
Effects of Patchwise Sampling Strategy to Three-Dimensional Convolutional Neural Network-Based Alzheimer’s Disease Classification

Abstract
:1. Introduction
2. Materials and Methods
2.1. Data-Set
2.2. Image Preprocessing
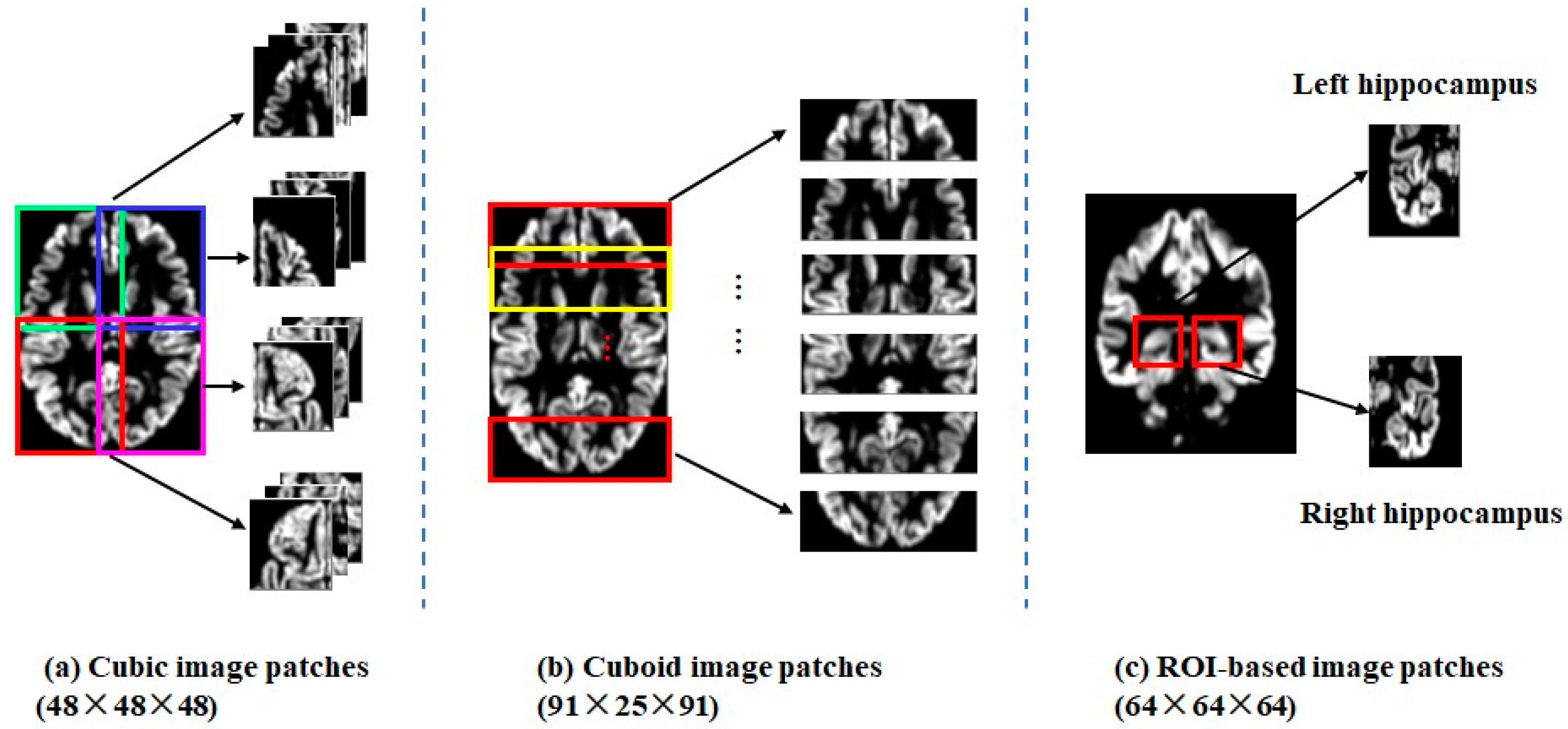
2.3. Patch Extraction
- (1).
- Cubic image patches: Twelve 48 × 48 × 48 local image patches, which were partially overlapped, were sampled to cover the whole brain, as shown in Figure 2a.
- (2).
- Cuboid image patches: Six 91 × 25 × 91 local image patches, which were also partially overlapped, were sampled along the coronal axis, as shown in Figure 2b.
- (3).
- ROI patches: Two 64 × 64 × 64 image patches were sampled to cover the left (or right) hippocampus with certain margins, as shown in Figure 2c.
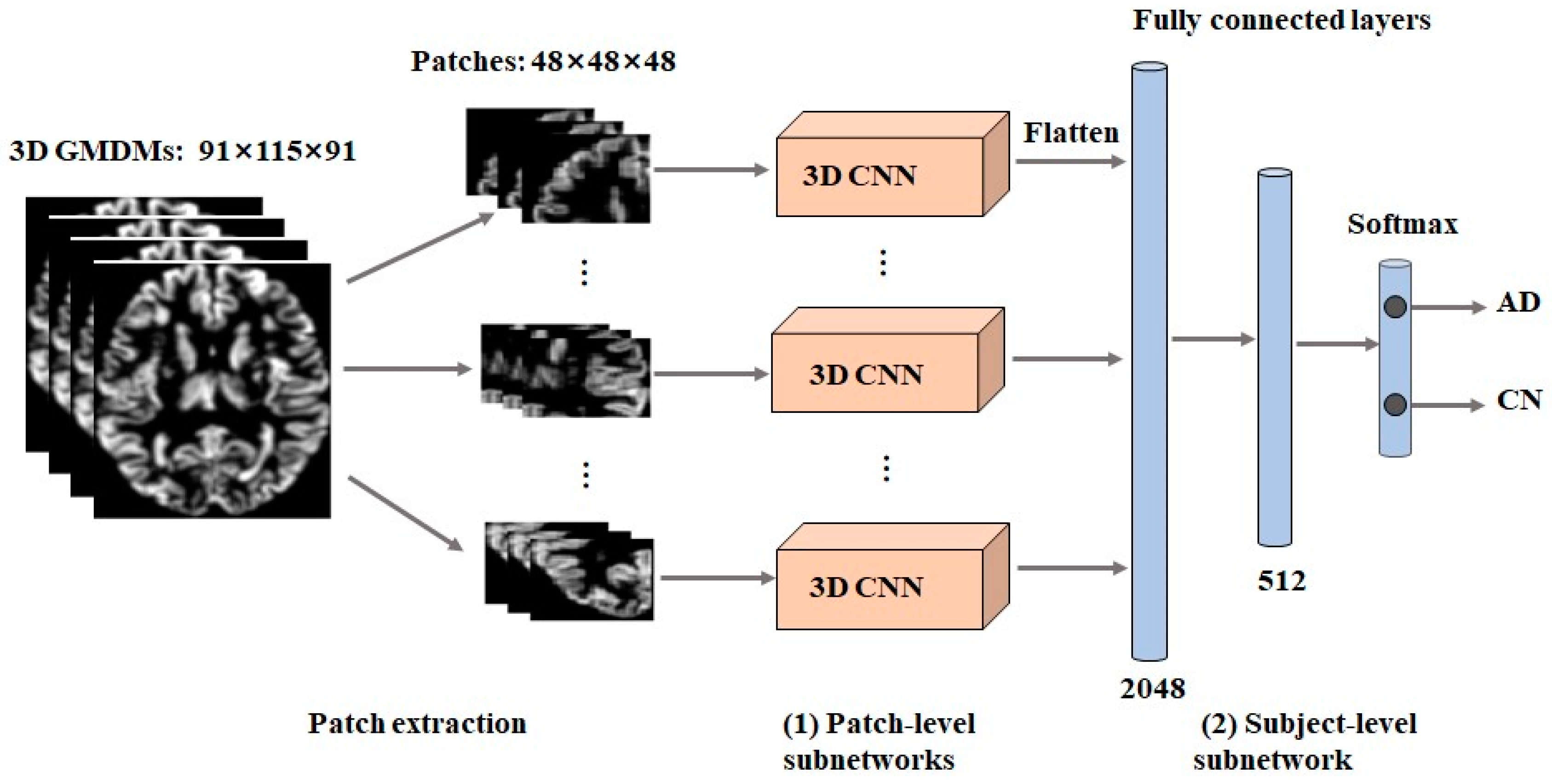
2.4. Network Architecture
2.4.1. Subject-Level CNNs
2.4.2. Image Patch-Level CNNs
- Patch-level subnetworks
- Subject-level subnetwork
2.5. Experiments and Implementation
3. Results
3.1. The Influence of Partition Methods
3.2. The Influence of Image Patch Size
3.3. The Relationship between Image Patch Size and Training Sample Size
4. Discussion
4.1. ROI Patches
4.2. The Effect of Patch Shape
4.3. The Relationship between Image Patch Size and Training Sample Size
4.4. Performance Comparison
4.5. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bharti, K.; Suppa, A.; Tommasin, S.; Zampogna, A.; Pietracupa, S.; Berardelli, A.; Pantano, P. Neuroimaging advances in Parkinson’s disease with freezing of gait: A systematic review. Neuroimage Clin. 2019, 24, 102059. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, A.N.; Barch, D.M.; Petersen, S.E.; Schlaggar, B.L.; Greene, D.J. Machine Learning With Neuroimaging: Evaluating Its Applications in Psychiatry. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 2020, 5, 791–798. [Google Scholar] [CrossRef] [PubMed]
- Davatzikos, C. Machine learning in neuroimaging: Progress and challenges. Neuroimage 2019, 197, 652–656. [Google Scholar] [CrossRef]
- Mateos-Pérez, J.M.; Dadar, M.; Lacalle-Aurioles, M.; Iturria-Medina, Y.; Zeighami, Y.; Evans, A.C. Structural neuroimaging as clinical predictor: A review of machine learning applications. NeuroImage Clin. 2018, 20, 506–522. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.G.; Jun, S.; Cho, Y.W.; Lee, H.; Kim, G.B.; Seo, J.B.; Kim, N. Deep learning in medical imaging: General overview. Korean J. Radiol. 2017, 18, 570–584. [Google Scholar] [CrossRef] [PubMed]
- Chan, H.P.; Samala, R.K.; Hadjiiski, L.M.; Zhou, C. Deep learning in medical image analysis. Adv. Exp. Med. Biol. 2020, 1213, 3–21. [Google Scholar]
- Jo, T.; Nho, K.; Saykin, A.J. Deep Learning in Alzheimer’s Disease: Diagnostic Classification and Prognostic Prediction Using Neuroimaging Data. Front. Aging Neurosci. 2019, 11, 220. [Google Scholar] [CrossRef]
- Huang, D.; Bai, H.; Wang, L.; Hou, Y.; Li, L.; Xia, Y.; Yan, Z.; Chen, W.; Chang, L.; Li, W. The Application and Development of Deep Learning in Radiotherapy: A Systematic Review. Technol. Cancer Res. Treat. 2021, 20, 15330338211016386. [Google Scholar] [CrossRef]
- Lin, L.; Zhang, G.; Wang, J.; Tian, M.; Wu, S. Utilizing transfer learning of pre-trained AlexNet and relevance vector machine for regression for predicting healthy older adult’s brain age from structural MRI. Multimed. Tools Appl. 2021, 80, 24719–24735. [Google Scholar] [CrossRef]
- Ebrahimi, A.; Luo, S. Convolutional neural networks for Alzheimer’s disease detection on MRI images. J. Med. Imaging (Bellingham) 2021, 8, 024503. [Google Scholar] [CrossRef]
- Mzoughi, H.; Njeh, I.; Wali, A.; Slima, M.B.; BenHamida, A.; Mhiri, C.; Mahfoudhe, K.B. Deep Multi-Scale 3D Convolutional Neural Network (CNN) for MRI Gliomas Brain Tumor Classification. J. Digit. Imaging 2020, 33, 903–915. [Google Scholar] [CrossRef] [PubMed]
- Lin, W.; Lin, W.; Chen, G.; Zhang, H.; Gao, Q.; Huang, Y.; Tong, T.; Du, M. Bidirectional Mapping of Brain MRI and PET With 3D Reversible GAN for the Diagnosis of Alzheimer’s Disease. Front. Neurosci. 2021, 15, 646013. [Google Scholar] [CrossRef] [PubMed]
- Rehman, A.; Khan, M.A.; Saba, T.; Mehmood, Z.; Tariq, U.; Ayesha, N. Microscopic brain tumor detection and classification using 3D CNN and feature selection architecture. Microsc. Res. Tech. 2021, 84, 133–149. [Google Scholar] [CrossRef] [PubMed]
- Jia, Q.; Shu, H. BiTr-Unet: A CNN-Transformer Combined Network for MRI Brain Tumor Segmentation. In International MICCAI Brainlesion Workshop; Springer: Cham, Switzerland, 2022; pp. 3–14. [Google Scholar]
- Wen, J.; Thibeau-Sutre, E.; Diaz-Melo, M.; Samper-Gonzalez, J.; Routier, A.; Bottani, S.; Dormont, D.; Durrleman, S.; Burgos, N.; Colliot, O. Australian Imaging Biomarkers and Lifestyle flagship study of ageing, Convolutional neural networks for classification of Alzheimer’s disease: Overview and reproducible evaluation. Med. Image Anal. 2020, 63, 101694. [Google Scholar] [CrossRef] [PubMed]
- Cheng, D.; Liu, M.; Fu, J.; Wang, Y. Classification of MR brain images by combination of multi-CNNs for AD diagnosis. In Proceedings of the Ninth International Conference on Digital Image Processing (ICDIP), Hong Kong, China, 19–22 May 2017; p. 1042042. [Google Scholar]
- Liu, J.; Pan, Y.; Li, M.; Chen, Z.; Tang, L.; Lu, C.; Wang, J. Applications of deep learning to MRI images: A survey. Big Data Min. Anal. 2018, 1, 1–18. [Google Scholar]
- Madala, V.C.; Chandrasekaran, S. CNNs are Myopic. arXiv 2022, arXiv:2205.10760. [Google Scholar]
- Kruthika, K.R.; Rajeswari; Maheshappa, H.D. CBIR system using Capsule Networks and 3D CNN for Alzheimer’s disease diagnosis. Inform. Med. Unlocked 2019, 14, 59–68. [Google Scholar] [CrossRef]
- Li, F.; Liu, M. Alzheimer’s disease diagnosis based on multiple cluster dense convolutional networks. Comput. Med. Imaging Graph. 2018, 70, 101–110. [Google Scholar] [CrossRef]
- Liu, M.; Cheng, D.; Wang, K. Multi-Modality Cascaded Convolutional Neural Networks for Alzheimer’s Disease Diagnosis. Neuroinformatics 2018, 6, 295–308. [Google Scholar] [CrossRef]
- Zhang, J.; Zheng, B.; Gao, A. A 3D densely connected convolution neural network with connection-wise attention mechanism for Alzheimer’s disease classification. Magn. Reson. Imaging 2021, 78, 119–126. [Google Scholar] [CrossRef] [PubMed]
- Suk, H.I.; Lee, S.W.; Shen, D. Deep ensemble learning of sparse regression models for brain disease diagnosis. Med. Image Anal. 2017, 37, 101–113. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Xu, J.; Zhou, Y.; Tong, T.; Zhuang, X. Diagnosis of Alzheimer’s Disease via multi-Modality 3D convolutional neural network. Front. Neurosci. 2019, 13, 509. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Li, F.; Yan, H.; Wang, K.; Ma, Y.; Shen, L.; Xu, M. A multi-model deep convolutional neural network for automatic hippocampus segmentation and classification in Alzheimer’s disease. NeuroImage 2020, 208, 116459. [Google Scholar] [CrossRef]
- Ashburner., J. Computational anatomy with the SPM software. Magn. Reason. Imaging 2009, 27, 1163–1174. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946v5. [Google Scholar]
- Zhang, B.; Lin, L.; Wu SAl-Masqari, Z. Multiple subtypes of Alzheimer’s disease base on brain atrophy pattern. Brain Sci. 2021, 11, 278. [Google Scholar] [CrossRef]
- Zhang, B.; Lin, L.; Wu, S. A review of brain atrophy subtypes definition and analysis for Alzheimer’s disease heterogeneity studies. J. Alzheimer’s Dis. 2021, 80, 1339–1352. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, J.; Adeli, E.; Shen, D. Landmark-based deep multi-instance for brain disease diagnosis. Med. Image Anal. 2018, 43, 157–168. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Characteristic | AD | CN |
|---|---|---|
| Subjects | 187 | 229 |
| Age | 75.26 ± 7.53 | 75.87 ± 5.02 |
| Gender (Male/Female) | 98/89 | 119/110 |
| Education | 14.66 ± 3.14 | 16.07 ± 2.85 |
| MMSE | 23.28 ± 2.04 | 29.11 ± 1.00 |
| Layer | Kernel Size | Stride | Output Size | Parameters |
|---|---|---|---|---|
| Input | - | - | 91 × 115 × 91 | - |
| Conv1 | 3 × 3 × 3 | 1 | 31 × 39 × 31 | 224 |
| Conv2 | 3 × 3 × 3 | 1 | 16 × 20 × 16 | 3472 |
| Conv3 | 3 × 3 × 3 | 1 | 8 × 10 × 8 | 13,856 |
| Conv4 | 3 × 3 × 3 | 1 | 4 × 5 × 4 | 55,360 |
| FC1 | 1024 | - | 1 × 1024 | 5,243,904 |
| FC2 | 128 | - | 1 × 128 | 131,200 |
| FC3 | 2 | - | 1 × 2 | 258 |
| Patch Size/Partition Method | ACC (%) | SEN (%) | SPE (%) | F1-Score (%) | AUC (%) |
|---|---|---|---|---|---|
| 48 × 48 × 48/cubic patches | 89.6 ± 1.8 | 89.8 ± 3.6 | 90.1 ± 4.4 | 89.6 ± 2.0 | 89.8 ± 1.9 |
| 64 × 64 × 64/ROIs patches | 87.6 ± 2.3 | 86.3 ± 3.2 | 89.7 ± 5.0 | 87.8 ± 2.4 | 87.6 ± 2.2 |
| 91 × 25 × 91/cuboid patches | 86.8 ± 2.5 | 85.6 ± 3.2 | 88.7 ± 4.9 | 87.0 ± 2.7 | 86.7 ± 2.4 |
| 91 × 115 × 91/baseline | 87.7 ± 2.8 | 87.5 ± 3.7 | 88.4 ± 4.4 | 87.7 ± 2.9 | 87.7 ± 2.7 |
| Patch Size | ACC (%) | SEN (%) | SPE (%) | F1-Score (%) | AUC (%) |
|---|---|---|---|---|---|
| 24 × 24 × 24 | 87.6 ± 2.2 | 87.4 ± 4.8 | 88.8 ± 5.1 | 87.7 ± 2.4 | 87.5 ± 2.2 |
| 32 × 32 × 32 | 87.8 ± 2.3 | 87.5 ± 3.3 | 88.5 ± 4.2 | 87.8 ± 2.5 | 87.8 ± 2.3 |
| 48 × 48 × 48 | 89.6 ± 1.8 | 89.8 ± 3.6 | 90.1 ± 4.4 | 89.6 ± 2.0 | 89.8 ± 1.9 |
| 64 × 64 × 64 | 87.9 ± 2.0 | 87.1 ± 3.7 | 89.3 ± 4.1 | 88.1 ± 1.9 | 87.7 ± 2.1 |
| Patch Size/Partition Method | ACC (%) | SEN (%) | SPE (%) | F1-Score (%) | AUC (%) |
|---|---|---|---|---|---|
| 24 × 24 × 24/cubic patches | 87.1 ± 3.1 | 86.8 ± 5.0 | 88.1 ± 5.1 | 87.2 ± 3.6 | 87.2 ± 3.1 |
| 32 × 32 × 32/cubic patches | 85.2 ± 4.5 | 84.4 ± 4.7 | 86.3 ± 5.2 | 85.4 ± 4.5 | 85.1 ± 4.6 |
| 48 × 48 × 48/cubic patches | 85.5 ± 4.5 | 85.1 ± 5.5 | 86.6 ± 5.3 | 85.6 ± 4.4 | 85.5 ± 4.7 |
| 64 × 64 × 64/cubic patches | 84.3 ± 5.5 | 83.7 ± 5.8 | 85.6 ± 6.9 | 84.4 ± 5.7 | 84.3 ± 5.5 |
| 64 × 64 × 64/ROIs | 83.6 ± 5.2 | 83.1 ± 6.0 | 84.7 ± 6.2 | 83.7 ± 5.3 | 83.4 ± 5.3 |
| 91 × 115 × 91/baseline | 85.0 ± 4.0 | 84.6 ± 4.6 | 85.7 ± 5.0 | 85.1 ± 4.1 | 84.9 ± 4.2 |
| Articles | Model | Patch Size | Sample Size | Image Modality | ACC (100%) |
|---|---|---|---|---|---|
| Chen et al. [17] | 3D VGG | 50 × 41 × 40 | AD: 229, CN: 199 | sMRI | 87.15 |
| Huang et al. [25] | 3D VGG | 96 × 96 × 48 | AD:647, CN:731 | sMRI/FDG-PET | 90.10 |
| Kruthika et al. [20] | 3D SAE | 7 × 7 × 7 | AD: 75, CN: 75 | sMRI | 97.60 |
| Li et al. [21] | 3D DenseNet | 32 × 32 × 32 | AD:199, CN:229 | sMRI | 89.5 |
| Liu et al. [22] | 3D VGG | 50 × 41 × 40 | AD: 93, CN: 100 | sMRI/FDG-PET | 93.26 |
| Liu et al. [26] | 3D U-Net+3D DenseNet | 62 × 48 × 58 | AD: 97, CN: 119 | sMRI | 88.90 |
| Zhang et al. [23] | 3D DenseNet with attention | 96 × 120 × 96 | AD: 280, CN: 275 | sMRI | 97.35 |
| Proposed approach | 3D VGG | 48 × 48 × 48 | AD: 187, CN: 229 | sMRI | 89.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, X.; Lin, L.; Xu, X.; Wu, S. Effects of Patchwise Sampling Strategy to Three-Dimensional Convolutional Neural Network-Based Alzheimer’s Disease Classification. Brain Sci. 2023, 13, 254. https://doi.org/10.3390/brainsci13020254
Shen X, Lin L, Xu X, Wu S. Effects of Patchwise Sampling Strategy to Three-Dimensional Convolutional Neural Network-Based Alzheimer’s Disease Classification. Brain Sciences. 2023; 13(2):254. https://doi.org/10.3390/brainsci13020254
Chicago/Turabian StyleShen, Xiaoqi, Lan Lin, Xinze Xu, and Shuicai Wu. 2023. "Effects of Patchwise Sampling Strategy to Three-Dimensional Convolutional Neural Network-Based Alzheimer’s Disease Classification" Brain Sciences 13, no. 2: 254. https://doi.org/10.3390/brainsci13020254
APA StyleShen, X., Lin, L., Xu, X., & Wu, S. (2023). Effects of Patchwise Sampling Strategy to Three-Dimensional Convolutional Neural Network-Based Alzheimer’s Disease Classification. Brain Sciences, 13(2), 254. https://doi.org/10.3390/brainsci13020254