
Perceived Anger in Clear and Conversational Speech: Contributions of Age and Hearing Loss


{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Emotion Recognition
1.2. Effect of Age on Emotion Recognition
1.3. Effect of Hearing Loss on Emotion Recognition
1.4. Previous Research
2. Materials and Methods
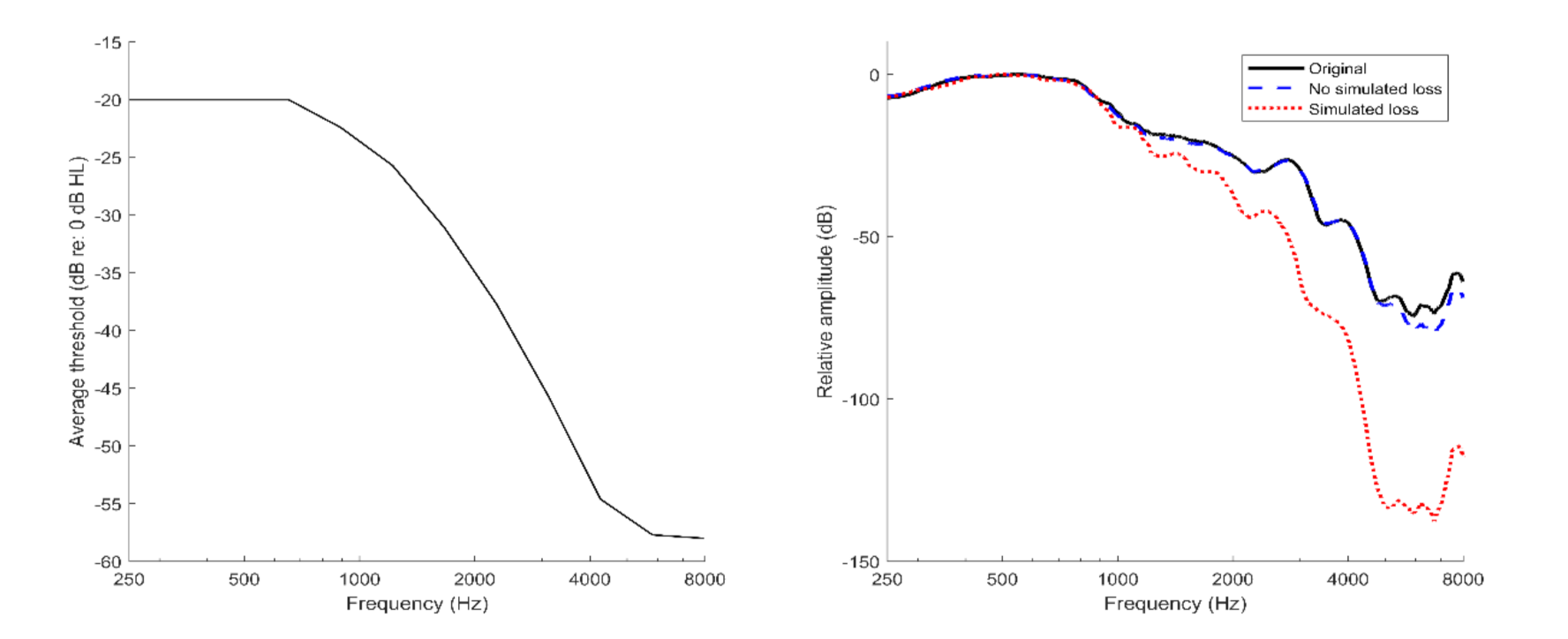
2.1. Experiment I: Young Adults with a Simulated Hearing Loss
2.1.1. Stimuli
2.1.2. Listeners
2.1.3. Procedures
2.1.4. Statistical Analysis
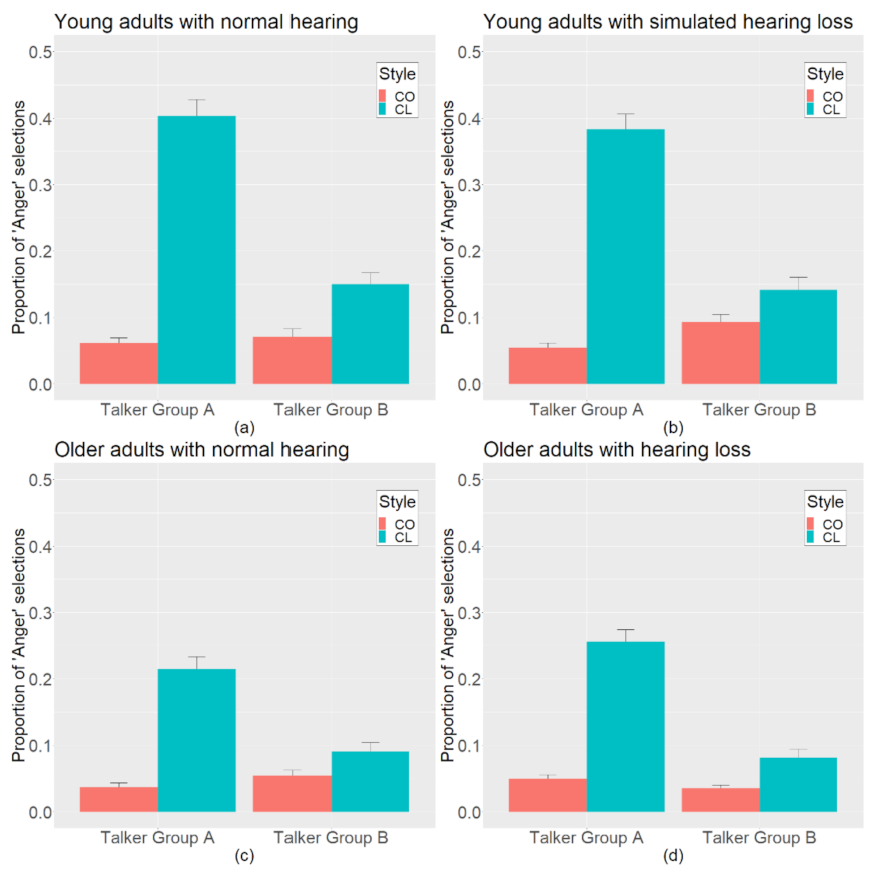
2.1.5. Results
2.2. Experiment II: Older Adults with Essentially Normal Hearing
2.2.1. Stimuli
2.2.2. Listeners
2.2.3. Procedures
2.2.4. Statistical Analysis
2.2.5. Results
3. General Discussion
Clinical Implications
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ferguson, S.H. Talker Differences in Clear and Conversational Speech: Vowel Intelligibility for Older Adults with Hearing Loss. J. Speech Lang. Hear. Res. 2012, 55, 779–790. [Google Scholar] [CrossRef] [Green Version]
- Rodman, C.; Moberly, A.C.; Janse, E.; Başkent, D.; Tamati, T.N. The impact of speaking style on speech recognition in quiet and multi-talker babble in adult cochlear implant users. J. Acoust. Soc. Am. 2020, 147, 101–107. [Google Scholar] [CrossRef]
- Smiljanić, R.; Bradlow, A.R. Speaking and Hearing Clearly: Talker and Listener Factors in Speaking Style Changes. Lang. Linguist. Compass 2009, 3, 236–264. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krause, J.C.; Braida, L.D. Evaluating the role of spectral and envelope characteristics in the intelligibility advantage of clear speech. J. Acoust. Soc. Am. 2009, 125, 3346–3357. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Picheny, M.A.; Durlach, N.I.; Braida, L.D. Speaking clearly for the hard of hearing II: Acoustic characteristics of clear and conversational speech. J. Speech Lang. Hear. Res. 1986, 29, 434–446. [Google Scholar] [CrossRef] [PubMed]
- Ferguson, S.H.; Morgana, S.D. Acoustic correlates of reported clear speech strategies. J. Acad. Rehabil. Audiol. 2010, 43, 45–64. [Google Scholar]
- Ferguson, S.H.; Kewley-Port, D. Talker Differences in Clear and Conversational Speech: Acoustic Characteristics of Vowels. J. Speech Lang. Hear. Res. 2007, 50, 1241–1255. [Google Scholar] [CrossRef]
- Whitfield, J.A.; Goberman, A.M. Articulatory-acoustic vowel space: Associations between acoustic and perceptual measures of clear speech. Int. J. Speech-Lang. Pathol. 2017, 19, 184–194. [Google Scholar] [CrossRef]
- Morgan, S.D.; Ferguson, S.H. Judgments of Emotion in Clear and Conversational Speech by Young Adults with Normal Hearing and Older Adults with Hearing Impairment. J. Speech Lang. Hear. Res. 2017, 60, 2271–2280. [Google Scholar] [CrossRef]
- Banse, R.; Scherer, K.R. Acoustic profiles in vocal emotion expression. J. Personal. Soc. Psychol. 1996, 70, 614–636. [Google Scholar] [CrossRef]
- Whiteside, S.P. Acoustic characteristics of vocal emotions simulated by actors. Percept. Mot. Ski. 1999, 89, 1195–1208. [Google Scholar] [CrossRef]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Russell, J.A. A Circumplex Model of Affect. J. Personal. Soc. Psychol. 1980, 39, 1161–1178. [Google Scholar] [CrossRef]
- Ekman, P.; Cordaro, D. What is Meant by Calling Emotions Basic. Emot. Rev. 2011, 3, 364–370. [Google Scholar] [CrossRef]
- Ruffman, T.; Halberstadt, J.; Murray, J. Recognition of Facial, Auditory, and Bodily Emotions in Older Adults. J. Gerontol. Ser. B Psychol. Sci. Soc. Sci. 2009, 64B, 696–703. [Google Scholar] [CrossRef]
- Ruffman, T.; Henry, J.; Livingstone, V.; Phillips, L.H. A meta-analytic review of emotion recognition and aging: Implications for neuropsychological models of aging. Neurosci. Biobehav. Rev. 2008, 32, 863–881. [Google Scholar] [CrossRef]
- Carstensen, L.L.; DeLiema, M. The positivity effect: A negativity bias in youth fades with age. Curr. Opin. Behav. Sci. 2018, 19, 7–12. [Google Scholar] [CrossRef] [PubMed]
- Carstensen, L.L.; Isaacowitz, D.M.; Charles, S.T. Taking time seriously: A theory of socioemotional selectivity. Am. Psychol. 1999, 54, 165. [Google Scholar] [CrossRef]
- Sander, D.; Grandjean, D.; Pourtois, G.; Schwartz, S.; Seghier, M.; Scherer, K.R.; Vuilleumier, P. Emotion and attention interactions in social cognition: Brain regions involved in processing anger prosody. NeuroImage 2005, 28, 848–858. [Google Scholar] [CrossRef]
- Amorim, M.; Anikin, A.; Mendes, A.J.; Lima, C.F.; Kotz, S.A.; Pinheiro, A.P. Changes in vocal emotion recognition across the life span. Emotion 2021, 21, 315–325. [Google Scholar] [CrossRef] [PubMed]
- Humes, L.E. The Contributions of Audibility and Cognitive Factors to the Benefit Provided by Amplified Speech to Older Adults. J. Am. Acad. Audiol. 2007, 18, 590–603. [Google Scholar] [CrossRef] [Green Version]
- Clinard, C.G.; Tremblay, K.L. Aging Degrades the Neural Encoding of Simple and Complex Sounds in the Human Brainstem. J. Am. Acad. Audiol. 2013, 24, 590–599. [Google Scholar] [CrossRef]
- Makary, C.A.; Shin, J.; Kujawa, S.G.; Liberman, M.C.; Merchant, S.N. Age-Related Primary Cochlear Neuronal Degeneration in Human Temporal Bones. J. Assoc. Res. Otolaryngol. 2011, 12, 711–717. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dupuis, K.; Pichora-Fuller, M.K. Aging Affects Identification of Vocal Emotions in Semantically Neutral Sentences. J. Speech Lang. Hear. Res. 2015, 58, 1061–1076. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, M.; Zion, D.J.; Deroche, M.L.; Burianek, B.A.; Limb, C.J.; Goren, A.P.; Kulkarni, A.M.; Christensen, J.A. Voice emotion recognition by cochlear-implanted children and their normally-hearing peers. Hear. Res. 2015, 322, 151–162. [Google Scholar] [CrossRef] [Green Version]
- Christensen, J.A.; Sis, J.; Kulkarni, A.M.; Chatterjee, M. Effects of Age and Hearing Loss on the Recognition of Emotions in Speech. Ear Hear. 2019, 40, 1069–1083. [Google Scholar] [CrossRef]
- Tinnemore, A.R.; Zion, D.J.; Kulkarni, A.M.; Chatterjee, M. Children’s Recognition of Emotional Prosody in Spectrally Degraded Speech Is Predicted by Their Age and Cognitive Status. Ear Hear. 2018, 39, 874–880. [Google Scholar] [CrossRef]
- Luo, X.; Fu, Q.-J.; Galvin, J.J. Cochlear Implants Special Issue Article: Vocal Emotion Recognition by Normal-Hearing Listeners and Cochlear Implant Users. Trends Amplif. 2007, 11, 301–315. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luo, X.; Kern, A.; Pulling, K.R. Vocal emotion recognition performance predicts the quality of life in adult cochlear implant users. J. Acoust. Soc. Am. 2018, 144, EL429–EL435. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferguson, S.H. Talker differences in clear and conversational speech: Vowel intelligibility for normal-hearing listeners. J. Acoust. Soc. Am. 2004, 116, 2365–2373. [Google Scholar] [CrossRef]
- Moore, B.C.J.; Glasberg, B.R. Simulation of the effects of loudness recruitment and threshold elevation on the intelligibility of speech in quiet and in a background of speech. J. Acoust. Soc. Am. 1993, 94, 2050–2062. [Google Scholar] [CrossRef]
- Auerbach, B.D.; Radziwon, K.; Salvi, R. Testing the Central Gain Model: Loudness Growth Correlates with Central Auditory Gain Enhancement in a Rodent Model of Hyperacusis. Neuroscience 2019, 407, 93–107. [Google Scholar] [CrossRef]
- Sardone, R.; Battista, P.; Panza, F.; Lozupone, M.; Griseta, C.; Castellana, F.; Capozzo, R.; Ruccia, M.; Resta, E.; Seripa, D.; et al. The Age-Related Central Auditory Processing Disorder: Silent Impairment of the Cognitive Ear. Front. Neurosci. 2019, 13, 619. [Google Scholar] [CrossRef] [PubMed]
- Uchanski, R.M. Clear speech. In The Handbook of Speech Perception; Pisoni, D.B., Remez, R.E., Eds.; Blackwell: Malden, MA, USA/Oxford, UK, 2005. [Google Scholar]
- Julayanont, P.; Nasreddine, Z.S. Montreal Cognitive Assessment (MoCA): Concept and clinical review. In Cognitive Screening Instruments; Springer: Berlin/Heidelberg, Germany, 2017; pp. 139–195. [Google Scholar]
- Matsumoto, D.; Ekman, P. The relationship among expressions, labels, and descriptions of contempt. J. Personal. Soc. Psychol. 2004, 87, 529–540. [Google Scholar] [CrossRef] [Green Version]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Brockhoff, P.B.; Christensen, R.H.B. lmerTest Package: Tests in linear mixed effects models. J. Stat. Softw. 2017, 82, 1–38. [Google Scholar] [CrossRef] [Green Version]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Satterthwaite, F.E. Synthesis of variance. Psychometrika 1941, 6, 309–316. [Google Scholar] [CrossRef]
- Luke, S.G. Evaluating significance in linear mixed-effects models in R. Behav. Res. Methods 2017, 49, 1494–1502. [Google Scholar] [CrossRef]
- Resnick, S.M.; Lamar, M.; Driscoll, I. Vulnerability of the Orbitofrontal Cortex to Age-Associated Structural and Functional Brain Changes. Ann. NY Acad. Sci. 2007, 1121, 562–575. [Google Scholar] [CrossRef] [PubMed]
- Phillips, L.H.; MacLean, R.; Allen, R. Age and the Understanding of Emotions: Neuropsychological and Sociocognitive Perspectives. J. Gerontol. Ser. B Psychol. Sci. Soc. Sci. 2002, 57, P526–P530. [Google Scholar] [CrossRef]
- Dougherty, L.M.; Abe, J.A.; Izard, C.E. Differential Emotions Theory and Emotional Development in Adulthood and Later Life. In Handbook of Emotion, Adult Development, and Aging; Elsevier: Amsterdam, The Netherlands, 1996; pp. 27–41. [Google Scholar]
- Hétu, R.; Jones, L.; Getty, L. The Impact of Acquired Hearing Impairment on Intimate Relationships: Implications for Rehabilitation. Int. J. Audiol. 1993, 32, 363–380. [Google Scholar] [CrossRef] [PubMed]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morgan, S.D.; Ferguson, S.H.; Crain, A.D.; Jennings, S.G. Perceived Anger in Clear and Conversational Speech: Contributions of Age and Hearing Loss. Brain Sci. 2022, 12, 210. https://doi.org/10.3390/brainsci12020210
Morgan SD, Ferguson SH, Crain AD, Jennings SG. Perceived Anger in Clear and Conversational Speech: Contributions of Age and Hearing Loss. Brain Sciences. 2022; 12(2):210. https://doi.org/10.3390/brainsci12020210
Chicago/Turabian StyleMorgan, Shae D., Sarah Hargus Ferguson, Ashton D. Crain, and Skyler G. Jennings. 2022. "Perceived Anger in Clear and Conversational Speech: Contributions of Age and Hearing Loss" Brain Sciences 12, no. 2: 210. https://doi.org/10.3390/brainsci12020210
APA StyleMorgan, S. D., Ferguson, S. H., Crain, A. D., & Jennings, S. G. (2022). Perceived Anger in Clear and Conversational Speech: Contributions of Age and Hearing Loss. Brain Sciences, 12(2), 210. https://doi.org/10.3390/brainsci12020210