This study aims to improve the metrics of the target detection algorithm under a limited set of labels. The specific implementation is as follows.
3.2.1. Data Preparation
The raw data obtained consisted of 5041 aerial images with a resolution of 1920 × 1080 (see
Figure 3a). Given that the original image had much information, each one is split into four equal parts and the resolution of each picture is 960 × 520 (see
Figure 3b).
Approximately 20,000 images were obtained after splitting all the original images. Given that not all images contained information on damaged buildings or ruins, and some were irrelevant to this study, such as images of seas and beaches, these images were initially screened out manually. Lastly, approximately 500 images containing objects to be identified are obtained. Thereafter, 70% of the total number of images were selected as part of the training data set, while the remaining 30% were included in the test data set.
3.2.2. SSD Model
The core of the SSD method is the use of a small convolution filter to predict the class score and position offset of a fixed set of default bounding boxes on the feature map and clearly separate the prediction using the aspect ratio.
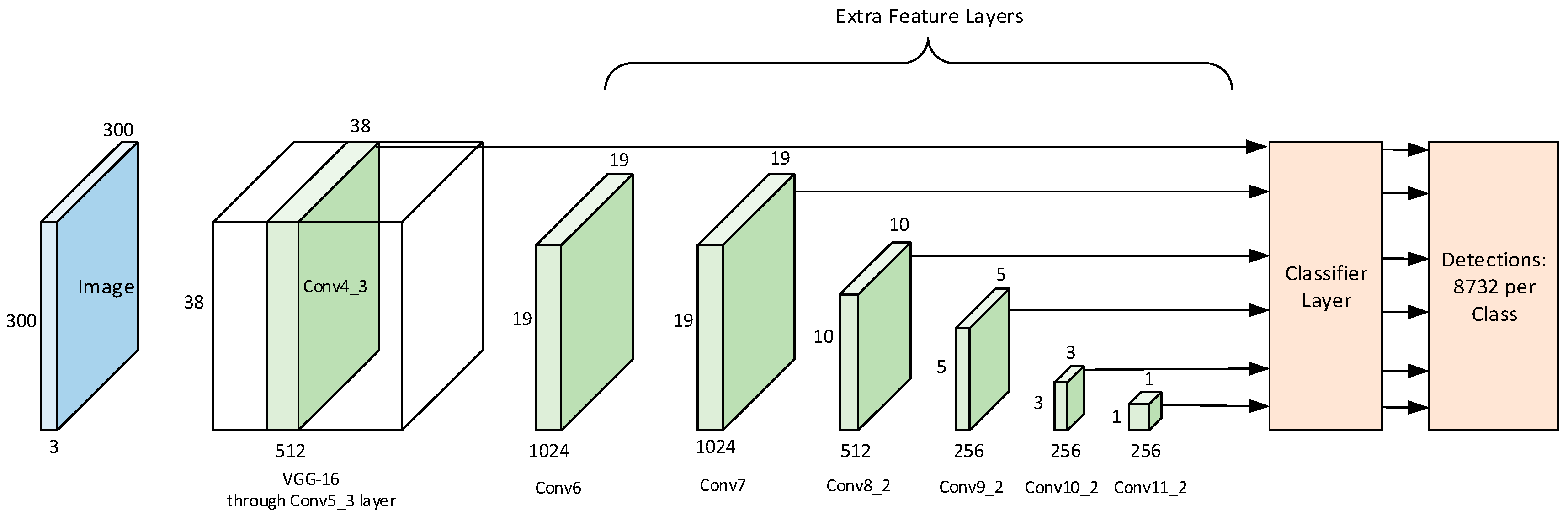
Figure 4 shows the network model [
11].
VGG-16 was used as the basic network to extract the feature information of the image, connecting multiple auxiliary convolution layers of decreasing size after VGG16 network. In order to obtain multi-scale detection prediction values, SSD selected six extra feature maps for detection, namely Conv4_3, Conv7, Conv8_2, Conv8_2, Conv9_2, Conv10_2, and Conv11_2. This way, we reduced the computational and memory requirements and the translation and scale invariance of the feature map on a certain scale. The specific position of the SSD design feature map is responsible for a specific area in the image and a specific object size. If we use
m feature maps to make predictions, then the default box size in each feature map is calculated as follows:
where
= 0.2 and
= 0.95, thereby representing the lowest and highest layer scales of 0.2 and 0.95, respectively.
If
represents the different aspect ratios of the default boxes, then the width and height of each default box are as follows:
The SSD network was based on the previously feed forward neural network (FFNN). It is capable of generating a set of fixed-size target location sets and target category scores for objects that exist in those target frames, and then using non-maximum suppression to produce the final results. In addition to the VGG16 base layer network, each additional feature layer used a set of convolution filters to obtain a fixed set of results. These convolution kernels either generated a score for a class or an offset from the object’s default frame position coordinates.
3.2.3. Proposed Method
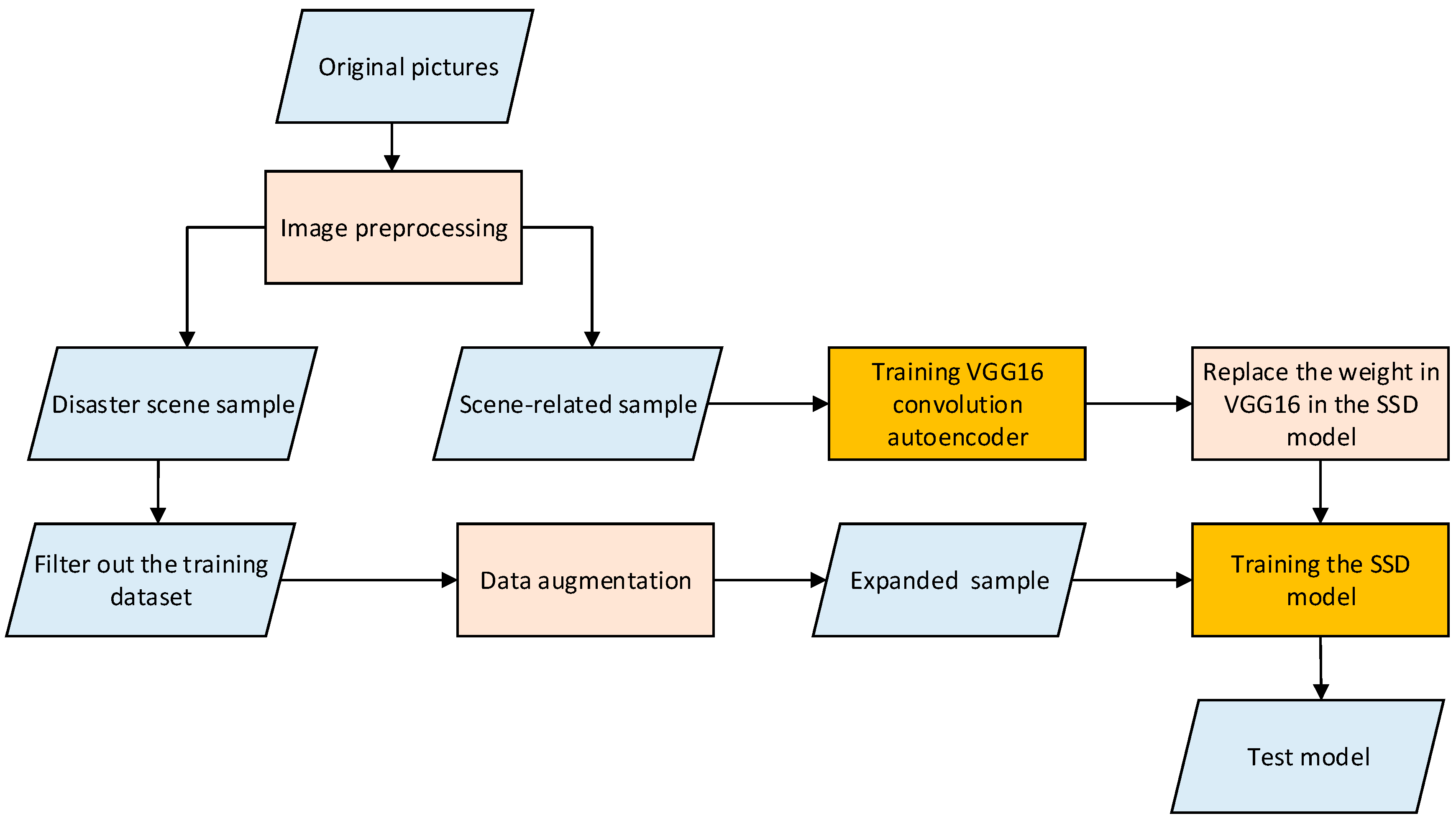
After data pre-processing, we only obtained approximately 500 images containing valid labels. Accordingly, this total was insufficient to train the deep networks. This study proposed two strategies to address this limitation. (1) In pretraining, a convolutional auto-encoder (CAE) that consists of an encoder and a decoder was built. The encoder part was the same as the VGG16 network, while the decoder part was symmetrical to the encoder part. The CAE model was trained using many unlabeled samples that are easily obtained. Approximately 15,000 scene-related unlabeled samples were used in this study to train the VGG16 convolutional autoencoder. After training, the parameters of the encoder part are transferred to the counterpart of the proposed SSD model. (2) In data augmentation, the labeled training images were expanded to 5000 images via rotating, mirroring, Gaussian noise, and Gaussian blur, among others.
Figure 5 shows the framework of the proposed method.
The purpose of convolution autoencoder creation was to use the convolution and pooling operations of CNNs to achieve the unsupervised feature invariant extraction. The use of the convolution auto-encoder to extract the feature weight of the background image related to the target detection to replace the weight of VGG16 in the pre-training SSD can make the trained model considerably convergent.
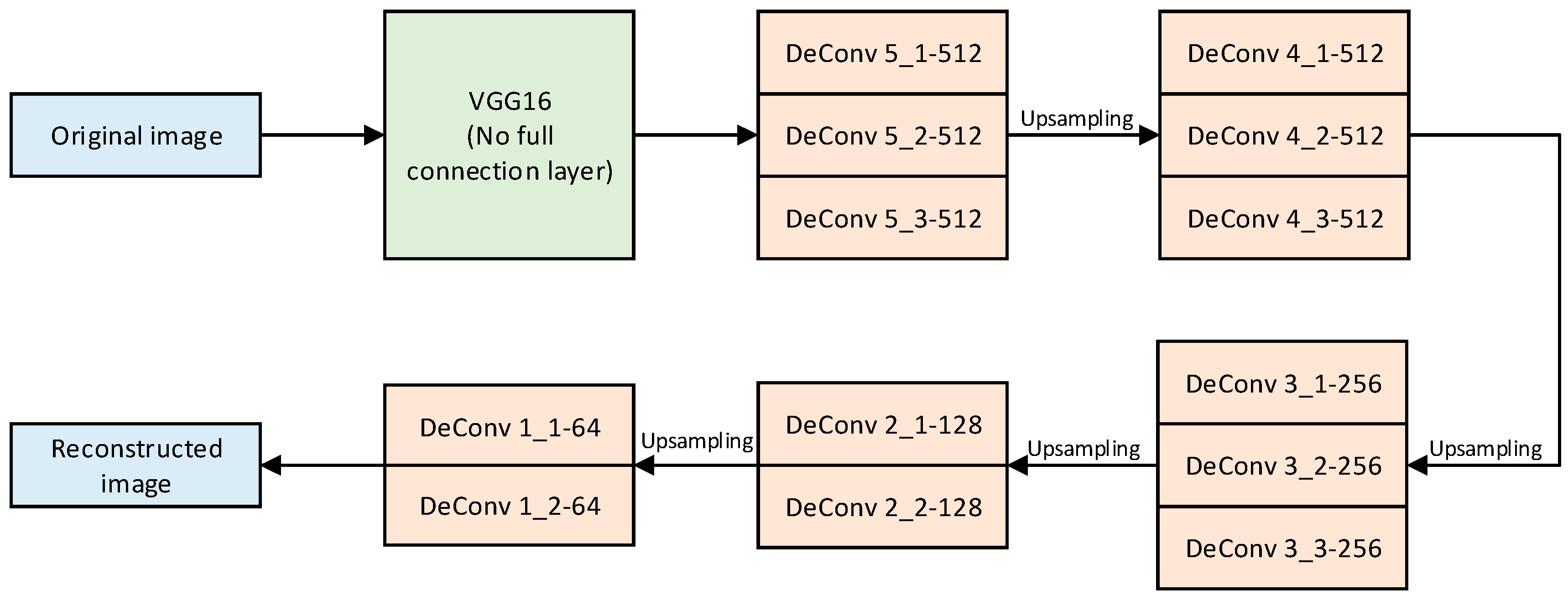
In the SSD paper, there were two sizes of pictures of 300 × 300 and 512 × 512 input into the model, although the research shows that the accuracy of SSD_512 is a little higher than the accuracy of SSD_300. However, combined with the need to quickly deploy rescue after the disaster and SSD512 detection speed was significantly lower than the SSD_300, we chose to convert the size of the picture to 300 × 300 as training data. A convolutional autoencoder was constructed on the basis of the VGG16 layer of SSD (see
Figure 4). Given that the SSD model will resize the input image to 300 × 300, the input of the convolution autoencoder is also changed to 300 × 300 to maintain consistency.
Figure 6 shows the specific structure.
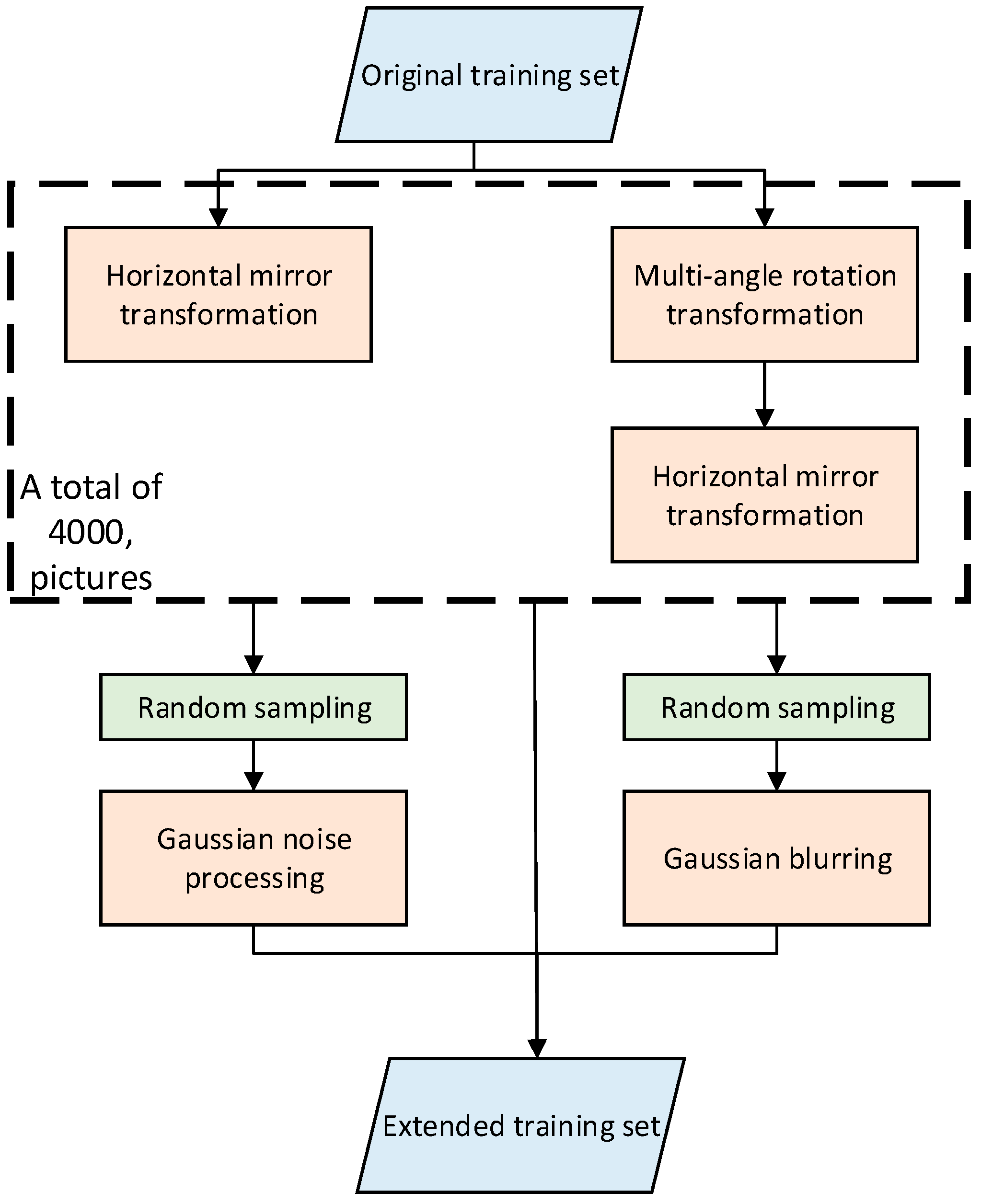
The data set is likewise augmented. First, 500 images with considerably prominent features are manually selected from the training data as the original data to be processed. Thereafter, 500 original images are horizontally mirrored and 90-, 180-, and 270-degrees rotated. This way, we obtain an additional four sets of 500 extended images. The next step is to mirror the images of the last three groups. The three processed sets of images plus 4000 images of the previously processed image and the original image are used. Lastly, 1000 images randomly sampled from these images are divided into two parts for the Gaussian noise processing and Gaussian blur processing. We eventually obtain 5000 training pictures.
Figure 7 shows the flow chart.
A total of 5000 images are labeled as the training set. The data without data augmentation processed were divided into test dataset and verification dataset. When training the model, the verification set is used to find the optimal model, while the test set is used in testing.
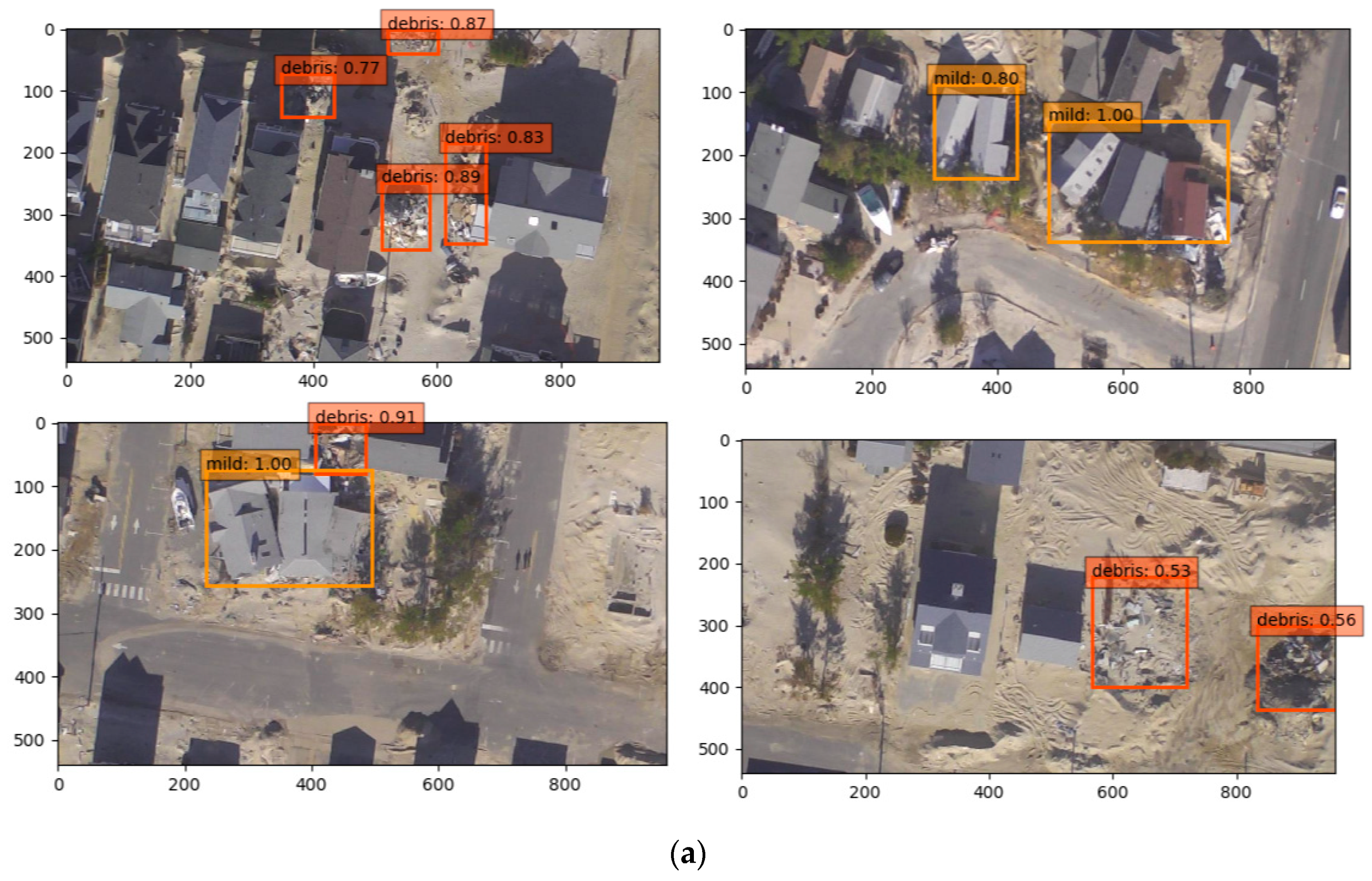
The objects to be identified in this research are categorized into two classes, namely, damaged buildings and debris. Damaged buildings in the current research refer to mildly damaged buildings. That is, the buildings are damaged but still standing. Meanwhile, debris refers to buildings destroyed and in ruins.
Figure 8 shows a few examples.
To make the target of the data to be detected prominently, the training data should be pre-processed before training the model. The brightness, contrast, hue, and saturation of the image must be randomly adjusted. The appropriate optical noise must be added to the image. Thereafter, the image was randomly cropped to substantially train the data of the small target. The SDD model was trained using the Windows platform. The loss function setting is as discussed in reference [
11]. The optimizer and hyperparameters that need to be set before training are shown in
Table 1.
After 80 k iterations, the learning rate dropped to 1 × 10−4, and after 100 k iterations to 1 × 10−4. The learning rate decay ensures that the model does not fluctuate substantially in the latter stages of training, thereby approximating the optimal solution.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}