Rapid Classification of Wheat Grain Varieties Using Hyperspectral Imaging and Chemometrics




Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Preparation of Wheat Seeds
2.2. Hyperspectral Imaging System
2.3. Hyperspectral Image Acquisition and Correction
2.4. Spectral Extraction and Preprocessing
2.5. Multivariate Data Analysis
2.5.1. Exploratory Classification
2.5.2. Feature Wavelengths Extraction
2.5.3. Discrimination Models
2.5.4. Visualization Map of Classification
- Isolating samples from background and extracting the average spectrum of each ROI and the spatial locations of each pixel in this ROI.
- Developing the optimal discrimination model.
- Predicting the given wheat samples’ variety according to the optimal model.
- Assigning the variety label to all pixels of spatial position of corresponding sample and forming visualization classification by pseudo-color map.
2.6. Software
3. Results and Discussion
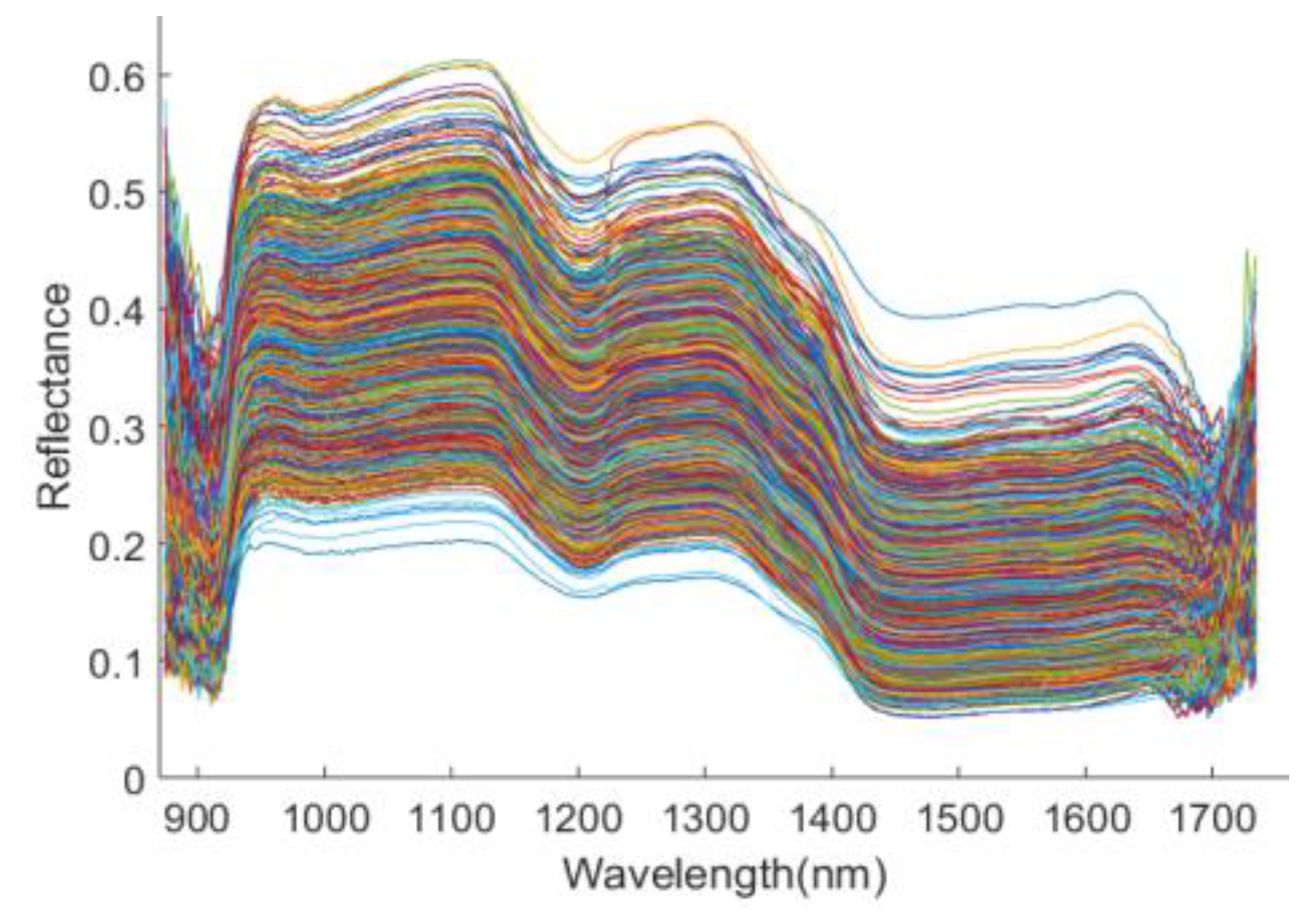
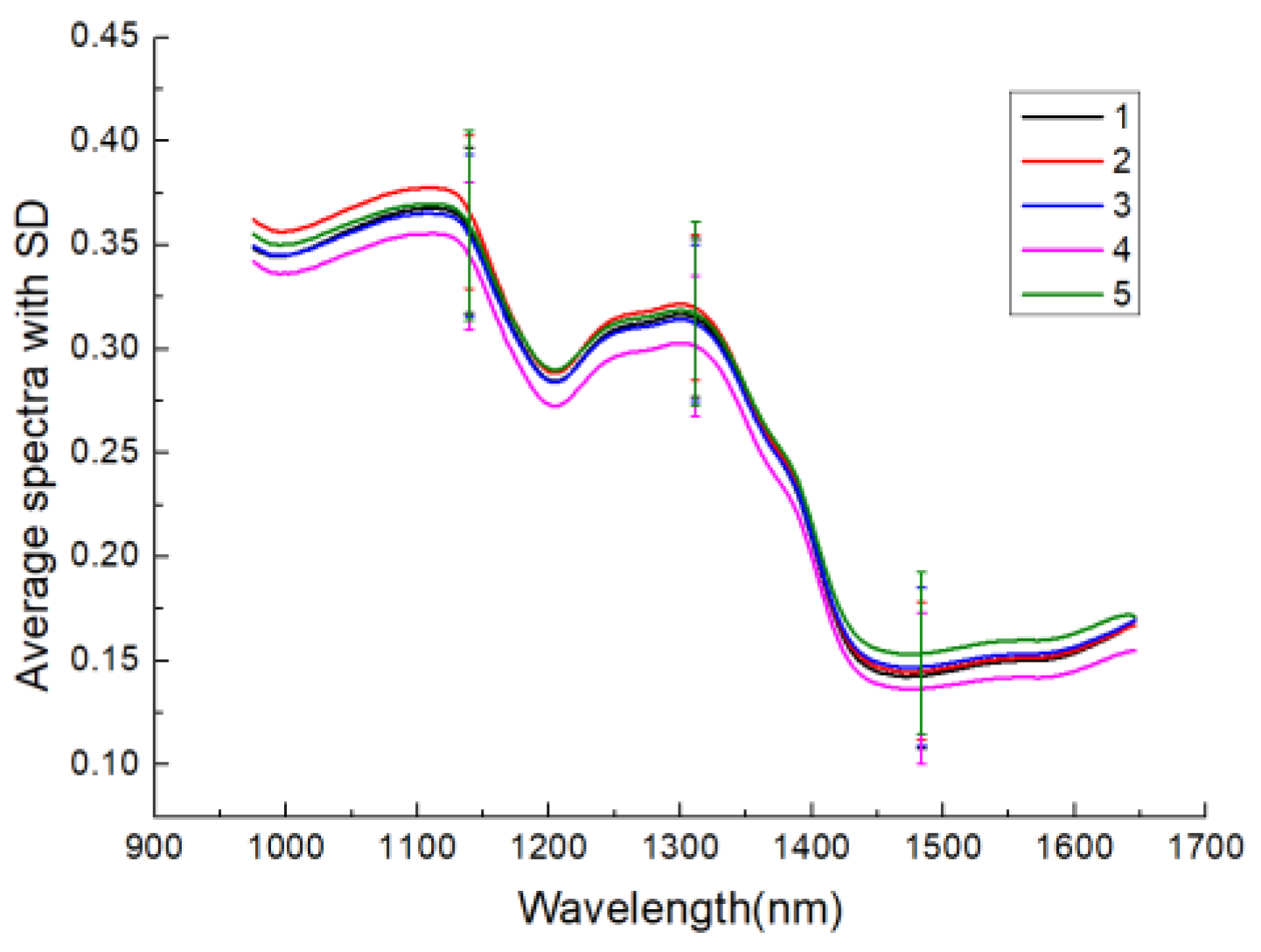
3.1. Analysis of Spectral Profiles
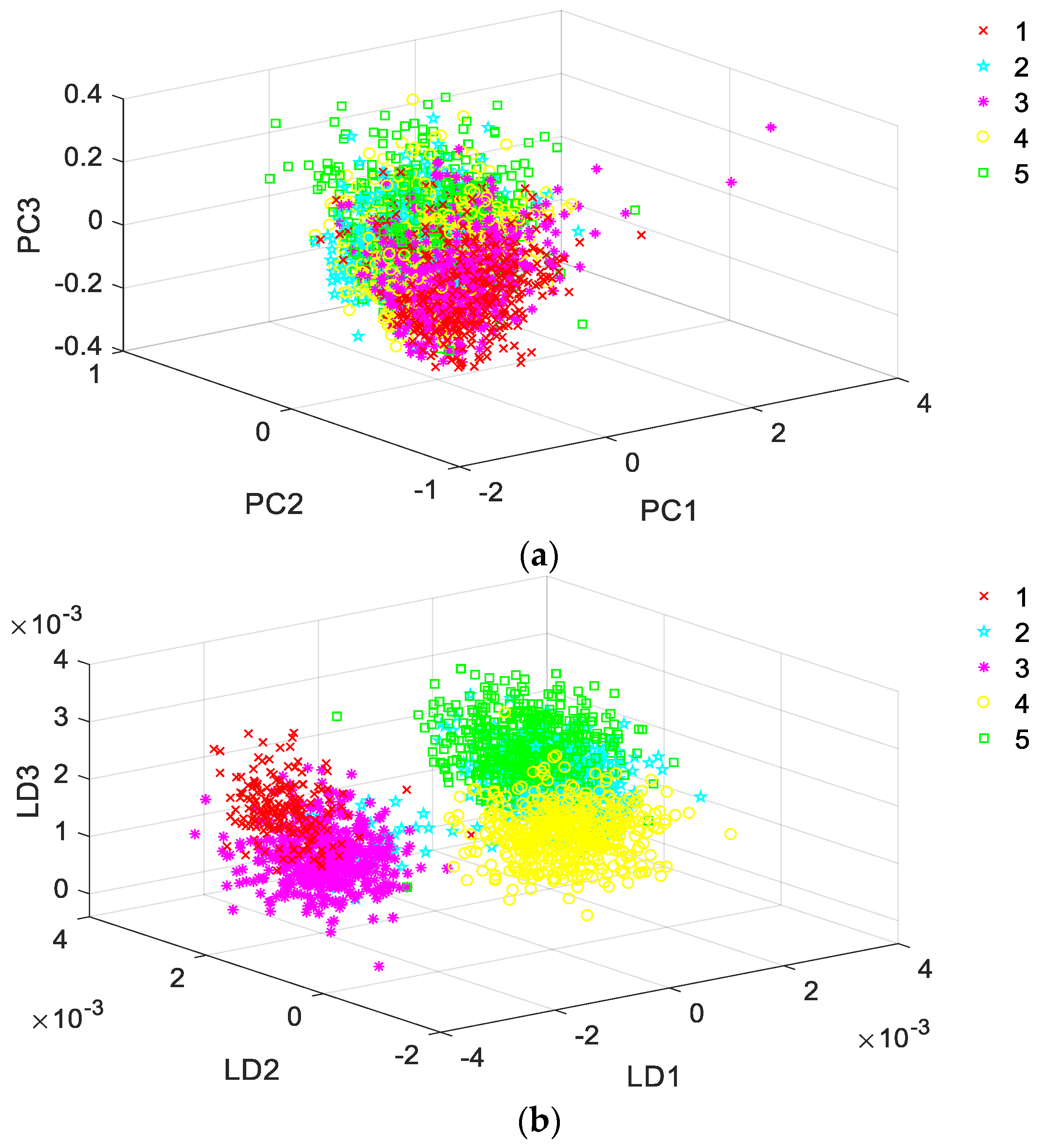
3.2. Exploratory Classification Analysis
3.3. Classification Results and Analysis of Discriminant Models Based on Full Wavelengths
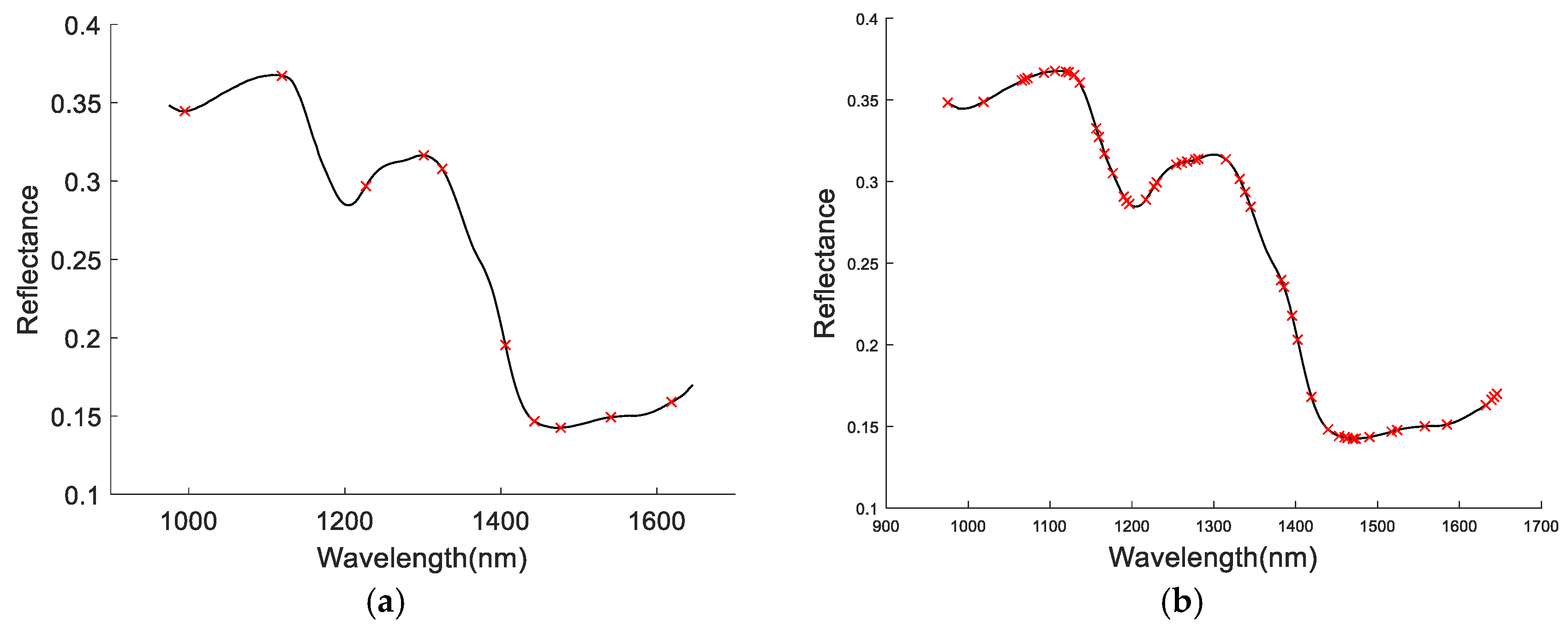
3.4. Extraction of Feature Wavelengths
3.5. Classification Results and Analysis of Discriminant Models Based on Feature Wavelengths
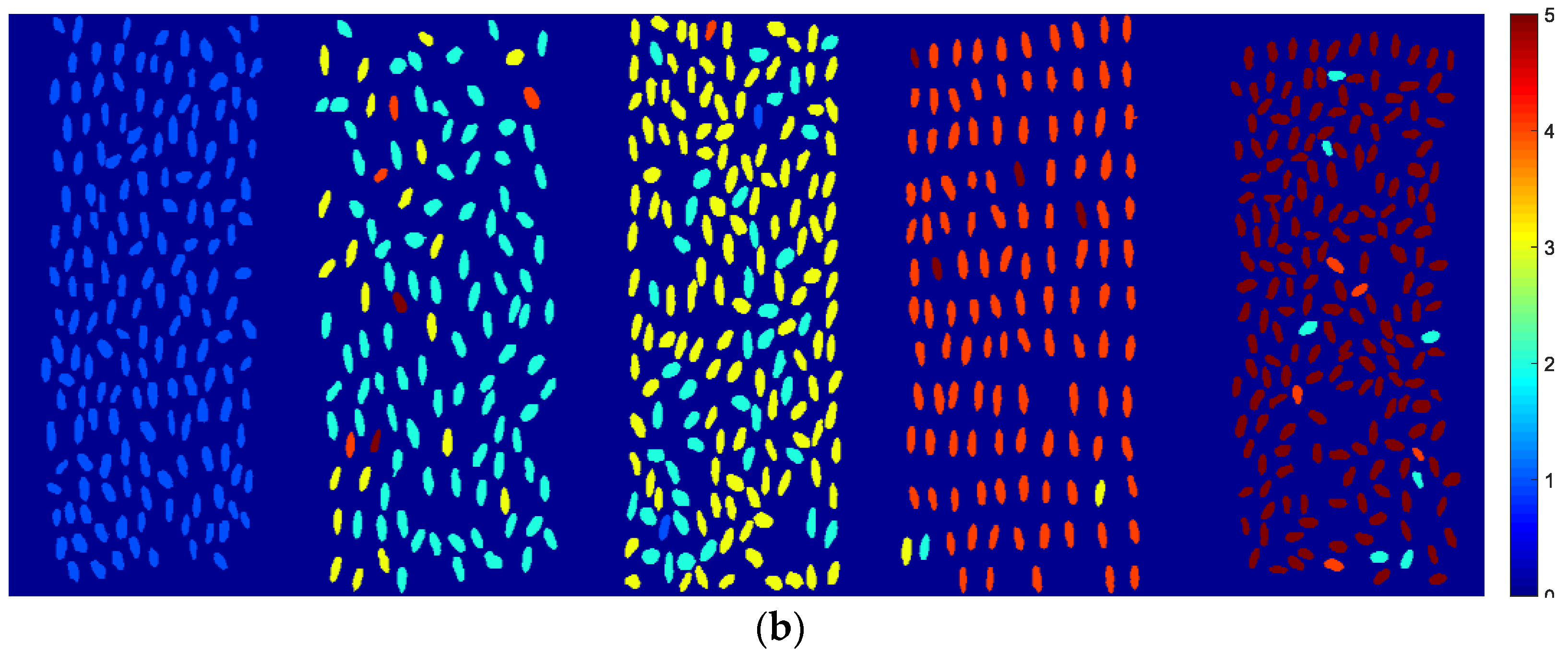
3.6. Classification Visualization of Wheat Varieties
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- FAOSTAT. Food and Agricultural Commodities Production. 2017. Available online: http://www.fao.org/faostat/en/#data/QC (accessed on 1 July 2019).
- FAOSTAT. Food Supply. 2013. Available online: http://www.fao.org/faostat/en/#data/CC (accessed on 1 July 2019).
- Fayyazi, S.; Abbaspourfard, M.H.; Rohani, A.; Monadjemi, S.A.; Sadrnia, H. Identification and classification of three Iranian rice varieties in mixed bulks using image processing and mlp neural network. J. Food Eng. 2017, 13, 20160121. [Google Scholar] [CrossRef]
- Manickavasagan, A.; Sathya, G.; Jayas, D.S.; White, N.D.G. Wheat class identification using monochrome images. J. Cereal Sci. 2008, 47, 518–527. [Google Scholar] [CrossRef]
- Li, G.; Li, Y.; Zhang, M. Study on identification of rice seeds by chemical oscillation fingerprints. RSC Adv. 2015, 5, 96472–96477. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, H.; Liu, F.; He, Y. Application of near-infrared hyperspectral imaging with variable selection methods to determine and visualize caffeine content of coffee beans. Food Bioprocess Technol. 2017, 10, 213–221. [Google Scholar] [CrossRef]
- Anisur, R.; Byoung-Kwan, C. Assessment of seed quality using non-destructive measurement techniques: A review. Seed Sci. Res. 2016, 26, 285–305. [Google Scholar]
- Gowen, A.A.; O’Donnell, C.P.; Cullen, P.J.; Downey, G.; Frias, J.M. Hyperspectral imaging–An emerging process analytical tool for food quality and safety control. Trends Food Sci. Technol. 2007, 18, 590–598. [Google Scholar] [CrossRef]
- Plaza, A.; Benediktsson, J.A.; Boardman, J.W.; Brazile, J.; Bruzzone, L.; Camps-Valls, G.; Chanussot, J.; Fauvel, M.; Gamba, P.; Gualtieri, A.; et al. Recent advances in techniques for hyperspectral image processing. Remote Sens. Environ. 2009, 113, S110–S122. [Google Scholar] [CrossRef]
- Rodionova, O.; Roger, J.M.; Walczak, B.; Tauler, R. Chemometrics in analytical chemistry—Part II: Modeling, validation, and applications. Anal. Bioanal. Chem. 2018, 410, 6691–6704. [Google Scholar]
- Zheng, Q.; Jian, C.; Zhao, Y.; Zhu, S.; He, Y.; Zhang, C. Variety identification of single rice seed using hyperspectral imaging combined with convolutional neural network. Appl. Sci. 2018, 8, 212. [Google Scholar]
- Huang, M.; He, C.; Zhu, Q.; Qin, J. Maize seed variety classification using the integration of spectral and image features combined with feature transformation based on hyperspectral imaging. Appl. Sci. 2016, 6, 183. [Google Scholar] [CrossRef]
- Du, Y.; Chen, X.; Liang, K.; Xu, J.H.; Shen, M.X.; Lu, W. Identification of deoxynivalenol content in wheat based on the hyperspectral image system. Sci. Technol. Food Ind. 2016, 37, 54–58. [Google Scholar]
- Ravikanth, L.; Singh, C.B.; Jayas, D.S.; White, N.D. Performance evaluation of a model for the classification of contaminants from wheat using near-infrared hyperspectral imaging. Biosyst. Eng. 2016, 147, 248–258. [Google Scholar] [CrossRef]
- Senthilkumar, T.; Jayas, D.S.; White, N.D.G.; Fields, P.G.; Gräfenhan, T. Detection of ochratoxin a contamination in stored wheat using near-infrared hyperspectral imaging. Infrared Phys. Technol. 2017, 81, 228–235. [Google Scholar] [CrossRef]
- Wu, N.; Zhang, Y.; Na, R.; Mi, C.; Zhu, S.; He, Y.; Zhang, C. Variety identification of oat seeds using hyperspectral imaging: Investigating the representation ability of deep convolutional neural network. RSC Adv. 2019, 9, 12635–12644. [Google Scholar] [CrossRef]
- Ravikanth, L.; Singh, C.B.; Jayas, D.S.; White, N.D. Classification of contaminants from wheat using near-infrared hyperspectral imaging. Biosyst. Eng. 2015, 135, 73–86. [Google Scholar] [CrossRef]
- Asmund, R.; Berg, F.V.D.; Søren, B.E. Review of the most common pre-processing techniques for near-infrared spectra. Trac-Trend Anal. Chem. 2009, 28, 1201–1222. [Google Scholar]
- De Luca, M.; Restuccia, D.; Clodoveo, M.L.; Puoci, F.; Ragno, G. Chemometric analysis for discrimination of extra virgin olive oils from whole and stoned olive pastes. Food Chem. 2016, 202, 432–437. [Google Scholar] [CrossRef] [PubMed]
- Puneet, M.; Alison, N.; Julius, T.; Guoping, L.; Sally, R.; Stephen, M. Near-infrared hyperspectral imaging for non-destructive classification of commercial tea products. J. Food Eng. 2018, 238, 70–77. [Google Scholar] [Green Version]
- Feng, X.; Zhao, Y.; Zhang, C.; Cheng, P.; He, Y. Discrimination of transgenic maize kernel using NIR hyperspectral imaging and multivariate data analysis. Sensors 2017, 17, 1894. [Google Scholar] [CrossRef]
- Nie, P.; Dong, T.; He, Y.; Xiao, S. Research on the effects of drying temperature on nitrogen detection of different soil types by near infrared sensors. Sensors 2018, 18, 391. [Google Scholar] [CrossRef]
- Milanez, K.D.T.M.; Nóbrega, T.C.A.; Nascimento, D.S.; Insausti, M.; Band, B.S.F.; Pontes, M.J.C. Multivariate modeling for detecting adulteration of extra virgin olive oil with soybean oil using fluorescence and UV–Vis spectroscopies: A preliminary approach. LWT-Food Sci. Technol. 2017, 85, 9–15. [Google Scholar] [CrossRef]
- Saerens, M.; Fouss, F.; Yen, L.; Dupont, P. The principal components analysis of a graph, and its relationship to spectral clustering. In Proceedings of the 15th European Conference on Machine Learning (ECML’04), Pisa, Italy, 20–24 September 2004; pp. 371–383. [Google Scholar]
- Li, H.D.; Xu, Q.S.; Liang, Y.Z. Random frog: An efficient reversible jump Markov Chain Monte Carlo-like approach for variable selection with applications to gene selection and disease classification. Anal. Chim. Acta 2012, 740, 20–26. [Google Scholar] [CrossRef] [PubMed]
- Hu, M.; Zhai, G.; Zhao, Y.; Wang, Z. Uses of selection strategies in both spectral and sample spaces for classifying hard and soft blueberry using near infrared data. Sci. Rep. 2018, 8, 6671. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gerhardt, N.; Schwolow, S.; Rohn, S.; Pérez-Cacho, P.R.; Galán-Soldevilla, H.; Arce, L.; Weller, P. Quality assessment of olive oils based on temperature-ramped HS-GC-IMS and sensory evaluation: Comparison of different processing approaches by LDA, kNN, and SVM. Food Chem. 2019, 286, 307–308. [Google Scholar] [CrossRef] [PubMed]
- Mavroforakis, M.E.; Theodoridis, S. A geometric approach to Support Vector Machine (SVM) classification. IEEE Trans. Neural Netw. Lear. 2006, 17, 671–682. [Google Scholar] [CrossRef]
- Yuan, Y.; Zhi, B.; Zhao, B. Novel variable selection method based on uninformative variable elimination and ridge extreme learning machine: CO gas concentration retrieval trial. Spectrosc. Spect. Anal. 2017, 37, 299–305. [Google Scholar]
- Zhang, C.; Liu, F.; He, Y. Identification of coffee bean varieties using hyperspectral imaging: Influence of preprocessing methods and pixel-wise spectra analysis. Sci. Rep. 2018, 8, 2166. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, Y.R. Two-dimensional correlation spectroscopy study of visible and near-infrared spectral intensity variations of chicken meats in cold storage. Appl. Spectrosc. 2000, 54, 1458–1470. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, Y.R.; Ozaki, Y. Two-dimensional visible/near-infrared correlation spectroscopy study of thermal treatment of chicken meats. J. Agric. Food Chem. 2000, 48, 901–908. [Google Scholar] [CrossRef]
- Ribeiro, J.S.; Ferreira, M.M.C.; Salva, T.J.G. Chemometric models for the qantitative descriptive sensory analysis of Arabica coffee beverages using near infrared spectroscopy. Talanta 2011, 83, 1352–1358. [Google Scholar] [CrossRef]
- Vance, C.K.; Tolleson, D.R.; Kinoshita, K.; Rodriguez, J.; Foley, W.J. Near infrared spectroscopy in wildlife and biodiversity. J. Near Infrared Spectrosc. 2016, 24, 1–25. [Google Scholar] [CrossRef]
- Serranti, S.; Cesare, D.; Marini, F.; Bonifazi, G. Classification of oat and groat kernels using NIR hyperspectral imaging. Talanta 2013, 103, 276–284. [Google Scholar] [CrossRef] [PubMed]
- Cen, H.; He, Y. Theory and application of near infrared reflectance spectroscopy in determination of food quality. Trends Food Sci. Technol. 2007, 18, 72–83. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhu, S.; Zhang, C.; Feng, X.; Feng, L.; He, Y. Application of hyperspectral imaging and chemometrics for variety classification of maize seeds. RSC Adv. 2018, 8, 1337–1345. [Google Scholar] [CrossRef] [Green Version]
- Feng, X.; Peng, C.; Chen, Y.; Liu, X.; Feng, X.; He, Y. Discrimination of CRISPR/Cas9-induced mutants of rice seeds using near-infrared hyperspectral imaging. Sci. Rep. 2017, 7, 15934. [Google Scholar] [CrossRef]
- Workman, J., Jr.; Weyer, L. Practical guide and spectral atlas for interpretive near-infrared spectroscopy. In Book Practical Guide and Spectral Atlas for Interpretive Near-Infrared Spectroscopy, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Liu, Y.; Chen, Y.R. Two-dimensional visible/near-infrared correlation spectroscopy study of thawing behavior of frozen chicken meats without exposure to air. Meat Sci. 2001, 57, 299–310. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prepro. | LDA | SVM | ELM | |||||
|---|---|---|---|---|---|---|---|---|
| Cal./% | Pre./% | (c, g) | Cal./% | Pre./% | n | Cal./% | Pre./% | |
| Raw | 85.19 | 84.02 | (23,170.475, 0.35355) | 90.13 | 87.81 | 2800 | 91.30 | 86.26 |
| WT | 82.30 | 81.81 | (32,768, 0.5) | 86.5 | 85.03 | 2100 | 88.97 | 85.35 |
| SNV | 84.32 | 82.93 | (1024, 0.5) | 92.82 | 87.70 | 2100 | 91.07 | 85.87 |
| MSC | 84.23 | 82.82 | (4096, 2.0) | 88.27 | 86.18 | 2700 | 90.96 | 85.64 |
| Var. | Calibration Set | Prediction Set | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | Acc./% | 1 | 2 | 3 | 4 | 5 | Acc./% | |
| 1 | 5831 | 12 | 64 | 3 | 0 | 98.66 | 1432 | 8 | 36 | 1 | 1 | 96.89 |
| 2 | 17 | 3906 | 735 | 34 | 300 | 78.25 | 11 | 894 | 250 | 10 | 83 | 71.63 |
| 3 | 179 | 632 | 4258 | 21 | 25 | 83.25 | 78 | 224 | 950 | 15 | 12 | 74.28 |
| 4 | 0 | 15 | 32 | 4915 | 98 | 97.13 | 0 | 12 | 16 | 1190 | 48 | 94.00 |
| 5 | 0 | 89 | 14 | 62 | 5551 | 97.11 | 1 | 61 | 17 | 37 | 1314 | 91.89 |
| Total | 91.30 | 86.26 | ||||||||||
| Method | Num. | The Feature Wavelengths (nm) |
|---|---|---|
| SPA | 10 | 995, 1119, 1301, 1405, 1442, 1475, 1618, 1324, 1227, 1540 |
| PCA loading | 36 | 995.15, 1005.22, 1025.37, 1048.88, 1062.31, 1095.92, 1102.64, 1112.72, 1122.81, 1129.54, 1173.26, 1179.99, 1200.19, 1203.55, 1227.12, 1281.01, 1301.23, 1304.60, 1311.35, 1321.46, 1372.05, 1378.80, 1395.67, 1405.79, 1412.54, 1439.55, 1446.31, 1469.95, 1473.33, 1483.46, 1551.07, 1561.21, 1574.74, 1584.89, 1622.12, 1628.89 |
| RF | 50 | 975.01, 1018.65, 1065.67, 1069.03, 1072.39, 1092.5601, 1106, 1119.45, 1122.81, 1129.54, 1136.26, 1156.4399, 1159.81, 1166.54, 1176.63, 1190.09, 1193.46, 1203.55, 1217.02, 1227.12, 1230.49, 1254.06, 1260.8, 1267.54, 1277.64, 1281.01, 1314.72, 1331.57, 1338.32, 1345.06, 1382.17, 1385.54, 1395.67, 1402.42, 1419.29, 1439.55, 1453.06, 1459.8101, 1463.19, 1469.95, 1473.33, 1490.22, 1517.26, 1524.02, 1557.83, 1584.89, 1632.27, 1639.04, 1642.43, 1645.82 |
| Feature Extracting Method | LDA | SVM | ELM | |||||
|---|---|---|---|---|---|---|---|---|
| Cal./% | Pre./% | (c, g) | Cal./% | Pre./% | n | Cal./% | Pre./% | |
| PCA loading | 60.72 | 61.12 | (32,768, 2) | 66.93 | 66.05 | 2600 | 79.39 | 72.0 |
| SPA | 64.89 | 65.54 | (32,768, 8) | 70.46 | 70.62 | 2400 | 70.06 | 70.54 |
| RF | 79.62 | 78.48 | (32,768, 2) | 84.37 | 82.00 | 2400 | 87.74 | 83.24 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bao, Y.; Mi, C.; Wu, N.; Liu, F.; He, Y. Rapid Classification of Wheat Grain Varieties Using Hyperspectral Imaging and Chemometrics. Appl. Sci. 2019, 9, 4119. https://doi.org/10.3390/app9194119
Bao Y, Mi C, Wu N, Liu F, He Y. Rapid Classification of Wheat Grain Varieties Using Hyperspectral Imaging and Chemometrics. Applied Sciences. 2019; 9(19):4119. https://doi.org/10.3390/app9194119
Chicago/Turabian StyleBao, Yidan, Chunxiao Mi, Na Wu, Fei Liu, and Yong He. 2019. "Rapid Classification of Wheat Grain Varieties Using Hyperspectral Imaging and Chemometrics" Applied Sciences 9, no. 19: 4119. https://doi.org/10.3390/app9194119
APA StyleBao, Y., Mi, C., Wu, N., Liu, F., & He, Y. (2019). Rapid Classification of Wheat Grain Varieties Using Hyperspectral Imaging and Chemometrics. Applied Sciences, 9(19), 4119. https://doi.org/10.3390/app9194119