Distributed Face Recognition Based on Load Balancing and Dynamic Prediction


Abstract
:Featured Application
Abstract
1. Introduction
2. Related Work
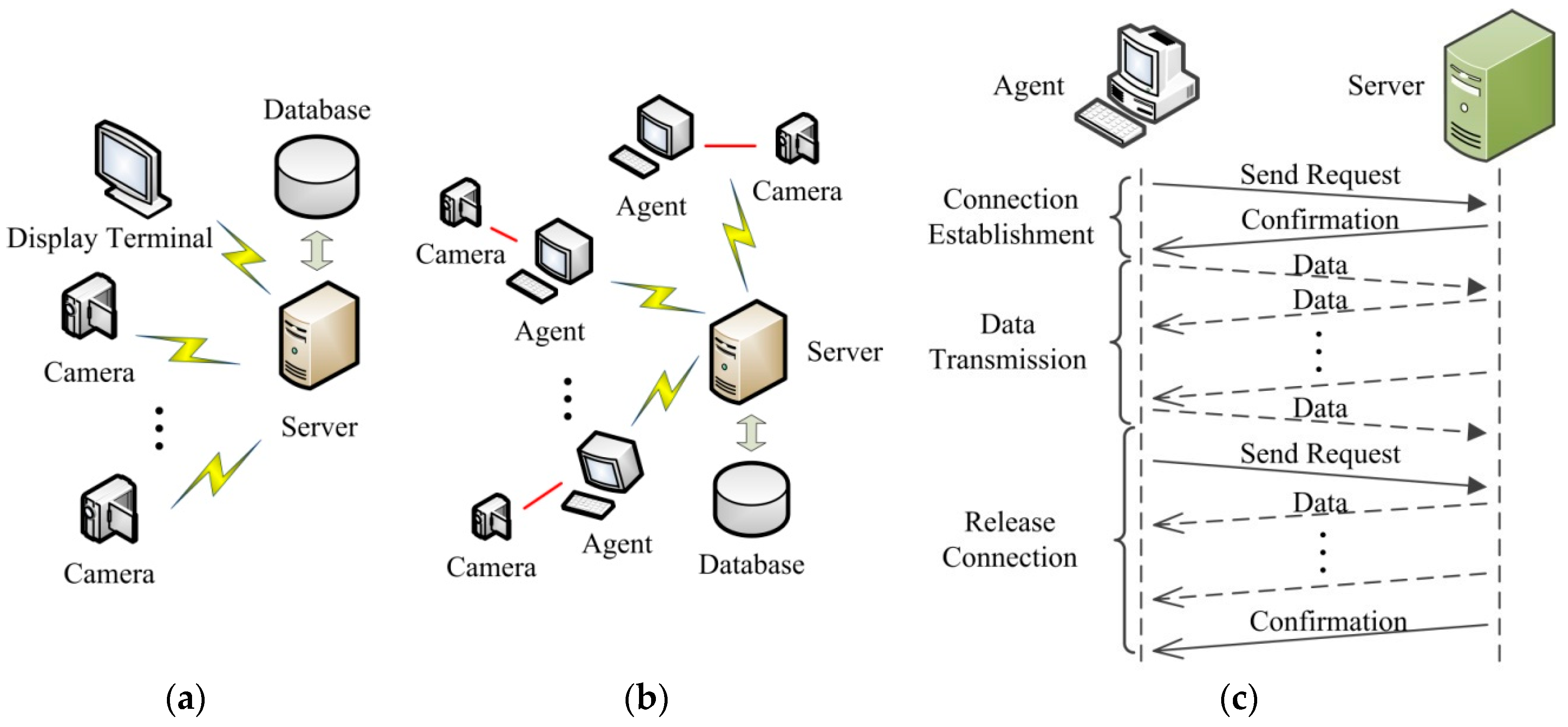
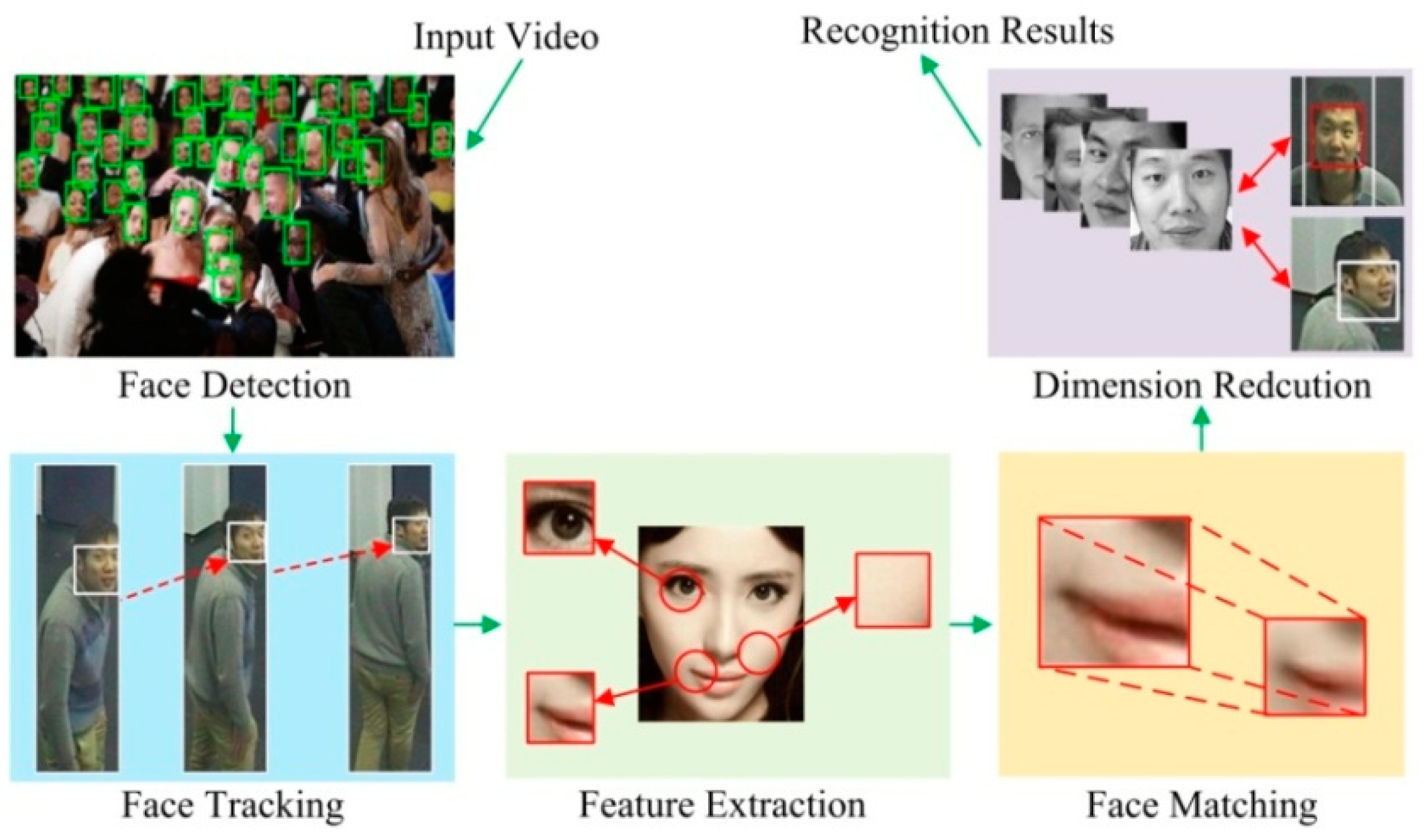
3. The Distributed Face Recognition Model
4. Load Balancing Based on an Improved Genetic Algorithm
5. Performance Optimization of Distributed Face Recognition
5.1. Dynamic Prediction Based on Extreme Learning Machine
5.2. Dynamic Load Balancing Optimization
- Initialization. Input the training sample set, randomly generate the weight and input bias .
- Calculate the hidden layer output matrix H, the coefficient matrix A and the output layer weight .
- Calculate the prediction matrix y according to Equation (19), and send the predicted value to the server.
- The server initializes the chromosome based on obtained information from the agent.
- Calculate the fitness value of each domain according to Equation (5), and then perform selection operations according to Equation (6).
- Calculate the threshold according to Equation (9). Stop if the threshold is satisfied, otherwise continue.
- Calculated the crossover probability according to Equation (7) to determine whether to perform the cross operation, and then repeat Step 5.
- Calculate the mutation probability according to Equation (8). If the probability satisfies the mutation probability , perform the mutation operation. Otherwise, perform the migration operation and repeat Step 5.
- Go to Step 6 to continue.
6. Experimental Results and Analysis
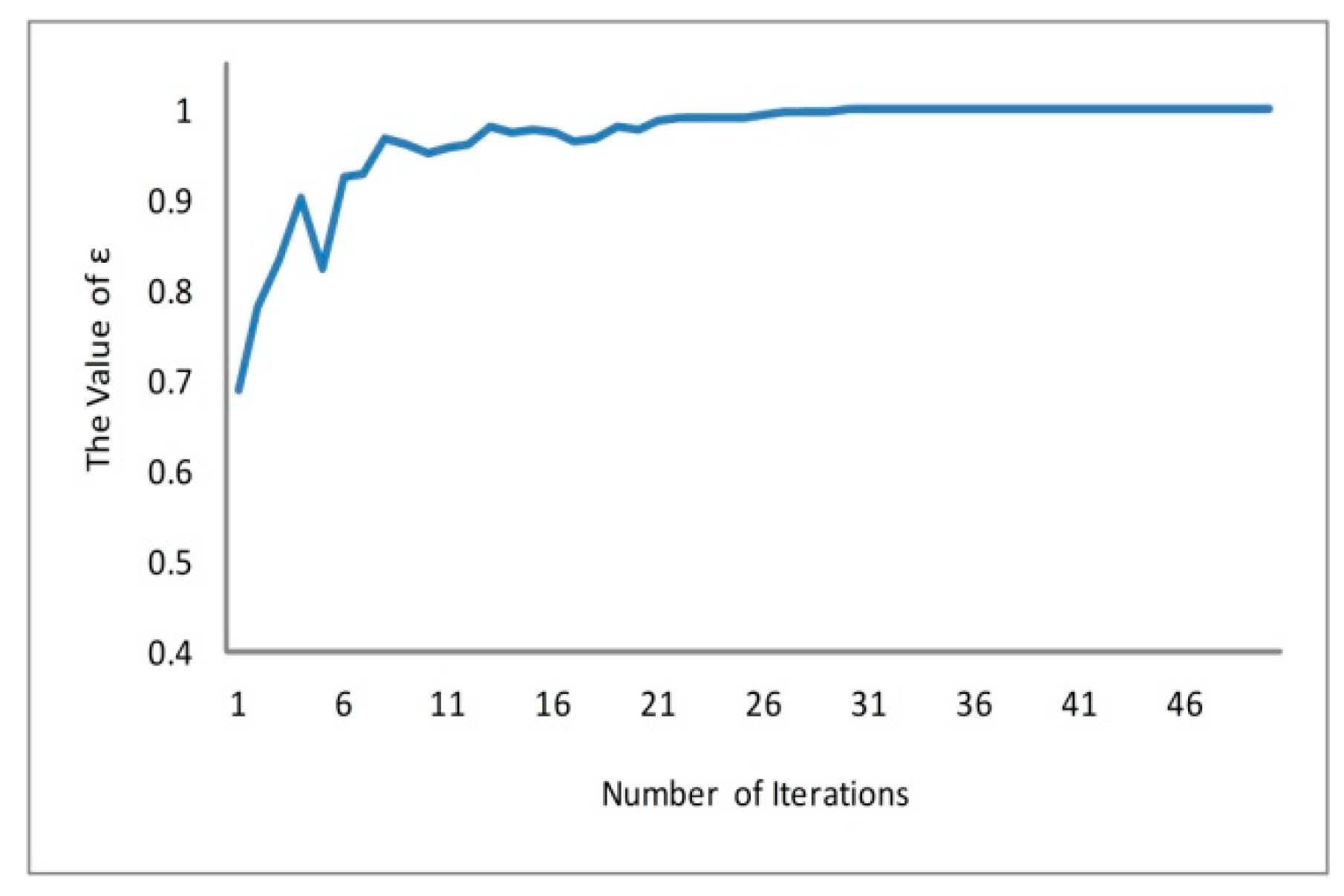
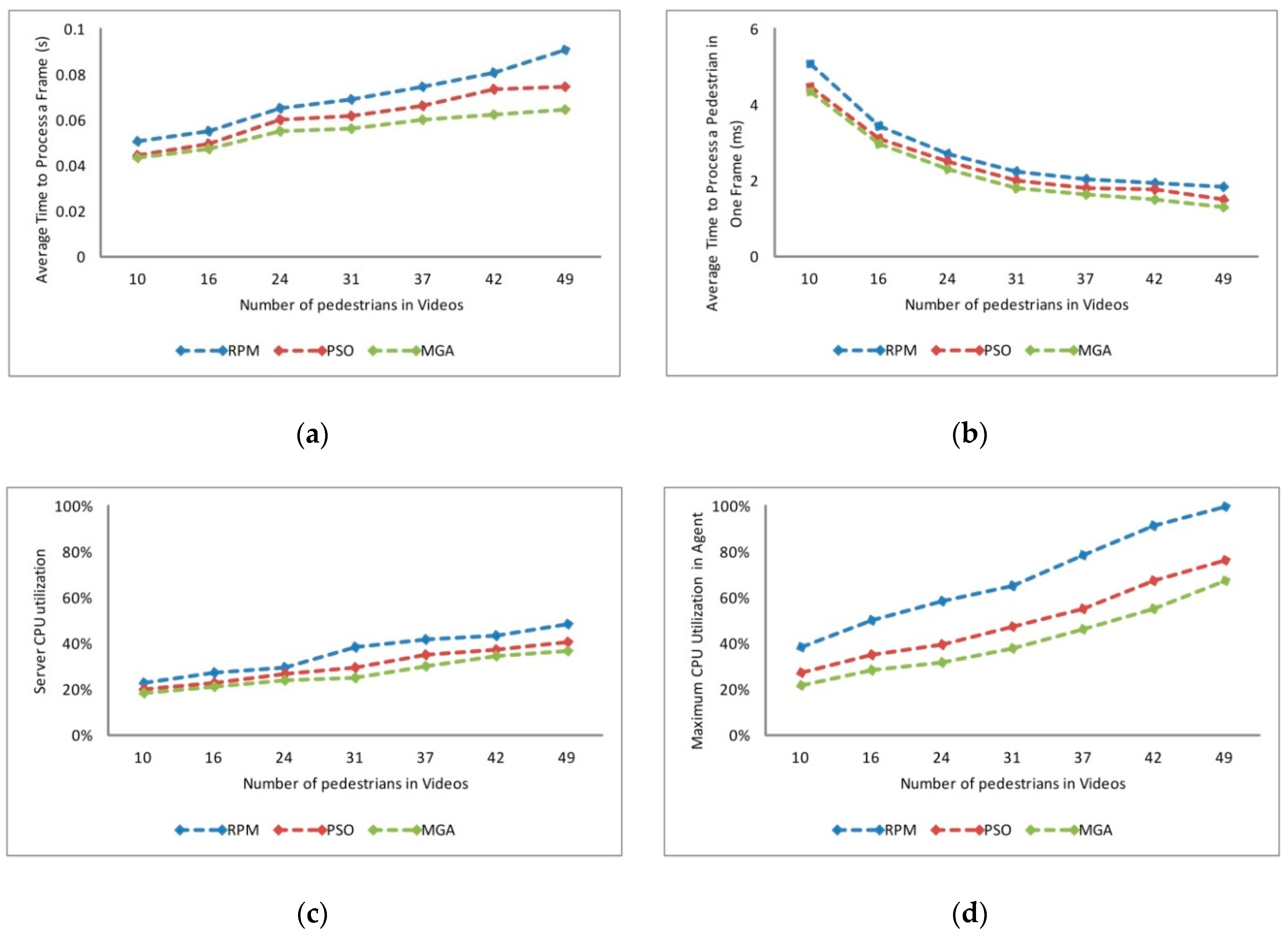
6.1. Analysis of Load Balancing Based on Genetic Algorithm
6.2. Analysis of Prediction Based on ELM
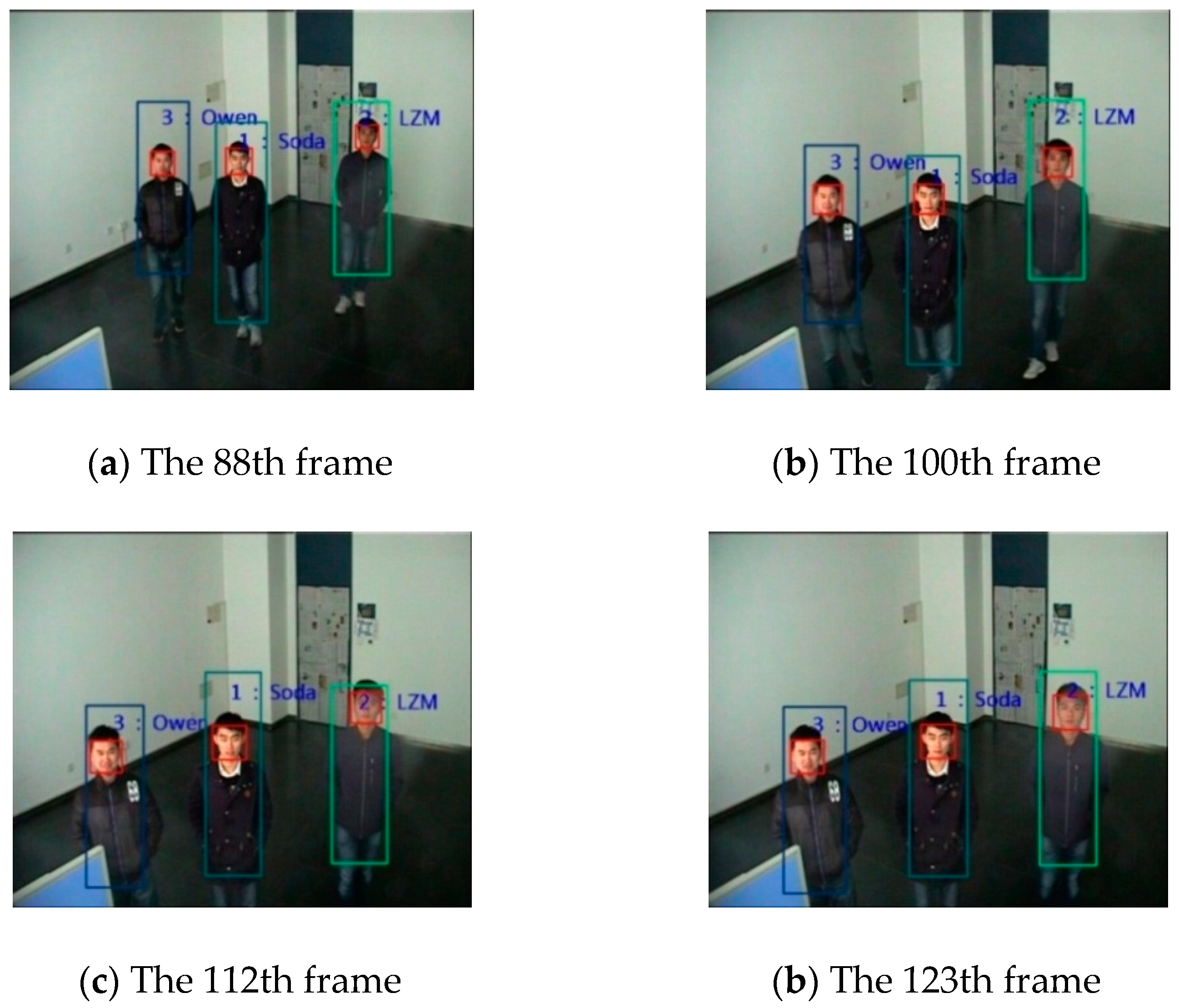
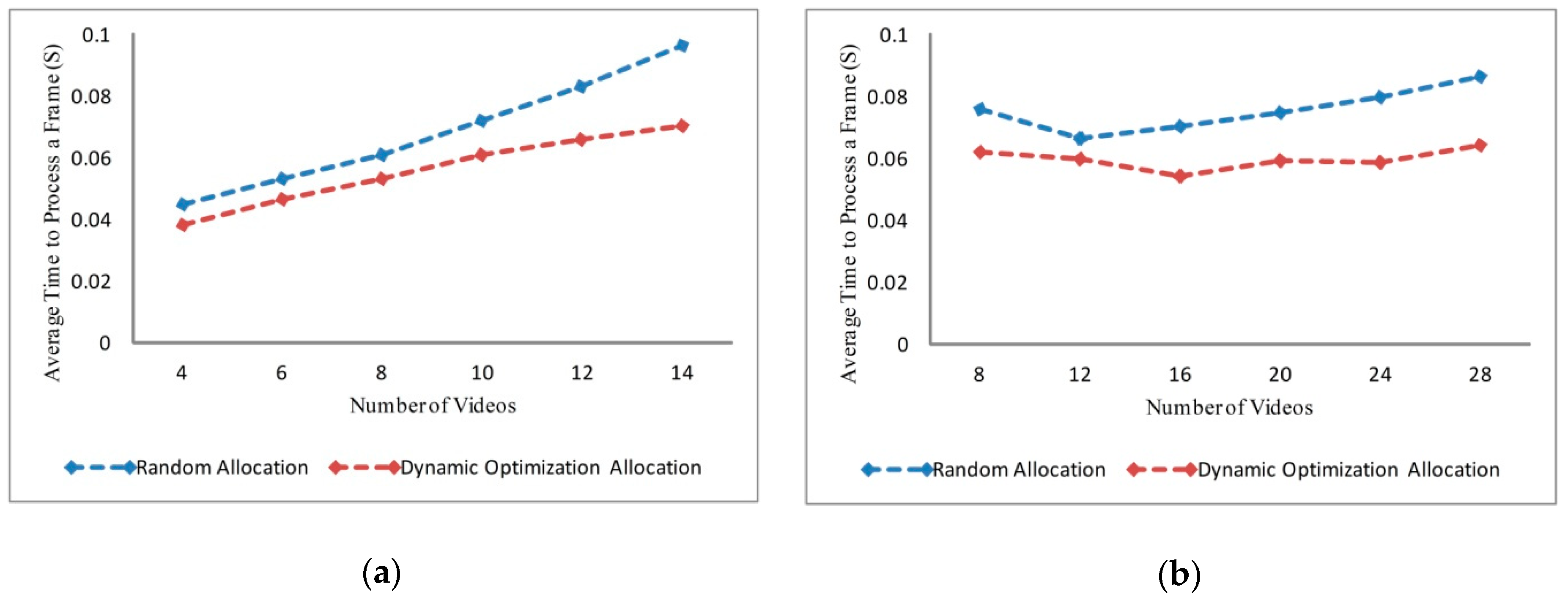
6.3. Analysis of Dynamic Optimization Based on Prediction
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Patel, R.; Yagnik, S.B. A literature survey on face recognition techniques. Int. J. Comput. Trends Technol. 2013, 5, 189–194. [Google Scholar]
- Poli, G.; Saito, J.H.; Mari, J.F.; Zorzan, M.R. Processing Neocognitron of Face Recognition on High Performance Environment Based on GPU with CUDA Architecture. Presented at the 20th International Symposium on Computer Architecture and High Performance Computing, Campo Grande, Brazil, 29 October–1 November 2008. [Google Scholar]
- Min, W.D.; Zhang, Y.; Li, J.; Xu, S.P. Recognition of pedestrian activity based on dropped-object detection. Signal Process. 2018, 44, 238–252. [Google Scholar] [CrossRef]
- Jiang, C.; Su, G.; Liu, X. A distributed parallel system for face recognition. In Proceedings of the Fourth International Conference on Parallel and Distributed Computing, Applications and Technologies, Chengdu, China, 29 August 2003; pp. 797–800. [Google Scholar]
- Yan, Y.; Osadciw, L.A. Distributed wireless face recognition system. Multimedia Content Access: Algorithms and Syst. 2009, 6820, 68200A-1–68200A-12. [Google Scholar] [CrossRef]
- Razzak, M.I.; Khan, M.K.; Alghathbar, K.; Park, J.H. Energy efficient distributed face recognition in wireless sensor network. Wirel. Pers. Commun. 2011, 60, 571–582. [Google Scholar] [CrossRef]
- Zhang, Z.; Guo, Y.; Song, G.Z. A distributed face recognition framework based on data fusion. Int. J. Database Theor. Appl. 2014, 7, 87–98. [Google Scholar] [CrossRef]
- Ali, U.; Bilal, M. Video based parallel face recognition using gabor filter on homogeneous distributed systems. Presented at the 2006 IEEE International Conference on Engineering of Intelligent Systems, Islamabad, Pakistan, 22–23 April 2006; pp. 1–5. [Google Scholar]
- Chetty, G.; Sharma, D. Distributed face recognition: A multiagent approach. In Proceedings of the International Conference on Knowledge-Based and Intelligent Information and Engineering Systems, Bournemouth, UK, 9–11 October 2006; pp. 1168–1175. [Google Scholar]
- Omara, F.A.; Arafa, M.M. Genetic algorithms for task scheduling problem. J. Parallel Distrib. Comput. 2010, 70, 13–22. [Google Scholar] [CrossRef]
- Lu, H.; Niu, R.; Liu, J.; Zhu, Z. A chaotic non-dominated sorting genetic algorithm for the multi-objective automatic test task scheduling problem. Appl. Soft Comput. 2013, 13, 2790–2802. [Google Scholar] [CrossRef]
- Zhan, Z.H.; Zhang, G.Y.; Gong, Y.J.; Zhang, J. Load balance aware genetic algorithm for task scheduling in cloud computing. In Proceedings of the Asia-Pacific Conference on Simulated Evolution and Learning, Dunedin, New Zealand, 15–18 December 2014; pp. 644–655. [Google Scholar]
- Makasarwala, H.A.; Hazari, P. Using genetic algorithm for load balancing in cloud computing. Presented at the 2016 8th International Conference on Electronics, Computers and Artificial Intelligence, Ploiesti, Romania, 30 June–2 July 2016; pp. 1–6. [Google Scholar]
- Siar, H.; Kiani, K.; Chronopoulos, A.T. A combination of game theory and genetic algorithm for load balancing in distributed computer systems. Int. J. Adv. Intell. Paradigms 2017, 9, 82. [Google Scholar] [CrossRef]
- Balakrishnan, S.M.; Nagarajan, S.K. Performance analysis of ant colony optimization and genetic algorithm for cloud load balancing. Int. J. Pharm. Technol. 2016, 8, 26092–26100. [Google Scholar]
- Min, W.; Fan, M.; Li, J.; Han, Q. Real-time face recognition based on face pre-identification detection and multi-scale classification. IET Comput. Vision 2018. [Google Scholar] [CrossRef]
- Wen, X.; Wen, J. Improved the minimum squared error algorithm for face recognition by integrating original face images and the mirror images. Optik 2016, 127, 883–889. [Google Scholar] [CrossRef]
- Dang, K.; Sharma, S. Review and comparison of face detection algorithms. Presented at the 2017 7th International Conference on Cloud Computing, Data Science & Engineering-Confluence, Noida, India, 12–13 January 2017. [Google Scholar]
- Hajati, F.; Tavakolian, M.; Gheisari, S.; Gao, Y.; Mian, A.S. Dynamic texture comparison using derivative sparse representation: Application to video-based face recognition. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 970–982. [Google Scholar] [CrossRef]
- Opitz, A.; Kriechbaumzabini, A. Evaluation of face recognition technologies for identity verification in an eGate based on operational data of an airport. Presented at 2015 12th IEEE International Conference on Advanced Video and Signal Based Surveillance, Karlsruhe, Germany, 25–28 August 2015. [Google Scholar]
- Ujire, N.S.S.; Manipal, S.C.M.; Ujire, A.G.P. Intruder recognition system. Electr. Electron. Eng. 2015, 5, 6–12. [Google Scholar] [CrossRef]
- Siswanto, A.R.S.; Nugroho, A.S.; Galinium, M. Implementation of face recognition algorithm for biometrics based time attendance system. Presented at the 2014 International Conference on ICT For Smart Society (ICISS), Bandung, Indonesia, 24–25 September 2014; pp. 149–154. [Google Scholar]
- Yu, L.; Li, K. Application of Face Recognition Technology in the Exam Identity Authentication System. In Proceedings of the 3rd International Conference on Social Science and Management, Xi’an, China, 8–9 April 2017; pp. 684–688. [Google Scholar]
- Okumura, A.; Hoshino, T.; Handa, S.; Yamada, E.; Tabuchi, M. Identity Verification of Ticket Holders at Large-scale Events Using Face Recognition. J. Inf. Process. 2017, 25, 448–458. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Li, T.; Xia, B.; Ni, M.; Liu, X.; Zhou, Q.; Qi, Y. First: Face identity recognition in smart bank. Int. J. Semant. Comput. 2016, 10, 569–591. [Google Scholar] [CrossRef]
- Gaynor, P.; Coore, D. Distributed face recognition using collaborative judgement aggregation in a swarm of tiny wireless sensor nodes. In Proceedings of the Southeast Con 2015, Fort Lauderdale, FL, USA, 9–12 April 2015; pp. 1–6. [Google Scholar]
- Monteiro, C.E.; Trevelin, L.C. Studies of computing techniques for performing face recognition with a focus in the crowds: A distributed architecture based on cloud computing. Presented at 2015 IEEE/ACS 12th International Conference of Computer Systems and Applications, Marrakech, Morocco, 17–20 November 2015; pp. 1–5. [Google Scholar]
- Liu, X.Z.; Yang, G. Distributed Face Recognition Using Multiple Kernel Discriminant Analysis in Wireless Sensor Networks. Int. J. Distrib. Sens. Netw. 2014, 2014, 1–7. [Google Scholar] [CrossRef]
- Liang, W.-Y.; Chiou, C.W.; Chen, Y.-L.; Weng, C.-Y. Design of a Parallel Face Detection Algorithm for Distributed Low Cost IP-based Surveillance Systems. J. Conver. Inf. Technol. 2011, 6, 306–318. [Google Scholar] [CrossRef]
- Hinojos, G.; Leon, P.L.D. Face recognition using distributed, mobile computing. Presented at the 2014 IEEE International Conference on Acoustic, Speech and Signal Processing, Florence, Italy, 4–9 May 2014; pp. 2179–2183. [Google Scholar]
- Rajeshwari, J.; Karibasappa, K. Face recognition in video systems on homogeneous distributed systems. Int. J. Adv. Comput. Math. Sci. 2013, 4, 143–147. [Google Scholar]
- Effatparvar, M.; Garshasbi, M.S. A genetic algorithm for static load balancing in parallel heterogeneous systems. Procedia-Soc. Behav. Sci. 2014, 129, 358–364. [Google Scholar] [CrossRef]
- Dasgupta, K.; Mandal, B.; Dutta, P.; Mandal, J.K.; Dam, S. A genetic algorithm (ga) based load balancing strategy for cloud computing. Procedia Technol. 2013, 10, 340–347. [Google Scholar] [CrossRef]
- Nourzadeh, R.; Effatparvar, M. A genetic-fuzzy algorithm for load balancing in multiprocessor systems. Int. J. Comput. Appl. Technol. 2014, 101, 39–42. [Google Scholar] [CrossRef]
- Cheng, H.; Yang, S.; Cao, J. Dynamic genetic algorithms for the dynamic load balanced clustering problem in mobile ad hoc networks. Expert Syst. Appl. 2013, 40, 1381–1392. [Google Scholar] [CrossRef]
- Kaliappan, M.; Augustine, S.; Paramasivan, B. Enhancing energy efficiency and load balancing in mobile ad hoc network using dynamic genetic algorithms. J. Netw. Comput. Appl. 2016, 73, 35–43. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef] [Green Version]
- Ding, S.; Zhao, H.; Zhang, Y.; Xu, X.; Nie, R. Extreme learning machine: Algorithm, theory and applications. Artif. Intell. Rev. 2013, 44, 103–115. [Google Scholar] [CrossRef]
- Deng, C.W.; Huang, G.B.; Xu, J.; Tang, J.X. Extreme learning machines: New trends and applications. Sci. Chin. Inf. Sci. 2015, 58, 1–16. [Google Scholar] [CrossRef]
- Shamshirband, S.; Mohammadi, K.; Tong, C.; Petković, D.; Porcu, E.; Mostafaeipour, A.; Ch, S.; Sedaghat, A. Application of extreme learning machine for estimation of wind speed distribution. Clim. Dyn. 2015, 46, 2025. [Google Scholar] [CrossRef]
- Ray, P.; Mishra, D. Application of extreme learning machine for underground cable fault location. Int. Trans. Electr. Energy Syst. 2016, 25, 3227–3247. [Google Scholar] [CrossRef]
- Qin, L.; Hu, L.; Mao, K.; Chen, W.; Fu, X. Application of extreme learning machine to gas flow measurement with multipath acoustic transducers. Flow Meas. Instrum. 2016, 49, 31–39. [Google Scholar] [CrossRef]
- Xiao, C.; Dong, Z.; Xu, Y.; Meng, K.; Zhou, X.; Zhang, X. Rational and self-adaptive evolutionary extreme learning machine for electricity price forecast. Memetic Comput. 2016, 8, 223–233. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Dai, W.; Tang, L. A novel decomposition ensemble model with extended extreme learning machine for crude oil price forecasting. Eng. Appl. Artif. Intell. 2016, 47, 110–121. [Google Scholar] [CrossRef]
- Zhu, X.; Ni, Z.; Cheng, M.; Jin, F.; Li, J.; Weckman, G. Selective ensemble based on extreme learning machine and improved discrete artificial fish swarm algorithm for haze forecast. Appl. Intell. 2017, 48, 1757–1775. [Google Scholar] [CrossRef]
- Tang, P.; Chen, D.; Hou, Y. Entropy method combined with extreme learning machine method for the short-term photovoltaic power generation forecasting. Chaos Solitons Fractals 2016, 89, 243–248. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, E.; Wang, S.; Ding, Q. Multimodal Biometric System Using Face-Iris Fusion Feature. J. Comput. 2011, 6, 931–938. [Google Scholar] [CrossRef]
- Wang, K. Implementation of face cartoon maker system based on android. Presented at the 2013 Fourth International Conference on Intelligent Control & Information Processing, Beijing, China, 9–11 June 2013; pp. 193–198. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | Central Server | Node Functions | Performances | Scalability | Fault Tolerance |
|---|---|---|---|---|---|
| Centralized system | One central controller | All nodes are passive for task allocation | Small throughput Poor Robustness Globally optimal | Poor | Poor |
| Distributed system | No controllers | All nodes are autonomous for task allocation | Large throughput Good scalability Locally optimal | Good | Good |
| Mutation Probability | 0.01 | 0.05 | 0.1 | 0.2 | 0.4 | 0.5 |
|---|---|---|---|---|---|---|
| Average time for processing one frame (s) | 0.0542 | 0.0474 | 0.0458 | 0.0423 | 0.0494 | 0.0512 |
| CPU utilization | 0.3391 | 0.3300 | 0.3255 | 0.3125 | 0.3141 | 0.3238 |
| Number of Pedestrians | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| Average time on the agent side (s) | 0.0213 | 0.0318 | 0.0466 | 0.0538 | 0.0648 |
| Average time on the server side (ms) | 0.1492 | 0.2688 | 0.3156 | 0.3674 | 0.4566 |
| Transmission time from agents to server (s) | 0.0089 | 0.0149 | 0.0216 | 0.0301 | 0.0365 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, F.; Li, J.; Min, W. Distributed Face Recognition Based on Load Balancing and Dynamic Prediction. Appl. Sci. 2019, 9, 794. https://doi.org/10.3390/app9040794
Zou F, Li J, Min W. Distributed Face Recognition Based on Load Balancing and Dynamic Prediction. Applied Sciences. 2019; 9(4):794. https://doi.org/10.3390/app9040794
Chicago/Turabian StyleZou, Fangyuan, Jing Li, and Weidong Min. 2019. "Distributed Face Recognition Based on Load Balancing and Dynamic Prediction" Applied Sciences 9, no. 4: 794. https://doi.org/10.3390/app9040794
APA StyleZou, F., Li, J., & Min, W. (2019). Distributed Face Recognition Based on Load Balancing and Dynamic Prediction. Applied Sciences, 9(4), 794. https://doi.org/10.3390/app9040794