The Roles of Statistics in Human Neuroscience


Abstract
:1. Prologue
2. A Statistical Enquiry Concerning the Human Brain
2.1. The Three Roles of Statistics in Brain Science
2.1.1. Three Types of Population: Hierarchies in the Human Brain
2.1.2. An Example
2.1.3. Three Classes of Variance: The Spell of Neural Diversity
2.1.4. Reduction of Large-Scale Brain Data: The Local Guide to a Global Picture
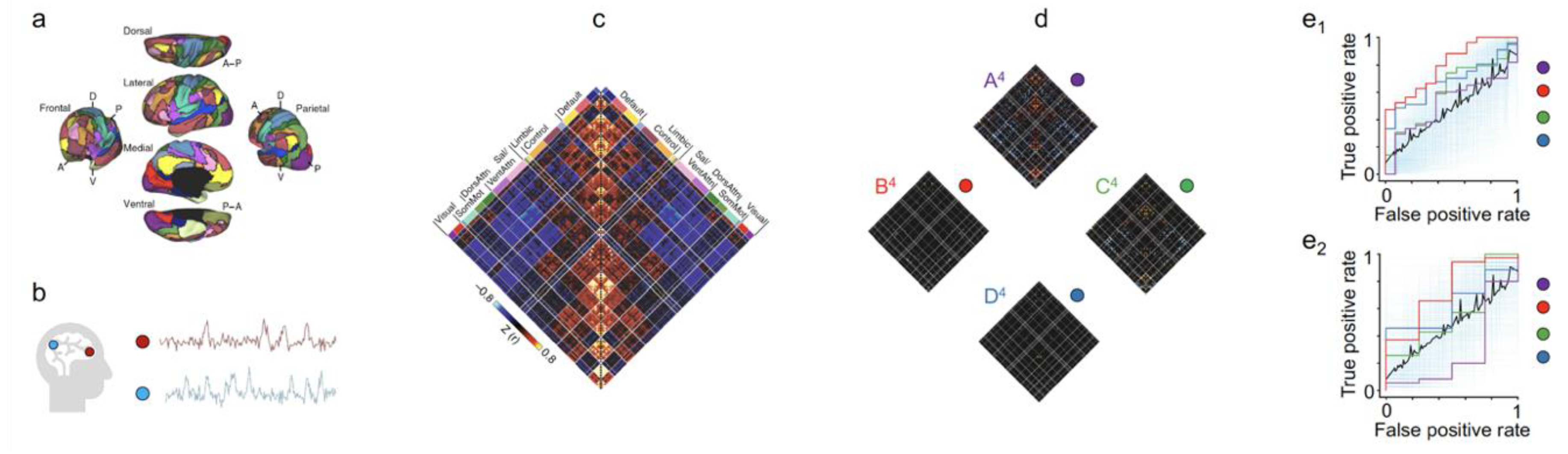
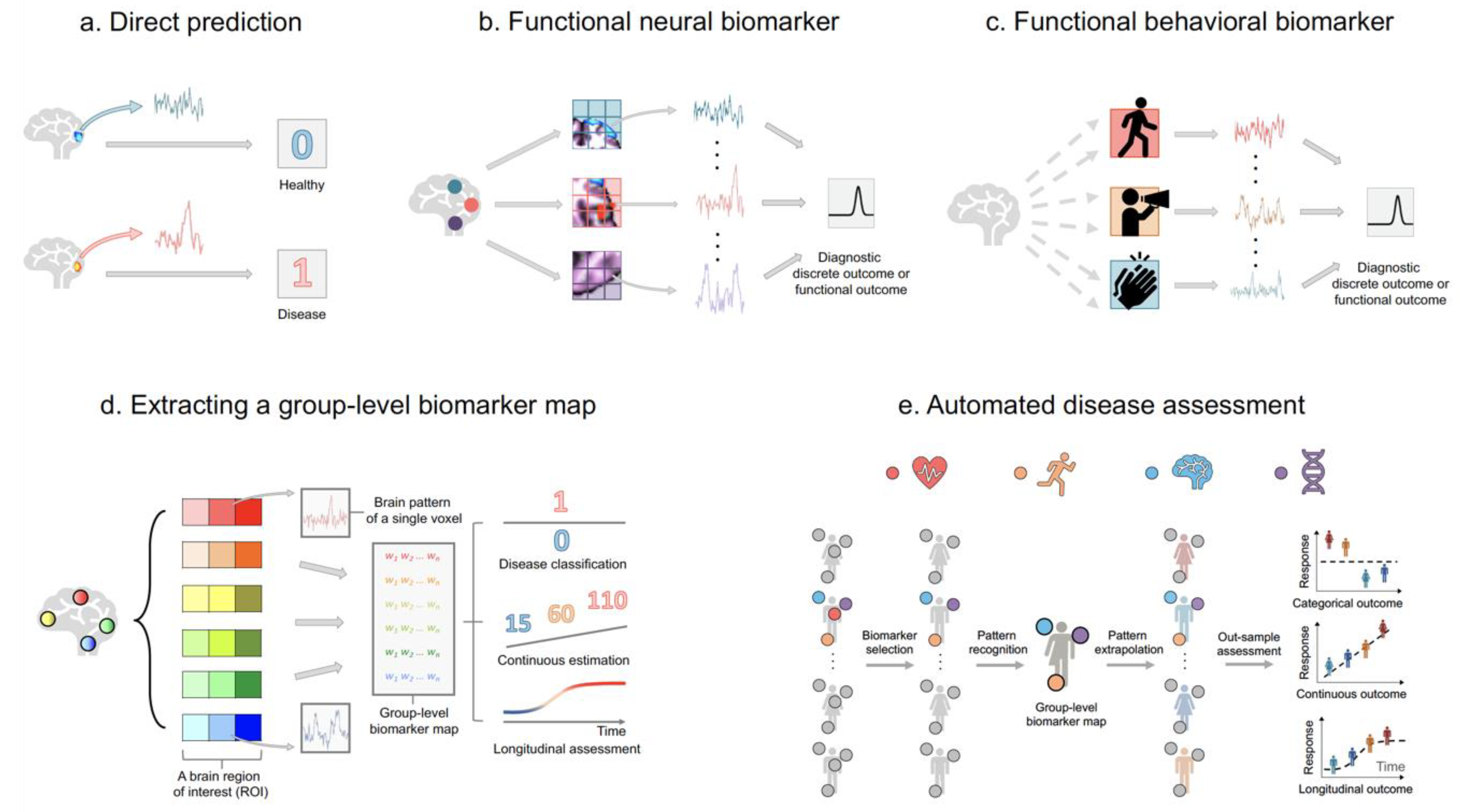
2.2. Diagnosing Brain Diseases and Monitoring Disease Development Using Statistical Predictive Models
2.3. Information Flow in the Brain: A Statistical Pursuit
3. Epilogue: The Paths to Decode the Brain?
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fisher, R.A. Statistical methods for research workers. In Biological Monographs and Manuals; Oliver and Boyd: Edinburgh, UK, 1925. [Google Scholar]
- Rubinov, M.; Sporns, O. Complex network measures of brain connectivity: Uses and interpretations. Neuroimage 2010, 52, 1059–1069. [Google Scholar] [CrossRef] [PubMed]
- Crainiceanu, C.M.; Caffo, B.S.; Luo, S.; Zipunnikov, V.M.; Punjabi, N.M. Population value decomposition, a framework for the analysis of image populations. J. Am. Stat. Assoc. 2011, 106, 775–790. [Google Scholar] [CrossRef] [PubMed]
- Chén, O.Y.; Crainiceanu, C.M.; Ogburn, E.L.; Caffo, B.S.; Wager, T.D.; Lindquist, M.A. High-dimensional multivariate mediation with application to neuroimaging data. Biostatistics 2018, 19, 121–136. [Google Scholar] [CrossRef] [PubMed]
- Raichle, M.E.; MacLeod, A.M.; Snyder, A.Z.; Powers, W.J.; Gusnard, D.A.; Shulman, G.L. A default mode of brain function. Proc. Natl. Acad. Sci. USA 2001, 98, 676–682. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haxby, J.V.; Gobbini, M.I.; Furey, M.L.; Ishai, A.; Schouten, J.L.; Pietrini, P. Distributed and overlapping representations of faces and objects in ventral temporal cortex. Science 2001, 293, 2425–2430. [Google Scholar] [CrossRef] [PubMed]
- Rosenberg, M.D.; Finn, E.S.; Scheinost, D.; Papademetris, X.; Shen, X.; Constable, R.T.; Chun, M.M. A neuromarker of sustained attention from whole-brain functional connectivity. Nat. Neurosci. 2015, 19, 165–171. [Google Scholar] [CrossRef] [Green Version]
- Chén, O.Y.; Cao, H.; Reinen, J.M.; Qian, T.; Gou, J.; Phan, H.; De Vos, M.; Cannon, T.D. Resting-state brain information flow predicts cognitive flexibility in humans. Sci. Rep. 2019, 9, 3879. [Google Scholar] [CrossRef] [Green Version]
- Reinen, J.M.; Chen, O.Y.; Hutchison, R.M.; Yeo, B.T.T.; Anderson, K.M.; Sabuncu, M.R.; Öngür, D.; Roffman, J.L.; Smoller, J.W.; Baker, J.T.; et al. The human cortex possesses a reconfigurable dynamic network architecture that is disrupted in psychosis. Nat. Commun. 2018, 9, 1157. [Google Scholar] [CrossRef] [Green Version]
- Cao, H.; Chén, O.Y.; Chung, Y.; Forsyth, J.K.; McEwen, S.C.; Gee, D.G.; Bearden, C.E.; Addington, J.; Goodyear, B.; Cadenhead, K.S.; et al. Cerebello-thalamo-cortical hyperconnectivity as a state-independent functional neural signature for psychosis prediction and characterization. Nat. Commun. 2018, 9, 3836. [Google Scholar] [CrossRef]
- Casey, B.; Giedd, J.N.; Thomas, K.M. Structural and functional brain development and its relation to cognitive development. Biol. Psychol. 2000, 54, 241–257. [Google Scholar] [CrossRef] [Green Version]
- Cao, H.; Chung, Y.; McEwen, S.C.; Bearden, C.E.; Addington, J.; Goodyear, B.; Cadenhead, K.S.; Mirzakhanian, H.; Cornblatt, B.A.; Carrión, R.; et al. Progressive reconfiguration of resting-state brain networks as psychosis develops: Preliminary results from the North American Prodrome Longitudinal Study (NAPLS) consortium. Schizophrenia Res. 2019, in press. [Google Scholar] [CrossRef] [PubMed]
- Zeki, S.; Watson, J.D.; Lueck, C.J.; Friston, K.J.; Kennard, C.; Frackowiak, R.S. A direct demonstration of functional specialization in human visual cortex. J. Neurosci. 1991, 11, 641–649. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zeki, S. A Vision of the Brain; Blackwell Scientific Publications: Oxford, UK, 1993. [Google Scholar]
- Hubel, D.H.; Wiesel, T.N. Ferrier Lecture: Functional Architecture of Macaque Monkey Visual Cortex. Proc. R. Soc. B Biol. Sci. 1977, 198, 1–59. [Google Scholar]
- Greve, D.N.; Brown, G.G.; Mueller, B.A.; Glover, G.; Liu, T.T. A survey of the sources of noise in fMRI. Psychometrika 2013, 78, 396–416. [Google Scholar] [CrossRef] [PubMed]
- Yeo, B.T.T.; Krienen, F.M.; Sepulcre, J.; Sabuncu, M.R.; Lashkari, D.; Hollinshead, M.; Roffman, J.L.; Smoller, J.W.; Zöllei, L.; Polimeni, J.R.; et al. The organization of the human cerebral cortex estimated by intrinsic functional connectivity. J. Neurophysiol. 2011, 106, 1125–1165. [Google Scholar] [PubMed]
- Van Essen, D.C. A Population-Average, Landmark- and Surface-based (PALS) atlas of human cerebral cortex. NeuroImage 2005, 28, 635–662. [Google Scholar] [CrossRef] [PubMed]
- Tikhonov, A.N. Solution of incorrectly formulated problems and the regularization method. Dokl. Akad. Nauk SSSR 1963, 151, 501–504. [Google Scholar]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Smith, S.M.; Nichols, T.E. Statistical Challenges in “Big Data” Human Neuroimaging. Neuron 2018, 97, 263–268. [Google Scholar] [CrossRef]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Di, C.-Z.; Crainiceanu, C.M.; Caffo, B.S.; Punjabi, N.M. Multilevel functional principal component analysis. Ann. Appl. Stat. 2009, 3, 458–488. [Google Scholar] [CrossRef] [PubMed]
- Byrom, B.; McCarthy, M.; Schueler, P.; Muehlhausen, W. Brain Monitoring Devices in Neuroscience Clinical Research: The Potential of Remote Monitoring Using Sensors, Wearables, and Mobile Devices. Clin. Pharmacol. Ther. 2018, 104, 59–71. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Z.; Ding, L.; He, B. Integration of EEG/MEG with MRI and fMRI. IEEE Eng. Med. Biol. Mag. 2006, 25, 46–53. [Google Scholar] [PubMed]
- Fan, J.; Liao, Y. Endogeneity in high dimensions. Ann. Stat. 2014, 42, 872–917. [Google Scholar] [CrossRef]
- Seth, A.K.; Barrett, A.B.; Barnett, L. Granger Causality Analysis in Neuroscience and Neuroimaging. J. Neurosci. 2015, 35, 3293–3297. [Google Scholar] [CrossRef]
- Friston, K.J.; Harrison, L.; Penny, W. Dynamic causal modelling. Neuroimage 2003, 19, 1273–1302. [Google Scholar] [CrossRef]
- Viol, A.; Palhano-Fontes, F.; Onias, H.; De Araujo, D.B.; Viswanathan, G.M. Shannon entropy of brain functional complex networks under the influence of the psychedelic Ayahuasca. Sci. Rep. 2017, 7, 7388. [Google Scholar] [CrossRef]
- Rajapakse, J.C.; Zhou, J. Learning effective brain connectivity with dynamic Bayesian networks. Neuroimage 2007, 37, 749–760. [Google Scholar] [CrossRef]
- Patel, R.S.; Bowman, F.D.; Rilling, J.K. A Bayesian approach to determining connectivity of the human brain. Human Brain Mapp. 2006, 27, 267–276. [Google Scholar] [CrossRef]
- Zhang, T.; Wu, J.; Li, F.; Caffo, B.; Boatman-Reich, D. A dynamic directional model for effective brain connectivity using electrocorticographic (ECoG) time series. J. Am. Stat. Assoc. 2015, 110, 93–106. [Google Scholar] [CrossRef]
- Smith, S.M.; Miller, K.L.; Salimi-Khorshidi, G.; Webster, M.; Beckmann, C.F.; Nichols, T.E.; Ramsey, J.D.; Woolrich, M.W. Network modelling methods for FMRI. Neuroimage 2011, 54, 875–891. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.J. Functional and Effective Connectivity: A Review. Brain Connect. 2011, 1, 13–36. [Google Scholar] [CrossRef] [PubMed]
- Hillebrand, A.; Tewarie, P.; van Dellen, E.; Yu, M.; Carbo, E.W.; Douw, L.; Gouw, A.A.; Van Straaten, E.C.; Stam, C.J. Direction of information flow in large-scale resting-state networks is frequency-dependent. Proc. Natl. Acad. Sci. USA 2016, 113, 3867–3872. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stam, C.J.; van Straaten, E.C.W. Go with the flow: Use of a directed phase lag index (dPLI) to characterize patterns of phase relations in a large-scale model of brain dynamics. Neuroimage 2012, 62, 1415–1428. [Google Scholar] [CrossRef] [PubMed]
- Moon, J.Y.; Lee, U.C.; Blain-Moraes, S.; Mashour, G.A. General relationship of global topology, local dynamics, and directionality in large-scale brain networks. PLoS Comput. Biol. 2015, 11, e1004225. [Google Scholar] [CrossRef] [PubMed]
- Yan, C.; He, Y. Driving and driven architectures of directed small-world human brain functional networks. PLoS ONE 2011, 6, e23460. [Google Scholar] [CrossRef]
- Liao, W.; Mantini, D.; Zhang, Z.; Pan, Z.; Ding, J.; Gong, Q.; Yang, Y.; Chen, H. Evaluating the effective connectivity of resting state networks using conditional Granger causality. Biol. Cybern. 2010, 102, 57–69. [Google Scholar] [CrossRef]
- Valdes-Sosa, P.A.; Roebroeck, A.; Daunizeau, J.; Friston, K. Effective connectivity: Influence, causality and biophysical modeling. NeuroImage 2011, 58, 339–361. [Google Scholar] [CrossRef]
- Kamitani, Y.; Tong, F. Decoding the visual and subjective contents of the human brain. Nat. Neurosci. 2005, 8, 679–685. [Google Scholar] [CrossRef] [Green Version]
- Naselaris, T.; Prenger, R.J.; Kay, K.N.; Oliver, M.; Gallant, J.L. Bayesian reconstruction of natural images from human brain activity. Neuron 2009, 63, 902–915. [Google Scholar] [CrossRef] [PubMed]
- Haynes, J.-D.; Sakai, K.; Rees, G.; Gilbert, S.; Frith, C.; Passingham, R.E. Reading Hidden Intentions in the Human Brain. Curr. Boil. 2007, 17, 323–328. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haynes, J.-D. Decoding and predicting intentions. Ann. N. Y. Acad. Sci. 2011, 1224, 9–21. [Google Scholar] [CrossRef] [PubMed]
- Horikawa, T.; Tamaki, M.; Miyawaki, Y.; Kamitani, Y. Neural Decoding of Visual Imagery During Sleep. Science 2013, 340, 639–642. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nishimoto, S.; Vu, A.T.; Naselaris, T.; Benjamini, Y.; Yu, B.; Gallant, J.L. Reconstructing visual experiences from brain activity evoked by natural movies. Curr. Boil. 2011, 21, 1641–1646. [Google Scholar] [CrossRef] [PubMed]
- Diedrichsen, J.; Kriegeskorte, N. Representational models: A common framework for understanding encoding, pattern-component, and representational-similarity analysis. PLoS Comput. Biol. 2017, 13, e1005508. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Receptive fields and functional architecture of monkey striate cortex. J. Physiol. 1968, 195, 215–243. [Google Scholar] [CrossRef]
- Zeki, S.M. Functional specialisation in the visual cortex of the rhesus monkey. Nature 1978, 274, 423–428. [Google Scholar] [CrossRef]
- Kay, K.N.; Naselaris, T.; Prenger, R.J.; Gallant, J.L. Identifying natural images from human brain activity. Nature 2008, 452, 352–355. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Driessche, G.V.D.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Fukushima, K. Neocognitron: A hierarchical neural network capable of visual pattern recognition. Neural Netw. 1988, 1, 119–130. [Google Scholar] [CrossRef]
- Russell, S.; Dewey, D.; Tegmark, M. Research priorities for robust and beneficial artificial intelligence. AI Mag. 2015, 36, 105–114. [Google Scholar] [CrossRef]
- Bostrom, N.; Yudkowsky, E. The ethics of artificial intelligence. In The Cambridge Handbook of Artificial Intelligence; Cambridge University Press: Cambridge, UK, 2014; pp. 316–334. [Google Scholar] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chén, O.Y. The Roles of Statistics in Human Neuroscience. Brain Sci. 2019, 9, 194. https://doi.org/10.3390/brainsci9080194
Chén OY. The Roles of Statistics in Human Neuroscience. Brain Sciences. 2019; 9(8):194. https://doi.org/10.3390/brainsci9080194
Chicago/Turabian StyleChén, Oliver Y. 2019. "The Roles of Statistics in Human Neuroscience" Brain Sciences 9, no. 8: 194. https://doi.org/10.3390/brainsci9080194
APA StyleChén, O. Y. (2019). The Roles of Statistics in Human Neuroscience. Brain Sciences, 9(8), 194. https://doi.org/10.3390/brainsci9080194