
Prediction of Significant Wave Height in Offshore China Based on the Machine Learning Method


Abstract
:1. Introduction
2. Materials and Methods
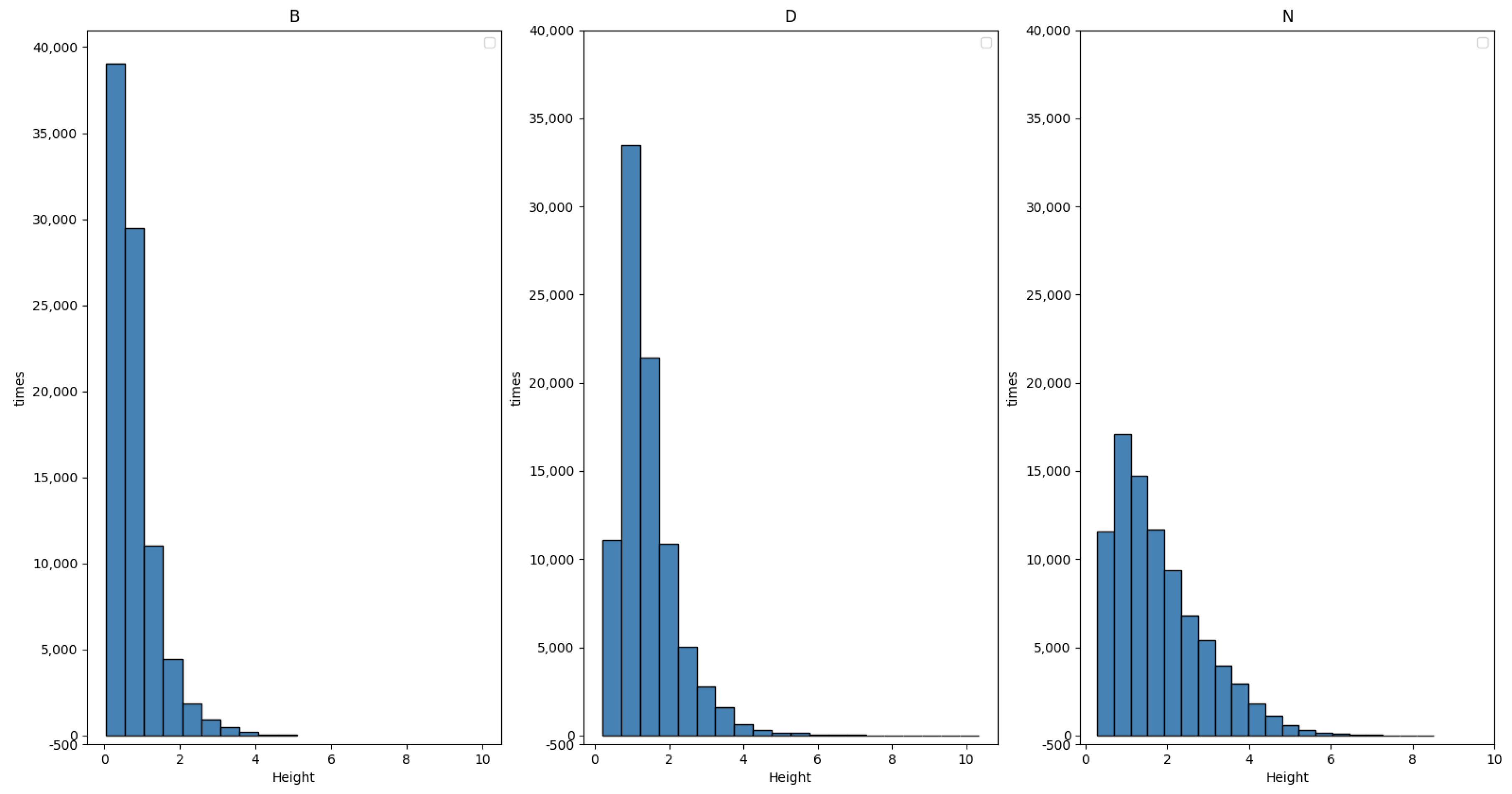
2.1. Materials
2.2. Methods
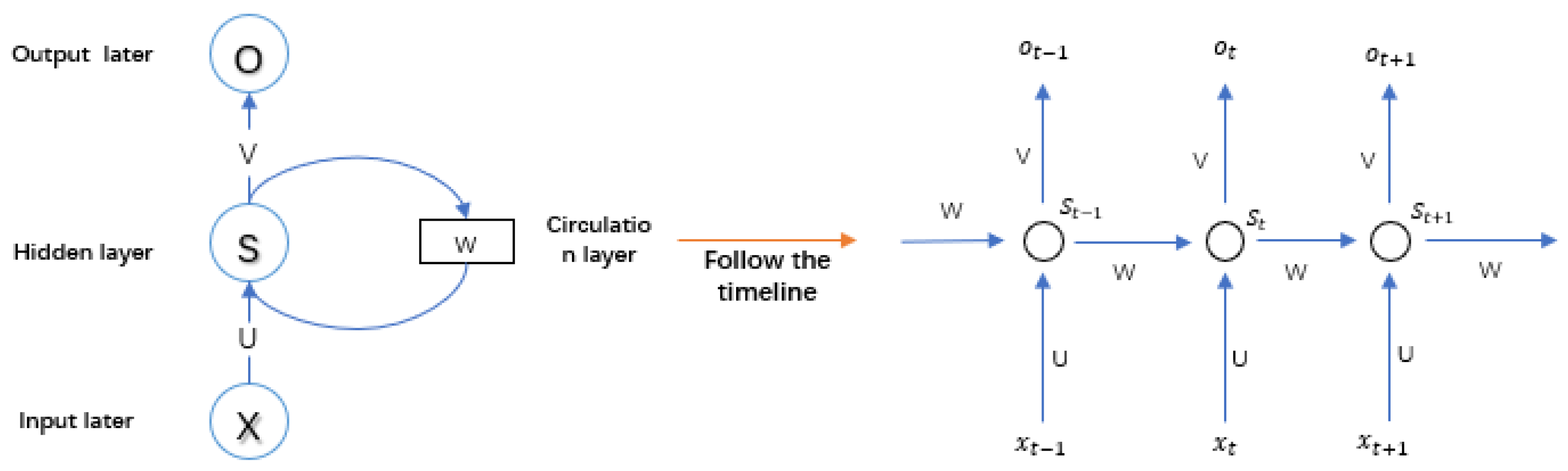
2.2.1. RNN
2.2.2. LSTM Network
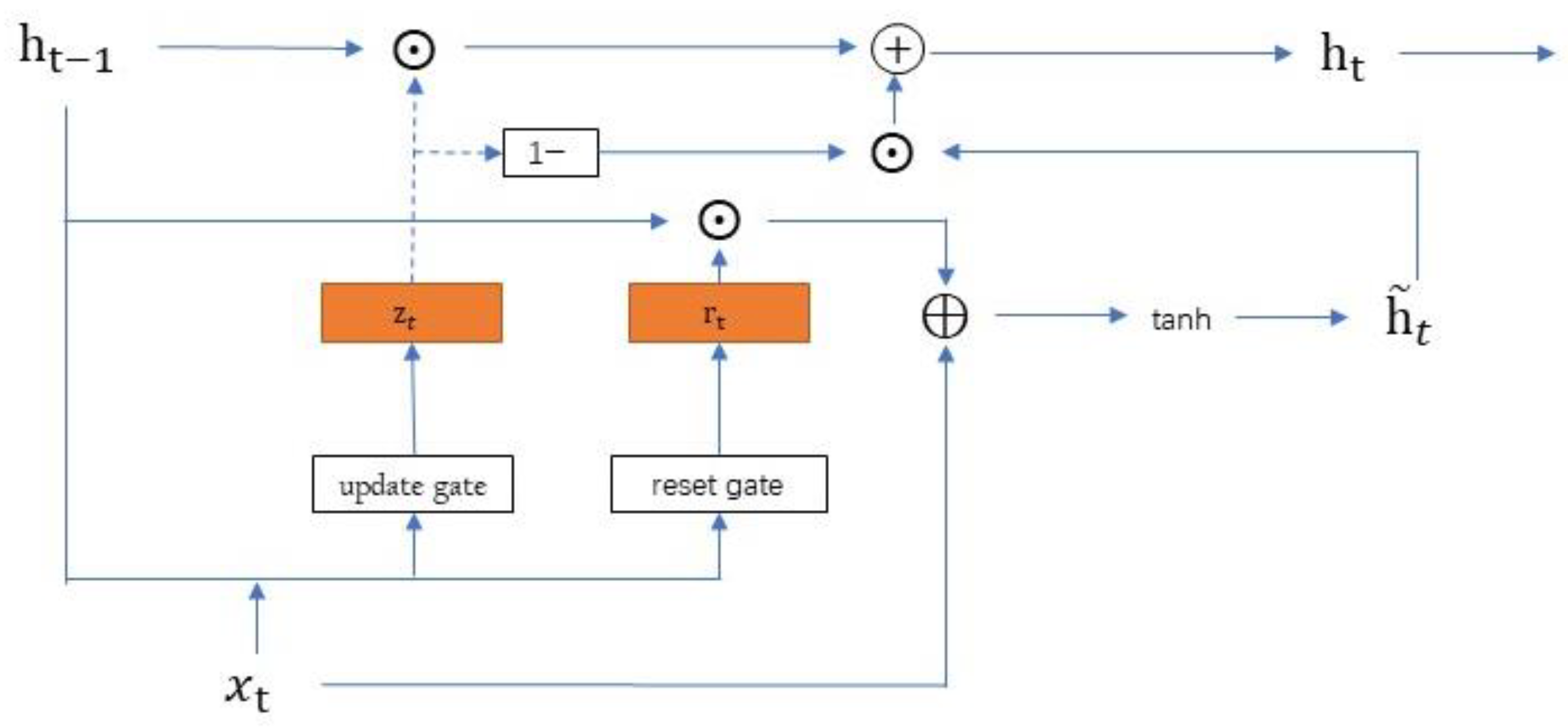
2.2.3. GRU
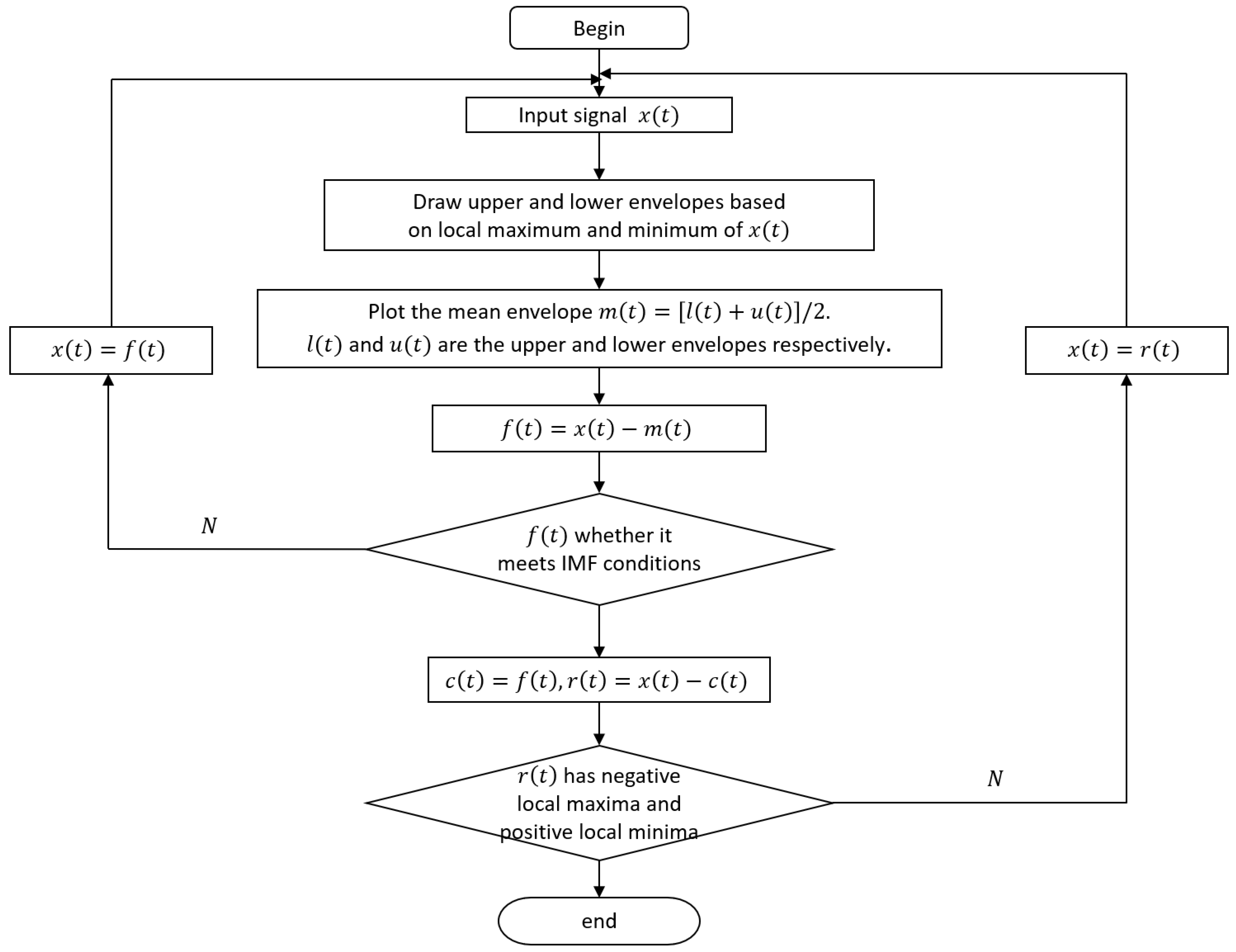
2.2.4. Empirical Mode Decomposition
- In the whole data segment, the number of local extreme value points and the number of zero crossing points must be equal or differ by a maximum of one.
- At any time, the average value of the upper envelope formed by the local maximum point and the lower envelope formed by the local minimum point is zero; that is, the upper and lower envelope are locally symmetric with respect to the time axis.
- The upper and lower envelope lines ( and respectively) are drawn according to spline interpolation among all the local maxima and the local minima of .
- Find the mean of the upper and lower envelope and plot the mean envelope .
- Subtract the mean envelope from the original signal to obtain the intermediate signal .
- Determine whether meets the two conditions of IMF. If so, is an IMF1; let us call it . If not, the analysis of (1)–(4) is repeated on the basis of until the two IMF conditions are met.
- After the first IMF is obtained using the above method, the original signal is subtracted from IMF1 as the new original signal, and then IMF2 can be obtained through the analysis of (1)–(4) to complete EMD decomposition. Finally, the signal that does not satisfy the decomposition condition is denoted .
- Through EMD algorithm, signals can be decomposed into:
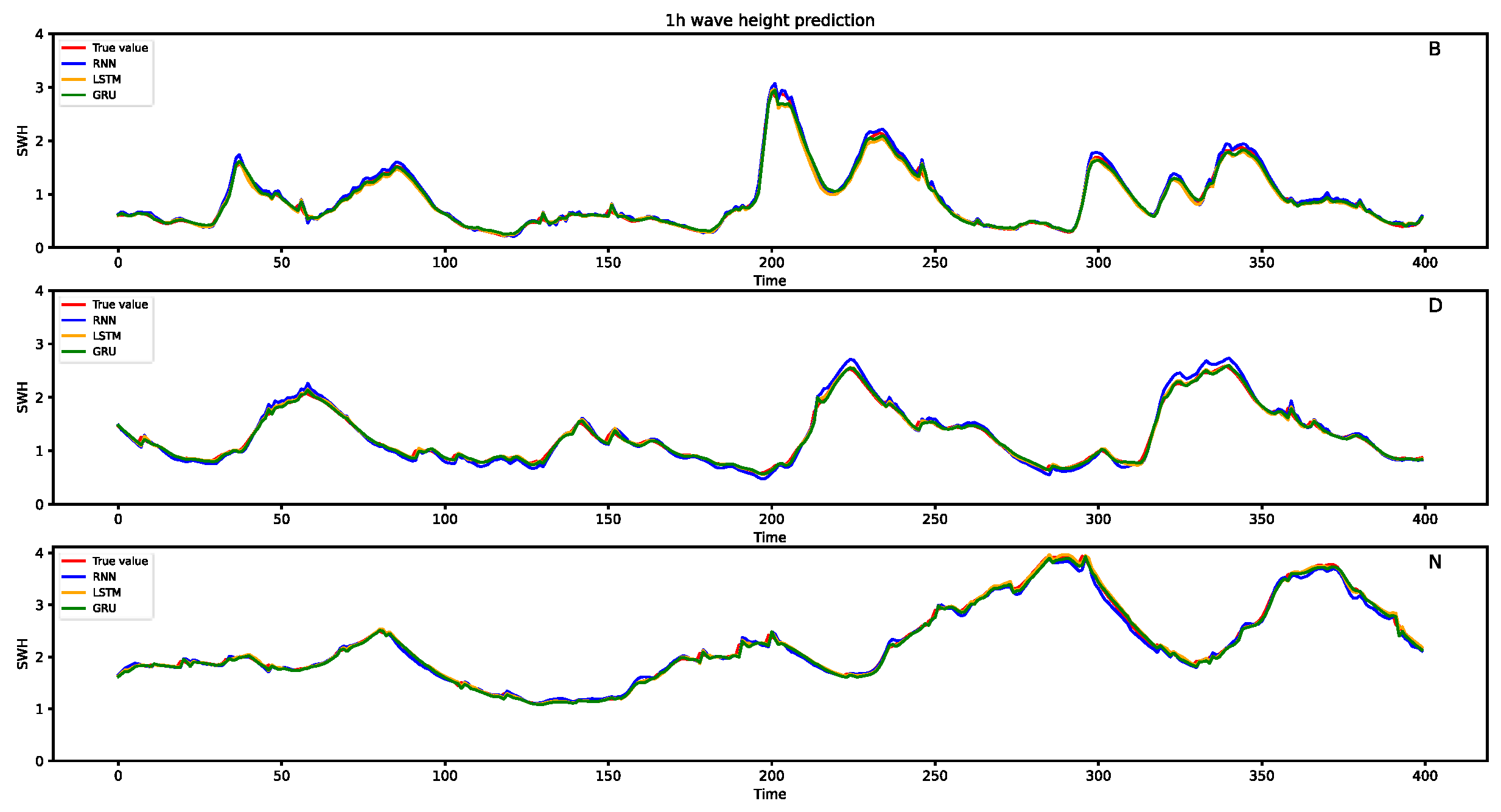
3. Results
3.1. Error Metrics
3.2. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Güner, H.A.A.; Yüksel, Y.; Çevik, E.Ö. Estimation of wave parameters based on nearshore wind–wave correlations. Ocean Eng. 2013, 63, 52–62. [Google Scholar] [CrossRef]
- Hashim, R.; Roy, C.; Motamedi, S.; Shamshirband, S.; Petković, D. Selection of climatic parameters affecting wave height prediction using an enhanced Takagi-Sugeno-based fuzzy methodology. Renew. Sustain. Energy Rev. 2016, 60, 246–257. [Google Scholar] [CrossRef]
- Cornejo-Bueno, L.; Nieto-Borge, J.C.; García-Díaz, P.; Rodríguez, G.; Salcedo-Sanz, S. Significant wave height and energy flux prediction for marine energy applications: A grouping genetic algorithm—Extreme Learning Machine approach. Renew. Energy 2016, 97, 380–389. [Google Scholar] [CrossRef]
- Mahjoobi, J.; Mosabbeb, E.A. Prediction of significant wave height using regressive support vector machines. Ocean Eng. 2009, 36, 339–347. [Google Scholar] [CrossRef]
- Abhigna, P.; Jerritta, S.; Srinivasan, R.; Rajendran, V. Analysis of feed forward and recurrent neural networks in predicting the significant wave height at the moored buoys in Bay of Bengal. In Proceedings of the 2017 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 6–8 April 2017; pp. 1856–1860. [Google Scholar]
- Makarynskyy, O.; Pires-Silva, A.A.; Makarynska, D.; Ventura-Soares, C. Artificial neural networks in wave predictions at the west coast of Portugal. Comput. Geosci. 2005, 31, 415–424. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 2002, 5, 157–166. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Theodoropoulos, P.; Spandonidis, C.C.; Themelis, N.; Giordamlis, C.; Fassois, S. Evaluation of Different Deep-Learning Models for the Prediction of a Ship’s Propulsion Power. J. Mar. Sci. Eng. 2021, 9, 116. [Google Scholar] [CrossRef]
- Gao, S.; Zhao, P.; Pan, B.; Li, Y.; Zhou, M.; Xu, J.; Zhong, S.; Shi, Z. A nowcasting model for the prediction of typhoon tracks based on a long short term memory neural network. Acta Oceanol. Sin. 2018, 37, 12–16. [Google Scholar] [CrossRef]
- Gao, S.; Huang, J.; Li, Y.; Liu, G.; Bi, F.; Bai, Z. A forecasting model for wave heights based on a long short-term memory neural network. Acta Oceanol. Sin. 2021, 40, 62–69. [Google Scholar] [CrossRef]
- Fan, S.; Xiao, N.; Dong, S. A novel model to predict significant wave height based on long short-term memory network. Ocean Eng. 2020, 205, 107298. [Google Scholar] [CrossRef]
- Zhang, D.; Kabuka, M.R. Combining Weather Condition Data to Predict Traffic Flow: A GRU Based Deep Learning Approach. IET Intell. Transp. Syst. 2018, 12, 578–585. [Google Scholar] [CrossRef]
- Dai, G.; Ma, C.; Xu, X. Short-term Traffic Flow Prediction Method for Urban Road Sections Based on Space-time Analysis and GRU. IEEE Access 2019, 7, 143025–143035. [Google Scholar] [CrossRef]
- Liu, H.; Mi, X.; Li, Y.; Duan, Z.; Xu, Y. Smart wind speed deep learning based multi-step forecasting model using singular spectrum analysis, convolutional Gated Recurrent Unit network and Support Vector Regression. Renew. Energy 2019, 143, 842–854. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.; Yang, J. Forecasting of significant wave height based on gated recurrent unit network in the Taiwan strait and its adjacent waters. Water 2021, 13, 86. [Google Scholar] [CrossRef]
- Sias, S.G. Data preprocessing for river flow forecasting using neural networks: Wavelet transforms and data partitioning. Phys. Chem. Earth Parts A/B/C 2006, 31, 1164–1171. [Google Scholar]
- Deka, P.C.; Prahlada, R. Discrete wavelet neural network approach in significant wave height forecasting for multistep lead time. Ocean Eng. 2012, 43, 32–42. [Google Scholar] [CrossRef]
- Oezger, M. Significant wave height forecasting using wavelet fuzzy logic approach. Ocean Eng. 2010, 37, 1443–1451. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Rios, R.A.; De Mello, R.F. Improving time series modeling by decomposing and analyzing stochastic and deterministic influences. Signal Process. 2013, 93, 3001–3013. [Google Scholar] [CrossRef]
- Duan, W.Y.; Han, Y.; Huang, L.M.; Zhao, B.B.; Wang, M.H. A hybrid EMD-SVR model for the short-term prediction of significant wave height. Ocean Eng. 2016, 124, 54–73. [Google Scholar] [CrossRef]
- Huang, W.; Dong, S. Improved short-term prediction of significant wave height by decomposing deterministic and stochastic components. Renew. Energy 2021, 177, 743–758. [Google Scholar] [CrossRef]
- Li, Z.; Li, S.; Hou, Y.; Mo, D.; Li, J.; Yin, B. Typhoon-induced wind waves in the northern East China Sea during two typhoon events: The impact of wind field and wave-current interaction. J. Oceanol. Limnol. 2022, 40, 934–949. [Google Scholar] [CrossRef]
- Li, A.; Liu, Z.; Hong, X.; Hou, Y.; Guan, S. Applicability of the ERA5 reanalysis data to China adjacent Sea under typhoon condition. Mar. Sci. 2021, 45, 10, (In Chinese with English abstract). [Google Scholar]
- Mahjoobi, J.; Etemad-Shahidi, A.; Kazeminezhad, M.H. Hindcasting of wave parameters using different soft computing methods. Appl. Ocean Res. 2008, 30, 28–36. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014; pp. 103–111. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location | Latitude (°N) | Longitude (°E) | Data Period | Total Number of Data Points |
|---|---|---|---|---|
| B | 39.00 | 120.00 | 1 January 2011–31 December 2020 | 87,672 |
| D | 31.00 | 124.00 | 1 January 2011–31 December 2020 | 87,672 |
| N | 18.00 | 116.00 | 1 January 2011–31 December 2020 | 87,672 |
| First Layer | Second Layer | Total Parameter | |
|---|---|---|---|
| RNN | 95 | 180 | 59,990 |
| LSTM | 60 | 80 | 60,885 |
| GRU | 70 | 90 | 59,945 |
| RNN | LSTM | GRU | EMD-LSTM | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Time Span | MAE | RMSE | R | MAE | RMSE | R | MAE | RMSE | R | MAE | RMSE | R | |
| B | 1 | 0.036 | 0.051 | 0.998 | 0.031 | 0.049 | 0.998 | 0.029 | 0.046 | 0.998 | |||
| 3 | 0.087 | 0.131 | 0.976 | 0.072 | 0.123 | 0.979 | 0.073 | 0.120 | 0.980 | ||||
| 6 | 0.182 | 0.272 | 0.891 | 0.156 | 0.258 | 0.900 | 0.159 | 0.256 | 0.901 | ||||
| 12 | 0.308 | 0.447 | 0.659 | 0.283 | 0.434 | 0.680 | 0.284 | 0.431 | 0.683 | 0.132 | 0.197 | 0.944 | |
| 24 | 0.388 | 0.554 | 0.345 | 0.372 | 0.552 | 0.371 | 0.378 | 0.552 | 0.373 | 0.223 | 0.335 | 0.825 | |
| D | 1 | 0.058 | 0.081 | 0.997 | 0.027 | 0.059 | 0.997 | 0.029 | 0.053 | 0.998 | |||
| 3 | 0.090 | 0.140 | 0.986 | 0.068 | 0.120 | 0.988 | 0.071 | 0.121 | 0.987 | ||||
| 6 | 0.149 | 0.243 | 0.951 | 0.133 | 0.224 | 0.956 | 0.135 | 0.226 | 0.955 | ||||
| 12 | 0.253 | 0.409 | 0.843 | 0.250 | 0.399 | 0.855 | 0.245 | 0.394 | 0.857 | 0.159 | 0.229 | 0.954 | |
| 24 | 0.407 | 0.617 | 0.586 | 0.421 | 0.622 | 0.602 | 0.410 | 0.602 | 0.610 | 0.268 | 0.396 | 0.853 | |
| N | 1 | 0.050 | 0.516 | 0.999 | 0.027 | 0.043 | 0.999 | 0.027 | 0.044 | 0.999 | |||
| 3 | 0.075 | 0.106 | 0.997 | 0.058 | 0.088 | 0.997 | 0.055 | 0.085 | 0.997 | ||||
| 6 | 0.121 | 0.169 | 0.990 | 0.107 | 0.160 | 0.990 | 0.104 | 0.154 | 0.991 | ||||
| 12 | 0.216 | 0.297 | 0.966 | 0.201 | 0.292 | 0.966 | 0.195 | 0.283 | 0.968 | 0.124 | 0.171 | 0.992 | |
| 24 | 0.386 | 0.516 | 0.894 | 0.360 | 0.510 | 0.892 | 0.369 | 0.499 | 0.896 | 0.176 | 0.263 | 0.974 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, Z.; Hu, P.; Li, S.; Mo, D. Prediction of Significant Wave Height in Offshore China Based on the Machine Learning Method. J. Mar. Sci. Eng. 2022, 10, 836. https://doi.org/10.3390/jmse10060836
Feng Z, Hu P, Li S, Mo D. Prediction of Significant Wave Height in Offshore China Based on the Machine Learning Method. Journal of Marine Science and Engineering. 2022; 10(6):836. https://doi.org/10.3390/jmse10060836
Chicago/Turabian StyleFeng, Zhijie, Po Hu, Shuiqing Li, and Dongxue Mo. 2022. "Prediction of Significant Wave Height in Offshore China Based on the Machine Learning Method" Journal of Marine Science and Engineering 10, no. 6: 836. https://doi.org/10.3390/jmse10060836
APA StyleFeng, Z., Hu, P., Li, S., & Mo, D. (2022). Prediction of Significant Wave Height in Offshore China Based on the Machine Learning Method. Journal of Marine Science and Engineering, 10(6), 836. https://doi.org/10.3390/jmse10060836