
Word Recognition and Frequency Selectivity in Cochlear Implant Simulation: Effect of Channel Interaction

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Subjects
2.2. Hardware
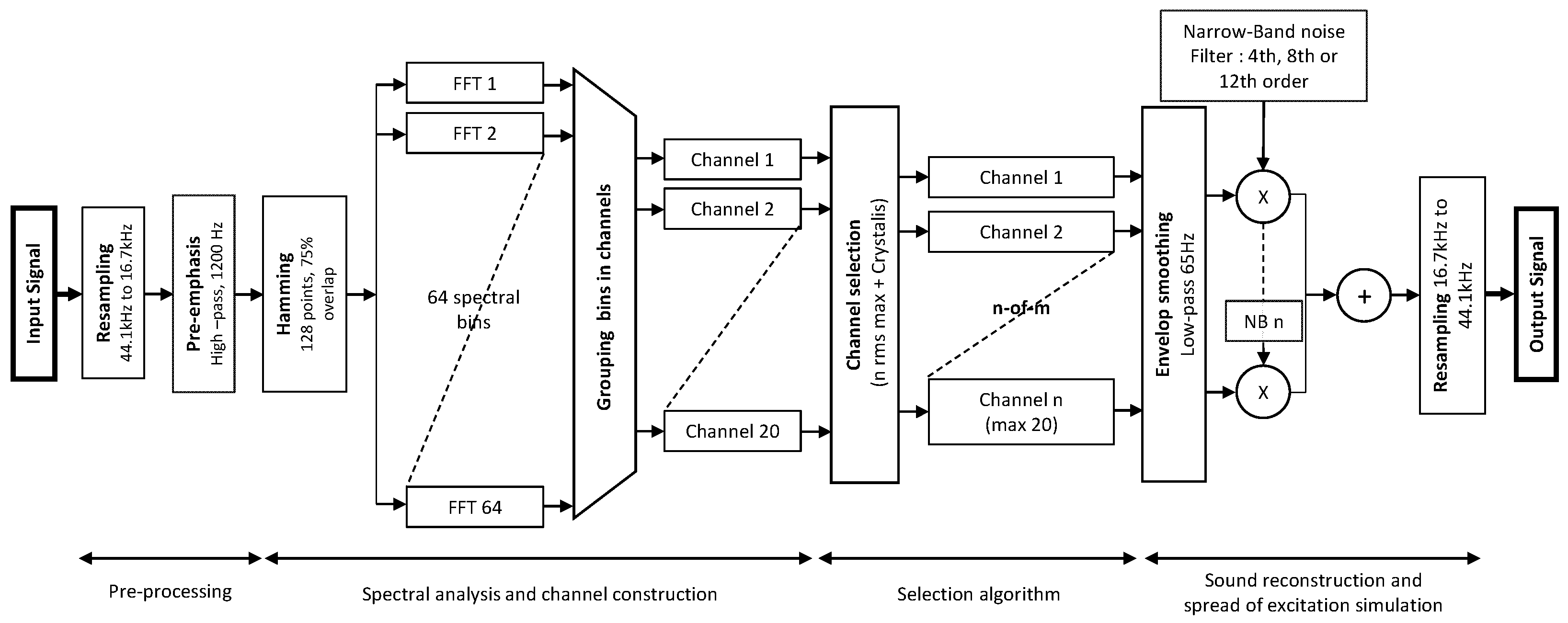
2.3. Vocoder Signal Processing
2.4. Speech Audiometry in Noise
2.5. Psychophysical Tuning Curves
2.5.1. Stimuli
2.5.2. Procedure
2.6. Tuning Curves Fitting and Q10dB
2.7. Statistical Analyses
3. Results
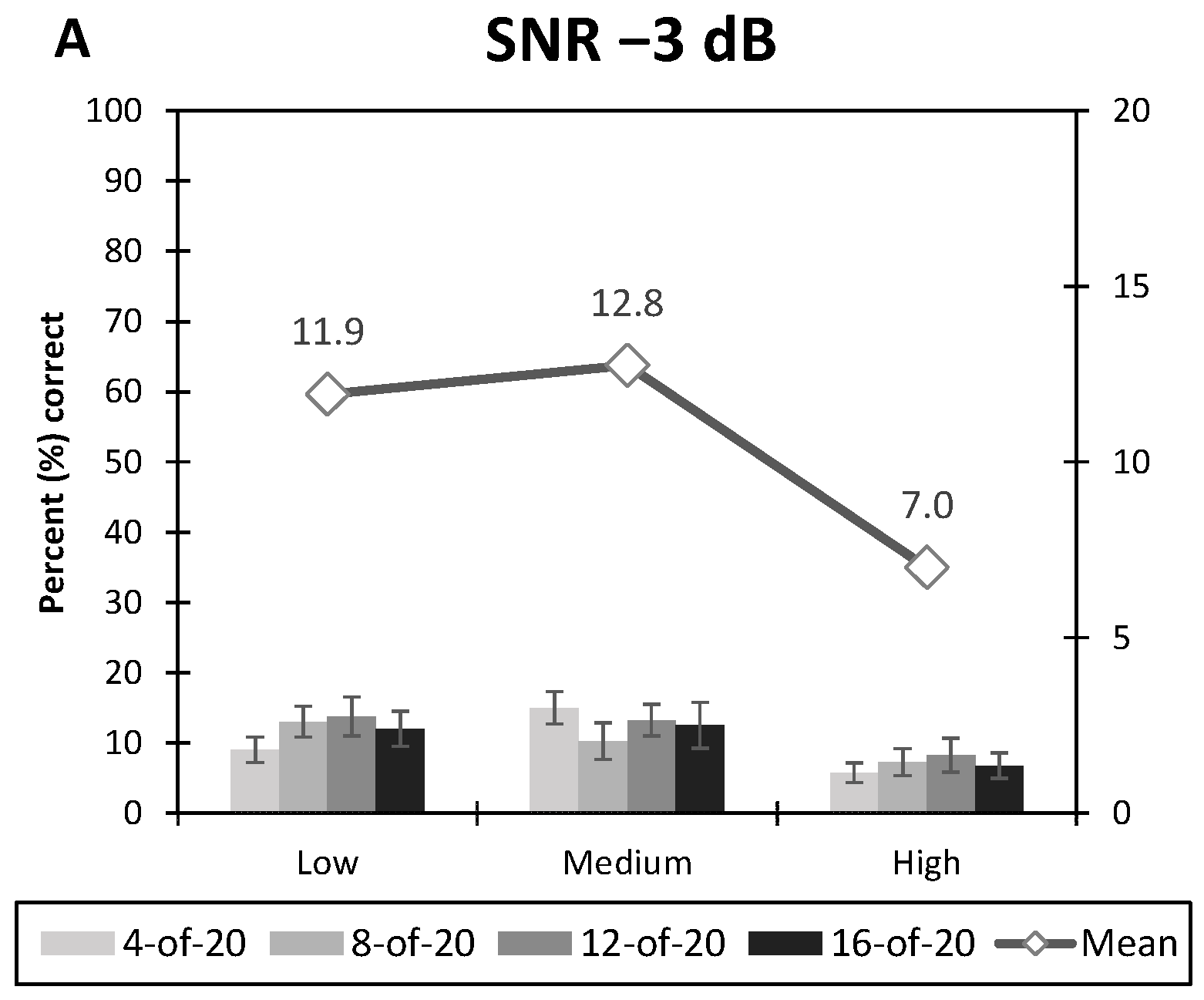
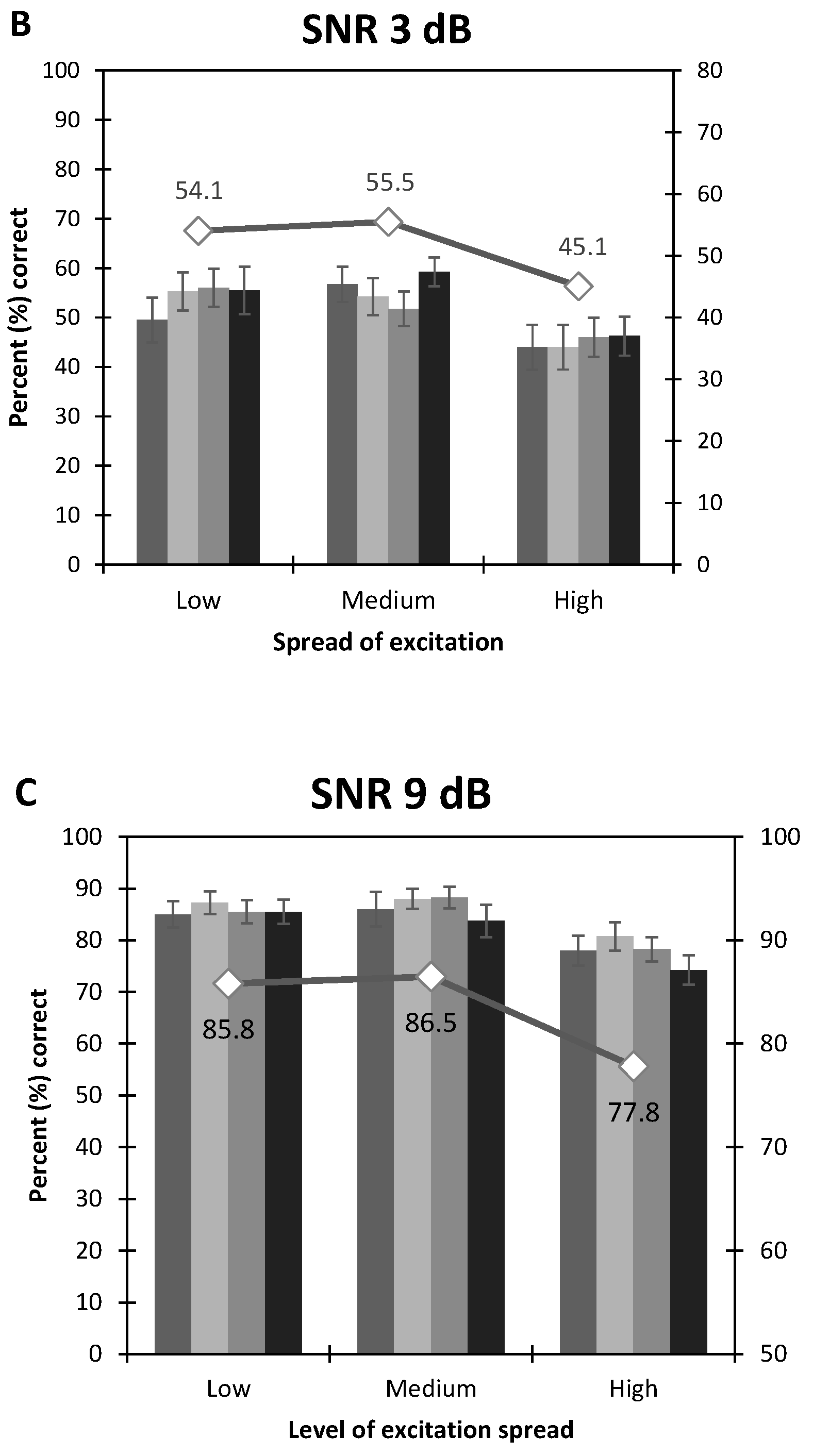
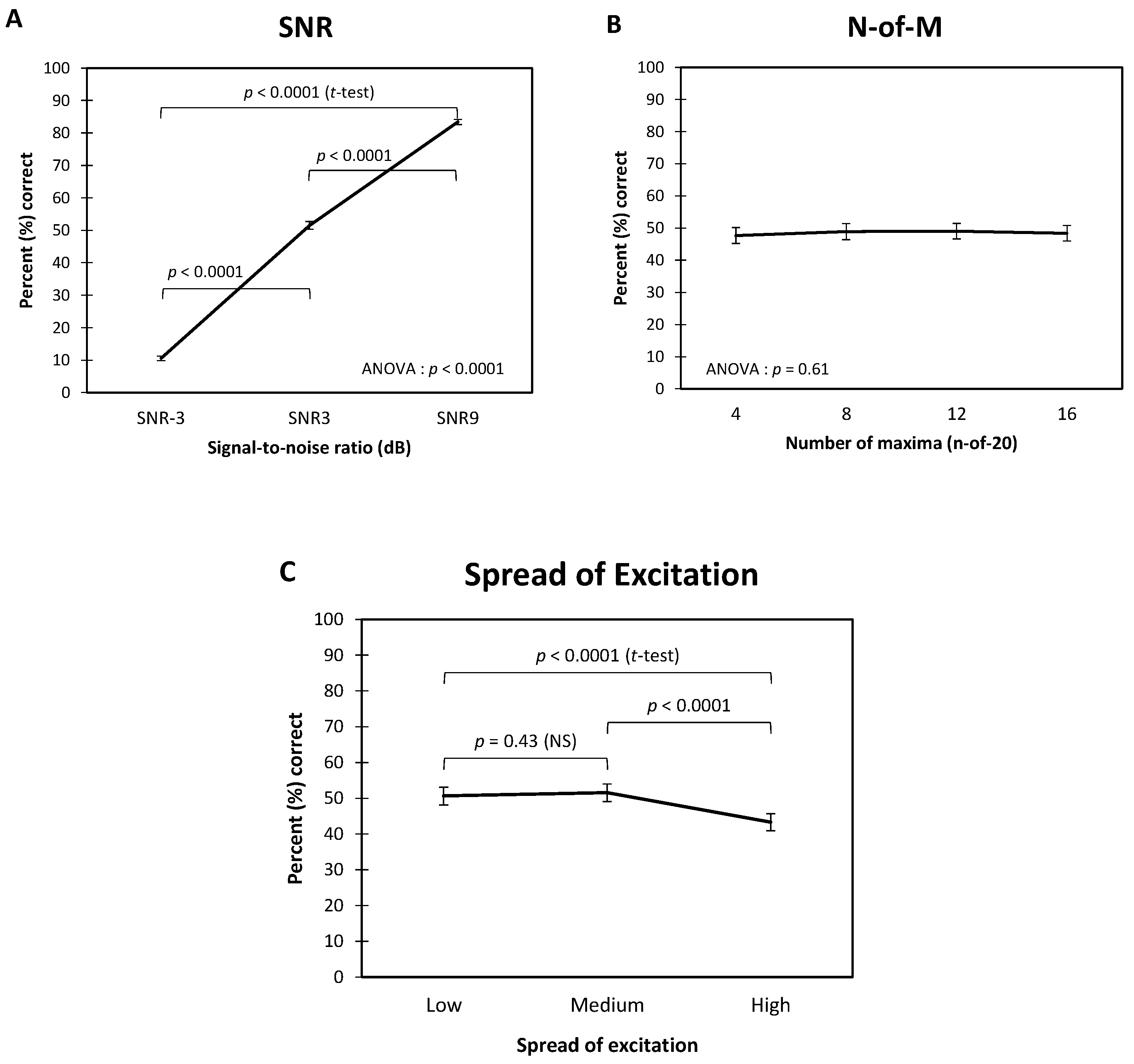
3.1. Speech Audiometry in Noise
- The Spread of excitation: F2, 677 = 23.80, p < 0.0001,
- The SNR: F2, 677 = 999.32, p < 0.0001,
- No effect of the Number of Maxima: F3, 677 = 0.60, p = 0.61.
- Spread of excitation × Number of Maxima: F6, 677 = 0.75, p = 0.61,
- Spread of excitation × SNR: F6, 677 = 0.18, p = 0.95,
- Number of Maxima × SNR: F6, 677 = 0.75, p = 0.61.
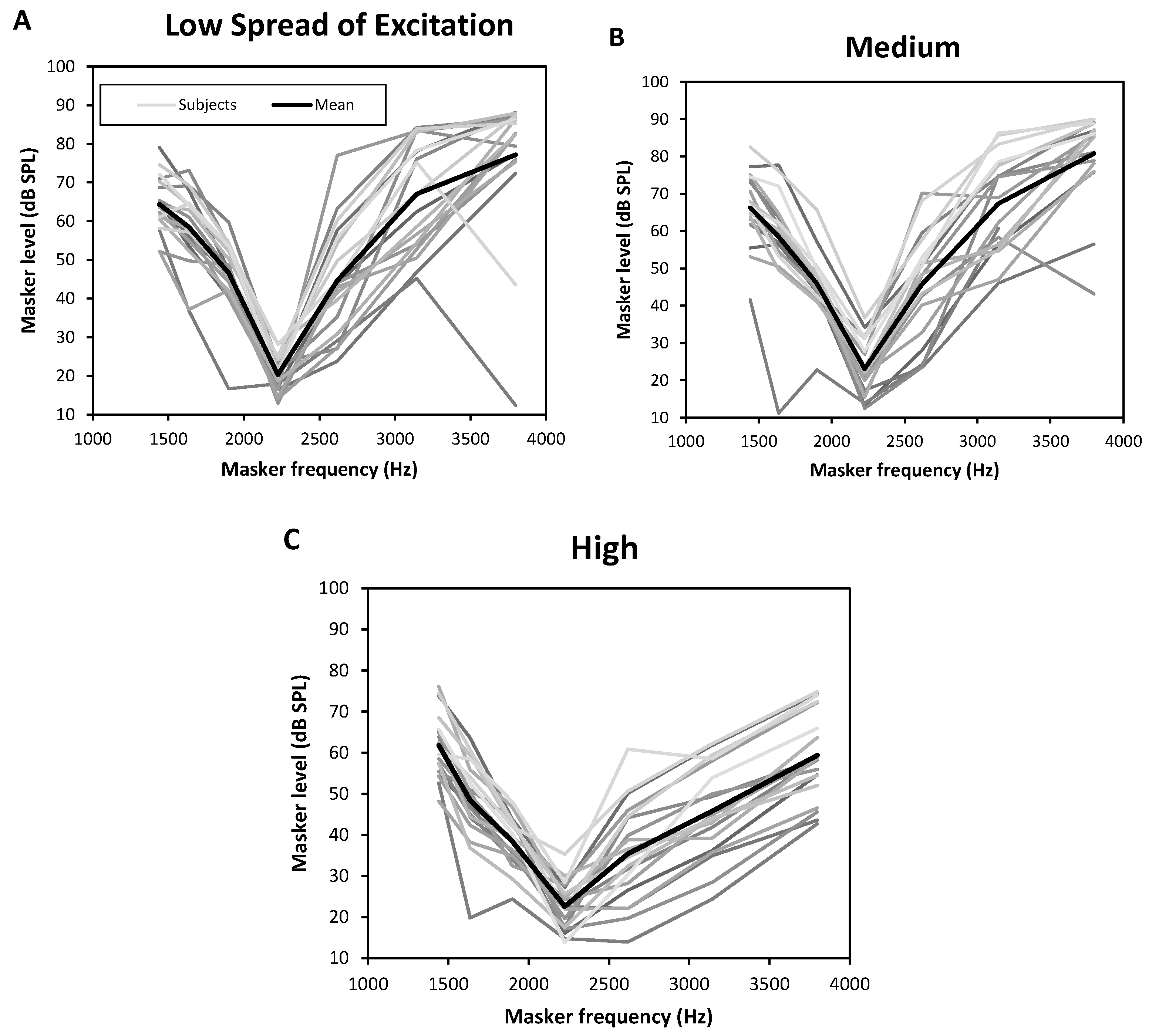
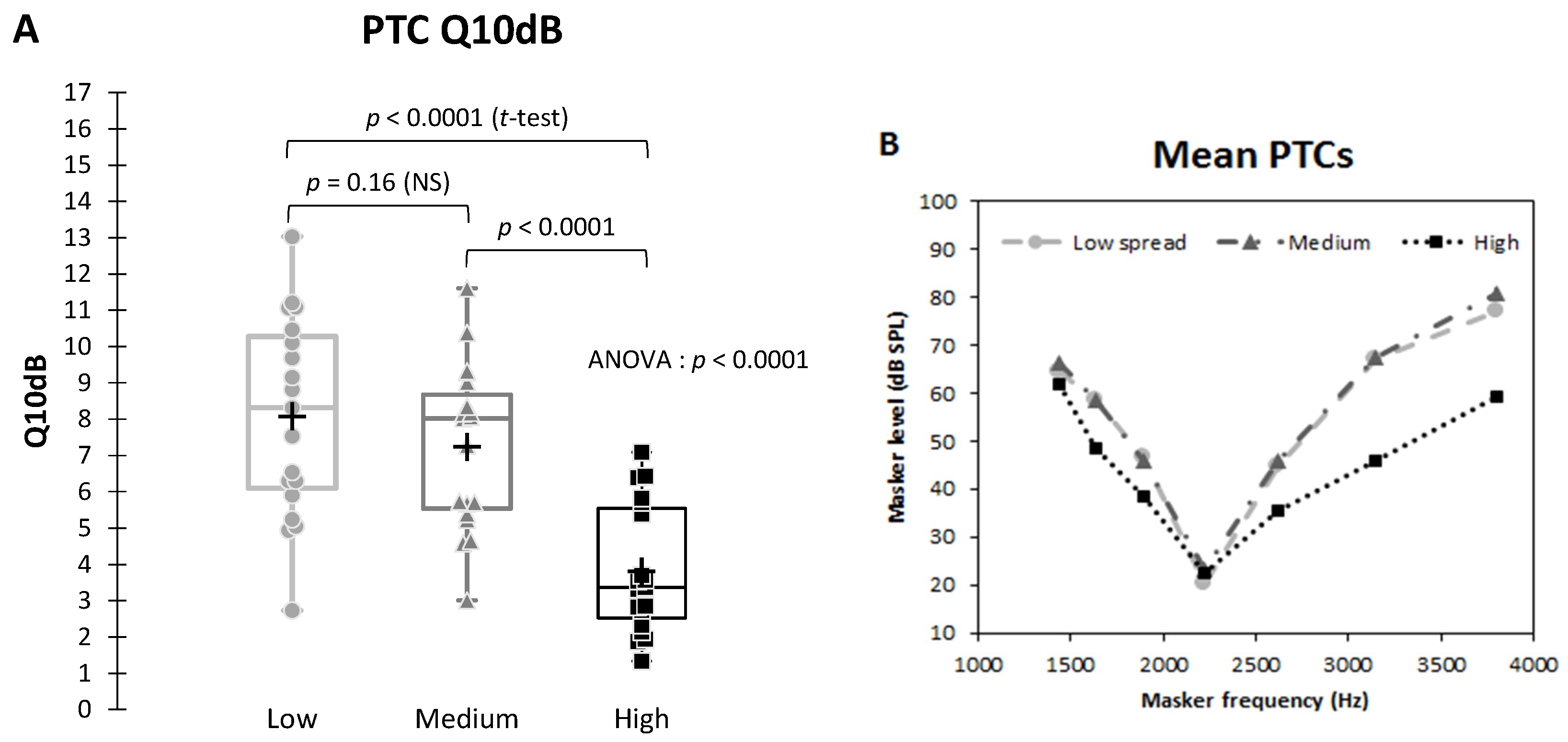
3.2. Psychophysical Tuning Curves
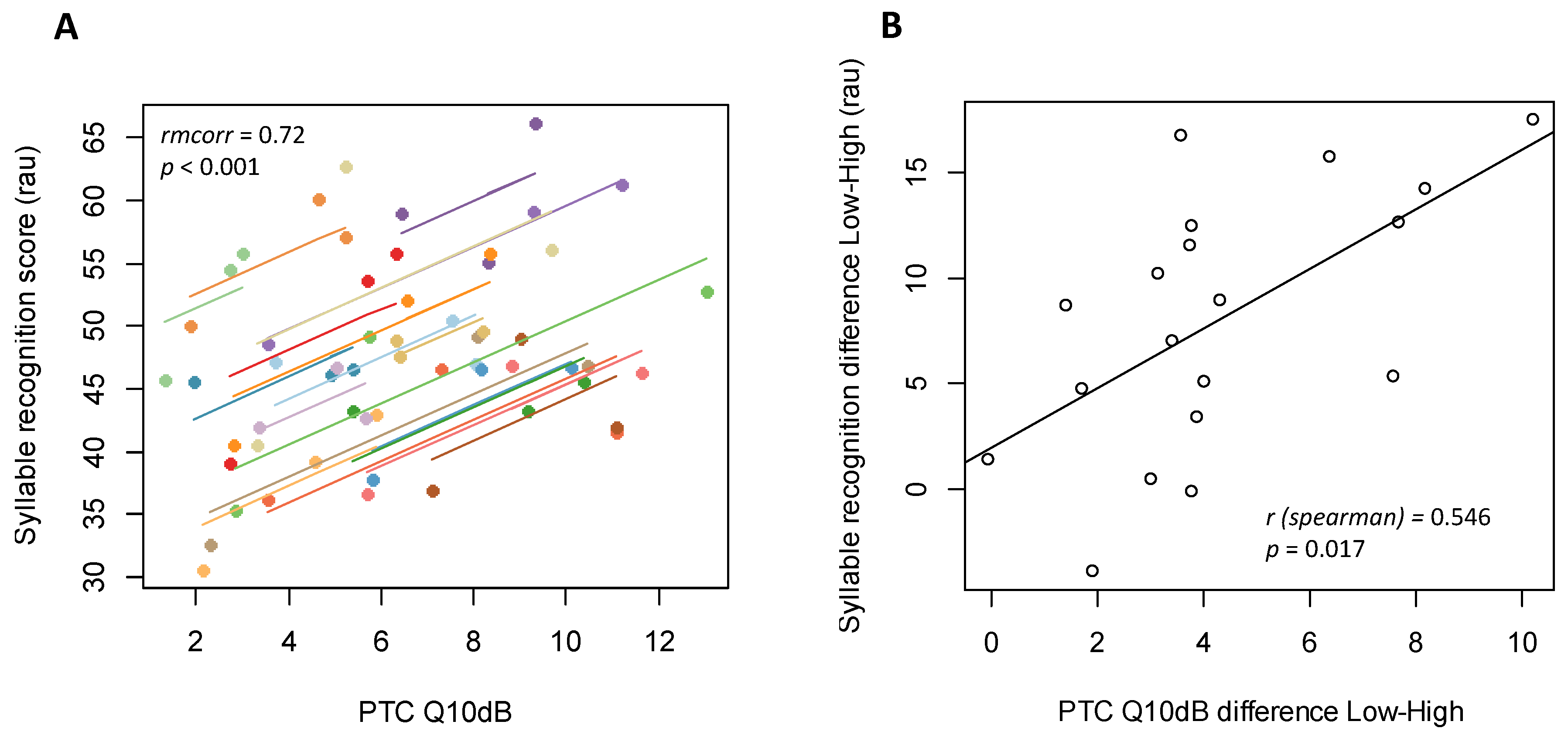
3.3. Correlation between Word Recognition and PTC Sharpness
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Clark, G. Cochlear Implants: Fundamentals and Applications; Springer Science & Business Media: New York, NY, USA, 2006; ISBN 978-0-387-21550-1. [Google Scholar]
- Dhanasingh, A.; Jolly, C. An Overview of Cochlear Implant Electrode Array Designs. Hear. Res. 2017, 356, 93–103. [Google Scholar] [CrossRef]
- McRackan, T.R.; Bauschard, M.; Hatch, J.L.; Franko-Tobin, E.; Droghini, H.R.; Nguyen, S.A.; Dubno, J.R. Meta-Analysis of Quality-of-Life Improvement after Cochlear Implantation and Associations with Speech Recognition Abilities. Laryngoscope 2018, 128, 982–990. [Google Scholar] [CrossRef]
- Mo, B.; Lindbaek, M.; Harris, S. Cochlear Implants and Quality of Life: A Prospective Study. Ear Hear. 2005, 26, 186–194. [Google Scholar] [CrossRef] [Green Version]
- Berger-Vachon, C.; Collet, L.; Djedou, B.; Morgon, A. Model for Understanding the Influence of Some Parameters in Cochlear Implantation. Ann. Otol. Rhinol. Laryngol. 1992, 101, 42–45. [Google Scholar] [CrossRef]
- Shannon, R.V. Multichannel Electrical Stimulation of the Auditory Nerve in Man. I. Basic Psychophysics. Hear. Res. 1983, 11, 157–189. [Google Scholar] [CrossRef]
- Friesen, L.M.; Shannon, R.V.; Baskent, D.; Wang, X. Speech Recognition in Noise as a Function of the Number of Spectral Channels: Comparison of Acoustic Hearing and Cochlear Implants. J. Acoust. Soc. Am. 2001, 110, 1150–1163. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garnham, C.; O’Driscoll, M.; Ramsden And, R.; Saeed, S. Speech Understanding in Noise with a Med-El COMBI 40+ Cochlear Implant Using Reduced Channel Sets. Ear Hear. 2002, 23, 540–552. [Google Scholar] [CrossRef]
- Snel-Bongers, J.; Briaire, J.J.; Vanpoucke, F.J.; Frijns, J.H.M. Spread of Excitation and Channel Interaction in Single- and Dual-Electrode Cochlear Implant Stimulation. Ear Hear. 2012, 33, 367–376. [Google Scholar] [CrossRef]
- Zeng, F.-G.; Rebscher, S.; Harrison, W.; Sun, X.; Feng, H. Cochlear Implants: System Design, Integration, and Evaluation. IEEE Rev. Biomed. Eng. 2008, 1, 115–142. [Google Scholar] [CrossRef] [Green Version]
- de Jong, M.A.M.; Briaire, J.J.; Frijns, J.H.M. Dynamic Current Focusing: A Novel Approach to Loudness Coding in Cochlear Implants. Ear Hear. 2019, 40, 34–44. [Google Scholar] [CrossRef] [PubMed]
- DeVries, L.; Arenberg, J.G. Current Focusing to Reduce Channel Interaction for Distant Electrodes in Cochlear Implant Programs. Trends Hear. 2018, 22. [Google Scholar] [CrossRef] [Green Version]
- Verschuur, C. Modeling the Effect of Channel Number and Interaction on Consonant Recognition in a Cochlear Implant Peak-Picking Strategy. J. Acoust. Soc. Am. 2009, 125, 1723–1736. [Google Scholar] [CrossRef]
- Cohen, L.T.; Richardson, L.M.; Saunders, E.; Cowan, R.S.C. Spatial Spread of Neural Excitation in Cochlear Implant Recipients: Comparison of Improved ECAP Method and Psychophysical Forward Masking. Hear. Res. 2003, 179, 72–87. [Google Scholar] [CrossRef]
- Guevara, N.; Hoen, M.; Truy, E.; Gallego, S. A Cochlear Implant Performance Prognostic Test Based on Electrical Field Interactions Evaluated by EABR (Electrical Auditory Brainstem Responses). PLoS ONE 2016, 11, e0155008. [Google Scholar] [CrossRef] [Green Version]
- Spitzer, E.R.; Choi, S.; Hughes, M.L. The Effect of Stimulus Polarity on the Relation Between Pitch Ranking and ECAP Spread of Excitation in Cochlear Implant Users. J. Assoc. Res. Otolaryngol. 2019, 20, 279–290. [Google Scholar] [CrossRef] [PubMed]
- Nelson, D.A.; Donaldson, G.S.; Kreft, H. Forward-Masked Spatial Tuning Curves in Cochlear Implant Users. J. Acoust. Soc. Am. 2008, 123, 1522–1543. [Google Scholar] [CrossRef] [Green Version]
- DeVries, L.; Arenberg, J.G. Psychophysical Tuning Curves as a Correlate of Electrode Position in Cochlear Implant Listeners. J. Assoc. Res. Otolaryngol. 2018, 19, 571–587. [Google Scholar] [CrossRef]
- Sek, A.; Alcántara, J.; Moore, B.C.J.; Kluk, K.; Wicher, A. Development of a Fast Method for Determining Psychophysical Tuning Curves. Int. J. Audiol. 2005, 44, 408–420. [Google Scholar] [CrossRef]
- Sęk, A.; Moore, B.C.J. Implementation of a Fast Method for Measuring Psychophysical Tuning Curves. Int. J. Audiol. 2011, 50, 237–242. [Google Scholar] [CrossRef]
- Kreft, H.A.; DeVries, L.A.; Arenberg, J.G.; Oxenham, A.J. Comparing Rapid and Traditional Forward-Masked Spatial Tuning Curves in Cochlear-Implant Users. Trends Hear. 2019, 23. [Google Scholar] [CrossRef] [Green Version]
- Anderson, E.S.; Nelson, D.A.; Kreft, H.; Nelson, P.B.; Oxenham, A.J. Comparing Spatial Tuning Curves, Spectral Ripple Resolution, and Speech Perception in Cochlear Implant Users. J. Acoust. Soc. Am. 2011, 130, 364–375. [Google Scholar] [CrossRef]
- Hughes, M.L.; Stille, L.J. Psychophysical versus Physiological Spatial Forward Masking and the Relation to Speech Perception in Cochlear Implants. Ear Hear. 2008, 29, 435–452. [Google Scholar] [CrossRef] [Green Version]
- DeVries, L.; Scheperle, R.; Bierer, J.A. Assessing the Electrode-Neuron Interface with the Electrically Evoked Compound Action Potential, Electrode Position, and Behavioral Thresholds. J. Assoc. Res. Otolaryngol. 2016, 17, 237–252. [Google Scholar] [CrossRef] [Green Version]
- Boëx, C.; Kós, M.-I.; Pelizzone, M. Forward Masking in Different Cochlear Implant Systems. J. Acoust. Soc. Am. 2003, 114, 2058–2065. [Google Scholar] [CrossRef]
- Nelson, D.A.; Kreft, H.A.; Anderson, E.S.; Donaldson, G.S. Spatial Tuning Curves from Apical, Middle, and Basal Electrodes in Cochlear Implant Users. J. Acoust Soc. Am. 2011, 129, 3916–3933. [Google Scholar] [CrossRef] [Green Version]
- Shannon, R.V.; Fu, Q.-J.; Galvin, J. The Number of Spectral Channels Required for Speech Recognition Depends on the Difficulty of the Listening Situation. Acta Otolaryngol. 2004, 124, 50–54. [Google Scholar] [CrossRef]
- Dorman, M.F.; Loizou, P.C.; Fitzke, J.; Tu, Z. Recognition of Monosyllabic Words by Cochlear Implant Patients and by Normal-Hearing Subjects Listening to Words Processed through Cochlear Implant Signal Processing Strategies. Ann. Otol. Rhinol. Laryngol. 2000, 185, 64–66. [Google Scholar] [CrossRef]
- Gnansia, D.; Péan, V.; Meyer, B.; Lorenzi, C. Effects of Spectral Smearing and Temporal Fine Structure Degradation on Speech Masking Release. J. Acoust. Soc. Am. 2009, 125, 4023–4033. [Google Scholar] [CrossRef]
- Hopkins, K.; Moore, B.C.J. The Contribution of Temporal Fine Structure to the Intelligibility of Speech in Steady and Modulated Noise. J. Acoust. Soc. Am. 2009, 125, 442–446. [Google Scholar] [CrossRef] [PubMed]
- Langner, F.; Jürgens, T. Forward-Masked Frequency Selectivity Improvements in Simulated and Actual Cochlear Implant Users Using a Preprocessing Algorithm. Trends Hear. 2016, 20. [Google Scholar] [CrossRef] [Green Version]
- International Bureau for Audiophonology Recommendations 02/1 Audiometric Classification of Hearing Impairments. Available online: https://www.biap.org/en/recommandations/recommendations/tc-02-classification (accessed on 20 May 2020).
- DiNino, M.; Wright, R.A.; Winn, M.B.; Bierer, J.A. Vowel and Consonant Confusions from Spectrally Manipulated Stimuli Designed to Simulate Poor Cochlear Implant Electrode-Neuron Interfaces. J. Acoust. Soc. Am. 2016, 140, 4404–4418. [Google Scholar] [CrossRef] [PubMed]
- Jahn, K.N.; DiNino, M.; Arenberg, J.G. Reducing Simulated Channel Interaction Reveals Differences in Phoneme Identification Between Children and Adults with Normal Hearing. Ear Hear. 2019, 40, 295–311. [Google Scholar] [CrossRef]
- Litvak, L.M.; Spahr, A.J.; Saoji, A.A.; Fridman, G.Y. Relationship between Perception of Spectral Ripple and Speech Recognition in Cochlear Implant and Vocoder Listeners. J. Acoust. Soc. Am. 2007, 122, 982–991. [Google Scholar] [CrossRef] [Green Version]
- Fournier, J.-E. Audiométrie Vocale: Les Epreuves D’intelligibilité et Leurs Applications au Diagnostic, à L’expertise et à la Correction Prothétique des Surdités; Maloine: Paris, France, 1951. [Google Scholar]
- Lafon, J.C. Phonetic test, phonation, audition. JFORL J. Fr. Otorhinolaryngol. Audiophonol. Chir. Maxillofac. 1972, 21, 223–229. [Google Scholar]
- Levitt, H. Transformed Up-down Methods in Psychoacoustics. J. Acoust. Soc. Am. 1971, 49, 467–477. [Google Scholar] [CrossRef]
- Studebaker, G.A. A “Rationalized” Arcsine Transform. J. Speech Hear. Res. 1985, 28, 455–462. [Google Scholar] [CrossRef]
- Sherbecoe, R.L.; Studebaker, G.A. Supplementary Formulas and Tables for Calculating and Interconverting Speech Recognition Scores in Transformed Arcsine Units. Int. J. Audiol. 2004, 43, 442–448. [Google Scholar] [CrossRef] [PubMed]
- Bakdash, J.Z.; Marusich, L.R. Repeated Measures Correlation. Front. Psychol. 2017, 8, 456. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qin, M.K.; Oxenham, A.J. Effects of Simulated Cochlear-Implant Processing on Speech Reception in Fluctuating Maskers. J. Acoust. Soc. Am. 2003, 114, 446–454. [Google Scholar] [CrossRef] [Green Version]
- Rosen, S.; Souza, P.; Ekelund, C.; Majeed, A.A. Listening to Speech in a Background of Other Talkers: Effects of Talker Number and Noise Vocoding. J. Acoust. Soc. Am. 2013, 133, 2431–2443. [Google Scholar] [CrossRef] [Green Version]
- Stickney, G.S.; Zeng, F.-G.; Litovsky, R.; Assmann, P. Cochlear Implant Speech Recognition with Speech Maskers. J. Acoust. Soc. Am. 2004, 116, 1081–1091. [Google Scholar] [CrossRef]
- Dorman, M.; Loizou, P. Speech Intelligibility as a Function of the Number of Channels of Stimulation for Normal-Hearing Listeners and Patients with Cochlear Implants. Am. J. Otol. 1997, 18, S113–S114. [Google Scholar] [PubMed]
- Loizou, P.C.; Dorman, M.; Tu, Z. On the Number of Channels Needed to Understand Speech. J. Acoust. Soc. Am. 1999, 106, 2097–2103. [Google Scholar] [CrossRef]
- Berg, K.A.; Noble, J.H.; Dawant, B.M.; Dwyer, R.T.; Labadie, R.F.; Gifford, R.H. Speech Recognition as a Function of the Number of Channels in Perimodiolar Electrode Recipients. J. Acoust. Soc. Am. 2019, 145, 1556–1564. [Google Scholar] [CrossRef]
- Croghan, N.B.H.; Duran, S.I.; Smith, Z.M. Re-Examining the Relationship between Number of Cochlear Implant Channels and Maximal Speech Intelligibility. J. Acoust. Soc. Am. 2017, 142, EL537–EL543. [Google Scholar] [CrossRef] [Green Version]
- Pals, C.; Sarampalis, A.; Baskent, D. Listening Effort with Cochlear Implant Simulations. J. Speech Lang. Hear. Res. 2013, 56, 1075–1084. [Google Scholar] [CrossRef]
- Winn, M.B.; Edwards, J.R.; Litovsky, R.Y. The Impact of Auditory Spectral Resolution on Listening Effort Revealed by Pupil Dilation. Ear Hear. 2015, 36, e153–e165. [Google Scholar] [CrossRef] [Green Version]
- Dorman, M.F.; Loizou, P.C.; Spahr, A.J.; Maloff, E. A Comparison of the Speech Understanding Provided by Acoustic Models of Fixed-Channel and Channel-Picking Signal Processors for Cochlear Implants. J. Speech Lang. Hear. Res. 2002, 45, 783–788. [Google Scholar] [CrossRef]
- Bingabr, M.; Espinoza-Varas, B.; Loizou, P.C. Simulating the Effect of Spread of Excitation in Cochlear Implants. Hear. Res. 2008, 241, 73–79. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bierer, J.A.; Litvak, L. Reducing Channel Interaction Through Cochlear Implant Programming May Improve Speech Perception: Current Focusing and Channel Deactivation. Trends Hear. 2016, 20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, Q.-J.; Nogaki, G. Noise Susceptibility of Cochlear Implant Users: The Role of Spectral Resolution and Smearing. JARO 2005, 6, 19–27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gaudrain, E.; Başkent, D. Discrimination of Voice Pitch and Vocal-Tract Length in Cochlear Implant Users. Ear Hear. 2018, 39, 226–237. [Google Scholar] [CrossRef] [Green Version]
- Kluk, K.; Moore, B.C.J. Factors Affecting Psychophysical Tuning Curves for Normally Hearing Subjects. Hear. Res. 2004, 194, 118–134. [Google Scholar] [CrossRef] [PubMed]
- Davies-Venn, E.; Nelson, P.; Souza, P. Comparing Auditory Filter Bandwidths, Spectral Ripple Modulation Detection, Spectral Ripple Discrimination, and Speech Recognition: Normal and Impaired Hearing. J. Acoust Soc. Am. 2015, 138, 492–503. [Google Scholar] [CrossRef] [PubMed] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Channel | Lower Cutoff (Hz) | Higher Cutoff (Hz) | Center Frequency (Hz) | Bin(s) Per Channel | Filter Bandwidth (Hz) | Equivalent Rectangular Bandwidth (Hz) |
|---|---|---|---|---|---|---|
| 20 | 195 | 326 | 261 | 1 | 131 | 53 |
| 19 | 326 | 456 | 391 | 1 | 130 | 67 |
| 18 | 456 | 586 | 521 | 1 | 130 | 81 |
| 17 | 586 | 716 | 651 | 1 | 130 | 95 |
| 16 | 716 | 846 | 781 | 1 | 130 | 109 |
| 15 | 846 | 977 | 912 | 1 | 131 | 123 |
| 14 | 977 | 1107 | 1042 | 1 | 130 | 137 |
| 13 | 1107 | 1237 | 1172 | 1 | 130 | 151 |
| 12 | 1237 | 1367 | 1302 | 1 | 130 | 165 |
| 11 | 1367 | 1497 | 1432 | 1 | 130 | 179 |
| 10 | 1497 | 1758 | 1628 | 2 | 261 | 200 |
| 9 | 1758 | 2018 | 1888 | 2 | 260 | 228 |
| 8 | 2018 | 2409 | 2214 | 3 | 391 | 264 |
| 7 | 2409 | 2799 | 2604 | 3 | 390 | 306 |
| 6 | 2799 | 3451 | 3125 | 5 | 652 | 362 |
| 5 | 3451 | 4102 | 3777 | 5 | 651 | 432 |
| 4 | 4102 | 4883 | 4493 | 6 | 781 | 510 |
| 3 | 4883 | 5794 | 5339 | 7 | 911 | 601 |
| 2 | 5794 | 6836 | 6315 | 8 | 1042 | 706 |
| 1 | 6836 | 8008 | 7422 | 9 | 1172 | 826 |
| Channel | Lowest Activation-Frequency (Hz) | Highest Activation-Frequency (Hz) | Center Frequency (Hz) |
|---|---|---|---|
| 20 | 195 | 265 | 230 |
| 19 | 390 | 396 | 393 |
| 18 | 521 | 527 | 524 |
| 17 | 652 | 658 | 655 |
| 16 | 783 | 789 | 786 |
| 15 | 914 | 920 | 917 |
| 14 | 1045 | 1051 | 1048 |
| 13 | 1176 | 1182 | 1179 |
| 12 | 1307 | 1312 | 1310 |
| 11 | 1438 | 1443 | 1441 |
| 10 | 1569 | 1705 | 1637 |
| 9 | 1830 | 1967 | 1899 |
| 8 | 2092 | 2360 | 2226 |
| 7 | 2485 | 2753 | 2619 |
| 6 | 2878 | 3408 | 3143 |
| 5 | 3533 | 4063 | 3798 |
| 4 | 4188 | 4848 | 4518 |
| 3 | 4973 | 5765 | 5369 |
| 2 | 5890 | 6813 | 6352 |
| 1 | 6938 | 8115 | 7527 |
| Parameter | Setting |
|---|---|
| Min. Stim | 9 ns |
| Max. Stim | 52 ns |
| Strategy | Crystalis XDP |
| Stimulation | 500 Hz |
| Maxima | 16 |
| Compression | Linear (personalized) |
| Dynamic range | 26–105 dB SPL |
| Audio input | Auxiliary only (0 dB Gain) |
| Factor | Variation | Unit | Mean | Standard Deviation |
|---|---|---|---|---|
| SNR | SNR-3 | % | 10.6 | 10.8 |
| rau | 6.5 | 16.1 | ||
| SNR3 | % | 51.5 | 18.6 | |
| rau | 51.3 | 17.9 | ||
| SNR9 | % | 83.4 | 12.4 | |
| rau | 84.9 | 16.2 | ||
| Number of Maxima | 4-of-20 | % | 47.7 | 33.4 |
| rau | 47.1 | 36.7 | ||
| 8-of-20 | % | 48.8 | 33.7 | |
| rau | 47.9 | 36.9 | ||
| 12-of-20 | % | 49.0 | 32.5 | |
| rau | 48.1 | 35.2 | ||
| 16-of-20 | % | 48.4 | 32.6 | |
| rau | 47.1 | 36.1 | ||
| Spread of excitation | Low | % | 50.6 | 33.3 |
| rau | 50.1 | 36.2 | ||
| Medium | % | 51.5 | 33.0 | |
| rau | 51.1 | 36.4 | ||
| High | % | 43.3 | 32.2 | |
| rau | 41.4 | 35.4 |
| Frequency (Hz)/Masking Threshold (dB SPL) | 1441 | 1637 | 1898.5 | 2226 | 2619 | 3143 | 3798 |
|---|---|---|---|---|---|---|---|
| Low spread | |||||||
| Mean | 64.4 | 58.4 | 46.5 | 20.3 | 44.6 | 67.0 | 77.2 |
| Standard error | 6.9 | 9.6 | 8.8 | 4.3 | 13.9 | 13.9 | 18.2 |
| Min | 52.1 | 36.8 | 16.6 | 12.8 | 23.8 | 45.2 | 12.3 |
| Max | 79.0 | 73.1 | 59.8 | 28.2 | 77.0 | 84.2 | 88.1 |
| Medium | |||||||
| Mean | 66.2 | 58.4 | 45.9 | 23.1 | 45.7 | 67.3 | 80.8 |
| Standard error | 9.2 | 13.9 | 7.9 | 7.3 | 13.8 | 12.6 | 12.1 |
| Min | 41.5 | 11.2 | 22.8 | 12.4 | 23.4 | 46.0 | 43.1 |
| Max | 82.5 | 77.7 | 65.6 | 36.7 | 70.2 | 86.3 | 90.0 |
| High | |||||||
| Mean | 61.8 | 48.4 | 38.4 | 22.6 | 35.4 | 45.7 | 59.3 |
| Standard error | 7.5 | 9.9 | 5.8 | 5.5 | 11.8 | 10.9 | 10.4 |
| Min | 48.2 | 19.8 | 24.4 | 13.8 | 13.9 | 24.3 | 42.7 |
| Max | 76.1 | 63.6 | 48.1 | 35.3 | 60.8 | 62.2 | 74.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cucis, P.-A.; Berger-Vachon, C.; Thaï-Van, H.; Hermann, R.; Gallego, S.; Truy, E. Word Recognition and Frequency Selectivity in Cochlear Implant Simulation: Effect of Channel Interaction. J. Clin. Med. 2021, 10, 679. https://doi.org/10.3390/jcm10040679
Cucis P-A, Berger-Vachon C, Thaï-Van H, Hermann R, Gallego S, Truy E. Word Recognition and Frequency Selectivity in Cochlear Implant Simulation: Effect of Channel Interaction. Journal of Clinical Medicine. 2021; 10(4):679. https://doi.org/10.3390/jcm10040679
Chicago/Turabian StyleCucis, Pierre-Antoine, Christian Berger-Vachon, Hung Thaï-Van, Ruben Hermann, Stéphane Gallego, and Eric Truy. 2021. "Word Recognition and Frequency Selectivity in Cochlear Implant Simulation: Effect of Channel Interaction" Journal of Clinical Medicine 10, no. 4: 679. https://doi.org/10.3390/jcm10040679
APA StyleCucis, P. -A., Berger-Vachon, C., Thaï-Van, H., Hermann, R., Gallego, S., & Truy, E. (2021). Word Recognition and Frequency Selectivity in Cochlear Implant Simulation: Effect of Channel Interaction. Journal of Clinical Medicine, 10(4), 679. https://doi.org/10.3390/jcm10040679