3D Convolutional Neural Networks for Remote Pulse Rate Measurement and Mapping from Facial Video



Abstract
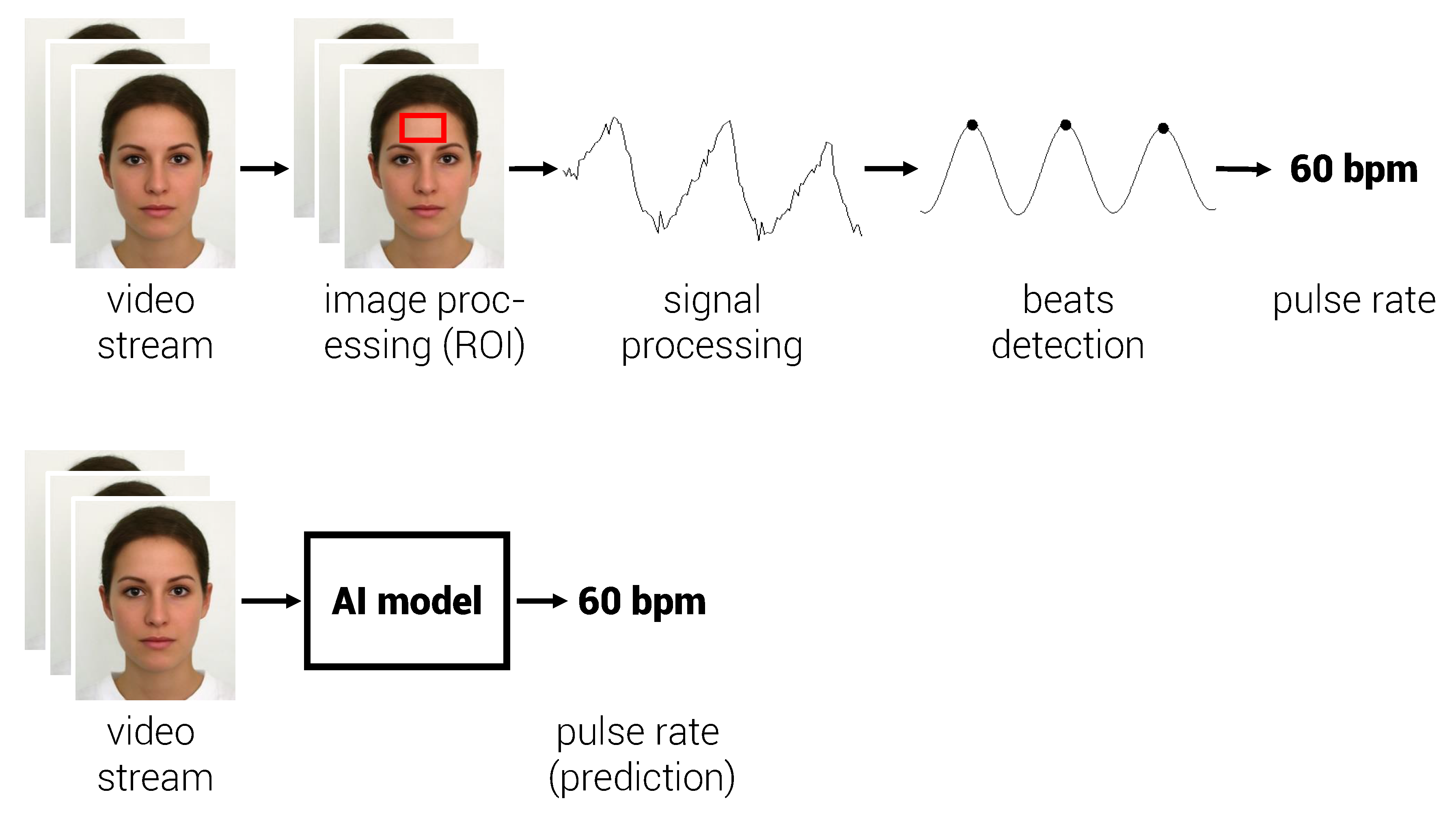
:1. Introduction
2. Related Works
2.1. Imaging Photoplethysmography
2.1.1. Video Recording
2.1.2. Image Processing
2.1.3. Signal Processing
2.1.4. Machine Learning
2.2. 3D Convolutional Networks
3. Materials and Methods
3.1. Datasets
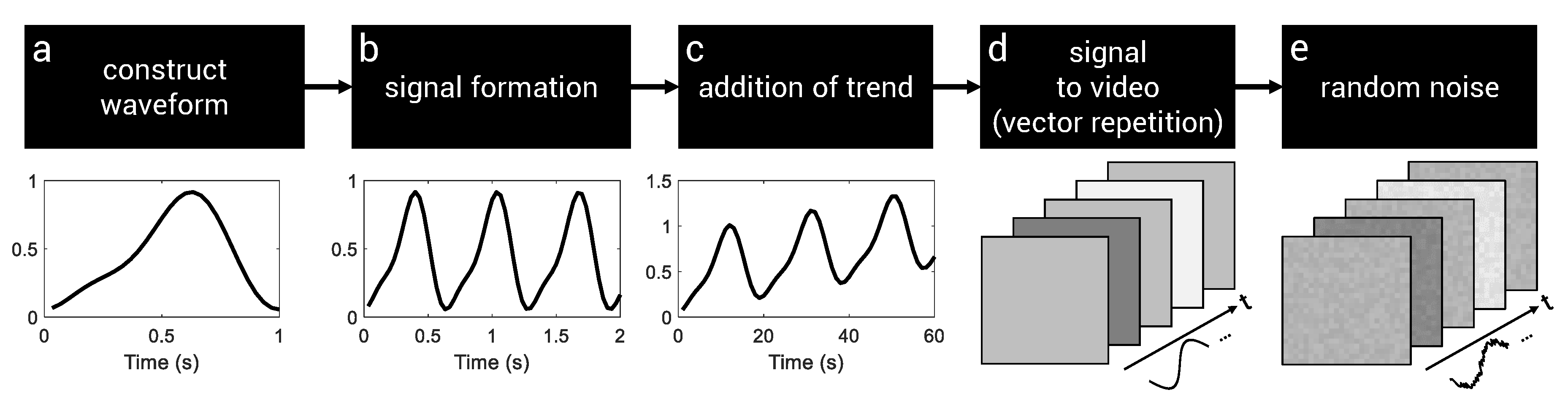
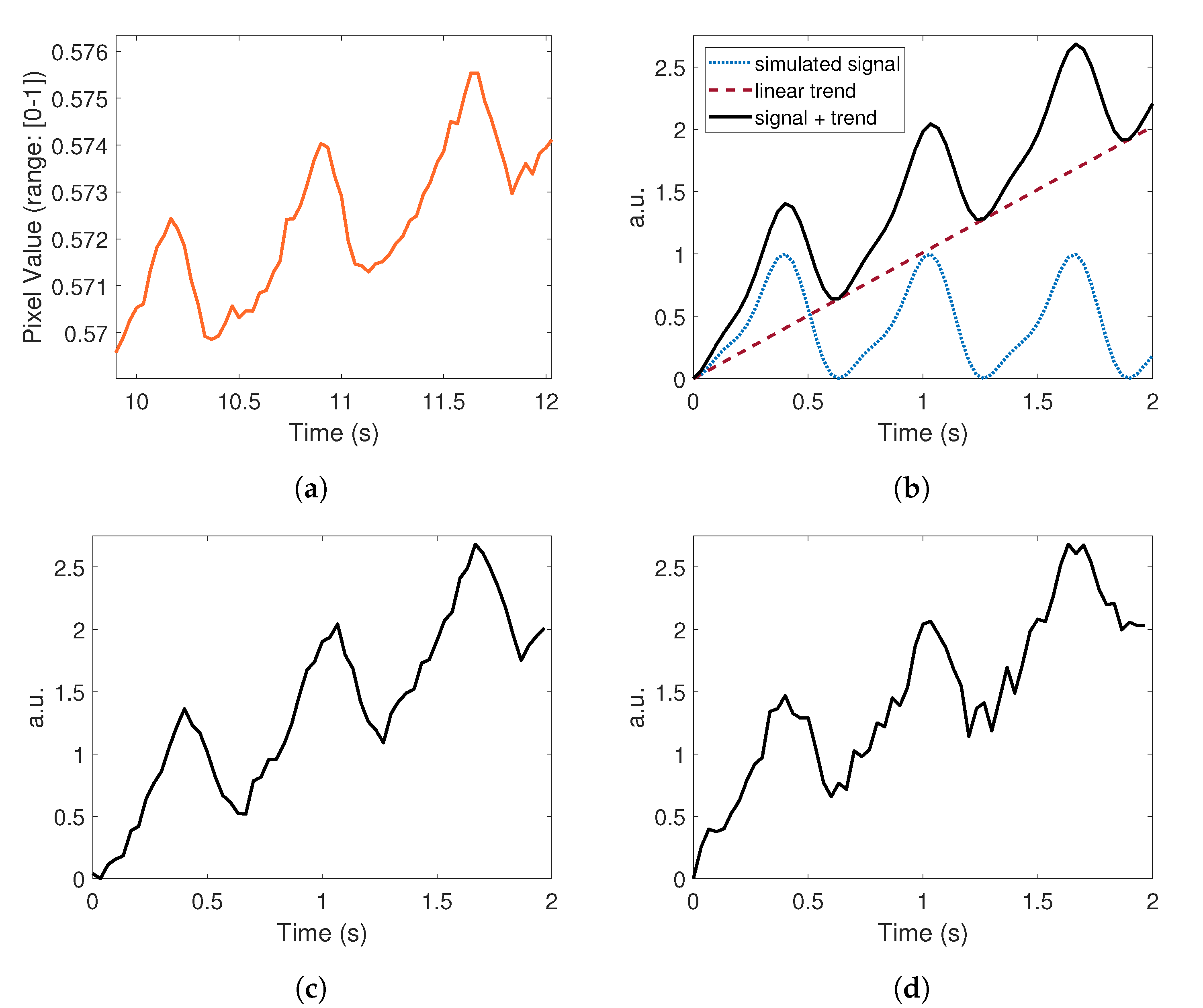
3.2. Synthetic Data Generation
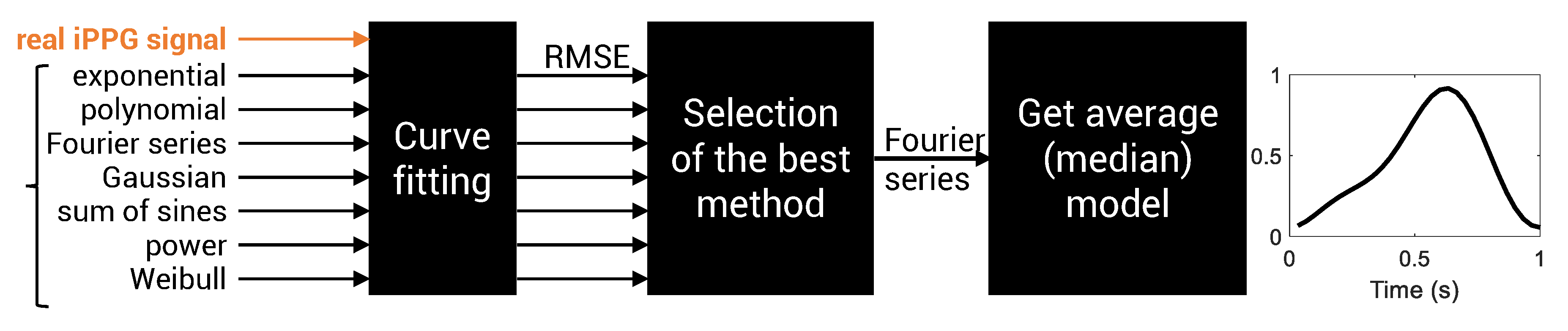
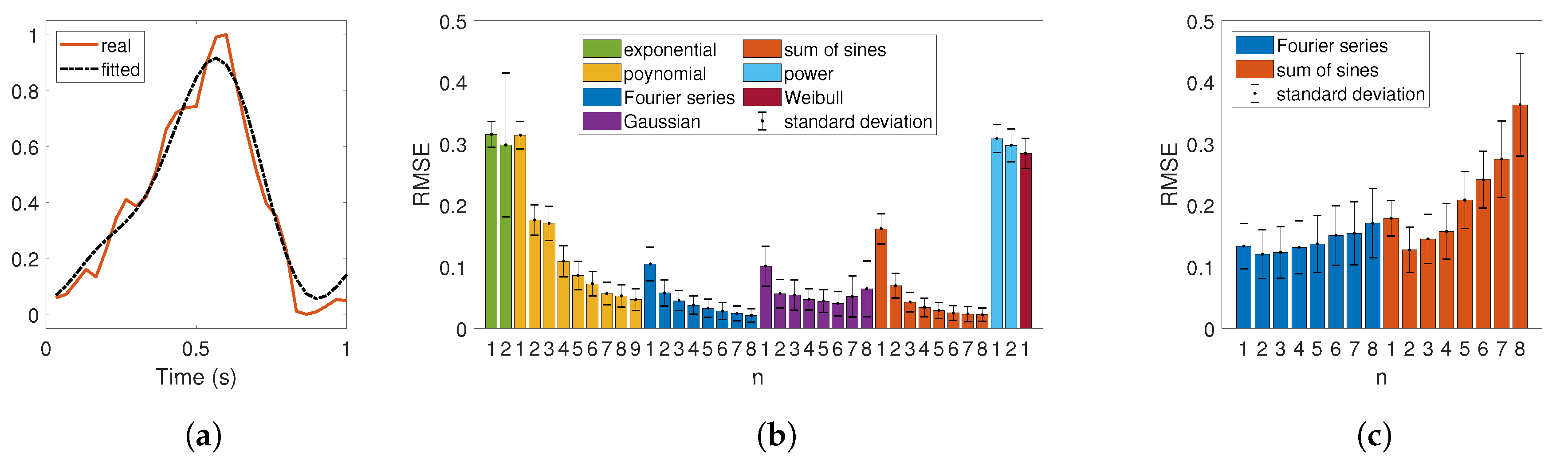
3.2.1. Modeling iPPG Waveforms
3.2.2. Signal Formation
3.2.3. Addition of Trends
3.2.4. From 1D (Signal) to 3D (Video)
3.2.5. Addition of Noise
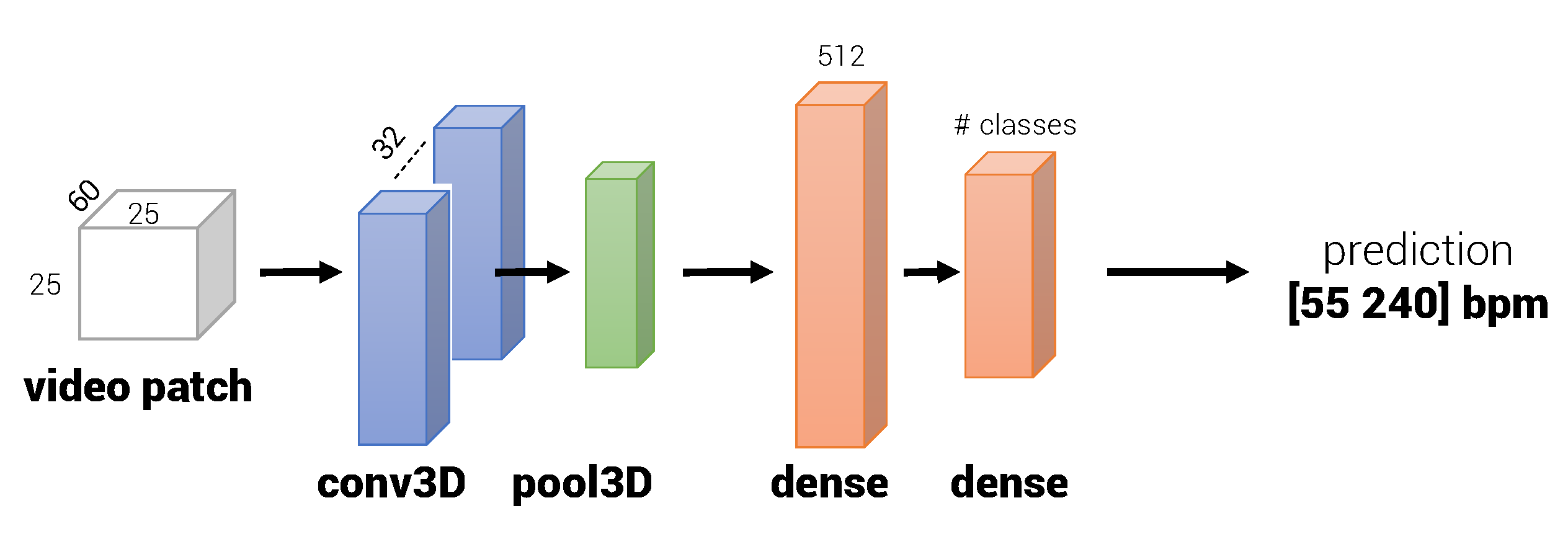
3.3. 3D CNN for Automatic Pulse Rate Estimation
3.3.1. Network Architecture
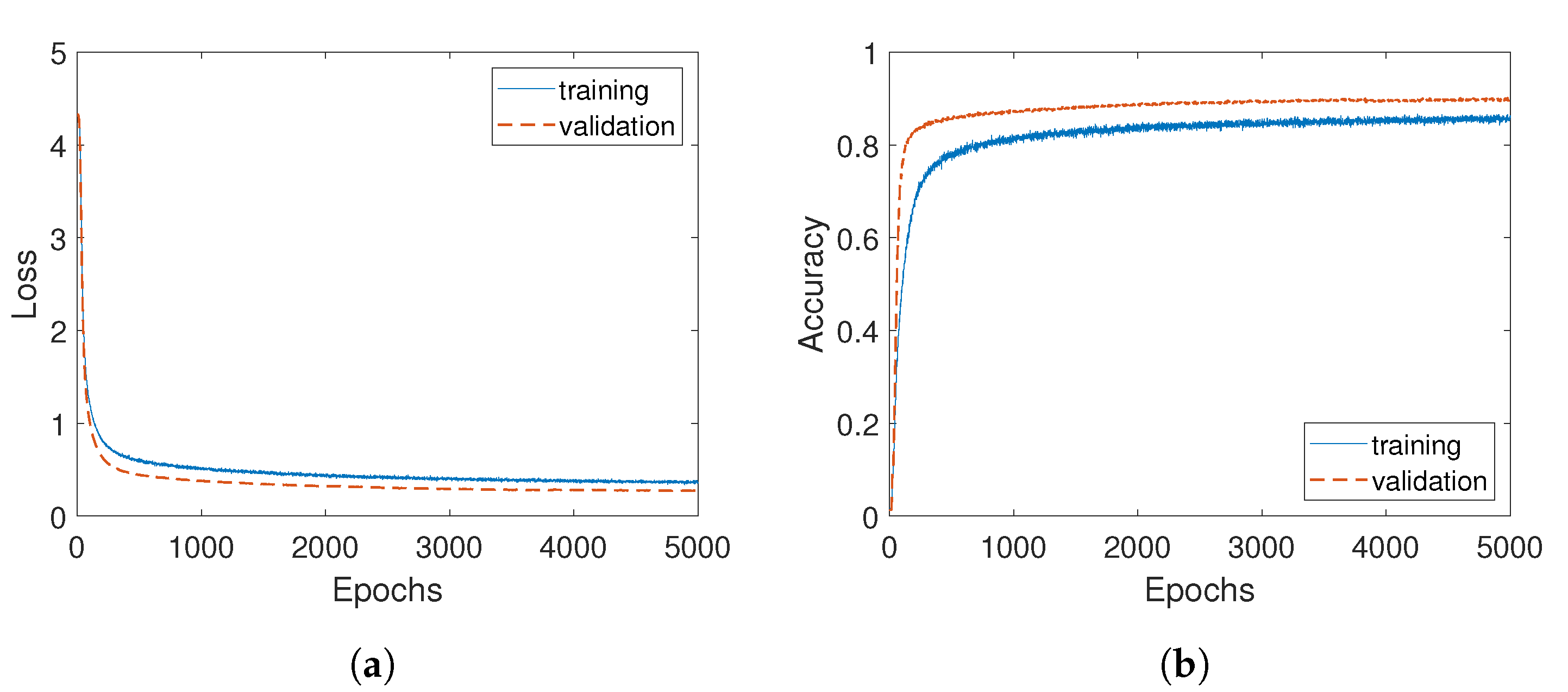
3.3.2. Learning the Model
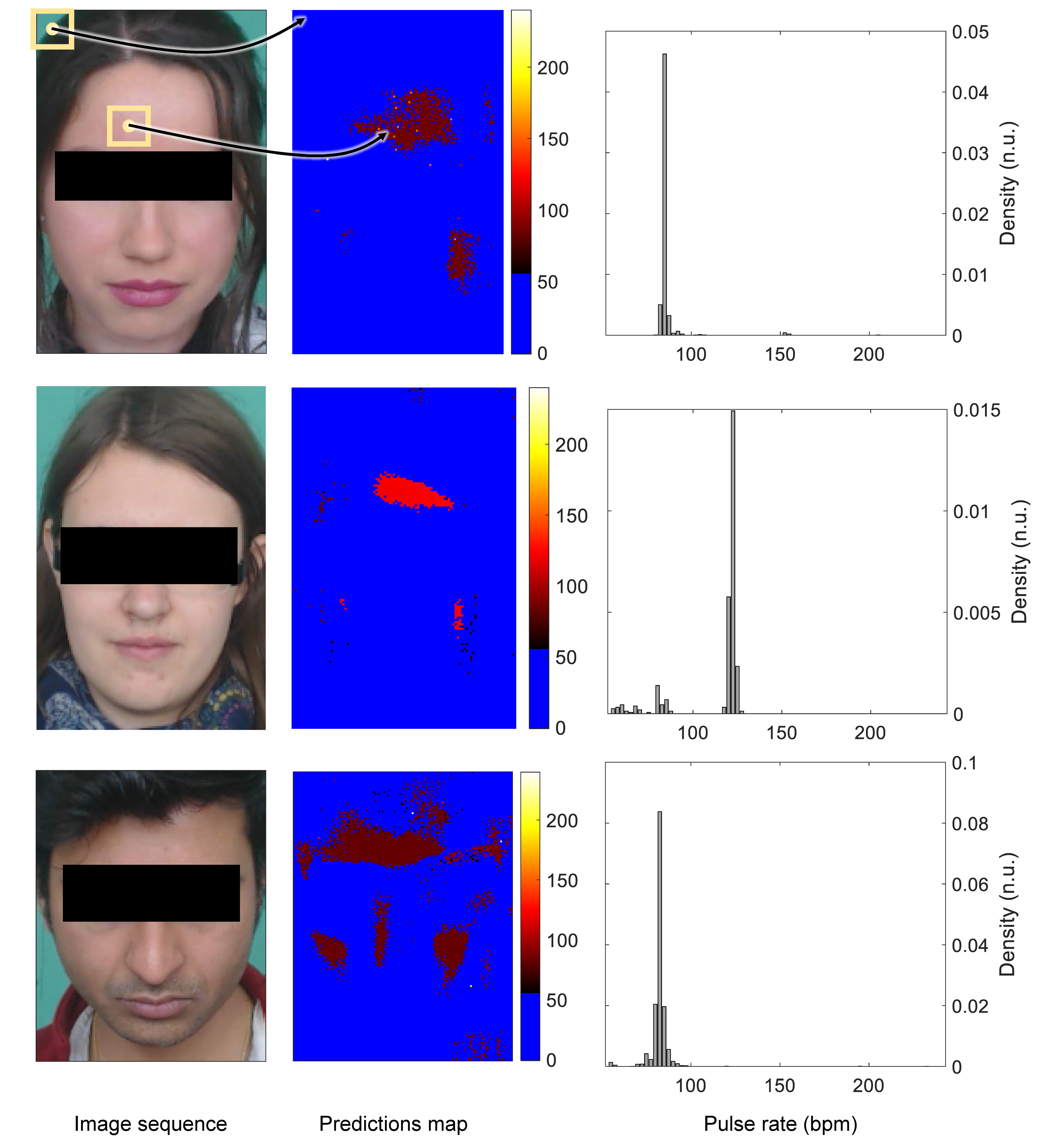
3.3.3. Pulse Rate Prediction
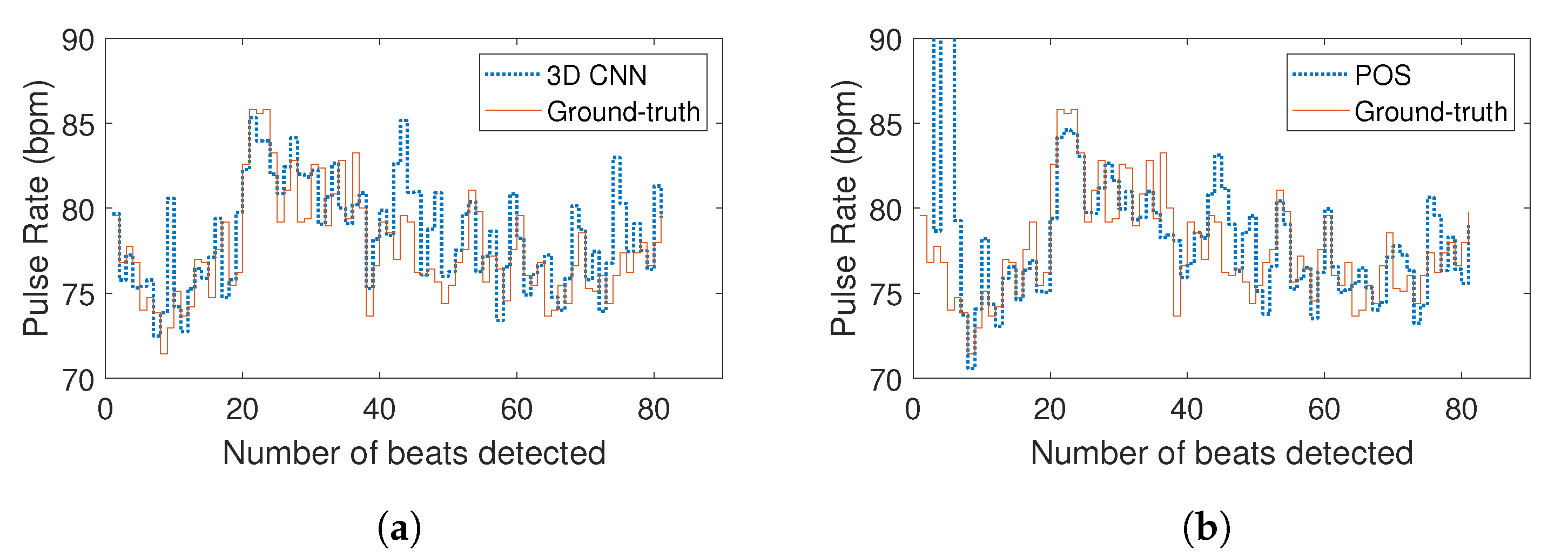
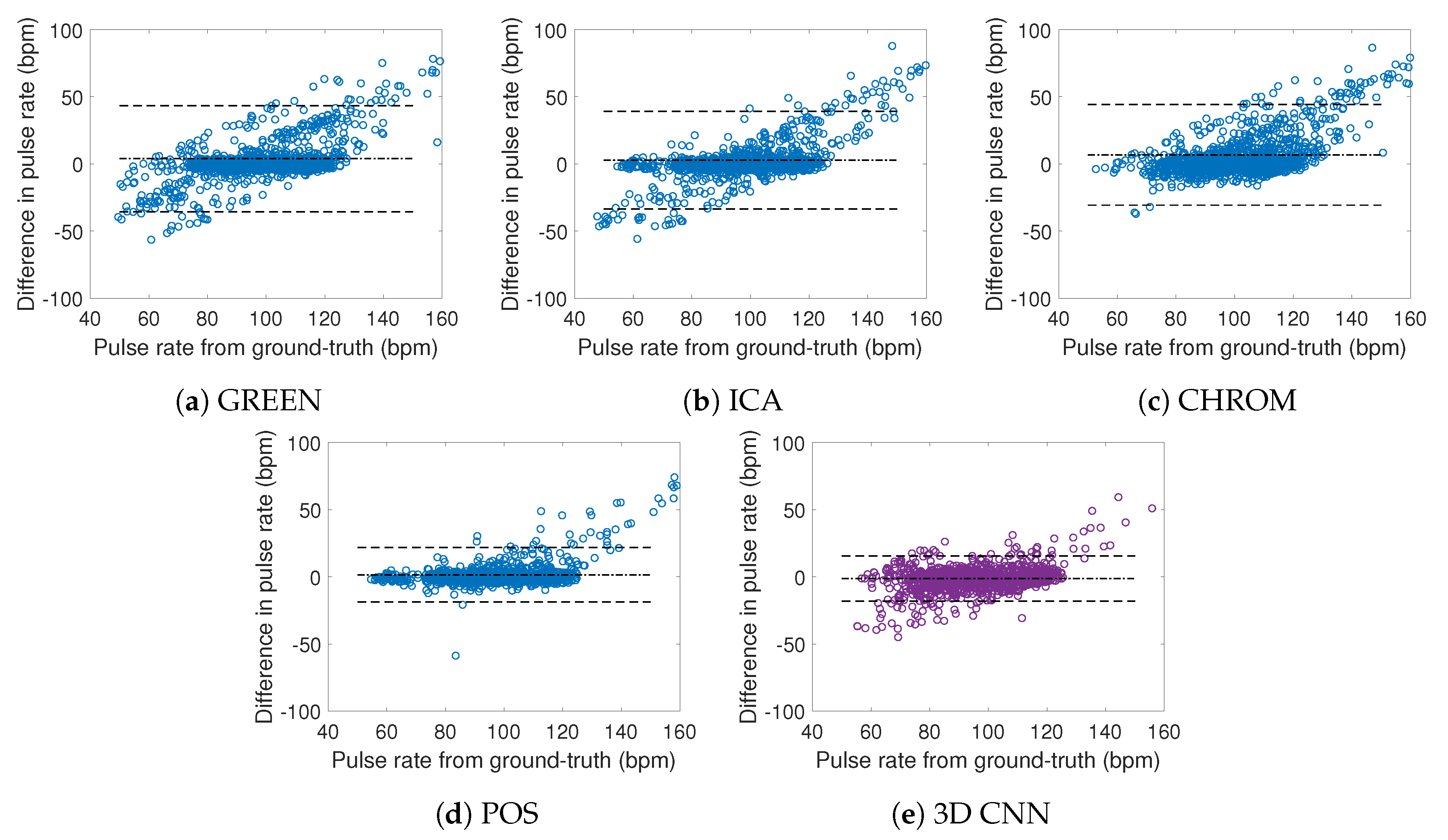
4. Results and Discussion
4.1. Evaluation Metrics and Methods
4.2. Results Analysis
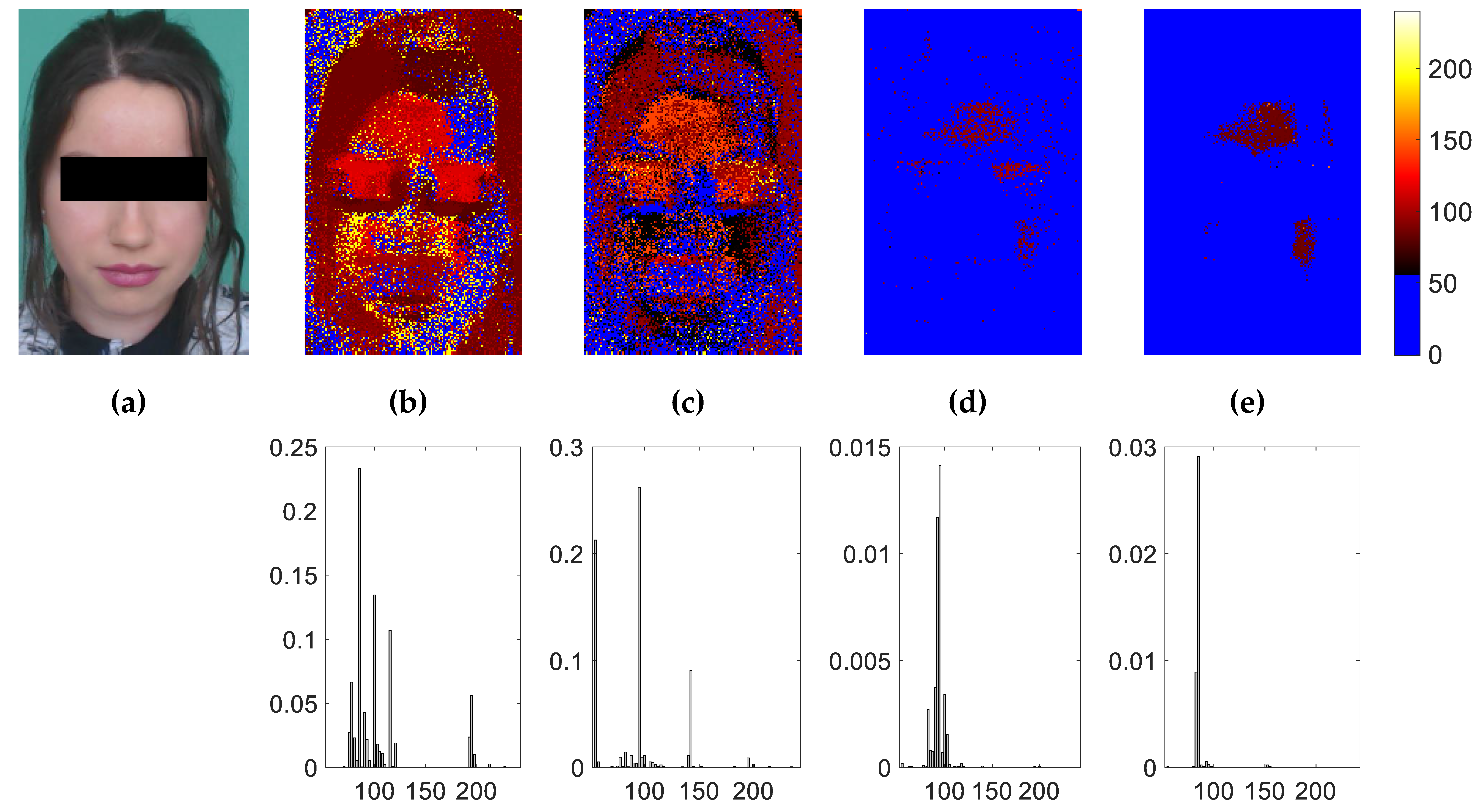
4.3. Improving the Network Architecture
4.4. Maps Convergence during Training
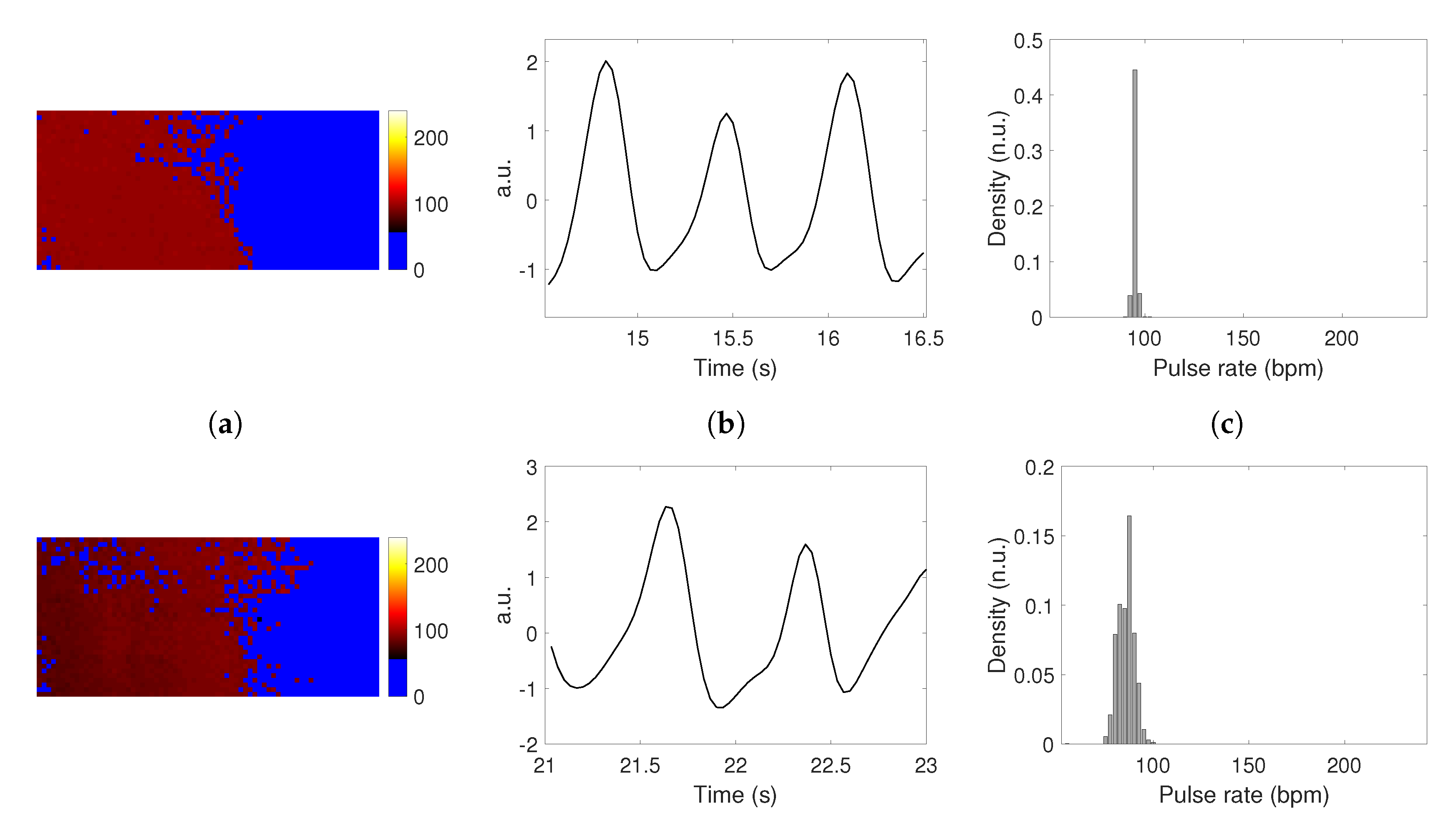
4.5. Non-Stationary Signals and Motion
4.6. Other Future Developments
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Balakrishnan, G.; Durand, F.; Guttag, J. Detecting pulse from head motions in video. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 3430–3437. [Google Scholar]
- Hassan, M.; Malik, A.; Fofi, D.; Saad, N.; Karasfi, B.; Ali, Y.; Meriaudeau, F. Heart rate estimation using facial video: A review. Biomed. Signal Process. Control 2017, 38, 346–360. [Google Scholar] [CrossRef]
- Haque, M.A.; Irani, R.; Nasrollahi, K.; Moeslund, T.B. Heartbeat rate measurement from facial video. IEEE Intell. Syst. 2016, 31, 40–48. [Google Scholar] [CrossRef]
- Wu, H.Y.; Rubinstein, M.; Shih, E.; Guttag, J.; Durand, F.; Freeman, W. Eulerian Video Magnification for Revealing Subtle Changes in the World. ACM Trans. Graph. 2012, 31, 65:1–65:8. [Google Scholar] [CrossRef]
- Ordóñez, C.; Cabo, C.; Menéndez, A.; Bello, A. Detection of human vital signs in hazardous environments by means of video magnification. PLoS ONE 2018, 13, e0195290. [Google Scholar] [CrossRef]
- Zaunseder, S.; Trumpp, A.; Wedekind, D.; Malberg, H. Cardiovascular assessment by imaging photoplethysmography—A review. Biomed. Eng./Biomedizinische Technik 2018, 63, 617–634. [Google Scholar] [CrossRef] [PubMed]
- Allen, J. Photoplethysmography and its application in clinical physiological measurement. Physiol. Meas. 2007, 28, R1–R39. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kamshilin, A.A.; Nippolainen, E.; Sidorov, I.S.; Vasilev, P.V.; Erofeev, N.P.; Podolian, N.P.; Romashko, R.V. A new look at the essence of the imaging photoplethysmography. Sci. Rep. 2015, 5, 10494. [Google Scholar] [CrossRef]
- Shao, D.; Liu, C.; Tsow, F.; Yang, Y.; Du, Z.; Iriya, R.; Yu, H.; Tao, N. Noncontact monitoring of blood oxygen saturation using camera and dual-wavelength imaging system. IEEE Trans. Biomed. Eng. 2016, 63, 1091–1098. [Google Scholar] [CrossRef]
- Van Gastel, M.; Stuijk, S.; De Haan, G. New principle for measuring arterial blood oxygenation, enabling motion-robust remote monitoring. Sci. Rep. 2016, 6, 38609. [Google Scholar] [CrossRef] [Green Version]
- Hassan, M.; Malik, A.; Fofi, D.; Saad, N.; Meriaudeau, F. Novel health monitoring method an using RGB camera. Biomed. Opt. Express 2017, 8, 4838–4854. [Google Scholar] [CrossRef]
- Van Gastel, M.; Stuijk, S.; de Haan, G. Robust respiration detection from remote photoplethysmography. Biomed. Opt. Express 2016, 7, 4941–4957. [Google Scholar] [CrossRef] [Green Version]
- Al-Naji, A.; Chahl, J. Simultaneous Tracking of Cardiorespiratory Signals for Multiple Persons Using a Machine Vision System With Noise Artifact Removal. IEEE J. Transl. Eng. Health Med. 2017, 5, 1–10. [Google Scholar] [CrossRef]
- Sugita, N.; Yoshizawa, M.; Abe, M.; Tanaka, A.; Homma, N.; Yambe, T. Contactless Technique for Measuring Blood-Pressure Variability from One Region in Video Plethysmography. J. Med. Biol. Eng. 2019, 39, 76–85. [Google Scholar] [CrossRef]
- Zhang, G.; Shan, C.; Kirenko, I.; Long, X.; Aarts, R.M. Hybrid optical unobtrusive blood pressure measurements. Sensors 2017, 17, 1541. [Google Scholar] [CrossRef]
- Bousefsaf, F.; Maaoui, C.; Pruski, A. Peripheral vasomotor activity assessment using a continuous wavelet analysis on webcam photoplethysmographic signals. Bio-Med. Mater. Eng. 2016, 27, 527–538. [Google Scholar] [CrossRef]
- Trumpp, A.; Schell, J.; Malberg, H.; Zaunseder, S. Vasomotor assessment by camera-based photoplethysmography. Curr. Dir. Biomed. Eng. 2016, 2, 199–202. [Google Scholar] [CrossRef]
- Kamshilin, A.A.; Zaytsev, V.V.; Mamontov, O.V. Novel contactless approach for assessment of venous occlusion plethysmography by video recordings at the green illumination. Sci. Rep. 2017, 7, 464. [Google Scholar] [CrossRef]
- Wang, W.; Stuijk, S.; de Haan, G. Living-Skin Classification via Remote-PPG. IEEE Trans. Biomed. Eng. 2017, 64, 2781–2792. [Google Scholar] [PubMed]
- Bobbia, S.; Macwan, R.; Benezeth, Y.; Mansouri, A.; Dubois, J. Unsupervised skin tissue segmentation for remote photoplethysmography. Pattern Recognit. Lett. 2019, 124, 82–90. [Google Scholar] [CrossRef]
- Al-Naji, A.; Gibson, K.; Lee, S.H.; Chahl, J. Monitoring of Cardiorespiratory Signal: Principles of Remote Measurements and Review of Methods. IEEE Access 2017, 5, 15776–15790. [Google Scholar] [CrossRef]
- Hurter, C.; McDuff, D. Cardiolens: Remote Physiological Monitoring in a Mixed Reality Environment; ACM SIGGRAPH 2017 Emerging Technologies; ACM: New York, NY, USA, 2017; p. 6. [Google Scholar]
- Villarroel, M.; Guazzi, A.; Jorge, J.; Davis, S.; Watkinson, P.; Green, G.; Shenvi, A.; McCormick, K.; Tarassenko, L. Continuous non-contact vital sign monitoring in neonatal intensive care unit. Healthc. Technol. Lett. 2014, 1, 87–91. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Zhou, Y.; Song, S.; Liang, G.; Ni, H. Heart Rate Extraction Based on Near-Infrared Camera: Towards Driver State Monitoring. IEEE Access 2018, 6, 33076–33087. [Google Scholar] [CrossRef]
- Liu, S.; Yuen, P.C.; Zhang, S.; Zhao, G. 3D mask face anti-spoofing with remote Photoplethysmography. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 85–100. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Huang, P.H.; Chang, C.C.; Huang, C.Y.; Hsiao, T.C. Can Very High Frequency Instantaneous Pulse Rate Variability Serve as an Obvious Indicator of Peripheral Circulation? J. Commun. Comput. 2017, 14, 65–72. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Graves, A.; Jaitly, N. Towards end-to-end speech recognition with recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1764–1772. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.r.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef]
- Miotto, R.; Wang, F.; Wang, S.; Jiang, X.; Dudley, J.T. Deep learning for healthcare: Review, opportunities and challenges. Briefings Bioinform. 2017, 19, 1236–1246. [Google Scholar] [CrossRef]
- Kranjec, J.; Beguš, S.; Geršak, G.; Drnovšek, J. Non-contact heart rate and heart rate variability measurements: A review. Biomed. Signal Process. Control 2014, 13, 102–112. [Google Scholar] [CrossRef]
- McDuff, D.J.; Estepp, J.R.; Piasecki, A.M.; Blackford, E.B. A survey of remote optical photoplethysmographic imaging methods. Engineering in Medicine and Biology Society (EMBC). In Proceedings of the 2015 37th Annual International Conference of the IEEE, Milano, Italy, 25–29 August 2015; pp. 6398–6404. [Google Scholar]
- Takano, C.; Ohta, Y. Heart rate measurement based on a time-lapse image. Med Eng. Phys. 2007, 29, 853–857. [Google Scholar] [CrossRef] [PubMed]
- Verkruysse, W.; Svaasand, L.O.; Nelson, J.S. Remote plethysmographic imaging using ambient light. Opt. Express 2008, 16, 21434–21445. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kamshilin, A.A.; Margaryants, N.B. Origin of Photoplethysmographic Waveform at Green Light. Phys. Procedia 2017, 86, 72–80. [Google Scholar] [CrossRef]
- van Gastel, M.; Stuijk, S.; de Haan, G. Motion robust remote-PPG in infrared. IEEE Trans. Biomed. Eng. 2015, 62, 1425–1433. [Google Scholar] [CrossRef] [PubMed]
- McDuff, D.; Gontarek, S.; Picard, R.W. Improvements in remote cardiopulmonary measurement using a five band digital camera. IEEE Trans. Biomed. Eng. 2014, 61, 2593–2601. [Google Scholar] [CrossRef] [PubMed]
- McDuff, D.J.; Blackford, E.B.; Estepp, J.R. The Impact of Video Compression on Remote Cardiac Pulse Measurement Using Imaging Photoplethysmography. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 63–70. [Google Scholar]
- Poh, M.Z.; McDuff, D.J.; Picard, R.W. Non-contact, automated cardiac pulse measurements using video imaging and blind source separation. Opt. Express 2010, 18, 10762–10774. [Google Scholar] [CrossRef]
- Bousefsaf, F.; Maaoui, C.; Pruski, A. Continuous wavelet filtering on webcam photoplethysmographic signals to remotely assess the instantaneous heart rate. Biomed. Signal Process. Control 2013, 8, 568–574. [Google Scholar] [CrossRef]
- Bousefsaf, F.; Maaoui, C.; Pruski, A. Automatic Selection of Webcam Photoplethysmographic Pixels Based on Lightness Criteria. J. Med Biol. Eng. 2017, 37, 374–385. [Google Scholar] [CrossRef]
- Stricker, R.; Müller, S.; Gross, H.M. Non-contact video-based pulse rate measurement on a mobile service robot. In Proceedings of the 2014 RO-MAN: The 23rd IEEE International Symposium on Robot and Human Interactive Communication, Edinburgh, UK, 25–29 August 2014; pp. 1056–1062. [Google Scholar]
- Po, L.M.; Feng, L.; Li, Y.; Xu, X.; Cheung, T.C.H.; Cheung, K.W. Block-based adaptive ROI for remote photoplethysmography. Multimedia Tools Appl. 2018, 77, 6503–6529. [Google Scholar] [CrossRef]
- Wang, W.; den Brinker, A.C.; Stuijk, S.; de Haan, G. Algorithmic Principles of Remote PPG. IEEE Trans. Biomed. Eng. 2017, 64, 1479–1491. [Google Scholar] [CrossRef]
- Poh, M.Z.; McDuff, D.J.; Picard, R.W. Advancements in noncontact, multiparameter physiological measurements using a webcam. IEEE Trans. Biomed. Eng. 2011, 58, 7–11. [Google Scholar] [CrossRef] [PubMed]
- Bousefsaf, F.; Maaoui, C.; Pruski, A. Remote detection of mental workload changes using cardiac parameters assessed with a low-cost webcam. Comput. Biol. Med. 2014, 53, 154–163. [Google Scholar] [CrossRef] [PubMed]
- McDuff, D.; Gontarek, S.; Picard, R.W. Remote detection of photoplethysmographic systolic and diastolic peaks using a digital camera. IEEE Trans. Biomed. Eng. 2014, 61, 2948–2954. [Google Scholar] [CrossRef] [PubMed]
- Monkaresi, H.; Calvo, R.A.; Yan, H. A machine learning approach to improve contactless heart rate monitoring using a webcam. IEEE J. Biomed. Health Inform. 2014, 18, 1153–1160. [Google Scholar] [CrossRef]
- Osman, A.; Turcot, J.; El Kaliouby, R. Supervised learning approach to remote heart rate estimation from facial videos. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 1, pp. 1–6. [Google Scholar]
- Hsu, Y.; Lin, Y.L.; Hsu, W. Learning-based heart rate detection from remote photoplethysmography features. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4433–4437. [Google Scholar]
- Hsu, G.S.; Ambikapathi, A.; Chen, M.S. Deep learning with time-frequency representation for pulse estimation from facial videos. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 383–389. [Google Scholar]
- Chen, W.; McDuff, D. DeepPhys: Video-Based Physiological Measurement Using Convolutional Attention Networks. arXiv 2018, arXiv:1805.07888. [Google Scholar]
- Chen, W.; McDuff, D. DeepMag: Source Specific Motion Magnification Using Gradient Ascent. arXiv 2018, arXiv:1808.03338. [Google Scholar]
- Chaichulee, S.; Villarroel, M.; Jorge, J.; Arteta, C.; Green, G.; McCormick, K.; Zisserman, A.; Tarassenko, L. Multi-task Convolutional Neural Network for Patient Detection and Skin Segmentation in Continuous Non-contact Vital Sign Monitoring. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 266–272. [Google Scholar]
- Špetlík, R.; Franc, V.; Matas, J. Visual Heart Rate Estimation with Convolutional Neural Network. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Niu, X.; Han, H.; Shan, S.; Chen, X. Synrhythm: Learning a deep heart rate estimator from general to specific. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3580–3585. [Google Scholar]
- Jindal, V.; Birjandtalab, J.; Pouyan, M.B.; Nourani, M. An adaptive deep learning approach for PPG-based identification. In Proceedings of the 2016 IEEE 38th Annual International Conference of the Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 6401–6404. [Google Scholar]
- Su, P.; Ding, X.R.; Zhang, Y.T.; Liu, J.; Miao, F.; Zhao, N. Long-term blood pressure prediction with deep recurrent neural networks. In Proceedings of the 2018 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Las Vegas, NV, USA, 4–7 March 2018; pp. 323–328. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 4489–4497. [Google Scholar]
- Varol, G.; Laptev, I.; Schmid, C. Long-term temporal convolutions for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1510–1517. [Google Scholar] [CrossRef]
- Graham, D.; Langroudi, S.H.F.; Kanan, C.; Kudithipudi, D. Convolutional Drift Networks for Video Classification. In Proceedings of the 2017 IEEE International Conference on Rebooting Computing (ICRC), Washington, DC, USA, 8–9 November 2017; pp. 1–8. [Google Scholar]
- Dwibedi, D.; Sermanet, P.; Tompson, J.; Diba, A.; Fayyaz, M.; Sharma, V.; Hossein Karami, A.; Mahdi Arzani, M.; Yousefzadeh, R.; Van Gool, L.; et al. Temporal Reasoning in Videos using Convolutional Gated Recurrent Units. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1111–1116. [Google Scholar]
- Lea, C.; Reiter, A.; Vidal, R.; Hager, G.D. Segmental spatiotemporal cnns for fine-grained action segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 36–52. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks for action recognition in videos. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2740–2755. [Google Scholar] [CrossRef]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1. [Google Scholar]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A multimodal database for affect recognition and implicit tagging. IEEE Trans. Affect. Comput. 2012, 3, 42–55. [Google Scholar] [CrossRef]
- Heusch, G.; Anjos, A.; Marcel, S. A Reproducible Study on Remote Heart Rate Measurement. arXiv 2017, arXiv:1709.00962. [Google Scholar]
- Tuccillo, D.; Decencière, E.; Velasco-Forero, S.; Huertas-Company, M. Deep learning for studies of galaxy morphology. Proc. Int. Astron. Union 2016, 12, 191–196. [Google Scholar] [CrossRef] [Green Version]
- George, D.; Huerta, E. Deep Learning for real-time gravitational wave detection and parameter estimation: Results with Advanced LIGO data. Phys. Lett. B 2018, 778, 64–70. [Google Scholar] [CrossRef]
- Quang, D.; Chen, Y.; Xie, X. DANN: A deep learning approach for annotating the pathogenicity of genetic variants. Bioinformatics 2014, 31, 761–763. [Google Scholar] [CrossRef]
- Plis, S.M.; Hjelm, D.R.; Salakhutdinov, R.; Allen, E.A.; Bockholt, H.J.; Long, J.D.; Johnson, H.J.; Paulsen, J.S.; Turner, J.A.; Calhoun, V.D. Deep learning for neuroimaging: A validation study. Front. Neurosci. 2014, 8, 229. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Liu, J.; Luo, H.; Zheng, P.P.; Wu, S.J.; Lee, K. Transdermal optical imaging revealed different spatiotemporal patterns of facial cardiovascular activities. Sci. Rep. 2018, 8, 10588. [Google Scholar] [CrossRef]
- McDuff, D.; Blackford, E. iPhys: An Open Non-Contact Imaging-Based Physiological Measurement Toolbox. arXiv 2019, arXiv:1901.04366. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Fits Periodic Functions? | Model Equation | Number of Coefficients |
|---|---|---|---|
| exponential | ✗ | ||
| polynomial | ✗ | n: polynomial degree | |
| Fourier series | ✓ | : fundamental frequency n: number of terms | |
| Gaussian model | ✗ | n: number of peaks | |
| sum of sines | ✓ | n: number of terms | |
| power series | ✗ | and | 2 and 3 |
| Weibull | ✗ | 2 |
| Coefficient | Value |
|---|---|
| 0.4402 | |
| −0.3345 | |
| −0.1990 | |
| −0.0502 | |
| 0.0993 |
| Method | ME | STDE | MAE | RMSE |
|---|---|---|---|---|
| GREEN [39] | 3.93 | 20.2 | 10.2 | 20.6 |
| ICA [50] | 2.82 | 18.6 | 8.43 | 18.8 |
| CHROM [49] | 6.78 | 19.1 | 10.6 | 20.3 |
| POS [49] | 1.47 | 10.4 | 4.12 | 10.5 |
| 3D CNN | −1.31 | 8.55 | 5.45 | 8.64 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bousefsaf, F.; Pruski, A.; Maaoui, C. 3D Convolutional Neural Networks for Remote Pulse Rate Measurement and Mapping from Facial Video. Appl. Sci. 2019, 9, 4364. https://doi.org/10.3390/app9204364
Bousefsaf F, Pruski A, Maaoui C. 3D Convolutional Neural Networks for Remote Pulse Rate Measurement and Mapping from Facial Video. Applied Sciences. 2019; 9(20):4364. https://doi.org/10.3390/app9204364
Chicago/Turabian StyleBousefsaf, Frédéric, Alain Pruski, and Choubeila Maaoui. 2019. "3D Convolutional Neural Networks for Remote Pulse Rate Measurement and Mapping from Facial Video" Applied Sciences 9, no. 20: 4364. https://doi.org/10.3390/app9204364
APA StyleBousefsaf, F., Pruski, A., & Maaoui, C. (2019). 3D Convolutional Neural Networks for Remote Pulse Rate Measurement and Mapping from Facial Video. Applied Sciences, 9(20), 4364. https://doi.org/10.3390/app9204364