1. Introduction
The continuous evolution of computational systems has led to intelligent systems that can notably help humans to carry out their daily tasks. Intelligent and pervasive systems make use of computational resources to obtain information from the environment, to manage the information and interact with the humans in a natural and transparent way [
1]. Besides, they require hardware devices that are installed in the environment to obtain information and actuate according to user preferences or needs, as well as advanced communication networks. The size and computational capacities of these hardware devices have been continuously improved during recent years [
2].
Intelligent systems are especially appropriate to develop intelligent environments that can help dependent or disabled people to integrate into our society. Furthermore, dependent elderlies have dramatically increased during the last decade and require new care solutions [
3,
4,
5,
6]. Pervasive systems can help dependent or disabled people to perform daily tasks in a non-obstructive manner [
7,
8]. In this sense, intelligent environments can improve services and can have a high social impact [
9]. Given the special characteristics of the disabled people and the high dynamicity of the organizations, it is necessary to improve pervasive systems with advanced capacities of computation, communication, and reasoning. Multi-agent systems are computational distributed systems with high capacities for learning and adaptation and can be very appropriate to design pervasive systems [
10]. Multi-agent systems have been successfully used to develop pervasive systems in different scenarios [
7,
11,
12] and can contribute to improving the labour and social integration of disabled people [
8]. Multi-agent systems not only provide distributed communication and computation capacities, but also reasoning and adaptation abilities, which allow us to design intelligent adaptive environments in a simple and flexible way, for example, to help visually disabled people in common tasks such as recognizing objects like coins in different situations of their daily life.
People use coins every day and everywhere, in banks, supermarkets, shops, etc., in a way that clearly connects our daily life to the use of coins in different scenarios [
13]. The design of new mechanisms to automate specific tasks related to coins can be beneficial. Automatic recognition systems have been proved to be useful for visually impaired people, giving them a new tool for their daily tasks [
14]. Most of the time individuals with visual impairment recognize coins by the sense of touch and the size of the coins, and improvement of existing recognition systems for coins can be considered a research challenge.
A review of existing technologies reveals three different techniques used to implement coin recognition systems: (i) Methods based on mechanical systems; (ii) electromagnetic detection of materials; and (iii) image recognition. Mechanical methods make use of parameters such as the radius, thickness, and weight to distinguish certain coins from others. Electromagnetic systems are centred on the oscillation of a coil for detecting the amplitude and the frequency direction [
15]. This last parameter helps to detect the particular material of the coin. The third group of detection mechanisms has had a significant impact in recent years and is based on image recognition. Several image recognition techniques have been developed to detect the characteristics of each coin and, thus, determine its corresponding value [
16]. The main problem that we can find in the existing solutions is to train different algorithms to make them able to differentiate a coin automatically. Generally, the training datasets are very large and need to take samples from a fixed point, i.e., the camera should always be in the same position to get reliable results. Thus, one of the main problems is that while all the existing systems can recognise the coins through colour and radius, there is always one requirement: the camera must be stationary, and the position for the training samples has to be the same as for the classification process. Therefore, the user does not have freedom of movement. This restriction of the camera’s movement can be a significant problem for people with disabilities, in particular people who have reduced visibility that cannot be sure where the camera is pointing, as with mobile phones, for example.
This paper presents a recognition system of legal tender in the European Union that allows us to identify the amount and the value of each coin, and to vary the position of the camera or the position of the coins, providing the user with greater freedom and ease of movement for recognition. The proposed system makes use of artificial intelligence techniques to develop intelligent environments. The study presents a virtual organization (VO) of agents which uses image processing and analysis algorithms for the automatic recognition of coins. The use of a virtual organization allows us to model the system as a social machine, and to incorporate roles that are specialized on processing techniques based on homography and classification mechanisms to recognize coins using mobile phones. The structure of the paper is as follows:
Section 2 presents the state of art;
Section 3 outlines the multiagent system;
Section 4 shows the intelligent system for coin recognition;
Section 5 describes the case study, and finally,
Section 6 presents the results and the conclusions, respectively.
2. State of the Art
Ambient intelligence [
1] attempts to adapt existing technology to the needs of the user and is based on such characteristics as context awareness, multimodal communication and user-centred interaction. Currently, the use of mobile devices is pervasive; as they facilitate the use of ubiquitous computing and intelligent interaction with users, the technology can be applied in ambient intelligence. Ambient intelligence requires typically a kind of technology that facilitates both the recovery of contextual information and user interaction, which typically requires the installation of sensors [
17]. However, these sensors usually have to be specified for each case study. The use of multiagent systems is becoming more widespread with applications using ambient intelligence [
1] [
18,
19], indicating that the former can facilitate the creation and establishment of the latter both quickly and efficiently.
Recent tendencies have led to the social computing paradigm of designing social systems. This perspective helps us to build sociotechnical tools that aim to create substantive human connections as part of the process of data analysis. Schuler [
20] describes social computing as any type of computing application in which software serves as an intermediary or a focus for a social relation, while Forrester Research [
21] describes it as a social structure in which technology puts power in individuals and communities, not institutions. Wang et al. [
22] define social computing as the computational facilitation of social studies and human social dynamics as well as the design and use of information and communications technologies (ICT) that consider social context. For social computing, there are systems that support social behaviour among people within the system and then make use of that behaviour for various purposes. Leo Von Ahn [
23] sees social computing as a kind of human-computer interaction that combines humans and computers to solve large scale problems that neither can solve alone, taking advantage of the human cycles. More specifically, technology for supporting any sort of social behaviour in or through computational systems (e.g., blogs, email, wiki, social networks, etc.). David Robertson [
24] indicates that the power of the social computer resides in the programmable combination of contributions from both humans and computers. In a social computer, the Internet supports the infrastructures within which social interactions and problem-solving activities will be performed according to the deeply interactive norms and patterns that regulate societies. In this sense, VO is an example of this paradigm.
A VO is an open system formed by the grouping and collaboration of heterogeneous entities; there is a separation between form and function that requires defining how behaviour will take place. Agent technology, which makes it possible to form dynamic VO of agents, is particularly well suited as a support for the development of these open systems. Modelling open multiagent organization makes it possible to describe structural compositions and functional behaviour, and it can incorporate normative regulations for controlling agent behaviour, dynamic entry/exit of components and dynamic formation of agent groups [
25]. As the development of open multiagent systems is still a new field in the multiagent system (MAS) paradigm, it is necessary to investigate new methods to model open agent-based VOs, and innovative techniques to provide advanced organizational abilities to VOs. One of the challenges of social computing is to model the interaction with the different actors of the environment, in this case, humans and wireless sensor networks (WSN). An important aspect to model the interaction with WSNs is the standardization and processing of the information, and information fusion (IF) has played an important role when working with traditional sensing systems. However, it is necessary to design new management models able to provide dynamic IF techniques and to support the dynamic integration of known WSNs or new technologies in the environment. VO of MAS are especially appropriate to design open architectures as well as to integrate heterogeneous WSN and to implement dynamic IF techniques. There are several technologies and areas that can assist in the creation of such a system. Such technologies are continuously evolving, and it is predicted that they will have a big impact in coming years. For example, VO and agent technology [
26,
27], WSN [
28], information fusion [
29], indoor locating systems [
30], etc.
The use of images to recognize coins is currently not a pervasive process; this process is usually carried out through electromechanical means which measure the characteristics of the coins, such as size, weight or width [
31]. A series of sensors are often included, which permits measuring the physical characteristics of the coins, as shown in [
15,
31]. Other studies are based on conductivity or other physical properties that obtain measures through specific hardware [
32]. Recent studies continue to evaluate aspects such as conductivity in order to classify the coins according to the material they are composed of [
33]. However, it is complicated to find studies that permit classifying and identifying coins through image recognition. One specialized study [
34] permits the recognition of coins from different member countries of the European Union before the incorporation of the euro coin. The study uses eigenspace decomposition for image analysis to recognize the different coins, although it poses a problem when attempting to recognize coins like the euro coins, as the reverse for every denomination of the euro coin is identical for all the member countries. However, the obverse side is different as each country chooses a unique design commemorating different national events, which makes this type of analysis harder.
In addition, there are issues such as damage of coins or even dirty coins which has a direct impact on the performance of classification methods. Those techniques whose performance relies in complex features based on textures could be significant affected by the coin grade.
There is prominent research line in the literature about the classification of ancient coins, where authors such as Callum Fare et al. [
35] have evaluated systematically the coin grade in ancient coins and their effects in different classification techniques. Brandon Conn et al. also highlights [
36] the significance of the coin condition (from poor to very fine) in coin classification and shows a way to detect coins using “coarse localization using coherent elliptical shape assumption”, they perform this process to detect coins but the elliptical shape in ancient coins could be due to damage or perspective of the camera. In our work, we assume euro coins with a grade in the condition scale from very good to very fine, which is the usual condition of euro coins. Thus our elliptical shapes are mainly related to a perspective deformation.
Concerning the recent classification methods employed in the literature, such as the work of Schlag et al. [
37] where they employ deep learning models to classify ancient coins. Like the previous works, these models relies on images with enough resolution for image classification. In our approach, we have focused on a pre-processing step in order to obtain simpler features such as colour and size to perform classification tasks
Regarding available mobile applications in this area, in the Apple Store it is possible to found Scybot Coin Counter [
38], which permits the recognition of legal tender in the USA, whereas on the Google Play, Coin Counter Camera, which counts euro coins of the same type from a taken photo. Nevertheless, characteristics used to classify coins, such as radius, do not provide a precise calculation. Thus, it is necessary to provide new intelligent solutions for coin recognition oriented to dependent and visually disabled people, favouring the real and effective integration of these collectives in our society. In the next section, we propose an intelligent system aimed at facilitating the recognition of coins for dependent and visually impaired people in a transparent non-intrusive manner.
3. Intelligent System for Coin Recognition
The proposed intelligent system in this paper is modelled as a social machine, where humans and computers collaborate to solve a social problem. This perspective allows us to study the problem from a social and organisational point of view, and to design the proposed intelligent system in terms of distributed intelligent entities. The entities form part of a social machine that can be easily extended in the future. The system also takes into account that image recognition processes are often characterized by a high computational cost, and it is of vital importance to use a scalable and flexible architecture that permits the simple distribution of computational processes throughout the system. In this section, we propose a social machine that is supported by a multiagent system, specialized in the identification and classification of coins in intelligent environments, with special attention placed upon the special needs of persons with a visual impairment. The proposed system allows a distributed and efficient image recognition and can be used in a mobile device. The system is developed using the previous existing PANGEA multiagent platform [
39]. PANGEA facilitates the creation of virtual organisations of agents by introducing a social perspective; it incorporates new communication mechanisms among the agents and supports integration with other agent architectures due to its communication prototype, which is based on IRC (Internet relay chat). The platform offers complete control and management of communication among the devices. One of the advantages of using this communication system in virtual organizations of agents is the use of the IRC protocol, which has a simplicity and lightness that permits rapid and efficient communication. PANGEA platform allows us to create intelligent environments capable of adapting dynamically to the needs of the users, taking social and organisational aspects into account. The use of PANGEA permits the implementation of intelligent systems, which are capable of offering services that automatically adapt to the needs of the environment. PANGEA provides the programmer with the use of different programming languages that can communicate among themselves through the exchange of simple text strings sent through sockets. The selected architecture can deploy agent organisations with different topologies and is also able to integrate FIPA-ACL agents.
To design the social machine, we have identified the tasks that can be carried out by each of the people participating in the system and the tasks that can be carried out by machines. Basically, in the proposed system there are government agents that facilitate the characteristics of the coins, user agents that obtain images about coins and request a classification service, and coin recognition agents that take care of the computational processes.
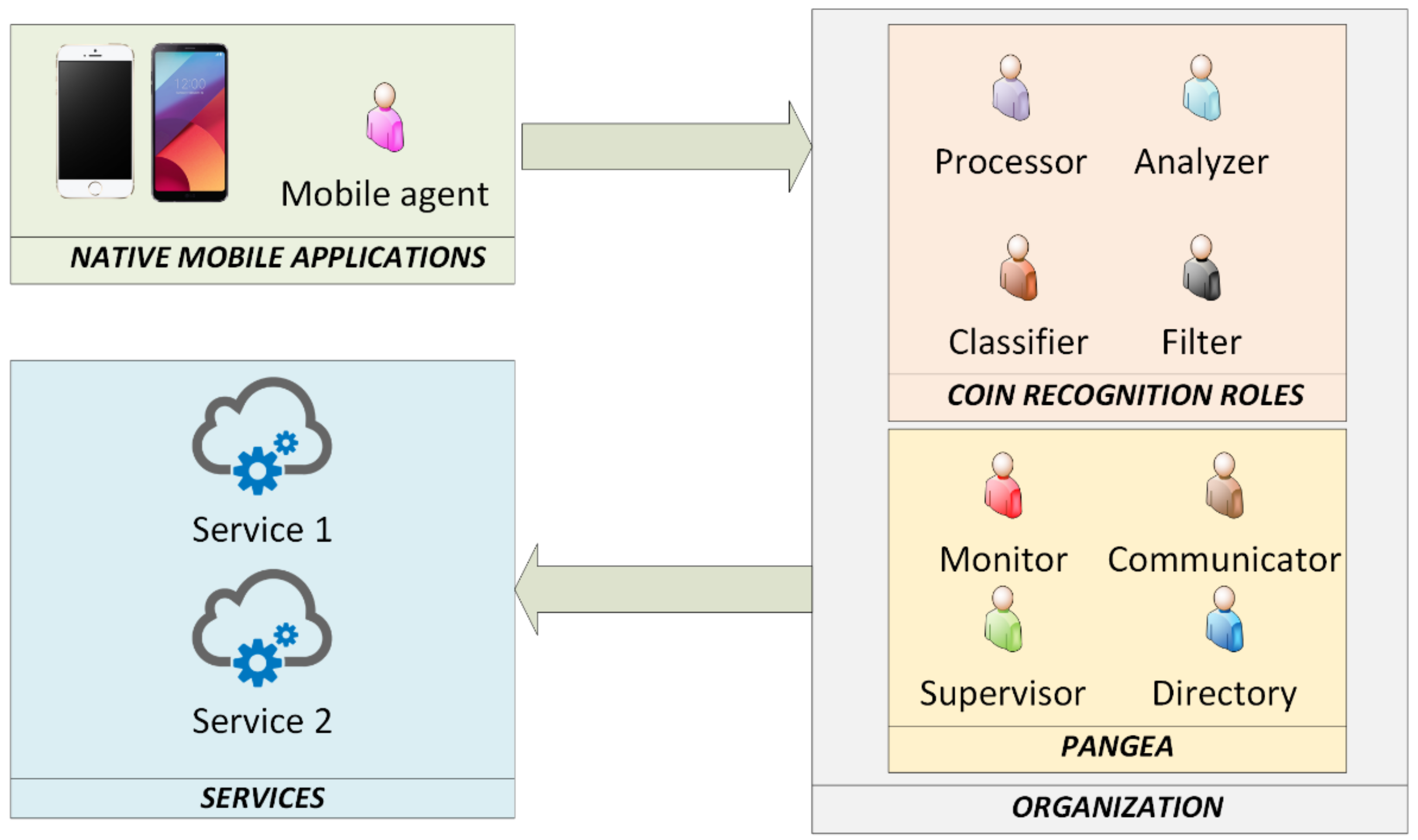
Figure 1 shows the roles identified in the virtual organisation of agents defined for the new intelligent environment. As can be seen in
Figure 1, we define a user role to interact with the user through mobile devices, which is played by the agents that are installed in mobile devices. The native application in the mobile devices represent the applications that have been created for the different devices and facilitate access to the different system functions. The organisation layer is divided into different roles associated with the classification of coins and to implement the social aspects of the virtual organisation (communication, norms, interaction, etc.). The roles from the organisation layer are deployed in the servers and carried out by the agents responsible for processing the information sent by the mobile agents. The PANGEA architecture is characterized by a distribution of functionalities using different services. This way, the agents can make use of different services that are available on different servers.
Components of the Proposed System
Mobile agents are context-aware and adapt to specific parameters within their environment, capable of functioning dynamically in any situation. For example, using the light sensor, the mobile agent can determine whether it is necessary to activate the camera flash to obtain an image with the correct lighting. To do so, a lighting threshold is established which can then turn on the camera flash. Additionally, the use of an accelerometer allows the mobile agent to obtain contextual information indicating when the subject has stopped moving, and then activate autofocus. As with the flash, the values obtained by the accelerometer are analysed to ensure they do not exceed a predefined threshold, thus eliminating the value corresponding to terrestrial gravity. It is possible to use the system in most existing mobile terminals, as the special characteristics of PANGEA allow us to run agents on devices with limited processing capabilities, including old terminals, and to distribute all the processing tasks in the agents and services of the organisation layer.
The services represent the system’s functionalities at the processing level. There are activities that are invoked either locally or remotely depending on the needs of the agents. The use of a service layer allows the abstraction of the logic of the system from the implementation, allowing dynamic modification of the algorithms, adding new services or modifying the services without needing to modify components of the architecture. This system provides the developers with a certain amount of liberty, as they can implement the entire functionality in any programming language.
The agents that undertake the roles are in charge of the communication and coordination of information among themselves, allowing them to share any required information during the process of image analysis. The roles undertaken by the agents within the organisation are listed as follows:
Classifier: once the characteristics of the image have been received, the agent in this role uses the service provided by the classifier function.
Filter: eliminates the noise from the image by applying a median filter [
40].
Processor: in charge of extracting the characteristics of the image, such as edge detection, circle detection, and the characteristics of each coin, such as diameter and colour.
Analyser: directs the flow of execution for the classification process.
Mobile: in charge of obtaining the image from the mobile device as well as the focus and flash for the camera.
In addition to the roles of the proposed system, there are additional roles from the PANGEA platform that are present in each of the organisations developed with this platform.
Monitor: its main task is to confirm that all the agents are functioning correctly and carrying out their asynchronous tasks; when a problem arises, it sends an error message.
Communicator: responsible for the communication among the different components in the platform; it manages the entry-exit requests to be processed by the different services.
Supervisor: its primary function is to validate the structure of the messages and confirm that the agents are connected to the system; when this is not the case, it will request a reconnection for the disconnected agent.
Directory: also known as the white pages agent. It has a list of all the active services that can be used in the architecture.
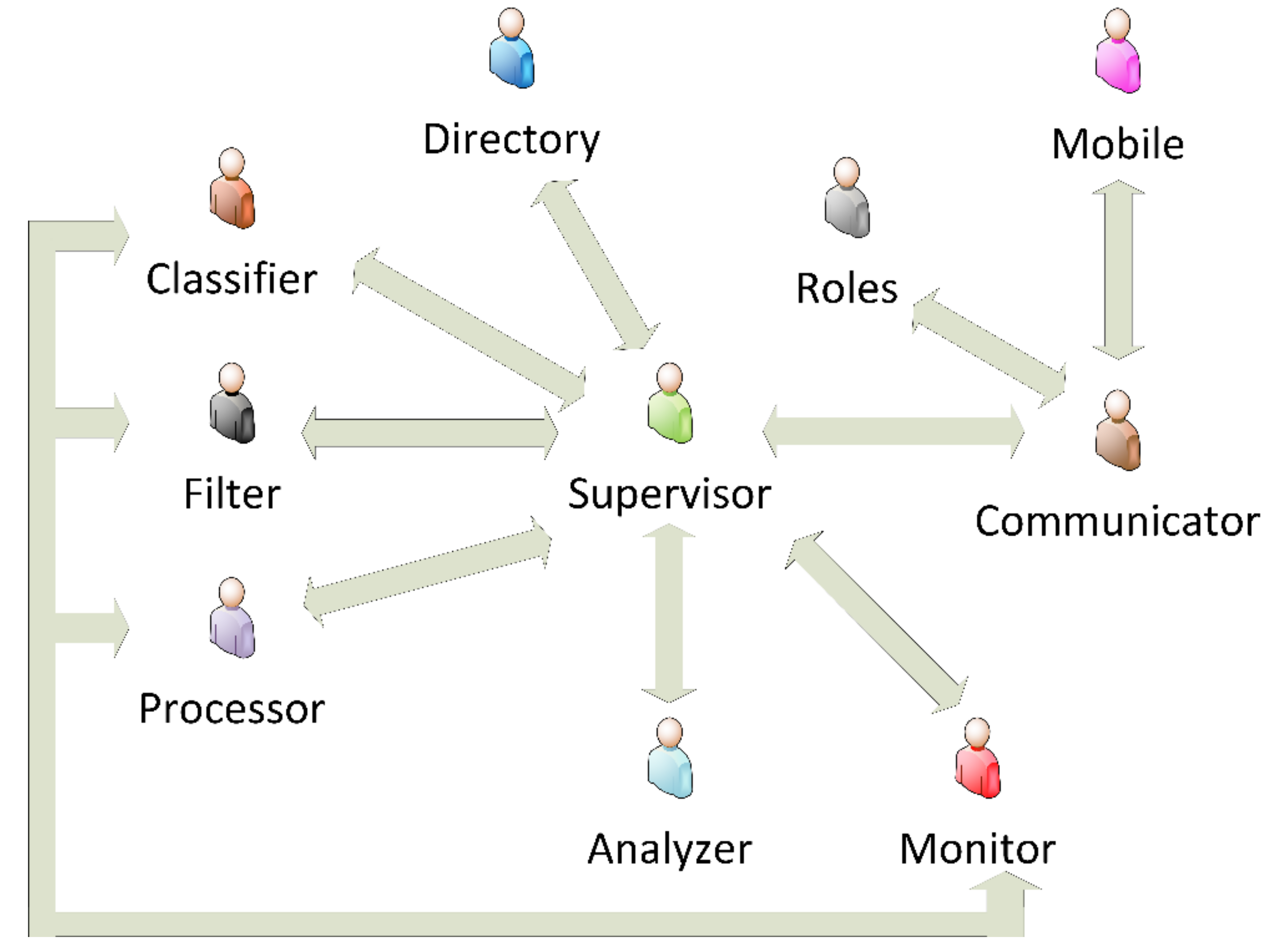
Figure 2 illustrates the interaction diagram for the agents in the architecture. The communications pass through the supervisor, and that is the reason why the analyser communicates with this agent to send data to the rest of the agents in the architecture.
Next,
Section 4 focuses on the coin recognition process.
Section 4 describes the process of recognising coins and the techniques used in each step of the process. Additionally, the relationship between the roles of a virtual organisation and the employed techniques is also established.
4. Coins Recognition Process
In this paper, we present a new recognition technique that can also be used in mobile devices. The proposed recognition process is composed of six stages and is implemented employing a multiagent system, as shown in
Figure 3.
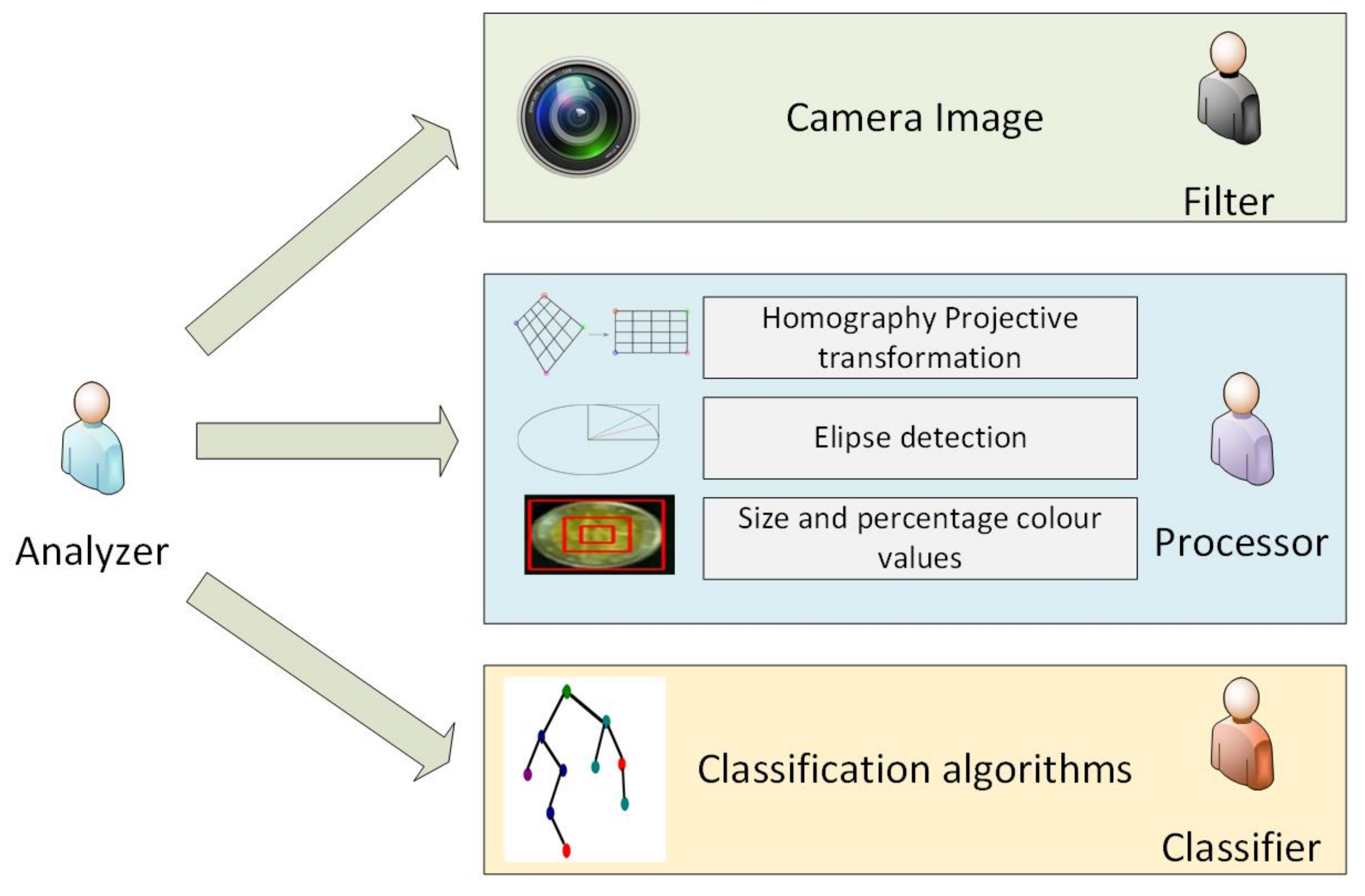
As can be seen in
Figure 3, the proposed multi-agent system is composed of four agents: Filter agent, which eliminates noise from the image; Processor agent, which processes the image once the noise has been removed and Classifier agent, which implements classification algorithms to identify coins and Analyzer agent, that supervises the whole process. In the following paragraphs, we present the relevant aspects of each of the agents that participate in the coin recognition process.
4.1. Camera Image
The image taken with the mobile device must accomplish a series of requirements to have a valid recognition process:
- 1.
There must not be another rectangle in the image taken by the camera.
- 2.
The coins must be placed inside of reference cardboard bounds; in other words, all the edges of the reference object must be visible to the camera. It is not possible to detect the size coins accurately if we do not detect the size of the reference object.
- 3.
The separation between coins has to be at least 1 mm.
- 4.
The angle for the photo has to be less than 45° from the coins’ cardboard.
- 5.
There should be a significant contrast in colour between the cardboard and the place on which the coins are placed to facilitate edge detection.
4.2. Cardboard Detection
In order to determine what type of coin appears in an image, it is necessary to know its size and colour. This work is based on the use of a smartphone, where the location of the camera is not fixed, and its position varies depending on the movement of the user. The movements that can be made with the smartphone during recognition make the distance between the camera and the coins will be variable. Depending on the distance of the coins to the camera, their sizes are different due to perspective of the image taken. Also, if the camera is not perpendicularly located on the objects to be recognised, a shadow is cast on each coin making detection difficult or making the coin size larger than the actual size. Therefore, if the position of the camera is unknown, a perspective effect is produced and knowing precisely the size of the coins becomes a complex task. It is of vital importance to add in the field of camera vision, a reference object with known dimensions. In our case study, and at the request of users, we have opted for the use of black cardboard that must always be visible during the recognition process. In order to obtain a relative scale of the dimension of the elements appearing in the image, the distances between the four vertices of our reference object are determined, and a scale is obtained. Next, we explain the steps followed for detecting our reference object: (1) Detect borders; (1a) Resize the image to a fixed size; (1b) Convert the input image and detect the edges using Canny Edge detection algorithm. Once all the edges in the image have been extracted, it is necessary to obtain the largest contour by obtaining the four points of the quadrilateral. In order to do this, the following process has been carried out: (2) Obtain the vertices of our reference object; (2a) Obtain the contours of the image; (2b) From each one of the contours determine its area, ordering them and obtaining the widest; (2c) Generate the convex hull of the contour using approxPolyDP function in order to obtain the polygon of minimum area containing a set of points; and finally (2d) Determine the 4 points of the quadrilateral. Next, Algorithm 1 shows the algorithm used in this phase.
| Algorithm 1. Pseudocode of cardboard detection algorithm. | |
Input: Image matrix: matrix
Output: Polygon corresponding to cardboard reference | |
| 1. // 1) Detect borders | |
| 2. grayScaleMatrix ← GrayScale(matrix) | 1a) |
| 3. resizedMatrix ← Resize(grayScaleMatrix) | |
| 4. blurMatrix ← BlurFilter(resizedMatrix) | |
| 5. blurMatrix ← BlurFilter(resizedMatrix) | |
| 6. thr1Histeresis ← 30 | |
| 7. thr2Histeresis ← 100 | |
| 8. edgesMatrix ← Canny(blurMatrix, thr1Histeresis, thr2Histeresis) | 1b) |
| 9. // 2) Obtain vertices of cardboard | |
| 10. retreivalMode ← RETR_EXTERNAL | |
| 11. method ← CHAIN_APPROX_NONE | |
| 12. contours ← findContours(edgesMatrix, retreivalMode, method) | 2a) |
| 13. for each contour in contours do | 2b) |
| 14. area ← calculateArea(contour) | |
| 15. areasCountourCollection.insert(<contour,area>) | |
| 16. end for | |
| 17. hull ← convexHull(widestAreaContour) | 2c) |
| 18. epsilonAccuracy ← 20 | |
| 19. polygon ← approxPolyDP(hull,epsilonAccuracy) | 2d) |
| 20. if isQuadrilateral(polygon) then | |
| 21. return polygon | |
| 22. else | |
| 23. return cardboardNotFound | |
| 24. end if | |
Figure 4 shows a real image of the result after the application of the algorithm used. As it can be seen in the image, the four vertices of the reference object that has been used to correct the effect of the perspective of the image have been correctly obtained.
4.3. Homography
The main objective of this stage is dealing with the aspect of freedom for the camera position. The existing methods usually limit camera position to a plane parallel to the coins.
Therefore, this is a significant stage in the proposed process since it permits the recognition of coins to occur in images taken from different angles, thus allowing easier recognition from mobile devices.
The image processing technique used in this step is based on a mathematical concept known as homography [
41,
42].
In geometry, a homography is a projective transformation that determines a correspondence between two geometric plane figures, so that each of the points and the lines of one of them will correspond, respectively, to a point and a line on the other, see
Figure 5. Homography can be used to rectify images under two assumptions: (a) when the terrain is flat, (b) when the plane to which it is projected is parallel to the surface.
Each pixel in an image is a 2D point that can be represented as a pair of values:
Additionally, points can be converted from
n-dim vectors to an
n + 1-dim space. In the case of an image pixel (or coordinate), it can be done by:
Homographies are given by a homogeneous and arbitrary 3 × 3
H matrix that transforms the points from one plane to another:
The resulting homogeneous coordinate
must be normalized to get an inhomogeneous result:
At the formal level, homographic expression can be defined as follows:
where:
A is the camera calibration matrix,
t is the position of the second view of the scene taken in the reference system of the first.
n is a normal vector to the scene plane in the reference system of the first view.
w is the inverse of the distance from the first view to the point of the scene
R is the rotation matrix.
As this transformation is not always enough to correct the deformation, in subsequent stages, we will apply contour detection techniques to the image, so that it is possible to identify whether the circles are really contained in the cardboard.
4.4. Ellipse Detection
Depending on the position and the perspective of the camera, it is possible to observe a deformation effect that causes a distortion when the circle detection algorithms are applied since the coins will present an elliptic form. To solve this problem, this paper proposes a new algorithm to detect ellipses. The algorithm is based on the detection of contours in the region of interest (ROI), and limited by the reference black cardboard. Once the contours have been detected, it is necessary to check whether the area enclosed by each of the contours approximates an ellipse (). If the difference between the area defined by the contour is very different at the ellipse area, it is discarded because it is not a coin.
4.5. Variables (Size, Percentage Colour Values)
The variables that can be extracted from a coin to determine its value are the diameter and the colour. The way to determine the diameter of a coin involves obtaining the width of the rectangle that the coin occupies in the image.
To get the colour of the coin, it is necessary to find the predominant colour of the region bound by the red rectangles that can be seen in
Figure 6.
The samples examined belong to the inner and outer regions bound by rectangles. From these samples, it is possible to obtain the colour percentages in the coin for further analysis.
4.6. Classification
The classification process is carried out using the variables obtained in the previous stage. The classification process is based on decision trees. There are several types of decision trees: LMT (logistic model trees) [
43], CLS (concept learning system) [
44], CART (classification and regression trees) [
45], REPTree [
46], ASSISTANT [
47], J48 [
48], etc. We have decided to use a decision tree for the classification process because it is possible to easily extract knowledge from the rules provided by the tree once the training is finished. This fact enables the algorithm to be efficiently run in a mobile device, avoiding the use of complex algorithms.
The proposed decision tree is J48 algorithm that facilitates the generation of a decision tree from weighted searches. The node selection is carried out using the gain according to the information
in a node
.
where
number of elements in class
in
and
the total number of elements.
The concept of gain and other concerns are introduced to avoid favouring variables with many values and branches with few elements.
5. Case Study
The case study focuses on the euro coins. The distinguishing characteristics of the euro coins are primarily material and size. The euro coins have three different types of materials which provide different colours for the coins. The coin size varies so that coins of the same material have a very different size, while coins of a different material may have a similar size. The size that some coins can reach vary by as little as 1 mm. Therefore, to only perform a classification based on this measurement is impossible in practice. Also, the euro coins have other aspects that greatly complicate processing. In euro coins, the reverse side is the same for all countries, but the obverse side varies for each of the countries, which in turn can result in the same coin with a different design. Based on the specific features on the faces used in the design, we decided to discard the use of the images displayed on either side for sorting the coins. In any case, even if both sides were the same for all countries, it would be challenging to distinguish the coins since the perspective and reflections of the camera would sometimes make it impossible to do so with the naked eye.
The characteristics of the euro coins are shown in
Table 1.
The system was designed and tested in collaboration with visually impaired residents of the city of Salamanca, Spain. Special attention was focused on recognising the coins, as well as the usability of the system by a visually impaired individual from a mobile device, adding accessibility content to the mobile application.
A multiagent system based on virtual organisations was implemented according to the design described in
Section 3 of this article. In this study, we focus on evaluating the coin recognition process and not the capacities of the social machine. These capacities and social aspects will be evaluated in future works. Special attention was placed on mobile and classifier agents. The image recognition hardware used was the Logitech HD webcam C-525; the used mobile devices were Nexus 4 and Samsung Galaxy SIII. The webcam was used to recover the images and to collect training data samples, as it was faster to gather the data.
6. Results and Conclusions
The system was tested using the case study, and three visually impaired people participated in the experiments. An intelligent environment was implemented based on the PANGEA multiagent architecture, incorporating the new roles, and three mobile agents were instantiated. The system was tested throughout 3 months, from April 2018 to June 2018, and the results obtained are promising.
To obtain an analysis of the system performance, the system was trained with the different types of coins. To complete the training process, we filled the cardboard with the same coin type and proceeded to measure the dimensions of each coin, moving the base. An example can be seen in
Figure 7 where it is possible to observe the image after performing the homography for the 20 cent coins.
The total number of measurements was 406,429 for different coins distributed as shown in
Table 2.
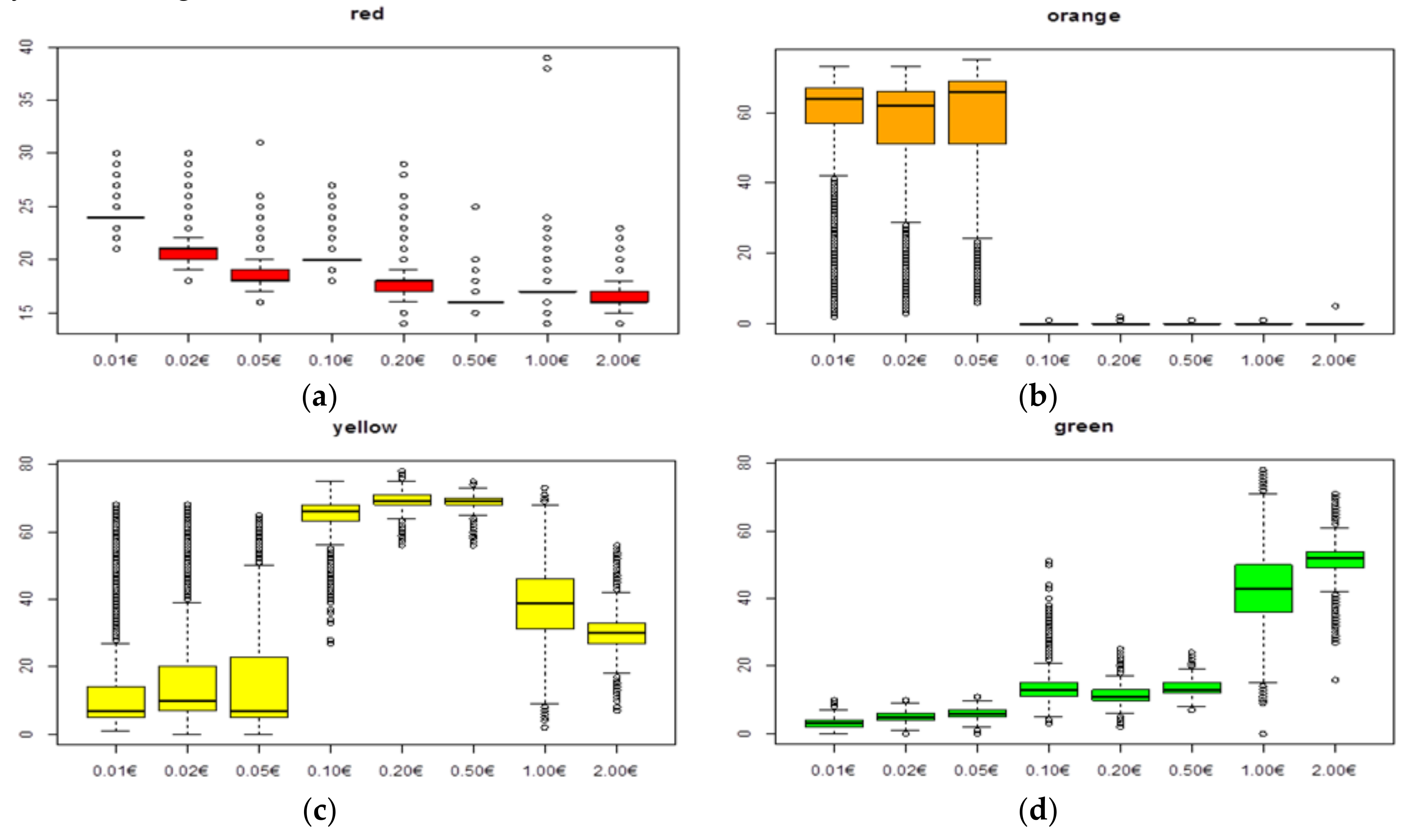
The diameter and the level of red, orange, yellow and green colours are calculated for each of the coins. The colour values were selected according to the characteristics of the euro coin and were used as the input for the classifier (previously presented in
Section 2). The output that the classifier provides is the type of coin.
The different tests were performed in a single room with 40 square meters. The lights are four units of 18W fluorescent tubes. We measured the different illuminance values during the collect data test. The values obtained varied between 520 lx and 1300 lx (obtained by the mobile ambient light sensor), in an indoor artificial light environment.
The measures obtained for the coins can change according to the perspective and the lighting of the scenario taken into account. Consequently, and in an attempt to provide the system with a wide range of action, different measures were obtained with different ambient light and different position over the surface of the detection rectangle.
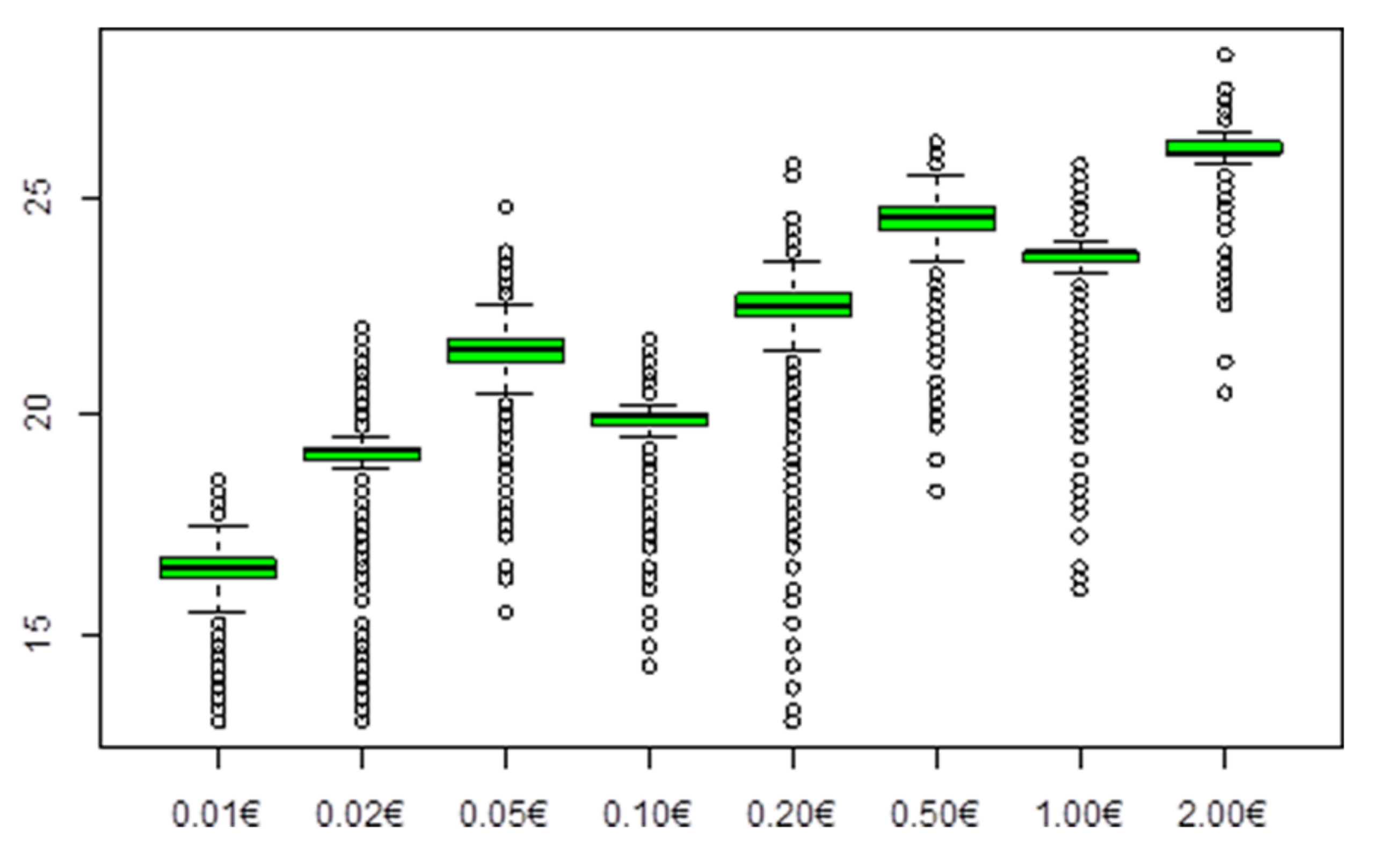
Figure 8 shows the variation of the diameters in a box plot for each coin denomination. As shown, the obtained values are mixed among the coins, which means that the diameter cannot be considered alone to classify the coins.
Figure 9a–d show the variation of the level of colours in red, orange, yellow and green.
We performed another experiment focused on analysing the performance of different classifiers for the classifier agent. For this purpose, a comparison was carried out using different classifiers. The obtained results are shown in
Table 3 using 10-fold cross-validation [
49].
The mobile application provides a list of the recognitions and detailed view of the measurements taken. This information is also provided through an audio message for those whose visual impairment is extreme. The individuals who participated in the experiment highlighted the accessibility features that the application provides, as well as its practical use.
Figure 10 shows two screenshots of the mobile application.
The proposed system in this paper is based on social computing and uses images to obtain the necessary information for classifying coins with enough precision to be used by impaired people in their daily life. The system is designed from the perspective of a social machine, which implies a new way to provide solutions to social problems related to money. The system incorporates agents specialised in image processing using mobile devices and classification tasks. Another characteristic presented in the paper is the use of homography, which allows the images to be transformed in order to obtain the coin measurements with a low error. The image transformation based on homography facilitates the process of calculating the diameter of the coins and the edge detection because the system only needs to focus on detecting circles in the image. The system was initially designed and tuned to be used with euro coins, but it can be used with other kinds of coins, with a previous study of the types of coins, keeping the used variables in the classifier or modifying them according to the characteristics of the coins.
The system was initially developed in OpenCV using C++, and it would be necessary to adapt the code to the platform languages of the different mobile devices. Once we developed the classification algorithm, which allows us to know the denomination of the coin in a given image, we implemented a prototype for people with visual impairment. The main function obtained is the ability to count money automatically using a mobile telephone, which saves a significant amount of time over counting the money by hand and sense of touch. The visually impaired users who participated in the experiment remarked on the usefulness and usability of the developed system.
Our future work will focus on the extension and evaluation of the proposed system. On the one hand, we will evaluate the use of recent techniques based on deep learning which require images with a high resolution in order to extract patterns from the coins images, this could be challenging in conditions where the image is distorted.
On the other we need to research in how to avoid use a physical reference such as the carboard which is the main drawback highlighted in the experimental part. In addition, we want to move the classification agent to the mobile device in order to classify in real time every valid frame obtained by the camera, this would enable us to perform an evaluation taking into account a large number of photographs for the same recognition, decreasing the classification error. As a final future work, we want to publish the application in order to obtain more training data in a collaborative way, including a mechanism to fix misclassified samples during the recognition in order to obtain better classification results.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







