Medical Image Segmentation with Adjustable Computational Complexity Using Data Density Functionals




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Featured Application
Abstract
1. Introduction
2. Theoretical Framework of Data Density Functionals
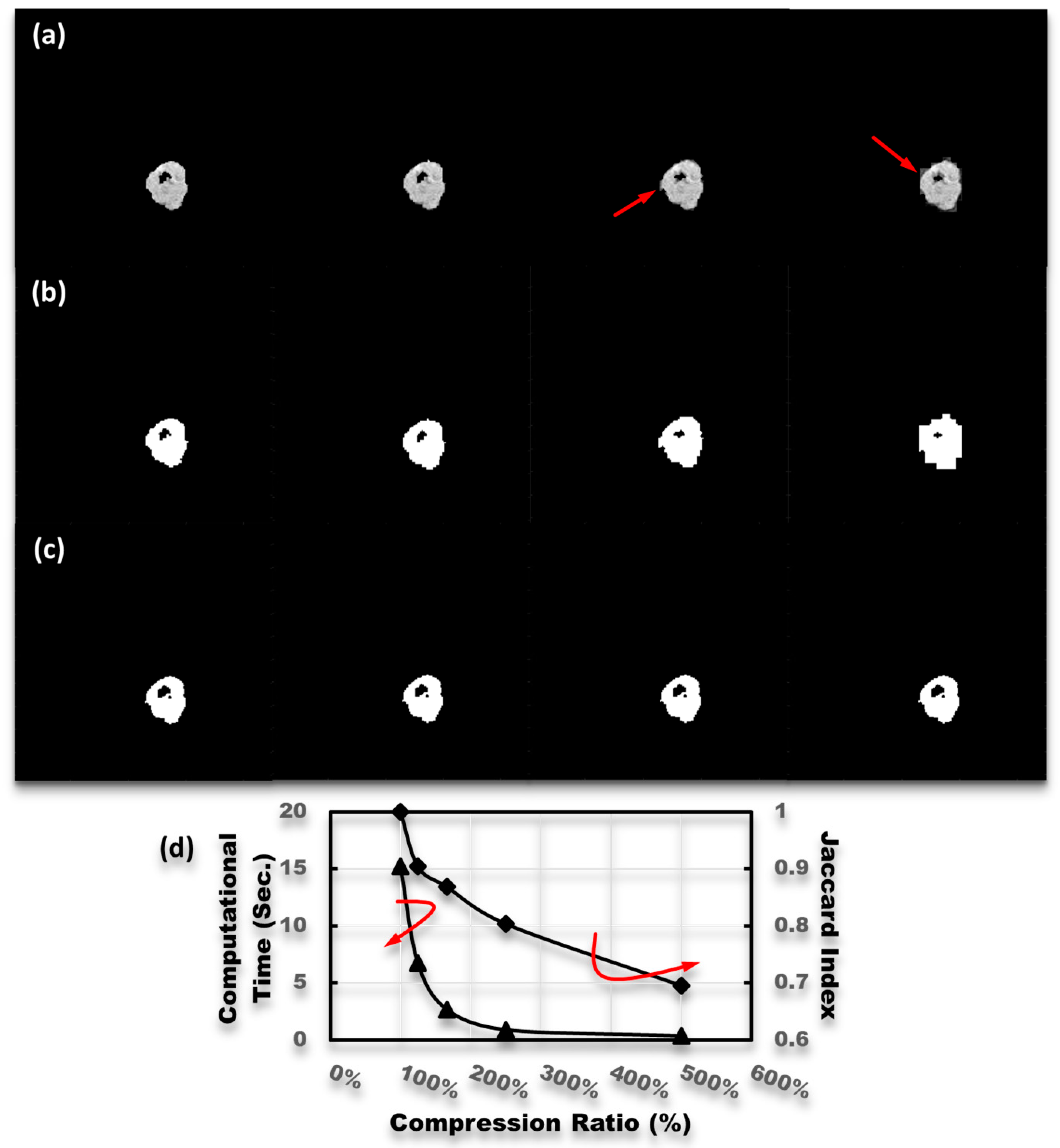
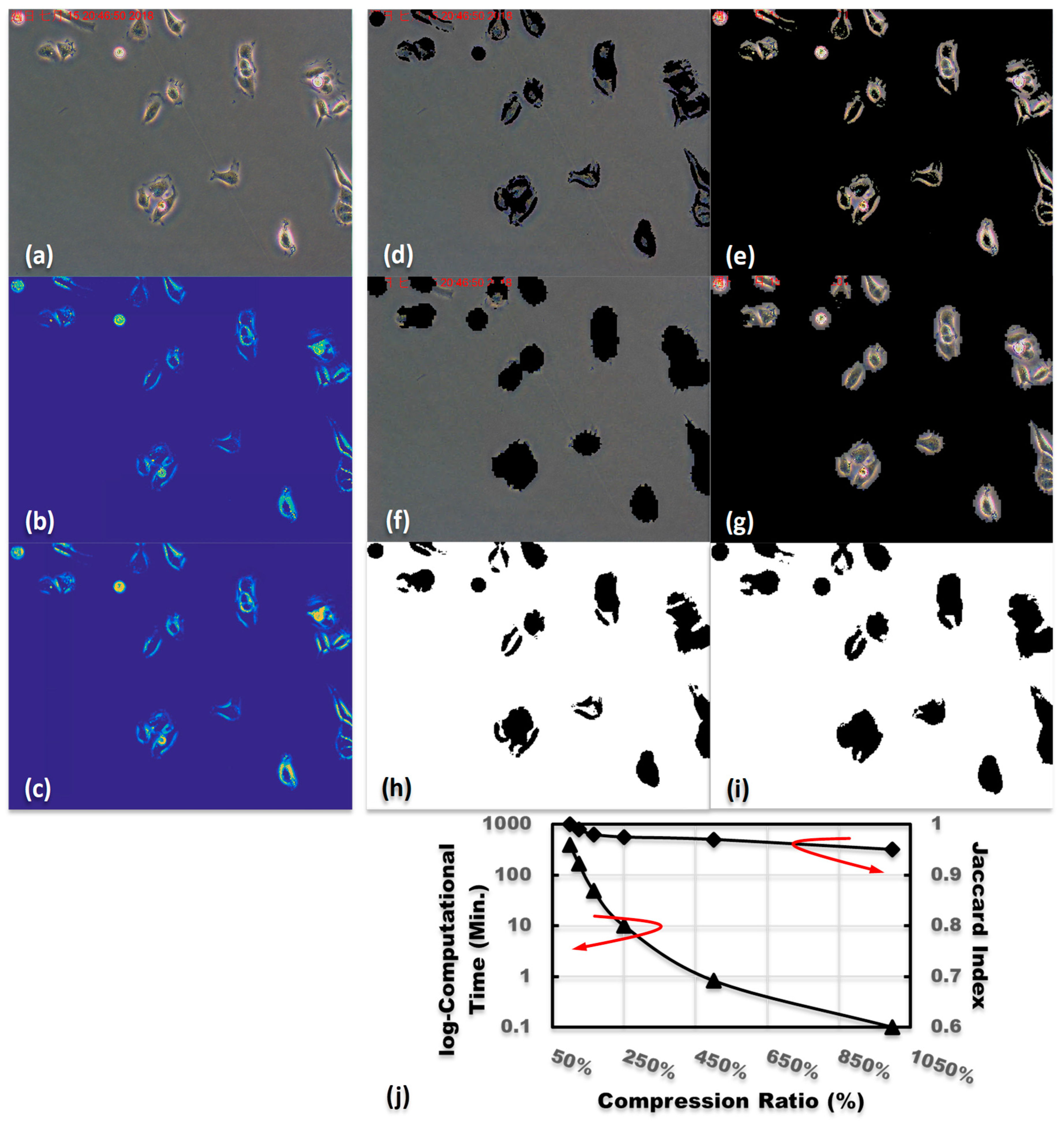
3. Segmentation Results of Brain MRIs and Cell Culturing Images
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Senft, C.; Bink, A.; Franz, K.; Vatter, H.; Gasser, T.; Seifert, V. Intraoperative MRI guidance and extent of resection in glioma surgery: A randomised, controlled trial. Oncology 2011, 12, 997–1003. [Google Scholar] [CrossRef]
- Bullock, P.; Dunaway, D.; McGurk, L.; Richards, R. Integration of image guidance and rapid prototyping technology in craniofacial surgery. Int. J. Oral Maxillofac. Surg. 2013, 42, 970–973. [Google Scholar] [CrossRef] [PubMed]
- Kenngott, H.G.; Wagner, M.; Gondan, M.; Nickel, F.; Nolden, M.; Fetzer, A.; Weitz, J.; Fischer, L.; Speidel, S.; Meinzer, H.-P.; et al. Real-time image guidance in laparoscopic liver surgery: First clinical experience with a guidance system based on intraoperative CT imaging. Surg. Endosc. 2014, 28, 933–940. [Google Scholar] [CrossRef] [PubMed]
- Nowitzke, A.; Wood, M.; Cooney, K. Improving accuracy and reducing errors in spinal surgery—A new technique for thoracolumbar-level localization using computer-assisted image guidance. Spine J. 2008, 8, 597–604. [Google Scholar] [CrossRef] [PubMed]
- Smistad, E.; Falch, T.L.; Bozorgi, M.; Elster, A.C.; Lindseth, F. Medical image segmentation on GPUs—A comprehensive review. Med. Image Anal. 2015, 20, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Liu, A.-A.; Chen, M.; Tasdizen, T.; Su, H. Special Issue on Biomedical Big Data: Understanding, Learning and Applications. IEEE Trans. Big Data 2017, 3, 375–377. [Google Scholar] [CrossRef]
- Hsieh, J.; Nett, B.; Yu, Z.; Sauer, K.; Thibault, J.-B.; Bouman, C.A. Recent Advances in CT Image Reconstruction. Curr. Radiol. Rep. 2013, 1, 39–51. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Duchin, Y.; Shamir, R.R.; Patriat, R.; Vitek, J.; Harel, N.; Sapiro, G. Automatic localization of the subthmlamic nucleus on patient-specific clinical by incorporating 7 T MRI and machine learning: Application in deep brain stimulation. Hum. Brain Mapp. 2018, 40, 679–698. [Google Scholar] [CrossRef]
- Bauer, S.; Wiest, R.; Nolte, L.P.; Reyes, M. A survey of MRI-based medical image analysis for brain tumor studies. Phys. Med. Biol. 2013, 58, R97–R129. [Google Scholar] [CrossRef] [PubMed]
- Norouzi, A.; Rahim, M.S.M.; Altameem, A.; Saba, T.; Rad, A.E.; Rehman, A.; Uddin, M. Medical Image Segmentation Methods, Algorithms, and Applications. IETE Tech. Rev. 2014, 31, 199–213. [Google Scholar] [CrossRef]
- Huang, S.-J.; Wu, C.-J.; Chen, C.-C. Pattern Recognition of Human Postures Using Data Density Functional Method. Appl. Sci. 2018, 8, 1615. [Google Scholar] [CrossRef]
- Wu, C.-J.; Huang, S.-J.; Chen, C.-C. Method on Pattern Recognition of Various Limb Postures. J. Biomed. Syst. Emerg. Technol. 2018, 5, 118. [Google Scholar]
- Přibil, J.; Přibilová, A.; Frollo, I. Two Methods of Automatic Evaluation of Speech Signal Enhancement Recorded in the Open-Air MRI Environment. Meas. Sci. Rev. 2017, 17, 257–263. [Google Scholar] [CrossRef] [Green Version]
- Glasser, M.F.; Smith, S.M.; Marcus, D.S.; Andersson, J.L.; Auerbach, E.J.; Behrens, T.E.; Coalson, T.S.; Harms, M.P.; Jenkinson, M.; Moeller, S.; et al. The Human Connectome Project’s neuroimaging approach. Nat. Neurosci. 2016, 19, 1175–1187. [Google Scholar] [CrossRef]
- Bas, E.; Erdogmus, D.; Draft, R.W.; Lichtman, J.W. Local tracing of curvilinear structures in volumetric color images: Application to the Brainbow analysis. J. Vis. Commun. Image R 2012, 23, 1260–1271. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, S.; Yang, K.; Luo, J.; Zhu, Y.M.; Liang, D. Highly Undersampled Magnetic Resonance Image Reconstruction Using Two-Level Bregman Method with Dictionary Updating. IEEE Trans. Med. Imaging 2013, 32, 1290–1301. [Google Scholar] [CrossRef] [PubMed]
- Qu, X.; Hou, Y.; Lam, F.; Guo, D.; Zhong, J.; Chen, Z. Magnetic resonance image reconstruction from undersampled measurements using a patch-based nonlocal operator. Med. Image Anal. 2014, 18, 843–856. [Google Scholar] [CrossRef]
- Trémoulhéac, B.; Dikaios, N.; Atkinson, D.; Arridge, S.R. Dynamic MR Image Reconstruction-Separation From Undersampled (k,t)-Space via Low-Rank Plus Sparse Prior. IEEE Trans. Med. Imaging 2014, 33, 1689–1701. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, Y.; Liu, G.; Phillips, P.; Yuan, T.F. Detection of Alzheimer’s Disease by Three-Dimensional Displacement Field Estimation in Structural Magnetic Resonance Imaging. J. Alzheimers Dis. 2016, 50, 233–248. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Phillips, P.; Yang, J.; Yuan, T.F. Three-Dimensional Eigenbrain for the Detection of Subjects and Brain Regions Related with Alzheimer’s Disease. J. Alzheimers Dis. 2016, 50, 1163–1179. [Google Scholar] [CrossRef]
- Dormont, D.; Seidenwurm, D.; Galanaud, D.; Cornu, P.; Yelnik, J.; Bardinet, E. Neuroimaging and deep brain stimulation. AJNR Am. J. Neuroradiol. 2010, 31, 15–23. [Google Scholar] [CrossRef]
- Volkmann, J. Update on surgery for Parkinson’s disease. Curr. Opin. Neurol. 2007, 20, 465–469. [Google Scholar] [CrossRef]
- Abosch, A.; Yacoub, E.; Ugurbil, K.; Harel, N. An assessment of current brain targets for deep brain stimulation surgery with susceptibility-weighted imaging as 7 tesla. Neurosurgery. 2010, 67, 1745–1756. [Google Scholar] [CrossRef]
- Lefranc, M.; Derrey, S.; Merle, P.; Tir, M.; Constans, J.M.; Montpellier, D.; Macron, J.M.; Le Gars, D.; Peltier, J.; Baledentt, O.; et al. High-Resolution 3-Dimensional T2*-Weighted Angiography (HR 3-D SWAN): An Optimized 3-T Magnetic Resonance Imaging Sequence for Targeting the Subthalamic Nucleus. Neurosurgery 2014, 74, 615–626. [Google Scholar] [CrossRef]
- Zonenshayn, M.; Rezai, A.R.; Mogilner, A.Y.; Beric, A.; Sterio, D.; Kelly, P.J. Comparison of Anatomic and Neurophysiological Methods for Subthalamic Nucleus Targeting. Neurosurgery 2000, 47, 282–292. [Google Scholar] [CrossRef]
- Vertinsky, A.T.; Coenen, V.A.; Lang, D.J.; Kolind, S.; Honey, C.R.; Li, D.; Rauscher, A. “Localization of the Subthalamic Nucleus: Optimization with Susceptibility-Weighted Phase MR Imaging. AJNR Am. J. Neuroradiol. 2009, 30, 1717–1724. [Google Scholar] [CrossRef]
- Schäfer, A.; Forstmann, B.U.; Neumann, J.; Wharton, S.; Mietke, A.; Bowtell, R.; Turner, R. “Direct visualization of the subthalamic nucleus and its iron distribution using high-resolution susceptibility mapping. Hum. Brain Mapp. 2012, 33, 2831–2842. [Google Scholar] [CrossRef]
- Manova, E.S.; Habib, C.A.; Boikov, A.S.; Ayaz, M.; Khan, A.; Kirsch, W.M.; Kido, D.K.; Haacke, E.M. Characterizing the Mesencephalon Using Susceptibility-Weighted Imaging. AJNR Am. J. Neuroradiol. 2009, 30, 569–574. [Google Scholar] [CrossRef]
- Bastos Leite, A.J.; van Straaten, E.C.; Scheltens, P.; Lycklama, G.; Barkhof, F. Thalamic Lesions in Vascular Dementia: Low Sensitivity of Fluid-Attenuated Inversion Recovery (FLAIR) Imaging. Stroke 2004, 35, 415–419. [Google Scholar] [CrossRef]
- Olindo, S.; Chausson, N.; Joux, J.; Saint-Vil, M.; Signate, A.; Edimonana-Kapute, M.; Jeannine, S.; Mejdoubi, M.; Aveillan, M.; Cabre, P.; et al. Fluid-Attenuated Inversion Recovery Vascular Hyperintensity: An Early Predictor of Clinical Outcome in Proximal Middle Cerebral Artery Occlusion. Arch. Neurol. 2012, 69, 1462–1468. [Google Scholar] [CrossRef]
- Essig, M.; Knopp, M.V.; Schoenberg, S.O.; Hawighorst, H.; Wenz, F.; Debus, J.; van Kaick, G. Cerebral Gliomas and Metastases: Assessment with Contrast-enhanced Fast Fluid-attenuated Inversion-Recovery MR Imaging. Radiology 1999, 210, 551–557. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.-C.; Juan, H.-H.; Tsai, M.-Y.; Lu, H.H.-S. Unsupervised Learning and Pattern Recognition of Biological Data Structures with Density Functional Theory and Machine Learning. Sci. Rep. 2018, 8, 557. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taubman, D. High Performance Scalable Image Compression with EBCOT. IEEE Trans. Image Process. 2000, 9, 1158–1170. [Google Scholar] [CrossRef] [PubMed]
- Shapiro, J.M. An embedded hierarchical image coder using zerotrees of wavelet coefficients. In Proceedings of the IEEE Data Compression Conference, Snowbird, UT, USA, 30 March–2 April 1993; pp. 214–223. [Google Scholar]
- Said, A.; Pearlman, W. A new, fast and efficient image codec based on set partitioning in hierarchical trees. IEEE Trans. Circuits Syst. Video Technol. 1996, 6, 243–250. [Google Scholar] [CrossRef]
- Taubman, D.; Zakhor, A. Multi-rate 3-D subband coding of video. IEEE Trans. Image Process. 1994, 3, 572–588. [Google Scholar] [CrossRef]
- Mallat, S.G. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Toderici, G.; Vincent, D.; Johnston, N.; Hwang, S.J.; Minnen, D.; Shor, J.; Covell, M. Full Resolution Image Compression with Recurrent Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, 21–26 July 2017. [Google Scholar]
- Toderici, G.; O’Malley, S.M.; Hwang, S.J.; Vincent, D.; Minnen, D.; Baluja, S.; Covell, M.; Sukthankar, R. Variable Rate Image Compression with Recurrent Neural Networks. arXiv 2016, arXiv:1511.06085. [Google Scholar]
- Theis, L.; Shi, W.; Cunningham, A.; Huszár, F. Lossy Image Compression with Compressive Autoencoders. arXiv 2017, arXiv:1703.00395v1. [Google Scholar]
- Kim, U.S.; Sunwoo, M.H. New Frame Rate Up-Conversion Algorithms with Low Computational Complexity. IEEE Trans. Circ. Syst. Vid. 2014, 24, 384–393. [Google Scholar] [CrossRef]
- Jiang, F.; Tao, W.; Liu, S.; Ren, J.; Guo, X.; Zhao, D. An End-to-End Compression Framework Based on Convolutional Neural Networks. IEEE Trans. Circ. Syst. Vid. 2018, 28, 3007–3018. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Chen, T.; Shen, Q.; Yue, T.; Ma, Z. Deep Image Compression via End-to-End Learning. arXiv 2018, arXiv:1806.01496v1. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. arXiv 2016, arXiv:1510.00149v5. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. arXiv 2017, arXiv:1707.01083v2. [Google Scholar]
- Han, S.; Liu, X.; Mao, H.; Pu, J.; Pedram, A.; Horowitz, M.A.; Dally, W.J. EIE: Efficient Inference Engine on Compressed Deep Neural Network. arXiv 2016, arXiv:1602.01528v2. [Google Scholar] [CrossRef]
- Pratondo, A.; Chui, C.-K.; Ong, S.-H. Robust Edge-Stop Functions for Edge-Based Active Contour Models in Medical Image Segmentation. IEEE Signal Proc. Lett. 2016, 23, 222–226. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Conventional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 4th International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Zhang, W.; Li, R.; Deng, H.; Wang, L.; Lin, W.; Ji, S.; Shen, D. Deep convolutional neural networks for multi-modality isointense infant brain image segmentation. Neuroimage 2015, 108, 214–224. [Google Scholar] [CrossRef]
- Hsu, Y.; Lu, H.H.-S. Brainbow image segmentation using Bayesian sequential partitioning. Int. J. Comput. Inf. Syst. Control Eng. 2013, 7, 891–896. [Google Scholar]
- Wu, T.-Y.; Juan, H.-H.; Lu, H.H.-S.; Chiang, A.-S. A crosstalk tolerated neural segmentation methodology for brainbow images. In Proceedings of the International Symposium on Applied Sciences in Biomedical and Communication Technologies (ACM ISABEL), Barcelona, Spain, 26–29 October 2011. [Google Scholar]
- Morar, A.; Moldoveanu, F.; Gröller, E. Image Segmentation Based on Active Contours without Edges. In Proceedings of the IEEE 8th International Conference on Intelligent Computer Communication and Processing, Cluj-Napoca, Romania, 30 August–1 September 2012. [Google Scholar]
- Kass, M.; Witkin, A.; Terzopoulos, D. Snakes: Active contour models. Int. J. Comput. Vision. 1988, 1, 321–331. [Google Scholar] [CrossRef] [Green Version]
- Arbeláez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour Detection and Hierarchical Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef] [Green Version]
- Mandal, D.; Chatterjee, A.; Maitra, M. Robust medical image segmentation using particle swarm optimization aided level set based global fitting energy active contour approach. Eng. Appl. Artif. Intell. 2014, 35, 199–214. [Google Scholar] [CrossRef]
- Wang, L.; Pan, C. Robust level set image segmentation via a local correntropy-based k-means clustering. Pattern Recognit. 2014, 47, 1917–1925. [Google Scholar] [CrossRef]
- Li, C.; Huang, R.; Ding, Z.; Gatenby, J.C.; Metaxas, D.N.; Gore, J.C. A Level Set Method for Image Segmentation in the Presence of Intensity Inhomogeneities with Application to MRI. IEEE Trans. Image Process. 2011, 20, 2007–2016. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Xu, C.; Gui, C.; Fox, M.D. Distance Regularization Level Set Evolution and Its Application to Image Segmentation. IEEE Trans. Image Process. 2010, 19, 3243–3254. [Google Scholar] [CrossRef] [PubMed]
- Rowlinson, J.S. The Yukawa potential. Phys. A Stat. Mech. Appl. 1989, 156, 15–34. [Google Scholar] [CrossRef]
- Moon, N.; Bullitt, E.; van Leemput, K.; Gerig, G. Automatic brain and tumor segmentation. In Proceedings of the 5th International Conference on Medical Image Computing and Computer-Assisted Intervention, Tokyo, Japan, 25–28 September 2002. [Google Scholar]
- Cai, H.; Yang, Z.; Cao, X.; Xia, W.; Xu, X. A New Iterative Triclass Thresholding Technique in Image Segmentation. IEEE Trans. Image Process. 2014, 23, 1038–1046. [Google Scholar] [CrossRef]





© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.-C.; Tsai, M.-Y.; Kao, M.-Z.; Lu, H.H.-S. Medical Image Segmentation with Adjustable Computational Complexity Using Data Density Functionals. Appl. Sci. 2019, 9, 1718. https://doi.org/10.3390/app9081718
Chen C-C, Tsai M-Y, Kao M-Z, Lu HH-S. Medical Image Segmentation with Adjustable Computational Complexity Using Data Density Functionals. Applied Sciences. 2019; 9(8):1718. https://doi.org/10.3390/app9081718
Chicago/Turabian StyleChen, Chien-Chang, Meng-Yuan Tsai, Ming-Ze Kao, and Henry Horng-Shing Lu. 2019. "Medical Image Segmentation with Adjustable Computational Complexity Using Data Density Functionals" Applied Sciences 9, no. 8: 1718. https://doi.org/10.3390/app9081718
APA StyleChen, C. -C., Tsai, M. -Y., Kao, M. -Z., & Lu, H. H. -S. (2019). Medical Image Segmentation with Adjustable Computational Complexity Using Data Density Functionals. Applied Sciences, 9(8), 1718. https://doi.org/10.3390/app9081718