
Does Musicality Assist Foreign Language Learning? Perception and Production of Thai Vowels, Consonants and Lexical Tones by Musicians and Non-Musicians


Abstract
:1. Introduction
2. Method
2.1. Participants
2.2. Stimuli
2.3. Speech Perception Procedure
2.4. Speech Production Procedure
3. Results
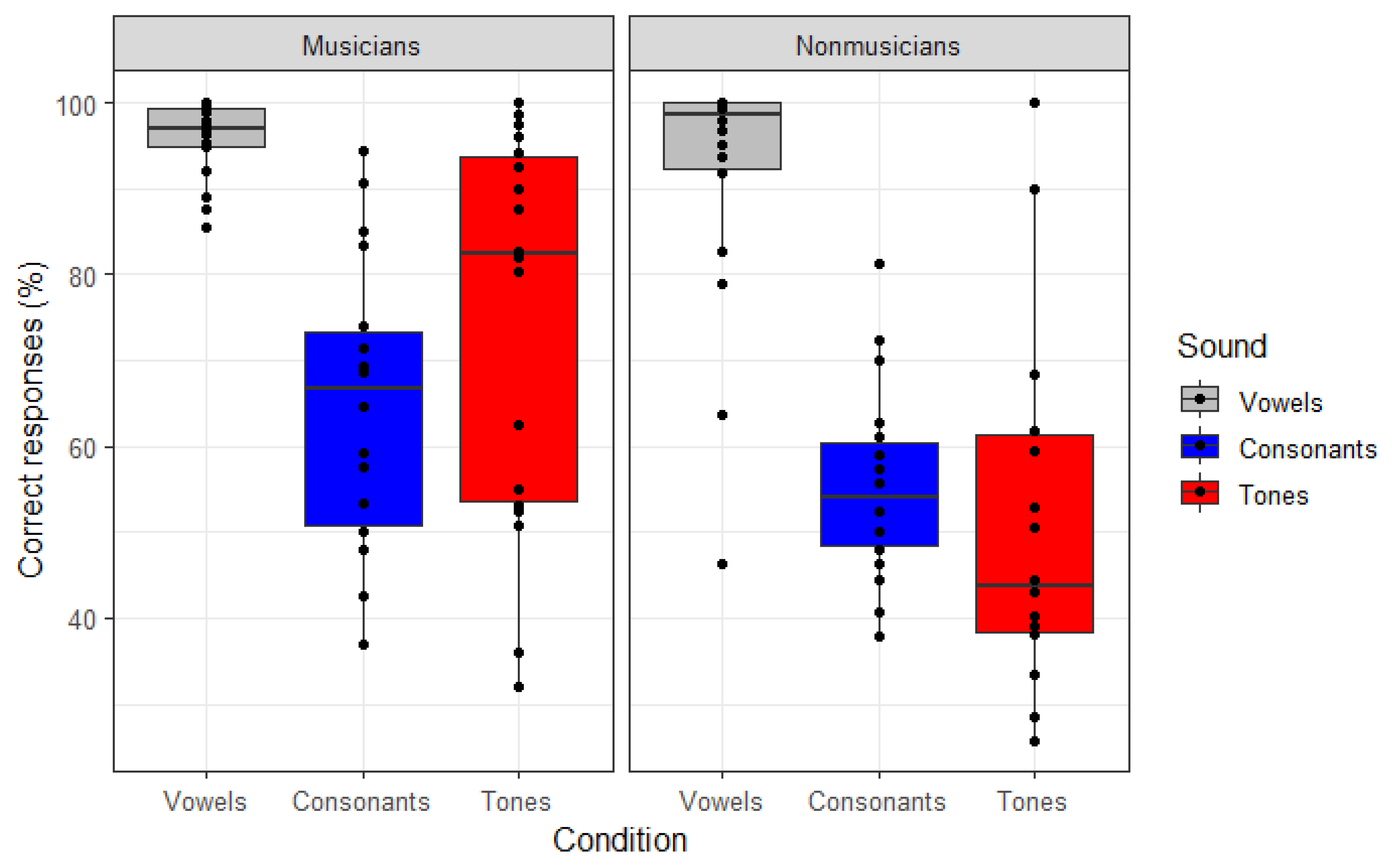
3.1. Perception
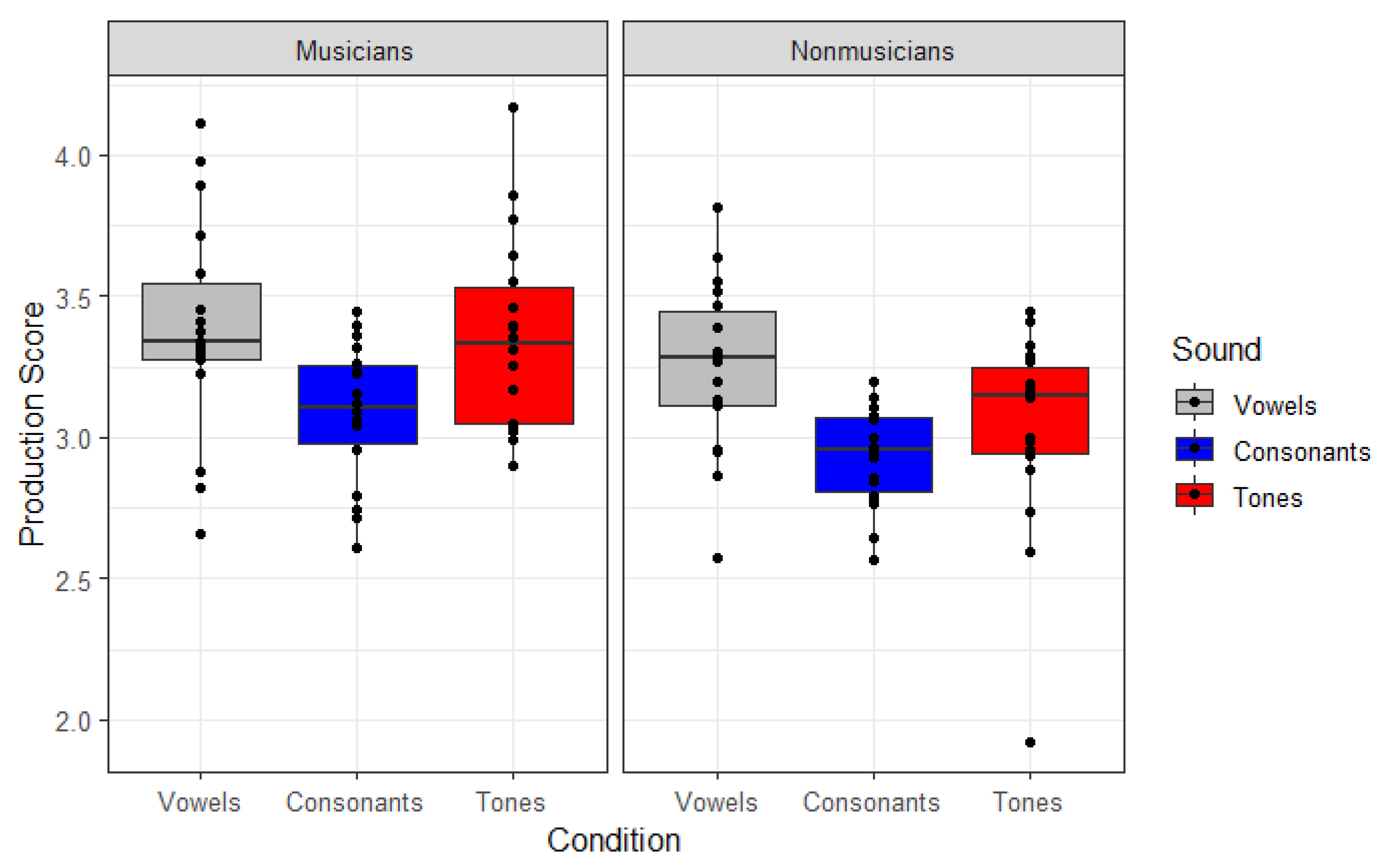
3.2. Production
3.3. Linking Perception with Production
4. Discussion
4.1. Musicianship
4.2. Speech Type
4.3. Specificity of Cross-Domain Transfer of Musicality
4.4. Further Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ladányi, E.; Lukács, Á.; Gervain, J. Does rhythmic priming improve grammatical processing in Hungarian-speaking children with and without developmental language disorder? Dev. Sci. 2021, 24, e13112. [Google Scholar] [CrossRef]
- François, C.; Chobert, J.; Besson, M.; Schön, D. Music training for the development of speech segmentation. Cereb. Cortex 2013, 23, 2038–2043. [Google Scholar] [CrossRef]
- Chobert, J.; François, C.; Velay, J.-L.; Besson, M. Twelve months of active musical training in 8-to 10-year-old children enhances the preattentive processing of syllabic duration and voice onset time. Cereb. Cortex 2014, 24, 956–967. [Google Scholar] [CrossRef]
- Moreno, S.; Marques, C.; Santos, A.; Santos, M.; Castro, S.L.; Besson, M. Musical Training Influences Linguistic Abilities in 8-Year-Old Children: More Evidence for Brain Plasticity. Cereb. Cortex 2009, 19, 712–723. [Google Scholar] [CrossRef] [PubMed]
- Magne, C.; Schön, D.; Besson, M. Musician Children Detect Pitch Violations in Both Music and Language Better than Nonmusician Children: Behavioral and Electrophysiological Approaches. J. Cogn. Neurosci. 2006, 18, 199–211. [Google Scholar] [CrossRef] [PubMed]
- Jentschke, S.; Koelsch, S. Musical training modulates the development of syntax processing in children. NeuroImage 2009, 47, 735–744. [Google Scholar] [CrossRef]
- Deutsch, D. The Tritone Paradox: An Influence of Language on Music Perception. Music Percept. 1991, 8, 335–347. [Google Scholar] [CrossRef]
- Wong, P.C.M.; Ciocca, V.; Chan, A.H.D.; Ha, L.Y.Y.; Tan, L.-H.; Peretz, I. Effects of Culture on Musical Pitch Perception. PLoS ONE 2012, 7, e33424. [Google Scholar] [CrossRef]
- Patel, A.D.; Daniele, J.R. An empirical comparison of rhythm in language and music. Cognition 2003, 87, B35–B45. [Google Scholar] [CrossRef]
- Temperley, N.; Temperley, D. Music-Language Correlations and the ‘Scotch Snap’. Music Percept. 2011, 29, 51–63. [Google Scholar] [CrossRef]
- Schellenberg, E.G. Cognitive performance after listening to music: A review of the Mozart effect. In Music, Health, and Wellbeing; Oxford University Press: Oxford, UK, 2012; pp. 324–338. [Google Scholar]
- Marie, C.; Delogu, F.; Lampis, G.; Belardinelli, M.O.; Besson, M. Influence of Musical Expertise on Segmental and Tonal Processing in Mandarin Chinese. J. Cogn. Neurosci. 2011, 23, 2701–2715. [Google Scholar] [CrossRef] [PubMed]
- Delogu, F.; Lampis, G.; Belardinelli, M.O. Music-to-language transfer effect: May melodic ability improve learning of tonal languages by native nontonal speakers? Cogn. Process. 2006, 7, 203–207. [Google Scholar] [CrossRef] [PubMed]
- Delogu, F.; Lampis, G.; Belardinelli, M.O. From melody to lexical tone: Musical ability enhances specific aspects of foreign language perception. Eur. J. Cogn. Psychol. 2010, 22, 46–61. [Google Scholar] [CrossRef]
- Studdert-Kennedy, M.; Shankweiler, D.; Pisoni, D. Auditory and phonetic processes in speech perception: Evidence from a dichotic study. Cogn. Psychol. 1972, 3, 455–466. [Google Scholar] [CrossRef]
- Pisoni, D.B. Auditory and phonetic memory codes in the discrimination of consonants and vowels. Percept. Psychophys. 1973, 13, 253–260. [Google Scholar] [CrossRef]
- Pisoni, D.B. Auditory short-term memory and vowel perception. Mem. Cognit. 1975, 3, 7–18. [Google Scholar] [CrossRef] [PubMed]
- Dittinger, E.; D’Imperio, M.; Besson, M. Enhanced neural and behavioural processing of a nonnative phonemic contrast in professional musicians. Eur. J. Neurosci. 2018, 47, 1504–1516. [Google Scholar] [CrossRef] [PubMed]
- Sadakata, M.; Sekiyama, K. Enhanced perception of various linguistic features by musicians: A cross-linguistic study. Acta Psychol. 2011, 138, 1–10. [Google Scholar] [CrossRef]
- Wishart, T. Beyond notation. Br. J. Music Educ. 1985, 2, 311–326. [Google Scholar] [CrossRef]
- McNeil, A.F. Aural Skills and the Performing Musician: Function, Training and Assessment. Ph.D. Thesis, University of Huddersfield, Huddersfield, UK, 2000. Available online: https://www.hud.ac.uk/news/ (accessed on 17 April 2023).
- Lisker, L.; Abramson, A.S. A Cross-Language Study of Voicing in Initial Stops: Acoustical Measurements. Word 1964, 20, 384–422. [Google Scholar] [CrossRef]
- Yip, M. Tone; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Fromkin, V.A. Tone: A Linguistic Survey; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Burnham, D.; Mattock, K.; Munro, M.J.; Bohn, O.S. The perception of tones and phones. In Language Experience in Second Language Speech Learning; John Benjamins B.V.: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Abramson, A.S. Noncategorical perception of tone categories in Thai. J. Acoust. Soc. Am. 1977, 61, S66. [Google Scholar] [CrossRef]
- Burnham, D.; Jones, C. Categorical perception of lexical tone by tonal and non-tonal language speakers. In Proceedings of the 9th International Conference on Speech Science and Technology, Canberra, Australia, 13–16 December 2022; pp. 2–5. [Google Scholar]
- Alexander, J.A.; Wong, P.C.; Bradlow, A.R. Lexical tone perception in musicians and non-musicians. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Burnham, D.; Kasisopa, B.; Reid, A.; Luksaneeyanawin, S.; Lacerda, F.; Attina, V.; Rattanasone, N.X.; Schwarz, I.C.; Webster, D. Universality and language-specific experience in the perception of lexical tone and pitch. Appl. Psycholinguist. 2015, 36, 1459–1491. [Google Scholar] [CrossRef]
- Chandrasekaran, B.; Krishnan, A.; Gandour, J.T. Relative influence of musical and linguistic experience on early cortical processing of pitch contours. Brain Lang. 2009, 108, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Wong, P.C.; Skoe, E.; Russo, N.M.; Dees, T.; Kraus, N. Musical experience shapes human brainstem encoding of linguistic pitch patterns. Nat. Neurosci. 2007, 10, 420–422. [Google Scholar] [CrossRef]
- Gottfried, T.L. Music and language learning. In Language Experience in Second Language Speech Learning; John Benjamins B.V.: Amsterdam, The Netherlands, 2007; pp. 221–237. [Google Scholar]
- Nikjeh, D.A.; Lister, J.J.; Frisch, S.A. The relationship between pitch discrimination and vocal production: Comparison of vocal and instrumental musicians. J. Acoust. Soc. Am. 2009, 125, 328–338. [Google Scholar] [CrossRef] [PubMed]
- Jekiel, M.; Malarski, K. Musical hearing and musical experience in second language English vowel acquisition. J. Speech Lang. Hear. Res. 2021, 64, 1666–1682. [Google Scholar] [CrossRef] [PubMed]
- Milovanov, R.; Pietilä, P.; Tervaniemi, M.; Esquef, P.A. Foreign language pronunciation skills and musical aptitude: A study of Finnish adults with higher education. Learn. Individ. Differ. 2010, 20, 56–60. [Google Scholar] [CrossRef]
- Slevc, L.R.; Miyake, A. Individual differences in second-language proficiency: Does musical ability matter? Psychol. Sci. 2006, 17, 675–681. [Google Scholar] [CrossRef] [PubMed]
- Golestani, N.; Zatorre, R.J. Individual differences in the acquisition of second language phonology. Brain Lang. 2009, 109, 55–67. [Google Scholar] [CrossRef] [PubMed]
- Amir, O.; Amir, N.; Kishon-Rabin, L. The effect of superior auditory skills on vocal accuracy. J. Acoust. Soc. Am. 2003, 113, 1102–1108. [Google Scholar] [CrossRef]
- Besson, M.; Schön, D. Comparison between language and music. Ann. N. Y. Acad. Sci. 2001, 930, 232–258. [Google Scholar] [CrossRef]
- Milovanov, R.; Huotilainen, M.; Välimäki, V.; Esquef, P.A.; Tervaniemi, M. Musical aptitude and second language pronunciation skills in school-aged children: Neural and behavioral evidence. Brain Res. 2008, 1194, 81–89. [Google Scholar] [CrossRef]
- Talamini, F.; Grassi, M.; Toffalini, E.; Santoni, R.; Carretti, B. Learning a second language: Can music aptitude or music training have a role? Learn. Individ. Differ. 2018, 64, 1–7. [Google Scholar] [CrossRef]
- Tallal, P.; Gaab, N. Dynamic auditory processing, musical experience and language development. Trends Neurosci. 2006, 29, 382–390. [Google Scholar] [CrossRef] [PubMed]
- Forster, K.I.; Forster, J.C. DMDX: A Windows display program with millisecond accuracy. Behav. Res. Methods Instrum. Comput. 2003, 35, 116–124. [Google Scholar] [CrossRef] [PubMed]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models using lme4. arXiv 2015, arXiv:1406.5823. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 15 February 2021).
- Schad, D.J.; Vasishth, S.; Hohenstein, S.; Kliegl, R. How to capitalize on a priori contrasts in linear (mixed) models: A tutorial. J. Mem. Lang. 2020, 110, 104038. [Google Scholar] [CrossRef]
- Best, C.T. The emergence of native-language phonological influences in infants: A perceptual assimilation model. In The Development of Speech Perception: The Transition from Speech Sounds to Spoken Words; MIT Press: Cambridge, MA, USA, 1994; Volume 167, pp. 233–277. [Google Scholar]
- Best, C.T.; Tyler, M.D. Nonnative and second-language speech. In Language Experience in Second Language Speech Learning; John Benjamins B.V.: Amsterdam, The Netherlands, 2007; Volume 17, p. 13. [Google Scholar]
- So, C.K.; Best, C.T. Cross-language perception of non-native tonal contrasts: Effects of native phonological and phonetic influences. Lang. Speech 2010, 53, 273–293. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Mid Tone (M) | Low Tone (L) | High Tone (H) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| /i:/ | /ɔ:/ | /u:/ | /i:/ | /ɔ:/ | /u:/ | /i:/ | /ɔ:/ | /u:/ | |
| /b/ | bi:0 | bɔ:0 | bu:0 | bi:1 | bɔ:1 | bu:1 | bi:3 | bɔ:3 | bu:3 |
| /p/ | pi:0 | pɔ:0 | pu:0 | pi:1 | pɔ:1 | pu:1 | pi:3 | pɔ:3 | pu:3 |
| /ph/ | phi:0 | phɔ:0 | phu:0 | phi:1 | phɔ:1 | phu:1 | phi:3 | phɔ:3 | phu:3 |
| Predictor | Estimate | SE | df | z-Value | Pr (>|t|) |
|---|---|---|---|---|---|
| (Intercept) | 0.723 | 0.012 | 280.670 | 58.265 | <0.001 |
| Musicians vs. Non-musicians | 0.069 | 0.021 | 280.679 | 3.248 | 0.001 |
| Tones and Consonants vs. Vowels | −0.213 | 0.020 | 64.681 | −10.919 | <0.001 |
| Tones vs. Consonants | 0.017 | 0.020 | 39.203 | 0.853 | 0.399 |
| Tone score | 0.019 | 0.022 | 280.655 | 0.886 | 0.377 |
| Rhythm score | 0.042 | 0.021 | 280.662 | 1.963 | 0.051 |
| Years of Training | −0.010 | 0.019 | 280.663 | −0.535 | 0.593 |
| Hours per Week of training | −0.036 | 0.017 | 280.670 | −2.154 | 0.032 |
| Musicians vs. Non-musicians: Tones vs. Consonants | 0.009 | 0.035 | 39.332 | 0.266 | 0.792 |
| Musicians vs. Non-musicians: Tones and Consonants vs. Vowels | 0.059 | 0.034 | 64.782 | 1.748 | 0.085 |
| Tones vs. Consonants: Tone score | −0.010 | 0.035 | 39.004 | −0.299 | 0.767 |
| Tones and Consonants: Tone score | −0.040 | 0.034 | 64.525 | −1.170 | 0.246 |
| Tones vs. Consonants: Rhythm score | 0.013 | 0.034 | 39.096 | 0.388 | 0.700 |
| Tones and Consonants: Rhythm score | 0.005 | 0.033 | 64.597 | 0.156 | 0.877 |
| Tones vs. Consonants: Years Training | −0.040 | 0.031 | 39.109 | −1.276 | 0.210 |
| Tones and Consonants: Years Training | 0.015 | 0.030 | 64.607 | 0.499 | 0.619 |
| Tones vs. Consonants: Hours/Week | 0.006 | 0.027 | 39.207 | 0.207 | 0.837 |
| Tones and Consonants: Hours/Week | 0.032 | 0.026 | 64.684 | 1.207 | 0.232 |
| Predictor | Estimate | SE | df | z-Value | Pr (>|t|) |
|---|---|---|---|---|---|
| (Intercept) | 3.173 | 0.036 | 36.366 | 87.726 | <0.001 |
| Musicians vs. Non-musicians | 0.257 | 0.062 | 36.540 | 4.123 | <0.001 |
| Tones and Consonants vs. Vowels | −0.150 | 0.038 | 284.729 | −3.985 | <0.001 |
| Tones vs. Consonants | 0.090 | 0.033 | 284.647 | 2.771 | 0.006 |
| Rhythm score | 0.042 | 0.062 | 37.110 | 0.680 | 0.500 |
| Years of Training | −0.102 | 0.058 | 39.408 | −1.770 | 0.084 |
| Hours per Week of training | 0.131 | 0.049 | 37.223 | 2.665 | 0.011 |
| Musicians vs. Non-musicians: Tones vs. Consonants | 0.007 | 0.056 | 284.535 | 0.131 | 0.896 |
| Musicians vs. Non-musicians: Tones and Consonants vs. Vowels | −0.064 | 0.065 | 284.809 | −0.985 | 0.326 |
| Tones vs. Consonants: Tone score | 0.001 | 0.058 | 285.792 | 0.010 | 0.992 |
| Tones and Consonants: Tone score | 0.000 | 0.066 | 284.968 | 0.004 | 0.997 |
| Tones vs. Consonants: Rhythm score | 0.028 | 0.056 | 285.394 | 0.504 | 0.615 |
| Tones and Consonants: Rhythm score | −0.025 | 0.065 | 284.887 | −0.384 | 0.701 |
| Tones vs. Consonants: Years Training | −0.061 | 0.051 | 284.502 | −1.209 | 0.228 |
| Tones and Consonants: Years Training | −0.118 | 0.063 | 286.018 | −1.865 | 0.063 |
| Tones vs. Consonants: Hours/Week | −0.004 | 0.044 | 284.337 | −0.092 | 0.926 |
| Tones and Consonants: Hours/Week | −0.007 | 0.052 | 286.009 | −0.126 | 0.900 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Götz, A.; Liu, L.; Nash, B.; Burnham, D. Does Musicality Assist Foreign Language Learning? Perception and Production of Thai Vowels, Consonants and Lexical Tones by Musicians and Non-Musicians. Brain Sci. 2023, 13, 810. https://doi.org/10.3390/brainsci13050810
Götz A, Liu L, Nash B, Burnham D. Does Musicality Assist Foreign Language Learning? Perception and Production of Thai Vowels, Consonants and Lexical Tones by Musicians and Non-Musicians. Brain Sciences. 2023; 13(5):810. https://doi.org/10.3390/brainsci13050810
Chicago/Turabian StyleGötz, Antonia, Liquan Liu, Barbara Nash, and Denis Burnham. 2023. "Does Musicality Assist Foreign Language Learning? Perception and Production of Thai Vowels, Consonants and Lexical Tones by Musicians and Non-Musicians" Brain Sciences 13, no. 5: 810. https://doi.org/10.3390/brainsci13050810
APA StyleGötz, A., Liu, L., Nash, B., & Burnham, D. (2023). Does Musicality Assist Foreign Language Learning? Perception and Production of Thai Vowels, Consonants and Lexical Tones by Musicians and Non-Musicians. Brain Sciences, 13(5), 810. https://doi.org/10.3390/brainsci13050810