A Compressed Equivalent Source Method Based on Equivalent Redundant Dictionary for Sound Field Reconstruction

Abstract
:Featured Application
Abstract

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Theory Background and Methodology
2.1. Description of the Equivalent Source Method
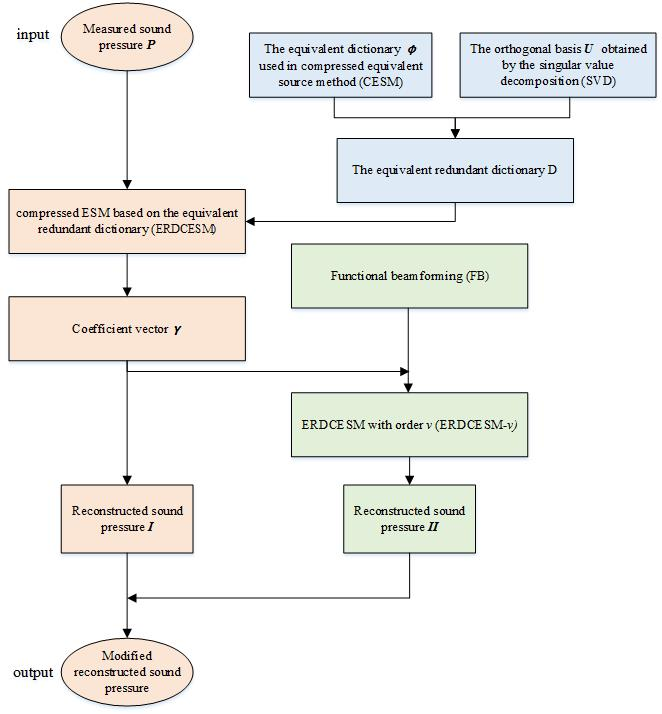
2.2. Compressed ESM Based on the Equivalent Redundant Dictionary
2.2.1. The Equivalent Dictionary Under the Sparse Assumption
2.2.2. Construction of the Equivalent Redundant Dictionary
2.3. A Reformative Method Combining with Functional Beamforming
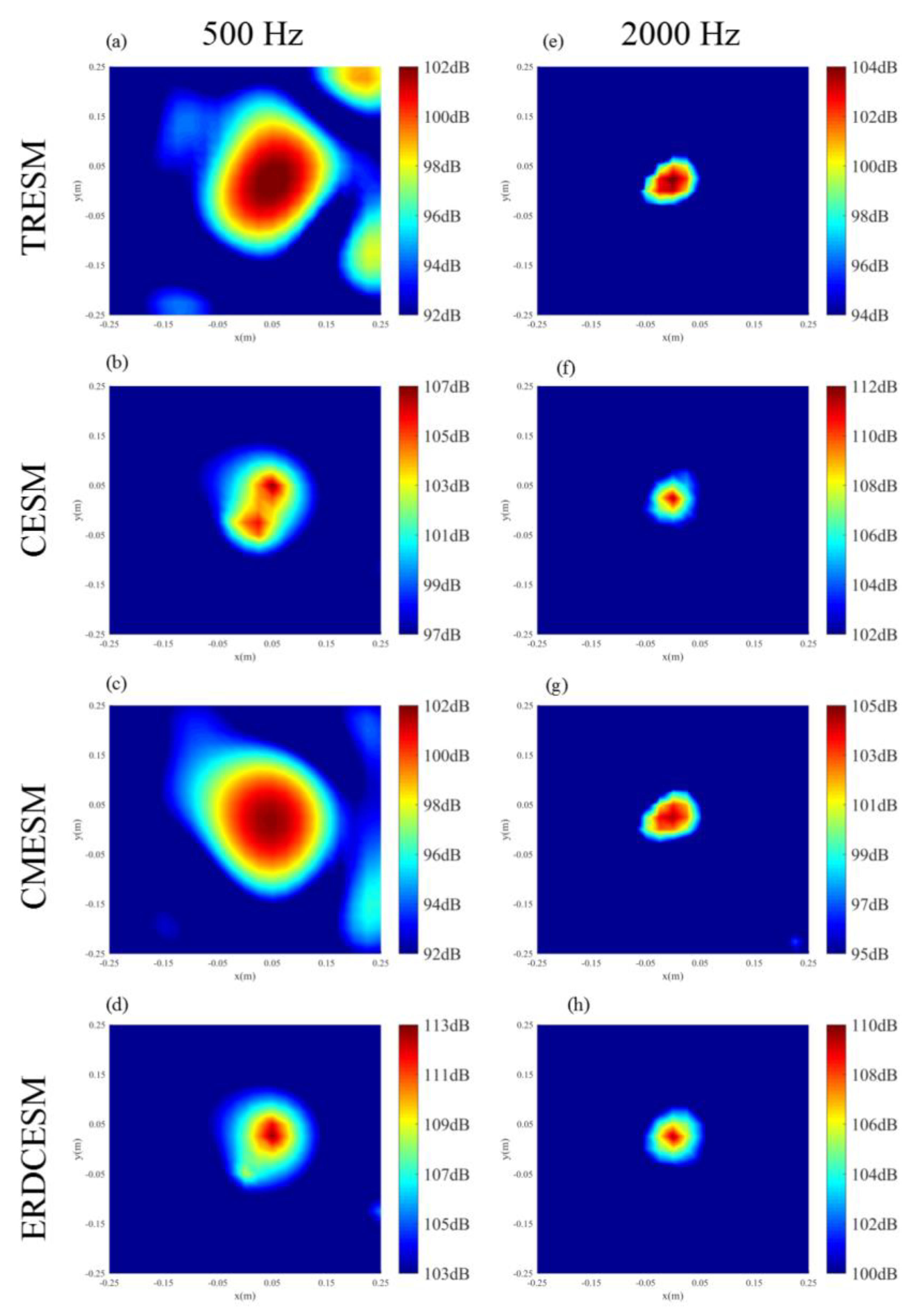
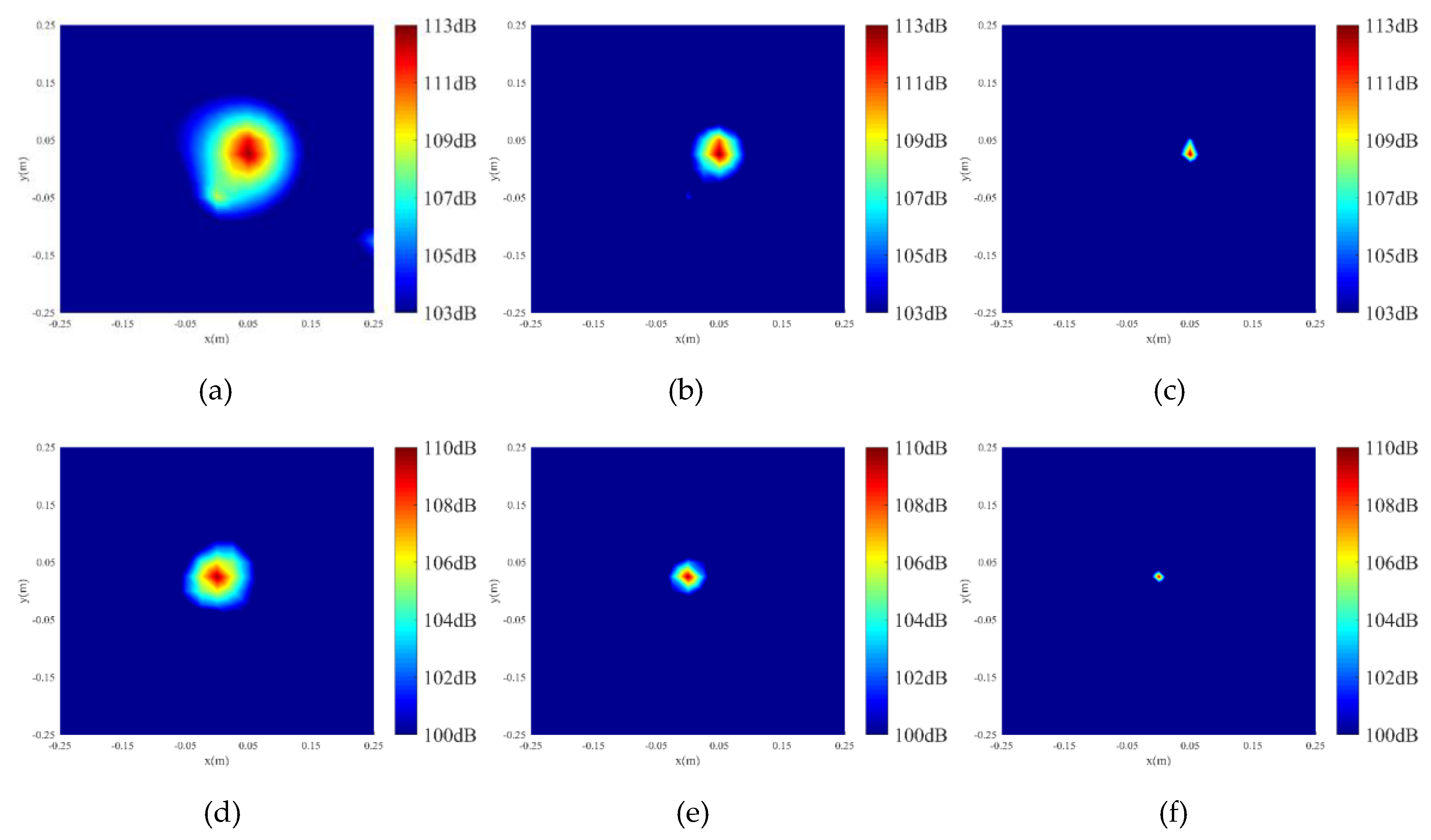
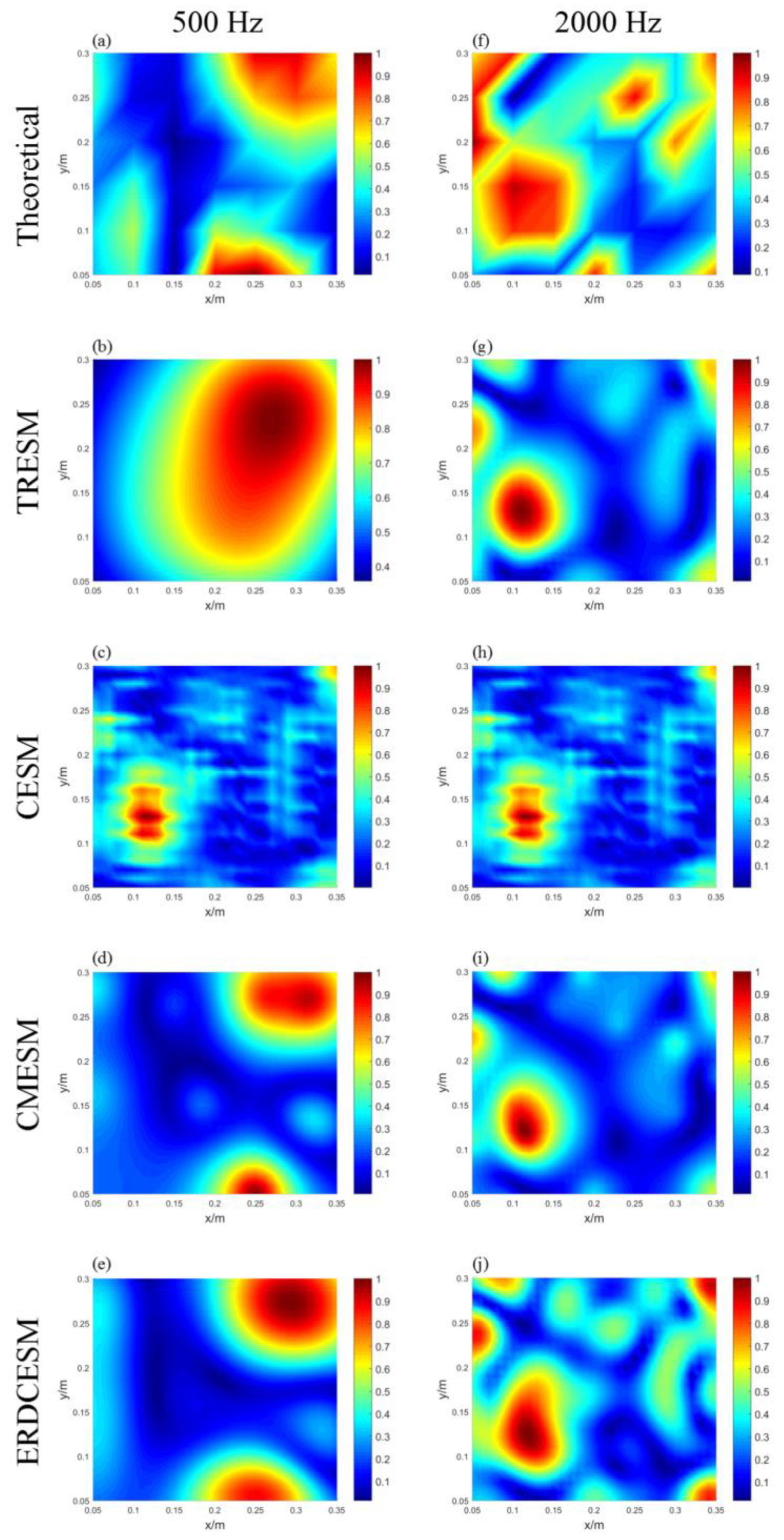
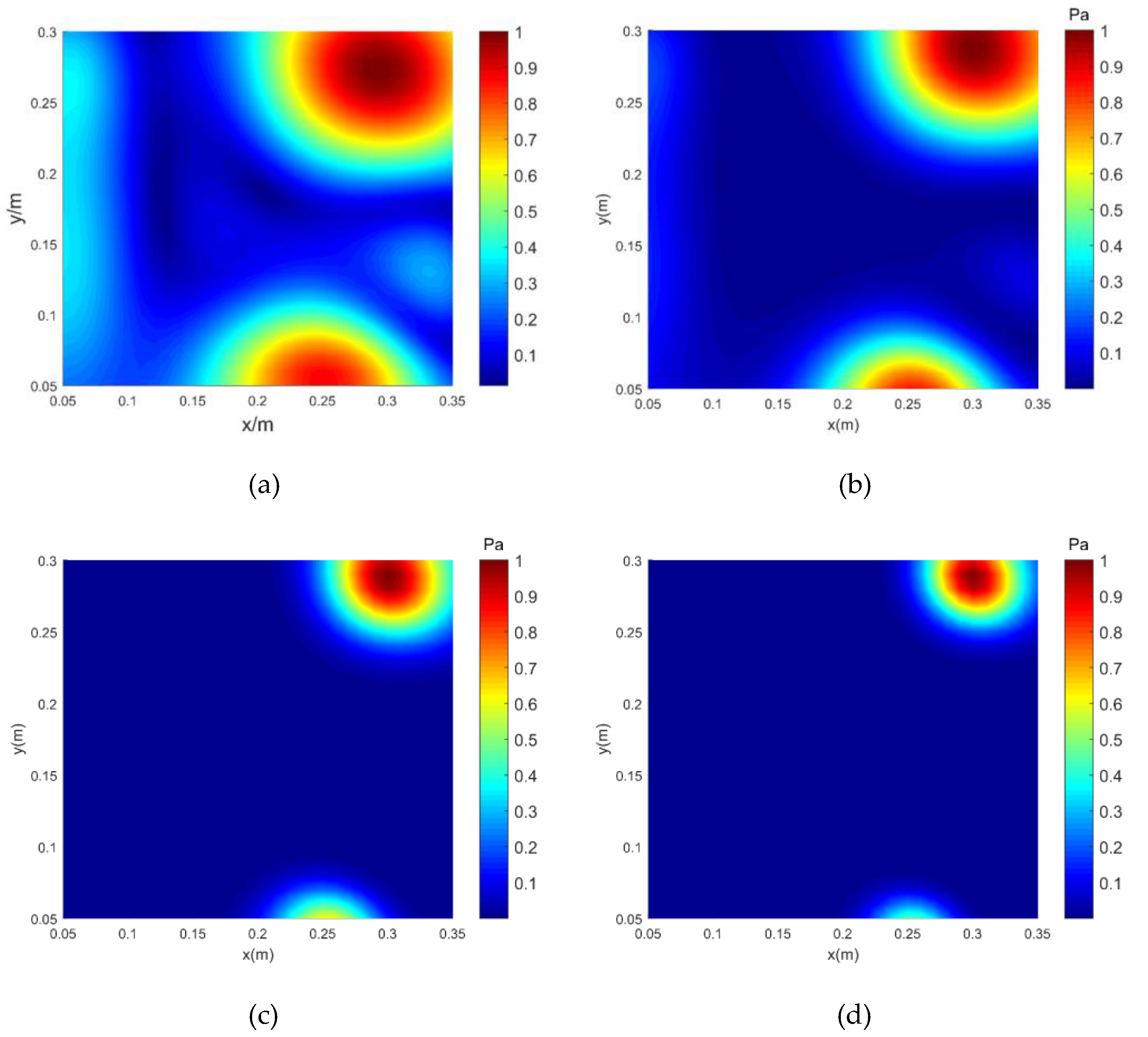
3. Simulated Measurements
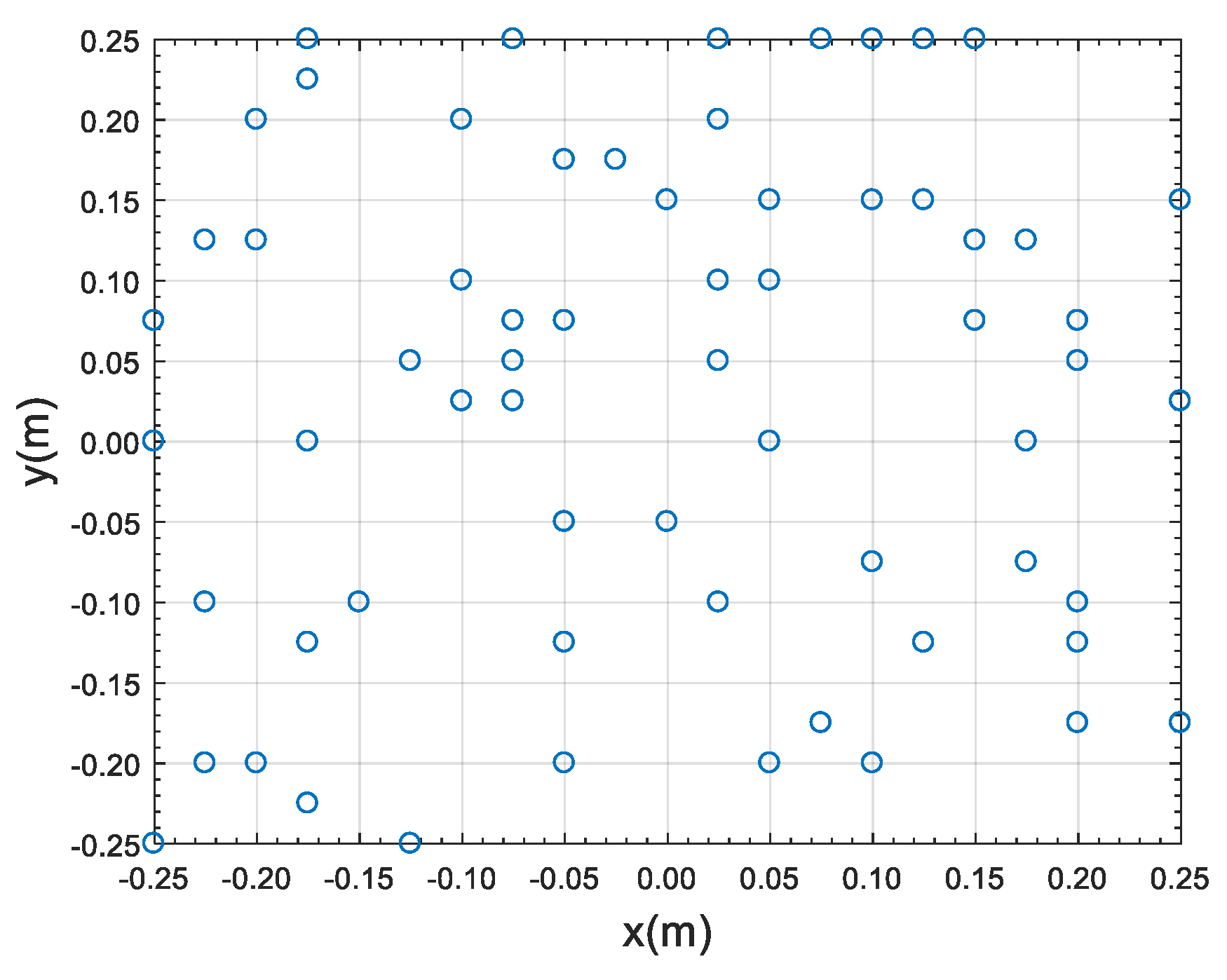
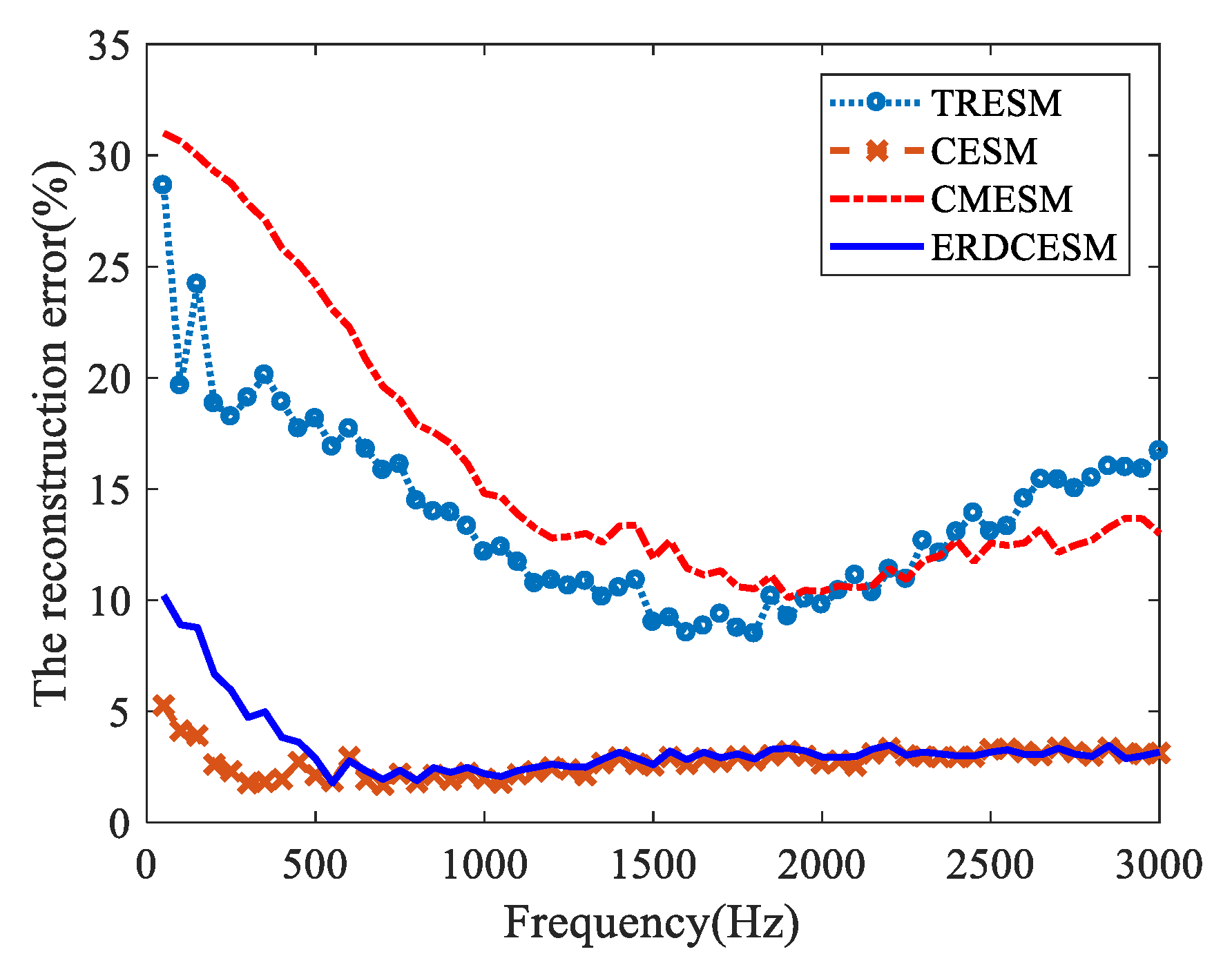
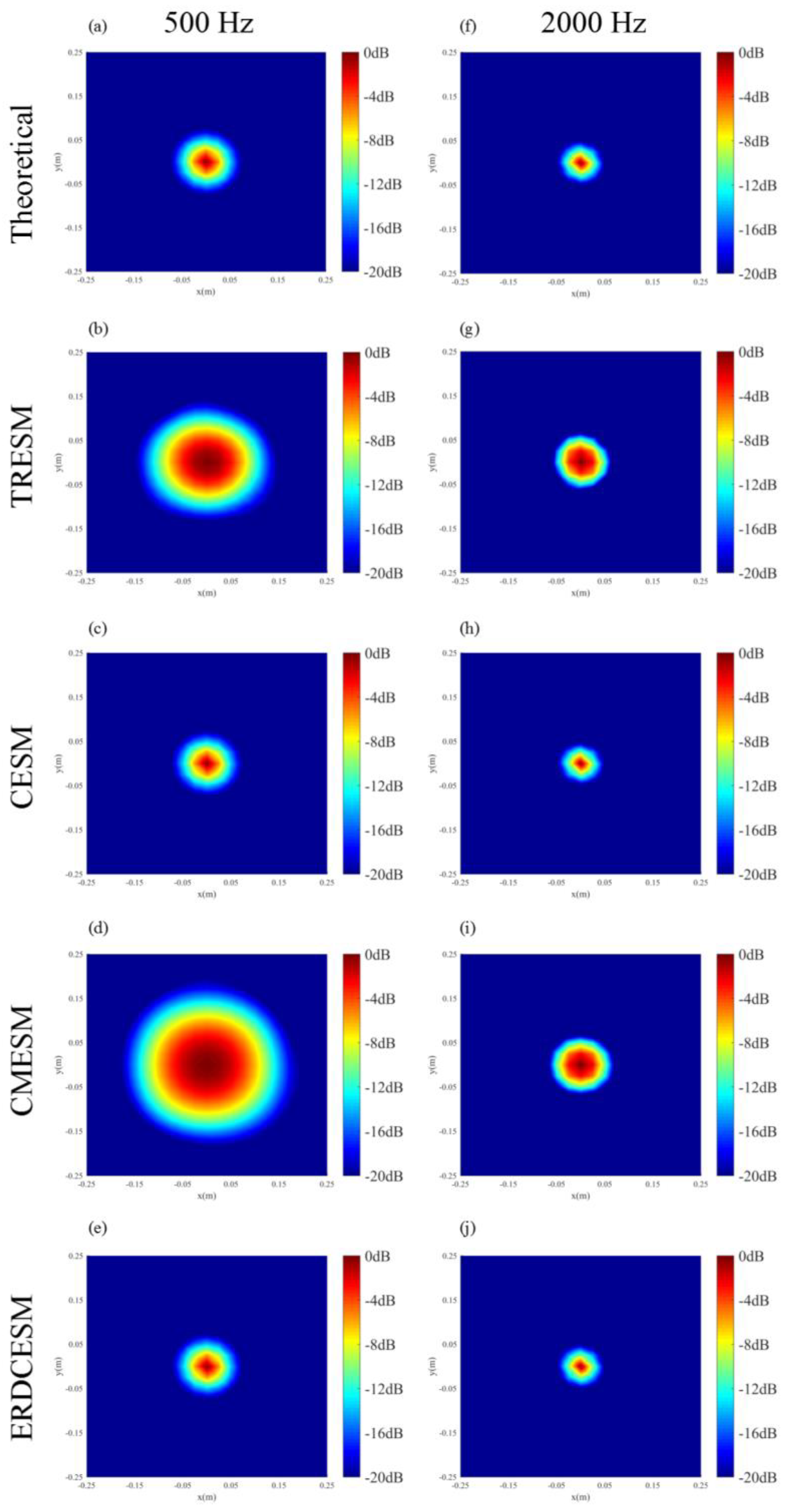
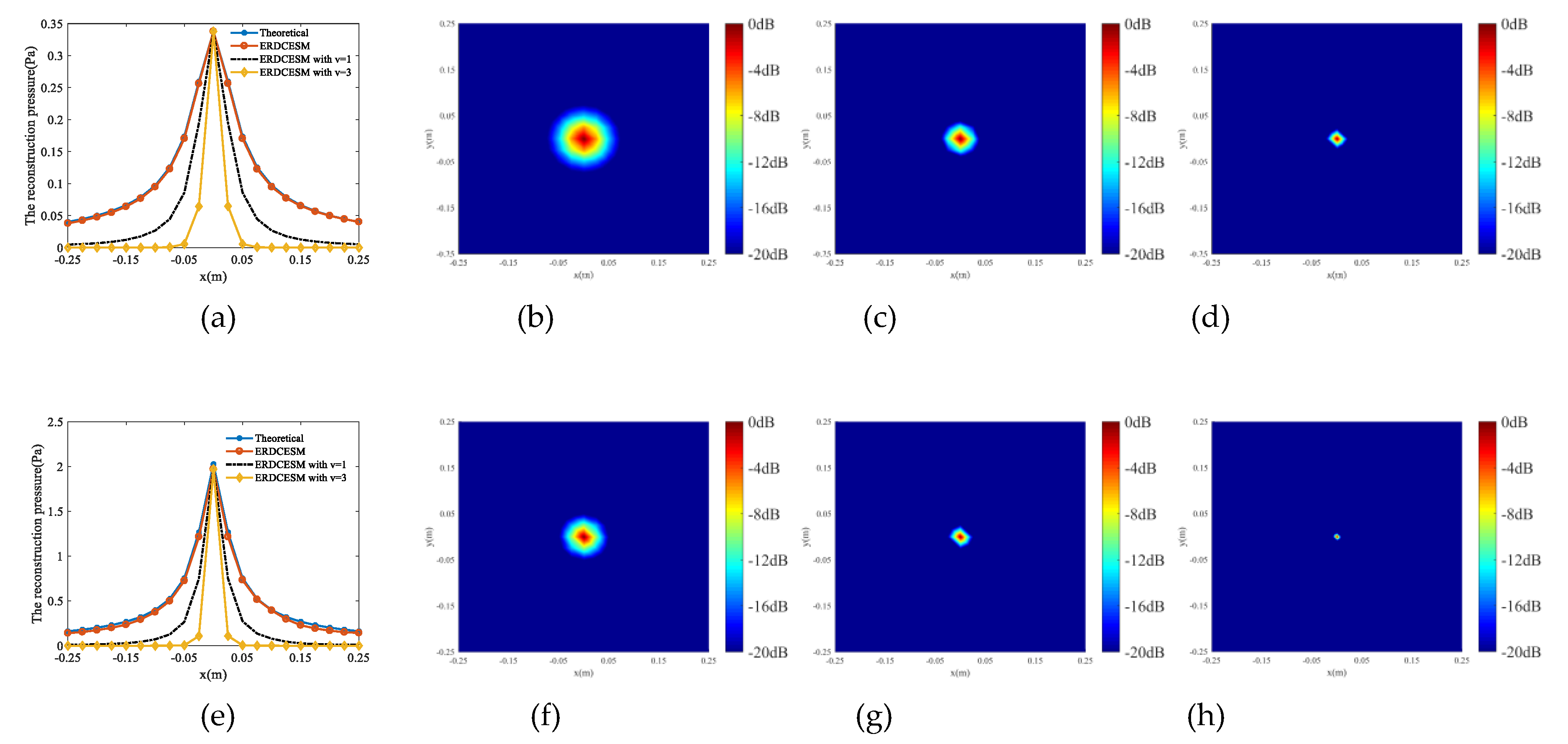
3.1. Single Sound Source
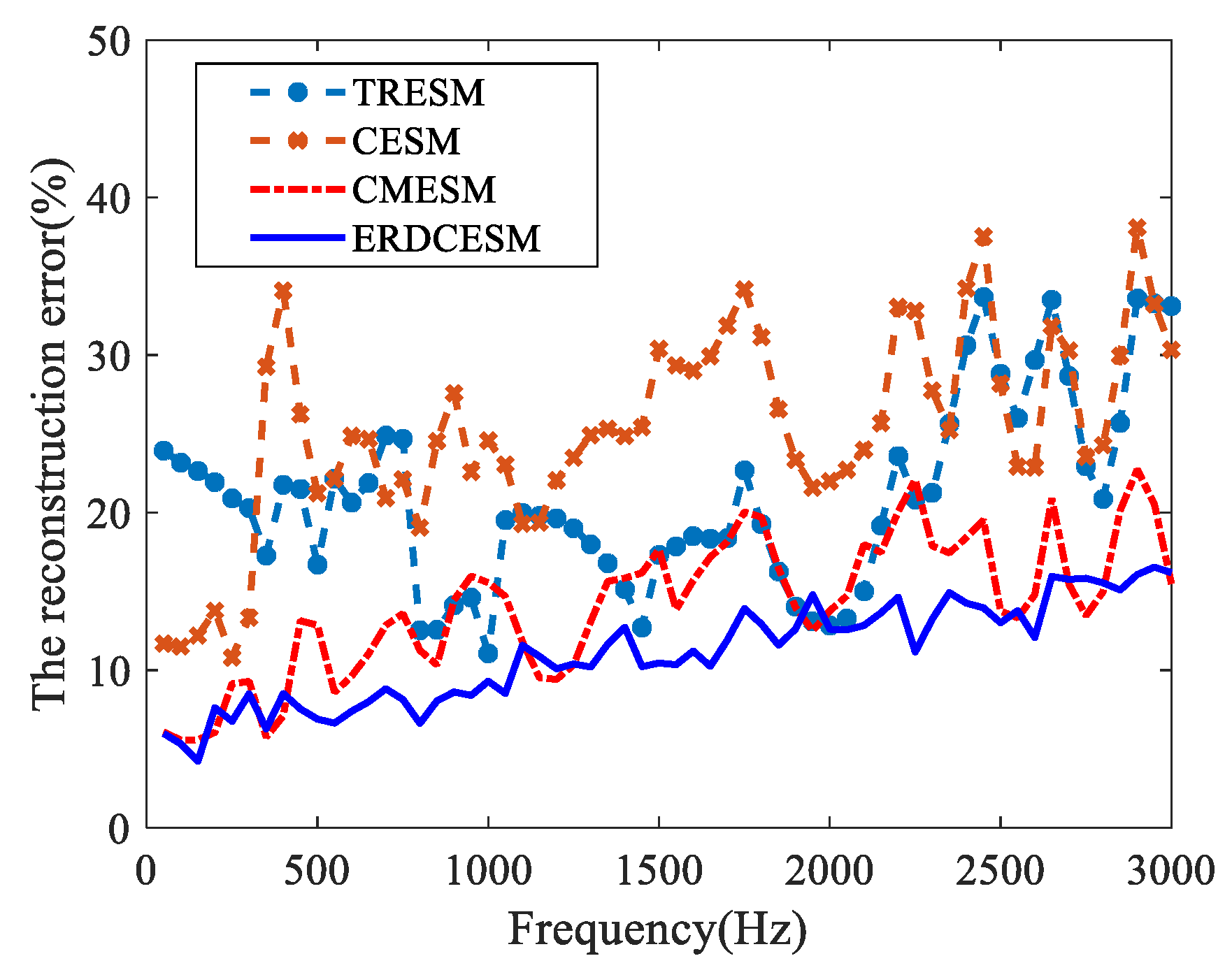
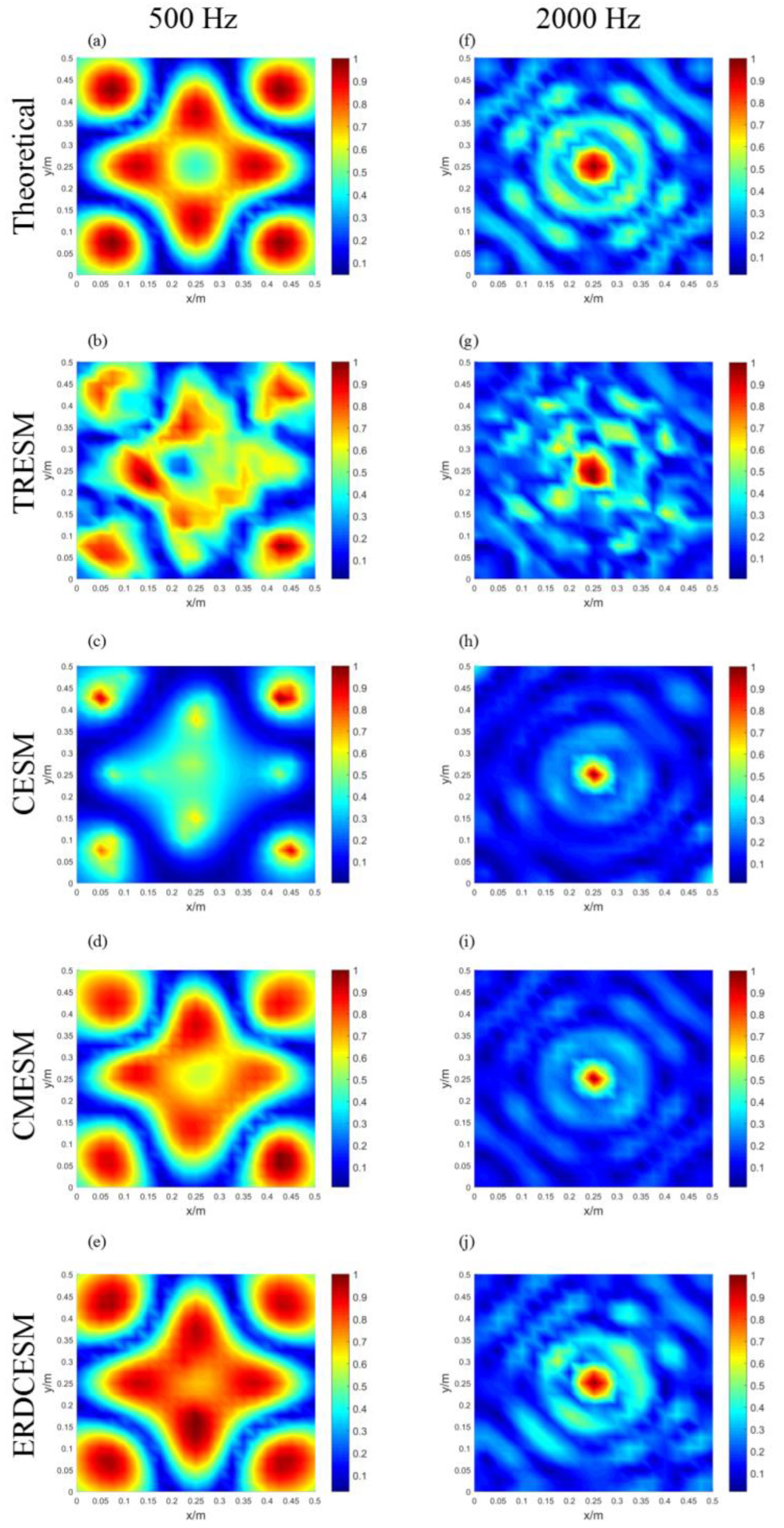
3.2. Simply supported plate
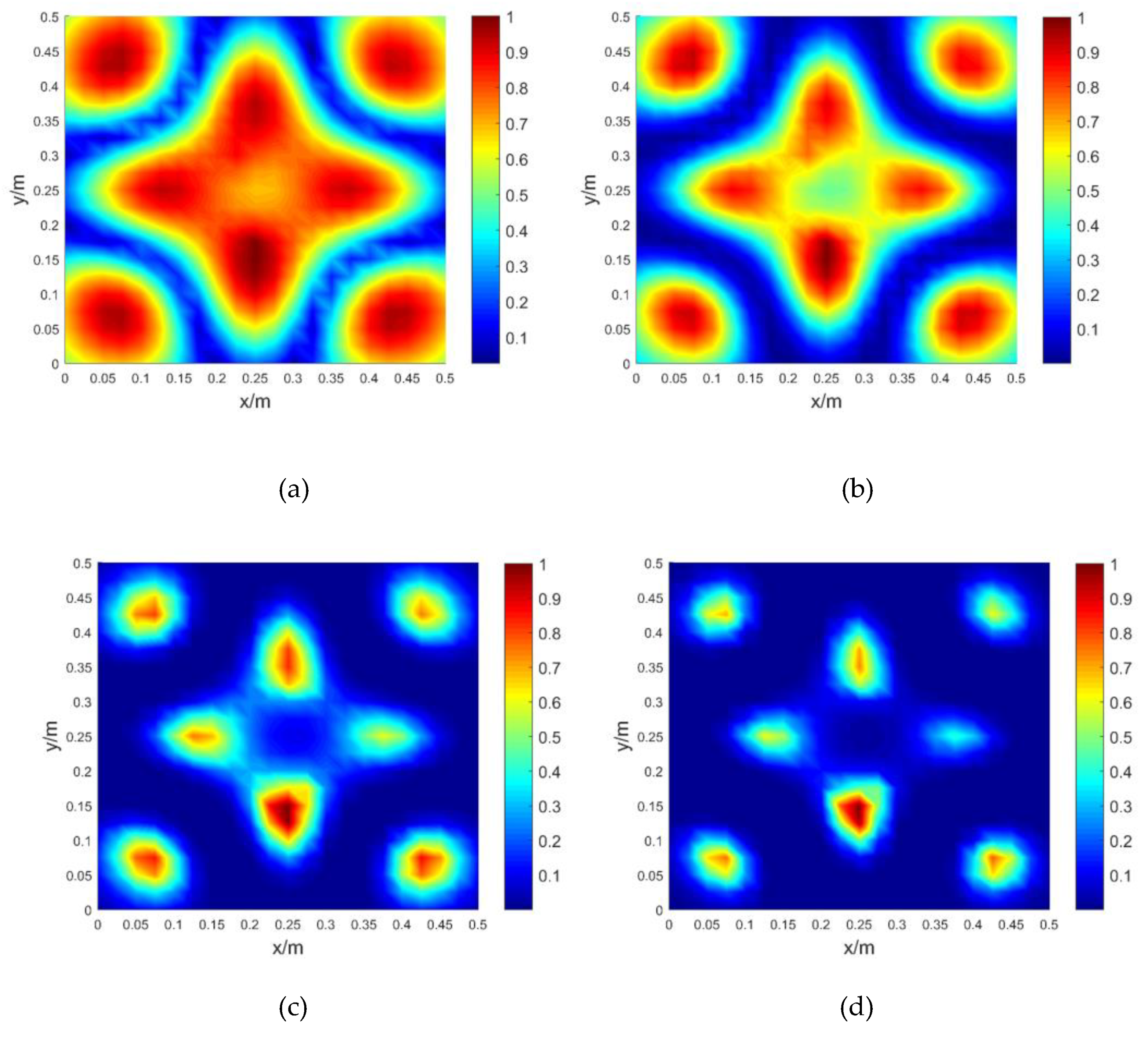
4. Experimental Application
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Nomenclature
| Symbol | Description |
| Sound pressure at the m-th point | |
| The pressure transfer function linking the -thequivalent source to the -th microphone | |
| Acoustic wavenumber, rad/m | |
| The distance between the considered source microphone couple | |
| The transfer matrix relating the measured pressures to the equivalent sources | |
| Angular frequency, rad/s | |
| Density, kg/m3 | |
| Measured sound pressure | |
| Source strength vector | |
| Cost function | |
| Regularization parameter | |
| Sound pressure on the reconstruction plane | |
| The transfer matrix relating the reconstruction points to the equivalent sources | |
| Identity matrix | |
| Coefficient vector of the basis | |
| Equivalent dictionary | |
| Unitary matrix | |
| Unitary matrix | |
| Conjugate transpose | |
| Real diagonal matrix | |
| Singular values | |
| Coefficient vector of the basis | |
| Equivalent redundant dictionary | |
| Moore–Penrose inverse | |
| Tolerance | |
| A small number | |
| Coefficient vector | |
| Cross spectral matrix | |
| Order | |
| Sound pressure at the-th point on the reconstruction plane | |
| Theoretical pressure | |
| Reconstructed pressure |
References
- Koopmann, G.H.; Song, L.; Fahnline, J.B. A method for computing acoustic fields based on the principle of wave superposition. J. Acoust. Soc. Am. 1989, 86, 2433–2438. [Google Scholar] [CrossRef]
- Sarkissian, A. Method of superposition applied to patch near-field acoustic holography. J. Acoust. Soc. Am. 2005, 118, 671–678. [Google Scholar] [CrossRef]
- Valdivia, N.P.; Williams, E.G. Study of the comparsion of the methods of equivalent sources and boundary element methods for near-field acoustic holography. J. Acoust. Soc. Am. 2006, 120, 3694–3705. [Google Scholar] [CrossRef] [PubMed]
- Ping, G.; Chu, Z.; Xu, Z.; Shen, L. A refined wideband acoustical holography based on equivalent source method. Sci. Rep. 2017, 7, 43458. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhongming, X.; Qinghua, W.; Yansong, H.; Zhifei, Z.; Shu, L.; Mengran, L. A monotonic two-step iterative shrinkage/thresholding algorithm for sound source identification based on equivalent source method. Appl. Acoust. 2018, 129, 386–396. [Google Scholar] [CrossRef]
- Xu, C.; Mao, Y.J.; Hu, Z.W. Improved Equivalent Source Method to Predict Sound Scattered by Solid Surfaces. AIAA J. 2018, 57, 513–520. [Google Scholar] [CrossRef]
- Bai, M.R. Application of BEM (boundary element method)-based acoustic holography to radiation analysis of sound sources with arbitrarily shaped geometries. J. Acoust. Soc. Am. 1992, 92, 533–549. [Google Scholar] [CrossRef]
- Wu, S.F.; Yu, J. Reconstructing interior acoustic pressure field via Helmholtz equation least-squares method. J. Acoust. Soc. Am. 1998, 104, 2054–2060. [Google Scholar] [CrossRef]
- Hald, J. Basic theory and properties of statistically optimized near-field acoustical holography. J. Acoust. Soc. Am. 2009, 125, 2105–2120. [Google Scholar] [CrossRef] [PubMed]
- Antoni, J. A Bayesian approach to sound source reconstruction: Optimal basis, regularization, and focusing. J. Acoust. Soc. Am. 2012, 131, 2873–2890. [Google Scholar] [CrossRef] [PubMed]
- Leclere, Q. Acoustic imaging using under-determined inverse approaches: Frequency limitations and optimal regularization. J. Sound Vib. 2009, 321, 605–619. [Google Scholar] [CrossRef]
- Bai, M.R.; Chung, C.; Wu, P.C. Solution strategies for linear inverse problems in spatial audio signal processing. Appl. Sci. 2017, 7, 582. [Google Scholar] [CrossRef]
- Gao, B.; Xiao, S.; Zhao, L. Convergence Gain in Compressive Deconvolution: Application to Medical Ultrasound Imaging. Appl. Sci. 2018, 8, 2558. [Google Scholar] [CrossRef]
- Jin, W.; Kleijn, W.B. Theory and design of multizone sound field reproduction using sparse methods. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 2343–2355. [Google Scholar]
- Candes, E.J.; Wakin, M.B. An introduction to compressive sampling. IEEE Signal Proc. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Chardon, G.; Daudet, L.; Peillot, A.; Bertin, N. Near-field acoustic holography using sparse regularization and compressive sampling principles. J. Acoust. Soc. Am. 2012, 132, 1521–1534. [Google Scholar] [CrossRef] [PubMed]
- Fernandez-Grande, E.; Xenaki, A. Compressive sensing with a spherical microphone array. J. Acoust. Soc. Am. 2016, 139, 45–49. [Google Scholar] [CrossRef] [PubMed]
- Fernandez-Grande, E.; Daudet, L. A sparse equivalent source method for near-field acoustic holography. J. Acoust. Soc. Am. 2017, 141, 532–542. [Google Scholar] [CrossRef] [PubMed]
- Hald, J. Wideband acoustical holography. In Proceedings of the Inter-Noise 2014, Melbourne, Australia, 16–19 November 2014. [Google Scholar]
- Hald, J. Fast wideband acoustical holography. J. Acoust. Soc. Am. 2016, 139, 1508–1517. [Google Scholar] [CrossRef] [PubMed]
- Fernandez-Grande, E.; Xenaki, A. The equivalent source method as a sparse signal reconstruction. In Proceedings of the Inter-Noise 2015, San Francisco, CA, USA, 9–12 August 2015. [Google Scholar]
- Fernandez-Grande, E.; Daudet, L. Near-field acoustic imaging based on Laplacian sparsity. In Proceedings of the 22nd International Congress on Acoustic, Buenos Aires, Argentina, 5–9 September 2016. [Google Scholar]
- Bi, C.X.; Liu, Y.; Xu, L.; Zhang, Y.B. Sound field reconstruction using compressed modal equivalent point source method. J. Acoust. Soc. Am. 2017, 141, 73–79. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Xu, Z.; He, Y.; Zhang, Z.; Song, S. Functional Generalized Inverse Beamforming Based on the Double-Layer Microphone Array Applied to Separate the Sound Sources. ASME J. Vib. Acoust. 2016, 138, 021013. [Google Scholar] [CrossRef]
- Harker, B.M.; Gee, K.L.; Neilsen, T.B.; Wall, A.T. Comparison of beamforming methods to reconstruct extended, partially-correlated sources. J. Acoust Soc. Am. 2017, 141, 3984. [Google Scholar] [CrossRef]
- Oudompheng, B.; Pereira, A.; Picard, C.; Leclere, Q.; Nicolas, B. A Theoretical and Experimental Comparison of the Iterative Equivalent Source Method and the Generalized Inverse Beamforming. In Proceedings of the Berlin Beamforming Conference, Berlin, Germany, 19–20 February 2014; pp. 1273–1282. [Google Scholar]
- Photiadis, D.M. The relationship of singular value decomposition to wave vector filtering in sound radiation problems. J. Acoust. Soc. Am. 1990, 88, 1152–1159. [Google Scholar] [CrossRef]
- Hu, D.Y.; Li, H.B.; Hu, Y.; Fang, Y. Sound field reconstruction with sparse sampling and the equivalent source method. Mech. Syst. Signal Process. 2018, 108, 317–325. [Google Scholar] [CrossRef]
- Williams, E.G.; Houston, B.H.; Herdic, P.C. Fast Fourier transform and singular value decomposition formulations for patch nearfield acoustical holography. J. Acoust. Soc. Am. 2003, 114, 1322–1333. [Google Scholar] [CrossRef] [PubMed]
- Cannistraro, G.; Cannistraro, M.; Cannistraro, A. Evaluation of the Sound Emission and Climate Acoustic in Proximity of one Railway Station. IJH T 2016, 34, S589–S596. [Google Scholar]
- Cannistraro, M.; Chao, J.; Ponterio, L. Experimental study of air pollution in the urban centre of the city of Messina. Model. Meas. Control C 2018, 79, 133–139. [Google Scholar] [CrossRef]
- Grant, M.; Boyd, S. CVX: MATLAB Software for Disciplined Convex Programming, Version 2.1. Available online: http://cvxr.com/cvx (accessed on 10 December 2018).













© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Chen, L.; Xu, Z.; Zhang, Z. A Compressed Equivalent Source Method Based on Equivalent Redundant Dictionary for Sound Field Reconstruction. Appl. Sci. 2019, 9, 808. https://doi.org/10.3390/app9040808
He Y, Chen L, Xu Z, Zhang Z. A Compressed Equivalent Source Method Based on Equivalent Redundant Dictionary for Sound Field Reconstruction. Applied Sciences. 2019; 9(4):808. https://doi.org/10.3390/app9040808
Chicago/Turabian StyleHe, Yansong, Liangsong Chen, Zhongming Xu, and Zhifei Zhang. 2019. "A Compressed Equivalent Source Method Based on Equivalent Redundant Dictionary for Sound Field Reconstruction" Applied Sciences 9, no. 4: 808. https://doi.org/10.3390/app9040808
APA StyleHe, Y., Chen, L., Xu, Z., & Zhang, Z. (2019). A Compressed Equivalent Source Method Based on Equivalent Redundant Dictionary for Sound Field Reconstruction. Applied Sciences, 9(4), 808. https://doi.org/10.3390/app9040808