This section includes active-slave spatial index decomposition for intersection, multi-strategy Hilbert ordering decomposition, and the parallel spatial union algorithm.
3.1. Active-Slave Spatial Index Decomposition for Intersection
From the dynamic nature of the overlay analysis, the superimposed layers are divided into the active layer (overlay layer) and passive layer (base layer). The point of parallel acceleration is the fast query of the geometric elements in the active layer. The intersection part of the layer and the spatial index is the key technology to achieve acceleration. According to the characteristics of the parallel overlay analysis in this paper, the storage of spatial data adopts a completely redundant mechanism, and each child node maintains a complete set of spatial data tables to be superimposed.
A data decomposition method is proposed for the parallel intersection operation. The process is to spatially decompose the active layer in advance and send the partition location information to the corresponding child node according to the FID (The name primarily used in the spatial data layer), the child node then locally extracts the active layer data in the range, then, the geographic elements in the passive layer all participate in the establishment of the whole spatial index tree; the elements in the active layer query the passive layer index and perform superposition operations on the intersecting candidate sets. Since the process of spatial query and the intersection operation in the overlay analysis are mostly the same operation, the data decomposition mode is adapted to be combined with the parallel intersection operation. In
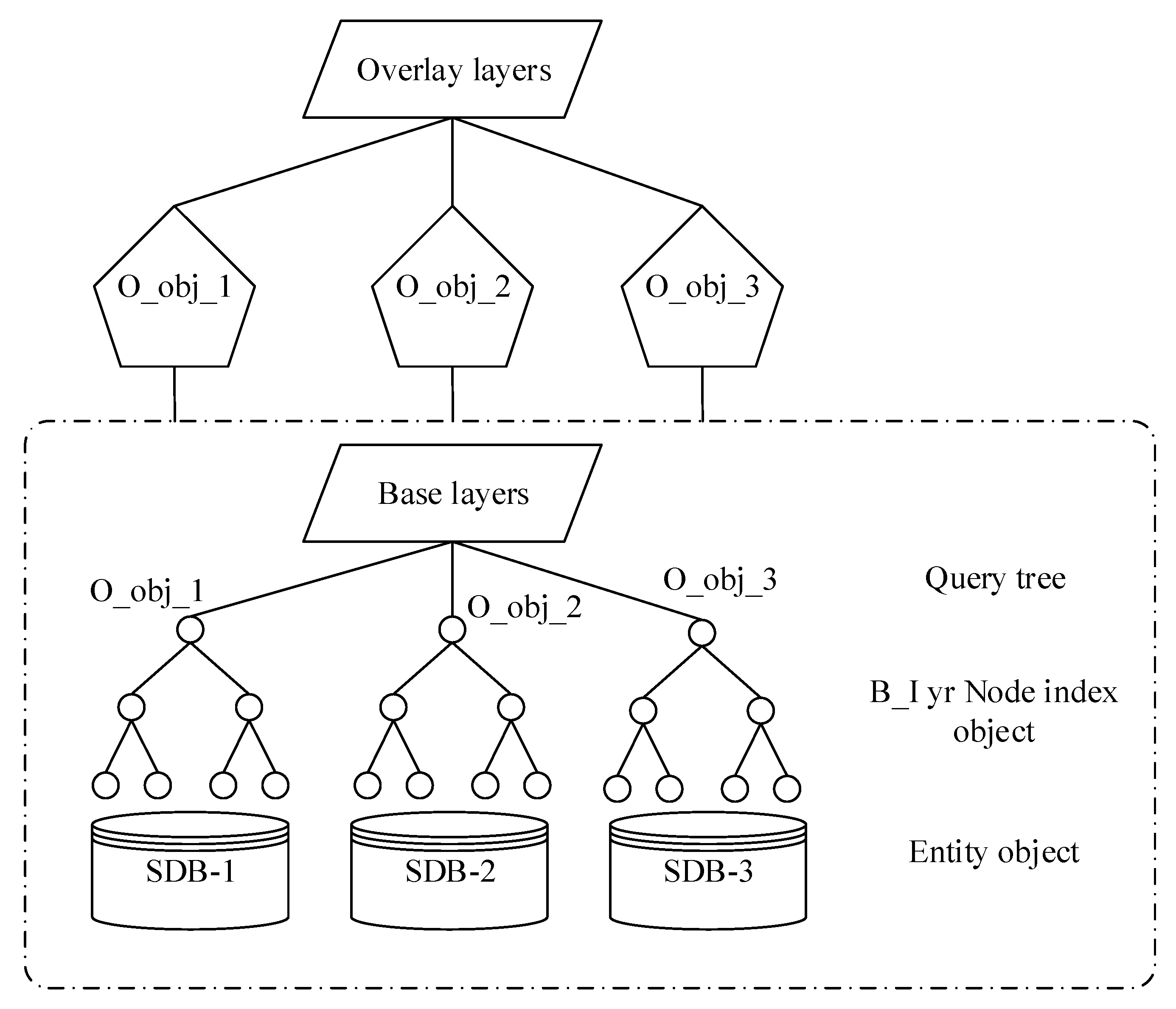
Figure 1, O_obj represents the entity object in the active overlay layer O_lyr. After the decomposition strategy, it is distributed to each child node, and the base layer B_lyr is parallelized.
The actual data decomposition is only the division and treatment of the overlay layer O_lyr, and the base layer is still a query as a whole. This solution enables acceleration in a reasonable computational complexity in small to medium data scale applications. The data decomposition characteristics of the above map overlay algorithm shows that if each child node resides in a base layer, the spatial index of the entire tree has two defects: first, when processing a layer with a large number of geographic features, each node needs to consume a lot of time and memory resources; second, each query is for the traversal of the entire tree, and there are a large number of invalid queries in the intersecting query of a single geometric object.
To improve the efficiency of massive spatial data management and processing in a parallel environment, an improved master-slave spatial indexing method MC-STR-tree was designed according to the current research results. The rapid management of data management and geometric intersections provides conditions.
The basic index structure of the index adopts STR-tree, and the modification of the R-tree object node is improved, and the conflict of data distribution among the nodes is reduced. It has good spatial clustering characteristics and extremely low spatial index packet overlap rate, so it has excellent parallelization characteristics. STR-tree is a highly balanced tree with simple and maximized space utilization.
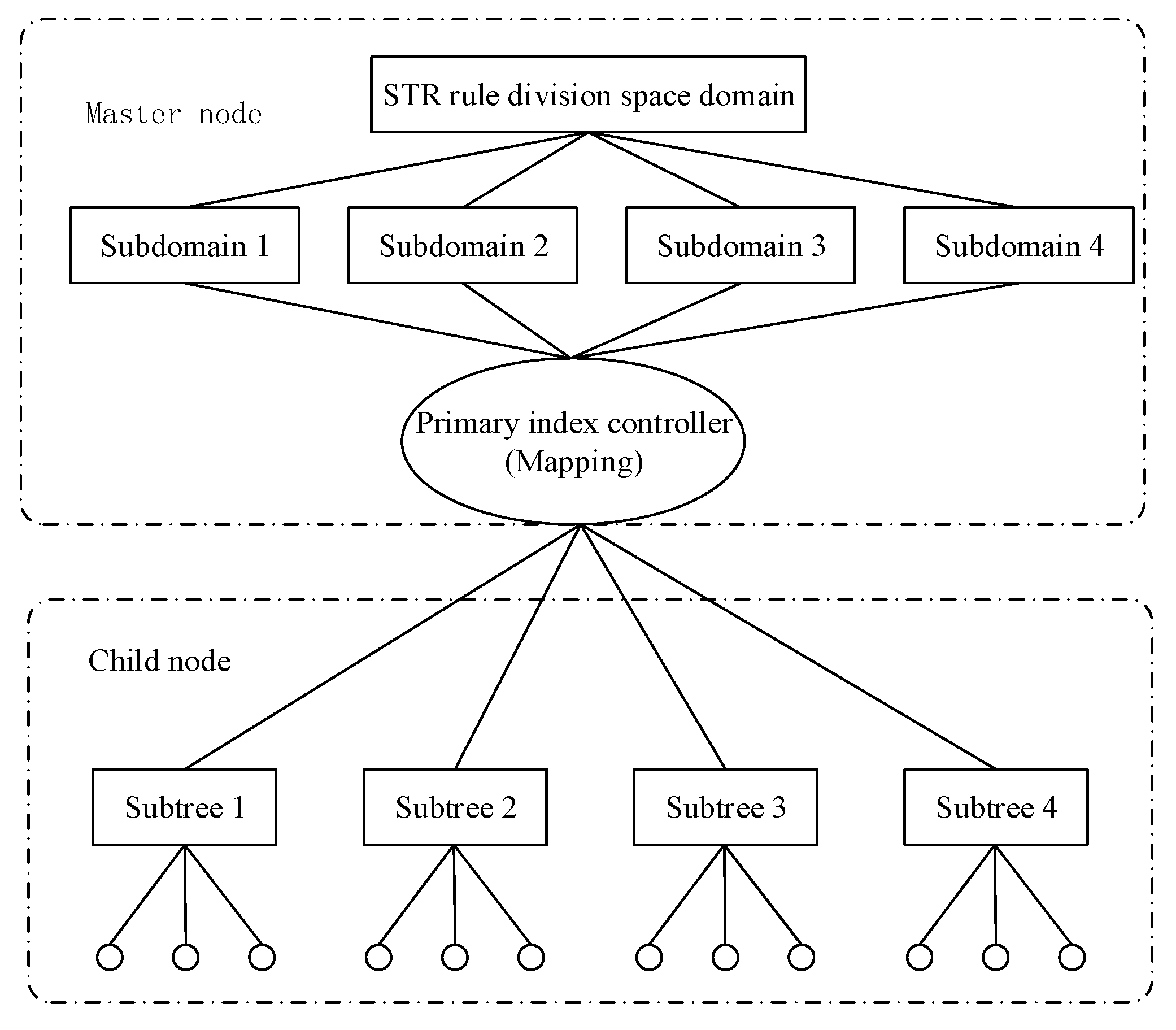
The processing steps of the improved master-slave parallel space index MC-STR-tree decomposition (
Figure 2) are as follows:
(1) Data preprocessing
The master node divides the MBR of the spatial data index node into n parts according to specific rules. The commonly used rules are Hilbert ordering and STR partitioning method, and n is an integer not larger than the cluster computing node. The master node needs to record the node tag to which each subtree is sent and the root node MBR of the subtree. In this paper, the leaf nodes are divided according to the STR rule, and each computing node corresponds to a stripe in the STR. To control the number of subtrees less than the number of computable nodes, node Vol is used to set the maximum number of indices sub-nodes allowed for each computed node in the STR-tree.
(2) Sending of the subtree index
The primary node sends the index entries to the child nodes according to a certain replication and allocation policy. The data structure uses an in-memory spatial index. Unlike the traditional hard disk-based spatial index, the in-memory spatial index has the characteristics of dynamic construction and fast query.
(3) The master node sets up the Master-R-tree
The master node builds a new spatial index into all non-leaf nodes in the original entire R-tree index tree in computer memory. The index tree records the index item information allocated by each computing node, and its function is equivalent to an overall index controller. The intersecting query of the active overlay layer is first filtered by the overall index tree.
(4) Computing node to build a Client-tree
According to the agreed STR-tree node organization rule, the index items sent by the master node are built into the client terminal tree. The entity object stored in the computer node is associated with the index item of the subtree, and the entity space data is extracted according to the index item MBR.
The parallel R-tree index decomposition based on the STR rule is analyzed. The essence is to replace the random partition in the form of elemental fid with the domain decomposition partition considering the neighboring spatial rule. The master node controls the overall spatial index R-tree of a large node, where the id information of the spatial data domain decomposition block in the cluster is recorded. The active layer first performs a query operation with the overall index tree. If one or more intersecting subdomains are queried, the master node notifies the child nodes having the subdomains to extract the active layer locally. The element is further intersected with the subtree, and the process will be analyzed in the parallelization of the intersection.
3.2. Multi-Strategy Hilbert Ordering Decomposition
It can be seen from the process of generating Hilbert code values that the determination of the code value is determined by the center point of the space grid, which is called the order method of the midpoint strategy. This section studies the difference between the middle strategy and the median strategy. Hilbert curve sorting is used to optimize the problem so that the sorting method can better take into account the spatial proximity of map features. The spatial sort is the reversible 1:1 correspondence between spatial feature points and consecutive integers in one-dimensional space as key values.
The middle strategy is easier to understand. In the process of dividing the spatial hierarchy, each cell is divided according to a fixed size, that is, at the middle point of the cell. The midpoint strategy is suitable for point set objects with a more balanced distribution in the low dimension in practical applications.
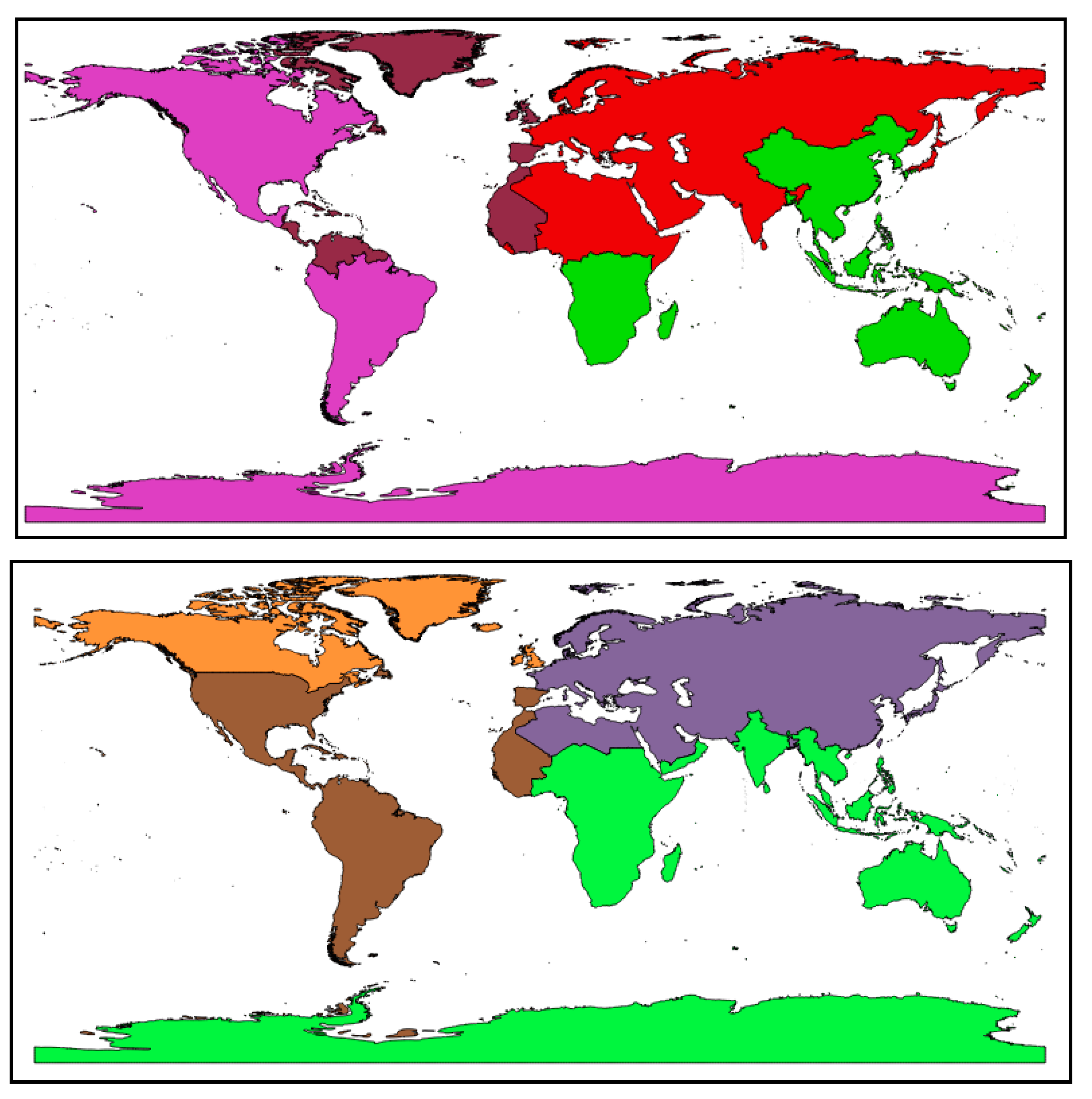
Unlike the middle strategy, the median strategy divides the cells in the space according to the median point in the x or y direction of the point to be sorted (
Figure 3). The geometric midpoint is an effective solution to the positioning of resource rules. In the high dimensional space, the median point can better represent the centrality of the clustering point. The median strategy is adapted to high-dimensional point sets or point set objects with uneven distribution.
From the definition of the median and the application context, the characteristics of maintaining clustering in Hilbert ordering can be better understood. The median is a concept in sequential statistics. In a set of n elements, the nth order statistic is the
i-th small element in the set. For example, in a set of elements, the minimum is the first order statistic (
i = 1), and the maximum is the nth order statistic (
n = 1). An informal definition of a median is the “midpoint element” of the collection it is in. When n is an odd number, the set has a unique median at
i = ((
n + 1))/2 out; when
n is even, it has two medians, which appear at
i =
n/2 and
i =
n/(2 + 1). If not considering the parity of
n, the median always appears at
i = ⌈((
n + 1))/2⌉ (upper median) and
i = ⌊((
n + 1))/2⌋ (lower median). In our study, the Hilbert median strategy sorting adopts the lower median by default. The CGAL library is used to assist Hilbert in sorting in the decomposition process of spatial data. Because the spatial data cannot be extracted from the data source directly according to the Hilbert code value, it must be the main processing data in parallel computing. After the node establishes the mapping relationship with the spatial database, the data is decomposed.
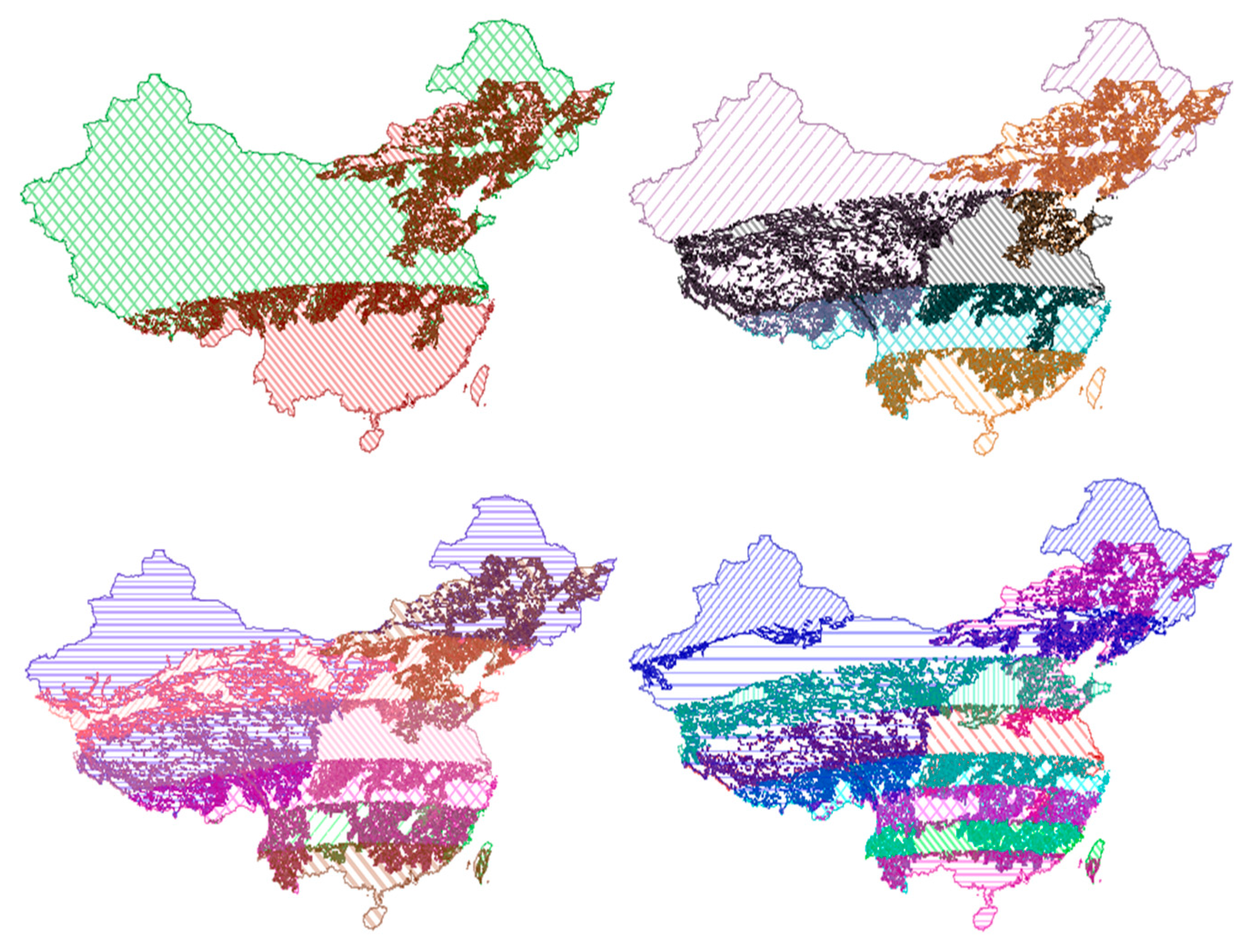
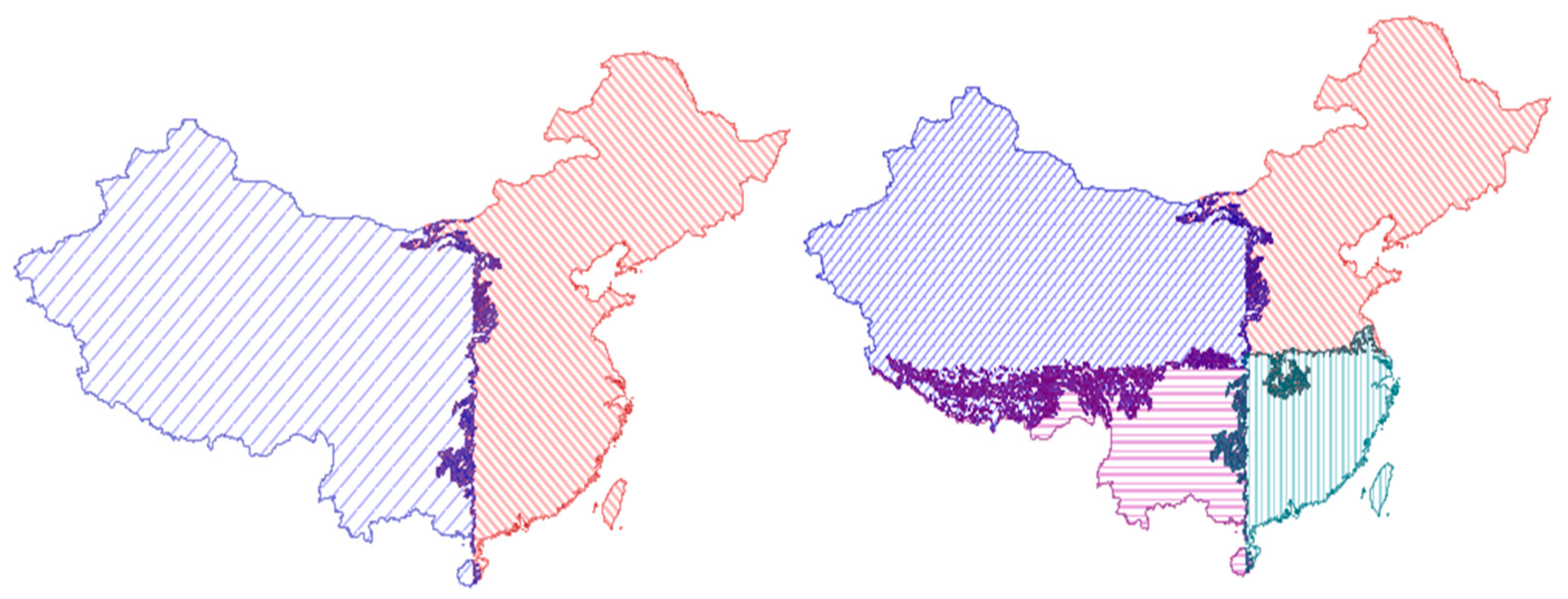
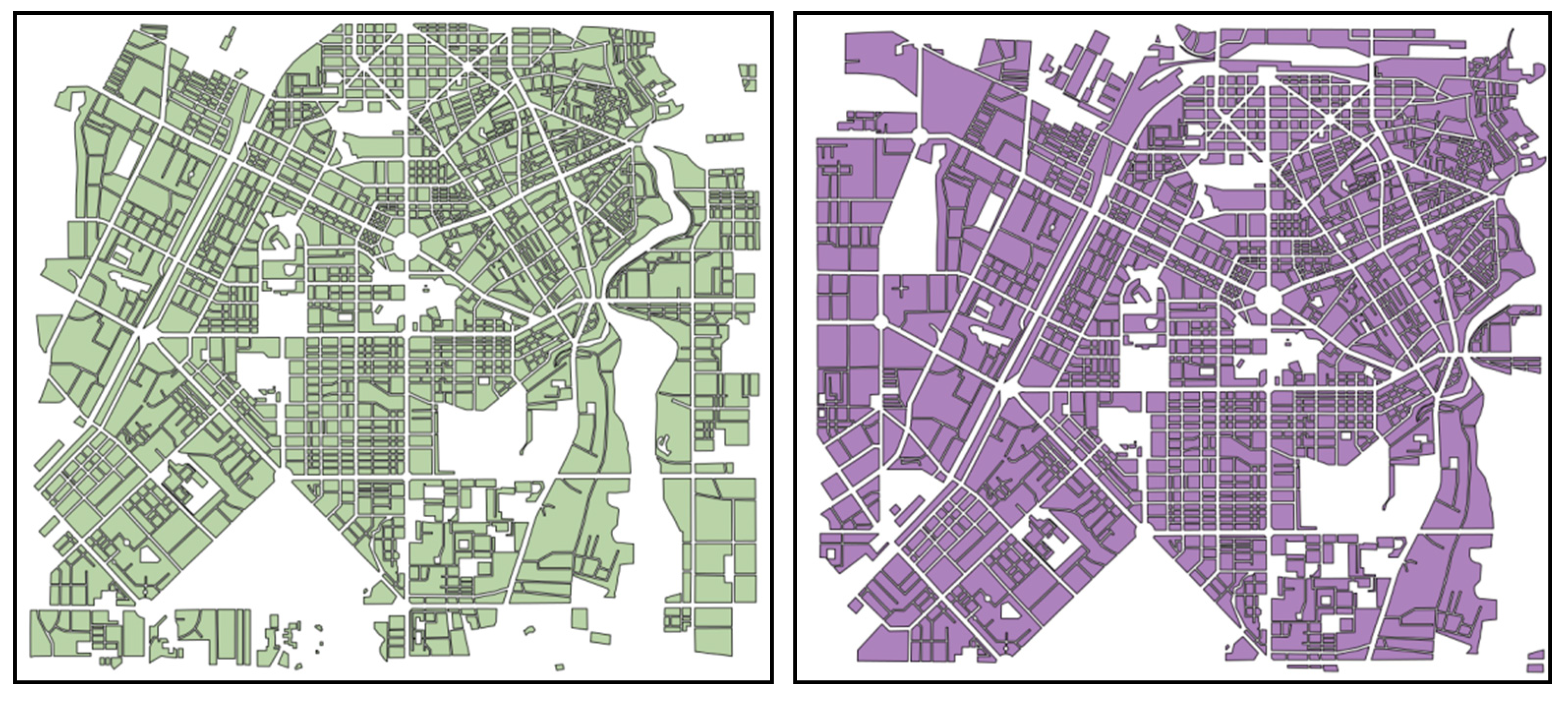
Figure 4 shows the world map divided by two different Hilbert sorting methods. Each color denotes the different classes for the result of Hilbert sorting methods.
The process based on Hilbert’s sorting decomposition is shown in
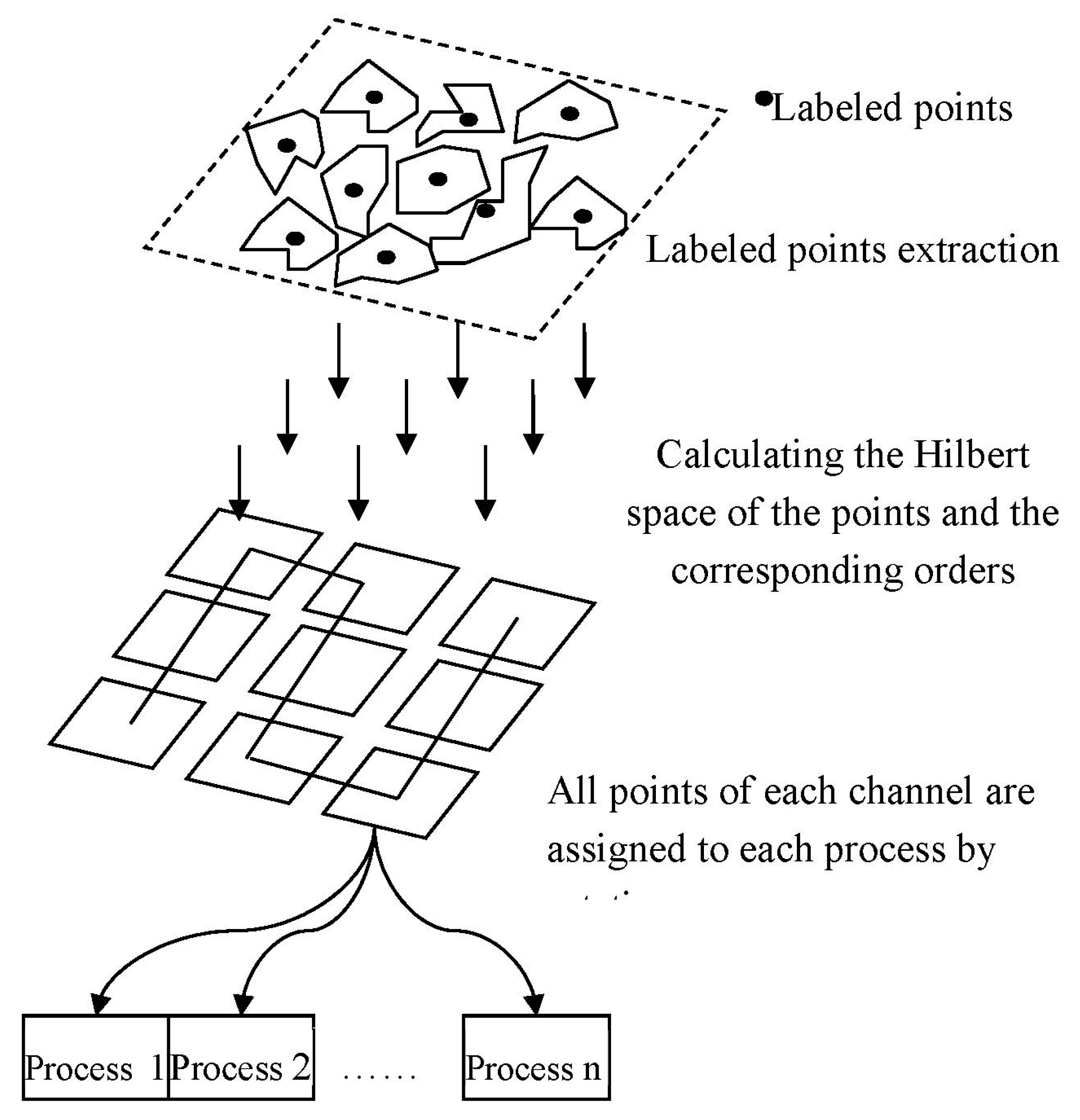
Figure 5. First, the feature points are extracted from the feature elements, and then the appropriate Hilbert space sorting strategy is selected according to the distribution characteristics of the spatial data. After Hilbert sorting, the main computing nodes follow the order of the one-dimensional Hilbert curve according to the multi-channel form, and the data-polling type is generated to each sub-node according to the interval division. Because the storage of vector data in this paper takes the form of a spatial database, what is referred to here is the location tag of the object in the spatial database table.
The most crucial purpose of spatial data domain decomposition in parallel GIS computing systems is that each child node can perform spatial data extraction or query work at the same time, without pulling information from the global control node; however, the traditional data partitioning method is based on the static clustering method. Reasonable spatial data partitioning should consider the spatial location distribution and length uncertainty of geographic data. It can be considered from two aspects whether the decomposition strategy of Hilbert ordering is the best, including whether each piece of sub-data can maintain spatial proximity to the maximum extent and whether the storage capacity of the data blocks in each node is equalized.
3.3. Parallel Spatial Union Algorithm
The parallel spatial union algorithm process is as follows:
(1) Polygon data feature point extraction
The Hilbert curve sorted objects are point objects with integer values, and the ordering of polygons was converted to the ordering of their representative feature points. The feature points of a polygon usually have an outer center point of the rectangle or four corner points, a geometric center point, and a mass center point. Since the calculation of the center point and the center of gravity of the polygon is time-consuming, it is not conducive to the parallel acceleration of the map overlay analysis. Therefore, the feature point of the outsourced rectangular is the center point. All the layers S are regarded as a set of all the layers L, and the feature point extraction is represented as, among them, a feature point set. The feature point set is constructed by the mapping function map.
(2) Feature point Hilbert space ordering
The function corresponding to the Hilbert curve sort is described as follows. Among them are integer coordinate values, and d is the Hilbert code value. For floating-point data in practical applications, it is necessary to scale to the nearest integer value. Constructing a Hilbert curve in a two-dimensional space maps the interval to a unit square interval, and each cell is recursively divided into four parts until each cell contains only one feature point. The computational complexity of constructing the Hilbert sorting curve algorithm is, where n is the number of hierarchical divisions of the Hilbert space. In the calculation process of Hilbert coded values in this paper, the value of n is not forced to be constrained so as to ensure that the point object clustering is denser and still maintains a good mapping unity.
In the parallel overlay analysis, Hilbert curve ordering is performed according to the distribution characteristics of the feature elements using two strategies: middle strategy and median strategy.
(3) Distribution of nearby polygons
In the parallel overlay analysis system, the Master node is responsible for loading all the map layers involved in the calculation and establishing the Hilbert sort number for its content. The elements in each layer are evenly distributed to each node according to the number of compute nodes. The number of layer elements and number of processors is n. It is necessary to map the code on the Hilbert curve string to the FID of the map element. The generation of the one–to–one correspondence depends on the previous Hilbert ordering process in which there are two mapping relationships, and the two mapping relationships are connected by feature point coordinates. The specific process can be described by the following formula, which is the Hilbert code value, the FID marked element, and the data extraction condition as the overlay query.
The implementation process of the Hilbert joint algorithm is as follows:
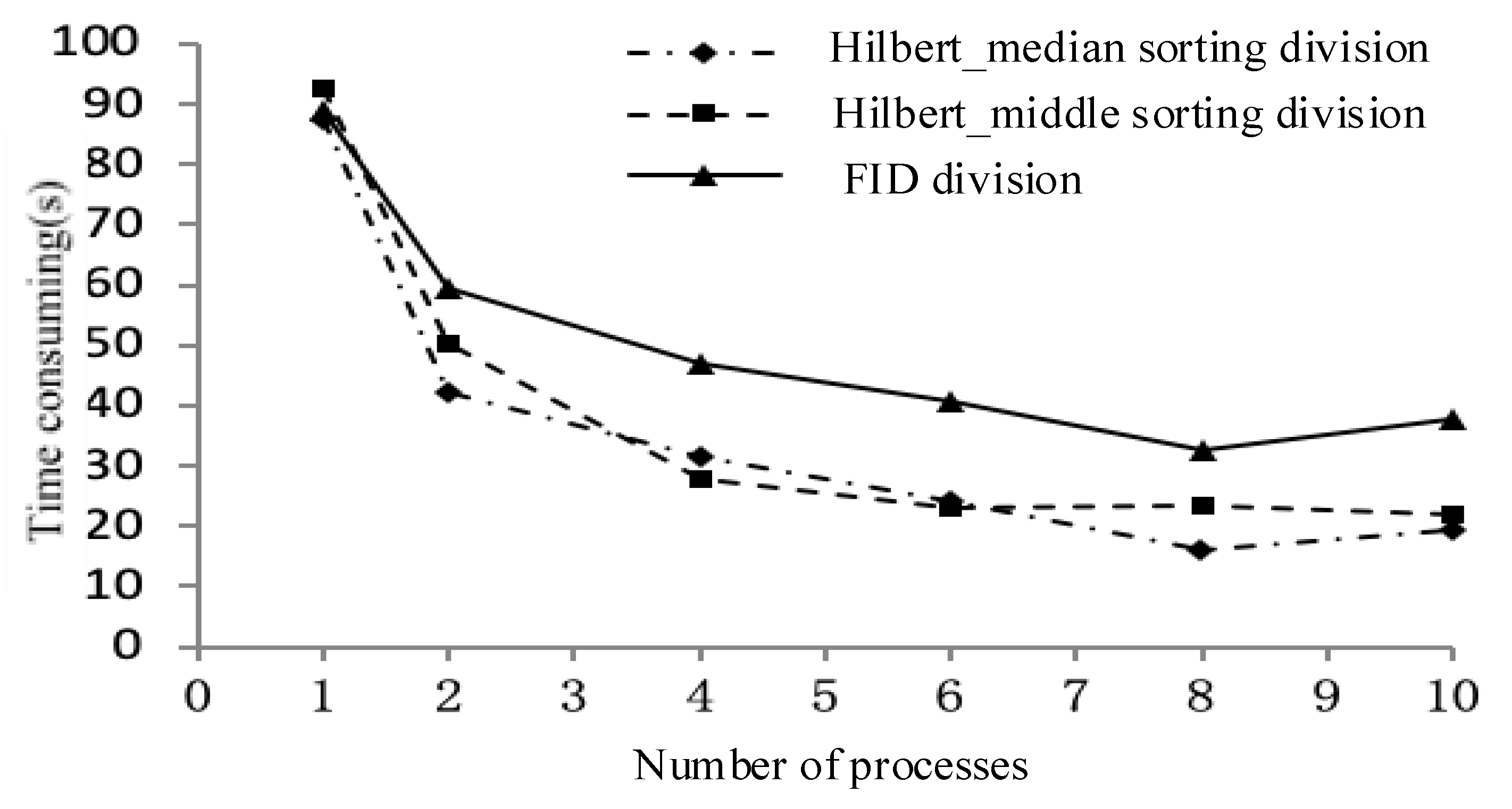
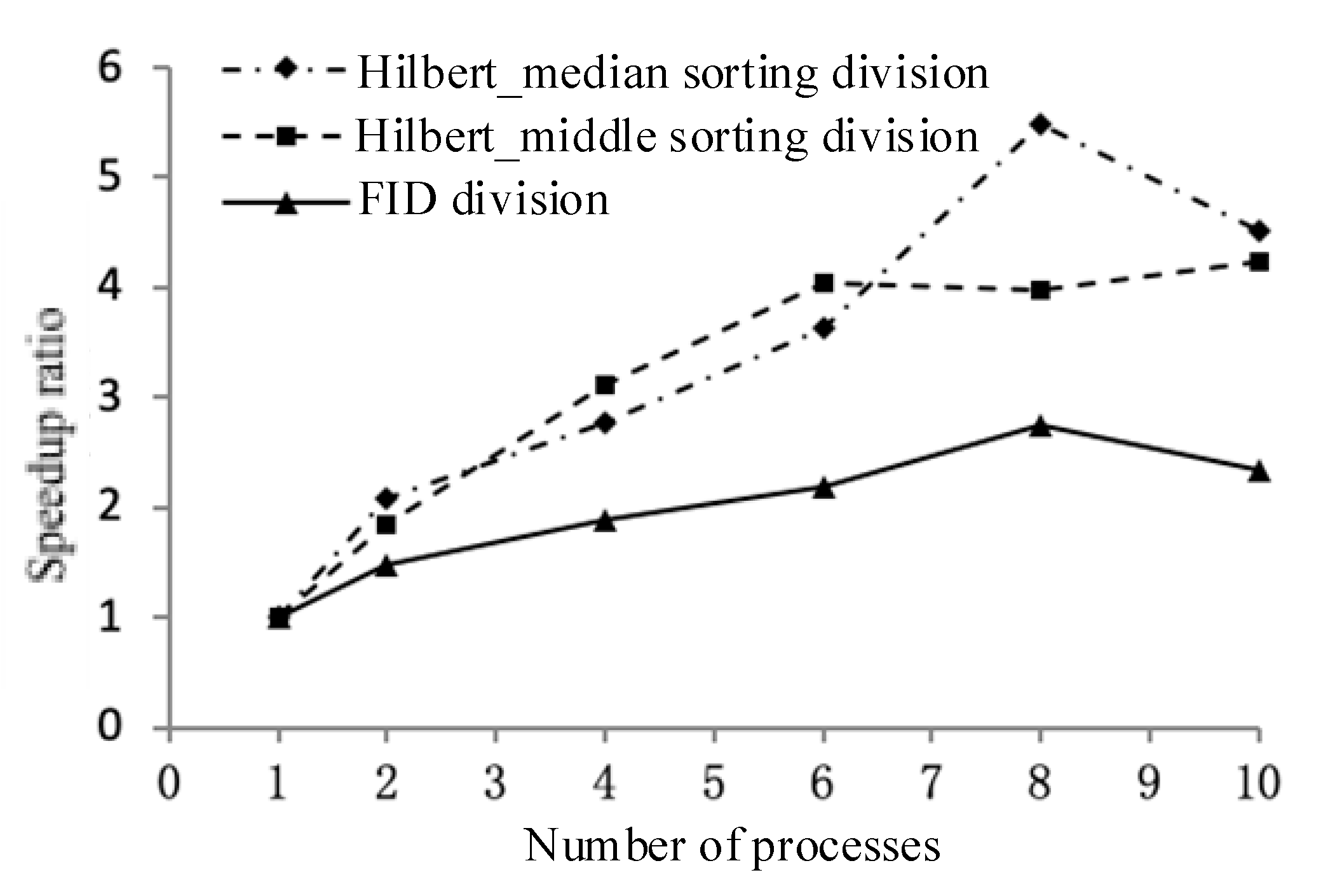
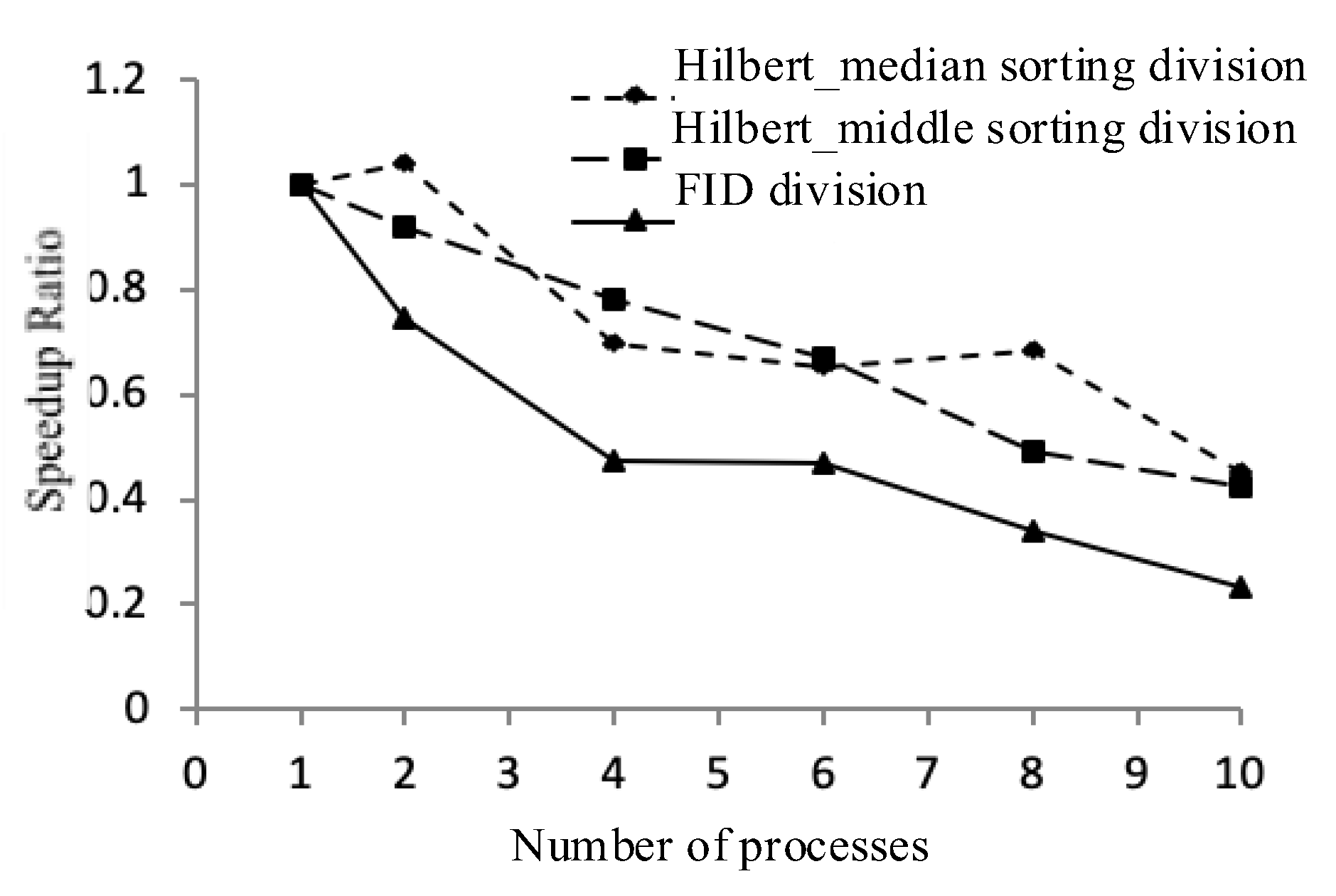
(i) A data partitioning strategy. The experiment uses three data distribution strategies in the order of fid, Hilbert_median, and Hilbert_middle. First, the master node determines the number of nodes participating in the calculation, and then equally distributes the ordered sets separately.
(ii) Independent calculations, generating intermediate results. Each computing node is responsible for the joint operation of the local polygons and writes the generated intermediate results to a temporary table in the MySQL spatial database.
(iii) Results are collected in conjunction. The master node loads the middle layer into the local memory in the order in which the child nodes complete the task, and then jointly outputs the final result layer to these layers.
The previous part is shown the operation of a single layer, the data decomposition hierarchy object is single, and it is easier to divide and conquer. For the overlaying and merging of two or more layers, it is necessary to consider the spatial data distribution of multiple layer species, such as the case of the line surface overlaying, to prevent the layer overlaying of the spatial distribution imbalance.
From the perspective of spatial data decomposition parallelism, the parallel stacking of multiple layers can use two methods.
(i) According to the above design, the Hilbert sorting decomposition parallel method is based on the spatial ordering of multi-level two-dimensional plan layers through high-dimensional Hilbert curves. For the processing of two-dimensional plane map data, the specific process can be divided into two processes of reducing the dimension and raising the dimension, but the two are not contradictory. Dimensionality reduction is for a polygon layer, extracting a single point from a polygon in the layer, such as the center point of the outer frame, a corner point, or the Centre’s CentreID point to uniquely identify the polygon as a mapping to the one-dimensional Hilbert function.
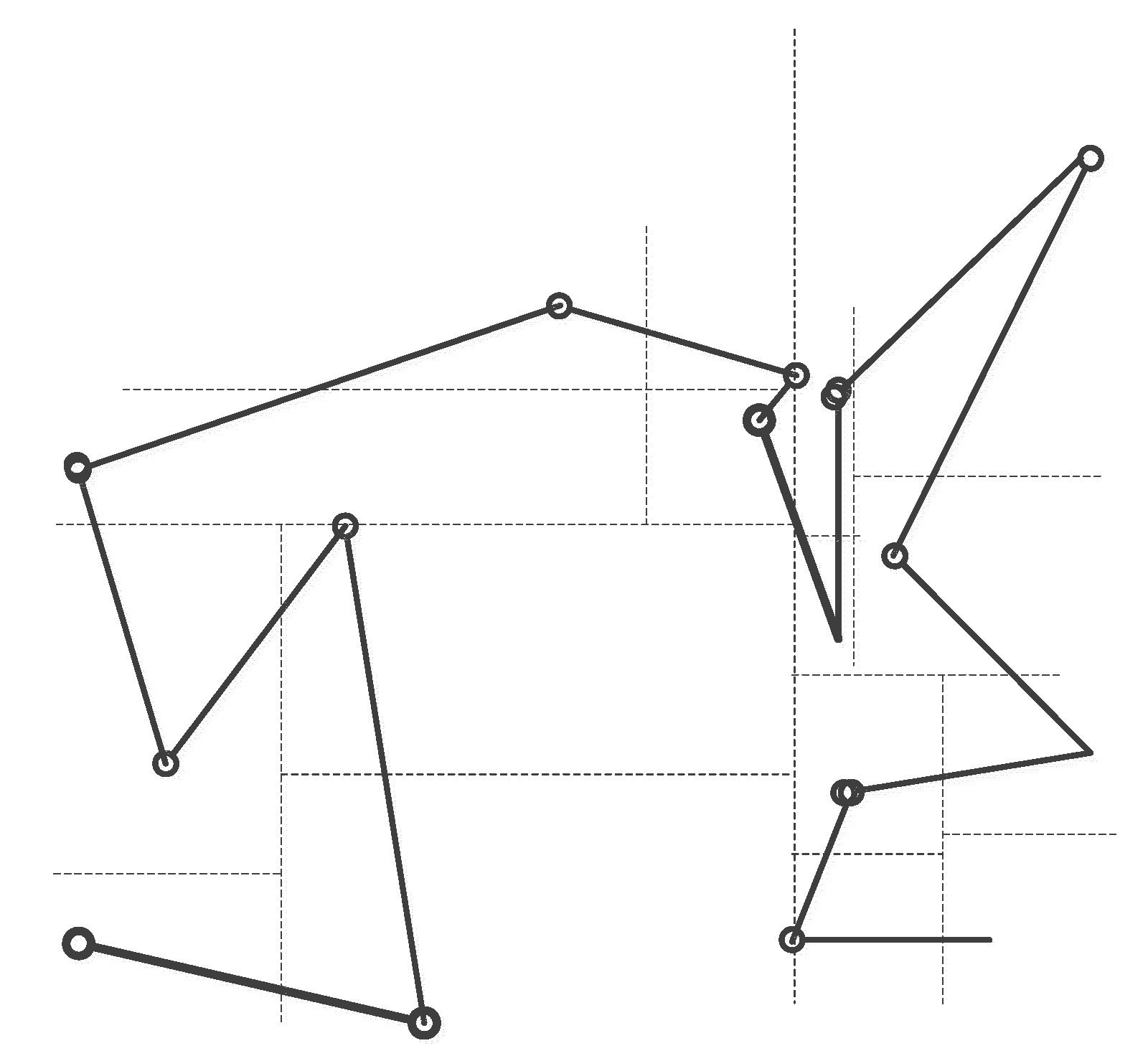
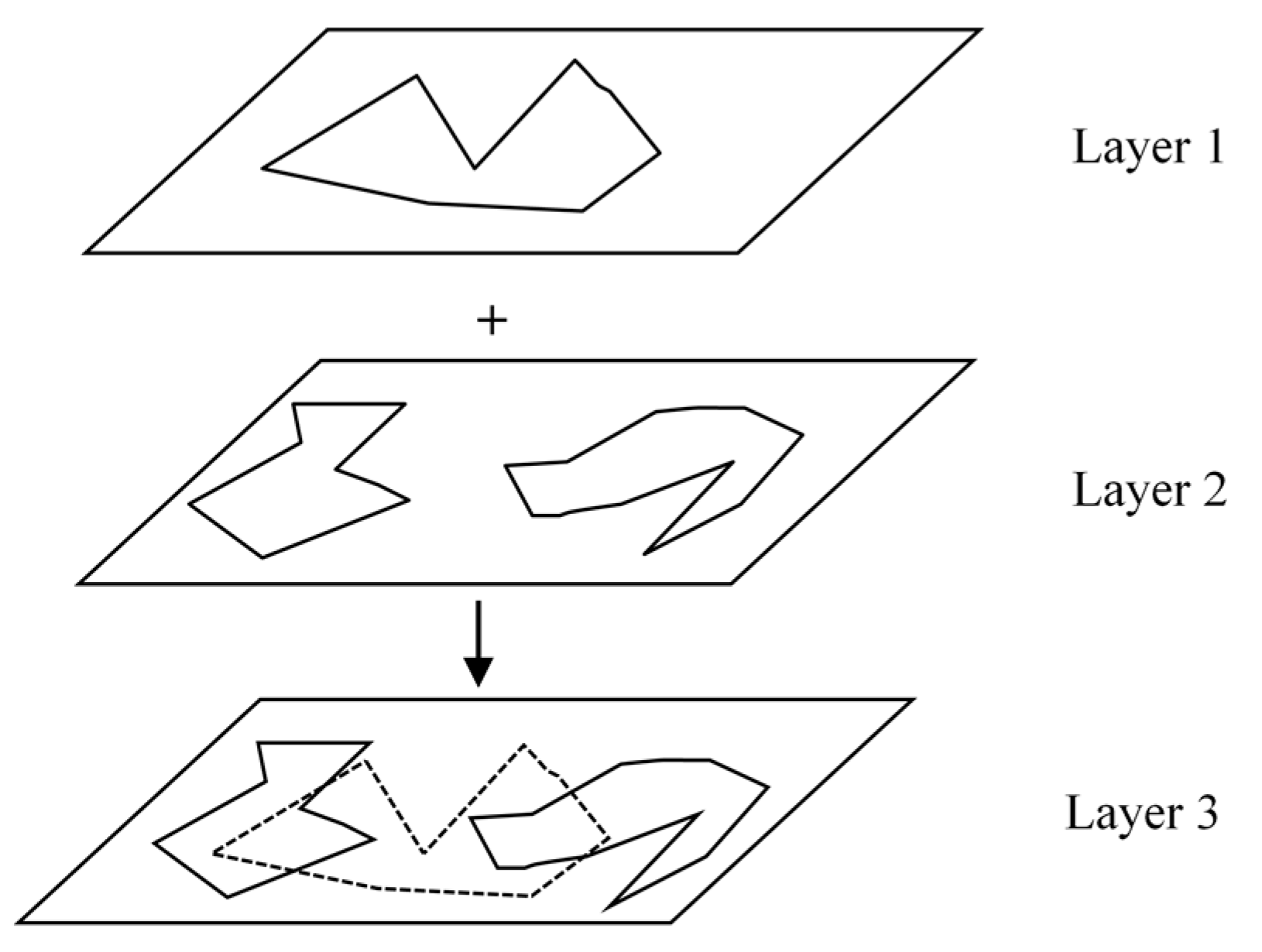
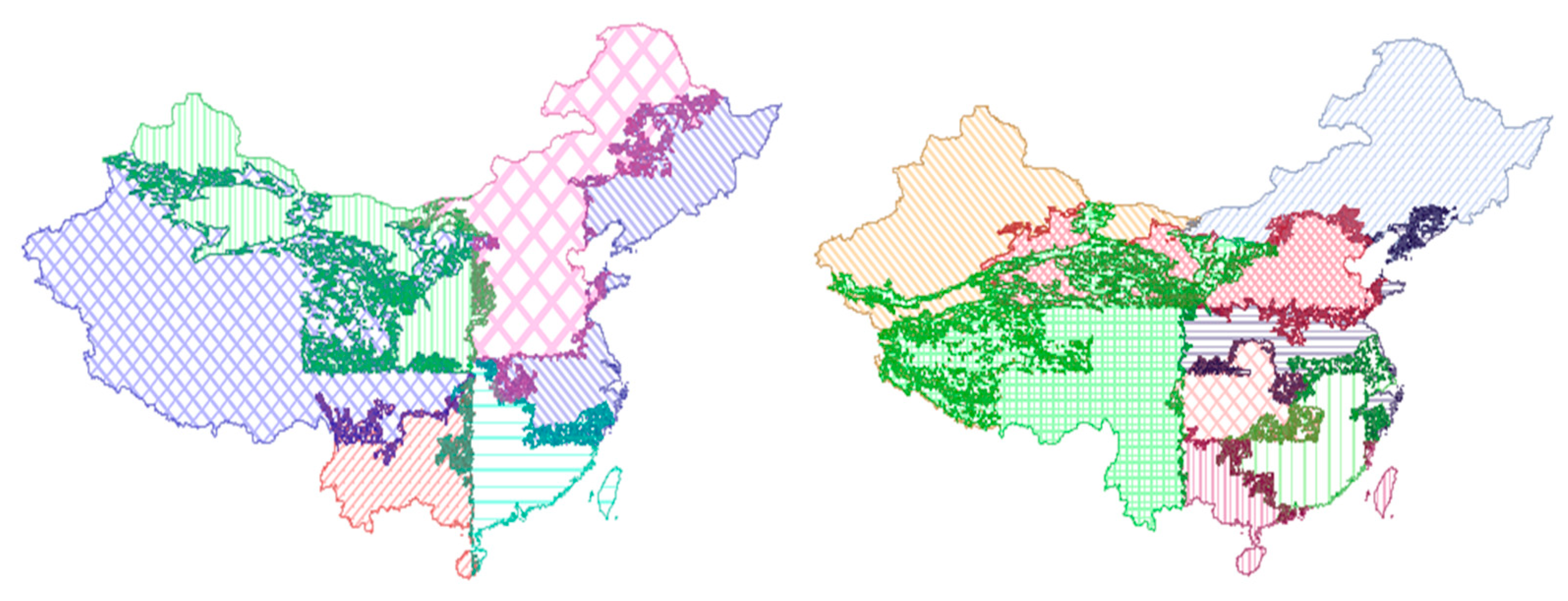
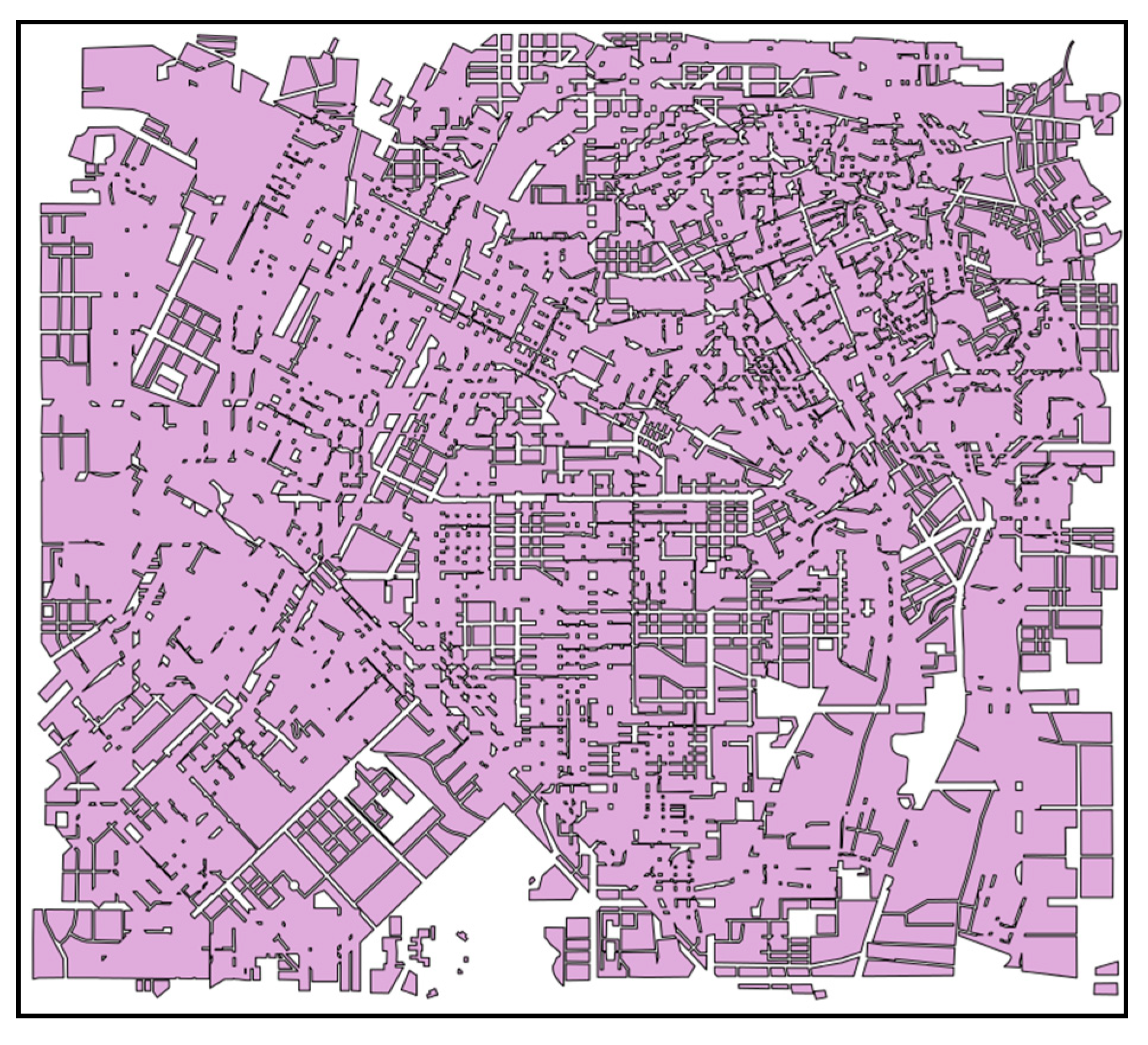
The polygon objects in the two layers were loaded into the same container, and the geometric objects in the container were manipulated according to the Hilbert parallel sorting algorithm to merge the individual layers. The advantage of this method is that it is not necessary to consider the combined correspondence of polygons in the container, and it can be divided according to Hilbert ordering. Polygons that do not want to intersect in the original single layer may be indirectly connected due to the addition of new layer features, as shown in
Figure 6. Indirect connectivity increases the complexity of parallel association. If the polygons in the two layers are only a one–to–one relationship, they can be directly merged in batch form. The polygons may be spread in pieces when considering indirect connectivity. In this way, the parallel joint process needs to continue the binary tree merging of the data decomposition results.
(ii) A combination of multi-layer filtering mechanisms using parallel master-slave indexes.
The master node establishes a coarse-grained spatial index for the two layers, which is equivalent to establishing a distribution for each layer to establish m and n spatial index subtrees. First, test the intersection of the root nodes of these subtrees and filter the separated subtrees. The information of the intersecting subtrees is sent to the child nodes for the merge operation of the independent subtrees. The merge mode can be understood as spatial analysis of different spatial data of different spatial granularity levels, which can be performed based on spatial data with lower spatial granularity level, and spatial analysis of different spatial data of the same spatial granularity level must be superimposed to generate Spatial data with a lower spatial granularity level, which is then based on spatial data with a lower spatial granularity level.
According to the implementation principle of the parallel master-slave index union, with data decomposition based on a spatial index, it is difficult to completely eliminate the redundancy of index objects, so different nodes will have the same geometric object, and the subtree merge is a recursive consumption. At the time of operation, the last master still needs to recycle and combine the intermediate results. The sprawling characteristics of joint operations determine that they cannot be parallelized in the form of batch processing. The parallel combination of master-slave index tree mode is difficult to implement in practical applications. The parallel joint research in this paper uses Hilbert as the experimental subject for the two layers as a whole, and the parallel master-slave index joint will be further studied in the next step.
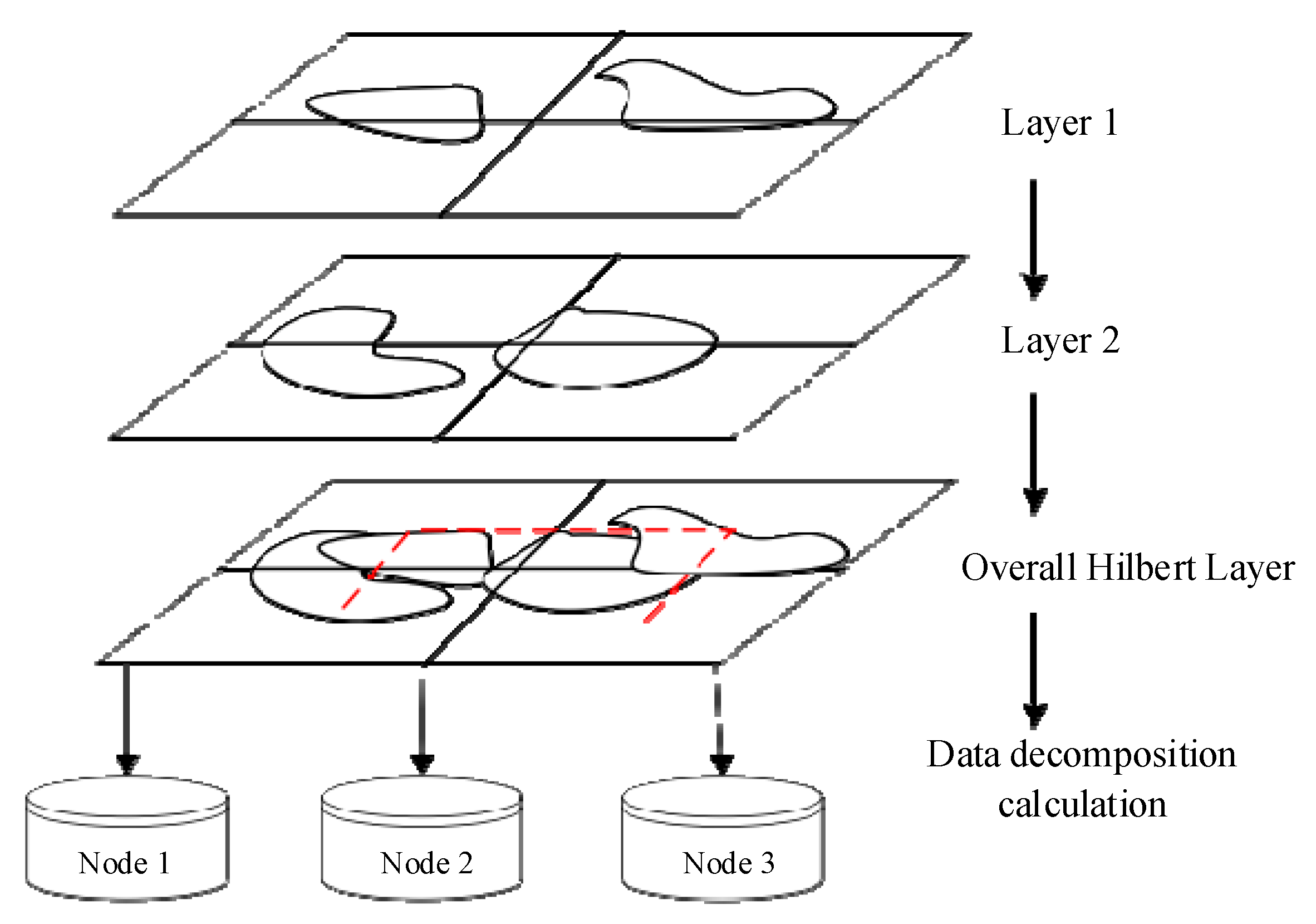
In our study, two joint layers are treated as an overall virtual layer and parallelized according to the strategy of polygon merging in the same layer (
Figure 7). The specific process is as follows:
(i) First, create a data structure featureInfo for each feature in each layer. The main member variables are fid, layer_num, hilbert_code, and mbr_pt. The fid is used to record the cursor of the feature in the layer. As a query condition for quickly extracting data in the future, layer_num records which layer is one of the filtering conditions of the data query. The hilbert_code defaults to a null value when the FeatureInfo is initialized, which is used to record the encoding of the Hilbert space sorting. Mbr_pt records the center point of the desired MBR as a feature point for Hilbert ordering.
typedef struct
{
long fid, hilber_code;
GTPoint* mbr_pt;
} featureInfo;
(ii) Put the featureInfo in the two layers into the vector array Vector<featureInfo*> and use the Hilbert spatial sorting function hilbert_sort() to sort and encode the elements in the array.
(iii) According to the number k of available computing nodes, the total n elements are sent to one node every n/k according to the Hilbert coding order. The polling method only sends the Hilbert space sorting number interval instead of sending the specific geometry object.
(iv) The child node receives the Hilbert space sorting coding interval, extracts the geometric objects of the feature from the local database according to fid and layer_num in featureInfo, and starts to merge the intersecting polygons in the interval.
(v) Continue the merge in the form of a single layer binary tree merge until all intersecting polygons are merged.
According to this layer, the overall layer is added to perform Hilbert sorting decomposition. The advantage is that the data is divided into non-redundant polygons of each node. The unique characteristics of Hilbert coded values can ensure the low coupling of joint calculation between processes. The binary tree parallel combination can reduce the pressure of the main node recovery. Therefore, the scheme is feasible, and theoretically, an acceleration effect can be obtained. The following is an experimental verification of the multi-layer Hilbert joint method using actual data.
The computational complexity of this algorithm is Ο(N+K), which is derived from the count of polygons for the overlayed map layers. Given N polygons in each layer, if using the brute-force overlay test, the complexity of this algorithm should be Ο(N2). However, we performed an intersecting filter process that can exclude the unnecessary computing for polygons that do not overlay to each other in the space. Thus, there would be K polygons in the overlayed layer that participate in overlay computation. Ultimately, the complexity of this algorithm should be Ο(N+K).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















