
fMRI Brain Decoding and Its Applications in Brain–Computer Interface: A Survey



Abstract
:1. Introduction
2. Brain Decoding Based on Learning
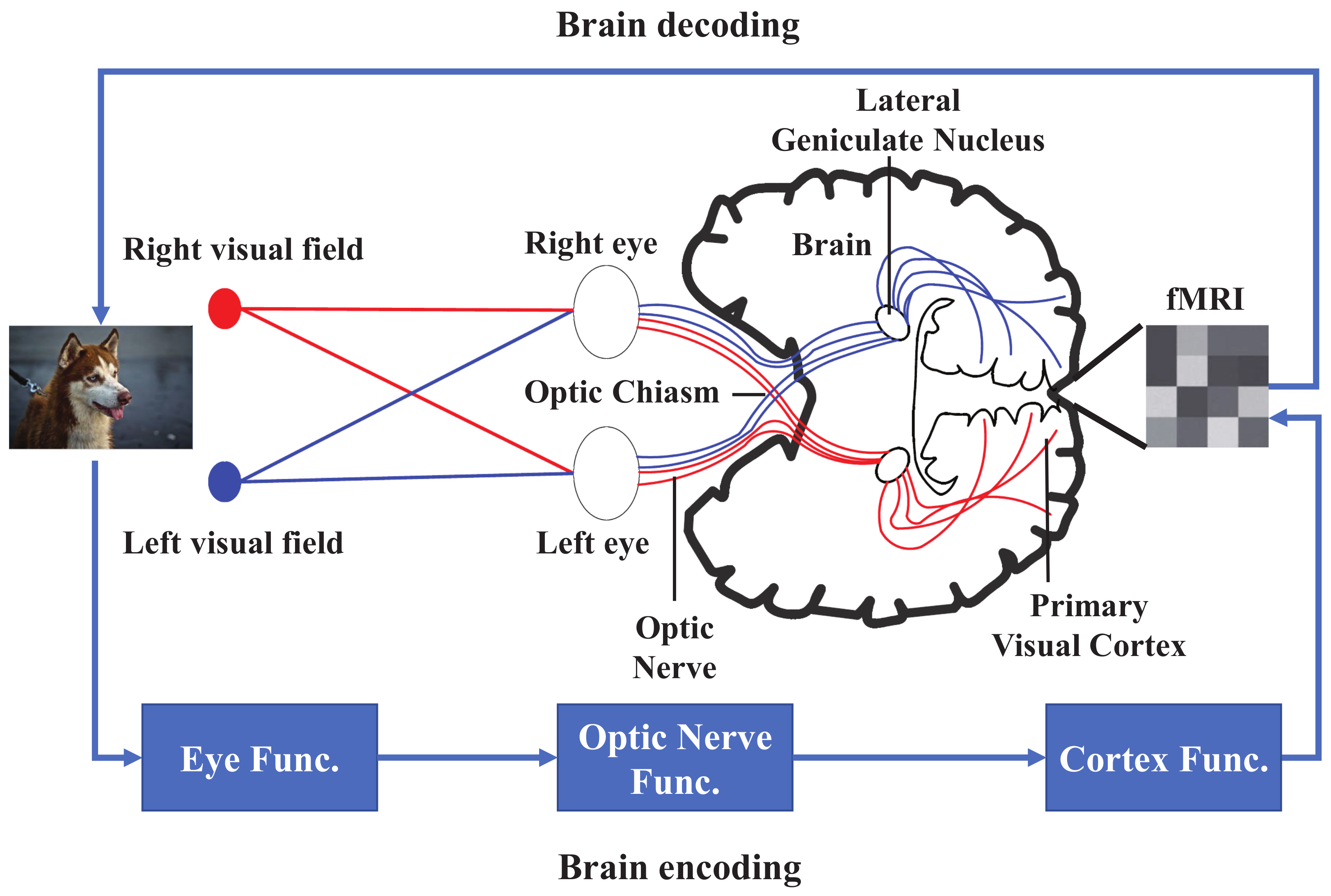
2.1. The Relationship between Brain Encoding and Decoding
2.2. Machine Learning and Deep Learning Preliminaries
2.2.1. Machine Learning
2.2.2. Deep Learning
3. Brain Decoding Based on Deep Learning
3.1. VAE-Based Brain Decoding
3.2. GAN-Based Brain Decoding
3.3. Graph Convolutional Neural Networks
4. fMRI-BCI Application to Psychopsychiatric Treatment
4.1. Stroke Rehabilitation
4.2. Chronic Pain Treatment
4.3. Emotional Disorders Treatment
4.4. Criminal Psychotherapy
5. Future Directions and Challenges
5.1. Mapping Model Capabilities
5.1.1. Multi-Analysis Mode and Deep Learning
5.1.2. ROI and Feature Selection
5.1.3. Unsupervised Learning and Prior Knowledge
5.2. Limited fMRI and Image Data
5.2.1. Few-Shot Learning
5.2.2. Transfer Learning
5.2.3. Graph Convolutional Networks
5.3. fMRI Noise
5.3.1. Hemodynamic Delay
5.3.2. Brain Cognitive Limitation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Haynes, J.D.; Rees, G. Decoding mental states from brain activity in humans. Nat. Rev. Neurosci. 2006, 7, 523–534. [Google Scholar] [CrossRef] [PubMed]
- Kavasidis, I.; Palazzo, S.; Spampinato, C.; Giordano, D.; Shah, M. Brain2image: Converting brain signals into images. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1809–1817. [Google Scholar]
- Cox, R.W.; Jesmanowicz, A.; Hyde, J.S. Real-time functional magnetic resonance imaging. Magn. Reson. Med. 1995, 33, 230–236. [Google Scholar] [CrossRef]
- Logothetis, N.K. The underpinnings of the BOLD functional magnetic resonance imaging signal. J. Neurosci. 2003, 23, 3963–3971. [Google Scholar] [CrossRef] [Green Version]
- Sulzer, J.; Haller, S.; Scharnowski, F.; Weiskopf, N.; Birbaumer, N.; Blefari, M.L.; Bruehl, A.B.; Cohen, L.G.; DeCharms, R.C.; Gassert, R.; et al. Real-time fMRI neurofeedback: Progress and challenges. Neuroimage 2013, 76, 386–399. [Google Scholar] [CrossRef] [Green Version]
- Thibault, R.T.; Lifshitz, M.; Raz, A. The climate of neurofeedback: scientific rigour and the perils of ideology. Brain 2018, 141, e11. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Zheng, N.; Ma, Y.; Wu, H.; Chen, B. A novel brain decoding method: A correlation network framework for revealing brain connections. IEEE Trans. Cogn. Dev. Syst. 2018, 11, 95–106. [Google Scholar] [CrossRef] [Green Version]
- Arns, M.; Batail, J.M.; Bioulac, S.; Congedo, M.; Daudet, C.; Drapier, D.; Fovet, T.; Jardri, R.; Le-Van-Quyen, M.; Lotte, F.; et al. Neurofeedback: One of today’s techniques in psychiatry? L’Encéphale 2017, 43, 135–145. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Felton, E.; Radwin, R.; Wilson, J.; Williams, J. Evaluation of a modified Fitts law brain—Computer interface target acquisition task in able and motor disabled individuals. J. Neural Eng. 2009, 6, 056002. [Google Scholar] [CrossRef]
- Spampinato, C.; Palazzo, S.; Kavasidis, I.; Giordano, D.; Souly, N.; Shah, M. Deep learning human mind for automated visual classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6809–6817. [Google Scholar]
- Wilson, J.A.; Walton, L.M.; Tyler, M.; Williams, J. Lingual electrotactile stimulation as an alternative sensory feedback pathway for brain—Computer interface applications. J. Neural Eng. 2012, 9, 045007. [Google Scholar] [CrossRef]
- Haxby, J.V.; Gobbini, M.I.; Furey, M.L.; Ishai, A.; Schouten, J.L.; Pietrini, P. Distributed and overlapping representations of faces and objects in ventral temporal cortex. Science 2001, 293, 2425–2430. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kamitani, Y.; Tong, F. Decoding the visual and subjective contents of the human brain. Nat. Neurosci. 2005, 8, 679–685. [Google Scholar] [CrossRef] [Green Version]
- Norman, K.A.; Polyn, S.M.; Detre, G.J.; Haxby, J.V. Beyond mind-reading: Multi-voxel pattern analysis of fMRI data. Trends Cogn. Sci. 2006, 10, 424–430. [Google Scholar] [CrossRef] [PubMed]
- Naselaris, T.; Kay, K.N.; Nishimoto, S.; Gallant, J.L. Encoding and decoding in fMRI. Neuroimage 2011, 56, 400–410. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Gerven, M.A.; Cseke, B.; De Lange, F.P.; Heskes, T. Efficient Bayesian multivariate fMRI analysis using a sparsifying spatio-temporal prior. NeuroImage 2010, 50, 150–161. [Google Scholar] [CrossRef] [PubMed]
- Huth, A.G.; De Heer, W.A.; Griffiths, T.L.; Theunissen, F.E.; Gallant, J.L. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature 2016, 532, 453–458. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kay, K.N.; Winawer, J.; Rokem, A.; Mezer, A.; Wandell, B.A. A two-stage cascade model of BOLD responses in human visual cortex. PLoS Comput. Biol. 2013, 9, e1003079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kay, K.N.; Naselaris, T.; Prenger, R.J.; Gallant, J.L. Identifying natural images from human brain activity. Nature 2008, 452, 352–355. [Google Scholar] [CrossRef]
- St-Yves, G.; Naselaris, T. The feature-weighted receptive field: An interpretable encoding model for complex feature spaces. NeuroImage 2018, 180, 188–202. [Google Scholar] [CrossRef]
- Du, C.; Du, C.; Huang, L.; He, H. Reconstructing perceived images from human brain activities with Bayesian deep multiview learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 2310–2323. [Google Scholar] [CrossRef] [PubMed]
- Fujiwara, Y.; Miyawaki, Y.; Kamitani, Y. Modular encoding and decoding models derived from Bayesian canonical correlation analysis. Neural Comput. 2013, 25, 979–1005. [Google Scholar] [CrossRef]
- Nishimoto, S.; Vu, A.T.; Naselaris, T.; Benjamini, Y.; Yu, B.; Gallant, J.L. Reconstructing visual experiences from brain activity evoked by natural movies. Curr. Biol. 2011, 21, 1641–1646. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schoenmakers, S.; Güçlü, U.; Van Gerven, M.; Heskes, T. Gaussian mixture models and semantic gating improve reconstructions from human brain activity. Front. Comput. Neurosci. 2015, 8, 173. [Google Scholar] [CrossRef] [Green Version]
- Engel, S.A.; Glover, G.H.; Wandell, B.A. Retinotopic organization in human visual cortex and the spatial precision of functional MRI. Cereb. Cortex 1997, 7, 181–192. [Google Scholar] [CrossRef]
- Sereno, M.I.; Dale, A.; Reppas, J.; Kwong, K.; Belliveau, J.; Brady, T.; Rosen, B.; Tootell, R. Borders of multiple visual areas in humans revealed by functional magnetic resonance imaging. Science 1995, 268, 889–893. [Google Scholar] [CrossRef] [Green Version]
- Cox, D.D.; Savoy, R.L. Functional magnetic resonance imaging (fMRI) “brain reading”: Detecting and classifying distributed patterns of fMRI activity in human visual cortex. Neuroimage 2003, 19, 261–270. [Google Scholar] [CrossRef]
- Horikawa, T.; Kamitani, Y. Generic decoding of seen and imagined objects using hierarchical visual features. Nat. Commun. 2017, 8, 15037. [Google Scholar] [CrossRef]
- Miyawaki, Y.; Uchida, H.; Yamashita, O.; Sato, M.A.; Morito, Y.; Tanabe, H.C.; Sadato, N.; Kamitani, Y. Visual image reconstruction from human brain activity using a combination of multiscale local image decoders. Neuron 2008, 60, 915–929. [Google Scholar] [CrossRef] [Green Version]
- Livezey, J.A.; Glaser, J.I. Deep learning approaches for neural decoding: from CNNs to LSTMs and spikes to fMRI. arXiv 2020, arXiv:2005.09687. [Google Scholar]
- Naselaris, T.; Prenger, R.J.; Kay, K.N.; Oliver, M.; Gallant, J.L. Bayesian reconstruction of natural images from human brain activity. Neuron 2009, 63, 902–915. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Horikawa, T.; Tamaki, M.; Miyawaki, Y.; Kamitani, Y. Neural decoding of visual imagery during sleep. Science 2013, 340, 639–642. [Google Scholar] [CrossRef] [Green Version]
- Cowen, A.S.; Chun, M.M.; Kuhl, B.A. Neural portraits of perception: reconstructing face images from evoked brain activity. Neuroimage 2014, 94, 12–22. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.; Kuhl, B.A. Reconstructing perceived and retrieved faces from activity patterns in lateral parietal cortex. J. Neurosci. 2016, 36, 6069–6082. [Google Scholar] [CrossRef] [PubMed]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Güçlütürk, Y.; Güçlü, U.; Seeliger, K.; Bosch, S.; van Lier, R.; van Gerven, M.A. Reconstructing perceived faces from brain activations with deep adversarial neural decoding. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4246–4257. [Google Scholar]
- Shen, G.; Horikawa, T.; Majima, K.; Kamitani, Y. Deep image reconstruction from human brain activity. PLoS Comput. Biol. 2019, 15, e1006633. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Hu, X.; Zhao, Y.; Makkie, M.; Dong, Q.; Zhao, S.; Guo, L.; Liu, T. Modeling task fMRI data via deep convolutional autoencoder. IEEE Trans. Med. Imaging 2017, 37, 1551–1561. [Google Scholar] [CrossRef] [PubMed]
- Wen, H.; Shi, J.; Zhang, Y.; Lu, K.H.; Cao, J.; Liu, Z. Neural encoding and decoding with deep learning for dynamic natural vision. Cereb. Cortex 2018, 28, 4136–4160. [Google Scholar] [CrossRef] [PubMed]
- Shen, G.; Dwivedi, K.; Majima, K.; Horikawa, T.; Kamitani, Y. End-to-end deep image reconstruction from human brain activity. Front. Comput. Neurosci. 2019, 13, 21. [Google Scholar] [CrossRef]
- Anumanchipalli, G.K.; Chartier, J.; Chang, E.F. Speech synthesis from neural decoding of spoken sentences. Nature 2019, 568, 493–498. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Fan, Y. Brain decoding from functional MRI using long short-term memory recurrent neural networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 320–328. [Google Scholar]
- Qiao, K.; Chen, J.; Wang, L.; Zhang, C.; Zeng, L.; Tong, L.; Yan, B. Category decoding of visual stimuli from human brain activity using a bidirectional recurrent neural network to simulate bidirectional information flows in human visual cortices. Front. Neurosci. 2019, 13, 692. [Google Scholar] [CrossRef] [PubMed]
- Gadgil, S.; Zhao, Q.; Adeli, E.; Pfefferbaum, A.; Sullivan, E.V.; Pohl, K.M. Spatio-Temporal Graph Convolution for Functional MRI Analysis. arXiv 2020, arXiv:2003.10613. [Google Scholar]
- Grigis, A.; Tasserie, J.; Frouin, V.; Jarraya, B.; Uhrig, L. Predicting Cortical Signatures of Consciousness using Dynamic Functional Connectivity Graph-Convolutional Neural Networks. bioRxiv 2020. [Google Scholar] [CrossRef]
- Zhang, Y.; Tetrel, L.; Thirion, B.; Bellec, P. Functional Annotation of Human Cognitive States using Deep Graph Convolution. bioRxiv 2020. [Google Scholar] [CrossRef]
- Huang, H.; Li, Z.; He, R.; Sun, Z.; Tan, T. Introvae: Introspective variational autoencoders for photographic image synthesis. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 52–63. [Google Scholar]
- Du, C.; Li, J.; Huang, L.; He, H. Brain Encoding and Decoding in fMRI with Bidirectional Deep Generative Models. Engineering 2019, 5, 948–953. [Google Scholar] [CrossRef]
- Han, K.; Wen, H.; Shi, J.; Lu, K.H.; Zhang, Y.; Fu, D.; Liu, Z. Variational autoencoder: An unsupervised model for encoding and decoding fMRI activity in visual cortex. NeuroImage 2019, 198, 125–136. [Google Scholar] [CrossRef]
- Du, C.; Du, C.; Huang, L.; He, H. Conditional Generative Neural Decoding with Structured CNN Feature Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 2629–2636. [Google Scholar]
- Hong, S.; Yang, D.; Choi, J.; Lee, H. Inferring semantic layout for hierarchical text-to-image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7986–7994. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. arXiv 2016, arXiv:1605.05396. [Google Scholar]
- Dong, H.; Neekhara, P.; Wu, C.; Guo, Y. Unsupervised image-to-image translation with generative adversarial networks. arXiv 2017, arXiv:1701.02676. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Huang, W.; Yan, H.; Wang, C.; Yang, X.; Li, J.; Zuo, Z.; Zhang, J.; Chen, H. Deep Natural Image Reconstruction from Human Brain Activity Based on Conditional Progressively Growing Generative Adversarial Networks. Neurosci. Bull. 2020, 37, 369–379. [Google Scholar] [CrossRef]
- Huang, W.; Yan, H.; Wang, C.; Li, J.; Zuo, Z.; Zhang, J.; Shen, Z.; Chen, H. Perception-to-Image: Reconstructing Natural Images from the Brain Activity of Visual Perception. Ann. Biomed. Eng. 2020, 48, 2323–2332. [Google Scholar] [CrossRef]
- Seeliger, K.; Güçlü, U.; Ambrogioni, L.; Güçlütürk, Y.; van Gerven, M.A. Generative adversarial networks for reconstructing natural images from brain activity. NeuroImage 2018, 181, 775–785. [Google Scholar] [CrossRef]
- St-Yves, G.; Naselaris, T. Generative adversarial networks conditioned on brain activity reconstruct seen images. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 1054–1061. [Google Scholar]
- Lin, Y.; Li, J.; Wang, H. DCNN-GAN: Reconstructing Realistic Image from fMRI. In Proceedings of the 2019 16th International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 27–31 May 2019; pp. 1–6. [Google Scholar]
- Hayashi, R.; Kawata, H. Image Reconstruction from Neural Activity Recorded from Monkey Inferior Temporal Cortex Using Generative Adversarial Networks. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 105–109. [Google Scholar]
- Dosovitskiy, A.; Brox, T. Generating images with perceptual similarity metrics based on deep networks. arXiv 2016, arXiv:1602.02644. [Google Scholar]
- Mourao-Miranda, J.; Bokde, A.L.; Born, C.; Hampel, H.; Stetter, M. Classifying brain states and determining the discriminating activation patterns: support vector machine on functional MRI data. NeuroImage 2005, 28, 980–995. [Google Scholar] [CrossRef]
- LaConte, S.M. Decoding fMRI brain states in real-time. Neuroimage 2011, 56, 440–454. [Google Scholar] [CrossRef]
- Sitaram, R.; Caria, A.; Birbaumer, N. Hemodynamic brain—Computer interfaces for communication and rehabilitation. Neural Netw. 2009, 22, 1320–1328. [Google Scholar] [CrossRef] [Green Version]
- Du, C.; Du, C.; He, H. Sharing deep generative representation for perceived image reconstruction from human brain activity. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1049–1056. [Google Scholar]
- Awangga, R.; Mengko, T.; Utama, N. A literature review of brain decoding research. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Chennai, India, 16–17 September 2020; Volume 830, p. 032049. [Google Scholar]
- Chen, M.; Han, J.; Hu, X.; Jiang, X.; Guo, L.; Liu, T. Survey of encoding and decoding of visual stimulus via FMRI: An image analysis perspective. Brain Imaging Behav. 2014, 8, 7–23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McIntosh, L.; Maheswaranathan, N.; Nayebi, A.; Ganguli, S.; Baccus, S. Deep learning models of the retinal response to natural scenes. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 1369–1377. [Google Scholar]
- Zhang, C.; Qiao, K.; Wang, L.; Tong, L.; Hu, G.; Zhang, R.Y.; Yan, B. A visual encoding model based on deep neural networks and transfer learning for brain activity measured by functional magnetic resonance imaging. J. Neurosci. Methods 2019, 325, 108318. [Google Scholar] [CrossRef] [PubMed]
- Zeidman, P.; Silson, E.H.; Schwarzkopf, D.S.; Baker, C.I.; Penny, W. Bayesian population receptive field modelling. NeuroImage 2018, 180, 173–187. [Google Scholar] [CrossRef] [PubMed]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [Green Version]
- Güçlü, U.; van Gerven, M.A. Deep neural networks reveal a gradient in the complexity of neural representations across the ventral stream. J. Neurosci. 2015, 35, 10005–10014. [Google Scholar] [CrossRef] [Green Version]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic backpropagation and approximate inference in deep generative models. arXiv 2014, arXiv:1401.4082. [Google Scholar]
- Fang, T.; Qi, Y.; Pan, G. Reconstructing Perceptive Images from Brain Activity by Shape-Semantic GAN. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33. [Google Scholar]
- Bontonou, M.; Farrugia, N.; Gripon, V. Few-shot Learning for Decoding Brain Signals. arXiv 2020, arXiv:2010.12500. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Doersch, C. Tutorial on variational autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Sohn, K.; Lee, H.; Yan, X. Learning structured output representation using deep conditional generative models. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 3483–3491. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Goodfellow, I. NIPS 2016 tutorial: Generative adversarial networks. arXiv 2016, arXiv:1701.00160. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Dvornek, N.C.; Ventola, P.; Pelphrey, K.A.; Duncan, J.S. Identifying autism from resting-state fMRI using long short-term memory networks. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Quebec City, QC, Canada, 10 September 2017; pp. 362–370. [Google Scholar]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. arXiv 2017, arXiv:1709.04875. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. arXiv 2018, arXiv:1801.07455. [Google Scholar]
- Sitaram, R.; Caria, A.; Veit, R.; Gaber, T.; Rota, G.; Kuebler, A.; Birbaumer, N. FMRI brain-computer interface: a tool for neuroscientific research and treatment. Comput. Intell. Neurosci. 2007, 2007, 25487. [Google Scholar] [CrossRef]
- Paret, C.; Goldway, N.; Zich, C.; Keynan, J.N.; Hendler, T.; Linden, D.; Kadosh, K.C. Current progress in real-time functional magnetic resonance-based neurofeedback: Methodological challenges and achievements. Neuroimage 2019, 202, 116107. [Google Scholar] [CrossRef] [PubMed]
- Hinterberger, T.; Neumann, N.; Pham, M.; Kübler, A.; Grether, A.; Hofmayer, N.; Wilhelm, B.; Flor, H.; Birbaumer, N. A multimodal brain-based feedback and communication system. Exp. Brain Res. 2004, 154, 521–526. [Google Scholar] [CrossRef]
- Brouwer, A.M.; Van Erp, J.B. A tactile P300 brain-computer interface. Front. Neurosci. 2010, 4, 19. [Google Scholar] [CrossRef] [Green Version]
- Mohanty, R.; Sinha, A.M.; Remsik, A.B.; Dodd, K.C.; Young, B.M.; Jacobson, T.; McMillan, M.; Thoma, J.; Advani, H.; Nair, V.A.; et al. Machine learning classification to identify the stage of brain-computer interface therapy for stroke rehabilitation using functional connectivity. Front. Neurosci. 2018, 12, 353. [Google Scholar] [CrossRef]
- Hinterberger, T.; Veit, R.; Strehl, U.; Trevorrow, T.; Erb, M.; Kotchoubey, B.; Flor, H.; Birbaumer, N. Brain areas activated in fMRI during self-regulation of slow cortical potentials (SCPs). Exp. Brain Res. 2003, 152, 113–122. [Google Scholar] [CrossRef] [PubMed]
- Hinterberger, T.; Weiskopf, N.; Veit, R.; Wilhelm, B.; Betta, E.; Birbaumer, N. An EEG-driven brain-computer interface combined with functional magnetic resonance imaging (fMRI). IEEE Trans. Biomed. Eng. 2004, 51, 971–974. [Google Scholar] [CrossRef] [PubMed]
- De Kroon, J.; Van der Lee, J.; IJzerman, M.J.; Lankhorst, G. Therapeutic electrical stimulation to improve motor control and functional abilities of the upper extremity after stroke: A systematic review. Clin. Rehabil. 2002, 16, 350–360. [Google Scholar] [CrossRef]
- Pichiorri, F.; Morone, G.; Petti, M.; Toppi, J.; Pisotta, I.; Molinari, M.; Paolucci, S.; Inghilleri, M.; Astolfi, L.; Cincotti, F.; et al. Brain—Computer interface boosts motor imagery practice during stroke recovery. Ann. Neurol. 2015, 77, 851–865. [Google Scholar] [CrossRef] [PubMed]
- DeCharms, R.C.; Maeda, F.; Glover, G.H.; Ludlow, D.; Pauly, J.M.; Soneji, D.; Gabrieli, J.D.; Mackey, S.C. Control over brain activation and pain learned by using real-time functional MRI. Proc. Natl. Acad. Sci. USA 2005, 102, 18626–18631. [Google Scholar] [CrossRef] [Green Version]
- Maeda, F.; Soneji, D.; Mackey, S. Learning to explicitly control activation in a localized brain region through real-time fMRI feedback based training, with result impact on pain perception. In Proceedings of the Society for Neuroscience; Society for Neuroscience: Washington, DC, USA, 2004; pp. 601–604. [Google Scholar]
- Guan, M.; Ma, L.; Li, L.; Yan, B.; Zhao, L.; Tong, L.; Dou, S.; Xia, L.; Wang, M.; Shi, D. Self-regulation of brain activity in patients with postherpetic neuralgia: a double-blind randomized study using real-time FMRI neurofeedback. PLoS ONE 2015, 10, e0123675. [Google Scholar] [CrossRef] [PubMed]
- Caria, A.; Veit, R.; Sitaram, R.; Lotze, M.; Weiskopf, N.; Grodd, W.; Birbaumer, N. Regulation of anterior insular cortex activity using real-time fMRI. Neuroimage 2007, 35, 1238–1246. [Google Scholar] [CrossRef]
- Caria, A.; Sitaram, R.; Veit, R.; Begliomini, C.; Birbaumer, N. Volitional control of anterior insula activity modulates the response to aversive stimuli. A real-time functional magnetic resonance imaging study. Biol. Psychiatry 2010, 68, 425–432. [Google Scholar] [CrossRef]
- Anders, S.; Lotze, M.; Erb, M.; Grodd, W.; Birbaumer, N. Brain activity underlying emotional valence and arousal: A response-related fMRI study. Hum. Brain Mapp. 2004, 23, 200–209. [Google Scholar] [CrossRef] [PubMed]
- Zotev, V.; Krueger, F.; Phillips, R.; Alvarez, R.P.; Simmons, W.K.; Bellgowan, P.; Drevets, W.C.; Bodurka, J. Self-regulation of amygdala activation using real-time fMRI neurofeedback. PLoS ONE 2011, 6, e24522. [Google Scholar] [CrossRef] [PubMed]
- Koush, Y.; Meskaldji, D.E.; Pichon, S.; Rey, G.; Rieger, S.W.; Linden, D.E.; Van De Ville, D.; Vuilleumier, P.; Scharnowski, F. Learning control over emotion networks through connectivity-based neurofeedback. Cereb. Cortex 2017, 27, 1193–1202. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Linden, D.E.; Habes, I.; Johnston, S.J.; Linden, S.; Tatineni, R.; Subramanian, L.; Sorger, B.; Healy, D.; Goebel, R. Real-time self-regulation of emotion networks in patients with depression. PLoS ONE 2012, 7, e38115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Viding, E. On the nature and nurture of antisocial behavior and violence. Ann. N. Y. Acad. Sci. 2004, 1036, 267–277. [Google Scholar] [CrossRef]
- Birbaumer, N.; Veit, R.; Lotze, M.; Erb, M.; Hermann, C.; Grodd, W.; Flor, H. Deficient fear conditioning in psychopathy: A functional magnetic resonance imaging study. Arch. Gen. Psychiatry 2005, 62, 799–805. [Google Scholar] [CrossRef] [Green Version]
- Veit, R.; Flor, H.; Erb, M.; Hermann, C.; Lotze, M.; Grodd, W.; Birbaumer, N. Brain circuits involved in emotional learning in antisocial behavior and social phobia in humans. Neurosci. Lett. 2002, 328, 233–236. [Google Scholar] [CrossRef]
- Cheng, X.; Ning, H.; Du, B. A Survey: Challenges and Future Research Directions of fMRI Based Brain Activity Decoding Model. In Proceedings of the 2021 International Wireless Communications and Mobile Computing (IWCMC), Harbin, China, 28 June–2 July 2021; pp. 957–960. [Google Scholar]
- Akamatsu, Y.; Harakawa, R.; Ogawa, T.; Haseyama, M. Multi-view bayesian generative model for multi-subject fmri data on brain decoding of viewed image categories. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1215–1219. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 23. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. arXiv 2017, arXiv:1703.01365. [Google Scholar]
- Zhang, Y.; Bellec, P. Transferability of brain decoding using graph convolutional networks. bioRxiv 2020. [Google Scholar] [CrossRef]
- Gao, Y.; Zhang, Y.; Wang, H.; Guo, X.; Zhang, J. Decoding behavior tasks from brain activity using deep transfer learning. IEEE Access 2019, 7, 43222–43232. [Google Scholar] [CrossRef]
- Shine, J.M.; Bissett, P.G.; Bell, P.T.; Koyejo, O.; Balsters, J.H.; Gorgolewski, K.J.; Moodie, C.A.; Poldrack, R.A. The dynamics of functional brain networks: integrated network states during cognitive task performance. Neuron 2016, 92, 544–554. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Li, X.; Huang, H.; Zhang, W.; Zhao, S.; Makkie, M.; Zhang, M.; Li, Q.; Liu, T. Four-Dimensional Modeling of fMRI Data via Spatio–Temporal Convolutional Neural Networks (ST-CNNs). IEEE Trans. Cogn. Dev. Syst. 2019, 12, 451–460. [Google Scholar] [CrossRef]
- Kazeminejad, A.; Sotero, R.C. Topological properties of resting-state fMRI functional networks improve machine learning-based autism classification. Front. Neurosci. 2019, 12, 1018. [Google Scholar] [CrossRef] [PubMed]
- Ktena, S.I.; Parisot, S.; Ferrante, E.; Rajchl, M.; Lee, M.; Glocker, B.; Rueckert, D. Distance metric learning using graph convolutional networks: Application to functional brain networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec, QC, Canada, 11–13 September 2017; pp. 469–477. [Google Scholar]
- Huth, A.G.; Nishimoto, S.; Vu, A.T.; Gallant, J.L. A continuous semantic space describes the representation of thousands of object and action categories across the human brain. Neuron 2012, 76, 1210–1224. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huth, A.G.; Lee, T.; Nishimoto, S.; Bilenko, N.Y.; Vu, A.T.; Gallant, J.L. Decoding the semantic content of natural movies from human brain activity. Front. Syst. Neurosci. 2016, 10, 81. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Walther, D.B.; Caddigan, E.; Fei-Fei, L.; Beck, D.M. Natural scene categories revealed in distributed patterns of activity in the human brain. J. Neurosci. 2009, 29, 10573–10581. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Literature | Objective | Model/Method | Explanation |
|---|---|---|---|
| [71] | Predict cortical responses | A pre-trained DNN | Train a nonlinear mapping from visual features to brain activity with a pre-trained DNN (i.e., AlexNet) using transfer learning technique. |
| [15] | Representation of information in the visual cortex | GLM | A systematic modeling method is proposed to estimate an encoding model for each voxel and then to perform decoding with the estimated encoding model. |
| [18] | Predict responses to a wide range of stimuli of the input images | Two-stage cascade model | This encoding model is a two-stage cascade architecture of a linear stage and nonlinear stage. The linear stage involves calculations of local filters and division normalization. The nonlinear stage involves compressive spatial summation and a second-order contrast. |
| [72] | Predict the response of a single voxel or brain neurons in a region of interest in any dimensional space of the stimulus | Receptive Field (rPF) | The encoding model quantifies the uncertainty of neuron parameters, rPF size, and location by estimating the covariance of the parameters. |
| [20] | Map the brain activity to natural scenes | Feature-weighted Receptive field | This method converts visual stimuli to corresponding visual features and assumes that spatial features are separable and uses visual feature maps to train deep neural networks. The pre-trained deep neural network weights the contribution of each feature map to voxel activity in brain regions. |
| Literature | Objective | Model/Method | Explanation |
|---|---|---|---|
| [12] | Classification of visual stimuli decoded from brain activity | GLM | For different types of stimuli (objects and pictures), the cerebral cortex has different response patterns through the fMRI of the abdominal temporal cortex. |
| [27] | fMRI and brain signals classification | MVPA | For fMRI in the pre-defined ROI of the cerebral cortex, the activated mode of fMRI is classified by the multivariate statistical pattern recognition. |
| [64] | fMRI signals classification | SVM | SVM classifier finds the best area in the cerebral cortex that can distinguish the brain state, and then SVM is trained to predict brain state through fMRI. |
| [14] | Classify fMRI activity patterns | MVPA Bayesian method | The Gaussian Naive Bayes classifier has high classification accuracy. Because it assumes that the importance of each voxel is the same and it does not consider the sparsity constraint, its interpretability is poor. |
| [29] | Reconstruct geometric images from brain activity | MVPA | Based on a modular modeling method, the multi-voxel pattern of fMRI signals and multi-scale vision are used to reconstruct geometric image stimuli that composes of flashing checkerboard patterns. |
| [31] | Reconstruct the structure and semantic content of natural images | Bayesian method | Use Bayes’ theorem to combine encoding model and prior information of natural images to calculate the probability of a measured brain response due to the visual stimuli of each image. However, only a simple correlation between the reconstructed image and the training image can be established. |
| [16] | Improve fMRI Bayesian classifier accuracy | MVPA Bayesian method | The sparsity constraint is added to the multivariate analysis model of the Bayesian network to quantify the uncertainty of voxel features. |
| [23] | Reconstruct spatio-temporal stimuli using image priors | Bayesian method | This method used a large amount of videos as a priori information and combines the videos with a Bayesian decoder to reconstruct visual stimuli from fMRI signals. |
| [33] | Decoding human dreams | SVM | SVM classifier is trained to map natural images to brain activities, and a vocabulary database is used to label the images with semantic tags to decode the semantic content of dreams. |
| [22] | Decode the reversible mapping between brain activity and visual images | BCCA | The encoding and decoding network is composed of generated multi-view models. The disadvantage is that its linear structure makes the model unable to express the multi-level visual features of the image, and its spherical covariance assumption cannot understand the correlation between fMRI voxels, making it more susceptible to noise. |
| [34] | Dimensionality reduction of high-dimensional fMRI data | PCA | PCA reduces the dimensionality of the facial training data set, and the partial least squares regression algorithm maps the fMRI activity pattern to the dimensionality-reduced facial features. |
| [24] | Infer the semantic category of the reconstructed image | Bayesian method | Propose a mixed Bayesian network based on the Gaussian mixture model. The Gaussian mixture model represents the prior distribution of the image and can infer high-order semantic categories from low-order image features through combining the prior distributions of different information sources. |
| [28] | Predict object categories in dreams | MVPA CNN | Based on CNN, train a decoder with the data set of the normal visual perceptions, and decode the neural activity to the object category. This process involves two parts: 1. map the fMRI signal to the feature space; 2. using correlation analysis to infer the object category based on the feature space. |
| [44] | Decode visual stimuli from human brain activity | RNN CNN | Use CNN to select a set of small fMRI voxel signals as the input and then use RNN to classify the selected fMRI voxels. |
| [41] | Capture the direct mapping between brain activity and perception | CNN | The generator is directly trained with fMRI data by an end-to-end approach. |
| [40] | Reconstruct dynamic video stimuli | CNN PCA | The CNN-based coding model extracts the linear combination of the input video features and then uses PCA to reduce the dimensionality of the extracted high-dimensional feature space while retaining the variance of 99% of the principal components. |
| Literature | Objective | Model/Method | Explanation |
|---|---|---|---|
| [21] | Reconstruct perception images from brain activity | Deep Generative Multiview Model (DGMM) | DGMM first uses DNN to extract the image’s hierarchical features. Based on the fact that the human brain’s processing model for external stimuli is sparse, a sparse linear model is used to avoid over-fitting of fMRI data. The statistical relationships between the visual stimuli and the evoked fMRI data are modeled by using two view-specific generators with a shared latent space to obtain multiple correspondences between fMRI voxel patterns and image pixel patterns. DGMM can be optimized with an automatically encoded Bayesian model [32,75]. |
| [37] | Reconstruct facial images | Deep Adversarial Neural Decoding (DAND) | DAND uses the maximum posterior estimation to transform brain activity linearly to the hidden features. Then, the pre-trained CNN and adversarial training are used to transform the hidden features nonlinearly to reconstruct human facial images. DAND showed good performance in reconstructing the details of the face’s gender, skin color, and facial expressions. |
| [48] | Improve the quality of reconstructed images | Introspective Variational Autoencoders (IntroVAE) | IntroVAE generator and inference model can be jointly trained in a self-assessment manner. The generator takes the output of the inference model noise as the input to generate the image. The inference model not only learns the potential popular structure of the input image but also classifies the real image and the generative image, which is similar to GAN’s adversarial learning. |
| [59] | Reconstruct natural images from brain activity | Deep Convolution Generative Adversarial Network (DCGAN) | DCGAN uses a large natural image data set to train a deep convolutional generation confrontation network in an unsupervised manner, and learn the potential space of stimuli. This DCGAN is used to generate arbitrary images from the stimulus domain. |
| [60] | Reconstruct the visual stimuli of brain activity | GAN | They used an encoding model to create surrogate brain activity samples, with which the generative adversarial networks (GANs) are trained to learn a generative model of images and then generalized to real fRMI data measured during the perception of images. The basic outline of the stimuli can finally be reconstructed. |
| [50] | Reconstruct visual stimuli (video) of brain activity | VAE | VAE is trained with a five-layer encoder and a five-layer decoder to learn visual representations from a diverse set of unlabeled images in an unsupervised way. VAE first converts the fMRI activity to the latent variables and then converts the latent variables to the reconstructed video frames through the VAE’s decoder. However, VAE could only provide relatively lower accuracy in higher-order visual areas compared to CNN. |
| [38] | Reconstruct color images and simple gray-scale images | GAN | A pre-trained DNN decodes the measured fMRI patterns into the hierarchical features that can represent the human visual layering mechanism. The DNN network extracts image features, and then compares them with the decoded human brain activity features, which guides the deep generator network (DGN) to reconstruct images and iteratively minimizes the errors of the two. A natural image prior introduced by an enhanced DGN semantically details to the reconstructions, which improves the visual quality of generated images. |
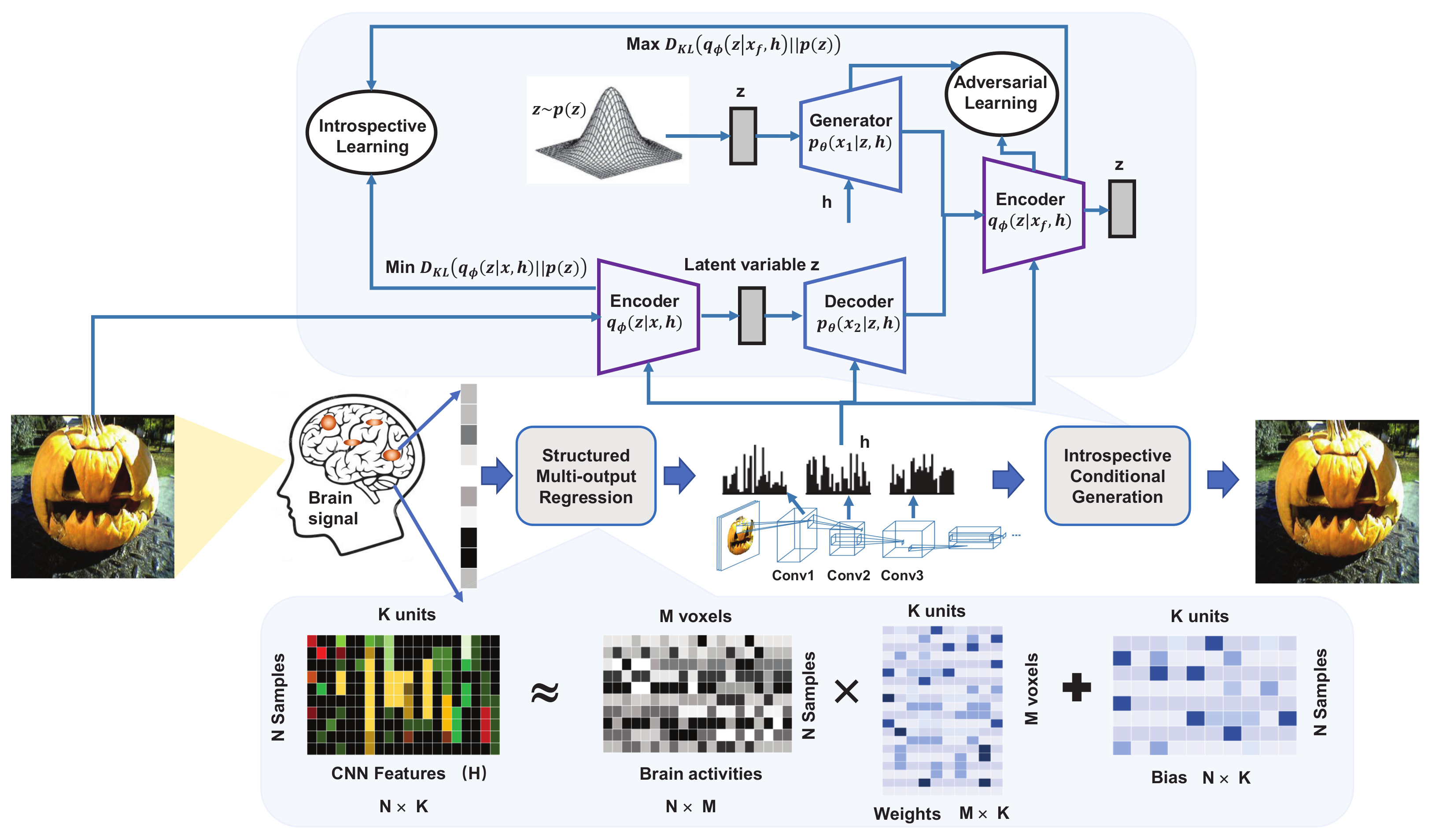
| [51] | Reconstruct the visual image from brain activity | A structured multi-output regression (SMR) model and Introspective Conditional Generation (ICG) | Decodes the brain activity to the intermediate CNN features and then maps these intermediate features to visual images. Combining maximum likelihood estimation and adversarial learning, ICG model uses divergence and reconstruction error for adversarial optimization, which can evaluate the difference between the generated image and the real image. |
| [76] | Use semantic features to add details to the generated image | Shape-Semantic GAN | This framework consists of a linear shape decoder, a semantic decoder based on DNN, and an image generator based on GAN. The output of the shape decoder and the semantic decoder are input to the GAN-based image generator, and the semantic features in GAN are used as a supplement to the image details to reconstruct high quality images. |
| [57] | Reconstruct natural images from brain activity | Progressively Growing GAN (PG-GAN) | This model adds a priori knowledge of potential features to (PG-GAN). The decoder decodes the measured response of the cerebral cortex into the latent features of the natural image and then reconstruct the natural image through the generator. |
| [58] | Reconstruct natural images from brain activity | Similarity-conditions generative adversarial network (SC-GAN) | SC-GAN not only extracts the response patterns of the cerebral cortex to natural images but also captures the high-level semantic features of natural images. The captured semantic features is input to GAN to reconstruct natural images. |
| Literature | Objective | Model/Method | Explanation |
|---|---|---|---|
| [45] | Localize brain regions and functional connections | Spatio-Temporal Graph Convolution Networks (ST-GCN) | Based on ST-GCN, the representation extracted from the fMRI data expresses both temporal dynamic information of brain activity and functional dependence between brain regions. Through training ST-GCN, this method can learn the edge importance matrix on short sub-sequences of BOLD time series to improve the prediction accuracy and interpretability of the model. |
| [46] | Decode the consciousness level from cortical activity recording | BrainNetCNN | BrainNetCNN is a GCN-based decoding model, which uses multi-layer non-linear units to extract features and predict brain consciousness states. |
| [47] | Predict human brain cognitive state | GCN | The brain annotation model uses six graph convolutional layers as feature extractors and two fully connected layers as classifiers to decode the cognitive state of the brain, taking a short series of fMRI data as the input, spreading the information in the annotation model network, and generating high-level domain-specific graph representations to predict the brain cognitive state. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, B.; Cheng, X.; Duan, Y.; Ning, H. fMRI Brain Decoding and Its Applications in Brain–Computer Interface: A Survey. Brain Sci. 2022, 12, 228. https://doi.org/10.3390/brainsci12020228
Du B, Cheng X, Duan Y, Ning H. fMRI Brain Decoding and Its Applications in Brain–Computer Interface: A Survey. Brain Sciences. 2022; 12(2):228. https://doi.org/10.3390/brainsci12020228
Chicago/Turabian StyleDu, Bing, Xiaomu Cheng, Yiping Duan, and Huansheng Ning. 2022. "fMRI Brain Decoding and Its Applications in Brain–Computer Interface: A Survey" Brain Sciences 12, no. 2: 228. https://doi.org/10.3390/brainsci12020228
APA StyleDu, B., Cheng, X., Duan, Y., & Ning, H. (2022). fMRI Brain Decoding and Its Applications in Brain–Computer Interface: A Survey. Brain Sciences, 12(2), 228. https://doi.org/10.3390/brainsci12020228