
A Comparative Study of Various Methods for Handling Missing Data in UNSODA


Abstract
:1. Introduction
- (i)
- Missing completely at random (MCAR): The missing data are not related to known values. With this type of missing data, we assume that a whole distribution of data is completely missing.
- (ii)
- Missing at random (MAR): The missing value depends on an already known value and does not depend upon the missing value itself.
- (iii)
- Not missing at random (NMAR): The missing value does not depend upon any given or missing value.
2. A Brief Review of Existing Missing Value Imputation Techniques

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics-Based | Machine Learning-Based |
|---|---|
| Expectation maximization (EM) [45] | Random forest (RF) * [36,46] |
| Hot deck (HD) [47,48] | Artificial neural networks (ANN) * [49] |
| Multiple imputation (MI) * [50] | Support vector regression (SVR) * [51] |
| Mean/mode * [52] | K-nearest neighbor (KNN) [53] |
| Gaussian mixture model (GMM) [54] | Decision tree (DT) [55] |
| Clustering [55,56] |
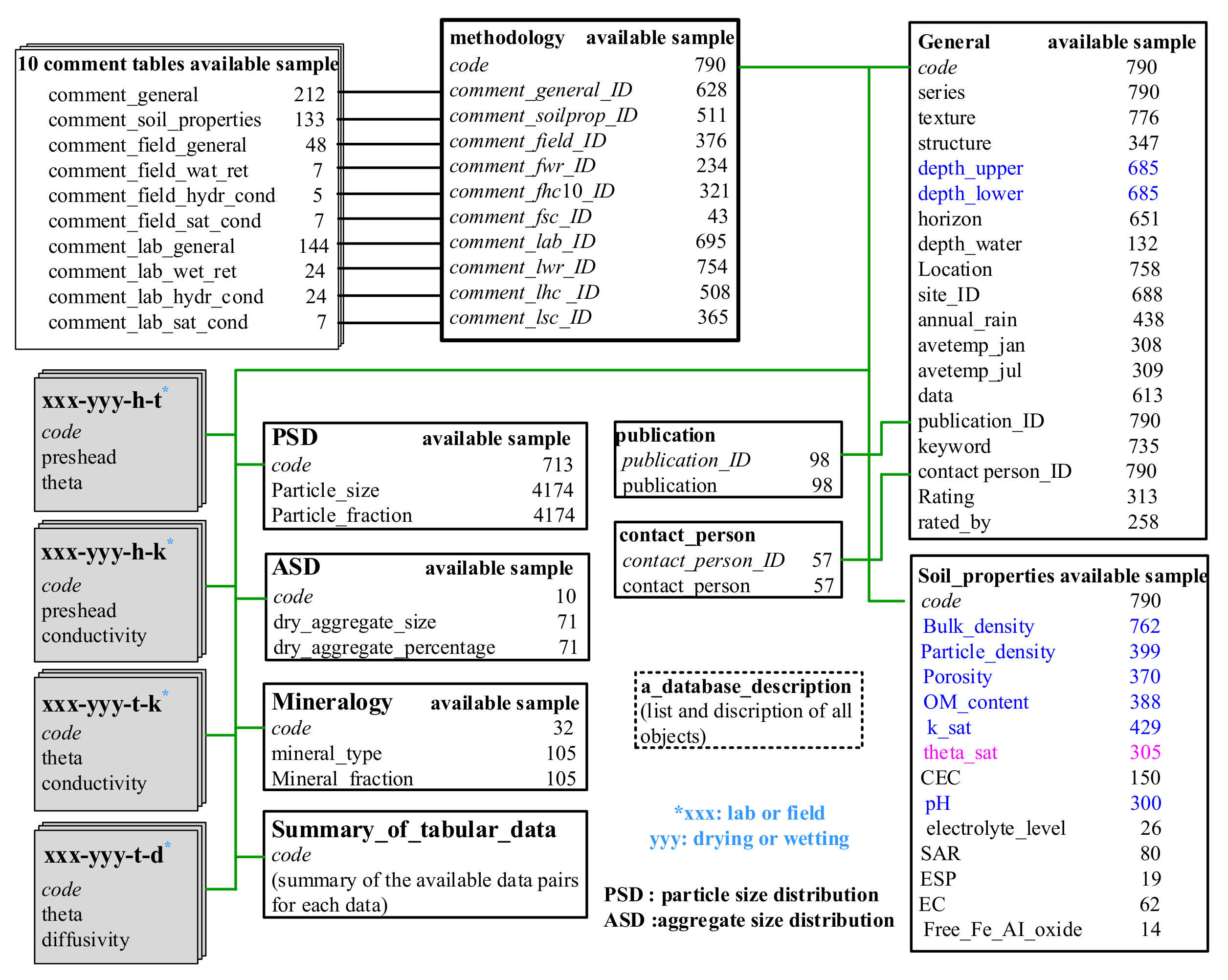
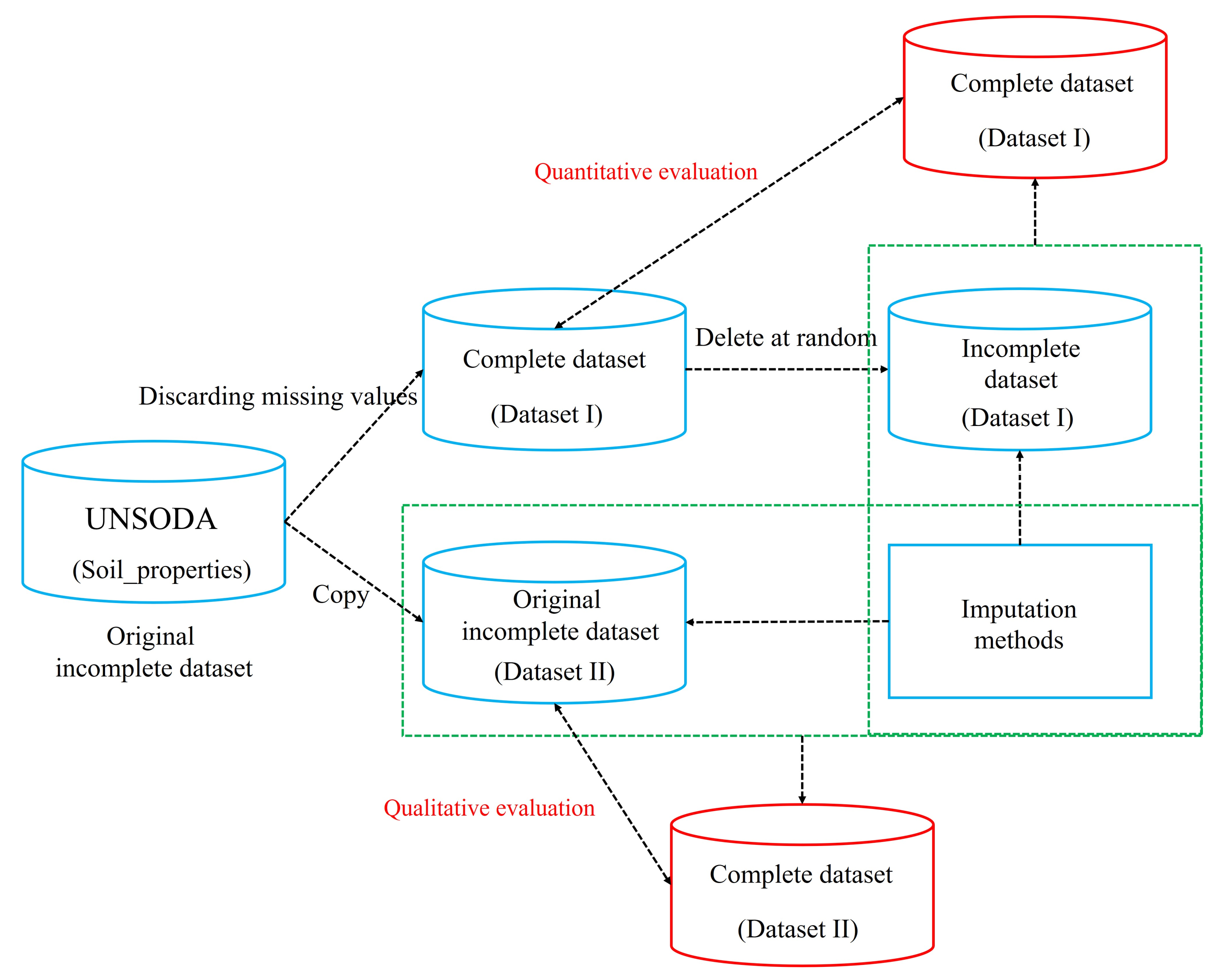
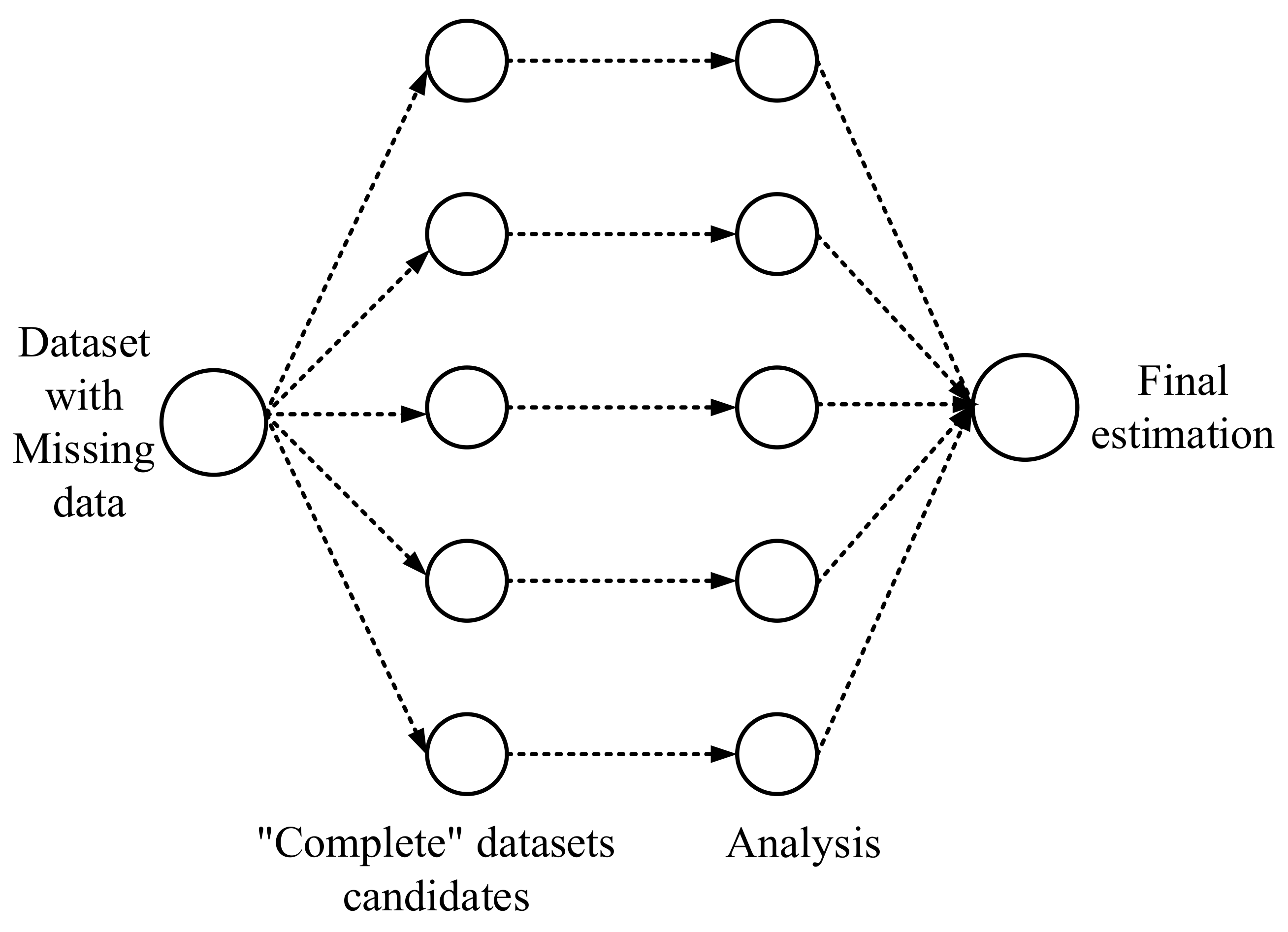
3. The UNSODA Dataset and Procedure for Missing Value Imputation
3.1. The UNSODA Dataset
3.2. Procedure for Missing Values Imputation
4. Methodology
- (i)
- Statistics-based methods, including mean and MI.
- (ii)
- Machine learning-based methods, including RF, SVR, and ANN.
4.1. General Notation
- (i)
- Non-missing values of variable , denoted by .
- (ii)
- Missing values of variable , denoted by .
- (iii)
- Variables other than , with observation , denoted by .
- (iv)
- Variables other than , with observation , denoted by .
4.2. Statistics-Based Methods
4.2.1. Mean Imputation
4.2.2. Multiple Imputation
4.3. Machine Learning-Based Methods
4.3.1. RF Imputation Method
| Algorithm 1: The RF imputation. |
 |
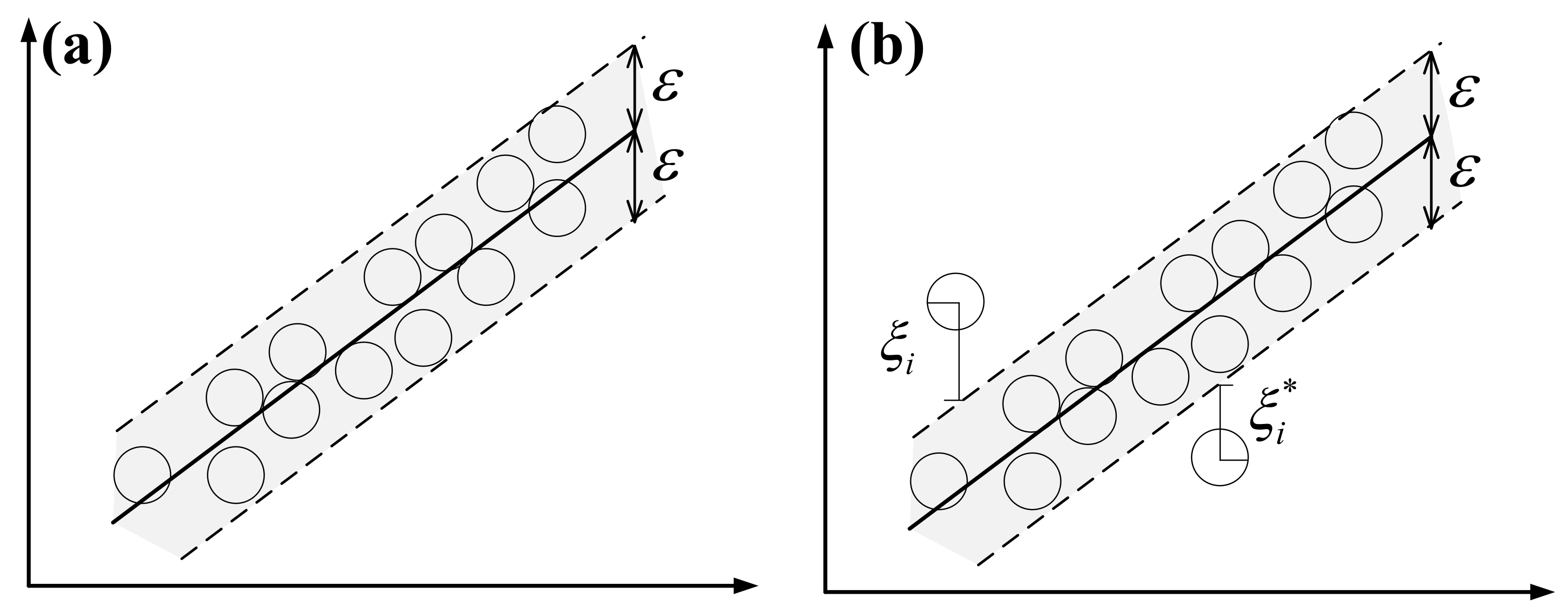
4.3.2. SVR Imputation Method
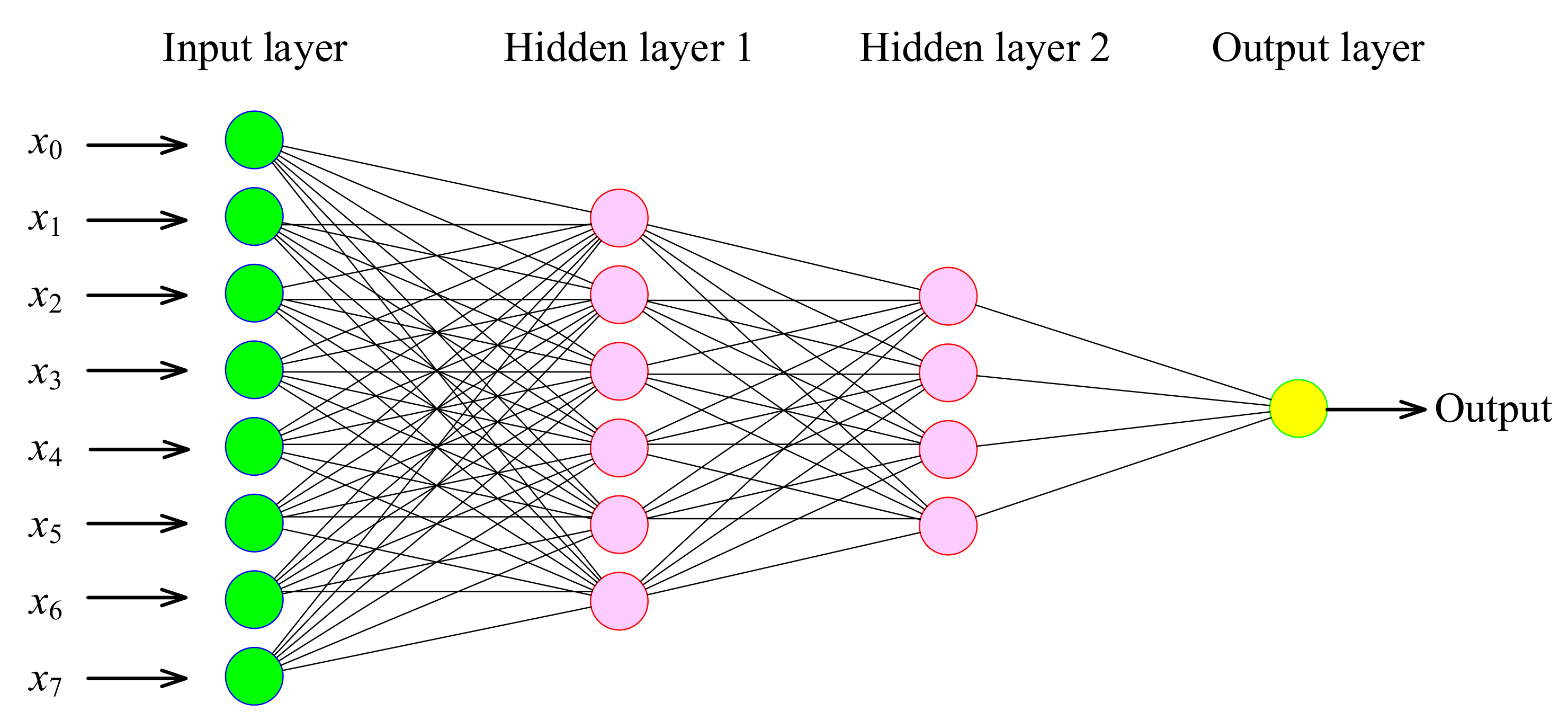
4.3.3. ANN Imputation Method
5. Model Evaluation
5.1. Quantitative Evaluation
5.2. Qualitative Evaluation
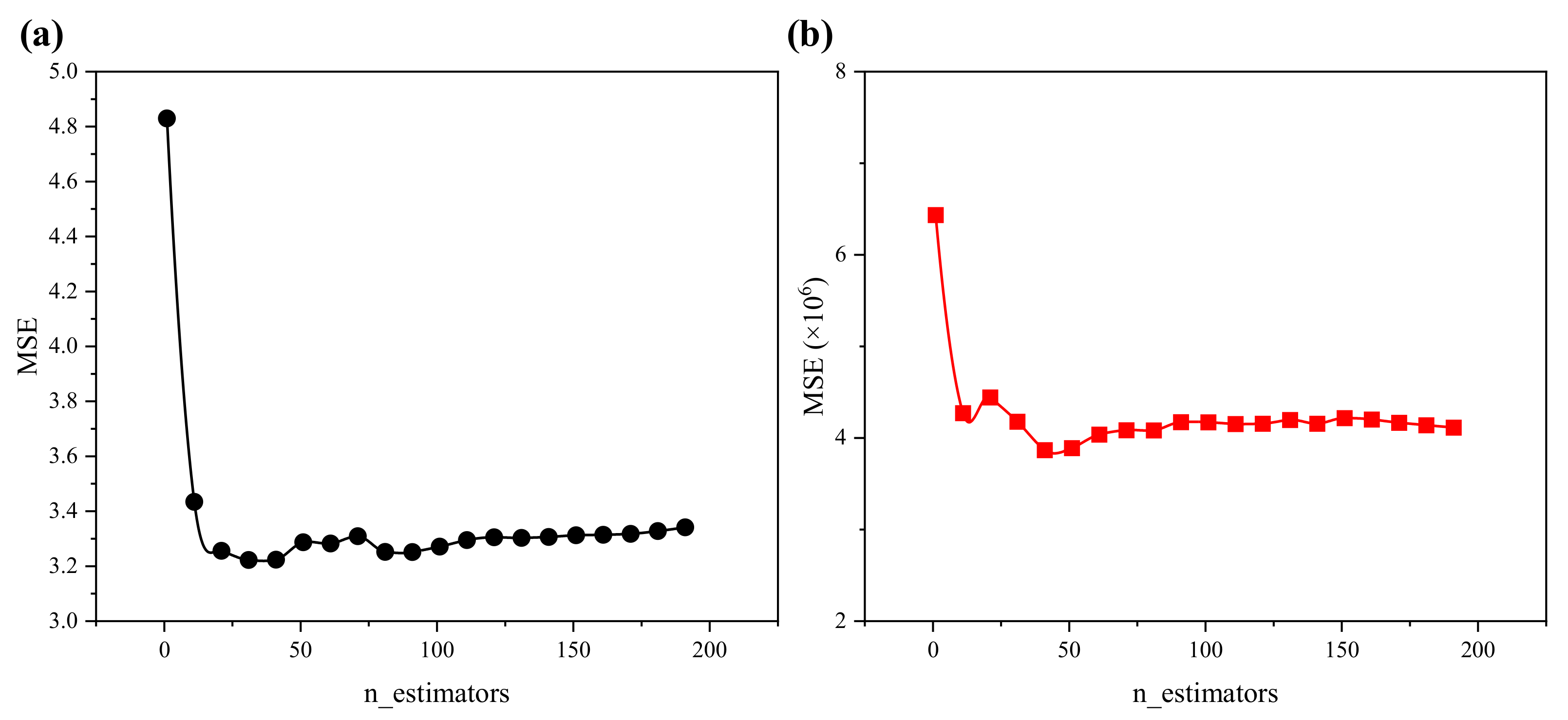
6. Parameter Determination and Sensitivity Analysis
7. Results
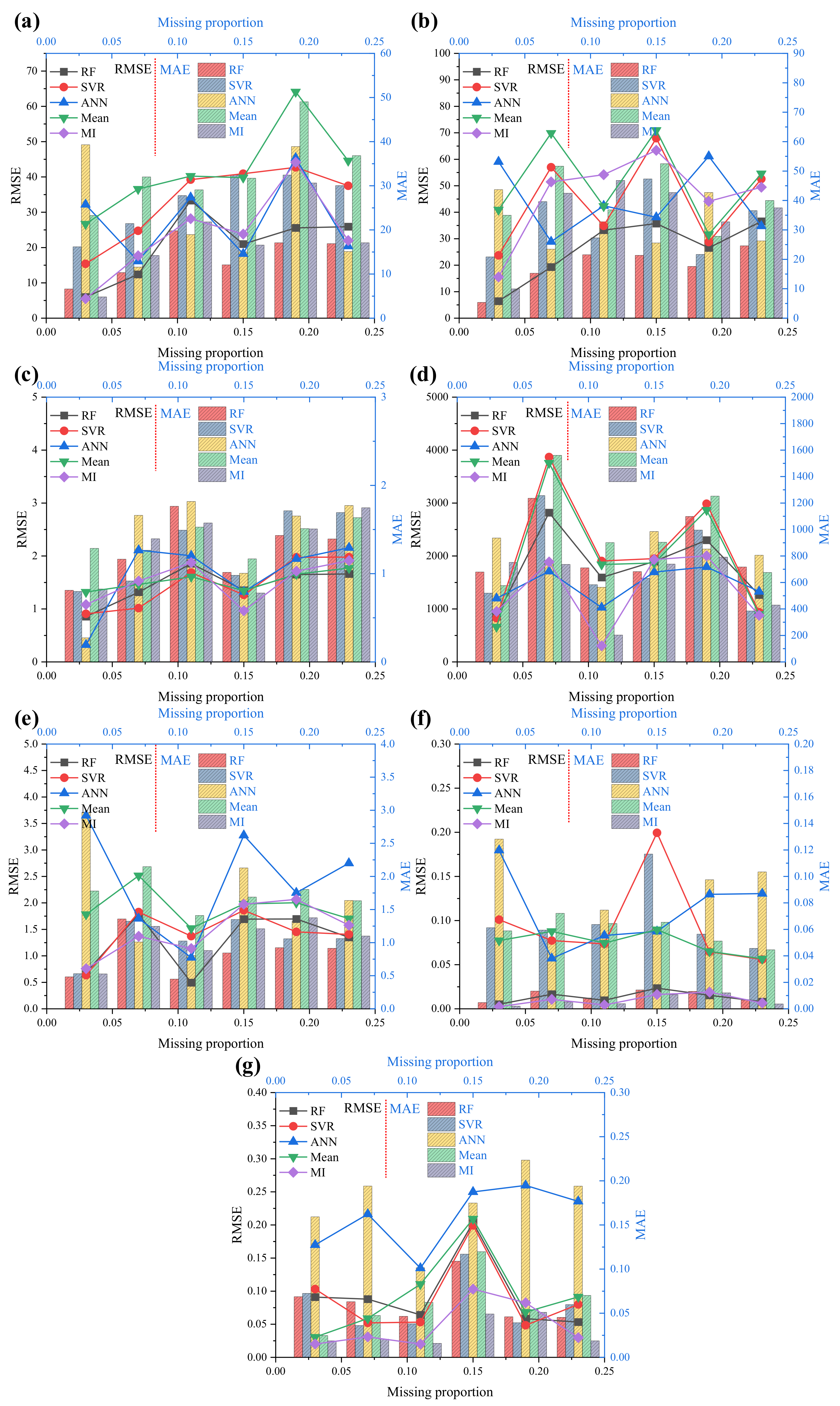
7.1. Quantitative Measures for Dataset I
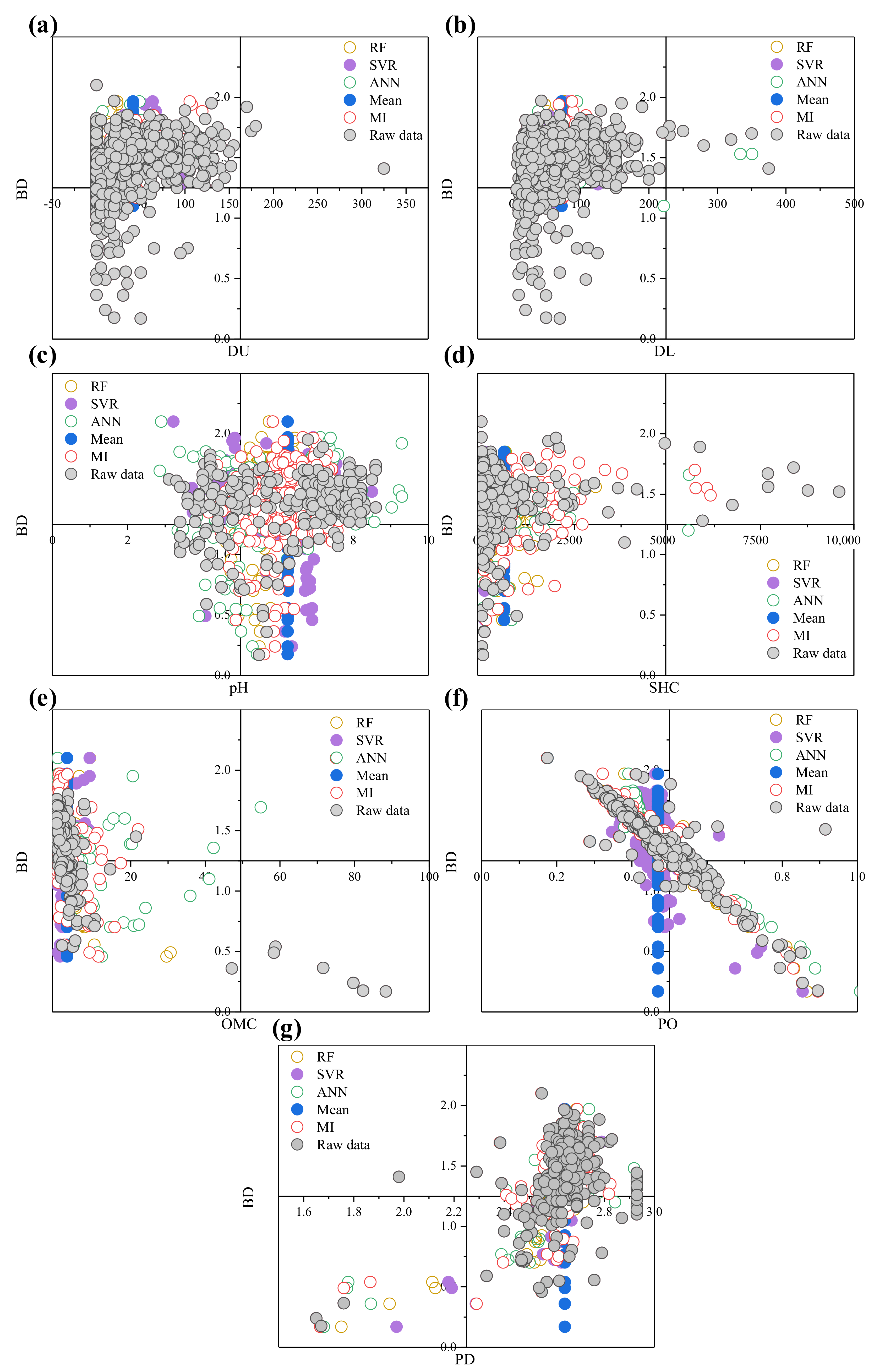
7.2. Qualitative Measures for Dataset II
8. Discussion
9. Conclusions
- (1)
- The RMSEs and MAEs of DU, DL, pH, SHC, OMC, PO, and PD for the complete dataset indicate that RF, SVR, ANN, mean, and MI methods are appropriate for imputing the missing values in UNSODA.
- (2)
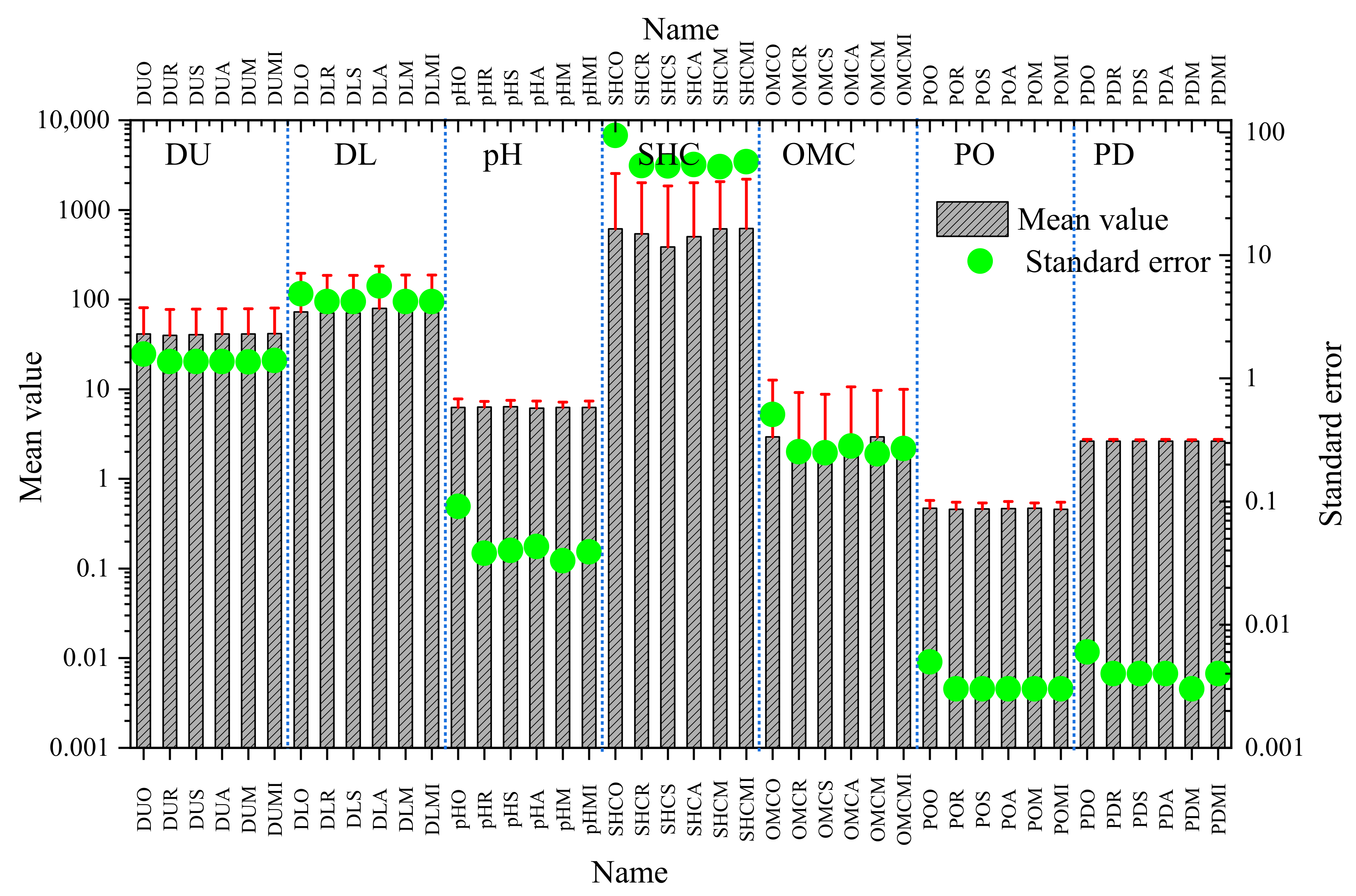
- The standard error significantly decreased after imputation, indicating that the sample means had become closer to the population mean. The decreased coefficients of variation and standard deviations indicate that the individual data points were closer to the sample mean values.
- (3)
- There were no significant differences before and after imputation for DU, DL, pH, SHC, OMC, PO, and PD.
- (4)
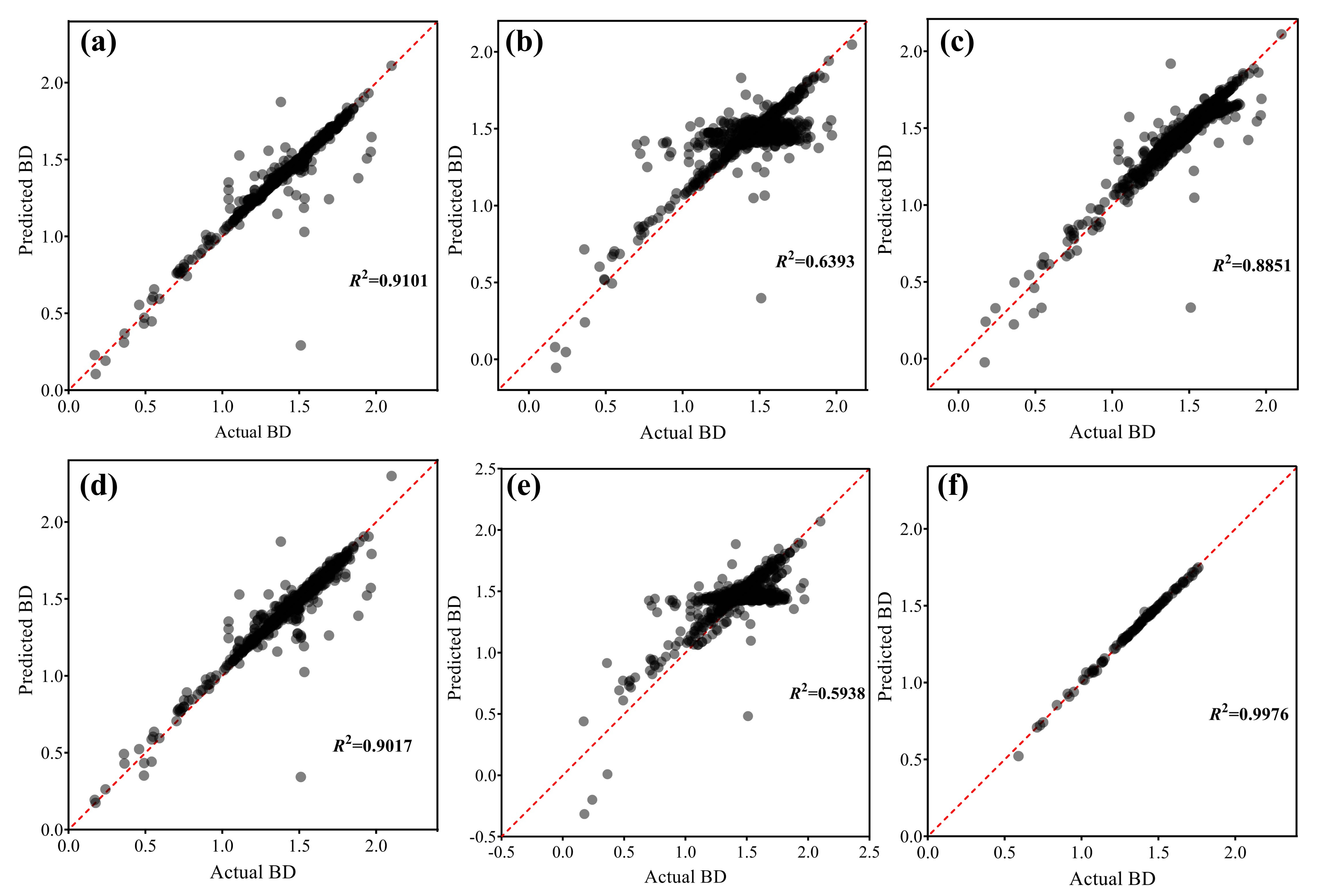
- DU, pH, SHC, OMC, PO, and PD explained 91.0%, 63.9%, 88.5%, 59.4%, and 90.2% of the variation in BD after RF, SVR, ANN, mean, and MI imputation, respectively; and this value was 99.8% when missing values were discarded.
- (5)
- This study suggests that the RF and MI methods may be best for imputing the missing data in UNSODA.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| UNSODA | international unsaturated soil database |
| RF | random forests |
| SVR | support vector |
| ANN | artificial neural network |
| MI | multiple imputation |
| SHC | saturated hydraulic conductivity |
| PO | porosity |
| PD | particle density |
| BD | bulk density |
| OMC | organic matter content |
| DU | upper depth |
| DL | lower depth |
| WC | water content |
| VIF | variance inflation factor |
| MSE | mean square error |
| MAE | mean absolute error |
| RMSE | root mean square error |
References
- Hartemink, A.E. Soil chemical and physical properties as indicators of sustainable land management under sugar cane in Papua New Guinea. Geoderma 1998, 85, 283–306. [Google Scholar] [CrossRef]
- Chung, R.S.; Wang, C.H.; Wang, C.W.; Wang, Y.P. Influence of organic matter and inorganic fertilizer on the growth and nitrogen accumulation of corn plants. J. Plant Nutr. 2000, 23, 297–311. [Google Scholar] [CrossRef]
- Islam, A.; Edwards, D.; Asher, C. pH optima for crop growth. Plant Soil 1980, 54, 339–357. [Google Scholar] [CrossRef]
- Karapouloutidou, S.; Gasparatos, D. Effects of biostimulant and organic amendment on soil properties and nutrient status of Lactuca sativa in a calcareous saline-sodic soil. Agriculture 2019, 9, 164. [Google Scholar] [CrossRef] [Green Version]
- Bruand, A.; Fernández, P.P.; Duval, O. Use of class pedotransfer functions based on texture and bulk density of clods to generate water retention curves. Soil Use Manag. 2003, 19, 232–242. [Google Scholar] [CrossRef]
- Shwetha, P.; Varija, K. Soil water retention curve from saturated hydraulic conductivity for sandy loam and loamy sand textured soils. Aquat. Procedia 2015, 4, 1142–1149. [Google Scholar] [CrossRef]
- Zhang, J.; Ma, G.; Huang, Y.; Aslani, F.; Nener, B. Modelling uniaxial compressive strength of lightweight self-compacting concrete using random forest regression. Constr. Build. Mater. 2019, 210, 713–719. [Google Scholar] [CrossRef]
- Peters, A.; Hohenbrink, T.L.; Iden, S.C.; Durner, W. A simple model to predict hydraulic conductivity in medium to dry soil from the water retention curve. Water Resour. Res. 2021, 57, e2020WR029211. [Google Scholar] [CrossRef]
- Fu, Y.; Liao, H.; Chai, X.; Li, Y.; Lv, L. A Hysteretic Model Considering Contact Angle Hysteresis for Fitting Soil-Water Characteristic Curves. Water Resour. Res. 2021, 57, e2019WR026889. [Google Scholar] [CrossRef]
- Abu-Hamdeh, N.H. Compaction and subsoiling effects on corn growth and soil bulk density. Soil Sci. Soc. Am. J. 2003, 67, 1213–1219. [Google Scholar] [CrossRef]
- Ghezzehei, T.A. Errors in determination of soil water content using time domain reflectometry caused by soil compaction around waveguides. Water Resour. Res. 2008, 44, W08451. [Google Scholar] [CrossRef] [Green Version]
- Yi, X.; Li, G.; Yin, Y. Pedotransfer functions for estimating soil bulk density: A case study in the Three-River Headwater region of Qinghai Province, China. Pedosphere 2016, 26, 362–373. [Google Scholar] [CrossRef]
- Mohanty, B.; Bowman, R.; Hendrickx, J.; Van Genuchten, M.T. New piecewise-continuous hydraulic functions for modeling preferential flow in an intermittent-flood-irrigated field. Water Resour. Res. 1997, 33, 2049–2063. [Google Scholar] [CrossRef]
- Curtis, R.O.; Post, B.W. Estimating bulk density from organic-matter content in some Vermont forest soils. Soil Sci. Soc. Am. J. 1964, 28, 285–286. [Google Scholar] [CrossRef]
- Kaur, R.; Kumar, S.; Gurung, H. A pedo-transfer function (PTF) for estimating soil bulk density from basic soil data and its comparison with existing PTFs. Soil Res. 2002, 40, 847–858. [Google Scholar] [CrossRef]
- Shiri, J.; Keshavarzi, A.; Kisi, O.; Karimi, S.; Iturraran-Viveros, U. Modeling soil bulk density through a complete data scanning procedure: Heuristic alternatives. J. Hydrol. 2017, 549, 592–602. [Google Scholar] [CrossRef]
- Bagarello, V.; Baiamonte, G.; Caia, C. Variability of near-surface saturated hydraulic conductivity for the clay soils of a small Sicilian basin. Geoderma 2019, 340, 133–145. [Google Scholar] [CrossRef]
- Zapata, C.E.; Houston, W.N.; Houston, S.L.; Walsh, K.D. Soil–water characteristic curve variability. In Advances in Unsaturated Geotechnics; CRC Press: Boca Raton, FL, USA, 2000; pp. 84–124. [Google Scholar]
- Bouma, J. Using soil survey data for quantitative land evaluation. In Advances in Soil Science; Springer: Berlin/Heidelberg, Germany, 1989; pp. 177–213. [Google Scholar]
- Wösten, J.; Pachepsky, Y.A.; Rawls, W. Pedotransfer functions: Bridging the gap between available basic soil data and missing soil hydraulic characteristics. J. Hydrol. 2001, 251, 123–150. [Google Scholar] [CrossRef]
- Nemes, A.D.; Schaap, M.; Leij, F.; Wösten, J. Description of the unsaturated soil hydraulic database UNSODA version 2.0. J. Hydrol. 2001, 251, 151–162. [Google Scholar] [CrossRef]
- Leij, F.J. The UNSODA Unsaturated Soil Hydraulic Database: User’s Manual; National Risk Management Research Laboratory, Office of Research and Development, US Environmental Protection Agency: Cincinnati, OH, USA, 1996.
- Wösten, J.; Lilly, A.; Nemes, A.; Le Bas, C. Development and use of a database of hydraulic properties of European soils. Geoderma 1999, 90, 169–185. [Google Scholar] [CrossRef]
- Nachtergaele, F.; van Velthuizen, H.; Verelst, L.; Batjes, N.; Dijkshoorn, K.; van Engelen, V.; Fischer, G.; Jones, A.; Montanarela, L. The harmonized world soil database. In Proceedings of the 19th World Congress of Soil Science, Soil Solutions for a Changing World, Brisbane, Australia, 1–6 August 2010; pp. 34–37. [Google Scholar]
- Huang, G.; Zhang, R. Evaluation of soil water retention curve with the pore–solid fractal model. Geoderma 2005, 127, 52–61. [Google Scholar] [CrossRef]
- Hwang, S.I.; Powers, S.E. Using particle-size distribution models to estimate soil hydraulic properties. Soil Sci. Soc. Am. J. 2003, 67, 1103–1112. [Google Scholar] [CrossRef]
- Hwang, S.; Yun, E.; Ro, H. Estimation of soil water retention function based on asymmetry between particle-and pore-size distributions. Eur. J. Soil Sci. 2011, 62, 195–205. [Google Scholar] [CrossRef]
- Mohammadi, M.H.; Vanclooster, M. Predicting the soil moisture characteristic curve from particle size distribution with a simple conceptual model. Vadose Zone J. 2011, 10, 594–602. [Google Scholar] [CrossRef]
- Chang, C.; Cheng, D. Predicting the soil water retention curve from the particle size distribution based on a pore space geometry containing slit-shaped spaces. Hydrol. Earth Syst. Sci. 2018, 22, 4621–4632. [Google Scholar] [CrossRef] [Green Version]
- Ghanbarian-Alavijeh, B.; Liaghat, A.; Huang, G.H.; Van Genuchten, M.T. Estimation of the van Genuchten soil water retention properties from soil textural data. Pedosphere 2010, 20, 456–465. [Google Scholar] [CrossRef]
- Haverkamp, R.; Leij, F.J.; Fuentes, C.; Sciortino, A.; Ross, P. Soil water retention: I. Introduction of a shape index. Soil Sci. Soc. Am. J. 2005, 69, 1881–1890. [Google Scholar] [CrossRef]
- Seki, K. SWRC fit—A nonlinear fitting program with a water retention curve for soils having unimodal and bimodal pore structure. Hydrol. Earth Syst. Sci. Discuss. 2007, 4, 407–437. [Google Scholar]
- Ghanbarian, B.; Hunt, A.G. Improving unsaturated hydraulic conductivity estimation in soils via percolation theory. Geoderma 2017, 303, 9–18. [Google Scholar] [CrossRef]
- Pham, K.; Kim, D.; Yoon, Y.; Choi, H. Analysis of neural network based pedotransfer function for predicting soil water characteristic curve. Geoderma 2019, 351, 92–102. [Google Scholar] [CrossRef]
- Vaz, C.M.P.; Ferreira, E.J.; Posadas, A.D. Evaluation of models for fitting soil particle-size distribution using UNSODA and a Brazilian dataset. Geoderma Reg. 2020, 21, e00273. [Google Scholar] [CrossRef]
- Tang, F.; Ishwaran, H. Random forest missing data algorithms. Stat. Anal. Data Min. ASA Data Sci. J. 2017, 10, 363–377. [Google Scholar] [CrossRef]
- Strike, K.; El Emam, K.; Madhavji, N. Software cost estimation with incomplete data. IEEE Trans. Softw. Eng. 2001, 27, 890–908. [Google Scholar] [CrossRef] [Green Version]
- Raymond, M.R.; Roberts, D.M. A comparison of methods for treating incomplete data in selection research. Educ. Psychol. Meas. 1987, 47, 13–26. [Google Scholar] [CrossRef]
- Lin, W.C.; Tsai, C.F. Missing value imputation: A review and analysis of the literature (2006–2017). Artif. Intell. Rev. 2020, 53, 1487–1509. [Google Scholar] [CrossRef]
- Puri, A.; Gupta, M. Review on Missing Value Imputation Techniques in Data Mining. In Proceedings of the International Conference on Machine Learning and Computational Intelligence, Sydney, Australia, 6–11 August 2017; pp. 35–40. [Google Scholar]
- Van Genuchten, M.T.; Leij, F.; Lund, L. Indirect Methods for Estimating the Hydraulic Properties of Unsaturated Soils; U.S. Department of Agriculture: North Bend, WA, USA, 1992.
- Lin, J.; Li, N.; Alam, M.A.; Ma, Y. Data-driven missing data imputation in cluster monitoring system based on deep neural network. Appl. Intell. 2020, 50, 860–877. [Google Scholar] [CrossRef] [Green Version]
- Rubin, D.B. Multiple imputation after 18+ years. J. Am. Stat. Assoc. 1996, 91, 473–489. [Google Scholar] [CrossRef]
- Jerez, J.M.; Molina, I.; García-Laencina, P.J.; Alba, E.; Ribelles, N.; Martín, M.; Franco, L. Missing data imputation using statistical and machine learning methods in a real breast cancer problem. Artif. Intell. Med. 2010, 50, 105–115. [Google Scholar] [CrossRef]
- Ghorbani, S.; Desmarais, M.C. Performance comparison of recent imputation methods for classification tasks over binary data. Appl. Artif. Intell. 2017, 31, 1–22. [Google Scholar]
- Shah, A.D.; Bartlett, J.W.; Carpenter, J.; Nicholas, O.; Hemingway, H. Comparison of random forest and parametric imputation models for imputing missing data using MICE: A CALIBER study. Am. J. Epidemiol. 2014, 179, 764–774. [Google Scholar] [CrossRef] [Green Version]
- Reilly, M. Data analysis using hot deck multiple imputation. J. R. Stat. Soc. Ser. D Stat. 1993, 42, 307–313. [Google Scholar] [CrossRef]
- Nishanth, K.J.; Ravi, V. Probabilistic neural network based categorical data imputation. Neurocomputing 2016, 218, 17–25. [Google Scholar] [CrossRef]
- Kuligowski, R.J.; Barros, A.P. Using artificial neural networks to estimate missing rainfall data 1. JAWRA J. Am. Water Resour. Assoc. 1998, 34, 1437–1447. [Google Scholar] [CrossRef]
- Hassani, H.; Kalantari, M.; Ghodsi, Z. Evaluating the Performance of Multiple Imputation Methods for Handling Missing Values in Time Series Data: A Study Focused on East Africa, Soil-Carbonate-Stable Isotope Data. Stats 2019, 2, 457–467. [Google Scholar] [CrossRef] [Green Version]
- Lorenzi, L.; Mercier, G.; Melgani, F. Support vector regression with kernel combination for missing data reconstruction. IEEE Geosci. Remote Sens. Lett. 2012, 10, 367–371. [Google Scholar] [CrossRef]
- Humphries, M. Missing Data & How to Deal: An Overview of Missing Data; Population Research Center, University of Texas: Austin, TX, USA, 2013; pp. 39–41. Available online: https://liberalarts.utexas.edu/prc/_files/cs/Missing-Data.pdf (accessed on 21 July 2021).
- Malarvizhi, R.; Thanamani, A.S. K-nearest neighbor in missing data imputation. Int. J. Eng. Res. Dev. 2012, 5, 5–7. [Google Scholar]
- Yan, X.; Xiong, W.; Hu, L.; Wang, F.; Zhao, K. Missing value imputation based on gaussian mixture model for the internet of things. Math. Probl. Eng. 2015, 2015, 548605. [Google Scholar] [CrossRef]
- Nikfalazar, S.; Yeh, C.H.; Bedingfield, S.; Khorshidi, H.A. Missing data imputation using decision trees and fuzzy clustering with iterative learning. Knowl. Inf. Syst. 2020, 62, 2419–2437. [Google Scholar] [CrossRef]
- Somasundaram, R.; Nedunchezhian, R. Evaluation of three simple imputation methods for enhancing preprocessing of data with missing values. Int. J. Comput. Appl. 2011, 21, 14–19. [Google Scholar] [CrossRef]
- Stekhoven, D.J.; Bühlmann, P. MissForest—non-parametric missing value imputation for mixed-type data. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef] [Green Version]
- Ließ, M.; Glaser, B.; Huwe, B. Uncertainty in the spatial prediction of soil texture: Comparison of regression tree and Random Forest models. Geoderma 2012, 170, 70–79. [Google Scholar] [CrossRef]
- Han, H.; Lee, S.; Kim, H.C.; Kim, M. Retrieval of Summer Sea Ice Concentration in the Pacific Arctic Ocean from AMSR2 Observations and Numerical Weather Data Using Random Forest Regression. Remote Sens. 2021, 13, 2283. [Google Scholar] [CrossRef]
- Ballabio, C. Spatial prediction of soil properties in temperate mountain regions using support vector regression. Geoderma 2009, 151, 338–350. [Google Scholar] [CrossRef]
- Hamasuna, Y.; Endo, Y.; Miyamoto, S. Support Vector Machine for data with tolerance based on Hard-margin and Soft-Margin. In Proceedings of the 2008 IEEE International Conference on Fuzzy Systems (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 750–755. [Google Scholar]
- Neaupane, K.M.; Adhikari, N. Prediction of tunneling-induced ground movement with the multi-layer perceptron. Tunn. Undergr. Space Technol. 2006, 21, 151–159. [Google Scholar] [CrossRef]
- Bisong, E. More supervised machine learning techniques with scikit-learn. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Springer: Berlin/Heidelberg, Germany, 2019; pp. 287–308. [Google Scholar]
- Pham, T.D.; Bui, N.D.; Nguyen, T.T.; Phan, H.C. Predicting the reduction of embankment pressure on the surface of the soft ground reinforced by sand drain with random forest regression. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2020; Volume 869, p. 072027. [Google Scholar]
- Siegel, A. Practical Business Statistics; Academic Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Salmerón Gómez, R.; García Pérez, J.; López Martín, M.D.M.; García, C.G. Collinearity diagnostic applied in ridge estimation through the variance inflation factor. J. Appl. Stat. 2016, 43, 1831–1849. [Google Scholar] [CrossRef]
- Adams, W. The effect of organic matter on the bulk and true densities of some uncultivated podzolic soils. J. Soil Sci. 1973, 24, 10–17. [Google Scholar] [CrossRef]
- Rawls, W.J. Estimating soil bulk density from particle size analysis and organic matter content1. Soil Sci. 1983, 135, 123–125. [Google Scholar] [CrossRef]














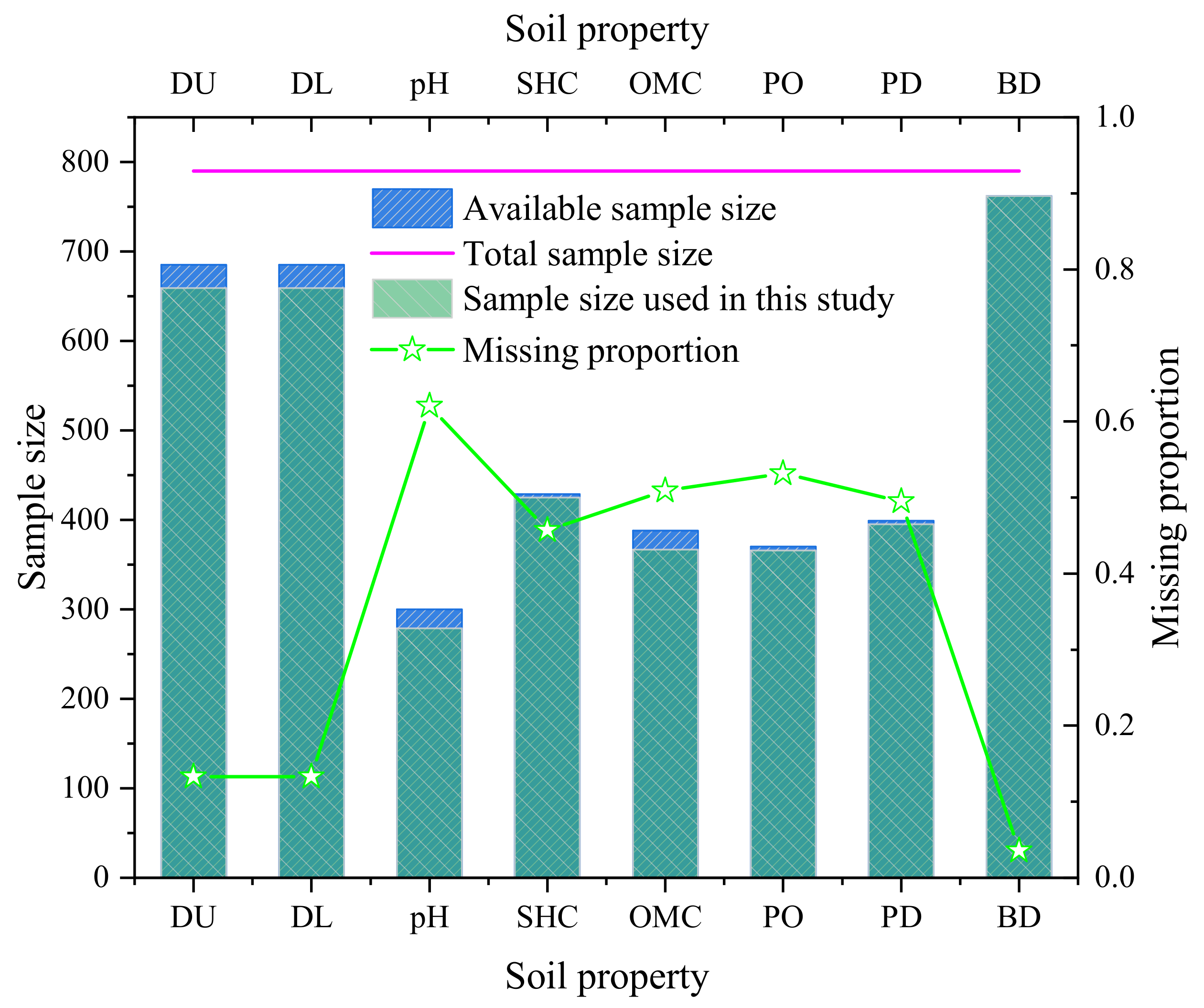
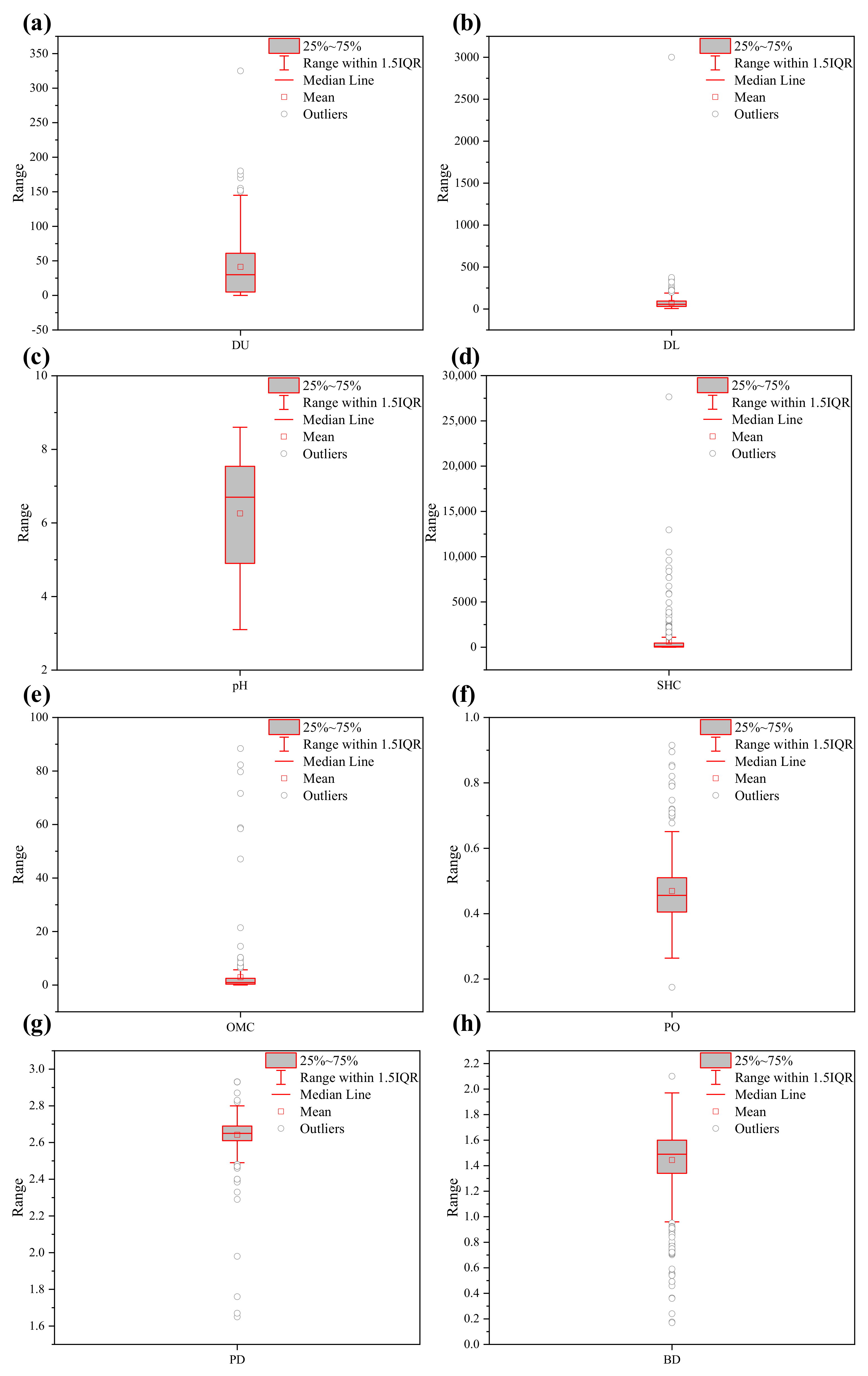
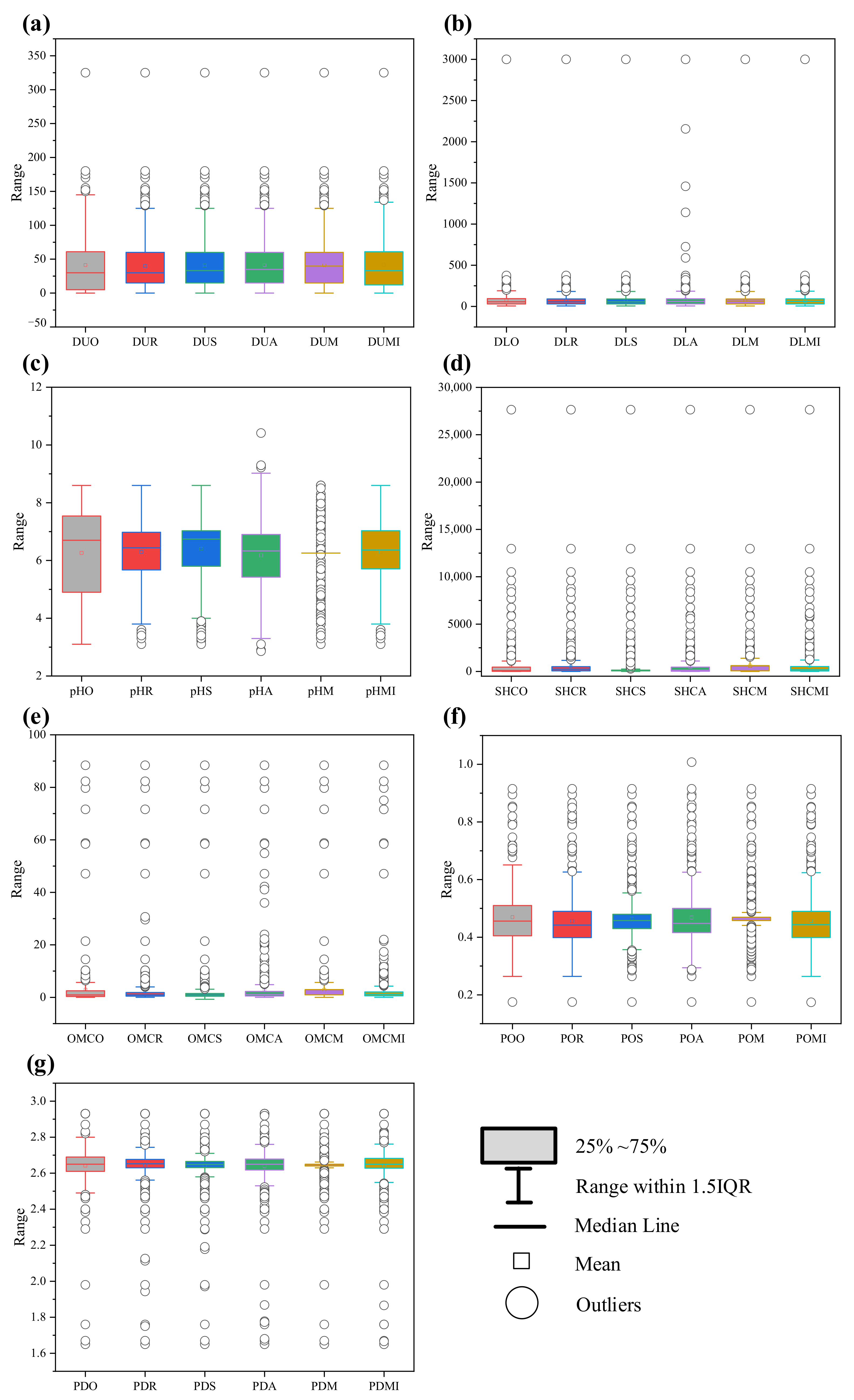
| Soil Property | Effective Sample | Data Sample * | Range | Mean | Q1 (25%) | Q2 (50%) | Q3 (75%) | Missing Proportion ** |
|---|---|---|---|---|---|---|---|---|
| DU | 685 | 659 | 0∼325 | 41.231 | 5.000 | 30.000 | 61.000 | 0.1329 |
| DL | 685 | 659 | 0∼3000 | 72.466 | 30.000 | 56.000 | 95.000 | 0.1329 |
| pH | 300 | 279 | 3.1∼8.6 | 6.259 | 4.900 | 6.700 | 7.540 | 0.6203 |
| SHC | 429 | 425 | 0.019∼27,648 | 613.559 | 20.818 | 95.900 | 459.400 | 0.4570 |
| OMC | 388 | 367 | 0.01∼88.4 | 2.942 | 0.340 | 0.940 | 2.500 | 0.5089 |
| PO | 370 | 366 | 0.175∼0.915 | 0.469 | 0.405 | 0.456 | 0.510 | 0.5316 |
| PD | 399 | 395 | 1.65∼2.93 | 2.642 | 2.610 | 2.650 | 2.690 | 0.4949 |
| BD | 762 | 762 | 0.17∼2.1 | 1.444 | 1.340 | 1.490 | 1.600 | 0.0354 |
| Imputation Methods | Parameters | |||
|---|---|---|---|---|
| RF | n_estimators | |||
| 100 | ||||
| SVR | C | kernel | ||
| 100 (50) | 0.01 | rbf | ||
| ANN | learning_rate_init | activation | solver | alpha |
| 0.005 (0.06) | relu | adam | 0.001 (1) | |
| Feature | Missing Proportion | RMSE RF | SVR | ANN | Mean | MI | MAE RF | SVR | ANN | Mean | MI |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DU | 0.03 | 5.99 | 15.39 | 32.2 | 26.68 | 5.5 | 6.61 | 16.17 | 39.28 | 23.27 | 4.8 |
| 0.07 | 12.39 | 24.74 | 16.12 | 36.57 | 17.68 | 10.32 | 21.43 | 11.57 | 32 | 14.2 | |
| 0.11 | 33.32 | 39.23 | 34.2 | 40.24 | 28.19 | 19.8 | 27.78 | 18.93 | 29.06 | 21.8 | |
| 0.15 | 20.98 | 40.91 | 18.23 | 39.81 | 23.82 | 12.07 | 32.42 | 15 | 31.71 | 16.55 | |
| 0.19 | 25.58 | 42.73 | 45.38 | 64.12 | 44.16 | 17.07 | 32.43 | 38.88 | 49.03 | 30.62 | |
| 0.23 | 25.91 | 37.49 | 20.4 | 44.6 | 21.98 | 16.87 | 30.03 | 15.09 | 36.83 | 17.08 | |
| DL | 0.03 | 6.43 | 23.72 | 59.07 | 40.9 | 15.57 | 5.36 | 20.81 | 43.67 | 34.97 | 9.93 |
| 0.07 | 19.3 | 57 | 28.89 | 69.87 | 51.48 | 15.26 | 39.6 | 23.43 | 51.66 | 42.44 | |
| 0.11 | 33.26 | 34.85 | 42.43 | 42.29 | 54.19 | 21.54 | 27.27 | 32.77 | 36.79 | 46.8 | |
| 0.15 | 35.75 | 67.96 | 38.1 | 70.98 | 63.37 | 21.34 | 47.33 | 25.55 | 52.49 | 42.68 | |
| 0.19 | 26.54 | 28.76 | 61.14 | 31.64 | 44.12 | 17.57 | 21.65 | 42.71 | 27.82 | 32.73 | |
| 0.23 | 36.56 | 52.57 | 34.76 | 54.58 | 49.47 | 24.57 | 36.55 | 26.23 | 39.99 | 37.49 | |
| pH | 0.03 | 0.86 | 0.91 | 0.32 | 1.32 | 1.08 | 0.81 | 0.8 | 0.27 | 1.29 | 0.83 |
| 0.07 | 1.32 | 1.02 | 2.11 | 1.46 | 1.53 | 1.16 | 0.92 | 1.66 | 1.27 | 1.39 | |
| 0.11 | 1.86 | 1.69 | 2 | 1.61 | 1.88 | 1.76 | 1.49 | 1.82 | 1.53 | 1.57 | |
| 0.15 | 1.35 | 1.27 | 1.33 | 1.35 | 0.97 | 1.01 | 0.98 | 1 | 1.17 | 0.78 | |
| 0.19 | 1.65 | 1.98 | 1.95 | 1.66 | 1.71 | 1.43 | 1.71 | 1.65 | 1.51 | 1.51 | |
| 0.23 | 1.66 | 1.98 | 2.16 | 1.77 | 1.91 | 1.39 | 1.69 | 1.77 | 1.63 | 1.75 | |
| SHC | 0.03 | 854.75 | 825.83 | 1200.1 | 662.66 | 953.15 | 679.27 | 519.22 | 935.43 | 576.29 | 751.7 |
| 0.07 | 2818.95 | 3867.88 | 1710.57 | 3756.35 | 1887.4 | 1236.26 | 1256.13 | 751.89 | 1560.21 | 736.49 | |
| 0.11 | 1594.87 | 1906.36 | 1026.96 | 1839.52 | 303.95 | 710.16 | 582.82 | 563.94 | 901.18 | 202.68 | |
| 0.15 | 1896.67 | 1951.17 | 1697.06 | 1867.5 | 1933.28 | 682.14 | 630.66 | 984.73 | 903.6 | 738.41 | |
| 0.19 | 2299.21 | 2986.01 | 1794.31 | 2867.45 | 2003.19 | 1098.22 | 995.45 | 852.43 | 1252.13 | 790.91 | |
| 0.23 | 1264.22 | 938.44 | 1328.83 | 899.61 | 879.01 | 717.31 | 384.24 | 805.91 | 674.99 | 428.77 | |
| OMC | 0.03 | 0.69 | 0.64 | 3.65 | 1.78 | 0.76 | 0.48 | 0.53 | 2.96 | 1.78 | 0.53 |
| 0.07 | 1.78 | 1.83 | 1.7 | 2.51 | 1.37 | 1.36 | 1.32 | 1.01 | 2.15 | 1.24 | |
| 0.11 | 0.49 | 1.37 | 0.97 | 1.52 | 1.14 | 0.45 | 1.02 | 0.8 | 1.41 | 0.88 | |
| 0.15 | 1.69 | 1.86 | 3.28 | 1.98 | 1.97 | 0.84 | 1.35 | 2.13 | 1.69 | 1.21 | |
| 0.19 | 1.7 | 1.45 | 2.19 | 2 | 2.07 | 0.92 | 1.06 | 1.32 | 1.8 | 1.37 | |
| 0.23 | 1.35 | 1.4 | 2.75 | 1.7 | 1.58 | 0.91 | 1.06 | 1.64 | 1.63 | 1.1 | |
| PO | 0.03 | 0.005 | 0.101 | 0.18 | 0.077 | 0.002 | 0.005 | 0.061 | 0.128 | 0.059 | 0.002 |
| 0.07 | 0.017 | 0.077 | 0.057 | 0.088 | 0.011 | 0.013 | 0.059 | 0.051 | 0.072 | 0.005 | |
| 0.11 | 0.01 | 0.074 | 0.083 | 0.074 | 0.004 | 0.008 | 0.064 | 0.075 | 0.064 | 0.004 | |
| 0.15 | 0.023 | 0.199 | 0.088 | 0.09 | 0.016 | 0.014 | 0.117 | 0.062 | 0.065 | 0.011 | |
| 0.19 | 0.015 | 0.065 | 0.13 | 0.065 | 0.019 | 0.013 | 0.056 | 0.097 | 0.051 | 0.012 | |
| 0.23 | 0.008 | 0.056 | 0.131 | 0.057 | 0.007 | 0.007 | 0.046 | 0.103 | 0.045 | 0.004 | |
| PD | 0.03 | 0.09 | 0.1 | 0.17 | 0.03 | 0.02 | 0.07 | 0.07 | 0.16 | 0.02 | 0.02 |
| 0.07 | 0.09 | 0.05 | 0.22 | 0.06 | 0.03 | 0.06 | 0.04 | 0.19 | 0.05 | 0.02 | |
| 0.11 | 0.06 | 0.05 | 0.13 | 0.11 | 0.02 | 0.05 | 0.04 | 0.1 | 0.06 | 0.02 | |
| 0.15 | 0.2 | 0.2 | 0.25 | 0.21 | 0.1 | 0.11 | 0.12 | 0.17 | 0.12 | 0.05 | |
| 0.19 | 0.06 | 0.05 | 0.26 | 0.07 | 0.08 | 0.05 | 0.04 | 0.22 | 0.05 | 0.05 | |
| 0.23 | 0.05 | 0.08 | 0.24 | 0.09 | 0.03 | 0.05 | 0.06 | 0.19 | 0.07 | 0.02 |
| Feature | Name | Sample Size | Min | Max | Mean | Standard Deviation | Standard Error | Median | Kurtosis | Skewness | Coefficient of Variation | Variance |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DU | DUO | 659 | 0 | 325 | 41.231 | 40.316 | 1.57 | 30 | 3.517 | 1.357 | 97.78% | 1625.378 |
| DUR | 762 | 0 | 325 | 39.736 | 37.752 | 1.368 | 30 | 4.562 | 1.541 | 95.01% | 1425.22 | |
| DUS | 762 | 0 | 325 | 40.704 | 37.85 | 1.371 | 33.205 | 4.348 | 1.473 | 92.99% | 1432.658 | |
| DUA | 762 | 0 | 325 | 41.234 | 37.936 | 1.374 | 35 | 4.258 | 1.441 | 92.00% | 1439.103 | |
| DUM | 762 | 0 | 325 | 41.231 | 37.488 | 1.358 | 40 | 4.532 | 1.459 | 90.92% | 1405.386 | |
| DUMI | 762 | 0 | 325 | 41.701 | 38.497 | 1.395 | 33 | 3.79 | 1.351 | 92.32% | 1482.011 | |
| DL | DLO | 659 | 6 | 3000 | 72.466 | 124.601 | 4.854 | 56 | 464.535 | 19.855 | 171.94% | 15,525.368 |
| DLR | 762 | 6 | 3000 | 70.533 | 116.087 | 4.205 | 57.21 | 534.314 | 21.27 | 164.59% | 13,476.125 | |
| DLS | 762 | 6 | 3000 | 70.87 | 116.049 | 4.204 | 55.284 | 534.77 | 21.283 | 163.75% | 13,467.300 | |
| DLA | 762 | 6 | 3000 | 79.92 | 155.859 | 5.646 | 60 | 213.387 | 13.278 | 195.02% | 24,291.898 | |
| DLM | 762 | 6 | 3000 | 72.466 | 115.862 | 4.197 | 65 | 537.058 | 21.344 | 159.89% | 13,424.037 | |
| DLMI | 762 | 6 | 3000 | 71.48 | 116.176 | 4.209 | 59.9 | 531.973 | 21.197 | 162.53% | 13,496.809 | |
| pH | pHO | 279 | 3.1 | 8.6 | 6.259 | 1.513 | 0.091 | 6.7 | −1.219 | −0.355 | 24.17% | 2.288 |
| pHR | 762 | 3.1 | 8.6 | 6.298 | 1.039 | 0.038 | 6.441 | 0.176 | −0.526 | 16.49% | 1.079 | |
| pHS | 762 | 3.1 | 8.6 | 6.407 | 1.104 | 0.04 | 6.744 | 0.182 | −0.846 | 17.23% | 1.219 | |
| pHA | 762 | 2.857 | 10.413 | 6.178 | 1.185 | 0.043 | 6.334 | −0.056 | −0.24 | 19.19% | 1.405 | |
| pHM | 762 | 3.1 | 8.6 | 6.259 | 0.914 | 0.033 | 6.259 | 1.884 | −0.584 | 14.61% | 0.836 | |
| pHMI | 762 | 3.1 | 8.6 | 6.29 | 1.064 | 0.039 | 6.36 | 0.027 | −0.484 | 16.91% | 1.131 | |
| SHC | SHCO | 425 | 0.019 | 27,648 | 613.559 | 1935.074 | 93.865 | 95.9 | 97.723 | 8.448 | 315.39% | 3,744,509.62 |
| SHCR | 762 | 0.019 | 27,648 | 540.376 | 1472.962 | 53.36 | 229.387 | 165.31 | 10.812 | 272.58% | 2,169,617.99 | |
| SHCS | 762 | 0.019 | 27,648 | 384.797 | 1467.129 | 53.148 | 96.737 | 172.699 | 11.23 | 381.27% | 2,152,468.57 | |
| SHCA | 762 | 0.019 | 27,648 | 501.111 | 1501.694 | 54.401 | 135.307 | 154.204 | 10.371 | 299.67% | 2,255,085.69 | |
| SHCM | 762 | 0.019 | 27,648 | 613.559 | 1444.402 | 52.325 | 613.559 | 176.677 | 11.294 | 235.41% | 2,086,297.08 | |
| SHCMI | 762 | 0.019 | 27,648 | 619.756 | 1585.248 | 57.427 | 207.092 | 122.024 | 8.941 | 255.79% | 2,513,012.29 | |
| OMC | OMCO | 367 | 0.01 | 88.4 | 2.942 | 9.727 | 0.508 | 0.94 | 50.679 | 6.976 | 330.61% | 94.611 |
| OMCR | 762 | 0.01 | 88.4 | 2.217 | 7.01 | 0.254 | 0.958 | 96.343 | 9.395 | 316.15% | 49.147 | |
| OMCS | 762 | −0.732 | 88.4 | 1.953 | 6.864 | 0.249 | 0.92 | 105.92 | 9.946 | 351.45% | 47.111 | |
| OMCA | 762 | 0.01 | 88.4 | 2.824 | 7.794 | 0.282 | 1.128 | 64.553 | 7.507 | 276.01% | 60.742 | |
| OMCM | 762 | 0.01 | 88.4 | 2.942 | 6.746 | 0.244 | 2.942 | 107.704 | 10.031 | 229.28% | 45.503 | |
| OMCMI | 762 | 0.01 | 88.4 | 2.48 | 7.459 | 0.27 | 1.116 | 84.869 | 8.843 | 300.78% | 55.642 | |
| PO | POO | 366 | 0.175 | 0.915 | 0.469 | 0.104 | 0.005 | 0.456 | 3.001 | 1.298 | 22.08% | 0.011 |
| POR | 762 | 0.175 | 0.915 | 0.456 | 0.091 | 0.003 | 0.442 | 4.52 | 1.598 | 20.02% | 0.008 | |
| POS | 762 | 0.175 | 0.915 | 0.464 | 0.077 | 0.003 | 0.458 | 8.156 | 1.989 | 16.66% | 0.006 | |
| POA | 762 | 0.175 | 1.008 | 0.468 | 0.091 | 0.003 | 0.448 | 5.628 | 1.8 | 19.50% | 0.008 | |
| POM | 762 | 0.175 | 0.915 | 0.469 | 0.072 | 0.003 | 0.469 | 9.445 | 1.869 | 15.29% | 0.005 | |
| POMI | 762 | 0.174 | 0.915 | 0.457 | 0.092 | 0.003 | 0.444 | 4.489 | 1.593 | 20.05% | 0.008 | |
| PD | PDO | 395 | 1.65 | 2.93 | 2.642 | 0.126 | 0.006 | 2.65 | 26.025 | −3.401 | 4.76% | 0.016 |
| PDR | 762 | 1.65 | 2.93 | 2.644 | 0.106 | 0.004 | 2.652 | 37.489 | −4.462 | 4.01% | 0.011 | |
| PDS | 762 | 1.65 | 2.93 | 2.642 | 0.099 | 0.004 | 2.648 | 40.998 | −4.4 | 3.73% | 0.01 | |
| PDA | 762 | 1.65 | 2.93 | 2.639 | 0.116 | 0.004 | 2.65 | 34.429 | −4.43 | 4.40% | 0.013 | |
| PDM | 762 | 1.65 | 2.93 | 2.642 | 0.091 | 0.003 | 2.642 | 52.684 | −4.716 | 3.43% | 0.008 | |
| PDMI | 762 | 1.65 | 2.93 | 2.644 | 0.113 | 0.004 | 2.65 | 36.35 | −4.484 | 4.26% | 0.013 |
| Feature | Median(,) | MannWhitney U | MannWhitney z | p | Feature | Median (,) | MannWhitney U | MannWhitney z | p | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| DU | Raw data (n = 659) | RF (n = 762) | 250,299.5 | −0.101 | 0.919 | Raw data (n = 425) | Mean (n = 762) | 116,598.5 | −8.098 | 0.000 ** | |
| 30.000(5.0,61.0) | 30.000(15.0,60.0) | SHC | 95.900(20.8,459.4) | 613.559(69.6,613.6) | |||||||
| SVR (n = 762) | 247,602.5 | −0.453 | 0.651 | MI (n = 762) | 135,141.5 | −4.73 | 0.000 ** | ||||
| 33.205(15.0,60.0) | 207.092(53.3,518.5) | ||||||||||
| ANN (n = 762) | 245,348.5 | −0.746 | 0.456 | Raw data (n = 367) | RF (n = 762) | 137,024 | −0.546 | 0.585 | |||
| 35.000(15.0,60.0) | 0.940(0.3,2.5) | 0.958(0.5,1.9) | |||||||||
| Mean (n = 762) | 243,611.5 | −0.973 | 0.331 | SVR (n = 762) | 132,498.5 | −1.428 | 0.153 | ||||
| 40.000(15.0,60.0) | 0.920(0.4,1.5) | ||||||||||
| MI (n = 762) | 245,028 | −0.788 | 0.431 | OMC | ANN (n = 762) | 126,483.5 | −2.6 | 0.009 ** | |||
| 33.000(12.0,61.0) | 1.128(0.5,2.3) | ||||||||||
| DL | Raw data (n = 659) | RF (n = 762) | 250,327.5 | −0.097 | 0.922 | Mean (n = 762) | 97,759.5 | −8.379 | 0.000 ** | ||
| 56.000(30.0,95.0) | 57.210(30.0,91.0) | 2.942(1.0,2.9) | |||||||||
| SVR (n = 762) | 249,248.5 | −0.237 | 0.812 | MI (n = 762) | 127,130.5 | −2.474 | 0.013 * | ||||
| 55.284(30.0,91.0) | 1.116(0.6,2.1) | ||||||||||
| ANN (n = 762) | 246,019.5 | −0.656 | 0.512 | Raw data (n = 366) | RF (n = 762) | 128,268 | −2.182 | 0.029 * | |||
| 60.000(30.0,93.0) | 0.456(0.4,0.5) | 0.442(0.4,0.5) | |||||||||
| Mean (n = 762) | 243,199.5 | −1.022 | 0.307 | SVR (n = 762) | 137,856 | −0.31 | 0.756 | ||||
| 65.000(30.0,91.0) | 0.458(0.4,0.5) | ||||||||||
| MI (n = 762) | 247,989 | −0.401 | 0.689 | PO | ANN (n = 762) | 139,339 | −0.021 | 0.983 | |||
| 59.900(30.0,92.0) | 0.448(0.4,0.5) | ||||||||||
| pH | Raw data (n = 279) | RF (n = 762) | 100,975.5 | −1.239 | 0.215 | Mean (n = 762) | 128,358 | −2.213 | 0.027 * | ||
| 6.700(4.9,7.5) | 6.441(5.7,7.0) | 0.469(0.5,0.5) | |||||||||
| SVR (n = 762) | 104,703.5 | −0.371 | 0.71 | MI (n = 762) | 128,777.5 | −2.083 | 0.037 * | ||||
| 6.744(5.8,7.0) | 0.444(0.4,0.5) | ||||||||||
| ANN (n = 762) | 97,681.5 | −2.006 | 0.045 * | Raw data (n = 395) | RF (n = 762) | 140,712 | −1.817 | 0.069 | |||
| 6.334(5.4,6.9) | 2.650(2.6,2.7) | 2.652(2.6,2.7) | |||||||||
| Mean (n = 762) | 96,880.5 | −2.311 | 0.021 * | SVR (n = 762) | 148,596.5 | −0.353 | 0.724 | ||||
| 6.259(6.3,6.3) | 2.648(2.6,2.7) | ||||||||||
| MI (n = 762) | 101,044.5 | −1.223 | 0.221 | PD | ANN (n = 762) | 149,471.5 | −0.19 | 0.849 | |||
| 6.360(5.7,7.0) | 2.650(2.6,2.7) | ||||||||||
| SHC | Raw data (n = 425) | RF (n = 762) | 134,844.5 | −4.783 | 0.000 ** | Mean (n = 762) | 148,109.5 | −0.45 | 0.653 | ||
| 95.900(20.8,459.4) | 229.387(60.4,512.5) | 2.642(2.6,2.6) | |||||||||
| SVR (n = 762) | 161,420.5 | −0.089 | 0.929 | MI (n = 762) | 144,380 | −1.136 | 0.256 | ||||
| 96.737(61.8,144.3) | 2.650(2.6,2.7) | ||||||||||
| ANN (n = 762) | 156,553.5 | −0.949 | 0.343 | ||||||||
| 135.307(22.7,455.4) | |||||||||||
| Imputation Method | Independent Variable | Unstandardized Coefficients | t | p | VIF | Adj | F | ||
|---|---|---|---|---|---|---|---|---|---|
| B | Standard Error | ||||||||
| RF | Constant | 1.483 | 0.11 | 13.426 | 0.000 ** | - | 0.910 | 0.909 | F(6,755) = 1273.712, p = 0.000 |
| DU | 0 | 0 | 2.579 | 0.010 * | 1.055 | ||||
| pH | −0.001 | 0.003 | −0.193 | 0.847 | 1.052 | ||||
| SHC | 0 | 0 | −0.325 | 0.745 | 1.035 | ||||
| OMC | 0.002 | 0.001 | 2.849 | 0.005 ** | 2.899 | ||||
| PO | −2.481 | 0.036 | −68.031 | 0.000 ** | 1.472 | ||||
| PD | 0.41 | 0.041 | 10.106 | 0.000 ** | 2.463 | ||||
| SVR | Constant | 1.836 | 0.223 | 8.234 | 0.000 ** | - | 0.639 | 0.636 | F(6,755) = 223.020, p = 0.000 |
| DU | 0 | 0 | −1.325 | 0.185 | 1.121 | ||||
| pH | 0.009 | 0.005 | 1.811 | 0.07 | 1.035 | ||||
| SHC | 0 | 0 | 0.659 | 0.51 | 1.064 | ||||
| OMC | −0.003 | 0.001 | −2.62 | 0.009 ** | 2.445 | ||||
| PO | −2.322 | 0.085 | −27.477 | 0.000 ** | 1.409 | ||||
| PD | 0.242 | 0.083 | 2.933 | 0.003 ** | 2.193 | ||||
| ANN | Constant | 1.454 | 0.119 | 12.245 | 0.000 ** | - | 0.885 | 0.884 | F(6,755) = 968.854, p = 0.000 |
| DU | 0 | 0 | −3.34 | 0.001 ** | 1.128 | ||||
| pH | 0.011 | 0.003 | 3.918 | 0.000 ** | 1.148 | ||||
| SHC | 0 | 0 | −2.396 | 0.017 * | 1.057 | ||||
| OMC | 0.003 | 0.001 | 4.78 | 0.000 ** | 3.123 | ||||
| PO | −2.501 | 0.042 | −58.998 | 0.000 ** | 1.554 | ||||
| PD | 0.416 | 0.045 | 9.319 | 0.000 ** | 2.79 | ||||
| Mean | Constant | 2.633 | 0.215 | 12.226 | 0.000 ** | - | 0.594 | 0.591 | F(6,755) = 183.955, p = 0.000 |
| DU | 0 | 0 | 3.077 | 0.002 ** | 1.046 | ||||
| pH | 0.016 | 0.006 | 2.486 | 0.013 * | 1.014 | ||||
| SHC | 0 | 0 | −0.462 | 0.644 | 1.042 | ||||
| OMC | −0.012 | 0.001 | −11.496 | 0.000 ** | 1.376 | ||||
| PO | −2.161 | 0.088 | −24.682 | 0.000 ** | 1.159 | ||||
| PD | −0.098 | 0.076 | −1.293 | 0.197 | 1.382 | ||||
| MI | Constant | 1.507 | 0.11 | 13.719 | 0.000** | - | 0.902 | 0.901 | F(6,755)=1154.513, p = 0.000 |
| DU | 0 | 0 | 2.252 | 0.025 * | 1.082 | ||||
| pH | 0.001 | 0.003 | 0.392 | 0.695 | 1.079 | ||||
| SHC | 0 | 0 | −0.691 | 0.49 | 1.044 | ||||
| OMC | 0.003 | 0.001 | 4.179 | 0.000 ** | 2.772 | ||||
| PO | −2.491 | 0.036 | −69.058 | 0.000 ** | 1.325 | ||||
| PD | 0.399 | 0.042 | 9.59 | 0.000 ** | 2.66 | ||||
| Zero | Constant | 1.48 | 0.013 | 112.448 | 0.000 ** | - | 0.379 | 0.374 | F(6,755) = 76.715, p = 0.000 |
| DU | 0.001 | 0 | 4.185 | 0.000 ** | 1.056 | ||||
| pH | −0.001 | 0.002 | −0.424 | 0.672 | 1.07 | ||||
| SHC | 0 | 0 | 4.029 | 0.000 ** | 1.021 | ||||
| OMC | −0.016 | 0.001 | −14.524 | 0.000 ** | 1.063 | ||||
| PO | −0.493 | 0.049 | −10.128 | 0.000 ** | 2.74 | ||||
| PD | 0.048 | 0.009 | 5.331 | 0.000 ** | 2.738 | ||||
| Discarding Missing values | Constant | 1.069 | 0.04 | 26.925 | 0.000 ** | - | 0.998 | 0.997 | F(6,102) = 6932.797, p = 0.000 |
| DU | 0 | 0 | 2.027 | 0.045 * | 1.341 | ||||
| pH | −0.002 | 0.001 | −2.084 | 0.040 * | 1.076 | ||||
| SHC | 0 | 0 | −2.762 | 0.007 ** | 2.747 | ||||
| OMC | 0.002 | 0.001 | 3.151 | 0.002 ** | 3.111 | ||||
| PO | −2.551 | 0.019 | −133.224 | 0.000 ** | 2.004 | ||||
| PD | 0.581 | 0.015 | 40.031 | 0.000 ** | 1.665 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Y.; Liao, H.; Lv, L. A Comparative Study of Various Methods for Handling Missing Data in UNSODA. Agriculture 2021, 11, 727. https://doi.org/10.3390/agriculture11080727
Fu Y, Liao H, Lv L. A Comparative Study of Various Methods for Handling Missing Data in UNSODA. Agriculture. 2021; 11(8):727. https://doi.org/10.3390/agriculture11080727
Chicago/Turabian StyleFu, Yingpeng, Hongjian Liao, and Longlong Lv. 2021. "A Comparative Study of Various Methods for Handling Missing Data in UNSODA" Agriculture 11, no. 8: 727. https://doi.org/10.3390/agriculture11080727
APA StyleFu, Y., Liao, H., & Lv, L. (2021). A Comparative Study of Various Methods for Handling Missing Data in UNSODA. Agriculture, 11(8), 727. https://doi.org/10.3390/agriculture11080727