
Prediction of Protein Content in Pea (Pisum sativum L.) Seeds Using Artificial Neural Networks




Abstract
:1. Introduction
2. Materials and Methods
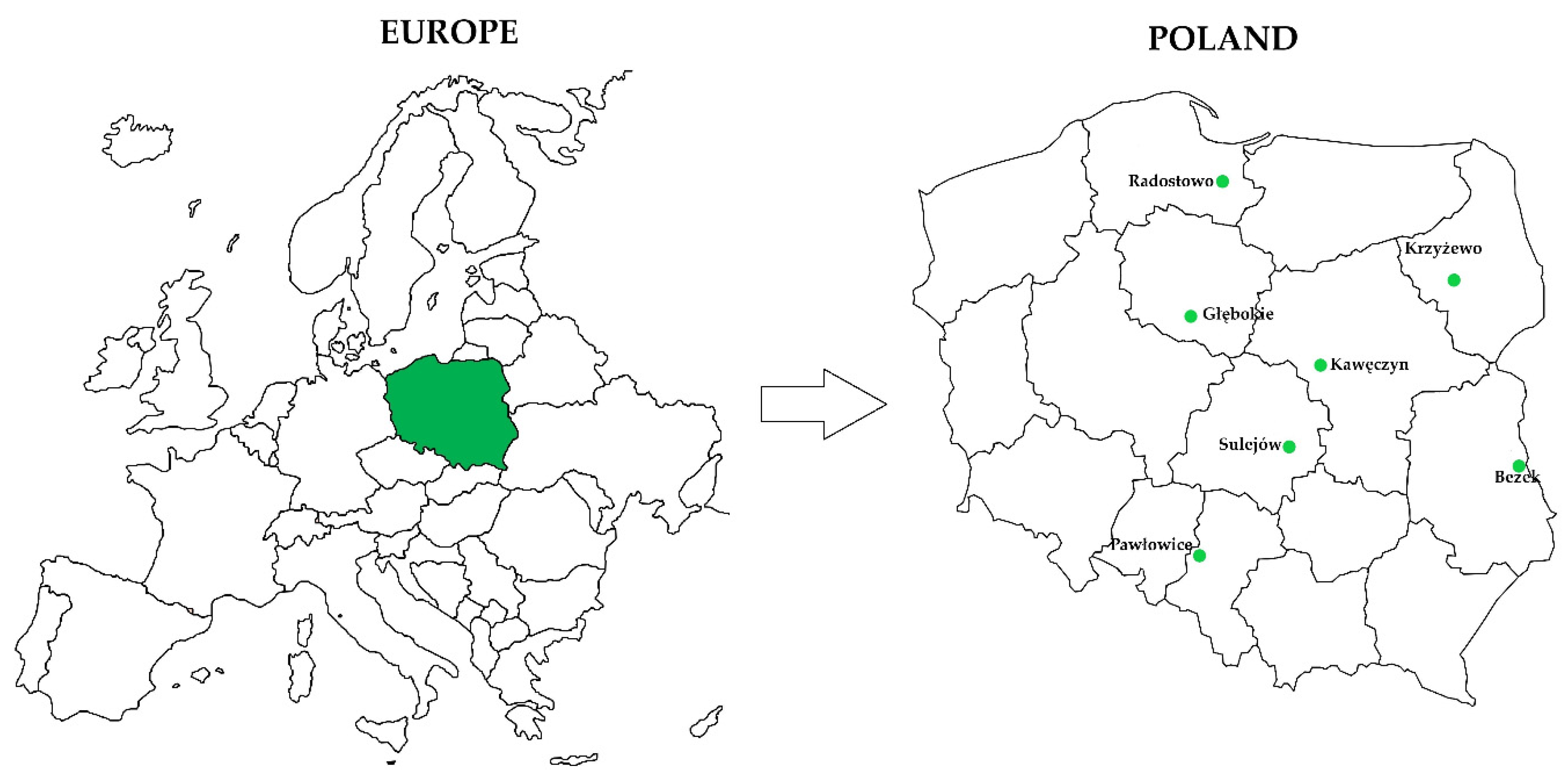
2.1. Data for Model Construction
2.2. Construction of the Database
2.3. Determination of Protein Content in Pea Seeds
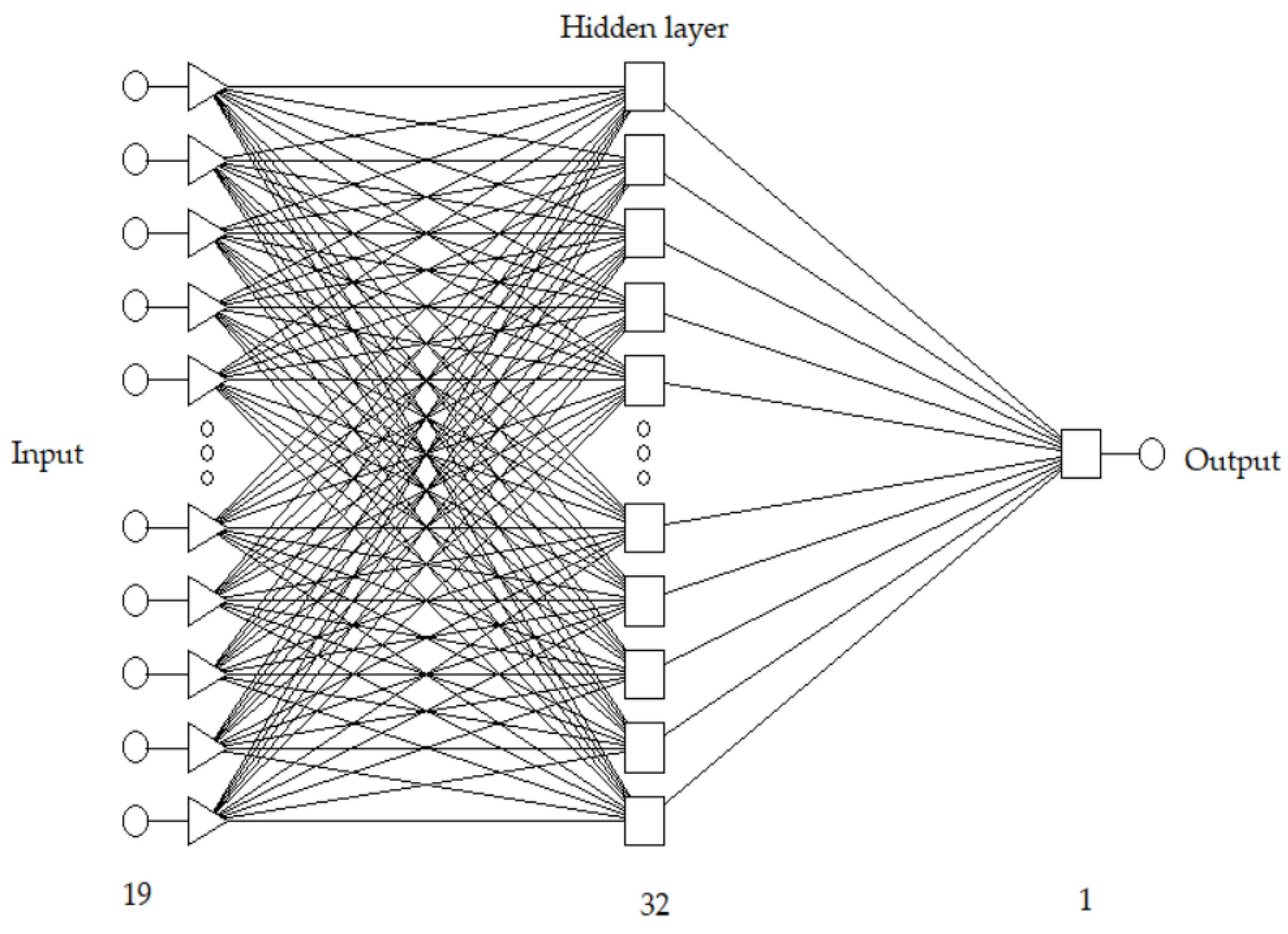
2.4. ANN Model Development
2.5. MLR Model Development
2.6. Verification of the N1 and RS Models
2.7. Sensitivity Analysis of the Neural Network
3. Results
3.1. Neural Network Learning and Quality Assessment of Models Predicting Protein Content in Pea Seeds
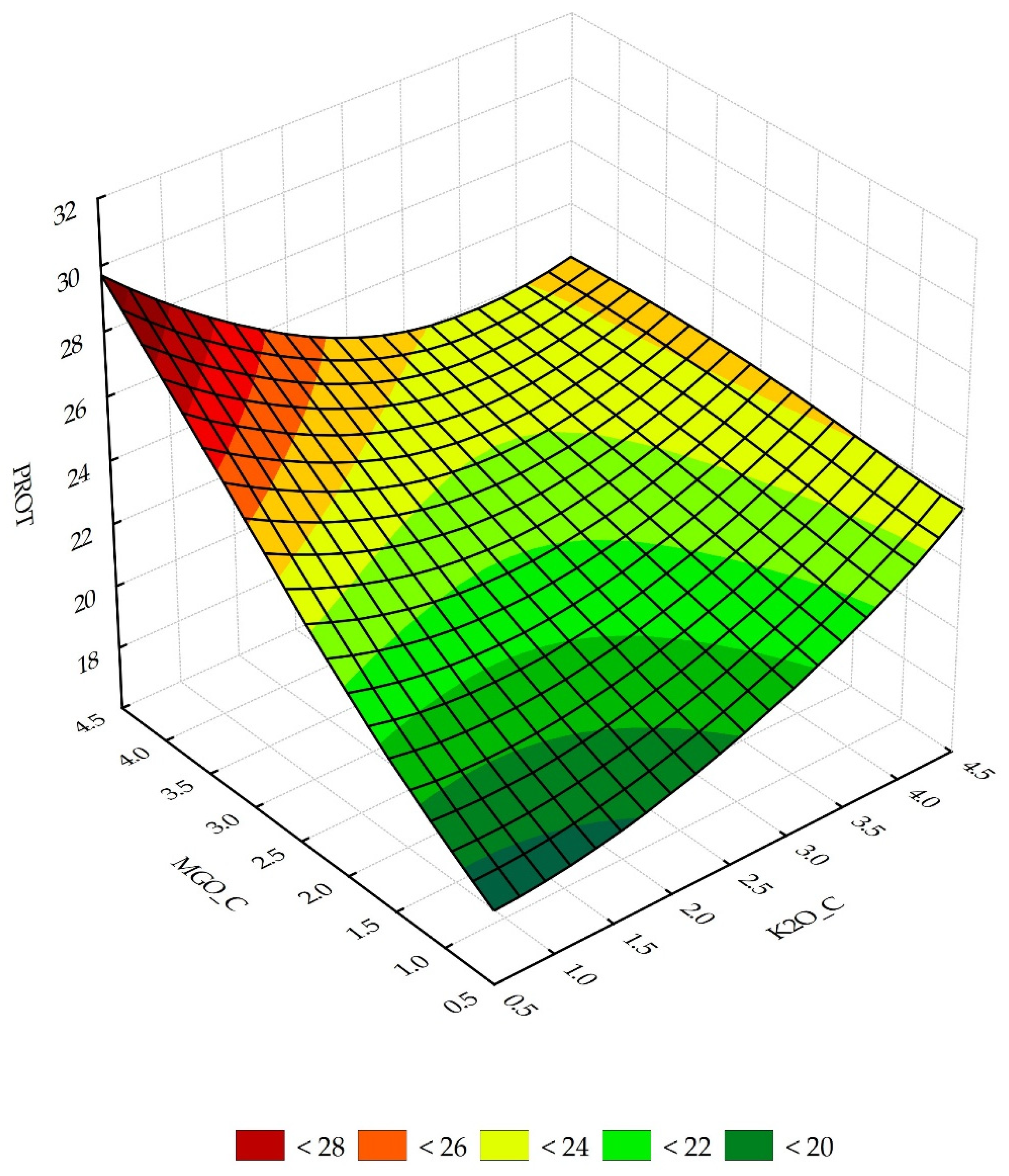
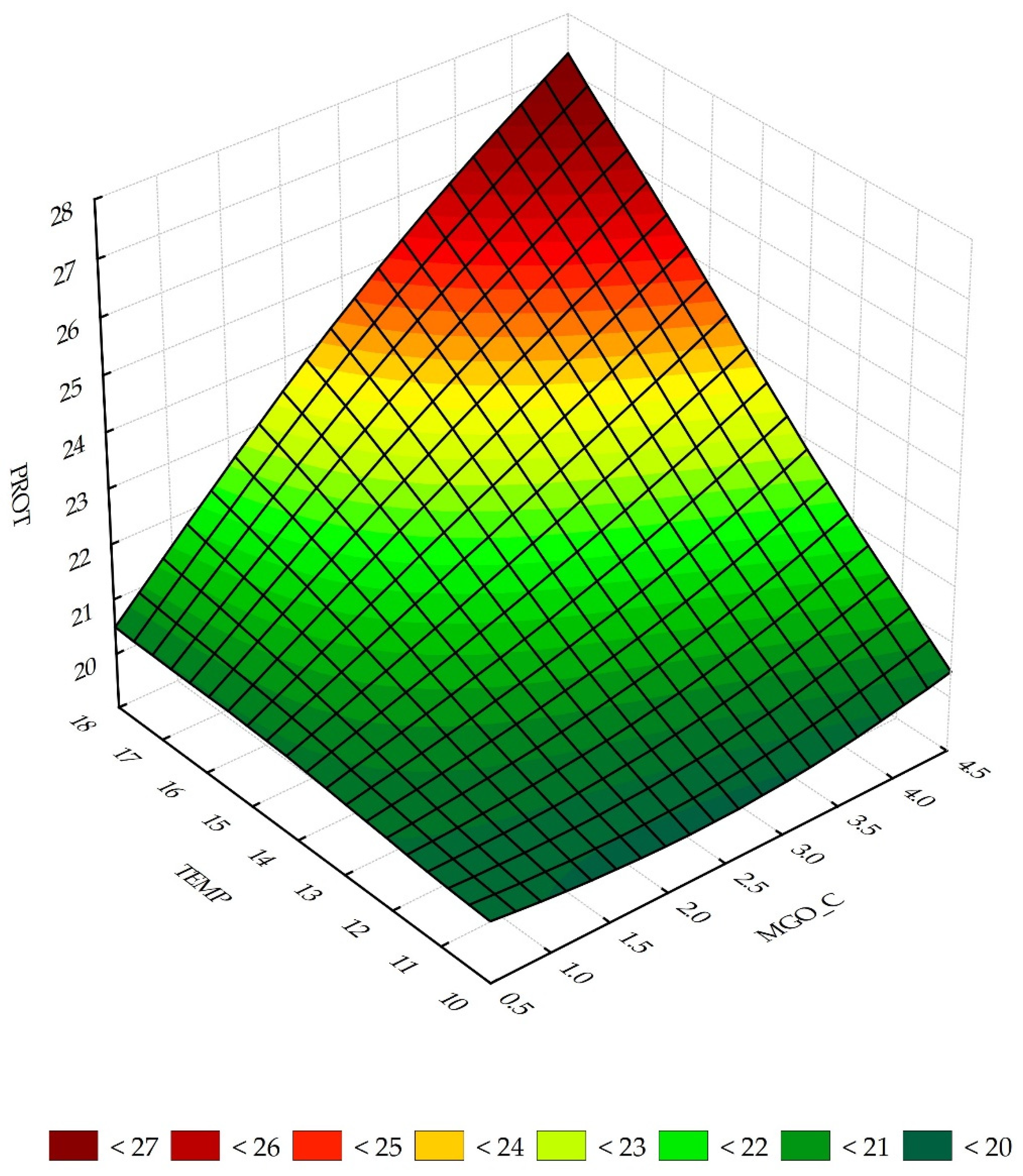
3.2. Sensitivity Analysis of Neural Networks
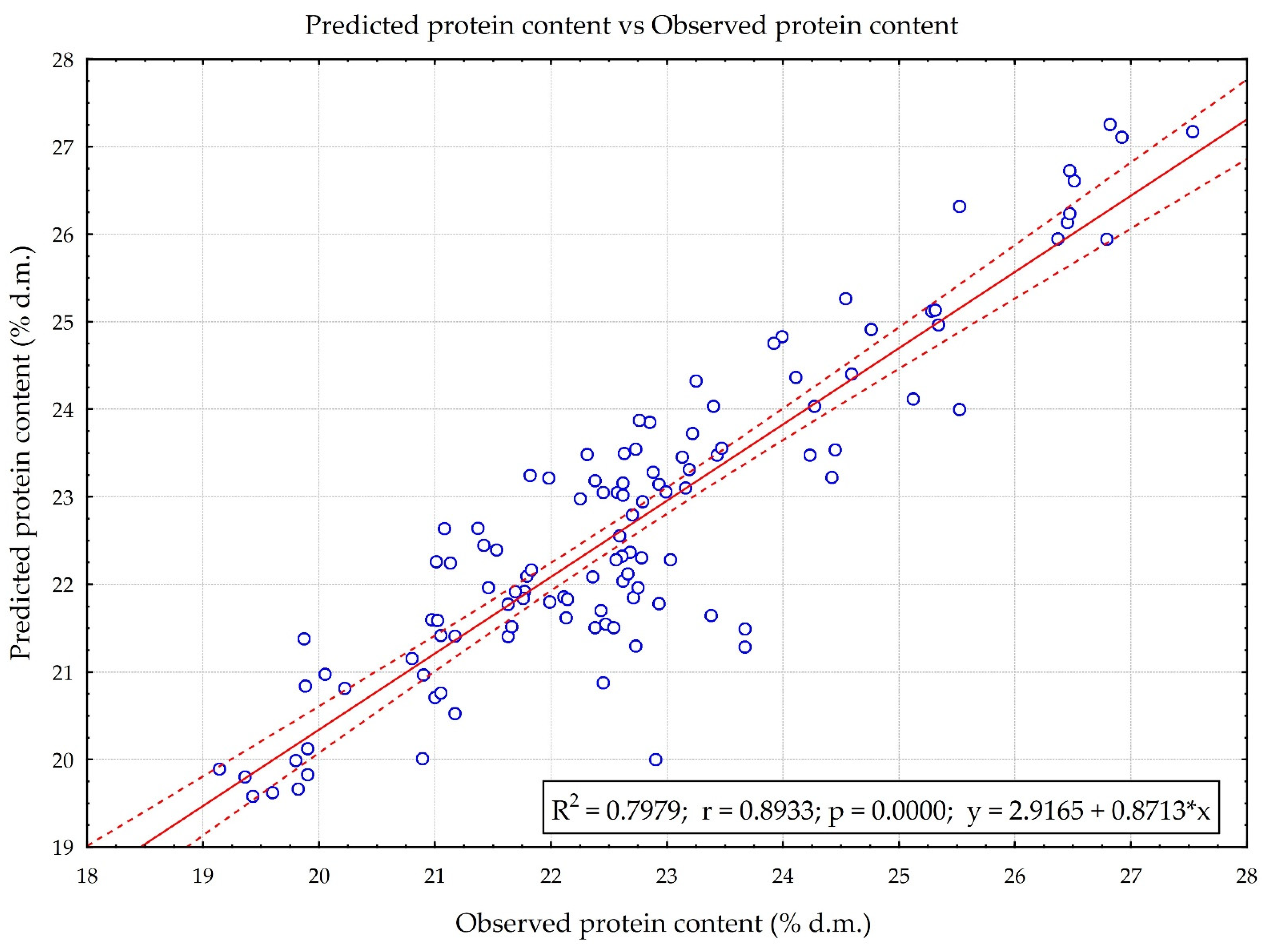
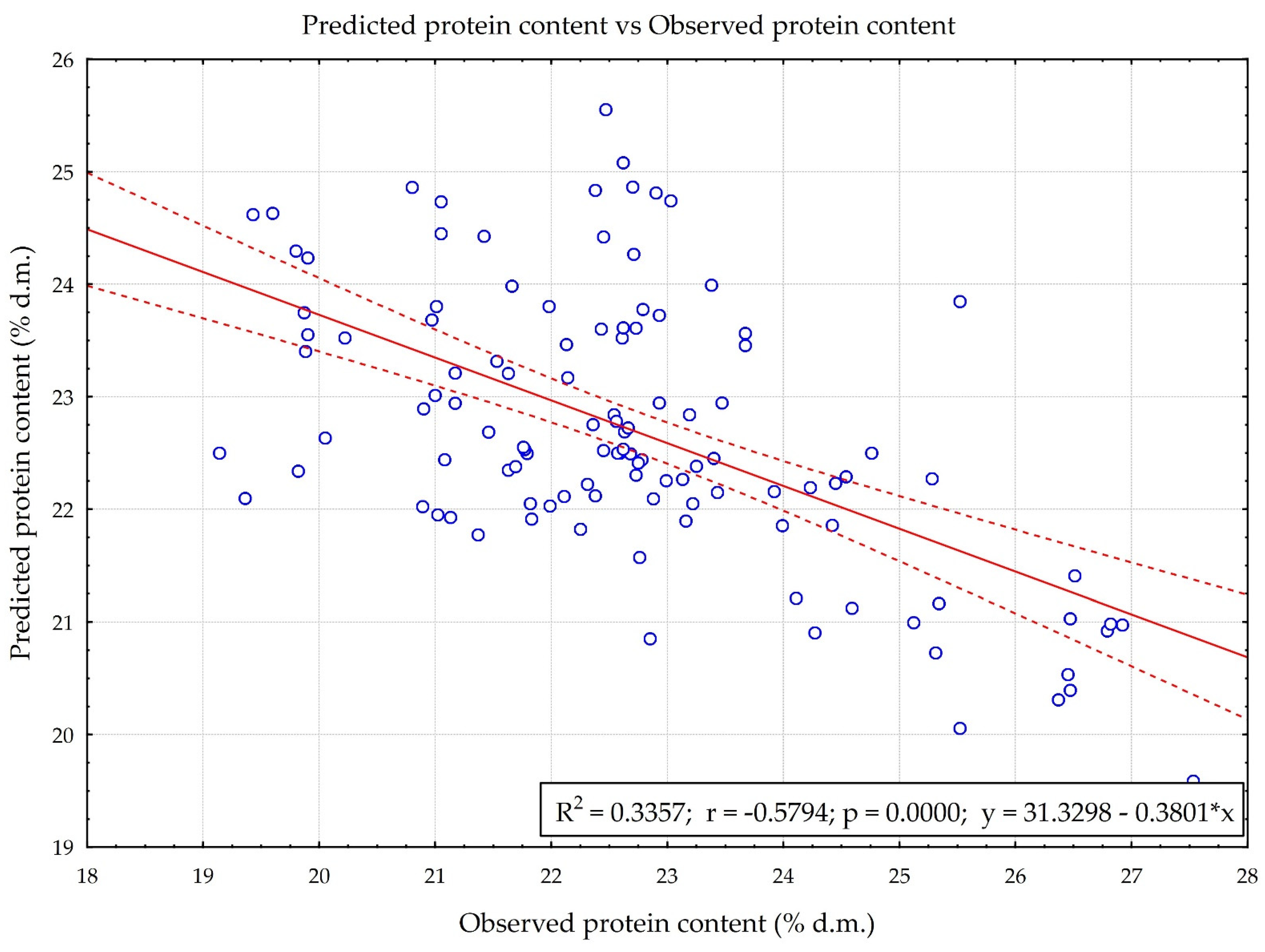
3.3. Predictive Properties of the N1 and RS Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
References
- Khatun, M.; Sarkar, S.; Era, F.M.; Islam, A.K.M.M.; Anwar, M.P.; Fahad, S.; Datta, R.; Islam, A.K.M.A. Drought Stress in Grain Legumes: Effects, Tolerance Mechanisms and Management. Agronomy 2021, 11, 2374. [Google Scholar] [CrossRef]
- Atnaf, M.; Tesfaye, K.; Dagne, K. The Importance of Legumes in the Ethiopian Farming System and Overall Economy: An Overview. Am. J. Exp. Agric. 2015, 7, 347–358. [Google Scholar] [CrossRef]
- Graham, P.H.; Vance, C.P. Legumes: Importance and Constraints to Greater Use. Plant Physiol. 2003, 131, 872–877. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kalembasa, S.; Szukała, J.; Faligowska, A.; Kalembasa, D.; Symanowicz, B.; Becher, M.; Gebus-Czupyt, B. Quantification of Biologically Fixed Nitrogen by White Lupin (Lupins albus L.) and Its Subsequent Uptake by Winter Wheat Using the 15N Isotope Dilution Method. Agronomy 2020, 10, 1392. [Google Scholar] [CrossRef]
- Putra, R.; Powell, J.R.; Hartley, S.E.; Johnson, S.N. Is it time to include legumes in plant silicon research? Funct. Ecol. 2020, 34, 1142–1157. [Google Scholar] [CrossRef] [Green Version]
- Daryanto, S.; Wang, L.; Jacinthe, P.-A. Global Synthesis of Drought Effects on Food Legume Production. PLoS ONE 2015, 10, e0127401. [Google Scholar] [CrossRef] [Green Version]
- Torabian, S.; Farhangi-Abriz, S.; Denton, M.D. Do tillage systems influence nitrogen fixation in legumes? A review. Soil Tillage Res. 2019, 185, 113–121. [Google Scholar] [CrossRef]
- Gentzbittel, L.; Andersen, S.U.; Ben, C.; Rickauer, M.; Stougaard, J.; Young, N.D. Naturally occurring diversity helps to reveal genes of adaptive importance in legumes. Front. Plant Sci. 2015, 6, 269. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Yang, Y.; Pei, K.; Zhou, J.; Peixoto, L.; Gunina, A.; Zeng, Z.; Zang, H.; Rasmussen, J.; Kuzyakov, Y. Nitrogen rhizodeposition by legumes and its fate in agroecosystems: A field study and literature review. Land Degrad. Dev. 2021, 32, 410–419. [Google Scholar] [CrossRef]
- Neugschwandtner, R.W.; Bernhuber, A.; Kammlander, S.; Wagentristl, H.; Klimek-Kopyra, A.; Lošák, T.; Zholamanov, K.K.; Kaul, H.-P. Nitrogen Yields and Biological Nitrogen Fixation of Winter Grain Legumes. Agronomy 2021, 11, 681. [Google Scholar] [CrossRef]
- Boukid, F.; Rosell, C.M.; Castellari, M. Pea protein ingredients: A mainstream ingredient to (re)formulate innovative foods and beverages. Trends Food Sci. Technol. 2021, 110, 729–742. [Google Scholar] [CrossRef]
- Powierzchnia Upraw w Gminach. Available online: https://rejestrupraw.arimr.gov.pl/ (accessed on 26 June 2022).
- Bogahawaththa, D.; Bao Chau, N.H.; Trivedi, J.; Dissanayake, M.; Vasiljevic, T. Impact of selected process parameters on solubility and heat stability of pea protein isolate. LWT 2019, 102, 246–253. [Google Scholar] [CrossRef]
- Pratap, A.; Das, A.; Kumar, S.; Gupta, S. Current Perspectives on Introgression Breeding in Food Legumes. Front. Plant Sci. 2021, 11, 589189. [Google Scholar] [CrossRef]
- Gao, Z.; Shen, P.; Lan, Y.; Cui, L.; Ohm, J.-B.; Chen, B.; Rao, J. Effect of alkaline extraction pH on structure properties, solubility, and beany flavor of yellow pea protein isolate. Food Res. Int. 2020, 131, 109045. [Google Scholar] [CrossRef]
- Chaudhary, A.; Marinangeli, C.; Tremorin, D.; Mathys, A. Nutritional Combined Greenhouse Gas Life Cycle Analysis for Incorporating Canadian Yellow Pea into Cereal-Based Food Products. Nutrients 2018, 10, 490. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Faligowska, A.; Kalembasa, S.; Kalembasa, D.; Panasiewicz, K.; Szymańska, G.; Ratajczak, K.; Skrzypczak, G. The Nitrogen Fixation and Yielding of Pea in Different Soil Tillage Systems. Agronomy 2022, 12, 352. [Google Scholar] [CrossRef]
- Kornet, C.; Venema, P.; Nijsse, J.; van der Linden, E.; van der Goot, A.J.; Meinders, M. Yellow pea aqueous fractionation increases the specific volume fraction and viscosity of its dispersions. Food Hydrocoll. 2020, 99, 105332. [Google Scholar] [CrossRef]
- Röhe, I.; Göbel, T.W.; Goodarzi Boroojeni, F.; Zentek, J. Effect of feeding soybean meal and differently processed peas on the gut mucosal immune system of broilers. Poult. Sci. 2017, 96, 2064–2073. [Google Scholar] [CrossRef]
- Florek, J. Potential utilization of legumes in feed production in Poland. Ann. Polish Assoc. Agric. Agribus. Econ. 2017, XIX, 40–45. [Google Scholar] [CrossRef]
- Niedbała, G. Application of artificial neural networks for multi-criteria yield prediction of winter rapeseed. Sustainability 2019, 11, 533. [Google Scholar] [CrossRef]
- Hara, P.; Piekutowska, M.; Niedbała, G. Selection of Independent Variables for Crop Yield Prediction Using Artificial Neural Network Models with Remote Sensing Data. Land 2021, 10, 609. [Google Scholar] [CrossRef]
- Chipanshi, A.; Zhang, Y.; Kouadio, L.; Newlands, N.; Davidson, A.; Hill, H.; Warren, R.; Qian, B.; Daneshfar, B.; Bedard, F.; et al. Evaluation of the Integrated Canadian Crop Yield Forecaster (ICCYF) model for in-season prediction of crop yield across the Canadian agricultural landscape. Agric. For. Meteorol. 2015, 206, 137–150. [Google Scholar] [CrossRef] [Green Version]
- Nazir, A.; Ullah, S.; Saqib, Z.A.; Abbas, A.; Ali, A.; Iqbal, M.S.; Hussain, K.; Shakir, M.; Shah, M.; Butt, M.U. Estimation and Forecasting of Rice Yield Using Phenology-Based Algorithm and Linear Regression Model on Sentinel-II Satellite Data. Agriculture 2021, 11, 1026. [Google Scholar] [CrossRef]
- Piekutowska, M.; Niedbała, G.; Piskier, T.; Lenartowicz, T.; Pilarski, K.; Wojciechowski, T.; Pilarska, A.A.; Czechowska-Kosacka, A. The Application of Multiple Linear Regression and Artificial Neural Network Models for Yield Prediction of Very Early Potato Cultivars before Harvest. Agronomy 2021, 11, 885. [Google Scholar] [CrossRef]
- Niedbała, G.; Wróbel, B.; Piekutowska, M.; Zielewicz, W.; Paszkiewicz-Jasińska, A.; Wojciechowski, T.; Niazian, M. Application of Artificial Neural Networks Sensitivity Analysis for the Pre-Identification of Highly Significant Factors Influencing the Yield and Digestibility of Grassland Sward in the Climatic Conditions of Central Poland. Agronomy 2022, 12, 1133. [Google Scholar] [CrossRef]
- Shahhosseini, M.; Hu, G.; Archontoulis, S.V. Forecasting Corn Yield with Machine Learning Ensembles. Front. Plant Sci. 2020, 11, 1120. [Google Scholar] [CrossRef]
- Kakati, N.; Deka, R.L.; Das, P.; Goswami, J.; Khanikar, P.G.; Saikia, H. Forecasting yield of rapeseed and mustard using multiple linear regression and ANN techniques in the Brahmaputra valley of Assam, North East India. Theor. Appl. Climatol. 2022, 150, 1201–1215. [Google Scholar] [CrossRef]
- Pentoś, K.; Mbah, J.T.; Pieczarka, K.; Niedbała, G.; Wojciechowski, T. Evaluation of Multiple Linear Regression and Machine Learning Approaches to Predict Soil Compaction and Shear Stress Based on Electrical Parameters. Appl. Sci. 2022, 12, 8791. [Google Scholar] [CrossRef]
- Niazian, M.; Sadat-Noori, S.A.; Abdipour, M. Artificial neural network and multiple regression analysis models to predict essential oil content of ajowan (Carum copticum L.). J. Appl. Res. Med. Aromat. Plants 2018, 9, 124–131. [Google Scholar] [CrossRef]
- van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Abrougui, K.; Gabsi, K.; Mercatoris, B.; Khemis, C.; Amami, R.; Chehaibi, S. Prediction of organic potato yield using tillage systems and soil properties by artificial neural network (ANN) and multiple linear regressions (MLR). Soil Tillage Res. 2019, 190, 202–208. [Google Scholar] [CrossRef]
- Rajković, D.; Marjanović Jeromela, A.; Pezo, L.; Lončar, B.; Zanetti, F.; Monti, A.; Kondić Špika, A. Yield and Quality Prediction of Winter Rapeseed—Artificial Neural Network and Random Forest Models. Agronomy 2021, 12, 58. [Google Scholar] [CrossRef]
- Abraham, E.R.; Mendes dos Reis, J.G.; Vendrametto, O.; de Oliveira Costa Neto, P.L.; Carlo Toloi, R.; de Souza, A.E.; Oliveira Morais, M. de Time Series Prediction with Artificial Neural Networks: An Analysis Using Brazilian Soybean Production. Agriculture 2020, 10, 475. [Google Scholar] [CrossRef]
- Rathod, S.; Yerram, S.; Arya, P.; Katti, G.; Rani, J.; Padmakumari, A.P.; Somasekhar, N.; Padmavathi, C.; Ondrasek, G.; Amudan, S.; et al. Climate-Based Modeling and Prediction of Rice Gall Midge Populations Using Count Time Series and Machine Learning Approaches. Agronomy 2021, 12, 22. [Google Scholar] [CrossRef]
- Sabzi-Nojadeh, M.; Niedbała, G.; Younessi-Hamzekhanlu, M.; Aharizad, S.; Esmaeilpour, M.; Abdipour, M.; Kujawa, S.; Niazian, M. Modeling the Essential Oil and Trans-Anethole Yield of Fennel (Foeniculum vulgare Mill. var. vulgare) by Application Artificial Neural Network and Multiple Linear Regression Methods. Agriculture 2021, 11, 1191. [Google Scholar] [CrossRef]
- Kujawa, S.; Dach, J.; Kozłowski, R.J.; Przybył, K.; Niedbała, G.; Mueller, W.; Tomczak, R.J.; Zaborowicz, M.; Koszela, K. Maturity classification for sewage sludge composted with rapeseed straw using neural image analysis. In Proceedings of the SPIE—The International Society for Optical Engineering, Chengu, China, 29 August 2016; Falco, C.M., Jiang, X., Eds.; SPIE: Bellingham, WA, USA, 2016; p. 100332H. [Google Scholar] [CrossRef]
- Maya Gopal, P.S.; Bhargavi, R. A novel approach for efficient crop yield prediction. Comput. Electron. Agric. 2019, 165, 104968. [Google Scholar] [CrossRef]
- Cieniawska, B.; Pentoś, K.; Łuczycka, D. Neural modeling and optimization of the coverage of the sprayed surface. Bull. Pol. Acad. Sci. Tech. Sci. 2020, 68, 601–608. [Google Scholar] [CrossRef]
- Marchant, J.; Onyango, C. Comparison of a Bayesian classifier with a multilayer feed-forward neural network using the example of plant/weed/soil discrimination. Comput. Electron. Agric. 2003, 39, 3–22. [Google Scholar] [CrossRef]
- Pentoś, K.; Łuczycka, D.; Kapłon, T. The identification of relationships between selected honey parameters by extracting the contribution of independent variables in a neural network model. Eur. Food Res. Technol. 2015, 241, 793–801. [Google Scholar] [CrossRef]
- Research Centre for Cultivar Testing (COBORU). Available online: https://coboru.gov.pl/ (accessed on 20 October 2022).
- Niedbała, G.; Tratwal, A.; Piekutowska, M.; Wojciechowski, T.; Uglis, J. A Framework for Financing Post-Registration Variety Testing System: A Case Study from Poland. Agronomy 2022, 12, 325. [Google Scholar] [CrossRef]
- Porejestrowe Doświadczalnictwo Odmianowe (PDO). Available online: https://coboru.gov.pl/pdo/pdo (accessed on 20 October 2022).
- Dane Publiczne IMGW. Available online: https://danepubliczne.imgw.pl/ (accessed on 20 October 2022).
- Mádlíková, M.; Krausová, I.; Mizera, J.; Táborský, J.; Faměra, O.; Chvátil, D. Nitrogen assay in winter wheat by short-time instrumental photon activation analysis and its comparison with the Kjeldahl method. J. Radioanal. Nucl. Chem. 2018, 317, 479–486. [Google Scholar] [CrossRef]
- Simonne, A.H.; Simonne, E.H.; Eitenmiller, R.R.; Mills, H.A.; Cresman, C.P. Could the Dumas Method Replace the Kjeldahl Digestion for Nitrogen and Crude Protein Determinations in Foods? J. Sci. Food Agric. 1997, 73, 39–45. [Google Scholar] [CrossRef]
- Ma, Y.; Zhang, Z.; Kang, Y.; Özdoğan, M. Corn yield prediction and uncertainty analysis based on remotely sensed variables using a Bayesian neural network approach. Remote Sens. Environ. 2021, 259, 112408. [Google Scholar] [CrossRef]
- Roy Choudhury, M.; Das, S.; Christopher, J.; Apan, A.; Chapman, S.; Menzies, N.W.; Dang, Y.P. Improving Biomass and Grain Yield Prediction of Wheat Genotypes on Sodic Soil Using Integrated High-Resolution Multispectral, Hyperspectral, 3D Point Cloud, and Machine Learning Techniques. Remote Sens. 2021, 13, 3482. [Google Scholar] [CrossRef]
- Priya, P.K.; Yuvaraj, N. An IoT Based Gradient Descent Approach for Precision Crop Suggestion using MLP. J. Phys. Conf. Ser. 2019, 1362, 012038. [Google Scholar] [CrossRef]
- Bhojani, S.H.; Bhatt, N. Wheat crop yield prediction using new activation functions in neural network. Neural Comput. Appl. 2020, 32, 13941–13951. [Google Scholar] [CrossRef]
- Niedbała, G.; Piekutowska, M.; Weres, J.; Korzeniewicz, R.; Witaszek, K.; Adamski, M.; Pilarski, K.; Czechowska-Kosacka, A.; Krysztofiak-Kaniewska, A. Application of artificial neural networks for yield modeling of winter rapeseed based on combined quantitative and qualitative data. Agronomy 2019, 9, 781. [Google Scholar] [CrossRef] [Green Version]
- Pazhanivelan, S.; Geethalakshmi, V.; Tamilmounika, R.; Sudarmanian, N.S.; Kaliaperumal, R.; Ramalingam, K.; Sivamurugan, A.P.; Mrunalini, K.; Yadav, M.K.; Quicho, E.D. Spatial Rice Yield Estimation Using Multiple Linear Regression Analysis, Semi-Physical Approach and Assimilating SAR Satellite Derived Products with DSSAT Crop Simulation Model. Agronomy 2022, 12, 2008. [Google Scholar] [CrossRef]
- Niedbała, G.; Kurek, J.; Świderski, B.; Wojciechowski, T.; Antoniuk, I.; Bobran, K. Prediction of Blueberry (Vaccinium corymbosum L.) Yield Based on Artificial Intelligence Methods. Agriculture 2022, 12, 2089. [Google Scholar] [CrossRef]
- Schwalbert, R.A.; Amado, T.; Corassa, G.; Pott, L.P.; Prasad, P.V.V.; Ciampitti, I.A. Satellite-based soybean yield forecast: Integrating machine learning and weather data for improving crop yield prediction in southern Brazil. Agric. For. Meteorol. 2020, 284, 107886. [Google Scholar] [CrossRef]
- Shankar, T.; Malik, G.C.; Banerjee, M.; Dutta, S.; Praharaj, S.; Lalichetti, S.; Mohanty, S.; Bhattacharyay, D.; Maitra, S.; Gaber, A.; et al. Prediction of the Effect of Nutrients on Plant Parameters of Rice by Artificial Neural Network. Agronomy 2022, 12, 2123. [Google Scholar] [CrossRef]
- Niedbała, G.; Kurasiak-Popowska, D.; Piekutowska, M.; Wojciechowski, T.; Kwiatek, M.; Nawracała, J. Application of Artificial Neural Network Sensitivity Analysis to Identify Key Determinants of Harvesting Date and Yield of Soybean (Glycine max [L.] Merrill) Cultivar Augusta. Agriculture 2022, 12, 754. [Google Scholar] [CrossRef]
- Wojciechowski, T.; Niedbala, G.; Czechlowski, M.; Nawrocka, J.R.; Piechnik, L.; Niemann, J. Rapeseed seeds quality classification with usage of VIS-NIR fiber optic probe and artificial neural networks. In Proceedings of the 2016 International Conference on Optoelectronics and Image Processing (ICOIP), Warsaw, Poland, 10–12 June 2016; IEEE: Warsaw, Poland, 2016; pp. 44–48. [Google Scholar] [CrossRef]
- Manish Lad, A.; Mani Bharathi, K.; Akash Saravanan, B.; Karthik, R. Factors affecting agriculture and estimation of crop yield using supervised learning algorithms. Mater. Today Proc. 2022, 62, 4629–4634. [Google Scholar] [CrossRef]
- Yildirim, T.; Moriasi, D.N.; Starks, P.J.; Chakraborty, D. Using Artificial Neural Network (ANN) for Short-Range Prediction of Cotton Yield in Data-Scarce Regions. Agronomy 2022, 12, 828. [Google Scholar] [CrossRef]
- Akbar, A.; Kuanar, A.; Patnaik, J.; Mishra, A.; Nayak, S. Application of Artificial Neural Network modeling for optimization and prediction of essential oil yield in turmeric (Curcuma longa L.). Comput. Electron. Agric. 2018, 148, 160–178. [Google Scholar] [CrossRef]
- Niedbała, G.; Kurasiak-Popowska, D.; Stuper-Szablewska, K.; Nawracała, J. Application of Artificial Neural Networks to Analyze the Concentration of Ferulic Acid, Deoxynivalenol, and Nivalenol in Winter Wheat Grain. Agriculture 2020, 10, 127. [Google Scholar] [CrossRef] [Green Version]
- Szwedziak, K.; Polańczyk, E.; Grzywacz, Ż.; Niedbała, G.; Wojtkiewicz, W. Neural Modeling of the Distribution of Protein, Water and Gluten in Wheat Grains during Storage. Sustainability 2020, 12, 5050. [Google Scholar] [CrossRef]
- Huang, S.; Liu, Y.; Sun, X.; Li, J. Application of Artificial Neural Network Based on Traditional Detection and GC-MS in Prediction of Free Radicals in Thermal Oxidation of Vegetable Oil. Molecules 2021, 26, 6717. [Google Scholar] [CrossRef]
- Niedbała, G. Simple model based on artificial neural network for early prediction and simulation winter rapeseed yield. J. Integr. Agric. 2019, 18, 54–61. [Google Scholar] [CrossRef] [Green Version]
- Peng, J.; Kim, M.; Kim, Y.; Jo, M.; Kim, B.; Sung, K.; Lv, S. Constructing Italian ryegrass yield prediction model based on climatic data by locations in South Korea. Grassl. Sci. 2017, 63, 184–195. [Google Scholar] [CrossRef]
- Nosratabadi, S.; Ardabili, S.; Lakner, Z.; Mako, C.; Mosavi, A. Prediction of Food Production Using Machine Learning Algorithms of Multilayer Perceptron and ANFIS. Agriculture 2021, 11, 408. [Google Scholar] [CrossRef]
- Ahmed, M.U.; Hussain, I. Prediction of Wheat Production Using Machine Learning Algorithms in northern areas of Pakistan. Telecomm. Policy 2022, 46, 102370. [Google Scholar] [CrossRef]
- Meerasri, J.; Sothornvit, R. Artificial neural networks (ANNs) and multiple linear regression (MLR) for prediction of moisture content for coated pineapple cubes. Case Stud. Therm. Eng. 2022, 33, 101942. [Google Scholar] [CrossRef]
- Saba, T.; Liu, W.; Wang, J.; Saleem, F.; Kang, X.; Hui, W.; Gong, W.; Li, H. Effects of organic supplementation to reduced rates of chemical fertilization on soil fertility of Zanthoxylum armatum. Dendrobiology 2022, 87, 123–136. [Google Scholar] [CrossRef]
- Dincă, L.C.; Grenni, P.; Onet, C.; Onet, A. Fertilization and Soil Microbial Community: A Review. Appl. Sci. 2022, 12, 1198. [Google Scholar] [CrossRef]
- Yano, K.; Kume, T. Root Morphological Plasticity for Heterogeneous Phosphorus Supply in Zea mays L. Plant Prod. Sci. 2005, 8, 427–432. [Google Scholar] [CrossRef]
- Gransee, A.; Führs, H. Magnesium mobility in soils as a challenge for soil and plant analysis, magnesium fertilization and root uptake under adverse growth conditions. Plant Soil 2013, 368, 5–21. [Google Scholar] [CrossRef] [Green Version]
- Wei, Q.; Guo, Y.; Kuai, B. Isolation and characterization of a chlorophyll degradation regulatory gene from tall fescue. Plant Cell Rep. 2011, 30, 1201–1207. [Google Scholar] [CrossRef]
- Xu, X.-F.; Wang, B.; Lou, Y.; Han, W.-J.; Lu, J.-Y.; Li, D.-D.; Li, L.-G.; Zhu, J.; Yang, Z.-N. Magnesium Transporter 5 plays an important role in Mg transport for male gametophyte development in Arabidopsis. Plant J. 2015, 84, 925–936. [Google Scholar] [CrossRef] [Green Version]
- Xie, K.; Cakmak, I.; Wang, S.; Zhang, F.; Guo, S. Synergistic and antagonistic interactions between potassium and magnesium in higher plants. Crop J. 2021, 9, 249–256. [Google Scholar] [CrossRef]
- Peng, W.T.; Qi, W.L.; Nie, M.M.; Xiao, Y.B.; Liao, H.; Chen, Z.C. Magnesium supports nitrogen uptake through regulating NRT2.1/2.2 in soybean. Plant Soil 2020, 457, 97–111. [Google Scholar] [CrossRef]
- Geng, G.; Cakmak, I.; Ren, T.; Lu, Z.; Lu, J. Effect of magnesium fertilization on seed yield, seed quality, carbon assimilation and nutrient uptake of rapeseed plants. F. Crop. Res. 2021, 264, 108082. [Google Scholar] [CrossRef]
- Chaudhry, A.H.; Nayab, S.; Hussain, S.B.; Ali, M.; Pan, Z. Current Understandings on Magnesium Deficiency and Future Outlooks for Sustainable Agriculture. Int. J. Mol. Sci. 2021, 22, 1819. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Hassan, M.U.; Nadeem, F.; Wu, L.; Zhang, F.; Li, X. Magnesium Fertilization Improves Crop Yield in Most Production Systems: A Meta-Analysis. Front. Plant Sci. 2020, 10, 1727. [Google Scholar] [CrossRef] [Green Version]
- Fischer, E.S.; Lohaus, G.; Heineke, D.; Heldt, H.W. Magnesium deficiency results in accumulation of carbohydrates and amino acids in source and sink leaves of spinach. Physiol. Plant. 1998, 102, 16–20. [Google Scholar] [CrossRef] [PubMed]
- Vrataric, M.; Sudaric, A.; Kovacevic, V.; Duvnjak, T.; Krizmanic, M.; Mijic, A. Response of soybean to foliar fertilization with magnesium sulfate (epsom salt). Cereal Res. Commun. 2006, 34, 709–712. [Google Scholar] [CrossRef]
- Sawan, Z.M.; Hafezb, S.A.; Basyony, A.E.; Alkassas, A.-E.-E.R. Cottonseed: Protein, oil yields, and oil properties as influenced by potassium fertilization and foliar application of zinc and phosphorus. Grasas Aceites 2007, 58, 40–48. [Google Scholar] [CrossRef] [Green Version]
- Skrzyczyńska, J.; Gąsiorowska, B. Uprawa Roślin; UPW: Wrocław, Poland, 2020; pp. 49–210. [Google Scholar]
- Walter, S.; Zehring, J.; Mink, K.; Quendt, U.; Zocher, K.; Rohn, S. Protein content of peas (Pisum sativum) and beans (Vicia faba)—Influence of cultivation conditions. J. Food Compos. Anal. 2022, 105, 104257. [Google Scholar] [CrossRef]
- Grzebisz, W. Nawożenie Roślin Uprawnych 2; Powszechne Wydawnictwo Rolnicze i Leśne: Poznań, Poland, 2009. [Google Scholar]
- Singh, S.K.; Reddy, V.R.; Fleisher, D.H.; Timlin, D.J. Phosphorus Nutrition Affects Temperature Response of Soybean Growth and Canopy Photosynthesis. Front. Plant Sci. 2018, 9, 1116. [Google Scholar] [CrossRef]
- Singh, S.K.; Reddy, V.R. Combined effects of phosphorus nutrition and elevated carbon dioxide concentration on chlorophyll fluorescence, photosynthesis, and nutrient efficiency of cotton. J. Plant Nutr. Soil Sci. 2014, 177, 892–902. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.K.; Reddy, V.R. Response of carbon assimilation and chlorophyll fluorescence to soybean leaf phosphorus across CO2: Alternative electron sink, nutrient efficiency and critical concentration. J. Photochem. Photobiol. B Biol. 2015, 151, 276–284. [Google Scholar] [CrossRef] [PubMed]
- Taliman, N.A.; Dong, Q.; Echigo, K.; Raboy, V.; Saneoka, H. Effect of Phosphorus Fertilization on the Growth, Photosynthesis, Nitrogen Fixation, Mineral Accumulation, Seed Yield, and Seed Quality of a Soybean Low-Phytate Line. Plants 2019, 8, 119. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jin, J.; Wang, G.; Liu, X.; Pan, X.; Herbert, S.J.; Tang, C. Interaction between Phosphorus Nutrition and Drought on Grain Yield, and Assimilation of Phosphorus and Nitrogen in Two Soybean Cultivars Differing in Protein Concentration in Grains. J. Plant Nutr. 2006, 29, 1433–1449. [Google Scholar] [CrossRef]
- Niedbała, G.; Kozłowski, R.J. Application of Artificial Neural Networks for Multi-Criteria Yield Prediction of Winter Wheat. J. Agric. Sci. Technol. 2019, 21, 51–61. [Google Scholar]
- Wu, W.; Ma, B.-L.; Fan, J.-J.; Sun, M.; Yi, Y.; Guo, W.-S.; Voldeng, H.D. Management of nitrogen fertilization to balance reducing lodging risk and increasing yield and protein content in spring wheat. Field Crop. Res. 2019, 241, 107584. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Unit of Measure | Variable Description | Data Range |
|---|---|---|---|
| Independent Variables | |||
| RAIN | mm | Total rainfall from sowing date to 14 July | 96.9–312.4 |
| SUN | h | Total sunshine from sowing date to 14 July | 630.5–1051.5 |
| TEMP | °C | Average air temperature from sowing date to 14 July | 11.0–17.5 |
| N_F | kg·ha−1 | Total nitrogen from mineral fertilizers | 10–90 |
| P2O5_F | kg·ha−1 | Total phosphorus from mineral fertilizers | 0–80 |
| K2O_F | kg·ha−1 | Total potassium from mineral fertilizers | 0–119 |
| SOWI | days | Number of days from 1 January to sowing date | 83–102 |
| P_EMER | days | Number of days from 1 January to the beginning of plant emergence | 96–133 |
| HAR | days | Number of days from 1 January to the date of harvesting | 184–221 |
| FLOWE | days | Number of days from 1 January to the beginning of flowering | 126–169 |
| INI_MA | days | Number of days from 1 January to onset of maturity | 167–211 |
| TECH_M | days | Number of days from 1 January to technical maturity | 171–216 |
| P_HIG | cm | Plant height | 43–156 |
| WEGW | days | Number of plant growing days | 87–137 |
| PH | - | Soil pH | 5.5–7.5 |
| P2O5_C | Scale from 0 to 4 * | P2O5 content in the soil | 0–4 |
| K2O_C | Scale from 0 to 4 * | K2O content in the soil | 0–4 |
| MGO_C | Scale from 0 to 4 * | MgO content in the soil | 0–4 |
| GEN | feature coded 101 to 111 | General variety of peas | - |
| Dependent variable | |||
| PROT | % | Percentage of protein in pea seeds | 18.56–29.22 |
| Resources | Phosphorus, mg P2O5·kg−1 Soil | Potassium, mg K2O·kg−1 Soil | Magnesium, mg MgO·kg−1 Soil | ||||
|---|---|---|---|---|---|---|---|
| Soil Agronomic Category | Soil Agronomic Category | ||||||
| Light | Medium | Heavy | Light | Medium | Heavy | ||
| very low | up to 50 | up to 100 | up to 105 | up to 170 | up to 80 | up to 105 | up to 120 |
| low | 51–80 | 101–160 | 106–170 | 171–260 | 81–135 | 106–160 | 121–220 |
| average | 81–115 | 161–275 | 171–310 | 261–350 | 136–200 | 161–265 | 221–330 |
| high | 116–185 | 276–380 | 311–420 | 351–510 | 201–285 | 266–330 | 331–460 |
| very high | >185 | >380 | >420 | >510 | >285 | >330 | >460 |
| Subsets | Teaching | Validation | Testing |
|---|---|---|---|
| Size of error | 0.0551 | 0.0535 | 0.0595 |
| Quality | 0.3642 | 0.4145 | 0.0551 |
| Epochs of learning | |||
| Back propagation method of error | 100 | ||
| Coupled gradients method | 55b * | ||
| Quality Measures | Value |
|---|---|
| Average | 22.857 |
| Standard deviation | 1.895 |
| Average error | 0.008 |
| Error deviation | 0.744 |
| Average absolute error | 0.574 |
| Deviation quotient | 0.393 |
| Correlation coefficient r | 0.920 |
| Factor | MLR: r = 0.6949 R2 = 0.4829 Standard Error of Estimate = 1.374 | |||||
|---|---|---|---|---|---|---|
| Beta | Standard Error Beta | b | Standard Error b | p | Significance | |
| Free Term | - | - | 40.445 | 0.859 | 0.000000 | + |
| MGO_C | 0.323 | 0.035 | 0.576 | 0.062 | 0.000000 | + |
| RAIN | −0.154 | 0.034 | −0.005 | 0.001 | 0.000007 | + |
| K2O_F | −0.298 | 0.041 | −0.021 | 0.003 | 0.000000 | + |
| N_F | −0.187 | 0.031 | −0.028 | 0.005 | 0.000000 | + |
| HAR | −0.316 | 0.041 | −0.065 | 0.009 | 0.000000 | + |
| P_HIG | 0.234 | 0.033 | 0.027 | 0.004 | 0.000000 | + |
| FLOWE | 0.062 | 0.042 | 0.021 | 0.015 | 0.146017 | − |
| TECH_M | −1.063 | 0.127 | −0.214 | 0.026 | 0.000000 | + |
| INI_A | 0.745 | 0.138 | 0.152 | 0.028 | 0.000000 | + |
| P2O5_F | 0.195 | 0.043 | 0.020 | 0.004 | 0.000006 | + |
| TEMP | −0.340 | 0.086 | −0.416 | 0.104 | 0.000077 | + |
| SOWI | 0.182 | 0.071 | 0.061 | 0.024 | 0.009821 | + |
| GEN | 0.0439 | 0.023 | 0.026 | 0.014 | 0.056315 | − |
| K2O_C | −0.055 | 0.031 | −0.102 | 0.063 | 0.083382 | − |
| SUN | 0.067 | 0.032 | 0.001 | 0.0006 | 0.036298 | + |
| P2O5_C | −0.036 | 0.029 | −0.074 | 0.060 | 0.211476 | − |
| PH | 0.040 | 0.032 | 0.158 | 0.128 | 0.219669 | − |
| Variable | Quotient | Rank |
|---|---|---|
| GEN | 1.082 | 18 |
| RAIN | 1.158 | 12 |
| SUN | 1.110 | 16 |
| TEMP | 1.396 | 4 |
| N_F | 1.110 | 15 |
| P2O5_F | 1.095 | 17 |
| K2O_F | 1.194 | 8 |
| SOWI | 1.364 | 5 |
| P_EMER | 1.160 | 11 |
| WEGE | 1.257 | 7 |
| HAR | 1.179 | 9 |
| FLOWE | 1.049 | 19 |
| INI_MA | 1.265 | 6 |
| TECH_M | 1.131 | 13 |
| P_HIG | 1.136 | 13 |
| PH | 1.175 | 10 |
| P2O5_C | 1.413 | 3 |
| K2O_C | 1.546 | 2 |
| MGO_C | 2.366 | 1 |
| Error Type | N1 Model | RS Model |
|---|---|---|
| RAE | 0.037 | 0.118 |
| RMS | 0.838 | 2.696 |
| MAE | 0.617 | 2.032 |
| MAPE | 2.721 | 8.852 |
| MAX | 2.977 | 7.943 |
| MAXP | 13.001 | 28.853 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hara, P.; Piekutowska, M.; Niedbała, G. Prediction of Protein Content in Pea (Pisum sativum L.) Seeds Using Artificial Neural Networks. Agriculture 2023, 13, 29. https://doi.org/10.3390/agriculture13010029
Hara P, Piekutowska M, Niedbała G. Prediction of Protein Content in Pea (Pisum sativum L.) Seeds Using Artificial Neural Networks. Agriculture. 2023; 13(1):29. https://doi.org/10.3390/agriculture13010029
Chicago/Turabian StyleHara, Patryk, Magdalena Piekutowska, and Gniewko Niedbała. 2023. "Prediction of Protein Content in Pea (Pisum sativum L.) Seeds Using Artificial Neural Networks" Agriculture 13, no. 1: 29. https://doi.org/10.3390/agriculture13010029
APA StyleHara, P., Piekutowska, M., & Niedbała, G. (2023). Prediction of Protein Content in Pea (Pisum sativum L.) Seeds Using Artificial Neural Networks. Agriculture, 13(1), 29. https://doi.org/10.3390/agriculture13010029