrusion detection. In Proceedings of the 12th Annual Conference on Cyber and Information Security Research, Oak Ridge, TN, USA, 4–6 April 2017; p. 11. [Google Scholar]
- Zang, D.; Liu, J.; Wang, H. Markov Chain-Based Feature Extraction for Anomaly Detection in Time Series and Its Industrial Application. In Proceedings of the Chinese Control and Decision Conference (CCDC), Shenyang, China, 9–11 June 2018. [Google Scholar]
- Wang, X.; Zhou, Q.; Harer, J.; Brown, G.; Chin, P. Deep learning-based classification and anomaly detection of side-channel signals. Cyber Sens. 2018. [Google Scholar] [CrossRef]
- Nawaz, S.; Calefati, A.; Ahmed, N.; Gallo, I. Handwritten Characters Recognition via Deep Metric Learning. In Proceedings of the 13th IAPR International Workshop on Document Analysis Systems (DAS), Vienna, Austria, 24–27 April 2018; pp. 417–422. [Google Scholar]
- Kumar, B.G.; Carneiro, G.; Reid, I. Learning local image descriptors with deep siamese and triplet convolutional networks by minimising global loss functions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5385–5394. [Google Scholar]
- Zhang, C.; Koishida, K. End-to-End Text-Independent Speaker Verification with Triplet Loss on Short Utterances. Interspeech 2017, 1487–1491. [Google Scholar] [CrossRef]
- Hoffer, E.; Ailon, N. Deep metric learning using triplet network. In Proceedings of the International Workshop on Similarity-Based Pattern Recognition, Copenhagen, Denmark, 12–14 October 2015; Springer: Cham, Germany; pp. 84–92. [Google Scholar]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person re-identification by multi-channel parts-based cnn with improved triplet loss function. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1335–1344. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv preprint 2017, arXiv:1703.07737. [Google Scholar]
- Li, K.; Mao, S.; Li, X.; Wu, Z.; Meng, H. Automatic lexical stress and pitch accent detection for L2 English speech using multi-distribution deep neural networks. Speech Commun. 2018, 96, 28–36. [Google Scholar] [CrossRef]
- Tuttle, A.H.; Molinaro, M.J.; Jethwa, J.F.; Sotocinal, S.G.; Prieto, J.C.; Styner, M.A.; Zylka, M.J. A deep neural network to assess spontaneous pain from mouse facial expressions. Mol. Pain 2018, 14, 1744806918763658. [Google Scholar] [CrossRef] [PubMed]
- Hannun, A.Y.; Rajpurkar, P.; Haghpanahi, M.; Tison, G.H.; Bourn, C.; Turakhia, M.P.; Ng, A.Y. Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network. Nat. Med. 2019, 25, 65. [Google Scholar] [CrossRef] [PubMed]








© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, A.; Li, Z.; Shen, Y. Anomaly Detection of CAN Bus Messages Using a Deep Neural Network for Autonomous Vehicles. Appl. Sci. 2019, 9, 3174. https://doi.org/10.3390/app9153174
Zhou A, Li Z, Shen Y. Anomaly Detection of CAN Bus Messages Using a Deep Neural Network for Autonomous Vehicles. Applied Sciences. 2019; 9(15):3174. https://doi.org/10.3390/app9153174
Chicago/Turabian StyleZhou, Aiguo, Zhenyu Li, and Yong Shen. 2019. "Anomaly Detection of CAN Bus Messages Using a Deep Neural Network for Autonomous Vehicles" Applied Sciences 9, no. 15: 3174. https://doi.org/10.3390/app9153174
APA StyleZhou, A., Li, Z., & Shen, Y. (2019). Anomaly Detection of CAN Bus Messages Using a Deep Neural Network for Autonomous Vehicles. Applied Sciences, 9(15), 3174. https://doi.org/10.3390/app9153174