An On-Line and Adaptive Method for Detecting Abnormal Events in Videos Using Spatio-Temporal ConvNet


Abstract
:1. Introduction
- We adapt a pretrained 3D CNN to extract robust feature maps related to shapes and motions which allow us to detect and localize complex abnormal events in non-crowded and crowded scenes.
- We propose a new method of outliers detection based on the selection of vectors of interest to construct a balanced distribution. This robust classifier is able to represent all normal events (redundant and rare ones) during the training phase, detects abnormalities and adapt to the appearance of new normal events during the testing phase.
2. Related work
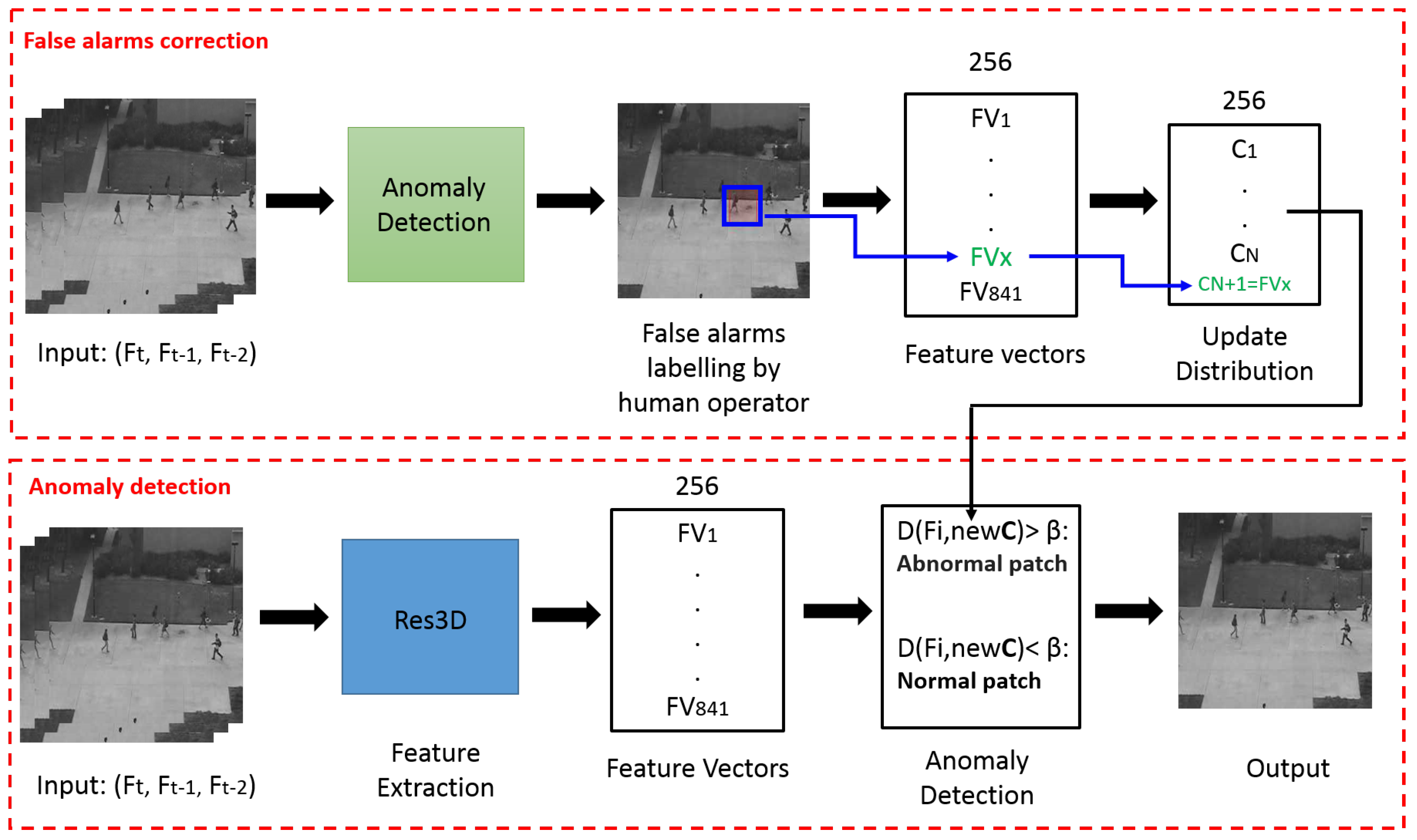
3. The Proposed Framework
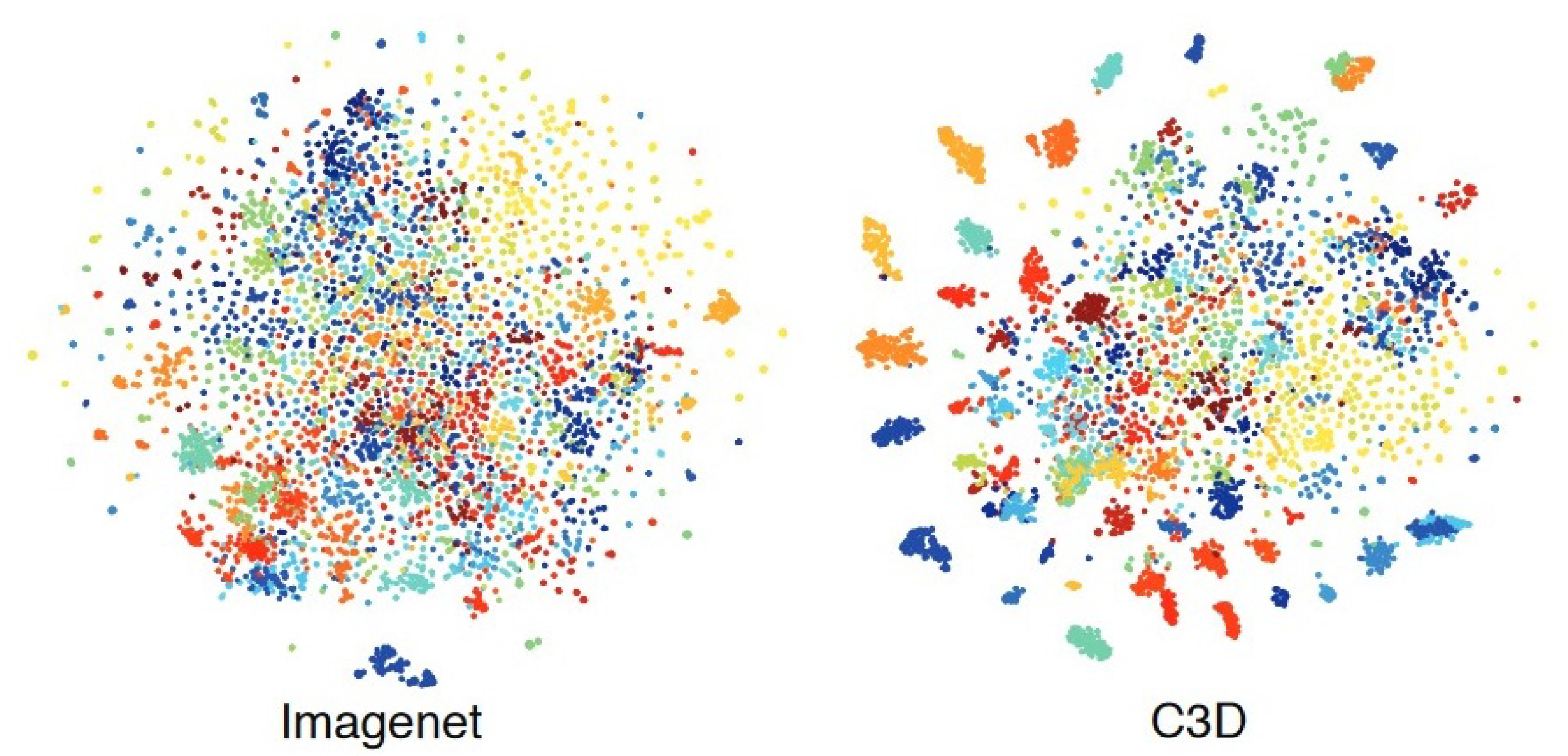
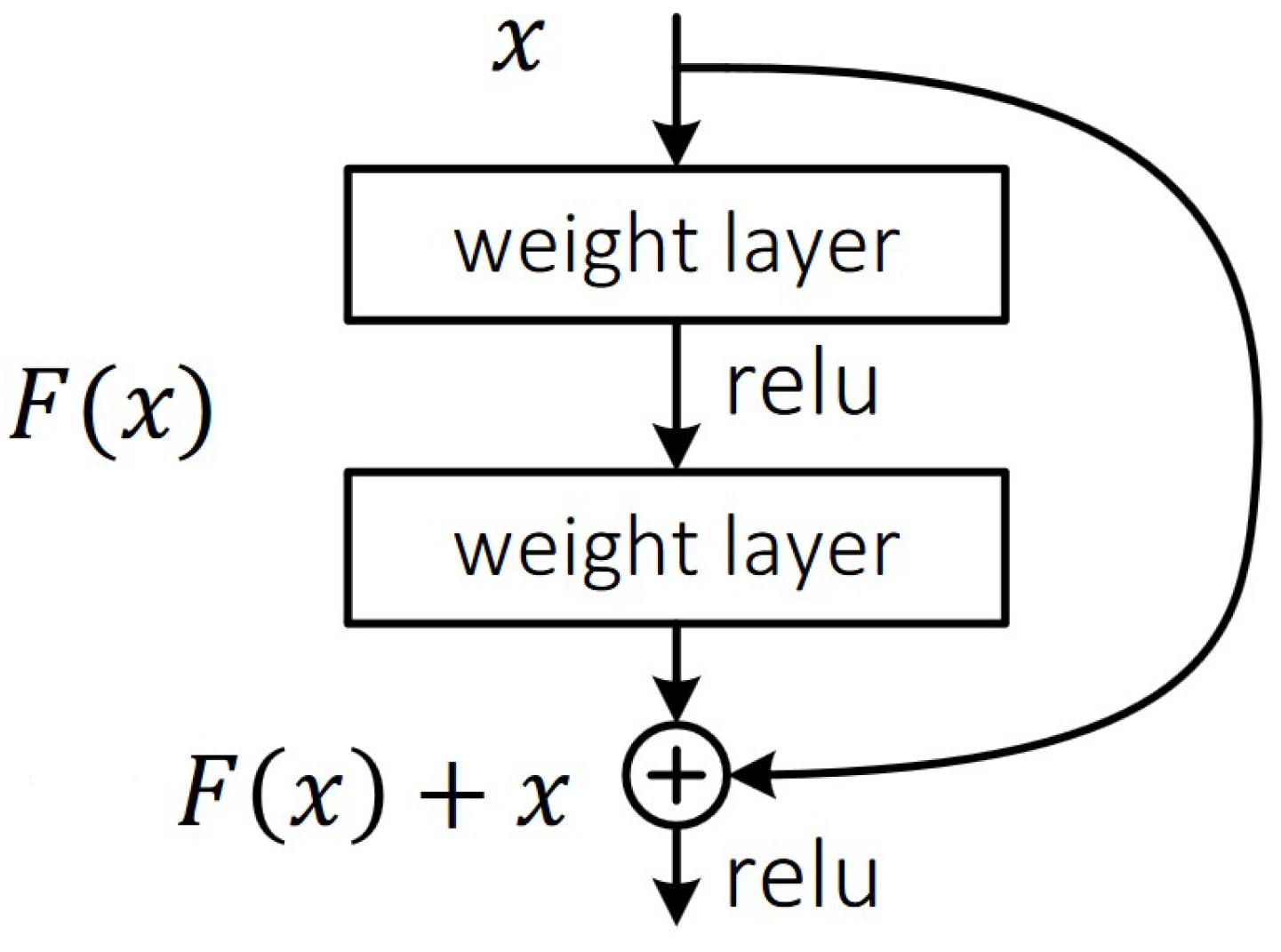
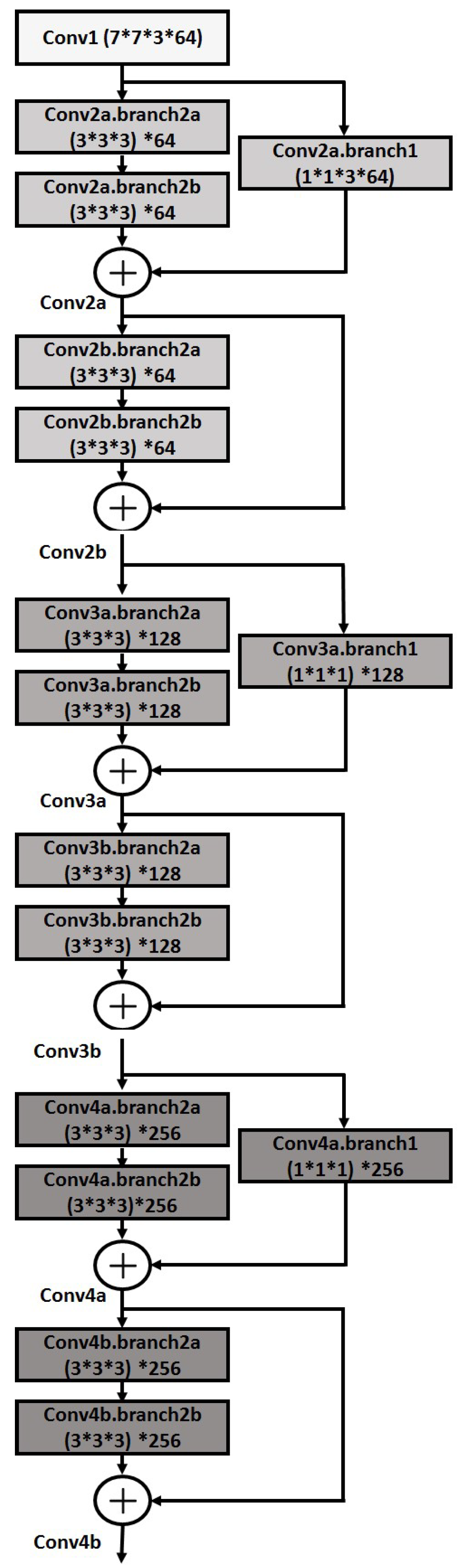
3.1. 3D Residual Convolutional Networks
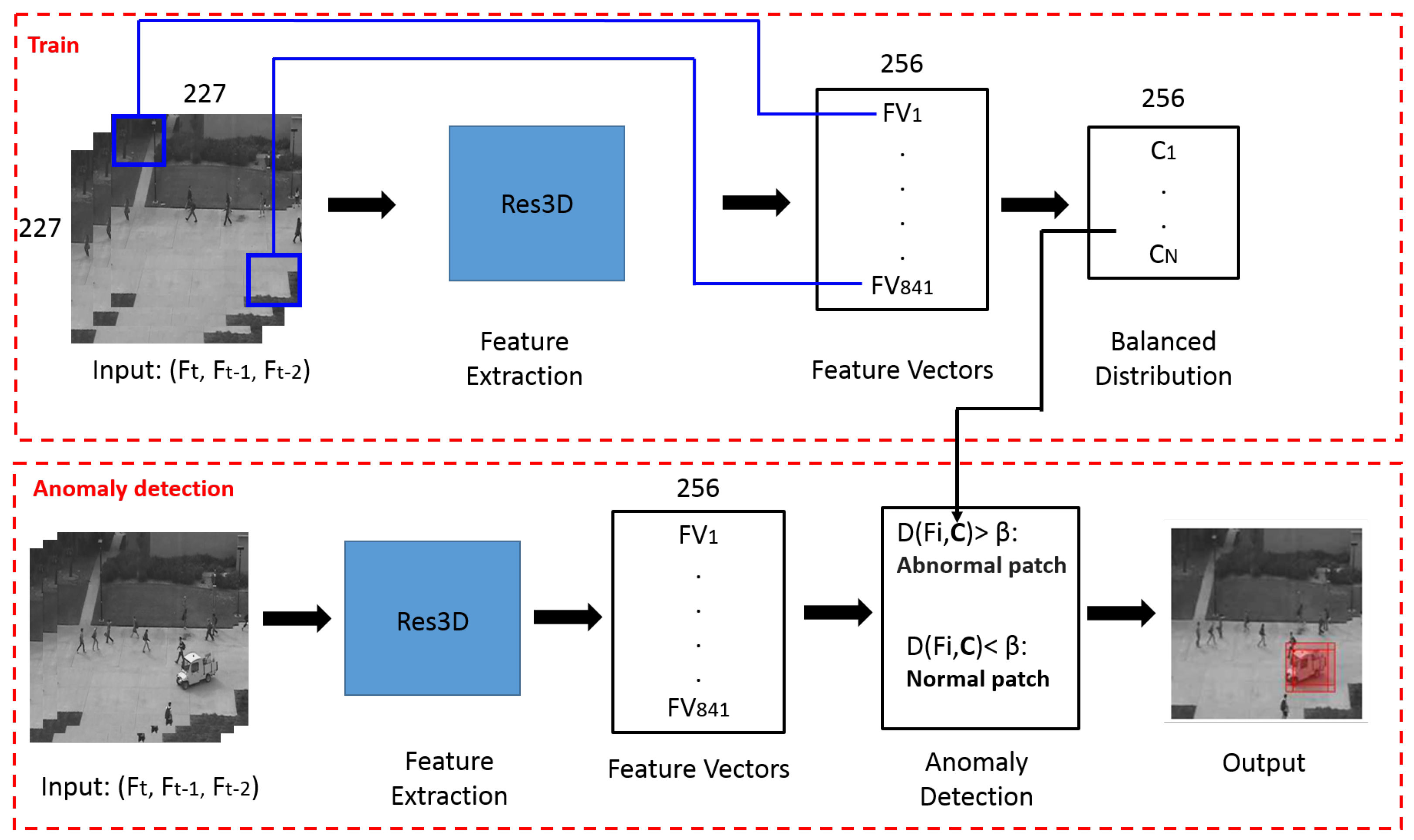
3.2. Anomaly Detection
3.2.1. Features Extraction
3.2.2. Classifier
| Algorithm 1: Construction of a balanced distribution and abnormal event detection. |
 |
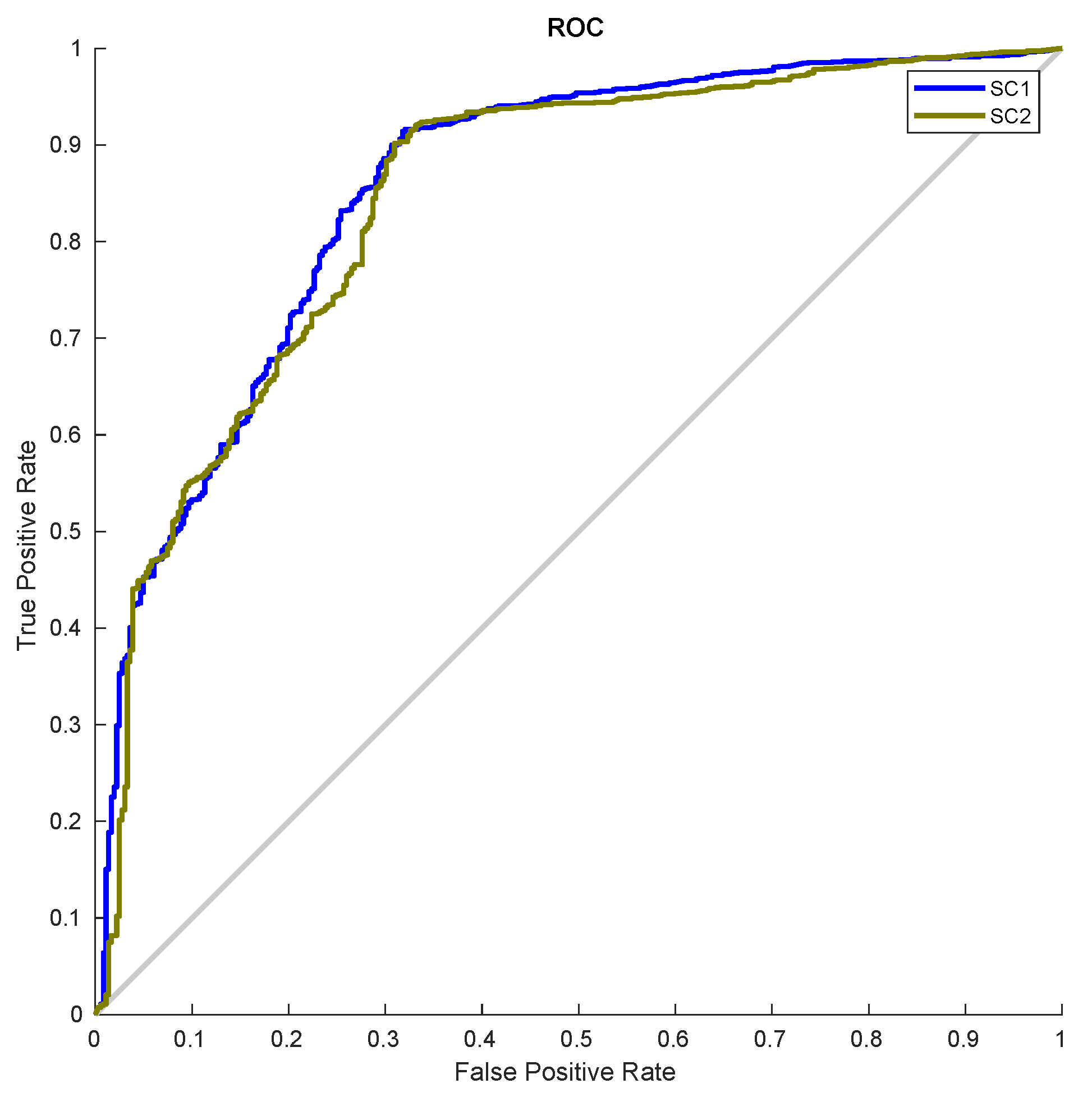
4. Results and Comparisons
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sulman, N.; Sanocki, T.; Goldgof, D.; Kasturi, R. How effective is human video surveillance performance? In Proceedings of the IEEE 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; 1–3. [Google Scholar]
- Green, M.W. The Appropriate and Effective Use of Security Technologies in US Schools: A Guide for Schools and Law Enforcement Agencies; Technical Report; Sandia National Laboratories: Albuquerque, NM, USA, 2005. [Google Scholar]
- Wu, S.; Moore, B.E.; Shah, M. Chaotic invariants of Lagrangian particle trajectories for anomaly detection in crowded scenes. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2054–2060. [Google Scholar] [CrossRef]
- Piciarelli, C.; Micheloni, C.; Foresti, G.L. Trajectory-based anomalous event detection. IEEE Trans. Circ. Syst. Video Technol. 2008, 18, 1544–1554. [Google Scholar] [CrossRef]
- Jiang, F.; Yuan, J.; Tsaftaris, S.A.; Katsaggelos, A.K. Anomalous video event detection using spatiotemporal context. Comput. Vis. Image Underst. 2011, 115, 323–333. [Google Scholar] [CrossRef]
- Ermis, E.B.; Saligrama, V.; Jodoin, P.M.; Konrad, J. Motion segmentation and abnormal behavior detection via behavior clustering. In Proceedings of the 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008. [Google Scholar]
- Reddy, V.; Sanderson, C.; Lovell, B.C. Improved anomaly detection in crowded scenes via cell-based analysis of foreground speed, size and texture. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Colorado Springs, CO, USA, 20–25 June 2011; pp. 55–61. [Google Scholar]
- Wang, T.; Snoussi, H. Detection of abnormal visual events via global optical flow orientation histogram. IEEE Trans. Inf. Forensics Secur. 2014, 9, 988–998. [Google Scholar] [CrossRef]
- Roshtkhari, M.J.; Levine, M.D. An on-line, real-time learning method for detecting anomalies in videos using spatio-temporal compositions. Comput. Vis. Image Underst. 2013, 117, 1436–1452. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Alipanahi, B.; Delong, A.; Weirauch, M.T.; Frey, B.J. Predicting the sequence specificities of DNA-and RNA-binding proteins by deep learning. Nat. Biotechnol. 2015, 33, 831. [Google Scholar] [CrossRef]
- Heaton, J.; Polson, N.; Witte, J.H. Deep learning for finance: Deep portfolios. Appl. Stoch. Mod. Bus. Ind. 2017, 33, 3–12. [Google Scholar] [CrossRef]
- Romero, A.; Ballas, N.; Kahou, S.; Chassang, A.; Gatta, C.; Bengio, Y. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Springer: Berlin, Germany, 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhou, S.; Shen, W.; Zeng, D.; Fang, M.; Wei, Y.; Zhang, Z. Spatial-temporal convolutional neural networks for anomaly detection and localization in crowded scenes. Signal Process. Image Commun. 2016, 47, 358–368. [Google Scholar] [CrossRef]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 733–742. [Google Scholar]
- Ravanbakhsh, M.; Nabi, M.; Sangineto, E.; Marcenaro, L.; Regazzoni, C.; Sebe, N. Abnormal event detection in videos using generative adversarial nets. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1577–1581. [Google Scholar]
- Bouindour, S.; Hittawe, M.M.; Mahfouz, S.; Snoussi, H. Abnormal event detection using convolutional neural networks and 1-class SVM classifier. In Proceedings of the 8th International Conference on Imaging for Crime Detection and Prevention (ICDP 2017), Madrid, Spain, 13–15 December 2017; pp. 1–6. [Google Scholar]
- Calderara, S.; Heinemann, U.; Prati, A.; Cucchiara, R.; Tishby, N. Detecting anomalies in people’s trajectories using spectral graph analysis. Comput. Vis. Image Underst. 2011, 115, 1099–1111. [Google Scholar] [CrossRef]
- Morris, B.T.; Trivedi, M.M. Trajectory learning for activity understanding: Unsupervised, multilevel, and long-term adaptive approach. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2287–2301. [Google Scholar] [CrossRef]
- Antonakaki, P.; Kosmopoulos, D.; Perantonis, S.J. Detecting abnormal human behaviour using multiple cameras. Signal Process. 2009, 89, 1723–1738. [Google Scholar] [CrossRef] [Green Version]
- Boiman, O.; Irani, M. Detecting irregularities in images and in video. Int. J. Comput. Vis. 2007, 74, 17–31. [Google Scholar] [CrossRef]
- Xiao, T.; Zhang, C.; Zha, H. Learning to detect anomalies in surveillance video. IEEE Signal Process. Lett. 2015, 22, 1477–1481. [Google Scholar] [CrossRef]
- Li, W.; Mahadevan, V.; Vasconcelos, N. Anomaly detection and localization in crowded scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 18–32. [Google Scholar] [PubMed]
- Chong, Y.S.; Tay, Y.H. Abnormal event detection in videos using spatiotemporal autoencoder. In International Symposium on Neural Networks; Springer: Berlin, Germany, 2017; pp. 189–196. [Google Scholar]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Moayed, Z.; Klette, R. Deep-anomaly: Fully convolutional neural network for fast anomaly detection in crowded scenes. Comput. Vis. Image Underst. 2018, 172, 88–97. [Google Scholar] [CrossRef] [Green Version]
- Sabokrou, M.; Fathy, M.; Hoseini, M.; Klette, R. Real-time anomaly detection and localization in crowded scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 56–62. [Google Scholar]
- Xu, D.; Yan, Y.; Ricci, E.; Sebe, N. Detecting anomalous events in videos by learning deep representations of appearance and motion. Comput. Vis. Image Underst. 2017, 156, 117–127. [Google Scholar] [CrossRef]
- Ravanbakhsh, M.; Nabi, M.; Mousavi, H.; Sangineto, E.; Sebe, N. Plug-and-play cnn for crowd motion analysis: An application in abnormal event detection. arXiv, 2016; arXiv:1610.00307. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4489–4497. [Google Scholar]
- Tran, D.; Ray, J.; Shou, Z.; Chang, S.F.; Paluri, M. Convnet architecture search for spatiotemporal feature learning. arXiv, 2017; arXiv:1708.05038. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5534–5542. [Google Scholar]
- Vapnik, V. Pattern recognition using generalized portrait method. Autom. Remote Control 1963, 24, 774–780. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 27. [Google Scholar] [CrossRef]
- Burges, C.J. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- De Maesschalck, R.; Jouan-Rimbaud, D.; Massart, D.L. The mahalanobis distance. Chemom. Intell. Lab. Syst. 2000, 50, 1–18. [Google Scholar] [CrossRef]
- Mehran, R.; Oyama, A.; Shah, M. Abnormal crowd behavior detection using social force model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 22–24 June 2009; pp. 935–942. [Google Scholar]
- Adam, A.; Rivlin, E.; Shimshoni, I.; Reinitz, D. Robust real-time unusual event detection using multiple fixed-location monitors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 555–560. [Google Scholar] [CrossRef] [PubMed]
- Bertini, M.; Del Bimbo, A.; Seidenari, L. Multi-scale and real-time non-parametric approach for anomaly detection and localization. Comput. Vis. Image Underst. 2012, 116, 320–329. [Google Scholar] [CrossRef]
- Kim, J.; Grauman, K. Observe locally, infer globally: A space-time MRF for detecting abnormal activities with incremental updates. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 22–24 June 2009; pp. 2921–2928. [Google Scholar]
- Mahadevan, V.; Li, W.; Bhalodia, V.; Vasconcelos, N. Anomaly detection in crowded scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1975–1981. [Google Scholar]
- Sabokrou, M.; Fathy, M.; Hoseini, M. Video anomaly detection and localisation based on the sparsity and reconstruction error of auto-encoder. Electron. Lett. 2016, 52, 1122–1124. [Google Scholar] [CrossRef]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Klette, R. Deep-cascade: Cascading 3D deep neural networks for fast anomaly detection and localization in crowded scenes. IEEE Trans. Image Process. 2017, 26, 1992–2004. [Google Scholar] [CrossRef]
- Sabokrou, M.; Fathy, M.; Moayed, Z.; Klette, R. Fast and accurate detection and localization of abnormal behavior in crowded scenes. Mach. Vis. Appl. 2017, 28, 965–985. [Google Scholar] [CrossRef]
- Fix, E.; Hodges J.L., Jr. Discriminatory Analysis-Nonparametric Discrimination: Consistency Properties; Technical Report; University of California: Berkeley, CA, USA, 1951. [Google Scholar]
- Nguyen, B.P.; Tay, W.L.; Chui, C.K. Robust Biometric Recognition From Palm Depth Images for Gloved Hands. IEEE Trans. Hum.-Mach. Syst. 2015, 45, 799–804. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantages | Disadvantages |
|---|---|---|
| Trajectory analysis | Effective for detecting deviant trajectories in non-crowded scenes | Occlusion-sensitive especially in crowded scenes. Inability to detect abnormal shapes without deviant trajectories |
| Handcrafted features | Effective for simple local shape or motion | Does not link between local patterns, not optimal for complex events |
| Deep learning: Supervised | Effective for behavior understanding High capacity on image processing | Need to use normal and abnormal examples during the training phase |
| Deep learning: Unsupervised | Effective for behavior understanding High capacity on image processing Does not require normal and abnormal training examples | - - - |
| Folder | NB-Frames | NB-FV | NB-VI |
|---|---|---|---|
| F1 | 120 | 100920 | 934 |
| F2 | 150 | 126150 | 923 |
| F3 | 150 | 126150 | 909 |
| F4 | 180 | 151380 | 1215 |
| F5 | 180 | 151380 | 1127 |
| F6 | 150 | 126150 | 1187 |
| F7 | 150 | 126150 | 1107 |
| F8 | 120 | 100920 | 981 |
| F9 | 180 | 151380 | 1134 |
| F10 | 180 | 151380 | 1177 |
| F11 | 180 | 151380 | 1109 |
| F12 | 180 | 151380 | 1108 |
| SC2 | 1920 | 1614720 | 1569 |
| Methods | EERFL | EERPL |
|---|---|---|
| Mehran [39] | 42 | 80 |
| Adam [40] | 42 | 76 |
| Bertini [41] | 30 | / |
| Kim(MPCCA) [42] | 30 | 71 |
| Zhou [15] | 24.40 | / |
| Mahadevan(MDT) [43] | 24 | 54 |
| Hasan [16] | 21.7 | / |
| Reddy [7] | 20 | / |
| Sabokrou [27] | 19 | 24 |
| Li [24] | 18.50 | 29.90 |
| Ravanbakhsh [29] | 18 | / |
| Xu (AMDN double fusion) [28] | 17 | / |
| Sabokrou [44] | 15 | / |
| Ravanbakhsh (GAN) [17] | 14 | / |
| Boiman(IBC) [22] | 13 | 26 |
| Roshtkhari(STC) [9] | 13 | 26 |
| Chong [25] | 12 | / |
| Tan Xiao [23] | 10 | 17 |
| Sabokrou [26] | 11 | 15 |
| Sabokrou [45] | 8.2 | 19 |
| Sabokrou [46] | 7.5 | 16 |
| SC1 | 6.25 | 9.82 |
| SC2 | 7.45 | 9.63 |
| Folder | EERFL | EERPL | FA | EERFL | EERPL |
|---|---|---|---|---|---|
| 4 | 4.4 | 7.7 | 1 | 3.3 | 7.2 |
| 7 | 24.4 | 33.3 | 5 | 18.8 | 28.8 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bouindour, S.; Snoussi, H.; Hittawe, M.M.; Tazi, N.; Wang, T. An On-Line and Adaptive Method for Detecting Abnormal Events in Videos Using Spatio-Temporal ConvNet. Appl. Sci. 2019, 9, 757. https://doi.org/10.3390/app9040757
Bouindour S, Snoussi H, Hittawe MM, Tazi N, Wang T. An On-Line and Adaptive Method for Detecting Abnormal Events in Videos Using Spatio-Temporal ConvNet. Applied Sciences. 2019; 9(4):757. https://doi.org/10.3390/app9040757
Chicago/Turabian StyleBouindour, Samir, Hichem Snoussi, Mohamad Mazen Hittawe, Nacef Tazi, and Tian Wang. 2019. "An On-Line and Adaptive Method for Detecting Abnormal Events in Videos Using Spatio-Temporal ConvNet" Applied Sciences 9, no. 4: 757. https://doi.org/10.3390/app9040757
APA StyleBouindour, S., Snoussi, H., Hittawe, M. M., Tazi, N., & Wang, T. (2019). An On-Line and Adaptive Method for Detecting Abnormal Events in Videos Using Spatio-Temporal ConvNet. Applied Sciences, 9(4), 757. https://doi.org/10.3390/app9040757