A Novel Massive Deployment Solution Based on the Peer-to-Peer Protocol


Abstract
:1. Introduction
2. Related Works
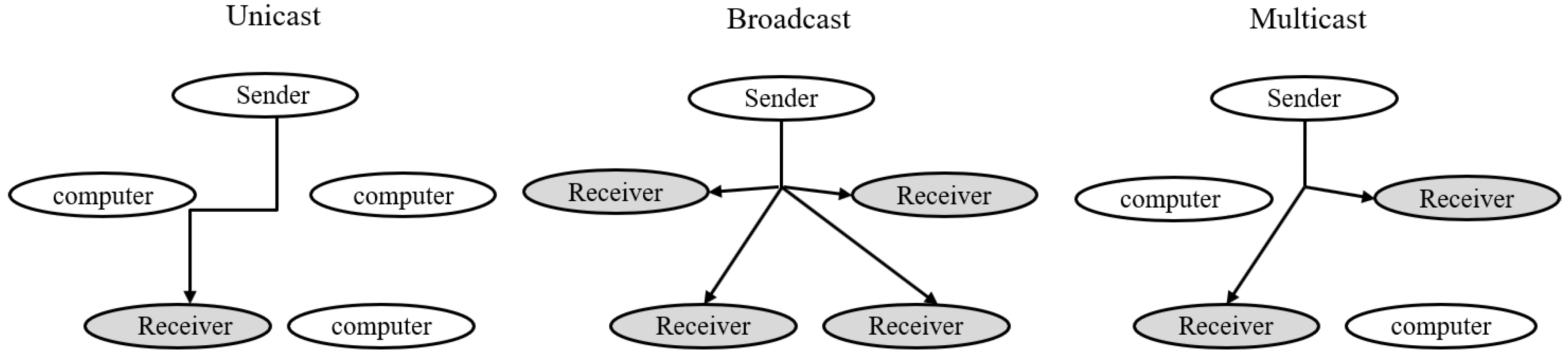
2.1. Unicast, Broadcast, and Multicast Protocols for System Deployment
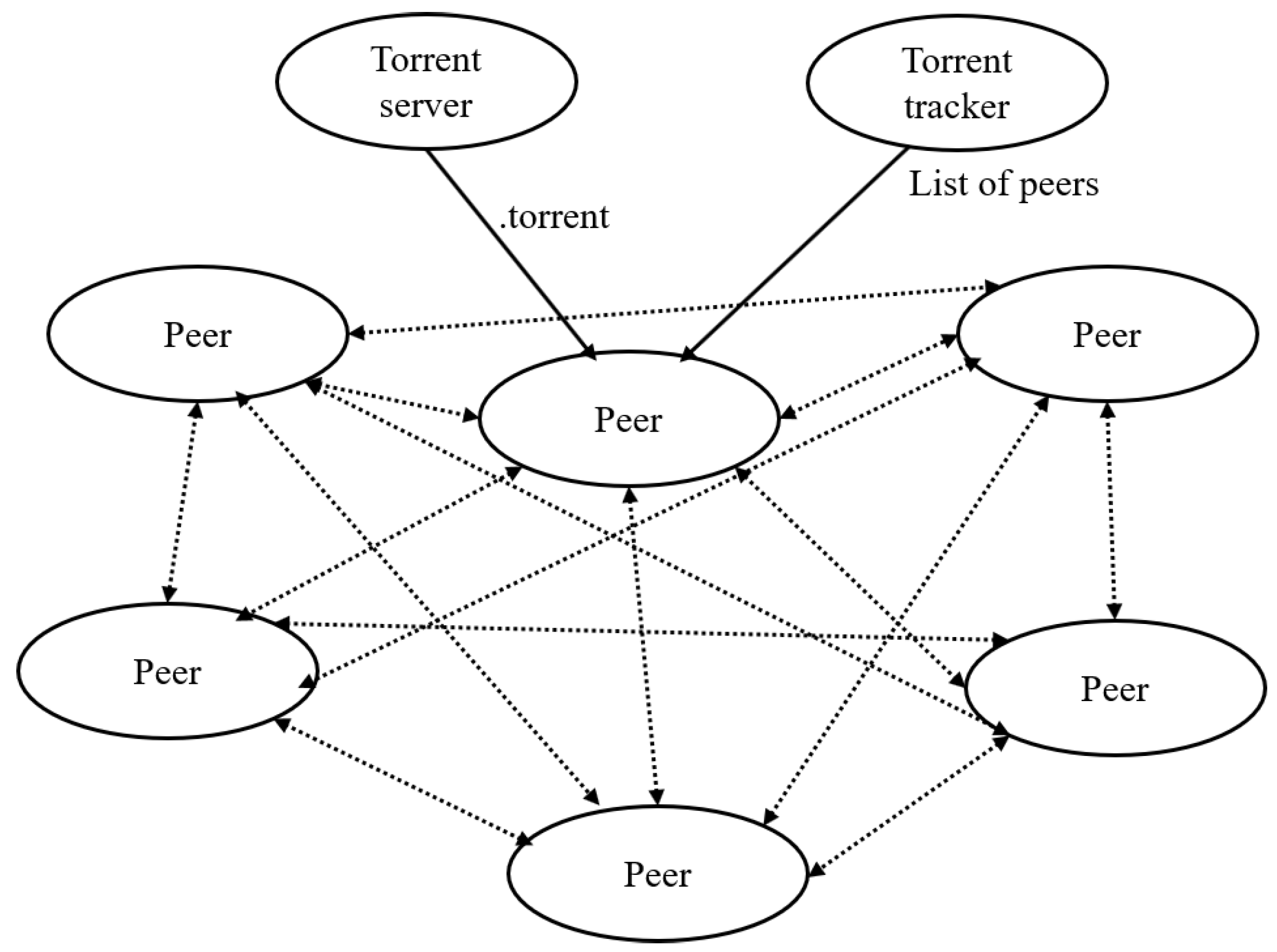
2.2. P2P Protocol for System Deployment
2.3. Other Related Works
2.3.1. Live System
2.3.2. Netboot
2.3.3. DHCP Relay Mechanism
2.3.4. Post-Deployment Tuning Process
3. Design and Implementation
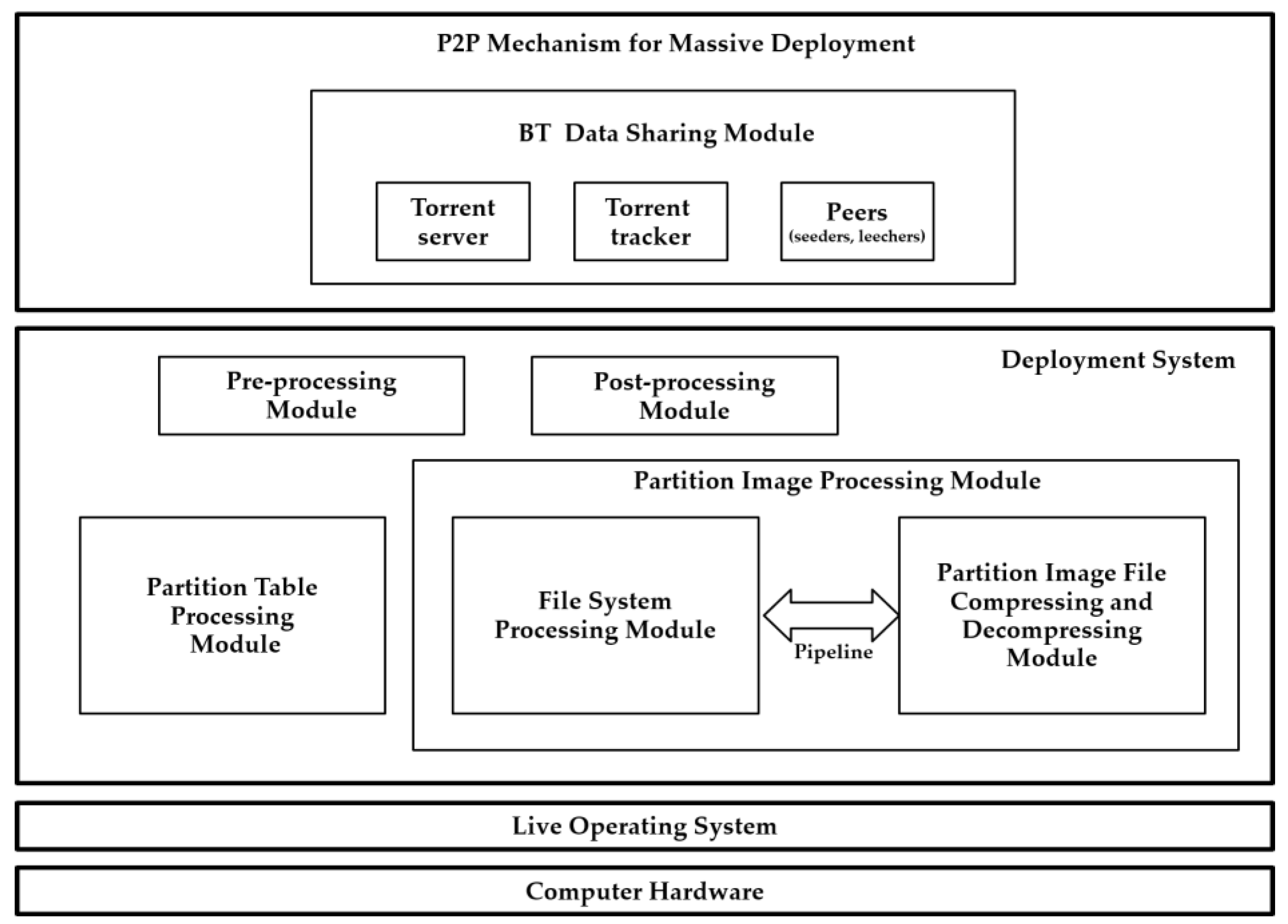
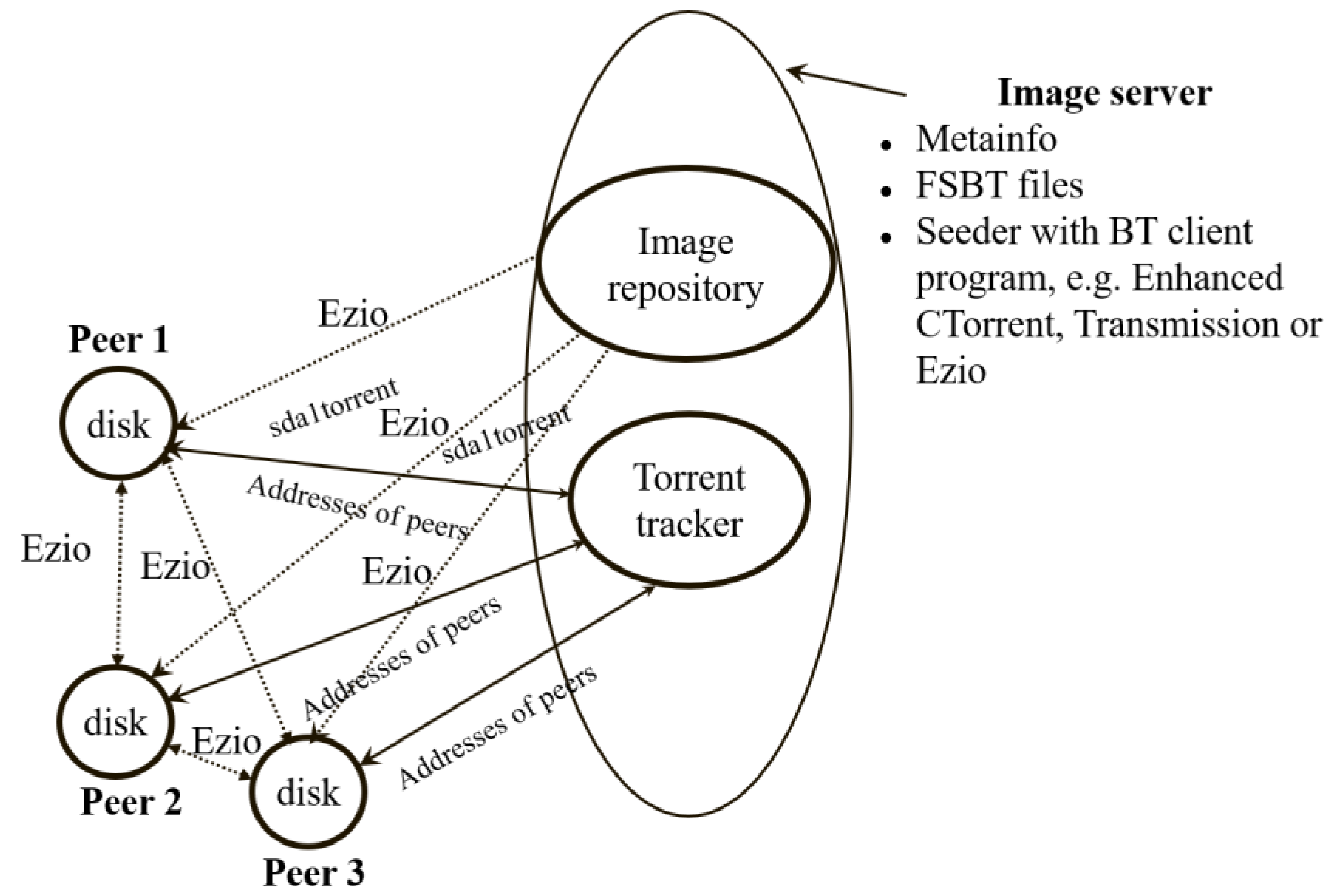
3.1. Software Architecture for P2P Massive System Deployment
3.2. Massive Deployment with the P2P Protocol
3.3. Software Implementation
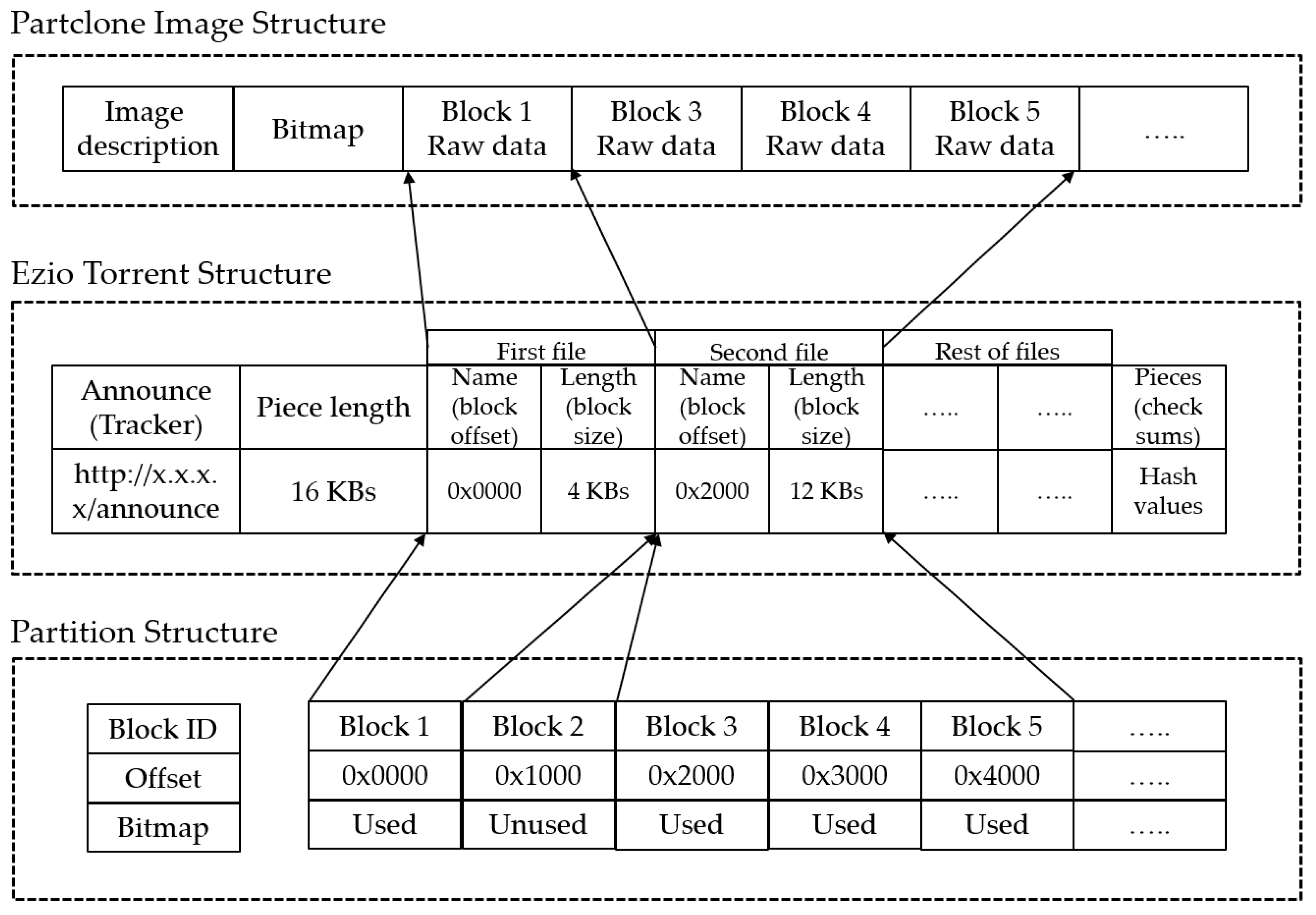
3.3.1. Implementation of the Ezio Program for Transferring Blocks of the File System
3.3.2. Implementation and Integration of P2P Protocol with Previous Work
4. Experimental Process and Results
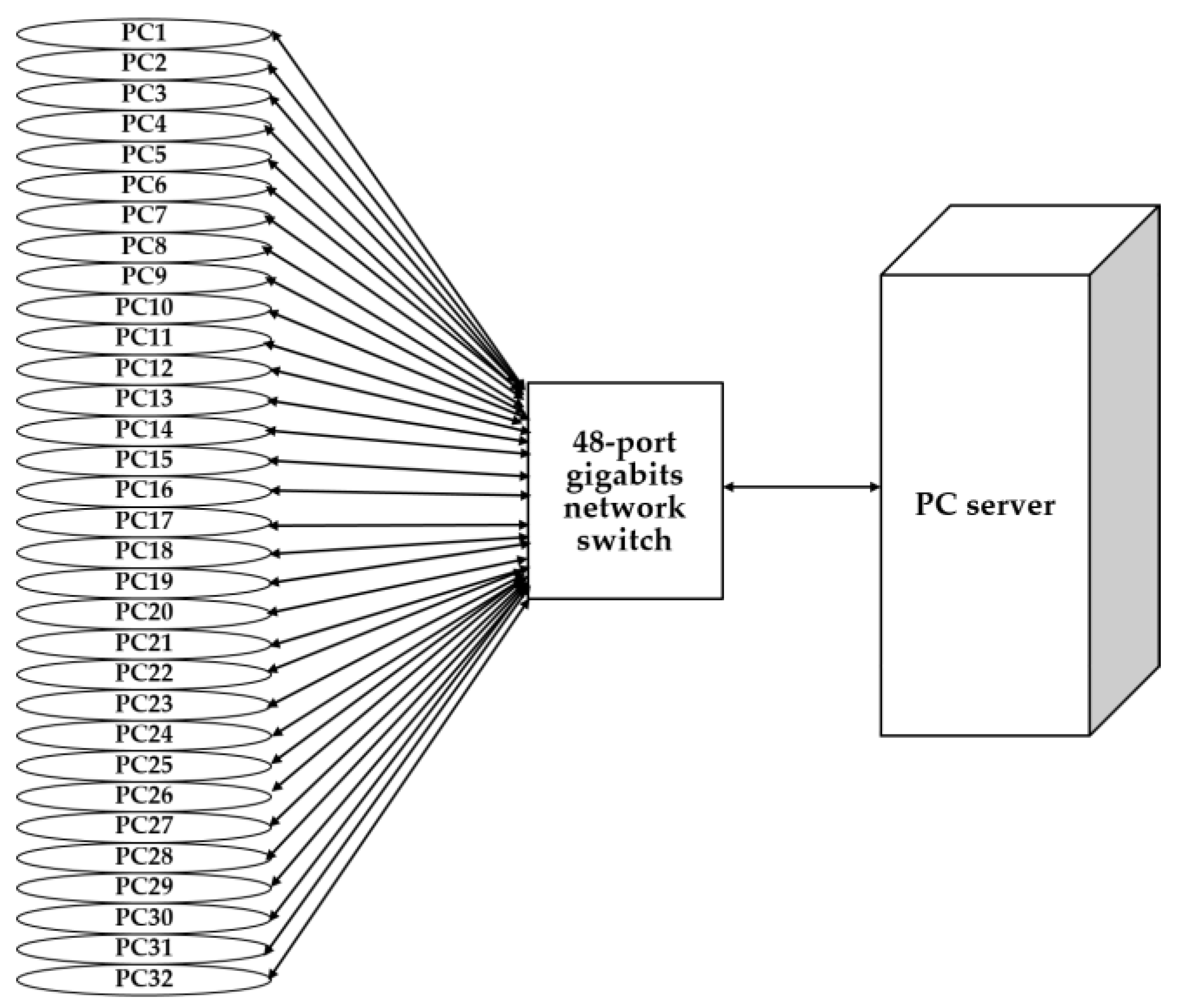
- Network switch: the Cisco Catalyst 3560G switch with 48 gigabits ports was used as the network switch. The multicast function was enabled, and the spanning tree protocol was disabled to avoid the timeout of network booting in the client machines.
- Server: a Dell T1700 machine plays the role of a server. The central processing unit (CPU) is the 3.3 GHz Intel Xeon E3-1226 processor. The size of the Dynamic Random Access Memory (DRAM) is 16 gigabytes (GB). The size of the hard disk is one terabyte (TB).
- PC clients: Dell T1700 PCs with the same configuration as the one serving as the server were used as clients.
- The image of the Linux and applications: an Ubuntu Linux system with applications and data installed on a template PC occupying 50 GB of the hard disk. The files were saved by Clonezilla live, and the image was compressed using the parallel Zstandard (pzstd), which is a fast lossless compression algorithm [58]. The image size is deliberately designed to be larger than the RAM size of the PC client in the experiment to ensure the feasibility of the proposed system to solve the temporary storage shortage issue.
5. Discussion
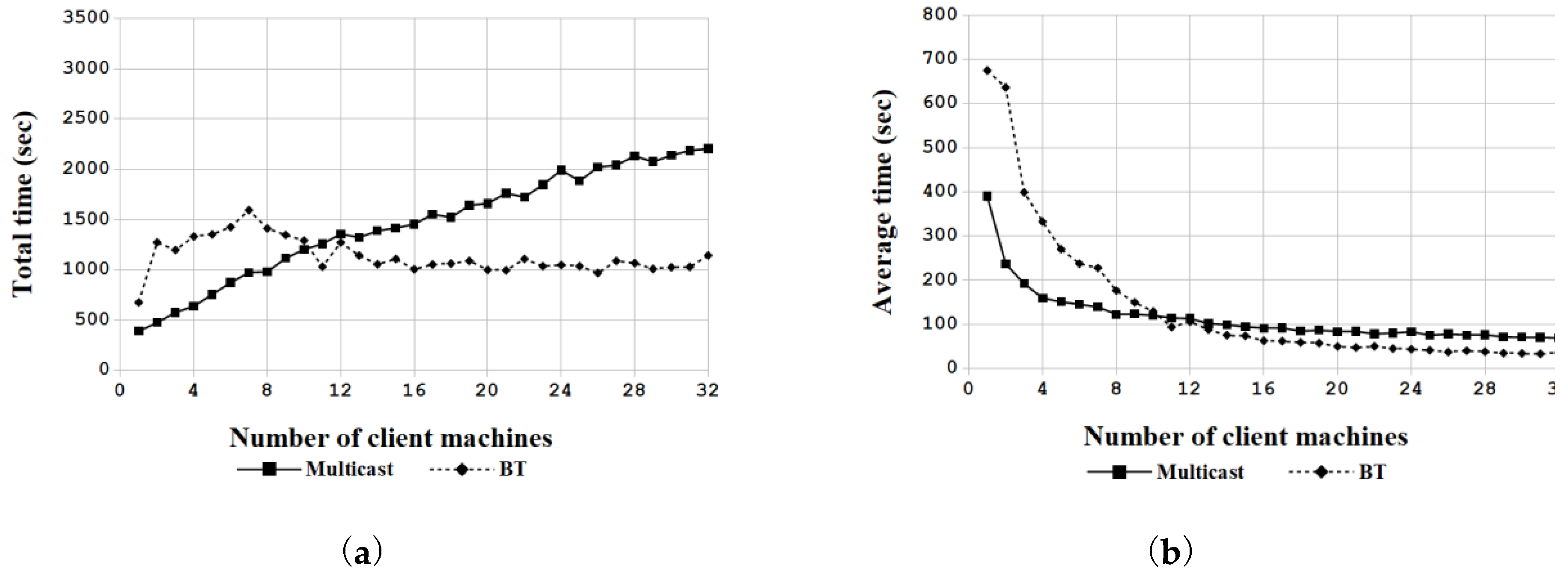
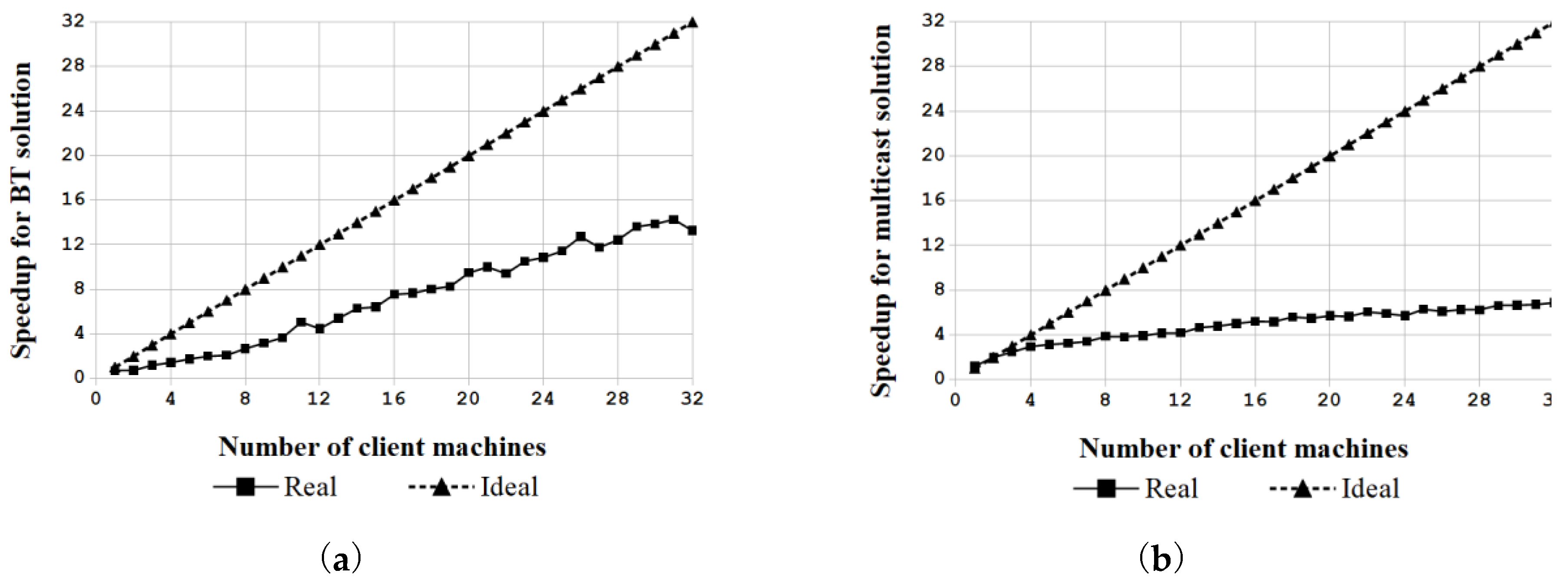
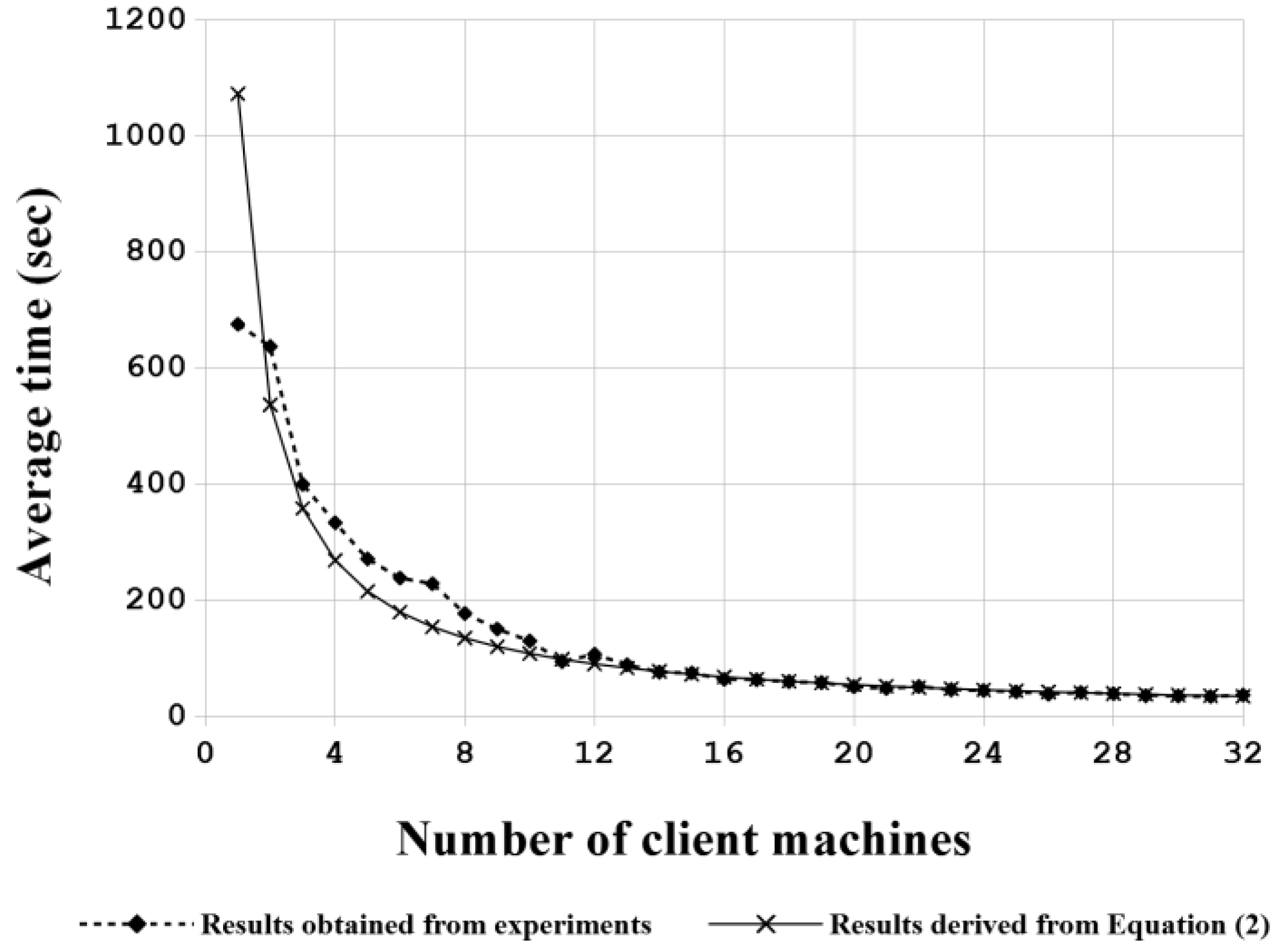
5.1. Performance of Massive Deployment by the Proposed BT Solution
5.2. Comparisons with Other BT Bare-Metal Provisioning Solutions
5.3. Limitations
5.3.1. File Format and Size of the Image for BT
5.3.2. Piece Transmissions in the Network
5.4. Future Research Possibilities
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Papadopoulos, P.M.; Katz, M.J.; Bruno, G. NPACI Rocks: Tools and techniques for easily deploying manageable linux clusters. Concurr. Comput. Pract. Exp. 2003, 15, 707–725. [Google Scholar] [CrossRef]
- Mirielli, E.; Webster, L.; Lynn, M. Developing a multi-boot computer environment and preparing for deployment to multiple workstations using Symantec Ghost: A cookbook approach. J. Comput. Sci. Coll. 2005, 20, 29–36. [Google Scholar]
- Shiau, S.J.; Sun, C.-K.; Tsai, Y.-C.; Juang, J.-N.; Huang, C.-Y. The Design and Implementation of a Novel Open Source Massive Deployment System. Appl. Sci. 2018, 8, 965. [Google Scholar] [CrossRef]
- Chandrasekar, A.; Gibson, G. A Comparative Study of Baremetal Provisioning Frameworks; Technical Report CMU-PDL-14-109; Parallel Data Laboratory, Carnegie Mellon University: Pittsburgh, PA, USA, 2014. [Google Scholar]
- Hirway, M. Hybrid Cloud for Developers: Develop and Deploy Cost-Effective Applications on the AWS and OpenStack Platforms with Ease; Packt Publishing: Birmingham, UK, 2018. [Google Scholar]
- Kickstart Document. Available online: https://docs.fedoraproject.org/en-US/Fedora/html/Installation_Guide/chap-kickstart-installations.html (accessed on 15 October 2018).
- FAI Project. Available online: https://fai-project.org (accessed on 15 October 2018).
- Aswani, K.; Anala, M.; Rathinam, S. Bare metal Cloud Builder. Imp. J. Interdiscip. Res. 2016, 2, 1844–1851. [Google Scholar]
- FSArchiver—File System Archiver for Linux. Available online: http://www.fsarchiver.org (accessed on 3 September 2017).
- Cougias, D.J.; Heiberger, E.L.; Koop, K. The Backup Book: Disaster Recovery from Desktop to Data Center; Network Frontiers: Lecanto, FL, USA, 2003. [Google Scholar]
- Petersen, R. Ubuntu 18.04 LTS Server: Administration and Reference; CreateSpace Independent Publishing Platform: Scotts Valley, CA, USA, 2018. [Google Scholar]
- Cornec, B. Mondo Rescue: A GPL disaster recovery solution. Proc. Linux Symp. 2008, 1, 77–84. [Google Scholar]
- Kumar, R.; Gupta, N.; Charu, S.; Jain, K.; Jangir, S.K. Open source solution for cloud computing platform using OpenStack. Int. J. Comput. Sci. Mob. Comput. 2014, 3, 89–98. [Google Scholar]
- Storix System Backup Administrator. Available online: https://www.storix.com (accessed on 3 September 2017).
- Partimage Software. Available online: http://www.partimage.org (accessed on 3 September 2017).
- Sanguino, T.M.; de Viana, I.F.; García, D.L.; Ancos, E.C. OpenGnSys: A novel system toward centralized deployment and management of computer laboratories. Comput. Educ. 2014, 75, 30–43. [Google Scholar] [CrossRef]
- Williamson, B. Developing IP Multicast Networks; Cisco Press: Indianapolis, IN, USA, 2000; Volume 1. [Google Scholar]
- Manini, D.; Gaeta, R.; Sereno, M. Performance modeling of P2P file sharing applications. In Proceedings of the Workshop on Techniques, Methodologies and Tools for Performance Evaluation of Complex Systems (FIRB-PERF’05), Torino, Italy, 19 September 2005; pp. 34–43. [Google Scholar]
- Schollmeier, R. A definition of peer-to-peer networking for the classification of peer-to-peer architectures and applications. In Proceedings of the First International Conference on Peer-to-Peer Computing, Linkoping, Sweden, 27–29 August 2001; pp. 101–102. [Google Scholar]
- Rossi, D.; Testa, C.; Valenti, S.; Muscariello, L. LEDBAT: The new BitTorrent congestion control protocol. In Proceedings of the 19th International Conference on Computer Communications and Networks (ICCCN), ETH Zurich, Switzerland, 2–5 August 2010; pp. 1–6. [Google Scholar]
- Saroiu, S.; Gummadi, P.K.; Gribble, S.D. Measurement study of peer-to-peer file sharing systems. In Proceedings of the Multimedia Computing and Networking, San Jose, CA, USA, 19–25 January 2002; pp. 156–171. [Google Scholar]
- Le Fessant, F.; Handurukande, S.; Kermarrec, A.-M.; Massoulié, L. Clustering in peer-to-peer file sharing workloads. In Proceedings of the International Workshop on Peer-to-Peer Systems, La Jolla, CA, USA, 26–27 February 2004; pp. 217–226. [Google Scholar]
- Shah, R.; Narmawala, Z. Mobile torrent: Peer-to-peer file sharing in Android devices. Int. J. Comput. Sci. Commun. 2016, 7, 20–34. [Google Scholar]
- Mastorakis, S.; Afanasyev, A.; Yu, Y.; Zhang, L. nTorrent: Peer-to-Peer File Sharing in Named Data Networking. In Proceedings of the 26th International Conference on Computer Communications and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017. [Google Scholar]
- Liu, Y.; Guo, Y.; Liang, C. A survey on peer-to-peer video streaming systems. Peer-to-Peer Netw. Appl. 2008, 1, 18–28. [Google Scholar] [CrossRef]
- Guha, S.; Daswani, N. An Experimental Study of the Skype Peer-to-Peer Voip System; Cornell University: Ithaca, NY, USA, 2005. [Google Scholar]
- Baset, S.A.; Gupta, G.; Schulzrinne, H. Openvoip: An open peer-to-peer voip and im system. In Proceedings of the ACM SIGCOMM, Seattle, WA, USA, 17–22 August 2008. [Google Scholar]
- Androutsellis-Theotokis, S.; Spinellis, D. A survey of peer-to-peer content distribution technologies. ACM Comput. Surv. 2004, 36, 335–371. [Google Scholar] [CrossRef] [Green Version]
- Antonopoulos, A.M. Mastering Bitcoin: Unlocking Digital Cryptocurrencies; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2014. [Google Scholar]
- Wood, G. Ethereum: A secure decentralised generalised transaction ledger. Ethereum Proj. Yellow Pap. 2014, 151, 1–32. [Google Scholar]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 15 October 2018).
- Feller, J.; Fitzgerald, B. Understanding Open Source Software Development; Addison-Wesley: London, UK, 2002. [Google Scholar]
- Stallman, R. Free Software, Free Society: Selected Essays of Richard M. Stallman; Lulu Press: Morrisville, NC, USA, 2002. [Google Scholar]
- Ren, S.; Tan, E.; Luo, T.; Chen, S.; Guo, L.; Zhang, X. TopBT: A topology-aware and infrastructure-independent bittorrent client. In Proceedings of the IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–9. [Google Scholar]
- Rosen, L. Open Source Licensing: Software Freedom and Intellectual Property Law; Prentice Hall PTR: Upper Saddle River, NJ, USA, 2004. [Google Scholar]
- The qBittorrent Project. Available online: https://www.qbittorrent.org/ (accessed on 12 October 2018).
- Wang, H.; Wang, C. Open source software adoption: A status report. IEEE Softw. 2001, 18, 90–95. [Google Scholar] [CrossRef]
- Ezio Project. Available online: https://github.com/tjjh89017/ezio (accessed on 18 August 2018).
- Lee, K.-M.; Teng, W.-G.; Wu, J.-N.; Huang, K.-M.; Ko, Y.-H.; Hou, T.-W. Multicast and customized deployment of large-scale operating systems. Autom. Softw. Eng. 2014, 21, 443–460. [Google Scholar] [CrossRef]
- Shojafar, M.; Abawajy, J.H.; Delkhah, Z.; Ahmadi, A.; Pooranian, Z.; Abraham, A. An efficient and distributed file search in unstructured peer-to-peer networks. Peer-to-Peer Netw. Appl. 2015, 8, 120–136. [Google Scholar] [CrossRef]
- Neumann, C.; Roca, V.; Walsh, R. Large scale content distribution protocols. ACM SIGCOMM Comput. Commun. Rev. 2005, 35, 85–92. [Google Scholar] [CrossRef] [Green Version]
- Grönvall, B.; Marsh, I.; Pink, S. A multicast-based distributed file system for the internet. In Proceedings of the 7th Workshop on ACM SIGOPS European Workshop: Systems Support for Worldwide Applications, Connemara, Ireland, 9–11 September 1996; pp. 95–102. [Google Scholar]
- Zhang, L.; Qin, B.; Wu, Q.; Zhang, F. Efficient many-to-one authentication with certificateless aggregate signatures. Comput. Netw. 2010, 54, 2482–2491. [Google Scholar] [CrossRef]
- Cohen, B. Incentives build robustness in BitTorrent. In Proceedings of the Workshop on Economics of Peer-to-Peer Systems, Berkeley, California, USA, 5–6 June 2003; pp. 68–72. [Google Scholar]
- Heckmann, O.; Bock, A.; Mauthe, A.; Steinmetz, R.; KOM, M.K. The eDonkey File-Sharing Network. GI Jahrestag. 2004, 51, 224–228. [Google Scholar]
- Wierzbicki, A.; Leibowitz, N.; Ripeanu, M.; Wozniak, R. Cache replacement policies revisited: The case of P2P traffic. In Proceedings of the IEEE International Symposium on Cluster Computing and the Grid, Chicago, IL, USA, 19–22 April 2004; pp. 182–189. [Google Scholar]
- Ripeanu, M. Peer-to-peer architecture case study: Gnutella network. In Proceedings of the First International Conference on the Peer-to-Peer Computing, Linkoping, Sweden, 27–29 August 2001; pp. 99–100. [Google Scholar]
- Clarke, I.; Sandberg, O.; Wiley, B.; Hong, T.W. Freenet: A distributed anonymous information storage and retrieval system. In Proceedings of the Designing Privacy Enhancing Technologies, Berkeley, CA, USA, 25–26 July 2000; pp. 46–66. [Google Scholar]
- Steinmetz, R.; Wehrle, K. Peer-to-Peer Systems and Applications; Springer: Berlin, Germany, 2005; Volume 3485. [Google Scholar]
- Legout, A.; Urvoy-Keller, G.; Michiardi, P. Rarest first and choke algorithms are enough. In Proceedings of the 6th ACM SIGCOMM Conference on Internet Measurement, Rio de Janeriro, Brazil, 25–27 October 2006; pp. 203–216. [Google Scholar]
- Dinger, J.; Waldhorst, O.P. Decentralized bootstrapping of P2P systems: A practical view. In Proceedings of the International Conference on Research in Networking, Aachen, Germany, 11–15 May 2009; pp. 703–715. [Google Scholar]
- Dosanjh, M.G.; Bridges, P.G.; Kelly, S.M.; Laros, J.H. A peer-to-peer architecture for supporting dynamic shared libraries in large-scale systems. In Proceedings of the 41st International Conference on Parallel Processing Workshops (ICPPW), Pittsburgh, PA, USA, 10–13 September 2012; pp. 55–61. [Google Scholar]
- García, Á.L.; del Castillo, E.F. Efficient image deployment in cloud environments. J. Netw. Comput. Appl. 2016, 63, 140–149. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Zhao, Y.; Miao, X.; Chen, Y.; Wang, Q. Rapid provisioning of cloud infrastructure leveraging peer-to-peer networks. In Proceedings of the 29th IEEE International Conference on Distributed Computing Systems Workshops, Montreal, QC, Canada, 22–26 June 2009; pp. 324–329. [Google Scholar]
- O’Donnell, C.M. Using BitTorrent to distribute virtual machine images for classes. In Proceedings of the 36th annual ACM SIGUCCS Fall Conference: Moving Mountains, Blazing Trails, Portland, OR, USA, 19–22 October 2008; pp. 287–290. [Google Scholar]
- Xue, Z.; Dong, X.; Li, J.; Tian, H. ESIR: A Deployment System for Large-Scale Server Cluster. In Proceedings of the Seventh International Conference on Grid and Cooperative Computing, Shenzhen, China, 24–26 October 2008; pp. 563–569. [Google Scholar]
- Jeanvoine, E.; Sarzyniec, L.; Nussbaum, L. Kadeploy3: Efficient and scalable operating system provisioning for clusters. USENIX Login 2013, 38, 38–44. [Google Scholar]
- Anton, B.; Norbert, A. Peer to Peer System Deployment. Acta Electrotech. Inform. 2016, 16, 11–14. [Google Scholar]
- Shestakov, A.; Arefiev, A. Patch File to Allow User to Provision Image Using Bittorrent Protocol in OpenStack. Available online: https://review.openstack.org/#/c/311091/ (accessed on 21 December 2018).
- Cut Ironic Provisioning Time Using Torrents. Available online: https://www.mirantis.com/blog/cut-ironic-provisioning-time-using-torrents/ (accessed on 21 December 2018).
- Abreu, R.M.; Froufe, H.J.; Queiroz, M.J.R.; Ferreira, I.C. MOLA: A bootable, self-configuring system for virtual screening using AutoDock4/Vina on computer clusters. J. Cheminform. 2010, 2, 10. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wang, L. An integrated open forensic environment for digital evidence investigation. Wuhan Univ. J. Nat. Sci. 2012, 17, 511–515. [Google Scholar] [CrossRef]
- Books, L. Network Booting: Preboot Execution Environment, Bootstrap Protocol, Netboot, Gpxe, Remote Initial Program Load; ACM: New York, NY, USA, 2010. [Google Scholar]
- Droms, R. Automated configuration of TCP/IP with DHCP. IEEE Internet Comput. 1999, 3, 45–53. [Google Scholar] [CrossRef]
- Debian Live Systems Manual. Available online: https://live-team.pages.debian.net/live-manual/html/live-manual/the-basics.en.html (accessed on 3 November 2018).
- Debian Live Image. Available online: https://www.debian.org/blends/hamradio/get/live (accessed on 22 October 2018).
- CentOS Linux ISO Images. Available online: https://wiki.centos.org/Download (accessed on 22 October 2018).
- Ubuntu Live. Available online: https://tutorials.ubuntu.com/tutorial/try-ubuntu-before-you-install (accessed on 22 October 2018).
- Windows PE (WinPE). Available online: https://docs.microsoft.com/zh-tw/windows-hardware/manufacture/desktop/winpe-intro (accessed on 22 October 2018).
- Nyström, M.; Nicholes, M.; Zimmer, V.J. UEFI Networking and Pre-Os Security. Intel Technol. J. 2011, 15, 80–100. [Google Scholar]
- Bricker, G. Unified extensible firmware interface (UEFI) and secure boot: Promise and pitfalls. J. Comput. Sci. Coll. 2013, 29, 60–63. [Google Scholar]
- Takano, Y.; Ando, R.; Takahashi, T.; Uda, S.; Inoue, T. A measurement study of open resolvers and DNS server version. In Proceedings of the Internet Conference, Tokyo, Japan, 24–25 October 2013. [Google Scholar]
- Patch File about Get Bootstrap Info from Proxy Offer Packet. Available online: https://lists.gnu.org/archive/html/grub-devel/2016-04/msg00051.html (accessed on 22 October 2018).
- Rhodes, C.; Bettany, A. An Introduction to Windows Installation Methodologies and Tools. In Windows Installation and Update Troubleshooting; Springer: Berlin, Germany, 2016; pp. 1–27. [Google Scholar]
- DRBL-Winroll Project. Available online: https://drbl-winroll.org/ (accessed on 22 October 2018).
- Deaconescu, R.; Rughinis, R.; Tapus, N. A bittorrent performance evaluation framework. In Proceedings of the Fifth International Conference on Networking and Services, Valencia, Spain, 20–25 April 2009; pp. 354–358. [Google Scholar]
- Sirivianos, M.; Park, J.H.; Chen, R.; Yang, X. Free-riding in BitTorrent Networks with the Large View Exploit. In Proceedings of the 6th International workshop on Peer-To-Peer Systems (IPTPS), Bellevue, WA, USA, 26–27 February 2007. [Google Scholar]
- LFTP Project. Available online: http://lftp.yar.ru/ (accessed on 12 October 2018).
- The rTorrent BitTorrent Client. Available online: https://github.com/rakshasa/rtorrent (accessed on 12 October 2018).
- Zeilemaker, N.; Pouwelse, J. 100 Million DHT replies. In Proceedings of the 14-th IEEE International Conference on Peer-to-Peer Computing (P2P), London, UK, 9–11 September 2014; pp. 1–4. [Google Scholar]
- Libtorrent Project. Available online: https://www.libtorrent.org/ (accessed on 6 October 2018).
- Carrier, B. Defining digital forensic examination and analysis tools using abstraction layers. Int. J. Digit. Evid. 2003, 1, 1–12. [Google Scholar]
- Ocs-Bttrack Source Code. Available online: https://gitlab.com/stevenshiau/ocs-bttrack (accessed on 18 August 2018).
- González-Briones, A.; Chamoso, P.; Yoe, H.; Corchado, J.M. GreenVMAS: Virtual organization based platform for heating greenhouses using waste energy from power plants. Sensors 2018, 18, 861. [Google Scholar] [CrossRef]
- González-Briones, A.; Prieto, J.; De La Prieta, F.; Herrera-Viedma, E.; Corchado, J.M. Energy optimization using a case-based reasoning strategy. Sensors 2018, 18, 865. [Google Scholar] [CrossRef]
- Schultz, B.B. Levene’s test for relative variation. Syst. Zool. 1985, 34, 449–456. [Google Scholar] [CrossRef]
- Sergio, A.; Carvalho, S.; Marco, R. On the Use of Compact Approaches in Evolution Strategies. Adv. Distrib. Comput. Artif. Intell. J. 2014, 3, 13–23. [Google Scholar]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Montreal, QC, Canada, 20–25 August 1995; pp. 1137–1145. [Google Scholar]
- Mikshowsky, A.A.; Gianola, D.; Weigel, K.A. Assessing genomic prediction accuracy for Holstein sires using bootstrap aggregation sampling and leave-one-out cross validation. J. Dairy Sci. 2017, 100, 453–464. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Guo, Z.; Wang, X.; Chen, F.; Lian, X.; Tang, J.; Wu, M.; Kaashoek, M.F.; Zhang, Z. D3S: Debugging deployed distributed systems. In Proceedings of the 5th USENIX Symposium on Networked Systems Design and Implementation, San Francisco, CA, USA, 16–18 April 2008. [Google Scholar]
- Legout, A. Peer-to-Peer Applications: From BitTorrent to Privacy; INRIA: Paris, France, 2010. [Google Scholar]
- Magharei, N.; Rejaie, R.; Guo, Y. Mesh or multiple-tree: A comparative study of live p2p streaming approaches. In Proceedings of the 26th IEEE International Conference on Computer Communications, Anchorage, Alaska, USA, 6–12 May 2007; pp. 1424–1432. [Google Scholar]
- Small, T.; Li, B.; Liang, B. Outreach: Peer-to-peer topology construction towards minimized server bandwidth costs. IEEE J. Sel. Areas Commun. 2007, 25, 35–45. [Google Scholar] [CrossRef]
- Silva, T.N.D.M.D. Bitocast: A Hybrid BitTorrent and IP Multicast Content Distribution Solution. Ph.D. Thesis, Universidade NOVA de Lisboa, Lisboa, Portugal, 2009. [Google Scholar]
- Agrawal, P.; Khandelwal, H.; Ghosh, R.K. MTorrent: A multicast enabled BitTorrent protocol. In Proceedings of the Second International Conference on Communication Systems and Networks (COMSNETS), Bangalore, India, 5–9 January 2010; pp. 1–10. [Google Scholar]
- Cecill and Free Software. Available online: http://www.cecill.info (accessed on 15 October 2018).
- Lima, S.; Rocha, Á.; Roque, L. An overview of OpenStack architecture: A message queuing services node. Cluster Comput. 2017, 1–12. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Solution | Network Protocol | Transmission | Bandwidth Comsumption | Scalability |
|---|---|---|---|---|
| Unicast | TCP | One to one | Average | Worst |
| Broadcast | UDP | One to many, many to many | Least | Average |
| Multicast | UDP | One to all | Least | Average |
| BT | TCP, uTP, etc. | Many to many | Most | Best |
| Number of Clients | tseq (1) | tBT (2) | tmulticast (3) | Ratio (tBT/tmulticast) |
|---|---|---|---|---|
| 1 | 474 | 675 | 390 | 1.731 |
| 2 | 948 | 1273 | 474 | 2.686 |
| 3 | 1422 | 1197 | 576 | 2.078 |
| 4 | 1896 | 1331 | 638 | 2.086 |
| 5 | 2370 | 1352 | 754 | 1.793 |
| 6 | 2844 | 1425 | 872 | 1.634 |
| 7 | 3318 | 1594 | 973 | 1.638 |
| 8 | 3792 | 1412 | 980 | 1.441 |
| 9 | 4266 | 1347 | 1114 | 1.209 |
| 10 | 4740 | 1291 | 1202 | 1.074 |
| 11 | 5214 | 1031 | 1258 | 0.820 |
| 12 | 5688 | 1272 | 1356 | 0.938 |
| 13 | 6162 | 1142 | 1322 | 0.864 |
| 14 | 6636 | 1055 | 1387 | 0.761 |
| 15 | 7110 | 1108 | 1416 | 0.782 |
| 16 | 7584 | 1005 | 1454 | 0.691 |
| 17 | 8058 | 1053 | 1553 | 0.678 |
| 18 | 8532 | 1062 | 1522 | 0.698 |
| 19 | 9006 | 1089 | 1640 | 0.664 |
| 20 | 9480 | 1000 | 1660 | 0.602 |
| 21 | 9954 | 995 | 1762 | 0.565 |
| 22 | 10428 | 1108 | 1722 | 0.643 |
| 23 | 10902 | 1036 | 1846 | 0.561 |
| 24 | 11376 | 1048 | 1992 | 0.526 |
| 25 | 11850 | 1036 | 1883 | 0.550 |
| 26 | 12324 | 968 | 2020 | 0.479 |
| 27 | 12798 | 1088 | 2041 | 0.533 |
| 28 | 13272 | 1067 | 2131 | 0.501 |
| 29 | 13746 | 1009 | 2074 | 0.486 |
| 30 | 14220 | 1025 | 2138 | 0.479 |
| 31 | 14694 | 1029 | 2186 | 0.471 |
| 32 | 15168 | 1143 | 2203 | 0.519 |
| Solution | Mean | Stdr. Deviation | t Stat | p value (1-tailed) | F | p value |
|---|---|---|---|---|---|---|
| BT | 1.13 × 103 | 1.74 × 102 | 2.860 | 3.75 × 10−3 | 1.02 × 101 | 2.17 × 10-3 |
| Multicast | 1.45 × 103 | 5.31 × 102 |
| Number of Client(s) | SFBT | SFMC | SRBT-MC | Time-Saving Ratio (%) | LOOCV (%) |
|---|---|---|---|---|---|
| 1 | 0.702 | 1.215 | 0.578 | −73.077 | 4.995 |
| 2 | 0.745 | 2.000 | 0.372 | −168.565 | 8.075 |
| 3 | 1.188 | 2.469 | 0.481 | −107.813 | 6.115 |
| 4 | 1.424 | 2.972 | 0.479 | −108.621 | 6.141 |
| 5 | 1.753 | 3.143 | 0.558 | −79.310 | 5.196 |
| 6 | 1.996 | 3.261 | 0.612 | −63.417 | 4.683 |
| 7 | 2.082 | 3.410 | 0.610 | −63.823 | 4.696 |
| 8 | 2.686 | 3.869 | 0.694 | −44.082 | 4.059 |
| 9 | 3.167 | 3.829 | 0.827 | −20.916 | 3.312 |
| 10 | 3.672 | 3.943 | 0.931 | −7.404 | 2.876 |
| 11 | 5.057 | 4.145 | 1.220 | 18.045 | 2.055 |
| 12 | 4.472 | 4.195 | 1.066 | 6.195 | 2.438 |
| 13 | 5.396 | 4.661 | 1.158 | 13.616 | 2.198 |
| 14 | 6.290 | 4.784 | 1.315 | 23.937 | 1.865 |
| 15 | 6.417 | 5.021 | 1.278 | 21.751 | 1.936 |
| 16 | 7.546 | 5.216 | 1.447 | 30.880 | 1.641 |
| 17 | 7.652 | 5.189 | 1.475 | 32.196 | 1.599 |
| 18 | 8.034 | 5.606 | 1.433 | 30.223 | 1.662 |
| 19 | 8.270 | 5.491 | 1.506 | 33.598 | 1.554 |
| 20 | 9.480 | 5.711 | 1.660 | 39.759 | 1.355 |
| 21 | 10.004 | 5.649 | 1.771 | 43.530 | 1.233 |
| 22 | 9.412 | 6.056 | 1.554 | 35.656 | 1.487 |
| 23 | 10.523 | 5.906 | 1.782 | 43.879 | 1.222 |
| 24 | 10.855 | 5.711 | 1.901 | 47.390 | 1.109 |
| 25 | 11.438 | 6.293 | 1.818 | 44.981 | 1.186 |
| 26 | 12.731 | 6.101 | 2.087 | 52.079 | 0.957 |
| 27 | 11.763 | 6.270 | 1.876 | 46.693 | 1.131 |
| 28 | 12.439 | 6.228 | 1.997 | 49.930 | 1.027 |
| 29 | 13.623 | 6.628 | 2.056 | 51.350 | 0.981 |
| 30 | 13.873 | 6.651 | 2.086 | 52.058 | 0.958 |
| 31 | 14.280 | 6.722 | 2.124 | 52.928 | 0.930 |
| 32 | 13.270 | 6.885 | 1.927 | 48.116 | 1.085 |
| Solution | Pros | Cons |
|---|---|---|
| BT | More reliable. More flexible. Better performance in larger scale. Scalable. | Quality barrier of network switch is higher. More image repository disk space requirement. |
| Multicast | Low bandwidth requirement. Better performance in smaller scale. No extra disk space is required. | Packet loss issue. Function may be disabled in network switch. Not scalable. |
| Solution | Feasibility | Efficiency | Relability | Scalability |
|---|---|---|---|---|
| Multicast | Yes | x | Average | Average |
| BT | Yes | 5.482x | Good | Good |
| Program | Software License | Case(*) | Notes | |||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| Clonezilla live | GPL | Yes | Yes | Yes | Yes | Open architecture, supports most of the mainstream OSs deployment. |
| ESIR [56] | N/A | U(**) | U(**) | U(**) | Yes | Dynamic module loading technique makes hardware independent deployment. |
| Kadeploy [57] | CeCILL | Yes | Yes | No | Yes | Provides a set of tools for cloning, configuring (post installation), and managing cluster nodes. |
| Work by Anton and Norbert [58] | N/A | U(**) | U(**) | No | Yes | Proposed system architecture utilizes P2P communication between nodes that leads to increasing throughput. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shiau, S.J.H.; Huang, Y.-C.; Yen, C.-H.; Tsai, Y.-C.; Sun, C.-K.; Juang, J.-N.; Huang, C.-Y.; Huang, C.-C.; Huang, S.-K. A Novel Massive Deployment Solution Based on the Peer-to-Peer Protocol. Appl. Sci. 2019, 9, 296. https://doi.org/10.3390/app9020296
Shiau SJH, Huang Y-C, Yen C-H, Tsai Y-C, Sun C-K, Juang J-N, Huang C-Y, Huang C-C, Huang S-K. A Novel Massive Deployment Solution Based on the Peer-to-Peer Protocol. Applied Sciences. 2019; 9(2):296. https://doi.org/10.3390/app9020296
Chicago/Turabian StyleShiau, Steven J. H., Yu-Chiang Huang, Ching-Hsuan Yen, Yu-Chin Tsai, Chen-Kai Sun, Jer-Nan Juang, Chi-Yo Huang, Ching-Chun Huang, and Shih-Kun Huang. 2019. "A Novel Massive Deployment Solution Based on the Peer-to-Peer Protocol" Applied Sciences 9, no. 2: 296. https://doi.org/10.3390/app9020296
APA StyleShiau, S. J. H., Huang, Y. -C., Yen, C. -H., Tsai, Y. -C., Sun, C. -K., Juang, J. -N., Huang, C. -Y., Huang, C. -C., & Huang, S. -K. (2019). A Novel Massive Deployment Solution Based on the Peer-to-Peer Protocol. Applied Sciences, 9(2), 296. https://doi.org/10.3390/app9020296