AUV 3D Path Planning Based on the Improved Hierarchical Deep Q Network


Abstract
:1. Introduction
2. Path Planning Algorithm
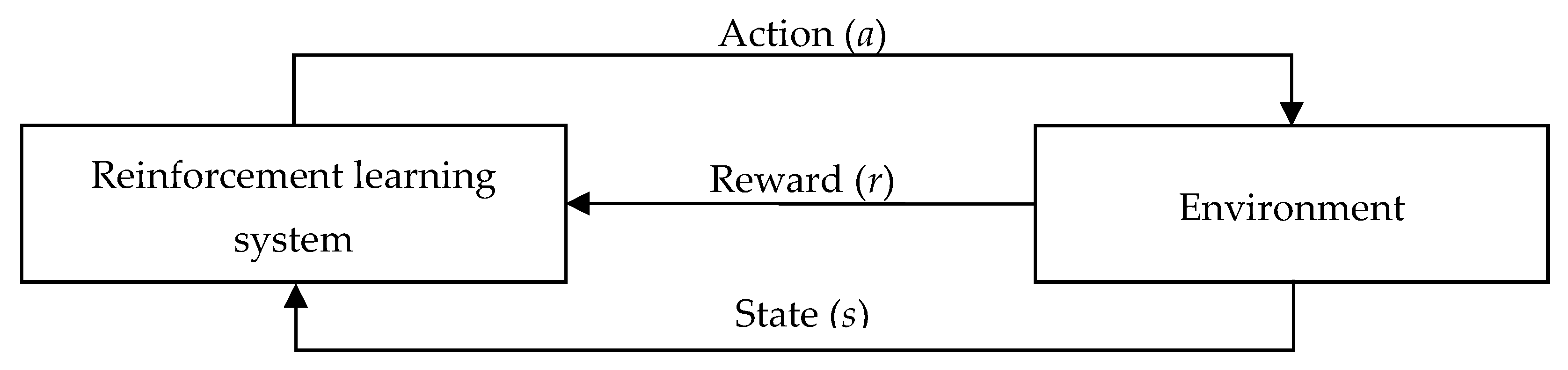
2.1. HDQN and Prioritized Experience Replay
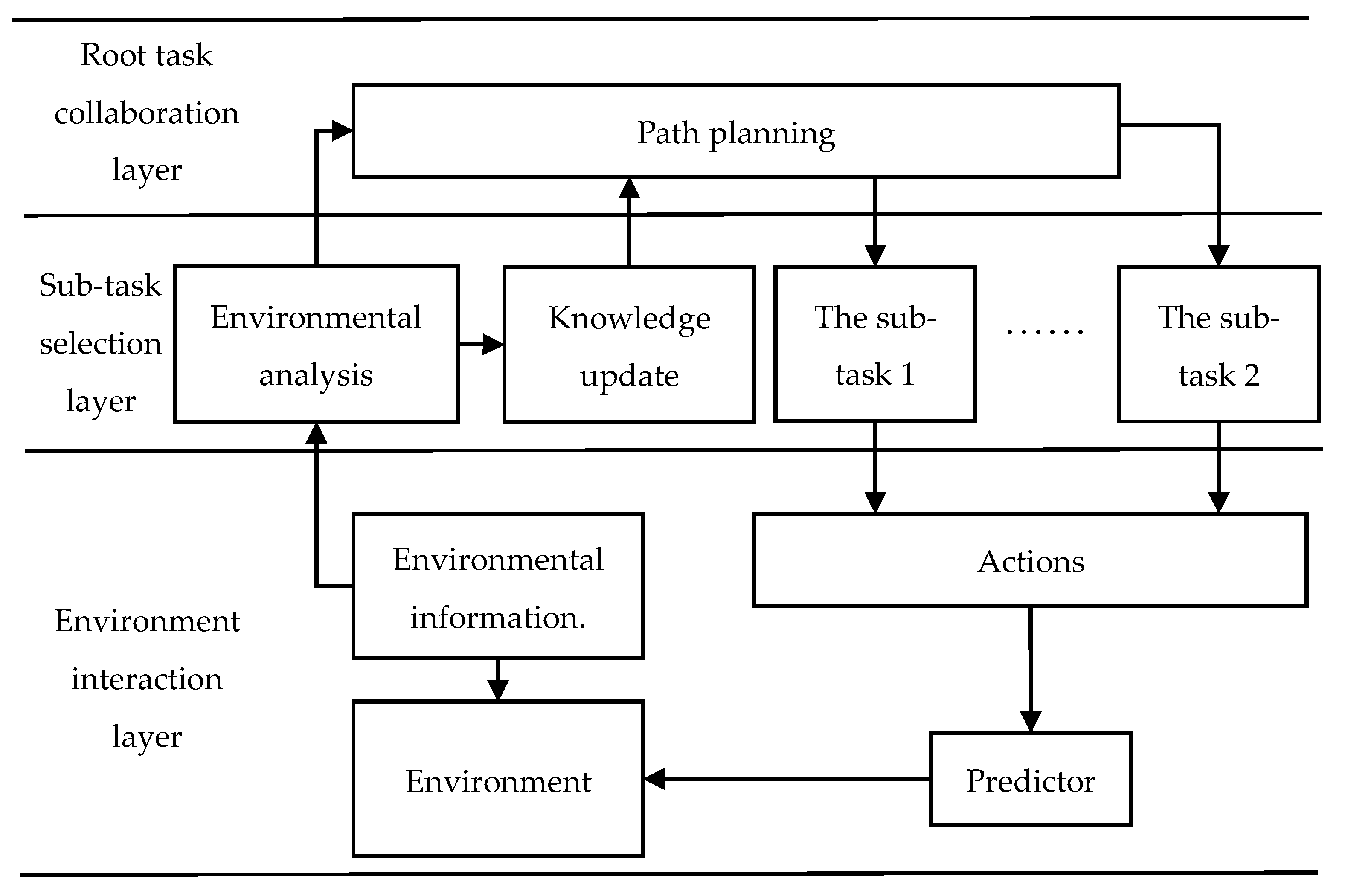
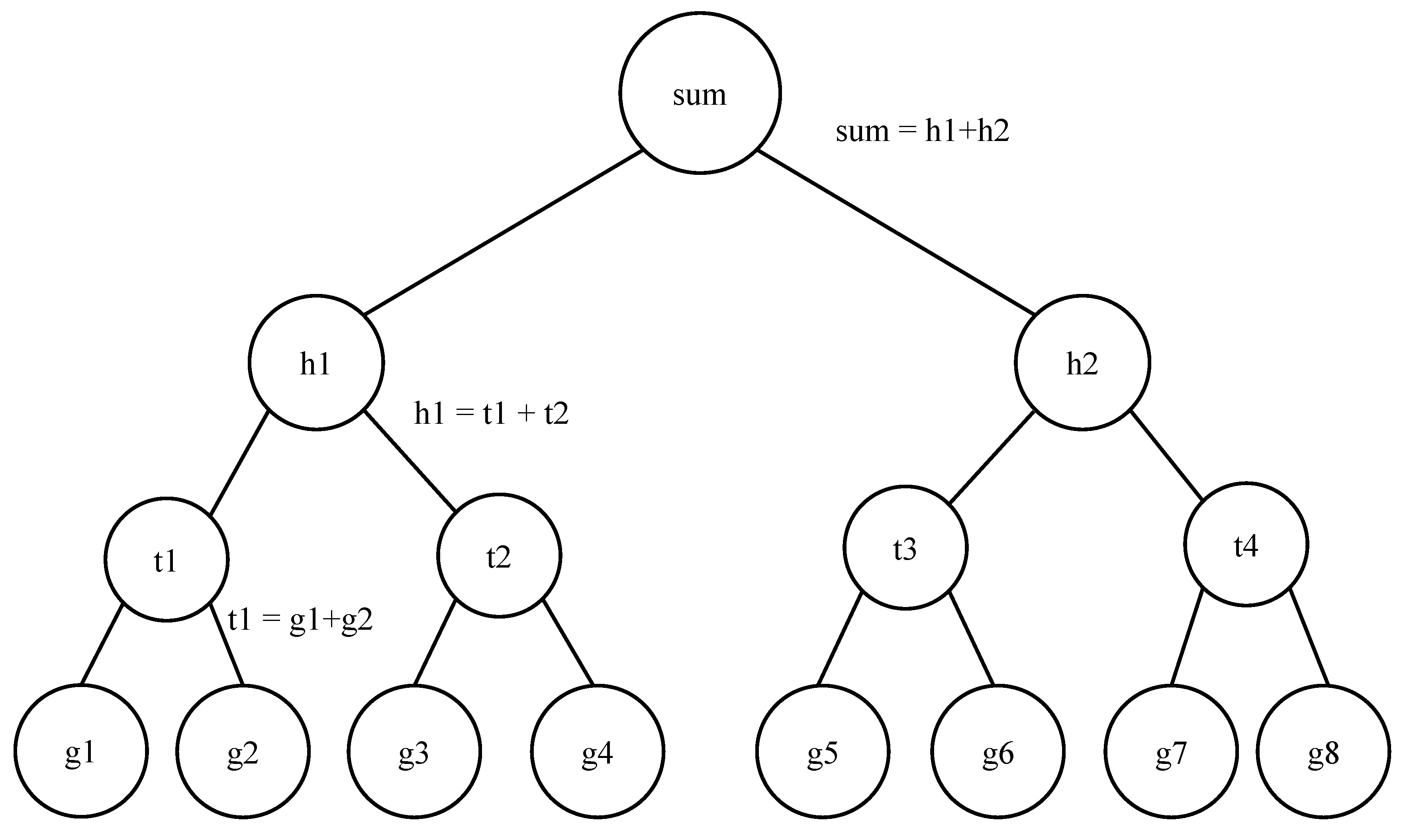
2.1.1. Hierarchy of the Path Planning Task
2.1.2. HDQN
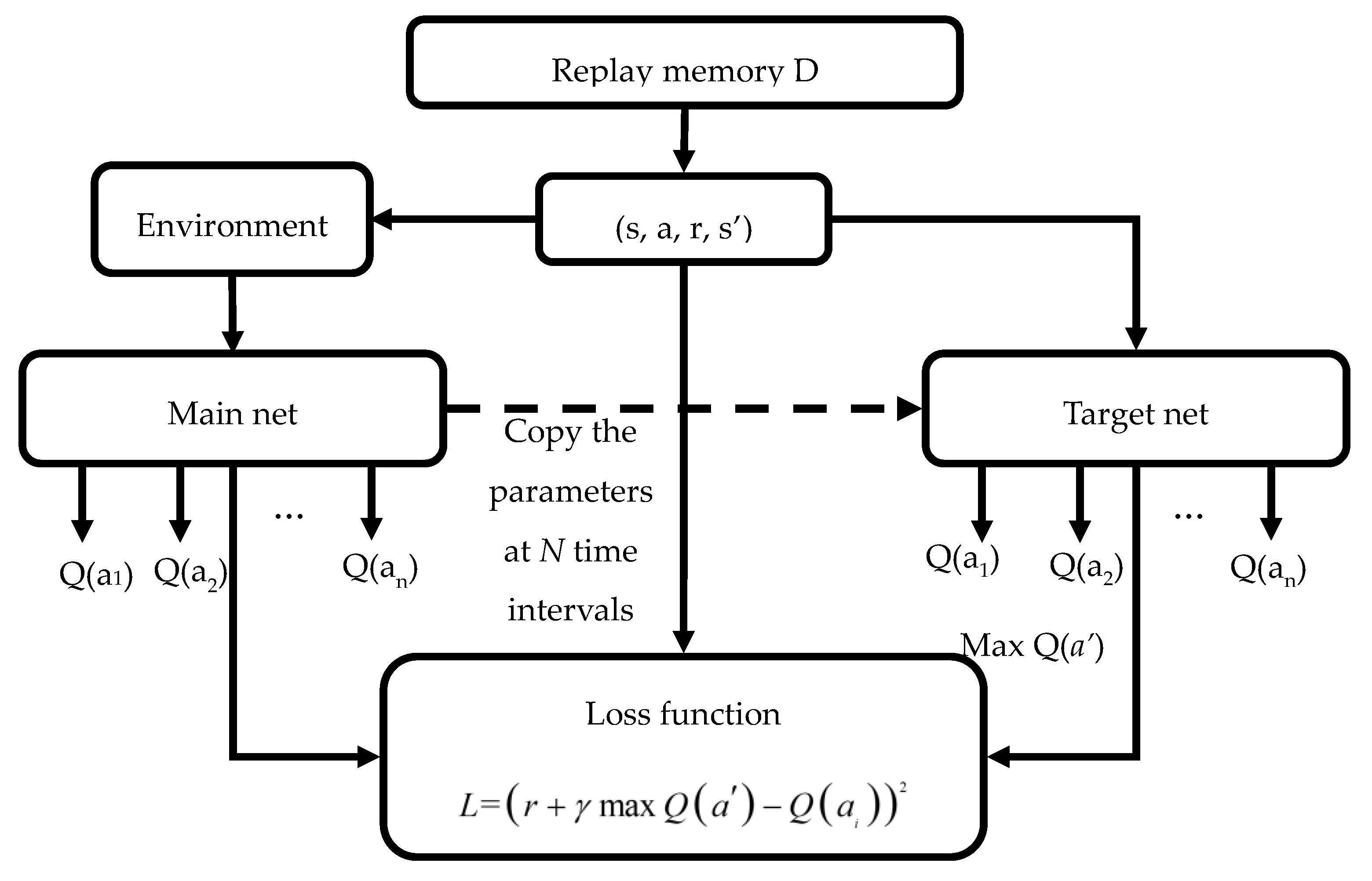
2.1.3. Prioritized Experience Replay
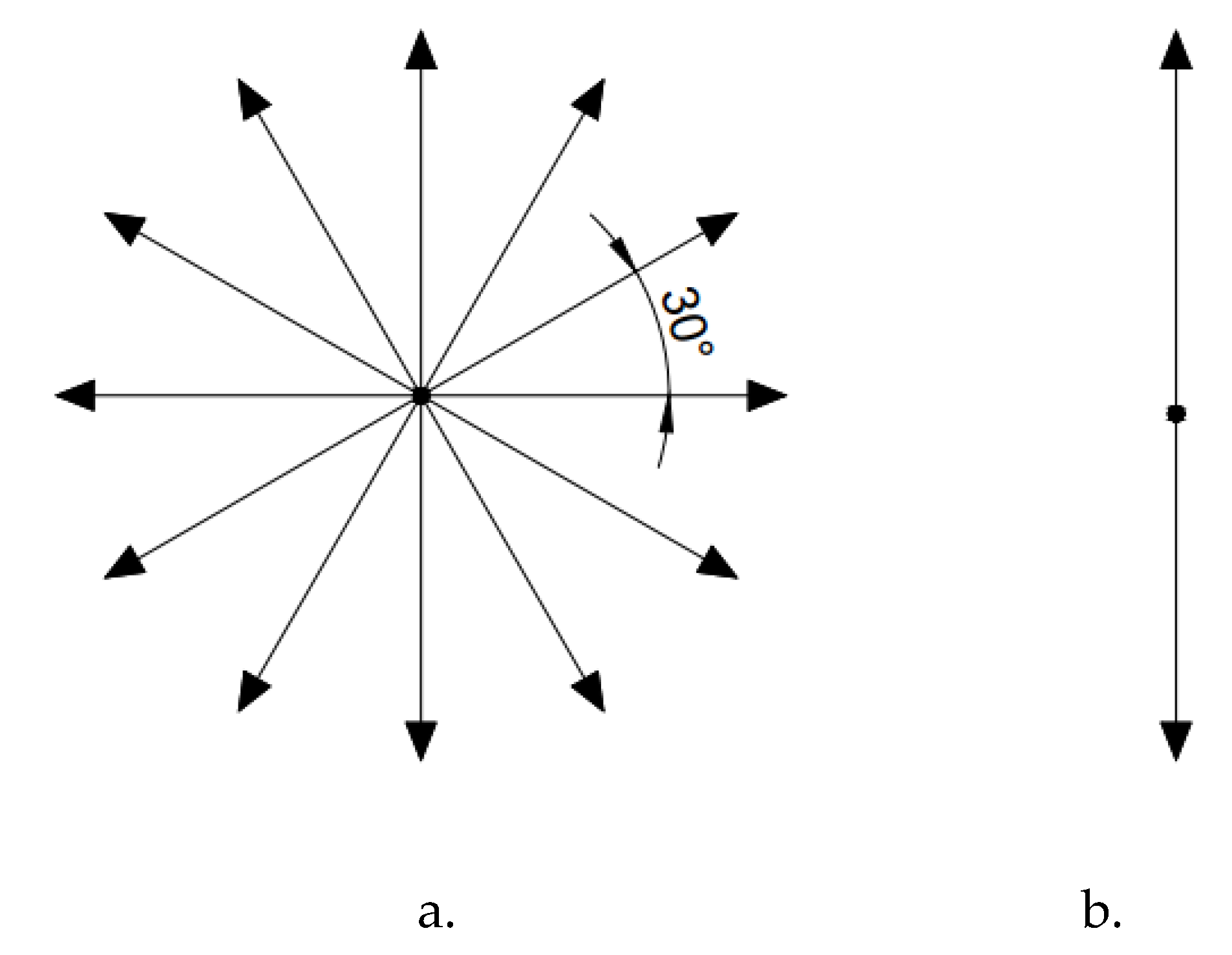
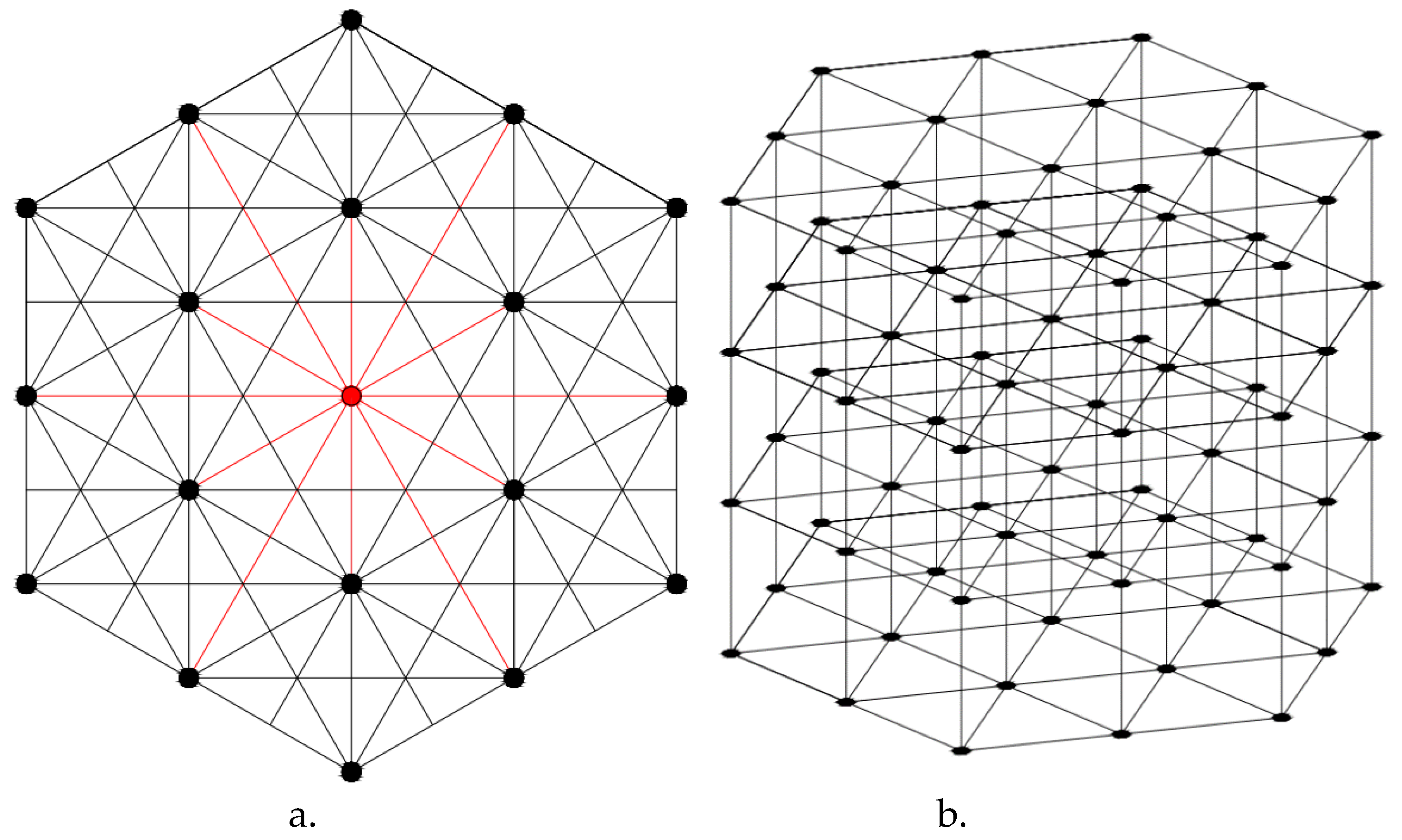
2.2. Set the Rewards and Actions
2.3. Algorithm Process
| Algorithm 1: the path plan training process. |
| Initialize parameters. |
| Initialize memory. |
| for episode in range (10000): |
| Initialize states. |
| for step in 1000: |
| Select a random action; Otherwise select the action according to the observation value of the state:; |
| The system performs the selected action to move to the next state s’; |
| Judge the current state and calculate the reward according to formula (13); |
| Save s, a, r, and s’ to the memory bank. |
| if (step > 200) and (step % 2 = 0): |
| Update the parameters of target_net every 500 times; |
| Calculate the td-error and to extract memories from the memory store according to the priority;Calculate q_target: ; |
| Select the action corresponding to the maximum Q value. To set the Q value of other actions to 0, the error value of the action selected is transferred back in the neural network as the update credential; |
| Perform a gradient descent step on with respect to the network parameters θ; |
| Increase the size of epsilon parameter to reduce the randomness of the action; |
| Use the next state as the state of the next loop. |
| if done: |
| Break; |
| step = step + 1; |
| end for; |
| end for; |
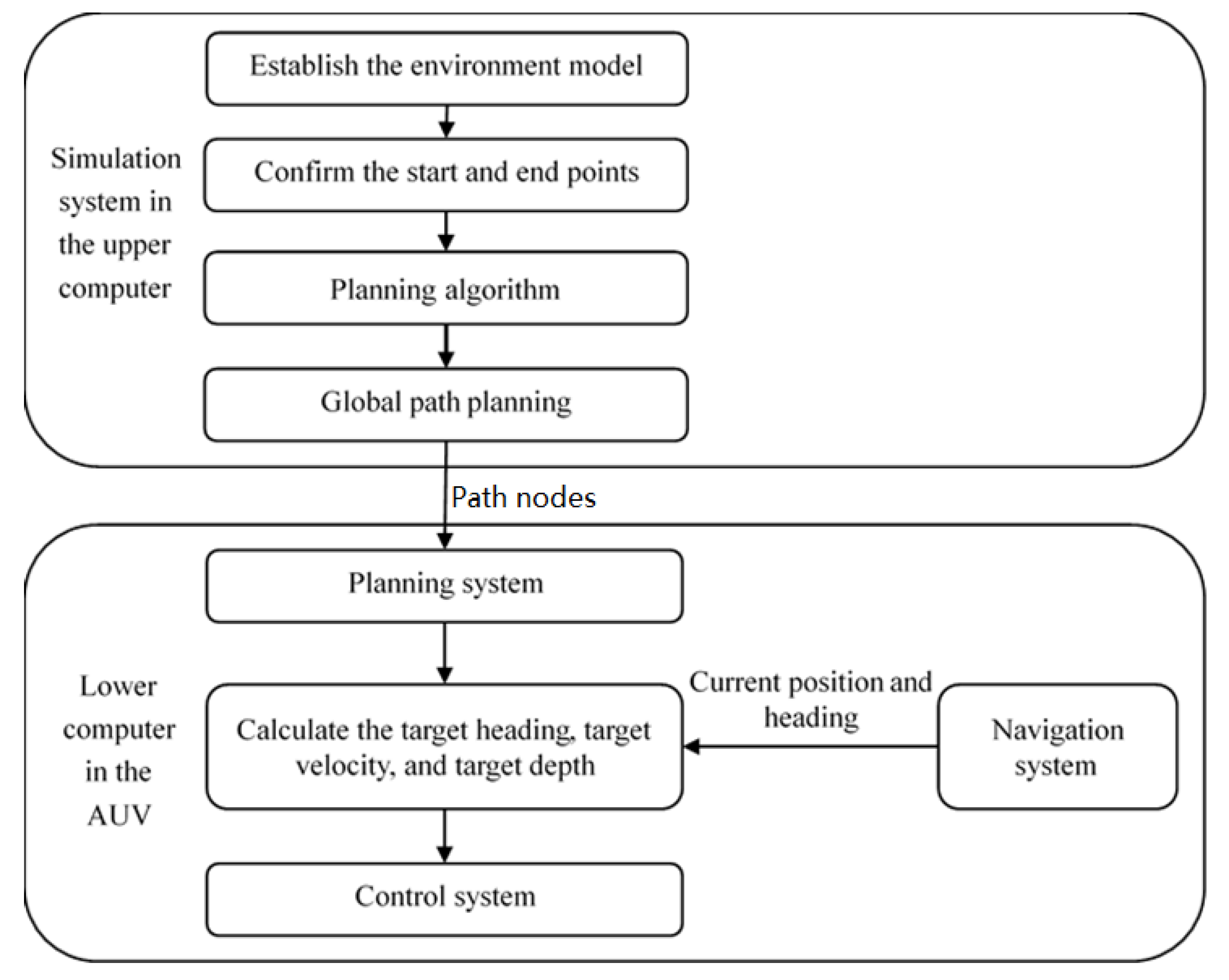
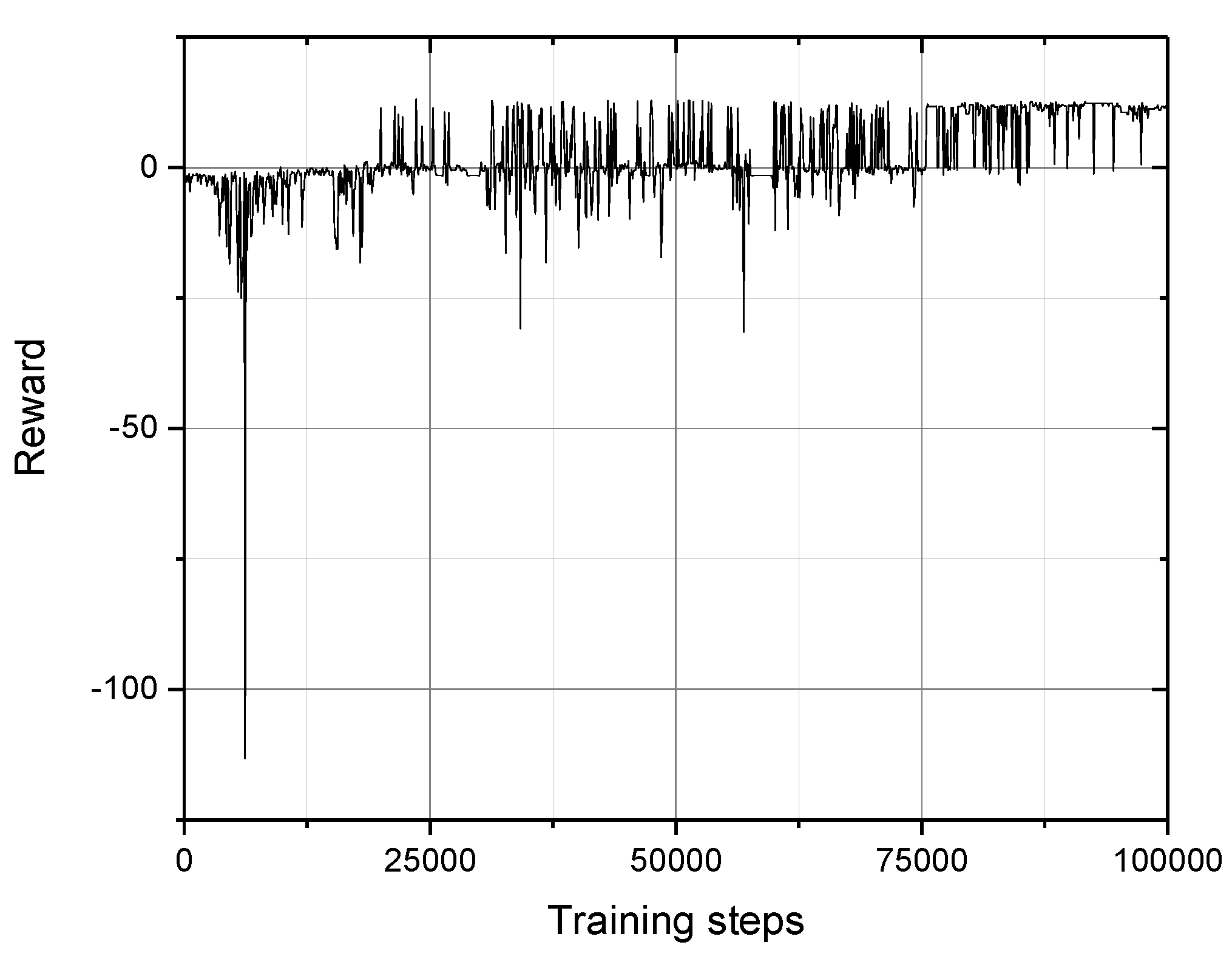
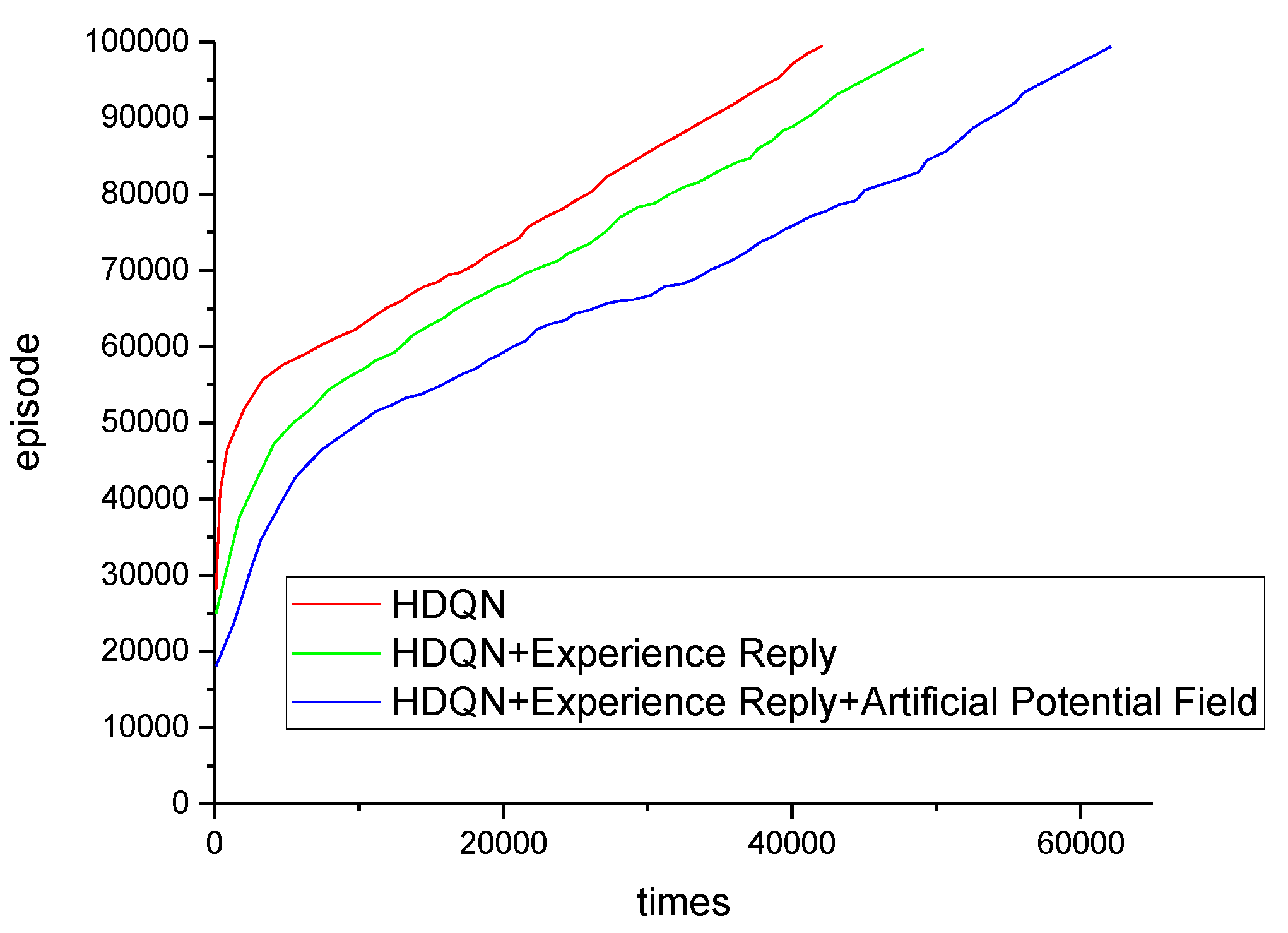
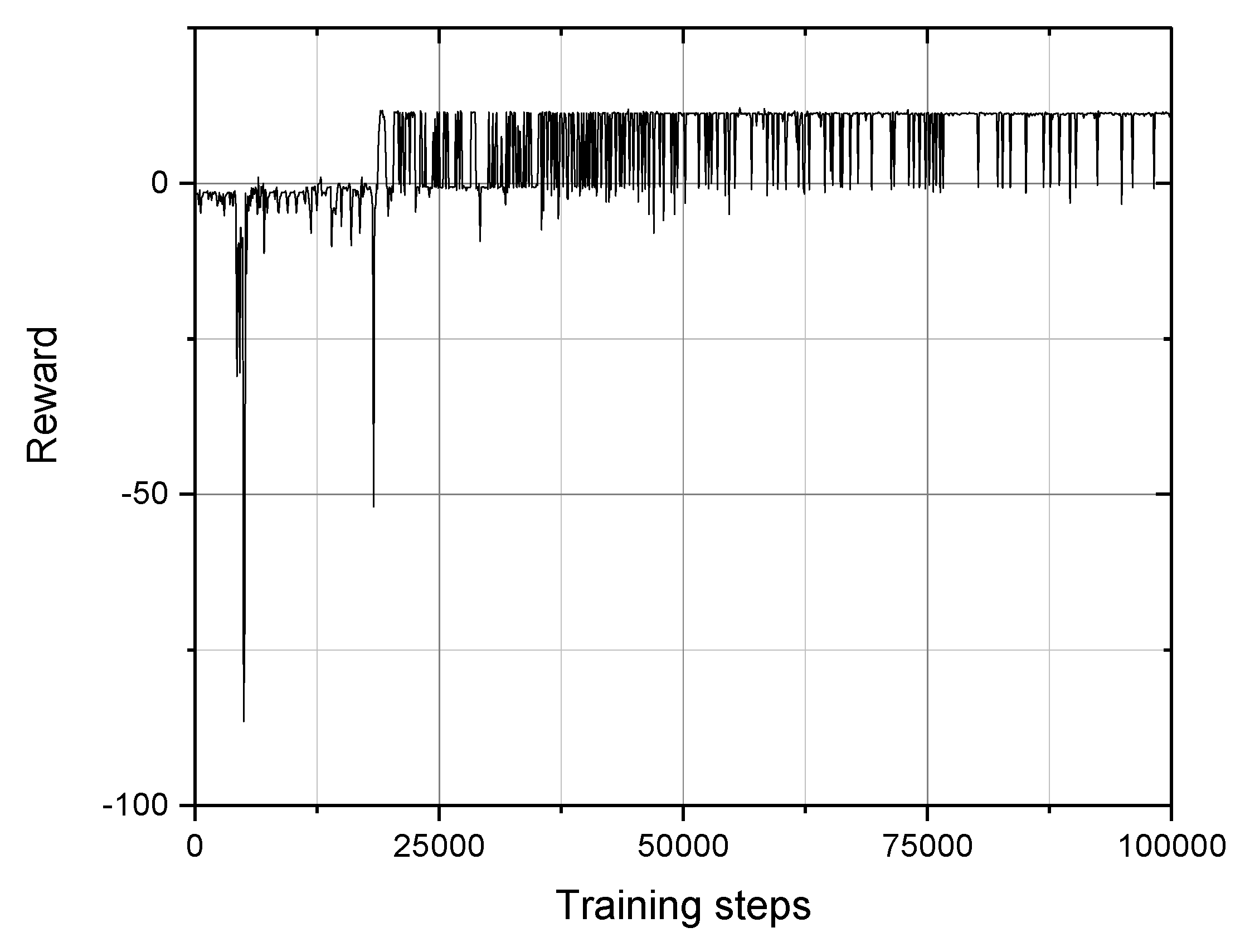
3. Simulation Experiment
3.1. Experimental Definition
3.2. Path Planning
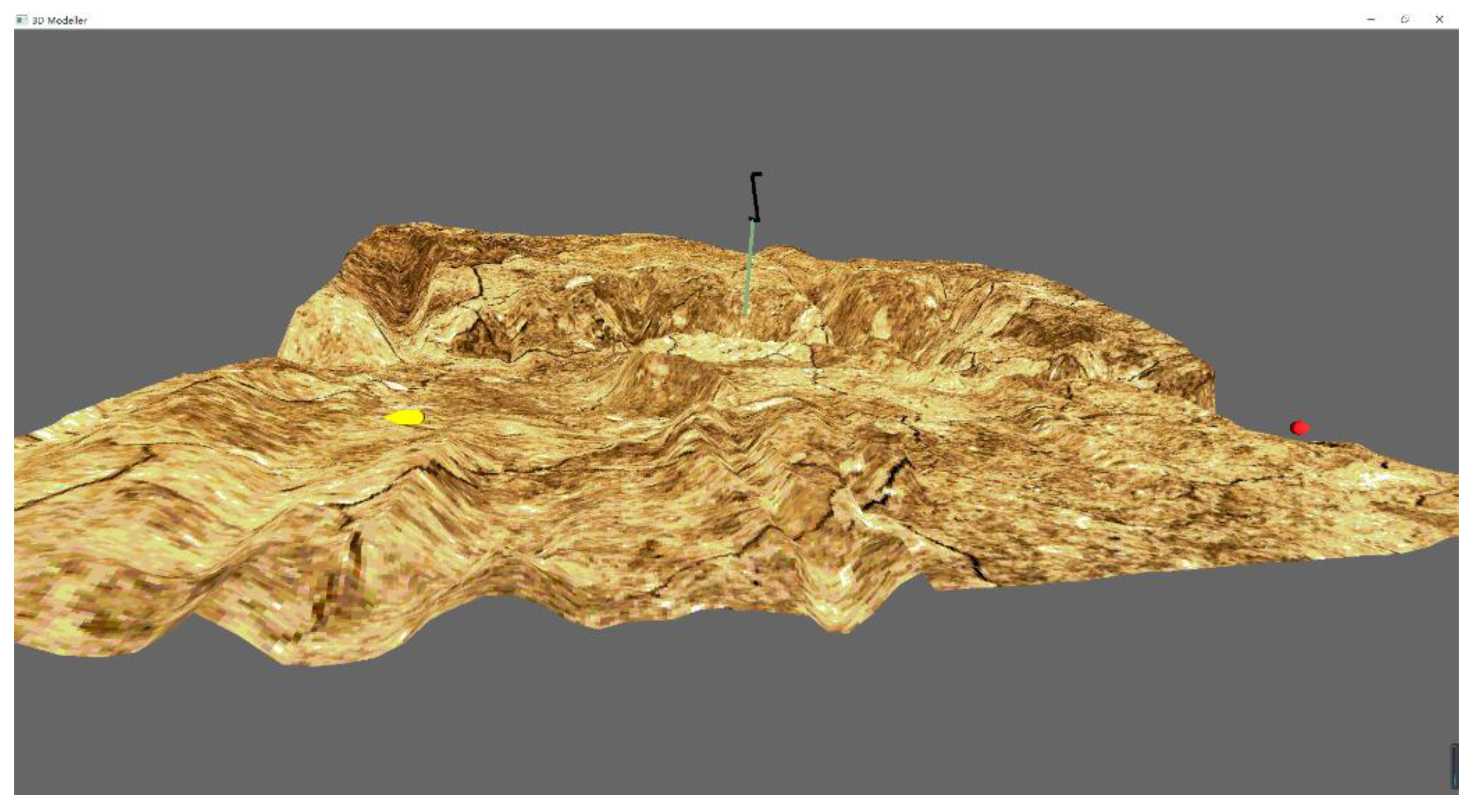
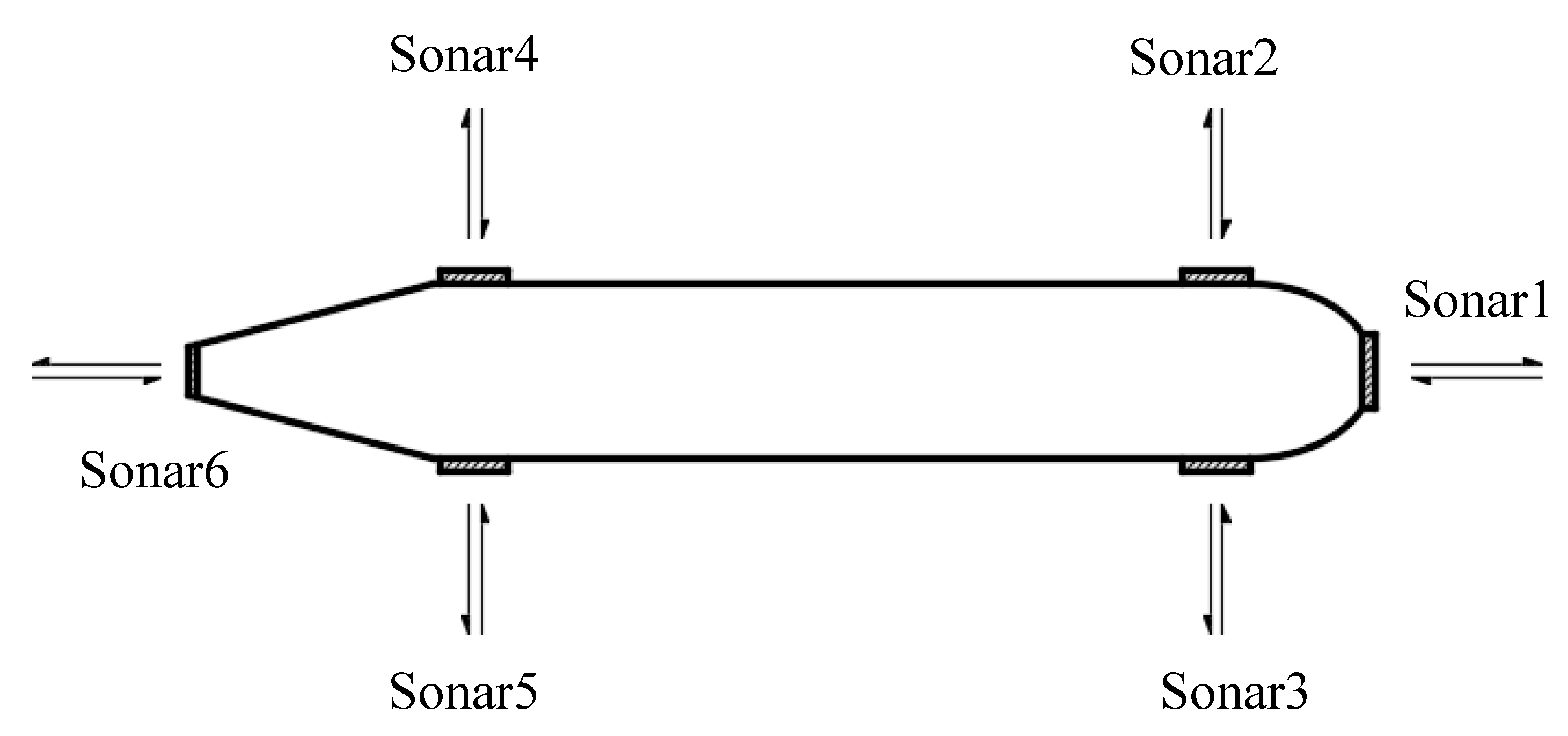
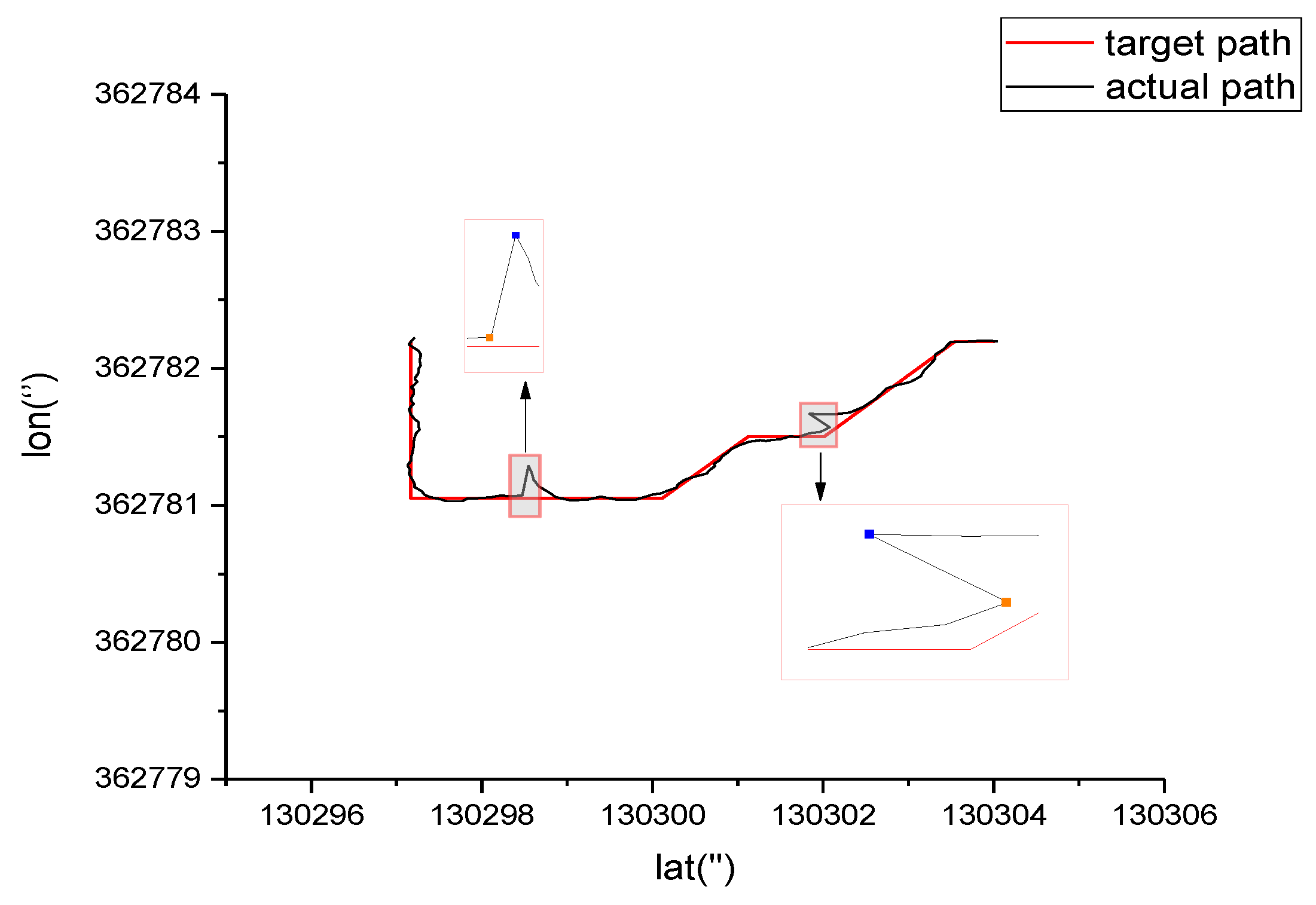
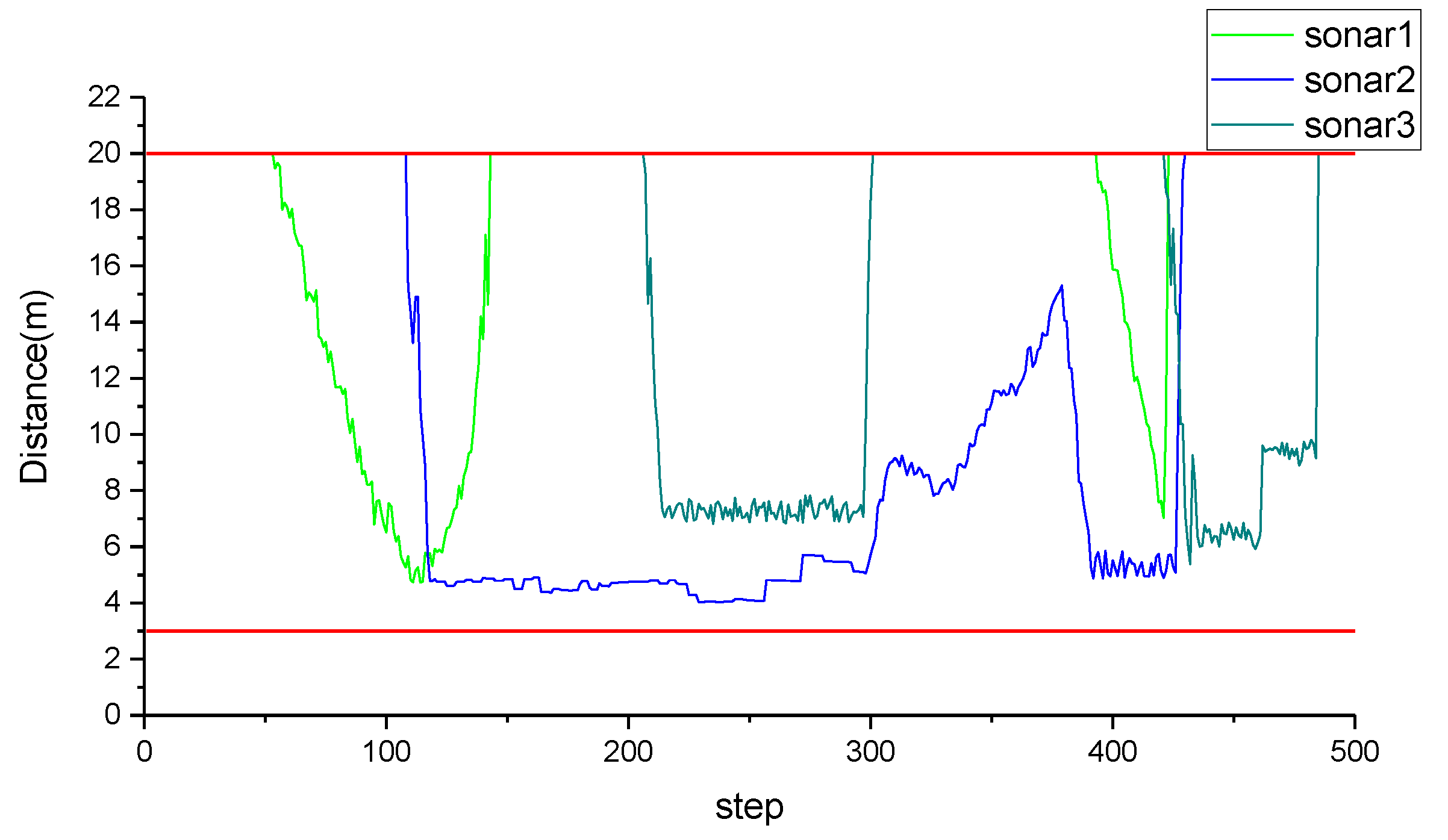
4. Field Experiment
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fan, J.; Li, Y.; Liao, Y.; Jiang, W.; Wang, L.; Jia, Q.; Wu, H. Second Path Planning for Unmanned Surface Vehicle Considering the Constraint of Motion Performance. J. Mar. Sci. Eng. 2019, 7, 104. [Google Scholar] [CrossRef] [Green Version]
- Kirkwood, W.J. AUV Technology and Application Basics. In Proceedings of the OCEANS 2008-MTS/IEEE Kobe Techno-Ocean, Kobe, Japan, 8–11 April 2008. [Google Scholar]
- Mullen, L.; Cochenour, B.; Laux, A.; Alley, D. Optical modulation techniques for underwater detection, ranging and imaging. Proc. SPIE. 2011, 8030, 803008. [Google Scholar]
- Williams, D.P. On optimal AUV track-spacing for underwater mine detection. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 4755–4762. [Google Scholar]
- Li, B.; Zhao, R.; Xu, G.; Wang, G.; Su, Z.; Chen, Z. Three-Dimensional Path Planning for an Under-Actuated Autonomous Underwater Vehicle. In Proceedings of the 29th International Ocean and Polar Engineering Conference, Honolulu, HI, USA, 16–21 June 2019. [Google Scholar]
- Hernández, J.D.; Vidal, E.; Vallicrosa, G.; Galceran, E.; Carreras, M. Online path planning for autonomous underwater vehicles in unknown environments. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1152–1157. [Google Scholar]
- Petres, C.; Pailhas, Y.; Patron, P.; Petillot, Y.; Evans, J.; Lane, D. Path Planning for Autonomous Underwater Vehicles. IEEE Trans. Robot. 2007, 23, 331–341. [Google Scholar] [CrossRef]
- Sun, B.; Zhu, D.; Yang, S.X. An Optimized Fuzzy Control Algorithm for Three-Dimensional AUV Path Planning. Int. J. Fuzzy Syst. 2018, 20, 597–610. [Google Scholar] [CrossRef]
- Sociological Research. Artificial Intelligence-A Modern Approach. Appl. Mech. Mater. 2009, 263, 2829–2833. [Google Scholar]
- Wehbe, B.; Hildebrandt, M.; Kirchner, F. Experimental evaluation of various machine learning regression methods for model identification of autonomous underwater vehicles. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4885–4890. [Google Scholar]
- Kawano, H.; Ura, T. Motion planning algorithm for nonholonomic autonomous underwater vehicle in disturbance using reinforcement learning and teaching method. In Proceedings of the 2002 IEEE International Conference on Robotics and Automation (Cat. No. 02CH37292), Washington, DC, USA, 11–15 May 2002; Volume 4, pp. 4032–4038. [Google Scholar]
- Yang, G.; Zhang, R.; Xu, D.; Zhang, Z. Local Planning of AUV Based on Fuzzy-Q Learning in Strong Sea Flow Field. In Proceedings of the 2009 International Joint Conference on Computational Sciences and Optimization, Sanya, China, 24–26 April 2009; Volume 1, pp. 994–998. [Google Scholar]
- Liu, B.; Lu, Z. AUV path planning under ocean current based on reinforcement learning in electronic chart. In Proceedings of the 2013 International Conference on Computational and Information Sciences, Shiyang, China, 21–23 June 2013; pp. 1939–1942. [Google Scholar]
- Cheng, Y.; Zhang, W. Concise deep reinforcement learning obstacle avoidance for underactuated unmanned marine vessels. Neurocomputing 2018, 272, 63–73. [Google Scholar] [CrossRef]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. ArXiv 2015, arXiv:arXiv:1511.05952. [Google Scholar]
- Cui, R.; Li, Y.; Yan, W. Mutual Information-Based Multi-AUV Path Planning for Scalar Field Sampling Using Multidimensional RRT*. IEEE Trans. Syst. Man Cybern. Syst. 2017, 46, 993–1004. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, G.C.; Sun, Y.S.; Pang, S.; Ran, X.R.; Wang, X.B. Design and Experiment of a Plateau Data-Gathering AUV. J. Mar. Sci. Eng. 2019, 7, 376. [Google Scholar] [CrossRef] [Green Version]
- Barto, A.G. Reinforcement Learning. A Bradford Book; MIT Press: Cambridge, MA, USA, 1998; Volume 15, pp. 665–685. [Google Scholar]
- Miletić, S.; Boag, R.J.; Forstmann, B.U. Mutual benefits: Combining reinforcement learning with sequential sampling models. Neuropsychologia 2020, 136, 107261. [Google Scholar] [CrossRef] [PubMed]
- Watkins CJ, C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Wei, Q.; Song, R.; Xu, Y.; Liu, D. Iterative Q-learning-based nonlinear optimal tracking control. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016. [Google Scholar]
- Wei, Q.; Liu, D.; Song, R. Discrete-time optimal control scheme based on Q-learning algorithm. In Proceedings of the 2016 Seventh International Conference on Intelligent Control and Information Processing (ICICIP), Siem Reap, Cambodia, 1–4 December 2016; pp. 125–130. [Google Scholar]
- Cherry, J.M.; Adler, C.; Ball, C.; Chervitz, S.A.; Dwight, S.S.; Hester, E.T.; Weng, S. SGD: Saccharomyces Genome Database. Nucleic Acids Res. 1998, 26, 73–79. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; McInnes, C.R. Reconfiguring smart structures using approximate heteroclinic connections. Smart Mater. Struct. 2015, 24, 105034. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; McInnes, C.R. Using instability to reconfigure smart structures in a spring-mass model. Mech. Syst. Signal Process. 2017, 91, 81–92. [Google Scholar] [CrossRef] [Green Version]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Frequency | Accuracy | Maximum Altitude | Minimum Altitude | Maximum Velocity | Maximum Ping Rate |
|---|---|---|---|---|---|---|
| NavQuest 600 Micro | 600 kHz | 1% ± 1 mm/s | 110 m | 0.3 m | ±20 knots | 5/s |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Ran, X.; Zhang, G.; Xu, H.; Wang, X. AUV 3D Path Planning Based on the Improved Hierarchical Deep Q Network. J. Mar. Sci. Eng. 2020, 8, 145. https://doi.org/10.3390/jmse8020145
Sun Y, Ran X, Zhang G, Xu H, Wang X. AUV 3D Path Planning Based on the Improved Hierarchical Deep Q Network. Journal of Marine Science and Engineering. 2020; 8(2):145. https://doi.org/10.3390/jmse8020145
Chicago/Turabian StyleSun, Yushan, Xiangrui Ran, Guocheng Zhang, Hao Xu, and Xiangbin Wang. 2020. "AUV 3D Path Planning Based on the Improved Hierarchical Deep Q Network" Journal of Marine Science and Engineering 8, no. 2: 145. https://doi.org/10.3390/jmse8020145
APA StyleSun, Y., Ran, X., Zhang, G., Xu, H., & Wang, X. (2020). AUV 3D Path Planning Based on the Improved Hierarchical Deep Q Network. Journal of Marine Science and Engineering, 8(2), 145. https://doi.org/10.3390/jmse8020145