
Identifying the Determinants of Regional Raw Milk Prices in Russia Using Machine Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Conceptual Framework and Hypotheses
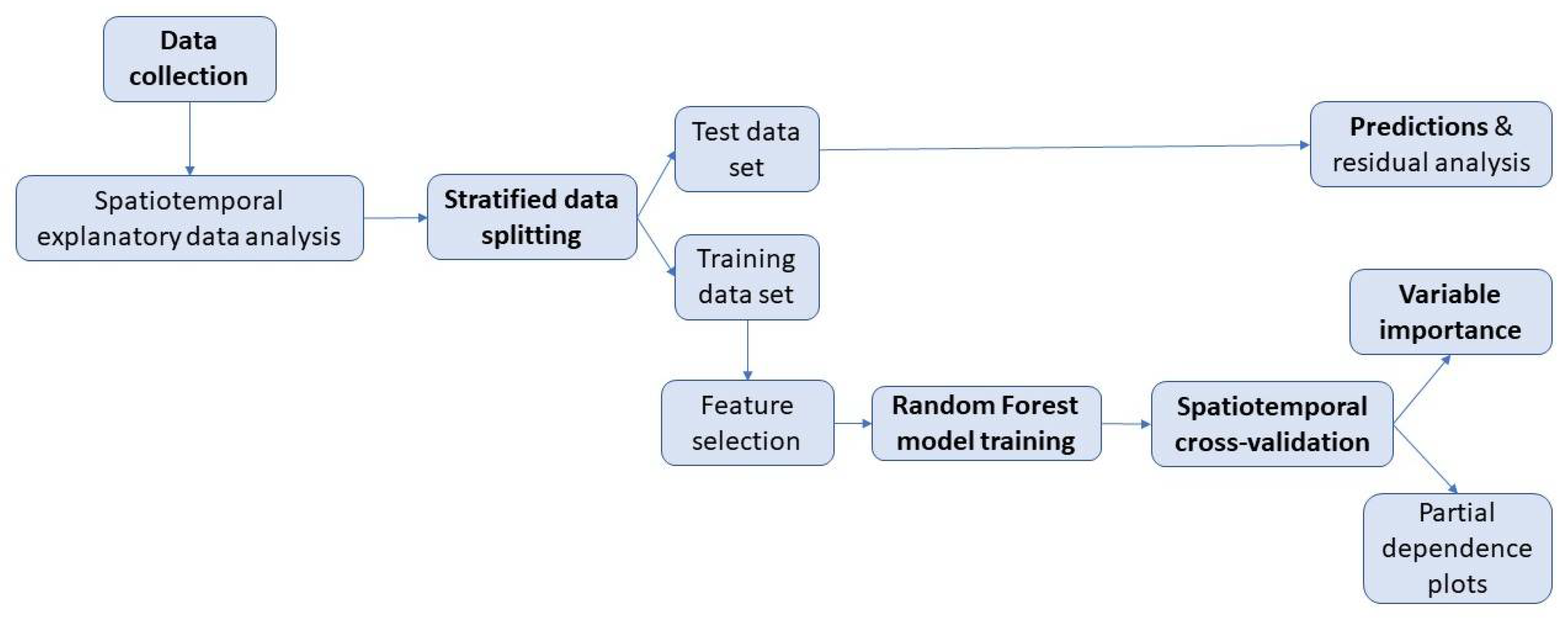
2.2. Analytical Framework
2.3. Data Collection
2.4. Data Imputation
2.5. Spatial Analysis
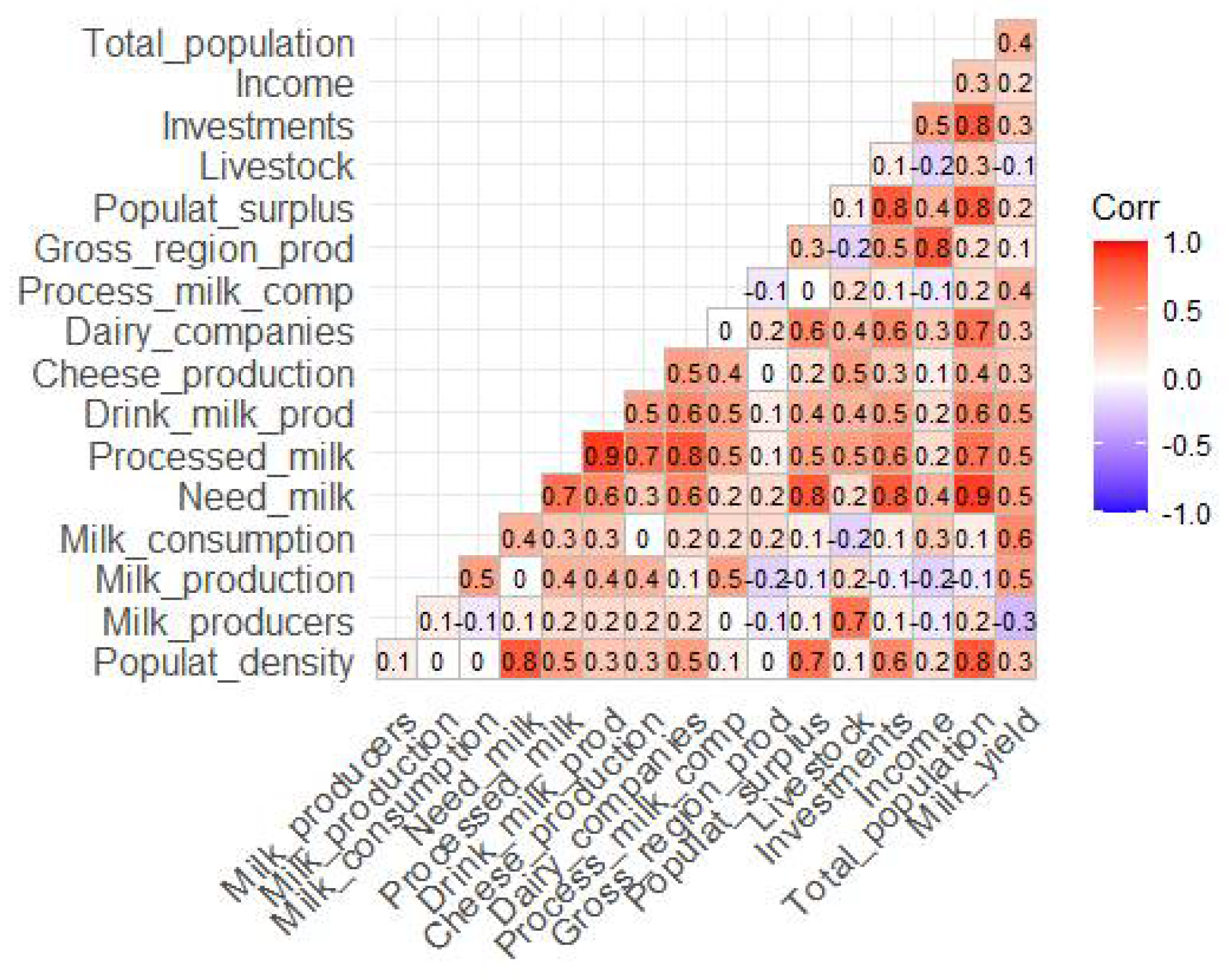
2.6. Feature Selection
2.7. Data Transformation
2.8. Random Forest
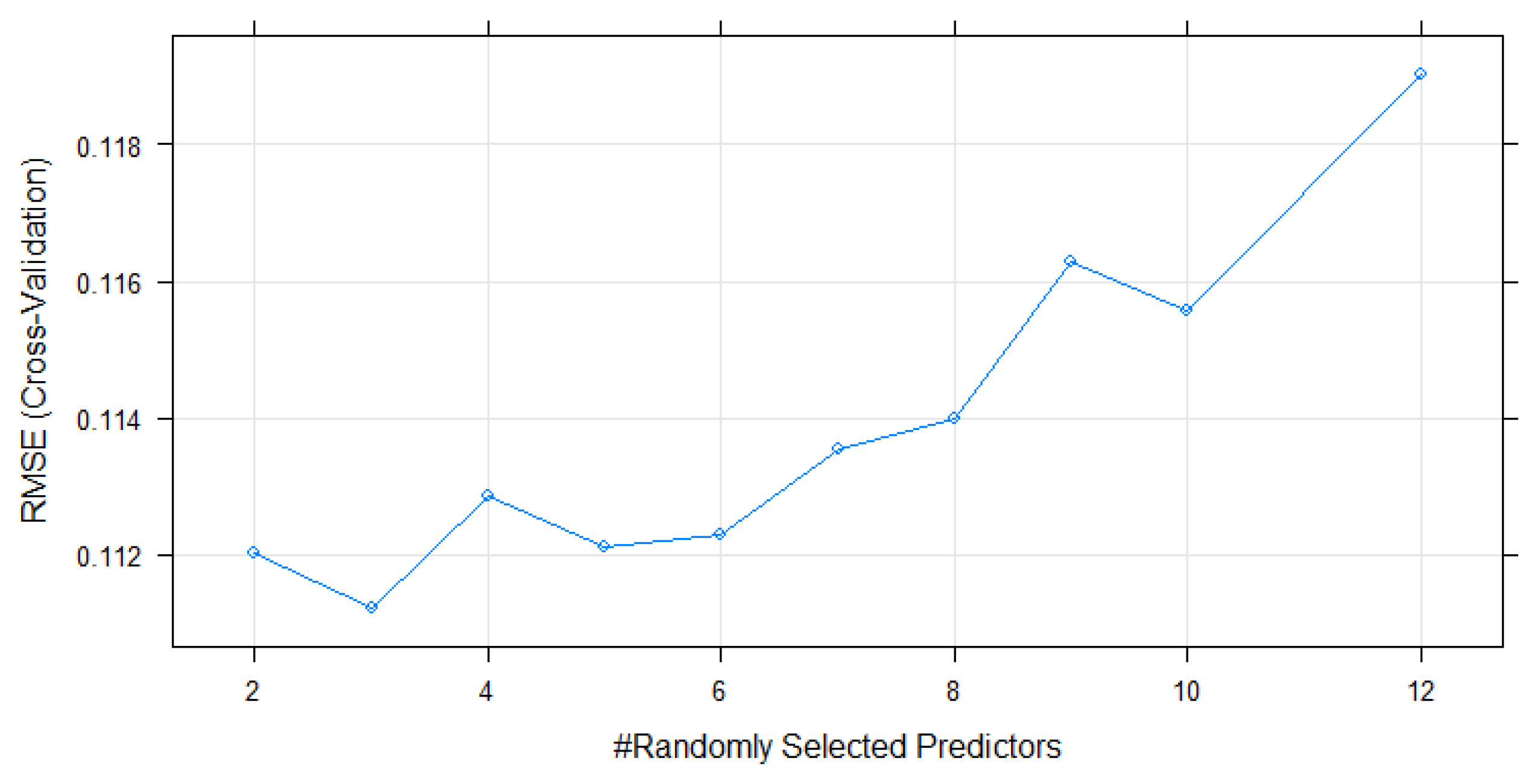
2.9. Model Training and Hyperparameter Optimisation
2.10. RF Variable Importance
3. Results
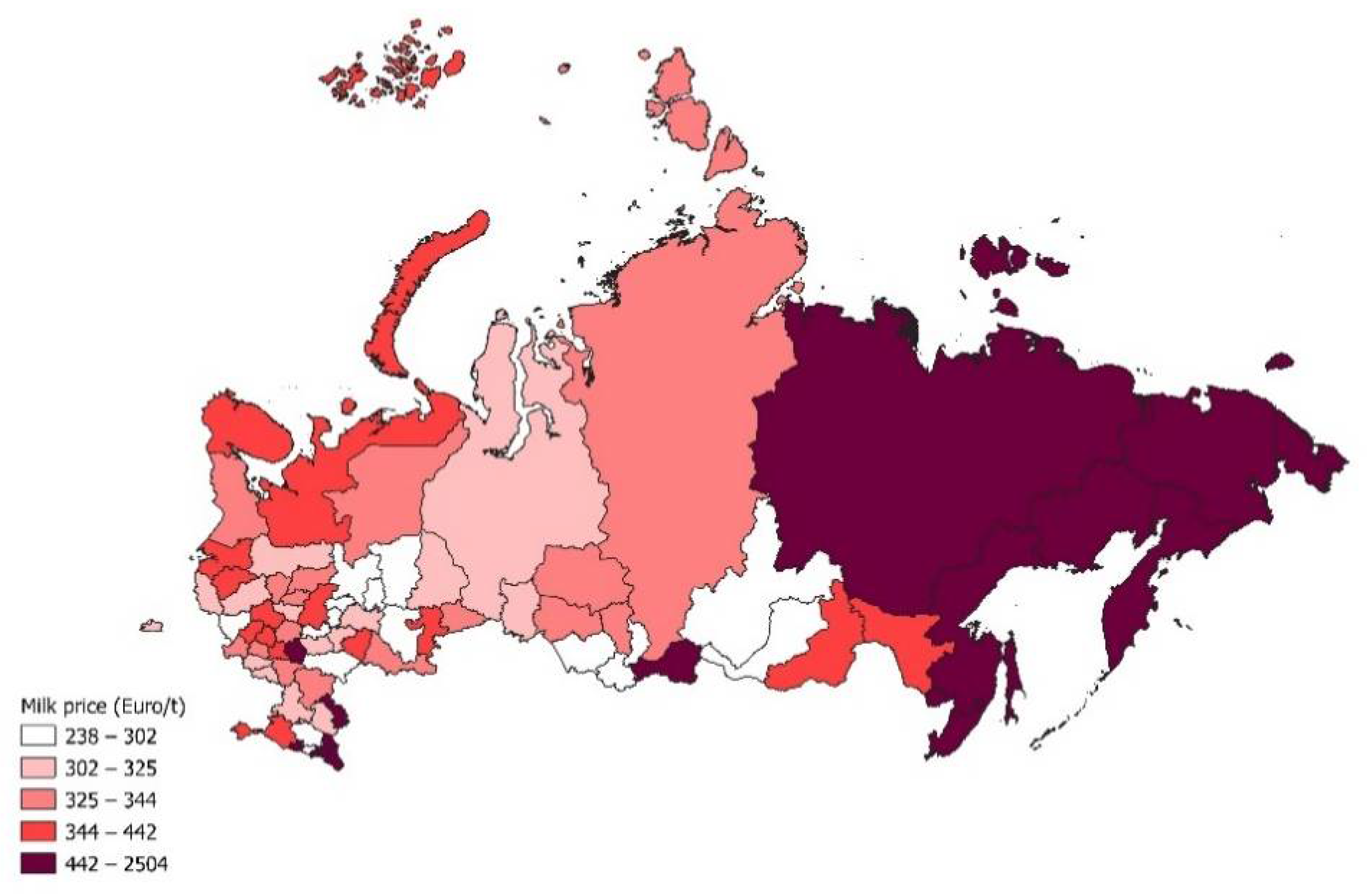
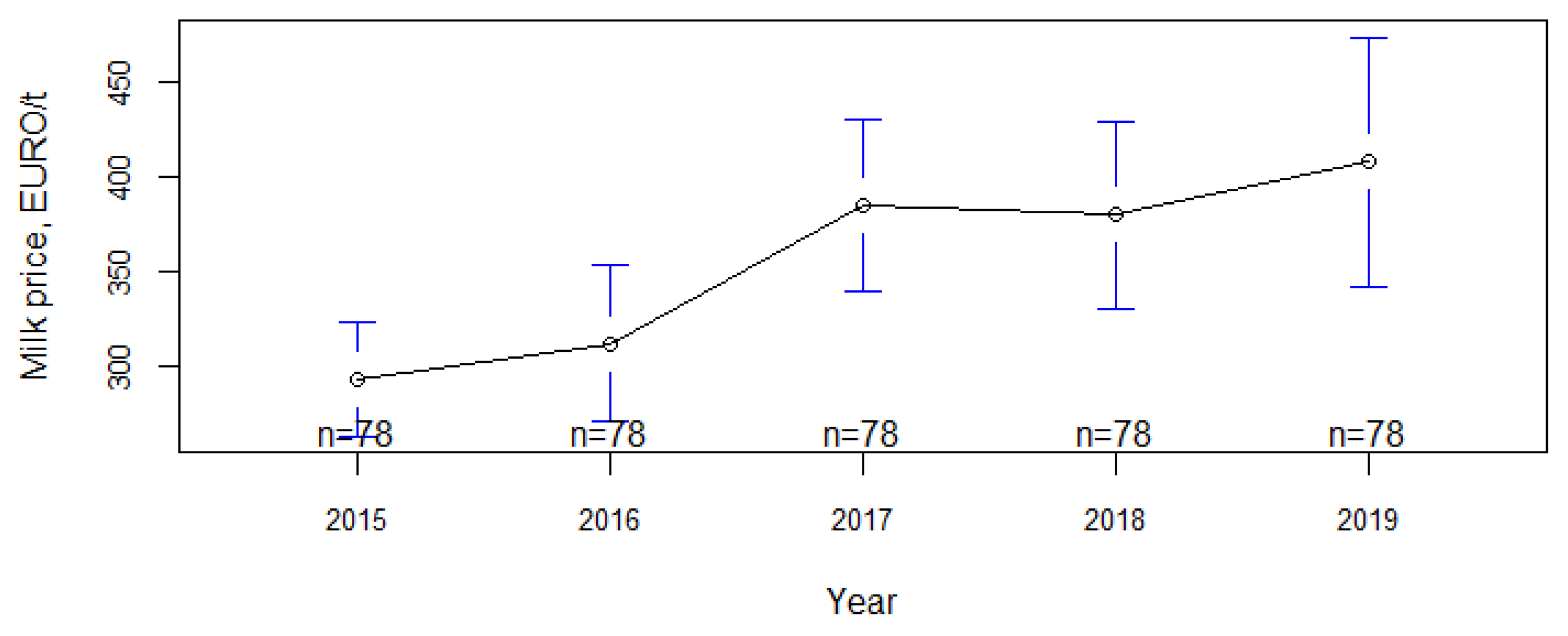
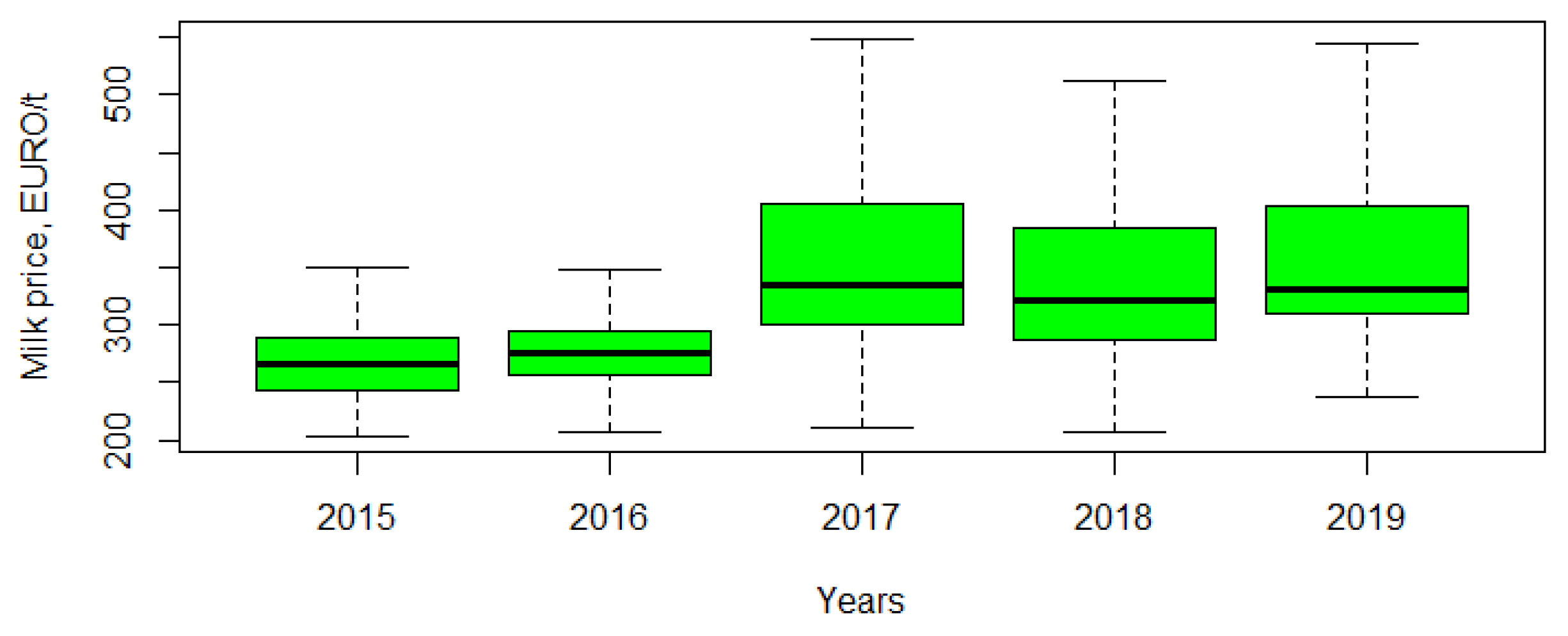
3.1. Exploratory Data Analysis
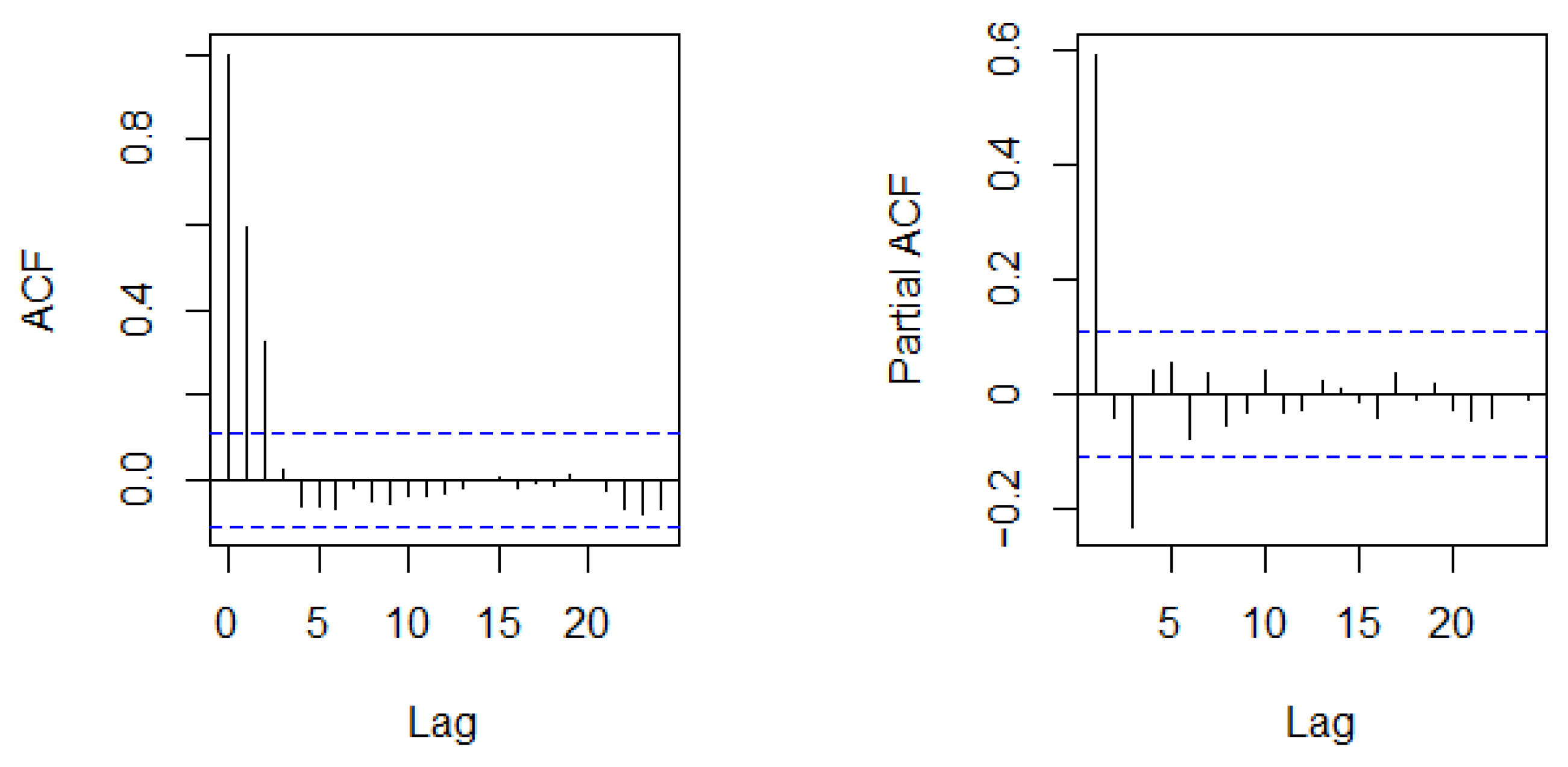
3.2. Spatial and Temporal Autocorrelation
3.3. Results of the Feature Selection
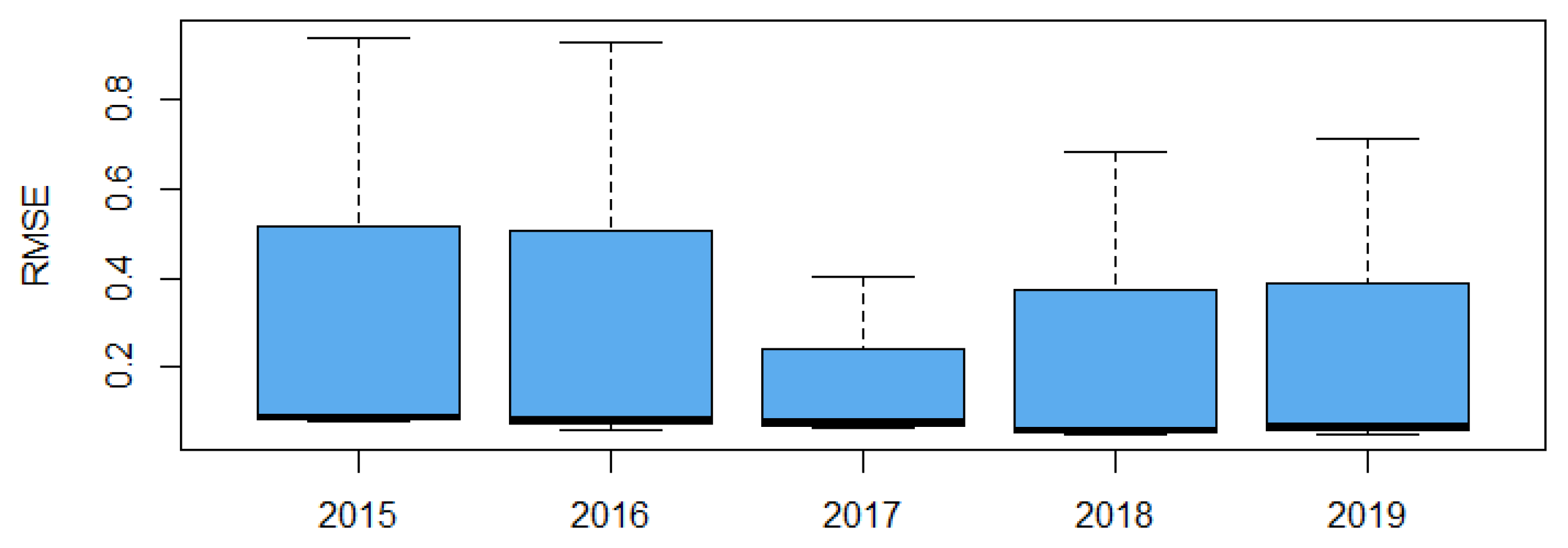
3.4. Results of RF Modelling
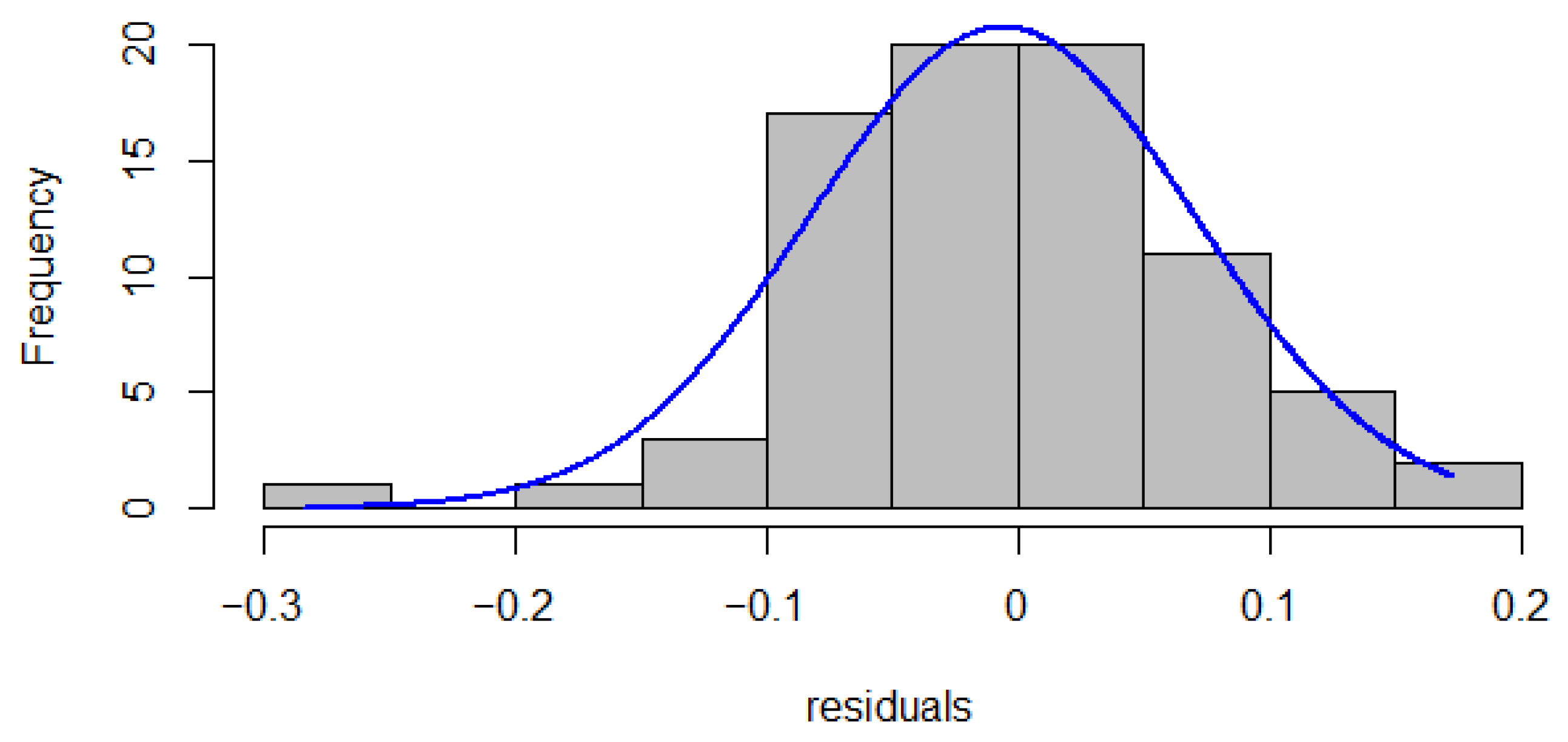
3.5. RF Model Interpretation
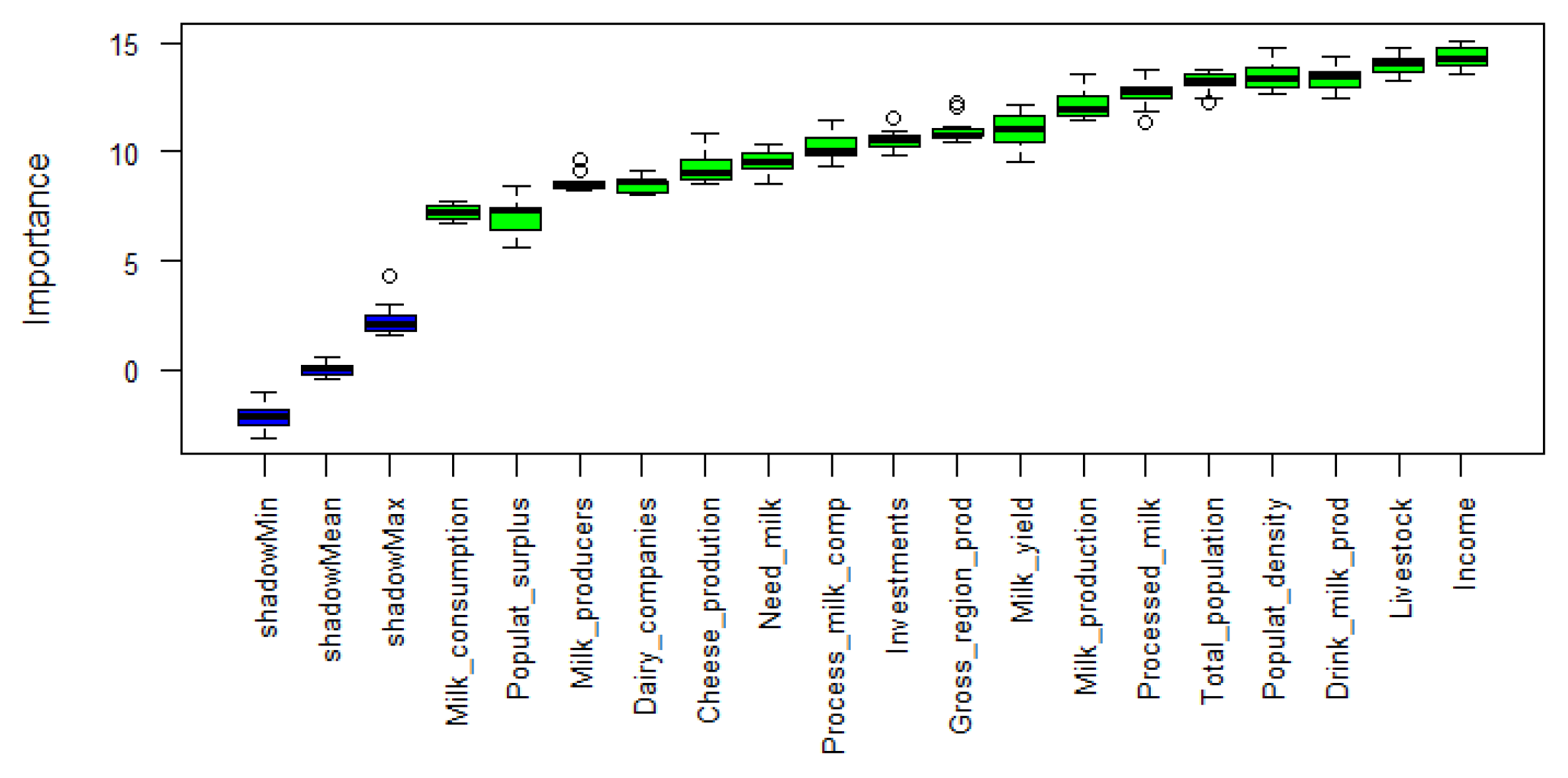
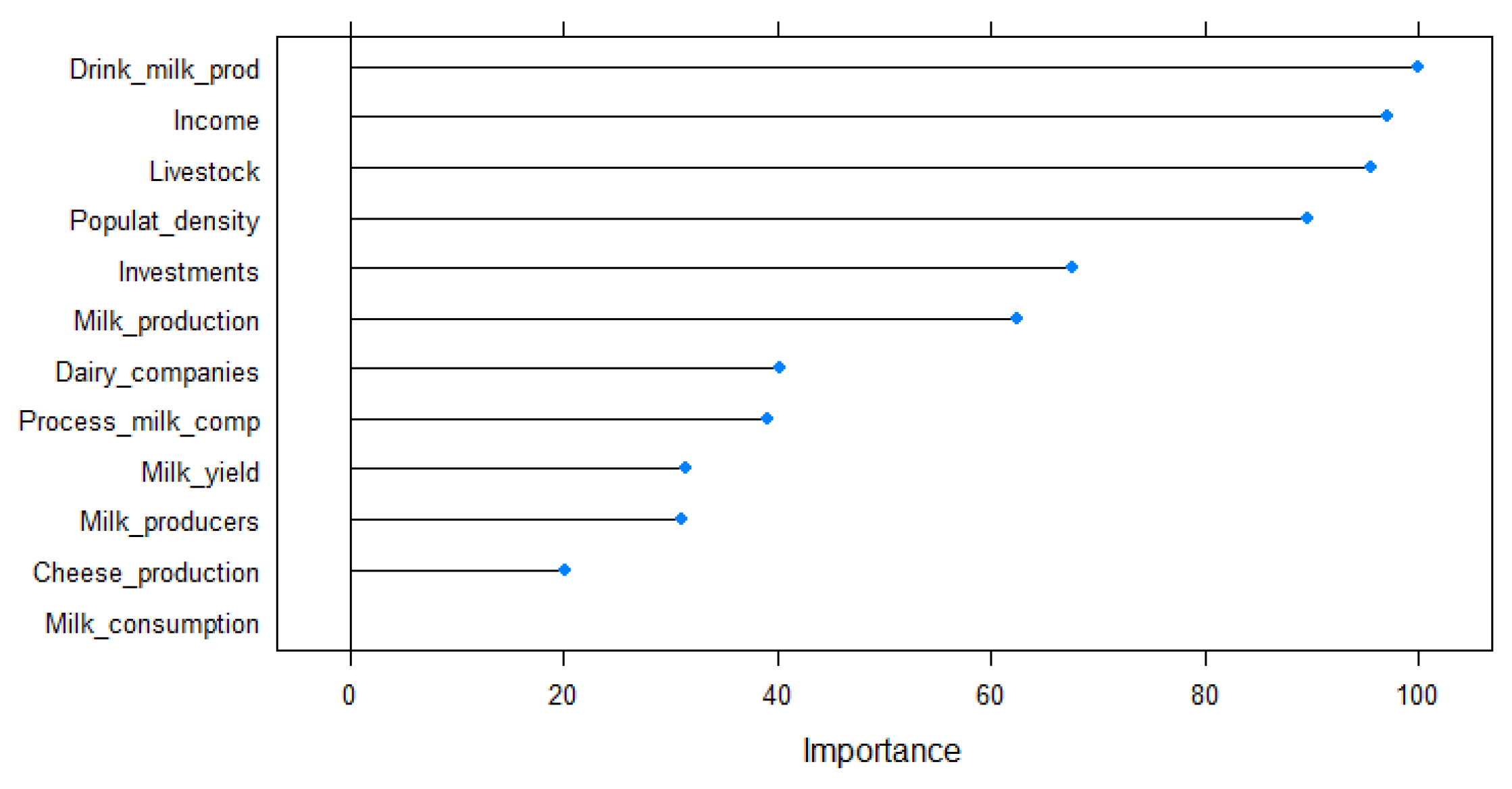
3.5.1. Variable Importance
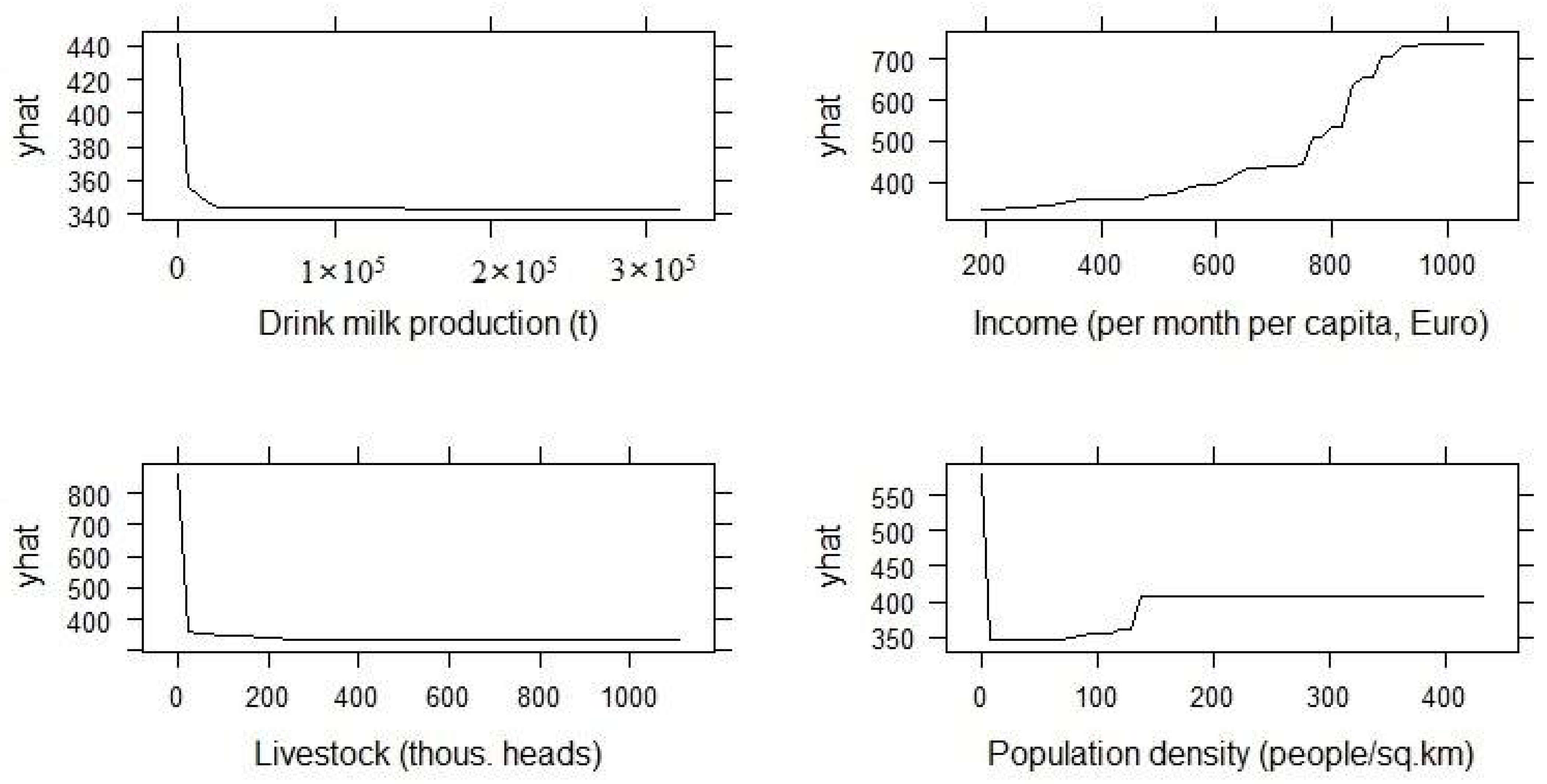
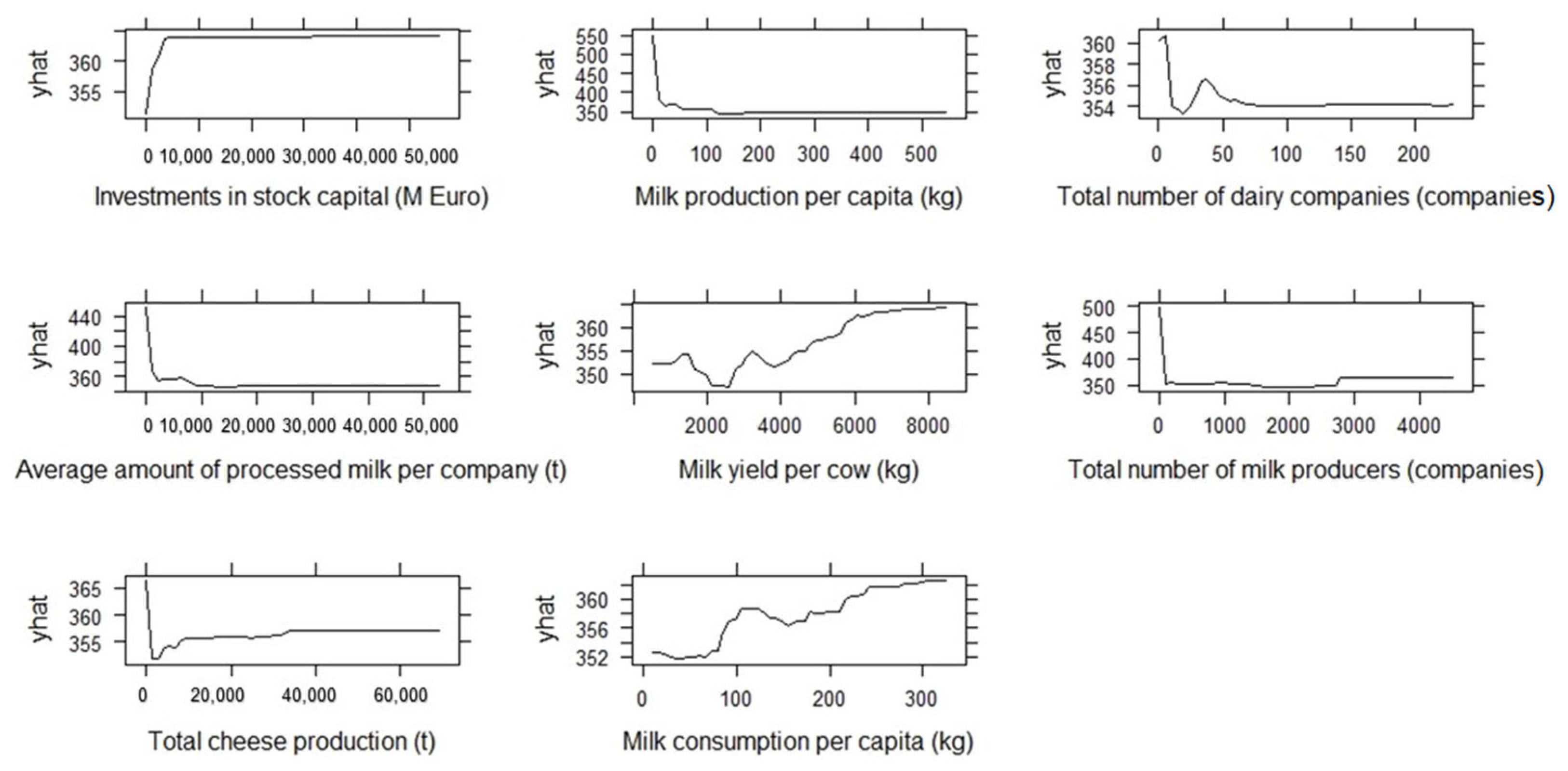
3.5.2. Partial Dependence Plots
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | n | Min | Pctile (25) | Median | Pctile (75) | Max | Mean | SD |
|---|---|---|---|---|---|---|---|---|
| Milk_price | 390 | 155.8 | 271.3 | 304.3 | 354.1 | 2503.7 | 356.1 | 215.1 |
| Log_milk_price | 390 | 2.2 | 2.4 | 2.5 | 2.6 | 3.4 | 2.5 | 0.1 |
| Populat_density | 390 | 0.1 | 5.2 | 23.3 | 42.4 | 432.8 | 33.9 | 52.2 |
| Milk_producers | 390 | 1 | 151.2 | 253.5 | 473 | 4506 | 393.3 | 481.2 |
| Milk_production | 390 | 0.2 | 55.1 | 98.95 | 170.2 | 542.6 | 132.1 | 108.4 |
| Milk_consumption | 390 | 10.1 | 86.3 | 144.0 | 193.0 | 324 | 142.4 | 67.4 |
| Need_milk | 390 | 3811 | 82,008.2 | 165,124.5 | 278,700 | 3,975,390 | 287,775.4 | 490,548.1 |
| Processed_milk | 390 | 1 | 41,225 | 135,650 | 294,650 | 1,830,000 | 234,591.4 | 290,050 |
| Drink_milk_prod | 390 | 0.3 | 9711.3 | 40,621.6 | 107,963.8 | 321,112.2 | 70,532.9 | 76,357.4 |
| Cheese_production | 390 | 0 | 116.5 | 857.3 | 4470.2 | 68,971.1 | 5300.9 | 10,872.7 |
| Dairy_companies | 390 | 1 | 12 | 23 | 34 | 229 | 30.3 | 33.6 |
| Process_milk_comp | 390 | 1 | 1953.2 | 6129.5 | 10,471.1 | 52,692.3 | 7794.5 | 7434.2 |
| Gross_region_prod | 390 | 1362.8 | 3304.8 | 4462.2 | 6142.6 | 30,680.6 | 5673.7 | 4405.5 |
| Populat_surplus | 390 | −22,135 | −7356.5 | −3576 | 960.5 | 154,016 | −137.1 | 17,253.0 |
| Livestock | 390 | 0 | 89.8 | 169.3 | 290.3 | 1110.9 | 234.6 | 220.3 |
| Investments | 390 | 116.4 | 641.3 | 1284.6 | 2546.9 | 55,544.7 | 2671.9 | 5498.4 |
| Income | 390 | 190.6 | 289.3 | 325.1 | 386.3 | 1062.4 | 357.8 | 126.5 |
| Total_population | 390 | 49,505 | 796,878.8 | 1,192,843 | 2,405,156 | 20,291,934 | 1,880,821 | 2,444,763 |
| Milk_yield | 390 | 515 | 3823.5 | 4584.5 | 5532.2 | 8462 | 4550.3 | 1518.7 |
References
- Wegren, S.K.; Elvestad, C. Russia’s food self-sufficiency and food security: An assessment. Post-Communist Econ. 2018, 30, 565–587. [Google Scholar] [CrossRef]
- Solodukha, P.V.; Maiorova, E.A.; Shinkareva, O.V. Social and economic consequences of influence of food embargo on production of milk and dairy products in Russia. Ecol. Agric. Sustain. Dev. 2019, 2019, 297–305. [Google Scholar]
- Decree of the President of the Russian Federation of 21 January 2020 N 20. On approval of the Doctrine of Food Security of the Russian Federation. Available online: http://ivo.garant.ru/#/document/73438425/paragraph/1/doclist/34006/showentries/0/highlight/%D0%A3%D0%BA%D0%B0%D0%B7%20%D0%9F%D1%80%D0%B5%D0%B7%D0%B8%D0%B4%D0%B5%D0%BD%D1%82%D0%B0%20%D0%A0%D0%A4%2021.01.2020:3 (accessed on 15 September 2021).
- Nosov, V.V.; Suray, N.M.; Mamaev, O.A.; Chemisenko, O.V.; Panov, P.A.; Pokidov, M.G. Milk production dynamics in the Russian Federation: Causes and consequences. IOP Conf. Ser Earth Environ. Sci. 2020, 548, 022091. [Google Scholar] [CrossRef]
- Kulikov, I.M.; Minakov, I.A. Food security: Problems and prospects in Russia. Sci. Pap. Ser. Manag. Econ. Eng. Agric. Rural. Dev. 2019, 19, 141–147. [Google Scholar]
- Wegren, S.K. The Russian food embargo and food security: Can household production fill the void? Eurasian Geogr. Econ. 2014, 55, 491–513. [Google Scholar] [CrossRef]
- Guziy, S. The market of milk and dairy products in Russia: Peculiarities, tendencies and prospects of development. In The Agri-Food Value Chain: Challenges for Natural Resources Management and Society; Slovak University of Agriculture: Nitra, Slovakia, 2016; pp. 770–776. [Google Scholar]
- Artemova, E.I.; Kremyanskaya, E.V. Determinants of the development of the domestic milk market in the context of import substitution. Polythem. Netw. Electron. Sc. J. Kuban State Agrar. Univ. 2016, 116, 882–896. [Google Scholar]
- McQueen, R.J.; Garner, S.R.; Nevill-Manning, C.G.; Witten, I.H. Applying machine learning to agricultural data. Comput. Electron. Agric. 1995, 12, 275–293. [Google Scholar] [CrossRef] [Green Version]
- Balducci, F.; Impedovo, D.; Pirlo, G. Machine learning applications on agricultural datasets for smart farm enhancement. Machines 2018, 6, 38. [Google Scholar] [CrossRef] [Green Version]
- Storm, H.; Baylis, K.; Heckelei, T. Machine learning in agricultural and applied economics. Eur. Rev. Agric. Econ. 2020, 47, 849–892. [Google Scholar] [CrossRef]
- Saltzman, B.; Yung, J. A machine learning approach to identifying different types of uncertainty. Econ. Lett. 2018, 171, 58–62. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph convolutional networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5966–5978. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Liu, N.; Xu, D. Advanced deep-learning techniques for salient and category-specific object detection: A survey. IEEE Signal Process. Mag. 2018, 35, 84–100. [Google Scholar] [CrossRef]
- Guo, C.; Cui, Y. Machine learning exhibited excellent advantages in the performance simulation and prediction of free water surface constructed wetlands. J. Environ. Manag. 2022, 309, 114694. [Google Scholar] [CrossRef]
- Dahiya, N.; Gupta, S.; Singh, S.A. Review Paper on Machine Learning Applications, Advantages, and Techniques. ECS Trans. 2022, 107, 6137. [Google Scholar] [CrossRef]
- Goodwin, B.K. Multivariate cointegration tests and the law of one price in international wheat markets. Appl. Econ. Perspect. Policy 1992, 14, 117–124. [Google Scholar] [CrossRef]
- Moritz, S.; Bartz-Beielstein, T. ImputeTS: Time Series Missing Value Imputation in R. R J. 2017, 9, 207–218. [Google Scholar] [CrossRef] [Green Version]
- Anselin, L. Spatial Econometrics: Methods and Models; Springer: Dordrecht, The Netherlands, 1988. [Google Scholar] [CrossRef] [Green Version]
- Kursa, M.B.; Rudnicki, W.R. Feature selection with the Boruta package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Degenhardt, F.; Seifert, S.; Szymczak, S. Evaluation of variable selection methods for random forests and omics data sets. Briefings Bioinf. 2019, 20, 492–503. [Google Scholar] [CrossRef] [Green Version]
- Wright, M.N.; Wager, S.; Probst, P. Package “ranger”: A Fast Implementation of Random Forests (Version 0.13.1) [R Package]. 2021. Available online: https://cran.r-project.org/web/packages/ranger/ranger.pdf (accessed on 15 September 2021).
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carré, G.; Marquéz, J.R.G.; Gruber, B.; Lafourcade, B.; Leitão, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 27–46. [Google Scholar] [CrossRef]
- Leeuwenberg, A.M.; van Smeden, M.; Langendijk, J.A.; van der Schaaf, A.; Mauer, M.E.; Moons, K.G.; Reitsma, J.B.; Schuit, E. Comparing methods addressing multi-collinearity when developing prediction models. arXiv 2021, arXiv:210101603. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. 2021. Available online: https://christophm.github.io/interpretable-ml-book/index.html (accessed on 15 September 2021).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Cukic, B.; Menzies, T. Can data transformation help in the detection of fault-prone modules? In DEFECTS’ 08: Proceedings of the 2008 Workshop on Defects in Large Software Systems; Association for Computing Machinery: New York, NY, USA, 2008; pp. 16–20. [Google Scholar] [CrossRef] [Green Version]
- Lütkepohl, H.; Xu, F. The role of the log transformation in forecasting economic variables. Empir. Econ. 2012, 42, 619–638. [Google Scholar] [CrossRef] [Green Version]
- Stevens, F.R.; Gaughan, A.E.; Linard, C.; Tatem, A.J. Disaggregating census data for population mapping using random forests with remotely-sensed and ancillary data. PLoS ONE 2015, 10, e0107042. [Google Scholar] [CrossRef] [Green Version]
- Curran-Everett, D. Explorations in statistics: The log transformation. Adv. Physiol. Educ. 2018, 42, 343–347. [Google Scholar] [CrossRef] [PubMed]
- Trawinski, B.; Smętek, M.; Telec, Z.; Lasota, T. Nonparametric statistical analysis for multiple comparison of machine learning regression algorithms. Int. J. Appl. Math. Comput. Sci. 2012, 22, 867–881. [Google Scholar] [CrossRef]
- Hall, M.A. Correlation-based feature selection of discrete and numeric class machine learning. In Computer Science Working Papers (Working Paper 00/08); University of Waikato, Department of Computer Science: Hamilton, New Zealand, 2000. [Google Scholar]
- Goldstein, B.A.; Navar, A.M.; Carter, R.E. Moving beyond regression techniques in cardiovascular risk prediction: Applying machine learning to address analytic challenges. Eur. Heart J. 2017, 38, 1805–1814. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shahinfar, S.; Page, D.; Guenther, J.; Cabrera, V.; Fricke, P.; Weigel, K. Prediction of insemination outcomes in Holstein dairy cattle using alternative machine learning algorithms. J. Dairy Sci. 2014, 97, 731–742. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Borchers, M.R.; Chang, Y.M.; Proudfoot, K.L.; Wadsworth, B.A.; Stone, A.E.; Bewley, J.M. Machine-learning-based calving prediction from activity, lying, and ruminating behaviors in dairy cattle. J. Dairy Sci. 2017, 100, 5664–5674. [Google Scholar] [CrossRef]
- Ma, W.; Fan, J.; Li, Q.; Tang, Y. A raw milk service platform using BP Neural Network and Fuzzy Inference. Inf. Process. Agric. 2018, 5, 308–319. [Google Scholar] [CrossRef]
- Volkmann, N.; Kulig, B.; Hoppe, S.; Stracke, J.; Hensel, O.; Kemper, N. On-farm detection of claw lesions in dairy cows based on acoustic analyses and machine learning. J. Dairy Sci. 2021, 104, 5921–5931. [Google Scholar] [CrossRef]
- Mota, L.F.; Pegolo, S.; Baba, T.; Peñagaricano, F.; Morota, G.; Bittante, G.; Cecchinato, A. Evaluating the performance of machine learning methods and variable selection methods for predicting difficult-to-measure traits in Holstein dairy cattle using milk infrared spectral data. J. Dairy Sci. 2021, 104, 8107–8121. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C., Jr.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef]
- Svetnik, V.; Liaw, A.; Tong, C.; Culberson, J.C.; Sheridan, R.P.; Feuston, B.P. Random forest: A classification and regression tool for compound classification and QSAR modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef]
- Ying, X. An overview of overfitting and its solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing. (Version 4.0.4) [Computer Software]; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 7 September 2021).
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B. Caret: Classification and Regression Training. [R Package] (Version 6.0-86). 2022. Available online: https://cran.r-project.org/web/packages/caret/caret.pdf (accessed on 15 September 2021).
- Liaw, A. Randomforest: Breiman and Cutler’s Random Forests for Classification and Regression. [R Package] (Version 4.7–1.1). Available online: https://cran.r-project.org/web/packages/randomForest/randomForest.pdf (accessed on 15 September 2021).
- Roberts, D.R.; Bahn, V.; Ciuti, S.; Boyce, M.S.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.J.; Schröder, B.; Thuiller, W.; et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef]
- Wang, Q.; Bovenhuis, H. Validation strategy can result in an overoptimistic view of the ability of milk infrared spectra to predict methane emission of dairy cattle. J. Dairy Sci. 2019, 102, 6288–6295. [Google Scholar] [CrossRef]
- Meyer, H.; Reudenbach, C.; Ludwig, M.; Nauss, T.; Pebesma, E. CAST: “Caret” Applications for Spatial-Temporal Models (Version 0.5.1) [R Package]. Available online: https://cran.r-project.org/web/packages/CAST/CAST.pdf (accessed on 16 September 2021).
- Meyer, H.; Reudenbach, C.; Hengl, T.; Katurji, M.; Nauss, T. Improving performance of spatio-temporal machine learning models using forward feature selection and target-oriented validation. Environ. Model. Softw. 2018, 101, 1–9. [Google Scholar] [CrossRef]
- Probst, P.; Wright, M.N.; Boulesteix, A.L. Hyperparameters and tuning strategies for random forest. WIREs Data Min. Knowl. Discovery 2019, 9, e1301. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How many trees in a random forest? In Machine Learning and Data Mining in Pattern Recognition; Perner, P., Ed.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 154–168. [Google Scholar] [CrossRef]
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Strobl, C.; Boulesteix, A.L.; Zeileis, A.; Hothorn, T. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinf. 2007, 8, 25. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Strobl, C.; Boulesteix, A.L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinf. 2008, 9, 307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Greenwell, B. Package “pdp”: Partial Dependence Plots (Version 0.6.0) [R Package]. 20 July 2017. Available online: https://mran.microsoft.com/snapshot/2018-06-07/web/packages/pdp/pdp.pdf (accessed on 15 September 2021).
- Greenwell, B. pdp: An R Package for Constructing Partial Dependence Plots. R J. 2017, 9, 421–436. [Google Scholar] [CrossRef] [Green Version]
- Artyukhova, S.I.; Tolstoguzova, T.T.; Gunkova, P.I.; Ushakova, S.G.; Luneva, O.N.; Voskanyan, O.S. Monitoring the degree of contamination of milk with residual amounts of antibiotics by manufacturers. IOP Conf. Ser. Earth Environ. Sci. 2020, 613, 012007. [Google Scholar] [CrossRef]
- Russia’s Restrictions on Imports of Agricultural and Food Products: An Initial Assessment. Available online: http://www.fao.org/3/i4055e/i4055e.pdf (accessed on 15 September 2021).
- Wegren, S.K.; Nilssen, F.; Elvestad, C. The impact of Russian food security policy on the performance of the food system. Eurasian Geogr. Econ. 2016, 57, 671–699. [Google Scholar] [CrossRef]
- Carvalho, G.R.; Bessler, D.; Hemme, T.; Schröer-Merker, E. Understanding International Milk Price Relationships. Paper presentation. In Proceedings of the Southern Agricultural Economics Association’s 2015 Annual meeting, Atlanta, GA, USA, 31 January–3 February 2015. [Google Scholar] [CrossRef]
- Melnikov, A.B.; Shcherbakov, P.A.; Voronkova, O.Y.; Mikhaylushkin, P.V.; Poltarykhin, A.L. Level of development of milk and dairy products market of the federal districts of the Russian Federation. Int. J. Mech. Eng. Technol. 2018, 9, 1214–1219. [Google Scholar]







| Variable (Unit) | Description | Abbreviation | Source |
|---|---|---|---|
| Population density (people/km2) | Population density | Popul_density | DIA |
| Total number of milk producers (companies) | Total number of milk producing companies | Milk_producers | DIA |
| Milk production per capita (kg) | Milk production per capita | Milk_production | DIA |
| Milk consumption per capita (kg) | Milk consumption per capita | Milk_consumption | DIA |
| Total need for milk (t) | Total need for milk | Need_milk | DIA |
| The total amount of processed milk (t) | Amount of processed milk | Processed_milk | DIA |
| Total drinking milk production (t) | Production of drinking milk | Drink_milk_prod | DIA |
| Total cheese production (t) | Cheese production | Cheese_production | DIA |
| Total number of dairy companies (companies) | Milk processing companies | Dairy_companies | DIA |
| Average amount of processed milk per company (t) | Calculated as total amount of processed milk divided by number of dairy companies | Process_milk_comp | DIA |
| Gross regional product per capita (Euro) | Gross regional product | Gross_region_prod | RFSSS |
| Population surplus (people) | Total increase in population | Populat_surplus | RFSSS |
| Livestock cattle (thousand heads) | Number of livestock cattle | Livestock | RFSSS |
| Investments in stock capital (M Euro) | Total investments in stock capital | Investments | RFSSS |
| Income per month per capita (Euro) | Average income per capita | Income | RFSSS |
| Total population (people) | Total population | Total_population | RFSSS |
| Milk yield per cow (kg) | RFSSS calculated it as the amount of milk from all dairy herd divided by the average livestock numbers | Milk_yield | RFSSS |
| 2015 | 2016 | 2017 | 2018 | 2019 | |
|---|---|---|---|---|---|
| Moran’s I | 0.559 | 0.526 | 0.627 | 0.621 | 0.451 |
| p-value | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| Training Dataset | Test Dataset | |||||
|---|---|---|---|---|---|---|
| RMSE | R-Squared | MAE | RMSE | R-Squared | MAE | |
| Temporal cross-validation | 0.082 | 0.717 | 0.062 | 0.077 | 0.741 | 0.059 |
| Back-transformed performance | - | - | - | 73.136 | 0.875 | 45.891 |
| Spatial cross-validation | 0.088 | 0.462 | 0.078 | 0.077 | 0.742 | 0.058 |
| Back-transformed performance | - | - | - | 71.594 | 0.877 | 45.841 |
| Spatiotemporal cross-validation | 0.111 | 0.488 | 0.083 | 0.077 | 0.744 | 0.058 |
| Back-transformed performance | - | - | - | 76.344 | 0.872 | 46.086 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kresova, S.; Hess, S. Identifying the Determinants of Regional Raw Milk Prices in Russia Using Machine Learning. Agriculture 2022, 12, 1006. https://doi.org/10.3390/agriculture12071006
Kresova S, Hess S. Identifying the Determinants of Regional Raw Milk Prices in Russia Using Machine Learning. Agriculture. 2022; 12(7):1006. https://doi.org/10.3390/agriculture12071006
Chicago/Turabian StyleKresova, Svetlana, and Sebastian Hess. 2022. "Identifying the Determinants of Regional Raw Milk Prices in Russia Using Machine Learning" Agriculture 12, no. 7: 1006. https://doi.org/10.3390/agriculture12071006
APA StyleKresova, S., & Hess, S. (2022). Identifying the Determinants of Regional Raw Milk Prices in Russia Using Machine Learning. Agriculture, 12(7), 1006. https://doi.org/10.3390/agriculture12071006