
Automatic Soil Sampling Site Selection in Management Zones Using a Multi-Objective Optimization Algorithm



Abstract
:1. Introduction
- The primary objective of this work is to provide a framework to automate the process of selecting benchmark sites by avoiding typical manual GIS processes like integrating different layers of information and manually comparing the values of objectives for selected points.
- The framework should be flexible and allow for the integration of new data and defining new objectives and constraints.
2. Background
2.1. Delineation of Management Zones
2.2. Benchmark Soil Sampling
2.3. Discrete Global Grid Systems
2.4. Solving a Multi-Objective Optimization Problem
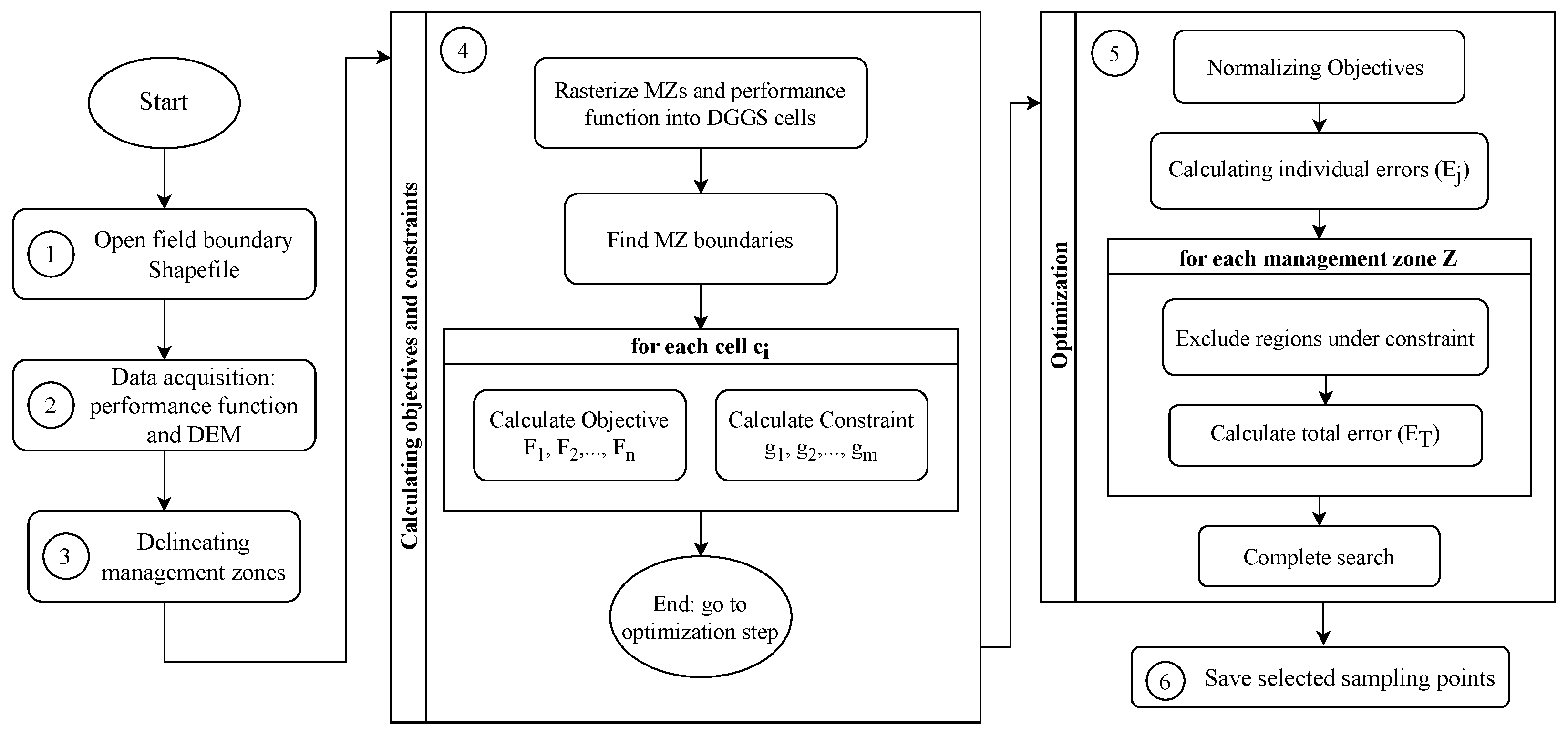
3. Methodology
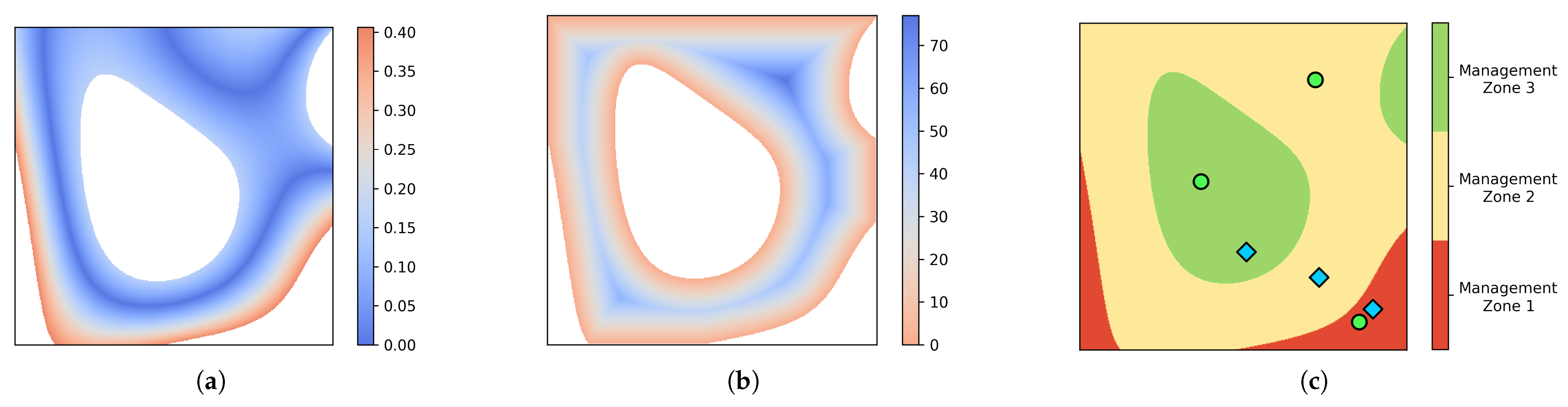
- Being close to the median of the performance function used for MZ delineation within each MZ: The median is statistically considered a good representative of a data set because it is a robust measure describing the central tendency of the data. Therefore, it is desired to select the benchmark site in a place where its performance function value is close to the median of its MZ. Figure 3a shows a visualization for this criterion for only one MZ in which blue regions have a smaller absolute difference to the median.
- Being far from the boundary of the MZ: Areas close to the MZ boundaries are more sensitive to input changes or year-to-year variation. To obtain more robust benchmark sites, it is better to find areas away from the boundaries of each MZ. Figure 3b shows this criterion for one MZ; locations with darker blue are farther from the boundary.
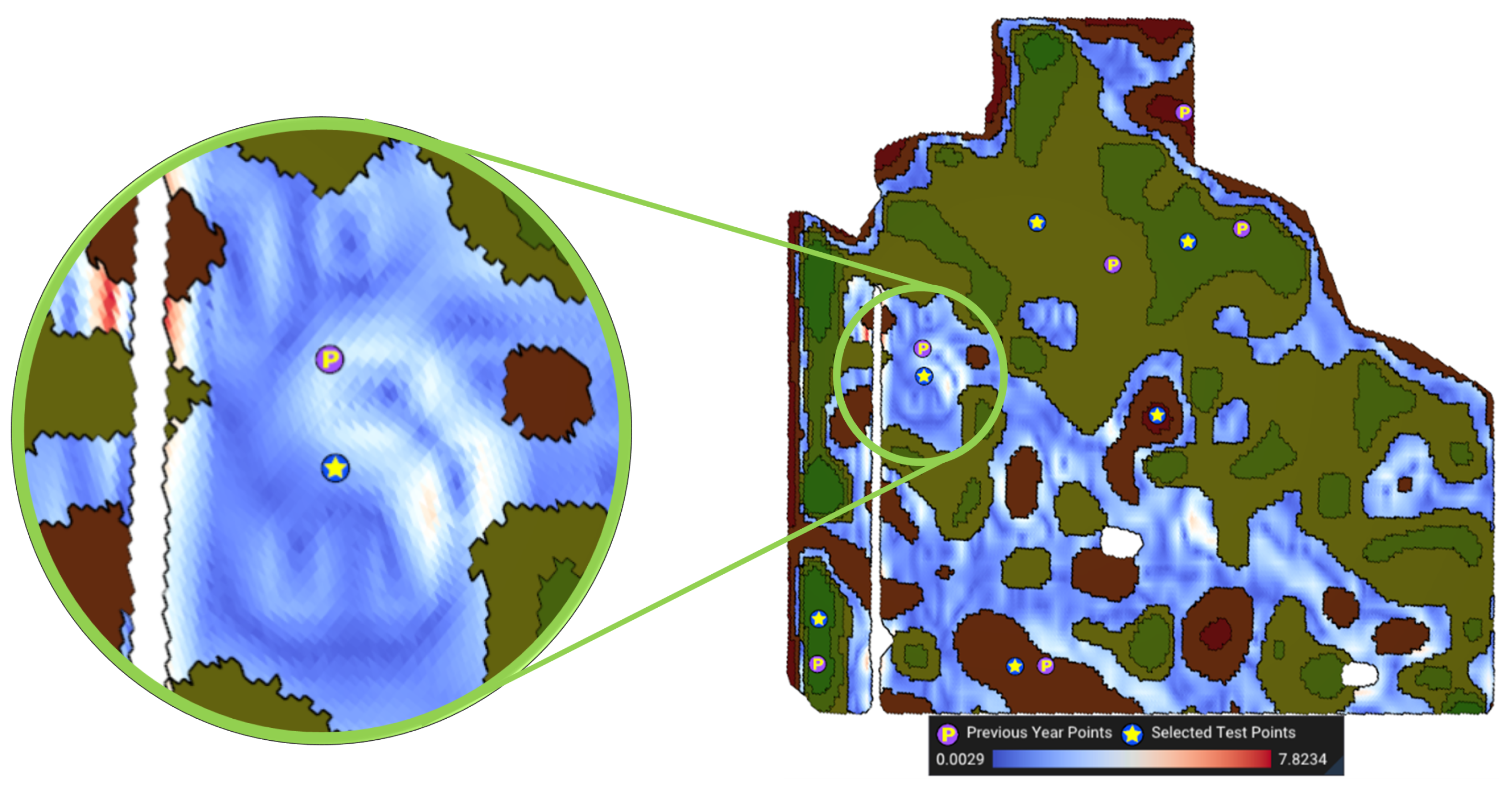
- Being close to the anchor points (e.g., sampled points from previous years): To perform benchmark sampling, if sampled points from previous years (or growing seasons) are available, it may be desirable to select the new benchmark site close to the previously tested points. These optional anchor points can be useful for scenarios in which the trend of soil changes over the years should be analyzed. Also, this criterion can be used if the growers, for any reason, prefer to find a benchmark site near some given anchor points.
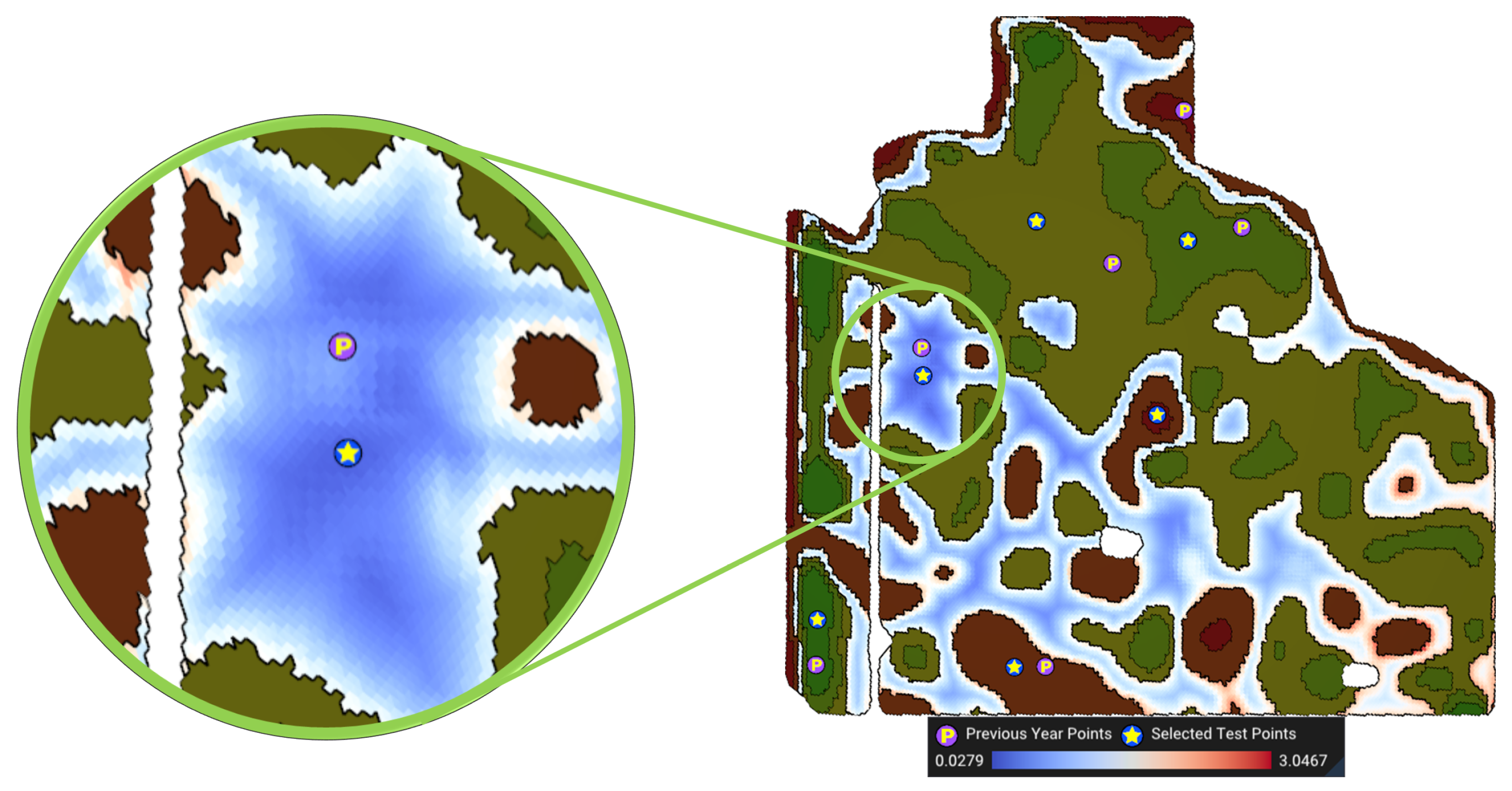
- Steepness: The nutrient levels at steep areas may vary a lot from year to year. Moreover, if an area is steep, it may not be accessible for the sampling truck. Therefore, it is desired to select benchmark sites away from steep regions.
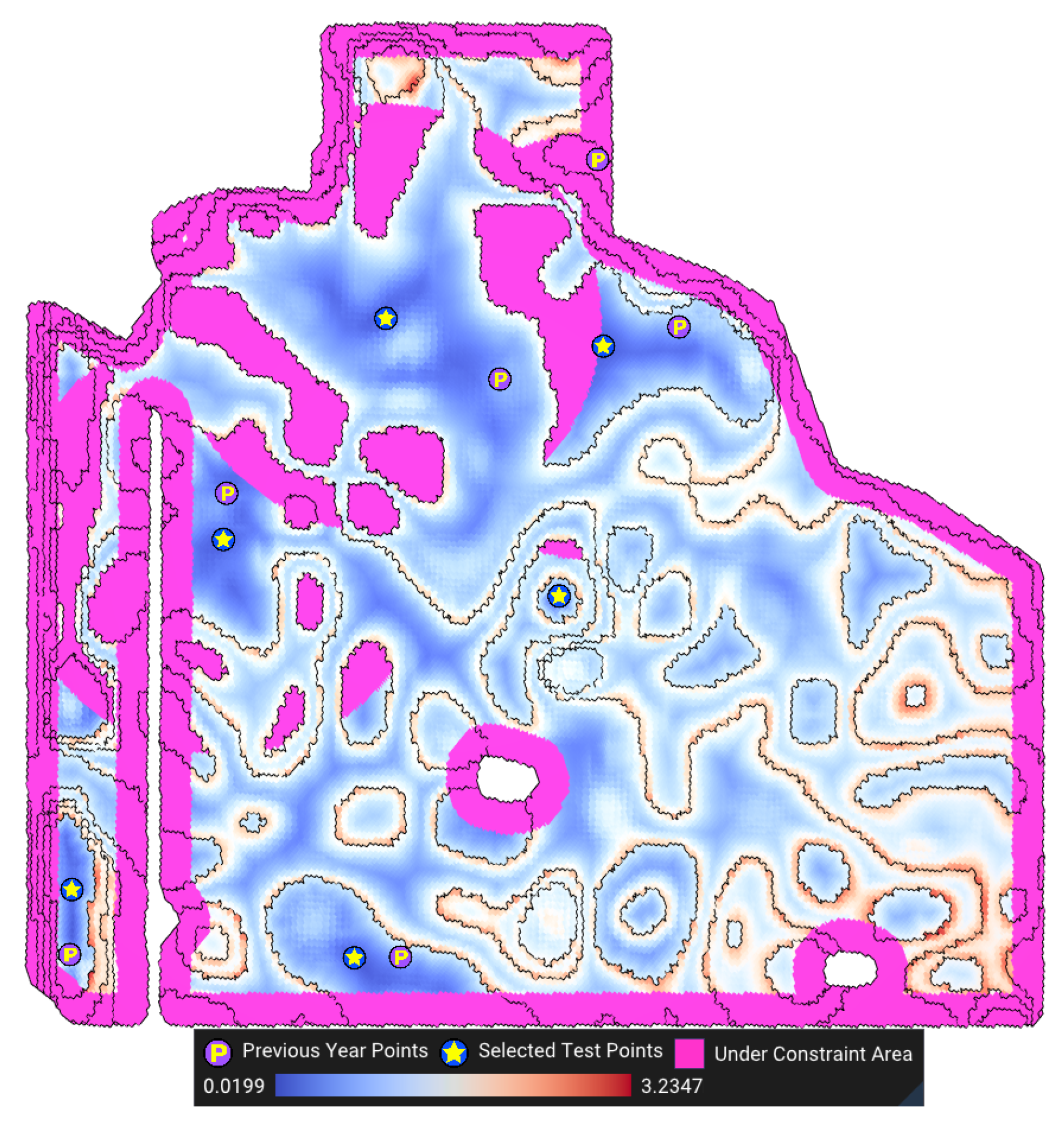
- Avoiding headlands: Headlands are areas of the farm field where heavy agricultural machines, such as combine harvesters, take turns. These areas might be affected by denser soil and overlapping application of fertilizer. Hence, these areas are not representative of the entire field and should be avoided.
- Avoiding inaccessible areas: Inaccessible areas should be avoided so that sampling trucks can collect samples.
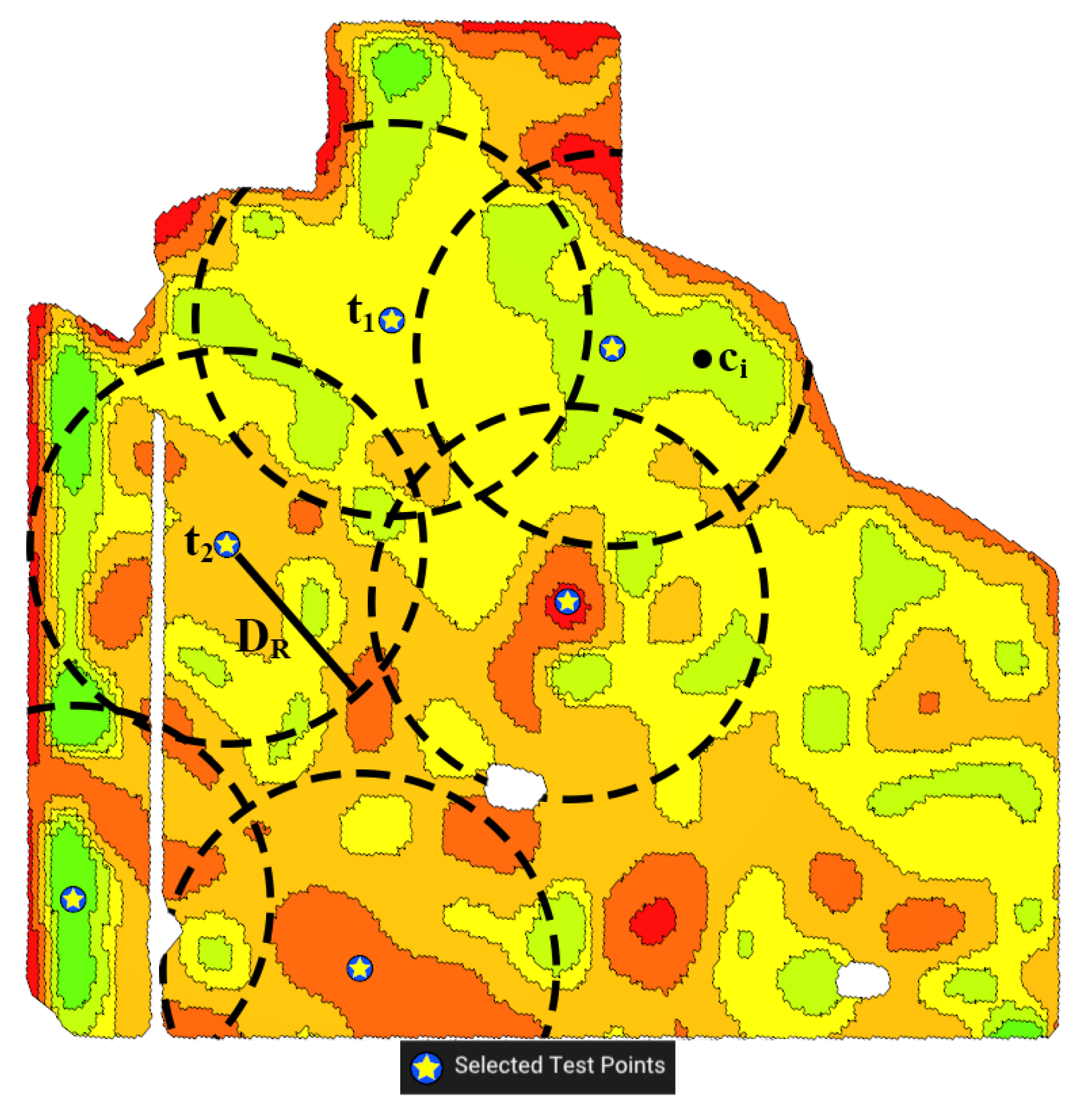
- Avoiding the proximity of benchmark sites in other MZs: The selected benchmark sites in different MZs should be far away from each other to ensure the benchmark sites do not all come from a small region of the field. Figure 3c shows an example of benchmark sites that are concentrated in a small area versus benchmark sites that are distanced from each other.

3.1. From Data to Management Zones
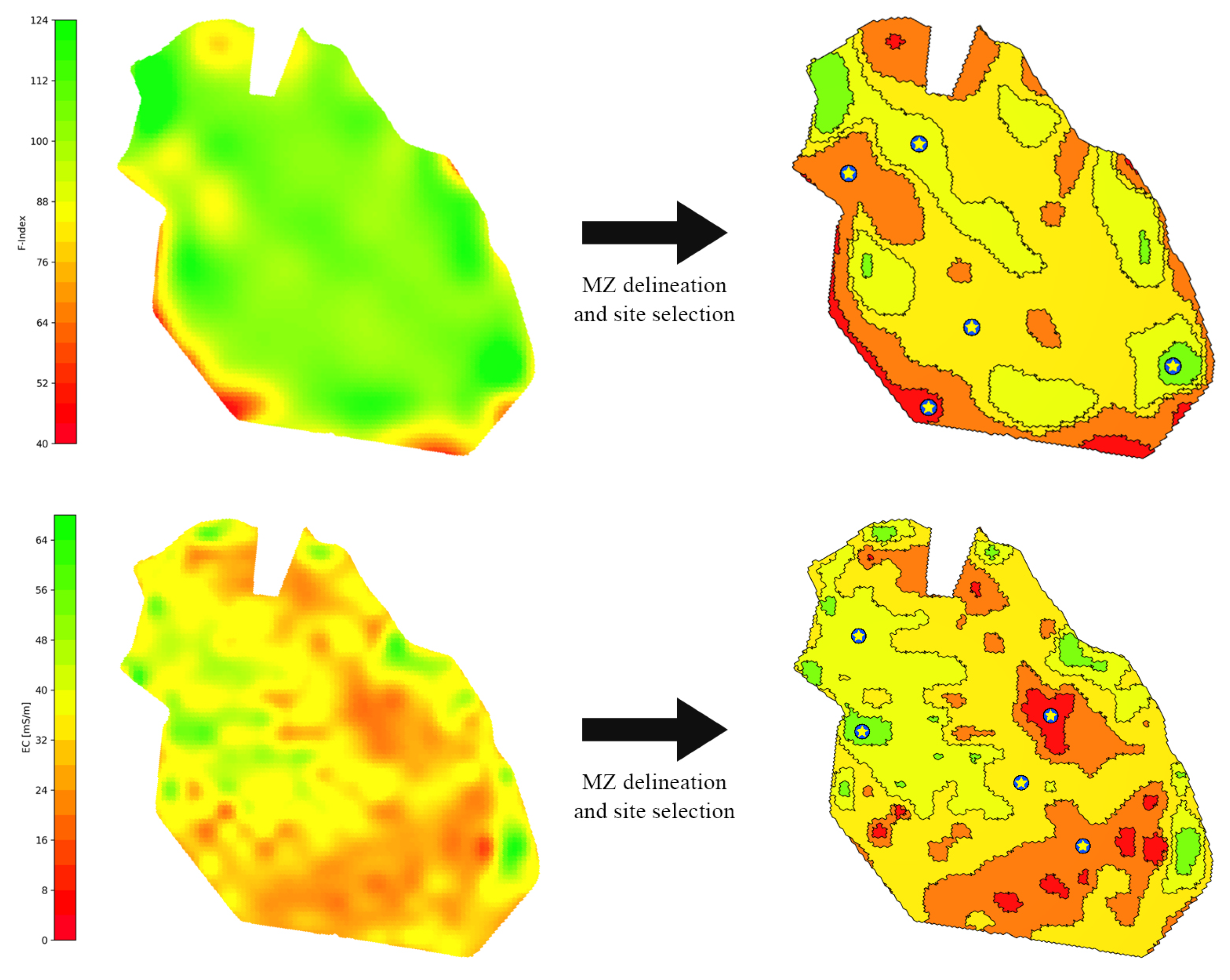
- Selecting images: One image as a good representative for each growing season is selected from the recent years (e.g., 3 to 6 years). The criteria for selecting this image stipulate that it should be both cloud- and haze-free and taken close to the harvest time to optimally showcase the soil’s potential. We use the cloud probability layer (CLP) with a threshold of 5% to ensure cloud-free images. This image represents the variation in soil fertility through the visual growth of plants. Figure 5 presents an example of the selected images for a given field. Note that, although these images are displayed in RGB colors, red, and near-infrared (NIR) bands are used in calculating performance function.
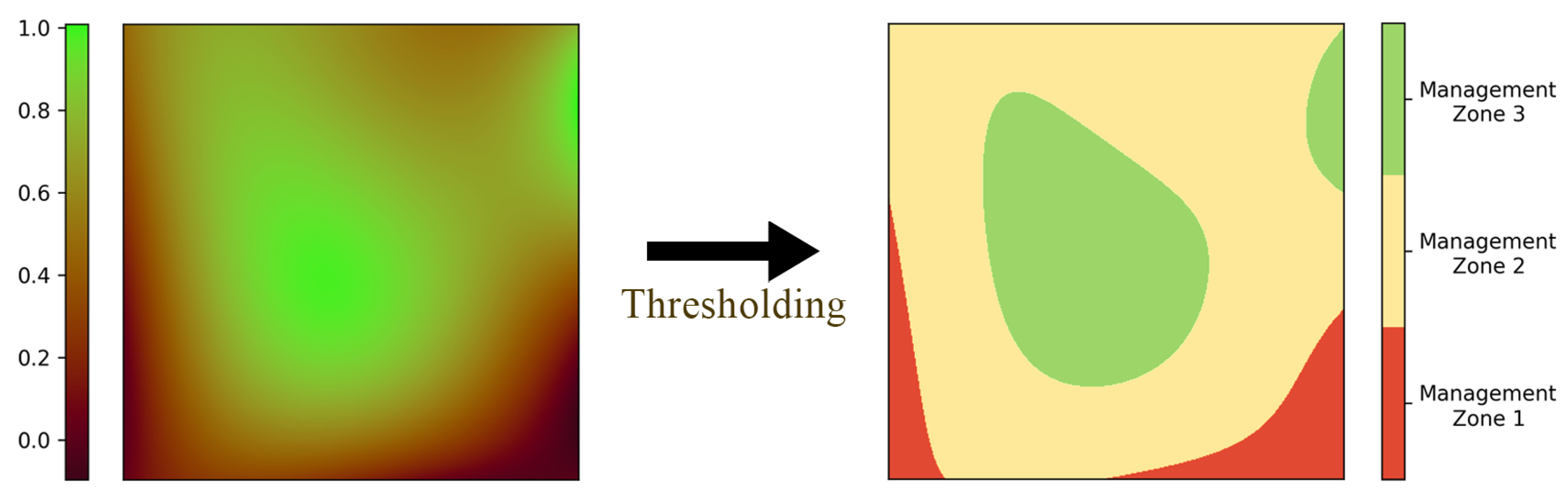
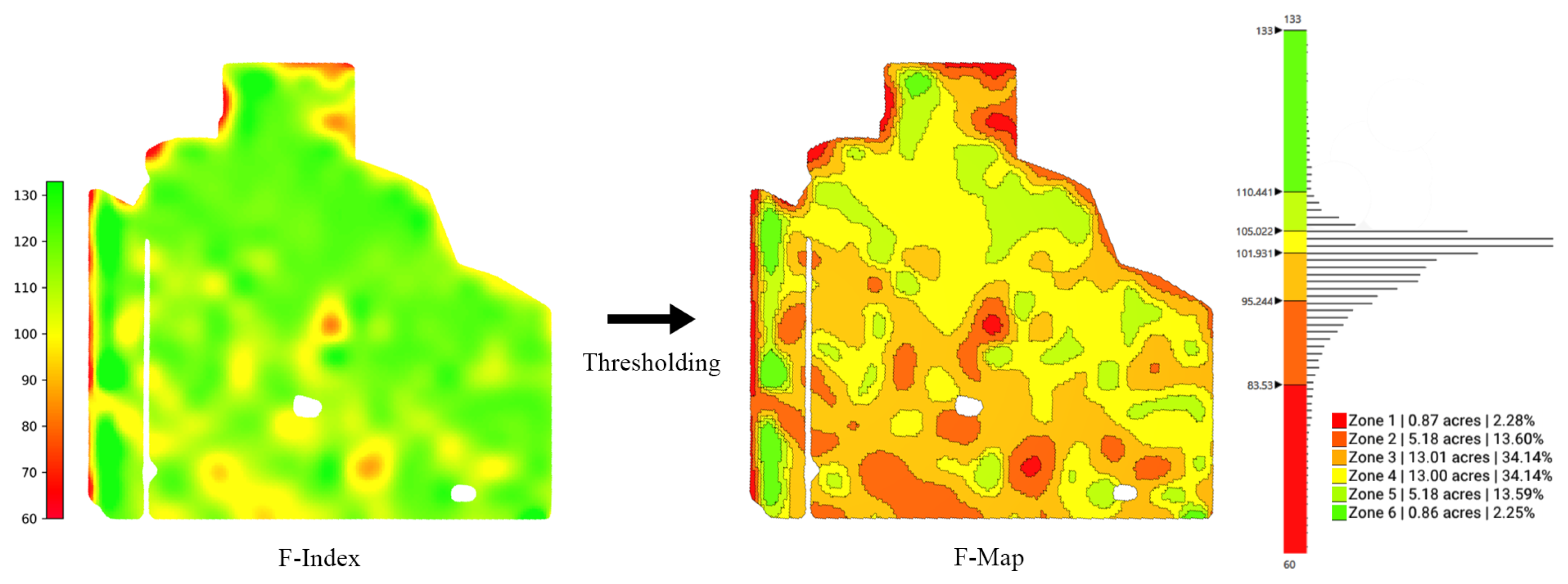
- Calculating the performance function—fertility index (F-index): The normalized difference vegetation index (NDVI) is calculated for each of the selected images using red and NIR bands [41]. While the range of the NDVI is between , for the selected images, the range of values is usually around with the mean around . Then, the NDVI values of each image are normalized and scaled in a way that the mean value M is a fixed number in the range (e.g., ). Finally, the normalized NDVI values are averaged and the resulting averaged normalized values are referred to as F-index (see Figure 6).
- Thresholding: To delineate the F-index into MZs, the next step is to divide the entire range of the F-index into a certain number of bins B (e.g., B = 6). The F-index thresholds are selected in a way that the area of the MZs forms a normal distribution. The resulting map after thresholding is called F-Map (see Figure 6). The number of bins (i.e., MZs) is usually chosen based on the area of the field. However, an arbitrary number of bins can be constructed using this method.


3.2. Optimization Model
- Objective , close to the value of the median F-index.
- Objective , away from the MZ boundaries.
- Objective , close to the anchor points (optional).
- Objective , belongs to the flatter regions.
- Constraint , avoids certain regions: In practice, it is desired to avoid locating the benchmark sites in certain regions (e.g., inaccessible and unrepresentative areas). Normally, the benchmark site should be at least meters (e.g., 30 m) away from any headlands (headland condition).
- Constraint , avoids the proximity of benchmark sites in other MZs
3.2.1. Computing the Objective Functions
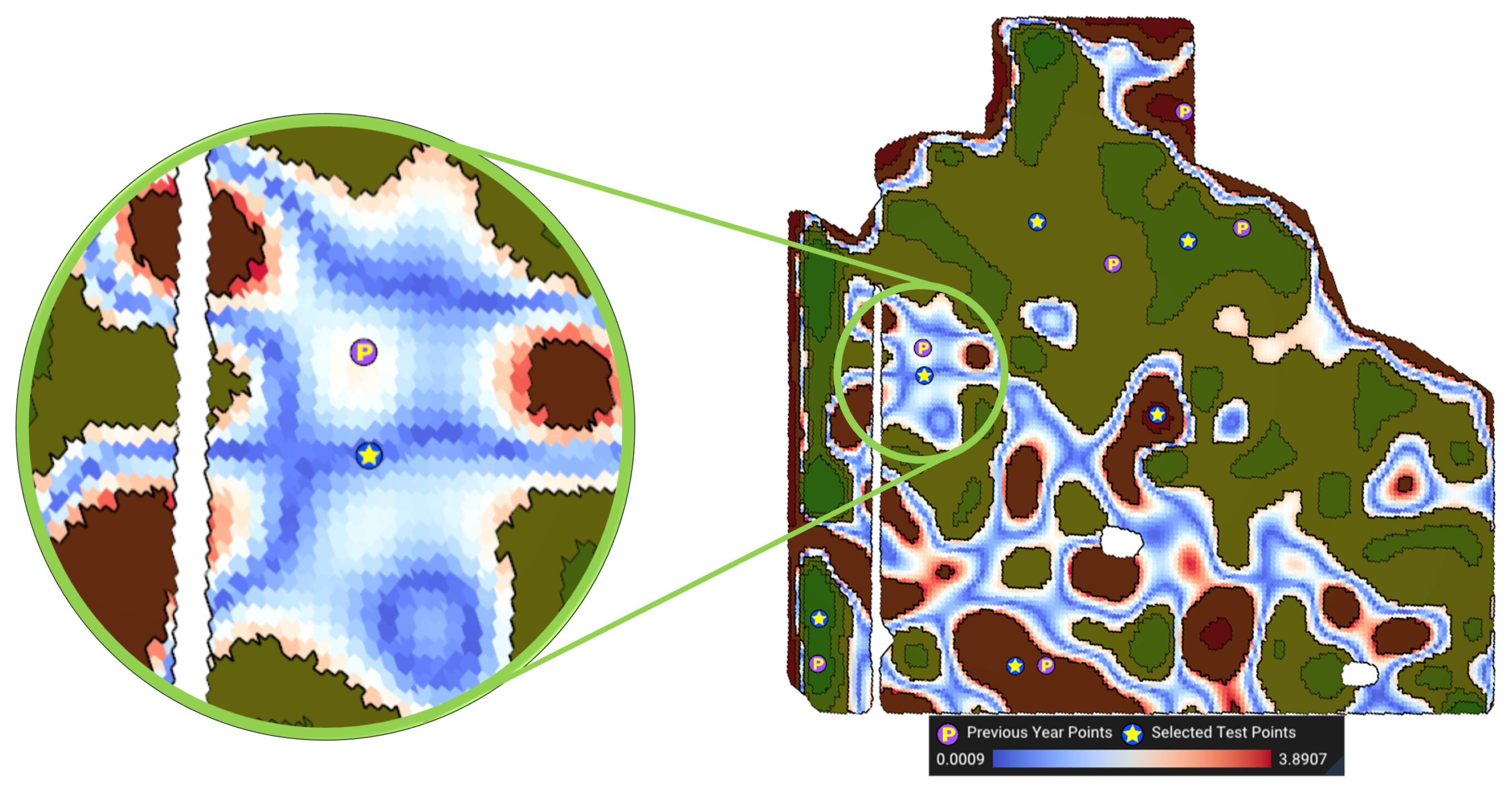
- Close to the value of the median F-index (): The first objective is to minimize the distance between the F-index values of the MZ cells and , the median of the management zone Z. Let us denote the DGGS cells of Z by , and their respective F-index values by . This objective is defined as:Figure 7 shows a visualization of this objective function. The blue colors in this visualization show a smaller absolute difference between each cell’s F-index and the median F-index.

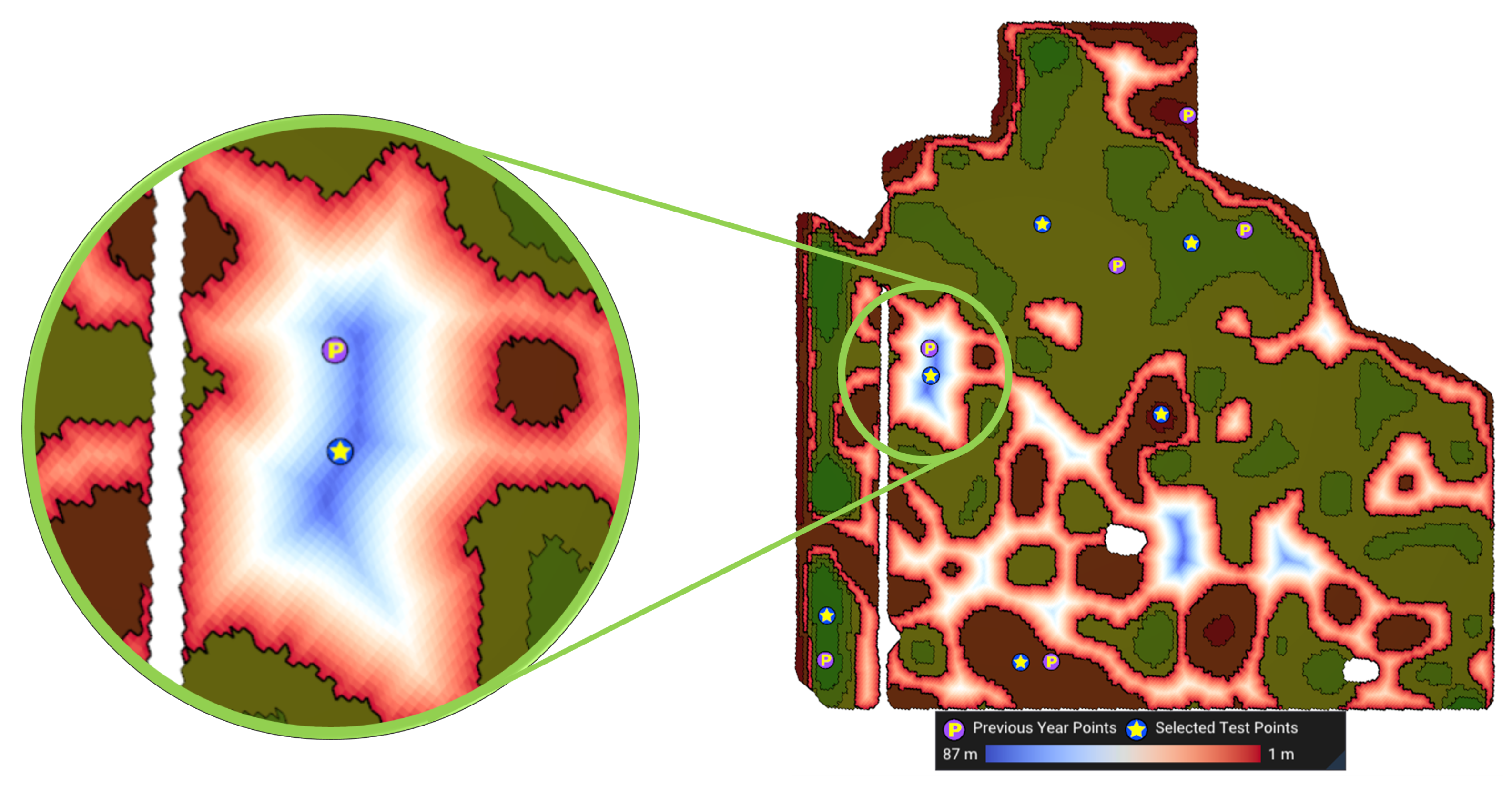
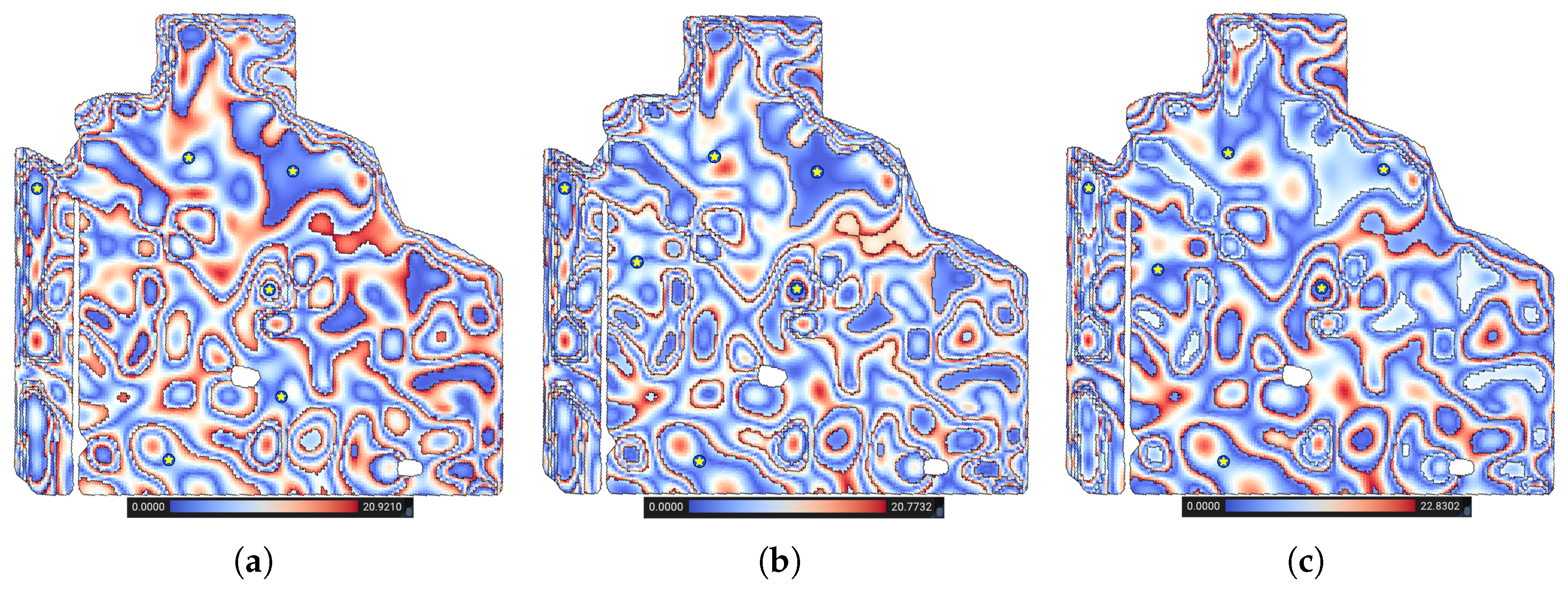
- Away from MZ boundaries (): We use the distance transform operator on top of the DGGS [33] to compute the geodesic distance of each cell to S, the spatial boundary of management zone Z. The distance transform efficiently calculates the geodesic distance of all cells in a region to a given vector feature (i.e., the MZ boundaries). The second objective is to maximize this distancewhere denotes the geodesic distance of to S. Figure 8 shows a visualization of this objective function. The cooler the colors (darker blue) the farther the cell is from the boundaries.

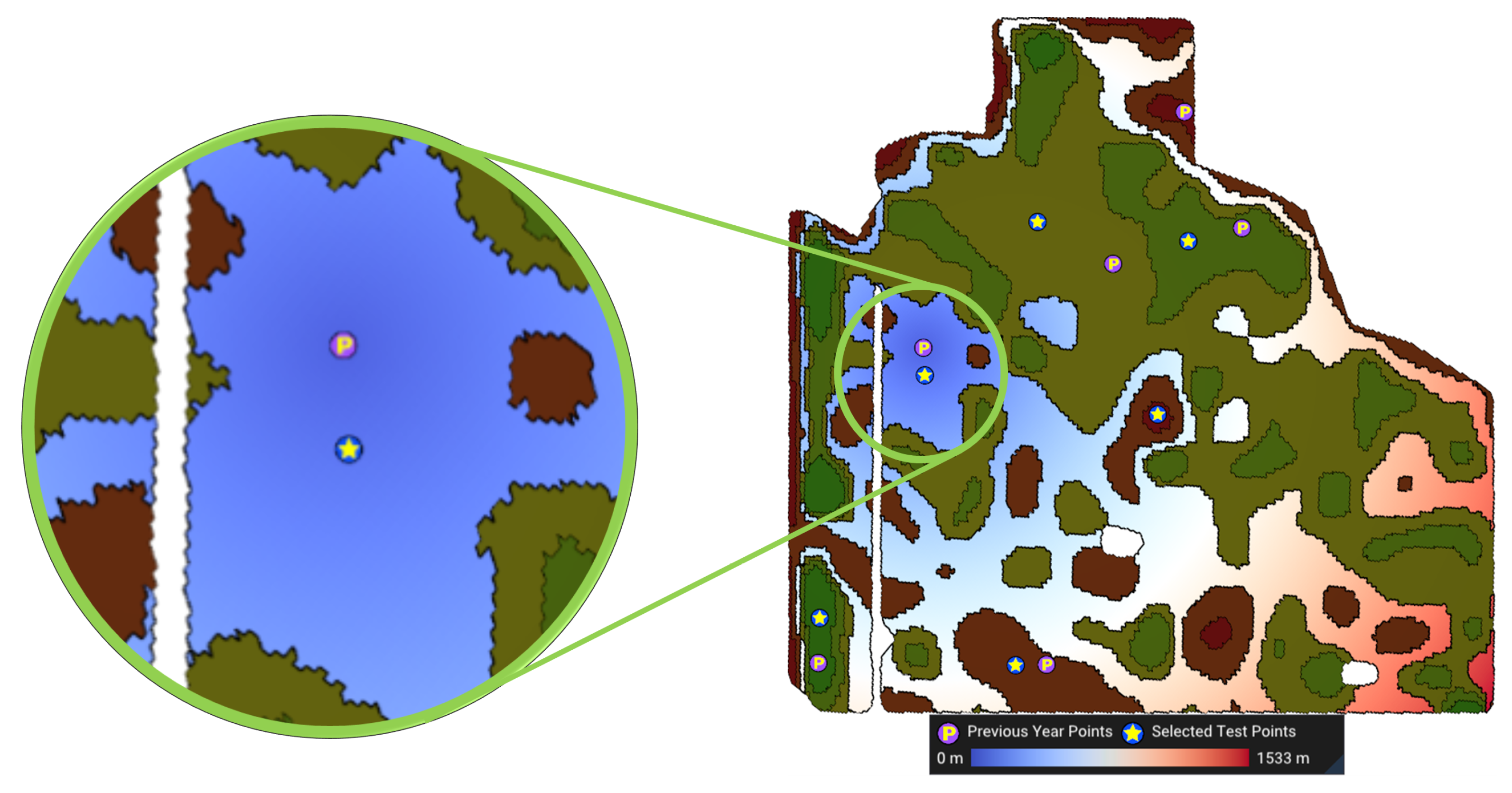
- Close to anchor points (): Let represent the anchor point for the management zone Z (e.g., the sampled point from previous years). Again, using distance transform [33], we determine the geodesic distance from the anchor point to the centroid of all cells within Z. The third objective, , is to minimize this distancewhere denotes the geodesic distance of to the anchor point . Figure 9 shows a visualization of this objective function. The cooler the colors (darker blue), the closer the cell is to the anchor point.

- Belongs to flatter regions (): The steepness of the cell (denoted by ) is calculated from the DEM of the field by calculating the gradient vector. The gradient vector shows the direction of change of elevation, which is approximated using the difference in elevation between neighboring cells. Steepness is then determined bywhere is the normal vector of the cell . Figure 10 shows a visualization of this objective function. The cooler (or darker blue) the colors, the flatter the region in which the cell is located.

3.2.2. Computing the Constraints
- Avoid Certain Regions () We trivially exclude any cells from the inaccessible and unrepresentative regions by subtracting these regions from the entire field. For the headland condition, we use the distance transform operation of DGGS [33] to calculate a buffer of meters from the boundary of the field to avoid the areas under the headland. Figure 11 shows the areas of the farm avoided due to headland.

- Avoid the Proximity of Benchmark Sites in Other MZs () Our goal is to select benchmark sites that are from a larger region of the field to better represent the entire field. To achieve this, we set a minimum radius between the sites (see Figure 12). This global constraint is unique compared to other criteria that are local to their respective MZs. We begin by selecting a benchmark site in one MZ and then limiting the areas in other MZs that are within the specified radius of this site. We continue this process iteratively until we have chosen benchmark sites for all MZs. To do this, we remove from the search space if for all already selected sites t (see Figure 12).
- By using this method, the benchmark sites selected earlier have an advantage over the ones chosen later, as the latter are subject to more constraints. If the is small, the change of order has a minimal impact. However, for a larger , it makes sense to prioritize MZs according to their level of importance. Therefore, we start with the most important MZ in order to find a more optimal benchmark site for it, and then we continue to select benchmark sites for less important MZs. The most important MZ is the one that best represents the entire field. Hence, the most important MZ is the one with its median F-index closest to that of the entire field. We sort the MZs based on the distance of their median F-index to the median F-index of the entire field. The radius mentioned above can be dynamically changed, but the default is set to be 15% of the field’s diameter. Figure 12 shows how we use this radius to force the selected benchmark sites to be at a reasonable distance from each other.

3.2.3. Solving the Optimization Problem
4. Results and Evaluation
4.1. Modularity and Extendability
4.2. Discussion
4.2.1. Optimization Weights
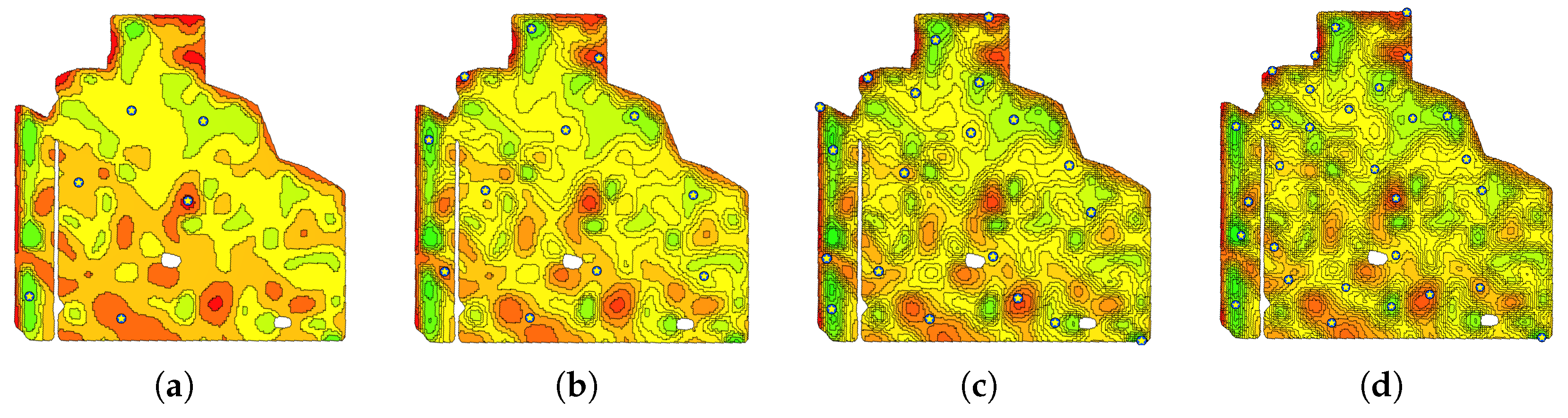
4.2.2. Number of MZs
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MZ | management zone |
| NIR | near-infrared |
| NDVI | normalized difference vegetation index |
| DGGS | discrete global grid system |
| GIS | geographic information system |
| AESA | Alberta Environmentally Sustainable Agriculture |
| UAV | unmanned areal vehicle |
| LiDAR | light detection and ranging |
| DEM | digital elevation model |
| GUI | graphical user interface |
| CLI | command-line interface |
| EC | electrical conductivity |
| BOA | bottom of the atmosphere |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MZ | Objective | Benchmark Site | Mean of All Cells | Percentage Improvement | Best | Range |
|---|---|---|---|---|---|---|
| 1 | Median F-index | 13.393 | 18.202 | 26.4% | 0.000 | [0.000, 47.910] |
| Distance To Boundary | 27.535 | 16.483 | 67.0% | 48.759 | [1.263, 48.759] | |
| Steepness | 2.207 | 2.843 | 22.4% | 1.395 | [1.395, 4.932] | |
| 2 | Median F-index | 2.920 | 4.453 | 34.4% | 0.017 | [0.017, 18.161] |
| Distance To Boundary | 40.850 | 9.775 | 317.9% | 43.235 | [1.263, 43.235] | |
| Steepness | 1.010 | 3.405 | 70.3% | 0.021 | [0.021, 10.844] | |
| 3 | Median F-index | 0.013 | 1.550 | 99.2% | 0.000 | [0.000, 4.431] |
| Distance To Boundary | 56.517 | 12.870 | 339.1% | 56.517 | [1.259, 56.517] | |
| Steepness | 1.046 | 2.700 | 61.3% | 0.006 | [0.006, 11.680] | |
| 4 | Median F-index | 0.140 | 1.075 | 87.0% | 0.000 | [0.000, 2.610] |
| Distance To Boundary | 55.644 | 12.011 | 363.3% | 59.418 | [1.259, 59.418] | |
| Steepness | 1.173 | 2.040 | 42.5% | 0.003 | [0.003, 9.167] | |
| 5 | Median F-index | 0.720 | 1.000 | 28.0% | 0.002 | [0.002, 2.917] |
| Distance To Boundary | 29.709 | 10.057 | 195.4% | 41.810 | [1.259, 41.810] | |
| Steepness | 1.863 | 2.226 | 16.3% | 0.013 | [0.013, 10.052] | |
| 6 | Median F-index | 3.272 | 3.351 | 2.4% | 0.000 | [0.000, 13.995] |
| Distance To Boundary | 23.627 | 9.387 | 151.7% | 33.618 | [1.259, 33.618] | |
| Steepness | 2.146 | 3.095 | 30.7% | 0.108 | [0.108, 8.438] |
| MZ | Objective | Benchmark Site | Mean of All Cells | Percentage Improvement | Best | Range |
|---|---|---|---|---|---|---|
| 1 | Median F-index | 4.590 | 2.883 | −59.2% | 0.126 | [0.126, 8.487] |
| Distance To Boundary | 23.519 | 11.948 | 96.8% | 27.191 | [1.298, 27.191] | |
| Steepness | 2.163 | 3.028 | 28.6% | 0.260 | [0.260, 6.357] | |
| 2 | Median F-index | 0.681 | 2.145 | 68.3% | 0.000 | [0.000, 6.899] |
| Distance To Boundary | 44.390 | 18.374 | 141.6% | 60.355 | [1.291, 60.355] | |
| Steepness | 0.868 | 2.521 | 65.6% | 0.031 | [0.031, 8.747] | |
| 3 | Median F-index | 0.268 | 1.939 | 86.2% | 0.000 | [0.000, 4.174] |
| Distance To Boundary | 86.394 | 18.537 | 366.1% | 91.327 | [1.291, 91.327] | |
| Steepness | 1.759 | 2.137 | 17.7% | 0.026 | [0.026, 9.368] | |
| 4 | Median F-index | 0.344 | 1.834 | 81.2% | 0.000 | [0.000, 5.624] |
| Distance To Boundary | 48.860 | 13.752 | 255.3% | 53.131 | [1.291, 53.131] | |
| Steepness | 1.863 | 2.167 | 14.0% | 0.002 | [0.002, 9.731] | |
| 5 | Median F-index | 0.144 | 1.805 | 92.0% | 0.022 | [0.022, 3.604] |
| Distance To Boundary | 17.555 | 6.031 | 191.1% | 18.800 | [1.295, 18.800] | |
| Steepness | 1.158 | 2.205 | 47.5% | 0.849 | [0.849, 4.675] |
| MZ | Objective | Benchmark Site | Mean of All Cells | Percentage Improvement | Best | Range |
|---|---|---|---|---|---|---|
| 1 | Median F-index | 1.450 | 1.861 | 22.1% | 0.000 | [0.000, 4.030] |
| Distance To Boundary | 24.923 | 11.987 | 107.9% | 34.016 | [1.305, 34.016] | |
| Steepness | 0.917 | 1.132 | 19.0% | 0.115 | [0.115, 2.264] | |
| 2 | Median F-index | 1.341 | 1.829 | 26.7% | 0.019 | [0.019, 6.067] |
| Distance To Boundary | 34.657 | 11.745 | 195.1% | 53.336 | [1.302, 53.336] | |
| Steepness | 0.163 | 1.116 | 85.4% | 0.023 | [0.023, 3.109] | |
| 3 | Median F-index | 0.149 | 1.326 | 88.8% | 0.000 | [0.000, 3.028] |
| Distance To Boundary | 44.455 | 12.907 | 244.4% | 49.212 | [1.298, 49.212] | |
| Steepness | 0.280 | 1.125 | 75.1% | 0.018 | [0.018, 3.517] | |
| 4 | Median F-index | 0.003 | 1.398 | 99.8% | 0.003 | [0.003, 4.184] |
| Distance To Boundary | 30.103 | 9.557 | 215.0% | 34.657 | [1.302, 34.657] | |
| Steepness | 0.737 | 1.093 | 32.6% | 0.014 | [0.014, 3.374] | |
| 5 | Median F-index | 0.034 | 0.626 | 94.6% | 0.034 | [0.034, 1.158] |
| Distance To Boundary | 15.860 | 5.758 | 175.5% | 18.325 | [1.302, 18.325] | |
| Steepness | 0.318 | 0.899 | 64.7% | 0.043 | [0.043, 2.574] |
| MZ | Objective | Benchmark Site | Mean of All Cells | Percentage Improvement | Best | Range |
|---|---|---|---|---|---|---|
| 1 | Median F-index | 2.340 | 5.078 | 53.9% | 0.294 | [0.294, 14.785] |
| Distance To Boundary | 18.382 | 10.907 | 68.5% | 32.534 | [1.216, 32.534] | |
| Steepness | 0.451 | 0.665 | 32.3% | 0.029 | [0.029, 1.712] | |
| 2 | Median F-index | 2.361 | 2.469 | 4.4% | 0.000 | [0.000, 10.209] |
| Distance To Boundary | 85.619 | 22.106 | 287.3% | 87.502 | [1.216, 87.502] | |
| Steepness | 0.510 | 0.934 | 45.4% | 0.010 | [0.010, 4.003] | |
| 3 | Median F-index | 0.168 | 1.441 | 88.4% | 0.000 | [0.000, 3.680] |
| Distance To Boundary | 105.288 | 26.053 | 304.1% | 109.590 | [1.212, 109.590] | |
| Steepness | 0.347 | 0.857 | 59.5% | 0.004 | [0.004, 3.446] | |
| 4 | Median F-index | 0.101 | 3.439 | 97.1% | 0.000 | [0.000, 16.610] |
| Distance To Boundary | 27.363 | 13.264 | 106.3% | 44.053 | [1.216, 44.053] | |
| Steepness | 0.861 | 1.045 | 17.7% | 0.050 | [0.050, 3.369] |
References
- Lavanya, G.; Rani, C.; Ganeshkumar, P. An automated low cost IoT based Fertilizer Intimation System for smart agriculture. Sustain. Comput. Inform. Syst. 2020, 28, 100300. [Google Scholar] [CrossRef]
- Schimmelpfennig, D. Farm Profits and Adoption of Precision Agriculture; Technical Report 1477-2016-121190; United States Department of Agriculture (USDA): Washington, DC, USA, 2016. [CrossRef]
- Harou, A.P.; Madajewicz, M.; Michelson, H.; Palm, C.A.; Amuri, N.; Magomba, C.; Semoka, J.M.; Tschirhart, K.; Weil, R. The joint effects of information and financing constraints on technology adoption: Evidence from a field experiment in rural Tanzania. J. Dev. Econ. 2022, 155, 102707. [Google Scholar] [CrossRef]
- Carter, M.R.; Gregorich, E.G. (Eds.) Soil Sampling and Methods of Analysis; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Alberta Agriculture and Food. Nutrient Management Planning Guide; Alberta Agriculture and Food: Edmonton, AB, Canada, 2015. [Google Scholar]
- Mulla, D.J. Twenty five years of remote sensing in precision agriculture: Key advances and remaining knowledge gaps. Biosyst. Eng. 2013, 114, 358–371. [Google Scholar] [CrossRef]
- Pierce, F.J.; Nowak, P. Aspects of Precision Agriculture. In Advances in Agronomy; Sparks, D.L., Ed.; Academic Press: Cambridge, MA, USA, 1999; Volume 67, pp. 1–85. [Google Scholar] [CrossRef]
- Keyes, D.; Gillund, G. Benchmark sampling of agricultural fields. In Proceedings of the Soils and Crops Workshop, Saskatoon, SK, Canada, 16 March 2021. [Google Scholar]
- Khanal, S.; KC, K.; Fulton, J.P.; Shearer, S.; Ozkan, E. Remote Sensing in Agriculture—Accomplishments, Limitations, and Opportunities. Remote Sens. 2020, 12, 3783. [Google Scholar] [CrossRef]
- Radočaj, D.; Jurišić, M.; Gašparović, M. The Role of Remote Sensing Data and Methods in a Modern Approach to Fertilization in Precision Agriculture. Remote Sens. 2022, 14, 778. [Google Scholar] [CrossRef]
- Hornung, A.; Khosla, R.; Reich, R.; Inman, D.; Westfall, D. Comparison of site-specific management zones: Soil-color-based and yield-based. Agron. J. 2006, 98, 407–415. [Google Scholar] [CrossRef]
- Fraisse, C.; Sudduth, K.; Kitchen, N. Delineation of site-specific management zones by unsupervised classification of topographic attributes and soil electrical conductivity. Trans. ASAE 2001, 44, 155. [Google Scholar] [CrossRef]
- Georgi, C.; Spengler, D.; Itzerott, S.; Kleinschmit, B. Automatic delineation algorithm for site-specific management zones based on satellite remote sensing data. Precis. Agric. 2018, 19, 684–707. [Google Scholar] [CrossRef]
- Tarr, A.B.; Moore, K.J.; Dixon, P.M.; Burras, C.L.; Wiedenhoeft, M.H. Use of Soil Electroconductivity in a Multistage Soil-Sampling Scheme. Crop Manag. 2003, 2, 1–9. [Google Scholar] [CrossRef]
- Yao, R.; Yang, J.; Zhao, X.; Chen, X.; Han, J.; Li, X.; Liu, M.; Shao, H. A new soil sampling design in coastal saline region using EM38 and VQT method. Clean–Soil Air Water 2012, 40, 972–979. [Google Scholar] [CrossRef]
- Stumpf, F.; Schmidt, K.; Behrens, T.; Schönbrodt-Stitt, S.; Buzzo, G.; Dumperth, C.; Wadoux, A.; Xiang, W.; Scholten, T. Incorporating limited field operability and legacy soil samples in a hypercube sampling design for digital soil mapping. J. Plant Nutr. Soil Sci. 2016, 179, 499–509. [Google Scholar] [CrossRef]
- An, Y.; Yang, L.; Zhu, A.X.; Qin, C.; Shi, J. Identification of representative samples from existing samples for digital soil mapping. Geoderma 2018, 311, 109–119. [Google Scholar] [CrossRef]
- Chabala, L.M.; Mulolwa, A.; Lungu, O. Landform classification for digital soil mapping in the Chongwe-Rufunsa area, Zambia. Agric. For. Fish 2013, 2, 156–160. [Google Scholar] [CrossRef]
- Fridgen, J.J.; Kitchen, N.R.; Sudduth, K.A.; Drummond, S.T.; Wiebold, W.J.; Fraisse, C.W. Management zone analyst (MZA) software for subfield management zone delineation. Agron. J. 2004, 96, 100–108. [Google Scholar]
- Kozar, B.J. Predicting Soil Water Distribution Using Topographic Models within Four Montana Farm Fields. Ph.D. Thesis, Montana State University-Bozeman, College of Agriculture, Bozeman, MT, USA, 2002. [Google Scholar]
- MacMillan, R. A protocol for preparing digital elevation (DEM) data for input and analysis using the landform segmentation model (LSM) programs. In Soil Variability Analysis to Enhance Crop Production (SVAECP) Project; LandMapper Environmental Solutions: Edmonton, AB, Canada, 2000. [Google Scholar]
- Milics, G.; Kauser, J.; Kovacs, A. Profit Maximization in Soybean (Glycine max (L.) Merr.) Using Variable Rate Technology (VRT) in the Sárrét Region, Hungary; Agri-Tech Economics Papers 296767; Harper Adams University, Land, Farm & Agribusiness Management Department: Newport, UK, 2019. [Google Scholar] [CrossRef]
- Cathcart, J.; Cannon, K.; Heinz, J. Selection and establishment of Alberta agricultural soil quality benchmark sites. Can. J. Soil Sci. 2008, 88, 399–408. [Google Scholar] [CrossRef]
- Card, S. Evaluation of Two Field Methods to Estimate Soil Organic Matter in Alberta Soils; AESA Soil Quality Monitoring Program: AB, Canada, 2004. [Google Scholar]
- Ines, R.L.; Tuazon, J.P.B.; Daag, M.N. Utilization of Small Farm Reservoir (SFR) for Upland Agriculture of Bataan, Philippines. Int. J. Appl. Agric. Sci. 2018, 4, 1–6. [Google Scholar] [CrossRef]
- Nutrien Ag Solutions. Soil Sampling Tips. 2019. Available online: https://www.nutrienagsolutions.ca/about/news/soil-sampling-tips (accessed on 1 May 2023).
- Canola Council of Canada. How to Take a Good Soil Sample. 2013. Available online: https://www.canolacouncil.org/canola-watch/2013/10/02/how-to-take-a-good-soil-sample/ (accessed on 1 May 2023).
- Bash, E.A.; Wecker, L.; Rahman, M.M.; Dow, C.F.; McDermid, G.; Samavati, F.F.; Whitehead, K.; Moorman, B.J.; Medrzycka, D.; Copland, L. A Multi-Resolution Approach to Point Cloud Registration without Control Points. Remote Sens. 2023, 15, 1161. [Google Scholar] [CrossRef]
- Goodchild, M.F. Reimagining the history of GIS. Ann. GIS 2018, 24, 1–8. [Google Scholar] [CrossRef]
- Mahdavi-Amiri, A.; Alderson, T.; Samavati, F. A survey of digital earth. Comput. Graph. 2015, 53, 95–117. [Google Scholar] [CrossRef]
- Alderson, T.; Purss, M.; Du, X.; Mahdavi-Amiri, A.; Samavati, F. Digital earth platforms. In Manual of Digital Earth; Springer: Singapore, 2020; pp. 25–54. [Google Scholar]
- Mahdavi Amiri, A.; Alderson, T.; Samavati, F. Geospatial Data Organization Methods with Emphasis on Aperture-3 Hexagonal Discrete Global Grid Systems. Cartogr. Int. J. Geogr. Inf. Geovis. 2019, 54, 30–50. [Google Scholar] [CrossRef]
- Kazemi, M.; Wecker, L.; Samavati, F. Efficient Calculation of Distance Transform on Discrete Global Grid Systems. ISPRS Int. J. Geo-Inf. 2022, 11, 322. [Google Scholar] [CrossRef]
- Hall, J.; Wecker, L.; Ulmer, B.; Samavati, F. Disdyakis Triacontahedron DGGS. ISPRS Int. J. Geo-Inf. 2020, 9, 315. [Google Scholar] [CrossRef]
- Marler, R.T.; Arora, J.S. Survey of multi-objective optimization methods for engineering. Struct. Multidiscip. Optim. 2004, 26, 369–395. [Google Scholar] [CrossRef]
- Everitt, B. Introduction to Optimization Methods and Their Application in Statistics; Springer: Dordrecht, The Netherlands, 2012. [Google Scholar]
- Wright, J.N.S.J. Numerical Optimization; Springer Series in Operations Research and Financial Engineering; Springer: New York, NY, USA, 2006. [Google Scholar] [CrossRef]
- Schmaltz, T.; Melnitchouk, A. Variable Zone Crop-Specific Inputs Prescription Method and Systems Therefor. Canada Patent CA 2663917, 30 December 2014. [Google Scholar]
- Mazur, P.; Gozdowski, D.; Wójcik-Gront, E. Soil Electrical Conductivity and Satellite-Derived Vegetation Indices for Evaluation of Phosphorus, Potassium and Magnesium Content, pH, and Delineation of Within-Field Management Zones. Agriculture 2022, 12, 883. [Google Scholar] [CrossRef]
- Sinergise Ltd. Sentinel Hub. 2023. Available online: https://www.sentinel-hub.com (accessed on 3 October 2023).
- Pettorelli, N. The Normalized Difference Vegetation Index; Oxford University Press: Oxford, UK, 2013. [Google Scholar]
- Serrano, J.; Shahidian, S.; Marques da Silva, J.; Paixão, L.; Moral, F.; Carmona-Cabezas, R.; Garcia, S.; Palha, J.; Noéme, J. Mapping Management Zones Based on Soil Apparent Electrical Conductivity and Remote Sensing for Implementation of Variable Rate Irrigation—Case Study of Corn under a Center Pivot. Water 2020, 12, 3427. [Google Scholar] [CrossRef]
- Pohle, M.; Werban, U. Near surface geophysical data (Electromagnetic Induction—EMI, Gamma-ray spectrometry), August 2017), Selbitz (Elbe), Germany, 2019. Supplement to: Rentschler, Tobias; Werban, Ulrike; Ahner, Mario; Behrens, Thorsten; Gries, Phillipp; Scholten, Thomas; Teuber, Sandra; Schmidt, Karsten (2020): 3D mapping of soil organic carbon content and soil moisture with multiple geophysical sensors and machine learning. Vadose Zone J. 2019, 19. [Google Scholar] [CrossRef]









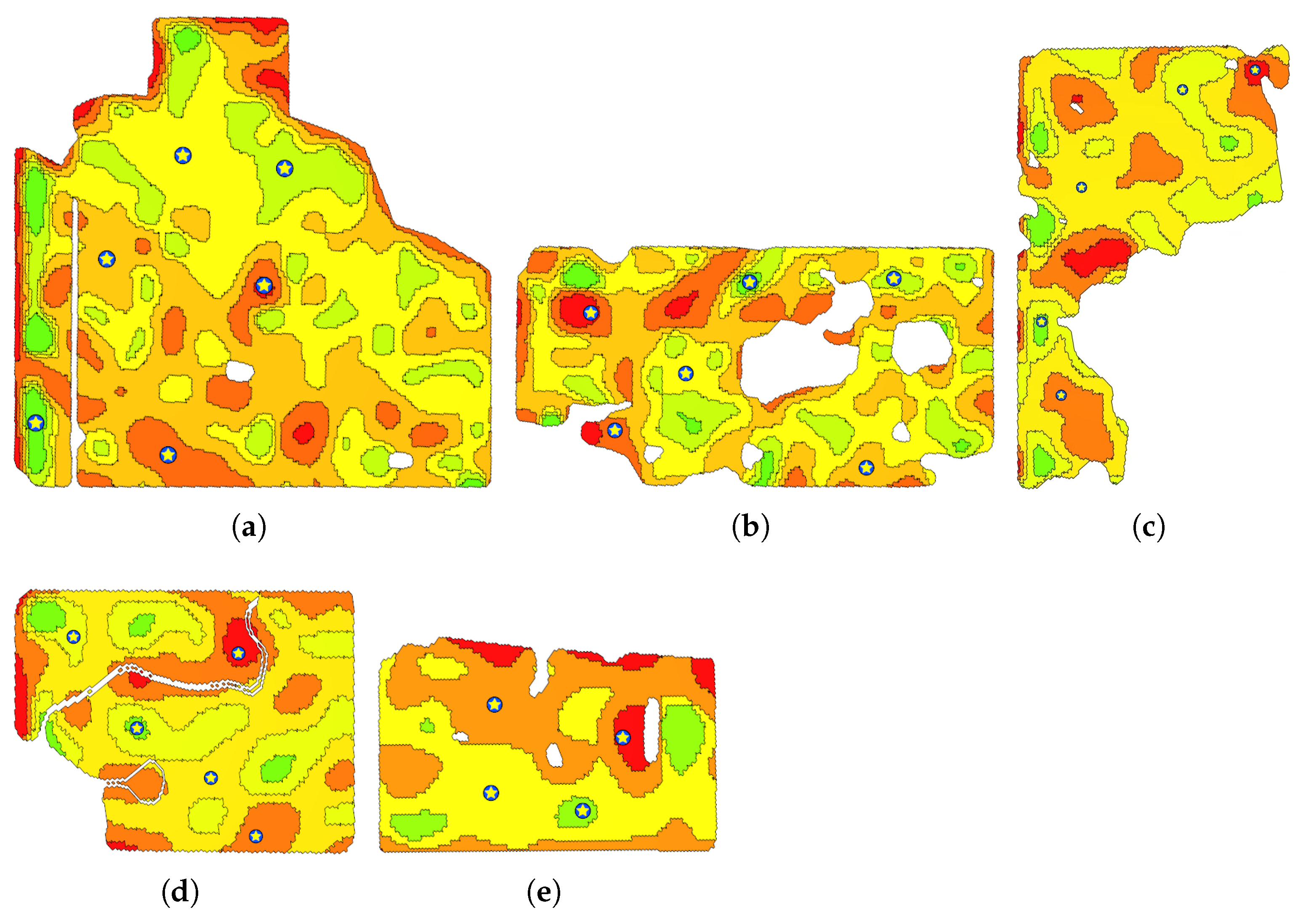
| Field Number | Field Shape | Location | Area (hectare) | Number of MZs | (meter) | Total Execution Time (second) | Steps 4 and 5 Time (second) |
|---|---|---|---|---|---|---|---|
| 1 |  | Southern Alberta (51.349, −113.486) | 198.2 | 6 | 350 | 22.91 | 13.82 |
| 2 |  | Southern Saskatchewan (52.031, −109.895) | 102.3 | 6 | 269 | 13.76 | 7.37 |
| 3 |  | Southern Saskatchewan (50.035, −102.525) | 59.1 | 5 | 218 | 8.22 | 3.20 |
| 4 |  | Southern Manitoba (49.375, −100.256) | 43.9 | 5 | 169 | 7.88 | 3.16 |
| 5 |  | Western Alberta (56.074, −118.529) | 36.5 | 4 | 141 | 8.87 | 3.13 |
| MZ | Objective | Benchmark Site | Mean of All Cells | Percentage Improvement | Best | Range |
|---|---|---|---|---|---|---|
| 1 | Median F-index | 1.359 | 1.966 | 30.9% | 0.126 | [0.126, 3.563] |
| Distance To Boundary | 23.910 | 7.916 | 202.1% | 24.560 | [1.238, 24.560] | |
| Steepness | 0.085 | 0.725 | 88.3% | 0.007 | [0.007, 1.826] | |
| 2 | Median F-index | 1.125 | 2.342 | 52.0% | 0.001 | [0.001, 8.562] |
| Distance To Boundary | 63.797 | 17.337 | 268.0% | 77.104 | [1.238, 77.104] | |
| Steepness | 0.358 | 1.234 | 71.0% | 0.015 | [0.015, 5.319] | |
| 3 | Median F-index | 0.037 | 1.586 | 97.7% | 0.001 | [0.001, 3.891] |
| Distance To Boundary | 80.167 | 19.285 | 315.7% | 87.775 | [1.238, 87.775] | |
| Steepness | 1.126 | 1.230 | 8.5% | 0.010 | [0.010, 5.179] | |
| 4 | Median F-index | 0.045 | 0.707 | 93.6% | 0.000 | [0.000, 1.715] |
| Distance To Boundary | 125.790 | 24.736 | 408.5% | 141.578 | [1.238, 141.578] | |
| Steepness | 0.943 | 0.953 | 1.0% | 0.002 | [0.002, 4.336] | |
| 5 | Median F-index | 0.038 | 0.899 | 95.8% | 0.001 | [0.001, 4.604] |
| Distance To Boundary | 81.755 | 14.912 | 448.3% | 83.902 | [1.238, 83.902] | |
| Steepness | 0.934 | 0.994 | 6.1% | 0.004 | [0.004, 4.322] | |
| 6 | Median F-index | 4.046 | 3.351 | −20.7% | 0.000 | [0.000, 18.670] |
| Distance To Boundary | 29.766 | 12.167 | 144.6% | 43.304 | [1.238, 43.304] | |
| Steepness | 0.797 | 1.123 | 29.1% | 0.015 | [0.015, 3.804] |
| Field Number | Median F-index | Distance to Boundary | Steepness |
|---|---|---|---|
| 1 | 58.2% | 297.9% | 34.0% |
| 2 | 46.2% | 239.1% | 40.6% |
| 3 | 53.7% | 210.2% | 34.7% |
| 4 | 66.4% | 187.6% | 55.4% |
| 5 | 60.9% | 191.6% | 38.7% |
| Objective | Median F-Index () | Distance to Boundary () | Steepness () |
|---|---|---|---|
| Range | [0.001, 8.562] | [1.238, 77.104] | [0.015, 5.319] |
| Best | 0.001 | 77.104 | 0.015 |
| Mean of all cells | 2.342 | 17.337 | 1.234 |
| , , | 1.125 | 63.797 | 0.358 |
| , , | 1.143 | 64.655 | 0.766 |
| , , | 0.933 | 61.139 | 0.535 |
| , , | 0.446 | 48.915 | 0.867 |
| , , | 0.001 | 38.603 | 0.289 |
| , , | 1.460 | 66.111 | 1.353 |
| Number of MZs | (meter) | Execution Time (second) | Mean Percentage Improvement | |
|---|---|---|---|---|
| 6 | 350 | 22.54 | Median F-index Distance To Boundary Steepness | 62.9% 337.2% 36.2% |
| 12 | 320 | 28.74 | Median F-index Distance To Boundary Steepness | 74.8% 326.0% 38.0% |
| 20 | 215 | 32.75 | Median F-index Distance To Boundary Steepness | 77.2% 355.8% 47.6% |
| 30 | 165 | 37.61 | Median F-index Distance To Boundary Steepness | 67.9% 354.1% 32.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kazemi, M.; Samavati, F.F. Automatic Soil Sampling Site Selection in Management Zones Using a Multi-Objective Optimization Algorithm. Agriculture 2023, 13, 1993. https://doi.org/10.3390/agriculture13101993
Kazemi M, Samavati FF. Automatic Soil Sampling Site Selection in Management Zones Using a Multi-Objective Optimization Algorithm. Agriculture. 2023; 13(10):1993. https://doi.org/10.3390/agriculture13101993
Chicago/Turabian StyleKazemi, Meysam, and Faramarz F. Samavati. 2023. "Automatic Soil Sampling Site Selection in Management Zones Using a Multi-Objective Optimization Algorithm" Agriculture 13, no. 10: 1993. https://doi.org/10.3390/agriculture13101993
APA StyleKazemi, M., & Samavati, F. F. (2023). Automatic Soil Sampling Site Selection in Management Zones Using a Multi-Objective Optimization Algorithm. Agriculture, 13(10), 1993. https://doi.org/10.3390/agriculture13101993